mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-17 19:31:34 +00:00
Compare commits
438 Commits
v0.19.2
...
performanc
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1fe53750fa | ||
|
|
8609c02383 | ||
|
|
355b0c496e | ||
|
|
cd6894acf4 | ||
|
|
b90b3a9c19 | ||
|
|
06cc0c57e8 | ||
|
|
87072707ed | ||
|
|
ef63319733 | ||
|
|
2068dd5510 | ||
|
|
3e1e171c66 | ||
|
|
5f9ed1a83c | ||
|
|
3d9e54d970 | ||
|
|
52a0fdef6c | ||
|
|
d9b02fb0a0 | ||
|
|
6c8de62b24 | ||
|
|
2d3d1b030a | ||
|
|
88acf0727b | ||
|
|
02839ec779 | ||
|
|
44a8f6a3bf | ||
|
|
751ea92576 | ||
|
|
02007b3619 | ||
|
|
fe0b9e7ef5 | ||
|
|
4b1c6b51f9 | ||
|
|
0b4689f311 | ||
|
|
b77eff8f6f | ||
|
|
2782a33ecf | ||
|
|
94c6cf1b3c | ||
|
|
3c8daacd3e | ||
|
|
2f9907b072 | ||
|
|
287c4d2b03 | ||
|
|
ba9d76b3f9 | ||
|
|
486afa9fcd | ||
|
|
1f189f5225 | ||
|
|
580b1fdd68 | ||
|
|
bad0198a36 | ||
|
|
252280b56e | ||
|
|
64bf9c8885 | ||
|
|
935c138736 | ||
|
|
5891b59790 | ||
|
|
4e020c3878 | ||
|
|
3004969a93 | ||
|
|
873e9714f8 | ||
|
|
fe24dd43d4 | ||
|
|
ed91ded2c1 | ||
|
|
757614d57f | ||
|
|
faff8c00b3 | ||
|
|
80244a09fe | ||
|
|
37e86257f5 | ||
|
|
c182c05c2f | ||
|
|
b02875a12b | ||
|
|
03332b2955 | ||
|
|
f1f99a2371 | ||
|
|
95116dbb5b | ||
|
|
868fd64adf | ||
|
|
2f7ab2d038 | ||
|
|
3d4a82cca2 | ||
|
|
6ba837d73d | ||
|
|
f4775d7673 | ||
|
|
429396aa02 | ||
|
|
8a5e9b71a5 | ||
|
|
fa78102eaf | ||
|
|
5466d474c5 | ||
|
|
80951ae973 | ||
|
|
d5662ef34c | ||
|
|
45bb955b55 | ||
|
|
4ddba7e44c | ||
|
|
37b31d10c8 | ||
|
|
c8bc25d11a | ||
|
|
4c06689ff5 | ||
|
|
a45c9d0192 | ||
|
|
34e2c4f90b | ||
|
|
c0e2023c81 | ||
|
|
108b55bdc3 | ||
|
|
a29367b7fe | ||
|
|
1d7e8349ed | ||
|
|
75d3d87d64 | ||
|
|
4ff3f6d4e8 | ||
|
|
d0773f3346 | ||
|
|
ee58d27d94 | ||
|
|
9e3da391a7 | ||
|
|
9f62ec2153 | ||
|
|
372eca76b8 | ||
|
|
e3cb050bbc | ||
|
|
0ae93c7f54 | ||
|
|
1f6386d760 | ||
|
|
66eb3964e2 | ||
|
|
f460d275ba | ||
|
|
fb91bad800 | ||
|
|
eaec22ae53 | ||
|
|
b7c1768cca | ||
|
|
387b26a202 | ||
|
|
8a1e6438f1 | ||
|
|
aaac5ff2e6 | ||
|
|
4dc29630b5 | ||
|
|
f716631439 | ||
|
|
648a780850 | ||
|
|
de0919ff88 | ||
|
|
8b1ea5fb6c | ||
|
|
85627aafcd | ||
|
|
49065158f5 | ||
|
|
bdb3049218 | ||
|
|
e10d1b0f86 | ||
|
|
83b98c8ebf | ||
|
|
b9d5123aa3 | ||
|
|
c09300bfd2 | ||
|
|
fc490cee7b | ||
|
|
3baa3d7fe8 | ||
|
|
764c7c0fdc | ||
|
|
c97ebbbf35 | ||
|
|
85fe32bd08 | ||
|
|
eba3fd2255 | ||
|
|
e2f2c07873 | ||
|
|
70850cd362 | ||
|
|
16992e6391 | ||
|
|
fd0d95140e | ||
|
|
ac65fcd557 | ||
|
|
4d246567b9 | ||
|
|
1ad1c834f3 | ||
|
|
41610b822c | ||
|
|
c794600242 | ||
|
|
9d414f6ec3 | ||
|
|
552e831306 | ||
|
|
c712c96a0b | ||
|
|
eb46bfc3d6 | ||
|
|
f52537b606 | ||
|
|
762419d2fe | ||
|
|
4feb7cb15b | ||
|
|
eb47b85148 | ||
|
|
9faa019a07 | ||
|
|
9589dc91fa | ||
|
|
14507a283e | ||
|
|
af0fe120ec | ||
|
|
16501ec1c6 | ||
|
|
bf867f6aff | ||
|
|
eb4ad4444f | ||
|
|
8fdba17ac6 | ||
|
|
abe8e83945 | ||
|
|
02cbae1f9f | ||
|
|
65908b395f | ||
|
|
4971395d5d | ||
|
|
eeec2038aa | ||
|
|
4fac086556 | ||
|
|
8818061d59 | ||
|
|
b195778eb9 | ||
|
|
de1763618a | ||
|
|
7485066ed4 | ||
|
|
15ce956380 | ||
|
|
e5c63884e2 | ||
|
|
9fef62d83e | ||
|
|
7563b997c2 | ||
|
|
291ff3600b | ||
|
|
2c405304ee | ||
|
|
1e5a7878e5 | ||
|
|
d89e1d7f85 | ||
|
|
98c015b775 | ||
|
|
a56502688f | ||
|
|
c0d757ab19 | ||
|
|
e68fd6eb7f | ||
|
|
90edc38859 | ||
|
|
0f018ea5dd | ||
|
|
1be6254363 | ||
|
|
760af71ed2 | ||
|
|
82f5e9f5b2 | ||
|
|
988c187db3 | ||
|
|
b23129982c | ||
|
|
4d5d0e2150 | ||
|
|
c0c487bf77 | ||
|
|
835d805079 | ||
|
|
c2a767184c | ||
|
|
1e7c8802eb | ||
|
|
a76ec42586 | ||
|
|
7418f36932 | ||
|
|
f9ef5e7e8e | ||
|
|
dbfa351395 | ||
|
|
e775f2b38e | ||
|
|
6f27454be4 | ||
|
|
201723d506 | ||
|
|
17555faaca | ||
|
|
36e0ab9f42 | ||
|
|
6017bd6cba | ||
|
|
30fed8d421 | ||
|
|
8ac5cdd2e1 | ||
|
|
114ac0793a | ||
|
|
d0b750461a | ||
|
|
9693170eb9 | ||
|
|
bbab6c2361 | ||
|
|
cfe3636c78 | ||
|
|
aadf3c702e | ||
|
|
1eac726a07 | ||
|
|
85e2c89794 | ||
|
|
fffcd3b404 | ||
|
|
fbfef4b1a3 | ||
|
|
526a6c0d0c | ||
|
|
1f33b6a74a | ||
|
|
95fc6d43e7 | ||
|
|
d8c261ffcf | ||
|
|
66ea0a9e0f | ||
|
|
435b542e7b | ||
|
|
10cd06f515 | ||
|
|
9da1868c3b | ||
|
|
2649fac4a4 | ||
|
|
6e05226e3b | ||
|
|
c1c3397f66 | ||
|
|
2065db2383 | ||
|
|
08fb868b63 | ||
|
|
8d39ef16b6 | ||
|
|
66c5082aa7 | ||
|
|
26fb58bd1b | ||
|
|
fed8826043 | ||
|
|
9af78a3249 | ||
|
|
bf1ad6cd17 | ||
|
|
15e995f2f5 | ||
|
|
b3e73b0de8 | ||
|
|
dd2633dfcb | ||
|
|
29f0278451 | ||
|
|
f0f98be692 | ||
|
|
5956a64b01 | ||
|
|
5fb36e3e2a | ||
|
|
9d295a1d91 | ||
|
|
39f350fe89 | ||
|
|
8c55e744b8 | ||
|
|
a260d4e25b | ||
|
|
509797588f | ||
|
|
2eed20f1f3 | ||
|
|
1d7b4c0db2 | ||
|
|
ac8cd788cb | ||
|
|
33dc970859 | ||
|
|
f73202734c | ||
|
|
32bacdab4b | ||
|
|
6113c3b533 | ||
|
|
1c634af489 | ||
|
|
428cdea2dc | ||
|
|
f14b55f839 | ||
|
|
5934d263b8 | ||
|
|
3860d919e6 | ||
|
|
fd0b9434ae | ||
|
|
efb30d0262 | ||
|
|
cee0bfbfa2 | ||
|
|
dc684d31d3 | ||
|
|
bfdf7f01b5 | ||
|
|
2cc0579b6e | ||
|
|
bfc472dc0f | ||
|
|
ea4e3680ab | ||
|
|
f02139956d | ||
|
|
cacbd1c212 | ||
|
|
3f78bb7819 | ||
|
|
aa65b01fe3 | ||
|
|
4f0968d678 | ||
|
|
118973cf79 | ||
|
|
df7cc0521f | ||
|
|
40c02d2cc9 | ||
|
|
be70b1a0c1 | ||
|
|
7ec5c122e1 | ||
|
|
a10ab99efc | ||
|
|
9f4398c557 | ||
|
|
d60f6bc89b | ||
|
|
617eeb4ff7 | ||
|
|
5b55825638 | ||
|
|
103d524db5 | ||
|
|
babd084a9b | ||
|
|
749f87397e | ||
|
|
307d47ebaf | ||
|
|
6acd4b91c1 | ||
|
|
f4a9530894 | ||
|
|
ab65385a16 | ||
|
|
ebd761e3dc | ||
|
|
3b942ec790 | ||
|
|
b373486908 | ||
|
|
c8cd5502f6 | ||
|
|
d6dd968c4f | ||
|
|
b8d73d2197 | ||
|
|
17e57f1e0b | ||
|
|
e21bf9fbc7 | ||
|
|
12e281f076 | ||
|
|
a5ce658755 | ||
|
|
ce30dfa82d | ||
|
|
c04d1e9d5c | ||
|
|
80031d122c | ||
|
|
943b090c90 | ||
|
|
39fd53d1f9 | ||
|
|
777e7b3b6d | ||
|
|
2783fe2a9f | ||
|
|
f5880cb001 | ||
|
|
26e501008a | ||
|
|
2c67e3f5c7 | ||
|
|
033596021d | ||
|
|
f36c72e085 | ||
|
|
fefaf7b4be | ||
|
|
91431401ad | ||
|
|
59d96c08a1 | ||
|
|
f10447395b | ||
|
|
c2b6222798 | ||
|
|
3a58c49184 | ||
|
|
440a5e49e2 | ||
|
|
77c10713a3 | ||
|
|
48e367ce2f | ||
|
|
934c23bf39 | ||
|
|
e0febcb6c3 | ||
|
|
044a6c6ea4 | ||
|
|
8ebbc10572 | ||
|
|
7435828082 | ||
|
|
369b595e8a | ||
|
|
9a6d30f03d | ||
|
|
6bdd01d52b | ||
|
|
bae9767498 | ||
|
|
b0e50dedb8 | ||
|
|
96bfb3b259 | ||
|
|
909068dfa8 | ||
|
|
f4c74968be | ||
|
|
0e958f3704 | ||
|
|
a8b2942f93 | ||
|
|
564fe62400 | ||
|
|
5c5013191b | ||
|
|
31989b85d1 | ||
|
|
5ed4af2372 | ||
|
|
4d18e391aa | ||
|
|
2feeb5b927 | ||
|
|
2853f07875 | ||
|
|
4e6adc07a1 | ||
|
|
6a5ed4f418 | ||
|
|
ef25698d3d | ||
|
|
429dcc7000 | ||
|
|
ab3f994626 | ||
|
|
5f8235fcfc | ||
|
|
db325d0fde | ||
|
|
8dc1f49ac7 | ||
|
|
9fe2b651ed | ||
|
|
24e4b75c35 | ||
|
|
34174abf26 | ||
|
|
af778312cb | ||
|
|
280f5614ef | ||
|
|
8566a46793 | ||
|
|
af3c3f4cbe | ||
|
|
034a44e625 | ||
|
|
84155fdff7 | ||
|
|
8255c913a3 | ||
|
|
4d4d17669b | ||
|
|
540a0422f5 | ||
|
|
de4d7d6273 | ||
|
|
1345d95589 | ||
|
|
a5bc19dd69 | ||
|
|
25b143c8cc | ||
|
|
82cca959e4 | ||
|
|
d52374a0b6 | ||
|
|
c71a18ca07 | ||
|
|
8d73ae2cc0 | ||
|
|
7b0c74ca3e | ||
|
|
62be9f9064 | ||
|
|
2fdc113d93 | ||
|
|
b70fb543f5 | ||
|
|
31c88f9f5a | ||
|
|
af3a818f12 | ||
|
|
a07532d4c7 | ||
|
|
fb449ca4bc | ||
|
|
4da65643c0 | ||
|
|
bf64db474c | ||
|
|
344a14416d | ||
|
|
be47a0c5db | ||
|
|
808b980301 | ||
|
|
3528480562 | ||
|
|
6bd263d23f | ||
|
|
2b9aa3864b | ||
|
|
81155caf88 | ||
|
|
c7c057483d | ||
|
|
7f5170ae4d | ||
|
|
49b8693b11 | ||
|
|
d7b0a14eb5 | ||
|
|
8996cb1e18 | ||
|
|
38f278cce0 | ||
|
|
bb4e475044 | ||
|
|
4fbe36a8e9 | ||
|
|
a1a40b562a | ||
|
|
3a4a1bb005 | ||
|
|
4f8c10c1aa | ||
|
|
4833348769 | ||
|
|
ad07d59a78 | ||
|
|
e8aaabd1d3 | ||
|
|
d7d7396eeb | ||
|
|
41538860cd | ||
|
|
5c9f8a0cf0 | ||
|
|
9086634c8f | ||
|
|
e88f1f1edb | ||
|
|
36d1bddc5b | ||
|
|
e01a10ced5 | ||
|
|
66f442ad76 | ||
|
|
11f1ecebcf | ||
|
|
e339cb27f6 | ||
|
|
bce3232b39 | ||
|
|
b08970ce39 | ||
|
|
533f88ceaf | ||
|
|
c8f0469a44 | ||
|
|
a1fc24e532 | ||
|
|
d80daa48df | ||
|
|
92aae2803f | ||
|
|
6c6649f912 | ||
|
|
55fbaabfda | ||
|
|
56c2518936 | ||
|
|
2b48152da6 | ||
|
|
e52a599be6 | ||
|
|
99744bd318 | ||
|
|
46d36cd412 | ||
|
|
a170764fc5 | ||
|
|
f72873a1ce | ||
|
|
82496c30b1 | ||
|
|
cb3c007acd | ||
|
|
cb460a797c | ||
|
|
1b666d01cf | ||
|
|
df24c7d2f8 | ||
|
|
133c15c0e2 | ||
|
|
ec0af7c97b | ||
|
|
a34a877737 | ||
|
|
f018794465 | ||
|
|
d45f5e9791 | ||
|
|
04bd0d834c | ||
|
|
ed4f0c4713 | ||
|
|
c747068d4a | ||
|
|
e91988f679 | ||
|
|
3ed1fce3fb | ||
|
|
e3ea0b511a | ||
|
|
c411c663de | ||
|
|
1c6f66fc14 | ||
|
|
1f927a374c | ||
|
|
07c4225aa8 | ||
|
|
16b098ea42 | ||
|
|
b31c4d407a | ||
|
|
330065f5e0 | ||
|
|
944db82553 | ||
|
|
c257361f05 | ||
|
|
ffdbfb018a | ||
|
|
cfa2bd6b08 | ||
|
|
51e90c3ce0 | ||
|
|
d69149f43e | ||
|
|
f261663f3d | ||
|
|
e5948dd1d3 | ||
|
|
5f13aab7d8 | ||
|
|
292d489592 | ||
|
|
0a01f20e35 | ||
|
|
2bd08d5c4c |
@@ -1,23 +1,27 @@
|
||||
[bumpversion]
|
||||
current_version = 0.19.1b2
|
||||
current_version = 0.21.0a1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
((?P<prerelease>[a-z]+)(?P<num>\d+))?
|
||||
((?P<prekind>a|b|rc)
|
||||
(?P<pre>\d+) # pre-release version num
|
||||
)?
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prerelease}{num}
|
||||
{major}.{minor}.{patch}{prekind}{pre}
|
||||
{major}.{minor}.{patch}
|
||||
commit = False
|
||||
tag = False
|
||||
|
||||
[bumpversion:part:prerelease]
|
||||
[bumpversion:part:prekind]
|
||||
first_value = a
|
||||
optional_value = final
|
||||
values =
|
||||
a
|
||||
b
|
||||
rc
|
||||
final
|
||||
|
||||
[bumpversion:part:num]
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
@@ -26,6 +30,8 @@ first_value = 1
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/setup.py]
|
||||
@@ -41,4 +47,3 @@ first_value = 1
|
||||
[bumpversion:file:plugins/snowflake/dbt/adapters/snowflake/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/dbt/adapters/bigquery/__version__.py]
|
||||
|
||||
|
||||
@@ -2,12 +2,19 @@ version: 2.1
|
||||
jobs:
|
||||
unit:
|
||||
docker: &test_only
|
||||
- image: fishtownanalytics/test-container:9
|
||||
- image: fishtownanalytics/test-container:12
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
DOCKER_TEST_DATABASE_HOST: "database"
|
||||
TOX_PARALLEL_NO_SPINNER: 1
|
||||
steps:
|
||||
- checkout
|
||||
- run: tox -e flake8,mypy,unit-py36,unit-py38
|
||||
- run: tox -p -e py36,py37,py38
|
||||
lint:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run: tox -e mypy,flake8 -- -v
|
||||
build-wheels:
|
||||
docker: *test_only
|
||||
steps:
|
||||
@@ -19,7 +26,7 @@ jobs:
|
||||
export PYTHON_BIN="${PYTHON_ENV}/bin/python"
|
||||
$PYTHON_BIN -m pip install -U pip setuptools
|
||||
$PYTHON_BIN -m pip install -r requirements.txt
|
||||
$PYTHON_BIN -m pip install -r dev_requirements.txt
|
||||
$PYTHON_BIN -m pip install -r dev-requirements.txt
|
||||
/bin/bash ./scripts/build-wheels.sh
|
||||
$PYTHON_BIN ./scripts/collect-dbt-contexts.py > ./dist/context_metadata.json
|
||||
$PYTHON_BIN ./scripts/collect-artifact-schema.py > ./dist/artifact_schemas.json
|
||||
@@ -28,20 +35,22 @@ jobs:
|
||||
- store_artifacts:
|
||||
path: ./dist
|
||||
destination: dist
|
||||
integration-postgres-py36:
|
||||
docker: &test_and_postgres
|
||||
- image: fishtownanalytics/test-container:9
|
||||
integration-postgres:
|
||||
docker:
|
||||
- image: fishtownanalytics/test-container:12
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
DOCKER_TEST_DATABASE_HOST: "database"
|
||||
TOX_PARALLEL_NO_SPINNER: 1
|
||||
- image: postgres
|
||||
name: database
|
||||
environment: &pgenv
|
||||
environment:
|
||||
POSTGRES_USER: "root"
|
||||
POSTGRES_PASSWORD: "password"
|
||||
POSTGRES_DB: "dbt"
|
||||
steps:
|
||||
- checkout
|
||||
- run: &setupdb
|
||||
- run:
|
||||
name: Setup postgres
|
||||
command: bash test/setup_db.sh
|
||||
environment:
|
||||
@@ -50,113 +59,39 @@ jobs:
|
||||
PGPASSWORD: password
|
||||
PGDATABASE: postgres
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-postgres-py36
|
||||
name: Postgres integration tests
|
||||
command: tox -p -e py36-postgres,py38-postgres -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake-py36:
|
||||
integration-snowflake:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-snowflake-py36
|
||||
no_output_timeout: 1h
|
||||
name: Snowflake integration tests
|
||||
command: tox -p -e py36-snowflake,py38-snowflake -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift-py36:
|
||||
integration-redshift:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-redshift-py36
|
||||
name: Redshift integration tests
|
||||
command: tox -p -e py36-redshift,py38-redshift -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery-py36:
|
||||
integration-bigquery:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-bigquery-py36
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-postgres-py38:
|
||||
docker: *test_and_postgres
|
||||
steps:
|
||||
- checkout
|
||||
- run: *setupdb
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-postgres-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-snowflake-py38
|
||||
no_output_timeout: 1h
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-redshift-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-bigquery-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
|
||||
integration-postgres-py39:
|
||||
docker: *test_and_postgres
|
||||
steps:
|
||||
- checkout
|
||||
- run: *setupdb
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-postgres-py39
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake-py39:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-snowflake-py39
|
||||
no_output_timeout: 1h
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift-py39:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-redshift-py39
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery-py39:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-bigquery-py39
|
||||
name: Bigquery integration test
|
||||
command: tox -p -e py36-bigquery,py38-bigquery -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
|
||||
@@ -164,55 +99,25 @@ workflows:
|
||||
version: 2
|
||||
test-everything:
|
||||
jobs:
|
||||
- lint
|
||||
- unit
|
||||
- integration-postgres-py36:
|
||||
- integration-postgres:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-bigquery-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-snowflake-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-postgres-py38:
|
||||
- integration-redshift:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- integration-bigquery-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- integration-snowflake-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- integration-postgres-py39:
|
||||
- integration-bigquery:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift-py39:
|
||||
- integration-snowflake:
|
||||
requires:
|
||||
- integration-postgres-py39
|
||||
- integration-bigquery-py39:
|
||||
requires:
|
||||
- integration-postgres-py39
|
||||
# - integration-snowflake-py39:
|
||||
# requires:
|
||||
# - integration-postgres-py39
|
||||
- unit
|
||||
- build-wheels:
|
||||
requires:
|
||||
- lint
|
||||
- unit
|
||||
- integration-postgres-py36
|
||||
- integration-redshift-py36
|
||||
- integration-bigquery-py36
|
||||
- integration-snowflake-py36
|
||||
- integration-postgres-py38
|
||||
- integration-redshift-py38
|
||||
- integration-bigquery-py38
|
||||
- integration-snowflake-py38
|
||||
- integration-postgres-py39
|
||||
- integration-redshift-py39
|
||||
- integration-bigquery-py39
|
||||
# - integration-snowflake-py39
|
||||
- integration-postgres
|
||||
- integration-redshift
|
||||
- integration-bigquery
|
||||
- integration-snowflake
|
||||
|
||||
29
.github/ISSUE_TEMPLATE/minor-version-release.md
vendored
Normal file
29
.github/ISSUE_TEMPLATE/minor-version-release.md
vendored
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
name: Minor version release
|
||||
about: Creates a tracking checklist of items for a minor version release
|
||||
title: "[Tracking] v#.##.# release "
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Release Core
|
||||
- [ ] [Engineering] dbt-release workflow
|
||||
- [ ] [Engineering] Create new protected `x.latest` branch
|
||||
- [ ] [Product] Finalize migration guide (next.docs.getdbt.com)
|
||||
|
||||
### Release Cloud
|
||||
- [ ] [Engineering] Create a platform issue to update dbt Cloud and verify it is completed
|
||||
- [ ] [Engineering] Determine if schemas have changed. If so, generate new schemas and push to schemas.getdbt.com
|
||||
|
||||
### Announce
|
||||
- [ ] [Product] Publish discourse
|
||||
- [ ] [Product] Announce in dbt Slack
|
||||
|
||||
### Post-release
|
||||
- [ ] [Engineering] [Bump plugin versions](https://www.notion.so/fishtownanalytics/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#59571f5bc1a040d9a8fd096e23d2c7db) (dbt-spark + dbt-presto), add compatibility as needed
|
||||
- [ ] Spark
|
||||
- [ ] Presto
|
||||
- [ ] [Engineering] Create a platform issue to update dbt-spark versions to dbt Cloud
|
||||
- [ ] [Product] Release new version of dbt-utils with new dbt version compatibility. If there are breaking changes requiring a minor version, plan upgrades of other packages that depend on dbt-utils.
|
||||
- [ ] [Engineering] If this isn't a final release, create an epic for the next release
|
||||
45
.github/dependabot.yml
vendored
Normal file
45
.github/dependabot.yml
vendored
Normal file
@@ -0,0 +1,45 @@
|
||||
version: 2
|
||||
updates:
|
||||
# python dependencies
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/core"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/bigquery"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/postgres"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/redshift"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/snowflake"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
|
||||
# docker dependencies
|
||||
- package-ecosystem: "docker"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "docker"
|
||||
directory: "/docker"
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
rebase-strategy: "disabled"
|
||||
181
.github/workflows/performance.yml
vendored
Normal file
181
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,181 @@
|
||||
|
||||
name: Performance Regression Testing
|
||||
# Schedule triggers
|
||||
on:
|
||||
# TODO this is just while developing
|
||||
pull_request:
|
||||
branches:
|
||||
- 'develop'
|
||||
- 'performance-regression-testing'
|
||||
schedule:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
- cron: '5 10,22 * * *'
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: '0.20.latest'
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final_calculations.json
|
||||
178
.github/workflows/tests.yml
vendored
Normal file
178
.github/workflows/tests.yml
vendored
Normal file
@@ -0,0 +1,178 @@
|
||||
# This is a workflow to run our unit and integration tests for windows and mac
|
||||
|
||||
name: dbt Tests
|
||||
|
||||
# Triggers
|
||||
on:
|
||||
# Triggers the workflow on push or pull request events and also adds a manual trigger
|
||||
push:
|
||||
branches:
|
||||
- 'develop'
|
||||
- '*.latest'
|
||||
- 'releases/*'
|
||||
pull_request_target:
|
||||
branches:
|
||||
- 'develop'
|
||||
- '*.latest'
|
||||
- 'pr/*'
|
||||
- 'releases/*'
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
Linting:
|
||||
runs-on: ubuntu-latest #no need to run on every OS
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Linting'
|
||||
run: tox -e mypy,flake8 -- -v
|
||||
|
||||
UnitTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, ubuntu-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run unit tests'
|
||||
run: python -m tox -e py -- -v
|
||||
|
||||
PostgresIntegrationTest:
|
||||
runs-on: 'windows-latest' #TODO: Add Mac support
|
||||
environment: 'Postgres'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: 'Install postgresql and set up database'
|
||||
shell: pwsh
|
||||
run: |
|
||||
$serviceName = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $serviceName -StartupType Automatic
|
||||
Start-Service -InputObject $serviceName
|
||||
& $env:PGBIN\createdb.exe -U postgres dbt
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE root WITH PASSWORD '$env:ROOT_PASSWORD';"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE root WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CREATE, CONNECT ON DATABASE dbt TO root WITH GRANT OPTION;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE noaccess WITH PASSWORD '$env:NOACCESS_PASSWORD' NOSUPERUSER;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE noaccess WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CONNECT ON DATABASE dbt TO noaccess;"
|
||||
env:
|
||||
ROOT_PASSWORD: ${{ secrets.ROOT_PASSWORD }}
|
||||
NOACCESS_PASSWORD: ${{ secrets.NOACCESS_PASSWORD }}
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-postgres -- -v -n4
|
||||
|
||||
# These three are all similar except secure environment variables, which MUST be passed along to their tasks,
|
||||
# but there's probably a better way to do this!
|
||||
SnowflakeIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Snowflake'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-snowflake -- -v -n4
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: ${{ secrets.SNOWFLAKE_TEST_ACCOUNT }}
|
||||
SNOWFLAKE_TEST_PASSWORD: ${{ secrets.SNOWFLAKE_TEST_PASSWORD }}
|
||||
SNOWFLAKE_TEST_USER: ${{ secrets.SNOWFLAKE_TEST_USER }}
|
||||
SNOWFLAKE_TEST_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN: ${{ secrets.SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_ID: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_ID }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET }}
|
||||
SNOWFLAKE_TEST_ALT_DATABASE: ${{ secrets.SNOWFLAKE_TEST_ALT_DATABASE }}
|
||||
SNOWFLAKE_TEST_ALT_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_ALT_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_DATABASE: ${{ secrets.SNOWFLAKE_TEST_DATABASE }}
|
||||
SNOWFLAKE_TEST_QUOTED_DATABASE: ${{ secrets.SNOWFLAKE_TEST_QUOTED_DATABASE }}
|
||||
SNOWFLAKE_TEST_ROLE: ${{ secrets.SNOWFLAKE_TEST_ROLE }}
|
||||
|
||||
BigQueryIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Bigquery'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-bigquery -- -v -n4
|
||||
env:
|
||||
BIGQUERY_SERVICE_ACCOUNT_JSON: ${{ secrets.BIGQUERY_SERVICE_ACCOUNT_JSON }}
|
||||
BIGQUERY_TEST_ALT_DATABASE: ${{ secrets.BIGQUERY_TEST_ALT_DATABASE }}
|
||||
|
||||
RedshiftIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Redshift'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-redshift -- -v -n4
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: ${{ secrets.REDSHIFT_TEST_DBNAME }}
|
||||
REDSHIFT_TEST_PASS: ${{ secrets.REDSHIFT_TEST_PASS }}
|
||||
REDSHIFT_TEST_USER: ${{ secrets.REDSHIFT_TEST_USER }}
|
||||
REDSHIFT_TEST_PORT: ${{ secrets.REDSHIFT_TEST_PORT }}
|
||||
REDSHIFT_TEST_HOST: ${{ secrets.REDSHIFT_TEST_HOST }}
|
||||
1
.gitignore
vendored
1
.gitignore
vendored
@@ -85,6 +85,7 @@ target/
|
||||
|
||||
# pycharm
|
||||
.idea/
|
||||
venv/
|
||||
|
||||
# AWS credentials
|
||||
.aws/
|
||||
|
||||
49
ARCHITECTURE.md
Normal file
49
ARCHITECTURE.md
Normal file
@@ -0,0 +1,49 @@
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
|
||||
## dbt-core
|
||||
|
||||
Most of the python code in the repository is within the `core/dbt` directory. Currently the main subdirectories are:
|
||||
- [`adapters`](core/dbt/adapters): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
- [`context`](core/dbt/context): Build and expose dbt-specific Jinja functionality
|
||||
- [`contracts`](core/dbt/contracts): Define Python objects (dataclasses) that dbt expects to create and validate
|
||||
- [`deps`](core/dbt/deps): Package installation and dependency resolution
|
||||
- [`graph`](core/dbt/graph): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`parser`](core/dbt/parser): Read project files, validate, construct python objects
|
||||
- [`rpc`](core/dbt/rpc): Provide remote procedure call server for invoking dbt, following JSON-RPC 2.0 spec
|
||||
- [`task`](core/dbt/task): Set forth the actions that dbt can perform when invoked
|
||||
|
||||
### Invoking dbt
|
||||
|
||||
There are two supported ways of invoking dbt: from the command line and using an RPC server.
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task/rpc should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
|
||||
core/dbt/include/index.html
|
||||
This is the docs website code. It comes from the dbt-docs repository, and is generated when a release is packaged.
|
||||
|
||||
## Adapters
|
||||
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. The four core adapters that are in the main repository, contained within the [`plugins`](plugins) subdirectory, are: Postgres Redshift, Snowflake and BigQuery. Other warehouses use adapter plugins defined in separate repositories (e.g. [dbt-spark](https://github.com/fishtown-analytics/dbt-spark), [dbt-presto](https://github.com/fishtown-analytics/dbt-presto)).
|
||||
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
|
||||
Each adapter plugin is a standalone python package that includes:
|
||||
|
||||
- `dbt/include/[name]`: A "sub-global" dbt project, of YAML and SQL files, that reimplements Jinja macros to use the adapter's supported SQL syntax
|
||||
- `dbt/adapters/[name]`: Python modules that inherit, and optionally reimplement, the base adapter classes defined in dbt-core
|
||||
- `setup.py`
|
||||
|
||||
The Postgres adapter code is the most central, and many of its implementations are used as the default defined in the dbt-core global project. The greater the distance of a data technology from Postgres, the more its adapter plugin may need to reimplement.
|
||||
|
||||
## Testing dbt
|
||||
|
||||
The [`test/`](test/) subdirectory includes unit and integration tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Integration tests perform end-to-end dbt invocations against real adapters (Postgres, Redshift, Snowflake, BigQuery) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
||||
|
||||
## Everything else
|
||||
|
||||
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
||||
- [etc](etc/): Images for README
|
||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, not are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||
244
CHANGELOG.md
244
CHANGELOG.md
@@ -1,11 +1,237 @@
|
||||
## dbt 0.19.1 (Release TBD)
|
||||
## dbt 0.21.0 (Release TBD)
|
||||
|
||||
### Features
|
||||
- Add `dbt build` command to run models, tests, seeds, and snapshots in DAG order. ([#2743] (https://github.com/dbt-labs/dbt/issues/2743), [#3490] (https://github.com/dbt-labs/dbt/issues/3490))
|
||||
|
||||
### Fixes
|
||||
- Fix docs generation for cross-db sources in REDSHIFT RA3 node ([#3236](https://github.com/fishtown-analytics/dbt/issues/3236), [#3408](https://github.com/fishtown-analytics/dbt/pull/3408))
|
||||
- Fix type coercion issues when fetching query result sets ([#2984](https://github.com/fishtown-analytics/dbt/issues/2984), [#3499](https://github.com/fishtown-analytics/dbt/pull/3499))
|
||||
- Handle whitespace after a plus sign on the project config ([#3526](https://github.com/dbt-labs/dbt/pull/3526))
|
||||
|
||||
### Under the hood
|
||||
- Add performance regression testing [#3602](https://github.com/dbt-labs/dbt/pull/3602)
|
||||
- Improve default view and table materialization performance by checking relational cache before attempting to drop temp relations ([#3112](https://github.com/fishtown-analytics/dbt/issues/3112), [#3468](https://github.com/fishtown-analytics/dbt/pull/3468))
|
||||
- Add optional `sslcert`, `sslkey`, and `sslrootcert` profile arguments to the Postgres connector. ([#3472](https://github.com/fishtown-analytics/dbt/pull/3472), [#3473](https://github.com/fishtown-analytics/dbt/pull/3473))
|
||||
- Move the example project used by `dbt init` into `dbt` repository, to avoid cloning an external repo ([#3005](https://github.com/fishtown-analytics/dbt/pull/3005), [#3474](https://github.com/fishtown-analytics/dbt/pull/3474), [#3536](https://github.com/fishtown-analytics/dbt/pull/3536))
|
||||
- Better interaction between `dbt init` and adapters. Avoid raising errors while initializing a project ([#2814](https://github.com/fishtown-analytics/dbt/pull/2814), [#3483](https://github.com/fishtown-analytics/dbt/pull/3483))
|
||||
- Update `create_adapter_plugins` script to include latest accessories, and stay up to date with latest dbt-core version ([#3002](https://github.com/fishtown-analytics/dbt/issues/3002), [#3509](https://github.com/fishtown-analytics/dbt/pull/3509))
|
||||
|
||||
### Dependencies
|
||||
- Require `werkzeug>=1`
|
||||
|
||||
Contributors:
|
||||
- [@kostek-pl](https://github.com/kostek-pl) ([#3236](https://github.com/fishtown-analytics/dbt/pull/3408))
|
||||
- [@tconbeer](https://github.com/tconbeer) [#3468](https://github.com/fishtown-analytics/dbt/pull/3468))
|
||||
- [@JLDLaughlin](https://github.com/JLDLaughlin) ([#3473](https://github.com/fishtown-analytics/dbt/pull/3473))
|
||||
- [@jmriego](https://github.com/jmriego) ([#3526](https://github.com/dbt-labs/dbt/pull/3526))
|
||||
|
||||
|
||||
## dbt 0.20.1 (Release TBD)
|
||||
|
||||
### Fixes
|
||||
- Fix `store_failures` config when defined as a modifier for `unique` and `not_null` tests ([#3575](https://github.com/fishtown-analytics/dbt/issues/3575), [#3577](https://github.com/fishtown-analytics/dbt/pull/3577))
|
||||
|
||||
|
||||
## dbt 0.20.0 (July 12, 2021)
|
||||
|
||||
### Fixes
|
||||
|
||||
- Avoid slowdown in column-level `persist_docs` on Snowflake, while preserving the error-avoidance from [#3149](https://github.com/fishtown-analytics/dbt/issues/3149) ([#3541](https://github.com/fishtown-analytics/dbt/issues/3541), [#3543](https://github.com/fishtown-analytics/dbt/pull/3543))
|
||||
- Partial parsing: handle already deleted nodes when schema block also deleted ([#3516](http://github.com/fishown-analystics/dbt/issues/3516), [#3522](http://github.com/fishown-analystics/dbt/issues/3522))
|
||||
|
||||
### Docs
|
||||
|
||||
- Update dbt logo and links ([docs#197](https://github.com/fishtown-analytics/dbt-docs/issues/197))
|
||||
|
||||
### Under the hood
|
||||
|
||||
- Add tracking for experimental parser accuracy ([3503](https://github.com/dbt-labs/dbt/pull/3503), [3553](https://github.com/dbt-labs/dbt/pull/3553))
|
||||
|
||||
## dbt 0.20.0rc2 (June 30, 2021)
|
||||
|
||||
### Fixes
|
||||
|
||||
- Handle quoted values within test configs, such as `where` ([#3458](https://github.com/fishtown-analytics/dbt/issues/3458), [#3459](https://github.com/fishtown-analytics/dbt/pull/3459))
|
||||
|
||||
### Docs
|
||||
|
||||
- Display `tags` on exposures ([docs#194](https://github.com/fishtown-analytics/dbt-docs/issues/194), [docs#195](https://github.com/fishtown-analytics/dbt-docs/issues/195))
|
||||
|
||||
### Under the hood
|
||||
|
||||
- Swap experimental parser implementation to use Rust [#3497](https://github.com/fishtown-analytics/dbt/pull/3497)
|
||||
- Dispatch the core SQL statement of the new test materialization, to benefit adapter maintainers ([#3465](https://github.com/fishtown-analytics/dbt/pull/3465), [#3461](https://github.com/fishtown-analytics/dbt/pull/3461))
|
||||
- Minimal validation of yaml dictionaries prior to partial parsing ([#3246](https://github.com/fishtown-analytics/dbt/issues/3246), [#3460](https://github.com/fishtown-analytics/dbt/pull/3460))
|
||||
- Add partial parsing tests and improve partial parsing handling of macros ([#3449](https://github.com/fishtown-analytics/dbt/issues/3449), [#3505](https://github.com/fishtown-analytics/dbt/pull/3505))
|
||||
- Update project loading event data to include experimental parser information. ([#3438](https://github.com/fishtown-analytics/dbt/issues/3438), [#3495](https://github.com/fishtown-analytics/dbt/pull/3495))
|
||||
|
||||
Contributors:
|
||||
- [@swanderz](https://github.com/swanderz) ([#3461](https://github.com/fishtown-analytics/dbt/pull/3461))
|
||||
- [@stkbailey](https://github.com/stkbailey) ([docs#195](https://github.com/fishtown-analytics/dbt-docs/issues/195))
|
||||
|
||||
## dbt 0.20.0rc1 (June 04, 2021)
|
||||
|
||||
|
||||
### Breaking changes
|
||||
- Fix adapter.dispatch macro resolution when statically extracting macros. Introduce new project-level `dispatch` config. The `packages` argument to `dispatch` no longer supports macro calls; there is backwards compatibility for existing packages. The argument will no longer be supported in a future release, instead provide the `macro_namespace` argument. ([#3362](https://github.com/fishtown-analytics/dbt/issues/3362), [#3363](https://github.com/fishtown-analytics/dbt/pull/3363), [#3383](https://github.com/fishtown-analytics/dbt/pull/3383), [#3403](https://github.com/fishtown-analytics/dbt/pull/3403))
|
||||
|
||||
### Features
|
||||
- Support optional `updated_at` config parameter with `check` strategy snapshots. If not supplied, will use current timestamp (default). ([#1844](https://github.com/fishtown-analytics/dbt/issues/1844), [#3376](https://github.com/fishtown-analytics/dbt/pull/3376))
|
||||
- Add the opt-in `--use-experimental-parser` flag ([#3307](https://github.com/fishtown-analytics/dbt/issues/3307), [#3374](https://github.com/fishtown-analytics/dbt/issues/3374))
|
||||
- Store test failures in the database ([#517](https://github.com/fishtown-analytics/dbt/issues/517), [#903](https://github.com/fishtown-analytics/dbt/issues/903), [#2593](https://github.com/fishtown-analytics/dbt/issues/2593), [#3316](https://github.com/fishtown-analytics/dbt/issues/3316))
|
||||
- Add new test configs: `where`, `limit`, `warn_if`, `error_if`, `fail_calc` ([#3258](https://github.com/fishtown-analytics/dbt/issues/3258), [#3321](https://github.com/fishtown-analytics/dbt/issues/3321), [#3336](https://github.com/fishtown-analytics/dbt/pull/3336))
|
||||
- Move partial parsing to end of parsing and implement new partial parsing method. ([#3217](https://github.com/fishtown-analytics/dbt/issues/3217), [#3364](https://github.com/fishtown-analytics/dbt/pull/3364))
|
||||
- Save doc file node references and use in partial parsing. ([#3425](https://github.com/fishtown-analytics/dbt/issues/3425), [#3432](https://github.com/fishtown-analytics/dbt/pull/3432))
|
||||
|
||||
### Fixes
|
||||
- Fix compiled sql for ephemeral models ([#3317](https://github.com/fishtown-analytics/dbt/issues/3317), [#3318](https://github.com/fishtown-analytics/dbt/pull/3318))
|
||||
- Now generating `run_results.json` even when no nodes are selected ([#3313](https://github.com/fishtown-analytics/dbt/issues/3313), [#3315](https://github.com/fishtown-analytics/dbt/pull/3315))
|
||||
- Add missing `packaging` dependency ([#3312](https://github.com/fishtown-analytics/dbt/issues/3312), [#3339](https://github.com/fishtown-analytics/dbt/pull/3339))
|
||||
- Fix references to macros with package names when rendering schema tests ([#3324](https://github.com/fishtown-analytics/dbt/issues/3324), [#3345](https://github.com/fishtown-analytics/dbt/pull/3345))
|
||||
- Stop clobbering default keyword arguments for jinja test definitions ([#3329](https://github.com/fishtown-analytics/dbt/issues/3329), [#3340](https://github.com/fishtown-analytics/dbt/pull/3340))
|
||||
- Fix unique_id generation for generic tests so tests with the same FQN but different configuration will run. ([#3254](https://github.com/fishtown-analytics/dbt/issues/3254), [#3335](https://github.com/fishtown-analytics/dbt/issues/3335))
|
||||
- Update the snowflake adapter to only comment on a column if it exists when using the persist_docs config ([#3039](https://github.com/fishtown-analytics/dbt/issues/3039), [#3149](https://github.com/fishtown-analytics/dbt/pull/3149))
|
||||
- Add a better error messages for undefined macros and when there are less packages installed than specified in `packages.yml`. ([#2999](https://github.com/fishtown-analytics/dbt/issues/2999))
|
||||
- Separate `compiled_path` from `build_path`, and print the former alongside node error messages ([#1985](https://github.com/fishtown-analytics/dbt/issues/1985), [#3327](https://github.com/fishtown-analytics/dbt/pull/3327))
|
||||
- Fix exception caused when running `dbt debug` with BigQuery connections ([#3314](https://github.com/fishtown-analytics/dbt/issues/3314), [#3351](https://github.com/fishtown-analytics/dbt/pull/3351))
|
||||
- Raise better error if snapshot is missing required configurations ([#3381](https://github.com/fishtown-analytics/dbt/issues/3381), [#3385](https://github.com/fishtown-analytics/dbt/pull/3385))
|
||||
- Fix `dbt run` errors caused from receiving non-JSON responses from Snowflake with Oauth ([#3350](https://github.com/fishtown-analytics/dbt/issues/3350))
|
||||
- Fix deserialization of Manifest lock attribute ([#3435](https://github.com/fishtown-analytics/dbt/issues/3435), [#3445](https://github.com/fishtown-analytics/dbt/pull/3445))
|
||||
- Fix `dbt run` errors caused from receiving non-JSON responses from Snowflake with Oauth ([#3350](https://github.com/fishtown-analytics/dbt/issues/3350)
|
||||
- Fix infinite recursion when parsing schema tests due to loops in macro calls ([#3444](https://github.com/fishtown-analytics/dbt/issues/3344), [#3454](https://github.com/fishtown-analytics/dbt/pull/3454))
|
||||
|
||||
### Docs
|
||||
- Reversed the rendering direction of relationship tests so that the test renders in the model it is defined in ([docs#181](https://github.com/fishtown-analytics/dbt-docs/issues/181), [docs#183](https://github.com/fishtown-analytics/dbt-docs/pull/183))
|
||||
- Support dots in model names: display them in the graphs ([docs#184](https://github.com/fishtown-analytics/dbt-docs/issues/184), [docs#185](https://github.com/fishtown-analytics/dbt-docs/issues/185))
|
||||
- Render meta tags for sources ([docs#192](https://github.com/fishtown-analytics/dbt-docs/issues/192), [docs#193](https://github.com/fishtown-analytics/dbt-docs/issues/193))
|
||||
|
||||
### Under the hood
|
||||
- Added logic for registry requests to raise a timeout error after a response hangs out for 30 seconds and 5 attempts have been made to reach the endpoint ([#3177](https://github.com/fishtown-analytics/dbt/issues/3177), [#3275](https://github.com/fishtown-analytics/dbt/pull/3275))
|
||||
- Added support for invoking the `list` task via the RPC server ([#3311](https://github.com/fishtown-analytics/dbt/issues/3311), [#3384](https://github.com/fishtown-analytics/dbt/pull/3384))
|
||||
- Added `unique_id` and `original_file_path` as keys to json responses from the `list` task ([#3356](https://github.com/fishtown-analytics/dbt/issues/3356), [#3384](https://github.com/fishtown-analytics/dbt/pull/3384))
|
||||
- Use shutil.which so Windows can pick up git.bat as a git executable ([#3035](https://github.com/fishtown-analytics/dbt/issues/3035), [#3134](https://github.com/fishtown-analytics/dbt/issues/3134))
|
||||
- Add `ssh-client` and update `git` version (using buster backports) in Docker image ([#3337](https://github.com/fishtown-analytics/dbt/issues/3337), [#3338](https://github.com/fishtown-analytics/dbt/pull/3338))
|
||||
- Add `tags` and `meta` properties to the exposure resource schema. ([#3404](https://github.com/fishtown-analytics/dbt/issues/3404), [#3405](https://github.com/fishtown-analytics/dbt/pull/3405))
|
||||
- Update test sub-query alias ([#3398](https://github.com/fishtown-analytics/dbt/issues/3398), [#3414](https://github.com/fishtown-analytics/dbt/pull/3414))
|
||||
- Bump schema versions for run results and manifest artifacts ([#3422](https://github.com/fishtown-analytics/dbt/issues/3422), [#3421](https://github.com/fishtown-analytics/dbt/pull/3421))
|
||||
- Add deprecation warning for using `packages` argument with `adapter.dispatch` ([#3419](https://github.com/fishtown-analytics/dbt/issues/3419), [#3420](https://github.com/fishtown-analytics/dbt/pull/3420))
|
||||
|
||||
Contributors:
|
||||
- [@TeddyCr](https://github.com/TeddyCr) ([#3275](https://github.com/fishtown-analytics/dbt/pull/3275))
|
||||
- [@panasenco](https://github.com/panasenco) ([#3315](https://github.com/fishtown-analytics/dbt/pull/3315))
|
||||
- [@dmateusp](https://github.com/dmateusp) ([#3338](https://github.com/fishtown-analytics/dbt/pull/3338))
|
||||
- [@peiwangdb](https://github.com/peiwangdb) ([#3344](https://github.com/fishtown-analytics/dbt/pull/3344))
|
||||
- [@elikastelein](https://github.com/elikastelein) ([#3149](https://github.com/fishtown-analytics/dbt/pull/3149))
|
||||
- [@majidaldo](https://github.com/majidaldo) ([#3134](https://github.com/fishtown-analytics/dbt/issues/3134))
|
||||
- [@jaypeedevlin](https://github.com/jaypeedevlin) ([#2999](https://github.com/fishtown-analytics/dbt/issues/2999))
|
||||
- [@PJGaetan](https://github.com/PJGaetan) ([#3315](https://github.com/fishtown-analytics/dbt/pull/3376))
|
||||
- [@jnatkins](https://github.com/jnatkins) ([#3385](https://github.com/fishtown-analytics/dbt/pull/3385))
|
||||
- [@matt-winkler](https://github.com/matt-winkler) ([#3365](https://github.com/fishtown-analytics/dbt/pull/3365))
|
||||
- [@stkbailey](https://github.com/stkbailey) ([#3404](https://github.com/fishtown-analytics/dbt/pull/3405))
|
||||
- [@mascah](https://github.com/mascah) ([docs#181](https://github.com/fishtown-analytics/dbt-docs/issues/181), [docs#183](https://github.com/fishtown-analytics/dbt-docs/pull/183))
|
||||
- [@monti-python](https://github.com/monti-python) ([docs#184](https://github.com/fishtown-analytics/dbt-docs/issues/184))
|
||||
- [@diegodewilde](https://github.com/diegodewilde) ([docs#193](https://github.com/fishtown-analytics/dbt-docs/issues/193))
|
||||
|
||||
## dbt 0.20.0b1 (May 03, 2021)
|
||||
|
||||
### Breaking changes
|
||||
|
||||
- Add Jinja tag for generic test definitions. Replacement for macros prefixed `test_` ([#1173](https://github.com/fishtown-analytics/dbt/issues/1173), [#3261](https://github.com/fishtown-analytics/dbt/pull/3261))
|
||||
- Update schema/generic tests to expect a set of rows instead of a single numeric value, and to use test materialization when executing. ([#3192](https://github.com/fishtown-analytics/dbt/issues/3192), [#3286](https://github.com/fishtown-analytics/dbt/pull/3286))
|
||||
- **Plugin maintainers:** For adapters that inherit from other adapters (e.g. `dbt-postgres` → `dbt-redshift`), `adapter.dispatch()` will now include parent macro implementations as viable candidates ([#2923](https://github.com/fishtown-analytics/dbt/issues/2923), [#3296](https://github.com/fishtown-analytics/dbt/pull/3296))
|
||||
|
||||
### Features
|
||||
- Support commit hashes in dbt deps package revision ([#3268](https://github.com/fishtown-analytics/dbt/issues/3268), [#3270](https://github.com/fishtown-analytics/dbt/pull/3270))
|
||||
- Add optional `subdirectory` key to install dbt packages that are not hosted at the root of a Git repository ([#275](https://github.com/fishtown-analytics/dbt/issues/275), [#3267](https://github.com/fishtown-analytics/dbt/pull/3267))
|
||||
- Add optional configs for `require_partition_filter` and `partition_expiration_days` in BigQuery ([#1843](https://github.com/fishtown-analytics/dbt/issues/1843), [#2928](https://github.com/fishtown-analytics/dbt/pull/2928))
|
||||
- Fix for EOL SQL comments prevent entire line execution ([#2731](https://github.com/fishtown-analytics/dbt/issues/2731), [#2974](https://github.com/fishtown-analytics/dbt/pull/2974))
|
||||
- Add optional `merge_update_columns` config to specify columns to update for `merge` statements in BigQuery and Snowflake ([#1862](https://github.com/fishtown-analytics/dbt/issues/1862), [#3100](https://github.com/fishtown-analytics/dbt/pull/3100))
|
||||
- Use query comment JSON as job labels for BigQuery adapter when `query-comment.job-label` is set to `true` ([#2483](https://github.com/fishtown-analytics/dbt/issues/2483)), ([#3145](https://github.com/fishtown-analytics/dbt/pull/3145))
|
||||
- Set application_name for Postgres connections ([#885](https://github.com/fishtown-analytics/dbt/issues/885), [#3182](https://github.com/fishtown-analytics/dbt/pull/3182))
|
||||
- Support disabling schema tests, and configuring tests from `dbt_project.yml` ([#3252](https://github.com/fishtown-analytics/dbt/issues/3252),
|
||||
[#3253](https://github.com/fishtown-analytics/dbt/issues/3253), [#3257](https://github.com/fishtown-analytics/dbt/pull/3257))
|
||||
- Add native support for Postgres index creation ([#804](https://github.com/fishtown-analytics/dbt/issues/804), [3106](https://github.com/fishtown-analytics/dbt/pull/3106))
|
||||
- Less greedy test selection: expand to select unselected tests if and only if all parents are selected ([#2891](https://github.com/fishtown-analytics/dbt/issues/2891), [#3235](https://github.com/fishtown-analytics/dbt/pull/3235))
|
||||
- Prevent locks in Redshift during full refresh in incremental materialization. ([#2426](https://github.com/fishtown-analytics/dbt/issues/2426), [#2998](https://github.com/fishtown-analytics/dbt/pull/2998))
|
||||
|
||||
### Fixes
|
||||
- Fix exit code from dbt debug not returning a failure when one of the tests fail ([#3017](https://github.com/fishtown-analytics/dbt/issues/3017), [#3018](https://github.com/fishtown-analytics/dbt/issues/3018))
|
||||
- Auto-generated CTEs in tests and ephemeral models have lowercase names to comply with dbt coding conventions ([#3027](https://github.com/fishtown-analytics/dbt/issues/3027), [#3028](https://github.com/fishtown-analytics/dbt/issues/3028))
|
||||
- Fix incorrect error message when a selector does not match any node [#3036](https://github.com/fishtown-analytics/dbt/issues/3036))
|
||||
- Fix variable `_dbt_max_partition` declaration and initialization for BigQuery incremental models ([#2940](https://github.com/fishtown-analytics/dbt/issues/2940), [#2976](https://github.com/fishtown-analytics/dbt/pull/2976))
|
||||
- Moving from 'master' to 'HEAD' default branch in git ([#3057](https://github.com/fishtown-analytics/dbt/issues/3057), [#3104](https://github.com/fishtown-analytics/dbt/issues/3104), [#3117](https://github.com/fishtown-analytics/dbt/issues/3117)))
|
||||
- Requirement on `dataclasses` is relaxed to be between `>=0.6,<0.9` allowing dbt to cohabit with other libraries which required higher versions. ([#3150](https://github.com/fishtown-analytics/dbt/issues/3150), [#3151](https://github.com/fishtown-analytics/dbt/pull/3151))
|
||||
- Add feature to add `_n` alias to same column names in SQL query ([#3147](https://github.com/fishtown-analytics/dbt/issues/3147), [#3158](https://github.com/fishtown-analytics/dbt/pull/3158))
|
||||
- Raise a proper error message if dbt parses a macro twice due to macro duplication or misconfiguration. ([#2449](https://github.com/fishtown-analytics/dbt/issues/2449), [#3165](https://github.com/fishtown-analytics/dbt/pull/3165))
|
||||
- Fix exposures missing in graph context variable. ([#3241](https://github.com/fishtown-analytics/dbt/issues/3241), [#3243](https://github.com/fishtown-analytics/dbt/issues/3243))
|
||||
- Ensure that schema test macros are properly processed ([#3229](https://github.com/fishtown-analytics/dbt/issues/3229), [#3272](https://github.com/fishtown-analytics/dbt/pull/3272))
|
||||
- Use absolute path for profiles directory instead of a path relative to the project directory. Note: If a user supplies a relative path to the profiles directory, the value of `args.profiles_dir` will still be absolute. ([#3133](https://github.com/fishtown-analytics/dbt/issues/3133), [#3176](https://github.com/fishtown-analytics/dbt/issues/3176))
|
||||
- Fix FQN selector unable to find models whose name contains dots ([#3246](https://github.com/fishtown-analytics/dbt/issues/3246), [#3247](https://github.com/fishtown-analytics/dbt/issues/3247))
|
||||
|
||||
### Under the hood
|
||||
- Add dependabot configuration for alerting maintainers about keeping dependencies up to date and secure. ([#3061](https://github.com/fishtown-analytics/dbt/issues/3061), [#3062](https://github.com/fishtown-analytics/dbt/pull/3062))
|
||||
- Update script to collect and write json schema for dbt artifacts ([#2870](https://github.com/fishtown-analytics/dbt/issues/2870), [#3065](https://github.com/fishtown-analytics/dbt/pull/3065))
|
||||
- Relax Google Cloud dependency pins to major versions. ([#3155](https://github.com/fishtown-analytics/dbt/pull/3156), [#3155](https://github.com/fishtown-analytics/dbt/pull/3156))
|
||||
- Bump `snowflake-connector-python` and releated dependencies, support Python 3.9 ([#2985](https://github.com/fishtown-analytics/dbt/issues/2985), [#3148](https://github.com/fishtown-analytics/dbt/pull/3148))
|
||||
- General development environment clean up and improve experience running tests locally ([#3194](https://github.com/fishtown-analytics/dbt/issues/3194), [#3204](https://github.com/fishtown-analytics/dbt/pull/3204), [#3228](https://github.com/fishtown-analytics/dbt/pull/3228))
|
||||
- Add a new materialization for tests, update data tests to use test materialization when executing. ([#3154](https://github.com/fishtown-analytics/dbt/issues/3154), [#3181](https://github.com/fishtown-analytics/dbt/pull/3181))
|
||||
- Switch from externally storing parsing state in ParseResult object to using Manifest ([#3163](http://github.com/fishtown-analytics/dbt/issues/3163), [#3219](https://github.com/fishtown-analytics/dbt/pull/3219))
|
||||
- Switch from loading project files in separate parsers to loading in one place([#3244](http://github.com/fishtown-analytics/dbt/issues/3244), [#3248](https://github.com/fishtown-analytics/dbt/pull/3248))
|
||||
|
||||
Contributors:
|
||||
- [@yu-iskw](https://github.com/yu-iskw) ([#2928](https://github.com/fishtown-analytics/dbt/pull/2928))
|
||||
- [@sdebruyn](https://github.com/sdebruyn) ([#3018](https://github.com/fishtown-analytics/dbt/pull/3018))
|
||||
- [@rvacaru](https://github.com/rvacaru) ([#2974](https://github.com/fishtown-analytics/dbt/pull/2974))
|
||||
- [@NiallRees](https://github.com/NiallRees) ([#3028](https://github.com/fishtown-analytics/dbt/pull/3028))
|
||||
- [@ran-eh](https://github.com/ran-eh) ([#3036](https://github.com/fishtown-analytics/dbt/pull/3036))
|
||||
- [@pcasteran](https://github.com/pcasteran) ([#2976](https://github.com/fishtown-analytics/dbt/pull/2976))
|
||||
- [@VasiliiSurov](https://github.com/VasiliiSurov) ([#3104](https://github.com/fishtown-analytics/dbt/pull/3104))
|
||||
- [@jmcarp](https://github.com/jmcarp) ([#3145](https://github.com/fishtown-analytics/dbt/pull/3145))
|
||||
- [@bastienboutonnet](https://github.com/bastienboutonnet) ([#3151](https://github.com/fishtown-analytics/dbt/pull/3151))
|
||||
- [@max-sixty](https://github.com/max-sixty) ([#3156](https://github.com/fishtown-analytics/dbt/pull/3156)
|
||||
- [@prratek](https://github.com/prratek) ([#3100](https://github.com/fishtown-analytics/dbt/pull/3100))
|
||||
- [@techytushar](https://github.com/techytushar) ([#3158](https://github.com/fishtown-analytics/dbt/pull/3158))
|
||||
- [@cgopalan](https://github.com/cgopalan) ([#3165](https://github.com/fishtown-analytics/dbt/pull/3165), [#3182](https://github.com/fishtown-analytics/dbt/pull/3182))
|
||||
- [@fux](https://github.com/fuchsst) ([#3243](https://github.com/fishtown-analytics/dbt/issues/3243))
|
||||
- [@arzavj](https://github.com/arzavj) ([3106](https://github.com/fishtown-analytics/dbt/pull/3106))
|
||||
- [@JCZuurmond](https://github.com/JCZuurmond) ([#3176](https://github.com/fishtown-analytics/dbt/pull/3176))
|
||||
- [@dmateusp](https://github.com/dmateusp) ([#3270](https://github.com/fishtown-analytics/dbt/pull/3270), [#3267](https://github.com/fishtown-analytics/dbt/pull/3267))
|
||||
- [@monti-python](https://github.com/monti-python) ([#3247](https://github.com/fishtown-analytics/dbt/issues/3247))
|
||||
- [@drkarthi](https://github.com/drkarthi) ([#2426](https://github.com/fishtown-analytics/dbt/issues/2426), [#2998](https://github.com/fishtown-analytics/dbt/pull/2998))
|
||||
|
||||
## dbt 0.19.2 (Release TBD)
|
||||
|
||||
### Breaking changes
|
||||
- Fix adapter.dispatch macro resolution when statically extracting macros. Introduce new project-level `dispatch` config. The `packages` argument to `dispatch` no longer supports macro calls; there is backwards compatibility for existing packages. The argument will no longer be supported in a future release, instead provide the `macro_namespace` argument. ([#3362](https://github.com/fishtown-analytics/dbt/issues/3362), [#3363](https://github.com/fishtown-analytics/dbt/pull/3363), [#3383](https://github.com/fishtown-analytics/dbt/pull/3383), [#3403](https://github.com/fishtown-analytics/dbt/pull/3403))
|
||||
|
||||
### Fixes
|
||||
- Fix references to macros with package names when rendering schema tests ([#3324](https://github.com/fishtown-analytics/dbt/issues/3324), [#3345](https://github.com/fishtown-analytics/dbt/pull/3345))
|
||||
|
||||
## dbt 0.19.1 (March 31, 2021)
|
||||
|
||||
## dbt 0.19.1rc2 (March 25, 2021)
|
||||
|
||||
### Fixes
|
||||
- Pass service-account scopes to gcloud-based oauth ([#3040](https://github.com/fishtown-analytics/dbt/issues/3040), [#3041](https://github.com/fishtown-analytics/dbt/pull/3041))
|
||||
|
||||
Contributors:
|
||||
- [@yu-iskw](https://github.com/yu-iskw) ([#3041](https://github.com/fishtown-analytics/dbt/pull/3041))
|
||||
|
||||
## dbt 0.19.1rc1 (March 15, 2021)
|
||||
|
||||
### Under the hood
|
||||
- Update code to use Mashumaro 2.0 ([#3138](https://github.com/fishtown-analytics/dbt/pull/3138))
|
||||
- Pin `agate<1.6.2` to avoid installation errors relating to its new dependency `PyICU` ([#3160](https://github.com/fishtown-analytics/dbt/issues/3160), [#3161](https://github.com/fishtown-analytics/dbt/pull/3161))
|
||||
- Add an event to track resource counts ([#3050](https://github.com/fishtown-analytics/dbt/issues/3050), [#3157](https://github.com/fishtown-analytics/dbt/pull/3157))
|
||||
|
||||
### Fixes
|
||||
|
||||
- Fix compiled sql for ephemeral models ([#3139](https://github.com/fishtown-analytics/dbt/pull/3139), [#3056](https://github.com/fishtown-analytics/dbt/pull/3056))
|
||||
|
||||
## dbt 0.19.1b2 (February 15, 2021)
|
||||
|
||||
|
||||
## dbt 0.19.1b1 (February 12, 2021)
|
||||
|
||||
|
||||
### Fixes
|
||||
|
||||
- On BigQuery, fix regressions for `insert_overwrite` incremental strategy with `int64` and `timestamp` partition columns ([#3063](https://github.com/fishtown-analytics/dbt/issues/3063), [#3095](https://github.com/fishtown-analytics/dbt/issues/3095), [#3098](https://github.com/fishtown-analytics/dbt/issues/3098))
|
||||
@@ -17,6 +243,7 @@
|
||||
Contributors:
|
||||
- [@Bl3f](https://github.com/Bl3f) ([#3011](https://github.com/fishtown-analytics/dbt/pull/3011))
|
||||
|
||||
|
||||
## dbt 0.19.0 (January 27, 2021)
|
||||
|
||||
## dbt 0.19.0rc3 (January 27, 2021)
|
||||
@@ -59,6 +286,7 @@ Contributors:
|
||||
- Normalize cli-style-strings in manifest selectors dictionary ([#2879](https://github.com/fishtown-anaytics/dbt/issues/2879), [#2895](https://github.com/fishtown-analytics/dbt/pull/2895))
|
||||
- Hourly, monthly and yearly partitions available in BigQuery ([#2476](https://github.com/fishtown-analytics/dbt/issues/2476), [#2903](https://github.com/fishtown-analytics/dbt/pull/2903))
|
||||
- Allow BigQuery to default to the environment's default project ([#2828](https://github.com/fishtown-analytics/dbt/pull/2828), [#2908](https://github.com/fishtown-analytics/dbt/pull/2908))
|
||||
- Rationalize run result status reporting and clean up artifact schema ([#2493](https://github.com/fishtown-analytics/dbt/issues/2493), [#2943](https://github.com/fishtown-analytics/dbt/pull/2943))
|
||||
|
||||
### Fixes
|
||||
- Respect `--project-dir` in `dbt clean` command ([#2840](https://github.com/fishtown-analytics/dbt/issues/2840), [#2841](https://github.com/fishtown-analytics/dbt/pull/2841))
|
||||
@@ -130,6 +358,15 @@ Contributors:
|
||||
- [@Mr-Nobody99](https://github.com/Mr-Nobody99) ([docs#138](https://github.com/fishtown-analytics/dbt-docs/pull/138))
|
||||
- [@jplynch77](https://github.com/jplynch77) ([docs#139](https://github.com/fishtown-analytics/dbt-docs/pull/139))
|
||||
|
||||
## dbt 0.18.2 (March 22, 2021)
|
||||
|
||||
## dbt 0.18.2rc1 (March 12, 2021)
|
||||
|
||||
### Under the hood
|
||||
- Pin `agate<1.6.2` to avoid installation errors relating to its new dependency
|
||||
`PyICU` ([#3160](https://github.com/fishtown-analytics/dbt/issues/3160),
|
||||
[#3161](https://github.com/fishtown-analytics/dbt/pull/3161))
|
||||
|
||||
## dbt 0.18.1 (October 13, 2020)
|
||||
|
||||
## dbt 0.18.1rc1 (October 01, 2020)
|
||||
@@ -950,7 +1187,6 @@ Thanks for your contributions to dbt!
|
||||
- [@bastienboutonnet](https://github.com/bastienboutonnet) ([#1591](https://github.com/fishtown-analytics/dbt/pull/1591), [#1689](https://github.com/fishtown-analytics/dbt/pull/1689))
|
||||
|
||||
|
||||
|
||||
## dbt 0.14.0 - Wilt Chamberlain (July 10, 2019)
|
||||
|
||||
### Overview
|
||||
|
||||
207
CONTRIBUTING.md
207
CONTRIBUTING.md
@@ -1,79 +1,86 @@
|
||||
# Contributing to dbt
|
||||
# Contributing to `dbt`
|
||||
|
||||
1. [About this document](#about-this-document)
|
||||
2. [Proposing a change](#proposing-a-change)
|
||||
3. [Getting the code](#getting-the-code)
|
||||
4. [Setting up an environment](#setting-up-an-environment)
|
||||
5. [Running dbt in development](#running-dbt-in-development)
|
||||
5. [Running `dbt` in development](#running-dbt-in-development)
|
||||
6. [Testing](#testing)
|
||||
7. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
|
||||
## About this document
|
||||
|
||||
This document is a guide intended for folks interested in contributing to dbt. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using dbt, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
This document is a guide intended for folks interested in contributing to `dbt`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the #development channel on [slack](community.getdbt.com).
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to dbt must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the dbt codebase. If you are unable to sign the CLA, then the dbt maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
Please note that all contributors to `dbt` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt` codebase. If you are unable to sign the CLA, then the `dbt` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
|
||||
## Proposing a change
|
||||
|
||||
dbt is Apache 2.0-licensed open source software. dbt is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
`dbt` is Apache 2.0-licensed open source software. `dbt` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in dbt, the first step is to open an issue. Please check the list of [open issues](https://github.com/fishtown-analytics/dbt/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The dbt maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt`, the first step is to open an issue. Please check the list of [open issues](https://github.com/fishtown-analytics/dbt/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
**Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
### Discussing the idea
|
||||
|
||||
After you open an issue, a dbt maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The dbt maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
After you open an issue, a `dbt` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
|
||||
### Submitting a change
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the dbt codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The dbt maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/fishtown-analytics/dbt/contribute) page.
|
||||
The `dbt` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/fishtown-analytics/dbt/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
- Outline your planned implementation. If you want help getting started, ask!
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the dbt maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding dbt's [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
|
||||
In some cases, the right resolution to an open issue might be tangential to the dbt codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the dbt maintainers are unwilling or unable to incorporate into the dbt codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the dbt repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt` maintainers are unwilling or unable to incorporate into the `dbt` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
|
||||
### Using issue labels
|
||||
|
||||
The dbt maintainers use labels to categorize open issues. Some labels indicate the databases impacted by the issue, while others describe the domain in the dbt codebase germane to the discussion. While most of these labels are self-explanatory (eg. `snowflake` or `bigquery`), there are others that are worth describing.
|
||||
The `dbt` maintainers use labels to categorize open issues. Some labels indicate the databases impacted by the issue, while others describe the domain in the `dbt` codebase germane to the discussion. While most of these labels are self-explanatory (eg. `snowflake` or `bigquery`), there are others that are worth describing.
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/fishtown-analytics/dbt/labels/triage) | This is a new issue which has not yet been reviewed by a dbt maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/fishtown-analytics/dbt/labels/bug) | This issue represents a defect or regression in dbt |
|
||||
| [enhancement](https://github.com/fishtown-analytics/dbt/labels/enhancement) | This issue represents net-new functionality in dbt |
|
||||
| [good first issue](https://github.com/fishtown-analytics/dbt/labels/good%20first%20issue) | This issue does not require deep knowledge of the dbt codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/fishtown-analytics/dbt/labels/help%20wanted) / [discussion](https://github.com/fishtown-analytics/dbt/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/fishtown-analytics/dbt/issues/duplicate) | This issue is functionally identical to another open issue. The dbt maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/fishtown-analytics/dbt/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The dbt maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/fishtown-analytics/dbt/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by dbt maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/fishtown-analytics/dbt/labels/wontfix) | This issue does not require a code change in the dbt repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
| [triage](https://github.com/fishtown-analytics/dbt/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/fishtown-analytics/dbt/labels/bug) | This issue represents a defect or regression in `dbt` |
|
||||
| [enhancement](https://github.com/fishtown-analytics/dbt/labels/enhancement) | This issue represents net-new functionality in `dbt` |
|
||||
| [good first issue](https://github.com/fishtown-analytics/dbt/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/fishtown-analytics/`dbt`/labels/help%20wanted) / [discussion](https://github.com/fishtown-analytics/dbt/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/fishtown-analytics/dbt/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/fishtown-analytics/dbt/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/fishtown-analytics/dbt/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/fishtown-analytics/dbt/labels/wontfix) | This issue does not require a code change in the `dbt` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
`dbt` has three types of branches:
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `develop` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk brnach or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
### Installing git
|
||||
|
||||
You will need `git` in order to download and modify the dbt source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
You will need `git` in order to download and modify the `dbt` source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
|
||||
### External contributors
|
||||
|
||||
If you are not a member of the `fishtown-analytics` GitHub organization, you can contribute to dbt by forking the dbt repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
If you are not a member of the `fishtown-analytics` GitHub organization, you can contribute to `dbt` by forking the `dbt` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
|
||||
1. fork the dbt repository
|
||||
1. fork the `dbt` repository
|
||||
2. clone your fork locally
|
||||
3. check out a new branch for your proposed changes
|
||||
4. push changes to your fork
|
||||
@@ -81,32 +88,30 @@ If you are not a member of the `fishtown-analytics` GitHub organization, you can
|
||||
|
||||
### Core contributors
|
||||
|
||||
If you are a member of the `fishtown-analytics` GitHub organization, you will have push access to the dbt repo. Rather than
|
||||
forking dbt to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
If you are a member of the `fishtown-analytics` GitHub organization, you will have push access to the `dbt` repo. Rather than forking `dbt` to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
## Setting up an environment
|
||||
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for dbt development, many of these tools are used commonly across open-source python projects.
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for `dbt` development, many of these tools are used commonly across open-source python projects.
|
||||
|
||||
### Tools
|
||||
|
||||
A short list of tools used in dbt testing that will be helpful to your understanding:
|
||||
A short list of tools used in `dbt` testing that will be helpful to your understanding:
|
||||
|
||||
- [virtualenv](https://virtualenv.pypa.io/en/stable/) to manage dependencies
|
||||
- [tox](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions
|
||||
- [pytest](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [make](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [flake8](https://gitlab.com/pycqa/flake8) for code linting
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.6, Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [CircleCI](https://circleci.com/product/) and [Azure Pipelines](https://azure.microsoft.com/en-us/services/devops/pipelines/)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to dbt, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
#### virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in dbt. We recommend creating this virtualenv
|
||||
in the root of the dbt repository. To create a new virtualenv, run:
|
||||
```
|
||||
We strongly recommend using virtual environments when developing code in `dbt`. We recommend creating this virtualenv
|
||||
in the root of the `dbt` repository. To create a new virtualenv, run:
|
||||
```sh
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
```
|
||||
@@ -115,30 +120,32 @@ This will create and activate a new Python virtual environment.
|
||||
|
||||
#### docker and docker-compose
|
||||
|
||||
Docker and docker-compose are both used in testing. For macOS, the easiest thing to do is to [download docker for mac](https://store.docker.com/editions/community/docker-ce-desktop-mac). You'll need to make an account. On Linux, you can use one of the packages [here](https://docs.docker.com/install/#server). We recommend installing from docker.com instead of from your package manager. On Linux you also have to install docker-compose separately, following [these instructions](https://docs.docker.com/compose/install/#install-compose).
|
||||
Docker and docker-compose are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
|
||||
|
||||
#### postgres (optional)
|
||||
|
||||
For testing, and later in the examples in this document, you may want to have `psql` available so you can poke around in the database and see what happened. We recommend that you use [homebrew](https://brew.sh/) for that on macOS, and your package manager on Linux. You can install any version of the postgres client that you'd like. On macOS, with homebrew setup, you can run:
|
||||
|
||||
```
|
||||
```sh
|
||||
brew install postgresql
|
||||
```
|
||||
|
||||
## Running dbt in development
|
||||
## Running `dbt` in development
|
||||
|
||||
### Installation
|
||||
|
||||
First make sure that you set up your `virtualenv` as described in section _Setting up an environment_. Next, install dbt (and its dependencies) with:
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Next, install `dbt` (and its dependencies) with:
|
||||
|
||||
```
|
||||
pip install -r editable_requirements.txt
|
||||
```sh
|
||||
make dev
|
||||
# or
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
```
|
||||
|
||||
When dbt is installed from source in this way, any changes you make to the dbt source code will be reflected immediately in your next `dbt` run.
|
||||
When `dbt` is installed this way, any changes you make to the `dbt` source code will be reflected immediately in your next `dbt` run.
|
||||
|
||||
### Running dbt
|
||||
### Running `dbt`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
|
||||
@@ -146,77 +153,79 @@ Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as
|
||||
|
||||
## Testing
|
||||
|
||||
Getting the dbt integration tests set up in your local environment will be very helpful as you start to make changes to your local version of dbt. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
Getting the `dbt` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
### Running tests via Docker
|
||||
Since `dbt` works with a number of different databases, you will need to supply credentials for one or more of these databases in your test environment. Most organizations don't have access to each of a BigQuery, Redshift, Snowflake, and Postgres database, so it's likely that you will be unable to run every integration test locally. Fortunately, Fishtown Analytics provides a CI environment with access to sandboxed Redshift, Snowflake, BigQuery, and Postgres databases. See the section on [_Submitting a Pull Request_](#submitting-a-pull-request) below for more information on this CI setup.
|
||||
|
||||
dbt's unit and integration tests run in Docker. Because dbt works with a number of different databases, you will need to supply credentials for one or more of these databases in your test environment. Most organizations don't have access to each of a BigQuery, Redshift, Snowflake, and Postgres database, so it's likely that you will be unable to run every integration test locally. Fortunately, Fishtown Analytics provides a CI environment with access to sandboxed Redshift, Snowflake, BigQuery, and Postgres databases. See the section on [_Submitting a Pull Request_](#submitting-a-pull-request) below for more information on this CI setup.
|
||||
### Initial setup
|
||||
|
||||
We recommend starting with `dbt`'s Postgres tests. These tests cover most of the functionality in `dbt`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
### Specifying your test credentials
|
||||
|
||||
dbt uses test credentials specified in a `test.env` file in the root of the repository. This `test.env` file is git-ignored, but please be _extra_ careful to never check in credentials or other sensitive information when developing against dbt. To create your `test.env` file, copy the provided sample file, then supply your relevant credentials:
|
||||
|
||||
```
|
||||
cp test.env.sample test.env
|
||||
atom test.env # supply your credentials
|
||||
```
|
||||
|
||||
We recommend starting with dbt's Postgres tests. These tests cover most of the functionality in dbt, are the fastest to run, and are the easiest to set up. dbt's test suite runs Postgres in a Docker container, so no setup should be required to run these tests.
|
||||
|
||||
If you additionally want to test Snowflake, Bigquery, or Redshift, locally you'll need to get credentials and add them to the `test.env` file. In general, it's most important to have successful unit and Postgres tests. Once you open a PR, dbt will automatically run integration tests for the other three core database adapters. Of course, if you are a BigQuery user, contributing a BigQuery-only feature, it's important to run BigQuery tests as well.
|
||||
|
||||
### Test commands
|
||||
|
||||
dbt's unit tests and Python linter can be run with:
|
||||
|
||||
```
|
||||
make test-unit
|
||||
```
|
||||
|
||||
To run the Postgres + Python 3.6 integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
```
|
||||
or, alternatively:
|
||||
```sh
|
||||
docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
```
|
||||
|
||||
To run a quick test for Python3 integration tests on Postgres, you can run:
|
||||
`dbt` uses test credentials specified in a `test.env` file in the root of the repository for non-Postgres databases. This `test.env` file is git-ignored, but please be _extra_ careful to never check in credentials or other sensitive information when developing against `dbt`. To create your `test.env` file, copy the provided sample file, then supply your relevant credentials. This step is only required to use non-Postgres databases.
|
||||
|
||||
```
|
||||
make test-quick
|
||||
cp test.env.sample test.env
|
||||
$EDITOR test.env
|
||||
```
|
||||
|
||||
To run tests for a specific database, invoke `tox` directly with the required flags:
|
||||
```
|
||||
# Run Postgres py36 tests
|
||||
docker-compose run test tox -e integration-postgres-py36 -- -x
|
||||
> In general, it's most important to have successful unit and Postgres tests. Once you open a PR, `dbt` will automatically run integration tests for the other three core database adapters. Of course, if you are a BigQuery user, contributing a BigQuery-only feature, it's important to run BigQuery tests as well.
|
||||
|
||||
# Run Snowflake py36 tests
|
||||
docker-compose run test tox -e integration-snowflake-py36 -- -x
|
||||
### Test commands
|
||||
|
||||
# Run BigQuery py36 tests
|
||||
docker-compose run test tox -e integration-bigquery-py36 -- -x
|
||||
There are a few methods for running tests locally.
|
||||
|
||||
# Run Redshift py36 tests
|
||||
docker-compose run test tox -e integration-redshift-py36 -- -x
|
||||
```
|
||||
#### Makefile
|
||||
|
||||
To run a specific test by itself:
|
||||
```
|
||||
docker-compose run test tox -e explicit-py36 -- -s -x -m profile_{adapter} {path_to_test_file_or_folder}
|
||||
```
|
||||
E.g.
|
||||
```
|
||||
docker-compose run test tox -e explicit-py36 -- -s -x -m profile_snowflake test/integration/001_simple_copy_test
|
||||
```
|
||||
There are multiple targets in the Makefile to run common test suites and code
|
||||
checks, most notably:
|
||||
|
||||
See the `Makefile` contents for more some other examples of ways to run `tox`.
|
||||
```sh
|
||||
# Runs unit tests with py38 and code checks in parallel.
|
||||
make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) installed locally,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run
|
||||
tests. You can also run tests in parallel, for example, you can run unit tests
|
||||
for Python 3.6, Python 3.7, Python 3.8, `flake8` checks, and `mypy` checks in
|
||||
parallel with `tox -p`. Also, you can run unit tests for specific python versions
|
||||
with `tox -e py36`. The configuration for these tests in located in `tox.ini`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv
|
||||
active and dev dependencies installed you can do things like:
|
||||
```sh
|
||||
# run specific postgres integration tests
|
||||
python -m pytest -m profile_postgres test/integration/001_simple_copy_test
|
||||
# run all unit tests in a file
|
||||
python -m pytest test/unit/test_graph.py
|
||||
# run a specific unit test
|
||||
python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
```
|
||||
> [Here](https://docs.pytest.org/en/reorganize-docs/new-docs/user/commandlineuseful.html)
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
## Submitting a Pull Request
|
||||
|
||||
Fishtown Analytics provides a sandboxed Redshift, Snowflake, and BigQuery database for use in a CI environment. When pull requests are submitted to the `fishtown-analytics/dbt` repo, GitHub will trigger automated tests in CircleCI and Azure Pipelines.
|
||||
|
||||
A dbt maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
A `dbt` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a dbt maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
Once all tests are passing and your PR has been approved, a `dbt` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
@@ -3,6 +3,9 @@ FROM ubuntu:18.04
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
software-properties-common \
|
||||
&& add-apt-repository ppa:git-core/ppa -y \
|
||||
&& apt-get dist-upgrade -y \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
netcat \
|
||||
@@ -46,9 +49,7 @@ RUN curl -LO https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_V
|
||||
&& tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
||||
&& rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
||||
|
||||
RUN pip3 install -U "tox==3.14.4" wheel "six>=1.14.0,<1.15.0" "virtualenv==20.0.3" setuptools
|
||||
# tox fails if the 'python' interpreter (python2) doesn't have `tox` installed
|
||||
RUN pip install -U "tox==3.14.4" "six>=1.14.0,<1.15.0" "virtualenv==20.0.3" setuptools
|
||||
RUN pip3 install -U tox wheel six setuptools
|
||||
|
||||
# These args are passed in via docker-compose, which reads then from the .env file.
|
||||
# On Linux, run `make .env` to create the .env file for the current user.
|
||||
|
||||
@@ -186,7 +186,7 @@
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
Copyright 2021 dbt Labs, Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
|
||||
101
Makefile
101
Makefile
@@ -1,29 +1,81 @@
|
||||
.PHONY: install test test-unit test-integration
|
||||
.DEFAULT_GOAL:=help
|
||||
|
||||
changed_tests := `git status --porcelain | grep '^\(M\| M\|A\| A\)' | awk '{ print $$2 }' | grep '\/test_[a-zA-Z_\-\.]\+.py'`
|
||||
# Optional flag to run target in a docker container.
|
||||
# (example `make test USE_DOCKER=true`)
|
||||
ifeq ($(USE_DOCKER),true)
|
||||
DOCKER_CMD := docker-compose run --rm test
|
||||
endif
|
||||
|
||||
install:
|
||||
pip install -e .
|
||||
.PHONY: dev
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies.
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
|
||||
test: .env
|
||||
@echo "Full test run starting..."
|
||||
@time docker-compose run --rm test tox
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy for static type checking.
|
||||
$(DOCKER_CMD) tox -e mypy
|
||||
|
||||
test-unit: .env
|
||||
@echo "Unit test run starting..."
|
||||
@time docker-compose run --rm test tox -e unit-py36,flake8
|
||||
.PHONY: flake8
|
||||
flake8: .env ## Runs flake8 to enforce style guide.
|
||||
$(DOCKER_CMD) tox -e flake8
|
||||
|
||||
test-integration: .env
|
||||
@echo "Integration test run starting..."
|
||||
@time docker-compose run --rm test tox -e integration-postgres-py36,integration-redshift-py36,integration-snowflake-py36,integration-bigquery-py36
|
||||
.PHONY: lint
|
||||
lint: .env ## Runs all code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e flake8,mypy
|
||||
|
||||
test-quick: .env
|
||||
@echo "Integration test run starting..."
|
||||
@time docker-compose run --rm test tox -e integration-postgres-py36 -- -x
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py38 and code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e py38,flake8,mypy
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env integration-postgres ## Alias for integration-postgres.
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env integration-postgres-fail-fast ## Alias for integration-postgres-fail-fast.
|
||||
|
||||
.PHONY: integration-postgres
|
||||
integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -nauto
|
||||
|
||||
.PHONY: integration-postgres-fail-fast
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: integration-redshift
|
||||
integration-redshift: .env ## Runs redshift integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -nauto
|
||||
|
||||
.PHONY: integration-redshift-fail-fast
|
||||
integration-redshift-fail-fast: .env ## Runs redshift integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -x -nauto
|
||||
|
||||
.PHONY: integration-snowflake
|
||||
integration-snowflake: .env ## Runs snowflake integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -nauto
|
||||
|
||||
.PHONY: integration-snowflake-fail-fast
|
||||
integration-snowflake-fail-fast: .env ## Runs snowflake integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -x -nauto
|
||||
|
||||
.PHONY: integration-bigquery
|
||||
integration-bigquery: .env ## Runs bigquery integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -nauto
|
||||
|
||||
.PHONY: integration-bigquery-fail-fast
|
||||
integration-bigquery-fail-fast: .env ## Runs bigquery integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
|
||||
# This rule creates a file named .env that is used by docker-compose for passing
|
||||
# the USER_ID and GROUP_ID arguments to the Docker image.
|
||||
.env:
|
||||
.env: ## Setup step for using using docker-compose with make target.
|
||||
@touch .env
|
||||
ifneq ($(OS),Windows_NT)
|
||||
ifneq ($(shell uname -s), Darwin)
|
||||
@@ -31,9 +83,9 @@ ifneq ($(shell uname -s), Darwin)
|
||||
@echo GROUP_ID=$(shell id -g) >> .env
|
||||
endif
|
||||
endif
|
||||
@time docker-compose build
|
||||
|
||||
clean:
|
||||
.PHONY: clean
|
||||
clean: ## Resets development environment.
|
||||
rm -f .coverage
|
||||
rm -rf .eggs/
|
||||
rm -f .env
|
||||
@@ -47,3 +99,14 @@ clean:
|
||||
rm -rf target/
|
||||
find . -type f -name '*.pyc' -delete
|
||||
find . -type d -name '__pycache__' -depth -delete
|
||||
|
||||
.PHONY: help
|
||||
help: ## Show this help message.
|
||||
@echo 'usage: make [target] [USE_DOCKER=true]'
|
||||
@echo
|
||||
@echo 'targets:'
|
||||
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
@echo
|
||||
@echo 'options:'
|
||||
@echo 'use USE_DOCKER=true to run target in a docker container'
|
||||
|
||||
|
||||
47
README.md
47
README.md
@@ -1,28 +1,21 @@
|
||||
<p align="center">
|
||||
<img src="/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt/ec7dee39f793aa4f7dd3dae37282cc87664813e4/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://codeclimate.com/github/fishtown-analytics/dbt">
|
||||
<img src="https://codeclimate.com/github/fishtown-analytics/dbt/badges/gpa.svg" alt="Code Climate"/>
|
||||
<a href="https://github.com/dbt-labs/dbt/actions/workflows/tests.yml?query=branch%3Adevelop">
|
||||
<img src="https://github.com/dbt-labs/dbt/actions/workflows/tests.yml/badge.svg" alt="GitHub Actions"/>
|
||||
</a>
|
||||
<a href="https://circleci.com/gh/fishtown-analytics/dbt/tree/master">
|
||||
<img src="https://circleci.com/gh/fishtown-analytics/dbt/tree/master.svg?style=svg" alt="CircleCI" />
|
||||
<a href="https://circleci.com/gh/dbt-labs/dbt/tree/develop">
|
||||
<img src="https://circleci.com/gh/dbt-labs/dbt/tree/develop.svg?style=svg" alt="CircleCI" />
|
||||
</a>
|
||||
<a href="https://ci.appveyor.com/project/DrewBanin/dbt/branch/development">
|
||||
<img src="https://ci.appveyor.com/api/projects/status/v01rwd3q91jnwp9m/branch/development?svg=true" alt="AppVeyor" />
|
||||
</a>
|
||||
<a href="https://community.getdbt.com">
|
||||
<img src="https://community.getdbt.com/badge.svg" alt="Slack" />
|
||||
<a href="https://dev.azure.com/fishtown-analytics/dbt/_build?definitionId=1&_a=summary&repositoryFilter=1&branchFilter=789%2C789%2C789%2C789">
|
||||
<img src="https://dev.azure.com/fishtown-analytics/dbt/_apis/build/status/fishtown-analytics.dbt?branchName=develop" alt="Azure Pipelines" />
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** (data build tool) enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
dbt is the T in ELT. Organize, cleanse, denormalize, filter, rename, and pre-aggregate the raw data in your warehouse so that it's ready for analysis.
|
||||
|
||||

|
||||
|
||||
dbt can be used to [aggregate pageviews into sessions](https://github.com/fishtown-analytics/snowplow), calculate [ad spend ROI](https://github.com/fishtown-analytics/facebook-ads), or report on [email campaign performance](https://github.com/fishtown-analytics/mailchimp).
|
||||
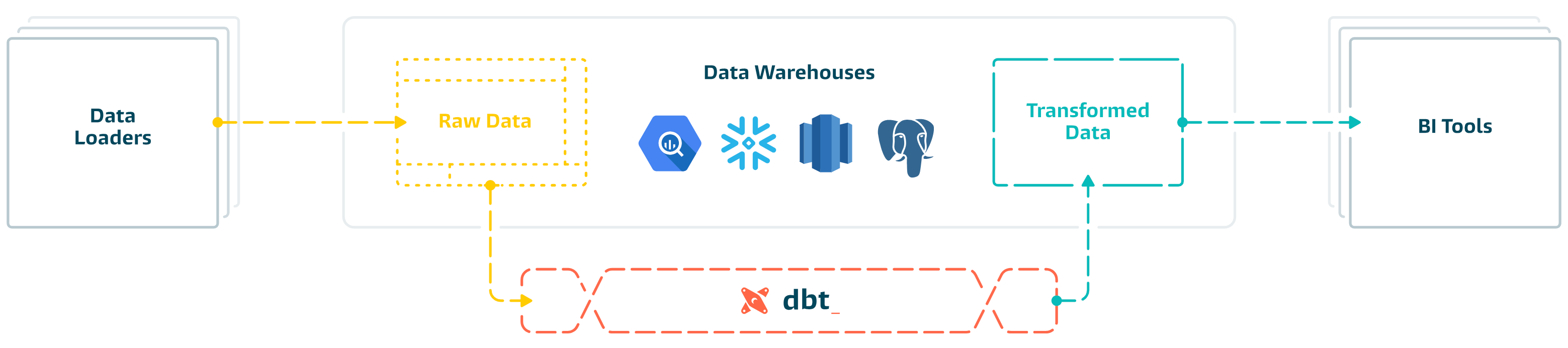
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -30,28 +23,22 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||

|
||||
|
||||
|
||||
## Getting started
|
||||
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [documentation](https://docs.getdbt.com/).
|
||||
- Productionize your dbt project with [dbt Cloud](https://www.getdbt.com)
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
|
||||
|
||||
## Find out more
|
||||
## Join the dbt Community
|
||||
|
||||
- Check out the [Introduction to dbt](https://docs.getdbt.com/docs/introduction/).
|
||||
- Read the [dbt Viewpoint](https://docs.getdbt.com/docs/about/viewpoint/).
|
||||
|
||||
## Join thousands of analysts in the dbt community
|
||||
|
||||
- Join the [chat](http://community.getdbt.com/) on Slack.
|
||||
- Find community posts on [dbt Discourse](https://discourse.getdbt.com).
|
||||
- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
|
||||
- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/fishtown-analytics/dbt/issues/new).
|
||||
- Want to help us build dbt? Check out the [Contributing Getting Started Guide](/CONTRIBUTING.md)
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
92
RELEASE.md
92
RELEASE.md
@@ -1,92 +0,0 @@
|
||||
### Release Procedure :shipit:
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
dbt has three types of branches:
|
||||
|
||||
- **Trunks** track the latest release of a minor version of dbt. Historically, we used the `master` branch as the trunk. Each minor version release has a corresponding trunk. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of dbt.
|
||||
- **Release Branches** track a specific, not yet complete release of dbt. These releases are codenamed since we don't always know what their semantic version will be. Example: `dev/lucretia-mott` became `0.11.1`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into a release branch.
|
||||
|
||||
#### Git & PyPI
|
||||
|
||||
1. Update CHANGELOG.md with the most recent changes
|
||||
2. If this is a release candidate, you want to create it off of your release branch. If it's an actual release, you must first merge to a master branch. Open a Pull Request in Github to merge it into the appropriate trunk (`X.X.latest`)
|
||||
3. Bump the version using `bumpversion`:
|
||||
- Dry run first by running `bumpversion --new-version <desired-version> <part>` and checking the diff. If it looks correct, clean up the chanages and move on:
|
||||
- Alpha releases: `bumpversion --commit --no-tag --new-version 0.10.2a1 num`
|
||||
- Patch releases: `bumpversion --commit --no-tag --new-version 0.10.2 patch`
|
||||
- Minor releases: `bumpversion --commit --no-tag --new-version 0.11.0 minor`
|
||||
- Major releases: `bumpversion --commit --no-tag --new-version 1.0.0 major`
|
||||
4. (If this is a not a release candidate) Merge to `x.x.latest` and (optionally) `master`.
|
||||
5. Update the default branch to the next dev release branch.
|
||||
6. Build source distributions for all packages by running `./scripts/build-sdists.sh`. Note that this will clean out your `dist/` folder, so if you have important stuff in there, don't run it!!!
|
||||
7. Deploy to pypi
|
||||
- `twine upload dist/*`
|
||||
8. Deploy to homebrew (see below)
|
||||
9. Deploy to conda-forge (see below)
|
||||
10. Git release notes (points to changelog)
|
||||
11. Post to slack (point to changelog)
|
||||
|
||||
After releasing a new version, it's important to merge the changes back into the other outstanding release branches. This avoids merge conflicts moving forward.
|
||||
|
||||
In some cases, where the branches have diverged wildly, it's ok to skip this step. But this means that the changes you just released won't be included in future releases.
|
||||
|
||||
#### Homebrew Release Process
|
||||
|
||||
1. Clone the `homebrew-dbt` repository:
|
||||
|
||||
```
|
||||
git clone git@github.com:fishtown-analytics/homebrew-dbt.git
|
||||
```
|
||||
|
||||
2. For ALL releases (prereleases and version releases), copy the relevant formula. To copy from the latest version release of dbt, do:
|
||||
|
||||
```bash
|
||||
cp Formula/dbt.rb Formula/dbt@{NEW-VERSION}.rb
|
||||
```
|
||||
|
||||
To copy from a different version, simply copy the corresponding file.
|
||||
|
||||
3. Open the file, and edit the following:
|
||||
- the name of the ruby class: this is important, homebrew won't function properly if the class name is wrong. Check historical versions to figure out the right name.
|
||||
- under the `bottle` section, remove all of the hashes (lines starting with `sha256`)
|
||||
|
||||
4. Create a **Python 3.7** virtualenv, activate it, and then install two packages: `homebrew-pypi-poet`, and the version of dbt you are preparing. I use:
|
||||
|
||||
```
|
||||
pyenv virtualenv 3.7.0 homebrew-dbt-{VERSION}
|
||||
pyenv activate homebrew-dbt-{VERSION}
|
||||
pip install dbt=={VERSION} homebrew-pypi-poet
|
||||
```
|
||||
|
||||
homebrew-pypi-poet is a program that generates a valid homebrew formula for an installed pip package. You want to use it to generate a diff against the existing formula. Then you want to apply the diff for the dependency packages only -- e.g. it will tell you that `google-api-core` has been updated and that you need to use the latest version.
|
||||
|
||||
5. reinstall, test, and audit dbt. if the test or audit fails, fix the formula with step 1.
|
||||
|
||||
```bash
|
||||
brew uninstall --force Formula/{YOUR-FILE}.rb
|
||||
brew install Formula/{YOUR-FILE}.rb
|
||||
brew test dbt
|
||||
brew audit --strict dbt
|
||||
```
|
||||
|
||||
6. Ask Connor to bottle the change (only his laptop can do it!)
|
||||
|
||||
#### Conda Forge Release Process
|
||||
|
||||
1. Clone the fork of `conda-forge/dbt-feedstock` [here](https://github.com/fishtown-analytics/dbt-feedstock)
|
||||
```bash
|
||||
git clone git@github.com:fishtown-analytics/dbt-feedstock.git
|
||||
|
||||
```
|
||||
2. Update the version and sha256 in `recipe/meta.yml`. To calculate the sha256, run:
|
||||
|
||||
```bash
|
||||
wget https://github.com/fishtown-analytics/dbt/archive/v{version}.tar.gz
|
||||
openssl sha256 v{version}.tar.gz
|
||||
```
|
||||
|
||||
3. Push the changes and create a PR against `conda-forge/dbt-feedstock`
|
||||
|
||||
4. Confirm that all automated conda-forge tests are passing
|
||||
@@ -6,8 +6,8 @@
|
||||
trigger:
|
||||
branches:
|
||||
include:
|
||||
- master
|
||||
- dev/*
|
||||
- develop
|
||||
- '*.latest'
|
||||
- pr/*
|
||||
|
||||
jobs:
|
||||
@@ -23,7 +23,7 @@ jobs:
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-unit
|
||||
- script: python -m tox -e py -- -v
|
||||
displayName: Run unit tests
|
||||
|
||||
- job: PostgresIntegrationTest
|
||||
@@ -54,7 +54,7 @@ jobs:
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-postgres
|
||||
- script: python -m tox -e py-postgres -- -v -n4
|
||||
displayName: Run integration tests
|
||||
|
||||
# These three are all similar except secure environment variables, which MUST be passed along to their tasks,
|
||||
@@ -62,7 +62,7 @@ jobs:
|
||||
- job: SnowflakeIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
@@ -73,7 +73,7 @@ jobs:
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-snowflake
|
||||
- script: python -m tox -e py-snowflake -- -v -n4
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: $(SNOWFLAKE_TEST_ACCOUNT)
|
||||
SNOWFLAKE_TEST_PASSWORD: $(SNOWFLAKE_TEST_PASSWORD)
|
||||
@@ -87,7 +87,7 @@ jobs:
|
||||
- job: BigQueryIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
@@ -96,7 +96,7 @@ jobs:
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
- script: python -m tox -e pywin-bigquery
|
||||
- script: python -m tox -e py-bigquery -- -v -n4
|
||||
env:
|
||||
BIGQUERY_SERVICE_ACCOUNT_JSON: $(BIGQUERY_SERVICE_ACCOUNT_JSON)
|
||||
displayName: Run integration tests
|
||||
@@ -104,7 +104,7 @@ jobs:
|
||||
- job: RedshiftIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
@@ -115,7 +115,7 @@ jobs:
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-redshift
|
||||
- script: python -m tox -e py-redshift -- -v -n4
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: $(REDSHIFT_TEST_DBNAME)
|
||||
REDSHIFT_TEST_PASS: $(REDSHIFT_TEST_PASS)
|
||||
@@ -139,7 +139,7 @@ jobs:
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip setuptools && python -m pip install -r requirements.txt && python -m pip install -r dev_requirements.txt
|
||||
- script: python -m pip install --upgrade pip setuptools && python -m pip install -r requirements.txt && python -m pip install -r dev-requirements.txt
|
||||
displayName: Install dependencies
|
||||
- task: ShellScript@2
|
||||
inputs:
|
||||
|
||||
@@ -1 +1 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
|
||||
@@ -273,8 +273,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def load_macro_manifest(self) -> MacroManifest:
|
||||
if self._macro_manifest_lazy is None:
|
||||
# avoid a circular import
|
||||
from dbt.parser.manifest import load_macro_manifest
|
||||
manifest = load_macro_manifest(
|
||||
from dbt.parser.manifest import ManifestLoader
|
||||
manifest = ManifestLoader.load_macros(
|
||||
self.config, self.connections.set_query_header
|
||||
)
|
||||
self._macro_manifest_lazy = manifest
|
||||
|
||||
@@ -45,7 +45,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
def __eq__(self, other):
|
||||
if not isinstance(other, self.__class__):
|
||||
return False
|
||||
return self.to_dict() == other.to_dict()
|
||||
return self.to_dict(omit_none=True) == other.to_dict(omit_none=True)
|
||||
|
||||
@classmethod
|
||||
def get_default_quote_policy(cls) -> Policy:
|
||||
@@ -185,10 +185,10 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
def create_from_source(
|
||||
cls: Type[Self], source: ParsedSourceDefinition, **kwargs: Any
|
||||
) -> Self:
|
||||
source_quoting = source.quoting.to_dict()
|
||||
source_quoting = source.quoting.to_dict(omit_none=True)
|
||||
source_quoting.pop('column', None)
|
||||
quote_policy = deep_merge(
|
||||
cls.get_default_quote_policy().to_dict(),
|
||||
cls.get_default_quote_policy().to_dict(omit_none=True),
|
||||
source_quoting,
|
||||
kwargs.get('quote_policy', {}),
|
||||
)
|
||||
@@ -203,7 +203,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
|
||||
@staticmethod
|
||||
def add_ephemeral_prefix(name: str):
|
||||
return f'__dbt__CTE__{name}'
|
||||
return f'__dbt__cte__{name}'
|
||||
|
||||
@classmethod
|
||||
def create_ephemeral_from_node(
|
||||
@@ -433,13 +433,14 @@ class SchemaSearchMap(Dict[InformationSchema, Set[Optional[str]]]):
|
||||
for schema in schemas:
|
||||
yield information_schema_name, schema
|
||||
|
||||
def flatten(self):
|
||||
def flatten(self, allow_multiple_databases: bool = False):
|
||||
new = self.__class__()
|
||||
|
||||
# make sure we don't have duplicates
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
# make sure we don't have multiple databases if allow_multiple_databases is set to False
|
||||
if not allow_multiple_databases:
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
|
||||
for information_schema_name, schema in self.search():
|
||||
path = {
|
||||
|
||||
@@ -99,7 +99,14 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
column_names: Iterable[str],
|
||||
rows: Iterable[Any]
|
||||
) -> List[Dict[str, Any]]:
|
||||
|
||||
unique_col_names = dict()
|
||||
for idx in range(len(column_names)):
|
||||
col_name = column_names[idx]
|
||||
if col_name in unique_col_names:
|
||||
unique_col_names[col_name] += 1
|
||||
column_names[idx] = f'{col_name}_{unique_col_names[col_name]}'
|
||||
else:
|
||||
unique_col_names[column_names[idx]] = 1
|
||||
return [dict(zip(column_names, row)) for row in rows]
|
||||
|
||||
@classmethod
|
||||
|
||||
@@ -35,7 +35,11 @@ class ISODateTime(agate.data_types.DateTime):
|
||||
)
|
||||
|
||||
|
||||
def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
def build_type_tester(
|
||||
text_columns: Iterable[str],
|
||||
string_null_values: Optional[Iterable[str]] = ('null', '')
|
||||
) -> agate.TypeTester:
|
||||
|
||||
types = [
|
||||
agate.data_types.Number(null_values=('null', '')),
|
||||
agate.data_types.Date(null_values=('null', ''),
|
||||
@@ -46,10 +50,10 @@ def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
agate.data_types.Boolean(true_values=('true',),
|
||||
false_values=('false',),
|
||||
null_values=('null', '')),
|
||||
agate.data_types.Text(null_values=('null', ''))
|
||||
agate.data_types.Text(null_values=string_null_values)
|
||||
]
|
||||
force = {
|
||||
k: agate.data_types.Text(null_values=('null', ''))
|
||||
k: agate.data_types.Text(null_values=string_null_values)
|
||||
for k in text_columns
|
||||
}
|
||||
return agate.TypeTester(force=force, types=types)
|
||||
@@ -66,7 +70,13 @@ def table_from_rows(
|
||||
if text_only_columns is None:
|
||||
column_types = DEFAULT_TYPE_TESTER
|
||||
else:
|
||||
column_types = build_type_tester(text_only_columns)
|
||||
# If text_only_columns are present, prevent coercing empty string or
|
||||
# literal 'null' strings to a None representation.
|
||||
column_types = build_type_tester(
|
||||
text_only_columns,
|
||||
string_null_values=()
|
||||
)
|
||||
|
||||
return agate.Table(rows, column_names, column_types=column_types)
|
||||
|
||||
|
||||
@@ -86,19 +96,34 @@ def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
|
||||
|
||||
def table_from_data_flat(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
"""
|
||||
Convert a list of dictionaries into an Agate table. This method does not
|
||||
coerce string values into more specific types (eg. '005' will not be
|
||||
coerced to '5'). Additionally, this method does not coerce values to
|
||||
None (eg. '' or 'null' will retain their string literal representations).
|
||||
"""
|
||||
|
||||
rows = []
|
||||
text_only_columns = set()
|
||||
for _row in data:
|
||||
row = []
|
||||
for value in list(_row.values()):
|
||||
for col_name in column_names:
|
||||
value = _row[col_name]
|
||||
if isinstance(value, (dict, list, tuple)):
|
||||
row.append(json.dumps(value, cls=dbt.utils.JSONEncoder))
|
||||
else:
|
||||
row.append(value)
|
||||
# Represent container types as json strings
|
||||
value = json.dumps(value, cls=dbt.utils.JSONEncoder)
|
||||
text_only_columns.add(col_name)
|
||||
elif isinstance(value, str):
|
||||
text_only_columns.add(col_name)
|
||||
row.append(value)
|
||||
|
||||
rows.append(row)
|
||||
|
||||
return table_from_rows(rows=rows, column_names=column_names)
|
||||
return table_from_rows(
|
||||
rows=rows,
|
||||
column_names=column_names,
|
||||
text_only_columns=text_only_columns
|
||||
)
|
||||
|
||||
|
||||
def empty_table():
|
||||
|
||||
@@ -4,21 +4,43 @@ import os.path
|
||||
from dbt.clients.system import run_cmd, rmdir
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from packaging import version
|
||||
|
||||
|
||||
def clone(repo, cwd, dirname=None, remove_git_dir=False, branch=None):
|
||||
def _is_commit(revision: str) -> bool:
|
||||
# match SHA-1 git commit
|
||||
return bool(re.match(r"\b[0-9a-f]{40}\b", revision))
|
||||
|
||||
|
||||
def clone(repo, cwd, dirname=None, remove_git_dir=False, revision=None, subdirectory=None):
|
||||
has_revision = revision is not None
|
||||
is_commit = _is_commit(revision or "")
|
||||
|
||||
clone_cmd = ['git', 'clone', '--depth', '1']
|
||||
if subdirectory:
|
||||
logger.debug(' Subdirectory specified: {}, using sparse checkout.'.format(subdirectory))
|
||||
out, _ = run_cmd(cwd, ['git', '--version'], env={'LC_ALL': 'C'})
|
||||
git_version = version.parse(re.search(r"\d+\.\d+\.\d+", out.decode("utf-8")).group(0))
|
||||
if not git_version >= version.parse("2.25.0"):
|
||||
# 2.25.0 introduces --sparse
|
||||
raise RuntimeError(
|
||||
"Please update your git version to pull a dbt package "
|
||||
"from a subdirectory: your version is {}, >= 2.25.0 needed".format(git_version)
|
||||
)
|
||||
clone_cmd.extend(['--filter=blob:none', '--sparse'])
|
||||
|
||||
if branch is not None:
|
||||
clone_cmd.extend(['--branch', branch])
|
||||
if has_revision and not is_commit:
|
||||
clone_cmd.extend(['--branch', revision])
|
||||
|
||||
clone_cmd.append(repo)
|
||||
|
||||
if dirname is not None:
|
||||
clone_cmd.append(dirname)
|
||||
|
||||
result = run_cmd(cwd, clone_cmd, env={'LC_ALL': 'C'})
|
||||
|
||||
if subdirectory:
|
||||
run_cmd(os.path.join(cwd, dirname or ''), ['git', 'sparse-checkout', 'set', subdirectory])
|
||||
|
||||
if remove_git_dir:
|
||||
rmdir(os.path.join(dirname, '.git'))
|
||||
|
||||
@@ -31,33 +53,38 @@ def list_tags(cwd):
|
||||
return tags
|
||||
|
||||
|
||||
def _checkout(cwd, repo, branch):
|
||||
logger.debug(' Checking out branch {}.'.format(branch))
|
||||
def _checkout(cwd, repo, revision):
|
||||
logger.debug(' Checking out revision {}.'.format(revision))
|
||||
|
||||
run_cmd(cwd, ['git', 'remote', 'set-branches', 'origin', branch])
|
||||
run_cmd(cwd, ['git', 'fetch', '--tags', '--depth', '1', 'origin', branch])
|
||||
fetch_cmd = ["git", "fetch", "origin", "--depth", "1"]
|
||||
|
||||
tags = list_tags(cwd)
|
||||
|
||||
# Prefer tags to branches if one exists
|
||||
if branch in tags:
|
||||
spec = 'tags/{}'.format(branch)
|
||||
if _is_commit(revision):
|
||||
run_cmd(cwd, fetch_cmd + [revision])
|
||||
else:
|
||||
spec = 'origin/{}'.format(branch)
|
||||
run_cmd(cwd, ['git', 'remote', 'set-branches', 'origin', revision])
|
||||
run_cmd(cwd, fetch_cmd + ["--tags", revision])
|
||||
|
||||
if _is_commit(revision):
|
||||
spec = revision
|
||||
# Prefer tags to branches if one exists
|
||||
elif revision in list_tags(cwd):
|
||||
spec = 'tags/{}'.format(revision)
|
||||
else:
|
||||
spec = 'origin/{}'.format(revision)
|
||||
|
||||
out, err = run_cmd(cwd, ['git', 'reset', '--hard', spec],
|
||||
env={'LC_ALL': 'C'})
|
||||
return out, err
|
||||
|
||||
|
||||
def checkout(cwd, repo, branch=None):
|
||||
if branch is None:
|
||||
branch = 'master'
|
||||
def checkout(cwd, repo, revision=None):
|
||||
if revision is None:
|
||||
revision = 'HEAD'
|
||||
try:
|
||||
return _checkout(cwd, repo, branch)
|
||||
return _checkout(cwd, repo, revision)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
stderr = exc.stderr.decode('utf-8').strip()
|
||||
dbt.exceptions.bad_package_spec(repo, branch, stderr)
|
||||
dbt.exceptions.bad_package_spec(repo, revision, stderr)
|
||||
|
||||
|
||||
def get_current_sha(cwd):
|
||||
@@ -71,11 +98,16 @@ def remove_remote(cwd):
|
||||
|
||||
|
||||
def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
branch=None):
|
||||
revision=None, subdirectory=None):
|
||||
exists = None
|
||||
try:
|
||||
_, err = clone(repo, cwd, dirname=dirname,
|
||||
remove_git_dir=remove_git_dir)
|
||||
_, err = clone(
|
||||
repo,
|
||||
cwd,
|
||||
dirname=dirname,
|
||||
remove_git_dir=remove_git_dir,
|
||||
subdirectory=subdirectory,
|
||||
)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
err = exc.stderr.decode('utf-8')
|
||||
exists = re.match("fatal: destination path '(.+)' already exists", err)
|
||||
@@ -97,7 +129,7 @@ def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
logger.debug('Pulling new dependency {}.', directory)
|
||||
full_path = os.path.join(cwd, directory)
|
||||
start_sha = get_current_sha(full_path)
|
||||
checkout(full_path, repo, branch)
|
||||
checkout(full_path, repo, revision)
|
||||
end_sha = get_current_sha(full_path)
|
||||
if exists:
|
||||
if start_sha == end_sha:
|
||||
@@ -107,4 +139,4 @@ def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
start_sha[:7], end_sha[:7])
|
||||
else:
|
||||
logger.debug(' Checked out at {}.', end_sha[:7])
|
||||
return directory
|
||||
return os.path.join(directory, subdirectory or '')
|
||||
|
||||
@@ -21,7 +21,7 @@ import jinja2.sandbox
|
||||
|
||||
from dbt.utils import (
|
||||
get_dbt_macro_name, get_docs_macro_name, get_materialization_macro_name,
|
||||
deep_map
|
||||
get_test_macro_name, deep_map
|
||||
)
|
||||
|
||||
from dbt.clients._jinja_blocks import BlockIterator, BlockData, BlockTag
|
||||
@@ -29,7 +29,8 @@ from dbt.contracts.graph.compiled import CompiledSchemaTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedSchemaTestNode
|
||||
from dbt.exceptions import (
|
||||
InternalException, raise_compiler_error, CompilationException,
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException,
|
||||
UndefinedMacroException
|
||||
)
|
||||
from dbt import flags
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
@@ -408,6 +409,20 @@ class DocumentationExtension(jinja2.ext.Extension):
|
||||
return node
|
||||
|
||||
|
||||
class TestExtension(jinja2.ext.Extension):
|
||||
tags = ['test']
|
||||
|
||||
def parse(self, parser):
|
||||
node = jinja2.nodes.Macro(lineno=next(parser.stream).lineno)
|
||||
test_name = parser.parse_assign_target(name_only=True).name
|
||||
|
||||
parser.parse_signature(node)
|
||||
node.name = get_test_macro_name(test_name)
|
||||
node.body = parser.parse_statements(('name:endtest',),
|
||||
drop_needle=True)
|
||||
return node
|
||||
|
||||
|
||||
def _is_dunder_name(name):
|
||||
return name.startswith('__') and name.endswith('__')
|
||||
|
||||
@@ -479,6 +494,7 @@ def get_environment(
|
||||
|
||||
args['extensions'].append(MaterializationExtension)
|
||||
args['extensions'].append(DocumentationExtension)
|
||||
args['extensions'].append(TestExtension)
|
||||
|
||||
env_cls: Type[jinja2.Environment]
|
||||
text_filter: Type
|
||||
@@ -503,7 +519,7 @@ def catch_jinja(node=None) -> Iterator[None]:
|
||||
e.translated = False
|
||||
raise CompilationException(str(e), node) from e
|
||||
except jinja2.exceptions.UndefinedError as e:
|
||||
raise CompilationException(str(e), node) from e
|
||||
raise UndefinedMacroException(str(e), node) from e
|
||||
except CompilationException as exc:
|
||||
exc.add_node(node)
|
||||
raise
|
||||
|
||||
225
core/dbt/clients/jinja_static.py
Normal file
225
core/dbt/clients/jinja_static.py
Normal file
@@ -0,0 +1,225 @@
|
||||
import jinja2
|
||||
from dbt.clients.jinja import get_environment
|
||||
from dbt.exceptions import raise_compiler_error
|
||||
|
||||
|
||||
def statically_extract_macro_calls(string, ctx, db_wrapper=None):
|
||||
# set 'capture_macros' to capture undefined
|
||||
env = get_environment(None, capture_macros=True)
|
||||
parsed = env.parse(string)
|
||||
|
||||
standard_calls = ['source', 'ref', 'config']
|
||||
possible_macro_calls = []
|
||||
for func_call in parsed.find_all(jinja2.nodes.Call):
|
||||
func_name = None
|
||||
if hasattr(func_call, 'node') and hasattr(func_call.node, 'name'):
|
||||
func_name = func_call.node.name
|
||||
else:
|
||||
# func_call for dbt_utils.current_timestamp macro
|
||||
# Call(
|
||||
# node=Getattr(
|
||||
# node=Name(
|
||||
# name='dbt_utils',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# attr='current_timestamp',
|
||||
# ctx='load
|
||||
# ),
|
||||
# args=[],
|
||||
# kwargs=[],
|
||||
# dyn_args=None,
|
||||
# dyn_kwargs=None
|
||||
# )
|
||||
if (hasattr(func_call, 'node') and
|
||||
hasattr(func_call.node, 'node') and
|
||||
type(func_call.node.node).__name__ == 'Name' and
|
||||
hasattr(func_call.node, 'attr')):
|
||||
package_name = func_call.node.node.name
|
||||
macro_name = func_call.node.attr
|
||||
if package_name == 'adapter':
|
||||
if macro_name == 'dispatch':
|
||||
ad_macro_calls = statically_parse_adapter_dispatch(
|
||||
func_call, ctx, db_wrapper)
|
||||
possible_macro_calls.extend(ad_macro_calls)
|
||||
else:
|
||||
# This skips calls such as adapter.parse_index
|
||||
continue
|
||||
else:
|
||||
func_name = f'{package_name}.{macro_name}'
|
||||
else:
|
||||
continue
|
||||
if not func_name:
|
||||
continue
|
||||
if func_name in standard_calls:
|
||||
continue
|
||||
elif ctx.get(func_name):
|
||||
continue
|
||||
else:
|
||||
if func_name not in possible_macro_calls:
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
return possible_macro_calls
|
||||
|
||||
|
||||
# Call(
|
||||
# node=Getattr(
|
||||
# node=Name(
|
||||
# name='adapter',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# attr='dispatch',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# args=[
|
||||
# Const(value='test_pkg_and_dispatch')
|
||||
# ],
|
||||
# kwargs=[
|
||||
# Keyword(
|
||||
# key='packages',
|
||||
# value=Call(node=Getattr(node=Name(name='local_utils', ctx='load'),
|
||||
# attr='_get_utils_namespaces', ctx='load'), args=[], kwargs=[],
|
||||
# dyn_args=None, dyn_kwargs=None)
|
||||
# )
|
||||
# ],
|
||||
# dyn_args=None,
|
||||
# dyn_kwargs=None
|
||||
# )
|
||||
def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
possible_macro_calls = []
|
||||
# This captures an adapter.dispatch('<macro_name>') call.
|
||||
|
||||
func_name = None
|
||||
# macro_name positional argument
|
||||
if len(func_call.args) > 0:
|
||||
func_name = func_call.args[0].value
|
||||
if func_name:
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
# packages positional argument
|
||||
packages = None
|
||||
macro_namespace = None
|
||||
packages_arg = None
|
||||
packages_arg_type = None
|
||||
|
||||
if len(func_call.args) > 1:
|
||||
packages_arg = func_call.args[1]
|
||||
# This can be a List or a Call
|
||||
packages_arg_type = type(func_call.args[1]).__name__
|
||||
|
||||
# keyword arguments
|
||||
if func_call.kwargs:
|
||||
for kwarg in func_call.kwargs:
|
||||
if kwarg.key == 'packages':
|
||||
# The packages keyword will be deprecated and
|
||||
# eventually removed
|
||||
packages_arg = kwarg.value
|
||||
# This can be a List or a Call
|
||||
packages_arg_type = type(kwarg.value).__name__
|
||||
elif kwarg.key == 'macro_name':
|
||||
# This will remain to enable static resolution
|
||||
if type(kwarg.value).__name__ == 'Const':
|
||||
func_name = kwarg.value.value
|
||||
possible_macro_calls.append(func_name)
|
||||
else:
|
||||
raise_compiler_error(f"The macro_name parameter ({kwarg.value.value}) "
|
||||
"to adapter.dispatch was not a string")
|
||||
elif kwarg.key == 'macro_namespace':
|
||||
# This will remain to enable static resolution
|
||||
kwarg_type = type(kwarg.value).__name__
|
||||
if kwarg_type == 'Const':
|
||||
macro_namespace = kwarg.value.value
|
||||
else:
|
||||
raise_compiler_error("The macro_namespace parameter to adapter.dispatch "
|
||||
f"is a {kwarg_type}, not a string")
|
||||
|
||||
# positional arguments
|
||||
if packages_arg:
|
||||
if packages_arg_type == 'List':
|
||||
# This will remain to enable static resolution
|
||||
packages = []
|
||||
for item in packages_arg.items:
|
||||
packages.append(item.value)
|
||||
elif packages_arg_type == 'Const':
|
||||
# This will remain to enable static resolution
|
||||
macro_namespace = packages_arg.value
|
||||
elif packages_arg_type == 'Call':
|
||||
# This is deprecated and should be removed eventually.
|
||||
# It is here to support (hackily) common ways of providing
|
||||
# a packages list to adapter.dispatch
|
||||
if (hasattr(packages_arg, 'node') and
|
||||
hasattr(packages_arg.node, 'node') and
|
||||
hasattr(packages_arg.node.node, 'name') and
|
||||
hasattr(packages_arg.node, 'attr')):
|
||||
package_name = packages_arg.node.node.name
|
||||
macro_name = packages_arg.node.attr
|
||||
if (macro_name.startswith('_get') and 'namespaces' in macro_name):
|
||||
# noqa: https://github.com/fishtown-analytics/dbt-utils/blob/9e9407b/macros/cross_db_utils/_get_utils_namespaces.sql
|
||||
var_name = f'{package_name}_dispatch_list'
|
||||
# hard code compatibility for fivetran_utils, just a teensy bit different
|
||||
# noqa: https://github.com/fivetran/dbt_fivetran_utils/blob/0978ba2/macros/_get_utils_namespaces.sql
|
||||
if package_name == 'fivetran_utils':
|
||||
default_packages = ['dbt_utils', 'fivetran_utils']
|
||||
else:
|
||||
default_packages = [package_name]
|
||||
|
||||
namespace_names = get_dispatch_list(ctx, var_name, default_packages)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
else:
|
||||
msg = (
|
||||
f"As of v0.19.2, custom macros, such as '{macro_name}', are no longer "
|
||||
"supported in the 'packages' argument of 'adapter.dispatch()'.\n"
|
||||
f"See https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch "
|
||||
"for details."
|
||||
).strip()
|
||||
raise_compiler_error(msg)
|
||||
elif packages_arg_type == 'Add':
|
||||
# This logic is for when there is a variable and an addition of a list,
|
||||
# like: packages = (var('local_utils_dispatch_list', []) + ['local_utils2'])
|
||||
# This is deprecated and should be removed eventually.
|
||||
namespace_var = None
|
||||
default_namespaces = []
|
||||
# This might be a single call or it might be the 'left' piece in an addition
|
||||
for var_call in packages_arg.find_all(jinja2.nodes.Call):
|
||||
if (hasattr(var_call, 'node') and
|
||||
var_call.node.name == 'var' and
|
||||
hasattr(var_call, 'args')):
|
||||
namespace_var = var_call.args[0].value
|
||||
if hasattr(packages_arg, 'right'): # we have a default list of namespaces
|
||||
for item in packages_arg.right.items:
|
||||
default_namespaces.append(item.value)
|
||||
if namespace_var:
|
||||
namespace_names = get_dispatch_list(ctx, namespace_var, default_namespaces)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
|
||||
if db_wrapper:
|
||||
macro = db_wrapper.dispatch(
|
||||
func_name,
|
||||
packages=packages,
|
||||
macro_namespace=macro_namespace
|
||||
).macro
|
||||
func_name = f'{macro.package_name}.{macro.name}'
|
||||
possible_macro_calls.append(func_name)
|
||||
else: # this is only for test/unit/test_macro_calls.py
|
||||
if macro_namespace:
|
||||
packages = [macro_namespace]
|
||||
if packages is None:
|
||||
packages = []
|
||||
for package_name in packages:
|
||||
possible_macro_calls.append(f'{package_name}.{func_name}')
|
||||
|
||||
return possible_macro_calls
|
||||
|
||||
|
||||
def get_dispatch_list(ctx, var_name, default_packages):
|
||||
namespace_list = None
|
||||
try:
|
||||
# match the logic currently used in package _get_namespaces() macro
|
||||
namespace_list = ctx['var'](var_name) + default_packages
|
||||
except Exception:
|
||||
pass
|
||||
namespace_list = namespace_list if namespace_list else default_packages
|
||||
return namespace_list
|
||||
@@ -28,11 +28,10 @@ def _wrap_exceptions(fn):
|
||||
attempt += 1
|
||||
try:
|
||||
return fn(*args, **kwargs)
|
||||
except requests.exceptions.ConnectionError as exc:
|
||||
except (requests.exceptions.ConnectionError, requests.exceptions.Timeout) as exc:
|
||||
if attempt < max_attempts:
|
||||
time.sleep(1)
|
||||
continue
|
||||
|
||||
raise RegistryException(
|
||||
'Unable to connect to registry hub'
|
||||
) from exc
|
||||
@@ -43,7 +42,7 @@ def _wrap_exceptions(fn):
|
||||
def _get(path, registry_base_url=None):
|
||||
url = _get_url(path, registry_base_url)
|
||||
logger.debug('Making package registry request: GET {}'.format(url))
|
||||
resp = requests.get(url)
|
||||
resp = requests.get(url, timeout=30)
|
||||
logger.debug('Response from registry: GET {} {}'.format(url,
|
||||
resp.status_code))
|
||||
resp.raise_for_status()
|
||||
|
||||
@@ -416,6 +416,9 @@ def run_cmd(
|
||||
full_env.update(env)
|
||||
|
||||
try:
|
||||
exe_pth = shutil.which(cmd[0])
|
||||
if exe_pth:
|
||||
cmd = [os.path.abspath(exe_pth)] + list(cmd[1:])
|
||||
proc = subprocess.Popen(
|
||||
cmd,
|
||||
cwd=cwd,
|
||||
|
||||
@@ -12,9 +12,8 @@ from dbt.clients.system import make_directory
|
||||
from dbt.context.providers import generate_runtime_model
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledDataTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
COMPILED_TYPES,
|
||||
CompiledSchemaTestNode,
|
||||
GraphMemberNode,
|
||||
InjectedCTE,
|
||||
ManifestNode,
|
||||
@@ -30,6 +29,7 @@ from dbt.graph import Graph
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import pluralize
|
||||
import dbt.tracking
|
||||
|
||||
graph_file_name = 'graph.gpickle'
|
||||
|
||||
@@ -58,6 +58,11 @@ def print_compile_stats(stats):
|
||||
results = {k: 0 for k in names.keys()}
|
||||
results.update(stats)
|
||||
|
||||
# create tracking event for resource_counts
|
||||
if dbt.tracking.active_user is not None:
|
||||
resource_counts = {k.pluralize(): v for k, v in results.items()}
|
||||
dbt.tracking.track_resource_counts(resource_counts)
|
||||
|
||||
stat_line = ", ".join([
|
||||
pluralize(ct, names.get(t)) for t, ct in results.items()
|
||||
if t in names
|
||||
@@ -138,7 +143,7 @@ class Linker:
|
||||
"""
|
||||
out_graph = self.graph.copy()
|
||||
for node_id in self.graph.nodes():
|
||||
data = manifest.expect(node_id).to_dict()
|
||||
data = manifest.expect(node_id).to_dict(omit_none=True)
|
||||
out_graph.add_node(node_id, **data)
|
||||
nx.write_gpickle(out_graph, outfile)
|
||||
|
||||
@@ -177,8 +182,7 @@ class Compiler:
|
||||
|
||||
def _get_relation_name(self, node: ParsedNode):
|
||||
relation_name = None
|
||||
if (node.resource_type in NodeType.refable() and
|
||||
not node.is_ephemeral_model):
|
||||
if node.is_relational and not node.is_ephemeral_model:
|
||||
adapter = get_adapter(self.config)
|
||||
relation_cls = adapter.Relation
|
||||
relation_name = str(relation_cls.create_from(self.config, node))
|
||||
@@ -191,11 +195,11 @@ class Compiler:
|
||||
[
|
||||
InjectedCTE(
|
||||
id="cte_id_1",
|
||||
sql="__dbt__CTE__ephemeral as (select * from table)",
|
||||
sql="__dbt__cte__ephemeral as (select * from table)",
|
||||
),
|
||||
InjectedCTE(
|
||||
id="cte_id_2",
|
||||
sql="__dbt__CTE__events as (select id, type from events)",
|
||||
sql="__dbt__cte__events as (select id, type from events)",
|
||||
),
|
||||
]
|
||||
|
||||
@@ -206,8 +210,8 @@ class Compiler:
|
||||
|
||||
This will spit out:
|
||||
|
||||
"with __dbt__CTE__ephemeral as (select * from table),
|
||||
__dbt__CTE__events as (select id, type from events),
|
||||
"with __dbt__cte__ephemeral as (select * from table),
|
||||
__dbt__cte__events as (select id, type from events),
|
||||
with internal_cte as (select * from sessions)
|
||||
select * from internal_cte"
|
||||
|
||||
@@ -245,22 +249,19 @@ class Compiler:
|
||||
|
||||
return str(parsed)
|
||||
|
||||
def _get_dbt_test_name(self) -> str:
|
||||
return 'dbt__CTE__INTERNAL_test'
|
||||
|
||||
# This method is called by the 'compile_node' method. Starting
|
||||
# from the node that it is passed in, it will recursively call
|
||||
# itself using the 'extra_ctes'. The 'ephemeral' models do
|
||||
# not produce SQL that is executed directly, instead they
|
||||
# are rolled up into the models that refer to them by
|
||||
# inserting CTEs into the SQL.
|
||||
def _recursively_prepend_ctes(
|
||||
self,
|
||||
model: NonSourceCompiledNode,
|
||||
manifest: Manifest,
|
||||
extra_context: Optional[Dict[str, Any]],
|
||||
) -> Tuple[NonSourceCompiledNode, List[InjectedCTE]]:
|
||||
|
||||
"""This method is called by the 'compile_node' method. Starting
|
||||
from the node that it is passed in, it will recursively call
|
||||
itself using the 'extra_ctes'. The 'ephemeral' models do
|
||||
not produce SQL that is executed directly, instead they
|
||||
are rolled up into the models that refer to them by
|
||||
inserting CTEs into the SQL.
|
||||
"""
|
||||
if model.compiled_sql is None:
|
||||
raise RuntimeException(
|
||||
'Cannot inject ctes into an unparsed node', model
|
||||
@@ -278,101 +279,67 @@ class Compiler:
|
||||
# gathered and then "injected" into the model.
|
||||
prepended_ctes: List[InjectedCTE] = []
|
||||
|
||||
dbt_test_name = self._get_dbt_test_name()
|
||||
|
||||
# extra_ctes are added to the model by
|
||||
# RuntimeRefResolver.create_relation, which adds an
|
||||
# extra_cte for every model relation which is an
|
||||
# ephemeral model.
|
||||
for cte in model.extra_ctes:
|
||||
if cte.id == dbt_test_name:
|
||||
sql = cte.sql
|
||||
if cte.id not in manifest.nodes:
|
||||
raise InternalException(
|
||||
f'During compilation, found a cte reference that '
|
||||
f'could not be resolved: {cte.id}'
|
||||
)
|
||||
cte_model = manifest.nodes[cte.id]
|
||||
|
||||
if not cte_model.is_ephemeral_model:
|
||||
raise InternalException(f'{cte.id} is not ephemeral')
|
||||
|
||||
# This model has already been compiled, so it's been
|
||||
# through here before
|
||||
if getattr(cte_model, 'compiled', False):
|
||||
assert isinstance(cte_model, tuple(COMPILED_TYPES.values()))
|
||||
cte_model = cast(NonSourceCompiledNode, cte_model)
|
||||
new_prepended_ctes = cte_model.extra_ctes
|
||||
|
||||
# if the cte_model isn't compiled, i.e. first time here
|
||||
else:
|
||||
if cte.id not in manifest.nodes:
|
||||
raise InternalException(
|
||||
f'During compilation, found a cte reference that '
|
||||
f'could not be resolved: {cte.id}'
|
||||
# This is an ephemeral parsed model that we can compile.
|
||||
# Compile and update the node
|
||||
cte_model = self._compile_node(
|
||||
cte_model, manifest, extra_context)
|
||||
# recursively call this method
|
||||
cte_model, new_prepended_ctes = \
|
||||
self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
cte_model = manifest.nodes[cte.id]
|
||||
# Save compiled SQL file and sync manifest
|
||||
self._write_node(cte_model)
|
||||
manifest.sync_update_node(cte_model)
|
||||
|
||||
if not cte_model.is_ephemeral_model:
|
||||
raise InternalException(f'{cte.id} is not ephemeral')
|
||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||
|
||||
# This model has already been compiled, so it's been
|
||||
# through here before
|
||||
if getattr(cte_model, 'compiled', False):
|
||||
assert isinstance(cte_model,
|
||||
tuple(COMPILED_TYPES.values()))
|
||||
cte_model = cast(NonSourceCompiledNode, cte_model)
|
||||
new_prepended_ctes = cte_model.extra_ctes
|
||||
|
||||
# if the cte_model isn't compiled, i.e. first time here
|
||||
else:
|
||||
# This is an ephemeral parsed model that we can compile.
|
||||
# Compile and update the node
|
||||
cte_model = self._compile_node(
|
||||
cte_model, manifest, extra_context)
|
||||
# recursively call this method
|
||||
cte_model, new_prepended_ctes = \
|
||||
self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
# Save compiled SQL file and sync manifest
|
||||
self._write_node(cte_model)
|
||||
manifest.sync_update_node(cte_model)
|
||||
|
||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||
|
||||
new_cte_name = self.add_ephemeral_prefix(cte_model.name)
|
||||
sql = f' {new_cte_name} as (\n{cte_model.compiled_sql}\n)'
|
||||
new_cte_name = self.add_ephemeral_prefix(cte_model.name)
|
||||
rendered_sql = (
|
||||
cte_model._pre_injected_sql or cte_model.compiled_sql
|
||||
)
|
||||
sql = f' {new_cte_name} as (\n{rendered_sql}\n)'
|
||||
|
||||
_add_prepended_cte(prepended_ctes, InjectedCTE(id=cte.id, sql=sql))
|
||||
|
||||
# We don't save injected_sql into compiled sql for ephemeral models
|
||||
# because it will cause problems with processing of subsequent models.
|
||||
# Ephemeral models do not produce executable SQL of their own.
|
||||
if not model.is_ephemeral_model:
|
||||
injected_sql = self._inject_ctes_into_sql(
|
||||
model.compiled_sql,
|
||||
prepended_ctes,
|
||||
)
|
||||
model.compiled_sql = injected_sql
|
||||
injected_sql = self._inject_ctes_into_sql(
|
||||
model.compiled_sql,
|
||||
prepended_ctes,
|
||||
)
|
||||
model._pre_injected_sql = model.compiled_sql
|
||||
model.compiled_sql = injected_sql
|
||||
model.extra_ctes_injected = True
|
||||
model.extra_ctes = prepended_ctes
|
||||
model.validate(model.to_dict())
|
||||
model.validate(model.to_dict(omit_none=True))
|
||||
|
||||
manifest.update_node(model)
|
||||
|
||||
return model, prepended_ctes
|
||||
|
||||
def _add_ctes(
|
||||
self,
|
||||
compiled_node: NonSourceCompiledNode,
|
||||
manifest: Manifest,
|
||||
extra_context: Dict[str, Any],
|
||||
) -> NonSourceCompiledNode:
|
||||
"""Wrap the data test SQL in a CTE."""
|
||||
|
||||
# for data tests, we need to insert a special CTE at the end of the
|
||||
# list containing the test query, and then have the "real" query be a
|
||||
# select count(*) from that model.
|
||||
# the benefit of doing it this way is that _add_ctes() can be
|
||||
# rewritten for different adapters to handle databases that don't
|
||||
# support CTEs, or at least don't have full support.
|
||||
if isinstance(compiled_node, CompiledDataTestNode):
|
||||
# the last prepend (so last in order) should be the data test body.
|
||||
# then we can add our select count(*) from _that_ cte as the "real"
|
||||
# compiled_sql, and do the regular prepend logic from CTEs.
|
||||
name = self._get_dbt_test_name()
|
||||
cte = InjectedCTE(
|
||||
id=name,
|
||||
sql=f' {name} as (\n{compiled_node.compiled_sql}\n)'
|
||||
)
|
||||
compiled_node.extra_ctes.append(cte)
|
||||
compiled_node.compiled_sql = f'\nselect count(*) from {name}'
|
||||
|
||||
return compiled_node
|
||||
|
||||
# creates a compiled_node from the ManifestNode passed in,
|
||||
# creates a "context" dictionary for jinja rendering,
|
||||
# and then renders the "compiled_sql" using the node, the
|
||||
@@ -388,7 +355,7 @@ class Compiler:
|
||||
|
||||
logger.debug("Compiling {}".format(node.unique_id))
|
||||
|
||||
data = node.to_dict()
|
||||
data = node.to_dict(omit_none=True)
|
||||
data.update({
|
||||
'compiled': False,
|
||||
'compiled_sql': None,
|
||||
@@ -411,12 +378,6 @@ class Compiler:
|
||||
|
||||
compiled_node.compiled = True
|
||||
|
||||
# add ctes for specific test nodes, and also for
|
||||
# possible future use in adapters
|
||||
compiled_node = self._add_ctes(
|
||||
compiled_node, manifest, extra_context
|
||||
)
|
||||
|
||||
return compiled_node
|
||||
|
||||
def write_graph_file(self, linker: Linker, manifest: Manifest):
|
||||
@@ -480,18 +441,13 @@ class Compiler:
|
||||
logger.debug(f'Writing injected SQL for node "{node.unique_id}"')
|
||||
|
||||
if node.compiled_sql:
|
||||
node.build_path = node.write_node(
|
||||
node.compiled_path = node.write_node(
|
||||
self.config.target_path,
|
||||
'compiled',
|
||||
node.compiled_sql
|
||||
)
|
||||
return node
|
||||
|
||||
# This is the main entry point into this code. It's called by
|
||||
# CompileRunner.compile, GenericRPCRunner.compile, and
|
||||
# RunTask.get_hook_sql. It calls '_compile_node' to convert
|
||||
# the node into a compiled node, and then calls the
|
||||
# recursive method to "prepend" the ctes.
|
||||
def compile_node(
|
||||
self,
|
||||
node: ManifestNode,
|
||||
@@ -499,6 +455,12 @@ class Compiler:
|
||||
extra_context: Optional[Dict[str, Any]] = None,
|
||||
write: bool = True,
|
||||
) -> NonSourceCompiledNode:
|
||||
"""This is the main entry point into this code. It's called by
|
||||
CompileRunner.compile, GenericRPCRunner.compile, and
|
||||
RunTask.get_hook_sql. It calls '_compile_node' to convert
|
||||
the node into a compiled node, and then calls the
|
||||
recursive method to "prepend" the ctes.
|
||||
"""
|
||||
node = self._compile_node(node, manifest, extra_context)
|
||||
|
||||
node, _ = self._recursively_prepend_ctes(
|
||||
|
||||
@@ -111,8 +111,8 @@ class Profile(HasCredentials):
|
||||
'credentials': self.credentials,
|
||||
}
|
||||
if serialize_credentials:
|
||||
result['config'] = self.config.to_dict()
|
||||
result['credentials'] = self.credentials.to_dict()
|
||||
result['config'] = self.config.to_dict(omit_none=True)
|
||||
result['credentials'] = self.credentials.to_dict(omit_none=True)
|
||||
return result
|
||||
|
||||
def to_target_dict(self) -> Dict[str, Any]:
|
||||
@@ -125,7 +125,7 @@ class Profile(HasCredentials):
|
||||
'name': self.target_name,
|
||||
'target_name': self.target_name,
|
||||
'profile_name': self.profile_name,
|
||||
'config': self.config.to_dict(),
|
||||
'config': self.config.to_dict(omit_none=True),
|
||||
})
|
||||
return target
|
||||
|
||||
@@ -138,7 +138,7 @@ class Profile(HasCredentials):
|
||||
def validate(self):
|
||||
try:
|
||||
if self.credentials:
|
||||
dct = self.credentials.to_dict()
|
||||
dct = self.credentials.to_dict(omit_none=True)
|
||||
self.credentials.validate(dct)
|
||||
dct = self.to_profile_info(serialize_credentials=True)
|
||||
ProfileConfig.validate(dct)
|
||||
|
||||
@@ -347,18 +347,22 @@ class PartialProject(RenderComponents):
|
||||
# break many things
|
||||
quoting: Dict[str, Any] = {}
|
||||
if cfg.quoting is not None:
|
||||
quoting = cfg.quoting.to_dict()
|
||||
quoting = cfg.quoting.to_dict(omit_none=True)
|
||||
|
||||
dispatch: List[Dict[str, Any]]
|
||||
models: Dict[str, Any]
|
||||
seeds: Dict[str, Any]
|
||||
snapshots: Dict[str, Any]
|
||||
sources: Dict[str, Any]
|
||||
tests: Dict[str, Any]
|
||||
vars_value: VarProvider
|
||||
|
||||
dispatch = cfg.dispatch
|
||||
models = cfg.models
|
||||
seeds = cfg.seeds
|
||||
snapshots = cfg.snapshots
|
||||
sources = cfg.sources
|
||||
tests = cfg.tests
|
||||
if cfg.vars is None:
|
||||
vars_dict: Dict[str, Any] = {}
|
||||
else:
|
||||
@@ -400,6 +404,7 @@ class PartialProject(RenderComponents):
|
||||
models=models,
|
||||
on_run_start=on_run_start,
|
||||
on_run_end=on_run_end,
|
||||
dispatch=dispatch,
|
||||
seeds=seeds,
|
||||
snapshots=snapshots,
|
||||
dbt_version=dbt_version,
|
||||
@@ -408,6 +413,7 @@ class PartialProject(RenderComponents):
|
||||
selectors=selectors,
|
||||
query_comment=query_comment,
|
||||
sources=sources,
|
||||
tests=tests,
|
||||
vars=vars_value,
|
||||
config_version=cfg.config_version,
|
||||
unrendered=unrendered,
|
||||
@@ -510,9 +516,11 @@ class Project:
|
||||
models: Dict[str, Any]
|
||||
on_run_start: List[str]
|
||||
on_run_end: List[str]
|
||||
dispatch: List[Dict[str, Any]]
|
||||
seeds: Dict[str, Any]
|
||||
snapshots: Dict[str, Any]
|
||||
sources: Dict[str, Any]
|
||||
tests: Dict[str, Any]
|
||||
vars: VarProvider
|
||||
dbt_version: List[VersionSpecifier]
|
||||
packages: Dict[str, Any]
|
||||
@@ -568,9 +576,11 @@ class Project:
|
||||
'models': self.models,
|
||||
'on-run-start': self.on_run_start,
|
||||
'on-run-end': self.on_run_end,
|
||||
'dispatch': self.dispatch,
|
||||
'seeds': self.seeds,
|
||||
'snapshots': self.snapshots,
|
||||
'sources': self.sources,
|
||||
'tests': self.tests,
|
||||
'vars': self.vars.to_dict(),
|
||||
'require-dbt-version': [
|
||||
v.to_version_string() for v in self.dbt_version
|
||||
@@ -578,10 +588,11 @@ class Project:
|
||||
'config-version': self.config_version,
|
||||
})
|
||||
if self.query_comment:
|
||||
result['query-comment'] = self.query_comment.to_dict()
|
||||
result['query-comment'] = \
|
||||
self.query_comment.to_dict(omit_none=True)
|
||||
|
||||
if with_packages:
|
||||
result.update(self.packages.to_dict())
|
||||
result.update(self.packages.to_dict(omit_none=True))
|
||||
|
||||
return result
|
||||
|
||||
@@ -641,3 +652,9 @@ class Project:
|
||||
f'{list(self.selectors)}'
|
||||
)
|
||||
return self.selectors[name]
|
||||
|
||||
def get_macro_search_order(self, macro_namespace: str):
|
||||
for dispatch_entry in self.dispatch:
|
||||
if dispatch_entry['macro_namespace'] == macro_namespace:
|
||||
return dispatch_entry['search_order']
|
||||
return None
|
||||
|
||||
@@ -145,9 +145,9 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
if first == 'vars':
|
||||
return False
|
||||
|
||||
if first in {'seeds', 'models', 'snapshots', 'seeds'}:
|
||||
if first in {'seeds', 'models', 'snapshots', 'tests'}:
|
||||
keypath_parts = {
|
||||
(k.lstrip('+') if isinstance(k, str) else k)
|
||||
(k.lstrip('+ ') if isinstance(k, str) else k)
|
||||
for k in keypath
|
||||
}
|
||||
# model-level hooks
|
||||
|
||||
@@ -78,7 +78,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
get_relation_class_by_name(profile.credentials.type)
|
||||
.get_default_quote_policy()
|
||||
.replace_dict(_project_quoting_dict(project, profile))
|
||||
).to_dict()
|
||||
).to_dict(omit_none=True)
|
||||
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, 'vars', '{}'))
|
||||
|
||||
@@ -102,6 +102,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
on_run_end=project.on_run_end,
|
||||
dispatch=project.dispatch,
|
||||
seeds=project.seeds,
|
||||
snapshots=project.snapshots,
|
||||
dbt_version=project.dbt_version,
|
||||
@@ -110,6 +111,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
selectors=project.selectors,
|
||||
query_comment=project.query_comment,
|
||||
sources=project.sources,
|
||||
tests=project.tests,
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
@@ -272,7 +274,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
return frozenset(paths)
|
||||
|
||||
def get_resource_config_paths(self) -> Dict[str, PathSet]:
|
||||
"""Return a dictionary with 'seeds' and 'models' keys whose values are
|
||||
"""Return a dictionary with resource type keys whose values are
|
||||
lists of lists of strings, where each inner list of strings represents
|
||||
a configured path in the resource.
|
||||
"""
|
||||
@@ -281,6 +283,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
'seeds': self._get_config_paths(self.seeds),
|
||||
'snapshots': self._get_config_paths(self.snapshots),
|
||||
'sources': self._get_config_paths(self.sources),
|
||||
'tests': self._get_config_paths(self.tests),
|
||||
}
|
||||
|
||||
def get_unused_resource_config_paths(
|
||||
@@ -326,6 +329,17 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
if self.dependencies is None:
|
||||
all_projects = {self.project_name: self}
|
||||
internal_packages = get_include_paths(self.credentials.type)
|
||||
# raise exception if fewer installed packages than in packages.yml
|
||||
count_packages_specified = len(self.packages.packages) # type: ignore
|
||||
count_packages_installed = len(tuple(self._get_project_directories()))
|
||||
if count_packages_specified > count_packages_installed:
|
||||
raise_compiler_error(
|
||||
f'dbt found {count_packages_specified} package(s) '
|
||||
f'specified in packages.yml, but only '
|
||||
f'{count_packages_installed} package(s) installed '
|
||||
f'in {self.modules_path}. Run "dbt deps" to '
|
||||
f'install package dependencies.'
|
||||
)
|
||||
project_paths = itertools.chain(
|
||||
internal_packages,
|
||||
self._get_project_directories()
|
||||
@@ -391,7 +405,7 @@ class UnsetConfig(UserConfig):
|
||||
f"'UnsetConfig' object has no attribute {name}"
|
||||
)
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
def __post_serialize__(self, dct):
|
||||
return {}
|
||||
|
||||
|
||||
@@ -480,6 +494,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
on_run_end=project.on_run_end,
|
||||
dispatch=project.dispatch,
|
||||
seeds=project.seeds,
|
||||
snapshots=project.snapshots,
|
||||
dbt_version=project.dbt_version,
|
||||
@@ -488,6 +503,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
selectors=project.selectors,
|
||||
query_comment=project.query_comment,
|
||||
sources=project.sources,
|
||||
tests=project.tests,
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
|
||||
@@ -538,4 +538,5 @@ class BaseContext(metaclass=ContextMeta):
|
||||
|
||||
def generate_base_context(cli_vars: Dict[str, Any]) -> Dict[str, Any]:
|
||||
ctx = BaseContext(cli_vars)
|
||||
# This is not a Mashumaro to_dict call
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -75,8 +75,26 @@ class SchemaYamlContext(ConfiguredContext):
|
||||
)
|
||||
|
||||
|
||||
class MacroResolvingContext(ConfiguredContext):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
@contextproperty
|
||||
def var(self) -> ConfiguredVar:
|
||||
return ConfiguredVar(
|
||||
self._ctx, self.config, self.config.project_name
|
||||
)
|
||||
|
||||
|
||||
def generate_schema_yml(
|
||||
config: AdapterRequiredConfig, project_name: str
|
||||
) -> Dict[str, Any]:
|
||||
ctx = SchemaYamlContext(config, project_name)
|
||||
return ctx.to_dict()
|
||||
|
||||
|
||||
def generate_macro_context(
|
||||
config: AdapterRequiredConfig,
|
||||
) -> Dict[str, Any]:
|
||||
ctx = MacroResolvingContext(config)
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -41,6 +41,8 @@ class UnrenderedConfig(ConfigSource):
|
||||
model_configs = unrendered.get('snapshots')
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = unrendered.get('sources')
|
||||
elif resource_type == NodeType.Test:
|
||||
model_configs = unrendered.get('tests')
|
||||
else:
|
||||
model_configs = unrendered.get('models')
|
||||
|
||||
@@ -61,6 +63,8 @@ class RenderedConfig(ConfigSource):
|
||||
model_configs = self.project.snapshots
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = self.project.sources
|
||||
elif resource_type == NodeType.Test:
|
||||
model_configs = self.project.tests
|
||||
else:
|
||||
model_configs = self.project.models
|
||||
return model_configs
|
||||
@@ -93,7 +97,7 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
result = {}
|
||||
for key, value in level_config.items():
|
||||
if key.startswith('+'):
|
||||
result[key[1:]] = deepcopy(value)
|
||||
result[key[1:].strip()] = deepcopy(value)
|
||||
elif not isinstance(value, dict):
|
||||
result[key] = deepcopy(value)
|
||||
|
||||
@@ -196,7 +200,7 @@ class ContextConfigGenerator(BaseContextConfigGenerator[C]):
|
||||
base=base,
|
||||
)
|
||||
finalized = config.finalize_and_validate()
|
||||
return finalized.to_dict()
|
||||
return finalized.to_dict(omit_none=True)
|
||||
|
||||
|
||||
class UnrenderedConfigGenerator(BaseContextConfigGenerator[Dict[str, Any]]):
|
||||
|
||||
@@ -57,14 +57,19 @@ class DocsRuntimeContext(SchemaYamlContext):
|
||||
else:
|
||||
doc_invalid_args(self.node, args)
|
||||
|
||||
# ParsedDocumentation
|
||||
target_doc = self.manifest.resolve_doc(
|
||||
doc_name,
|
||||
doc_package_name,
|
||||
self._project_name,
|
||||
self.node.package_name,
|
||||
)
|
||||
|
||||
if target_doc is None:
|
||||
if target_doc:
|
||||
file_id = target_doc.file_id
|
||||
if file_id in self.manifest.files:
|
||||
source_file = self.manifest.files[file_id]
|
||||
source_file.add_node(self.node.unique_id)
|
||||
else:
|
||||
doc_target_not_found(self.node, doc_name, doc_package_name)
|
||||
|
||||
return target_doc.block_contents
|
||||
@@ -77,4 +82,5 @@ def generate_runtime_docs(
|
||||
current_project: str,
|
||||
) -> Dict[str, Any]:
|
||||
ctx = DocsRuntimeContext(config, target, manifest, current_project)
|
||||
# This is not a Mashumaro to_dict call
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -14,8 +14,12 @@ MacroNamespace = Dict[str, ParsedMacro]
|
||||
# so that higher precedence macros are found first.
|
||||
# This functionality is also provided by the MacroNamespace,
|
||||
# but the intention is to eventually replace that class.
|
||||
# This enables us to get the macor unique_id without
|
||||
# This enables us to get the macro unique_id without
|
||||
# processing every macro in the project.
|
||||
# Note: the root project macros override everything in the
|
||||
# dbt internal projects. External projects (dependencies) will
|
||||
# use their own macros first, then pull from the root project
|
||||
# followed by dbt internal projects.
|
||||
class MacroResolver:
|
||||
def __init__(
|
||||
self,
|
||||
@@ -48,18 +52,29 @@ class MacroResolver:
|
||||
self.internal_packages_namespace.update(
|
||||
self.internal_packages[pkg])
|
||||
|
||||
# search order:
|
||||
# local_namespace (package of particular node), not including
|
||||
# the internal packages or the root package
|
||||
# This means that within an extra package, it uses its own macros
|
||||
# root package namespace
|
||||
# non-internal packages (that aren't local or root)
|
||||
# dbt internal packages
|
||||
def _build_macros_by_name(self):
|
||||
macros_by_name = {}
|
||||
# search root package macros
|
||||
for macro in self.root_package_macros.values():
|
||||
|
||||
# all internal packages (already in the right order)
|
||||
for macro in self.internal_packages_namespace.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
# search miscellaneous non-internal packages
|
||||
|
||||
# non-internal packages
|
||||
for fnamespace in self.packages.values():
|
||||
for macro in fnamespace.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
# search all internal packages
|
||||
for macro in self.internal_packages_namespace.values():
|
||||
|
||||
# root package macros
|
||||
for macro in self.root_package_macros.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
|
||||
self.macros_by_name = macros_by_name
|
||||
|
||||
def _add_macro_to(
|
||||
@@ -97,18 +112,26 @@ class MacroResolver:
|
||||
for macro in self.macros.values():
|
||||
self.add_macro(macro)
|
||||
|
||||
def get_macro_id(self, local_package, macro_name):
|
||||
def get_macro(self, local_package, macro_name):
|
||||
local_package_macros = {}
|
||||
if (local_package not in self.internal_package_names and
|
||||
local_package in self.packages):
|
||||
local_package_macros = self.packages[local_package]
|
||||
# First: search the local packages for this macro
|
||||
if macro_name in local_package_macros:
|
||||
return local_package_macros[macro_name].unique_id
|
||||
return local_package_macros[macro_name]
|
||||
# Now look up in the standard search order
|
||||
if macro_name in self.macros_by_name:
|
||||
return self.macros_by_name[macro_name].unique_id
|
||||
return self.macros_by_name[macro_name]
|
||||
return None
|
||||
|
||||
def get_macro_id(self, local_package, macro_name):
|
||||
macro = self.get_macro(local_package, macro_name)
|
||||
if macro is None:
|
||||
return None
|
||||
else:
|
||||
return macro.unique_id
|
||||
|
||||
|
||||
# Currently this is just used by test processing in the schema
|
||||
# parser (in connection with the MacroResolver). Future work
|
||||
@@ -122,16 +145,37 @@ class TestMacroNamespace:
|
||||
):
|
||||
self.macro_resolver = macro_resolver
|
||||
self.ctx = ctx
|
||||
self.node = node
|
||||
self.node = node # can be none
|
||||
self.thread_ctx = thread_ctx
|
||||
local_namespace = {}
|
||||
self.local_namespace = {}
|
||||
self.project_namespace = {}
|
||||
if depends_on_macros:
|
||||
for macro_unique_id in depends_on_macros:
|
||||
macro = self.manifest.macros[macro_unique_id]
|
||||
local_namespace[macro.name] = MacroGenerator(
|
||||
macro, self.ctx, self.node, self.thread_ctx,
|
||||
)
|
||||
self.local_namespace = local_namespace
|
||||
dep_macros = []
|
||||
self.recursively_get_depends_on_macros(depends_on_macros, dep_macros)
|
||||
for macro_unique_id in dep_macros:
|
||||
if macro_unique_id in self.macro_resolver.macros:
|
||||
# Split up the macro unique_id to get the project_name
|
||||
(_, project_name, macro_name) = macro_unique_id.split('.')
|
||||
# Save the plain macro_name in the local_namespace
|
||||
macro = self.macro_resolver.macros[macro_unique_id]
|
||||
macro_gen = MacroGenerator(
|
||||
macro, self.ctx, self.node, self.thread_ctx,
|
||||
)
|
||||
self.local_namespace[macro_name] = macro_gen
|
||||
# We also need the two part macro name
|
||||
if project_name not in self.project_namespace:
|
||||
self.project_namespace[project_name] = {}
|
||||
self.project_namespace[project_name][macro_name] = macro_gen
|
||||
|
||||
def recursively_get_depends_on_macros(self, depends_on_macros, dep_macros):
|
||||
for macro_unique_id in depends_on_macros:
|
||||
if macro_unique_id in dep_macros:
|
||||
continue
|
||||
dep_macros.append(macro_unique_id)
|
||||
if macro_unique_id in self.macro_resolver.macros:
|
||||
macro = self.macro_resolver.macros[macro_unique_id]
|
||||
if macro.depends_on.macros:
|
||||
self.recursively_get_depends_on_macros(macro.depends_on.macros, dep_macros)
|
||||
|
||||
def get_from_package(
|
||||
self, package_name: Optional[str], name: str
|
||||
@@ -141,12 +185,14 @@ class TestMacroNamespace:
|
||||
macro = self.macro_resolver.macros_by_name.get(name)
|
||||
elif package_name == GLOBAL_PROJECT_NAME:
|
||||
macro = self.macro_resolver.internal_packages_namespace.get(name)
|
||||
elif package_name in self.resolver.packages:
|
||||
elif package_name in self.macro_resolver.packages:
|
||||
macro = self.macro_resolver.packages[package_name].get(name)
|
||||
else:
|
||||
raise_compiler_error(
|
||||
f"Could not find package '{package_name}'"
|
||||
)
|
||||
if not macro:
|
||||
return None
|
||||
macro_func = MacroGenerator(
|
||||
macro, self.ctx, self.node, self.thread_ctx
|
||||
)
|
||||
|
||||
@@ -19,13 +19,17 @@ FullNamespace = Dict[str, NamespaceMember]
|
||||
# and provide the ability to flatten them into the ManifestContexts
|
||||
# that are created for jinja, so that macro calls can be resolved.
|
||||
# Creates special iterators and _keys methods to flatten the lists.
|
||||
# When this class is created it has a static 'local_namespace' which
|
||||
# depends on the package of the node, so it only works for one
|
||||
# particular local package at a time for "flattening" into a context.
|
||||
# 'get_by_package' should work for any macro.
|
||||
class MacroNamespace(Mapping):
|
||||
def __init__(
|
||||
self,
|
||||
global_namespace: FlatNamespace,
|
||||
local_namespace: FlatNamespace,
|
||||
global_project_namespace: FlatNamespace,
|
||||
packages: Dict[str, FlatNamespace],
|
||||
global_namespace: FlatNamespace, # root package macros
|
||||
local_namespace: FlatNamespace, # packages for *this* node
|
||||
global_project_namespace: FlatNamespace, # internal packages
|
||||
packages: Dict[str, FlatNamespace], # non-internal packages
|
||||
):
|
||||
self.global_namespace: FlatNamespace = global_namespace
|
||||
self.local_namespace: FlatNamespace = local_namespace
|
||||
@@ -33,13 +37,13 @@ class MacroNamespace(Mapping):
|
||||
self.global_project_namespace: FlatNamespace = global_project_namespace
|
||||
|
||||
def _search_order(self) -> Iterable[Union[FullNamespace, FlatNamespace]]:
|
||||
yield self.local_namespace
|
||||
yield self.global_namespace
|
||||
yield self.packages
|
||||
yield self.local_namespace # local package
|
||||
yield self.global_namespace # root package
|
||||
yield self.packages # non-internal packages
|
||||
yield {
|
||||
GLOBAL_PROJECT_NAME: self.global_project_namespace,
|
||||
GLOBAL_PROJECT_NAME: self.global_project_namespace, # dbt
|
||||
}
|
||||
yield self.global_project_namespace
|
||||
yield self.global_project_namespace # other internal project besides dbt
|
||||
|
||||
# provides special keys method for MacroNamespace iterator
|
||||
# returns keys from local_namespace, global_namespace, packages,
|
||||
@@ -98,7 +102,9 @@ class MacroNamespaceBuilder:
|
||||
# internal packages comes from get_adapter_package_names
|
||||
self.internal_package_names = set(internal_packages)
|
||||
self.internal_package_names_order = internal_packages
|
||||
# macro_func is added here if in root package
|
||||
# macro_func is added here if in root package, since
|
||||
# the root package acts as a "global" namespace, overriding
|
||||
# everything else except local external package macro calls
|
||||
self.globals: FlatNamespace = {}
|
||||
# macro_func is added here if it's the package for this node
|
||||
self.locals: FlatNamespace = {}
|
||||
@@ -169,8 +175,8 @@ class MacroNamespaceBuilder:
|
||||
global_project_namespace.update(self.internal_packages[pkg])
|
||||
|
||||
return MacroNamespace(
|
||||
global_namespace=self.globals,
|
||||
local_namespace=self.locals,
|
||||
global_project_namespace=global_project_namespace,
|
||||
packages=self.packages,
|
||||
global_namespace=self.globals, # root package macros
|
||||
local_namespace=self.locals, # packages for *this* node
|
||||
global_project_namespace=global_project_namespace, # internal packages
|
||||
packages=self.packages, # non internal_packages
|
||||
)
|
||||
|
||||
@@ -2,7 +2,7 @@ from typing import List
|
||||
|
||||
from dbt.clients.jinja import MacroStack
|
||||
from dbt.contracts.connection import AdapterRequiredConfig
|
||||
from dbt.contracts.graph.manifest import Manifest, AnyManifest
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.context.macro_resolver import TestMacroNamespace
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ class ManifestContext(ConfiguredContext):
|
||||
def __init__(
|
||||
self,
|
||||
config: AdapterRequiredConfig,
|
||||
manifest: AnyManifest,
|
||||
manifest: Manifest,
|
||||
search_package: str,
|
||||
) -> None:
|
||||
super().__init__(config)
|
||||
@@ -62,6 +62,7 @@ class ManifestContext(ConfiguredContext):
|
||||
# keys in the manifest dictionary
|
||||
if isinstance(self.namespace, TestMacroNamespace):
|
||||
dct.update(self.namespace.local_namespace)
|
||||
dct.update(self.namespace.project_namespace)
|
||||
else:
|
||||
dct.update(self.namespace)
|
||||
return dct
|
||||
|
||||
@@ -8,7 +8,9 @@ from typing_extensions import Protocol
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.adapters.base.column import Column
|
||||
from dbt.adapters.factory import get_adapter, get_adapter_package_names
|
||||
from dbt.adapters.factory import (
|
||||
get_adapter, get_adapter_package_names, get_adapter_type_names
|
||||
)
|
||||
from dbt.clients import agate_helper
|
||||
from dbt.clients.jinja import get_rendered, MacroGenerator, MacroStack
|
||||
from dbt.config import RuntimeConfig, Project
|
||||
@@ -20,7 +22,7 @@ from .macros import MacroNamespaceBuilder, MacroNamespace
|
||||
from .manifest import ManifestContext
|
||||
from dbt.contracts.connection import AdapterResponse
|
||||
from dbt.contracts.graph.manifest import (
|
||||
Manifest, AnyManifest, Disabled, MacroManifest
|
||||
Manifest, Disabled
|
||||
)
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledResource,
|
||||
@@ -107,14 +109,18 @@ class BaseDatabaseWrapper:
|
||||
return self._adapter.commit_if_has_connection()
|
||||
|
||||
def _get_adapter_macro_prefixes(self) -> List[str]:
|
||||
# a future version of this could have plugins automatically call fall
|
||||
# back to their dependencies' dependencies by using
|
||||
# `get_adapter_type_names` instead of `[self.config.credentials.type]`
|
||||
search_prefixes = [self._adapter.type(), 'default']
|
||||
# order matters for dispatch:
|
||||
# 1. current adapter
|
||||
# 2. any parent adapters (dependencies)
|
||||
# 3. 'default'
|
||||
search_prefixes = get_adapter_type_names(self._adapter.type()) + ['default']
|
||||
return search_prefixes
|
||||
|
||||
def dispatch(
|
||||
self, macro_name: str, packages: Optional[List[str]] = None
|
||||
self,
|
||||
macro_name: str,
|
||||
macro_namespace: Optional[str] = None,
|
||||
packages: Optional[List[str]] = None,
|
||||
) -> MacroGenerator:
|
||||
search_packages: List[Optional[str]]
|
||||
|
||||
@@ -128,15 +134,25 @@ class BaseDatabaseWrapper:
|
||||
)
|
||||
raise CompilationException(msg)
|
||||
|
||||
if packages is None:
|
||||
if packages is not None:
|
||||
deprecations.warn('dispatch-packages', macro_name=macro_name)
|
||||
|
||||
namespace = packages if packages else macro_namespace
|
||||
|
||||
if namespace is None:
|
||||
search_packages = [None]
|
||||
elif isinstance(packages, str):
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a string packages argument '
|
||||
f'("{packages}"), but packages should be None or a list.'
|
||||
)
|
||||
elif isinstance(namespace, str):
|
||||
search_packages = self._adapter.config.get_macro_search_order(namespace)
|
||||
if not search_packages and namespace in self._adapter.config.dependencies:
|
||||
search_packages = [namespace]
|
||||
if not search_packages:
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a string packages argument '
|
||||
f'("{packages}"), but packages should be None or a list.'
|
||||
)
|
||||
else:
|
||||
search_packages = packages
|
||||
# Not a string and not None so must be a list
|
||||
search_packages = namespace
|
||||
|
||||
attempts = []
|
||||
|
||||
@@ -1115,7 +1131,7 @@ class ProviderContext(ManifestContext):
|
||||
|
||||
@contextproperty('model')
|
||||
def ctx_model(self) -> Dict[str, Any]:
|
||||
return self.model.to_dict()
|
||||
return self.model.to_dict(omit_none=True)
|
||||
|
||||
@contextproperty
|
||||
def pre_hooks(self) -> Optional[List[Dict[str, Any]]]:
|
||||
@@ -1179,14 +1195,13 @@ class ProviderContext(ManifestContext):
|
||||
"""
|
||||
deprecations.warn('adapter-macro', macro_name=name)
|
||||
original_name = name
|
||||
package_names: Optional[List[str]] = None
|
||||
package_name = None
|
||||
if '.' in name:
|
||||
package_name, name = name.split('.', 1)
|
||||
package_names = [package_name]
|
||||
|
||||
try:
|
||||
macro = self.db_wrapper.dispatch(
|
||||
macro_name=name, packages=package_names
|
||||
macro_name=name, macro_namespace=package_name
|
||||
)
|
||||
except CompilationException as exc:
|
||||
raise CompilationException(
|
||||
@@ -1210,7 +1225,7 @@ class MacroContext(ProviderContext):
|
||||
self,
|
||||
model: ParsedMacro,
|
||||
config: RuntimeConfig,
|
||||
manifest: AnyManifest,
|
||||
manifest: Manifest,
|
||||
provider: Provider,
|
||||
search_package: Optional[str],
|
||||
) -> None:
|
||||
@@ -1231,7 +1246,7 @@ class ModelContext(ProviderContext):
|
||||
if isinstance(self.model, ParsedSourceDefinition):
|
||||
return []
|
||||
return [
|
||||
h.to_dict() for h in self.model.config.pre_hook
|
||||
h.to_dict(omit_none=True) for h in self.model.config.pre_hook
|
||||
]
|
||||
|
||||
@contextproperty
|
||||
@@ -1239,7 +1254,7 @@ class ModelContext(ProviderContext):
|
||||
if isinstance(self.model, ParsedSourceDefinition):
|
||||
return []
|
||||
return [
|
||||
h.to_dict() for h in self.model.config.post_hook
|
||||
h.to_dict(omit_none=True) for h in self.model.config.post_hook
|
||||
]
|
||||
|
||||
@contextproperty
|
||||
@@ -1300,7 +1315,7 @@ class ModelContext(ProviderContext):
|
||||
def generate_parser_model(
|
||||
model: ManifestNode,
|
||||
config: RuntimeConfig,
|
||||
manifest: MacroManifest,
|
||||
manifest: Manifest,
|
||||
context_config: ContextConfig,
|
||||
) -> Dict[str, Any]:
|
||||
# The __init__ method of ModelContext also initializes
|
||||
@@ -1317,7 +1332,7 @@ def generate_parser_model(
|
||||
def generate_generate_component_name_macro(
|
||||
macro: ParsedMacro,
|
||||
config: RuntimeConfig,
|
||||
manifest: MacroManifest,
|
||||
manifest: Manifest,
|
||||
) -> Dict[str, Any]:
|
||||
ctx = MacroContext(
|
||||
macro, config, manifest, GenerateNameProvider(), None
|
||||
@@ -1370,7 +1385,7 @@ class ExposureSourceResolver(BaseResolver):
|
||||
def generate_parse_exposure(
|
||||
exposure: ParsedExposure,
|
||||
config: RuntimeConfig,
|
||||
manifest: MacroManifest,
|
||||
manifest: Manifest,
|
||||
package_name: str,
|
||||
) -> Dict[str, Any]:
|
||||
project = config.load_dependencies()[package_name]
|
||||
@@ -1408,7 +1423,12 @@ class TestContext(ProviderContext):
|
||||
self.macro_resolver = macro_resolver
|
||||
self.thread_ctx = MacroStack()
|
||||
super().__init__(model, config, manifest, provider, context_config)
|
||||
self._build_test_namespace
|
||||
self._build_test_namespace()
|
||||
# We need to rebuild this because it's already been built by
|
||||
# the ProviderContext with the wrong namespace.
|
||||
self.db_wrapper = self.provider.DatabaseWrapper(
|
||||
self.adapter, self.namespace
|
||||
)
|
||||
|
||||
def _build_namespace(self):
|
||||
return {}
|
||||
@@ -1421,11 +1441,17 @@ class TestContext(ProviderContext):
|
||||
depends_on_macros = []
|
||||
if self.model.depends_on and self.model.depends_on.macros:
|
||||
depends_on_macros = self.model.depends_on.macros
|
||||
lookup_macros = depends_on_macros.copy()
|
||||
for macro_unique_id in lookup_macros:
|
||||
lookup_macro = self.macro_resolver.macros.get(macro_unique_id)
|
||||
if lookup_macro:
|
||||
depends_on_macros.extend(lookup_macro.depends_on.macros)
|
||||
|
||||
macro_namespace = TestMacroNamespace(
|
||||
self.macro_resolver, self.ctx, self.node, self.thread_ctx,
|
||||
self.macro_resolver, self._ctx, self.model, self.thread_ctx,
|
||||
depends_on_macros
|
||||
)
|
||||
self._namespace = macro_namespace
|
||||
self.namespace = macro_namespace
|
||||
|
||||
|
||||
def generate_test_context(
|
||||
|
||||
@@ -9,7 +9,7 @@ from dbt.utils import translate_aliases
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from typing_extensions import Protocol
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, StrEnum, ExtensibleDbtClassMixin,
|
||||
dbtClassMixin, StrEnum, ExtensibleDbtClassMixin, HyphenatedDbtClassMixin,
|
||||
ValidatedStringMixin, register_pattern
|
||||
)
|
||||
from dbt.contracts.util import Replaceable
|
||||
@@ -132,7 +132,7 @@ class Credentials(
|
||||
) -> Iterable[Tuple[str, Any]]:
|
||||
"""Return an ordered iterator of key/value pairs for pretty-printing.
|
||||
"""
|
||||
as_dict = self.to_dict(options={'keep_none': True})
|
||||
as_dict = self.to_dict(omit_none=False)
|
||||
connection_keys = set(self._connection_keys())
|
||||
aliases: List[str] = []
|
||||
if with_aliases:
|
||||
@@ -148,8 +148,8 @@ class Credentials(
|
||||
raise NotImplementedError
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
data = cls.translate_aliases(data)
|
||||
return data
|
||||
|
||||
@@ -159,7 +159,7 @@ class Credentials(
|
||||
) -> Dict[str, Any]:
|
||||
return translate_aliases(kwargs, cls._ALIASES, recurse)
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
def __post_serialize__(self, dct):
|
||||
# no super() -- do we need it?
|
||||
if self._ALIASES:
|
||||
dct.update({
|
||||
@@ -212,9 +212,10 @@ DEFAULT_QUERY_COMMENT = '''
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueryComment(dbtClassMixin):
|
||||
class QueryComment(HyphenatedDbtClassMixin):
|
||||
comment: str = DEFAULT_QUERY_COMMENT
|
||||
append: bool = False
|
||||
job_label: bool = False
|
||||
|
||||
|
||||
class AdapterRequiredConfig(HasCredentials, Protocol):
|
||||
|
||||
@@ -1,19 +1,43 @@
|
||||
import hashlib
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
from typing import List, Optional, Union
|
||||
from mashumaro.types import SerializableType
|
||||
from typing import List, Optional, Union, Dict, Any
|
||||
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
from dbt.exceptions import InternalException
|
||||
|
||||
from .util import MacroKey, SourceKey
|
||||
from .util import SourceKey
|
||||
|
||||
|
||||
MAXIMUM_SEED_SIZE = 1 * 1024 * 1024
|
||||
MAXIMUM_SEED_SIZE_NAME = '1MB'
|
||||
|
||||
|
||||
class ParseFileType(StrEnum):
|
||||
Macro = 'macro'
|
||||
Model = 'model'
|
||||
Snapshot = 'snapshot'
|
||||
Analysis = 'analysis'
|
||||
Test = 'test'
|
||||
Seed = 'seed'
|
||||
Documentation = 'docs'
|
||||
Schema = 'schema'
|
||||
Hook = 'hook' # not a real filetype, from dbt_project.yml
|
||||
|
||||
|
||||
parse_file_type_to_parser = {
|
||||
ParseFileType.Macro: 'MacroParser',
|
||||
ParseFileType.Model: 'ModelParser',
|
||||
ParseFileType.Snapshot: 'SnapshotParser',
|
||||
ParseFileType.Analysis: 'AnalysisParser',
|
||||
ParseFileType.Test: 'DataTestParser',
|
||||
ParseFileType.Seed: 'SeedParser',
|
||||
ParseFileType.Documentation: 'DocumentationParser',
|
||||
ParseFileType.Schema: 'SchemaParser',
|
||||
ParseFileType.Hook: 'HookParser',
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class FilePath(dbtClassMixin):
|
||||
searched_path: str
|
||||
@@ -110,48 +134,57 @@ class RemoteFile(dbtClassMixin):
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFile(dbtClassMixin):
|
||||
class BaseSourceFile(dbtClassMixin, SerializableType):
|
||||
"""Define a source file in dbt"""
|
||||
path: Union[FilePath, RemoteFile] # the path information
|
||||
checksum: FileHash
|
||||
# Seems like knowing which project the file came from would be useful
|
||||
project_name: Optional[str] = None
|
||||
# Parse file type: i.e. which parser will process this file
|
||||
parse_file_type: Optional[ParseFileType] = None
|
||||
# we don't want to serialize this
|
||||
_contents: Optional[str] = None
|
||||
contents: Optional[str] = None
|
||||
# the unique IDs contained in this file
|
||||
nodes: List[str] = field(default_factory=list)
|
||||
docs: List[str] = field(default_factory=list)
|
||||
macros: List[str] = field(default_factory=list)
|
||||
sources: List[str] = field(default_factory=list)
|
||||
exposures: List[str] = field(default_factory=list)
|
||||
# any node patches in this file. The entries are names, not unique ids!
|
||||
patches: List[str] = field(default_factory=list)
|
||||
# any macro patches in this file. The entries are package, name pairs.
|
||||
macro_patches: List[MacroKey] = field(default_factory=list)
|
||||
# any source patches in this file. The entries are package, name pairs
|
||||
source_patches: List[SourceKey] = field(default_factory=list)
|
||||
|
||||
@property
|
||||
def search_key(self) -> Optional[str]:
|
||||
def file_id(self):
|
||||
if isinstance(self.path, RemoteFile):
|
||||
return None
|
||||
if self.checksum.name == 'none':
|
||||
return None
|
||||
return self.path.search_key
|
||||
return f'{self.project_name}://{self.path.original_file_path}'
|
||||
|
||||
@property
|
||||
def contents(self) -> str:
|
||||
if self._contents is None:
|
||||
raise InternalException('SourceFile has no contents!')
|
||||
return self._contents
|
||||
|
||||
@contents.setter
|
||||
def contents(self, value):
|
||||
self._contents = value
|
||||
def _serialize(self):
|
||||
dct = self.to_dict()
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def empty(cls, path: FilePath) -> 'SourceFile':
|
||||
self = cls(path=path, checksum=FileHash.empty())
|
||||
self.contents = ''
|
||||
return self
|
||||
def _deserialize(cls, dct: Dict[str, int]):
|
||||
if dct['parse_file_type'] == 'schema':
|
||||
sf = SchemaSourceFile.from_dict(dct)
|
||||
else:
|
||||
sf = SourceFile.from_dict(dct)
|
||||
return sf
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
# remove empty lists to save space
|
||||
dct_keys = list(dct.keys())
|
||||
for key in dct_keys:
|
||||
if isinstance(dct[key], list) and not dct[key]:
|
||||
del dct[key]
|
||||
# remove contents. Schema files will still have 'dict_from_yaml'
|
||||
# from the contents
|
||||
if 'contents' in dct:
|
||||
del dct['contents']
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFile(BaseSourceFile):
|
||||
nodes: List[str] = field(default_factory=list)
|
||||
docs: List[str] = field(default_factory=list)
|
||||
macros: List[str] = field(default_factory=list)
|
||||
|
||||
@classmethod
|
||||
def big_seed(cls, path: FilePath) -> 'SourceFile':
|
||||
@@ -160,8 +193,106 @@ class SourceFile(dbtClassMixin):
|
||||
self.contents = ''
|
||||
return self
|
||||
|
||||
def add_node(self, value):
|
||||
if value not in self.nodes:
|
||||
self.nodes.append(value)
|
||||
|
||||
# TODO: do this a different way. This remote file kludge isn't going
|
||||
# to work long term
|
||||
@classmethod
|
||||
def remote(cls, contents: str) -> 'SourceFile':
|
||||
self = cls(path=RemoteFile(), checksum=FileHash.empty())
|
||||
self.contents = contents
|
||||
def remote(cls, contents: str, project_name: str) -> 'SourceFile':
|
||||
self = cls(
|
||||
path=RemoteFile(),
|
||||
checksum=FileHash.from_contents(contents),
|
||||
project_name=project_name,
|
||||
contents=contents,
|
||||
)
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class SchemaSourceFile(BaseSourceFile):
|
||||
dfy: Dict[str, Any] = field(default_factory=dict)
|
||||
# these are in the manifest.nodes dictionary
|
||||
tests: Dict[str, Any] = field(default_factory=dict)
|
||||
sources: List[str] = field(default_factory=list)
|
||||
exposures: List[str] = field(default_factory=list)
|
||||
# node patches contain models, seeds, snapshots, analyses
|
||||
ndp: List[str] = field(default_factory=list)
|
||||
# any macro patches in this file by macro unique_id.
|
||||
mcp: List[str] = field(default_factory=list)
|
||||
# any source patches in this file. The entries are package, name pairs
|
||||
# Patches are only against external sources. Sources can be
|
||||
# created too, but those are in 'sources'
|
||||
sop: List[SourceKey] = field(default_factory=list)
|
||||
pp_dict: Optional[Dict[str, Any]] = None
|
||||
pp_test_index: Optional[Dict[str, Any]] = None
|
||||
|
||||
@property
|
||||
def dict_from_yaml(self):
|
||||
return self.dfy
|
||||
|
||||
@property
|
||||
def node_patches(self):
|
||||
return self.ndp
|
||||
|
||||
@property
|
||||
def macro_patches(self):
|
||||
return self.mcp
|
||||
|
||||
@property
|
||||
def source_patches(self):
|
||||
return self.sop
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
# Remove partial parsing specific data
|
||||
for key in ('pp_files', 'pp_test_index', 'pp_dict'):
|
||||
if key in dct:
|
||||
del dct[key]
|
||||
return dct
|
||||
|
||||
def append_patch(self, yaml_key, unique_id):
|
||||
self.node_patches.append(unique_id)
|
||||
|
||||
def add_test(self, node_unique_id, test_from):
|
||||
name = test_from['name']
|
||||
key = test_from['key']
|
||||
if key not in self.tests:
|
||||
self.tests[key] = {}
|
||||
if name not in self.tests[key]:
|
||||
self.tests[key][name] = []
|
||||
self.tests[key][name].append(node_unique_id)
|
||||
|
||||
def remove_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
del self.tests[yaml_key][name]
|
||||
|
||||
def get_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
return self.tests[yaml_key][name]
|
||||
return []
|
||||
|
||||
def get_key_and_name_for_test(self, test_unique_id):
|
||||
yaml_key = None
|
||||
block_name = None
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
for unique_id in self.tests[key][name]:
|
||||
if unique_id == test_unique_id:
|
||||
yaml_key = key
|
||||
block_name = name
|
||||
break
|
||||
return (yaml_key, block_name)
|
||||
|
||||
def get_all_test_ids(self):
|
||||
test_ids = []
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
test_ids.extend(self.tests[key][name])
|
||||
return test_ids
|
||||
|
||||
|
||||
AnySourceFile = Union[SchemaSourceFile, SourceFile]
|
||||
|
||||
@@ -43,6 +43,7 @@ class CompiledNode(ParsedNode, CompiledNodeMixin):
|
||||
extra_ctes_injected: bool = False
|
||||
extra_ctes: List[InjectedCTE] = field(default_factory=list)
|
||||
relation_name: Optional[str] = None
|
||||
_pre_injected_sql: Optional[str] = None
|
||||
|
||||
def set_cte(self, cte_id: str, sql: str):
|
||||
"""This is the equivalent of what self.extra_ctes[cte_id] = sql would
|
||||
@@ -55,6 +56,12 @@ class CompiledNode(ParsedNode, CompiledNodeMixin):
|
||||
else:
|
||||
self.extra_ctes.append(InjectedCTE(id=cte_id, sql=sql))
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if '_pre_injected_sql' in dct:
|
||||
del dct['_pre_injected_sql']
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledAnalysisNode(CompiledNode):
|
||||
@@ -112,15 +119,6 @@ class CompiledSchemaTestNode(CompiledNode, HasTestMetadata):
|
||||
column_name: Optional[str] = None
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
|
||||
def same_config(self, other) -> bool:
|
||||
return (
|
||||
self.unrendered_config.get('severity') ==
|
||||
other.unrendered_config.get('severity')
|
||||
)
|
||||
|
||||
def same_column_name(self, other) -> bool:
|
||||
return self.column_name == other.column_name
|
||||
|
||||
def same_contents(self, other) -> bool:
|
||||
if other is None:
|
||||
return False
|
||||
@@ -178,7 +176,7 @@ def parsed_instance_for(compiled: CompiledNode) -> ParsedResource:
|
||||
raise ValueError('invalid resource_type: {}'
|
||||
.format(compiled.resource_type))
|
||||
|
||||
return cls.from_dict(compiled.to_dict())
|
||||
return cls.from_dict(compiled.to_dict(omit_none=True))
|
||||
|
||||
|
||||
NonSourceCompiledNode = Union[
|
||||
|
||||
@@ -1,11 +1,11 @@
|
||||
import abc
|
||||
import enum
|
||||
from dataclasses import dataclass, field
|
||||
from itertools import chain, islice
|
||||
from mashumaro import DataClassMessagePackMixin
|
||||
from multiprocessing.synchronize import Lock
|
||||
from typing import (
|
||||
Dict, List, Optional, Union, Mapping, MutableMapping, Any, Set, Tuple,
|
||||
TypeVar, Callable, Iterable, Generic, cast, AbstractSet
|
||||
TypeVar, Callable, Iterable, Generic, cast, AbstractSet, ClassVar
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
from uuid import UUID
|
||||
@@ -15,20 +15,25 @@ from dbt.contracts.graph.compiled import (
|
||||
)
|
||||
from dbt.contracts.graph.parsed import (
|
||||
ParsedMacro, ParsedDocumentation, ParsedNodePatch, ParsedMacroPatch,
|
||||
ParsedSourceDefinition, ParsedExposure
|
||||
ParsedSourceDefinition, ParsedExposure, HasUniqueID,
|
||||
UnpatchedSourceDefinition, ManifestNodes
|
||||
)
|
||||
from dbt.contracts.files import SourceFile
|
||||
from dbt.contracts.graph.unparsed import SourcePatch
|
||||
from dbt.contracts.files import SourceFile, SchemaSourceFile, FileHash, AnySourceFile
|
||||
from dbt.contracts.util import (
|
||||
BaseArtifactMetadata, MacroKey, SourceKey, ArtifactMixin, schema_version
|
||||
BaseArtifactMetadata, SourceKey, ArtifactMixin, schema_version
|
||||
)
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
from dbt.exceptions import (
|
||||
CompilationException,
|
||||
raise_duplicate_resource_name, raise_compiler_error, warn_or_error,
|
||||
raise_invalid_patch,
|
||||
raise_duplicate_patch_name,
|
||||
raise_duplicate_macro_patch_name, raise_duplicate_source_patch_name,
|
||||
)
|
||||
from dbt.helper_types import PathSet
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt import deprecations
|
||||
from dbt.ui import line_wrap_message
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
import dbt.utils
|
||||
@@ -40,72 +45,70 @@ RefName = str
|
||||
UniqueID = str
|
||||
|
||||
|
||||
K_T = TypeVar('K_T')
|
||||
V_T = TypeVar('V_T')
|
||||
|
||||
|
||||
class PackageAwareCache(Generic[K_T, V_T]):
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self.storage: Dict[K_T, Dict[PackageName, UniqueID]] = {}
|
||||
self._manifest = manifest
|
||||
self.populate()
|
||||
|
||||
@abc.abstractmethod
|
||||
def populate(self):
|
||||
pass
|
||||
|
||||
@abc.abstractmethod
|
||||
def perform_lookup(self, unique_id: UniqueID) -> V_T:
|
||||
pass
|
||||
|
||||
def find_cached_value(
|
||||
self, key: K_T, package: Optional[PackageName]
|
||||
) -> Optional[V_T]:
|
||||
unique_id = self.find_unique_id_for_package(key, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id)
|
||||
def find_unique_id_for_package(storage, key, package: Optional[PackageName]):
|
||||
if key not in storage:
|
||||
return None
|
||||
|
||||
def find_unique_id_for_package(
|
||||
self, key: K_T, package: Optional[PackageName]
|
||||
) -> Optional[UniqueID]:
|
||||
if key not in self.storage:
|
||||
pkg_dct: Mapping[PackageName, UniqueID] = storage[key]
|
||||
|
||||
if package is None:
|
||||
if not pkg_dct:
|
||||
return None
|
||||
|
||||
pkg_dct: Mapping[PackageName, UniqueID] = self.storage[key]
|
||||
|
||||
if package is None:
|
||||
if not pkg_dct:
|
||||
return None
|
||||
else:
|
||||
return next(iter(pkg_dct.values()))
|
||||
elif package in pkg_dct:
|
||||
return pkg_dct[package]
|
||||
else:
|
||||
return None
|
||||
return next(iter(pkg_dct.values()))
|
||||
elif package in pkg_dct:
|
||||
return pkg_dct[package]
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class DocCache(PackageAwareCache[DocName, ParsedDocumentation]):
|
||||
class DocLookup(dbtClassMixin):
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self.storage: Dict[str, Dict[PackageName, UniqueID]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def get_unique_id(self, key, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, key, package)
|
||||
|
||||
def find(self, key, package: Optional[PackageName], manifest: 'Manifest'):
|
||||
unique_id = self.get_unique_id(key, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id, manifest)
|
||||
return None
|
||||
|
||||
def add_doc(self, doc: ParsedDocumentation):
|
||||
if doc.name not in self.storage:
|
||||
self.storage[doc.name] = {}
|
||||
self.storage[doc.name][doc.package_name] = doc.unique_id
|
||||
|
||||
def populate(self):
|
||||
for doc in self._manifest.docs.values():
|
||||
def populate(self, manifest):
|
||||
for doc in manifest.docs.values():
|
||||
self.add_doc(doc)
|
||||
|
||||
def perform_lookup(
|
||||
self, unique_id: UniqueID
|
||||
self, unique_id: UniqueID, manifest
|
||||
) -> ParsedDocumentation:
|
||||
if unique_id not in self._manifest.docs:
|
||||
if unique_id not in manifest.docs:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Doc {unique_id} found in cache but not found in manifest'
|
||||
)
|
||||
return self._manifest.docs[unique_id]
|
||||
return manifest.docs[unique_id]
|
||||
|
||||
|
||||
class SourceCache(PackageAwareCache[SourceKey, ParsedSourceDefinition]):
|
||||
class SourceLookup(dbtClassMixin):
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self.storage: Dict[Tuple[str, str], Dict[PackageName, UniqueID]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def get_unique_id(self, key, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, key, package)
|
||||
|
||||
def find(self, key, package: Optional[PackageName], manifest: 'Manifest'):
|
||||
unique_id = self.get_unique_id(key, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id, manifest)
|
||||
return None
|
||||
|
||||
def add_source(self, source: ParsedSourceDefinition):
|
||||
key = (source.source_name, source.name)
|
||||
if key not in self.storage:
|
||||
@@ -113,46 +116,63 @@ class SourceCache(PackageAwareCache[SourceKey, ParsedSourceDefinition]):
|
||||
|
||||
self.storage[key][source.package_name] = source.unique_id
|
||||
|
||||
def populate(self):
|
||||
for source in self._manifest.sources.values():
|
||||
self.add_source(source)
|
||||
def populate(self, manifest):
|
||||
for source in manifest.sources.values():
|
||||
if hasattr(source, 'source_name'):
|
||||
self.add_source(source)
|
||||
|
||||
def perform_lookup(
|
||||
self, unique_id: UniqueID
|
||||
self, unique_id: UniqueID, manifest: 'Manifest'
|
||||
) -> ParsedSourceDefinition:
|
||||
if unique_id not in self._manifest.sources:
|
||||
if unique_id not in manifest.sources:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Source {unique_id} found in cache but not found in manifest'
|
||||
)
|
||||
return self._manifest.sources[unique_id]
|
||||
return manifest.sources[unique_id]
|
||||
|
||||
|
||||
class RefableCache(PackageAwareCache[RefName, ManifestNode]):
|
||||
class RefableLookup(dbtClassMixin):
|
||||
# model, seed, snapshot
|
||||
_lookup_types: ClassVar[set] = set(NodeType.refable())
|
||||
|
||||
# refables are actually unique, so the Dict[PackageName, UniqueID] will
|
||||
# only ever have exactly one value, but doing 3 dict lookups instead of 1
|
||||
# is not a big deal at all and retains consistency
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self._cached_types = set(NodeType.refable())
|
||||
super().__init__(manifest)
|
||||
self.storage: Dict[str, Dict[PackageName, UniqueID]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def get_unique_id(self, key, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, key, package)
|
||||
|
||||
def find(self, key, package: Optional[PackageName], manifest: 'Manifest'):
|
||||
unique_id = self.get_unique_id(key, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id, manifest)
|
||||
return None
|
||||
|
||||
def add_node(self, node: ManifestNode):
|
||||
if node.resource_type in self._cached_types:
|
||||
if node.resource_type in self._lookup_types:
|
||||
if node.name not in self.storage:
|
||||
self.storage[node.name] = {}
|
||||
self.storage[node.name][node.package_name] = node.unique_id
|
||||
|
||||
def populate(self):
|
||||
for node in self._manifest.nodes.values():
|
||||
def populate(self, manifest):
|
||||
for node in manifest.nodes.values():
|
||||
self.add_node(node)
|
||||
|
||||
def perform_lookup(
|
||||
self, unique_id: UniqueID
|
||||
self, unique_id: UniqueID, manifest
|
||||
) -> ManifestNode:
|
||||
if unique_id not in self._manifest.nodes:
|
||||
if unique_id not in manifest.nodes:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Node {unique_id} found in cache but not found in manifest'
|
||||
)
|
||||
return self._manifest.nodes[unique_id]
|
||||
return manifest.nodes[unique_id]
|
||||
|
||||
|
||||
class AnalysisLookup(RefableLookup):
|
||||
_lookup_types: ClassVar[set] = set(NodeType.Analysis)
|
||||
|
||||
|
||||
def _search_packages(
|
||||
@@ -223,7 +243,7 @@ def _sort_values(dct):
|
||||
return {k: sorted(v) for k, v in dct.items()}
|
||||
|
||||
|
||||
def build_edges(nodes: List[ManifestNode]):
|
||||
def build_node_edges(nodes: List[ManifestNode]):
|
||||
"""Build the forward and backward edges on the given list of ParsedNodes
|
||||
and return them as two separate dictionaries, each mapping unique IDs to
|
||||
lists of edges.
|
||||
@@ -239,8 +259,20 @@ def build_edges(nodes: List[ManifestNode]):
|
||||
return _sort_values(forward_edges), _sort_values(backward_edges)
|
||||
|
||||
|
||||
# Build a map of children of macros
|
||||
def build_macro_edges(nodes: List[Any]):
|
||||
forward_edges: Dict[str, List[str]] = {
|
||||
n.unique_id: [] for n in nodes if n.unique_id.startswith('macro') or n.depends_on.macros
|
||||
}
|
||||
for node in nodes:
|
||||
for unique_id in node.depends_on.macros:
|
||||
if unique_id in forward_edges.keys():
|
||||
forward_edges[unique_id].append(node.unique_id)
|
||||
return _sort_values(forward_edges)
|
||||
|
||||
|
||||
def _deepcopy(value):
|
||||
return value.from_dict(value.to_dict())
|
||||
return value.from_dict(value.to_dict(omit_none=True))
|
||||
|
||||
|
||||
class Locality(enum.IntEnum):
|
||||
@@ -506,26 +538,71 @@ class MacroMethods:
|
||||
|
||||
|
||||
@dataclass
|
||||
class Manifest(MacroMethods):
|
||||
class ParsingInfo:
|
||||
static_analysis_parsed_path_count: int = 0
|
||||
static_analysis_path_count: int = 0
|
||||
|
||||
|
||||
@dataclass
|
||||
class ManifestStateCheck(dbtClassMixin):
|
||||
vars_hash: FileHash = field(default_factory=FileHash.empty)
|
||||
profile_hash: FileHash = field(default_factory=FileHash.empty)
|
||||
project_hashes: MutableMapping[str, FileHash] = field(default_factory=dict)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
"""The manifest for the full graph, after parsing and during compilation.
|
||||
"""
|
||||
# These attributes are both positional and by keyword. If an attribute
|
||||
# is added it must all be added in the __reduce_ex__ method in the
|
||||
# args tuple in the right position.
|
||||
nodes: MutableMapping[str, ManifestNode]
|
||||
sources: MutableMapping[str, ParsedSourceDefinition]
|
||||
macros: MutableMapping[str, ParsedMacro]
|
||||
docs: MutableMapping[str, ParsedDocumentation]
|
||||
exposures: MutableMapping[str, ParsedExposure]
|
||||
selectors: MutableMapping[str, Any]
|
||||
disabled: List[CompileResultNode]
|
||||
files: MutableMapping[str, SourceFile]
|
||||
nodes: MutableMapping[str, ManifestNode] = field(default_factory=dict)
|
||||
sources: MutableMapping[str, ParsedSourceDefinition] = field(default_factory=dict)
|
||||
macros: MutableMapping[str, ParsedMacro] = field(default_factory=dict)
|
||||
docs: MutableMapping[str, ParsedDocumentation] = field(default_factory=dict)
|
||||
exposures: MutableMapping[str, ParsedExposure] = field(default_factory=dict)
|
||||
selectors: MutableMapping[str, Any] = field(default_factory=dict)
|
||||
disabled: List[CompileResultNode] = field(default_factory=list)
|
||||
files: MutableMapping[str, AnySourceFile] = field(default_factory=dict)
|
||||
metadata: ManifestMetadata = field(default_factory=ManifestMetadata)
|
||||
flat_graph: Dict[str, Any] = field(default_factory=dict)
|
||||
_docs_cache: Optional[DocCache] = None
|
||||
_sources_cache: Optional[SourceCache] = None
|
||||
_refs_cache: Optional[RefableCache] = None
|
||||
_lock: Lock = field(default_factory=flags.MP_CONTEXT.Lock)
|
||||
state_check: ManifestStateCheck = field(default_factory=ManifestStateCheck)
|
||||
# Moved from the ParseResult object
|
||||
source_patches: MutableMapping[SourceKey, SourcePatch] = field(default_factory=dict)
|
||||
# following is from ParseResult
|
||||
_disabled: MutableMapping[str, List[CompileResultNode]] = field(default_factory=dict)
|
||||
_doc_lookup: Optional[DocLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_source_lookup: Optional[SourceLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_ref_lookup: Optional[RefableLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_analysis_lookup: Optional[AnalysisLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_parsing_info: ParsingInfo = field(
|
||||
default_factory=ParsingInfo,
|
||||
metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_lock: Lock = field(
|
||||
default_factory=flags.MP_CONTEXT.Lock,
|
||||
metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
|
||||
def __pre_serialize__(self):
|
||||
# serialization won't work with anything except an empty source_patches because
|
||||
# tuple keys are not supported, so ensure it's empty
|
||||
self.source_patches = {}
|
||||
return self
|
||||
|
||||
@classmethod
|
||||
def __post_deserialize__(cls, obj):
|
||||
obj._lock = flags.MP_CONTEXT.Lock()
|
||||
return obj
|
||||
|
||||
def sync_update_node(
|
||||
self, new_node: NonSourceCompiledNode
|
||||
@@ -563,12 +640,16 @@ class Manifest(MacroMethods):
|
||||
manifest!
|
||||
"""
|
||||
self.flat_graph = {
|
||||
'exposures': {
|
||||
k: v.to_dict(omit_none=False)
|
||||
for k, v in self.exposures.items()
|
||||
},
|
||||
'nodes': {
|
||||
k: v.to_dict(options={'keep_none': True})
|
||||
k: v.to_dict(omit_none=False)
|
||||
for k, v in self.nodes.items()
|
||||
},
|
||||
'sources': {
|
||||
k: v.to_dict(options={'keep_none': True})
|
||||
k: v.to_dict(omit_none=False)
|
||||
for k, v in self.sources.items()
|
||||
}
|
||||
}
|
||||
@@ -629,7 +710,7 @@ class Manifest(MacroMethods):
|
||||
|
||||
def get_resource_fqns(self) -> Mapping[str, PathSet]:
|
||||
resource_fqns: Dict[str, Set[Tuple[str, ...]]] = {}
|
||||
all_resources = chain(self.nodes.values(), self.sources.values())
|
||||
all_resources = chain(self.exposures.values(), self.nodes.values(), self.sources.values())
|
||||
for resource in all_resources:
|
||||
resource_type_plural = resource.resource_type.pluralize()
|
||||
if resource_type_plural not in resource_fqns:
|
||||
@@ -637,74 +718,59 @@ class Manifest(MacroMethods):
|
||||
resource_fqns[resource_type_plural].add(tuple(resource.fqn))
|
||||
return resource_fqns
|
||||
|
||||
def add_nodes(self, new_nodes: Mapping[str, ManifestNode]):
|
||||
"""Add the given dict of new nodes to the manifest."""
|
||||
for unique_id, node in new_nodes.items():
|
||||
if unique_id in self.nodes:
|
||||
raise_duplicate_resource_name(node, self.nodes[unique_id])
|
||||
self.nodes[unique_id] = node
|
||||
# fixup the cache if it exists.
|
||||
if self._refs_cache is not None:
|
||||
if node.resource_type in NodeType.refable():
|
||||
self._refs_cache.add_node(node)
|
||||
|
||||
def patch_macros(
|
||||
self, patches: MutableMapping[MacroKey, ParsedMacroPatch]
|
||||
# This is called by 'parse_patch' in the NodePatchParser
|
||||
def add_patch(
|
||||
self, source_file: SchemaSourceFile, patch: ParsedNodePatch,
|
||||
) -> None:
|
||||
for macro in self.macros.values():
|
||||
key = (macro.package_name, macro.name)
|
||||
patch = patches.pop(key, None)
|
||||
if not patch:
|
||||
continue
|
||||
macro.patch(patch)
|
||||
|
||||
if patches:
|
||||
for patch in patches.values():
|
||||
warn_or_error(
|
||||
f'WARNING: Found documentation for macro "{patch.name}" '
|
||||
f'which was not found'
|
||||
)
|
||||
|
||||
def patch_nodes(
|
||||
self, patches: MutableMapping[str, ParsedNodePatch]
|
||||
) -> None:
|
||||
"""Patch nodes with the given dict of patches. Note that this consumes
|
||||
the input!
|
||||
This relies on the fact that all nodes have unique _name_ fields, not
|
||||
just unique unique_id fields.
|
||||
"""
|
||||
# because we don't have any mapping from node _names_ to nodes, and we
|
||||
# only have the node name in the patch, we have to iterate over all the
|
||||
# nodes looking for matching names. We could use a NameSearcher if we
|
||||
# were ok with doing an O(n*m) search (one nodes scan per patch)
|
||||
for node in self.nodes.values():
|
||||
patch = patches.pop(node.name, None)
|
||||
if not patch:
|
||||
continue
|
||||
|
||||
expected_key = node.resource_type.pluralize()
|
||||
if expected_key != patch.yaml_key:
|
||||
if patch.yaml_key == 'models':
|
||||
deprecations.warn(
|
||||
'models-key-mismatch',
|
||||
patch=patch, node=node, expected_key=expected_key
|
||||
)
|
||||
else:
|
||||
raise_invalid_patch(
|
||||
node, patch.yaml_key, patch.original_file_path
|
||||
)
|
||||
if patch.yaml_key in ['models', 'seeds', 'snapshots']:
|
||||
unique_id = self.ref_lookup.get_unique_id(patch.name, None)
|
||||
elif patch.yaml_key == 'analyses':
|
||||
unique_id = self.analysis_lookup.get_unique_id(patch.name, None)
|
||||
else:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Unexpected yaml_key {patch.yaml_key} for patch in '
|
||||
f'file {source_file.path.original_file_path}'
|
||||
)
|
||||
if unique_id is None:
|
||||
# This will usually happen when a node is disabled
|
||||
return
|
||||
|
||||
# patches can't be overwritten
|
||||
node = self.nodes.get(unique_id)
|
||||
if node:
|
||||
if node.patch_path:
|
||||
package_name, existing_file_path = node.patch_path.split('://')
|
||||
raise_duplicate_patch_name(patch, existing_file_path)
|
||||
source_file.append_patch(patch.yaml_key, unique_id)
|
||||
node.patch(patch)
|
||||
|
||||
# log debug-level warning about nodes we couldn't find
|
||||
if patches:
|
||||
for patch in patches.values():
|
||||
# since patches aren't nodes, we can't use the existing
|
||||
# target_not_found warning
|
||||
logger.debug((
|
||||
'WARNING: Found documentation for resource "{}" which was '
|
||||
'not found or is disabled').format(patch.name)
|
||||
)
|
||||
def add_macro_patch(
|
||||
self, source_file: SchemaSourceFile, patch: ParsedMacroPatch,
|
||||
) -> None:
|
||||
# macros are fully namespaced
|
||||
unique_id = f'macro.{patch.package_name}.{patch.name}'
|
||||
macro = self.macros.get(unique_id)
|
||||
if not macro:
|
||||
warn_or_error(
|
||||
f'WARNING: Found documentation for macro "{patch.name}" '
|
||||
f'which was not found'
|
||||
)
|
||||
return
|
||||
if macro.patch_path:
|
||||
package_name, existing_file_path = macro.patch_path.split('://')
|
||||
raise_duplicate_macro_patch_name(patch, existing_file_path)
|
||||
source_file.macro_patches.append(unique_id)
|
||||
macro.patch(patch)
|
||||
|
||||
def add_source_patch(
|
||||
self, source_file: SchemaSourceFile, patch: SourcePatch,
|
||||
) -> None:
|
||||
# source patches must be unique
|
||||
key = (patch.overrides, patch.name)
|
||||
if key in self.source_patches:
|
||||
raise_duplicate_source_patch_name(patch, self.source_patches[key])
|
||||
self.source_patches[key] = patch
|
||||
source_file.source_patches.append(key)
|
||||
|
||||
def get_used_schemas(self, resource_types=None):
|
||||
return frozenset({
|
||||
@@ -719,6 +785,7 @@ class Manifest(MacroMethods):
|
||||
chain(self.nodes.values(), self.sources.values())
|
||||
)
|
||||
|
||||
# This is used in dbt.task.rpc.sql_commands 'add_new_refs'
|
||||
def deepcopy(self):
|
||||
return Manifest(
|
||||
nodes={k: _deepcopy(v) for k, v in self.nodes.items()},
|
||||
@@ -726,20 +793,33 @@ class Manifest(MacroMethods):
|
||||
macros={k: _deepcopy(v) for k, v in self.macros.items()},
|
||||
docs={k: _deepcopy(v) for k, v in self.docs.items()},
|
||||
exposures={k: _deepcopy(v) for k, v in self.exposures.items()},
|
||||
selectors=self.root_project.manifest_selectors,
|
||||
selectors={k: _deepcopy(v) for k, v in self.selectors.items()},
|
||||
metadata=self.metadata,
|
||||
disabled=[_deepcopy(n) for n in self.disabled],
|
||||
files={k: _deepcopy(v) for k, v in self.files.items()},
|
||||
state_check=_deepcopy(self.state_check),
|
||||
)
|
||||
|
||||
def writable_manifest(self):
|
||||
def build_parent_and_child_maps(self):
|
||||
edge_members = list(chain(
|
||||
self.nodes.values(),
|
||||
self.sources.values(),
|
||||
self.exposures.values(),
|
||||
))
|
||||
forward_edges, backward_edges = build_edges(edge_members)
|
||||
forward_edges, backward_edges = build_node_edges(edge_members)
|
||||
self.child_map = forward_edges
|
||||
self.parent_map = backward_edges
|
||||
|
||||
def build_macro_child_map(self):
|
||||
edge_members = list(chain(
|
||||
self.nodes.values(),
|
||||
self.macros.values(),
|
||||
))
|
||||
forward_edges = build_macro_edges(edge_members)
|
||||
return forward_edges
|
||||
|
||||
def writable_manifest(self):
|
||||
self.build_parent_and_child_maps()
|
||||
return WritableManifest(
|
||||
nodes=self.nodes,
|
||||
sources=self.sources,
|
||||
@@ -749,18 +829,15 @@ class Manifest(MacroMethods):
|
||||
selectors=self.selectors,
|
||||
metadata=self.metadata,
|
||||
disabled=self.disabled,
|
||||
child_map=forward_edges,
|
||||
parent_map=backward_edges,
|
||||
child_map=self.child_map,
|
||||
parent_map=self.parent_map,
|
||||
)
|
||||
|
||||
# When 'to_dict' is called on the Manifest, it substitues a
|
||||
# WritableManifest
|
||||
def __pre_serialize__(self, options=None):
|
||||
return self.writable_manifest()
|
||||
|
||||
def write(self, path):
|
||||
self.writable_manifest().write(path)
|
||||
|
||||
# Called in dbt.compilation.Linker.write_graph and
|
||||
# dbt.graph.queue.get and ._include_in_cost
|
||||
def expect(self, unique_id: str) -> GraphMemberNode:
|
||||
if unique_id in self.nodes:
|
||||
return self.nodes[unique_id]
|
||||
@@ -775,29 +852,40 @@ class Manifest(MacroMethods):
|
||||
)
|
||||
|
||||
@property
|
||||
def docs_cache(self) -> DocCache:
|
||||
if self._docs_cache is not None:
|
||||
return self._docs_cache
|
||||
cache = DocCache(self)
|
||||
self._docs_cache = cache
|
||||
return cache
|
||||
def doc_lookup(self) -> DocLookup:
|
||||
if self._doc_lookup is None:
|
||||
self._doc_lookup = DocLookup(self)
|
||||
return self._doc_lookup
|
||||
|
||||
def rebuild_doc_lookup(self):
|
||||
self._doc_lookup = DocLookup(self)
|
||||
|
||||
@property
|
||||
def source_cache(self) -> SourceCache:
|
||||
if self._sources_cache is not None:
|
||||
return self._sources_cache
|
||||
cache = SourceCache(self)
|
||||
self._sources_cache = cache
|
||||
return cache
|
||||
def source_lookup(self) -> SourceLookup:
|
||||
if self._source_lookup is None:
|
||||
self._source_lookup = SourceLookup(self)
|
||||
return self._source_lookup
|
||||
|
||||
def rebuild_source_lookup(self):
|
||||
self._source_lookup = SourceLookup(self)
|
||||
|
||||
@property
|
||||
def refs_cache(self) -> RefableCache:
|
||||
if self._refs_cache is not None:
|
||||
return self._refs_cache
|
||||
cache = RefableCache(self)
|
||||
self._refs_cache = cache
|
||||
return cache
|
||||
def ref_lookup(self) -> RefableLookup:
|
||||
if self._ref_lookup is None:
|
||||
self._ref_lookup = RefableLookup(self)
|
||||
return self._ref_lookup
|
||||
|
||||
def rebuild_ref_lookup(self):
|
||||
self._ref_lookup = RefableLookup(self)
|
||||
|
||||
@property
|
||||
def analysis_lookup(self) -> AnalysisLookup:
|
||||
if self._analysis_lookup is None:
|
||||
self._analysis_lookup = AnalysisLookup(self)
|
||||
return self._analysis_lookup
|
||||
|
||||
# Called by dbt.parser.manifest._resolve_refs_for_exposure
|
||||
# and dbt.parser.manifest._process_refs_for_node
|
||||
def resolve_ref(
|
||||
self,
|
||||
target_model_name: str,
|
||||
@@ -813,7 +901,7 @@ class Manifest(MacroMethods):
|
||||
current_project, node_package, target_model_package
|
||||
)
|
||||
for pkg in candidates:
|
||||
node = self.refs_cache.find_cached_value(target_model_name, pkg)
|
||||
node = self.ref_lookup.find(target_model_name, pkg, self)
|
||||
|
||||
if node is not None and node.config.enabled:
|
||||
return node
|
||||
@@ -828,6 +916,8 @@ class Manifest(MacroMethods):
|
||||
return Disabled(disabled)
|
||||
return None
|
||||
|
||||
# Called by dbt.parser.manifest._resolve_sources_for_exposure
|
||||
# and dbt.parser.manifest._process_source_for_node
|
||||
def resolve_source(
|
||||
self,
|
||||
target_source_name: str,
|
||||
@@ -842,7 +932,7 @@ class Manifest(MacroMethods):
|
||||
disabled: Optional[ParsedSourceDefinition] = None
|
||||
|
||||
for pkg in candidates:
|
||||
source = self.source_cache.find_cached_value(key, pkg)
|
||||
source = self.source_lookup.find(key, pkg, self)
|
||||
if source is not None and source.config.enabled:
|
||||
return source
|
||||
|
||||
@@ -855,6 +945,7 @@ class Manifest(MacroMethods):
|
||||
return Disabled(disabled)
|
||||
return None
|
||||
|
||||
# Called by DocsRuntimeContext.doc
|
||||
def resolve_doc(
|
||||
self,
|
||||
name: str,
|
||||
@@ -871,11 +962,12 @@ class Manifest(MacroMethods):
|
||||
)
|
||||
|
||||
for pkg in candidates:
|
||||
result = self.docs_cache.find_cached_value(name, pkg)
|
||||
result = self.doc_lookup.find(name, pkg, self)
|
||||
if result is not None:
|
||||
return result
|
||||
return None
|
||||
|
||||
# Called by RunTask.defer_to_manifest
|
||||
def merge_from_artifact(
|
||||
self,
|
||||
adapter,
|
||||
@@ -908,6 +1000,91 @@ class Manifest(MacroMethods):
|
||||
f'Merged {len(merged)} items from state (sample: {sample})'
|
||||
)
|
||||
|
||||
# Methods that were formerly in ParseResult
|
||||
|
||||
def add_macro(self, source_file: SourceFile, macro: ParsedMacro):
|
||||
if macro.unique_id in self.macros:
|
||||
# detect that the macro exists and emit an error
|
||||
other_path = self.macros[macro.unique_id].original_file_path
|
||||
# subtract 2 for the "Compilation Error" indent
|
||||
# note that the line wrap eats newlines, so if you want newlines,
|
||||
# this is the result :(
|
||||
msg = line_wrap_message(
|
||||
f'''\
|
||||
dbt found two macros named "{macro.name}" in the project
|
||||
"{macro.package_name}".
|
||||
|
||||
|
||||
To fix this error, rename or remove one of the following
|
||||
macros:
|
||||
|
||||
- {macro.original_file_path}
|
||||
|
||||
- {other_path}
|
||||
''',
|
||||
subtract=2
|
||||
)
|
||||
raise_compiler_error(msg)
|
||||
|
||||
self.macros[macro.unique_id] = macro
|
||||
source_file.macros.append(macro.unique_id)
|
||||
|
||||
def has_file(self, source_file: SourceFile) -> bool:
|
||||
key = source_file.file_id
|
||||
if key is None:
|
||||
return False
|
||||
if key not in self.files:
|
||||
return False
|
||||
my_checksum = self.files[key].checksum
|
||||
return my_checksum == source_file.checksum
|
||||
|
||||
def add_source(
|
||||
self, source_file: SchemaSourceFile, source: UnpatchedSourceDefinition
|
||||
):
|
||||
# sources can't be overwritten!
|
||||
_check_duplicates(source, self.sources)
|
||||
self.sources[source.unique_id] = source # type: ignore
|
||||
source_file.sources.append(source.unique_id)
|
||||
|
||||
def add_node_nofile(self, node: ManifestNodes):
|
||||
# nodes can't be overwritten!
|
||||
_check_duplicates(node, self.nodes)
|
||||
self.nodes[node.unique_id] = node
|
||||
|
||||
def add_node(self, source_file: AnySourceFile, node: ManifestNodes, test_from=None):
|
||||
self.add_node_nofile(node)
|
||||
if isinstance(source_file, SchemaSourceFile):
|
||||
assert test_from
|
||||
source_file.add_test(node.unique_id, test_from)
|
||||
else:
|
||||
source_file.nodes.append(node.unique_id)
|
||||
|
||||
def add_exposure(self, source_file: SchemaSourceFile, exposure: ParsedExposure):
|
||||
_check_duplicates(exposure, self.exposures)
|
||||
self.exposures[exposure.unique_id] = exposure
|
||||
source_file.exposures.append(exposure.unique_id)
|
||||
|
||||
def add_disabled_nofile(self, node: CompileResultNode):
|
||||
if node.unique_id in self._disabled:
|
||||
self._disabled[node.unique_id].append(node)
|
||||
else:
|
||||
self._disabled[node.unique_id] = [node]
|
||||
|
||||
def add_disabled(self, source_file: AnySourceFile, node: CompileResultNode, test_from=None):
|
||||
self.add_disabled_nofile(node)
|
||||
if isinstance(source_file, SchemaSourceFile):
|
||||
assert test_from
|
||||
source_file.add_test(node.unique_id, test_from)
|
||||
else:
|
||||
source_file.nodes.append(node.unique_id)
|
||||
|
||||
def add_doc(self, source_file: SourceFile, doc: ParsedDocumentation):
|
||||
_check_duplicates(doc, self.docs)
|
||||
self.docs[doc.unique_id] = doc
|
||||
source_file.docs.append(doc.unique_id)
|
||||
|
||||
# end of methods formerly in ParseResult
|
||||
|
||||
# Provide support for copy.deepcopy() - we just need to avoid the lock!
|
||||
# pickle and deepcopy use this. It returns a callable object used to
|
||||
# create the initial version of the object and a tuple of arguments
|
||||
@@ -927,17 +1104,19 @@ class Manifest(MacroMethods):
|
||||
self.files,
|
||||
self.metadata,
|
||||
self.flat_graph,
|
||||
self._docs_cache,
|
||||
self._sources_cache,
|
||||
self._refs_cache,
|
||||
self.state_check,
|
||||
self.source_patches,
|
||||
self._disabled,
|
||||
self._doc_lookup,
|
||||
self._source_lookup,
|
||||
self._ref_lookup,
|
||||
)
|
||||
return self.__class__, args
|
||||
|
||||
|
||||
class MacroManifest(MacroMethods):
|
||||
def __init__(self, macros, files):
|
||||
def __init__(self, macros):
|
||||
self.macros = macros
|
||||
self.files = files
|
||||
self.metadata = ManifestMetadata()
|
||||
# This is returned by the 'graph' context property
|
||||
# in the ProviderContext class.
|
||||
@@ -948,7 +1127,7 @@ AnyManifest = Union[Manifest, MacroManifest]
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('manifest', 1)
|
||||
@schema_version('manifest', 2)
|
||||
class WritableManifest(ArtifactMixin):
|
||||
nodes: Mapping[UniqueID, ManifestNode] = field(
|
||||
metadata=dict(description=(
|
||||
@@ -992,3 +1171,26 @@ class WritableManifest(ArtifactMixin):
|
||||
metadata: ManifestMetadata = field(metadata=dict(
|
||||
description='Metadata about the manifest',
|
||||
))
|
||||
|
||||
|
||||
def _check_duplicates(
|
||||
value: HasUniqueID, src: Mapping[str, HasUniqueID]
|
||||
):
|
||||
if value.unique_id in src:
|
||||
raise_duplicate_resource_name(value, src[value.unique_id])
|
||||
|
||||
|
||||
K_T = TypeVar('K_T')
|
||||
V_T = TypeVar('V_T')
|
||||
|
||||
|
||||
def _expect_value(
|
||||
key: K_T, src: Mapping[K_T, V_T], old_file: SourceFile, name: str
|
||||
) -> V_T:
|
||||
if key not in src:
|
||||
raise CompilationException(
|
||||
'Expected to find "{}" in cached "result.{}" based '
|
||||
'on cached file information: {}!'
|
||||
.format(key, name, old_file)
|
||||
)
|
||||
return src[key]
|
||||
|
||||
@@ -2,14 +2,13 @@ from dataclasses import field, Field, dataclass
|
||||
from enum import Enum
|
||||
from itertools import chain
|
||||
from typing import (
|
||||
Any, List, Optional, Dict, MutableMapping, Union, Type,
|
||||
TypeVar, Callable,
|
||||
Any, List, Optional, Dict, Union, Type, TypeVar
|
||||
)
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ValidationError, register_pattern,
|
||||
)
|
||||
from dbt.contracts.graph.unparsed import AdditionalPropertiesAllowed
|
||||
from dbt.exceptions import CompilationException, InternalException
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.contracts.util import Replaceable, list_str
|
||||
from dbt import hooks
|
||||
from dbt.node_types import NodeType
|
||||
@@ -182,53 +181,29 @@ T = TypeVar('T', bound='BaseConfig')
|
||||
|
||||
@dataclass
|
||||
class BaseConfig(
|
||||
AdditionalPropertiesAllowed, Replaceable, MutableMapping[str, Any]
|
||||
AdditionalPropertiesAllowed, Replaceable
|
||||
):
|
||||
# Implement MutableMapping so this config will behave as some macros expect
|
||||
# during parsing (notably, syntax like `{{ node.config['schema'] }}`)
|
||||
|
||||
# enable syntax like: config['key']
|
||||
def __getitem__(self, key):
|
||||
"""Handle parse-time use of `config` as a dictionary, making the extra
|
||||
values available during parsing.
|
||||
"""
|
||||
return self.get(key)
|
||||
|
||||
# like doing 'get' on a dictionary
|
||||
def get(self, key, default=None):
|
||||
if hasattr(self, key):
|
||||
return getattr(self, key)
|
||||
else:
|
||||
elif key in self._extra:
|
||||
return self._extra[key]
|
||||
else:
|
||||
return default
|
||||
|
||||
# enable syntax like: config['key'] = value
|
||||
def __setitem__(self, key, value):
|
||||
if hasattr(self, key):
|
||||
setattr(self, key, value)
|
||||
else:
|
||||
self._extra[key] = value
|
||||
|
||||
def __delitem__(self, key):
|
||||
if hasattr(self, key):
|
||||
msg = (
|
||||
'Error, tried to delete config key "{}": Cannot delete '
|
||||
'built-in keys'
|
||||
).format(key)
|
||||
raise CompilationException(msg)
|
||||
else:
|
||||
del self._extra[key]
|
||||
|
||||
def _content_iterator(self, include_condition: Callable[[Field], bool]):
|
||||
seen = set()
|
||||
for fld, _ in self._get_fields():
|
||||
seen.add(fld.name)
|
||||
if include_condition(fld):
|
||||
yield fld.name
|
||||
|
||||
for key in self._extra:
|
||||
if key not in seen:
|
||||
seen.add(key)
|
||||
yield key
|
||||
|
||||
def __iter__(self):
|
||||
yield from self._content_iterator(include_condition=lambda f: True)
|
||||
|
||||
def __len__(self):
|
||||
return len(self._get_fields()) + len(self._extra)
|
||||
|
||||
@staticmethod
|
||||
def compare_key(
|
||||
unrendered: Dict[str, Any],
|
||||
@@ -307,7 +282,7 @@ class BaseConfig(
|
||||
"""
|
||||
# sadly, this is a circular import
|
||||
from dbt.adapters.factory import get_config_class_by_name
|
||||
dct = self.to_dict(options={'keep_none': True})
|
||||
dct = self.to_dict(omit_none=False)
|
||||
|
||||
adapter_config_cls = get_config_class_by_name(adapter_type)
|
||||
|
||||
@@ -326,12 +301,12 @@ class BaseConfig(
|
||||
return self.from_dict(dct)
|
||||
|
||||
def finalize_and_validate(self: T) -> T:
|
||||
dct = self.to_dict(options={'keep_none': True})
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
return self.from_dict(dct)
|
||||
|
||||
def replace(self, **kwargs):
|
||||
dct = self.to_dict()
|
||||
dct = self.to_dict(omit_none=True)
|
||||
|
||||
mapping = self.field_mapping()
|
||||
for key, value in kwargs.items():
|
||||
@@ -396,8 +371,8 @@ class NodeConfig(BaseConfig):
|
||||
full_refresh: Optional[bool] = None
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
field_map = {'post-hook': 'post_hook', 'pre-hook': 'pre_hook'}
|
||||
# create a new dict because otherwise it gets overwritten in
|
||||
# tests
|
||||
@@ -414,8 +389,8 @@ class NodeConfig(BaseConfig):
|
||||
data[new_name] = data.pop(field_name)
|
||||
return data
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
dct = super().__post_serialize__(dct, options=options)
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
field_map = {'post_hook': 'post-hook', 'pre_hook': 'pre-hook'}
|
||||
for field_name in field_map:
|
||||
if field_name in dct:
|
||||
@@ -436,8 +411,42 @@ class SeedConfig(NodeConfig):
|
||||
|
||||
@dataclass
|
||||
class TestConfig(NodeConfig):
|
||||
schema: Optional[str] = field(
|
||||
default='dbt_test__audit',
|
||||
metadata=CompareBehavior.Exclude.meta(),
|
||||
)
|
||||
materialized: str = 'test'
|
||||
severity: Severity = Severity('ERROR')
|
||||
store_failures: Optional[bool] = None
|
||||
where: Optional[str] = None
|
||||
limit: Optional[int] = None
|
||||
fail_calc: str = 'count(*)'
|
||||
warn_if: str = '!= 0'
|
||||
error_if: str = '!= 0'
|
||||
|
||||
@classmethod
|
||||
def same_contents(
|
||||
cls, unrendered: Dict[str, Any], other: Dict[str, Any]
|
||||
) -> bool:
|
||||
"""This is like __eq__, except it explicitly checks certain fields."""
|
||||
modifiers = [
|
||||
'severity',
|
||||
'where',
|
||||
'limit',
|
||||
'fail_calc',
|
||||
'warn_if',
|
||||
'error_if',
|
||||
'store_failures'
|
||||
]
|
||||
|
||||
seen = set()
|
||||
for _, target_name in cls._get_fields():
|
||||
key = target_name
|
||||
seen.add(key)
|
||||
if key in modifiers:
|
||||
if not cls.compare_key(unrendered, other, key):
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -457,6 +466,11 @@ class SnapshotConfig(EmptySnapshotConfig):
|
||||
@classmethod
|
||||
def validate(cls, data):
|
||||
super().validate(data)
|
||||
if not data.get('strategy') or not data.get('unique_key') or not \
|
||||
data.get('target_schema'):
|
||||
raise ValidationError(
|
||||
"Snapshots must be configured with a 'strategy', 'unique_key', "
|
||||
"and 'target_schema'.")
|
||||
if data.get('strategy') == 'check':
|
||||
if not data.get('check_cols'):
|
||||
raise ValidationError(
|
||||
@@ -480,7 +494,7 @@ class SnapshotConfig(EmptySnapshotConfig):
|
||||
# formerly supported with GenericSnapshotConfig
|
||||
|
||||
def finalize_and_validate(self):
|
||||
data = self.to_dict()
|
||||
data = self.to_dict(omit_none=True)
|
||||
self.validate(data)
|
||||
return self.from_dict(data)
|
||||
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
import os
|
||||
import time
|
||||
from dataclasses import dataclass, field
|
||||
from mashumaro.types import SerializableType
|
||||
from pathlib import Path
|
||||
from typing import (
|
||||
Optional,
|
||||
@@ -99,8 +101,8 @@ class HasRelationMetadata(dbtClassMixin, Replaceable):
|
||||
# because it messes up the subclasses and default parameters
|
||||
# so hack it here
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'database' not in data:
|
||||
data['database'] = None
|
||||
return data
|
||||
@@ -115,6 +117,21 @@ class ParsedNodeMixins(dbtClassMixin):
|
||||
def is_refable(self):
|
||||
return self.resource_type in NodeType.refable()
|
||||
|
||||
@property
|
||||
def should_store_failures(self):
|
||||
return self.resource_type == NodeType.Test and (
|
||||
self.config.store_failures if self.config.store_failures is not None
|
||||
else flags.STORE_FAILURES
|
||||
)
|
||||
|
||||
# will this node map to an object in the database?
|
||||
@property
|
||||
def is_relational(self):
|
||||
return (
|
||||
self.resource_type in NodeType.refable() or
|
||||
self.should_store_failures
|
||||
)
|
||||
|
||||
@property
|
||||
def is_ephemeral(self):
|
||||
return self.config.materialized == 'ephemeral'
|
||||
@@ -131,7 +148,9 @@ class ParsedNodeMixins(dbtClassMixin):
|
||||
"""Given a ParsedNodePatch, add the new information to the node."""
|
||||
# explicitly pick out the parts to update so we don't inadvertently
|
||||
# step on the model name or anything
|
||||
self.patch_path: Optional[str] = patch.original_file_path
|
||||
self.patch_path: Optional[str] = patch.file_id
|
||||
# update created_at so process_docs will run in partial parsing
|
||||
self.created_at = int(time.time())
|
||||
self.description = patch.description
|
||||
self.columns = patch.columns
|
||||
self.meta = patch.meta
|
||||
@@ -141,7 +160,7 @@ class ParsedNodeMixins(dbtClassMixin):
|
||||
# Maybe there should be validation or restrictions
|
||||
# elsewhere?
|
||||
assert isinstance(self, dbtClassMixin)
|
||||
dct = self.to_dict(options={'keep_none': True})
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
|
||||
def get_materialization(self):
|
||||
@@ -179,9 +198,11 @@ class ParsedNodeDefaults(ParsedNodeMandatory):
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
docs: Docs = field(default_factory=Docs)
|
||||
patch_path: Optional[str] = None
|
||||
compiled_path: Optional[str] = None
|
||||
build_path: Optional[str] = None
|
||||
deferred: bool = False
|
||||
unrendered_config: Dict[str, Any] = field(default_factory=dict)
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
def write_node(self, target_path: str, subdirectory: str, payload: str):
|
||||
if (os.path.basename(self.path) ==
|
||||
@@ -203,7 +224,39 @@ T = TypeVar('T', bound='ParsedNode')
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins):
|
||||
class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins, SerializableType):
|
||||
|
||||
def _serialize(self):
|
||||
return self.to_dict()
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, dct: Dict[str, int]):
|
||||
# The serialized ParsedNodes do not differ from each other
|
||||
# in fields that would allow 'from_dict' to distinguis
|
||||
# between them.
|
||||
resource_type = dct['resource_type']
|
||||
if resource_type == 'model':
|
||||
return ParsedModelNode.from_dict(dct)
|
||||
elif resource_type == 'analysis':
|
||||
return ParsedAnalysisNode.from_dict(dct)
|
||||
elif resource_type == 'seed':
|
||||
return ParsedSeedNode.from_dict(dct)
|
||||
elif resource_type == 'rpc':
|
||||
return ParsedRPCNode.from_dict(dct)
|
||||
elif resource_type == 'test':
|
||||
if 'test_metadata' in dct:
|
||||
return ParsedSchemaTestNode.from_dict(dct)
|
||||
else:
|
||||
return ParsedDataTestNode.from_dict(dct)
|
||||
elif resource_type == 'operation':
|
||||
return ParsedHookNode.from_dict(dct)
|
||||
elif resource_type == 'seed':
|
||||
return ParsedSeedNode.from_dict(dct)
|
||||
elif resource_type == 'snapshot':
|
||||
return ParsedSnapshotNode.from_dict(dct)
|
||||
else:
|
||||
return cls.from_dict(dct)
|
||||
|
||||
def _persist_column_docs(self) -> bool:
|
||||
return bool(self.config.persist_docs.get('columns'))
|
||||
|
||||
@@ -368,15 +421,6 @@ class ParsedSchemaTestNode(ParsedNode, HasTestMetadata):
|
||||
column_name: Optional[str] = None
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
|
||||
def same_config(self, other) -> bool:
|
||||
return (
|
||||
self.unrendered_config.get('severity') ==
|
||||
other.unrendered_config.get('severity')
|
||||
)
|
||||
|
||||
def same_column_name(self, other) -> bool:
|
||||
return self.column_name == other.column_name
|
||||
|
||||
def same_contents(self, other) -> bool:
|
||||
if other is None:
|
||||
return False
|
||||
@@ -441,20 +485,22 @@ class ParsedMacro(UnparsedBaseNode, HasUniqueID):
|
||||
docs: Docs = field(default_factory=Docs)
|
||||
patch_path: Optional[str] = None
|
||||
arguments: List[MacroArgument] = field(default_factory=list)
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
def local_vars(self):
|
||||
return {}
|
||||
|
||||
def patch(self, patch: ParsedMacroPatch):
|
||||
self.patch_path: Optional[str] = patch.original_file_path
|
||||
self.patch_path: Optional[str] = patch.file_id
|
||||
self.description = patch.description
|
||||
self.created_at = int(time.time())
|
||||
self.meta = patch.meta
|
||||
self.docs = patch.docs
|
||||
self.arguments = patch.arguments
|
||||
if flags.STRICT_MODE:
|
||||
# What does this actually validate?
|
||||
assert isinstance(self, dbtClassMixin)
|
||||
dct = self.to_dict(options={'keep_none': True})
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
|
||||
def same_contents(self, other: Optional['ParsedMacro']) -> bool:
|
||||
@@ -546,7 +592,8 @@ class ParsedSourceDefinition(
|
||||
UnparsedBaseNode,
|
||||
HasUniqueID,
|
||||
HasRelationMetadata,
|
||||
HasFqn
|
||||
HasFqn,
|
||||
|
||||
):
|
||||
name: str
|
||||
source_name: str
|
||||
@@ -567,6 +614,7 @@ class ParsedSourceDefinition(
|
||||
patch_path: Optional[Path] = None
|
||||
unrendered_config: Dict[str, Any] = field(default_factory=dict)
|
||||
relation_name: Optional[str] = None
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
def same_database_representation(
|
||||
self, other: 'ParsedSourceDefinition'
|
||||
@@ -642,6 +690,10 @@ class ParsedSourceDefinition(
|
||||
def depends_on_nodes(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def depends_on(self):
|
||||
return {'nodes': []}
|
||||
|
||||
@property
|
||||
def refs(self):
|
||||
return []
|
||||
@@ -667,10 +719,13 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
resource_type: NodeType = NodeType.Exposure
|
||||
description: str = ''
|
||||
maturity: Optional[MaturityType] = None
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
url: Optional[str] = None
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
@property
|
||||
def depends_on_nodes(self):
|
||||
@@ -680,11 +735,6 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
def search_name(self):
|
||||
return self.name
|
||||
|
||||
# no tags for now, but we could definitely add them
|
||||
@property
|
||||
def tags(self):
|
||||
return []
|
||||
|
||||
def same_depends_on(self, old: 'ParsedExposure') -> bool:
|
||||
return set(self.depends_on.nodes) == set(old.depends_on.nodes)
|
||||
|
||||
@@ -705,6 +755,7 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
|
||||
def same_contents(self, old: Optional['ParsedExposure']) -> bool:
|
||||
# existing when it didn't before is a change!
|
||||
# metadata/tags changes are not "changes"
|
||||
if old is None:
|
||||
return True
|
||||
|
||||
@@ -720,6 +771,18 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
)
|
||||
|
||||
|
||||
ManifestNodes = Union[
|
||||
ParsedAnalysisNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedRPCNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
]
|
||||
|
||||
|
||||
ParsedResource = Union[
|
||||
ParsedDocumentation,
|
||||
ParsedMacro,
|
||||
|
||||
@@ -25,6 +25,10 @@ class UnparsedBaseNode(dbtClassMixin, Replaceable):
|
||||
path: str
|
||||
original_file_path: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasSQL:
|
||||
@@ -116,6 +120,10 @@ class HasYamlMetadata(dbtClassMixin):
|
||||
yaml_key: str
|
||||
package_name: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedAnalysisUpdate(HasColumnDocs, HasDocs, HasYamlMetadata):
|
||||
@@ -231,12 +239,9 @@ class UnparsedSourceTableDefinition(HasColumnTests, HasTests):
|
||||
external: Optional[ExternalTable] = None
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
keep_none = False
|
||||
if options and 'keep_none' in options and options['keep_none']:
|
||||
keep_none = True
|
||||
if not keep_none and self.freshness is None:
|
||||
if 'freshness' not in dct and self.freshness is None:
|
||||
dct['freshness'] = None
|
||||
return dct
|
||||
|
||||
@@ -261,12 +266,9 @@ class UnparsedSourceDefinition(dbtClassMixin, Replaceable):
|
||||
def yaml_key(self) -> 'str':
|
||||
return 'sources'
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
keep_none = False
|
||||
if options and 'keep_none' in options and options['keep_none']:
|
||||
keep_none = True
|
||||
if not keep_none and self.freshness is None:
|
||||
if 'freshnewss' not in dct and self.freshness is None:
|
||||
dct['freshness'] = None
|
||||
return dct
|
||||
|
||||
@@ -290,7 +292,7 @@ class SourceTablePatch(dbtClassMixin):
|
||||
columns: Optional[Sequence[UnparsedColumn]] = None
|
||||
|
||||
def to_patch_dict(self) -> Dict[str, Any]:
|
||||
dct = self.to_dict()
|
||||
dct = self.to_dict(omit_none=True)
|
||||
remove_keys = ('name')
|
||||
for key in remove_keys:
|
||||
if key in dct:
|
||||
@@ -327,7 +329,7 @@ class SourcePatch(dbtClassMixin, Replaceable):
|
||||
tags: Optional[List[str]] = None
|
||||
|
||||
def to_patch_dict(self) -> Dict[str, Any]:
|
||||
dct = self.to_dict()
|
||||
dct = self.to_dict(omit_none=True)
|
||||
remove_keys = ('name', 'overrides', 'tables', 'path')
|
||||
for key in remove_keys:
|
||||
if key in dct:
|
||||
@@ -353,6 +355,10 @@ class UnparsedDocumentation(dbtClassMixin, Replaceable):
|
||||
path: str
|
||||
original_file_path: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
@property
|
||||
def resource_type(self):
|
||||
return NodeType.Documentation
|
||||
@@ -419,5 +425,7 @@ class UnparsedExposure(dbtClassMixin, Replaceable):
|
||||
owner: ExposureOwner
|
||||
description: str = ''
|
||||
maturity: Optional[MaturityType] = None
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
url: Optional[str] = None
|
||||
depends_on: List[str] = field(default_factory=list)
|
||||
|
||||
@@ -70,6 +70,7 @@ class GitPackage(Package):
|
||||
git: str
|
||||
revision: Optional[RawVersion] = None
|
||||
warn_unpinned: Optional[bool] = None
|
||||
subdirectory: Optional[str] = None
|
||||
|
||||
def get_revisions(self) -> List[str]:
|
||||
if self.revision is None:
|
||||
@@ -190,11 +191,13 @@ class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
on_run_start: Optional[List[str]] = field(default_factory=list_str)
|
||||
on_run_end: Optional[List[str]] = field(default_factory=list_str)
|
||||
require_dbt_version: Optional[Union[List[str], str]] = None
|
||||
dispatch: List[Dict[str, Any]] = field(default_factory=list)
|
||||
models: Dict[str, Any] = field(default_factory=dict)
|
||||
seeds: Dict[str, Any] = field(default_factory=dict)
|
||||
snapshots: Dict[str, Any] = field(default_factory=dict)
|
||||
analyses: Dict[str, Any] = field(default_factory=dict)
|
||||
sources: Dict[str, Any] = field(default_factory=dict)
|
||||
tests: Dict[str, Any] = field(default_factory=dict)
|
||||
vars: Optional[Dict[str, Any]] = field(
|
||||
default=None,
|
||||
metadata=dict(
|
||||
@@ -211,6 +214,13 @@ class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
raise ValidationError(
|
||||
f"Invalid project name: {data['name']} is a reserved word"
|
||||
)
|
||||
# validate dispatch config
|
||||
if 'dispatch' in data and data['dispatch']:
|
||||
entries = data['dispatch']
|
||||
for entry in entries:
|
||||
if ('macro_namespace' not in entry or 'search_order' not in entry or
|
||||
not isinstance(entry['search_order'], list)):
|
||||
raise ValidationError(f"Invalid project dispatch config: {entry}")
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -52,7 +52,7 @@ class FakeAPIObject(dbtClassMixin, Replaceable, Mapping):
|
||||
return len(fields(self.__class__))
|
||||
|
||||
def incorporate(self, **kwargs):
|
||||
value = self.to_dict()
|
||||
value = self.to_dict(omit_none=True)
|
||||
value = deep_merge(value, kwargs)
|
||||
return self.from_dict(value)
|
||||
|
||||
|
||||
@@ -78,6 +78,7 @@ class TestStatus(StrEnum):
|
||||
Error = NodeStatus.Error
|
||||
Fail = NodeStatus.Fail
|
||||
Warn = NodeStatus.Warn
|
||||
Skipped = NodeStatus.Skipped
|
||||
|
||||
|
||||
class FreshnessStatus(StrEnum):
|
||||
@@ -94,13 +95,16 @@ class BaseResult(dbtClassMixin):
|
||||
thread_id: str
|
||||
execution_time: float
|
||||
adapter_response: Dict[str, Any]
|
||||
message: Optional[Union[str, int]]
|
||||
message: Optional[str]
|
||||
failures: Optional[int]
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'message' not in data:
|
||||
data['message'] = None
|
||||
if 'failures' not in data:
|
||||
data['failures'] = None
|
||||
return data
|
||||
|
||||
|
||||
@@ -157,7 +161,8 @@ def process_run_result(result: RunResult) -> RunResultOutput:
|
||||
thread_id=result.thread_id,
|
||||
execution_time=result.execution_time,
|
||||
message=result.message,
|
||||
adapter_response=result.adapter_response
|
||||
adapter_response=result.adapter_response,
|
||||
failures=result.failures
|
||||
)
|
||||
|
||||
|
||||
@@ -180,7 +185,7 @@ class RunExecutionResult(
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('run-results', 1)
|
||||
@schema_version('run-results', 2)
|
||||
class RunResultsArtifact(ExecutionResult, ArtifactMixin):
|
||||
results: Sequence[RunResultOutput]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
@@ -206,7 +211,7 @@ class RunResultsArtifact(ExecutionResult, ArtifactMixin):
|
||||
)
|
||||
|
||||
def write(self, path: str):
|
||||
write_json(path, self.to_dict(options={'keep_none': True}))
|
||||
write_json(path, self.to_dict(omit_none=False))
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -378,6 +383,7 @@ class FreshnessExecutionResultArtifact(
|
||||
|
||||
|
||||
Primitive = Union[bool, str, float, None]
|
||||
PrimitiveDict = Dict[str, Primitive]
|
||||
|
||||
CatalogKey = NamedTuple(
|
||||
'CatalogKey',
|
||||
@@ -448,8 +454,8 @@ class CatalogResults(dbtClassMixin):
|
||||
errors: Optional[List[str]] = None
|
||||
_compile_results: Optional[Any] = None
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
dct = super().__post_serialize__(dct, options=options)
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if '_compile_results' in dct:
|
||||
del dct['_compile_results']
|
||||
return dct
|
||||
|
||||
@@ -38,8 +38,8 @@ class RPCParameters(dbtClassMixin):
|
||||
timeout: Optional[float]
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data, omit_none=True):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'timeout' not in data:
|
||||
data['timeout'] = None
|
||||
if 'task_tags' not in data:
|
||||
@@ -63,6 +63,16 @@ class RPCCompileParameters(RPCParameters):
|
||||
state: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCListParameters(RPCParameters):
|
||||
resource_types: Optional[List[str]] = None
|
||||
models: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
output: Optional[str] = 'json'
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCRunParameters(RPCParameters):
|
||||
threads: Optional[int] = None
|
||||
@@ -190,6 +200,13 @@ class RemoteResult(VersionedSchema):
|
||||
logs: List[LogMessage]
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-list-results', 1)
|
||||
class RemoteListResults(RemoteResult):
|
||||
output: List[Any]
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-deps-result', 1)
|
||||
class RemoteDepsResult(RemoteResult):
|
||||
@@ -428,8 +445,8 @@ class TaskTiming(dbtClassMixin):
|
||||
# These ought to be defaults but superclass order doesn't
|
||||
# allow that to work
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
for field_name in ('start', 'end', 'elapsed'):
|
||||
if field_name not in data:
|
||||
data[field_name] = None
|
||||
@@ -496,8 +513,8 @@ class PollResult(RemoteResult, TaskTiming):
|
||||
# These ought to be defaults but superclass order doesn't
|
||||
# allow that to work
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
for field_name in ('start', 'end', 'elapsed'):
|
||||
if field_name not in data:
|
||||
data[field_name] = None
|
||||
|
||||
@@ -14,7 +14,6 @@ from dbt.version import __version__
|
||||
from dbt.tracking import get_invocation_id
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
|
||||
MacroKey = Tuple[str, str]
|
||||
SourceKey = Tuple[str, str]
|
||||
|
||||
|
||||
@@ -58,7 +57,7 @@ class Mergeable(Replaceable):
|
||||
class Writable:
|
||||
def write(self, path: str):
|
||||
write_json(
|
||||
path, self.to_dict(options={'keep_none': True}) # type: ignore
|
||||
path, self.to_dict(omit_none=False) # type: ignore
|
||||
)
|
||||
|
||||
|
||||
@@ -74,7 +73,7 @@ class AdditionalPropertiesMixin:
|
||||
# not in the class definitions and puts them in an
|
||||
# _extra dict in the class
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
def __pre_deserialize__(cls, data):
|
||||
# dir() did not work because fields with
|
||||
# metadata settings are not found
|
||||
# The original version of this would create the
|
||||
@@ -93,18 +92,18 @@ class AdditionalPropertiesMixin:
|
||||
else:
|
||||
new_dict[key] = value
|
||||
data = new_dict
|
||||
data = super().__pre_deserialize__(data, options=options)
|
||||
data = super().__pre_deserialize__(data)
|
||||
return data
|
||||
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
data = super().__post_serialize__(dct, options=options)
|
||||
def __post_serialize__(self, dct):
|
||||
data = super().__post_serialize__(dct)
|
||||
data.update(self.extra)
|
||||
if '_extra' in data:
|
||||
del data['_extra']
|
||||
return data
|
||||
|
||||
def replace(self, **kwargs):
|
||||
dct = self.to_dict(options={'keep_none': True})
|
||||
dct = self.to_dict(omit_none=False)
|
||||
dct.update(kwargs)
|
||||
return self.from_dict(dct)
|
||||
|
||||
@@ -126,7 +125,8 @@ class Readable:
|
||||
return cls.from_dict(data) # type: ignore
|
||||
|
||||
|
||||
BASE_SCHEMAS_URL = 'https://schemas.getdbt.com/dbt/{name}/v{version}.json'
|
||||
BASE_SCHEMAS_URL = 'https://schemas.getdbt.com/'
|
||||
SCHEMA_PATH = 'dbt/{name}/v{version}.json'
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
@@ -134,12 +134,16 @@ class SchemaVersion:
|
||||
name: str
|
||||
version: int
|
||||
|
||||
def __str__(self) -> str:
|
||||
return BASE_SCHEMAS_URL.format(
|
||||
@property
|
||||
def path(self) -> str:
|
||||
return SCHEMA_PATH.format(
|
||||
name=self.name,
|
||||
version=self.version,
|
||||
version=self.version
|
||||
)
|
||||
|
||||
def __str__(self) -> str:
|
||||
return BASE_SCHEMAS_URL + self.path
|
||||
|
||||
|
||||
SCHEMA_VERSION_KEY = 'dbt_schema_version'
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
from typing import (
|
||||
Type, ClassVar, Dict, cast, TypeVar
|
||||
Type, ClassVar, cast,
|
||||
)
|
||||
import re
|
||||
from dataclasses import fields
|
||||
@@ -9,29 +9,28 @@ from dateutil.parser import parse
|
||||
|
||||
from hologram import JsonSchemaMixin, FieldEncoder, ValidationError
|
||||
|
||||
# type: ignore
|
||||
from mashumaro import DataClassDictMixin
|
||||
from mashumaro.types import SerializableEncoder, SerializableType
|
||||
from mashumaro.config import (
|
||||
TO_DICT_ADD_OMIT_NONE_FLAG, BaseConfig as MashBaseConfig
|
||||
)
|
||||
from mashumaro.types import SerializableType, SerializationStrategy
|
||||
|
||||
|
||||
class DateTimeSerializableEncoder(SerializableEncoder[datetime]):
|
||||
@classmethod
|
||||
def _serialize(cls, value: datetime) -> str:
|
||||
class DateTimeSerialization(SerializationStrategy):
|
||||
def serialize(self, value):
|
||||
out = value.isoformat()
|
||||
# Assume UTC if timezone is missing
|
||||
if value.tzinfo is None:
|
||||
out = out + "Z"
|
||||
return out
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, value: str) -> datetime:
|
||||
def deserialize(self, value):
|
||||
return (
|
||||
value if isinstance(value, datetime) else parse(cast(str, value))
|
||||
)
|
||||
|
||||
|
||||
TV = TypeVar("TV")
|
||||
|
||||
|
||||
# This class pulls in both JsonSchemaMixin from Hologram and
|
||||
# DataClassDictMixin from our fork of Mashumaro. The 'to_dict'
|
||||
# and 'from_dict' methods come from Mashumaro. Building
|
||||
@@ -43,23 +42,21 @@ class dbtClassMixin(DataClassDictMixin, JsonSchemaMixin):
|
||||
against the schema
|
||||
"""
|
||||
|
||||
_serializable_encoders: ClassVar[Dict[str, SerializableEncoder]] = {
|
||||
'datetime.datetime': DateTimeSerializableEncoder(),
|
||||
}
|
||||
class Config(MashBaseConfig):
|
||||
code_generation_options = [
|
||||
TO_DICT_ADD_OMIT_NONE_FLAG,
|
||||
]
|
||||
serialization_strategy = {
|
||||
datetime: DateTimeSerialization(),
|
||||
}
|
||||
|
||||
_hyphenated: ClassVar[bool] = False
|
||||
ADDITIONAL_PROPERTIES: ClassVar[bool] = False
|
||||
|
||||
# This is called by the mashumaro to_dict in order to handle
|
||||
# nested classes.
|
||||
# Munges the dict that's returned.
|
||||
def __post_serialize__(self, dct, options=None):
|
||||
keep_none = False
|
||||
if options and 'keep_none' in options and options['keep_none']:
|
||||
keep_none = True
|
||||
if not keep_none: # remove attributes that are None
|
||||
new_dict = {k: v for k, v in dct.items() if v is not None}
|
||||
dct = new_dict
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
if self._hyphenated:
|
||||
new_dict = {}
|
||||
for key in dct:
|
||||
@@ -75,8 +72,10 @@ class dbtClassMixin(DataClassDictMixin, JsonSchemaMixin):
|
||||
# This is called by the mashumaro _from_dict method, before
|
||||
# performing the conversion to a dict
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, options=None):
|
||||
if cls._hyphenated:
|
||||
def __pre_deserialize__(cls, data):
|
||||
# `data` might not be a dict, e.g. for `query_comment`, which accepts
|
||||
# a dict or a string; only snake-case for dict values.
|
||||
if cls._hyphenated and isinstance(data, dict):
|
||||
new_dict = {}
|
||||
for key in data:
|
||||
if '-' in key:
|
||||
@@ -92,8 +91,8 @@ class dbtClassMixin(DataClassDictMixin, JsonSchemaMixin):
|
||||
# hologram and in mashumaro.
|
||||
def _local_to_dict(self, **kwargs):
|
||||
args = {}
|
||||
if 'omit_none' in kwargs and kwargs['omit_none'] is False:
|
||||
args['options'] = {'keep_none': True}
|
||||
if 'omit_none' in kwargs:
|
||||
args['omit_none'] = kwargs['omit_none']
|
||||
return self.to_dict(**args)
|
||||
|
||||
|
||||
|
||||
@@ -43,6 +43,20 @@ class DBTDeprecation:
|
||||
active_deprecations.add(self.name)
|
||||
|
||||
|
||||
class DispatchPackagesDeprecation(DBTDeprecation):
|
||||
_name = 'dispatch-packages'
|
||||
_description = '''\
|
||||
The "packages" argument of adapter.dispatch() has been deprecated.
|
||||
Use the "macro_namespace" argument instead.
|
||||
|
||||
Raised during dispatch for: {macro_name}
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch
|
||||
'''
|
||||
|
||||
|
||||
class MaterializationReturnDeprecation(DBTDeprecation):
|
||||
_name = 'materialization-return'
|
||||
|
||||
@@ -155,6 +169,7 @@ def warn(name, *args, **kwargs):
|
||||
active_deprecations: Set[str] = set()
|
||||
|
||||
deprecations_list: List[DBTDeprecation] = [
|
||||
DispatchPackagesDeprecation(),
|
||||
MaterializationReturnDeprecation(),
|
||||
NotADictionaryDeprecation(),
|
||||
ColumnQuotingDeprecation(),
|
||||
|
||||
@@ -93,6 +93,9 @@ class PinnedPackage(BasePackage):
|
||||
dest_dirname = self.get_project_name(project, renderer)
|
||||
return os.path.join(project.modules_path, dest_dirname)
|
||||
|
||||
def get_subdirectory(self):
|
||||
return None
|
||||
|
||||
|
||||
SomePinned = TypeVar('SomePinned', bound=PinnedPackage)
|
||||
SomeUnpinned = TypeVar('SomeUnpinned', bound='UnpinnedPackage')
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
import hashlib
|
||||
from typing import List
|
||||
from typing import List, Optional
|
||||
|
||||
from dbt.clients import git, system
|
||||
from dbt.config import Project
|
||||
@@ -37,18 +37,37 @@ class GitPackageMixin:
|
||||
|
||||
class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
def __init__(
|
||||
self, git: str, revision: str, warn_unpinned: bool = True
|
||||
self,
|
||||
git: str,
|
||||
revision: str,
|
||||
warn_unpinned: bool = True,
|
||||
subdirectory: Optional[str] = None,
|
||||
) -> None:
|
||||
super().__init__(git)
|
||||
self.revision = revision
|
||||
self.warn_unpinned = warn_unpinned
|
||||
self.subdirectory = subdirectory
|
||||
self._checkout_name = md5sum(self.git)
|
||||
|
||||
def get_version(self):
|
||||
return self.revision
|
||||
|
||||
def get_subdirectory(self):
|
||||
return self.subdirectory
|
||||
|
||||
def nice_version_name(self):
|
||||
return 'revision {}'.format(self.revision)
|
||||
if self.revision == 'HEAD':
|
||||
return 'HEAD (default revision)'
|
||||
else:
|
||||
return 'revision {}'.format(self.revision)
|
||||
|
||||
def unpinned_msg(self):
|
||||
if self.revision == 'HEAD':
|
||||
return 'not pinned, using HEAD (default branch)'
|
||||
elif self.revision in ('main', 'master'):
|
||||
return f'pinned to the "{self.revision}" branch'
|
||||
else:
|
||||
return None
|
||||
|
||||
def _checkout(self):
|
||||
"""Performs a shallow clone of the repository into the downloads
|
||||
@@ -57,8 +76,8 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
the path to the checked out directory."""
|
||||
try:
|
||||
dir_ = git.clone_and_checkout(
|
||||
self.git, get_downloads_path(), branch=self.revision,
|
||||
dirname=self._checkout_name
|
||||
self.git, get_downloads_path(), revision=self.revision,
|
||||
dirname=self._checkout_name, subdirectory=self.subdirectory
|
||||
)
|
||||
except ExecutableError as exc:
|
||||
if exc.cmd and exc.cmd[0] == 'git':
|
||||
@@ -72,11 +91,12 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
|
||||
def _fetch_metadata(self, project, renderer) -> ProjectPackageMetadata:
|
||||
path = self._checkout()
|
||||
if self.revision == 'master' and self.warn_unpinned:
|
||||
|
||||
if self.unpinned_msg() and self.warn_unpinned:
|
||||
warn_or_error(
|
||||
'The git package "{}" is not pinned.\n\tThis can introduce '
|
||||
'The git package "{}" \n\tis {}.\n\tThis can introduce '
|
||||
'breaking changes into your project without warning!\n\nSee {}'
|
||||
.format(self.git, PIN_PACKAGE_URL),
|
||||
.format(self.git, self.unpinned_msg(), PIN_PACKAGE_URL),
|
||||
log_fmt=ui.yellow('WARNING: {}')
|
||||
)
|
||||
loaded = Project.from_project_root(path, renderer)
|
||||
@@ -95,11 +115,16 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
|
||||
class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
def __init__(
|
||||
self, git: str, revisions: List[str], warn_unpinned: bool = True
|
||||
self,
|
||||
git: str,
|
||||
revisions: List[str],
|
||||
warn_unpinned: bool = True,
|
||||
subdirectory: Optional[str] = None,
|
||||
) -> None:
|
||||
super().__init__(git)
|
||||
self.revisions = revisions
|
||||
self.warn_unpinned = warn_unpinned
|
||||
self.subdirectory = subdirectory
|
||||
|
||||
@classmethod
|
||||
def from_contract(
|
||||
@@ -110,7 +135,7 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
# we want to map None -> True
|
||||
warn_unpinned = contract.warn_unpinned is not False
|
||||
return cls(git=contract.git, revisions=revisions,
|
||||
warn_unpinned=warn_unpinned)
|
||||
warn_unpinned=warn_unpinned, subdirectory=contract.subdirectory)
|
||||
|
||||
def all_names(self) -> List[str]:
|
||||
if self.git.endswith('.git'):
|
||||
@@ -128,12 +153,13 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
git=self.git,
|
||||
revisions=self.revisions + other.revisions,
|
||||
warn_unpinned=warn_unpinned,
|
||||
subdirectory=self.subdirectory,
|
||||
)
|
||||
|
||||
def resolved(self) -> GitPinnedPackage:
|
||||
requested = set(self.revisions)
|
||||
if len(requested) == 0:
|
||||
requested = {'master'}
|
||||
requested = {'HEAD'}
|
||||
elif len(requested) > 1:
|
||||
raise_dependency_error(
|
||||
'git dependencies should contain exactly one version. '
|
||||
@@ -141,5 +167,5 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
|
||||
return GitPinnedPackage(
|
||||
git=self.git, revision=requested.pop(),
|
||||
warn_unpinned=self.warn_unpinned
|
||||
warn_unpinned=self.warn_unpinned, subdirectory=self.subdirectory
|
||||
)
|
||||
|
||||
@@ -289,6 +289,15 @@ class JinjaRenderingException(CompilationException):
|
||||
pass
|
||||
|
||||
|
||||
class UndefinedMacroException(CompilationException):
|
||||
|
||||
def __str__(self, prefix='! ') -> str:
|
||||
msg = super().__str__(prefix)
|
||||
return f'{msg}. This can happen when calling a macro that does ' \
|
||||
'not exist. Check for typos and/or install package dependencies ' \
|
||||
'with "dbt deps".'
|
||||
|
||||
|
||||
class UnknownAsyncIDException(Exception):
|
||||
CODE = 10012
|
||||
MESSAGE = 'RPC server got an unknown async ID'
|
||||
@@ -845,11 +854,11 @@ def _fix_dupe_msg(path_1: str, path_2: str, name: str, type_name: str) -> str:
|
||||
)
|
||||
|
||||
|
||||
def raise_duplicate_patch_name(patch_1, patch_2):
|
||||
def raise_duplicate_patch_name(patch_1, existing_patch_path):
|
||||
name = patch_1.name
|
||||
fix = _fix_dupe_msg(
|
||||
patch_1.original_file_path,
|
||||
patch_2.original_file_path,
|
||||
existing_patch_path,
|
||||
name,
|
||||
'resource',
|
||||
)
|
||||
@@ -860,12 +869,12 @@ def raise_duplicate_patch_name(patch_1, patch_2):
|
||||
)
|
||||
|
||||
|
||||
def raise_duplicate_macro_patch_name(patch_1, patch_2):
|
||||
def raise_duplicate_macro_patch_name(patch_1, existing_patch_path):
|
||||
package_name = patch_1.package_name
|
||||
name = patch_1.name
|
||||
fix = _fix_dupe_msg(
|
||||
patch_1.original_file_path,
|
||||
patch_2.original_file_path,
|
||||
existing_patch_path,
|
||||
name,
|
||||
'macros'
|
||||
)
|
||||
|
||||
@@ -13,9 +13,11 @@ FULL_REFRESH = None
|
||||
USE_CACHE = None
|
||||
WARN_ERROR = None
|
||||
TEST_NEW_PARSER = None
|
||||
USE_EXPERIMENTAL_PARSER = None
|
||||
WRITE_JSON = None
|
||||
PARTIAL_PARSE = None
|
||||
USE_COLORS = None
|
||||
STORE_FAILURES = None
|
||||
|
||||
|
||||
def env_set_truthy(key: str) -> Optional[str]:
|
||||
@@ -53,22 +55,26 @@ MP_CONTEXT = _get_context()
|
||||
|
||||
def reset():
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS
|
||||
USE_EXPERIMENTAL_PARSER, WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS, \
|
||||
STORE_FAILURES
|
||||
|
||||
STRICT_MODE = False
|
||||
FULL_REFRESH = False
|
||||
USE_CACHE = True
|
||||
WARN_ERROR = False
|
||||
TEST_NEW_PARSER = False
|
||||
USE_EXPERIMENTAL_PARSER = False
|
||||
WRITE_JSON = True
|
||||
PARTIAL_PARSE = False
|
||||
MP_CONTEXT = _get_context()
|
||||
USE_COLORS = True
|
||||
STORE_FAILURES = False
|
||||
|
||||
|
||||
def set_from_args(args):
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS
|
||||
USE_EXPERIMENTAL_PARSER, WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS, \
|
||||
STORE_FAILURES
|
||||
|
||||
USE_CACHE = getattr(args, 'use_cache', USE_CACHE)
|
||||
|
||||
@@ -80,6 +86,7 @@ def set_from_args(args):
|
||||
)
|
||||
|
||||
TEST_NEW_PARSER = getattr(args, 'test_new_parser', TEST_NEW_PARSER)
|
||||
USE_EXPERIMENTAL_PARSER = getattr(args, 'use_experimental_parser', USE_EXPERIMENTAL_PARSER)
|
||||
WRITE_JSON = getattr(args, 'write_json', WRITE_JSON)
|
||||
PARTIAL_PARSE = getattr(args, 'partial_parse', None)
|
||||
MP_CONTEXT = _get_context()
|
||||
@@ -91,6 +98,8 @@ def set_from_args(args):
|
||||
if use_colors_override is not None:
|
||||
USE_COLORS = use_colors_override
|
||||
|
||||
STORE_FAILURES = getattr(args, 'store_failures', STORE_FAILURES)
|
||||
|
||||
|
||||
# initialize everything to the defaults on module load
|
||||
reset()
|
||||
|
||||
@@ -26,7 +26,7 @@ SCHEMA_TEST_SELECTOR: str = 'test_type:schema'
|
||||
|
||||
|
||||
def parse_union(
|
||||
components: List[str], expect_exists: bool
|
||||
components: List[str], expect_exists: bool, greedy: bool = False
|
||||
) -> SelectionUnion:
|
||||
# turn ['a b', 'c'] -> ['a', 'b', 'c']
|
||||
raw_specs = itertools.chain.from_iterable(
|
||||
@@ -37,7 +37,7 @@ def parse_union(
|
||||
# ['a', 'b', 'c,d'] -> union('a', 'b', intersection('c', 'd'))
|
||||
for raw_spec in raw_specs:
|
||||
intersection_components: List[SelectionSpec] = [
|
||||
SelectionCriteria.from_single_spec(part)
|
||||
SelectionCriteria.from_single_spec(part, greedy=greedy)
|
||||
for part in raw_spec.split(INTERSECTION_DELIMITER)
|
||||
]
|
||||
union_components.append(SelectionIntersection(
|
||||
@@ -45,7 +45,6 @@ def parse_union(
|
||||
expect_exists=expect_exists,
|
||||
raw=raw_spec,
|
||||
))
|
||||
|
||||
return SelectionUnion(
|
||||
components=union_components,
|
||||
expect_exists=False,
|
||||
@@ -54,21 +53,21 @@ def parse_union(
|
||||
|
||||
|
||||
def parse_union_from_default(
|
||||
raw: Optional[List[str]], default: List[str]
|
||||
raw: Optional[List[str]], default: List[str], greedy: bool = False
|
||||
) -> SelectionUnion:
|
||||
components: List[str]
|
||||
expect_exists: bool
|
||||
if raw is None:
|
||||
return parse_union(components=default, expect_exists=False)
|
||||
return parse_union(components=default, expect_exists=False, greedy=greedy)
|
||||
else:
|
||||
return parse_union(components=raw, expect_exists=True)
|
||||
return parse_union(components=raw, expect_exists=True, greedy=greedy)
|
||||
|
||||
|
||||
def parse_difference(
|
||||
include: Optional[List[str]], exclude: Optional[List[str]]
|
||||
) -> SelectionDifference:
|
||||
included = parse_union_from_default(include, DEFAULT_INCLUDES)
|
||||
excluded = parse_union_from_default(exclude, DEFAULT_EXCLUDES)
|
||||
excluded = parse_union_from_default(exclude, DEFAULT_EXCLUDES, greedy=True)
|
||||
return SelectionDifference(components=[included, excluded])
|
||||
|
||||
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
import threading
|
||||
from queue import PriorityQueue
|
||||
from typing import (
|
||||
Dict, Set, Optional
|
||||
)
|
||||
|
||||
import networkx as nx # type: ignore
|
||||
import threading
|
||||
|
||||
from queue import PriorityQueue
|
||||
from typing import Dict, Set, List, Generator, Optional
|
||||
|
||||
from .graph import UniqueId
|
||||
from dbt.contracts.graph.parsed import ParsedSourceDefinition, ParsedExposure
|
||||
@@ -21,9 +19,8 @@ class GraphQueue:
|
||||
that separate threads do not call `.empty()` or `__len__()` and `.get()` at
|
||||
the same time, as there is an unlocked race!
|
||||
"""
|
||||
def __init__(
|
||||
self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]
|
||||
):
|
||||
|
||||
def __init__(self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]):
|
||||
self.graph = graph
|
||||
self.manifest = manifest
|
||||
self._selected = selected
|
||||
@@ -37,7 +34,7 @@ class GraphQueue:
|
||||
# this lock controls most things
|
||||
self.lock = threading.Lock()
|
||||
# store the 'score' of each node as a number. Lower is higher priority.
|
||||
self._scores = self._calculate_scores()
|
||||
self._scores = self._get_scores(self.graph)
|
||||
# populate the initial queue
|
||||
self._find_new_additions()
|
||||
# awaits after task end
|
||||
@@ -56,30 +53,59 @@ class GraphQueue:
|
||||
return False
|
||||
return True
|
||||
|
||||
def _calculate_scores(self) -> Dict[UniqueId, int]:
|
||||
"""Calculate the 'value' of each node in the graph based on how many
|
||||
blocking descendants it has. We use this score for the internal
|
||||
priority queue's ordering, so the quality of this metric is important.
|
||||
@staticmethod
|
||||
def _grouped_topological_sort(
|
||||
graph: nx.DiGraph,
|
||||
) -> Generator[List[str], None, None]:
|
||||
"""Topological sort of given graph that groups ties.
|
||||
|
||||
The score is stored as a negative number because the internal
|
||||
PriorityQueue picks lowest values first.
|
||||
Adapted from `nx.topological_sort`, this function returns a topo sort of a graph however
|
||||
instead of arbitrarily ordering ties in the sort order, ties are grouped together in
|
||||
lists.
|
||||
|
||||
We could do this in one pass over the graph instead of len(self.graph)
|
||||
passes but this is easy. For large graphs this may hurt performance.
|
||||
Args:
|
||||
graph: The graph to be sorted.
|
||||
|
||||
This operates on the graph, so it would require a lock if called from
|
||||
outside __init__.
|
||||
|
||||
:return Dict[str, int]: The score dict, mapping unique IDs to integer
|
||||
scores. Lower scores are higher priority.
|
||||
Returns:
|
||||
A generator that yields lists of nodes, one list per graph depth level.
|
||||
"""
|
||||
indegree_map = {v: d for v, d in graph.in_degree() if d > 0}
|
||||
zero_indegree = [v for v, d in graph.in_degree() if d == 0]
|
||||
|
||||
while zero_indegree:
|
||||
yield zero_indegree
|
||||
new_zero_indegree = []
|
||||
for v in zero_indegree:
|
||||
for _, child in graph.edges(v):
|
||||
indegree_map[child] -= 1
|
||||
if not indegree_map[child]:
|
||||
new_zero_indegree.append(child)
|
||||
zero_indegree = new_zero_indegree
|
||||
|
||||
def _get_scores(self, graph: nx.DiGraph) -> Dict[str, int]:
|
||||
"""Scoring nodes for processing order.
|
||||
|
||||
Scores are calculated by the graph depth level. Lowest score (0) should be processed first.
|
||||
|
||||
Args:
|
||||
graph: The graph to be scored.
|
||||
|
||||
Returns:
|
||||
A dictionary consisting of `node name`:`score` pairs.
|
||||
"""
|
||||
# split graph by connected subgraphs
|
||||
subgraphs = (
|
||||
graph.subgraph(x) for x in nx.connected_components(nx.Graph(graph))
|
||||
)
|
||||
|
||||
# score all nodes in all subgraphs
|
||||
scores = {}
|
||||
for node in self.graph.nodes():
|
||||
score = -1 * len([
|
||||
d for d in nx.descendants(self.graph, node)
|
||||
if self._include_in_cost(d)
|
||||
])
|
||||
scores[node] = score
|
||||
for subgraph in subgraphs:
|
||||
grouped_nodes = self._grouped_topological_sort(subgraph)
|
||||
for level, group in enumerate(grouped_nodes):
|
||||
for node in group:
|
||||
scores[node] = level
|
||||
|
||||
return scores
|
||||
|
||||
def get(
|
||||
@@ -133,8 +159,6 @@ class GraphQueue:
|
||||
def _find_new_additions(self) -> None:
|
||||
"""Find any nodes in the graph that need to be added to the internal
|
||||
queue and add them.
|
||||
|
||||
Callers must hold the lock.
|
||||
"""
|
||||
for node, in_degree in self.graph.in_degree():
|
||||
if not self._already_known(node) and in_degree == 0:
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
from typing import Set, List, Optional
|
||||
from typing import Set, List, Optional, Tuple
|
||||
|
||||
from .graph import Graph, UniqueId
|
||||
from .queue import GraphQueue
|
||||
@@ -25,11 +25,23 @@ def get_package_names(nodes):
|
||||
def alert_non_existence(raw_spec, nodes):
|
||||
if len(nodes) == 0:
|
||||
warn_or_error(
|
||||
f"The selector '{str(raw_spec)}' does not match any nodes and will"
|
||||
f" be ignored"
|
||||
f"The selection criterion '{str(raw_spec)}' does not match"
|
||||
f" any nodes"
|
||||
)
|
||||
|
||||
|
||||
def can_select_indirectly(node):
|
||||
"""If a node is not selected itself, but its parent(s) are, it may qualify
|
||||
for indirect selection.
|
||||
Today, only Test nodes can be indirectly selected. In the future,
|
||||
other node types or invocation flags might qualify.
|
||||
"""
|
||||
if node.resource_type == NodeType.Test:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
class NodeSelector(MethodManager):
|
||||
"""The node selector is aware of the graph and manifest,
|
||||
"""
|
||||
@@ -61,8 +73,8 @@ class NodeSelector(MethodManager):
|
||||
|
||||
def get_nodes_from_criteria(
|
||||
self,
|
||||
spec: SelectionCriteria,
|
||||
) -> Set[UniqueId]:
|
||||
spec: SelectionCriteria
|
||||
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
"""Get all nodes specified by the single selection criteria.
|
||||
|
||||
- collect the directly included nodes
|
||||
@@ -79,11 +91,14 @@ class NodeSelector(MethodManager):
|
||||
f"The '{spec.method}' selector specified in {spec.raw} is "
|
||||
f"invalid. Must be one of [{valid_selectors}]"
|
||||
)
|
||||
return set()
|
||||
return set(), set()
|
||||
|
||||
extras = self.collect_specified_neighbors(spec, collected)
|
||||
result = self.expand_selection(collected | extras)
|
||||
return result
|
||||
neighbors = self.collect_specified_neighbors(spec, collected)
|
||||
direct_nodes, indirect_nodes = self.expand_selection(
|
||||
selected=(collected | neighbors),
|
||||
greedy=spec.greedy
|
||||
)
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def collect_specified_neighbors(
|
||||
self, spec: SelectionCriteria, selected: Set[UniqueId]
|
||||
@@ -106,24 +121,46 @@ class NodeSelector(MethodManager):
|
||||
additional.update(self.graph.select_children(selected, depth))
|
||||
return additional
|
||||
|
||||
def select_nodes(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""Select the nodes in the graph according to the spec.
|
||||
|
||||
If the spec is a composite spec (a union, difference, or intersection),
|
||||
def select_nodes_recursively(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
"""If the spec is a composite spec (a union, difference, or intersection),
|
||||
recurse into its selections and combine them. If the spec is a concrete
|
||||
selection criteria, resolve that using the given graph.
|
||||
"""
|
||||
if isinstance(spec, SelectionCriteria):
|
||||
result = self.get_nodes_from_criteria(spec)
|
||||
direct_nodes, indirect_nodes = self.get_nodes_from_criteria(spec)
|
||||
else:
|
||||
node_selections = [
|
||||
self.select_nodes(component)
|
||||
bundles = [
|
||||
self.select_nodes_recursively(component)
|
||||
for component in spec
|
||||
]
|
||||
result = spec.combined(node_selections)
|
||||
|
||||
direct_sets = []
|
||||
indirect_sets = []
|
||||
|
||||
for direct, indirect in bundles:
|
||||
direct_sets.append(direct)
|
||||
indirect_sets.append(direct | indirect)
|
||||
|
||||
initial_direct = spec.combined(direct_sets)
|
||||
indirect_nodes = spec.combined(indirect_sets)
|
||||
|
||||
direct_nodes = self.incorporate_indirect_nodes(initial_direct, indirect_nodes)
|
||||
|
||||
if spec.expect_exists:
|
||||
alert_non_existence(spec.raw, result)
|
||||
return result
|
||||
alert_non_existence(spec.raw, direct_nodes)
|
||||
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def select_nodes(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""Select the nodes in the graph according to the spec.
|
||||
|
||||
This is the main point of entry for turning a spec into a set of nodes:
|
||||
- Recurse through spec, select by criteria, combine by set operation
|
||||
- Return final (unfiltered) selection set
|
||||
"""
|
||||
|
||||
direct_nodes, indirect_nodes = self.select_nodes_recursively(spec)
|
||||
return direct_nodes
|
||||
|
||||
def _is_graph_member(self, unique_id: UniqueId) -> bool:
|
||||
if unique_id in self.manifest.sources:
|
||||
@@ -162,12 +199,55 @@ class NodeSelector(MethodManager):
|
||||
unique_id for unique_id in selected if self._is_match(unique_id)
|
||||
}
|
||||
|
||||
def expand_selection(self, selected: Set[UniqueId]) -> Set[UniqueId]:
|
||||
"""Perform selector-specific expansion."""
|
||||
def expand_selection(
|
||||
self, selected: Set[UniqueId], greedy: bool = False
|
||||
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
# Test selection can expand to include an implicitly/indirectly selected test.
|
||||
# In this way, `dbt test -m model_a` also includes tests that directly depend on `model_a`.
|
||||
# Expansion has two modes, GREEDY and NOT GREEDY.
|
||||
#
|
||||
# GREEDY mode: If ANY parent is selected, select the test. We use this for EXCLUSION.
|
||||
#
|
||||
# NOT GREEDY mode:
|
||||
# - If ALL parents are selected, select the test.
|
||||
# - If ANY parent is missing, return it separately. We'll keep it around
|
||||
# for later and see if its other parents show up.
|
||||
# We use this for INCLUSION.
|
||||
|
||||
direct_nodes = set(selected)
|
||||
indirect_nodes = set()
|
||||
|
||||
for unique_id in self.graph.select_successors(selected):
|
||||
if unique_id in self.manifest.nodes:
|
||||
node = self.manifest.nodes[unique_id]
|
||||
if can_select_indirectly(node):
|
||||
# should we add it in directly?
|
||||
if greedy or set(node.depends_on.nodes) <= set(selected):
|
||||
direct_nodes.add(unique_id)
|
||||
# if not:
|
||||
else:
|
||||
indirect_nodes.add(unique_id)
|
||||
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def incorporate_indirect_nodes(
|
||||
self, direct_nodes: Set[UniqueId], indirect_nodes: Set[UniqueId] = set()
|
||||
) -> Set[UniqueId]:
|
||||
# Check tests previously selected indirectly to see if ALL their
|
||||
# parents are now present.
|
||||
|
||||
selected = set(direct_nodes)
|
||||
|
||||
for unique_id in indirect_nodes:
|
||||
if unique_id in self.manifest.nodes:
|
||||
node = self.manifest.nodes[unique_id]
|
||||
if set(node.depends_on.nodes) <= set(selected):
|
||||
selected.add(unique_id)
|
||||
|
||||
return selected
|
||||
|
||||
def get_selected(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""get_selected runs trhough the node selection process:
|
||||
"""get_selected runs through the node selection process:
|
||||
|
||||
- node selection. Based on the include/exclude sets, the set
|
||||
of matched unique IDs is returned
|
||||
|
||||
@@ -49,25 +49,23 @@ class MethodName(StrEnum):
|
||||
Exposure = 'exposure'
|
||||
|
||||
|
||||
def is_selected_node(real_node, node_selector):
|
||||
for i, selector_part in enumerate(node_selector):
|
||||
def is_selected_node(fqn: List[str], node_selector: str):
|
||||
|
||||
is_last = (i == len(node_selector) - 1)
|
||||
# If qualified_name exactly matches model name (fqn's leaf), return True
|
||||
if fqn[-1] == node_selector:
|
||||
return True
|
||||
# Flatten node parts. Dots in model names act as namespace separators
|
||||
flat_fqn = [item for segment in fqn for item in segment.split('.')]
|
||||
# Selector components cannot be more than fqn's
|
||||
if len(flat_fqn) < len(node_selector.split('.')):
|
||||
return False
|
||||
|
||||
for i, selector_part in enumerate(node_selector.split('.')):
|
||||
# if we hit a GLOB, then this node is selected
|
||||
if selector_part == SELECTOR_GLOB:
|
||||
return True
|
||||
|
||||
# match package.node_name or package.dir.node_name
|
||||
elif is_last and selector_part == real_node[-1]:
|
||||
return True
|
||||
|
||||
elif len(real_node) <= i:
|
||||
return False
|
||||
|
||||
elif real_node[i] == selector_part:
|
||||
elif flat_fqn[i] == selector_part:
|
||||
continue
|
||||
|
||||
else:
|
||||
return False
|
||||
|
||||
@@ -154,31 +152,20 @@ class SelectorMethod(metaclass=abc.ABCMeta):
|
||||
|
||||
|
||||
class QualifiedNameSelectorMethod(SelectorMethod):
|
||||
def node_is_match(
|
||||
self,
|
||||
qualified_name: List[str],
|
||||
package_names: Set[str],
|
||||
fqn: List[str],
|
||||
) -> bool:
|
||||
"""Determine if a qualfied name matches an fqn, given the set of package
|
||||
def node_is_match(self, qualified_name: str, fqn: List[str]) -> bool:
|
||||
"""Determine if a qualified name matches an fqn for all package
|
||||
names in the graph.
|
||||
|
||||
:param List[str] qualified_name: The components of the selector or node
|
||||
name, split on '.'.
|
||||
:param Set[str] package_names: The set of pacakge names in the graph.
|
||||
:param str qualified_name: The qualified name to match the nodes with
|
||||
:param List[str] fqn: The node's fully qualified name in the graph.
|
||||
"""
|
||||
if len(qualified_name) == 1 and fqn[-1] == qualified_name[0]:
|
||||
unscoped_fqn = fqn[1:]
|
||||
|
||||
if is_selected_node(fqn, qualified_name):
|
||||
return True
|
||||
# Match nodes across different packages
|
||||
elif is_selected_node(unscoped_fqn, qualified_name):
|
||||
return True
|
||||
|
||||
if qualified_name[0] in package_names:
|
||||
if is_selected_node(fqn, qualified_name):
|
||||
return True
|
||||
|
||||
for package_name in package_names:
|
||||
local_qualified_node_name = [package_name] + qualified_name
|
||||
if is_selected_node(fqn, local_qualified_node_name):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
@@ -189,15 +176,9 @@ class QualifiedNameSelectorMethod(SelectorMethod):
|
||||
|
||||
:param str selector: The selector or node name
|
||||
"""
|
||||
qualified_name = selector.split(".")
|
||||
parsed_nodes = list(self.parsed_nodes(included_nodes))
|
||||
package_names = {n.package_name for _, n in parsed_nodes}
|
||||
for node, real_node in parsed_nodes:
|
||||
if self.node_is_match(
|
||||
qualified_name,
|
||||
package_names,
|
||||
real_node.fqn,
|
||||
):
|
||||
if self.node_is_match(selector, real_node.fqn):
|
||||
yield node
|
||||
|
||||
|
||||
|
||||
@@ -66,6 +66,7 @@ class SelectionCriteria:
|
||||
parents_depth: Optional[int]
|
||||
children: bool
|
||||
children_depth: Optional[int]
|
||||
greedy: bool = False
|
||||
|
||||
def __post_init__(self):
|
||||
if self.children and self.childrens_parents:
|
||||
@@ -103,7 +104,7 @@ class SelectionCriteria:
|
||||
|
||||
@classmethod
|
||||
def selection_criteria_from_dict(
|
||||
cls, raw: Any, dct: Dict[str, Any]
|
||||
cls, raw: Any, dct: Dict[str, Any], greedy: bool = False
|
||||
) -> 'SelectionCriteria':
|
||||
if 'value' not in dct:
|
||||
raise RuntimeException(
|
||||
@@ -123,10 +124,11 @@ class SelectionCriteria:
|
||||
parents_depth=parents_depth,
|
||||
children=bool(dct.get('children')),
|
||||
children_depth=children_depth,
|
||||
greedy=greedy
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def dict_from_single_spec(cls, raw: str):
|
||||
def dict_from_single_spec(cls, raw: str, greedy: bool = False):
|
||||
result = RAW_SELECTOR_PATTERN.match(raw)
|
||||
if result is None:
|
||||
return {'error': 'Invalid selector spec'}
|
||||
@@ -146,13 +148,13 @@ class SelectionCriteria:
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def from_single_spec(cls, raw: str) -> 'SelectionCriteria':
|
||||
def from_single_spec(cls, raw: str, greedy: bool = False) -> 'SelectionCriteria':
|
||||
result = RAW_SELECTOR_PATTERN.match(raw)
|
||||
if result is None:
|
||||
# bad spec!
|
||||
raise RuntimeException(f'Invalid selector spec "{raw}"')
|
||||
|
||||
return cls.selection_criteria_from_dict(raw, result.groupdict())
|
||||
return cls.selection_criteria_from_dict(raw, result.groupdict(), greedy=greedy)
|
||||
|
||||
|
||||
class BaseSelectionGroup(Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
|
||||
@@ -51,6 +51,29 @@
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
{% macro get_create_index_sql(relation, index_dict) -%}
|
||||
{{ return(adapter.dispatch('get_create_index_sql')(relation, index_dict)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_create_index_sql(relation, index_dict) -%}
|
||||
{% do return(None) %}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_indexes(relation) -%}
|
||||
{{ adapter.dispatch('create_indexes')(relation) }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__create_indexes(relation) -%}
|
||||
{%- set _indexes = config.get('indexes', default=[]) -%}
|
||||
|
||||
{% for _index_dict in _indexes %}
|
||||
{% set create_index_sql = get_create_index_sql(relation, _index_dict) %}
|
||||
{% if create_index_sql %}
|
||||
{% do run_query(create_index_sql) %}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_view_as(relation, sql) -%}
|
||||
{{ adapter.dispatch('create_view_as')(relation, sql) }}
|
||||
{%- endmacro %}
|
||||
|
||||
@@ -18,6 +18,7 @@
|
||||
{% macro default__get_merge_sql(target, source, unique_key, dest_columns, predicates) -%}
|
||||
{%- set predicates = [] if predicates is none else [] + predicates -%}
|
||||
{%- set dest_cols_csv = get_quoted_csv(dest_columns | map(attribute="name")) -%}
|
||||
{%- set update_columns = config.get('merge_update_columns', default = dest_columns | map(attribute="quoted") | list) -%}
|
||||
{%- set sql_header = config.get('sql_header', none) -%}
|
||||
|
||||
{% if unique_key %}
|
||||
@@ -37,8 +38,8 @@
|
||||
|
||||
{% if unique_key %}
|
||||
when matched then update set
|
||||
{% for column in dest_columns -%}
|
||||
{{ adapter.quote(column.name) }} = DBT_INTERNAL_SOURCE.{{ adapter.quote(column.name) }}
|
||||
{% for column_name in update_columns -%}
|
||||
{{ column_name }} = DBT_INTERNAL_SOURCE.{{ column_name }}
|
||||
{%- if not loop.last %}, {%- endif %}
|
||||
{%- endfor %}
|
||||
{% endif %}
|
||||
|
||||
@@ -72,3 +72,12 @@
|
||||
{% endif %}
|
||||
{% do return(config_full_refresh) %}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro should_store_failures() %}
|
||||
{% set config_store_failures = config.get('store_failures') %}
|
||||
{% if config_store_failures is none %}
|
||||
{% set config_store_failures = flags.STORE_FAILURES %}
|
||||
{% endif %}
|
||||
{% do return(config_store_failures) %}
|
||||
{% endmacro %}
|
||||
|
||||
@@ -5,7 +5,22 @@
|
||||
|
||||
{% set target_relation = this.incorporate(type='table') %}
|
||||
{% set existing_relation = load_relation(this) %}
|
||||
{% set tmp_relation = make_temp_relation(this) %}
|
||||
|
||||
{% set tmp_identifier = model['name'] + '__dbt_tmp' %}
|
||||
{% set backup_identifier = model['name'] + "__dbt_backup" %}
|
||||
|
||||
-- the intermediate_ and backup_ relations should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation. This has to happen before
|
||||
-- BEGIN, in a separate transaction
|
||||
{% set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{% set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
@@ -16,13 +31,11 @@
|
||||
{% if existing_relation is none %}
|
||||
{% set build_sql = create_table_as(False, target_relation, sql) %}
|
||||
{% elif existing_relation.is_view or should_full_refresh() %}
|
||||
{#-- Make sure the backup doesn't exist so we don't encounter issues with the rename below #}
|
||||
{% set backup_identifier = existing_relation.identifier ~ "__dbt_backup" %}
|
||||
{% set intermediate_relation = existing_relation.incorporate(path={"identifier": tmp_identifier}) %}
|
||||
{% set backup_relation = existing_relation.incorporate(path={"identifier": backup_identifier}) %}
|
||||
{% do adapter.drop_relation(backup_relation) %}
|
||||
|
||||
{% do adapter.rename_relation(target_relation, backup_relation) %}
|
||||
{% set build_sql = create_table_as(False, target_relation, sql) %}
|
||||
{% set build_sql = create_table_as(False, intermediate_relation, sql) %}
|
||||
{% set need_swap = true %}
|
||||
{% do to_drop.append(backup_relation) %}
|
||||
{% else %}
|
||||
{% set tmp_relation = make_temp_relation(target_relation) %}
|
||||
@@ -37,8 +50,17 @@
|
||||
{{ build_sql }}
|
||||
{% endcall %}
|
||||
|
||||
{% if need_swap %}
|
||||
{% do adapter.rename_relation(target_relation, backup_relation) %}
|
||||
{% do adapter.rename_relation(intermediate_relation, target_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if existing_relation is none or existing_relation.is_view or should_full_refresh() %}
|
||||
{% do create_indexes(target_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
-- `COMMIT` happens here
|
||||
|
||||
@@ -142,6 +142,10 @@
|
||||
{% set target_relation = this.incorporate(type='table') %}
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if full_refresh_mode or not exists_as_table %}
|
||||
{% do create_indexes(target_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
-- `COMMIT` happens here
|
||||
|
||||
@@ -263,6 +263,10 @@
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if not target_relation_exists %}
|
||||
{% do create_indexes(target_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
{{ adapter.commit() }}
|
||||
|
||||
@@ -144,7 +144,7 @@
|
||||
{% if now is none or now is undefined -%}
|
||||
{%- do exceptions.raise_compiler_error('Could not get a snapshot start time from the database') -%}
|
||||
{%- endif %}
|
||||
{% set updated_at = snapshot_string_as_time(now) %}
|
||||
{% set updated_at = config.get('updated_at', snapshot_string_as_time(now)) %}
|
||||
|
||||
{% set column_added = false %}
|
||||
|
||||
|
||||
@@ -12,7 +12,12 @@
|
||||
schema=schema,
|
||||
database=database,
|
||||
type='table') -%}
|
||||
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
See ../view/view.sql for more information about this relation.
|
||||
*/
|
||||
@@ -21,14 +26,15 @@
|
||||
schema=schema,
|
||||
database=database,
|
||||
type=backup_relation_type) -%}
|
||||
|
||||
{%- set exists_as_table = (old_relation is not none and old_relation.is_table) -%}
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
|
||||
-- drop the temp relations if they exists for some reason
|
||||
{{ adapter.drop_relation(intermediate_relation) }}
|
||||
{{ adapter.drop_relation(backup_relation) }}
|
||||
-- drop the temp relations if they exist already in the database
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
@@ -47,6 +53,8 @@
|
||||
|
||||
{{ adapter.rename_relation(intermediate_relation, target_relation) }}
|
||||
|
||||
{% do create_indexes(target_relation) %}
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
@@ -0,0 +1,64 @@
|
||||
{% macro get_test_sql(main_sql, fail_calc, warn_if, error_if, limit) -%}
|
||||
{{ adapter.dispatch('get_test_sql')(main_sql, fail_calc, warn_if, error_if, limit) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{% macro default__get_test_sql(main_sql, fail_calc, warn_if, error_if, limit) -%}
|
||||
select
|
||||
{{ fail_calc }} as failures,
|
||||
{{ fail_calc }} {{ warn_if }} as should_warn,
|
||||
{{ fail_calc }} {{ error_if }} as should_error
|
||||
from (
|
||||
{{ main_sql }}
|
||||
{{ "limit " ~ limit if limit != none }}
|
||||
) dbt_internal_test
|
||||
{%- endmacro %}
|
||||
|
||||
{%- materialization test, default -%}
|
||||
|
||||
{% set relations = [] %}
|
||||
|
||||
{% if should_store_failures() %}
|
||||
|
||||
{% set identifier = model['alias'] %}
|
||||
{% set old_relation = adapter.get_relation(database=database, schema=schema, identifier=identifier) %}
|
||||
{% set target_relation = api.Relation.create(
|
||||
identifier=identifier, schema=schema, database=database, type='table') -%} %}
|
||||
|
||||
{% if old_relation %}
|
||||
{% do adapter.drop_relation(old_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{% call statement(auto_begin=True) %}
|
||||
{{ create_table_as(False, target_relation, sql) }}
|
||||
{% endcall %}
|
||||
|
||||
{% do relations.append(target_relation) %}
|
||||
|
||||
{% set main_sql %}
|
||||
select *
|
||||
from {{ target_relation }}
|
||||
{% endset %}
|
||||
|
||||
{{ adapter.commit() }}
|
||||
|
||||
{% else %}
|
||||
|
||||
{% set main_sql = sql %}
|
||||
|
||||
{% endif %}
|
||||
|
||||
{% set limit = config.get('limit') %}
|
||||
{% set fail_calc = config.get('fail_calc') %}
|
||||
{% set warn_if = config.get('warn_if') %}
|
||||
{% set error_if = config.get('error_if') %}
|
||||
|
||||
{% call statement('main', fetch_result=True) -%}
|
||||
|
||||
{{ get_test_sql(main_sql, fail_calc, warn_if, error_if, limit)}}
|
||||
|
||||
{%- endcall %}
|
||||
|
||||
{{ return({'relations': relations}) }}
|
||||
|
||||
{%- endmaterialization -%}
|
||||
@@ -1,6 +1,6 @@
|
||||
|
||||
{% macro handle_existing_table(full_refresh, old_relation) %}
|
||||
{{ adapter.dispatch("handle_existing_table", packages=['dbt'])(full_refresh, old_relation) }}
|
||||
{{ adapter.dispatch('handle_existing_table', macro_namespace = 'dbt')(full_refresh, old_relation) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__handle_existing_table(full_refresh, old_relation) %}
|
||||
|
||||
@@ -9,7 +9,12 @@
|
||||
type='view') -%}
|
||||
{%- set intermediate_relation = api.Relation.create(identifier=tmp_identifier,
|
||||
schema=schema, database=database, type='view') -%}
|
||||
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
This relation (probably) doesn't exist yet. If it does exist, it's a leftover from
|
||||
a previous run, and we're going to try to drop it immediately. At the end of this
|
||||
@@ -27,14 +32,16 @@
|
||||
{%- set backup_relation = api.Relation.create(identifier=backup_identifier,
|
||||
schema=schema, database=database,
|
||||
type=backup_relation_type) -%}
|
||||
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
-- drop the temp relations if they exists for some reason
|
||||
{{ adapter.drop_relation(intermediate_relation) }}
|
||||
{{ adapter.drop_relation(backup_relation) }}
|
||||
-- drop the temp relations if they exist already in the database
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
-- `BEGIN` happens here:
|
||||
{{ run_hooks(pre_hooks, inside_transaction=True) }}
|
||||
|
||||
@@ -1,43 +1,33 @@
|
||||
|
||||
{% macro default__test_accepted_values(model, values) %}
|
||||
|
||||
{% set column_name = kwargs.get('column_name', kwargs.get('field')) %}
|
||||
{% set quote_values = kwargs.get('quote', True) %}
|
||||
{% macro default__test_accepted_values(model, column_name, values, quote=True) %}
|
||||
|
||||
with all_values as (
|
||||
|
||||
select distinct
|
||||
{{ column_name }} as value_field
|
||||
select
|
||||
{{ column_name }} as value_field,
|
||||
count(*) as n_records
|
||||
|
||||
from {{ model }}
|
||||
group by 1
|
||||
|
||||
),
|
||||
|
||||
validation_errors as (
|
||||
|
||||
select
|
||||
value_field
|
||||
|
||||
from all_values
|
||||
where value_field not in (
|
||||
{% for value in values -%}
|
||||
{% if quote_values -%}
|
||||
'{{ value }}'
|
||||
{%- else -%}
|
||||
{{ value }}
|
||||
{%- endif -%}
|
||||
{%- if not loop.last -%},{%- endif %}
|
||||
{%- endfor %}
|
||||
)
|
||||
)
|
||||
|
||||
select count(*) as validation_errors
|
||||
from validation_errors
|
||||
select *
|
||||
from all_values
|
||||
where value_field not in (
|
||||
{% for value in values -%}
|
||||
{% if quote -%}
|
||||
'{{ value }}'
|
||||
{%- else -%}
|
||||
{{ value }}
|
||||
{%- endif -%}
|
||||
{%- if not loop.last -%},{%- endif %}
|
||||
{%- endfor %}
|
||||
)
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro test_accepted_values(model, values) %}
|
||||
{% test accepted_values(model, column_name, values, quote=True) %}
|
||||
{% set macro = adapter.dispatch('test_accepted_values') %}
|
||||
{{ macro(model, values, **kwargs) }}
|
||||
{% endmacro %}
|
||||
{{ macro(model, column_name, values, quote) }}
|
||||
{% endtest %}
|
||||
|
||||
@@ -1,17 +1,13 @@
|
||||
{% macro default__test_not_null(model, column_name) %}
|
||||
|
||||
{% macro default__test_not_null(model) %}
|
||||
|
||||
{% set column_name = kwargs.get('column_name', kwargs.get('arg')) %}
|
||||
|
||||
select count(*) as validation_errors
|
||||
select *
|
||||
from {{ model }}
|
||||
where {{ column_name }} is null
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
|
||||
{% macro test_not_null(model) %}
|
||||
{% test not_null(model, column_name) %}
|
||||
{% set macro = adapter.dispatch('test_not_null') %}
|
||||
{{ macro(model, **kwargs) }}
|
||||
{% endmacro %}
|
||||
{{ macro(model, column_name) }}
|
||||
{% endtest %}
|
||||
|
||||
@@ -1,24 +1,21 @@
|
||||
|
||||
{% macro default__test_relationships(model, to, field) %}
|
||||
{% macro default__test_relationships(model, column_name, to, field) %}
|
||||
|
||||
{% set column_name = kwargs.get('column_name', kwargs.get('from')) %}
|
||||
select
|
||||
child.{{ column_name }}
|
||||
|
||||
from {{ model }} as child
|
||||
|
||||
select count(*) as validation_errors
|
||||
from (
|
||||
select {{ column_name }} as id from {{ model }}
|
||||
) as child
|
||||
left join (
|
||||
select {{ field }} as id from {{ to }}
|
||||
) as parent on parent.id = child.id
|
||||
where child.id is not null
|
||||
and parent.id is null
|
||||
left join {{ to }} as parent
|
||||
on child.{{ column_name }} = parent.{{ field }}
|
||||
|
||||
where child.{{ column_name }} is not null
|
||||
and parent.{{ field }} is null
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
|
||||
{% macro test_relationships(model, to, field) %}
|
||||
{% test relationships(model, column_name, to, field) %}
|
||||
{% set macro = adapter.dispatch('test_relationships') %}
|
||||
{{ macro(model, to, field, **kwargs) }}
|
||||
{% endmacro %}
|
||||
{{ macro(model, column_name, to, field) }}
|
||||
{% endtest %}
|
||||
|
||||
@@ -1,25 +1,18 @@
|
||||
{% macro default__test_unique(model, column_name) %}
|
||||
|
||||
{% macro default__test_unique(model) %}
|
||||
select
|
||||
{{ column_name }},
|
||||
count(*) as n_records
|
||||
|
||||
{% set column_name = kwargs.get('column_name', kwargs.get('arg')) %}
|
||||
|
||||
select count(*) as validation_errors
|
||||
from (
|
||||
|
||||
select
|
||||
{{ column_name }}
|
||||
|
||||
from {{ model }}
|
||||
where {{ column_name }} is not null
|
||||
group by {{ column_name }}
|
||||
having count(*) > 1
|
||||
|
||||
) validation_errors
|
||||
from {{ model }}
|
||||
where {{ column_name }} is not null
|
||||
group by {{ column_name }}
|
||||
having count(*) > 1
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro test_unique(model) %}
|
||||
{% test unique(model, column_name) %}
|
||||
{% set macro = adapter.dispatch('test_unique') %}
|
||||
{{ macro(model, **kwargs) }}
|
||||
{% endmacro %}
|
||||
{{ macro(model, column_name) }}
|
||||
{% endtest %}
|
||||
|
||||
File diff suppressed because one or more lines are too long
4
core/dbt/include/starter_project/.gitignore
vendored
Normal file
4
core/dbt/include/starter_project/.gitignore
vendored
Normal file
@@ -0,0 +1,4 @@
|
||||
|
||||
target/
|
||||
dbt_modules/
|
||||
logs/
|
||||
15
core/dbt/include/starter_project/README.md
Normal file
15
core/dbt/include/starter_project/README.md
Normal file
@@ -0,0 +1,15 @@
|
||||
Welcome to your new dbt project!
|
||||
|
||||
### Using the starter project
|
||||
|
||||
Try running the following commands:
|
||||
- dbt run
|
||||
- dbt test
|
||||
|
||||
|
||||
### Resources:
|
||||
- Learn more about dbt [in the docs](https://docs.getdbt.com/docs/introduction)
|
||||
- Check out [Discourse](https://discourse.getdbt.com/) for commonly asked questions and answers
|
||||
- Join the [chat](https://community.getdbt.com/) on Slack for live discussions and support
|
||||
- Find [dbt events](https://events.getdbt.com) near you
|
||||
- Check out [the blog](https://blog.getdbt.com/) for the latest news on dbt's development and best practices
|
||||
3
core/dbt/include/starter_project/__init__.py
Normal file
3
core/dbt/include/starter_project/__init__.py
Normal file
@@ -0,0 +1,3 @@
|
||||
import os
|
||||
|
||||
PACKAGE_PATH = os.path.dirname(__file__)
|
||||
38
core/dbt/include/starter_project/dbt_project.yml
Normal file
38
core/dbt/include/starter_project/dbt_project.yml
Normal file
@@ -0,0 +1,38 @@
|
||||
|
||||
# Name your project! Project names should contain only lowercase characters
|
||||
# and underscores. A good package name should reflect your organization's
|
||||
# name or the intended use of these models
|
||||
name: 'my_new_project'
|
||||
version: '1.0.0'
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project.
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `source-paths` config, for example, states that models in this project can be
|
||||
# found in the "models/" directory. You probably won't need to change these!
|
||||
source-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
test-paths: ["tests"]
|
||||
data-paths: ["data"]
|
||||
macro-paths: ["macros"]
|
||||
snapshot-paths: ["snapshots"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_modules"
|
||||
|
||||
|
||||
# Configuring models
|
||||
# Full documentation: https://docs.getdbt.com/docs/configuring-models
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as tables. These settings can be overridden in the individual model files
|
||||
# using the `{{ config(...) }}` macro.
|
||||
models:
|
||||
my_new_project:
|
||||
# Config indicated by + and applies to all files under models/example/
|
||||
example:
|
||||
+materialized: view
|
||||
0
core/dbt/include/starter_project/macros/.gitkeep
Normal file
0
core/dbt/include/starter_project/macros/.gitkeep
Normal file
@@ -0,0 +1,27 @@
|
||||
|
||||
/*
|
||||
Welcome to your first dbt model!
|
||||
Did you know that you can also configure models directly within SQL files?
|
||||
This will override configurations stated in dbt_project.yml
|
||||
|
||||
Try changing "table" to "view" below
|
||||
*/
|
||||
|
||||
{{ config(materialized='table') }}
|
||||
|
||||
with source_data as (
|
||||
|
||||
select 1 as id
|
||||
union all
|
||||
select null as id
|
||||
|
||||
)
|
||||
|
||||
select *
|
||||
from source_data
|
||||
|
||||
/*
|
||||
Uncomment the line below to remove records with null `id` values
|
||||
*/
|
||||
|
||||
-- where id is not null
|
||||
@@ -0,0 +1,6 @@
|
||||
|
||||
-- Use the `ref` function to select from other models
|
||||
|
||||
select *
|
||||
from {{ ref('my_first_dbt_model') }}
|
||||
where id = 1
|
||||
21
core/dbt/include/starter_project/models/example/schema.yml
Normal file
21
core/dbt/include/starter_project/models/example/schema.yml
Normal file
@@ -0,0 +1,21 @@
|
||||
|
||||
version: 2
|
||||
|
||||
models:
|
||||
- name: my_first_dbt_model
|
||||
description: "A starter dbt model"
|
||||
columns:
|
||||
- name: id
|
||||
description: "The primary key for this table"
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
|
||||
- name: my_second_dbt_model
|
||||
description: "A starter dbt model"
|
||||
columns:
|
||||
- name: id
|
||||
description: "The primary key for this table"
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
0
core/dbt/include/starter_project/snapshots/.gitkeep
Normal file
0
core/dbt/include/starter_project/snapshots/.gitkeep
Normal file
0
core/dbt/include/starter_project/tests/.gitkeep
Normal file
0
core/dbt/include/starter_project/tests/.gitkeep
Normal file
@@ -95,7 +95,8 @@ class JsonFormatter(LogMessageFormatter):
|
||||
# utils imports exceptions which imports logger...
|
||||
import dbt.utils
|
||||
log_message = super().__call__(record, handler)
|
||||
return json.dumps(log_message.to_dict(), cls=dbt.utils.JSONEncoder)
|
||||
dct = log_message.to_dict(omit_none=True)
|
||||
return json.dumps(dct, cls=dbt.utils.JSONEncoder)
|
||||
|
||||
|
||||
class FormatterMixin:
|
||||
@@ -127,6 +128,7 @@ class OutputHandler(logbook.StreamHandler, FormatterMixin):
|
||||
The `format_string` parameter only changes the default text output, not
|
||||
debug mode or json.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
stream,
|
||||
@@ -220,7 +222,8 @@ class TimingProcessor(logbook.Processor):
|
||||
|
||||
def process(self, record):
|
||||
if self.timing_info is not None:
|
||||
record.extra['timing_info'] = self.timing_info.to_dict()
|
||||
record.extra['timing_info'] = self.timing_info.to_dict(
|
||||
omit_none=True)
|
||||
|
||||
|
||||
class DbtProcessState(logbook.Processor):
|
||||
@@ -349,6 +352,7 @@ def make_log_dir_if_missing(log_dir):
|
||||
class DebugWarnings(logbook.compat.redirected_warnings):
|
||||
"""Log warnings, except send them to 'debug' instead of 'warning' level.
|
||||
"""
|
||||
|
||||
def make_record(self, message, exception, filename, lineno):
|
||||
rv = super().make_record(message, exception, filename, lineno)
|
||||
rv.level = logbook.DEBUG
|
||||
|
||||
@@ -11,6 +11,7 @@ from pathlib import Path
|
||||
import dbt.version
|
||||
import dbt.flags as flags
|
||||
import dbt.task.run as run_task
|
||||
import dbt.task.build as build_task
|
||||
import dbt.task.compile as compile_task
|
||||
import dbt.task.debug as debug_task
|
||||
import dbt.task.clean as clean_task
|
||||
@@ -367,7 +368,6 @@ def _build_init_subparser(subparsers, base_subparser):
|
||||
)
|
||||
sub.add_argument(
|
||||
'--adapter',
|
||||
default='redshift',
|
||||
type=str,
|
||||
help='''
|
||||
Write sample profiles.yml for which adapter
|
||||
@@ -377,6 +377,30 @@ def _build_init_subparser(subparsers, base_subparser):
|
||||
return sub
|
||||
|
||||
|
||||
def _build_build_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'build',
|
||||
parents=[base_subparser],
|
||||
help='''
|
||||
Run all Seeds, Models, Snapshots, and tests in DAG order
|
||||
'''
|
||||
)
|
||||
sub.set_defaults(
|
||||
cls=build_task.BuildTask,
|
||||
which='build',
|
||||
rpc_method='build'
|
||||
)
|
||||
sub.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
action='store_true',
|
||||
help='''
|
||||
Stop execution upon a first failure.
|
||||
'''
|
||||
)
|
||||
return sub
|
||||
|
||||
|
||||
def _build_clean_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'clean',
|
||||
@@ -719,6 +743,13 @@ def _build_test_subparser(subparsers, base_subparser):
|
||||
Stop execution upon a first test failure.
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--store-failures',
|
||||
action='store_true',
|
||||
help='''
|
||||
Store test results (failing rows) in the database
|
||||
'''
|
||||
)
|
||||
|
||||
sub.set_defaults(cls=test_task.TestTask, which='test', rpc_method='test')
|
||||
return sub
|
||||
@@ -998,12 +1029,23 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
# if set, extract all models and blocks with the jinja block extractor, and
|
||||
# verify that we don't fail anywhere the actual jinja parser passes. The
|
||||
# reverse (passing files that ends up failing jinja) is fine.
|
||||
# TODO remove?
|
||||
p.add_argument(
|
||||
'--test-new-parser',
|
||||
action='store_true',
|
||||
help=argparse.SUPPRESS
|
||||
)
|
||||
|
||||
# if set, will use the tree-sitter-jinja2 parser and extractor instead of
|
||||
# jinja rendering when possible.
|
||||
p.add_argument(
|
||||
'--use-experimental-parser',
|
||||
action='store_true',
|
||||
help='''
|
||||
Uses an experimental parser to extract jinja values.
|
||||
'''
|
||||
)
|
||||
|
||||
subs = p.add_subparsers(title="Available sub-commands")
|
||||
|
||||
base_subparser = _build_base_subparser()
|
||||
@@ -1020,6 +1062,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
_build_deps_subparser(subs, base_subparser)
|
||||
_build_list_subparser(subs, base_subparser)
|
||||
|
||||
build_sub = _build_build_subparser(subs, base_subparser)
|
||||
snapshot_sub = _build_snapshot_subparser(subs, base_subparser)
|
||||
rpc_sub = _build_rpc_subparser(subs, base_subparser)
|
||||
run_sub = _build_run_subparser(subs, base_subparser)
|
||||
@@ -1033,7 +1076,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
rpc_sub, seed_sub, parse_sub)
|
||||
# --models, --exclude
|
||||
# list_sub sets up its own arguments.
|
||||
_add_selection_arguments(run_sub, compile_sub, generate_sub, test_sub)
|
||||
_add_selection_arguments(build_sub, run_sub, compile_sub, generate_sub, test_sub)
|
||||
_add_selection_arguments(snapshot_sub, seed_sub, models_name='select')
|
||||
# --defer
|
||||
_add_defer_argument(run_sub, test_sub)
|
||||
@@ -1051,7 +1094,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
parsed = p.parse_args(args)
|
||||
|
||||
if hasattr(parsed, 'profiles_dir'):
|
||||
parsed.profiles_dir = os.path.expanduser(parsed.profiles_dir)
|
||||
parsed.profiles_dir = os.path.abspath(parsed.profiles_dir)
|
||||
|
||||
if getattr(parsed, 'project_dir', None) is not None:
|
||||
expanded_user = os.path.expanduser(parsed.project_dir)
|
||||
|
||||
@@ -5,12 +5,11 @@ from .docs import DocumentationParser # noqa
|
||||
from .hooks import HookParser # noqa
|
||||
from .macros import MacroParser # noqa
|
||||
from .models import ModelParser # noqa
|
||||
from .results import ParseResult # noqa
|
||||
from .schemas import SchemaParser # noqa
|
||||
from .seeds import SeedParser # noqa
|
||||
from .snapshots import SnapshotParser # noqa
|
||||
|
||||
from . import ( # noqa
|
||||
analysis, base, data_test, docs, hooks, macros, models, results, schemas,
|
||||
analysis, base, data_test, docs, hooks, macros, models, schemas,
|
||||
snapshots
|
||||
)
|
||||
|
||||
@@ -3,15 +3,10 @@ import os
|
||||
from dbt.contracts.graph.parsed import ParsedAnalysisNode
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FilesystemSearcher, FileBlock
|
||||
from dbt.parser.search import FileBlock
|
||||
|
||||
|
||||
class AnalysisParser(SimpleSQLParser[ParsedAnalysisNode]):
|
||||
def get_paths(self):
|
||||
return FilesystemSearcher(
|
||||
self.project, self.project.analysis_paths, '.sql'
|
||||
)
|
||||
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedAnalysisNode:
|
||||
if validate:
|
||||
ParsedAnalysisNode.validate(dct)
|
||||
|
||||
@@ -2,14 +2,13 @@ import abc
|
||||
import itertools
|
||||
import os
|
||||
from typing import (
|
||||
List, Dict, Any, Iterable, Generic, TypeVar
|
||||
List, Dict, Any, Generic, Optional, TypeVar
|
||||
)
|
||||
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from dbt import utils
|
||||
from dbt.clients.jinja import MacroGenerator
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.context.providers import (
|
||||
generate_parser_model,
|
||||
generate_generate_component_name_macro,
|
||||
@@ -20,18 +19,14 @@ from dbt.config import Project, RuntimeConfig
|
||||
from dbt.context.context_config import (
|
||||
ContextConfig
|
||||
)
|
||||
from dbt.contracts.files import (
|
||||
SourceFile, FilePath, FileHash
|
||||
)
|
||||
from dbt.contracts.graph.manifest import MacroManifest
|
||||
from dbt.contracts.graph.parsed import HasUniqueID
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.graph.parsed import HasUniqueID, ManifestNodes
|
||||
from dbt.contracts.graph.unparsed import UnparsedNode
|
||||
from dbt.exceptions import (
|
||||
CompilationException, validator_error_message, InternalException
|
||||
)
|
||||
from dbt import hooks
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.results import ParseResult, ManifestNodes
|
||||
from dbt.parser.search import FileBlock
|
||||
|
||||
# internally, the parser may store a less-restrictive type that will be
|
||||
@@ -48,20 +43,9 @@ ConfiguredBlockType = TypeVar('ConfiguredBlockType', bound=FileBlock)
|
||||
|
||||
|
||||
class BaseParser(Generic[FinalValue]):
|
||||
def __init__(self, results: ParseResult, project: Project) -> None:
|
||||
self.results = results
|
||||
def __init__(self, project: Project, manifest: Manifest) -> None:
|
||||
self.project = project
|
||||
# this should be a superset of [x.path for x in self.results.files]
|
||||
# because we fill it via search()
|
||||
self.searched: List[FilePath] = []
|
||||
|
||||
@abc.abstractmethod
|
||||
def get_paths(self) -> Iterable[FilePath]:
|
||||
pass
|
||||
|
||||
def search(self) -> List[FilePath]:
|
||||
self.searched = list(self.get_paths())
|
||||
return self.searched
|
||||
self.manifest = manifest
|
||||
|
||||
@abc.abstractmethod
|
||||
def parse_file(self, block: FileBlock) -> None:
|
||||
@@ -71,47 +55,44 @@ class BaseParser(Generic[FinalValue]):
|
||||
def resource_type(self) -> NodeType:
|
||||
pass
|
||||
|
||||
def generate_unique_id(self, resource_name: str) -> str:
|
||||
"""Returns a unique identifier for a resource"""
|
||||
return "{}.{}.{}".format(self.resource_type,
|
||||
self.project.project_name,
|
||||
resource_name)
|
||||
|
||||
def load_file(
|
||||
def generate_unique_id(
|
||||
self,
|
||||
path: FilePath,
|
||||
*,
|
||||
set_contents: bool = True,
|
||||
) -> SourceFile:
|
||||
file_contents = load_file_contents(path.absolute_path, strip=False)
|
||||
checksum = FileHash.from_contents(file_contents)
|
||||
source_file = SourceFile(path=path, checksum=checksum)
|
||||
if set_contents:
|
||||
source_file.contents = file_contents.strip()
|
||||
else:
|
||||
source_file.contents = ''
|
||||
return source_file
|
||||
resource_name: str,
|
||||
hash: Optional[str] = None
|
||||
) -> str:
|
||||
"""Returns a unique identifier for a resource
|
||||
An optional hash may be passed in to ensure uniqueness for edge cases"""
|
||||
|
||||
return '.'.join(
|
||||
filter(
|
||||
None,
|
||||
[
|
||||
self.resource_type,
|
||||
self.project.project_name,
|
||||
resource_name,
|
||||
hash
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class Parser(BaseParser[FinalValue], Generic[FinalValue]):
|
||||
def __init__(
|
||||
self,
|
||||
results: ParseResult,
|
||||
project: Project,
|
||||
manifest: Manifest,
|
||||
root_project: RuntimeConfig,
|
||||
macro_manifest: MacroManifest,
|
||||
) -> None:
|
||||
super().__init__(results, project)
|
||||
super().__init__(project, manifest)
|
||||
self.root_project = root_project
|
||||
self.macro_manifest = macro_manifest
|
||||
|
||||
|
||||
class RelationUpdate:
|
||||
def __init__(
|
||||
self, config: RuntimeConfig, macro_manifest: MacroManifest,
|
||||
self, config: RuntimeConfig, manifest: Manifest,
|
||||
component: str
|
||||
) -> None:
|
||||
macro = macro_manifest.find_generate_macro_by_name(
|
||||
macro = manifest.find_generate_macro_by_name(
|
||||
component=component,
|
||||
root_project_name=config.project_name,
|
||||
)
|
||||
@@ -121,7 +102,7 @@ class RelationUpdate:
|
||||
)
|
||||
|
||||
root_context = generate_generate_component_name_macro(
|
||||
macro, config, macro_manifest
|
||||
macro, config, manifest
|
||||
)
|
||||
self.updater = MacroGenerator(macro, root_context)
|
||||
self.component = component
|
||||
@@ -142,23 +123,22 @@ class ConfiguredParser(
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
results: ParseResult,
|
||||
project: Project,
|
||||
manifest: Manifest,
|
||||
root_project: RuntimeConfig,
|
||||
macro_manifest: MacroManifest,
|
||||
) -> None:
|
||||
super().__init__(results, project, root_project, macro_manifest)
|
||||
super().__init__(project, manifest, root_project)
|
||||
|
||||
self._update_node_database = RelationUpdate(
|
||||
macro_manifest=macro_manifest, config=root_project,
|
||||
manifest=manifest, config=root_project,
|
||||
component='database'
|
||||
)
|
||||
self._update_node_schema = RelationUpdate(
|
||||
macro_manifest=macro_manifest, config=root_project,
|
||||
manifest=manifest, config=root_project,
|
||||
component='schema'
|
||||
)
|
||||
self._update_node_alias = RelationUpdate(
|
||||
macro_manifest=macro_manifest, config=root_project,
|
||||
manifest=manifest, config=root_project,
|
||||
component='alias'
|
||||
)
|
||||
|
||||
@@ -252,7 +232,7 @@ class ConfiguredParser(
|
||||
'raw_sql': block.contents,
|
||||
'unique_id': self.generate_unique_id(name),
|
||||
'config': self.config_dict(config),
|
||||
'checksum': block.file.checksum.to_dict(),
|
||||
'checksum': block.file.checksum.to_dict(omit_none=True),
|
||||
}
|
||||
dct.update(kwargs)
|
||||
try:
|
||||
@@ -273,7 +253,7 @@ class ConfiguredParser(
|
||||
self, parsed_node: IntermediateNode, config: ContextConfig
|
||||
) -> Dict[str, Any]:
|
||||
return generate_parser_model(
|
||||
parsed_node, self.root_project, self.macro_manifest, config
|
||||
parsed_node, self.root_project, self.manifest, config
|
||||
)
|
||||
|
||||
def render_with_context(
|
||||
@@ -301,8 +281,8 @@ class ConfiguredParser(
|
||||
self, parsed_node: IntermediateNode, config_dict: Dict[str, Any]
|
||||
) -> None:
|
||||
# Overwrite node config
|
||||
final_config_dict = parsed_node.config.to_dict()
|
||||
final_config_dict.update(config_dict)
|
||||
final_config_dict = parsed_node.config.to_dict(omit_none=True)
|
||||
final_config_dict.update({k.strip(): v for (k, v) in config_dict.items()})
|
||||
# re-mangle hooks, in case we got new ones
|
||||
self._mangle_hooks(final_config_dict)
|
||||
parsed_node.config = parsed_node.config.from_dict(final_config_dict)
|
||||
@@ -386,9 +366,9 @@ class ConfiguredParser(
|
||||
|
||||
def add_result_node(self, block: FileBlock, node: ManifestNodes):
|
||||
if node.config.enabled:
|
||||
self.results.add_node(block.file, node)
|
||||
self.manifest.add_node(block.file, node)
|
||||
else:
|
||||
self.results.add_disabled(block.file, node)
|
||||
self.manifest.add_disabled(block.file, node)
|
||||
|
||||
def parse_node(self, block: ConfiguredBlockType) -> FinalNode:
|
||||
compiled_path: str = self.get_compiled_path(block)
|
||||
|
||||
@@ -1,16 +1,11 @@
|
||||
from dbt.contracts.graph.parsed import ParsedDataTestNode
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FilesystemSearcher, FileBlock
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.utils import get_pseudo_test_path
|
||||
|
||||
|
||||
class DataTestParser(SimpleSQLParser[ParsedDataTestNode]):
|
||||
def get_paths(self):
|
||||
return FilesystemSearcher(
|
||||
self.project, self.project.test_paths, '.sql'
|
||||
)
|
||||
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedDataTestNode:
|
||||
if validate:
|
||||
ParsedDataTestNode.validate(dct)
|
||||
|
||||
@@ -1,13 +1,14 @@
|
||||
from typing import Iterable
|
||||
from typing import Iterable, Optional
|
||||
|
||||
import re
|
||||
|
||||
from dbt.clients.jinja import get_rendered
|
||||
from dbt.contracts.files import SourceFile
|
||||
from dbt.contracts.graph.parsed import ParsedDocumentation
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import Parser
|
||||
from dbt.parser.search import (
|
||||
BlockContents, FileBlock, FilesystemSearcher, BlockSearcher
|
||||
BlockContents, FileBlock, BlockSearcher
|
||||
)
|
||||
|
||||
|
||||
@@ -15,13 +16,6 @@ SHOULD_PARSE_RE = re.compile(r'{[{%]')
|
||||
|
||||
|
||||
class DocumentationParser(Parser[ParsedDocumentation]):
|
||||
def get_paths(self):
|
||||
return FilesystemSearcher(
|
||||
project=self.project,
|
||||
relative_dirs=self.project.docs_paths,
|
||||
extension='.md',
|
||||
)
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.Documentation
|
||||
@@ -30,7 +24,7 @@ class DocumentationParser(Parser[ParsedDocumentation]):
|
||||
def get_compiled_path(cls, block: FileBlock):
|
||||
return block.path.relative_path
|
||||
|
||||
def generate_unique_id(self, resource_name: str) -> str:
|
||||
def generate_unique_id(self, resource_name: str, _: Optional[str] = None) -> str:
|
||||
# because docs are in their own graph namespace, node type doesn't
|
||||
# need to be part of the unique ID.
|
||||
return '{}.{}'.format(self.project.project_name, resource_name)
|
||||
@@ -53,6 +47,7 @@ class DocumentationParser(Parser[ParsedDocumentation]):
|
||||
return [doc]
|
||||
|
||||
def parse_file(self, file_block: FileBlock):
|
||||
assert isinstance(file_block.file, SourceFile)
|
||||
searcher: Iterable[BlockContents] = BlockSearcher(
|
||||
source=[file_block],
|
||||
allowed_blocks={'docs'},
|
||||
@@ -60,6 +55,4 @@ class DocumentationParser(Parser[ParsedDocumentation]):
|
||||
)
|
||||
for block in searcher:
|
||||
for parsed in self.parse_block(block):
|
||||
self.results.add_doc(file_block.file, parsed)
|
||||
# mark the file as seen, even if there are no macros in it
|
||||
self.results.get_file(file_block.file)
|
||||
self.manifest.add_doc(file_block.file, parsed)
|
||||
|
||||
@@ -70,13 +70,14 @@ class HookParser(SimpleParser[HookBlock, ParsedHookNode]):
|
||||
def transform(self, node):
|
||||
return node
|
||||
|
||||
def get_paths(self) -> List[FilePath]:
|
||||
# Hooks are only in the dbt_project.yml file for the project
|
||||
def get_path(self) -> FilePath:
|
||||
path = FilePath(
|
||||
project_root=self.project.project_root,
|
||||
searched_path='.',
|
||||
relative_path='dbt_project.yml',
|
||||
)
|
||||
return [path]
|
||||
return path
|
||||
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedHookNode:
|
||||
if validate:
|
||||
|
||||
@@ -5,6 +5,7 @@ import jinja2
|
||||
from dbt.clients import jinja
|
||||
from dbt.contracts.graph.unparsed import UnparsedMacro
|
||||
from dbt.contracts.graph.parsed import ParsedMacro
|
||||
from dbt.contracts.files import FilePath, SourceFile
|
||||
from dbt.exceptions import CompilationException
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
@@ -14,12 +15,14 @@ from dbt.utils import MACRO_PREFIX
|
||||
|
||||
|
||||
class MacroParser(BaseParser[ParsedMacro]):
|
||||
def get_paths(self):
|
||||
return FilesystemSearcher(
|
||||
# This is only used when creating a MacroManifest separate
|
||||
# from the normal parsing flow.
|
||||
def get_paths(self) -> List[FilePath]:
|
||||
return list(FilesystemSearcher(
|
||||
project=self.project,
|
||||
relative_dirs=self.project.macro_paths,
|
||||
extension='.sql',
|
||||
)
|
||||
))
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
@@ -53,7 +56,7 @@ class MacroParser(BaseParser[ParsedMacro]):
|
||||
t for t in
|
||||
jinja.extract_toplevel_blocks(
|
||||
base_node.raw_sql,
|
||||
allowed_blocks={'macro', 'materialization'},
|
||||
allowed_blocks={'macro', 'materialization', 'test'},
|
||||
collect_raw_data=False,
|
||||
)
|
||||
if isinstance(t, jinja.BlockTag)
|
||||
@@ -89,12 +92,10 @@ class MacroParser(BaseParser[ParsedMacro]):
|
||||
yield node
|
||||
|
||||
def parse_file(self, block: FileBlock):
|
||||
# mark the file as seen, even if there are no macros in it
|
||||
self.results.get_file(block.file)
|
||||
assert isinstance(block.file, SourceFile)
|
||||
source_file = block.file
|
||||
|
||||
assert isinstance(source_file.contents, str)
|
||||
original_file_path = source_file.path.original_file_path
|
||||
|
||||
logger.debug("Parsing {}".format(original_file_path))
|
||||
|
||||
# this is really only used for error messages
|
||||
@@ -108,4 +109,4 @@ class MacroParser(BaseParser[ParsedMacro]):
|
||||
)
|
||||
|
||||
for node in self.parse_unparsed_macros(base_node):
|
||||
self.results.add_macro(block.file, node)
|
||||
self.manifest.add_macro(block.file, node)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user