forked from repo-mirrors/dbt-core
Compare commits
321 Commits
fix-microb
...
move-preco
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b66dff7278 | ||
|
|
22d21edb4b | ||
|
|
bef7928e22 | ||
|
|
c573131d91 | ||
|
|
f10d84d05e | ||
|
|
79a4c8969e | ||
|
|
9a80308fcf | ||
|
|
7a13d08376 | ||
|
|
9e9f5b8e57 | ||
|
|
9cd6a23eba | ||
|
|
e46c37cf07 | ||
|
|
df23f398a6 | ||
|
|
97df9278c0 | ||
|
|
748d352b6b | ||
|
|
bbd8fa02f1 | ||
|
|
61009f6ba7 | ||
|
|
ee7ecdc29f | ||
|
|
d74b58a137 | ||
|
|
12b04e7d2f | ||
|
|
5d56a052a7 | ||
|
|
62a8ea05a6 | ||
|
|
1219bd49aa | ||
|
|
791d1ebdcd | ||
|
|
148b9b41a5 | ||
|
|
d096a6776e | ||
|
|
8ff86d35ea | ||
|
|
087f8167ec | ||
|
|
bcb07ceb7b | ||
|
|
c559848044 | ||
|
|
3de0160b00 | ||
|
|
2c7f49a71e | ||
|
|
518c360a29 | ||
|
|
8cf51fddba | ||
|
|
8e128eee8e | ||
|
|
94b69b1578 | ||
|
|
0216e32c7f | ||
|
|
bbd078089e | ||
|
|
575bac3172 | ||
|
|
bca2211246 | ||
|
|
0015e35a1b | ||
|
|
09bce7af63 | ||
|
|
cb7c4a7dce | ||
|
|
5555a3dd25 | ||
|
|
0e30db4e82 | ||
|
|
b2ff6ab5a7 | ||
|
|
48218be274 | ||
|
|
500208c009 | ||
|
|
0162b71e94 | ||
|
|
811e4ee955 | ||
|
|
b79ec3c33b | ||
|
|
e32718e666 | ||
|
|
f6e0793d00 | ||
|
|
39cf2ec94f | ||
|
|
3caddd0b65 | ||
|
|
5dd516608b | ||
|
|
11ada88e48 | ||
|
|
b9e5c144a9 | ||
|
|
001e729664 | ||
|
|
7e10fc72d5 | ||
|
|
c170211ce3 | ||
|
|
8e800cee4c | ||
|
|
1bd81f5025 | ||
|
|
65a122b34a | ||
|
|
785304732f | ||
|
|
4693918a0f | ||
|
|
96738d5edc | ||
|
|
780544dc7f | ||
|
|
2190fa64a3 | ||
|
|
deb2f3e890 | ||
|
|
34f0190a14 | ||
|
|
7f9449660e | ||
|
|
ea172aa668 | ||
|
|
f0d3b8a51d | ||
|
|
c6afa4d0f2 | ||
|
|
98a1b6e272 | ||
|
|
d5071fa135 | ||
|
|
db284a14c1 | ||
|
|
4017802800 | ||
|
|
17a8816ee3 | ||
|
|
3bd425fdc9 | ||
|
|
db9a6e10c1 | ||
|
|
4a78a78c2b | ||
|
|
5ee5bf4129 | ||
|
|
ac445ca1fd | ||
|
|
1258728d9a | ||
|
|
15722264aa | ||
|
|
a6d4091b6b | ||
|
|
b1b3839715 | ||
|
|
963251df4e | ||
|
|
8c929c337e | ||
|
|
e949d1a6f9 | ||
|
|
538de17f78 | ||
|
|
96c9d80f83 | ||
|
|
2f842055f0 | ||
|
|
faeee357b1 | ||
|
|
bca5c4d454 | ||
|
|
b3d059e427 | ||
|
|
b783c97eff | ||
|
|
5add25db0c | ||
|
|
ad6ea20277 | ||
|
|
472b8057a9 | ||
|
|
2915c3e284 | ||
|
|
537daa8476 | ||
|
|
b48ad8282b | ||
|
|
7cab753863 | ||
|
|
19393a8080 | ||
|
|
1e61e3bfc6 | ||
|
|
a9dae5cac1 | ||
|
|
15010f1e6b | ||
|
|
2564b3d1f9 | ||
|
|
34bb3f94dd | ||
|
|
593a151220 | ||
|
|
1a251ee081 | ||
|
|
9b7cf25c33 | ||
|
|
26333f7f21 | ||
|
|
9bc7333e19 | ||
|
|
ee8884731b | ||
|
|
f1106ad61e | ||
|
|
ada5d3b82a | ||
|
|
64b58ec628 | ||
|
|
1e713db2fa | ||
|
|
6b7b1ad74b | ||
|
|
3e31117ba1 | ||
|
|
451b745aea | ||
|
|
d27232a946 | ||
|
|
b1705fb6f3 | ||
|
|
0e50851fa6 | ||
|
|
b75d5e701e | ||
|
|
f8b1a6dcd1 | ||
|
|
9010537499 | ||
|
|
56d3c9318b | ||
|
|
1fcce443ba | ||
|
|
de03d6f44f | ||
|
|
5db78ca6dd | ||
|
|
ada9e63c13 | ||
|
|
69d19eb5fc | ||
|
|
55bb3c304a | ||
|
|
693564de40 | ||
|
|
04a3df7324 | ||
|
|
31d974f5eb | ||
|
|
c1f64e216f | ||
|
|
8fa6e037d0 | ||
|
|
e1c98e8123 | ||
|
|
9955ea760a | ||
|
|
fdd0546700 | ||
|
|
45f21a7cda | ||
|
|
f250b503d5 | ||
|
|
aa42ff8986 | ||
|
|
3c2fdfe735 | ||
|
|
303c63ccc8 | ||
|
|
17ec11ad30 | ||
|
|
65598f3dc6 | ||
|
|
240a6056fb | ||
|
|
7cd8935b13 | ||
|
|
cd5d4be7ab | ||
|
|
5a23894584 | ||
|
|
70ad9319d2 | ||
|
|
8873581c5a | ||
|
|
1ffd059442 | ||
|
|
091ba5fe0b | ||
|
|
6bbcce1f1c | ||
|
|
0fff5760ff | ||
|
|
f4988c62e3 | ||
|
|
2e6d4f493d | ||
|
|
3e593600e0 | ||
|
|
87584c73b0 | ||
|
|
709bd11c71 | ||
|
|
f7f53732b2 | ||
|
|
32b8097a1f | ||
|
|
36f1143c31 | ||
|
|
cf7a465338 | ||
|
|
465aa0c2fc | ||
|
|
a0284edb6b | ||
|
|
d2bfb4e215 | ||
|
|
38443640ce | ||
|
|
86e0ad49aa | ||
|
|
972eb23d03 | ||
|
|
f56c3868cf | ||
|
|
66fc546766 | ||
|
|
c71d5f6665 | ||
|
|
6e0564a98b | ||
|
|
99827ea220 | ||
|
|
0db83d0abd | ||
|
|
98711cec75 | ||
|
|
4a8f9c181c | ||
|
|
5165716e3d | ||
|
|
65d428004a | ||
|
|
14fc39a76f | ||
|
|
8b4e2a138c | ||
|
|
a11ee322ae | ||
|
|
db8ca25da9 | ||
|
|
c264a7f2b9 | ||
|
|
da6f0a1bd7 | ||
|
|
c643a1d482 | ||
|
|
0f8f42639d | ||
|
|
ec2cf9b561 | ||
|
|
c6b7655b65 | ||
|
|
3e80ad7cc7 | ||
|
|
1efad4e68e | ||
|
|
f5e0a3b1b3 | ||
|
|
a64b5be25b | ||
|
|
b31718a31f | ||
|
|
f6d83c765c | ||
|
|
5b3b22a2e9 | ||
|
|
a9b26d03ce | ||
|
|
31cb5a9b72 | ||
|
|
e5dd4c57a6 | ||
|
|
e7a1c6c315 | ||
|
|
e355be6186 | ||
|
|
12850a36ec | ||
|
|
010411fed3 | ||
|
|
f64a4883eb | ||
|
|
2883933549 | ||
|
|
fe9c78eed8 | ||
|
|
a5ec58dab9 | ||
|
|
29a79557d5 | ||
|
|
35fc3fdda2 | ||
|
|
8931262fa2 | ||
|
|
85d31db1d4 | ||
|
|
d48476a08d | ||
|
|
02f695b423 | ||
|
|
3c95db9c00 | ||
|
|
fec20ff914 | ||
|
|
de38bc9b0d | ||
|
|
f4114130c9 | ||
|
|
e920053306 | ||
|
|
511ff8e0e9 | ||
|
|
0220941849 | ||
|
|
7594d42e02 | ||
|
|
bd08d13ddc | ||
|
|
5095e8d1e8 | ||
|
|
a1958c1193 | ||
|
|
2a4da100ff | ||
|
|
9c91ab27b1 | ||
|
|
3f56cbce5f | ||
|
|
7cca8470e0 | ||
|
|
c82ceaaf39 | ||
|
|
e2e86b788c | ||
|
|
6b747fe801 | ||
|
|
9e6facc4d1 | ||
|
|
5cd966cafa | ||
|
|
47d5d99693 | ||
|
|
359b195d23 | ||
|
|
2a64b7365f | ||
|
|
c6aeb4a291 | ||
|
|
5001e4f0e1 | ||
|
|
61648b5ed2 | ||
|
|
4aa5169212 | ||
|
|
729caf0d5e | ||
|
|
f26d82217e | ||
|
|
e264675db7 | ||
|
|
300aa09fc5 | ||
|
|
493008417c | ||
|
|
906e07c1f2 | ||
|
|
6a954e2d24 | ||
|
|
3b724acc54 | ||
|
|
b0ca1256ae | ||
|
|
9d7820c356 | ||
|
|
1fc193167d | ||
|
|
d9f96a95c1 | ||
|
|
138a2acf84 | ||
|
|
88ada4aa31 | ||
|
|
77d8e3262a | ||
|
|
94b6ae13b3 | ||
|
|
f7c4c3c9cc | ||
|
|
71a93b0cd3 | ||
|
|
7bdf27af31 | ||
|
|
e60b41d9fa | ||
|
|
2ba765d360 | ||
|
|
93e27548ce | ||
|
|
aa89740311 | ||
|
|
aa306693a5 | ||
|
|
7041e5822f | ||
|
|
a08255e4cb | ||
|
|
2cde93bf63 | ||
|
|
f29836fcf3 | ||
|
|
7f32e42230 | ||
|
|
55e0df181f | ||
|
|
588cbabe94 | ||
|
|
5f873da929 | ||
|
|
fdabe9534c | ||
|
|
c0423707b0 | ||
|
|
48d9afa677 | ||
|
|
d71f309c1e | ||
|
|
cb323ef78c | ||
|
|
22bc1c374e | ||
|
|
31881d2a3b | ||
|
|
1dcdcd2f52 | ||
|
|
3de3b827bf | ||
|
|
8a8857a85c | ||
|
|
e4d5a4e777 | ||
|
|
b414ef2cc5 | ||
|
|
57e279cc1b | ||
|
|
2eb1a5c3ea | ||
|
|
dcc9a0ca29 | ||
|
|
892c545985 | ||
|
|
a8702b8374 | ||
|
|
1592987de8 | ||
|
|
710600546a | ||
|
|
0bf38ce294 | ||
|
|
459d156e85 | ||
|
|
95c090bed0 | ||
|
|
f2222d2621 | ||
|
|
97ffc37405 | ||
|
|
bf18b59845 | ||
|
|
88e953e8aa | ||
|
|
6076cf7114 | ||
|
|
a1757934ef | ||
|
|
6c61cb7f7a | ||
|
|
4b1f1c4029 | ||
|
|
7df04b0fe4 | ||
|
|
662101590d | ||
|
|
fc6167a2ee | ||
|
|
983cbb4f28 | ||
|
|
c9582c2323 | ||
|
|
03fdb4c157 | ||
|
|
afe25a99fe | ||
|
|
e32b8a90ac | ||
|
|
1472b86ee2 | ||
|
|
ff6745c795 | ||
|
|
fdfe03d561 |
@@ -1,37 +0,0 @@
|
||||
[bumpversion]
|
||||
current_version = 1.10.0a1
|
||||
parse = (?P<major>[\d]+) # major version number
|
||||
\.(?P<minor>[\d]+) # minor version number
|
||||
\.(?P<patch>[\d]+) # patch version number
|
||||
(?P<prerelease> # optional pre-release - ex: a1, b2, rc25
|
||||
(?P<prekind>a|b|rc) # pre-release type
|
||||
(?P<num>[\d]+) # pre-release version number
|
||||
)?
|
||||
( # optional nightly release indicator
|
||||
\.(?P<nightly>dev[0-9]+) # ex: .dev02142023
|
||||
)? # expected matches: `1.15.0`, `1.5.0a11`, `1.5.0a1.dev123`, `1.5.0.dev123457`, expected failures: `1`, `1.5`, `1.5.2-a1`, `text1.5.0`
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prekind}{num}.{nightly}
|
||||
{major}.{minor}.{patch}.{nightly}
|
||||
{major}.{minor}.{patch}{prekind}{num}
|
||||
{major}.{minor}.{patch}
|
||||
commit = False
|
||||
tag = False
|
||||
|
||||
[bumpversion:part:prekind]
|
||||
first_value = a
|
||||
optional_value = final
|
||||
values =
|
||||
a
|
||||
b
|
||||
rc
|
||||
final
|
||||
|
||||
[bumpversion:part:num]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:part:nightly]
|
||||
|
||||
[bumpversion:file:core/setup.py]
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
@@ -3,6 +3,9 @@
|
||||
For information on prior major and minor releases, see their changelogs:
|
||||
|
||||
|
||||
* [1.10](https://github.com/dbt-labs/dbt-core/blob/1.10.latest/CHANGELOG.md)
|
||||
* [1.9](https://github.com/dbt-labs/dbt-core/blob/1.9.latest/CHANGELOG.md)
|
||||
* [1.8](https://github.com/dbt-labs/dbt-core/blob/1.8.latest/CHANGELOG.md)
|
||||
* [1.7](https://github.com/dbt-labs/dbt-core/blob/1.7.latest/CHANGELOG.md)
|
||||
* [1.6](https://github.com/dbt-labs/dbt-core/blob/1.6.latest/CHANGELOG.md)
|
||||
* [1.5](https://github.com/dbt-labs/dbt-core/blob/1.5.latest/CHANGELOG.md)
|
||||
|
||||
6
.changes/unreleased/Dependencies-20251118-155354.yaml
Normal file
6
.changes/unreleased/Dependencies-20251118-155354.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Dependencies
|
||||
body: Use EventCatcher from dbt-common instead of maintaining a local copy
|
||||
time: 2025-11-18T15:53:54.284561+05:30
|
||||
custom:
|
||||
Author: 3loka
|
||||
Issue: "12124"
|
||||
@@ -1,6 +0,0 @@
|
||||
kind: Features
|
||||
body: Add new hard_deletes="new_record" mode for snapshots.
|
||||
time: 2024-11-04T12:00:53.95191-05:00
|
||||
custom:
|
||||
Author: peterallenwebb
|
||||
Issue: "10235"
|
||||
@@ -1,6 +0,0 @@
|
||||
kind: Features
|
||||
body: Add `batch` context object to model jinja context
|
||||
time: 2024-11-21T12:56:30.715473-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "11025"
|
||||
6
.changes/unreleased/Features-20251006-140352.yaml
Normal file
6
.changes/unreleased/Features-20251006-140352.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Features
|
||||
body: Support partial parsing for function nodes
|
||||
time: 2025-10-06T14:03:52.258104-05:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "12072"
|
||||
6
.changes/unreleased/Features-20251117-141053.yaml
Normal file
6
.changes/unreleased/Features-20251117-141053.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Features
|
||||
body: Allow for defining funciton arguments with default values
|
||||
time: 2025-11-17T14:10:53.860178-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "12044"
|
||||
6
.changes/unreleased/Features-20251201-165209.yaml
Normal file
6
.changes/unreleased/Features-20251201-165209.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Features
|
||||
body: Raise jsonschema-based deprecation warnings by default
|
||||
time: 2025-12-01T16:52:09.354436-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: 12240
|
||||
6
.changes/unreleased/Features-20251203-122926.yaml
Normal file
6
.changes/unreleased/Features-20251203-122926.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Features
|
||||
body: ':bug: :snowman: Disable unit tests whose model is disabled'
|
||||
time: 2025-12-03T12:29:26.209248-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "10540"
|
||||
6
.changes/unreleased/Features-20251210-202001.yaml
Normal file
6
.changes/unreleased/Features-20251210-202001.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Features
|
||||
body: Implement config.meta_get and config.meta_require
|
||||
time: 2025-12-10T20:20:01.354288-05:00
|
||||
custom:
|
||||
Author: gshank
|
||||
Issue: "12012"
|
||||
@@ -1,6 +0,0 @@
|
||||
kind: Fixes
|
||||
body: dbt retry does not respect --threads
|
||||
time: 2024-08-22T12:21:32.358066+05:30
|
||||
custom:
|
||||
Author: donjin-master
|
||||
Issue: "10584"
|
||||
@@ -1,6 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Catch DbtRuntimeError for hooks
|
||||
time: 2024-11-21T18:17:39.753235Z
|
||||
custom:
|
||||
Author: aranke
|
||||
Issue: "11012"
|
||||
6
.changes/unreleased/Fixes-20250922-151726.yaml
Normal file
6
.changes/unreleased/Fixes-20250922-151726.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Address Click 8.2+ deprecation warning
|
||||
time: 2025-09-22T15:17:26.983151-06:00
|
||||
custom:
|
||||
Author: edgarrmondragon
|
||||
Issue: "12038"
|
||||
6
.changes/unreleased/Fixes-20251117-140649.yaml
Normal file
6
.changes/unreleased/Fixes-20251117-140649.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Include macros in unit test parsing
|
||||
time: 2025-11-17T14:06:49.518566-05:00
|
||||
custom:
|
||||
Author: michelleark nathanskone
|
||||
Issue: "10157"
|
||||
6
.changes/unreleased/Fixes-20251117-185025.yaml
Normal file
6
.changes/unreleased/Fixes-20251117-185025.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Allow dbt deps to run when vars lack defaults in dbt_project.yml
|
||||
time: 2025-11-17T18:50:25.759091+05:30
|
||||
custom:
|
||||
Author: 3loka
|
||||
Issue: "8913"
|
||||
6
.changes/unreleased/Fixes-20251118-171106.yaml
Normal file
6
.changes/unreleased/Fixes-20251118-171106.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Restore DuplicateResourceNameError for intra-project node name duplication, behind behavior flag `require_unique_project_resource_names`
|
||||
time: 2025-11-18T17:11:06.454784-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "12152"
|
||||
6
.changes/unreleased/Fixes-20251119-195034.yaml
Normal file
6
.changes/unreleased/Fixes-20251119-195034.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Allow the usage of `function` with `--exclude-resource-type` flag
|
||||
time: 2025-11-19T19:50:34.703236-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "12143"
|
||||
6
.changes/unreleased/Fixes-20251124-155629.yaml
Normal file
6
.changes/unreleased/Fixes-20251124-155629.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Fix bug where schemas of functions weren't guaranteed to exist
|
||||
time: 2025-11-24T15:56:29.467004-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "12142"
|
||||
6
.changes/unreleased/Fixes-20251124-155756.yaml
Normal file
6
.changes/unreleased/Fixes-20251124-155756.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Fix generation of deprecations summary
|
||||
time: 2025-11-24T15:57:56.544123-08:00
|
||||
custom:
|
||||
Author: asiunov
|
||||
Issue: "12146"
|
||||
6
.changes/unreleased/Fixes-20251124-170855.yaml
Normal file
6
.changes/unreleased/Fixes-20251124-170855.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Correctly reference foreign key references when --defer and --state provided'
|
||||
time: 2025-11-24T17:08:55.387946-05:00
|
||||
custom:
|
||||
Author: michellark
|
||||
Issue: "11885"
|
||||
7
.changes/unreleased/Fixes-20251125-120246.yaml
Normal file
7
.changes/unreleased/Fixes-20251125-120246.yaml
Normal file
@@ -0,0 +1,7 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Add exception when using --state and referring to a removed
|
||||
test'
|
||||
time: 2025-11-25T12:02:46.635026-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "10630"
|
||||
6
.changes/unreleased/Fixes-20251125-122020.yaml
Normal file
6
.changes/unreleased/Fixes-20251125-122020.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Stop emitting `NoNodesForSelectionCriteria` three times during `build` command'
|
||||
time: 2025-11-25T12:20:20.132379-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "11627"
|
||||
6
.changes/unreleased/Fixes-20251127-141308.yaml
Normal file
6
.changes/unreleased/Fixes-20251127-141308.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ":bug: :snowman: Fix long Python stack traces appearing when package dependencies have incompatible version requirements"
|
||||
time: 2025-11-27T14:13:08.082542-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "12049"
|
||||
7
.changes/unreleased/Fixes-20251127-145929.yaml
Normal file
7
.changes/unreleased/Fixes-20251127-145929.yaml
Normal file
@@ -0,0 +1,7 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Fixed issue where changing data type size/precision/scale (e.g.,
|
||||
varchar(3) to varchar(10)) incorrectly triggered a breaking change error fo'
|
||||
time: 2025-11-27T14:59:29.256274-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "11186"
|
||||
6
.changes/unreleased/Fixes-20251127-170124.yaml
Normal file
6
.changes/unreleased/Fixes-20251127-170124.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Support unit testing models that depend on sources with the same name'
|
||||
time: 2025-11-27T17:01:24.193516-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: 11975 10433
|
||||
6
.changes/unreleased/Fixes-20251128-102129.yaml
Normal file
6
.changes/unreleased/Fixes-20251128-102129.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Fix bug in partial parsing when updating a model with a schema file that is referenced by a singular test
|
||||
time: 2025-11-28T10:21:29.911147Z
|
||||
custom:
|
||||
Author: mattogburke
|
||||
Issue: "12223"
|
||||
6
.changes/unreleased/Fixes-20251128-122838.yaml
Normal file
6
.changes/unreleased/Fixes-20251128-122838.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Avoid retrying successful run-operation commands'
|
||||
time: 2025-11-28T12:28:38.546261-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "11850"
|
||||
7
.changes/unreleased/Fixes-20251128-161937.yaml
Normal file
7
.changes/unreleased/Fixes-20251128-161937.yaml
Normal file
@@ -0,0 +1,7 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Fix `dbt deps --add-package` crash when packages.yml contains `warn-unpinned:
|
||||
false`'
|
||||
time: 2025-11-28T16:19:37.608722-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "9104"
|
||||
7
.changes/unreleased/Fixes-20251128-163144.yaml
Normal file
7
.changes/unreleased/Fixes-20251128-163144.yaml
Normal file
@@ -0,0 +1,7 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Improve `dbt deps --add-package` duplicate detection with better
|
||||
cross-source matching and word boundaries'
|
||||
time: 2025-11-28T16:31:44.344099-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "12239"
|
||||
6
.changes/unreleased/Fixes-20251202-133705.yaml
Normal file
6
.changes/unreleased/Fixes-20251202-133705.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: ':bug: :snowman: Fix false positive deprecation warning of pre/post-hook SQL configs'
|
||||
time: 2025-12-02T13:37:05.012112-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "12244"
|
||||
6
.changes/unreleased/Fixes-20251209-175031.yaml
Normal file
6
.changes/unreleased/Fixes-20251209-175031.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Ensure recent deprecation warnings include event name in message
|
||||
time: 2025-12-09T17:50:31.334618-06:00
|
||||
custom:
|
||||
Author: QMalcolm
|
||||
Issue: "12264"
|
||||
6
.changes/unreleased/Fixes-20251210-143935.yaml
Normal file
6
.changes/unreleased/Fixes-20251210-143935.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Fixes
|
||||
body: Improve error message clarity when detecting nodes with space in name
|
||||
time: 2025-12-10T14:39:35.107841-08:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "11835"
|
||||
6
.changes/unreleased/Under the Hood-20251119-110110.yaml
Normal file
6
.changes/unreleased/Under the Hood-20251119-110110.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Under the Hood
|
||||
body: Update jsonschemas for schema.yml and dbt_project.yml deprecations
|
||||
time: 2025-11-19T11:01:10.616676-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "12180"
|
||||
6
.changes/unreleased/Under the Hood-20251121-140515.yaml
Normal file
6
.changes/unreleased/Under the Hood-20251121-140515.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Under the Hood
|
||||
body: Replace setuptools and tox with hatch for build, test, and environment management.
|
||||
time: 2025-11-21T14:05:15.838252-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "12151"
|
||||
6
.changes/unreleased/Under the Hood-20251209-131857.yaml
Normal file
6
.changes/unreleased/Under the Hood-20251209-131857.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
kind: Under the Hood
|
||||
body: Add add_catalog_integration call even if we have a pre-existing manifest
|
||||
time: 2025-12-09T13:18:57.043254-08:00
|
||||
custom:
|
||||
Author: colin-rogers-dbt
|
||||
Issue: "12262"
|
||||
@@ -41,32 +41,26 @@ newlines:
|
||||
endOfVersion: 1
|
||||
|
||||
custom:
|
||||
- key: Author
|
||||
label: GitHub Username(s) (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 3
|
||||
- key: Issue
|
||||
label: GitHub Issue Number (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 1
|
||||
- key: Author
|
||||
label: GitHub Username(s) (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 3
|
||||
- key: Issue
|
||||
label: GitHub Issue Number (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 1
|
||||
|
||||
footerFormat: |
|
||||
{{- $contributorDict := dict }}
|
||||
{{- /* ensure all names in this list are all lowercase for later matching purposes */}}
|
||||
{{- $core_team := splitList " " .Env.CORE_TEAM }}
|
||||
{{- /* ensure we always skip snyk and dependabot in addition to the core team */}}
|
||||
{{- $maintainers := list "dependabot[bot]" "snyk-bot"}}
|
||||
{{- range $team_member := $core_team }}
|
||||
{{- $team_member_lower := lower $team_member }}
|
||||
{{- $maintainers = append $maintainers $team_member_lower }}
|
||||
{{- end }}
|
||||
{{- /* ensure we always skip snyk and dependabot */}}
|
||||
{{- $bots := list "dependabot[bot]" "snyk-bot"}}
|
||||
{{- range $change := .Changes }}
|
||||
{{- $authorList := splitList " " $change.Custom.Author }}
|
||||
{{- /* loop through all authors for a single changelog */}}
|
||||
{{- range $author := $authorList }}
|
||||
{{- $authorLower := lower $author }}
|
||||
{{- /* we only want to include non-core team contributors */}}
|
||||
{{- if not (has $authorLower $maintainers)}}
|
||||
{{- /* we only want to include non-bot contributors */}}
|
||||
{{- if not (has $authorLower $bots)}}
|
||||
{{- $changeList := splitList " " $change.Custom.Author }}
|
||||
{{- $IssueList := list }}
|
||||
{{- $changeLink := $change.Kind }}
|
||||
|
||||
1
.flake8
1
.flake8
@@ -10,6 +10,5 @@ ignore =
|
||||
E704 # makes Flake8 work like black
|
||||
E741
|
||||
E501 # long line checking is done in black
|
||||
exclude = test/
|
||||
per-file-ignores =
|
||||
*/__init__.py: F401
|
||||
|
||||
4
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
4
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -61,8 +61,8 @@ body:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.9.12 (`python3 --version`)
|
||||
- **OS**: Ubuntu 24.04
|
||||
- **Python**: 3.10.12 (`python3 --version`)
|
||||
- **dbt-core**: 1.1.1 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
|
||||
15
.github/ISSUE_TEMPLATE/config.yml
vendored
15
.github/ISSUE_TEMPLATE/config.yml
vendored
@@ -12,15 +12,6 @@ contact_links:
|
||||
- name: Participate in Discussions
|
||||
url: https://github.com/dbt-labs/dbt-core/discussions
|
||||
about: Do you have a Big Idea for dbt? Read open discussions, or start a new one
|
||||
- name: Create an issue for dbt-redshift
|
||||
url: https://github.com/dbt-labs/dbt-redshift/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-redshift
|
||||
- name: Create an issue for dbt-bigquery
|
||||
url: https://github.com/dbt-labs/dbt-bigquery/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-bigquery
|
||||
- name: Create an issue for dbt-snowflake
|
||||
url: https://github.com/dbt-labs/dbt-snowflake/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-snowflake
|
||||
- name: Create an issue for dbt-spark
|
||||
url: https://github.com/dbt-labs/dbt-spark/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-spark
|
||||
- name: Create an issue for adapters
|
||||
url: https://github.com/dbt-labs/dbt-adapters/issues/new/choose
|
||||
about: Report a bug or request a feature for an adapter
|
||||
|
||||
4
.github/ISSUE_TEMPLATE/regression-report.yml
vendored
4
.github/ISSUE_TEMPLATE/regression-report.yml
vendored
@@ -55,8 +55,8 @@ body:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.9.12 (`python3 --version`)
|
||||
- **OS**: Ubuntu 24.04
|
||||
- **Python**: 3.10.12 (`python3 --version`)
|
||||
- **dbt-core (working version)**: 1.1.1 (`dbt --version`)
|
||||
- **dbt-core (regression version)**: 1.2.0 (`dbt --version`)
|
||||
value: |
|
||||
|
||||
8
.github/_README.md
vendored
8
.github/_README.md
vendored
@@ -120,7 +120,7 @@ Some triggers of note that we use:
|
||||
```yaml
|
||||
jobs:
|
||||
dependency_changelog:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
|
||||
steps:
|
||||
- name: Get File Name Timestamp
|
||||
@@ -188,6 +188,12 @@ ___
|
||||
- The [GitHub CLI](https://cli.github.com/) is available in the default runners
|
||||
- Actions run in your context. ie, using an action from the marketplace that uses the GITHUB_TOKEN uses the GITHUB_TOKEN generated by your workflow run.
|
||||
|
||||
### Runners
|
||||
- We dynamically set runners based on repository vars. Admins can view repository vars and reset them. Current values are the following but are subject to change:
|
||||
- `vars.UBUNTU_LATEST` -> `ubuntu-latest`
|
||||
- `vars.WINDOWS_LATEST` -> `windows-latest`
|
||||
- `vars.MACOS_LATEST` -> `macos-14`
|
||||
|
||||
### Actions from the Marketplace
|
||||
- Don’t use external actions for things that can easily be accomplished manually.
|
||||
- Always read through what an external action does before using it! Often an action in the GitHub Actions Marketplace can be replaced with a few lines in bash. This is much more maintainable (and won’t change under us) and clear as to what’s actually happening. It also prevents any
|
||||
|
||||
2
.github/actions/latest-wrangler/README.md
vendored
2
.github/actions/latest-wrangler/README.md
vendored
@@ -33,7 +33,7 @@ on:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Wrangle latest tag
|
||||
|
||||
@@ -3,24 +3,24 @@ on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
description: The package to publish
|
||||
required: true
|
||||
description: The package to publish
|
||||
required: true
|
||||
version_number:
|
||||
description: The version number
|
||||
required: true
|
||||
description: The version number
|
||||
required: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Wrangle latest tag
|
||||
id: is_latest
|
||||
uses: ./.github/actions/latest-wrangler
|
||||
with:
|
||||
package: ${{ github.event.inputs.package }}
|
||||
new_version: ${{ github.event.inputs.new_version }}
|
||||
gh_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Print the results
|
||||
run: |
|
||||
echo "Is it latest? Survey says: ${{ steps.is_latest.outputs.latest }} !"
|
||||
- uses: actions/checkout@v3
|
||||
- name: Wrangle latest tag
|
||||
id: is_latest
|
||||
uses: ./.github/actions/latest-wrangler
|
||||
with:
|
||||
package: ${{ github.event.inputs.package }}
|
||||
new_version: ${{ github.event.inputs.new_version }}
|
||||
gh_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Print the results
|
||||
run: |
|
||||
echo "Is it latest? Survey says: ${{ steps.is_latest.outputs.latest }} !"
|
||||
|
||||
5
.github/actions/latest-wrangler/main.py
vendored
5
.github/actions/latest-wrangler/main.py
vendored
@@ -1,9 +1,10 @@
|
||||
import os
|
||||
from packaging.version import Version, parse
|
||||
import requests
|
||||
import sys
|
||||
from typing import List
|
||||
|
||||
import requests
|
||||
from packaging.version import Version, parse
|
||||
|
||||
|
||||
def main():
|
||||
package_name: str = os.environ["INPUT_PACKAGE_NAME"]
|
||||
|
||||
19
.github/actions/setup-postgres-linux/action.yml
vendored
19
.github/actions/setup-postgres-linux/action.yml
vendored
@@ -1,19 +0,0 @@
|
||||
name: "Set up postgres (linux)"
|
||||
description: "Set up postgres service on linux vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
sudo apt-get --purge remove postgresql postgresql-*
|
||||
sudo apt update -y
|
||||
sudo apt install gnupg2 wget vim -y
|
||||
sudo sh -c 'echo "deb https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
|
||||
curl -fsSL https://www.postgresql.org/media/keys/ACCC4CF8.asc|sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/postgresql.gpg
|
||||
sudo apt update -y
|
||||
sudo apt install postgresql-16
|
||||
sudo apt-get -y install postgresql postgresql-contrib
|
||||
sudo systemctl start postgresql
|
||||
sudo systemctl enable postgresql
|
||||
pg_isready
|
||||
sudo -u postgres bash ${{ github.action_path }}/setup_db.sh
|
||||
@@ -1 +0,0 @@
|
||||
../../../test/setup_db.sh
|
||||
26
.github/actions/setup-postgres-macos/action.yml
vendored
26
.github/actions/setup-postgres-macos/action.yml
vendored
@@ -1,26 +0,0 @@
|
||||
name: "Set up postgres (macos)"
|
||||
description: "Set up postgres service on macos vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
brew install postgresql@16
|
||||
brew link postgresql@16 --force
|
||||
brew services start postgresql@16
|
||||
echo "Check PostgreSQL service is running"
|
||||
i=10
|
||||
COMMAND='pg_isready'
|
||||
while [ $i -gt -1 ]; do
|
||||
if [ $i == 0 ]; then
|
||||
echo "PostgreSQL service not ready, all attempts exhausted"
|
||||
exit 1
|
||||
fi
|
||||
echo "Check PostgreSQL service status"
|
||||
eval $COMMAND && break
|
||||
echo "PostgreSQL service not ready, wait 10 more sec, attempts left: $i"
|
||||
sleep 10
|
||||
((i--))
|
||||
done
|
||||
createuser -s postgres
|
||||
bash ${{ github.action_path }}/setup_db.sh
|
||||
@@ -1 +0,0 @@
|
||||
../../../test/setup_db.sh
|
||||
@@ -1 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
../../../scripts/setup_db.sh
|
||||
186
.github/workflows/artifact-reviews.yml
vendored
Normal file
186
.github/workflows/artifact-reviews.yml
vendored
Normal file
@@ -0,0 +1,186 @@
|
||||
# **what?**
|
||||
# Enforces 2 reviews when artifact or validation files are modified.
|
||||
|
||||
# **why?**
|
||||
# Ensure artifact changes receive proper review from designated team members. GitHub doesn't support
|
||||
# multiple reviews on a single PR based on files changed, so we need to enforce this manually.
|
||||
|
||||
# **when?**
|
||||
# This will run when reviews are submitted and dismissed.
|
||||
|
||||
name: "Enforce Additional Reviews on Artifact and Validations Changes"
|
||||
|
||||
permissions:
|
||||
checks: write
|
||||
pull-requests: write
|
||||
contents: read
|
||||
|
||||
on:
|
||||
# trigger check on review events. use pull_request_target for forks.
|
||||
pull_request_target:
|
||||
types: [opened, reopened, ready_for_review, synchronize, review_requested]
|
||||
pull_request_review:
|
||||
types: [submitted, edited, dismissed]
|
||||
|
||||
# only run this once per PR at a time
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event.pull_request.number }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
required_approvals: 2
|
||||
team: "core-group"
|
||||
|
||||
jobs:
|
||||
check-reviews:
|
||||
name: "Validate Additional Reviews"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: "Get list of changed files"
|
||||
id: changed_files
|
||||
run: |
|
||||
# Fetch files as JSON and process with jq to sanitize output
|
||||
gh api repos/${{ github.repository }}/pulls/${{ github.event.pull_request.number }}/files \
|
||||
| jq -r '.[].filename' \
|
||||
| while IFS= read -r file; do
|
||||
# Sanitize the filename by removing any special characters and command injection attempts
|
||||
clean_file=$(echo "$file" | sed 's/[^a-zA-Z0-9\.\/\-_]//g')
|
||||
echo "$clean_file"
|
||||
done > changed_files.txt
|
||||
echo "CHANGED_FILES<<EOF" >> $GITHUB_OUTPUT
|
||||
cat changed_files.txt >> $GITHUB_OUTPUT
|
||||
echo "EOF" >> $GITHUB_OUTPUT
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: "Check if any artifact files changed"
|
||||
id: artifact_files_changed
|
||||
run: |
|
||||
artifact_changes=false
|
||||
while IFS= read -r file; do
|
||||
# Only process if file path looks legitimate
|
||||
if [[ "$file" =~ ^[a-zA-Z0-9\.\/\-_]+$ ]]; then
|
||||
if [[ "$file" == "core/dbt/artifacts/"* ]] ; then
|
||||
artifact_changes=true
|
||||
break
|
||||
fi
|
||||
fi
|
||||
done < changed_files.txt
|
||||
echo "artifact_changes=$artifact_changes" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: "Get Core Team Members"
|
||||
if: steps.artifact_files_changed.outputs.artifact_changes == 'true'
|
||||
id: core_members
|
||||
run: |
|
||||
gh api -H "Accept: application/vnd.github+json" \
|
||||
/orgs/dbt-labs/teams/${{ env.team }}/members > core_members.json
|
||||
|
||||
# Extract usernames and set as multiline output
|
||||
echo "membership<<EOF" >> $GITHUB_OUTPUT
|
||||
jq -r '.[].login' core_members.json >> $GITHUB_OUTPUT
|
||||
echo "EOF" >> $GITHUB_OUTPUT
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.IT_TEAM_MEMBERSHIP }}
|
||||
|
||||
- name: "Verify ${{ env.required_approvals }} core team approvals"
|
||||
if: steps.artifact_files_changed.outputs.artifact_changes == 'true'
|
||||
id: check_approvals
|
||||
run: |
|
||||
|
||||
# Get all reviews
|
||||
REVIEWS=$(gh api repos/${{ github.repository }}/pulls/${{ github.event.pull_request.number }}/reviews)
|
||||
echo "All reviews:"
|
||||
echo "$REVIEWS"
|
||||
# Count approved reviews from core team members (only most recent review per user)
|
||||
CORE_APPROVALS=0
|
||||
while IFS= read -r member; do
|
||||
echo "Checking member: $member"
|
||||
APPROVED=$(echo "$REVIEWS" | jq --arg user "$member" '
|
||||
group_by(.user.login) |
|
||||
map(select(.[0].user.login == $user) |
|
||||
sort_by(.submitted_at) |
|
||||
last) |
|
||||
map(select(.state == "APPROVED" and (.state != "DISMISSED"))) |
|
||||
length')
|
||||
echo "Latest review state for $member: $APPROVED"
|
||||
CORE_APPROVALS=$((CORE_APPROVALS + APPROVED))
|
||||
echo "Running total: $CORE_APPROVALS"
|
||||
done <<< "${{ steps.core_members.outputs.membership }}"
|
||||
|
||||
echo "CORE_APPROVALS=$CORE_APPROVALS" >> $GITHUB_OUTPUT
|
||||
echo "CORE_APPROVALS=$CORE_APPROVALS"
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: "Find Comment"
|
||||
if: steps.artifact_files_changed.outputs.artifact_changes == 'true' && steps.check_approvals.outputs.CORE_APPROVALS < env.required_approvals
|
||||
uses: peter-evans/find-comment@a54c31d7fa095754bfef525c0c8e5e5674c4b4b1 # peter-evans/find-comment@v2
|
||||
id: find-comment
|
||||
with:
|
||||
issue-number: ${{ github.event.pull_request.number }}
|
||||
comment-author: 'github-actions[bot]'
|
||||
body-includes: "### Additional Artifact Review Required"
|
||||
|
||||
- name: "Create Comment"
|
||||
if: steps.artifact_files_changed.outputs.artifact_changes == 'true' && steps.find-comment.outputs.comment-id == '' && steps.check_approvals.outputs.CORE_APPROVALS < env.required_approvals
|
||||
uses: peter-evans/create-or-update-comment@23ff15729ef2fc348714a3bb66d2f655ca9066f2 # peter-evans/create-or-update-comment@v3
|
||||
with:
|
||||
issue-number: ${{ github.event.pull_request.number }}
|
||||
body: |
|
||||
### Additional Artifact Review Required
|
||||
|
||||
Changes to artifact directory files requires at least ${{ env.required_approvals }} approvals from core team members.
|
||||
|
||||
- name: "Notify if not enough approvals"
|
||||
if: steps.artifact_files_changed.outputs.artifact_changes == 'true'
|
||||
run: |
|
||||
if [[ "${{ steps.check_approvals.outputs.CORE_APPROVALS }}" -ge "${{ env.required_approvals }}" ]]; then
|
||||
title="Extra requirements met"
|
||||
message="Changes to artifact directory files requires at least ${{ env.required_approvals }} approvals from core team members. Current number of core team approvals: ${{ steps.check_approvals.outputs.CORE_APPROVALS }} "
|
||||
echo "::notice title=$title::$message"
|
||||
echo "REVIEW_STATUS=success" >> $GITHUB_OUTPUT
|
||||
else
|
||||
title="PR Approval Requirements Not Met"
|
||||
message="Changes to artifact directory files requires at least ${{ env.required_approvals }} approvals from core team members. Current number of core team approvals: ${{ steps.check_approvals.outputs.CORE_APPROVALS }} "
|
||||
echo "::notice title=$title::$message"
|
||||
echo "REVIEW_STATUS=neutral" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
id: review_check
|
||||
|
||||
- name: "Set check status"
|
||||
id: status_check
|
||||
run: |
|
||||
if [[ "${{ steps.artifact_files_changed.outputs.artifact_changes }}" == 'false' ]]; then
|
||||
# no extra review required
|
||||
echo "current_status=success" >> $GITHUB_OUTPUT
|
||||
elif [[ "${{ steps.review_check.outputs.REVIEW_STATUS }}" == "success" ]]; then
|
||||
# we have all the required reviews
|
||||
echo "current_status=success" >> $GITHUB_OUTPUT
|
||||
else
|
||||
# neutral exit - neither success nor failure
|
||||
# we can't fail here because we use multiple triggers for this workflow and they won't reset the check
|
||||
# workaround is to use a neutral exit to skip the check run until it's actually successful
|
||||
echo "current_status=neutral" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: "Post Event"
|
||||
# This step posts the status of the check because the workflow is triggered by multiple events
|
||||
# and we need to ensure the check is always updated. Otherwise we would end up with duplicate
|
||||
# checks in the GitHub UI.
|
||||
run: |
|
||||
if [[ "${{ steps.status_check.outputs.current_status }}" == "success" ]]; then
|
||||
state="success"
|
||||
else
|
||||
state="failure"
|
||||
fi
|
||||
|
||||
gh api \
|
||||
--method POST \
|
||||
-H "Accept: application/vnd.github+json" \
|
||||
/repos/${{ github.repository }}/statuses/${{ github.event.pull_request.base.sha }} \
|
||||
-f state="$state" \
|
||||
-f description="Artifact Review Check" \
|
||||
-f context="Artifact Review Check" \
|
||||
-f target_url="${{ github.server_url }}/${{ github.repository }}/actions/runs/${{ github.run_id }}"
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
50
.github/workflows/auto-respond-bug-reports.yml
vendored
Normal file
50
.github/workflows/auto-respond-bug-reports.yml
vendored
Normal file
@@ -0,0 +1,50 @@
|
||||
# **what?**
|
||||
# Check if the an issue is opened near or during an extended holiday period.
|
||||
# If so, post an automatically-generated comment about the holiday for bug reports.
|
||||
# Also provide specific information to customers of dbt Cloud.
|
||||
|
||||
# **why?**
|
||||
# Explain why responses will be delayed during our holiday period.
|
||||
|
||||
# **when?**
|
||||
# This will run when new issues are opened.
|
||||
|
||||
name: Auto-Respond to Bug Reports During Holiday Period
|
||||
|
||||
on:
|
||||
issues:
|
||||
types:
|
||||
- opened
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
issues: write
|
||||
|
||||
jobs:
|
||||
auto-response:
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
steps:
|
||||
- name: Check if current date is within holiday period
|
||||
id: date-check
|
||||
run: |
|
||||
current_date=$(date -u +"%Y-%m-%d")
|
||||
start_date="2024-12-23"
|
||||
end_date="2025-01-05"
|
||||
|
||||
if [[ "$current_date" < "$start_date" || "$current_date" > "$end_date" ]]; then
|
||||
echo "outside_holiday=true" >> $GITHUB_ENV
|
||||
else
|
||||
echo "outside_holiday=false" >> $GITHUB_ENV
|
||||
fi
|
||||
|
||||
- name: Post comment
|
||||
if: ${{ env.outside_holiday == 'false' && contains(github.event.issue.labels.*.name, 'bug') }}
|
||||
run: |
|
||||
gh issue comment ${{ github.event.issue.number }} --repo ${{ github.repository }} --body "Thank you for your bug report! Our team is will be out of the office for [Christmas and our Global Week of Rest](https://handbook.getdbt.com/docs/time_off#2024-us-holidays), from December 25, 2024, through January 3, 2025.
|
||||
|
||||
We will review your issue as soon as possible after returning.
|
||||
Thank you for your understanding, and happy holidays! 🎄🎉
|
||||
|
||||
If you are a customer of dbt Cloud, please contact our Customer Support team via the dbt Cloud web interface or email **support@dbtlabs.com**."
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
4
.github/workflows/backport.yml
vendored
4
.github/workflows/backport.yml
vendored
@@ -28,13 +28,13 @@ permissions:
|
||||
jobs:
|
||||
backport:
|
||||
name: Backport
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
# Only react to merged PRs for security reasons.
|
||||
# See https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#pull_request_target.
|
||||
if: >
|
||||
github.event.pull_request.merged
|
||||
&& contains(github.event.label.name, 'backport')
|
||||
steps:
|
||||
- uses: tibdex/backport@v2.0.4
|
||||
- uses: tibdex/backport@9565281eda0731b1d20c4025c43339fb0a23812e # tibdex/backport@v2.0.4
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
4
.github/workflows/bot-changelog.yml
vendored
4
.github/workflows/bot-changelog.yml
vendored
@@ -41,14 +41,14 @@ jobs:
|
||||
include:
|
||||
- label: "dependencies"
|
||||
changie_kind: "Dependencies"
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
|
||||
steps:
|
||||
|
||||
- name: Create and commit changelog on bot PR
|
||||
if: ${{ contains(github.event.pull_request.labels.*.name, matrix.label) }}
|
||||
id: bot_changelog
|
||||
uses: emmyoop/changie_bot@v1.1.0
|
||||
uses: emmyoop/changie_bot@22b70618b13d0d1c64ea95212bafca2d2bf6b764 # emmyoop/changie_bot@v1.1.0
|
||||
with:
|
||||
GITHUB_TOKEN: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
commit_author_name: "Github Build Bot"
|
||||
|
||||
12
.github/workflows/check-artifact-changes.yml
vendored
12
.github/workflows/check-artifact-changes.yml
vendored
@@ -4,22 +4,26 @@ on:
|
||||
pull_request:
|
||||
types: [ opened, reopened, labeled, unlabeled, synchronize ]
|
||||
paths-ignore: [ '.changes/**', '.github/**', 'tests/**', '**.md', '**.yml' ]
|
||||
|
||||
merge_group:
|
||||
types: [checks_requested]
|
||||
workflow_dispatch:
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
check-artifact-changes:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
if: ${{ !contains(github.event.pull_request.labels.*.name, 'artifact_minor_upgrade') }}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Check for changes in core/dbt/artifacts
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
uses: dorny/paths-filter@v3
|
||||
uses: dorny/paths-filter@de90cc6fb38fc0963ad72b210f1f284cd68cea36 # dorny/paths-filter@v3
|
||||
id: check_artifact_changes
|
||||
with:
|
||||
filters: |
|
||||
|
||||
13
.github/workflows/community-label.yml
vendored
13
.github/workflows/community-label.yml
vendored
@@ -7,7 +7,6 @@
|
||||
# **when?**
|
||||
# When a PR is opened, not in draft or moved from draft to ready for review
|
||||
|
||||
|
||||
name: Label community PRs
|
||||
|
||||
on:
|
||||
@@ -29,9 +28,15 @@ jobs:
|
||||
# If this PR is opened and not draft, determine if it needs to be labeled
|
||||
# if the PR is converted out of draft, determine if it needs to be labeled
|
||||
if: |
|
||||
(!contains(github.event.pull_request.labels.*.name, 'community') &&
|
||||
(github.event.action == 'opened' && github.event.pull_request.draft == false ) ||
|
||||
github.event.action == 'ready_for_review' )
|
||||
(
|
||||
!contains(github.event.pull_request.labels.*.name, 'community')
|
||||
&& (
|
||||
(github.event.action == 'opened' && github.event.pull_request.draft == false)
|
||||
|| github.event.action == 'ready_for_review'
|
||||
)
|
||||
&& github.event.pull_request.user.type != 'Bot'
|
||||
&& github.event.pull_request.user.login != 'dependabot[bot]'
|
||||
)
|
||||
uses: dbt-labs/actions/.github/workflows/label-community.yml@main
|
||||
with:
|
||||
github_team: 'core-group'
|
||||
|
||||
388
.github/workflows/cut-release-branch.yml
vendored
388
.github/workflows/cut-release-branch.yml
vendored
@@ -1,25 +1,44 @@
|
||||
# **what?**
|
||||
# Cuts a new `*.latest` branch
|
||||
# Also cleans up all files in `.changes/unreleased` and `.changes/previous verion on
|
||||
# `main` and bumps `main` to the input version.
|
||||
# Cuts the `*.latest` branch, bumps dependencies on it, cleans up all files in `.changes/unreleased`
|
||||
# and `.changes/previous verion on main and bumps main to the input version.
|
||||
|
||||
# **why?**
|
||||
# Generally reduces the workload of engineers and reduces error. Allow automation.
|
||||
# Clean up the main branch after a release branch is cut and automate cutting the release branch.
|
||||
# Generally reduces the workload of engineers and reducing error.
|
||||
|
||||
# **when?**
|
||||
# This will run when called manually.
|
||||
# This will run when called manually or when triggered in another workflow.
|
||||
|
||||
# Example Usage including required permissions: TODO: update once finalized
|
||||
|
||||
# permissions:
|
||||
# contents: read
|
||||
# pull-requests: write
|
||||
#
|
||||
# name: Cut Release Branch
|
||||
# jobs:
|
||||
# changelog:
|
||||
# uses: dbt-labs/actions/.github/workflows/cut-release-branch.yml@main
|
||||
# with:
|
||||
# new_branch_name: 1.7.latest
|
||||
# PR_title: "Cleanup main after cutting new 1.7.latest branch"
|
||||
# PR_body: "All adapter PRs will fail CI until the dbt-core PR has been merged due to release version conflicts."
|
||||
# secrets:
|
||||
# FISHTOWN_BOT_PAT: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
# TODOs
|
||||
# add note to eventually commit changes directly and bypass checks - same as release - when we move to this model run test action after merge
|
||||
|
||||
name: Cut new release branch
|
||||
run-name: "Cutting New Branch: ${{ inputs.new_branch_name }}"
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version_to_bump_main:
|
||||
description: 'The alpha version main should bump to (ex. 1.6.0a1)'
|
||||
required: true
|
||||
new_branch_name:
|
||||
description: 'The full name of the new branch (ex. 1.5.latest)'
|
||||
description: "The full name of the new branch (ex. 1.5.latest)"
|
||||
required: true
|
||||
type: string
|
||||
|
||||
defaults:
|
||||
run:
|
||||
@@ -27,15 +46,346 @@ defaults:
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
env:
|
||||
PYTHON_TARGET_VERSION: "3.10"
|
||||
PR_TITLE: "Cleanup main after cutting new ${{ inputs.new_branch_name }} branch"
|
||||
PR_BODY: "All adapter PRs will fail CI until the dbt-core PR has been merged due to release version conflicts."
|
||||
|
||||
jobs:
|
||||
cut_branch:
|
||||
name: "Cut branch and clean up main for dbt-core"
|
||||
uses: dbt-labs/actions/.github/workflows/cut-release-branch.yml@main
|
||||
with:
|
||||
version_to_bump_main: ${{ inputs.version_to_bump_main }}
|
||||
new_branch_name: ${{ inputs.new_branch_name }}
|
||||
PR_title: "Cleanup main after cutting new ${{ inputs.new_branch_name }} branch"
|
||||
PR_body: "All adapter PRs will fail CI until the dbt-core PR has been merged due to release version conflicts."
|
||||
secrets:
|
||||
FISHTOWN_BOT_PAT: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
prep_work:
|
||||
name: "Prep Work"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: "[DEBUG] Print Inputs"
|
||||
run: |
|
||||
echo "new_branch_name: ${{ inputs.new_branch_name }}"
|
||||
echo "PR_title: ${{ env.PR_TITLE }}"
|
||||
echo "PR_body: ${{ env.PR_BODY }}"
|
||||
|
||||
create_temp_branch:
|
||||
name: "Create Temp branch off main"
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
temp_branch_name: ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
|
||||
steps:
|
||||
- name: "Set Branch Value"
|
||||
id: variables
|
||||
run: |
|
||||
echo "BRANCH_NAME=cutting_release_branch/main_cleanup_$GITHUB_RUN_ID" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: "main"
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "Create PR Branch"
|
||||
run: |
|
||||
user="Github Build Bot"
|
||||
email="buildbot@fishtownanalytics.com"
|
||||
git config user.name "$user"
|
||||
git config user.email "$email"
|
||||
git checkout -b ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
git push --set-upstream origin ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
|
||||
- name: "[Notification] Temp branch created"
|
||||
run: |
|
||||
message="Temp branch ${{ steps.variables.outputs.BRANCH_NAME }} created"
|
||||
echo "::notice title="Temporary branch created": $title::$message"
|
||||
|
||||
cleanup_changelog:
|
||||
name: "Clean Up Changelog"
|
||||
needs: ["create_temp_branch"]
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
next-version: ${{ steps.semver-current.outputs.next-minor-alpha-version }}
|
||||
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ needs.create_temp_branch.outputs.temp_branch_name }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "Add Homebrew To PATH"
|
||||
run: |
|
||||
echo "/home/linuxbrew/.linuxbrew/bin:/home/linuxbrew/.linuxbrew/sbin" >> $GITHUB_PATH
|
||||
|
||||
- name: "Install Homebrew Packages"
|
||||
run: |
|
||||
brew install pre-commit
|
||||
brew tap miniscruff/changie https://github.com/miniscruff/changie
|
||||
brew install changie
|
||||
|
||||
- name: "Check Current Version In Code"
|
||||
id: determine_version
|
||||
run: |
|
||||
current_version=$(grep '^version = ' core/pyproject.toml | sed 's/version = "\(.*\)"/\1/')
|
||||
echo "current_version=$current_version" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: "[Notification] Check Current Version In Code"
|
||||
run: |
|
||||
message="The current version is ${{ steps.determine_version.outputs.current_version }}"
|
||||
echo "::notice title="Version Bump Check": $title::$message"
|
||||
|
||||
- name: "Parse Current Version Into Parts for Changelog Directories"
|
||||
id: semver-current
|
||||
uses: dbt-labs/actions/parse-semver@main
|
||||
with:
|
||||
version: ${{ steps.determine_version.outputs.current_version }}
|
||||
|
||||
- name: "[Notification] Next Alpha Version"
|
||||
run: |
|
||||
message="The next alpha version is ${{ steps.semver-current.outputs.next-minor-alpha-version }}"
|
||||
echo "::notice title="Version Bump Check": $title::$message"
|
||||
|
||||
- name: "Delete Unreleased Changelog YAMLs"
|
||||
# removal fails if no files exist. OK to continue since we're just cleaning up the files.
|
||||
continue-on-error: true
|
||||
run: |
|
||||
rm .changes/unreleased/*.yaml || true
|
||||
|
||||
- name: "Delete Pre Release Changelogs and YAMLs"
|
||||
# removal fails if no files exist. OK to continue since we're just cleaning up the files.
|
||||
continue-on-error: true
|
||||
run: |
|
||||
rm .changes/${{ steps.semver-current.outputs.base-version }}/*.yaml || true
|
||||
rm .changes/${{ steps.semver-current.outputs.major }}.${{ steps.semver-current.outputs.minor }}.*.md || true
|
||||
|
||||
- name: "Cleanup CHANGELOG.md"
|
||||
run: |
|
||||
changie merge
|
||||
|
||||
- name: "Commit Changelog Cleanup to Branch"
|
||||
run: |
|
||||
user="Github Build Bot"
|
||||
email="buildbot@fishtownanalytics.com"
|
||||
git config user.name "$user"
|
||||
git config user.email "$email"
|
||||
git status
|
||||
git add .
|
||||
git commit -m "Clean up changelog on main"
|
||||
git push
|
||||
|
||||
- name: "[Notification] Changelog cleaned up"
|
||||
run: |
|
||||
message="Changelog on ${{ needs.create_temp_branch.outputs.temp_branch_name }} cleaned up"
|
||||
echo "::notice title="Changelog cleaned up": $title::$message"
|
||||
|
||||
bump_version:
|
||||
name: "Bump to next minor version"
|
||||
needs: ["cleanup_changelog", "create_temp_branch"]
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ needs.create_temp_branch.outputs.temp_branch_name }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "Set up Python - ${{ env.PYTHON_TARGET_VERSION }}"
|
||||
uses: actions/setup-python@a26af69be951a213d495a4c3e4e4022e16d87065 # actions/setup-python@v5
|
||||
with:
|
||||
python-version: "${{ env.PYTHON_TARGET_VERSION }}"
|
||||
|
||||
- name: "Install Spark Dependencies"
|
||||
if: ${{ contains(github.repository, 'dbt-labs/dbt-spark') }}
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get install libsasl2-dev
|
||||
|
||||
- name: "Install Python Dependencies"
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install hatch
|
||||
|
||||
- name: "Bump Version To ${{ needs.cleanup_changelog.outputs.next-version }}"
|
||||
run: |
|
||||
cd core
|
||||
hatch version ${{ needs.cleanup_changelog.outputs.next-version }}
|
||||
hatch run dev-req
|
||||
dbt --version
|
||||
|
||||
- name: "Commit Version Bump to Branch"
|
||||
run: |
|
||||
user="Github Build Bot"
|
||||
email="buildbot@fishtownanalytics.com"
|
||||
git config user.name "$user"
|
||||
git config user.email "$email"
|
||||
git status
|
||||
git add .
|
||||
git commit -m "Bumping version to ${{ needs.cleanup_changelog.outputs.next-version }}"
|
||||
git push
|
||||
|
||||
- name: "[Notification] Version Bump completed"
|
||||
run: |
|
||||
message="Version on ${{ needs.create_temp_branch.outputs.temp_branch_name }} bumped to ${{ needs.cleanup_changelog.outputs.next-version }}"
|
||||
echo "::notice title="Version Bump Completed": $title::$message"
|
||||
|
||||
cleanup:
|
||||
name: "Cleanup Code Quality"
|
||||
needs: ["create_temp_branch", "bump_version"]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ needs.create_temp_branch.outputs.temp_branch_name }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "Add Homebrew To PATH"
|
||||
run: |
|
||||
echo "/home/linuxbrew/.linuxbrew/bin:/home/linuxbrew/.linuxbrew/sbin" >> $GITHUB_PATH
|
||||
|
||||
- name: "brew install pre-commit"
|
||||
run: |
|
||||
brew install pre-commit
|
||||
|
||||
# this step will fail on whitespace errors but also correct them
|
||||
- name: "Cleanup - Remove Trailing Whitespace Via Pre-commit"
|
||||
continue-on-error: true
|
||||
run: |
|
||||
pre-commit run trailing-whitespace --files CHANGELOG.md .changes/* || true
|
||||
|
||||
# this step will fail on newline errors but also correct them
|
||||
- name: "Cleanup - Remove Extra Newlines Via Pre-commit"
|
||||
continue-on-error: true
|
||||
run: |
|
||||
pre-commit run end-of-file-fixer --files CHANGELOG.md .changes/* || true
|
||||
|
||||
- name: "Commit Version Bump to Branch"
|
||||
run: |
|
||||
user="Github Build Bot"
|
||||
email="buildbot@fishtownanalytics.com"
|
||||
git config user.name "$user"
|
||||
git config user.email "$email"
|
||||
git status
|
||||
git add .
|
||||
git commit -m "Code quality cleanup"
|
||||
git push
|
||||
|
||||
open_pr:
|
||||
name: "Open PR Against main"
|
||||
needs: ["cleanup_changelog", "create_temp_branch", "cleanup"]
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
pr_number: ${{ steps.create_pr.outputs.pull-request-number }}
|
||||
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ needs.create_temp_branch.outputs.temp_branch_name }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "Determine PR Title"
|
||||
id: pr_title
|
||||
run: |
|
||||
echo "pr_title=${{ env.PR_TITLE }}" >> $GITHUB_OUTPUT
|
||||
if [${{ env.PR_TITLE }} == ""]; then
|
||||
echo "pr_title='Clean up changelogs and bump to version ${{ needs.cleanup_changelog.outputs.next-version }}'" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: "Determine PR Body"
|
||||
id: pr_body
|
||||
run: |
|
||||
echo "pr_body=${{ env.PR_BODY }}" >> $GITHUB_OUTPUT
|
||||
if [${{ env.PR_BODY }} == ""]; then
|
||||
echo "pr_body='Clean up changelogs and bump to version ${{ needs.cleanup_changelog.outputs.next-version }}'" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: "Add Branch Details"
|
||||
id: pr_body_branch
|
||||
run: |
|
||||
branch_details="The workflow that generated this PR also created a new branch: ${{ inputs.new_branch_name }}"
|
||||
full_body="${{ steps.pr_body.outputs.pr_body }} $branch_details"
|
||||
echo "pr_full_body=$full_body" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: "Open Pull Request"
|
||||
id: create_pr
|
||||
run: |
|
||||
pr_url=$(gh pr create -B main -H ${{ needs.create_temp_branch.outputs.temp_branch_name }} -l "Skip Changelog" -t "${{ steps.pr_title.outputs.pr_title }}" -b "${{ steps.pr_body_branch.outputs.pr_full_body }}")
|
||||
echo "pr_url=$pr_url" >> $GITHUB_OUTPUT
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: "[Notification] Pull Request Opened"
|
||||
run: |
|
||||
message="PR opened at ${{ steps.create_pr.outputs.pr_url }}"
|
||||
echo "::notice title="Pull Request Opened": $title::$message"
|
||||
|
||||
cut_new_branch:
|
||||
# don't cut the new branch until we're done opening the PR against main
|
||||
name: "Cut New Branch ${{ inputs.new_branch_name }}"
|
||||
needs: [open_pr]
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }}"
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
fetch-depth: 0
|
||||
|
||||
- name: "Ensure New Branch Does Not Exist"
|
||||
id: check_new_branch
|
||||
run: |
|
||||
title="Check New Branch Existence"
|
||||
if git show-ref --quiet ${{ inputs.new_branch_name }}; then
|
||||
message="Branch ${{ inputs.new_branch_name }} already exists. Exiting."
|
||||
echo "::error $title::$message"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
- name: "Create New Release Branch"
|
||||
run: |
|
||||
git checkout -b ${{ inputs.new_branch_name }}
|
||||
|
||||
- name: "Push up New Branch"
|
||||
run: |
|
||||
#Data for commit
|
||||
user="Github Build Bot"
|
||||
email="buildbot@fishtownanalytics.com"
|
||||
git config user.name "$user"
|
||||
git config user.email "$email"
|
||||
git push --set-upstream origin ${{ inputs.new_branch_name }}
|
||||
|
||||
- name: "[Notification] New branch created"
|
||||
run: |
|
||||
message="New branch ${{ inputs.new_branch_name }} created"
|
||||
echo "::notice title="New branch created": $title::$message"
|
||||
|
||||
- name: "Bump dependencies via script"
|
||||
# This bumps the dependency on dbt-core in the adapters
|
||||
if: ${{ !contains(github.repository, 'dbt-core') }}
|
||||
run: |
|
||||
echo ${{ github.repository }}
|
||||
echo "running update_dependencies script"
|
||||
bash ${GITHUB_WORKSPACE}/.github/scripts/update_dependencies.sh ${{ inputs.new_branch_name }}
|
||||
commit_message="bumping .latest branch variable in update_dependencies.sh to ${{ inputs.new_branch_name }}"
|
||||
git status
|
||||
git add .
|
||||
git commit -m "$commit_message"
|
||||
git push
|
||||
|
||||
- name: "Bump env variable via script"
|
||||
# bumps the RELEASE_BRANCH variable in nightly-release.yml in adapters
|
||||
if: ${{ !contains(github.repository, 'dbt-core') }}
|
||||
run: |
|
||||
file="./.github/scripts/update_release_branch.sh"
|
||||
if test -f "$file"; then
|
||||
echo ${{ github.repository }}
|
||||
echo "running some script yet to be written now"
|
||||
bash $file ${{ inputs.new_branch_name }}
|
||||
commit_message="updating env variable to ${{ inputs.new_branch_name }} in nightly-release.yml"
|
||||
git status
|
||||
git add .
|
||||
git commit -m "$commit_message"
|
||||
git push
|
||||
else
|
||||
echo "no $file seen skipping step"
|
||||
fi
|
||||
|
||||
219
.github/workflows/main.yml
vendored
219
.github/workflows/main.yml
vendored
@@ -20,6 +20,8 @@ on:
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
merge_group:
|
||||
types: [checks_requested]
|
||||
workflow_dispatch:
|
||||
|
||||
permissions: read-all
|
||||
@@ -47,27 +49,33 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: '3.9'
|
||||
python-version: "3.10"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
make dev
|
||||
make dev_req
|
||||
mypy --version
|
||||
dbt --version
|
||||
python -m pip install hatch
|
||||
cd core
|
||||
hatch run setup
|
||||
|
||||
- name: Verify dbt installation
|
||||
run: |
|
||||
cd core
|
||||
hatch run dbt --version
|
||||
|
||||
- name: Run pre-commit hooks
|
||||
run: pre-commit run --all-files --show-diff-on-failure
|
||||
run: |
|
||||
cd core
|
||||
hatch run code-quality
|
||||
|
||||
unit:
|
||||
name: unit test / python ${{ matrix.python-version }}
|
||||
name: "unit test / python ${{ matrix.python-version }}"
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 10
|
||||
@@ -75,17 +83,14 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: [ "3.9", "3.10", "3.11", "3.12" ]
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
@@ -93,15 +98,15 @@ jobs:
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
tox --version
|
||||
python -m pip install hatch
|
||||
hatch --version
|
||||
|
||||
- name: Run unit tests
|
||||
uses: nick-fields/retry@v3
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 10
|
||||
max_attempts: 3
|
||||
command: tox -e unit
|
||||
command: cd core && hatch run ci:unit-tests
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
@@ -112,10 +117,11 @@ jobs:
|
||||
|
||||
- name: Upload Unit Test Coverage to Codecov
|
||||
if: ${{ matrix.python-version == '3.11' }}
|
||||
uses: codecov/codecov-action@v4
|
||||
uses: codecov/codecov-action@5a1091511ad55cbe89839c7260b706298ca349f7 # codecov/codecov-action@v5
|
||||
with:
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
flags: unit
|
||||
fail_ci_if_error: false
|
||||
|
||||
integration-metadata:
|
||||
name: integration test metadata generation
|
||||
@@ -140,7 +146,7 @@ jobs:
|
||||
- name: generate include
|
||||
id: generate-include
|
||||
run: |
|
||||
INCLUDE=('"python-version":"3.9","os":"windows-latest"' '"python-version":"3.9","os":"macos-14"' )
|
||||
INCLUDE=('"python-version":"3.10","os":"windows-latest"' '"python-version":"3.10","os":"macos-14"' )
|
||||
INCLUDE_GROUPS="["
|
||||
for include in ${INCLUDE[@]}; do
|
||||
for group in $(seq 1 ${{ env.PYTHON_INTEGRATION_TEST_WORKERS }}); do
|
||||
@@ -152,7 +158,102 @@ jobs:
|
||||
echo "include=${INCLUDE_GROUPS}"
|
||||
echo "include=${INCLUDE_GROUPS}" >> $GITHUB_OUTPUT
|
||||
|
||||
integration:
|
||||
integration-postgres:
|
||||
name: "(${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}"
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
timeout-minutes: 30
|
||||
needs:
|
||||
- integration-metadata
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
||||
os: ["ubuntu-latest"]
|
||||
split-group: ${{ fromJson(needs.integration-metadata.outputs.split-groups) }}
|
||||
env:
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
DD_CIVISIBILITY_AGENTLESS_ENABLED: true
|
||||
DD_API_KEY: ${{ secrets.DATADOG_API_KEY }}
|
||||
DD_SITE: datadoghq.com
|
||||
DD_ENV: ci
|
||||
DD_SERVICE: ${{ github.event.repository.name }}
|
||||
|
||||
services:
|
||||
# Label used to access the service container
|
||||
postgres:
|
||||
# Docker Hub image
|
||||
image: postgres
|
||||
# Provide the password for postgres
|
||||
env:
|
||||
POSTGRES_PASSWORD: password
|
||||
POSTGRES_USER: postgres
|
||||
# Set health checks to wait until postgres has started
|
||||
options: >-
|
||||
--health-cmd pg_isready
|
||||
--health-interval 10s
|
||||
--health-timeout 5s
|
||||
--health-retries 5
|
||||
ports:
|
||||
- 5432:5432
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Run postgres setup script
|
||||
run: |
|
||||
./scripts/setup_db.sh
|
||||
env:
|
||||
PGHOST: localhost
|
||||
PGPORT: 5432
|
||||
PGPASSWORD: password
|
||||
|
||||
- name: Install python tools
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install hatch
|
||||
hatch --version
|
||||
|
||||
- name: Run integration tests
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 30
|
||||
max_attempts: 3
|
||||
shell: bash
|
||||
command: cd core && hatch run ci:integration-tests -- --ddtrace --splits ${{ env.PYTHON_INTEGRATION_TEST_WORKERS }} --group ${{ matrix.split-group }}
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: |
|
||||
CURRENT_DATE=$(date +'%Y-%m-%dT%H_%M_%S') # no colons allowed for artifacts
|
||||
echo "date=$CURRENT_DATE" >> $GITHUB_OUTPUT
|
||||
|
||||
- uses: actions/upload-artifact@ea165f8d65b6e75b540449e92b4886f43607fa02 # actions/upload-artifact@v4
|
||||
if: always()
|
||||
with:
|
||||
name: logs_${{ matrix.python-version }}_${{ matrix.os }}_${{ matrix.split-group }}_${{ steps.date.outputs.date }}
|
||||
path: ./logs
|
||||
|
||||
- name: Upload Integration Test Coverage to Codecov
|
||||
if: ${{ matrix.python-version == '3.11' }}
|
||||
uses: codecov/codecov-action@5a1091511ad55cbe89839c7260b706298ca349f7 # codecov/codecov-action@v5
|
||||
with:
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
flags: integration
|
||||
fail_ci_if_error: false
|
||||
|
||||
integration-mac-windows:
|
||||
name: (${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
@@ -162,12 +263,9 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: [ "3.9", "3.10", "3.11", "3.12" ]
|
||||
os: [ubuntu-20.04]
|
||||
split-group: ${{ fromJson(needs.integration-metadata.outputs.split-groups) }}
|
||||
# already includes split group and runs mac + windows
|
||||
include: ${{ fromJson(needs.integration-metadata.outputs.include) }}
|
||||
env:
|
||||
TOXENV: integration
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
@@ -180,20 +278,21 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 10
|
||||
max_attempts: 3
|
||||
command: ./scripts/setup_db.sh
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: runner.os == 'Windows'
|
||||
@@ -203,17 +302,16 @@ jobs:
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
tox --version
|
||||
python -m pip install hatch
|
||||
hatch --version
|
||||
|
||||
- name: Run integration tests
|
||||
uses: nick-fields/retry@v3
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 30
|
||||
max_attempts: 3
|
||||
command: tox -- --ddtrace
|
||||
env:
|
||||
PYTEST_ADDOPTS: ${{ format('--splits {0} --group {1}', env.PYTHON_INTEGRATION_TEST_WORKERS, matrix.split-group) }}
|
||||
shell: bash
|
||||
command: cd core && hatch run ci:integration-tests -- --ddtrace --splits ${{ env.PYTHON_INTEGRATION_TEST_WORKERS }} --group ${{ matrix.split-group }}
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
@@ -222,7 +320,7 @@ jobs:
|
||||
CURRENT_DATE=$(date +'%Y-%m-%dT%H_%M_%S') # no colons allowed for artifacts
|
||||
echo "date=$CURRENT_DATE" >> $GITHUB_OUTPUT
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
- uses: actions/upload-artifact@ea165f8d65b6e75b540449e92b4886f43607fa02 # actions/upload-artifact@v4
|
||||
if: always()
|
||||
with:
|
||||
name: logs_${{ matrix.python-version }}_${{ matrix.os }}_${{ matrix.split-group }}_${{ steps.date.outputs.date }}
|
||||
@@ -230,19 +328,20 @@ jobs:
|
||||
|
||||
- name: Upload Integration Test Coverage to Codecov
|
||||
if: ${{ matrix.python-version == '3.11' }}
|
||||
uses: codecov/codecov-action@v4
|
||||
uses: codecov/codecov-action@5a1091511ad55cbe89839c7260b706298ca349f7 # codecov/codecov-action@v5
|
||||
with:
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
flags: integration
|
||||
fail_ci_if_error: false
|
||||
|
||||
integration-report:
|
||||
if: ${{ always() }}
|
||||
name: Integration Test Suite
|
||||
runs-on: ubuntu-latest
|
||||
needs: integration
|
||||
needs: [integration-mac-windows, integration-postgres]
|
||||
steps:
|
||||
- name: "Integration Tests Failed"
|
||||
if: ${{ contains(needs.integration.result, 'failure') || contains(needs.integration.result, 'cancelled') }}
|
||||
if: ${{ contains(needs.integration-mac-windows.result, 'failure') || contains(needs.integration-mac-windows.result, 'cancelled') || contains(needs.integration-postgres.result, 'failure') || contains(needs.integration-postgres.result, 'cancelled') }}
|
||||
# when this is true the next step won't execute
|
||||
run: |
|
||||
echo "::notice title='Integration test suite failed'"
|
||||
@@ -259,17 +358,17 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: '3.9'
|
||||
python-version: "3.10"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
python -m pip install --upgrade hatch twine check-wheel-contents
|
||||
python -m pip --version
|
||||
|
||||
- name: Build distributions
|
||||
@@ -278,27 +377,7 @@ jobs:
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Check distribution descriptions
|
||||
- name: Check and verify distributions
|
||||
run: |
|
||||
twine check dist/*
|
||||
|
||||
- name: Check wheel contents
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
dbt --version
|
||||
|
||||
- name: Install source distributions
|
||||
# ignore dbt-1.0.0, which intentionally raises an error when installed from source
|
||||
run: |
|
||||
find ./dist/*.gz -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
dbt --version
|
||||
cd core
|
||||
hatch run build:check-all
|
||||
|
||||
265
.github/workflows/model_performance.yml
vendored
265
.github/workflows/model_performance.yml
vendored
@@ -1,265 +0,0 @@
|
||||
# **what?**
|
||||
# This workflow models the performance characteristics of a point in time in dbt.
|
||||
# It runs specific dbt commands on committed projects multiple times to create and
|
||||
# commit information about the distribution to the current branch. For more information
|
||||
# see the readme in the performance module at /performance/README.md.
|
||||
#
|
||||
# **why?**
|
||||
# When developing new features, we can take quick performance samples and compare
|
||||
# them against the commited baseline measurements produced by this workflow to detect
|
||||
# some performance regressions at development time before they reach users.
|
||||
#
|
||||
# **when?**
|
||||
# This is only run once directly after each release (for non-prereleases). If for some
|
||||
# reason the results of a run are not satisfactory, it can also be triggered manually.
|
||||
|
||||
name: Model Performance Characteristics
|
||||
|
||||
on:
|
||||
# runs after non-prereleases are published.
|
||||
release:
|
||||
types: [released]
|
||||
# run manually from the actions tab
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
release_id:
|
||||
description: 'dbt version to model (must be non-prerelease in Pypi)'
|
||||
type: string
|
||||
required: true
|
||||
|
||||
env:
|
||||
RUNNER_CACHE_PATH: performance/runner/target/release/runner
|
||||
|
||||
# both jobs need to write
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
set-variables:
|
||||
name: Setting Variables
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
cache_key: ${{ steps.variables.outputs.cache_key }}
|
||||
release_id: ${{ steps.semver.outputs.base-version }}
|
||||
release_branch: ${{ steps.variables.outputs.release_branch }}
|
||||
steps:
|
||||
|
||||
# explicitly checkout the performance runner from main regardless of which
|
||||
# version we are modeling.
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: main
|
||||
|
||||
- name: Parse version into parts
|
||||
id: semver
|
||||
uses: dbt-labs/actions/parse-semver@v1
|
||||
with:
|
||||
version: ${{ github.event.inputs.release_id || github.event.release.tag_name }}
|
||||
|
||||
# collect all the variables that need to be used in subsequent jobs
|
||||
- name: Set variables
|
||||
id: variables
|
||||
run: |
|
||||
# create a cache key that will be used in the next job. without this the
|
||||
# next job would have to checkout from main and hash the files itself.
|
||||
echo "cache_key=${{ runner.os }}-${{ hashFiles('performance/runner/Cargo.toml')}}-${{ hashFiles('performance/runner/src/*') }}" >> $GITHUB_OUTPUT
|
||||
|
||||
branch_name="${{steps.semver.outputs.major}}.${{steps.semver.outputs.minor}}.latest"
|
||||
echo "release_branch=$branch_name" >> $GITHUB_OUTPUT
|
||||
echo "release branch is inferred to be ${branch_name}"
|
||||
|
||||
latest-runner:
|
||||
name: Build or Fetch Runner
|
||||
runs-on: ubuntu-latest
|
||||
needs: [set-variables]
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- name: '[DEBUG] print variables'
|
||||
run: |
|
||||
echo "all variables defined in set-variables"
|
||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
||||
|
||||
# explicitly checkout the performance runner from main regardless of which
|
||||
# version we are modeling.
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: main
|
||||
|
||||
# attempts to access a previously cached runner
|
||||
- uses: actions/cache@v4
|
||||
id: cache
|
||||
with:
|
||||
path: ${{ env.RUNNER_CACHE_PATH }}
|
||||
key: ${{ needs.set-variables.outputs.cache_key }}
|
||||
|
||||
- name: Fetch Rust Toolchain
|
||||
if: steps.cache.outputs.cache-hit != 'true'
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
|
||||
- name: Add fmt
|
||||
if: steps.cache.outputs.cache-hit != 'true'
|
||||
run: rustup component add rustfmt
|
||||
|
||||
- name: Cargo fmt
|
||||
if: steps.cache.outputs.cache-hit != 'true'
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
- name: Test
|
||||
if: steps.cache.outputs.cache-hit != 'true'
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
- name: Build (optimized)
|
||||
if: steps.cache.outputs.cache-hit != 'true'
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
# the cache action automatically caches this binary at the end of the job
|
||||
|
||||
model:
|
||||
# depends on `latest-runner` as a separate job so that failures in this job do not prevent
|
||||
# a successfully tested and built binary from being cached.
|
||||
needs: [set-variables, latest-runner]
|
||||
name: Model a release
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
- name: '[DEBUG] print variables'
|
||||
run: |
|
||||
echo "all variables defined in set-variables"
|
||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.9"
|
||||
|
||||
- name: Install dbt
|
||||
run: pip install dbt-postgres==${{ needs.set-variables.outputs.release_id }}
|
||||
|
||||
- name: Install Hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
|
||||
# explicitly checkout main to get the latest project definitions
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: main
|
||||
|
||||
# this was built in the previous job so it will be there.
|
||||
- name: Fetch Runner
|
||||
uses: actions/cache@v4
|
||||
id: cache
|
||||
with:
|
||||
path: ${{ env.RUNNER_CACHE_PATH }}
|
||||
key: ${{ needs.set-variables.outputs.cache_key }}
|
||||
|
||||
- name: Move Runner
|
||||
run: mv performance/runner/target/release/runner performance/app
|
||||
|
||||
- name: Change Runner Permissions
|
||||
run: chmod +x ./performance/app
|
||||
|
||||
- name: '[DEBUG] ls baseline directory before run'
|
||||
run: ls -R performance/baselines/
|
||||
|
||||
# `${{ github.workspace }}` is used to pass the absolute path
|
||||
- name: Create directories
|
||||
run: |
|
||||
mkdir ${{ github.workspace }}/performance/tmp/
|
||||
mkdir -p performance/baselines/${{ needs.set-variables.outputs.release_id }}/
|
||||
|
||||
# Run modeling with taking 20 samples
|
||||
- name: Run Measurement
|
||||
run: |
|
||||
performance/app model -v ${{ needs.set-variables.outputs.release_id }} -b ${{ github.workspace }}/performance/baselines/ -p ${{ github.workspace }}/performance/projects/ -t ${{ github.workspace }}/performance/tmp/ -n 20
|
||||
|
||||
- name: '[DEBUG] ls baseline directory after run'
|
||||
run: ls -R performance/baselines/
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: baseline
|
||||
path: performance/baselines/${{ needs.set-variables.outputs.release_id }}/
|
||||
|
||||
create-pr:
|
||||
name: Open PR for ${{ matrix.base-branch }}
|
||||
|
||||
# depends on `model` as a separate job so that the baseline can be committed to more than one branch
|
||||
# i.e. release branch and main
|
||||
needs: [set-variables, latest-runner, model]
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- base-branch: refs/heads/main
|
||||
target-branch: performance-bot/main_${{ needs.set-variables.outputs.release_id }}_${{GITHUB.RUN_ID}}
|
||||
- base-branch: refs/heads/${{ needs.set-variables.outputs.release_branch }}
|
||||
target-branch: performance-bot/release_${{ needs.set-variables.outputs.release_id }}_${{GITHUB.RUN_ID}}
|
||||
|
||||
steps:
|
||||
- name: '[DEBUG] print variables'
|
||||
run: |
|
||||
echo "all variables defined in set-variables"
|
||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
||||
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ matrix.base-branch }}
|
||||
|
||||
- name: Create PR branch
|
||||
run: |
|
||||
git checkout -b ${{ matrix.target-branch }}
|
||||
git push origin ${{ matrix.target-branch }}
|
||||
git branch --set-upstream-to=origin/${{ matrix.target-branch }} ${{ matrix.target-branch }}
|
||||
|
||||
- uses: actions/download-artifact@v4
|
||||
with:
|
||||
name: baseline
|
||||
path: performance/baselines/${{ needs.set-variables.outputs.release_id }}
|
||||
|
||||
- name: '[DEBUG] ls baselines after artifact download'
|
||||
run: ls -R performance/baselines/
|
||||
|
||||
- name: Commit baseline
|
||||
uses: EndBug/add-and-commit@v9
|
||||
with:
|
||||
add: 'performance/baselines/*'
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'adding performance baseline for ${{ needs.set-variables.outputs.release_id }}'
|
||||
push: 'origin origin/${{ matrix.target-branch }}'
|
||||
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v6
|
||||
with:
|
||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
||||
base: ${{ matrix.base-branch }}
|
||||
branch: '${{ matrix.target-branch }}'
|
||||
title: 'Adding performance modeling for ${{needs.set-variables.outputs.release_id}} to ${{ matrix.base-branch }}'
|
||||
body: 'Committing perf results for tracking for the ${{needs.set-variables.outputs.release_id}}'
|
||||
labels: |
|
||||
Skip Changelog
|
||||
Performance
|
||||
8
.github/workflows/nightly-release.yml
vendored
8
.github/workflows/nightly-release.yml
vendored
@@ -31,7 +31,7 @@ env:
|
||||
|
||||
jobs:
|
||||
aggregate-release-data:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
|
||||
outputs:
|
||||
version_number: ${{ steps.nightly-release-version.outputs.number }}
|
||||
@@ -39,14 +39,14 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: "Checkout ${{ github.repository }} Branch ${{ env.RELEASE_BRANCH }}"
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ env.RELEASE_BRANCH }}
|
||||
|
||||
- name: "Get Current Version Number"
|
||||
id: version-number-sources
|
||||
run: |
|
||||
current_version=`awk -F"current_version = " '{print $2}' .bumpversion.cfg | tr '\n' ' '`
|
||||
current_version=$(grep '^version = ' core/dbt/__version__.py | sed 's/version = "\(.*\)"/\1/')
|
||||
echo "current_version=$current_version" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: "Audit Version And Parse Into Parts"
|
||||
@@ -76,7 +76,7 @@ jobs:
|
||||
echo "name=${{ env.RELEASE_BRANCH }}" >> $GITHUB_OUTPUT
|
||||
|
||||
log-outputs-aggregate-release-data:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
needs: [aggregate-release-data]
|
||||
|
||||
steps:
|
||||
|
||||
55
.github/workflows/release.yml
vendored
55
.github/workflows/release.yml
vendored
@@ -72,12 +72,15 @@ defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
env:
|
||||
MIN_HATCH_VERSION: "1.11.0"
|
||||
|
||||
jobs:
|
||||
job-setup:
|
||||
name: Log Inputs
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
outputs:
|
||||
starting_sha: ${{ steps.set_sha.outputs.starting_sha }}
|
||||
use_hatch: ${{ steps.use_hatch.outputs.use_hatch }}
|
||||
steps:
|
||||
- name: "[DEBUG] Print Variables"
|
||||
run: |
|
||||
@@ -88,19 +91,29 @@ jobs:
|
||||
echo Nightly release: ${{ inputs.nightly_release }}
|
||||
echo Only Docker: ${{ inputs.only_docker }}
|
||||
|
||||
- name: "Checkout target branch"
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ inputs.target_branch }}
|
||||
|
||||
# release-prep.yml really shouldn't take in the sha but since core + all adapters
|
||||
# depend on it now this workaround lets us not input it manually with risk of error.
|
||||
# The changes always get merged into the head so we can't use a specific commit for
|
||||
# releases anyways.
|
||||
- name: "Capture sha"
|
||||
id: set_sha
|
||||
# In version env.HATCH_VERSION we started to use hatch for build tooling. Before that we used setuptools.
|
||||
# This needs to check if we're using hatch or setuptools based on the version being released. We should
|
||||
# check if the version is greater than or equal to env.HATCH_VERSION. If it is, we use hatch, otherwise we use setuptools.
|
||||
- name: "Check if using hatch"
|
||||
id: use_hatch
|
||||
run: |
|
||||
echo "starting_sha=$(git rev-parse HEAD)" >> $GITHUB_OUTPUT
|
||||
# Extract major.minor from versions like 1.11.0a1 -> 1.11
|
||||
INPUT_MAJ_MIN=$(echo "${{ inputs.version_number }}" | sed -E 's/^([0-9]+\.[0-9]+).*/\1/')
|
||||
HATCH_MAJ_MIN=$(echo "${{ env.MIN_HATCH_VERSION }}" | sed -E 's/^([0-9]+\.[0-9]+).*/\1/')
|
||||
|
||||
if [ $(echo "$INPUT_MAJ_MIN >= $HATCH_MAJ_MIN" | bc) -eq 1 ]; then
|
||||
echo "use_hatch=true" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "use_hatch=false" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: "Notify if using hatch"
|
||||
run: |
|
||||
if [ ${{ steps.use_hatch.outputs.use_hatch }} = "true" ]; then
|
||||
echo "::notice title="Using Hatch": $title::Using Hatch for release"
|
||||
else
|
||||
echo "::notice title="Using Setuptools": $title::Using Setuptools for release"
|
||||
fi
|
||||
|
||||
bump-version-generate-changelog:
|
||||
name: Bump package version, Generate changelog
|
||||
@@ -110,12 +123,13 @@ jobs:
|
||||
uses: dbt-labs/dbt-release/.github/workflows/release-prep.yml@main
|
||||
|
||||
with:
|
||||
sha: ${{ needs.job-setup.outputs.starting_sha }}
|
||||
version_number: ${{ inputs.version_number }}
|
||||
hatch_directory: "core"
|
||||
target_branch: ${{ inputs.target_branch }}
|
||||
env_setup_script_path: "scripts/env-setup.sh"
|
||||
test_run: ${{ inputs.test_run }}
|
||||
nightly_release: ${{ inputs.nightly_release }}
|
||||
use_hatch: ${{ needs.job-setup.outputs.use_hatch == 'true' }} # workflow outputs are strings...
|
||||
|
||||
secrets: inherit
|
||||
|
||||
@@ -125,7 +139,7 @@ jobs:
|
||||
|
||||
needs: [bump-version-generate-changelog]
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
|
||||
steps:
|
||||
- name: Print variables
|
||||
@@ -143,16 +157,13 @@ jobs:
|
||||
with:
|
||||
sha: ${{ needs.bump-version-generate-changelog.outputs.final_sha }}
|
||||
version_number: ${{ inputs.version_number }}
|
||||
hatch_directory: "core"
|
||||
changelog_path: ${{ needs.bump-version-generate-changelog.outputs.changelog_path }}
|
||||
build_script_path: "scripts/build-dist.sh"
|
||||
s3_bucket_name: "core-team-artifacts"
|
||||
package_test_command: "dbt --version"
|
||||
test_run: ${{ inputs.test_run }}
|
||||
nightly_release: ${{ inputs.nightly_release }}
|
||||
|
||||
secrets:
|
||||
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
|
||||
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
|
||||
use_hatch: ${{ needs.job-setup.outputs.use_hatch == 'true' }} # workflow outputs are strings...
|
||||
|
||||
github-release:
|
||||
name: GitHub Release
|
||||
@@ -188,7 +199,7 @@ jobs:
|
||||
# determine if we need to release dbt-core or both dbt-core and dbt-postgres
|
||||
name: Determine Docker Package
|
||||
if: ${{ !failure() && !cancelled() }}
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
needs: [pypi-release]
|
||||
outputs:
|
||||
matrix: ${{ steps.determine-docker-package.outputs.matrix }}
|
||||
|
||||
47
.github/workflows/schema-check.yml
vendored
47
.github/workflows/schema-check.yml
vendored
@@ -9,15 +9,21 @@
|
||||
# occur so we want to proactively alert to it.
|
||||
#
|
||||
# **when?**
|
||||
# On pushes to `develop` and release branches. Manual runs are also enabled.
|
||||
# Only can be run manually
|
||||
name: Artifact Schema Check
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [ opened, reopened, labeled, unlabeled, synchronize ]
|
||||
paths-ignore: [ '.changes/**', '.github/**', 'tests/**', '**.md', '**.yml' ]
|
||||
# pull_request:
|
||||
# types: [ opened, reopened, labeled, unlabeled, synchronize ]
|
||||
# paths-ignore: [ '.changes/**', '.github/**', 'tests/**', '**.md', '**.yml' ]
|
||||
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
target_branch:
|
||||
description: "The branch to check against"
|
||||
type: string
|
||||
default: "main"
|
||||
required: true
|
||||
|
||||
# no special access is needed
|
||||
permissions: read-all
|
||||
@@ -31,22 +37,23 @@ env:
|
||||
jobs:
|
||||
checking-schemas:
|
||||
name: "Post-merge schema changes required"
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
|
||||
steps:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: 3.9
|
||||
python-version: "3.10"
|
||||
|
||||
- name: Checkout dbt repo
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
path: ${{ env.DBT_REPO_DIRECTORY }}
|
||||
path: ${{ env.DBT_REPO_DIRECTORY }}
|
||||
ref: ${{ inputs.target_branch }}
|
||||
|
||||
- name: Check for changes in core/dbt/artifacts
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
uses: dorny/paths-filter@v3
|
||||
uses: dorny/paths-filter@de90cc6fb38fc0963ad72b210f1f284cd68cea36 # dorny/paths-filter@v3
|
||||
id: check_artifact_changes
|
||||
with:
|
||||
filters: |
|
||||
@@ -62,21 +69,19 @@ jobs:
|
||||
|
||||
- name: Checkout schemas.getdbt.com repo
|
||||
if: steps.check_artifact_changes.outputs.artifacts_changed == 'true'
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
repository: dbt-labs/schemas.getdbt.com
|
||||
ref: 'main'
|
||||
ref: "main"
|
||||
path: ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
|
||||
- name: Generate current schema
|
||||
if: steps.check_artifact_changes.outputs.artifacts_changed == 'true'
|
||||
run: |
|
||||
cd ${{ env.DBT_REPO_DIRECTORY }}
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
python scripts/collect-artifact-schema.py --path ${{ env.LATEST_SCHEMA_PATH }}
|
||||
cd ${{ env.DBT_REPO_DIRECTORY }}/core
|
||||
pip install --upgrade pip hatch
|
||||
hatch run setup
|
||||
hatch run json-schema -- --path ${{ env.LATEST_SCHEMA_PATH }}
|
||||
|
||||
# Copy generated schema files into the schemas.getdbt.com repo
|
||||
# Do a git diff to find any changes
|
||||
@@ -89,8 +94,8 @@ jobs:
|
||||
git diff -I='*[0-9]{4}-[0-9]{2}-[0-9]{2}' -I='*[0-9]+\.[0-9]+\.[0-9]+' --exit-code > ${{ env.SCHEMA_DIFF_ARTIFACT }}
|
||||
|
||||
- name: Upload schema diff
|
||||
uses: actions/upload-artifact@v4
|
||||
uses: actions/upload-artifact@ea165f8d65b6e75b540449e92b4886f43607fa02 # actions/upload-artifact@v4
|
||||
if: ${{ failure() && steps.check_artifact_changes.outputs.artifacts_changed == 'true' }}
|
||||
with:
|
||||
name: 'schema_changes.txt'
|
||||
path: '${{ env.SCHEMA_DIFF_ARTIFACT }}'
|
||||
name: "schema_changes.txt"
|
||||
path: "${{ env.SCHEMA_DIFF_ARTIFACT }}"
|
||||
|
||||
@@ -14,6 +14,8 @@ on:
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
merge_group:
|
||||
types: [checks_requested]
|
||||
workflow_dispatch:
|
||||
|
||||
permissions: read-all
|
||||
@@ -45,7 +47,7 @@ jobs:
|
||||
# run the performance measurements on the current or default branch
|
||||
test-schema:
|
||||
name: Test Log Schema
|
||||
runs-on: ubuntu-20.04
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 30
|
||||
needs:
|
||||
- integration-metadata
|
||||
@@ -67,26 +69,49 @@ jobs:
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
|
||||
services:
|
||||
# Label used to access the service container
|
||||
postgres:
|
||||
# Docker Hub image
|
||||
image: postgres
|
||||
# Provide the password for postgres
|
||||
env:
|
||||
POSTGRES_PASSWORD: password
|
||||
POSTGRES_USER: postgres
|
||||
# Set health checks to wait until postgres has started
|
||||
options: >-
|
||||
--health-cmd pg_isready
|
||||
--health-interval 10s
|
||||
--health-timeout 5s
|
||||
--health-retries 5
|
||||
ports:
|
||||
- 5432:5432
|
||||
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: "3.9"
|
||||
python-version: "3.10"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
pip install hatch
|
||||
hatch --version
|
||||
|
||||
- name: Set up postgres
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
- name: Run postgres setup script
|
||||
run: |
|
||||
./scripts/setup_db.sh
|
||||
env:
|
||||
PGHOST: localhost
|
||||
PGPORT: 5432
|
||||
PGPASSWORD: password
|
||||
|
||||
- name: ls
|
||||
run: ls
|
||||
@@ -94,11 +119,11 @@ jobs:
|
||||
# integration tests generate a ton of logs in different files. the next step will find them all.
|
||||
# we actually care if these pass, because the normal test run doesn't usually include many json log outputs
|
||||
- name: Run integration tests
|
||||
uses: nick-fields/retry@v3
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 30
|
||||
max_attempts: 3
|
||||
command: tox -e integration -- -nauto
|
||||
command: cd core && hatch run ci:integration-tests -- -nauto
|
||||
env:
|
||||
PYTEST_ADDOPTS: ${{ format('--splits {0} --group {1}', env.PYTHON_INTEGRATION_TEST_WORKERS, matrix.split-group) }}
|
||||
|
||||
|
||||
60
.github/workflows/test-repeater.yml
vendored
60
.github/workflows/test-repeater.yml
vendored
@@ -14,34 +14,33 @@ on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
branch:
|
||||
description: 'Branch to check out'
|
||||
description: "Branch to check out"
|
||||
type: string
|
||||
required: true
|
||||
default: 'main'
|
||||
default: "main"
|
||||
test_path:
|
||||
description: 'Path to single test to run (ex: tests/functional/retry/test_retry.py::TestRetry::test_fail_fast)'
|
||||
description: "Path to single test to run (ex: tests/functional/retry/test_retry.py::TestRetry::test_fail_fast)"
|
||||
type: string
|
||||
required: true
|
||||
default: 'tests/functional/...'
|
||||
default: "tests/functional/..."
|
||||
python_version:
|
||||
description: 'Version of Python to Test Against'
|
||||
description: "Version of Python to Test Against"
|
||||
type: choice
|
||||
options:
|
||||
- '3.9'
|
||||
- '3.10'
|
||||
- '3.11'
|
||||
- "3.10"
|
||||
- "3.11"
|
||||
os:
|
||||
description: 'OS to run test in'
|
||||
description: "OS to run test in"
|
||||
type: choice
|
||||
options:
|
||||
- 'ubuntu-latest'
|
||||
- 'macos-14'
|
||||
- 'windows-latest'
|
||||
- "ubuntu-latest"
|
||||
- "macos-14"
|
||||
- "windows-latest"
|
||||
num_runs_per_batch:
|
||||
description: 'Max number of times to run the test per batch. We always run 10 batches.'
|
||||
description: "Max number of times to run the test per batch. We always run 10 batches."
|
||||
type: number
|
||||
required: true
|
||||
default: '50'
|
||||
default: "50"
|
||||
|
||||
permissions: read-all
|
||||
|
||||
@@ -51,7 +50,7 @@ defaults:
|
||||
|
||||
jobs:
|
||||
debug:
|
||||
runs-on: ubuntu-latest
|
||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||
steps:
|
||||
- name: "[DEBUG] Output Inputs"
|
||||
run: |
|
||||
@@ -82,26 +81,37 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: "Checkout code"
|
||||
uses: actions/checkout@v4
|
||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||
with:
|
||||
ref: ${{ inputs.branch }}
|
||||
|
||||
- name: "Setup Python"
|
||||
uses: actions/setup-python@v5
|
||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
||||
with:
|
||||
python-version: "${{ inputs.python_version }}"
|
||||
|
||||
- name: "Install hatch"
|
||||
run: python -m pip install --user --upgrade pip hatch
|
||||
|
||||
- name: "Setup Dev Environment"
|
||||
run: make dev
|
||||
run: |
|
||||
cd core
|
||||
hatch run setup
|
||||
|
||||
- name: "Set up postgres (linux)"
|
||||
if: inputs.os == 'ubuntu-latest'
|
||||
run: make setup-db
|
||||
if: inputs.os == '${{ vars.UBUNTU_LATEST }}'
|
||||
run: |
|
||||
cd core
|
||||
hatch run setup-db
|
||||
|
||||
# mac and windows don't use make due to limitations with docker with those runners in GitHub
|
||||
- name: "Set up postgres (macos)"
|
||||
if: inputs.os == 'macos-14'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
- name: Set up postgres (macos)
|
||||
if: runner.os == 'macOS'
|
||||
uses: nick-fields/retry@ce71cc2ab81d554ebbe88c79ab5975992d79ba08 # nick-fields/retry@v3
|
||||
with:
|
||||
timeout_minutes: 10
|
||||
max_attempts: 3
|
||||
command: ./scripts/setup_db.sh
|
||||
|
||||
- name: "Set up postgres (windows)"
|
||||
if: inputs.os == 'windows-latest'
|
||||
@@ -150,5 +160,5 @@ jobs:
|
||||
- name: "Error for Failures"
|
||||
if: ${{ steps.pytest.outputs.failure }}
|
||||
run: |
|
||||
echo "Batch ${{ matrix.batch }} failed ${{ steps.pytest.outputs.failure }} of ${{ inputs.num_runs_per_batch }} tests"
|
||||
exit 1
|
||||
echo "Batch ${{ matrix.batch }} failed ${{ steps.pytest.outputs.failure }} of ${{ inputs.num_runs_per_batch }} tests"
|
||||
exit 1
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -15,6 +15,7 @@ build/
|
||||
!core/dbt/docs/build
|
||||
develop-eggs/
|
||||
dist/
|
||||
dist-*/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
@@ -95,6 +96,7 @@ target/
|
||||
# pycharm
|
||||
.idea/
|
||||
venv/
|
||||
.venv*/
|
||||
|
||||
# AWS credentials
|
||||
.aws/
|
||||
|
||||
@@ -1,71 +1,91 @@
|
||||
# Configuration for pre-commit hooks (see https://pre-commit.com/).
|
||||
# Eventually the hooks described here will be run as tests before merging each PR.
|
||||
|
||||
exclude: ^(core/dbt/docs/build/|core/dbt/common/events/types_pb2.py|core/dbt/events/core_types_pb2.py|core/dbt/adapters/events/adapter_types_pb2.py)
|
||||
exclude: ^(core/dbt/docs/build/|core/dbt/common/events/types_pb2.py|core/dbt/adapters/events/adapter_types_pb2.py)
|
||||
|
||||
# Force all unspecified python hooks to run python 3.9
|
||||
# Force all unspecified python hooks to run python 3.10
|
||||
default_language_version:
|
||||
python: python3
|
||||
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v3.2.0
|
||||
hooks:
|
||||
- id: check-yaml
|
||||
args: [--unsafe]
|
||||
- id: check-json
|
||||
- id: end-of-file-fixer
|
||||
exclude: schemas/dbt/manifest/
|
||||
- id: trailing-whitespace
|
||||
exclude_types:
|
||||
- "markdown"
|
||||
- id: check-case-conflict
|
||||
- repo: https://github.com/pycqa/isort
|
||||
# rev must match what's in dev-requirements.txt
|
||||
rev: 5.13.2
|
||||
hooks:
|
||||
- id: isort
|
||||
- repo: https://github.com/psf/black
|
||||
# rev must match what's in dev-requirements.txt
|
||||
rev: 24.3.0
|
||||
hooks:
|
||||
- id: black
|
||||
- id: black
|
||||
alias: black-check
|
||||
stages: [manual]
|
||||
args:
|
||||
- "--check"
|
||||
- "--diff"
|
||||
- repo: https://github.com/pycqa/flake8
|
||||
# rev must match what's in dev-requirements.txt
|
||||
rev: 4.0.1
|
||||
hooks:
|
||||
- id: flake8
|
||||
- id: flake8
|
||||
alias: flake8-check
|
||||
stages: [manual]
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
# rev must match what's in dev-requirements.txt
|
||||
rev: v1.4.1
|
||||
hooks:
|
||||
- id: mypy
|
||||
# N.B.: Mypy is... a bit fragile.
|
||||
#
|
||||
# By using `language: system` we run this hook in the local
|
||||
# environment instead of a pre-commit isolated one. This is needed
|
||||
# to ensure mypy correctly parses the project.
|
||||
|
||||
# It may cause trouble
|
||||
# in that it adds environmental variables out of our control to the
|
||||
# mix. Unfortunately, there's nothing we can do about per pre-commit's
|
||||
# author.
|
||||
# See https://github.com/pre-commit/pre-commit/issues/730 for details.
|
||||
args: [--show-error-codes]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
- id: mypy
|
||||
alias: mypy-check
|
||||
stages: [manual]
|
||||
args: [--show-error-codes, --pretty]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v3.2.0
|
||||
hooks:
|
||||
- id: check-yaml
|
||||
args: [--unsafe]
|
||||
- id: check-json
|
||||
- id: end-of-file-fixer
|
||||
exclude: schemas/dbt/manifest/
|
||||
- id: trailing-whitespace
|
||||
exclude_types:
|
||||
- "markdown"
|
||||
- id: check-case-conflict
|
||||
# local hooks are used to run the hooks in the local environment instead of a pre-commit isolated one.
|
||||
# This ensures that the hooks are run with the same version of the dependencies as the local environment
|
||||
# without having to manually keep them in sync.
|
||||
- repo: local
|
||||
hooks:
|
||||
# Formatter/linter/type-checker pins live in the pyproject.dev optional dependency.
|
||||
- id: isort
|
||||
name: isort
|
||||
entry: python -m isort
|
||||
language: system
|
||||
types: [python]
|
||||
- id: black
|
||||
name: black
|
||||
entry: python -m black
|
||||
language: system
|
||||
types: [python]
|
||||
- id: black-check
|
||||
name: black-check
|
||||
entry: python -m black
|
||||
args:
|
||||
- "--check"
|
||||
- "--diff"
|
||||
language: system
|
||||
stages: [manual]
|
||||
types: [python]
|
||||
- id: flake8
|
||||
name: flake8
|
||||
entry: python -m flake8
|
||||
language: system
|
||||
types: [python]
|
||||
- id: flake8-check
|
||||
name: flake8-check
|
||||
entry: python -m flake8
|
||||
language: system
|
||||
stages: [manual]
|
||||
types: [python]
|
||||
# N.B.: Mypy is... a bit fragile.
|
||||
#
|
||||
# By using `language: system` we run this hook in the local
|
||||
# environment instead of a pre-commit isolated one. This is needed
|
||||
# to ensure mypy correctly parses the project.
|
||||
#
|
||||
# It may cause trouble
|
||||
# in that it adds environmental variables out of our control to the
|
||||
# mix. Unfortunately, there's nothing we can do about per pre-commit's
|
||||
# author.
|
||||
# See https://github.com/pre-commit/pre-commit/issues/730 for details.
|
||||
- id: mypy
|
||||
name: mypy
|
||||
entry: python -m mypy
|
||||
args: [--show-error-codes]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
types: [python]
|
||||
- id: mypy-check
|
||||
name: mypy-check
|
||||
entry: python -m mypy
|
||||
args: [--show-error-codes, --pretty]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
stages: [manual]
|
||||
types: [python]
|
||||
- id: no_versioned_artifact_resource_imports
|
||||
name: no_versioned_artifact_resource_imports
|
||||
entry: python scripts/pre-commit-hooks/no_versioned_artifact_resource_imports.py
|
||||
language: system
|
||||
files: ^core/dbt/
|
||||
types: [python]
|
||||
pass_filenames: true
|
||||
|
||||
@@ -6,7 +6,6 @@ Most of the python code in the repository is within the `core/dbt` directory.
|
||||
- [`single python files`](core/dbt/README.md): A number of individual files, such as 'compilation.py' and 'exceptions.py'
|
||||
|
||||
The main subdirectories of core/dbt:
|
||||
- [`adapters`](core/dbt/adapters/README.md): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients/README.md): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config/README.md): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
- [`context`](core/dbt/context/README.md): Build and expose dbt-specific Jinja functionality
|
||||
@@ -14,14 +13,10 @@ The main subdirectories of core/dbt:
|
||||
- [`deps`](core/dbt/deps/README.md): Package installation and dependency resolution
|
||||
- [`events`](core/dbt/events/README.md): Logging events
|
||||
- [`graph`](core/dbt/graph/README.md): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include/README.md): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`include`](core/dbt/include/README.md): Set up the starter project scaffold.
|
||||
- [`parser`](core/dbt/parser/README.md): Read project files, validate, construct python objects
|
||||
- [`task`](core/dbt/task/README.md): Set forth the actions that dbt can perform when invoked
|
||||
|
||||
Legacy tests are found in the 'test' directory:
|
||||
- [`unit tests`](core/dbt/test/unit/README.md): Unit tests
|
||||
- [`integration tests`](core/dbt/test/integration/README.md): Integration tests
|
||||
|
||||
### Invoking dbt
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
@@ -32,7 +27,7 @@ This is the docs website code. It comes from the dbt-docs repository, and is gen
|
||||
## Adapters
|
||||
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc.
|
||||
Note: dbt-postgres used to exist in dbt-core but is now in [its own repo](https://github.com/dbt-labs/dbt-postgres)
|
||||
Note: dbt-postgres used to exist in dbt-core but is now in [the dbt-adapters repo](https://github.com/dbt-labs/dbt-adapters/tree/main/dbt-postgres)
|
||||
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
|
||||
@@ -40,16 +35,15 @@ Each adapter plugin is a standalone python package that includes:
|
||||
|
||||
- `dbt/include/[name]`: A "sub-global" dbt project, of YAML and SQL files, that reimplements Jinja macros to use the adapter's supported SQL syntax
|
||||
- `dbt/adapters/[name]`: Python modules that inherit, and optionally reimplement, the base adapter classes defined in dbt-core
|
||||
- `setup.py`
|
||||
- `pyproject.toml`
|
||||
|
||||
The Postgres adapter code is the most central, and many of its implementations are used as the default defined in the dbt-core global project. The greater the distance of a data technology from Postgres, the more its adapter plugin may need to reimplement.
|
||||
|
||||
## Testing dbt
|
||||
|
||||
The [`test/`](test/) subdirectory includes unit and integration tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Integration tests perform end-to-end dbt invocations against real adapters (Postgres, Redshift, Snowflake, BigQuery) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
||||
The [`tests/`](tests/) subdirectory includes unit and fuctional tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Functional tests perform end-to-end dbt invocations against real adapters (Postgres) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
||||
|
||||
## Everything else
|
||||
|
||||
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
||||
- [etc](etc/): Images for README
|
||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, nor are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||
|
||||
@@ -9,7 +9,8 @@
|
||||
|
||||
For information on prior major and minor releases, see their changelogs:
|
||||
|
||||
|
||||
* [1.11](https://github.com/dbt-labs/dbt-core/blob/1.11.latest/CHANGELOG.md)
|
||||
* [1.10](https://github.com/dbt-labs/dbt-core/blob/1.10.latest/CHANGELOG.md)
|
||||
* [1.9](https://github.com/dbt-labs/dbt-core/blob/1.9.latest/CHANGELOG.md)
|
||||
* [1.8](https://github.com/dbt-labs/dbt-core/blob/1.8.latest/CHANGELOG.md)
|
||||
* [1.7](https://github.com/dbt-labs/dbt-core/blob/1.7.latest/CHANGELOG.md)
|
||||
|
||||
159
CONTRIBUTING.md
159
CONTRIBUTING.md
@@ -2,21 +2,39 @@
|
||||
|
||||
`dbt-core` is open source software. It is what it is today because community members have opened issues, provided feedback, and [contributed to the knowledge loop](https://www.getdbt.com/dbt-labs/values/). Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
1. [About this document](#about-this-document)
|
||||
2. [Getting the code](#getting-the-code)
|
||||
3. [Setting up an environment](#setting-up-an-environment)
|
||||
4. [Running dbt-core in development](#running-dbt-core-in-development)
|
||||
5. [Testing dbt-core](#testing)
|
||||
6. [Debugging](#debugging)
|
||||
7. [Adding or modifying a changelog entry](#adding-or-modifying-a-changelog-entry)
|
||||
8. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
9. [Troubleshooting Tips](#troubleshooting-tips)
|
||||
- [Contributing to `dbt-core`](#contributing-to-dbt-core)
|
||||
- [About this document](#about-this-document)
|
||||
- [Notes](#notes)
|
||||
- [Getting the code](#getting-the-code)
|
||||
- [Installing git](#installing-git)
|
||||
- [External contributors](#external-contributors)
|
||||
- [dbt Labs contributors](#dbt-labs-contributors)
|
||||
- [Setting up an environment](#setting-up-an-environment)
|
||||
- [Tools](#tools)
|
||||
- [Virtual environments](#virtual-environments)
|
||||
- [Docker and `docker-compose`](#docker-and-docker-compose)
|
||||
- [Postgres (optional)](#postgres-optional)
|
||||
- [Running `dbt-core` in development](#running-dbt-core-in-development)
|
||||
- [Installation](#installation)
|
||||
- [Running `dbt-core`](#running-dbt-core)
|
||||
- [Testing](#testing)
|
||||
- [Initial setup](#initial-setup)
|
||||
- [Test commands](#test-commands)
|
||||
- [Hatch scripts](#hatch-scripts)
|
||||
- [`pre-commit`](#pre-commit)
|
||||
- [`pytest`](#pytest)
|
||||
- [Unit, Integration, Functional?](#unit-integration-functional)
|
||||
- [Debugging](#debugging)
|
||||
- [Assorted development tips](#assorted-development-tips)
|
||||
- [Adding or modifying a CHANGELOG Entry](#adding-or-modifying-a-changelog-entry)
|
||||
- [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
- [Troubleshooting Tips](#troubleshooting-tips)
|
||||
|
||||
## About this document
|
||||
|
||||
There are many ways to contribute to the ongoing development of `dbt-core`, such as by participating in discussions and issues. We encourage you to first read our higher-level document: ["Expectations for Open Source Contributors"](https://docs.getdbt.com/docs/contributing/oss-expectations).
|
||||
|
||||
The rest of this document serves as a more granular guide for contributing code changes to `dbt-core` (this repository). It is not intended as a guide for using `dbt-core`, and some pieces assume a level of familiarity with Python development (virtualenvs, `pip`, etc). Specific code snippets in this guide assume you are using macOS or Linux and are comfortable with the command line.
|
||||
The rest of this document serves as a more granular guide for contributing code changes to `dbt-core` (this repository). It is not intended as a guide for using `dbt-core`, and some pieces assume a level of familiarity with Python development and package managers. Specific code snippets in this guide assume you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
If you get stuck, we're happy to help! Drop us a line in the `#dbt-core-development` channel in the [dbt Community Slack](https://community.getdbt.com).
|
||||
|
||||
@@ -55,28 +73,22 @@ There are some tools that will be helpful to you in developing locally. While th
|
||||
|
||||
These are the tools used in `dbt-core` development and testing:
|
||||
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.8, 3.9, 3.10 and 3.11
|
||||
- [`hatch`](https://hatch.pypa.io/) for build backend, environment management, and running tests across Python versions (3.10, 3.11, 3.12, and 3.13)
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to define, discover, and run tests
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`black`](https://github.com/psf/black) for code formatting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [`pre-commit`](https://pre-commit.com) to easily run those checks
|
||||
- [`changie`](https://changie.dev/) to create changelog entries, without merge conflicts
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) to run multiple setup or test steps in combination. Don't worry too much, nobody _really_ understands how `make` works, and our Makefile aims to be super simple.
|
||||
- [GitHub Actions](https://github.com/features/actions) for automating tests and checks, once a PR is pushed to the `dbt-core` repository
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about each one.
|
||||
|
||||
#### Virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in `dbt-core`. We recommend creating this virtualenv
|
||||
in the root of the `dbt-core` repository. To create a new virtualenv, run:
|
||||
```sh
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
```
|
||||
dbt-core uses [Hatch](https://hatch.pypa.io/) for dependency and environment management. Hatch automatically creates and manages isolated environments for development, testing, and building, so you don't need to manually create virtual environments.
|
||||
|
||||
This will create and activate a new Python virtual environment.
|
||||
For more information on how Hatch manages environments, see the [Hatch environment documentation](https://hatch.pypa.io/latest/environment/).
|
||||
|
||||
#### Docker and `docker-compose`
|
||||
|
||||
@@ -95,22 +107,42 @@ brew install postgresql
|
||||
|
||||
### Installation
|
||||
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Also ensure you have the latest version of pip installed with `pip install --upgrade pip`. Next, install `dbt-core` (and its dependencies):
|
||||
First make sure you have Python 3.10 or later installed. Ensure you have the latest version of pip installed with `pip install --upgrade pip`. Next, install `hatch`. Finally set up `dbt-core` for development:
|
||||
|
||||
```sh
|
||||
make dev
|
||||
cd core
|
||||
hatch run setup
|
||||
```
|
||||
or, alternatively:
|
||||
|
||||
This will install all development dependencies and set up pre-commit hooks.
|
||||
|
||||
By default, hatch will use whatever Python version is active in your environment. To specify a particular Python version, set the `HATCH_PYTHON` environment variable:
|
||||
|
||||
```sh
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
pre-commit install
|
||||
export HATCH_PYTHON=3.12
|
||||
hatch env create
|
||||
```
|
||||
|
||||
Or add it to your shell profile (e.g., `~/.zshrc` or `~/.bashrc`) for persistence.
|
||||
|
||||
When installed in this way, any changes you make to your local copy of the source code will be reflected immediately in your next `dbt` run.
|
||||
|
||||
#### Building dbt-core
|
||||
|
||||
dbt-core uses [Hatch](https://hatch.pypa.io/) (specifically `hatchling`) as its build backend. To build distribution packages:
|
||||
|
||||
```sh
|
||||
cd core
|
||||
hatch build
|
||||
```
|
||||
|
||||
This will create both wheel (`.whl`) and source distribution (`.tar.gz`) files in the `dist/` directory.
|
||||
|
||||
The build configuration is defined in `core/pyproject.toml`. You can also use the standard `python -m build` command if you prefer.
|
||||
|
||||
### Running `dbt-core`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
Once you've run `hatch run setup`, the `dbt` command will be available in your PATH. You can verify this by running `which dbt`.
|
||||
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local Postgres instance, or a specific test sandbox within your data warehouse if appropriate. Make sure to create a profile before running integration tests.
|
||||
|
||||
@@ -128,45 +160,78 @@ Although `dbt-core` works with a number of different databases, you won't need t
|
||||
Postgres offers the easiest way to test most `dbt-core` functionality today. They are the fastest to run, and the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
cd core
|
||||
hatch run setup-db
|
||||
```
|
||||
or, alternatively:
|
||||
|
||||
Alternatively, you can run the setup commands directly:
|
||||
|
||||
```sh
|
||||
docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash scripts/setup_db.sh
|
||||
```
|
||||
|
||||
### Test commands
|
||||
|
||||
There are a few methods for running tests locally.
|
||||
|
||||
#### Makefile
|
||||
#### Hatch scripts
|
||||
|
||||
There are multiple targets in the Makefile to run common test suites and code
|
||||
checks, most notably:
|
||||
The primary way to run tests and checks is using hatch scripts (defined in `core/hatch.toml`):
|
||||
|
||||
```sh
|
||||
# Runs unit tests with py38 and code checks in parallel.
|
||||
make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a local installation of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
cd core
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
# Run all unit tests
|
||||
hatch run unit-tests
|
||||
|
||||
# Run unit tests and all code quality checks
|
||||
hatch run test
|
||||
|
||||
# Run integration tests
|
||||
hatch run integration-tests
|
||||
|
||||
# Run integration tests in fail-fast mode
|
||||
hatch run integration-tests-fail-fast
|
||||
|
||||
# Run linting checks only
|
||||
hatch run lint
|
||||
hatch run flake8
|
||||
hatch run mypy
|
||||
hatch run black
|
||||
|
||||
# Run all pre-commit hooks
|
||||
hatch run code-quality
|
||||
|
||||
# Clean build artifacts
|
||||
hatch run clean
|
||||
```
|
||||
|
||||
Hatch manages isolated environments and dependencies automatically. The commands above use the `default` environment which is recommended for most local development.
|
||||
|
||||
**Using the `ci` environment (optional)**
|
||||
|
||||
If you need to replicate exactly what runs in GitHub Actions (e.g., with coverage reporting), use the `ci` environment:
|
||||
|
||||
```sh
|
||||
cd core
|
||||
|
||||
# Run unit tests with coverage
|
||||
hatch run ci:unit-tests
|
||||
|
||||
# Run unit tests with a specific Python version
|
||||
hatch run +py=3.11 ci:unit-tests
|
||||
```
|
||||
|
||||
> **Note:** Most developers should use the default environment (`hatch run unit-tests`). The `ci` environment is primarily for debugging CI failures or running tests with coverage.
|
||||
|
||||
#### `pre-commit`
|
||||
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment (we recommend running this command with a python virtual environment active). This command installs several pip executables including black, mypy, and flake8. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.8, Python 3.9, Python 3.10 and Python 3.11 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py38`. The configuration for these tests in located in `tox.ini`.
|
||||
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `hatch run setup` to install `pre-commit` in your local environment (we recommend running this command with a python virtual environment active). This installs several pip executables including black, mypy, and flake8. Once installed, hooks will run automatically on `git commit`, or you can run them manually with `hatch run code-quality`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv active and dev dependencies installed you can do things like:
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. After running `hatch run setup`, you can run pytest commands like:
|
||||
|
||||
```sh
|
||||
# run all unit tests in a file
|
||||
@@ -224,7 +289,9 @@ Code can be merged into the current development branch `main` by opening a pull
|
||||
|
||||
Automated tests run via GitHub Actions. If you're a first-time contributor, all tests (including code checks and unit tests) will require a maintainer to approve. Changes in the `dbt-core` repository trigger integration tests against Postgres. dbt Labs also provides CI environments in which to test changes to other adapters, triggered by PRs in those adapters' repositories, as well as periodic maintenance checks of each adapter in concert with the latest `dbt-core` code changes.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a `dbt-core` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
We require signed git commits. See docs [here](https://docs.github.com/en/authentication/managing-commit-signature-verification/signing-commits) for setting up code signing.
|
||||
|
||||
Once all tests are passing, all comments are resolved, and your PR has been approved, a `dbt-core` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
## Troubleshooting Tips
|
||||
|
||||
|
||||
@@ -33,9 +33,6 @@ RUN apt-get update \
|
||||
python-is-python3 \
|
||||
python-dev-is-python3 \
|
||||
python3-pip \
|
||||
python3.9 \
|
||||
python3.9-dev \
|
||||
python3.9-venv \
|
||||
python3.10 \
|
||||
python3.10-dev \
|
||||
python3.10-venv \
|
||||
@@ -50,7 +47,7 @@ RUN curl -LO https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_V
|
||||
&& tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
||||
&& rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
||||
|
||||
RUN pip3 install -U tox wheel six setuptools
|
||||
RUN pip3 install -U hatch wheel pre-commit
|
||||
|
||||
# These args are passed in via docker-compose, which reads then from the .env file.
|
||||
# On Linux, run `make .env` to create the .env file for the current user.
|
||||
@@ -65,7 +62,6 @@ RUN if [ ${USER_ID:-0} -ne 0 ] && [ ${GROUP_ID:-0} -ne 0 ]; then \
|
||||
useradd -mU -l dbt_test_user; \
|
||||
fi
|
||||
RUN mkdir /usr/app && chown dbt_test_user /usr/app
|
||||
RUN mkdir /home/tox && chown dbt_test_user /home/tox
|
||||
|
||||
WORKDIR /usr/app
|
||||
VOLUME /usr/app
|
||||
|
||||
167
Makefile
167
Makefile
@@ -1,150 +1,95 @@
|
||||
# ============================================================================
|
||||
# DEPRECATED: This Makefile is maintained for backwards compatibility only.
|
||||
#
|
||||
# dbt-core now uses Hatch for task management and development workflows.
|
||||
# Please migrate to using hatch commands directly:
|
||||
#
|
||||
# make dev → cd core && hatch run setup
|
||||
# make unit → cd core && hatch run unit-tests
|
||||
# make test → cd core && hatch run test
|
||||
# make integration → cd core && hatch run integration-tests
|
||||
# make lint → cd core && hatch run lint
|
||||
# make code_quality → cd core && hatch run code-quality
|
||||
# make setup-db → cd core && hatch run setup-db
|
||||
# make clean → cd core && hatch run clean
|
||||
#
|
||||
# See core/pyproject.toml [tool.hatch.envs.default.scripts] for all available
|
||||
# commands and CONTRIBUTING.md for detailed usage instructions.
|
||||
#
|
||||
# This Makefile will be removed in a future version of dbt-core.
|
||||
# ============================================================================
|
||||
|
||||
.DEFAULT_GOAL:=help
|
||||
|
||||
# Optional flag to run target in a docker container.
|
||||
# (example `make test USE_DOCKER=true`)
|
||||
ifeq ($(USE_DOCKER),true)
|
||||
DOCKER_CMD := docker-compose run --rm test
|
||||
endif
|
||||
|
||||
#
|
||||
# To override CI_flags, create a file at this repo's root dir named `makefile.test.env`. Fill it
|
||||
# with any ENV_VAR overrides required by your test environment, e.g.
|
||||
# DBT_TEST_USER_1=user
|
||||
# LOG_DIR="dir with a space in it"
|
||||
#
|
||||
# Warn: Restrict each line to one variable only.
|
||||
#
|
||||
ifeq (./makefile.test.env,$(wildcard ./makefile.test.env))
|
||||
include ./makefile.test.env
|
||||
endif
|
||||
|
||||
CI_FLAGS =\
|
||||
DBT_TEST_USER_1=$(if $(DBT_TEST_USER_1),$(DBT_TEST_USER_1),dbt_test_user_1)\
|
||||
DBT_TEST_USER_2=$(if $(DBT_TEST_USER_2),$(DBT_TEST_USER_2),dbt_test_user_2)\
|
||||
DBT_TEST_USER_3=$(if $(DBT_TEST_USER_3),$(DBT_TEST_USER_3),dbt_test_user_3)\
|
||||
RUSTFLAGS=$(if $(RUSTFLAGS),$(RUSTFLAGS),"-D warnings")\
|
||||
LOG_DIR=$(if $(LOG_DIR),$(LOG_DIR),./logs)\
|
||||
DBT_LOG_FORMAT=$(if $(DBT_LOG_FORMAT),$(DBT_LOG_FORMAT),json)
|
||||
|
||||
|
||||
.PHONY: dev_req
|
||||
dev_req: ## Installs dbt-* packages in develop mode along with only development dependencies.
|
||||
@\
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
@cd core && hatch run dev-req
|
||||
|
||||
.PHONY: dev
|
||||
dev: dev_req ## Installs dbt-* packages in develop mode along with development dependencies and pre-commit.
|
||||
@\
|
||||
pre-commit install
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies and pre-commit.
|
||||
@cd core && hatch run setup
|
||||
|
||||
.PHONY: dev-uninstall
|
||||
dev-uninstall: ## Uninstall all packages in venv except for build tools
|
||||
@\
|
||||
pip freeze | grep -v "^-e" | cut -d "@" -f1 | xargs pip uninstall -y; \
|
||||
pip uninstall -y dbt-core
|
||||
|
||||
.PHONY: core_proto_types
|
||||
core_proto_types: ## generates google protobuf python file from core_types.proto
|
||||
protoc -I=./core/dbt/events --python_out=./core/dbt/events ./core/dbt/events/core_types.proto
|
||||
@pip freeze | grep -v "^-e" | cut -d "@" -f1 | xargs pip uninstall -y; \
|
||||
pip uninstall -y dbt-core
|
||||
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy against staged changes for static type checking.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual mypy-check | grep -v "INFO"
|
||||
mypy: ## Runs mypy against staged changes for static type checking.
|
||||
@cd core && hatch run mypy
|
||||
|
||||
.PHONY: flake8
|
||||
flake8: .env ## Runs flake8 against staged changes to enforce style guide.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual flake8-check | grep -v "INFO"
|
||||
flake8: ## Runs flake8 against staged changes to enforce style guide.
|
||||
@cd core && hatch run flake8
|
||||
|
||||
.PHONY: black
|
||||
black: .env ## Runs black against staged changes to enforce style guide.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual black-check -v | grep -v "INFO"
|
||||
black: ## Runs black against staged changes to enforce style guide.
|
||||
@cd core && hatch run black
|
||||
|
||||
.PHONY: lint
|
||||
lint: .env ## Runs flake8 and mypy code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
lint: ## Runs flake8 and mypy code checks against staged changes.
|
||||
@cd core && hatch run lint
|
||||
|
||||
.PHONY: code_quality
|
||||
code_quality: ## Runs all pre-commit hooks against all files.
|
||||
@cd core && hatch run code-quality
|
||||
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py
|
||||
unit: ## Runs unit tests with py
|
||||
@cd core && hatch run unit-tests
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py and code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py; \
|
||||
$(DOCKER_CMD) pre-commit run black-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
test: ## Runs unit tests with py and code checks against staged changes.
|
||||
@cd core && hatch run test
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env ## Runs core integration tests using postgres with py-integration
|
||||
@\
|
||||
$(CI_FLAGS) $(DOCKER_CMD) tox -e py-integration -- -nauto
|
||||
integration: ## Runs core integration tests using postgres with py-integration
|
||||
@cd core && hatch run integration-tests
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env ## Runs core integration tests using postgres with py-integration in "fail fast" mode.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py-integration -- -x -nauto
|
||||
|
||||
.PHONY: interop
|
||||
interop: clean
|
||||
@\
|
||||
mkdir $(LOG_DIR) && \
|
||||
$(CI_FLAGS) $(DOCKER_CMD) tox -e py-integration -- -nauto && \
|
||||
LOG_DIR=$(LOG_DIR) cargo run --manifest-path test/interop/log_parsing/Cargo.toml
|
||||
integration-fail-fast: ## Runs core integration tests using postgres with py-integration in "fail fast" mode.
|
||||
@cd core && hatch run integration-tests-fail-fast
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
@\
|
||||
docker-compose up -d database && \
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
|
||||
# This rule creates a file named .env that is used by docker-compose for passing
|
||||
# the USER_ID and GROUP_ID arguments to the Docker image.
|
||||
.env: ## Setup step for using using docker-compose with make target.
|
||||
@touch .env
|
||||
ifneq ($(OS),Windows_NT)
|
||||
ifneq ($(shell uname -s), Darwin)
|
||||
@echo USER_ID=$(shell id -u) > .env
|
||||
@echo GROUP_ID=$(shell id -g) >> .env
|
||||
endif
|
||||
endif
|
||||
@cd core && hatch run setup-db
|
||||
|
||||
.PHONY: clean
|
||||
clean: ## Resets development environment.
|
||||
@echo 'cleaning repo...'
|
||||
@rm -f .coverage
|
||||
@rm -f .coverage.*
|
||||
@rm -rf .eggs/
|
||||
@rm -f .env
|
||||
@rm -rf .tox/
|
||||
@rm -rf build/
|
||||
@rm -rf dbt.egg-info/
|
||||
@rm -f dbt_project.yml
|
||||
@rm -rf dist/
|
||||
@rm -f htmlcov/*.{css,html,js,json,png}
|
||||
@rm -rf logs/
|
||||
@rm -rf target/
|
||||
@find . -type f -name '*.pyc' -delete
|
||||
@find . -type d -name '__pycache__' -depth -delete
|
||||
@echo 'done.'
|
||||
@cd core && hatch run clean
|
||||
|
||||
.PHONY: json_schema
|
||||
json_schema: ## Update generated JSON schema using code changes.
|
||||
@cd core && hatch run json-schema
|
||||
|
||||
.PHONY: help
|
||||
help: ## Show this help message.
|
||||
@echo 'usage: make [target] [USE_DOCKER=true]'
|
||||
@echo 'usage: make [target]'
|
||||
@echo
|
||||
@echo 'DEPRECATED: This Makefile is a compatibility shim.'
|
||||
@echo 'Please use "cd core && hatch run <command>" directly.'
|
||||
@echo
|
||||
@echo 'targets:'
|
||||
@grep -E '^[8+a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
@echo
|
||||
@echo 'options:'
|
||||
@echo 'use USE_DOCKER=true to run target in a docker container'
|
||||
|
||||
.PHONY: json_schema
|
||||
json_schema: ## Update generated JSON schema using code changes.
|
||||
scripts/collect-artifact-schema.py --path schemas
|
||||
@echo 'For more information, see CONTRIBUTING.md'
|
||||
|
||||
@@ -5,6 +5,7 @@
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
</a>
|
||||
<a href="https://www.bestpractices.dev/projects/11095"><img src="https://www.bestpractices.dev/projects/11095/badge"></a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
25
codecov.yml
25
codecov.yml
@@ -2,37 +2,22 @@ ignore:
|
||||
- ".github"
|
||||
- ".changes"
|
||||
|
||||
# Disable all status checks to prevent red X's in CI
|
||||
# Coverage data is still uploaded and PR comments are still posted
|
||||
coverage:
|
||||
status:
|
||||
project:
|
||||
default:
|
||||
target: auto
|
||||
threshold: 0.1% # Reduce noise by ignoring rounding errors in coverage drops
|
||||
patch:
|
||||
default:
|
||||
target: auto
|
||||
threshold: 80%
|
||||
project: off
|
||||
patch: off
|
||||
|
||||
comment:
|
||||
layout: "header, diff, flags, components" # show component info in the PR comment
|
||||
layout: "header, diff, flags, components" # show component info in the PR comment
|
||||
|
||||
component_management:
|
||||
default_rules: # default rules that will be inherited by all components
|
||||
statuses:
|
||||
- type: project # in this case every component that doens't have a status defined will have a project type one
|
||||
target: auto
|
||||
threshold: 0.1%
|
||||
- type: patch
|
||||
target: 80%
|
||||
individual_components:
|
||||
- component_id: unittests
|
||||
name: "Unit Tests"
|
||||
flag_regexes:
|
||||
- "unit"
|
||||
statuses:
|
||||
- type: patch
|
||||
target: 80%
|
||||
threshold: 5%
|
||||
- component_id: integrationtests
|
||||
name: "Integration Tests"
|
||||
flag_regexes:
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
include dbt/py.typed
|
||||
recursive-include dbt/task/docs *.html
|
||||
@@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/docs/images/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
@@ -9,7 +9,7 @@
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
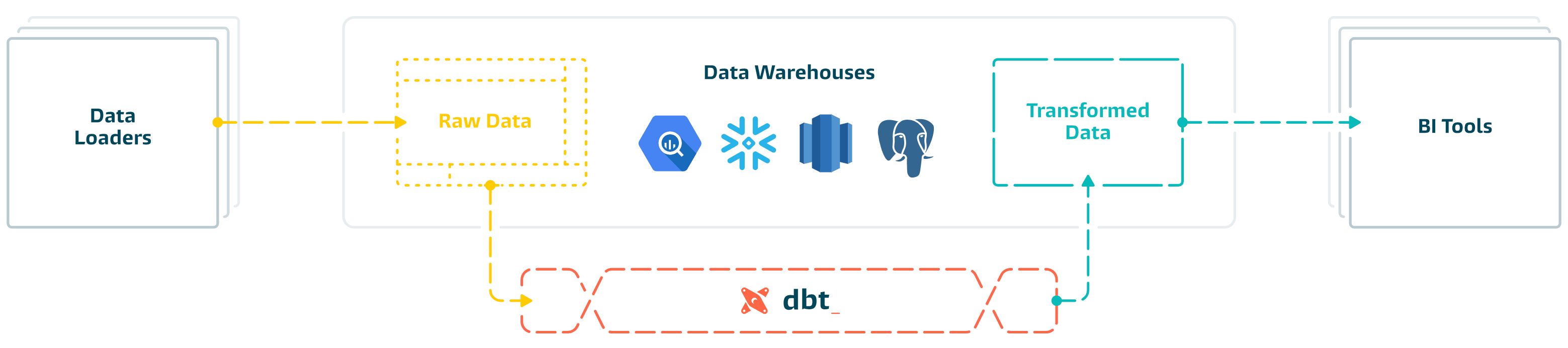
|
||||

|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -17,7 +17,7 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||
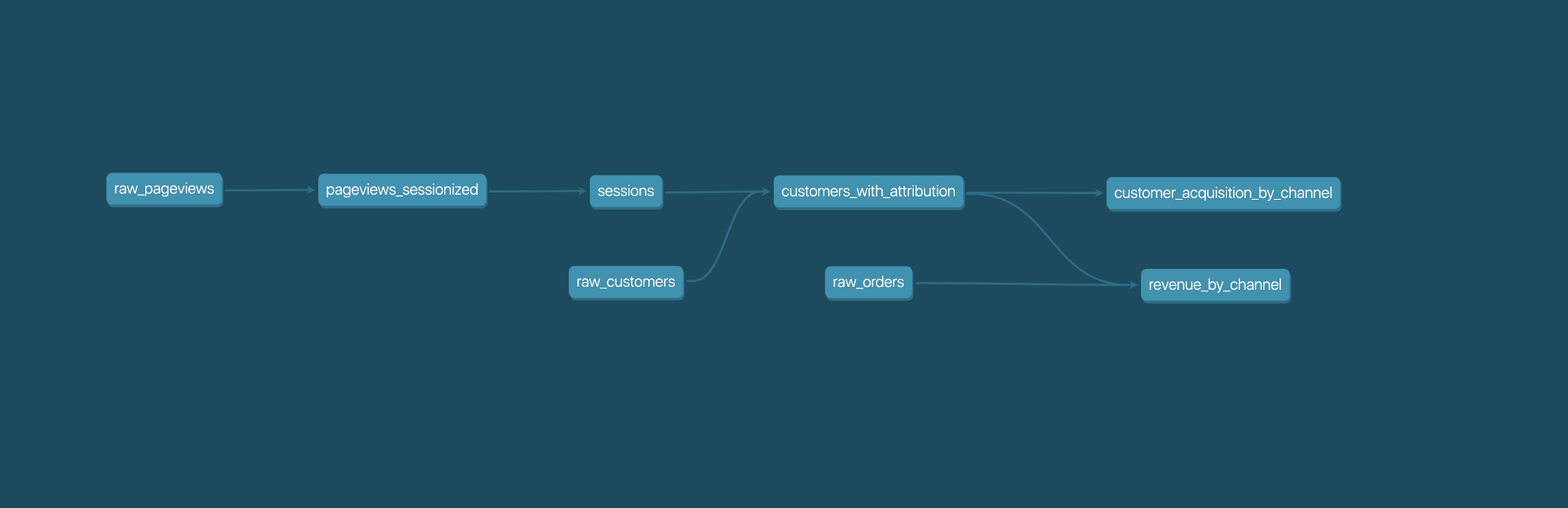
|
||||

|
||||
|
||||
## Getting started
|
||||
|
||||
|
||||
1
core/dbt/__version__.py
Normal file
1
core/dbt/__version__.py
Normal file
@@ -0,0 +1 @@
|
||||
version = "1.12.0a1"
|
||||
26
core/dbt/_pydantic_shim.py
Normal file
26
core/dbt/_pydantic_shim.py
Normal file
@@ -0,0 +1,26 @@
|
||||
# type: ignore
|
||||
|
||||
"""Shim to allow support for both Pydantic 1 and Pydantic 2.
|
||||
|
||||
dbt-core must support both major versions of Pydantic because dbt-core users might be using an environment with
|
||||
either version, and we can't restrict them to one or the other. Here, we essentially import all Pydantic objects
|
||||
from version 1 that we use. Throughout the repo, we import these objects from this file instead of from Pydantic
|
||||
directly, meaning that we essentially only use Pydantic 1 in dbt-core currently, but without forcing that restriction
|
||||
on dbt users. The development environment for this repo should be pinned to Pydantic 1 to ensure devs get appropriate
|
||||
type hints.
|
||||
"""
|
||||
|
||||
from importlib.metadata import version
|
||||
|
||||
pydantic_version = version("pydantic")
|
||||
# Pydantic uses semantic versioning, i.e. <major>.<minor>.<patch>, and we need to know the major
|
||||
pydantic_major = pydantic_version.split(".")[0]
|
||||
|
||||
if pydantic_major == "1":
|
||||
from pydantic import BaseSettings # noqa: F401
|
||||
elif pydantic_major == "2":
|
||||
from pydantic.v1 import BaseSettings # noqa: F401
|
||||
else:
|
||||
raise RuntimeError(
|
||||
f"Currently only pydantic 1 and 2 are supported, found pydantic {pydantic_version}"
|
||||
)
|
||||
@@ -1,8 +1,10 @@
|
||||
from dbt.artifacts.resources.base import BaseResource, Docs, FileHash, GraphResource
|
||||
from dbt.artifacts.resources.v1.analysis import Analysis
|
||||
from dbt.artifacts.resources.v1.catalog import Catalog, CatalogWriteIntegrationConfig
|
||||
|
||||
# alias to latest resource definitions
|
||||
from dbt.artifacts.resources.v1.components import (
|
||||
ColumnConfig,
|
||||
ColumnInfo,
|
||||
CompiledResource,
|
||||
Contract,
|
||||
@@ -23,6 +25,8 @@ from dbt.artifacts.resources.v1.config import (
|
||||
NodeAndTestConfig,
|
||||
NodeConfig,
|
||||
TestConfig,
|
||||
list_str,
|
||||
metas,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.documentation import Documentation
|
||||
from dbt.artifacts.resources.v1.exposure import (
|
||||
@@ -31,8 +35,15 @@ from dbt.artifacts.resources.v1.exposure import (
|
||||
ExposureType,
|
||||
MaturityType,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.function import (
|
||||
Function,
|
||||
FunctionArgument,
|
||||
FunctionConfig,
|
||||
FunctionMandatory,
|
||||
FunctionReturns,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.generic_test import GenericTest, TestMetadata
|
||||
from dbt.artifacts.resources.v1.group import Group
|
||||
from dbt.artifacts.resources.v1.group import Group, GroupConfig
|
||||
from dbt.artifacts.resources.v1.hook import HookNode
|
||||
from dbt.artifacts.resources.v1.macro import Macro, MacroArgument, MacroDependsOn
|
||||
from dbt.artifacts.resources.v1.metric import (
|
||||
@@ -40,13 +51,20 @@ from dbt.artifacts.resources.v1.metric import (
|
||||
ConversionTypeParams,
|
||||
CumulativeTypeParams,
|
||||
Metric,
|
||||
MetricAggregationParams,
|
||||
MetricConfig,
|
||||
MetricInput,
|
||||
MetricInputMeasure,
|
||||
MetricTimeWindow,
|
||||
MetricTypeParams,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.model import Model, ModelConfig, TimeSpine
|
||||
from dbt.artifacts.resources.v1.model import (
|
||||
CustomGranularity,
|
||||
Model,
|
||||
ModelConfig,
|
||||
ModelFreshness,
|
||||
TimeSpine,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.owner import Owner
|
||||
from dbt.artifacts.resources.v1.saved_query import (
|
||||
Export,
|
||||
@@ -59,6 +77,8 @@ from dbt.artifacts.resources.v1.saved_query import (
|
||||
from dbt.artifacts.resources.v1.seed import Seed, SeedConfig
|
||||
from dbt.artifacts.resources.v1.semantic_layer_components import (
|
||||
FileSlice,
|
||||
MeasureAggregationParameters,
|
||||
NonAdditiveDimension,
|
||||
SourceFileMetadata,
|
||||
WhereFilter,
|
||||
WhereFilterIntersection,
|
||||
@@ -70,9 +90,8 @@ from dbt.artifacts.resources.v1.semantic_model import (
|
||||
DimensionValidityParams,
|
||||
Entity,
|
||||
Measure,
|
||||
MeasureAggregationParameters,
|
||||
NodeRelation,
|
||||
NonAdditiveDimension,
|
||||
SemanticLayerElementConfig,
|
||||
SemanticModel,
|
||||
SemanticModelConfig,
|
||||
)
|
||||
|
||||
@@ -35,6 +35,7 @@ class NodeType(StrEnum):
|
||||
SemanticModel = "semantic_model"
|
||||
Unit = "unit_test"
|
||||
Fixture = "fixture"
|
||||
Function = "function"
|
||||
|
||||
def pluralize(self) -> str:
|
||||
if self is self.Analysis:
|
||||
@@ -75,3 +76,18 @@ class BatchSize(StrEnum):
|
||||
day = "day"
|
||||
month = "month"
|
||||
year = "year"
|
||||
|
||||
def plural(self) -> str:
|
||||
return str(self) + "s"
|
||||
|
||||
|
||||
class FunctionType(StrEnum):
|
||||
Scalar = "scalar"
|
||||
Aggregate = "aggregate"
|
||||
Table = "table"
|
||||
|
||||
|
||||
class FunctionVolatility(StrEnum):
|
||||
Deterministic = "deterministic"
|
||||
Stable = "stable"
|
||||
NonDeterministic = "non-deterministic"
|
||||
|
||||
23
core/dbt/artifacts/resources/v1/catalog.py
Normal file
23
core/dbt/artifacts/resources/v1/catalog.py
Normal file
@@ -0,0 +1,23 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Optional
|
||||
|
||||
from dbt.adapters.catalogs import CatalogIntegrationConfig
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
|
||||
|
||||
@dataclass
|
||||
class CatalogWriteIntegrationConfig(CatalogIntegrationConfig):
|
||||
name: str
|
||||
catalog_type: str
|
||||
external_volume: Optional[str] = None
|
||||
table_format: Optional[str] = None
|
||||
catalog_name: Optional[str] = None
|
||||
file_format: Optional[str] = None
|
||||
adapter_properties: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Catalog(dbtClassMixin):
|
||||
name: str
|
||||
active_write_integration: Optional[str] = None
|
||||
write_integrations: List[CatalogWriteIntegrationConfig] = field(default_factory=list)
|
||||
@@ -6,6 +6,7 @@ from typing import Any, Dict, List, Optional, Union
|
||||
from dbt.artifacts.resources.base import Docs, FileHash, GraphResource
|
||||
from dbt.artifacts.resources.types import NodeType, TimePeriod
|
||||
from dbt.artifacts.resources.v1.config import NodeConfig
|
||||
from dbt_common.contracts.config.base import BaseConfig, MergeBehavior
|
||||
from dbt_common.contracts.config.properties import AdditionalPropertiesMixin
|
||||
from dbt_common.contracts.constraints import ColumnLevelConstraint
|
||||
from dbt_common.contracts.util import Mergeable
|
||||
@@ -15,6 +16,20 @@ from dbt_semantic_interfaces.type_enums import TimeGranularity
|
||||
NodeVersion = Union[str, float]
|
||||
|
||||
|
||||
def _backcompat_doc_blocks(doc_blocks: Any) -> List[str]:
|
||||
"""
|
||||
Make doc_blocks backwards-compatible for scenarios where a user specifies `doc_blocks` on a model or column.
|
||||
Mashumaro will raise a serialization error if the specified `doc_blocks` isn't a list of strings.
|
||||
In such a scenario, this method returns an empty list to avoid a serialization error.
|
||||
Further along, `_get_doc_blocks` in `manifest.py` populates the correct `doc_blocks` for the happy path.
|
||||
"""
|
||||
|
||||
if isinstance(doc_blocks, list) and all(isinstance(x, str) for x in doc_blocks):
|
||||
return doc_blocks
|
||||
|
||||
return []
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroDependsOn(dbtClassMixin):
|
||||
macros: List[str] = field(default_factory=list)
|
||||
@@ -55,6 +70,12 @@ class RefArgs(dbtClassMixin):
|
||||
return {}
|
||||
|
||||
|
||||
@dataclass
|
||||
class ColumnConfig(BaseConfig):
|
||||
meta: Dict[str, Any] = field(default_factory=dict, metadata=MergeBehavior.Update.meta())
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ColumnInfo(AdditionalPropertiesMixin, ExtensibleDbtClassMixin):
|
||||
"""Used in all ManifestNodes and SourceDefinition"""
|
||||
@@ -65,9 +86,16 @@ class ColumnInfo(AdditionalPropertiesMixin, ExtensibleDbtClassMixin):
|
||||
data_type: Optional[str] = None
|
||||
constraints: List[ColumnLevelConstraint] = field(default_factory=list)
|
||||
quote: Optional[bool] = None
|
||||
config: ColumnConfig = field(default_factory=ColumnConfig)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
_extra: Dict[str, Any] = field(default_factory=dict)
|
||||
granularity: Optional[TimeGranularity] = None
|
||||
doc_blocks: List[str] = field(default_factory=list)
|
||||
|
||||
def __post_serialize__(self, dct: Dict, context: Optional[Dict] = None) -> dict:
|
||||
dct = super().__post_serialize__(dct, context)
|
||||
dct["doc_blocks"] = _backcompat_doc_blocks(dct["doc_blocks"])
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -197,13 +225,18 @@ class ParsedResource(ParsedResourceMandatory):
|
||||
unrendered_config_call_dict: Dict[str, Any] = field(default_factory=dict)
|
||||
relation_name: Optional[str] = None
|
||||
raw_code: str = ""
|
||||
doc_blocks: List[str] = field(default_factory=list)
|
||||
|
||||
def __post_serialize__(self, dct: Dict, context: Optional[Dict] = None):
|
||||
dct = super().__post_serialize__(dct, context)
|
||||
|
||||
if context and context.get("artifact") and "config_call_dict" in dct:
|
||||
del dct["config_call_dict"]
|
||||
if context and context.get("artifact") and "unrendered_config_call_dict" in dct:
|
||||
del dct["unrendered_config_call_dict"]
|
||||
|
||||
dct["doc_blocks"] = _backcompat_doc_blocks(dct["doc_blocks"])
|
||||
|
||||
return dct
|
||||
|
||||
|
||||
@@ -216,6 +249,7 @@ class CompiledResource(ParsedResource):
|
||||
refs: List[RefArgs] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
metrics: List[List[str]] = field(default_factory=list)
|
||||
functions: List[List[str]] = field(default_factory=list)
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
compiled_path: Optional[str] = None
|
||||
compiled: bool = False
|
||||
|
||||
@@ -181,7 +181,7 @@ class TestConfig(NodeAndTestConfig):
|
||||
warn_if: str = "!= 0"
|
||||
error_if: str = "!= 0"
|
||||
|
||||
def __post_init__(self):
|
||||
def finalize_and_validate(self):
|
||||
"""
|
||||
The presence of a setting for `store_failures_as` overrides any existing setting for `store_failures`,
|
||||
regardless of level of granularity. If `store_failures_as` is not set, then `store_failures` takes effect.
|
||||
@@ -207,6 +207,7 @@ class TestConfig(NodeAndTestConfig):
|
||||
but still allow for backwards compatibility for `store_failures`.
|
||||
See https://github.com/dbt-labs/dbt-core/issues/6914 for more information.
|
||||
"""
|
||||
super().finalize_and_validate()
|
||||
|
||||
# if `store_failures_as` is not set, it gets set by `store_failures`
|
||||
# the settings below mimic existing behavior prior to `store_failures_as`
|
||||
@@ -229,6 +230,8 @@ class TestConfig(NodeAndTestConfig):
|
||||
else:
|
||||
self.store_failures = get_store_failures_map.get(self.store_failures_as, True)
|
||||
|
||||
return self
|
||||
|
||||
@classmethod
|
||||
def same_contents(cls, unrendered: Dict[str, Any], other: Dict[str, Any]) -> bool:
|
||||
"""This is like __eq__, except it explicitly checks certain fields."""
|
||||
|
||||
@@ -27,6 +27,8 @@ class MaturityType(StrEnum):
|
||||
@dataclass
|
||||
class ExposureConfig(BaseConfig):
|
||||
enabled: bool = True
|
||||
tags: List[str] = field(default_factory=list)
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
53
core/dbt/artifacts/resources/v1/function.py
Normal file
53
core/dbt/artifacts/resources/v1/function.py
Normal file
@@ -0,0 +1,53 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, List, Literal, Optional
|
||||
|
||||
from dbt.artifacts.resources.types import FunctionType, FunctionVolatility, NodeType
|
||||
from dbt.artifacts.resources.v1.components import CompiledResource
|
||||
from dbt.artifacts.resources.v1.config import NodeConfig
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
|
||||
# =============
|
||||
# Function config, and supporting classes
|
||||
# =============
|
||||
|
||||
|
||||
@dataclass
|
||||
class FunctionConfig(NodeConfig):
|
||||
# The fact that this is a property, that can be changed, seems wrong.
|
||||
# A function's materialization should never be changed, so why allow for it?
|
||||
materialized: str = "function"
|
||||
type: FunctionType = FunctionType.Scalar
|
||||
volatility: Optional[FunctionVolatility] = None
|
||||
runtime_version: Optional[str] = None
|
||||
entry_point: Optional[str] = None
|
||||
|
||||
|
||||
# =============
|
||||
# Function resource, and supporting classes
|
||||
# =============
|
||||
|
||||
|
||||
@dataclass
|
||||
class FunctionArgument(dbtClassMixin):
|
||||
name: str
|
||||
data_type: str
|
||||
description: Optional[str] = None
|
||||
default_value: Optional[Any] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class FunctionReturns(dbtClassMixin):
|
||||
data_type: str
|
||||
description: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class FunctionMandatory(dbtClassMixin):
|
||||
returns: FunctionReturns
|
||||
|
||||
|
||||
@dataclass
|
||||
class Function(CompiledResource, FunctionMandatory):
|
||||
resource_type: Literal[NodeType.Function]
|
||||
config: FunctionConfig
|
||||
arguments: List[FunctionArgument] = field(default_factory=list)
|
||||
@@ -1,9 +1,15 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Literal
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, Literal, Optional
|
||||
|
||||
from dbt.artifacts.resources.base import BaseResource
|
||||
from dbt.artifacts.resources.types import NodeType
|
||||
from dbt.artifacts.resources.v1.owner import Owner
|
||||
from dbt_common.contracts.config.base import BaseConfig, MergeBehavior
|
||||
|
||||
|
||||
@dataclass
|
||||
class GroupConfig(BaseConfig):
|
||||
meta: Dict[str, Any] = field(default_factory=dict, metadata=MergeBehavior.Update.meta())
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -11,3 +17,5 @@ class Group(BaseResource):
|
||||
name: str
|
||||
owner: Owner
|
||||
resource_type: Literal[NodeType.Group]
|
||||
description: Optional[str] = None
|
||||
config: GroupConfig = field(default_factory=GroupConfig)
|
||||
|
||||
@@ -6,6 +6,8 @@ from dbt.artifacts.resources.base import GraphResource
|
||||
from dbt.artifacts.resources.types import NodeType
|
||||
from dbt.artifacts.resources.v1.components import DependsOn, RefArgs
|
||||
from dbt.artifacts.resources.v1.semantic_layer_components import (
|
||||
MeasureAggregationParameters,
|
||||
NonAdditiveDimension,
|
||||
SourceFileMetadata,
|
||||
WhereFilterIntersection,
|
||||
)
|
||||
@@ -13,6 +15,7 @@ from dbt_common.contracts.config.base import BaseConfig, CompareBehavior, MergeB
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_semantic_interfaces.references import MeasureReference, MetricReference
|
||||
from dbt_semantic_interfaces.type_enums import (
|
||||
AggregationType,
|
||||
ConversionCalculationType,
|
||||
MetricType,
|
||||
PeriodAggregation,
|
||||
@@ -46,7 +49,15 @@ class MetricInputMeasure(dbtClassMixin):
|
||||
@dataclass
|
||||
class MetricTimeWindow(dbtClassMixin):
|
||||
count: int
|
||||
granularity: TimeGranularity
|
||||
granularity: str
|
||||
|
||||
@property
|
||||
def window_string(self) -> str: # noqa: D
|
||||
return f"{self.count} {self.granularity}"
|
||||
|
||||
@property
|
||||
def is_standard_granularity(self) -> bool: # noqa: D
|
||||
return self.granularity.casefold() in {item.value.casefold() for item in TimeGranularity}
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -55,7 +66,7 @@ class MetricInput(dbtClassMixin):
|
||||
filter: Optional[WhereFilterIntersection] = None
|
||||
alias: Optional[str] = None
|
||||
offset_window: Optional[MetricTimeWindow] = None
|
||||
offset_to_grain: Optional[TimeGranularity] = None
|
||||
offset_to_grain: Optional[str] = None
|
||||
|
||||
def as_reference(self) -> MetricReference:
|
||||
return MetricReference(element_name=self.name)
|
||||
@@ -83,8 +94,19 @@ class ConversionTypeParams(dbtClassMixin):
|
||||
@dataclass
|
||||
class CumulativeTypeParams(dbtClassMixin):
|
||||
window: Optional[MetricTimeWindow] = None
|
||||
grain_to_date: Optional[TimeGranularity] = None
|
||||
grain_to_date: Optional[str] = None
|
||||
period_agg: PeriodAggregation = PeriodAggregation.FIRST
|
||||
metric: Optional[MetricInput] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class MetricAggregationParams(dbtClassMixin):
|
||||
semantic_model: str
|
||||
agg: AggregationType
|
||||
agg_params: Optional[MeasureAggregationParameters] = None
|
||||
agg_time_dimension: Optional[str] = None
|
||||
non_additive_dimension: Optional[NonAdditiveDimension] = None
|
||||
expr: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -95,10 +117,13 @@ class MetricTypeParams(dbtClassMixin):
|
||||
denominator: Optional[MetricInput] = None
|
||||
expr: Optional[str] = None
|
||||
window: Optional[MetricTimeWindow] = None
|
||||
grain_to_date: Optional[TimeGranularity] = None
|
||||
grain_to_date: Optional[TimeGranularity] = (
|
||||
None # legacy, use cumulative_type_params.grain_to_date
|
||||
)
|
||||
metrics: Optional[List[MetricInput]] = None
|
||||
conversion_type_params: Optional[ConversionTypeParams] = None
|
||||
cumulative_type_params: Optional[CumulativeTypeParams] = None
|
||||
metric_aggregation_params: Optional[MetricAggregationParams] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -121,7 +146,7 @@ class Metric(GraphResource):
|
||||
type_params: MetricTypeParams
|
||||
filter: Optional[WhereFilterIntersection] = None
|
||||
metadata: Optional[SourceFileMetadata] = None
|
||||
time_granularity: Optional[TimeGranularity] = None
|
||||
time_granularity: Optional[str] = None
|
||||
resource_type: Literal[NodeType.Metric]
|
||||
meta: Dict[str, Any] = field(default_factory=dict, metadata=MergeBehavior.Update.meta())
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
import enum
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime
|
||||
from typing import Dict, List, Literal, Optional
|
||||
|
||||
from dbt.artifacts.resources.types import AccessType, NodeType
|
||||
from dbt.artifacts.resources.types import AccessType, NodeType, TimePeriod
|
||||
from dbt.artifacts.resources.v1.components import (
|
||||
CompiledResource,
|
||||
DeferRelation,
|
||||
@@ -11,7 +12,63 @@ from dbt.artifacts.resources.v1.components import (
|
||||
from dbt.artifacts.resources.v1.config import NodeConfig
|
||||
from dbt_common.contracts.config.base import MergeBehavior
|
||||
from dbt_common.contracts.constraints import ModelLevelConstraint
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_common.contracts.util import Mergeable
|
||||
from dbt_common.dataclass_schema import (
|
||||
ExtensibleDbtClassMixin,
|
||||
ValidationError,
|
||||
dbtClassMixin,
|
||||
)
|
||||
|
||||
|
||||
class ModelFreshnessUpdatesOnOptions(enum.Enum):
|
||||
all = "all"
|
||||
any = "any"
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelBuildAfter(ExtensibleDbtClassMixin):
|
||||
count: Optional[int] = None
|
||||
period: Optional[TimePeriod] = None
|
||||
updates_on: ModelFreshnessUpdatesOnOptions = ModelFreshnessUpdatesOnOptions.any
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModelFreshness(ExtensibleDbtClassMixin, Mergeable):
|
||||
build_after: ModelBuildAfter
|
||||
|
||||
|
||||
def merge_model_freshness(*thresholds: Optional[ModelFreshness]) -> Optional[ModelFreshness]:
|
||||
if not thresholds:
|
||||
return None
|
||||
|
||||
current_merged_value: Optional[ModelFreshness] = thresholds[0]
|
||||
|
||||
for i in range(1, len(thresholds)):
|
||||
base = current_merged_value
|
||||
update = thresholds[i]
|
||||
|
||||
if base is not None and update is not None:
|
||||
# When both base and update freshness are defined,
|
||||
# create a new ModelFreshness instance using the build_after from the 'update'.
|
||||
# This effectively means 'update's build_after configuration takes precedence.
|
||||
merged_freshness_obj = base.merged(update)
|
||||
if (
|
||||
base.build_after.updates_on == ModelFreshnessUpdatesOnOptions.all
|
||||
or update.build_after.updates_on == ModelFreshnessUpdatesOnOptions.all
|
||||
):
|
||||
merged_freshness_obj.build_after.updates_on = ModelFreshnessUpdatesOnOptions.all
|
||||
current_merged_value = merged_freshness_obj
|
||||
elif base is None and update is not None:
|
||||
# If the current merged value is None but the new update is defined,
|
||||
# take the update.
|
||||
current_merged_value = update
|
||||
else:
|
||||
# This covers cases where 'update' is None (regardless of 'base'),
|
||||
# or both 'base' and 'update' are None.
|
||||
# The result of the pair-merge is None.
|
||||
current_merged_value = base
|
||||
|
||||
return current_merged_value
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -20,6 +77,40 @@ class ModelConfig(NodeConfig):
|
||||
default=AccessType.Protected,
|
||||
metadata=MergeBehavior.Clobber.meta(),
|
||||
)
|
||||
freshness: Optional[ModelFreshness] = None
|
||||
|
||||
def __post_init__(self):
|
||||
super().__post_init__()
|
||||
if (
|
||||
self.freshness
|
||||
and self.freshness.build_after.period
|
||||
and self.freshness.build_after.count is None
|
||||
):
|
||||
raise ValidationError(
|
||||
"`freshness.build_after` must have a value for `count` if a `period` is provided"
|
||||
)
|
||||
elif (
|
||||
self.freshness
|
||||
and self.freshness.build_after.count is not None
|
||||
and not self.freshness.build_after.period
|
||||
):
|
||||
raise ValidationError(
|
||||
"`freshness.build_after` must have a value for `period` if a `count` is provided"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
# scrub out model configs where "build_after" is not defined
|
||||
if (
|
||||
"freshness" in data
|
||||
and isinstance(data["freshness"], dict)
|
||||
and "build_after" in data["freshness"]
|
||||
):
|
||||
data["freshness"] = ModelFreshness.from_dict(data["freshness"]).to_dict()
|
||||
else:
|
||||
data.pop("freshness", None)
|
||||
return data
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
from typing import List, Optional, Union
|
||||
|
||||
from dbt_common.contracts.config.properties import AdditionalPropertiesAllowed
|
||||
|
||||
|
||||
@dataclass
|
||||
class Owner(AdditionalPropertiesAllowed):
|
||||
email: Optional[str] = None
|
||||
email: Union[str, List[str], None] = None
|
||||
name: Optional[str] = None
|
||||
|
||||
@@ -2,16 +2,18 @@ from __future__ import annotations
|
||||
|
||||
import time
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Literal, Optional
|
||||
from typing import Any, Dict, List, Literal, Optional, Union
|
||||
|
||||
from dbt.artifacts.resources.base import GraphResource
|
||||
from dbt.artifacts.resources.types import NodeType
|
||||
from dbt.artifacts.resources.v1.components import DependsOn, RefArgs
|
||||
from dbt.artifacts.resources.v1.config import list_str, metas
|
||||
from dbt.artifacts.resources.v1.semantic_layer_components import (
|
||||
SourceFileMetadata,
|
||||
WhereFilterIntersection,
|
||||
)
|
||||
from dbt_common.contracts.config.base import BaseConfig, CompareBehavior, MergeBehavior
|
||||
from dbt_common.contracts.config.metadata import ShowBehavior
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_semantic_interfaces.type_enums.export_destination_type import (
|
||||
ExportDestinationType,
|
||||
@@ -95,6 +97,10 @@ class SavedQuery(SavedQueryMandatory):
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
created_at: float = field(default_factory=lambda: time.time())
|
||||
refs: List[RefArgs] = field(default_factory=list)
|
||||
tags: Union[List[str], str] = field(
|
||||
default_factory=list_str,
|
||||
metadata=metas(ShowBehavior.Hide, MergeBehavior.Append, CompareBehavior.Exclude),
|
||||
)
|
||||
|
||||
@property
|
||||
def metrics(self) -> List[str]:
|
||||
|
||||
@@ -1,28 +1,36 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Sequence, Tuple
|
||||
from typing import List, Optional, Sequence, Tuple
|
||||
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_semantic_interfaces.call_parameter_sets import FilterCallParameterSets
|
||||
from dbt_semantic_interfaces.parsing.where_filter.where_filter_parser import (
|
||||
WhereFilterParser,
|
||||
from dbt_semantic_interfaces.call_parameter_sets import JinjaCallParameterSets
|
||||
from dbt_semantic_interfaces.parsing.where_filter.jinja_object_parser import (
|
||||
JinjaObjectParser,
|
||||
QueryItemLocation,
|
||||
)
|
||||
from dbt_semantic_interfaces.type_enums import AggregationType
|
||||
|
||||
|
||||
@dataclass
|
||||
class WhereFilter(dbtClassMixin):
|
||||
where_sql_template: str
|
||||
|
||||
@property
|
||||
def call_parameter_sets(self) -> FilterCallParameterSets:
|
||||
return WhereFilterParser.parse_call_parameter_sets(self.where_sql_template)
|
||||
def call_parameter_sets(
|
||||
self, custom_granularity_names: Sequence[str]
|
||||
) -> JinjaCallParameterSets:
|
||||
return JinjaObjectParser.parse_call_parameter_sets(
|
||||
self.where_sql_template,
|
||||
custom_granularity_names=custom_granularity_names,
|
||||
query_item_location=QueryItemLocation.NON_ORDER_BY,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class WhereFilterIntersection(dbtClassMixin):
|
||||
where_filters: List[WhereFilter]
|
||||
|
||||
@property
|
||||
def filter_expression_parameter_sets(self) -> Sequence[Tuple[str, FilterCallParameterSets]]:
|
||||
def filter_expression_parameter_sets(
|
||||
self, custom_granularity_names: Sequence[str]
|
||||
) -> Sequence[Tuple[str, JinjaCallParameterSets]]:
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@@ -48,3 +56,17 @@ class SourceFileMetadata(dbtClassMixin):
|
||||
|
||||
repo_file_path: str
|
||||
file_slice: FileSlice
|
||||
|
||||
|
||||
@dataclass
|
||||
class MeasureAggregationParameters(dbtClassMixin):
|
||||
percentile: Optional[float] = None
|
||||
use_discrete_percentile: bool = False
|
||||
use_approximate_percentile: bool = False
|
||||
|
||||
|
||||
@dataclass
|
||||
class NonAdditiveDimension(dbtClassMixin):
|
||||
name: str
|
||||
window_choice: AggregationType
|
||||
window_groupings: List[str]
|
||||
|
||||
@@ -5,6 +5,11 @@ from typing import Any, Dict, List, Optional, Sequence
|
||||
from dbt.artifacts.resources import SourceFileMetadata
|
||||
from dbt.artifacts.resources.base import GraphResource
|
||||
from dbt.artifacts.resources.v1.components import DependsOn, RefArgs
|
||||
from dbt.artifacts.resources.v1.metric import Metric
|
||||
from dbt.artifacts.resources.v1.semantic_layer_components import (
|
||||
MeasureAggregationParameters,
|
||||
NonAdditiveDimension,
|
||||
)
|
||||
from dbt_common.contracts.config.base import BaseConfig, CompareBehavior, MergeBehavior
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_semantic_interfaces.references import (
|
||||
@@ -19,6 +24,7 @@ from dbt_semantic_interfaces.type_enums import (
|
||||
AggregationType,
|
||||
DimensionType,
|
||||
EntityType,
|
||||
MetricType,
|
||||
TimeGranularity,
|
||||
)
|
||||
|
||||
@@ -31,6 +37,14 @@ https://github.com/dbt-labs/dbt-semantic-interfaces/blob/main/dbt_semantic_inter
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class SemanticLayerElementConfig(dbtClassMixin):
|
||||
meta: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Defaults(dbtClassMixin):
|
||||
agg_time_dimension: Optional[str] = None
|
||||
@@ -72,6 +86,7 @@ class Dimension(dbtClassMixin):
|
||||
type_params: Optional[DimensionTypeParams] = None
|
||||
expr: Optional[str] = None
|
||||
metadata: Optional[SourceFileMetadata] = None
|
||||
config: Optional[SemanticLayerElementConfig] = None
|
||||
|
||||
@property
|
||||
def reference(self) -> DimensionReference:
|
||||
@@ -106,6 +121,7 @@ class Entity(dbtClassMixin):
|
||||
label: Optional[str] = None
|
||||
role: Optional[str] = None
|
||||
expr: Optional[str] = None
|
||||
config: Optional[SemanticLayerElementConfig] = None
|
||||
|
||||
@property
|
||||
def reference(self) -> EntityReference:
|
||||
@@ -117,25 +133,11 @@ class Entity(dbtClassMixin):
|
||||
|
||||
|
||||
# ====================================
|
||||
# Measure objects
|
||||
# Measure object
|
||||
# Measure protocols: https://github.com/dbt-labs/dbt-semantic-interfaces/blob/main/dbt_semantic_interfaces/protocols/measure.py
|
||||
# ====================================
|
||||
|
||||
|
||||
@dataclass
|
||||
class MeasureAggregationParameters(dbtClassMixin):
|
||||
percentile: Optional[float] = None
|
||||
use_discrete_percentile: bool = False
|
||||
use_approximate_percentile: bool = False
|
||||
|
||||
|
||||
@dataclass
|
||||
class NonAdditiveDimension(dbtClassMixin):
|
||||
name: str
|
||||
window_choice: AggregationType
|
||||
window_groupings: List[str]
|
||||
|
||||
|
||||
@dataclass
|
||||
class Measure(dbtClassMixin):
|
||||
name: str
|
||||
@@ -147,6 +149,7 @@ class Measure(dbtClassMixin):
|
||||
agg_params: Optional[MeasureAggregationParameters] = None
|
||||
non_additive_dimension: Optional[NonAdditiveDimension] = None
|
||||
agg_time_dimension: Optional[str] = None
|
||||
config: Optional[SemanticLayerElementConfig] = None
|
||||
|
||||
@property
|
||||
def reference(self) -> MeasureReference:
|
||||
@@ -263,6 +266,45 @@ class SemanticModel(GraphResource):
|
||||
)
|
||||
return TimeDimensionReference(element_name=agg_time_dimension_name)
|
||||
|
||||
def checked_agg_time_dimension_for_simple_metric(
|
||||
self, metric: Metric
|
||||
) -> TimeDimensionReference:
|
||||
assert (
|
||||
metric.type == MetricType.SIMPLE
|
||||
), "Only simple metrics can have an agg time dimension."
|
||||
metric_agg_params = metric.type_params.metric_aggregation_params
|
||||
# There are validations elsewhere to check this for metrics and provide messaging for it.
|
||||
assert metric_agg_params, "Simple metrics must have metric_aggregation_params."
|
||||
# This indicates a validation bug / dev error, not a user error that should appear
|
||||
# in a user's YAML.
|
||||
assert (
|
||||
metric_agg_params.semantic_model == self.name
|
||||
), "Cannot retrieve the agg time dimension for a metric from a different model "
|
||||
f"than the one that the metric belongs to. Metric `{metric.name}` belongs to model "
|
||||
f"`{metric_agg_params.semantic_model}`, but we requested the agg time dimension from model `{self.name}`."
|
||||
|
||||
metric_time_dimension_name = None
|
||||
if (
|
||||
metric.type_params
|
||||
and metric.type_params.metric_aggregation_params
|
||||
and metric.type_params.metric_aggregation_params.agg_time_dimension
|
||||
):
|
||||
metric_time_dimension_name = (
|
||||
metric.type_params.metric_aggregation_params.agg_time_dimension
|
||||
)
|
||||
|
||||
default_agg_time_dimension = (
|
||||
self.defaults.agg_time_dimension if self.defaults is not None else None
|
||||
)
|
||||
agg_time_dimension_name = metric_time_dimension_name or default_agg_time_dimension
|
||||
|
||||
assert agg_time_dimension_name is not None, (
|
||||
f"Aggregation time dimension for metric {metric.name} is not set! This should either be set directly on "
|
||||
f"the metric specification in the model, or else defaulted to the time dimension in the data "
|
||||
f"source containing the metric."
|
||||
)
|
||||
return TimeDimensionReference(element_name=agg_time_dimension_name)
|
||||
|
||||
@property
|
||||
def primary_entity_reference(self) -> Optional[EntityReference]:
|
||||
return (
|
||||
|
||||
@@ -20,7 +20,7 @@ class SnapshotMetaColumnNames(dbtClassMixin):
|
||||
class SnapshotConfig(NodeConfig):
|
||||
materialized: str = "snapshot"
|
||||
strategy: Optional[str] = None
|
||||
unique_key: Optional[Union[str, List[str]]] = None
|
||||
unique_key: Union[str, List[str], None] = None
|
||||
target_schema: Optional[str] = None
|
||||
target_database: Optional[str] = None
|
||||
updated_at: Optional[str] = None
|
||||
|
||||
@@ -10,7 +10,7 @@ from dbt.artifacts.resources.v1.components import (
|
||||
HasRelationMetadata,
|
||||
Quoting,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.config import BaseConfig
|
||||
from dbt.artifacts.resources.v1.config import BaseConfig, MergeBehavior
|
||||
from dbt_common.contracts.config.properties import AdditionalPropertiesAllowed
|
||||
from dbt_common.contracts.util import Mergeable
|
||||
from dbt_common.exceptions import CompilationError
|
||||
@@ -20,6 +20,11 @@ from dbt_common.exceptions import CompilationError
|
||||
class SourceConfig(BaseConfig):
|
||||
enabled: bool = True
|
||||
event_time: Any = None
|
||||
freshness: Optional[FreshnessThreshold] = field(default_factory=FreshnessThreshold)
|
||||
loaded_at_field: Optional[str] = None
|
||||
loaded_at_query: Optional[str] = None
|
||||
meta: Dict[str, Any] = field(default_factory=dict, metadata=MergeBehavior.Update.meta())
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -59,6 +64,7 @@ class ParsedSourceMandatory(GraphResource, HasRelationMetadata):
|
||||
class SourceDefinition(ParsedSourceMandatory):
|
||||
quoting: Quoting = field(default_factory=Quoting)
|
||||
loaded_at_field: Optional[str] = None
|
||||
loaded_at_query: Optional[str] = None
|
||||
freshness: Optional[FreshnessThreshold] = None
|
||||
external: Optional[ExternalTable] = None
|
||||
description: str = ""
|
||||
@@ -73,3 +79,4 @@ class SourceDefinition(ParsedSourceMandatory):
|
||||
created_at: float = field(default_factory=lambda: time.time())
|
||||
unrendered_database: Optional[str] = None
|
||||
unrendered_schema: Optional[str] = None
|
||||
doc_blocks: List[str] = field(default_factory=list)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import dataclasses
|
||||
import functools
|
||||
from datetime import datetime
|
||||
from datetime import datetime, timezone
|
||||
from typing import Any, ClassVar, Dict, Optional, Type, TypeVar
|
||||
|
||||
from mashumaro.jsonschema import build_json_schema
|
||||
@@ -12,7 +12,7 @@ from dbt_common.clients.system import read_json, write_json
|
||||
from dbt_common.dataclass_schema import dbtClassMixin
|
||||
from dbt_common.events.functions import get_metadata_vars
|
||||
from dbt_common.exceptions import DbtInternalError, DbtRuntimeError
|
||||
from dbt_common.invocation import get_invocation_id
|
||||
from dbt_common.invocation import get_invocation_id, get_invocation_started_at
|
||||
|
||||
BASE_SCHEMAS_URL = "https://schemas.getdbt.com/"
|
||||
SCHEMA_PATH = "dbt/{name}/v{version}.json"
|
||||
@@ -55,8 +55,13 @@ class Readable:
|
||||
class BaseArtifactMetadata(dbtClassMixin):
|
||||
dbt_schema_version: str
|
||||
dbt_version: str = __version__
|
||||
generated_at: datetime = dataclasses.field(default_factory=datetime.utcnow)
|
||||
generated_at: datetime = dataclasses.field(
|
||||
default_factory=lambda: datetime.now(timezone.utc).replace(tzinfo=None)
|
||||
)
|
||||
invocation_id: Optional[str] = dataclasses.field(default_factory=get_invocation_id)
|
||||
invocation_started_at: Optional[datetime] = dataclasses.field(
|
||||
default_factory=get_invocation_started_at
|
||||
)
|
||||
env: Dict[str, str] = dataclasses.field(default_factory=get_metadata_vars)
|
||||
|
||||
def __post_serialize__(self, dct: Dict, context: Optional[Dict] = None):
|
||||
@@ -176,3 +181,11 @@ def get_artifact_schema_version(dct: dict) -> int:
|
||||
# 4. Convert to int
|
||||
# TODO: If this gets more complicated, turn into a regex
|
||||
return int(schema_version.split("/")[-1].split(".")[0][1:])
|
||||
|
||||
|
||||
def get_artifact_dbt_version(dct: dict) -> Optional[str]:
|
||||
dbt_version = dct.get("metadata", {}).get("dbt_version", None)
|
||||
if dbt_version is None:
|
||||
return None
|
||||
|
||||
return str(dbt_version)
|
||||
|
||||
@@ -1,11 +1,14 @@
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime
|
||||
from typing import Any, Dict, Iterable, List, Mapping, Optional, Tuple, Union
|
||||
from uuid import UUID
|
||||
|
||||
from dbt import tracking
|
||||
from dbt.artifacts.resources import (
|
||||
Analysis,
|
||||
Documentation,
|
||||
Exposure,
|
||||
Function,
|
||||
GenericTest,
|
||||
Group,
|
||||
HookNode,
|
||||
@@ -21,25 +24,25 @@ from dbt.artifacts.resources import (
|
||||
SqlOperation,
|
||||
UnitTestDefinition,
|
||||
)
|
||||
from dbt.artifacts.resources.v1.components import Quoting
|
||||
from dbt.artifacts.schemas.base import (
|
||||
ArtifactMixin,
|
||||
BaseArtifactMetadata,
|
||||
get_artifact_dbt_version,
|
||||
get_artifact_schema_version,
|
||||
schema_version,
|
||||
)
|
||||
from dbt.artifacts.schemas.upgrades import upgrade_manifest_json
|
||||
from dbt.artifacts.schemas.upgrades import (
|
||||
upgrade_manifest_json,
|
||||
upgrade_manifest_json_dbt_version,
|
||||
)
|
||||
from dbt.version import __version__
|
||||
from dbt_common.exceptions import DbtInternalError
|
||||
|
||||
NodeEdgeMap = Dict[str, List[str]]
|
||||
UniqueID = str
|
||||
ManifestResource = Union[
|
||||
Seed,
|
||||
Analysis,
|
||||
SingularTest,
|
||||
HookNode,
|
||||
Model,
|
||||
SqlOperation,
|
||||
GenericTest,
|
||||
Snapshot,
|
||||
Seed, Analysis, SingularTest, HookNode, Model, SqlOperation, GenericTest, Snapshot, Function
|
||||
]
|
||||
DisabledManifestResource = Union[
|
||||
ManifestResource,
|
||||
@@ -87,6 +90,14 @@ class ManifestMetadata(BaseArtifactMetadata):
|
||||
default=None,
|
||||
metadata=dict(description="The type name of the adapter"),
|
||||
)
|
||||
quoting: Optional[Quoting] = field(
|
||||
default_factory=Quoting,
|
||||
metadata=dict(description="The quoting configuration for the project"),
|
||||
)
|
||||
run_started_at: Optional[datetime] = field(
|
||||
default=tracking.active_user.run_started_at if tracking.active_user is not None else None,
|
||||
metadata=dict(description="The timestamp when the run started"),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def default(cls):
|
||||
@@ -158,6 +169,10 @@ class WritableManifest(ArtifactMixin):
|
||||
description="The unit tests defined in the project",
|
||||
)
|
||||
)
|
||||
functions: Mapping[UniqueID, Function] = field(
|
||||
default_factory=dict,
|
||||
metadata=dict(description=("The functions defined in the dbt project")),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def compatible_previous_versions(cls) -> Iterable[Tuple[str, int]]:
|
||||
@@ -179,4 +194,18 @@ class WritableManifest(ArtifactMixin):
|
||||
manifest_schema_version = get_artifact_schema_version(data)
|
||||
if manifest_schema_version < cls.dbt_schema_version.version:
|
||||
data = upgrade_manifest_json(data, manifest_schema_version)
|
||||
|
||||
manifest_dbt_version = get_artifact_dbt_version(data)
|
||||
if manifest_dbt_version and manifest_dbt_version != __version__:
|
||||
data = upgrade_manifest_json_dbt_version(data)
|
||||
return cls.from_dict(data)
|
||||
|
||||
@classmethod
|
||||
def validate(cls, _):
|
||||
# When dbt try to load an artifact with additional optional fields
|
||||
# that are not present in the schema, from_dict will work fine.
|
||||
# As long as validate is not called, the schema will not be enforced.
|
||||
# This is intentional, as it allows for safer schema upgrades.
|
||||
raise DbtInternalError(
|
||||
"The WritableManifest should never be validated directly to allow for schema upgrades."
|
||||
)
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
from dataclasses import dataclass
|
||||
from datetime import datetime
|
||||
from datetime import datetime, timezone
|
||||
from typing import Any, Callable, Dict, List, Optional, Sequence, Union
|
||||
|
||||
from dbt.contracts.graph.nodes import ResultNode
|
||||
@@ -21,10 +21,10 @@ class TimingInfo(dbtClassMixin):
|
||||
completed_at: Optional[datetime] = None
|
||||
|
||||
def begin(self):
|
||||
self.started_at = datetime.utcnow()
|
||||
self.started_at = datetime.now(timezone.utc).replace(tzinfo=None)
|
||||
|
||||
def end(self):
|
||||
self.completed_at = datetime.utcnow()
|
||||
self.completed_at = datetime.now(timezone.utc).replace(tzinfo=None)
|
||||
|
||||
def to_msg_dict(self):
|
||||
msg_dict = {"name": str(self.name)}
|
||||
@@ -64,6 +64,7 @@ class NodeStatus(StrEnum):
|
||||
PartialSuccess = "partial success"
|
||||
Pass = "pass"
|
||||
RuntimeErr = "runtime error"
|
||||
NoOp = "no-op"
|
||||
|
||||
|
||||
class RunStatus(StrEnum):
|
||||
@@ -71,6 +72,7 @@ class RunStatus(StrEnum):
|
||||
Error = NodeStatus.Error
|
||||
Skipped = NodeStatus.Skipped
|
||||
PartialSuccess = NodeStatus.PartialSuccess
|
||||
NoOp = NodeStatus.NoOp
|
||||
|
||||
|
||||
class TestStatus(StrEnum):
|
||||
|
||||
@@ -3,7 +3,7 @@ from __future__ import annotations
|
||||
import copy
|
||||
import threading
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime
|
||||
from datetime import datetime, timezone
|
||||
from typing import Any, Dict, Iterable, Optional, Sequence, Tuple
|
||||
|
||||
# https://github.com/dbt-labs/dbt-core/issues/10098
|
||||
@@ -101,7 +101,9 @@ class RunExecutionResult(
|
||||
):
|
||||
results: Sequence[RunResult]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
generated_at: datetime = field(
|
||||
default_factory=lambda: datetime.now(timezone.utc).replace(tzinfo=None)
|
||||
)
|
||||
|
||||
def write(self, path: str):
|
||||
writable = RunResultsArtifact.from_execution_results(
|
||||
|
||||
@@ -1 +1,4 @@
|
||||
from dbt.artifacts.schemas.upgrades.upgrade_manifest import upgrade_manifest_json
|
||||
from dbt.artifacts.schemas.upgrades.upgrade_manifest_dbt_version import (
|
||||
upgrade_manifest_json_dbt_version,
|
||||
)
|
||||
|
||||
@@ -0,0 +1,2 @@
|
||||
def upgrade_manifest_json_dbt_version(manifest: dict) -> dict:
|
||||
return manifest
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user