mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-17 19:31:34 +00:00
Compare commits
136 Commits
leahwicz-p
...
performanc
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1fe53750fa | ||
|
|
8609c02383 | ||
|
|
355b0c496e | ||
|
|
cd6894acf4 | ||
|
|
b90b3a9c19 | ||
|
|
06cc0c57e8 | ||
|
|
87072707ed | ||
|
|
ef63319733 | ||
|
|
2068dd5510 | ||
|
|
3e1e171c66 | ||
|
|
5f9ed1a83c | ||
|
|
3d9e54d970 | ||
|
|
52a0fdef6c | ||
|
|
d9b02fb0a0 | ||
|
|
6c8de62b24 | ||
|
|
2d3d1b030a | ||
|
|
88acf0727b | ||
|
|
02839ec779 | ||
|
|
44a8f6a3bf | ||
|
|
751ea92576 | ||
|
|
02007b3619 | ||
|
|
fe0b9e7ef5 | ||
|
|
4b1c6b51f9 | ||
|
|
0b4689f311 | ||
|
|
b77eff8f6f | ||
|
|
2782a33ecf | ||
|
|
94c6cf1b3c | ||
|
|
3c8daacd3e | ||
|
|
2f9907b072 | ||
|
|
287c4d2b03 | ||
|
|
ba9d76b3f9 | ||
|
|
486afa9fcd | ||
|
|
1f189f5225 | ||
|
|
580b1fdd68 | ||
|
|
bad0198a36 | ||
|
|
252280b56e | ||
|
|
64bf9c8885 | ||
|
|
935c138736 | ||
|
|
5891b59790 | ||
|
|
4e020c3878 | ||
|
|
3004969a93 | ||
|
|
873e9714f8 | ||
|
|
fe24dd43d4 | ||
|
|
ed91ded2c1 | ||
|
|
757614d57f | ||
|
|
faff8c00b3 | ||
|
|
80244a09fe | ||
|
|
37e86257f5 | ||
|
|
c182c05c2f | ||
|
|
b02875a12b | ||
|
|
03332b2955 | ||
|
|
f1f99a2371 | ||
|
|
95116dbb5b | ||
|
|
868fd64adf | ||
|
|
2f7ab2d038 | ||
|
|
3d4a82cca2 | ||
|
|
6ba837d73d | ||
|
|
f4775d7673 | ||
|
|
429396aa02 | ||
|
|
8a5e9b71a5 | ||
|
|
fa78102eaf | ||
|
|
5466d474c5 | ||
|
|
80951ae973 | ||
|
|
d5662ef34c | ||
|
|
45bb955b55 | ||
|
|
4ddba7e44c | ||
|
|
37b31d10c8 | ||
|
|
c8bc25d11a | ||
|
|
4c06689ff5 | ||
|
|
a45c9d0192 | ||
|
|
34e2c4f90b | ||
|
|
c0e2023c81 | ||
|
|
108b55bdc3 | ||
|
|
a29367b7fe | ||
|
|
1d7e8349ed | ||
|
|
75d3d87d64 | ||
|
|
4ff3f6d4e8 | ||
|
|
d0773f3346 | ||
|
|
ee58d27d94 | ||
|
|
9e3da391a7 | ||
|
|
9f62ec2153 | ||
|
|
372eca76b8 | ||
|
|
e3cb050bbc | ||
|
|
0ae93c7f54 | ||
|
|
1f6386d760 | ||
|
|
66eb3964e2 | ||
|
|
f460d275ba | ||
|
|
fb91bad800 | ||
|
|
eaec22ae53 | ||
|
|
b7c1768cca | ||
|
|
387b26a202 | ||
|
|
8a1e6438f1 | ||
|
|
aaac5ff2e6 | ||
|
|
4dc29630b5 | ||
|
|
f716631439 | ||
|
|
648a780850 | ||
|
|
de0919ff88 | ||
|
|
8b1ea5fb6c | ||
|
|
85627aafcd | ||
|
|
49065158f5 | ||
|
|
bdb3049218 | ||
|
|
e10d1b0f86 | ||
|
|
83b98c8ebf | ||
|
|
b9d5123aa3 | ||
|
|
c09300bfd2 | ||
|
|
fc490cee7b | ||
|
|
3baa3d7fe8 | ||
|
|
764c7c0fdc | ||
|
|
c97ebbbf35 | ||
|
|
85fe32bd08 | ||
|
|
eba3fd2255 | ||
|
|
e2f2c07873 | ||
|
|
70850cd362 | ||
|
|
16992e6391 | ||
|
|
fd0d95140e | ||
|
|
ac65fcd557 | ||
|
|
4d246567b9 | ||
|
|
1ad1c834f3 | ||
|
|
41610b822c | ||
|
|
c794600242 | ||
|
|
9d414f6ec3 | ||
|
|
552e831306 | ||
|
|
c712c96a0b | ||
|
|
eb46bfc3d6 | ||
|
|
f52537b606 | ||
|
|
762419d2fe | ||
|
|
4feb7cb15b | ||
|
|
eb47b85148 | ||
|
|
9faa019a07 | ||
|
|
9589dc91fa | ||
|
|
14507a283e | ||
|
|
af0fe120ec | ||
|
|
16501ec1c6 | ||
|
|
bf867f6aff | ||
|
|
eb4ad4444f | ||
|
|
8fdba17ac6 |
@@ -1,23 +1,27 @@
|
||||
[bumpversion]
|
||||
current_version = 0.20.0rc1
|
||||
current_version = 0.21.0a1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
((?P<prerelease>[a-z]+)(?P<num>\d+))?
|
||||
((?P<prekind>a|b|rc)
|
||||
(?P<pre>\d+) # pre-release version num
|
||||
)?
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prerelease}{num}
|
||||
{major}.{minor}.{patch}{prekind}{pre}
|
||||
{major}.{minor}.{patch}
|
||||
commit = False
|
||||
tag = False
|
||||
|
||||
[bumpversion:part:prerelease]
|
||||
[bumpversion:part:prekind]
|
||||
first_value = a
|
||||
optional_value = final
|
||||
values =
|
||||
a
|
||||
b
|
||||
rc
|
||||
final
|
||||
|
||||
[bumpversion:part:num]
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
@@ -26,6 +30,8 @@ first_value = 1
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/setup.py]
|
||||
@@ -41,4 +47,3 @@ first_value = 1
|
||||
[bumpversion:file:plugins/snowflake/dbt/adapters/snowflake/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/dbt/adapters/bigquery/__version__.py]
|
||||
|
||||
|
||||
29
.github/ISSUE_TEMPLATE/minor-version-release.md
vendored
Normal file
29
.github/ISSUE_TEMPLATE/minor-version-release.md
vendored
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
name: Minor version release
|
||||
about: Creates a tracking checklist of items for a minor version release
|
||||
title: "[Tracking] v#.##.# release "
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Release Core
|
||||
- [ ] [Engineering] dbt-release workflow
|
||||
- [ ] [Engineering] Create new protected `x.latest` branch
|
||||
- [ ] [Product] Finalize migration guide (next.docs.getdbt.com)
|
||||
|
||||
### Release Cloud
|
||||
- [ ] [Engineering] Create a platform issue to update dbt Cloud and verify it is completed
|
||||
- [ ] [Engineering] Determine if schemas have changed. If so, generate new schemas and push to schemas.getdbt.com
|
||||
|
||||
### Announce
|
||||
- [ ] [Product] Publish discourse
|
||||
- [ ] [Product] Announce in dbt Slack
|
||||
|
||||
### Post-release
|
||||
- [ ] [Engineering] [Bump plugin versions](https://www.notion.so/fishtownanalytics/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#59571f5bc1a040d9a8fd096e23d2c7db) (dbt-spark + dbt-presto), add compatibility as needed
|
||||
- [ ] Spark
|
||||
- [ ] Presto
|
||||
- [ ] [Engineering] Create a platform issue to update dbt-spark versions to dbt Cloud
|
||||
- [ ] [Product] Release new version of dbt-utils with new dbt version compatibility. If there are breaking changes requiring a minor version, plan upgrades of other packages that depend on dbt-utils.
|
||||
- [ ] [Engineering] If this isn't a final release, create an epic for the next release
|
||||
181
.github/workflows/performance.yml
vendored
Normal file
181
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,181 @@
|
||||
|
||||
name: Performance Regression Testing
|
||||
# Schedule triggers
|
||||
on:
|
||||
# TODO this is just while developing
|
||||
pull_request:
|
||||
branches:
|
||||
- 'develop'
|
||||
- 'performance-regression-testing'
|
||||
schedule:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
- cron: '5 10,22 * * *'
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: '0.20.latest'
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final_calculations.json
|
||||
74
CHANGELOG.md
74
CHANGELOG.md
@@ -1,4 +1,73 @@
|
||||
## dbt 0.20.0 (Release TBD)
|
||||
## dbt 0.21.0 (Release TBD)
|
||||
|
||||
### Features
|
||||
- Add `dbt build` command to run models, tests, seeds, and snapshots in DAG order. ([#2743] (https://github.com/dbt-labs/dbt/issues/2743), [#3490] (https://github.com/dbt-labs/dbt/issues/3490))
|
||||
|
||||
### Fixes
|
||||
- Fix docs generation for cross-db sources in REDSHIFT RA3 node ([#3236](https://github.com/fishtown-analytics/dbt/issues/3236), [#3408](https://github.com/fishtown-analytics/dbt/pull/3408))
|
||||
- Fix type coercion issues when fetching query result sets ([#2984](https://github.com/fishtown-analytics/dbt/issues/2984), [#3499](https://github.com/fishtown-analytics/dbt/pull/3499))
|
||||
- Handle whitespace after a plus sign on the project config ([#3526](https://github.com/dbt-labs/dbt/pull/3526))
|
||||
|
||||
### Under the hood
|
||||
- Add performance regression testing [#3602](https://github.com/dbt-labs/dbt/pull/3602)
|
||||
- Improve default view and table materialization performance by checking relational cache before attempting to drop temp relations ([#3112](https://github.com/fishtown-analytics/dbt/issues/3112), [#3468](https://github.com/fishtown-analytics/dbt/pull/3468))
|
||||
- Add optional `sslcert`, `sslkey`, and `sslrootcert` profile arguments to the Postgres connector. ([#3472](https://github.com/fishtown-analytics/dbt/pull/3472), [#3473](https://github.com/fishtown-analytics/dbt/pull/3473))
|
||||
- Move the example project used by `dbt init` into `dbt` repository, to avoid cloning an external repo ([#3005](https://github.com/fishtown-analytics/dbt/pull/3005), [#3474](https://github.com/fishtown-analytics/dbt/pull/3474), [#3536](https://github.com/fishtown-analytics/dbt/pull/3536))
|
||||
- Better interaction between `dbt init` and adapters. Avoid raising errors while initializing a project ([#2814](https://github.com/fishtown-analytics/dbt/pull/2814), [#3483](https://github.com/fishtown-analytics/dbt/pull/3483))
|
||||
- Update `create_adapter_plugins` script to include latest accessories, and stay up to date with latest dbt-core version ([#3002](https://github.com/fishtown-analytics/dbt/issues/3002), [#3509](https://github.com/fishtown-analytics/dbt/pull/3509))
|
||||
|
||||
### Dependencies
|
||||
- Require `werkzeug>=1`
|
||||
|
||||
Contributors:
|
||||
- [@kostek-pl](https://github.com/kostek-pl) ([#3236](https://github.com/fishtown-analytics/dbt/pull/3408))
|
||||
- [@tconbeer](https://github.com/tconbeer) [#3468](https://github.com/fishtown-analytics/dbt/pull/3468))
|
||||
- [@JLDLaughlin](https://github.com/JLDLaughlin) ([#3473](https://github.com/fishtown-analytics/dbt/pull/3473))
|
||||
- [@jmriego](https://github.com/jmriego) ([#3526](https://github.com/dbt-labs/dbt/pull/3526))
|
||||
|
||||
|
||||
## dbt 0.20.1 (Release TBD)
|
||||
|
||||
### Fixes
|
||||
- Fix `store_failures` config when defined as a modifier for `unique` and `not_null` tests ([#3575](https://github.com/fishtown-analytics/dbt/issues/3575), [#3577](https://github.com/fishtown-analytics/dbt/pull/3577))
|
||||
|
||||
|
||||
## dbt 0.20.0 (July 12, 2021)
|
||||
|
||||
### Fixes
|
||||
|
||||
- Avoid slowdown in column-level `persist_docs` on Snowflake, while preserving the error-avoidance from [#3149](https://github.com/fishtown-analytics/dbt/issues/3149) ([#3541](https://github.com/fishtown-analytics/dbt/issues/3541), [#3543](https://github.com/fishtown-analytics/dbt/pull/3543))
|
||||
- Partial parsing: handle already deleted nodes when schema block also deleted ([#3516](http://github.com/fishown-analystics/dbt/issues/3516), [#3522](http://github.com/fishown-analystics/dbt/issues/3522))
|
||||
|
||||
### Docs
|
||||
|
||||
- Update dbt logo and links ([docs#197](https://github.com/fishtown-analytics/dbt-docs/issues/197))
|
||||
|
||||
### Under the hood
|
||||
|
||||
- Add tracking for experimental parser accuracy ([3503](https://github.com/dbt-labs/dbt/pull/3503), [3553](https://github.com/dbt-labs/dbt/pull/3553))
|
||||
|
||||
## dbt 0.20.0rc2 (June 30, 2021)
|
||||
|
||||
### Fixes
|
||||
|
||||
- Handle quoted values within test configs, such as `where` ([#3458](https://github.com/fishtown-analytics/dbt/issues/3458), [#3459](https://github.com/fishtown-analytics/dbt/pull/3459))
|
||||
|
||||
### Docs
|
||||
|
||||
- Display `tags` on exposures ([docs#194](https://github.com/fishtown-analytics/dbt-docs/issues/194), [docs#195](https://github.com/fishtown-analytics/dbt-docs/issues/195))
|
||||
|
||||
### Under the hood
|
||||
|
||||
- Swap experimental parser implementation to use Rust [#3497](https://github.com/fishtown-analytics/dbt/pull/3497)
|
||||
- Dispatch the core SQL statement of the new test materialization, to benefit adapter maintainers ([#3465](https://github.com/fishtown-analytics/dbt/pull/3465), [#3461](https://github.com/fishtown-analytics/dbt/pull/3461))
|
||||
- Minimal validation of yaml dictionaries prior to partial parsing ([#3246](https://github.com/fishtown-analytics/dbt/issues/3246), [#3460](https://github.com/fishtown-analytics/dbt/pull/3460))
|
||||
- Add partial parsing tests and improve partial parsing handling of macros ([#3449](https://github.com/fishtown-analytics/dbt/issues/3449), [#3505](https://github.com/fishtown-analytics/dbt/pull/3505))
|
||||
- Update project loading event data to include experimental parser information. ([#3438](https://github.com/fishtown-analytics/dbt/issues/3438), [#3495](https://github.com/fishtown-analytics/dbt/pull/3495))
|
||||
|
||||
Contributors:
|
||||
- [@swanderz](https://github.com/swanderz) ([#3461](https://github.com/fishtown-analytics/dbt/pull/3461))
|
||||
- [@stkbailey](https://github.com/stkbailey) ([docs#195](https://github.com/fishtown-analytics/dbt-docs/issues/195))
|
||||
|
||||
## dbt 0.20.0rc1 (June 04, 2021)
|
||||
|
||||
@@ -26,7 +95,10 @@
|
||||
- Separate `compiled_path` from `build_path`, and print the former alongside node error messages ([#1985](https://github.com/fishtown-analytics/dbt/issues/1985), [#3327](https://github.com/fishtown-analytics/dbt/pull/3327))
|
||||
- Fix exception caused when running `dbt debug` with BigQuery connections ([#3314](https://github.com/fishtown-analytics/dbt/issues/3314), [#3351](https://github.com/fishtown-analytics/dbt/pull/3351))
|
||||
- Raise better error if snapshot is missing required configurations ([#3381](https://github.com/fishtown-analytics/dbt/issues/3381), [#3385](https://github.com/fishtown-analytics/dbt/pull/3385))
|
||||
- Fix `dbt run` errors caused from receiving non-JSON responses from Snowflake with Oauth ([#3350](https://github.com/fishtown-analytics/dbt/issues/3350))
|
||||
- Fix deserialization of Manifest lock attribute ([#3435](https://github.com/fishtown-analytics/dbt/issues/3435), [#3445](https://github.com/fishtown-analytics/dbt/pull/3445))
|
||||
- Fix `dbt run` errors caused from receiving non-JSON responses from Snowflake with Oauth ([#3350](https://github.com/fishtown-analytics/dbt/issues/3350)
|
||||
- Fix infinite recursion when parsing schema tests due to loops in macro calls ([#3444](https://github.com/fishtown-analytics/dbt/issues/3344), [#3454](https://github.com/fishtown-analytics/dbt/pull/3454))
|
||||
|
||||
### Docs
|
||||
- Reversed the rendering direction of relationship tests so that the test renders in the model it is defined in ([docs#181](https://github.com/fishtown-analytics/dbt-docs/issues/181), [docs#183](https://github.com/fishtown-analytics/dbt-docs/pull/183))
|
||||
|
||||
@@ -186,7 +186,7 @@
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
Copyright 2021 dbt Labs, Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
|
||||
47
README.md
47
README.md
@@ -1,28 +1,21 @@
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/fishtown-analytics/dbt/6c6649f9129d5d108aa3b0526f634cd8f3a9d1ed/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt/ec7dee39f793aa4f7dd3dae37282cc87664813e4/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://codeclimate.com/github/fishtown-analytics/dbt">
|
||||
<img src="https://codeclimate.com/github/fishtown-analytics/dbt/badges/gpa.svg" alt="Code Climate"/>
|
||||
<a href="https://github.com/dbt-labs/dbt/actions/workflows/tests.yml?query=branch%3Adevelop">
|
||||
<img src="https://github.com/dbt-labs/dbt/actions/workflows/tests.yml/badge.svg" alt="GitHub Actions"/>
|
||||
</a>
|
||||
<a href="https://circleci.com/gh/fishtown-analytics/dbt/tree/master">
|
||||
<img src="https://circleci.com/gh/fishtown-analytics/dbt/tree/master.svg?style=svg" alt="CircleCI" />
|
||||
<a href="https://circleci.com/gh/dbt-labs/dbt/tree/develop">
|
||||
<img src="https://circleci.com/gh/dbt-labs/dbt/tree/develop.svg?style=svg" alt="CircleCI" />
|
||||
</a>
|
||||
<a href="https://ci.appveyor.com/project/DrewBanin/dbt/branch/development">
|
||||
<img src="https://ci.appveyor.com/api/projects/status/v01rwd3q91jnwp9m/branch/development?svg=true" alt="AppVeyor" />
|
||||
</a>
|
||||
<a href="https://community.getdbt.com">
|
||||
<img src="https://community.getdbt.com/badge.svg" alt="Slack" />
|
||||
<a href="https://dev.azure.com/fishtown-analytics/dbt/_build?definitionId=1&_a=summary&repositoryFilter=1&branchFilter=789%2C789%2C789%2C789">
|
||||
<img src="https://dev.azure.com/fishtown-analytics/dbt/_apis/build/status/fishtown-analytics.dbt?branchName=develop" alt="Azure Pipelines" />
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** (data build tool) enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
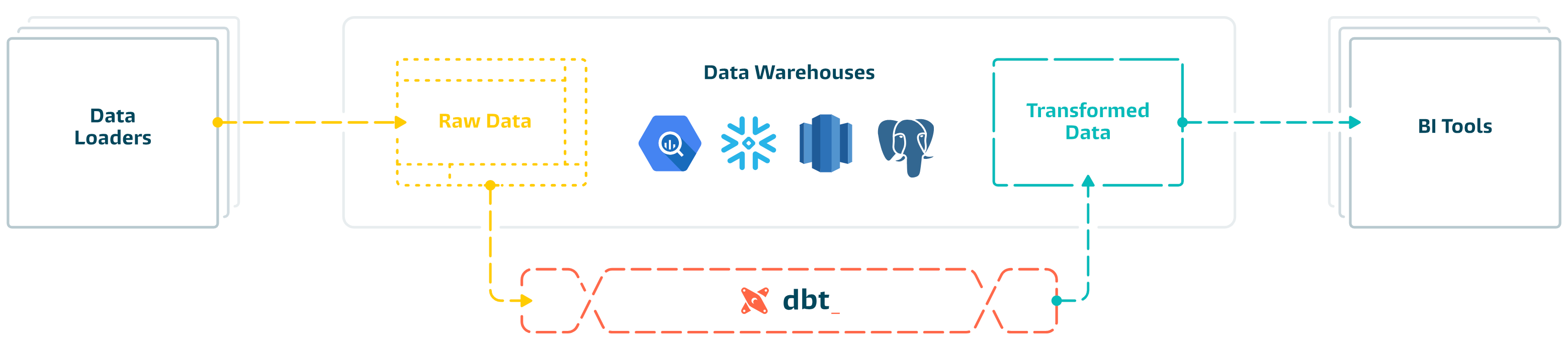
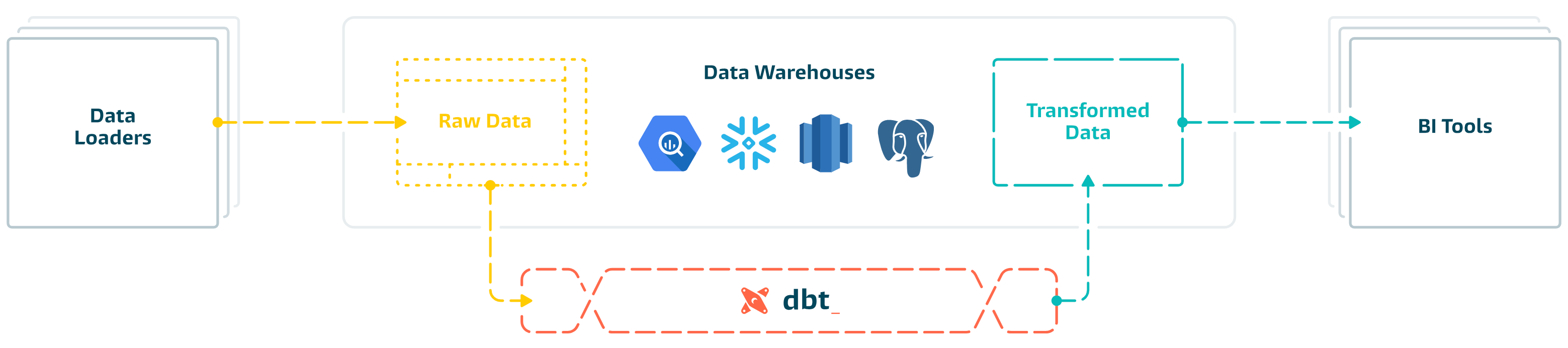
dbt is the T in ELT. Organize, cleanse, denormalize, filter, rename, and pre-aggregate the raw data in your warehouse so that it's ready for analysis.
|
||||
|
||||
|
||||
|
||||
dbt can be used to [aggregate pageviews into sessions](https://github.com/fishtown-analytics/snowplow), calculate [ad spend ROI](https://github.com/fishtown-analytics/facebook-ads), or report on [email campaign performance](https://github.com/fishtown-analytics/mailchimp).
|
||||
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -30,28 +23,22 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
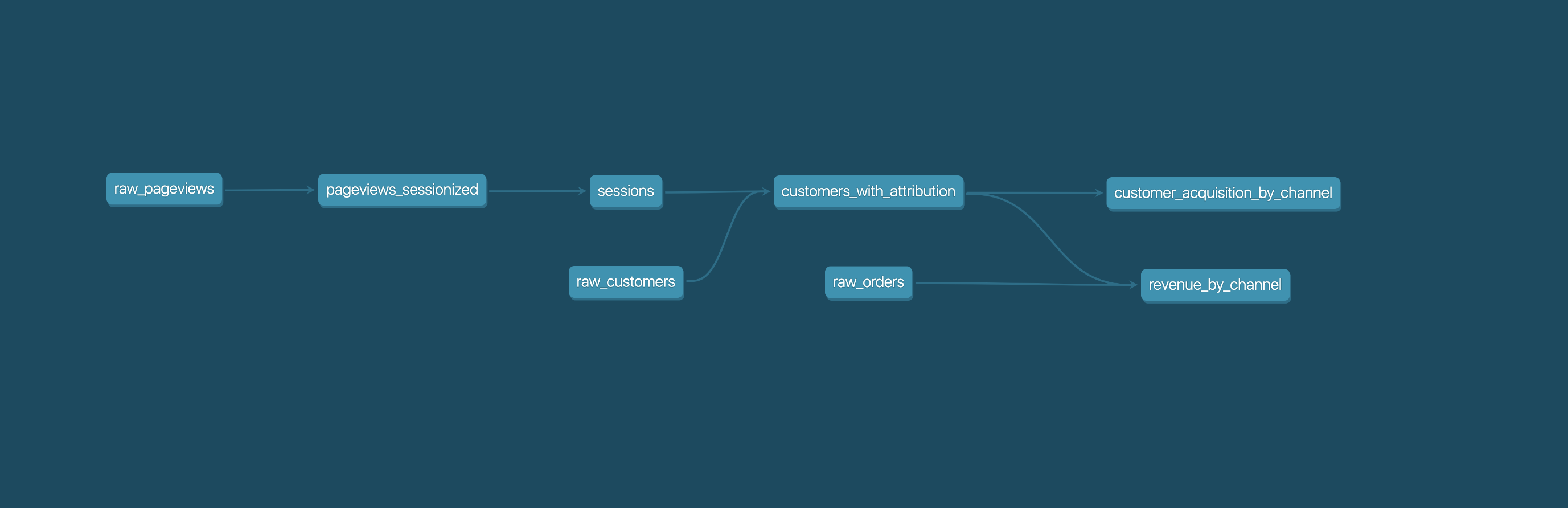
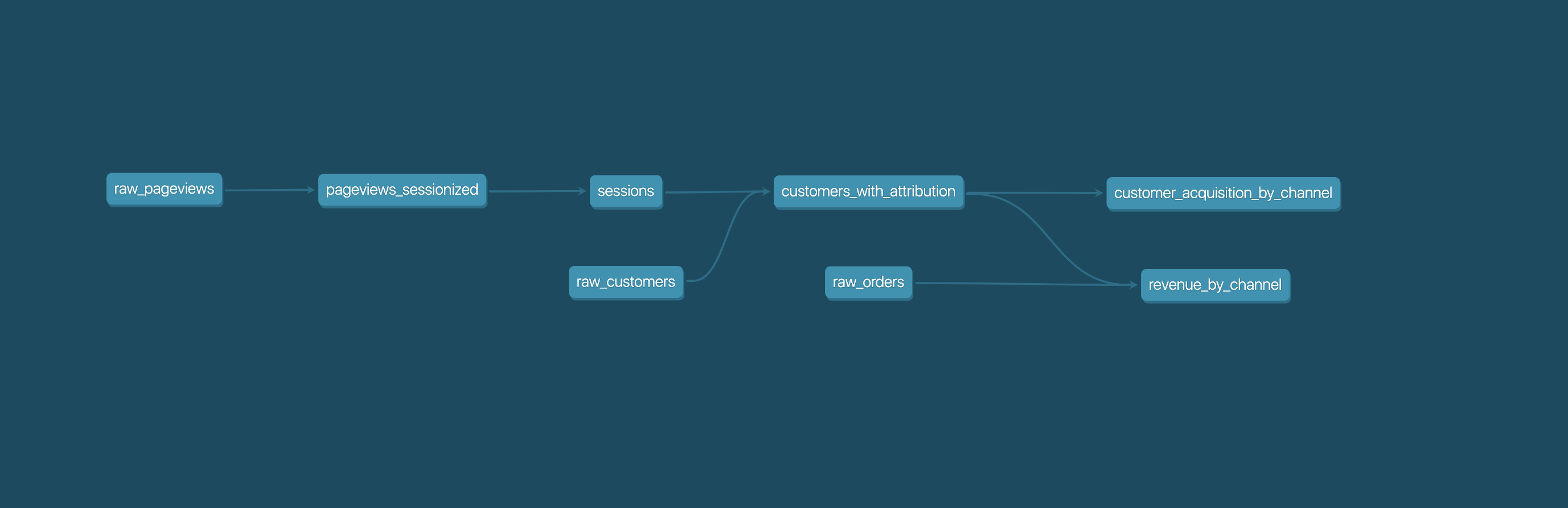
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||
|
||||
|
||||
|
||||
## Getting started
|
||||
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [documentation](https://docs.getdbt.com/).
|
||||
- Productionize your dbt project with [dbt Cloud](https://www.getdbt.com)
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
|
||||
|
||||
## Find out more
|
||||
## Join the dbt Community
|
||||
|
||||
- Check out the [Introduction to dbt](https://docs.getdbt.com/docs/introduction/).
|
||||
- Read the [dbt Viewpoint](https://docs.getdbt.com/docs/about/viewpoint/).
|
||||
|
||||
## Join thousands of analysts in the dbt community
|
||||
|
||||
- Join the [chat](http://community.getdbt.com/) on Slack.
|
||||
- Find community posts on [dbt Discourse](https://discourse.getdbt.com).
|
||||
- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
|
||||
- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/fishtown-analytics/dbt/issues/new).
|
||||
- Want to help us build dbt? Check out the [Contributing Getting Started Guide](https://github.com/fishtown-analytics/dbt/blob/HEAD/CONTRIBUTING.md)
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
@@ -1 +1 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
|
||||
@@ -433,13 +433,14 @@ class SchemaSearchMap(Dict[InformationSchema, Set[Optional[str]]]):
|
||||
for schema in schemas:
|
||||
yield information_schema_name, schema
|
||||
|
||||
def flatten(self):
|
||||
def flatten(self, allow_multiple_databases: bool = False):
|
||||
new = self.__class__()
|
||||
|
||||
# make sure we don't have duplicates
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
# make sure we don't have multiple databases if allow_multiple_databases is set to False
|
||||
if not allow_multiple_databases:
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
|
||||
for information_schema_name, schema in self.search():
|
||||
path = {
|
||||
|
||||
@@ -35,7 +35,11 @@ class ISODateTime(agate.data_types.DateTime):
|
||||
)
|
||||
|
||||
|
||||
def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
def build_type_tester(
|
||||
text_columns: Iterable[str],
|
||||
string_null_values: Optional[Iterable[str]] = ('null', '')
|
||||
) -> agate.TypeTester:
|
||||
|
||||
types = [
|
||||
agate.data_types.Number(null_values=('null', '')),
|
||||
agate.data_types.Date(null_values=('null', ''),
|
||||
@@ -46,10 +50,10 @@ def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
agate.data_types.Boolean(true_values=('true',),
|
||||
false_values=('false',),
|
||||
null_values=('null', '')),
|
||||
agate.data_types.Text(null_values=('null', ''))
|
||||
agate.data_types.Text(null_values=string_null_values)
|
||||
]
|
||||
force = {
|
||||
k: agate.data_types.Text(null_values=('null', ''))
|
||||
k: agate.data_types.Text(null_values=string_null_values)
|
||||
for k in text_columns
|
||||
}
|
||||
return agate.TypeTester(force=force, types=types)
|
||||
@@ -66,7 +70,13 @@ def table_from_rows(
|
||||
if text_only_columns is None:
|
||||
column_types = DEFAULT_TYPE_TESTER
|
||||
else:
|
||||
column_types = build_type_tester(text_only_columns)
|
||||
# If text_only_columns are present, prevent coercing empty string or
|
||||
# literal 'null' strings to a None representation.
|
||||
column_types = build_type_tester(
|
||||
text_only_columns,
|
||||
string_null_values=()
|
||||
)
|
||||
|
||||
return agate.Table(rows, column_names, column_types=column_types)
|
||||
|
||||
|
||||
@@ -86,19 +96,34 @@ def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
|
||||
|
||||
def table_from_data_flat(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
"""
|
||||
Convert a list of dictionaries into an Agate table. This method does not
|
||||
coerce string values into more specific types (eg. '005' will not be
|
||||
coerced to '5'). Additionally, this method does not coerce values to
|
||||
None (eg. '' or 'null' will retain their string literal representations).
|
||||
"""
|
||||
|
||||
rows = []
|
||||
text_only_columns = set()
|
||||
for _row in data:
|
||||
row = []
|
||||
for value in list(_row.values()):
|
||||
for col_name in column_names:
|
||||
value = _row[col_name]
|
||||
if isinstance(value, (dict, list, tuple)):
|
||||
row.append(json.dumps(value, cls=dbt.utils.JSONEncoder))
|
||||
else:
|
||||
row.append(value)
|
||||
# Represent container types as json strings
|
||||
value = json.dumps(value, cls=dbt.utils.JSONEncoder)
|
||||
text_only_columns.add(col_name)
|
||||
elif isinstance(value, str):
|
||||
text_only_columns.add(col_name)
|
||||
row.append(value)
|
||||
|
||||
rows.append(row)
|
||||
|
||||
return table_from_rows(rows=rows, column_names=column_names)
|
||||
return table_from_rows(
|
||||
rows=rows,
|
||||
column_names=column_names,
|
||||
text_only_columns=text_only_columns
|
||||
)
|
||||
|
||||
|
||||
def empty_table():
|
||||
|
||||
@@ -147,7 +147,7 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
|
||||
if first in {'seeds', 'models', 'snapshots', 'tests'}:
|
||||
keypath_parts = {
|
||||
(k.lstrip('+') if isinstance(k, str) else k)
|
||||
(k.lstrip('+ ') if isinstance(k, str) else k)
|
||||
for k in keypath
|
||||
}
|
||||
# model-level hooks
|
||||
|
||||
@@ -97,7 +97,7 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
result = {}
|
||||
for key, value in level_config.items():
|
||||
if key.startswith('+'):
|
||||
result[key[1:]] = deepcopy(value)
|
||||
result[key[1:].strip()] = deepcopy(value)
|
||||
elif not isinstance(value, dict):
|
||||
result[key] = deepcopy(value)
|
||||
|
||||
|
||||
@@ -169,6 +169,8 @@ class TestMacroNamespace:
|
||||
|
||||
def recursively_get_depends_on_macros(self, depends_on_macros, dep_macros):
|
||||
for macro_unique_id in depends_on_macros:
|
||||
if macro_unique_id in dep_macros:
|
||||
continue
|
||||
dep_macros.append(macro_unique_id)
|
||||
if macro_unique_id in self.macro_resolver.macros:
|
||||
macro = self.macro_resolver.macros[macro_unique_id]
|
||||
|
||||
@@ -156,20 +156,11 @@ class BaseSourceFile(dbtClassMixin, SerializableType):
|
||||
|
||||
def _serialize(self):
|
||||
dct = self.to_dict()
|
||||
if 'pp_files' in dct:
|
||||
del dct['pp_files']
|
||||
if 'pp_test_index' in dct:
|
||||
del dct['pp_test_index']
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, dct: Dict[str, int]):
|
||||
if dct['parse_file_type'] == 'schema':
|
||||
# TODO: why are these keys even here
|
||||
if 'pp_files' in dct:
|
||||
del dct['pp_files']
|
||||
if 'pp_test_index' in dct:
|
||||
del dct['pp_test_index']
|
||||
sf = SchemaSourceFile.from_dict(dct)
|
||||
else:
|
||||
sf = SourceFile.from_dict(dct)
|
||||
@@ -223,7 +214,7 @@ class SourceFile(BaseSourceFile):
|
||||
class SchemaSourceFile(BaseSourceFile):
|
||||
dfy: Dict[str, Any] = field(default_factory=dict)
|
||||
# these are in the manifest.nodes dictionary
|
||||
tests: List[str] = field(default_factory=list)
|
||||
tests: Dict[str, Any] = field(default_factory=dict)
|
||||
sources: List[str] = field(default_factory=list)
|
||||
exposures: List[str] = field(default_factory=list)
|
||||
# node patches contain models, seeds, snapshots, analyses
|
||||
@@ -255,14 +246,53 @@ class SchemaSourceFile(BaseSourceFile):
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if 'pp_files' in dct:
|
||||
del dct['pp_files']
|
||||
if 'pp_test_index' in dct:
|
||||
del dct['pp_test_index']
|
||||
# Remove partial parsing specific data
|
||||
for key in ('pp_files', 'pp_test_index', 'pp_dict'):
|
||||
if key in dct:
|
||||
del dct[key]
|
||||
return dct
|
||||
|
||||
def append_patch(self, yaml_key, unique_id):
|
||||
self.node_patches.append(unique_id)
|
||||
|
||||
def add_test(self, node_unique_id, test_from):
|
||||
name = test_from['name']
|
||||
key = test_from['key']
|
||||
if key not in self.tests:
|
||||
self.tests[key] = {}
|
||||
if name not in self.tests[key]:
|
||||
self.tests[key][name] = []
|
||||
self.tests[key][name].append(node_unique_id)
|
||||
|
||||
def remove_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
del self.tests[yaml_key][name]
|
||||
|
||||
def get_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
return self.tests[yaml_key][name]
|
||||
return []
|
||||
|
||||
def get_key_and_name_for_test(self, test_unique_id):
|
||||
yaml_key = None
|
||||
block_name = None
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
for unique_id in self.tests[key][name]:
|
||||
if unique_id == test_unique_id:
|
||||
yaml_key = key
|
||||
block_name = name
|
||||
break
|
||||
return (yaml_key, block_name)
|
||||
|
||||
def get_all_test_ids(self):
|
||||
test_ids = []
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
test_ids.extend(self.tests[key][name])
|
||||
return test_ids
|
||||
|
||||
|
||||
AnySourceFile = Union[SchemaSourceFile, SourceFile]
|
||||
|
||||
@@ -243,7 +243,7 @@ def _sort_values(dct):
|
||||
return {k: sorted(v) for k, v in dct.items()}
|
||||
|
||||
|
||||
def build_edges(nodes: List[ManifestNode]):
|
||||
def build_node_edges(nodes: List[ManifestNode]):
|
||||
"""Build the forward and backward edges on the given list of ParsedNodes
|
||||
and return them as two separate dictionaries, each mapping unique IDs to
|
||||
lists of edges.
|
||||
@@ -259,6 +259,18 @@ def build_edges(nodes: List[ManifestNode]):
|
||||
return _sort_values(forward_edges), _sort_values(backward_edges)
|
||||
|
||||
|
||||
# Build a map of children of macros
|
||||
def build_macro_edges(nodes: List[Any]):
|
||||
forward_edges: Dict[str, List[str]] = {
|
||||
n.unique_id: [] for n in nodes if n.unique_id.startswith('macro') or n.depends_on.macros
|
||||
}
|
||||
for node in nodes:
|
||||
for unique_id in node.depends_on.macros:
|
||||
if unique_id in forward_edges.keys():
|
||||
forward_edges[unique_id].append(node.unique_id)
|
||||
return _sort_values(forward_edges)
|
||||
|
||||
|
||||
def _deepcopy(value):
|
||||
return value.from_dict(value.to_dict(omit_none=True))
|
||||
|
||||
@@ -525,6 +537,12 @@ class MacroMethods:
|
||||
return candidates
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsingInfo:
|
||||
static_analysis_parsed_path_count: int = 0
|
||||
static_analysis_path_count: int = 0
|
||||
|
||||
|
||||
@dataclass
|
||||
class ManifestStateCheck(dbtClassMixin):
|
||||
vars_hash: FileHash = field(default_factory=FileHash.empty)
|
||||
@@ -566,9 +584,13 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
_analysis_lookup: Optional[AnalysisLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_parsing_info: ParsingInfo = field(
|
||||
default_factory=ParsingInfo,
|
||||
metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_lock: Lock = field(
|
||||
default_factory=flags.MP_CONTEXT.Lock,
|
||||
metadata={'serialize': lambda x: None, 'deserialize': lambda x: flags.MP_CONTEXT.Lock}
|
||||
metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
|
||||
def __pre_serialize__(self):
|
||||
@@ -577,6 +599,11 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
self.source_patches = {}
|
||||
return self
|
||||
|
||||
@classmethod
|
||||
def __post_deserialize__(cls, obj):
|
||||
obj._lock = flags.MP_CONTEXT.Lock()
|
||||
return obj
|
||||
|
||||
def sync_update_node(
|
||||
self, new_node: NonSourceCompiledNode
|
||||
) -> NonSourceCompiledNode:
|
||||
@@ -779,10 +806,18 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
self.sources.values(),
|
||||
self.exposures.values(),
|
||||
))
|
||||
forward_edges, backward_edges = build_edges(edge_members)
|
||||
forward_edges, backward_edges = build_node_edges(edge_members)
|
||||
self.child_map = forward_edges
|
||||
self.parent_map = backward_edges
|
||||
|
||||
def build_macro_child_map(self):
|
||||
edge_members = list(chain(
|
||||
self.nodes.values(),
|
||||
self.macros.values(),
|
||||
))
|
||||
forward_edges = build_macro_edges(edge_members)
|
||||
return forward_edges
|
||||
|
||||
def writable_manifest(self):
|
||||
self.build_parent_and_child_maps()
|
||||
return WritableManifest(
|
||||
@@ -1016,10 +1051,11 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
_check_duplicates(node, self.nodes)
|
||||
self.nodes[node.unique_id] = node
|
||||
|
||||
def add_node(self, source_file: AnySourceFile, node: ManifestNodes):
|
||||
def add_node(self, source_file: AnySourceFile, node: ManifestNodes, test_from=None):
|
||||
self.add_node_nofile(node)
|
||||
if isinstance(source_file, SchemaSourceFile):
|
||||
source_file.tests.append(node.unique_id)
|
||||
assert test_from
|
||||
source_file.add_test(node.unique_id, test_from)
|
||||
else:
|
||||
source_file.nodes.append(node.unique_id)
|
||||
|
||||
@@ -1034,10 +1070,11 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
else:
|
||||
self._disabled[node.unique_id] = [node]
|
||||
|
||||
def add_disabled(self, source_file: AnySourceFile, node: CompileResultNode):
|
||||
def add_disabled(self, source_file: AnySourceFile, node: CompileResultNode, test_from=None):
|
||||
self.add_disabled_nofile(node)
|
||||
if isinstance(source_file, SchemaSourceFile):
|
||||
source_file.tests.append(node.unique_id)
|
||||
assert test_from
|
||||
source_file.add_test(node.unique_id, test_from)
|
||||
else:
|
||||
source_file.nodes.append(node.unique_id)
|
||||
|
||||
|
||||
@@ -592,7 +592,8 @@ class ParsedSourceDefinition(
|
||||
UnparsedBaseNode,
|
||||
HasUniqueID,
|
||||
HasRelationMetadata,
|
||||
HasFqn
|
||||
HasFqn,
|
||||
|
||||
):
|
||||
name: str
|
||||
source_name: str
|
||||
@@ -689,6 +690,10 @@ class ParsedSourceDefinition(
|
||||
def depends_on_nodes(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def depends_on(self):
|
||||
return {'nodes': []}
|
||||
|
||||
@property
|
||||
def refs(self):
|
||||
return []
|
||||
|
||||
@@ -78,6 +78,7 @@ class TestStatus(StrEnum):
|
||||
Error = NodeStatus.Error
|
||||
Fail = NodeStatus.Fail
|
||||
Warn = NodeStatus.Warn
|
||||
Skipped = NodeStatus.Skipped
|
||||
|
||||
|
||||
class FreshnessStatus(StrEnum):
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
import threading
|
||||
from queue import PriorityQueue
|
||||
from typing import (
|
||||
Dict, Set, Optional
|
||||
)
|
||||
|
||||
import networkx as nx # type: ignore
|
||||
import threading
|
||||
|
||||
from queue import PriorityQueue
|
||||
from typing import Dict, Set, List, Generator, Optional
|
||||
|
||||
from .graph import UniqueId
|
||||
from dbt.contracts.graph.parsed import ParsedSourceDefinition, ParsedExposure
|
||||
@@ -21,9 +19,8 @@ class GraphQueue:
|
||||
that separate threads do not call `.empty()` or `__len__()` and `.get()` at
|
||||
the same time, as there is an unlocked race!
|
||||
"""
|
||||
def __init__(
|
||||
self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]
|
||||
):
|
||||
|
||||
def __init__(self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]):
|
||||
self.graph = graph
|
||||
self.manifest = manifest
|
||||
self._selected = selected
|
||||
@@ -37,7 +34,7 @@ class GraphQueue:
|
||||
# this lock controls most things
|
||||
self.lock = threading.Lock()
|
||||
# store the 'score' of each node as a number. Lower is higher priority.
|
||||
self._scores = self._calculate_scores()
|
||||
self._scores = self._get_scores(self.graph)
|
||||
# populate the initial queue
|
||||
self._find_new_additions()
|
||||
# awaits after task end
|
||||
@@ -56,30 +53,59 @@ class GraphQueue:
|
||||
return False
|
||||
return True
|
||||
|
||||
def _calculate_scores(self) -> Dict[UniqueId, int]:
|
||||
"""Calculate the 'value' of each node in the graph based on how many
|
||||
blocking descendants it has. We use this score for the internal
|
||||
priority queue's ordering, so the quality of this metric is important.
|
||||
@staticmethod
|
||||
def _grouped_topological_sort(
|
||||
graph: nx.DiGraph,
|
||||
) -> Generator[List[str], None, None]:
|
||||
"""Topological sort of given graph that groups ties.
|
||||
|
||||
The score is stored as a negative number because the internal
|
||||
PriorityQueue picks lowest values first.
|
||||
Adapted from `nx.topological_sort`, this function returns a topo sort of a graph however
|
||||
instead of arbitrarily ordering ties in the sort order, ties are grouped together in
|
||||
lists.
|
||||
|
||||
We could do this in one pass over the graph instead of len(self.graph)
|
||||
passes but this is easy. For large graphs this may hurt performance.
|
||||
Args:
|
||||
graph: The graph to be sorted.
|
||||
|
||||
This operates on the graph, so it would require a lock if called from
|
||||
outside __init__.
|
||||
|
||||
:return Dict[str, int]: The score dict, mapping unique IDs to integer
|
||||
scores. Lower scores are higher priority.
|
||||
Returns:
|
||||
A generator that yields lists of nodes, one list per graph depth level.
|
||||
"""
|
||||
indegree_map = {v: d for v, d in graph.in_degree() if d > 0}
|
||||
zero_indegree = [v for v, d in graph.in_degree() if d == 0]
|
||||
|
||||
while zero_indegree:
|
||||
yield zero_indegree
|
||||
new_zero_indegree = []
|
||||
for v in zero_indegree:
|
||||
for _, child in graph.edges(v):
|
||||
indegree_map[child] -= 1
|
||||
if not indegree_map[child]:
|
||||
new_zero_indegree.append(child)
|
||||
zero_indegree = new_zero_indegree
|
||||
|
||||
def _get_scores(self, graph: nx.DiGraph) -> Dict[str, int]:
|
||||
"""Scoring nodes for processing order.
|
||||
|
||||
Scores are calculated by the graph depth level. Lowest score (0) should be processed first.
|
||||
|
||||
Args:
|
||||
graph: The graph to be scored.
|
||||
|
||||
Returns:
|
||||
A dictionary consisting of `node name`:`score` pairs.
|
||||
"""
|
||||
# split graph by connected subgraphs
|
||||
subgraphs = (
|
||||
graph.subgraph(x) for x in nx.connected_components(nx.Graph(graph))
|
||||
)
|
||||
|
||||
# score all nodes in all subgraphs
|
||||
scores = {}
|
||||
for node in self.graph.nodes():
|
||||
score = -1 * len([
|
||||
d for d in nx.descendants(self.graph, node)
|
||||
if self._include_in_cost(d)
|
||||
])
|
||||
scores[node] = score
|
||||
for subgraph in subgraphs:
|
||||
grouped_nodes = self._grouped_topological_sort(subgraph)
|
||||
for level, group in enumerate(grouped_nodes):
|
||||
for node in group:
|
||||
scores[node] = level
|
||||
|
||||
return scores
|
||||
|
||||
def get(
|
||||
@@ -133,8 +159,6 @@ class GraphQueue:
|
||||
def _find_new_additions(self) -> None:
|
||||
"""Find any nodes in the graph that need to be added to the internal
|
||||
queue and add them.
|
||||
|
||||
Callers must hold the lock.
|
||||
"""
|
||||
for node, in_degree in self.graph.in_degree():
|
||||
if not self._already_known(node) and in_degree == 0:
|
||||
|
||||
@@ -6,6 +6,22 @@
|
||||
{% set target_relation = this.incorporate(type='table') %}
|
||||
{% set existing_relation = load_relation(this) %}
|
||||
|
||||
{% set tmp_identifier = model['name'] + '__dbt_tmp' %}
|
||||
{% set backup_identifier = model['name'] + "__dbt_backup" %}
|
||||
|
||||
-- the intermediate_ and backup_ relations should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation. This has to happen before
|
||||
-- BEGIN, in a separate transaction
|
||||
{% set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{% set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
-- `BEGIN` happens here:
|
||||
@@ -15,16 +31,9 @@
|
||||
{% if existing_relation is none %}
|
||||
{% set build_sql = create_table_as(False, target_relation, sql) %}
|
||||
{% elif existing_relation.is_view or should_full_refresh() %}
|
||||
{#-- Make sure the backup doesn't exist so we don't encounter issues with the rename below #}
|
||||
{% set tmp_identifier = model['name'] + '__dbt_tmp' %}
|
||||
{% set backup_identifier = model['name'] + "__dbt_backup" %}
|
||||
|
||||
{% set intermediate_relation = existing_relation.incorporate(path={"identifier": tmp_identifier}) %}
|
||||
{% set backup_relation = existing_relation.incorporate(path={"identifier": backup_identifier}) %}
|
||||
|
||||
{% do adapter.drop_relation(intermediate_relation) %}
|
||||
{% do adapter.drop_relation(backup_relation) %}
|
||||
|
||||
{% set build_sql = create_table_as(False, intermediate_relation, sql) %}
|
||||
{% set need_swap = true %}
|
||||
{% do to_drop.append(backup_relation) %}
|
||||
|
||||
@@ -12,7 +12,12 @@
|
||||
schema=schema,
|
||||
database=database,
|
||||
type='table') -%}
|
||||
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
See ../view/view.sql for more information about this relation.
|
||||
*/
|
||||
@@ -21,14 +26,15 @@
|
||||
schema=schema,
|
||||
database=database,
|
||||
type=backup_relation_type) -%}
|
||||
|
||||
{%- set exists_as_table = (old_relation is not none and old_relation.is_table) -%}
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
|
||||
-- drop the temp relations if they exists for some reason
|
||||
{{ adapter.drop_relation(intermediate_relation) }}
|
||||
{{ adapter.drop_relation(backup_relation) }}
|
||||
-- drop the temp relations if they exist already in the database
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
|
||||
@@ -1,3 +1,19 @@
|
||||
{% macro get_test_sql(main_sql, fail_calc, warn_if, error_if, limit) -%}
|
||||
{{ adapter.dispatch('get_test_sql')(main_sql, fail_calc, warn_if, error_if, limit) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{% macro default__get_test_sql(main_sql, fail_calc, warn_if, error_if, limit) -%}
|
||||
select
|
||||
{{ fail_calc }} as failures,
|
||||
{{ fail_calc }} {{ warn_if }} as should_warn,
|
||||
{{ fail_calc }} {{ error_if }} as should_error
|
||||
from (
|
||||
{{ main_sql }}
|
||||
{{ "limit " ~ limit if limit != none }}
|
||||
) dbt_internal_test
|
||||
{%- endmacro %}
|
||||
|
||||
{%- materialization test, default -%}
|
||||
|
||||
{% set relations = [] %}
|
||||
@@ -39,14 +55,7 @@
|
||||
|
||||
{% call statement('main', fetch_result=True) -%}
|
||||
|
||||
select
|
||||
{{ fail_calc }} as failures,
|
||||
{{ fail_calc }} {{ warn_if }} as should_warn,
|
||||
{{ fail_calc }} {{ error_if }} as should_error
|
||||
from (
|
||||
{{ main_sql }}
|
||||
{{ "limit " ~ limit if limit != none }}
|
||||
) dbt_internal_test
|
||||
{{ get_test_sql(main_sql, fail_calc, warn_if, error_if, limit)}}
|
||||
|
||||
{%- endcall %}
|
||||
|
||||
|
||||
@@ -9,7 +9,12 @@
|
||||
type='view') -%}
|
||||
{%- set intermediate_relation = api.Relation.create(identifier=tmp_identifier,
|
||||
schema=schema, database=database, type='view') -%}
|
||||
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
This relation (probably) doesn't exist yet. If it does exist, it's a leftover from
|
||||
a previous run, and we're going to try to drop it immediately. At the end of this
|
||||
@@ -27,14 +32,16 @@
|
||||
{%- set backup_relation = api.Relation.create(identifier=backup_identifier,
|
||||
schema=schema, database=database,
|
||||
type=backup_relation_type) -%}
|
||||
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
-- drop the temp relations if they exists for some reason
|
||||
{{ adapter.drop_relation(intermediate_relation) }}
|
||||
{{ adapter.drop_relation(backup_relation) }}
|
||||
-- drop the temp relations if they exist already in the database
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
-- `BEGIN` happens here:
|
||||
{{ run_hooks(pre_hooks, inside_transaction=True) }}
|
||||
|
||||
File diff suppressed because one or more lines are too long
4
core/dbt/include/starter_project/.gitignore
vendored
Normal file
4
core/dbt/include/starter_project/.gitignore
vendored
Normal file
@@ -0,0 +1,4 @@
|
||||
|
||||
target/
|
||||
dbt_modules/
|
||||
logs/
|
||||
15
core/dbt/include/starter_project/README.md
Normal file
15
core/dbt/include/starter_project/README.md
Normal file
@@ -0,0 +1,15 @@
|
||||
Welcome to your new dbt project!
|
||||
|
||||
### Using the starter project
|
||||
|
||||
Try running the following commands:
|
||||
- dbt run
|
||||
- dbt test
|
||||
|
||||
|
||||
### Resources:
|
||||
- Learn more about dbt [in the docs](https://docs.getdbt.com/docs/introduction)
|
||||
- Check out [Discourse](https://discourse.getdbt.com/) for commonly asked questions and answers
|
||||
- Join the [chat](https://community.getdbt.com/) on Slack for live discussions and support
|
||||
- Find [dbt events](https://events.getdbt.com) near you
|
||||
- Check out [the blog](https://blog.getdbt.com/) for the latest news on dbt's development and best practices
|
||||
3
core/dbt/include/starter_project/__init__.py
Normal file
3
core/dbt/include/starter_project/__init__.py
Normal file
@@ -0,0 +1,3 @@
|
||||
import os
|
||||
|
||||
PACKAGE_PATH = os.path.dirname(__file__)
|
||||
0
core/dbt/include/starter_project/data/.gitkeep
Normal file
0
core/dbt/include/starter_project/data/.gitkeep
Normal file
38
core/dbt/include/starter_project/dbt_project.yml
Normal file
38
core/dbt/include/starter_project/dbt_project.yml
Normal file
@@ -0,0 +1,38 @@
|
||||
|
||||
# Name your project! Project names should contain only lowercase characters
|
||||
# and underscores. A good package name should reflect your organization's
|
||||
# name or the intended use of these models
|
||||
name: 'my_new_project'
|
||||
version: '1.0.0'
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project.
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `source-paths` config, for example, states that models in this project can be
|
||||
# found in the "models/" directory. You probably won't need to change these!
|
||||
source-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
test-paths: ["tests"]
|
||||
data-paths: ["data"]
|
||||
macro-paths: ["macros"]
|
||||
snapshot-paths: ["snapshots"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_modules"
|
||||
|
||||
|
||||
# Configuring models
|
||||
# Full documentation: https://docs.getdbt.com/docs/configuring-models
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as tables. These settings can be overridden in the individual model files
|
||||
# using the `{{ config(...) }}` macro.
|
||||
models:
|
||||
my_new_project:
|
||||
# Config indicated by + and applies to all files under models/example/
|
||||
example:
|
||||
+materialized: view
|
||||
0
core/dbt/include/starter_project/macros/.gitkeep
Normal file
0
core/dbt/include/starter_project/macros/.gitkeep
Normal file
@@ -0,0 +1,27 @@
|
||||
|
||||
/*
|
||||
Welcome to your first dbt model!
|
||||
Did you know that you can also configure models directly within SQL files?
|
||||
This will override configurations stated in dbt_project.yml
|
||||
|
||||
Try changing "table" to "view" below
|
||||
*/
|
||||
|
||||
{{ config(materialized='table') }}
|
||||
|
||||
with source_data as (
|
||||
|
||||
select 1 as id
|
||||
union all
|
||||
select null as id
|
||||
|
||||
)
|
||||
|
||||
select *
|
||||
from source_data
|
||||
|
||||
/*
|
||||
Uncomment the line below to remove records with null `id` values
|
||||
*/
|
||||
|
||||
-- where id is not null
|
||||
@@ -0,0 +1,6 @@
|
||||
|
||||
-- Use the `ref` function to select from other models
|
||||
|
||||
select *
|
||||
from {{ ref('my_first_dbt_model') }}
|
||||
where id = 1
|
||||
21
core/dbt/include/starter_project/models/example/schema.yml
Normal file
21
core/dbt/include/starter_project/models/example/schema.yml
Normal file
@@ -0,0 +1,21 @@
|
||||
|
||||
version: 2
|
||||
|
||||
models:
|
||||
- name: my_first_dbt_model
|
||||
description: "A starter dbt model"
|
||||
columns:
|
||||
- name: id
|
||||
description: "The primary key for this table"
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
|
||||
- name: my_second_dbt_model
|
||||
description: "A starter dbt model"
|
||||
columns:
|
||||
- name: id
|
||||
description: "The primary key for this table"
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
0
core/dbt/include/starter_project/snapshots/.gitkeep
Normal file
0
core/dbt/include/starter_project/snapshots/.gitkeep
Normal file
0
core/dbt/include/starter_project/tests/.gitkeep
Normal file
0
core/dbt/include/starter_project/tests/.gitkeep
Normal file
@@ -11,6 +11,7 @@ from pathlib import Path
|
||||
import dbt.version
|
||||
import dbt.flags as flags
|
||||
import dbt.task.run as run_task
|
||||
import dbt.task.build as build_task
|
||||
import dbt.task.compile as compile_task
|
||||
import dbt.task.debug as debug_task
|
||||
import dbt.task.clean as clean_task
|
||||
@@ -367,7 +368,6 @@ def _build_init_subparser(subparsers, base_subparser):
|
||||
)
|
||||
sub.add_argument(
|
||||
'--adapter',
|
||||
default='redshift',
|
||||
type=str,
|
||||
help='''
|
||||
Write sample profiles.yml for which adapter
|
||||
@@ -377,6 +377,30 @@ def _build_init_subparser(subparsers, base_subparser):
|
||||
return sub
|
||||
|
||||
|
||||
def _build_build_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'build',
|
||||
parents=[base_subparser],
|
||||
help='''
|
||||
Run all Seeds, Models, Snapshots, and tests in DAG order
|
||||
'''
|
||||
)
|
||||
sub.set_defaults(
|
||||
cls=build_task.BuildTask,
|
||||
which='build',
|
||||
rpc_method='build'
|
||||
)
|
||||
sub.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
action='store_true',
|
||||
help='''
|
||||
Stop execution upon a first failure.
|
||||
'''
|
||||
)
|
||||
return sub
|
||||
|
||||
|
||||
def _build_clean_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'clean',
|
||||
@@ -1038,6 +1062,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
_build_deps_subparser(subs, base_subparser)
|
||||
_build_list_subparser(subs, base_subparser)
|
||||
|
||||
build_sub = _build_build_subparser(subs, base_subparser)
|
||||
snapshot_sub = _build_snapshot_subparser(subs, base_subparser)
|
||||
rpc_sub = _build_rpc_subparser(subs, base_subparser)
|
||||
run_sub = _build_run_subparser(subs, base_subparser)
|
||||
@@ -1051,7 +1076,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
rpc_sub, seed_sub, parse_sub)
|
||||
# --models, --exclude
|
||||
# list_sub sets up its own arguments.
|
||||
_add_selection_arguments(run_sub, compile_sub, generate_sub, test_sub)
|
||||
_add_selection_arguments(build_sub, run_sub, compile_sub, generate_sub, test_sub)
|
||||
_add_selection_arguments(snapshot_sub, seed_sub, models_name='select')
|
||||
# --defer
|
||||
_add_defer_argument(run_sub, test_sub)
|
||||
|
||||
@@ -282,7 +282,7 @@ class ConfiguredParser(
|
||||
) -> None:
|
||||
# Overwrite node config
|
||||
final_config_dict = parsed_node.config.to_dict(omit_none=True)
|
||||
final_config_dict.update(config_dict)
|
||||
final_config_dict.update({k.strip(): v for (k, v) in config_dict.items()})
|
||||
# re-mangle hooks, in case we got new ones
|
||||
self._mangle_hooks(final_config_dict)
|
||||
parsed_node.config = parsed_node.config.from_dict(final_config_dict)
|
||||
|
||||
@@ -31,7 +31,7 @@ from dbt.parser.read_files import read_files, load_source_file
|
||||
from dbt.parser.partial import PartialParsing
|
||||
from dbt.contracts.graph.compiled import ManifestNode
|
||||
from dbt.contracts.graph.manifest import (
|
||||
Manifest, Disabled, MacroManifest, ManifestStateCheck
|
||||
Manifest, Disabled, MacroManifest, ManifestStateCheck, ParsingInfo
|
||||
)
|
||||
from dbt.contracts.graph.parsed import (
|
||||
ParsedSourceDefinition, ParsedNode, ParsedMacro, ColumnInfo, ParsedExposure
|
||||
@@ -71,7 +71,7 @@ DEFAULT_PARTIAL_PARSE = False
|
||||
class ParserInfo(dbtClassMixin):
|
||||
parser: str
|
||||
elapsed: float
|
||||
path_count: int = 0
|
||||
parsed_path_count: int = 0
|
||||
|
||||
|
||||
# Part of saved performance info
|
||||
@@ -80,14 +80,18 @@ class ProjectLoaderInfo(dbtClassMixin):
|
||||
project_name: str
|
||||
elapsed: float
|
||||
parsers: List[ParserInfo] = field(default_factory=list)
|
||||
path_count: int = 0
|
||||
parsed_path_count: int = 0
|
||||
|
||||
|
||||
# Part of saved performance info
|
||||
@dataclass
|
||||
class ManifestLoaderInfo(dbtClassMixin, Writable):
|
||||
path_count: int = 0
|
||||
parsed_path_count: int = 0
|
||||
static_analysis_path_count: int = 0
|
||||
static_analysis_parsed_path_count: int = 0
|
||||
is_partial_parse_enabled: Optional[bool] = None
|
||||
is_static_analysis_enabled: Optional[bool] = None
|
||||
read_files_elapsed: Optional[float] = None
|
||||
load_macros_elapsed: Optional[float] = None
|
||||
parse_project_elapsed: Optional[float] = None
|
||||
@@ -135,8 +139,6 @@ class ManifestLoader:
|
||||
# have been enabled, but not happening because of some issue.
|
||||
self.partially_parsing = False
|
||||
|
||||
self._perf_info = self.build_perf_info()
|
||||
|
||||
# This is a saved manifest from a previous run that's used for partial parsing
|
||||
self.saved_manifest: Optional[Manifest] = self.read_manifest_for_partial_parse()
|
||||
|
||||
@@ -184,7 +186,6 @@ class ManifestLoader:
|
||||
|
||||
# This is where the main action happens
|
||||
def load(self):
|
||||
|
||||
# Read files creates a dictionary of projects to a dictionary
|
||||
# of parsers to lists of file strings. The file strings are
|
||||
# used to get the SourceFiles from the manifest files.
|
||||
@@ -196,6 +197,7 @@ class ManifestLoader:
|
||||
project_parser_files = {}
|
||||
for project in self.all_projects.values():
|
||||
read_files(project, self.manifest.files, project_parser_files)
|
||||
self._perf_info.path_count = len(self.manifest.files)
|
||||
self._perf_info.read_files_elapsed = (time.perf_counter() - start_read_files)
|
||||
|
||||
skip_parsing = False
|
||||
@@ -208,13 +210,15 @@ class ManifestLoader:
|
||||
# files are different, we need to create a new set of
|
||||
# project_parser_files.
|
||||
project_parser_files = partial_parsing.get_parsing_files()
|
||||
self.manifest = self.saved_manifest
|
||||
self.partially_parsing = True
|
||||
|
||||
self.manifest = self.saved_manifest
|
||||
|
||||
if self.manifest._parsing_info is None:
|
||||
self.manifest._parsing_info = ParsingInfo()
|
||||
|
||||
if skip_parsing:
|
||||
logger.info("Partial parsing enabled, no changes found, skipping parsing")
|
||||
self.manifest = self.saved_manifest
|
||||
|
||||
else:
|
||||
# Load Macros
|
||||
# We need to parse the macros first, so they're resolvable when
|
||||
@@ -230,6 +234,8 @@ class ManifestLoader:
|
||||
for file_id in parser_files['MacroParser']:
|
||||
block = FileBlock(self.manifest.files[file_id])
|
||||
parser.parse_file(block)
|
||||
# increment parsed path count for performance tracking
|
||||
self._perf_info.parsed_path_count = self._perf_info.parsed_path_count + 1
|
||||
# Look at changed macros and update the macro.depends_on.macros
|
||||
self.macro_depends_on()
|
||||
self._perf_info.load_macros_elapsed = (time.perf_counter() - start_load_macros)
|
||||
@@ -301,9 +307,17 @@ class ManifestLoader:
|
||||
self.process_sources(self.root_project.project_name)
|
||||
self.process_refs(self.root_project.project_name)
|
||||
self.process_docs(self.root_project)
|
||||
|
||||
# update tracking data
|
||||
self._perf_info.process_manifest_elapsed = (
|
||||
time.perf_counter() - start_process
|
||||
)
|
||||
self._perf_info.static_analysis_parsed_path_count = (
|
||||
self.manifest._parsing_info.static_analysis_parsed_path_count
|
||||
)
|
||||
self._perf_info.static_analysis_path_count = (
|
||||
self.manifest._parsing_info.static_analysis_path_count
|
||||
)
|
||||
|
||||
# write out the fully parsed manifest
|
||||
self.write_manifest_for_partial_parse()
|
||||
@@ -321,7 +335,7 @@ class ManifestLoader:
|
||||
|
||||
project_loader_info = self._perf_info._project_index[project.project_name]
|
||||
start_timer = time.perf_counter()
|
||||
total_path_count = 0
|
||||
total_parsed_path_count = 0
|
||||
|
||||
# Loop through parsers with loaded files.
|
||||
for parser_cls in parser_types:
|
||||
@@ -331,7 +345,7 @@ class ManifestLoader:
|
||||
continue
|
||||
|
||||
# Initialize timing info
|
||||
parser_path_count = 0
|
||||
project_parsed_path_count = 0
|
||||
parser_start_timer = time.perf_counter()
|
||||
|
||||
# Parse the project files for this parser
|
||||
@@ -347,15 +361,15 @@ class ManifestLoader:
|
||||
parser.parse_file(block, dct=dct)
|
||||
else:
|
||||
parser.parse_file(block)
|
||||
parser_path_count = parser_path_count + 1
|
||||
project_parsed_path_count = project_parsed_path_count + 1
|
||||
|
||||
# Save timing info
|
||||
project_loader_info.parsers.append(ParserInfo(
|
||||
parser=parser.resource_type,
|
||||
path_count=parser_path_count,
|
||||
parsed_path_count=project_parsed_path_count,
|
||||
elapsed=time.perf_counter() - parser_start_timer
|
||||
))
|
||||
total_path_count = total_path_count + parser_path_count
|
||||
total_parsed_path_count = total_parsed_path_count + project_parsed_path_count
|
||||
|
||||
# HookParser doesn't run from loaded files, just dbt_project.yml,
|
||||
# so do separately
|
||||
@@ -372,10 +386,12 @@ class ManifestLoader:
|
||||
|
||||
# Store the performance info
|
||||
elapsed = time.perf_counter() - start_timer
|
||||
project_loader_info.path_count = project_loader_info.path_count + total_path_count
|
||||
project_loader_info.parsed_path_count = (
|
||||
project_loader_info.parsed_path_count + total_parsed_path_count
|
||||
)
|
||||
project_loader_info.elapsed = project_loader_info.elapsed + elapsed
|
||||
self._perf_info.path_count = (
|
||||
self._perf_info.path_count + total_path_count
|
||||
self._perf_info.parsed_path_count = (
|
||||
self._perf_info.parsed_path_count + total_parsed_path_count
|
||||
)
|
||||
|
||||
# Loop through macros in the manifest and statically parse
|
||||
@@ -501,12 +517,12 @@ class ManifestLoader:
|
||||
|
||||
def build_perf_info(self):
|
||||
mli = ManifestLoaderInfo(
|
||||
is_partial_parse_enabled=self._partial_parse_enabled()
|
||||
is_partial_parse_enabled=self._partial_parse_enabled(),
|
||||
is_static_analysis_enabled=flags.USE_EXPERIMENTAL_PARSER
|
||||
)
|
||||
for project in self.all_projects.values():
|
||||
project_info = ProjectLoaderInfo(
|
||||
project_name=project.project_name,
|
||||
path_count=0,
|
||||
elapsed=0,
|
||||
)
|
||||
mli.projects.append(project_info)
|
||||
@@ -603,6 +619,7 @@ class ManifestLoader:
|
||||
"invocation_id": invocation_id,
|
||||
"project_id": self.root_project.hashed_name(),
|
||||
"path_count": self._perf_info.path_count,
|
||||
"parsed_path_count": self._perf_info.parsed_path_count,
|
||||
"read_files_elapsed": self._perf_info.read_files_elapsed,
|
||||
"load_macros_elapsed": self._perf_info.load_macros_elapsed,
|
||||
"parse_project_elapsed": self._perf_info.parse_project_elapsed,
|
||||
@@ -614,6 +631,9 @@ class ManifestLoader:
|
||||
"is_partial_parse_enabled": (
|
||||
self._perf_info.is_partial_parse_enabled
|
||||
),
|
||||
"is_static_analysis_enabled": self._perf_info.is_static_analysis_enabled,
|
||||
"static_analysis_path_count": self._perf_info.static_analysis_path_count,
|
||||
"static_analysis_parsed_path_count": self._perf_info.static_analysis_parsed_path_count,
|
||||
})
|
||||
|
||||
# Takes references in 'refs' array of nodes and exposures, finds the target
|
||||
|
||||
@@ -2,9 +2,14 @@ from dbt.context.context_config import ContextConfig
|
||||
from dbt.contracts.graph.parsed import ParsedModelNode
|
||||
import dbt.flags as flags
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import IntermediateNode, SimpleSQLParser
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.tree_sitter_jinja.extractor import extract_from_source
|
||||
import dbt.tracking as tracking
|
||||
from dbt import utils
|
||||
from dbt_extractor import ExtractionError, py_extract_from_source # type: ignore
|
||||
import itertools
|
||||
import random
|
||||
from typing import Any, Dict, List, Tuple
|
||||
|
||||
|
||||
class ModelParser(SimpleSQLParser[ParsedModelNode]):
|
||||
@@ -22,46 +27,126 @@ class ModelParser(SimpleSQLParser[ParsedModelNode]):
|
||||
return block.path.relative_path
|
||||
|
||||
def render_update(
|
||||
self, node: IntermediateNode, config: ContextConfig
|
||||
self, node: ParsedModelNode, config: ContextConfig
|
||||
) -> None:
|
||||
self.manifest._parsing_info.static_analysis_path_count += 1
|
||||
|
||||
# `True` roughly 1/100 times this function is called
|
||||
sample: bool = random.randint(1, 101) == 100
|
||||
|
||||
# run the experimental parser if the flag is on or if we're sampling
|
||||
if flags.USE_EXPERIMENTAL_PARSER or sample:
|
||||
try:
|
||||
experimentally_parsed: Dict[str, List[Any]] = py_extract_from_source(node.raw_sql)
|
||||
|
||||
# second config format
|
||||
config_calls: List[Dict[str, str]] = []
|
||||
for c in experimentally_parsed['configs']:
|
||||
config_calls.append({c[0]: c[1]})
|
||||
|
||||
# format sources TODO change extractor to match this type
|
||||
source_calls: List[List[str]] = []
|
||||
for s in experimentally_parsed['sources']:
|
||||
source_calls.append([s[0], s[1]])
|
||||
experimentally_parsed['sources'] = source_calls
|
||||
|
||||
except ExtractionError as e:
|
||||
experimentally_parsed = e
|
||||
|
||||
# normal dbt run
|
||||
if not flags.USE_EXPERIMENTAL_PARSER:
|
||||
# normal rendering
|
||||
super().render_update(node, config)
|
||||
# if we're sampling, compare for correctness
|
||||
if sample:
|
||||
result: List[str] = []
|
||||
# experimental parser couldn't parse
|
||||
if isinstance(experimentally_parsed, Exception):
|
||||
result += ["01_experimental_parser_cannot_parse"]
|
||||
else:
|
||||
# rearrange existing configs to match:
|
||||
real_configs: List[Tuple[str, Any]] = list(
|
||||
itertools.chain.from_iterable(
|
||||
map(lambda x: x.items(), config._config_calls)
|
||||
)
|
||||
)
|
||||
|
||||
# if the --use-experimental-parser flag was set
|
||||
else:
|
||||
# look for false positive configs
|
||||
for c in experimentally_parsed['configs']:
|
||||
if c not in real_configs:
|
||||
result += ["02_false_positive_config_value"]
|
||||
break
|
||||
|
||||
# run dbt-jinja extractor (powered by tree-sitter)
|
||||
res = extract_from_source(node.raw_sql)
|
||||
# look for missed configs
|
||||
for c in real_configs:
|
||||
if c not in experimentally_parsed['configs']:
|
||||
result += ["03_missed_config_value"]
|
||||
break
|
||||
|
||||
# if it doesn't need python jinja, fit the refs, sources, and configs
|
||||
# look for false positive sources
|
||||
for s in experimentally_parsed['sources']:
|
||||
if s not in node.sources:
|
||||
result += ["04_false_positive_source_value"]
|
||||
break
|
||||
|
||||
# look for missed sources
|
||||
for s in node.sources:
|
||||
if s not in experimentally_parsed['sources']:
|
||||
result += ["05_missed_source_value"]
|
||||
break
|
||||
|
||||
# look for false positive refs
|
||||
for r in experimentally_parsed['refs']:
|
||||
if r not in node.refs:
|
||||
result += ["06_false_positive_ref_value"]
|
||||
break
|
||||
|
||||
# look for missed refs
|
||||
for r in node.refs:
|
||||
if r not in experimentally_parsed['refs']:
|
||||
result += ["07_missed_ref_value"]
|
||||
break
|
||||
|
||||
# if there are no errors, return a success value
|
||||
if not result:
|
||||
result = ["00_exact_match"]
|
||||
|
||||
# fire a tracking event. this fires one event for every sample
|
||||
# so that we have data on a per file basis. Not only can we expect
|
||||
# no false positives or misses, we can expect the number model
|
||||
# files parseable by the experimental parser to match our internal
|
||||
# testing.
|
||||
tracking.track_experimental_parser_sample({
|
||||
"project_id": self.root_project.hashed_name(),
|
||||
"file_id": utils.get_hash(node),
|
||||
"status": result
|
||||
})
|
||||
|
||||
# if the --use-experimental-parser flag was set, and the experimental parser succeeded
|
||||
elif not isinstance(experimentally_parsed, Exception):
|
||||
# since it doesn't need python jinja, fit the refs, sources, and configs
|
||||
# into the node. Down the line the rest of the node will be updated with
|
||||
# this information. (e.g. depends_on etc.)
|
||||
if not res['python_jinja']:
|
||||
config._config_calls = config_calls
|
||||
|
||||
config_calls = []
|
||||
for c in res['configs']:
|
||||
config_calls.append({c[0]: c[1]})
|
||||
# this uses the updated config to set all the right things in the node.
|
||||
# if there are hooks present, it WILL render jinja. Will need to change
|
||||
# when the experimental parser supports hooks
|
||||
self.update_parsed_node(node, config)
|
||||
|
||||
config._config_calls = config_calls
|
||||
# update the unrendered config with values from the file.
|
||||
# values from yaml files are in there already
|
||||
node.unrendered_config.update(dict(experimentally_parsed['configs']))
|
||||
|
||||
# this uses the updated config to set all the right things in the node
|
||||
# if there are hooks present, it WILL render jinja. Will need to change
|
||||
# when we support hooks
|
||||
self.update_parsed_node(node, config)
|
||||
# set refs, sources, and configs on the node object
|
||||
node.refs += experimentally_parsed['refs']
|
||||
node.sources += experimentally_parsed['sources']
|
||||
for configv in experimentally_parsed['configs']:
|
||||
node.config[configv[0]] = configv[1]
|
||||
|
||||
# udpate the unrendered config with values from the file
|
||||
# values from yaml files are in there already
|
||||
node.unrendered_config.update(dict(res['configs']))
|
||||
self.manifest._parsing_info.static_analysis_parsed_path_count += 1
|
||||
|
||||
# set refs, sources, and configs on the node object
|
||||
node.refs = node.refs + res['refs']
|
||||
for sourcev in res['sources']:
|
||||
# TODO change extractor to match type here
|
||||
node.sources.append([sourcev[0], sourcev[1]])
|
||||
for configv in res['configs']:
|
||||
node.config[configv[0]] = configv[1]
|
||||
|
||||
else:
|
||||
super().render_update(node, config)
|
||||
# the experimental parser tried and failed on this model.
|
||||
# fall back to python jinja rendering.
|
||||
else:
|
||||
super().render_update(node, config)
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import MutableMapping, Dict
|
||||
from typing import MutableMapping, Dict, List
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.files import (
|
||||
AnySourceFile, ParseFileType, parse_file_type_to_parser,
|
||||
@@ -44,6 +44,7 @@ class PartialParsing:
|
||||
self.saved_files = self.saved_manifest.files
|
||||
self.project_parser_files = {}
|
||||
self.deleted_manifest = Manifest()
|
||||
self.macro_child_map: Dict[str, List[str]] = {}
|
||||
self.build_file_diff()
|
||||
|
||||
def skip_parsing(self):
|
||||
@@ -63,6 +64,7 @@ class PartialParsing:
|
||||
deleted_all_files = saved_file_ids.difference(new_file_ids)
|
||||
added = new_file_ids.difference(saved_file_ids)
|
||||
common = saved_file_ids.intersection(new_file_ids)
|
||||
changed_or_deleted_macro_file = False
|
||||
|
||||
# separate out deleted schema files
|
||||
deleted_schema_files = []
|
||||
@@ -71,6 +73,8 @@ class PartialParsing:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Schema:
|
||||
deleted_schema_files.append(file_id)
|
||||
else:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Macro:
|
||||
changed_or_deleted_macro_file = True
|
||||
deleted.append(file_id)
|
||||
|
||||
changed = []
|
||||
@@ -87,6 +91,8 @@ class PartialParsing:
|
||||
raise Exception(f"Serialization failure for {file_id}")
|
||||
changed_schema_files.append(file_id)
|
||||
else:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Macro:
|
||||
changed_or_deleted_macro_file = True
|
||||
changed.append(file_id)
|
||||
file_diff = {
|
||||
"deleted": deleted,
|
||||
@@ -96,6 +102,8 @@ class PartialParsing:
|
||||
"changed_schema_files": changed_schema_files,
|
||||
"unchanged": unchanged,
|
||||
}
|
||||
if changed_or_deleted_macro_file:
|
||||
self.macro_child_map = self.saved_manifest.build_macro_child_map()
|
||||
logger.info(f"Partial parsing enabled: "
|
||||
f"{len(deleted) + len(deleted_schema_files)} files deleted, "
|
||||
f"{len(added)} files added, "
|
||||
@@ -174,7 +182,7 @@ class PartialParsing:
|
||||
|
||||
# macros
|
||||
if saved_source_file.parse_file_type == ParseFileType.Macro:
|
||||
self.delete_macro_file(saved_source_file)
|
||||
self.delete_macro_file(saved_source_file, follow_references=True)
|
||||
|
||||
# docs
|
||||
if saved_source_file.parse_file_type == ParseFileType.Documentation:
|
||||
@@ -214,6 +222,10 @@ class PartialParsing:
|
||||
self.remove_node_in_saved(new_source_file, unique_id)
|
||||
|
||||
def remove_node_in_saved(self, source_file, unique_id):
|
||||
# Has already been deleted by another action
|
||||
if unique_id not in self.saved_manifest.nodes:
|
||||
return
|
||||
|
||||
# delete node in saved
|
||||
node = self.saved_manifest.nodes.pop(unique_id)
|
||||
self.deleted_manifest.nodes[unique_id] = node
|
||||
@@ -239,7 +251,7 @@ class PartialParsing:
|
||||
schema_file.node_patches.remove(unique_id)
|
||||
|
||||
def update_macro_in_saved(self, new_source_file, old_source_file):
|
||||
self.handle_macro_file_links(old_source_file)
|
||||
self.handle_macro_file_links(old_source_file, follow_references=True)
|
||||
file_id = new_source_file.file_id
|
||||
self.saved_files[file_id] = new_source_file
|
||||
self.add_to_pp_files(new_source_file)
|
||||
@@ -289,7 +301,7 @@ class PartialParsing:
|
||||
source_element = self.get_schema_element(sources, source.source_name)
|
||||
if source_element:
|
||||
self.delete_schema_source(schema_file, source_element)
|
||||
self.remove_tests(schema_file, source_element['name'])
|
||||
self.remove_tests(schema_file, 'sources', source_element['name'])
|
||||
self.merge_patch(schema_file, 'sources', source_element)
|
||||
elif unique_id in self.saved_manifest.exposures:
|
||||
exposure = self.saved_manifest.exposures[unique_id]
|
||||
@@ -312,41 +324,41 @@ class PartialParsing:
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
|
||||
def delete_macro_file(self, source_file):
|
||||
self.handle_macro_file_links(source_file)
|
||||
def delete_macro_file(self, source_file, follow_references=False):
|
||||
self.handle_macro_file_links(source_file, follow_references)
|
||||
file_id = source_file.file_id
|
||||
self.deleted_manifest.files[file_id] = self.saved_files.pop(file_id)
|
||||
|
||||
def handle_macro_file_links(self, source_file):
|
||||
def recursively_gather_macro_references(self, macro_unique_id, referencing_nodes):
|
||||
for unique_id in self.macro_child_map[macro_unique_id]:
|
||||
if unique_id in referencing_nodes:
|
||||
continue
|
||||
referencing_nodes.append(unique_id)
|
||||
if unique_id.startswith('macro.'):
|
||||
self.recursively_gather_macro_references(unique_id, referencing_nodes)
|
||||
|
||||
def handle_macro_file_links(self, source_file, follow_references=False):
|
||||
# remove the macros in the 'macros' dictionary
|
||||
for unique_id in source_file.macros:
|
||||
macros = source_file.macros.copy()
|
||||
for unique_id in macros:
|
||||
if unique_id not in self.saved_manifest.macros:
|
||||
# This happens when a macro has already been removed
|
||||
source_file.macros.remove(unique_id)
|
||||
continue
|
||||
|
||||
base_macro = self.saved_manifest.macros.pop(unique_id)
|
||||
self.deleted_manifest.macros[unique_id] = base_macro
|
||||
# loop through all macros, finding references to this macro: macro.depends_on.macros
|
||||
for macro in self.saved_manifest.macros.values():
|
||||
for macro_unique_id in macro.depends_on.macros:
|
||||
if (macro_unique_id == unique_id and
|
||||
macro_unique_id in self.saved_manifest.macros):
|
||||
# schedule file for parsing
|
||||
dep_file_id = macro.file_id
|
||||
if dep_file_id in self.saved_files:
|
||||
source_file = self.saved_files[dep_file_id]
|
||||
dep_macro = self.saved_manifest.macros.pop(macro.unique_id)
|
||||
self.deleted_manifest.macros[macro.unqiue_id] = dep_macro
|
||||
self.add_to_pp_files(source_file)
|
||||
break
|
||||
# loop through all nodes, finding references to this macro: node.depends_on.macros
|
||||
for node in self.saved_manifest.nodes.values():
|
||||
for macro_unique_id in node.depends_on.macros:
|
||||
if (macro_unique_id == unique_id and
|
||||
macro_unique_id in self.saved_manifest.macros):
|
||||
# schedule file for parsing
|
||||
dep_file_id = node.file_id
|
||||
if dep_file_id in self.saved_files:
|
||||
source_file = self.saved_files[dep_file_id]
|
||||
self.remove_node_in_saved(source_file, node.unique_id)
|
||||
self.add_to_pp_files(source_file)
|
||||
break
|
||||
|
||||
# Recursively check children of this macro
|
||||
# The macro_child_map might not exist if a macro is removed by
|
||||
# schedule_nodes_for parsing. We only want to follow
|
||||
# references if the macro file itself has been updated or
|
||||
# deleted, not if we're just updating referenced nodes.
|
||||
if self.macro_child_map and follow_references:
|
||||
referencing_nodes = []
|
||||
self.recursively_gather_macro_references(unique_id, referencing_nodes)
|
||||
self.schedule_macro_nodes_for_parsing(referencing_nodes)
|
||||
|
||||
if base_macro.patch_path:
|
||||
file_id = base_macro.patch_path
|
||||
if file_id in self.saved_files:
|
||||
@@ -357,6 +369,44 @@ class PartialParsing:
|
||||
macro_patch = self.get_schema_element(macro_patches, base_macro.name)
|
||||
self.delete_schema_macro_patch(schema_file, macro_patch)
|
||||
self.merge_patch(schema_file, 'macros', macro_patch)
|
||||
source_file.macros.remove(unique_id)
|
||||
|
||||
# similar to schedule_nodes_for_parsing but doesn't do sources and exposures
|
||||
# and handles schema tests
|
||||
def schedule_macro_nodes_for_parsing(self, unique_ids):
|
||||
for unique_id in unique_ids:
|
||||
if unique_id in self.saved_manifest.nodes:
|
||||
node = self.saved_manifest.nodes[unique_id]
|
||||
if node.resource_type == NodeType.Test:
|
||||
schema_file_id = node.file_id
|
||||
schema_file = self.saved_manifest.files[schema_file_id]
|
||||
(key, name) = schema_file.get_key_and_name_for_test(node.unique_id)
|
||||
if key and name:
|
||||
patch_list = []
|
||||
if key in schema_file.dict_from_yaml:
|
||||
patch_list = schema_file.dict_from_yaml[key]
|
||||
node_patch = self.get_schema_element(patch_list, name)
|
||||
if node_patch:
|
||||
self.delete_schema_mssa_links(schema_file, key, node_patch)
|
||||
self.merge_patch(schema_file, key, node_patch)
|
||||
if unique_id in schema_file.node_patches:
|
||||
schema_file.node_patches.remove(unique_id)
|
||||
else:
|
||||
file_id = node.file_id
|
||||
if file_id in self.saved_files and file_id not in self.file_diff['deleted']:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.remove_mssat_file(source_file)
|
||||
# content of non-schema files is only in new files
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
elif unique_id in self.saved_manifest.macros:
|
||||
macro = self.saved_manifest.macros[unique_id]
|
||||
file_id = macro.file_id
|
||||
if file_id in self.saved_files and file_id not in self.file_diff['deleted']:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.delete_macro_file(source_file)
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
|
||||
def delete_doc_node(self, source_file):
|
||||
# remove the nodes in the 'docs' dictionary
|
||||
@@ -424,14 +474,14 @@ class PartialParsing:
|
||||
if 'overrides' in source: # This is a source patch; need to re-parse orig source
|
||||
self.remove_source_override_target(source)
|
||||
self.delete_schema_source(schema_file, source)
|
||||
self.remove_tests(schema_file, source['name'])
|
||||
self.remove_tests(schema_file, 'sources', source['name'])
|
||||
self.merge_patch(schema_file, 'sources', source)
|
||||
if source_diff['deleted']:
|
||||
for source in source_diff['deleted']:
|
||||
if 'overrides' in source: # This is a source patch; need to re-parse orig source
|
||||
self.remove_source_override_target(source)
|
||||
self.delete_schema_source(schema_file, source)
|
||||
self.remove_tests(schema_file, source['name'])
|
||||
self.remove_tests(schema_file, 'sources', source['name'])
|
||||
if source_diff['added']:
|
||||
for source in source_diff['added']:
|
||||
if 'overrides' in source: # This is a source patch; need to re-parse orig source
|
||||
@@ -556,49 +606,14 @@ class PartialParsing:
|
||||
# for models, seeds, snapshots (not analyses)
|
||||
if dict_key in ['models', 'seeds', 'snapshots']:
|
||||
# find related tests and remove them
|
||||
self.remove_tests(schema_file, elem['name'])
|
||||
self.remove_tests(schema_file, dict_key, elem['name'])
|
||||
|
||||
def remove_tests(self, schema_file, name):
|
||||
tests = self.get_tests_for(schema_file, name)
|
||||
def remove_tests(self, schema_file, dict_key, name):
|
||||
tests = schema_file.get_tests(dict_key, name)
|
||||
for test_unique_id in tests:
|
||||
node = self.saved_manifest.nodes.pop(test_unique_id)
|
||||
self.deleted_manifest.nodes[test_unique_id] = node
|
||||
schema_file.tests.remove(test_unique_id)
|
||||
|
||||
# Create a pp_test_index in the schema file if it doesn't exist
|
||||
# and look for test names related to this yaml dict element name
|
||||
def get_tests_for(self, schema_file, name):
|
||||
if not schema_file.pp_test_index:
|
||||
pp_test_index = {}
|
||||
for test_unique_id in schema_file.tests:
|
||||
test_node = self.saved_manifest.nodes[test_unique_id]
|
||||
if test_node.sources:
|
||||
for source_ref in test_node.sources:
|
||||
source_name = source_ref[0]
|
||||
if source_name in pp_test_index:
|
||||
pp_test_index[source_name].append(test_unique_id)
|
||||
else:
|
||||
pp_test_index[source_name] = [test_unique_id]
|
||||
elif test_node.depends_on.nodes:
|
||||
tested_node_id = test_node.depends_on.nodes[0]
|
||||
parts = tested_node_id.split('.')
|
||||
elem_name = parts[-1]
|
||||
if elem_name in pp_test_index:
|
||||
pp_test_index[elem_name].append(test_unique_id)
|
||||
else:
|
||||
pp_test_index[elem_name] = [test_unique_id]
|
||||
elif (hasattr(test_node, 'test_metadata') and
|
||||
'model' in test_node.test_metadata.kwargs):
|
||||
(_, elem_name, _) = test_node.test_metadata.kwargs['model'].split("'")
|
||||
if elem_name:
|
||||
if elem_name in pp_test_index:
|
||||
pp_test_index[elem_name].append(test_unique_id)
|
||||
else:
|
||||
pp_test_index[elem_name] = [test_unique_id]
|
||||
schema_file.pp_test_index = pp_test_index
|
||||
if name in schema_file.pp_test_index:
|
||||
return schema_file.pp_test_index[name]
|
||||
return []
|
||||
schema_file.remove_tests(dict_key, name)
|
||||
|
||||
def delete_schema_source(self, schema_file, source_dict):
|
||||
# both patches, tests, and source nodes
|
||||
@@ -675,6 +690,6 @@ class PartialParsing:
|
||||
(orig_file, orig_source) = self.get_source_override_file_and_dict(source_dict)
|
||||
if orig_source:
|
||||
self.delete_schema_source(orig_file, orig_source)
|
||||
self.remove_tests(orig_file, orig_source['name'])
|
||||
self.remove_tests(orig_file, 'sources', orig_source['name'])
|
||||
self.merge_patch(orig_file, 'sources', orig_source)
|
||||
self.add_to_pp_files(orig_file)
|
||||
|
||||
@@ -3,7 +3,8 @@ from dbt.contracts.files import (
|
||||
FilePath, ParseFileType, SourceFile, FileHash, AnySourceFile, SchemaSourceFile
|
||||
)
|
||||
|
||||
from dbt.parser.schemas import yaml_from_file
|
||||
from dbt.parser.schemas import yaml_from_file, schema_file_keys, check_format_version
|
||||
from dbt.exceptions import CompilationException
|
||||
from dbt.parser.search import FilesystemSearcher
|
||||
|
||||
|
||||
@@ -17,11 +18,36 @@ def load_source_file(
|
||||
source_file = sf_cls(path=path, checksum=checksum,
|
||||
parse_file_type=parse_file_type, project_name=project_name)
|
||||
source_file.contents = file_contents.strip()
|
||||
if parse_file_type == ParseFileType.Schema:
|
||||
source_file.dfy = yaml_from_file(source_file)
|
||||
if parse_file_type == ParseFileType.Schema and source_file.contents:
|
||||
dfy = yaml_from_file(source_file)
|
||||
validate_yaml(source_file.path.original_file_path, dfy)
|
||||
source_file.dfy = dfy
|
||||
return source_file
|
||||
|
||||
|
||||
# Do some minimal validation of the yaml in a schema file.
|
||||
# Check version, that key values are lists and that each element in
|
||||
# the lists has a 'name' key
|
||||
def validate_yaml(file_path, dct):
|
||||
check_format_version(file_path, dct)
|
||||
for key in schema_file_keys:
|
||||
if key in dct:
|
||||
if not isinstance(dct[key], list):
|
||||
msg = (f"The schema file at {file_path} is "
|
||||
f"invalid because the value of '{key}' is not a list")
|
||||
raise CompilationException(msg)
|
||||
for element in dct[key]:
|
||||
if not isinstance(element, dict):
|
||||
msg = (f"The schema file at {file_path} is "
|
||||
f"invalid because a list element for '{key}' is not a dictionary")
|
||||
raise CompilationException(msg)
|
||||
if 'name' not in element:
|
||||
msg = (f"The schema file at {file_path} is "
|
||||
f"invalid because a list element for '{key}' does not have a "
|
||||
"name attribute.")
|
||||
raise CompilationException(msg)
|
||||
|
||||
|
||||
# Special processing for big seed files
|
||||
def load_seed_source_file(match: FilePath, project_name) -> SourceFile:
|
||||
if match.seed_too_large():
|
||||
|
||||
@@ -355,8 +355,10 @@ class TestBuilder(Generic[Testable]):
|
||||
|
||||
def construct_config(self) -> str:
|
||||
configs = ",".join([
|
||||
f"{key}=" + (f"'{value}'" if isinstance(value, str)
|
||||
else str(value))
|
||||
f"{key}=" + (
|
||||
("\"" + value.replace('\"', '\\\"') + "\"") if isinstance(value, str)
|
||||
else str(value)
|
||||
)
|
||||
for key, value
|
||||
in self.modifiers.items()
|
||||
])
|
||||
|
||||
@@ -70,6 +70,11 @@ UnparsedSchemaYaml = Union[
|
||||
|
||||
TestDef = Union[str, Dict[str, Any]]
|
||||
|
||||
schema_file_keys = (
|
||||
'models', 'seeds', 'snapshots', 'sources',
|
||||
'macros', 'analyses', 'exposures',
|
||||
)
|
||||
|
||||
|
||||
def error_context(
|
||||
path: str,
|
||||
@@ -93,10 +98,10 @@ def error_context(
|
||||
|
||||
def yaml_from_file(
|
||||
source_file: SchemaSourceFile
|
||||
) -> Optional[Dict[str, Any]]:
|
||||
) -> Dict[str, Any]:
|
||||
"""If loading the yaml fails, raise an exception.
|
||||
"""
|
||||
path: str = source_file.path.relative_path
|
||||
path = source_file.path.relative_path
|
||||
try:
|
||||
return load_yaml_text(source_file.contents)
|
||||
except ValidationException as e:
|
||||
@@ -105,7 +110,6 @@ def yaml_from_file(
|
||||
'Error reading {}: {} - {}'
|
||||
.format(source_file.project_name, path, reason)
|
||||
)
|
||||
return None
|
||||
|
||||
|
||||
class ParserRef:
|
||||
@@ -200,25 +204,6 @@ class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
ParsedSchemaTestNode.validate(dct)
|
||||
return ParsedSchemaTestNode.from_dict(dct)
|
||||
|
||||
def _check_format_version(
|
||||
self, yaml: YamlBlock
|
||||
) -> None:
|
||||
path = yaml.path.relative_path
|
||||
if 'version' not in yaml.data:
|
||||
raise_invalid_schema_yml_version(path, 'no version is specified')
|
||||
|
||||
version = yaml.data['version']
|
||||
# if it's not an integer, the version is malformed, or not
|
||||
# set. Either way, only 'version: 2' is supported.
|
||||
if not isinstance(version, int):
|
||||
raise_invalid_schema_yml_version(
|
||||
path, 'the version is not an integer'
|
||||
)
|
||||
if version != 2:
|
||||
raise_invalid_schema_yml_version(
|
||||
path, 'version {} is not supported'.format(version)
|
||||
)
|
||||
|
||||
def parse_column_tests(
|
||||
self, block: TestBlock, column: UnparsedColumn
|
||||
) -> None:
|
||||
@@ -403,6 +388,9 @@ class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
if builder.fail_calc is not None:
|
||||
node.unrendered_config['fail_calc'] = builder.fail_calc
|
||||
node.config['fail_calc'] = builder.fail_calc
|
||||
if builder.store_failures is not None:
|
||||
node.unrendered_config['store_failures'] = builder.store_failures
|
||||
node.config['store_failures'] = builder.store_failures
|
||||
# source node tests are processed at patch_source time
|
||||
if isinstance(builder.target, UnpatchedSourceDefinition):
|
||||
sources = [builder.target.fqn[-2], builder.target.fqn[-1]]
|
||||
@@ -439,9 +427,16 @@ class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
tags=block.tags,
|
||||
column_name=block.column_name,
|
||||
)
|
||||
self.add_result_node(block, node)
|
||||
self.add_test_node(block, node)
|
||||
return node
|
||||
|
||||
def add_test_node(self, block: SchemaTestBlock, node: ParsedSchemaTestNode):
|
||||
test_from = {"key": block.target.yaml_key, "name": block.target.name}
|
||||
if node.config.enabled:
|
||||
self.manifest.add_node(block.file, node, test_from)
|
||||
else:
|
||||
self.manifest.add_disabled(block.file, node, test_from)
|
||||
|
||||
def render_with_context(
|
||||
self, node: ParsedSchemaTestNode, config: ContextConfig,
|
||||
) -> None:
|
||||
@@ -514,9 +509,6 @@ class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
# contains the FileBlock and the data (dictionary)
|
||||
yaml_block = YamlBlock.from_file_block(block, dct)
|
||||
|
||||
# checks version
|
||||
self._check_format_version(yaml_block)
|
||||
|
||||
parser: YamlDocsReader
|
||||
|
||||
# There are 7 kinds of parsers:
|
||||
@@ -565,6 +557,25 @@ class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
self.manifest.add_exposure(yaml_block.file, node)
|
||||
|
||||
|
||||
def check_format_version(
|
||||
file_path, yaml_dct
|
||||
) -> None:
|
||||
if 'version' not in yaml_dct:
|
||||
raise_invalid_schema_yml_version(file_path, 'no version is specified')
|
||||
|
||||
version = yaml_dct['version']
|
||||
# if it's not an integer, the version is malformed, or not
|
||||
# set. Either way, only 'version: 2' is supported.
|
||||
if not isinstance(version, int):
|
||||
raise_invalid_schema_yml_version(
|
||||
file_path, 'the version is not an integer'
|
||||
)
|
||||
if version != 2:
|
||||
raise_invalid_schema_yml_version(
|
||||
file_path, 'version {} is not supported'.format(version)
|
||||
)
|
||||
|
||||
|
||||
Parsed = TypeVar(
|
||||
'Parsed',
|
||||
UnpatchedSourceDefinition, ParsedNodePatch, ParsedMacroPatch
|
||||
|
||||
@@ -77,7 +77,8 @@ class SourcePatcher:
|
||||
self.manifest.add_disabled_nofile(test)
|
||||
# save the test unique_id in the schema_file, so we can
|
||||
# process in partial parsing
|
||||
schema_file.tests.append(test.unique_id)
|
||||
test_from = {"key": 'sources', "name": patched.source.name}
|
||||
schema_file.add_test(test.unique_id, test_from)
|
||||
|
||||
# Convert UnpatchedSourceDefinition to a ParsedSourceDefinition
|
||||
parsed = self.parse_source(patched)
|
||||
|
||||
43
core/dbt/task/build.py
Normal file
43
core/dbt/task/build.py
Normal file
@@ -0,0 +1,43 @@
|
||||
from .compile import CompileTask
|
||||
|
||||
from .run import ModelRunner as run_model_runner
|
||||
from .snapshot import SnapshotRunner as snapshot_model_runner
|
||||
from .seed import SeedRunner as seed_runner
|
||||
from .test import TestRunner as test_runner
|
||||
|
||||
from dbt.graph import ResourceTypeSelector
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.node_types import NodeType
|
||||
|
||||
|
||||
class BuildTask(CompileTask):
|
||||
"""The Build task processes all assets of a given process and attempts to 'build'
|
||||
them in an opinionated fashion. Every resource type outlined in RUNNER_MAP
|
||||
will be processed by the mapped runner class.
|
||||
|
||||
I.E. a resource of type Model is handled by the ModelRunner which is imported
|
||||
as run_model_runner.
|
||||
"""
|
||||
|
||||
RUNNER_MAP = {
|
||||
NodeType.Model: run_model_runner,
|
||||
NodeType.Snapshot: snapshot_model_runner,
|
||||
NodeType.Seed: seed_runner,
|
||||
NodeType.Test: test_runner,
|
||||
}
|
||||
|
||||
def get_node_selector(self) -> ResourceTypeSelector:
|
||||
if self.manifest is None or self.graph is None:
|
||||
raise InternalException(
|
||||
'manifest and graph must be set to get node selection'
|
||||
)
|
||||
|
||||
return ResourceTypeSelector(
|
||||
graph=self.graph,
|
||||
manifest=self.manifest,
|
||||
previous_state=self.previous_state,
|
||||
resource_types=[x for x in self.RUNNER_MAP.keys()],
|
||||
)
|
||||
|
||||
def get_runner_type(self, node):
|
||||
return self.RUNNER_MAP.get(node.resource_type)
|
||||
@@ -56,7 +56,7 @@ class CompileTask(GraphRunnableTask):
|
||||
resource_types=NodeType.executable(),
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return CompileRunner
|
||||
|
||||
def task_end_messages(self, results):
|
||||
|
||||
@@ -155,7 +155,7 @@ class FreshnessTask(GraphRunnableTask):
|
||||
previous_state=self.previous_state,
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return FreshnessRunner
|
||||
|
||||
def write_result(self, result):
|
||||
|
||||
@@ -2,23 +2,25 @@ import os
|
||||
import shutil
|
||||
|
||||
import dbt.config
|
||||
import dbt.clients.git
|
||||
import dbt.clients.system
|
||||
from dbt.version import _get_adapter_plugin_names
|
||||
from dbt.adapters.factory import load_plugin, get_include_paths
|
||||
from dbt.exceptions import RuntimeException
|
||||
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
|
||||
from dbt.include.starter_project import PACKAGE_PATH as starter_project_directory
|
||||
|
||||
from dbt.task.base import BaseTask
|
||||
|
||||
STARTER_REPO = 'https://github.com/fishtown-analytics/dbt-starter-project.git'
|
||||
STARTER_BRANCH = 'dbt-yml-config-version-2'
|
||||
DOCS_URL = 'https://docs.getdbt.com/docs/configure-your-profile'
|
||||
SLACK_URL = 'https://community.getdbt.com/'
|
||||
|
||||
# This file is not needed for the starter project but exists for finding the resource path
|
||||
IGNORE_FILES = ["__init__.py", "__pycache__"]
|
||||
|
||||
ON_COMPLETE_MESSAGE = """
|
||||
Your new dbt project "{project_name}" was created! If this is your first time
|
||||
using dbt, you'll need to set up your profiles.yml file (we've created a sample
|
||||
file for you to connect to {sample_adapter}) -- this file will tell dbt how
|
||||
using dbt, you'll need to set up your profiles.yml file -- this file will tell dbt how
|
||||
to connect to your database. You can find this file by running:
|
||||
|
||||
{open_cmd} {profiles_path}
|
||||
@@ -30,23 +32,24 @@ please consult the dbt documentation here:
|
||||
|
||||
One more thing:
|
||||
|
||||
Need help? Don't hesitate to reach out to us via GitHub issues or on Slack --
|
||||
There's a link to our Slack group in the GitHub Readme. Happy modeling!
|
||||
Need help? Don't hesitate to reach out to us via GitHub issues or on Slack:
|
||||
|
||||
{slack_url}
|
||||
|
||||
Happy modeling!
|
||||
"""
|
||||
|
||||
|
||||
class InitTask(BaseTask):
|
||||
def clone_starter_repo(self, project_name):
|
||||
dbt.clients.git.clone(
|
||||
STARTER_REPO,
|
||||
cwd='.',
|
||||
dirname=project_name,
|
||||
remove_git_dir=True,
|
||||
revision=STARTER_BRANCH,
|
||||
)
|
||||
def copy_starter_repo(self, project_name):
|
||||
logger.debug("Starter project path: " + starter_project_directory)
|
||||
shutil.copytree(starter_project_directory, project_name,
|
||||
ignore=shutil.ignore_patterns(*IGNORE_FILES))
|
||||
|
||||
def create_profiles_dir(self, profiles_dir):
|
||||
if not os.path.exists(profiles_dir):
|
||||
msg = "Creating dbt configuration folder at {}"
|
||||
logger.info(msg.format(profiles_dir))
|
||||
dbt.clients.system.make_directory(profiles_dir)
|
||||
return True
|
||||
return False
|
||||
@@ -58,47 +61,51 @@ class InitTask(BaseTask):
|
||||
sample_profiles_path = adapter_path / 'sample_profiles.yml'
|
||||
|
||||
if not sample_profiles_path.exists():
|
||||
raise RuntimeException(f'No sample profile for {sample_adapter}')
|
||||
logger.debug(f"No sample profile found for {sample_adapter}, skipping")
|
||||
return False
|
||||
|
||||
if not os.path.exists(profiles_file):
|
||||
msg = "With sample profiles.yml for {}"
|
||||
logger.info(msg.format(sample_adapter))
|
||||
shutil.copyfile(sample_profiles_path, profiles_file)
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def get_addendum(self, project_name, profiles_path, sample_adapter):
|
||||
def get_addendum(self, project_name, profiles_path):
|
||||
open_cmd = dbt.clients.system.open_dir_cmd()
|
||||
|
||||
return ON_COMPLETE_MESSAGE.format(
|
||||
open_cmd=open_cmd,
|
||||
project_name=project_name,
|
||||
sample_adapter=sample_adapter,
|
||||
profiles_path=profiles_path,
|
||||
docs_url=DOCS_URL
|
||||
docs_url=DOCS_URL,
|
||||
slack_url=SLACK_URL
|
||||
)
|
||||
|
||||
def run(self):
|
||||
project_dir = self.args.project_name
|
||||
sample_adapter = self.args.adapter
|
||||
if not sample_adapter:
|
||||
try:
|
||||
# pick first one available, often postgres
|
||||
sample_adapter = next(_get_adapter_plugin_names())
|
||||
except StopIteration:
|
||||
logger.debug("No adapters installed, skipping")
|
||||
|
||||
profiles_dir = dbt.config.PROFILES_DIR
|
||||
profiles_file = os.path.join(profiles_dir, 'profiles.yml')
|
||||
|
||||
msg = "Creating dbt configuration folder at {}"
|
||||
logger.info(msg.format(profiles_dir))
|
||||
|
||||
msg = "With sample profiles.yml for {}"
|
||||
logger.info(msg.format(sample_adapter))
|
||||
|
||||
self.create_profiles_dir(profiles_dir)
|
||||
self.create_profiles_file(profiles_file, sample_adapter)
|
||||
if sample_adapter:
|
||||
self.create_profiles_file(profiles_file, sample_adapter)
|
||||
|
||||
if os.path.exists(project_dir):
|
||||
raise RuntimeError("directory {} already exists!".format(
|
||||
project_dir
|
||||
))
|
||||
|
||||
self.clone_starter_repo(project_dir)
|
||||
self.copy_starter_repo(project_dir)
|
||||
|
||||
addendum = self.get_addendum(project_dir, profiles_dir, sample_adapter)
|
||||
addendum = self.get_addendum(project_dir, profiles_dir)
|
||||
logger.info(addendum)
|
||||
|
||||
@@ -202,12 +202,12 @@ class RemoteRunSQLTask(RPCTask[RPCExecParameters]):
|
||||
class RemoteCompileTask(RemoteRunSQLTask, CompileTask):
|
||||
METHOD_NAME = 'compile_sql'
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return RPCCompileRunner
|
||||
|
||||
|
||||
class RemoteRunTask(RemoteRunSQLTask, RunTask):
|
||||
METHOD_NAME = 'run_sql'
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return RPCExecuteRunner
|
||||
|
||||
@@ -452,7 +452,7 @@ class RunTask(CompileTask):
|
||||
resource_types=[NodeType.Model],
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return ModelRunner
|
||||
|
||||
def task_end_messages(self, results):
|
||||
|
||||
@@ -12,6 +12,7 @@ from .printer import (
|
||||
print_run_end_messages,
|
||||
print_cancel_line,
|
||||
)
|
||||
|
||||
from dbt import ui
|
||||
from dbt.task.base import ConfiguredTask
|
||||
from dbt.adapters.base import BaseRelation
|
||||
@@ -37,8 +38,9 @@ from dbt.exceptions import (
|
||||
InternalException,
|
||||
NotImplementedException,
|
||||
RuntimeException,
|
||||
FailFastException
|
||||
FailFastException,
|
||||
)
|
||||
|
||||
from dbt.graph import GraphQueue, NodeSelector, SelectionSpec, Graph
|
||||
from dbt.parser.manifest import ManifestLoader
|
||||
|
||||
@@ -127,7 +129,7 @@ class GraphRunnableTask(ManifestTask):
|
||||
|
||||
self.job_queue = self.get_graph_queue()
|
||||
|
||||
# we use this a couple times. order does not matter.
|
||||
# we use this a couple of times. order does not matter.
|
||||
self._flattened_nodes = []
|
||||
for uid in self.job_queue.get_selected_nodes():
|
||||
if uid in self.manifest.nodes:
|
||||
@@ -148,7 +150,7 @@ class GraphRunnableTask(ManifestTask):
|
||||
def raise_on_first_error(self):
|
||||
return False
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, node):
|
||||
raise NotImplementedException('Not Implemented')
|
||||
|
||||
def result_path(self):
|
||||
@@ -165,7 +167,7 @@ class GraphRunnableTask(ManifestTask):
|
||||
run_count = self.run_count
|
||||
num_nodes = self.num_nodes
|
||||
|
||||
cls = self.get_runner_type()
|
||||
cls = self.get_runner_type(node)
|
||||
return cls(self.config, adapter, node, run_count, num_nodes)
|
||||
|
||||
def call_runner(self, runner):
|
||||
|
||||
@@ -57,7 +57,7 @@ class SeedTask(RunTask):
|
||||
resource_types=[NodeType.Seed],
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return SeedRunner
|
||||
|
||||
def task_end_messages(self, results):
|
||||
|
||||
@@ -38,5 +38,5 @@ class SnapshotTask(RunTask):
|
||||
resource_types=[NodeType.Snapshot],
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return SnapshotRunner
|
||||
|
||||
@@ -192,5 +192,5 @@ class TestTask(RunTask):
|
||||
previous_state=self.previous_state,
|
||||
)
|
||||
|
||||
def get_runner_type(self):
|
||||
def get_runner_type(self, _):
|
||||
return TestRunner
|
||||
|
||||
@@ -28,9 +28,9 @@ INVOCATION_ENV_SPEC = 'iglu:com.dbt/invocation_env/jsonschema/1-0-0'
|
||||
PACKAGE_INSTALL_SPEC = 'iglu:com.dbt/package_install/jsonschema/1-0-0'
|
||||
RPC_REQUEST_SPEC = 'iglu:com.dbt/rpc_request/jsonschema/1-0-1'
|
||||
DEPRECATION_WARN_SPEC = 'iglu:com.dbt/deprecation_warn/jsonschema/1-0-0'
|
||||
LOAD_ALL_TIMING_SPEC = 'iglu:com.dbt/load_all_timing/jsonschema/1-0-2'
|
||||
LOAD_ALL_TIMING_SPEC = 'iglu:com.dbt/load_all_timing/jsonschema/1-0-3'
|
||||
RESOURCE_COUNTS = 'iglu:com.dbt/resource_counts/jsonschema/1-0-0'
|
||||
|
||||
EXPERIMENTAL_PARSER = 'iglu:com.dbt/experimental_parser/jsonschema/1-0-0'
|
||||
DBT_INVOCATION_ENV = 'DBT_INVOCATION_ENV'
|
||||
|
||||
|
||||
@@ -423,6 +423,20 @@ def track_invalid_invocation(
|
||||
)
|
||||
|
||||
|
||||
def track_experimental_parser_sample(options):
|
||||
context = [SelfDescribingJson(EXPERIMENTAL_PARSER, options)]
|
||||
assert active_user is not None, \
|
||||
'Cannot track project loading time when active user is None'
|
||||
|
||||
track(
|
||||
active_user,
|
||||
category='dbt',
|
||||
action='experimental_parser',
|
||||
label=active_user.invocation_id,
|
||||
context=context
|
||||
)
|
||||
|
||||
|
||||
def flush():
|
||||
logger.debug("Flushing usage events")
|
||||
tracker.flush()
|
||||
|
||||
@@ -1,38 +0,0 @@
|
||||
# tree_sitter_jinja Module
|
||||
|
||||
This module contains a tool that processes the most common jinja value templates in dbt model files. The tool uses `tree-sitter-jinja2` and the python bindings for tree-sitter as dependencies.
|
||||
|
||||
# Strategy
|
||||
|
||||
The current strategy is for this processor to be 100% certain when it can accurately extract values from a given model file. Anything less than 100% certainty returns an exception so that the model can be rendered with python Jinja instead.
|
||||
|
||||
There are two cases we want to avoid because they would risk correctness to user's projects:
|
||||
1. Confidently extracting values that would not be extracted by python jinja (false positives)
|
||||
2. Confidently extracting a set of values that do not include values that python jinja would have extracted. (misses)
|
||||
|
||||
If we instead error when we could have confidently extracted values, there is no correctness risk to the user. Only an opportunity to expand the rules to encompass this class of cases as well.
|
||||
|
||||
Even though dbt's usage of jinja is not typed, the type checker statically determines whether or not the current implementation can confidently extract values without relying on python jinja rendering, which is when these errors would otherwise surface. This type checker will become more permissive over time as this tool expands to include more dbt and jinja features.
|
||||
|
||||
# Architecture
|
||||
|
||||
This architecture is optimized for value extraction and for future flexibility. This architecture is expected to change, and is coded in fp-style stages to make those changes easier for the future.
|
||||
|
||||
This processor is composed of several stages:
|
||||
1. parser
|
||||
2. type checker
|
||||
3. extractor
|
||||
|
||||
The parser generated by tree-sitter in the package `tree-sitter-jinja2`. The python hooks are used to traverse the concrete syntax tree that tree-sitter makes in order to create a typed abstract syntax tree in the type checking stage (in Python, we have chosen to represent this with a nested tuple of strings). The errors in the type checking stage are not raised to the user, and are instead used by developers to debug tests.
|
||||
|
||||
The parser is solely responsible for turning text into recognized values, while the type checker does arity checking, and enforces argument list types (e.g. nested function calls like `{{ config(my_ref=ref('table')) }}` will parse but not type check even though it is valid dbt syntax. The tool at this time doesn't have an agreed serialization to communicate refs as config values, but could in the future.)
|
||||
|
||||
The extractor uses the typed abstract syntax tree to easily identify all the refs, sources, and configs present and extract them to a dictionary.
|
||||
|
||||
## Tests
|
||||
|
||||
- Tests are in `test/unit/test_tree_sitter_jinja.py` and run with dbt unit tests
|
||||
|
||||
## Future
|
||||
|
||||
- This module will eventually be rewritten in Rust for the added type safety
|
||||
@@ -1,292 +0,0 @@
|
||||
from dataclasses import dataclass
|
||||
from functools import reduce
|
||||
from itertools import dropwhile
|
||||
from tree_sitter import Parser # type: ignore
|
||||
from tree_sitter_jinja2 import JINJA2_LANGUAGE # type: ignore
|
||||
|
||||
|
||||
# global values
|
||||
parser = Parser()
|
||||
parser.set_language(JINJA2_LANGUAGE)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParseFailure(Exception):
|
||||
msg: str
|
||||
|
||||
|
||||
@dataclass
|
||||
class TypeCheckFailure(Exception):
|
||||
msg: str
|
||||
|
||||
|
||||
def named_children(node):
|
||||
return list(filter(lambda x: x.is_named, node.children))
|
||||
|
||||
|
||||
def text_from_node(source_bytes, node):
|
||||
return source_bytes[node.start_byte:node.end_byte].decode('utf8')
|
||||
|
||||
|
||||
def strip_quotes(text):
|
||||
if text:
|
||||
return text[1:-1]
|
||||
|
||||
|
||||
# flatten([[1,2],[3,4]]) = [1,2,3,4]
|
||||
def flatten(list_of_lists):
|
||||
return [item for sublist in list_of_lists for item in sublist]
|
||||
|
||||
|
||||
def has_kwarg_child_named(name_list, node):
|
||||
kwargs = node[1:]
|
||||
for kwarg in kwargs:
|
||||
if kwarg[1] in name_list:
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
# if all positional args come before kwargs return True.
|
||||
# otherwise return false.
|
||||
def kwargs_last(args):
|
||||
def not_kwarg(node):
|
||||
return node.type != 'kwarg'
|
||||
|
||||
no_leading_positional_args = dropwhile(not_kwarg, args)
|
||||
dangling_positional_args = filter(not_kwarg, no_leading_positional_args)
|
||||
return len(list(dangling_positional_args)) == 0
|
||||
|
||||
|
||||
def error_count(node):
|
||||
if node.has_error:
|
||||
return 1
|
||||
|
||||
if node.children:
|
||||
return reduce(lambda a, b: a + b, map(lambda x: error_count(x), node.children))
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
# meat of the type checker
|
||||
# throws a TypeCheckError or returns a typed ast in the form of a nested tuple
|
||||
def _to_typed(source_bytes, node):
|
||||
if node.type == 'lit_string':
|
||||
return strip_quotes(text_from_node(source_bytes, node))
|
||||
|
||||
if node.type == 'bool':
|
||||
text = text_from_node(source_bytes, node)
|
||||
if text == 'True':
|
||||
return True
|
||||
if text == 'False':
|
||||
return False
|
||||
|
||||
if node.type == 'jinja_expression':
|
||||
raise TypeCheckFailure("jinja expressions are unsupported: {% syntax like this %}")
|
||||
|
||||
elif node.type == 'list':
|
||||
elems = named_children(node)
|
||||
for elem in elems:
|
||||
if elem.type == 'fn_call':
|
||||
raise TypeCheckFailure("list elements cannot be function calls")
|
||||
return ('list', *(_to_typed(source_bytes, elem) for elem in elems))
|
||||
|
||||
elif node.type == 'kwarg':
|
||||
value_node = node.child_by_field_name('value')
|
||||
if value_node.type == 'fn_call':
|
||||
raise TypeCheckFailure("keyword arguments can not be function calls")
|
||||
key_node = node.child_by_field_name('key')
|
||||
key_text = text_from_node(source_bytes, key_node)
|
||||
return ('kwarg', key_text, _to_typed(source_bytes, value_node))
|
||||
|
||||
elif node.type == 'dict':
|
||||
# locally mutate list of kv pairs
|
||||
pairs = []
|
||||
for pair in named_children(node):
|
||||
key = pair.child_by_field_name('key')
|
||||
value = pair.child_by_field_name('value')
|
||||
if key.type != 'lit_string':
|
||||
raise TypeCheckFailure("all dict keys must be string literals")
|
||||
if value.type == 'fn_call':
|
||||
raise TypeCheckFailure("dict values cannot be function calls")
|
||||
pairs.append((key, value))
|
||||
return (
|
||||
'dict',
|
||||
*(
|
||||
(
|
||||
strip_quotes(text_from_node(source_bytes, pair[0])),
|
||||
_to_typed(source_bytes, pair[1])
|
||||
) for pair in pairs
|
||||
))
|
||||
|
||||
elif node.type == 'source_file':
|
||||
children = named_children(node)
|
||||
return ('root', *(_to_typed(source_bytes, child) for child in children))
|
||||
|
||||
elif node.type == 'fn_call':
|
||||
name = text_from_node(source_bytes, node.child_by_field_name('fn_name'))
|
||||
arg_list = node.child_by_field_name('argument_list')
|
||||
arg_count = arg_list.named_child_count
|
||||
args = named_children(arg_list)
|
||||
if not kwargs_last(args):
|
||||
raise TypeCheckFailure("keyword arguments must all be at the end")
|
||||
|
||||
if name == 'ref':
|
||||
if arg_count != 1 and arg_count != 2:
|
||||
raise TypeCheckFailure(f"expected ref to have 1 or 2 arguments. found {arg_count}")
|
||||
for arg in args:
|
||||
if arg.type != 'lit_string':
|
||||
raise TypeCheckFailure(f"all ref arguments must be strings. found {arg.type}")
|
||||
return ('ref', *(_to_typed(source_bytes, arg) for arg in args))
|
||||
|
||||
elif name == 'source':
|
||||
if arg_count != 2:
|
||||
raise TypeCheckFailure(f"expected source to 2 arguments. found {arg_count}")
|
||||
for arg in args:
|
||||
if arg.type != 'kwarg' and arg.type != 'lit_string':
|
||||
raise TypeCheckFailure(f"unexpected argument type in source. Found {arg.type}")
|
||||
# note: keyword vs positional argument order is checked above in fn_call checks
|
||||
if args[0].type == 'kwarg':
|
||||
key_name = text_from_node(source_bytes, args[0].child_by_field_name('key'))
|
||||
if key_name != 'source_name':
|
||||
raise TypeCheckFailure(
|
||||
"first keyword argument in source must be source_name found"
|
||||
f"{args[0].child_by_field_name('key')}"
|
||||
)
|
||||
if args[1].type == 'kwarg':
|
||||
key_name = text_from_node(source_bytes, args[1].child_by_field_name('key'))
|
||||
if key_name != 'table_name':
|
||||
raise TypeCheckFailure(
|
||||
"second keyword argument in source must be table_name found"
|
||||
f"{args[1].child_by_field_name('key')}"
|
||||
)
|
||||
|
||||
# restructure source calls to look like they
|
||||
# were all called positionally for uniformity
|
||||
source_name = args[0]
|
||||
table_name = args[1]
|
||||
if args[0].type == 'kwarg':
|
||||
source_name = args[0].child_by_field_name('value')
|
||||
if args[1].type == 'kwarg':
|
||||
table_name = args[1].child_by_field_name('value')
|
||||
|
||||
return (
|
||||
'source',
|
||||
_to_typed(source_bytes, source_name),
|
||||
_to_typed(source_bytes, table_name)
|
||||
)
|
||||
|
||||
elif name == 'config':
|
||||
if arg_count < 1:
|
||||
raise TypeCheckFailure(
|
||||
f"expected config to have at least one argument. found {arg_count}"
|
||||
)
|
||||
excluded_config_args = ['post-hook', 'post_hook', 'pre-hook', 'pre_hook']
|
||||
for arg in args:
|
||||
if arg.type != 'kwarg':
|
||||
raise TypeCheckFailure(
|
||||
f"unexpected non keyword argument in config. found {arg.type}"
|
||||
)
|
||||
key_name = text_from_node(source_bytes, arg.child_by_field_name('key'))
|
||||
if key_name in excluded_config_args:
|
||||
raise TypeCheckFailure(f"excluded config kwarg found: {key_name}")
|
||||
return ('config', *(_to_typed(source_bytes, arg) for arg in args))
|
||||
|
||||
else:
|
||||
raise TypeCheckFailure(f"unexpected function call to {name}")
|
||||
|
||||
else:
|
||||
raise TypeCheckFailure(f"unexpected node type: {node.type}")
|
||||
|
||||
|
||||
# Entry point for type checking. Either returns a single TypeCheckFailure or
|
||||
# a typed-ast in the form of nested tuples.
|
||||
# Depends on the source because we check for built-ins. It's a bit of a hack,
|
||||
# but it works well at this scale.
|
||||
def type_check(source_bytes, node):
|
||||
try:
|
||||
return _to_typed(source_bytes, node)
|
||||
# if an error was thrown, return it instead.
|
||||
except TypeCheckFailure as e:
|
||||
return e
|
||||
|
||||
|
||||
# operates on a typed ast
|
||||
def _extract(node, data):
|
||||
# reached a leaf
|
||||
if not isinstance(node, tuple):
|
||||
return node
|
||||
|
||||
if node[0] == 'list':
|
||||
return list(_extract(child, data) for child in node[1:])
|
||||
|
||||
if node[0] == 'dict':
|
||||
return {pair[0]: _extract(pair[1], data) for pair in node[1:]}
|
||||
|
||||
if node[0] == 'ref':
|
||||
# no package name
|
||||
if len(node) == 2:
|
||||
ref = [node[1]]
|
||||
else:
|
||||
ref = [node[1], node[2]]
|
||||
data['refs'].append(ref)
|
||||
|
||||
# configs are the only ones that can recurse like this
|
||||
# e.g. {{ config(key=[{'nested':'values'}]) }}
|
||||
if node[0] == 'config':
|
||||
for kwarg in node[1:]:
|
||||
data['configs'].append((kwarg[1], _extract(kwarg[2], data)))
|
||||
|
||||
if node[0] == 'source':
|
||||
for arg in node[1:]:
|
||||
data['sources'].add((node[1], node[2]))
|
||||
|
||||
# generator statement evaluated as tuple for effects
|
||||
tuple(_extract(child, data) for child in node[1:])
|
||||
|
||||
|
||||
def extract(node):
|
||||
data = {
|
||||
'refs': [],
|
||||
'sources': set(),
|
||||
'configs': [],
|
||||
'python_jinja': False
|
||||
}
|
||||
_extract(node, data)
|
||||
return data
|
||||
|
||||
|
||||
# returns a fully processed, typed ast or an exception
|
||||
def process_source(parser, string):
|
||||
source_bytes = bytes(string, "utf8")
|
||||
tree = parser.parse(source_bytes)
|
||||
count = error_count(tree.root_node)
|
||||
|
||||
# check for parser errors
|
||||
if count > 0:
|
||||
return ParseFailure("tree-sitter found errors")
|
||||
|
||||
# if there are no parsing errors check for type errors
|
||||
checked_ast_or_error = type_check(source_bytes, tree.root_node)
|
||||
if isinstance(checked_ast_or_error, TypeCheckFailure):
|
||||
err = checked_ast_or_error
|
||||
return err
|
||||
|
||||
# if there are no parsing errors and no type errors, return the typed ast
|
||||
typed_root = checked_ast_or_error
|
||||
return typed_root
|
||||
|
||||
|
||||
# entry point function
|
||||
def extract_from_source(string):
|
||||
res = process_source(parser, string)
|
||||
|
||||
if isinstance(res, Exception):
|
||||
return {
|
||||
'refs': [],
|
||||
'sources': set(),
|
||||
'configs': [],
|
||||
'python_jinja': True
|
||||
}
|
||||
|
||||
typed_root = res
|
||||
return extract(typed_root)
|
||||
@@ -96,5 +96,5 @@ def _get_dbt_plugins_info():
|
||||
yield plugin_name, mod.version
|
||||
|
||||
|
||||
__version__ = '0.20.0rc1'
|
||||
__version__ = '0.21.0a1'
|
||||
installed = get_installed_version()
|
||||
|
||||
@@ -14,12 +14,12 @@ macro-paths: ["macros"]
|
||||
|
||||
SETUP_PY_TEMPLATE = '''
|
||||
#!/usr/bin/env python
|
||||
from setuptools import find_packages
|
||||
from setuptools import setup
|
||||
from setuptools import find_namespace_packages, setup
|
||||
|
||||
package_name = "dbt-{adapter}"
|
||||
# make sure this always matches dbt/adapters/{adapter}/__version__.py
|
||||
package_version = "{version}"
|
||||
description = """The {adapter} adapter plugin for dbt (data build tool)"""
|
||||
description = """The {adapter} adapter plugin for dbt"""
|
||||
|
||||
setup(
|
||||
name=package_name,
|
||||
@@ -29,18 +29,18 @@ setup(
|
||||
author={author_name},
|
||||
author_email={author_email},
|
||||
url={url},
|
||||
packages=find_packages(),
|
||||
package_data={{
|
||||
'dbt': [
|
||||
{package_data}
|
||||
]
|
||||
}},
|
||||
packages=find_namespace_packages(include=['dbt', 'dbt.*']),
|
||||
include_package_data=True,
|
||||
install_requires=[
|
||||
"{dbt_core_str}",{dependencies}
|
||||
]
|
||||
)
|
||||
'''.lstrip()
|
||||
|
||||
|
||||
MANIFEST_IN_TEMPLATE = "recursive-include dbt/include *.sql *.yml *.md"
|
||||
|
||||
|
||||
ADAPTER_INIT_TEMPLATE = '''
|
||||
from dbt.adapters.{adapter}.connections import {title_adapter}ConnectionManager
|
||||
from dbt.adapters.{adapter}.connections import {title_adapter}Credentials
|
||||
@@ -115,6 +115,44 @@ PACKAGE_PATH = os.path.dirname(__file__)
|
||||
""".lstrip()
|
||||
|
||||
|
||||
SAMPLE_PROFILE_TEMPLATE = '''
|
||||
default:
|
||||
outputs:
|
||||
dev:
|
||||
type: {adapter}
|
||||
# Add sample credentials here, like:
|
||||
# host: <host>
|
||||
# port: <port_num>
|
||||
# username: <user>
|
||||
# password: <pass>
|
||||
target: dev
|
||||
'''
|
||||
|
||||
|
||||
DBTSPEC_TEMPLATE = '''
|
||||
# See https://github.com/fishtown-analytics/dbt-adapter-tests
|
||||
# for installation and use
|
||||
|
||||
target:
|
||||
type: {adapter}
|
||||
# Add CI credentials here, like:
|
||||
# host: localhost
|
||||
# port: 5432
|
||||
# username: root
|
||||
# password: pass
|
||||
sequences:
|
||||
test_dbt_empty: empty
|
||||
test_dbt_base: base
|
||||
test_dbt_ephemeral: ephemeral
|
||||
test_dbt_incremental: incremental
|
||||
test_dbt_snapshot_strategy_timestamp: snapshot_strategy_timestamp
|
||||
test_dbt_snapshot_strategy_check_cols: snapshot_strategy_check_cols
|
||||
test_dbt_data_test: data_test
|
||||
test_dbt_schema_test: schema_test
|
||||
test_dbt_ephemeral_data_tests: data_test_ephemeral_models
|
||||
'''
|
||||
|
||||
|
||||
class Builder:
|
||||
def __init__(self, args):
|
||||
self.args = args
|
||||
@@ -131,6 +169,7 @@ class Builder:
|
||||
self.write_setup()
|
||||
self.write_adapter()
|
||||
self.write_include()
|
||||
self.write_test_spec()
|
||||
|
||||
def include_paths(self):
|
||||
return [
|
||||
@@ -162,9 +201,9 @@ class Builder:
|
||||
url=self.args.url,
|
||||
dbt_core_str=dbt_core_str,
|
||||
dependencies=self.args.dependency,
|
||||
package_data=package_data,
|
||||
)
|
||||
self.dest_path('setup.py').write_text(setup_py_contents)
|
||||
self.dest_path('MANIFEST.in').write_text(MANIFEST_IN_TEMPLATE)
|
||||
|
||||
def _make_adapter_kwargs(self):
|
||||
if self.args.sql:
|
||||
@@ -197,10 +236,12 @@ class Builder:
|
||||
adapter=self.adapter,
|
||||
title_adapter=self.args.title_case
|
||||
)
|
||||
version_text = f'{self.args.package_version}'
|
||||
connections_text = ADAPTER_CONNECTIONS_TEMPLATE.format(**kwargs)
|
||||
impl_text = ADAPTER_IMPL_TEMPLATE.format(**kwargs)
|
||||
|
||||
(adapters_dest / '__init__.py').write_text(init_text)
|
||||
(adapters_dest / '__version__.py').write_text(version_text)
|
||||
(adapters_dest / 'connections.py').write_text(connections_text)
|
||||
(adapters_dest / 'impl.py').write_text(impl_text)
|
||||
|
||||
@@ -214,15 +255,26 @@ class Builder:
|
||||
adapter=self.adapter,
|
||||
version=self.args.project_version,
|
||||
)
|
||||
sample_profiles_text = SAMPLE_PROFILE_TEMPLATE.format(
|
||||
adapter=self.adapter
|
||||
)
|
||||
catalog_macro_text = CATALOG_MACRO_TEMPLATE.format(
|
||||
adapter=self.adapter
|
||||
)
|
||||
|
||||
(include_dest / '__init__.py').write_text(INCLUDE_INIT_TEXT)
|
||||
(include_dest / 'dbt_project.yml').write_text(dbt_project_text)
|
||||
(include_dest / 'sample_profiles.yml').write_text(sample_profiles_text)
|
||||
# make sure something satisfies the 'include/macros/*.sql' in setup.py
|
||||
(macros_dest / 'catalog.sql').write_text(catalog_macro_text)
|
||||
|
||||
def write_test_spec(self):
|
||||
test_dest = self.dest_path('test')
|
||||
test_dest.mkdir(parents=True, exist_ok=True)
|
||||
spec_file = f'{self.adapter}.dbtspec'
|
||||
spec_text = DBTSPEC_TEMPLATE.format(adapter=self.adapter)
|
||||
(test_dest / spec_file).write_text(spec_text)
|
||||
|
||||
|
||||
def parse_args(argv=None):
|
||||
if argv is None:
|
||||
@@ -232,12 +284,12 @@ def parse_args(argv=None):
|
||||
parser.add_argument('adapter')
|
||||
parser.add_argument('--title-case', '-t', default=None)
|
||||
parser.add_argument('--dependency', action='append')
|
||||
parser.add_argument('--dbt-core-version', default='0.16.1rc1')
|
||||
parser.add_argument('--dbt-core-version', default='0.21.0a1')
|
||||
parser.add_argument('--email')
|
||||
parser.add_argument('--author')
|
||||
parser.add_argument('--url')
|
||||
parser.add_argument('--sql', action='store_true')
|
||||
parser.add_argument('--package-version', default='0.0.1')
|
||||
parser.add_argument('--package-version', default='0.21.0a1')
|
||||
parser.add_argument('--project-version', default='1.0')
|
||||
parser.add_argument(
|
||||
'--no-dependency', action='store_false', dest='set_dependency'
|
||||
|
||||
@@ -24,7 +24,7 @@ def read(fname):
|
||||
|
||||
|
||||
package_name = "dbt-core"
|
||||
package_version = "0.20.0rc1"
|
||||
package_version = "0.21.0a1"
|
||||
description = """dbt (data build tool) is a command line tool that helps \
|
||||
analysts and engineers transform data in their warehouse more effectively"""
|
||||
|
||||
@@ -38,17 +38,7 @@ setup(
|
||||
author_email="info@fishtownanalytics.com",
|
||||
url="https://github.com/fishtown-analytics/dbt",
|
||||
packages=find_namespace_packages(include=['dbt', 'dbt.*']),
|
||||
package_data={
|
||||
'dbt': [
|
||||
'include/index.html',
|
||||
'include/global_project/dbt_project.yml',
|
||||
'include/global_project/docs/*.md',
|
||||
'include/global_project/macros/*.sql',
|
||||
'include/global_project/macros/**/*.sql',
|
||||
'include/global_project/macros/**/**/*.sql',
|
||||
'py.typed',
|
||||
]
|
||||
},
|
||||
include_package_data = True,
|
||||
test_suite='test',
|
||||
entry_points={
|
||||
'console_scripts': [
|
||||
@@ -73,13 +63,12 @@ setup(
|
||||
'networkx>=2.3,<3',
|
||||
'packaging~=20.9',
|
||||
'sqlparse>=0.2.3,<0.4',
|
||||
'tree-sitter==0.19.0',
|
||||
'tree-sitter-jinja2==0.1.0a1',
|
||||
'typing-extensions>=3.7.4,<3.8',
|
||||
'werkzeug>=0.15,<2.0',
|
||||
'dbt-extractor==0.2.0',
|
||||
'typing-extensions>=3.7.4,<3.11',
|
||||
'werkzeug>=1,<3',
|
||||
# the following are all to match snowflake-connector-python
|
||||
'requests<3.0.0',
|
||||
'idna>=2.5,<3',
|
||||
'idna>=2.5,<4',
|
||||
'cffi>=1.9,<2.0.0',
|
||||
],
|
||||
zip_safe=False,
|
||||
|
||||
75
docker/requirements/requirements.0.20.0.txt
Normal file
75
docker/requirements/requirements.0.20.0.txt
Normal file
@@ -0,0 +1,75 @@
|
||||
agate==1.6.1
|
||||
asn1crypto==1.4.0
|
||||
attrs==21.2.0
|
||||
azure-common==1.1.27
|
||||
azure-core==1.16.0
|
||||
azure-storage-blob==12.8.1
|
||||
Babel==2.9.1
|
||||
boto3==1.17.109
|
||||
botocore==1.20.109
|
||||
cachetools==4.2.2
|
||||
certifi==2021.5.30
|
||||
cffi==1.14.6
|
||||
chardet==4.0.0
|
||||
colorama==0.4.4
|
||||
cryptography==3.4.7
|
||||
decorator==4.4.2
|
||||
google-api-core==1.31.0
|
||||
google-auth==1.32.1
|
||||
google-cloud-bigquery==2.20.0
|
||||
google-cloud-core==1.7.1
|
||||
google-crc32c==1.1.2
|
||||
google-resumable-media==1.3.1
|
||||
googleapis-common-protos==1.53.0
|
||||
grpcio==1.38.1
|
||||
hologram==0.0.14
|
||||
idna==2.10
|
||||
importlib-metadata==4.6.1
|
||||
isodate==0.6.0
|
||||
jeepney==0.7.0
|
||||
Jinja2==2.11.3
|
||||
jmespath==0.10.0
|
||||
json-rpc==1.13.0
|
||||
jsonschema==3.1.1
|
||||
keyring==21.8.0
|
||||
leather==0.3.3
|
||||
Logbook==1.5.3
|
||||
MarkupSafe==2.0.1
|
||||
mashumaro==2.5
|
||||
minimal-snowplow-tracker==0.0.2
|
||||
msgpack==1.0.2
|
||||
msrest==0.6.21
|
||||
networkx==2.5.1
|
||||
oauthlib==3.1.1
|
||||
oscrypto==1.2.1
|
||||
packaging==20.9
|
||||
parsedatetime==2.6
|
||||
proto-plus==1.19.0
|
||||
protobuf==3.17.3
|
||||
psycopg2-binary==2.9.1
|
||||
pyasn1==0.4.8
|
||||
pyasn1-modules==0.2.8
|
||||
pycparser==2.20
|
||||
pycryptodomex==3.10.1
|
||||
PyJWT==2.1.0
|
||||
pyOpenSSL==20.0.1
|
||||
pyparsing==2.4.7
|
||||
pyrsistent==0.18.0
|
||||
python-dateutil==2.8.1
|
||||
python-slugify==5.0.2
|
||||
pytimeparse==1.1.8
|
||||
pytz==2021.1
|
||||
PyYAML==5.4.1
|
||||
requests==2.25.1
|
||||
requests-oauthlib==1.3.0
|
||||
rsa==4.7.2
|
||||
s3transfer==0.4.2
|
||||
SecretStorage==3.3.1
|
||||
six==1.16.0
|
||||
snowflake-connector-python==2.4.6
|
||||
sqlparse==0.3.1
|
||||
text-unidecode==1.3
|
||||
typing-extensions==3.10.0.0
|
||||
urllib3==1.26.6
|
||||
Werkzeug==2.0.1
|
||||
zipp==3.5.0
|
||||
75
docker/requirements/requirements.0.20.0rc2.txt
Normal file
75
docker/requirements/requirements.0.20.0rc2.txt
Normal file
@@ -0,0 +1,75 @@
|
||||
agate==1.6.1
|
||||
asn1crypto==1.4.0
|
||||
attrs==21.2.0
|
||||
azure-common==1.1.27
|
||||
azure-core==1.15.0
|
||||
azure-storage-blob==12.8.1
|
||||
Babel==2.9.1
|
||||
boto3==1.17.102
|
||||
botocore==1.20.102
|
||||
cachetools==4.2.2
|
||||
certifi==2021.5.30
|
||||
cffi==1.14.5
|
||||
chardet==4.0.0
|
||||
colorama==0.4.4
|
||||
cryptography==3.4.7
|
||||
decorator==4.4.2
|
||||
google-api-core==1.30.0
|
||||
google-auth==1.32.0
|
||||
google-cloud-bigquery==2.20.0
|
||||
google-cloud-core==1.7.1
|
||||
google-crc32c==1.1.2
|
||||
google-resumable-media==1.3.1
|
||||
googleapis-common-protos==1.53.0
|
||||
grpcio==1.38.1
|
||||
hologram==0.0.14
|
||||
idna==2.10
|
||||
importlib-metadata==4.6.0
|
||||
isodate==0.6.0
|
||||
jeepney==0.6.0
|
||||
Jinja2==2.11.3
|
||||
jmespath==0.10.0
|
||||
json-rpc==1.13.0
|
||||
jsonschema==3.1.1
|
||||
keyring==21.8.0
|
||||
leather==0.3.3
|
||||
Logbook==1.5.3
|
||||
MarkupSafe==2.0.1
|
||||
mashumaro==2.5
|
||||
minimal-snowplow-tracker==0.0.2
|
||||
msgpack==1.0.2
|
||||
msrest==0.6.21
|
||||
networkx==2.5.1
|
||||
oauthlib==3.1.1
|
||||
oscrypto==1.2.1
|
||||
packaging==20.9
|
||||
parsedatetime==2.6
|
||||
proto-plus==1.19.0
|
||||
protobuf==3.17.3
|
||||
psycopg2-binary==2.9.1
|
||||
pyasn1==0.4.8
|
||||
pyasn1-modules==0.2.8
|
||||
pycparser==2.20
|
||||
pycryptodomex==3.10.1
|
||||
PyJWT==2.1.0
|
||||
pyOpenSSL==20.0.1
|
||||
pyparsing==2.4.7
|
||||
pyrsistent==0.18.0
|
||||
python-dateutil==2.8.1
|
||||
python-slugify==5.0.2
|
||||
pytimeparse==1.1.8
|
||||
pytz==2021.1
|
||||
PyYAML==5.4.1
|
||||
requests==2.25.1
|
||||
requests-oauthlib==1.3.0
|
||||
rsa==4.7.2
|
||||
s3transfer==0.4.2
|
||||
SecretStorage==3.3.1
|
||||
six==1.16.0
|
||||
snowflake-connector-python==2.4.6
|
||||
sqlparse==0.3.1
|
||||
text-unidecode==1.3
|
||||
typing-extensions==3.10.0.0
|
||||
urllib3==1.26.6
|
||||
Werkzeug==2.0.1
|
||||
zipp==3.4.1
|
||||
{kind=link}
@@ -1 +1,7 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 520 190"><defs><style>.cls-1{fill:#ff694b;}</style></defs><g id="dbt-logo-full"><path d="M279.1,27.33l-.49,41.27c-20.65-4.48-34-1.36-34-1.36s-15.48,1.91-25.26,18.36-5.29,48.34-5.29,48.34a44.06,44.06,0,0,0,5.22,15.53c4.36,7.51,10.43,9.65,10.43,9.65s1.57,1.36,8.36,2.86S257,162,257,162s7.21-1.29,9.29-2.72,11.14-12,11.14-12h1.63l3.83,15.33h22.43l.2-135.21Zm-.27,112.08s-14.63,6-28.18,1.63c-6-1.92-8.41-8.6-9.46-14.22a68.92,68.92,0,0,1,.18-25.49c1-4.84,3.32-9.63,7.59-12.38a16.68,16.68,0,0,1,7.92-2.44c16.94-1.08,21.95.82,21.95.82Z"/><path d="M358.56,27.33H332V162.54h4.56l7.32-5s22.15,6.9,40.31,4.62,21.95-6.27,21.95-6.27,14.11-6.43,17.53-33.46-1.91-50.1-18-54.47a56.65,56.65,0,0,0-22-1.33c-6.58.84-12.26,1.94-16.46,7.47L360,82.25h-1.47ZM395.75,128.6s0,4.89-6.81,10.5-30.3,1.79-30.3,1.79V89.58s4.17-2.39,18.25-2.87,16.95,6.21,16.95,6.21C400.16,104.61,395.75,128.6,395.75,128.6Z"/><path d="M507.4,138.91s-19.52,4.5-24.81,1.85-4.22-14.13-4.22-14.13V87.8h26.11L508,68.18H478.28V48L451.6,53V68.22H440l-1.44,19.41H451.6v46.12a41.84,41.84,0,0,0,2.12,13.82,23.06,23.06,0,0,0,6.1,9.67c5.36,4.86,13.65,5.31,20.51,5.34a90,90,0,0,0,24.54-3.29Z"/><path class="cls-1" d="M170.84,14.16a17.8,17.8,0,0,0-6.26-2.7,19.77,19.77,0,0,0-7-.27,21.69,21.69,0,0,0-7,2.23l-10.25,5.64-10.24,5.63-10.24,5.63L109.63,36A29.72,29.72,0,0,1,102.56,39a27.25,27.25,0,0,1-7.36,1.08,27.59,27.59,0,0,1-7.38-.91,29.39,29.39,0,0,1-7.11-2.92l-9.93-5.4-9.92-5.4-9.93-5.41L41,14.67A18.19,18.19,0,0,0,28.57,12,19.92,19.92,0,0,0,12.29,27.61a18,18,0,0,0,2.22,12.47L18,46.46l7.67,14c2.78,5.1,5.57,10.21,7.67,14l3.48,6.38a29.25,29.25,0,0,1,3,7A27.79,27.79,0,0,1,40,102.71a29.83,29.83,0,0,1-3,7.12L31.53,120l-5.46,10.14-5.46,10.15-5.46,10.14a22.69,22.69,0,0,0-2.09,5.27,18.66,18.66,0,0,0-.6,5.32,16.6,16.6,0,0,0,1,5.16A17.52,17.52,0,0,0,16,171,19,19,0,0,0,21,175.7a19.68,19.68,0,0,0,6.26,2.73,20,20,0,0,0,7,.45,20.38,20.38,0,0,0,7-2.13l10.62-5.83,10.62-5.82,10.63-5.83,10.62-5.83a57.39,57.39,0,0,1-8.81-7.8,78.47,78.47,0,0,1-7.33-9.28c-2.23-3.28-4.27-6.7-6.17-10.18-1.69-3.1-3.26-6.24-4.77-9.36,2.67,5,8.42,10.31,15.9,15.64a263.43,263.43,0,0,0,28.35,17c10.29,5.48,20.87,10.66,30,15.24s16.87,8.55,21.46,11.58a16.9,16.9,0,0,0,12.32,1.94A19.32,19.32,0,0,0,174.69,172a21.4,21.4,0,0,0,5.1-11,18.86,18.86,0,0,0-2.51-12.45L171,137.23l-13.76-25-13.75-25L137.27,76a71.23,71.23,0,0,0-4.33-6.5,62.1,62.1,0,0,0-5-5.85,54.23,54.23,0,0,0-5.68-5.13,51.67,51.67,0,0,0-6.46-4.34c3.52,1.6,7.08,3.26,10.59,5.05a114.89,114.89,0,0,1,10.28,5.87,73.27,73.27,0,0,1,9.39,7.14,54.64,54.64,0,0,1,8,8.9l5.65-10.34,5.64-10.34L171,50.1l5.65-10.34a18.18,18.18,0,0,0,2.1-4.95,18.62,18.62,0,0,0-.37-10.69,17.3,17.3,0,0,0-2.61-4.9A17.74,17.74,0,0,0,170.84,14.16ZM39.8,159a7.39,7.39,0,0,1-7.76,7.9,7.83,7.83,0,1,1-.14-15.66A7.39,7.39,0,0,1,39.8,159ZM24.31,31.31a7.4,7.4,0,0,1,7.77-7.9A7.4,7.4,0,0,1,40,31.18a7.4,7.4,0,0,1-7.76,7.9A7.41,7.41,0,0,1,24.31,31.31ZM167.6,158.76a7.84,7.84,0,1,1-7.9-7.76A7.4,7.4,0,0,1,167.6,158.76Zm-53-66.57c-2.3-3.78-6.12-5.26-10.68-5.21a15.64,15.64,0,0,0-10.5,26.75A18.65,18.65,0,0,1,77.28,92.61C78.74,82.7,88.59,75,98.5,76.39,106.88,77.81,113.76,83.82,114.57,92.19Zm53.56-61.54a7.84,7.84,0,0,1-15.67.14,7.84,7.84,0,0,1,15.67-.14Z"/></g></svg>
|
||||
<svg width="242" height="90" viewBox="0 0 242 90" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||
<path d="M240.384 74.5122L239.905 75.8589H239.728L239.249 74.5156V75.8589H238.941V74.0234H239.324L239.816 75.3872L240.309 74.0234H240.691V75.8589H240.384V74.5122ZM238.671 74.3003H238.169V75.8589H237.858V74.3003H237.352V74.0234H238.671V74.3003Z" fill="#262A38"/>
|
||||
<path d="M154.123 13.915V75.3527H141.672V69.0868C140.37 71.2839 138.499 73.0742 136.22 74.2134C133.779 75.434 131.012 76.085 128.246 76.085C124.828 76.1664 121.41 75.1899 118.562 73.2369C115.633 71.2839 113.354 68.5986 111.889 65.425C110.262 61.7631 109.448 57.8572 109.529 53.8698C109.448 49.8825 110.262 45.9765 111.889 42.3961C113.354 39.3038 115.633 36.6185 118.481 34.7469C121.41 32.8753 124.828 31.9801 128.246 32.0615C130.931 32.0615 133.616 32.6311 135.976 33.8517C138.255 34.991 140.126 36.6999 141.428 38.8156V18.0651L154.123 13.915ZM139.15 63.2279C140.777 61.1121 141.672 58.0199 141.672 54.0326C141.672 50.0452 140.859 47.0344 139.15 44.9187C137.441 42.8029 134.755 41.5823 131.989 41.6637C129.222 41.5009 126.537 42.7215 124.746 44.8373C123.038 46.953 122.142 49.9639 122.142 53.8698C122.142 57.8572 123.038 60.9494 124.746 63.1465C126.455 65.3436 129.222 66.5642 131.989 66.4828C135.081 66.4828 137.522 65.3436 139.15 63.2279Z" fill="#262A38"/>
|
||||
<path d="M198.635 34.6655C201.564 36.5371 203.843 39.2225 205.226 42.3147C206.853 45.8952 207.667 49.8011 207.586 53.7885C207.667 57.7758 206.853 61.7632 205.226 65.3436C203.761 68.5172 201.483 71.2026 198.553 73.1556C195.705 75.0272 192.287 76.0037 188.87 75.9223C186.103 76.0037 183.336 75.3527 180.895 74.0507C178.617 72.9114 176.745 71.1212 175.524 68.9241V75.2713H162.993V18.0651L175.606 13.915V38.9783C176.826 36.7812 178.698 34.991 180.976 33.8517C183.418 32.5498 186.103 31.8988 188.87 31.9801C192.287 31.8988 195.705 32.8753 198.635 34.6655ZM192.45 63.1465C194.159 60.9494 194.973 57.8572 194.973 53.7885C194.973 49.8825 194.159 46.8716 192.45 44.7559C190.741 42.6402 188.381 41.5823 185.289 41.5823C182.523 41.4196 179.837 42.6402 178.047 44.8373C176.338 47.0344 175.524 50.0452 175.524 53.9512C175.524 57.9386 176.338 61.0308 178.047 63.1465C179.756 65.3436 182.441 66.5642 185.289 66.4015C188.056 66.5642 190.741 65.3436 192.45 63.1465Z" fill="#262A38"/>
|
||||
<path d="M225 42.4774V58.915C225 61.2749 225.651 62.9838 226.791 64.0416C228.093 65.1809 229.801 65.7505 231.592 65.6691C232.975 65.6691 234.44 65.425 235.742 65.0995V74.8644C233.382 75.6782 230.941 76.085 228.499 76.0037C223.292 76.0037 219.304 74.5389 216.537 71.6094C213.771 68.68 212.387 64.5299 212.387 59.1592V23.1103L225 19.0416V33.038H235.742V42.4774H225Z" fill="#262A38"/>
|
||||
<path d="M86.1754 3.74322C88.2911 5.77758 89.6745 8.46293 90 11.3924C90 12.613 89.6745 13.4268 88.9421 14.9729C88.2098 16.519 79.1772 32.1429 76.4919 36.4557C74.9458 38.9783 74.132 41.9892 74.132 44.9186C74.132 47.9295 74.9458 50.859 76.4919 53.3816C79.1772 57.6944 88.2098 73.3996 88.9421 74.9457C89.6745 76.4919 90 77.2242 90 78.4448C89.6745 81.3743 88.3725 84.0597 86.2568 86.0127C84.2224 88.1284 81.5371 89.5118 78.689 89.7559C77.4684 89.7559 76.6546 89.4304 75.1899 88.698C73.7251 87.9656 57.7758 79.1772 53.4629 76.4919C53.1374 76.3291 52.8119 76.085 52.4051 75.9222L31.085 63.3092C31.5732 67.3779 33.3635 71.2839 36.2929 74.132C36.8626 74.7016 37.4322 75.1899 38.0832 75.6781C37.5949 75.9222 37.0253 76.1664 36.5371 76.4919C32.2242 79.1772 16.519 88.2098 14.9729 88.9421C13.4268 89.6745 12.6944 90 11.3924 90C8.46293 89.6745 5.77758 88.3725 3.82459 86.2568C1.70886 84.2224 0.325497 81.5371 0 78.6076C0.0813743 77.387 0.406872 76.1664 1.05787 75.1085C1.79024 73.5624 10.8228 57.8571 13.5081 53.5443C15.0542 51.0217 15.868 48.0922 15.868 45.0814C15.868 42.0705 15.0542 39.141 13.5081 36.6184C10.8228 32.1429 1.70886 16.4376 1.05787 14.8915C0.406872 13.8336 0.0813743 12.613 0 11.3924C0.325497 8.46293 1.62749 5.77758 3.74322 3.74322C5.77758 1.62749 8.46293 0.325497 11.3924 0C12.613 0.0813743 13.8336 0.406872 14.9729 1.05787C16.2749 1.62749 27.7486 8.30018 33.8517 11.8807L35.2351 12.6944C35.7233 13.0199 36.1302 13.264 36.4557 13.4268L37.1067 13.8336L58.8336 26.6908C58.3454 21.8083 55.8228 17.3327 51.9168 14.3219C52.4051 14.0778 52.9747 13.8336 53.4629 13.5081C57.7758 10.8228 73.481 1.70886 75.0271 1.05787C76.085 0.406872 77.3056 0.0813743 78.6076 0C81.4557 0.325497 84.1411 1.62749 86.1754 3.74322ZM46.1392 50.7776L50.7776 46.1392C51.4286 45.4882 51.4286 44.5118 50.7776 43.8608L46.1392 39.2224C45.4882 38.5714 44.5118 38.5714 43.8608 39.2224L39.2224 43.8608C38.5714 44.5118 38.5714 45.4882 39.2224 46.1392L43.8608 50.7776C44.4304 51.3472 45.4882 51.3472 46.1392 50.7776Z" fill="#FF694A"/>
|
||||
</svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 3.2 KiB After Width: | Height: | Size: 4.6 KiB |
18
performance/README.md
Normal file
18
performance/README.md
Normal file
@@ -0,0 +1,18 @@
|
||||
# Performance Regression Testing
|
||||
This directory includes dbt project setups to test on and a test runner written in Rust which runs specific dbt commands on each of the projects. Orchestration is done via the GitHub Action workflow in `/.github/workflows/performance.yml`. The workflow is scheduled to run every night, but it can also be triggered manually.
|
||||
|
||||
The github workflow hardcodes our baseline branch for performance metrics as `0.20.latest`. As future versions become faster, this branch will be updated to hold us to those new standards.
|
||||
|
||||
## Adding a new dbt project
|
||||
Just make a new directory under `performance/projects/`. It will automatically be picked up by the tests.
|
||||
|
||||
## Adding a new dbt command
|
||||
In `runner/src/measure.rs::measure` add a metric to the `metrics` Vec. The Github Action will handle recompilation if you don't have the rust toolchain installed.
|
||||
|
||||
## Future work
|
||||
- add more projects to test different configurations that have been known bottlenecks
|
||||
- add more dbt commands to measure
|
||||
- possibly using the uploaded json artifacts to store these results so they can be graphed over time
|
||||
- reading new metrics from a file so no one has to edit rust source to add them to the suite
|
||||
- instead of building the rust every time, we could publish and pull down the latest version.
|
||||
- instead of manually setting the baseline version of dbt to test, pull down the latest stable version as the baseline.
|
||||
1
performance/project_config/.user.yml
Normal file
1
performance/project_config/.user.yml
Normal file
@@ -0,0 +1 @@
|
||||
id: 5d0c160e-f817-4b77-bce3-ffb2e37f0c9b
|
||||
12
performance/project_config/profiles.yml
Normal file
12
performance/project_config/profiles.yml
Normal file
@@ -0,0 +1,12 @@
|
||||
default:
|
||||
target: dev
|
||||
outputs:
|
||||
dev:
|
||||
type: postgres
|
||||
host: localhost
|
||||
user: dummy
|
||||
password: dummy_password
|
||||
port: 5432
|
||||
dbname: dummy
|
||||
schema: dummy
|
||||
threads: 4
|
||||
38
performance/projects/01_dummy_project/dbt_project.yml
Normal file
38
performance/projects/01_dummy_project/dbt_project.yml
Normal file
@@ -0,0 +1,38 @@
|
||||
|
||||
# Name your package! Package names should contain only lowercase characters
|
||||
# and underscores. A good package name should reflect your organization's
|
||||
# name or the intended use of these models
|
||||
name: 'my_new_package'
|
||||
version: 1.0.0
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project. Profiles contain
|
||||
# database connection information, and should be configured in the ~/.dbt/profiles.yml file
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `source-paths` config, for example, states that source models can be found
|
||||
# in the "models/" directory. You probably won't need to change these!
|
||||
source-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
test-paths: ["tests"]
|
||||
data-paths: ["data"]
|
||||
macro-paths: ["macros"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_modules"
|
||||
|
||||
# You can define configurations for models in the `source-paths` directory here.
|
||||
# Using these configurations, you can enable or disable models, change how they
|
||||
# are materialized, and more!
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as views (the default). These settings can be overridden in the individual model files
|
||||
# using the `{{ config(...) }}` macro.
|
||||
models:
|
||||
my_new_package:
|
||||
# Applies to all files under models/example/
|
||||
example:
|
||||
materialized: view
|
||||
@@ -0,0 +1 @@
|
||||
select 1 as id
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_0
|
||||
version: 2
|
||||
@@ -0,0 +1,3 @@
|
||||
select 1 as id
|
||||
union all
|
||||
select * from {{ ref('node_0') }}
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_1
|
||||
version: 2
|
||||
@@ -0,0 +1,3 @@
|
||||
select 1 as id
|
||||
union all
|
||||
select * from {{ ref('node_0') }}
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_2
|
||||
version: 2
|
||||
38
performance/projects/02_dummy_project/dbt_project.yml
Normal file
38
performance/projects/02_dummy_project/dbt_project.yml
Normal file
@@ -0,0 +1,38 @@
|
||||
|
||||
# Name your package! Package names should contain only lowercase characters
|
||||
# and underscores. A good package name should reflect your organization's
|
||||
# name or the intended use of these models
|
||||
name: 'my_new_package'
|
||||
version: 1.0.0
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project. Profiles contain
|
||||
# database connection information, and should be configured in the ~/.dbt/profiles.yml file
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `source-paths` config, for example, states that source models can be found
|
||||
# in the "models/" directory. You probably won't need to change these!
|
||||
source-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
test-paths: ["tests"]
|
||||
data-paths: ["data"]
|
||||
macro-paths: ["macros"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_modules"
|
||||
|
||||
# You can define configurations for models in the `source-paths` directory here.
|
||||
# Using these configurations, you can enable or disable models, change how they
|
||||
# are materialized, and more!
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as views (the default). These settings can be overridden in the individual model files
|
||||
# using the `{{ config(...) }}` macro.
|
||||
models:
|
||||
my_new_package:
|
||||
# Applies to all files under models/example/
|
||||
example:
|
||||
materialized: view
|
||||
@@ -0,0 +1 @@
|
||||
select 1 as id
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_0
|
||||
version: 2
|
||||
@@ -0,0 +1,3 @@
|
||||
select 1 as id
|
||||
union all
|
||||
select * from {{ ref('node_0') }}
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_1
|
||||
version: 2
|
||||
@@ -0,0 +1,3 @@
|
||||
select 1 as id
|
||||
union all
|
||||
select * from {{ ref('node_0') }}
|
||||
@@ -0,0 +1,11 @@
|
||||
models:
|
||||
- columns:
|
||||
- name: id
|
||||
tests:
|
||||
- unique
|
||||
- not_null
|
||||
- relationships:
|
||||
field: id
|
||||
to: node_0
|
||||
name: node_2
|
||||
version: 2
|
||||
5
performance/results/.gitignore
vendored
Normal file
5
performance/results/.gitignore
vendored
Normal file
@@ -0,0 +1,5 @@
|
||||
# all files here are generated results
|
||||
*
|
||||
|
||||
# except this one
|
||||
!.gitignore
|
||||
2
performance/runner/.gitignore
vendored
Normal file
2
performance/runner/.gitignore
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
target/
|
||||
projects/*/logs
|
||||
307
performance/runner/Cargo.lock
generated
Normal file
307
performance/runner/Cargo.lock
generated
Normal file
@@ -0,0 +1,307 @@
|
||||
# This file is automatically @generated by Cargo.
|
||||
# It is not intended for manual editing.
|
||||
version = 3
|
||||
|
||||
[[package]]
|
||||
name = "ansi_term"
|
||||
version = "0.11.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b"
|
||||
dependencies = [
|
||||
"winapi",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "atty"
|
||||
version = "0.2.14"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "d9b39be18770d11421cdb1b9947a45dd3f37e93092cbf377614828a319d5fee8"
|
||||
dependencies = [
|
||||
"hermit-abi",
|
||||
"libc",
|
||||
"winapi",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "bitflags"
|
||||
version = "1.2.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "cf1de2fe8c75bc145a2f577add951f8134889b4795d47466a54a5c846d691693"
|
||||
|
||||
[[package]]
|
||||
name = "clap"
|
||||
version = "2.33.3"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "37e58ac78573c40708d45522f0d80fa2f01cc4f9b4e2bf749807255454312002"
|
||||
dependencies = [
|
||||
"ansi_term",
|
||||
"atty",
|
||||
"bitflags",
|
||||
"strsim",
|
||||
"textwrap",
|
||||
"unicode-width",
|
||||
"vec_map",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "either"
|
||||
version = "1.6.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "e78d4f1cc4ae33bbfc157ed5d5a5ef3bc29227303d595861deb238fcec4e9457"
|
||||
|
||||
[[package]]
|
||||
name = "heck"
|
||||
version = "0.3.3"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "6d621efb26863f0e9924c6ac577e8275e5e6b77455db64ffa6c65c904e9e132c"
|
||||
dependencies = [
|
||||
"unicode-segmentation",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "hermit-abi"
|
||||
version = "0.1.19"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "62b467343b94ba476dcb2500d242dadbb39557df889310ac77c5d99100aaac33"
|
||||
dependencies = [
|
||||
"libc",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "itertools"
|
||||
version = "0.10.1"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "69ddb889f9d0d08a67338271fa9b62996bc788c7796a5c18cf057420aaed5eaf"
|
||||
dependencies = [
|
||||
"either",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "itoa"
|
||||
version = "0.4.7"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "dd25036021b0de88a0aff6b850051563c6516d0bf53f8638938edbb9de732736"
|
||||
|
||||
[[package]]
|
||||
name = "lazy_static"
|
||||
version = "1.4.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "e2abad23fbc42b3700f2f279844dc832adb2b2eb069b2df918f455c4e18cc646"
|
||||
|
||||
[[package]]
|
||||
name = "libc"
|
||||
version = "0.2.98"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "320cfe77175da3a483efed4bc0adc1968ca050b098ce4f2f1c13a56626128790"
|
||||
|
||||
[[package]]
|
||||
name = "proc-macro-error"
|
||||
version = "1.0.4"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "da25490ff9892aab3fcf7c36f08cfb902dd3e71ca0f9f9517bea02a73a5ce38c"
|
||||
dependencies = [
|
||||
"proc-macro-error-attr",
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
"version_check",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "proc-macro-error-attr"
|
||||
version = "1.0.4"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "a1be40180e52ecc98ad80b184934baf3d0d29f979574e439af5a55274b35f869"
|
||||
dependencies = [
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"version_check",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "proc-macro2"
|
||||
version = "1.0.28"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "5c7ed8b8c7b886ea3ed7dde405212185f423ab44682667c8c6dd14aa1d9f6612"
|
||||
dependencies = [
|
||||
"unicode-xid",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "quote"
|
||||
version = "1.0.9"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "c3d0b9745dc2debf507c8422de05d7226cc1f0644216dfdfead988f9b1ab32a7"
|
||||
dependencies = [
|
||||
"proc-macro2",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "runner"
|
||||
version = "0.1.0"
|
||||
dependencies = [
|
||||
"itertools",
|
||||
"serde",
|
||||
"serde_json",
|
||||
"structopt",
|
||||
"thiserror",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ryu"
|
||||
version = "1.0.5"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "71d301d4193d031abdd79ff7e3dd721168a9572ef3fe51a1517aba235bd8f86e"
|
||||
|
||||
[[package]]
|
||||
name = "serde"
|
||||
version = "1.0.127"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "f03b9878abf6d14e6779d3f24f07b2cfa90352cfec4acc5aab8f1ac7f146fae8"
|
||||
dependencies = [
|
||||
"serde_derive",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "serde_derive"
|
||||
version = "1.0.127"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "a024926d3432516606328597e0f224a51355a493b49fdd67e9209187cbe55ecc"
|
||||
dependencies = [
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "serde_json"
|
||||
version = "1.0.66"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "336b10da19a12ad094b59d870ebde26a45402e5b470add4b5fd03c5048a32127"
|
||||
dependencies = [
|
||||
"itoa",
|
||||
"ryu",
|
||||
"serde",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "strsim"
|
||||
version = "0.8.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "8ea5119cdb4c55b55d432abb513a0429384878c15dde60cc77b1c99de1a95a6a"
|
||||
|
||||
[[package]]
|
||||
name = "structopt"
|
||||
version = "0.3.22"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "69b041cdcb67226aca307e6e7be44c8806423d83e018bd662360a93dabce4d71"
|
||||
dependencies = [
|
||||
"clap",
|
||||
"lazy_static",
|
||||
"structopt-derive",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "structopt-derive"
|
||||
version = "0.4.15"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "7813934aecf5f51a54775e00068c237de98489463968231a51746bbbc03f9c10"
|
||||
dependencies = [
|
||||
"heck",
|
||||
"proc-macro-error",
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "syn"
|
||||
version = "1.0.74"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "1873d832550d4588c3dbc20f01361ab00bfe741048f71e3fecf145a7cc18b29c"
|
||||
dependencies = [
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"unicode-xid",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "textwrap"
|
||||
version = "0.11.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "d326610f408c7a4eb6f51c37c330e496b08506c9457c9d34287ecc38809fb060"
|
||||
dependencies = [
|
||||
"unicode-width",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "thiserror"
|
||||
version = "1.0.26"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "93119e4feac1cbe6c798c34d3a53ea0026b0b1de6a120deef895137c0529bfe2"
|
||||
dependencies = [
|
||||
"thiserror-impl",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "thiserror-impl"
|
||||
version = "1.0.26"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "060d69a0afe7796bf42e9e2ff91f5ee691fb15c53d38b4b62a9a53eb23164745"
|
||||
dependencies = [
|
||||
"proc-macro2",
|
||||
"quote",
|
||||
"syn",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "unicode-segmentation"
|
||||
version = "1.8.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "8895849a949e7845e06bd6dc1aa51731a103c42707010a5b591c0038fb73385b"
|
||||
|
||||
[[package]]
|
||||
name = "unicode-width"
|
||||
version = "0.1.8"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "9337591893a19b88d8d87f2cec1e73fad5cdfd10e5a6f349f498ad6ea2ffb1e3"
|
||||
|
||||
[[package]]
|
||||
name = "unicode-xid"
|
||||
version = "0.2.2"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "8ccb82d61f80a663efe1f787a51b16b5a51e3314d6ac365b08639f52387b33f3"
|
||||
|
||||
[[package]]
|
||||
name = "vec_map"
|
||||
version = "0.8.2"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "f1bddf1187be692e79c5ffeab891132dfb0f236ed36a43c7ed39f1165ee20191"
|
||||
|
||||
[[package]]
|
||||
name = "version_check"
|
||||
version = "0.9.3"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "5fecdca9a5291cc2b8dcf7dc02453fee791a280f3743cb0905f8822ae463b3fe"
|
||||
|
||||
[[package]]
|
||||
name = "winapi"
|
||||
version = "0.3.9"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "5c839a674fcd7a98952e593242ea400abe93992746761e38641405d28b00f419"
|
||||
dependencies = [
|
||||
"winapi-i686-pc-windows-gnu",
|
||||
"winapi-x86_64-pc-windows-gnu",
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "winapi-i686-pc-windows-gnu"
|
||||
version = "0.4.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6"
|
||||
|
||||
[[package]]
|
||||
name = "winapi-x86_64-pc-windows-gnu"
|
||||
version = "0.4.0"
|
||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||
checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f"
|
||||
11
performance/runner/Cargo.toml
Normal file
11
performance/runner/Cargo.toml
Normal file
@@ -0,0 +1,11 @@
|
||||
[package]
|
||||
name = "runner"
|
||||
version = "0.1.0"
|
||||
edition = "2018"
|
||||
|
||||
[dependencies]
|
||||
itertools = "0.10.1"
|
||||
serde = { version = "1.0", features = ["derive"] }
|
||||
serde_json = "1.0"
|
||||
structopt = "0.3"
|
||||
thiserror = "1.0.26"
|
||||
269
performance/runner/src/calculate.rs
Normal file
269
performance/runner/src/calculate.rs
Normal file
@@ -0,0 +1,269 @@
|
||||
use crate::exceptions::{CalculateError, IOError};
|
||||
use itertools::Itertools;
|
||||
use serde::{Deserialize, Serialize};
|
||||
use std::fs;
|
||||
use std::fs::DirEntry;
|
||||
use std::path::{Path, PathBuf};
|
||||
|
||||
// This type exactly matches the type of array elements
|
||||
// from hyperfine's output. Deriving `Serialize` and `Deserialize`
|
||||
// gives us read and write capabilities via json_serde.
|
||||
#[derive(Debug, Clone, Serialize, Deserialize, PartialEq)]
|
||||
pub struct Measurement {
|
||||
pub command: String,
|
||||
pub mean: f64,
|
||||
pub stddev: f64,
|
||||
pub median: f64,
|
||||
pub user: f64,
|
||||
pub system: f64,
|
||||
pub min: f64,
|
||||
pub max: f64,
|
||||
pub times: Vec<f64>,
|
||||
}
|
||||
|
||||
// This type exactly matches the type of hyperfine's output.
|
||||
// Deriving `Serialize` and `Deserialize` gives us read and
|
||||
// write capabilities via json_serde.
|
||||
#[derive(Debug, Clone, Serialize, Deserialize, PartialEq)]
|
||||
pub struct Measurements {
|
||||
pub results: Vec<Measurement>,
|
||||
}
|
||||
|
||||
// Output data from a comparison between runs on the baseline
|
||||
// and dev branches.
|
||||
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
|
||||
pub struct Data {
|
||||
pub threshold: f64,
|
||||
pub difference: f64,
|
||||
pub baseline: f64,
|
||||
pub dev: f64,
|
||||
}
|
||||
|
||||
// The full output from a comparison between runs on the baseline
|
||||
// and dev branches.
|
||||
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
|
||||
pub struct Calculation {
|
||||
pub metric: String,
|
||||
pub regression: bool,
|
||||
pub data: Data,
|
||||
}
|
||||
|
||||
// A type to describe which measurement we are working with. This
|
||||
// information is parsed from the filename of hyperfine's output.
|
||||
#[derive(Debug, Clone, PartialEq)]
|
||||
pub struct MeasurementGroup {
|
||||
pub version: String,
|
||||
pub run: String,
|
||||
pub measurement: Measurement,
|
||||
}
|
||||
|
||||
// Given two measurements, return all the calculations. Calculations are
|
||||
// flagged as regressions or not regressions.
|
||||
fn calculate(metric: &str, dev: &Measurement, baseline: &Measurement) -> Vec<Calculation> {
|
||||
let median_threshold = 1.05; // 5% regression threshold
|
||||
let median_difference = dev.median / baseline.median;
|
||||
|
||||
let stddev_threshold = 1.20; // 20% regression threshold
|
||||
let stddev_difference = dev.stddev / baseline.stddev;
|
||||
|
||||
vec![
|
||||
Calculation {
|
||||
metric: ["median", metric].join("_"),
|
||||
regression: median_difference > median_threshold,
|
||||
data: Data {
|
||||
threshold: median_threshold,
|
||||
difference: median_difference,
|
||||
baseline: baseline.median,
|
||||
dev: dev.median,
|
||||
},
|
||||
},
|
||||
Calculation {
|
||||
metric: ["stddev", metric].join("_"),
|
||||
regression: stddev_difference > stddev_threshold,
|
||||
data: Data {
|
||||
threshold: stddev_threshold,
|
||||
difference: stddev_difference,
|
||||
baseline: baseline.stddev,
|
||||
dev: dev.stddev,
|
||||
},
|
||||
},
|
||||
]
|
||||
}
|
||||
|
||||
// Given a directory, read all files in the directory and return each
|
||||
// filename with the deserialized json contents of that file.
|
||||
fn measurements_from_files(
|
||||
results_directory: &Path,
|
||||
) -> Result<Vec<(PathBuf, Measurements)>, CalculateError> {
|
||||
fs::read_dir(results_directory)
|
||||
.or_else(|e| Err(IOError::ReadErr(results_directory.to_path_buf(), Some(e))))
|
||||
.or_else(|e| Err(CalculateError::CalculateIOError(e)))?
|
||||
.into_iter()
|
||||
.map(|entry| {
|
||||
let ent: DirEntry = entry
|
||||
.or_else(|e| Err(IOError::ReadErr(results_directory.to_path_buf(), Some(e))))
|
||||
.or_else(|e| Err(CalculateError::CalculateIOError(e)))?;
|
||||
|
||||
Ok(ent.path())
|
||||
})
|
||||
.collect::<Result<Vec<PathBuf>, CalculateError>>()?
|
||||
.iter()
|
||||
.filter(|path| {
|
||||
path.extension()
|
||||
.and_then(|ext| ext.to_str())
|
||||
.map_or(false, |ext| ext.ends_with("json"))
|
||||
})
|
||||
.map(|path| {
|
||||
fs::read_to_string(path)
|
||||
.or_else(|e| Err(IOError::BadFileContentsErr(path.clone(), Some(e))))
|
||||
.or_else(|e| Err(CalculateError::CalculateIOError(e)))
|
||||
.and_then(|contents| {
|
||||
serde_json::from_str::<Measurements>(&contents)
|
||||
.or_else(|e| Err(CalculateError::BadJSONErr(path.clone(), Some(e))))
|
||||
})
|
||||
.map(|m| (path.clone(), m))
|
||||
})
|
||||
.collect()
|
||||
}
|
||||
|
||||
// Given a list of filename-measurement pairs, detect any regressions by grouping
|
||||
// measurements together by filename.
|
||||
fn calculate_regressions(
|
||||
measurements: &[(&PathBuf, &Measurement)],
|
||||
) -> Result<Vec<Calculation>, CalculateError> {
|
||||
/*
|
||||
Strategy of this function body:
|
||||
1. [Measurement] -> [MeasurementGroup]
|
||||
2. Sort the MeasurementGroups
|
||||
3. Group the MeasurementGroups by "run"
|
||||
4. Call `calculate` with the two resulting Measurements as input
|
||||
*/
|
||||
|
||||
let mut measurement_groups: Vec<MeasurementGroup> = measurements
|
||||
.iter()
|
||||
.map(|(p, m)| {
|
||||
p.file_name()
|
||||
.ok_or_else(|| IOError::MissingFilenameErr(p.to_path_buf()))
|
||||
.and_then(|name| {
|
||||
name.to_str()
|
||||
.ok_or_else(|| IOError::FilenameNotUnicodeErr(p.to_path_buf()))
|
||||
})
|
||||
.map(|name| {
|
||||
let parts: Vec<&str> = name.split("_").collect();
|
||||
MeasurementGroup {
|
||||
version: parts[0].to_owned(),
|
||||
run: parts[1..].join("_"),
|
||||
measurement: (*m).clone(),
|
||||
}
|
||||
})
|
||||
})
|
||||
.collect::<Result<Vec<MeasurementGroup>, IOError>>()
|
||||
.or_else(|e| Err(CalculateError::CalculateIOError(e)))?;
|
||||
|
||||
measurement_groups.sort_by(|x, y| (&x.run, &x.version).cmp(&(&y.run, &y.version)));
|
||||
|
||||
// locking up mutation
|
||||
let sorted_measurement_groups = measurement_groups;
|
||||
|
||||
let calculations: Vec<Calculation> = sorted_measurement_groups
|
||||
.iter()
|
||||
.group_by(|x| &x.run)
|
||||
.into_iter()
|
||||
.map(|(_, g)| {
|
||||
let mut groups: Vec<&MeasurementGroup> = g.collect();
|
||||
groups.sort_by(|x, y| x.version.cmp(&y.version));
|
||||
|
||||
match groups.len() {
|
||||
2 => {
|
||||
let dev = &groups[1];
|
||||
let baseline = &groups[0];
|
||||
|
||||
if dev.version == "dev" && baseline.version == "baseline" {
|
||||
Ok(calculate(&dev.run, &dev.measurement, &baseline.measurement))
|
||||
} else {
|
||||
Err(CalculateError::BadBranchNameErr(
|
||||
baseline.version.clone(),
|
||||
dev.version.clone(),
|
||||
))
|
||||
}
|
||||
}
|
||||
i => {
|
||||
let gs: Vec<MeasurementGroup> = groups.into_iter().map(|x| x.clone()).collect();
|
||||
Err(CalculateError::BadGroupSizeErr(i, gs))
|
||||
}
|
||||
}
|
||||
})
|
||||
.collect::<Result<Vec<Vec<Calculation>>, CalculateError>>()?
|
||||
.concat();
|
||||
|
||||
Ok(calculations)
|
||||
}
|
||||
|
||||
// Top-level function. Given a path for the result directory, call the above
|
||||
// functions to compare and collect calculations. Calculations include both
|
||||
// metrics that fall within the threshold and regressions.
|
||||
pub fn regressions(results_directory: &PathBuf) -> Result<Vec<Calculation>, CalculateError> {
|
||||
measurements_from_files(Path::new(&results_directory)).and_then(|v| {
|
||||
// exit early with an Err if there are no results to process
|
||||
if v.len() <= 0 {
|
||||
Err(CalculateError::NoResultsErr(results_directory.clone()))
|
||||
// we expect two runs for each project-metric pairing: one for each branch, baseline
|
||||
// and dev. An odd result count is unexpected.
|
||||
} else if v.len() % 2 == 1 {
|
||||
Err(CalculateError::OddResultsCountErr(
|
||||
v.len(),
|
||||
results_directory.clone(),
|
||||
))
|
||||
} else {
|
||||
// otherwise, we can do our comparisons
|
||||
let measurements = v
|
||||
.iter()
|
||||
// the way we're running these, the files will each contain exactly one measurement, hence `results[0]`
|
||||
.map(|(p, ms)| (p, &ms.results[0]))
|
||||
.collect::<Vec<(&PathBuf, &Measurement)>>();
|
||||
|
||||
calculate_regressions(&measurements[..])
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use super::*;
|
||||
|
||||
#[test]
|
||||
fn detects_5_percent_regression() {
|
||||
let dev = Measurement {
|
||||
command: "some command".to_owned(),
|
||||
mean: 1.06,
|
||||
stddev: 1.06,
|
||||
median: 1.06,
|
||||
user: 1.06,
|
||||
system: 1.06,
|
||||
min: 1.06,
|
||||
max: 1.06,
|
||||
times: vec![],
|
||||
};
|
||||
|
||||
let baseline = Measurement {
|
||||
command: "some command".to_owned(),
|
||||
mean: 1.00,
|
||||
stddev: 1.00,
|
||||
median: 1.00,
|
||||
user: 1.00,
|
||||
system: 1.00,
|
||||
min: 1.00,
|
||||
max: 1.00,
|
||||
times: vec![],
|
||||
};
|
||||
|
||||
let calculations = calculate("test_metric", &dev, &baseline);
|
||||
let regressions: Vec<&Calculation> =
|
||||
calculations.iter().filter(|calc| calc.regression).collect();
|
||||
|
||||
// expect one regression for median
|
||||
println!("{:#?}", regressions);
|
||||
assert_eq!(regressions.len(), 1);
|
||||
assert_eq!(regressions[0].metric, "median_test_metric");
|
||||
}
|
||||
}
|
||||
155
performance/runner/src/exceptions.rs
Normal file
155
performance/runner/src/exceptions.rs
Normal file
@@ -0,0 +1,155 @@
|
||||
use crate::calculate::*;
|
||||
use std::io;
|
||||
#[cfg(test)]
|
||||
use std::path::Path;
|
||||
use std::path::PathBuf;
|
||||
use thiserror::Error;
|
||||
|
||||
// Custom IO Error messages for the IO errors we encounter.
|
||||
// New constructors should be added to wrap any new IO errors.
|
||||
// The desired output of these errors is tested below.
|
||||
#[derive(Debug, Error)]
|
||||
pub enum IOError {
|
||||
#[error("ReadErr: The file cannot be read.\nFilepath: {}\nOriginating Exception: {}", .0.to_string_lossy().into_owned(), .1.as_ref().map_or("None".to_owned(), |e| format!("{}", e)))]
|
||||
ReadErr(PathBuf, Option<io::Error>),
|
||||
#[error("MissingFilenameErr: The path provided does not specify a file.\nFilepath: {}", .0.to_string_lossy().into_owned())]
|
||||
MissingFilenameErr(PathBuf),
|
||||
#[error("FilenameNotUnicodeErr: The filename is not expressible in unicode. Consider renaming the file.\nFilepath: {}", .0.to_string_lossy().into_owned())]
|
||||
FilenameNotUnicodeErr(PathBuf),
|
||||
#[error("BadFileContentsErr: Check that the file exists and is readable.\nFilepath: {}\nOriginating Exception: {}", .0.to_string_lossy().into_owned(), .1.as_ref().map_or("None".to_owned(), |e| format!("{}", e)))]
|
||||
BadFileContentsErr(PathBuf, Option<io::Error>),
|
||||
#[error("CommandErr: System command failed to run.\nOriginating Exception: {}", .0.as_ref().map_or("None".to_owned(), |e| format!("{}", e)))]
|
||||
CommandErr(Option<io::Error>),
|
||||
}
|
||||
|
||||
// Custom Error messages for the error states we could encounter
|
||||
// during calculation, and are not prevented at compile time. New
|
||||
// constructors should be added for any new error situations that
|
||||
// come up. The desired output of these errors is tested below.
|
||||
#[derive(Debug, Error)]
|
||||
pub enum CalculateError {
|
||||
#[error("BadJSONErr: JSON in file cannot be deserialized as expected.\nFilepath: {}\nOriginating Exception: {}", .0.to_string_lossy().into_owned(), .1.as_ref().map_or("None".to_owned(), |e| format!("{}", e)))]
|
||||
BadJSONErr(PathBuf, Option<serde_json::Error>),
|
||||
#[error("{}", .0)]
|
||||
CalculateIOError(IOError),
|
||||
#[error("NoResultsErr: The results directory has no json files in it.\nFilepath: {}", .0.to_string_lossy().into_owned())]
|
||||
NoResultsErr(PathBuf),
|
||||
#[error("OddResultsCountErr: The results directory has an odd number of results in it. Expected an even number.\nFile Count: {}\nFilepath: {}", .0, .1.to_string_lossy().into_owned())]
|
||||
OddResultsCountErr(usize, PathBuf),
|
||||
#[error("BadGroupSizeErr: Expected two results per group, one for each branch-project pair.\nCount: {}\nGroup: {:?}", .0, .1.into_iter().map(|group| (&group.version[..], &group.run[..])).collect::<Vec<(&str, &str)>>())]
|
||||
BadGroupSizeErr(usize, Vec<MeasurementGroup>),
|
||||
#[error("BadBranchNameErr: Branch names must be 'baseline' and 'dev'.\nFound: {}, {}", .0, .1)]
|
||||
BadBranchNameErr(String, String),
|
||||
}
|
||||
|
||||
// Tests for exceptions
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use super::*;
|
||||
|
||||
// Tests the output fo io error messages. There should be at least one per enum constructor.
|
||||
#[test]
|
||||
fn test_io_error_messages() {
|
||||
let pairs = vec![
|
||||
(
|
||||
IOError::ReadErr(Path::new("dummy/path/file.json").to_path_buf(), None),
|
||||
r#"ReadErr: The file cannot be read.
|
||||
Filepath: dummy/path/file.json
|
||||
Originating Exception: None"#,
|
||||
),
|
||||
(
|
||||
IOError::MissingFilenameErr(Path::new("dummy/path/no_file/").to_path_buf()),
|
||||
r#"MissingFilenameErr: The path provided does not specify a file.
|
||||
Filepath: dummy/path/no_file/"#,
|
||||
),
|
||||
(
|
||||
IOError::FilenameNotUnicodeErr(Path::new("dummy/path/no_file/").to_path_buf()),
|
||||
r#"FilenameNotUnicodeErr: The filename is not expressible in unicode. Consider renaming the file.
|
||||
Filepath: dummy/path/no_file/"#,
|
||||
),
|
||||
(
|
||||
IOError::BadFileContentsErr(
|
||||
Path::new("dummy/path/filenotexist.json").to_path_buf(),
|
||||
None,
|
||||
),
|
||||
r#"BadFileContentsErr: Check that the file exists and is readable.
|
||||
Filepath: dummy/path/filenotexist.json
|
||||
Originating Exception: None"#,
|
||||
),
|
||||
(
|
||||
IOError::CommandErr(None),
|
||||
r#"CommandErr: System command failed to run.
|
||||
Originating Exception: None"#,
|
||||
),
|
||||
];
|
||||
|
||||
for (err, msg) in pairs {
|
||||
assert_eq!(format!("{}", err), msg)
|
||||
}
|
||||
}
|
||||
|
||||
// Tests the output fo calculate error messages. There should be at least one per enum constructor.
|
||||
#[test]
|
||||
fn test_calculate_error_messages() {
|
||||
let pairs = vec![
|
||||
(
|
||||
CalculateError::BadJSONErr(Path::new("dummy/path/file.json").to_path_buf(), None),
|
||||
r#"BadJSONErr: JSON in file cannot be deserialized as expected.
|
||||
Filepath: dummy/path/file.json
|
||||
Originating Exception: None"#,
|
||||
),
|
||||
(
|
||||
CalculateError::BadJSONErr(Path::new("dummy/path/file.json").to_path_buf(), None),
|
||||
r#"BadJSONErr: JSON in file cannot be deserialized as expected.
|
||||
Filepath: dummy/path/file.json
|
||||
Originating Exception: None"#,
|
||||
),
|
||||
(
|
||||
CalculateError::NoResultsErr(Path::new("dummy/path/no_file/").to_path_buf()),
|
||||
r#"NoResultsErr: The results directory has no json files in it.
|
||||
Filepath: dummy/path/no_file/"#,
|
||||
),
|
||||
(
|
||||
CalculateError::OddResultsCountErr(
|
||||
3,
|
||||
Path::new("dummy/path/no_file/").to_path_buf(),
|
||||
),
|
||||
r#"OddResultsCountErr: The results directory has an odd number of results in it. Expected an even number.
|
||||
File Count: 3
|
||||
Filepath: dummy/path/no_file/"#,
|
||||
),
|
||||
(
|
||||
CalculateError::BadGroupSizeErr(
|
||||
1,
|
||||
vec![MeasurementGroup {
|
||||
version: "dev".to_owned(),
|
||||
run: "some command".to_owned(),
|
||||
measurement: Measurement {
|
||||
command: "some command".to_owned(),
|
||||
mean: 1.0,
|
||||
stddev: 1.0,
|
||||
median: 1.0,
|
||||
user: 1.0,
|
||||
system: 1.0,
|
||||
min: 1.0,
|
||||
max: 1.0,
|
||||
times: vec![1.0, 1.1, 0.9, 1.0, 1.1, 0.9, 1.1],
|
||||
},
|
||||
}],
|
||||
),
|
||||
r#"BadGroupSizeErr: Expected two results per group, one for each branch-project pair.
|
||||
Count: 1
|
||||
Group: [("dev", "some command")]"#,
|
||||
),
|
||||
(
|
||||
CalculateError::BadBranchNameErr("boop".to_owned(), "noop".to_owned()),
|
||||
r#"BadBranchNameErr: Branch names must be 'baseline' and 'dev'.
|
||||
Found: boop, noop"#,
|
||||
),
|
||||
];
|
||||
|
||||
for (err, msg) in pairs {
|
||||
assert_eq!(format!("{}", err), msg)
|
||||
}
|
||||
}
|
||||
}
|
||||
119
performance/runner/src/main.rs
Normal file
119
performance/runner/src/main.rs
Normal file
@@ -0,0 +1,119 @@
|
||||
extern crate structopt;
|
||||
|
||||
mod calculate;
|
||||
mod exceptions;
|
||||
mod measure;
|
||||
|
||||
use crate::calculate::Calculation;
|
||||
use crate::exceptions::CalculateError;
|
||||
use std::fs::File;
|
||||
use std::io::Write;
|
||||
use std::path::PathBuf;
|
||||
use structopt::StructOpt;
|
||||
|
||||
// This type defines the commandline interface and is generated
|
||||
// by `derive(StructOpt)`
|
||||
#[derive(Clone, Debug, StructOpt)]
|
||||
#[structopt(name = "performance", about = "performance regression testing runner")]
|
||||
enum Opt {
|
||||
#[structopt(name = "measure")]
|
||||
Measure {
|
||||
#[structopt(parse(from_os_str))]
|
||||
#[structopt(short)]
|
||||
projects_dir: PathBuf,
|
||||
#[structopt(short)]
|
||||
branch_name: String,
|
||||
},
|
||||
#[structopt(name = "calculate")]
|
||||
Calculate {
|
||||
#[structopt(parse(from_os_str))]
|
||||
#[structopt(short)]
|
||||
results_dir: PathBuf,
|
||||
},
|
||||
}
|
||||
|
||||
// enables proper useage of exit() in main.
|
||||
// https://doc.rust-lang.org/std/process/fn.exit.html#examples
|
||||
//
|
||||
// This is where all the printing should happen. Exiting happens
|
||||
// in main, and module functions should only return values.
|
||||
fn run_app() -> Result<i32, CalculateError> {
|
||||
// match what the user inputs from the cli
|
||||
match Opt::from_args() {
|
||||
// measure subcommand
|
||||
Opt::Measure {
|
||||
projects_dir,
|
||||
branch_name,
|
||||
} => {
|
||||
// if there are any nonzero exit codes from the hyperfine runs,
|
||||
// return the first one. otherwise return zero.
|
||||
measure::measure(&projects_dir, &branch_name)
|
||||
.or_else(|e| Err(CalculateError::CalculateIOError(e)))?
|
||||
.iter()
|
||||
.map(|status| status.code())
|
||||
.flatten()
|
||||
.filter(|code| *code != 0)
|
||||
.collect::<Vec<i32>>()
|
||||
.get(0)
|
||||
.map_or(Ok(0), |x| {
|
||||
println!("Main: a child process exited with a nonzero status code.");
|
||||
Ok(*x)
|
||||
})
|
||||
}
|
||||
|
||||
// calculate subcommand
|
||||
Opt::Calculate { results_dir } => {
|
||||
// get all the calculations or gracefully show the user an exception
|
||||
let calculations = calculate::regressions(&results_dir)?;
|
||||
|
||||
// print all calculations to stdout so they can be easily debugged
|
||||
// via CI.
|
||||
println!(":: All Calculations ::\n");
|
||||
for c in &calculations {
|
||||
println!("{:#?}\n", c);
|
||||
}
|
||||
|
||||
// indented json string representation of the calculations array
|
||||
let json_calcs = serde_json::to_string_pretty(&calculations)
|
||||
.expect("Main: Failed to serialize calculations to json");
|
||||
|
||||
// create the empty destination file, and write the json string
|
||||
let outfile = &mut results_dir.into_os_string();
|
||||
outfile.push("/final_calculations.json");
|
||||
let mut f = File::create(outfile).expect("Main: Unable to create file");
|
||||
f.write_all(json_calcs.as_bytes())
|
||||
.expect("Main: Unable to write data");
|
||||
|
||||
// filter for regressions
|
||||
let regressions: Vec<&Calculation> =
|
||||
calculations.iter().filter(|c| c.regression).collect();
|
||||
|
||||
// return a non-zero exit code if there are regressions
|
||||
match regressions[..] {
|
||||
[] => {
|
||||
println!("congrats! no regressions :)");
|
||||
Ok(0)
|
||||
}
|
||||
_ => {
|
||||
// print all calculations to stdout so they can be easily
|
||||
// debugged via CI.
|
||||
println!(":: Regressions Found ::\n");
|
||||
for r in regressions {
|
||||
println!("{:#?}\n", r);
|
||||
}
|
||||
Ok(1)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn main() {
|
||||
std::process::exit(match run_app() {
|
||||
Ok(code) => code,
|
||||
Err(err) => {
|
||||
eprintln!("{}", err);
|
||||
1
|
||||
}
|
||||
});
|
||||
}
|
||||
89
performance/runner/src/measure.rs
Normal file
89
performance/runner/src/measure.rs
Normal file
@@ -0,0 +1,89 @@
|
||||
use crate::exceptions::IOError;
|
||||
use std::fs;
|
||||
use std::path::PathBuf;
|
||||
use std::process::{Command, ExitStatus};
|
||||
|
||||
// `Metric` defines a dbt command that we want to measure on both the
|
||||
// baseline and dev branches.
|
||||
#[derive(Debug, Clone)]
|
||||
struct Metric<'a> {
|
||||
name: &'a str,
|
||||
prepare: &'a str,
|
||||
cmd: &'a str,
|
||||
}
|
||||
|
||||
impl Metric<'_> {
|
||||
// Returns the proper filename for the hyperfine output for this metric.
|
||||
fn outfile(&self, project: &str, branch: &str) -> String {
|
||||
[branch, "_", self.name, "_", project, ".json"].join("")
|
||||
}
|
||||
}
|
||||
|
||||
// Calls hyperfine via system command, and returns all the exit codes for each hyperfine run.
|
||||
pub fn measure<'a>(
|
||||
projects_directory: &PathBuf,
|
||||
dbt_branch: &str,
|
||||
) -> Result<Vec<ExitStatus>, IOError> {
|
||||
/*
|
||||
Strategy of this function body:
|
||||
1. Read all directory names in `projects_directory`
|
||||
2. Pair `n` projects with `m` metrics for a total of n*m pairs
|
||||
3. Run hyperfine on each project-metric pair
|
||||
*/
|
||||
|
||||
// To add a new metric to the test suite, simply define it in this list:
|
||||
// TODO: This could be read from a config file in a future version.
|
||||
let metrics: Vec<Metric> = vec![Metric {
|
||||
name: "parse",
|
||||
prepare: "rm -rf target/",
|
||||
cmd: "dbt parse --no-version-check",
|
||||
}];
|
||||
|
||||
fs::read_dir(projects_directory)
|
||||
.or_else(|e| Err(IOError::ReadErr(projects_directory.to_path_buf(), Some(e))))?
|
||||
.map(|entry| {
|
||||
let path = entry
|
||||
.or_else(|e| Err(IOError::ReadErr(projects_directory.to_path_buf(), Some(e))))?
|
||||
.path();
|
||||
|
||||
let project_name: String = path
|
||||
.file_name()
|
||||
.ok_or_else(|| IOError::MissingFilenameErr(path.clone().to_path_buf()))
|
||||
.and_then(|x| {
|
||||
x.to_str()
|
||||
.ok_or_else(|| IOError::FilenameNotUnicodeErr(path.clone().to_path_buf()))
|
||||
})?
|
||||
.to_owned();
|
||||
|
||||
// each project-metric pair we will run
|
||||
let pairs = metrics
|
||||
.iter()
|
||||
.map(|metric| (path.clone(), project_name.clone(), metric))
|
||||
.collect::<Vec<(PathBuf, String, &Metric<'a>)>>();
|
||||
|
||||
Ok(pairs)
|
||||
})
|
||||
.collect::<Result<Vec<Vec<(PathBuf, String, &Metric<'a>)>>, IOError>>()?
|
||||
.concat()
|
||||
.iter()
|
||||
// run hyperfine on each pairing
|
||||
.map(|(path, project_name, metric)| {
|
||||
Command::new("hyperfine")
|
||||
.current_dir(path)
|
||||
// warms filesystem caches by running the command first without counting it.
|
||||
// alternatively we could clear them before each run
|
||||
.arg("--warmup")
|
||||
.arg("1")
|
||||
.arg("--prepare")
|
||||
.arg(metric.prepare)
|
||||
.arg([metric.cmd, " --profiles-dir ", "../../project_config/"].join(""))
|
||||
.arg("--export-json")
|
||||
.arg(["../../results/", &metric.outfile(project_name, dbt_branch)].join(""))
|
||||
// this prevents hyperfine from capturing dbt's output.
|
||||
// Noisy, but good for debugging when tests fail.
|
||||
.arg("--show-output")
|
||||
.status() // use spawn() here instead for more information
|
||||
.or_else(|e| Err(IOError::CommandErr(Some(e))))
|
||||
})
|
||||
.collect()
|
||||
}
|
||||
@@ -1 +1 @@
|
||||
version = '0.20.0rc1'
|
||||
version = '0.21.0a1'
|
||||
|
||||
@@ -20,7 +20,7 @@ except ImportError:
|
||||
|
||||
|
||||
package_name = "dbt-bigquery"
|
||||
package_version = "0.20.0rc1"
|
||||
package_version = "0.21.0a1"
|
||||
description = """The bigquery adapter plugin for dbt (data build tool)"""
|
||||
|
||||
this_directory = os.path.abspath(os.path.dirname(__file__))
|
||||
|
||||
@@ -1 +1 @@
|
||||
version = '0.20.0rc1'
|
||||
version = '0.21.0a1'
|
||||
|
||||
@@ -23,6 +23,9 @@ class PostgresCredentials(Credentials):
|
||||
search_path: Optional[str] = None
|
||||
keepalives_idle: int = 0 # 0 means to use the default value
|
||||
sslmode: Optional[str] = None
|
||||
sslcert: Optional[str] = None
|
||||
sslkey: Optional[str] = None
|
||||
sslrootcert: Optional[str] = None
|
||||
application_name: Optional[str] = 'dbt'
|
||||
|
||||
_ALIASES = {
|
||||
@@ -94,6 +97,15 @@ class PostgresConnectionManager(SQLConnectionManager):
|
||||
if credentials.sslmode:
|
||||
kwargs['sslmode'] = credentials.sslmode
|
||||
|
||||
if credentials.sslcert is not None:
|
||||
kwargs["sslcert"] = credentials.sslcert
|
||||
|
||||
if credentials.sslkey is not None:
|
||||
kwargs["sslkey"] = credentials.sslkey
|
||||
|
||||
if credentials.sslrootcert is not None:
|
||||
kwargs["sslrootcert"] = credentials.sslrootcert
|
||||
|
||||
if credentials.application_name:
|
||||
kwargs['application_name'] = credentials.application_name
|
||||
|
||||
|
||||
@@ -112,7 +112,7 @@ class PostgresAdapter(SQLAdapter):
|
||||
self.cache.add_link(referenced, dependent)
|
||||
|
||||
def _get_catalog_schemas(self, manifest):
|
||||
# postgres/redshift only allow one database (the main one)
|
||||
# postgres only allow one database (the main one)
|
||||
schemas = super()._get_catalog_schemas(manifest)
|
||||
try:
|
||||
return schemas.flatten()
|
||||
|
||||
@@ -41,7 +41,7 @@ def _dbt_psycopg2_name():
|
||||
|
||||
|
||||
package_name = "dbt-postgres"
|
||||
package_version = "0.20.0rc1"
|
||||
package_version = "0.21.0a1"
|
||||
description = """The postgres adpter plugin for dbt (data build tool)"""
|
||||
|
||||
this_directory = os.path.abspath(os.path.dirname(__file__))
|
||||
|
||||
@@ -1 +1 @@
|
||||
version = '0.20.0rc1'
|
||||
version = '0.21.0a1'
|
||||
|
||||
@@ -49,6 +49,7 @@ class RedshiftCredentials(PostgresCredentials):
|
||||
keepalives_idle: int = 240
|
||||
autocreate: bool = False
|
||||
db_groups: List[str] = field(default_factory=list)
|
||||
ra3_node: Optional[bool] = False
|
||||
|
||||
@property
|
||||
def type(self):
|
||||
|
||||
@@ -1,11 +1,14 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
from dbt.adapters.base.impl import AdapterConfig
|
||||
from dbt.adapters.sql import SQLAdapter
|
||||
from dbt.adapters.base.meta import available
|
||||
from dbt.adapters.postgres import PostgresAdapter
|
||||
from dbt.adapters.redshift import RedshiftConnectionManager
|
||||
from dbt.adapters.redshift import RedshiftColumn
|
||||
from dbt.adapters.redshift import RedshiftRelation
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
import dbt.exceptions
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -16,7 +19,7 @@ class RedshiftConfig(AdapterConfig):
|
||||
bind: Optional[bool] = None
|
||||
|
||||
|
||||
class RedshiftAdapter(PostgresAdapter):
|
||||
class RedshiftAdapter(PostgresAdapter, SQLAdapter):
|
||||
Relation = RedshiftRelation
|
||||
ConnectionManager = RedshiftConnectionManager
|
||||
Column = RedshiftColumn
|
||||
@@ -57,3 +60,29 @@ class RedshiftAdapter(PostgresAdapter):
|
||||
@classmethod
|
||||
def convert_time_type(cls, agate_table, col_idx):
|
||||
return "varchar(24)"
|
||||
|
||||
@available
|
||||
def verify_database(self, database):
|
||||
if database.startswith('"'):
|
||||
database = database.strip('"')
|
||||
expected = self.config.credentials.database
|
||||
ra3_node = self.config.credentials.ra3_node
|
||||
|
||||
if database.lower() != expected.lower() and not ra3_node:
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'Cross-db references allowed only in RA3.* node. ({} vs {})'
|
||||
.format(database, expected)
|
||||
)
|
||||
# return an empty string on success so macros can call this
|
||||
return ''
|
||||
|
||||
def _get_catalog_schemas(self, manifest):
|
||||
# redshift(besides ra3) only allow one database (the main one)
|
||||
schemas = super(SQLAdapter, self)._get_catalog_schemas(manifest)
|
||||
try:
|
||||
return schemas.flatten(allow_multiple_databases=self.config.credentials.ra3_node)
|
||||
except dbt.exceptions.RuntimeException as exc:
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
'Cross-db references allowed only in {} RA3.* node. Got {}'
|
||||
.format(self.type(), exc.msg)
|
||||
)
|
||||
|
||||
@@ -20,7 +20,7 @@ except ImportError:
|
||||
|
||||
|
||||
package_name = "dbt-redshift"
|
||||
package_version = "0.20.0rc1"
|
||||
package_version = "0.21.0a1"
|
||||
description = """The redshift adapter plugin for dbt (data build tool)"""
|
||||
|
||||
this_directory = os.path.abspath(os.path.dirname(__file__))
|
||||
|
||||
@@ -1 +1 @@
|
||||
version = '0.20.0rc1'
|
||||
version = '0.21.0a1'
|
||||
|
||||
@@ -155,8 +155,10 @@
|
||||
|
||||
|
||||
{% macro snowflake__alter_column_comment(relation, column_dict) -%}
|
||||
{% for column_name in column_dict %}
|
||||
comment if exists on column {{ relation }}.{{ adapter.quote(column_name) if column_dict[column_name]['quote'] else column_name }} is $${{ column_dict[column_name]['description'] | replace('$', '[$]') }}$$;
|
||||
{% set existing_columns = adapter.get_columns_in_relation(relation) | map(attribute="name") | list %}
|
||||
alter {{ relation.type }} {{ relation }} alter
|
||||
{% for column_name in column_dict if (column_name in existing_columns) or (column_name|upper in existing_columns) %}
|
||||
{{ adapter.quote(column_name) if column_dict[column_name]['quote'] else column_name }} COMMENT $${{ column_dict[column_name]['description'] | replace('$', '[$]') }}$$ {{ ',' if not loop.last else ';' }}
|
||||
{% endfor %}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ except ImportError:
|
||||
|
||||
|
||||
package_name = "dbt-snowflake"
|
||||
package_version = "0.20.0rc1"
|
||||
package_version = "0.21.0a1"
|
||||
description = """The snowflake adapter plugin for dbt (data build tool)"""
|
||||
|
||||
this_directory = os.path.abspath(os.path.dirname(__file__))
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user