Compare commits
48 Commits
er/hatch-i
...
enable-pos
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
cf4384da38 | ||
|
|
71a6e53102 | ||
|
|
c4dc80dcd2 | ||
|
|
8097a34726 | ||
|
|
b66dff7278 | ||
|
|
22d21edb4b | ||
|
|
bef7928e22 | ||
|
|
c573131d91 | ||
|
|
f10d84d05e | ||
|
|
79a4c8969e | ||
|
|
9a80308fcf | ||
|
|
7a13d08376 | ||
|
|
9e9f5b8e57 | ||
|
|
9cd6a23eba | ||
|
|
e46c37cf07 | ||
|
|
df23f398a6 | ||
|
|
97df9278c0 | ||
|
|
748d352b6b | ||
|
|
bbd8fa02f1 | ||
|
|
61009f6ba7 | ||
|
|
ee7ecdc29f | ||
|
|
d74b58a137 | ||
|
|
12b04e7d2f | ||
|
|
5d56a052a7 | ||
|
|
62a8ea05a6 | ||
|
|
1219bd49aa | ||
|
|
791d1ebdcd | ||
|
|
148b9b41a5 | ||
|
|
d096a6776e | ||
|
|
8ff86d35ea | ||
|
|
087f8167ec | ||
|
|
bcb07ceb7b | ||
|
|
c559848044 | ||
|
|
3de0160b00 | ||
|
|
2c7f49a71e | ||
|
|
518c360a29 | ||
|
|
8cf51fddba | ||
|
|
8e128eee8e | ||
|
|
94b69b1578 | ||
|
|
0216e32c7f | ||
|
|
bbd078089e | ||
|
|
575bac3172 | ||
|
|
bca2211246 | ||
|
|
0015e35a1b | ||
|
|
09bce7af63 | ||
|
|
cb7c4a7dce | ||
|
|
5555a3dd25 | ||
|
|
0e30db4e82 |
@@ -1,37 +0,0 @@
|
|||||||
[bumpversion]
|
|
||||||
current_version = 1.12.0a1
|
|
||||||
parse = (?P<major>[\d]+) # major version number
|
|
||||||
\.(?P<minor>[\d]+) # minor version number
|
|
||||||
\.(?P<patch>[\d]+) # patch version number
|
|
||||||
(?P<prerelease> # optional pre-release - ex: a1, b2, rc25
|
|
||||||
(?P<prekind>a|b|rc) # pre-release type
|
|
||||||
(?P<num>[\d]+) # pre-release version number
|
|
||||||
)?
|
|
||||||
( # optional nightly release indicator
|
|
||||||
\.(?P<nightly>dev[0-9]+) # ex: .dev02142023
|
|
||||||
)? # expected matches: `1.15.0`, `1.5.0a11`, `1.5.0a1.dev123`, `1.5.0.dev123457`, expected failures: `1`, `1.5`, `1.5.2-a1`, `text1.5.0`
|
|
||||||
serialize =
|
|
||||||
{major}.{minor}.{patch}{prekind}{num}.{nightly}
|
|
||||||
{major}.{minor}.{patch}.{nightly}
|
|
||||||
{major}.{minor}.{patch}{prekind}{num}
|
|
||||||
{major}.{minor}.{patch}
|
|
||||||
commit = False
|
|
||||||
tag = False
|
|
||||||
|
|
||||||
[bumpversion:part:prekind]
|
|
||||||
first_value = a
|
|
||||||
optional_value = final
|
|
||||||
values =
|
|
||||||
a
|
|
||||||
b
|
|
||||||
rc
|
|
||||||
final
|
|
||||||
|
|
||||||
[bumpversion:part:num]
|
|
||||||
first_value = 1
|
|
||||||
|
|
||||||
[bumpversion:part:nightly]
|
|
||||||
|
|
||||||
[bumpversion:file:core/dbt/__version__.py]
|
|
||||||
search = version = "{current_version}"
|
|
||||||
replace = version = "{new_version}"
|
|
||||||
6
.changes/unreleased/Features-20251006-140352.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Features
|
||||||
|
body: Support partial parsing for function nodes
|
||||||
|
time: 2025-10-06T14:03:52.258104-05:00
|
||||||
|
custom:
|
||||||
|
Author: QMalcolm
|
||||||
|
Issue: "12072"
|
||||||
6
.changes/unreleased/Features-20251201-165209.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Features
|
||||||
|
body: Raise jsonschema-based deprecation warnings by default
|
||||||
|
time: 2025-12-01T16:52:09.354436-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: 12240
|
||||||
6
.changes/unreleased/Features-20251203-122926.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Features
|
||||||
|
body: ':bug: :snowman: Disable unit tests whose model is disabled'
|
||||||
|
time: 2025-12-03T12:29:26.209248-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: "10540"
|
||||||
6
.changes/unreleased/Features-20251210-202001.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Features
|
||||||
|
body: Implement config.meta_get and config.meta_require
|
||||||
|
time: 2025-12-10T20:20:01.354288-05:00
|
||||||
|
custom:
|
||||||
|
Author: gshank
|
||||||
|
Issue: "12012"
|
||||||
6
.changes/unreleased/Fixes-20250922-151726.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Address Click 8.2+ deprecation warning
|
||||||
|
time: 2025-09-22T15:17:26.983151-06:00
|
||||||
|
custom:
|
||||||
|
Author: edgarrmondragon
|
||||||
|
Issue: "12038"
|
||||||
6
.changes/unreleased/Fixes-20251117-185025.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Allow dbt deps to run when vars lack defaults in dbt_project.yml
|
||||||
|
time: 2025-11-17T18:50:25.759091+05:30
|
||||||
|
custom:
|
||||||
|
Author: 3loka
|
||||||
|
Issue: "8913"
|
||||||
6
.changes/unreleased/Fixes-20251118-171106.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Restore DuplicateResourceNameError for intra-project node name duplication, behind behavior flag `require_unique_project_resource_names`
|
||||||
|
time: 2025-11-18T17:11:06.454784-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: "12152"
|
||||||
6
.changes/unreleased/Fixes-20251124-155629.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Fix bug where schemas of functions weren't guaranteed to exist
|
||||||
|
time: 2025-11-24T15:56:29.467004-06:00
|
||||||
|
custom:
|
||||||
|
Author: QMalcolm
|
||||||
|
Issue: "12142"
|
||||||
6
.changes/unreleased/Fixes-20251124-155756.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Fix generation of deprecations summary
|
||||||
|
time: 2025-11-24T15:57:56.544123-08:00
|
||||||
|
custom:
|
||||||
|
Author: asiunov
|
||||||
|
Issue: "12146"
|
||||||
6
.changes/unreleased/Fixes-20251124-170855.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Correctly reference foreign key references when --defer and --state provided'
|
||||||
|
time: 2025-11-24T17:08:55.387946-05:00
|
||||||
|
custom:
|
||||||
|
Author: michellark
|
||||||
|
Issue: "11885"
|
||||||
7
.changes/unreleased/Fixes-20251125-120246.yaml
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Add exception when using --state and referring to a removed
|
||||||
|
test'
|
||||||
|
time: 2025-11-25T12:02:46.635026-05:00
|
||||||
|
custom:
|
||||||
|
Author: emmyoop
|
||||||
|
Issue: "10630"
|
||||||
6
.changes/unreleased/Fixes-20251125-122020.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Stop emitting `NoNodesForSelectionCriteria` three times during `build` command'
|
||||||
|
time: 2025-11-25T12:20:20.132379-06:00
|
||||||
|
custom:
|
||||||
|
Author: QMalcolm
|
||||||
|
Issue: "11627"
|
||||||
6
.changes/unreleased/Fixes-20251127-141308.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ":bug: :snowman: Fix long Python stack traces appearing when package dependencies have incompatible version requirements"
|
||||||
|
time: 2025-11-27T14:13:08.082542-05:00
|
||||||
|
custom:
|
||||||
|
Author: emmyoop
|
||||||
|
Issue: "12049"
|
||||||
7
.changes/unreleased/Fixes-20251127-145929.yaml
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Fixed issue where changing data type size/precision/scale (e.g.,
|
||||||
|
varchar(3) to varchar(10)) incorrectly triggered a breaking change error fo'
|
||||||
|
time: 2025-11-27T14:59:29.256274-05:00
|
||||||
|
custom:
|
||||||
|
Author: emmyoop
|
||||||
|
Issue: "11186"
|
||||||
6
.changes/unreleased/Fixes-20251127-170124.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Support unit testing models that depend on sources with the same name'
|
||||||
|
time: 2025-11-27T17:01:24.193516-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: 11975 10433
|
||||||
6
.changes/unreleased/Fixes-20251128-102129.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Fix bug in partial parsing when updating a model with a schema file that is referenced by a singular test
|
||||||
|
time: 2025-11-28T10:21:29.911147Z
|
||||||
|
custom:
|
||||||
|
Author: mattogburke
|
||||||
|
Issue: "12223"
|
||||||
6
.changes/unreleased/Fixes-20251128-122838.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Avoid retrying successful run-operation commands'
|
||||||
|
time: 2025-11-28T12:28:38.546261-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: "11850"
|
||||||
7
.changes/unreleased/Fixes-20251128-161937.yaml
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Fix `dbt deps --add-package` crash when packages.yml contains `warn-unpinned:
|
||||||
|
false`'
|
||||||
|
time: 2025-11-28T16:19:37.608722-05:00
|
||||||
|
custom:
|
||||||
|
Author: emmyoop
|
||||||
|
Issue: "9104"
|
||||||
7
.changes/unreleased/Fixes-20251128-163144.yaml
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Improve `dbt deps --add-package` duplicate detection with better
|
||||||
|
cross-source matching and word boundaries'
|
||||||
|
time: 2025-11-28T16:31:44.344099-05:00
|
||||||
|
custom:
|
||||||
|
Author: emmyoop
|
||||||
|
Issue: "12239"
|
||||||
6
.changes/unreleased/Fixes-20251202-133705.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: ':bug: :snowman: Fix false positive deprecation warning of pre/post-hook SQL configs'
|
||||||
|
time: 2025-12-02T13:37:05.012112-05:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: "12244"
|
||||||
6
.changes/unreleased/Fixes-20251209-175031.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Ensure recent deprecation warnings include event name in message
|
||||||
|
time: 2025-12-09T17:50:31.334618-06:00
|
||||||
|
custom:
|
||||||
|
Author: QMalcolm
|
||||||
|
Issue: "12264"
|
||||||
6
.changes/unreleased/Fixes-20251210-143935.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Fixes
|
||||||
|
body: Improve error message clarity when detecting nodes with space in name
|
||||||
|
time: 2025-12-10T14:39:35.107841-08:00
|
||||||
|
custom:
|
||||||
|
Author: michelleark
|
||||||
|
Issue: "11835"
|
||||||
@@ -1,5 +1,5 @@
|
|||||||
kind: Under the Hood
|
kind: Under the Hood
|
||||||
body: Switch hatchling for build tooling.
|
body: Replace setuptools and tox with hatch for build, test, and environment management.
|
||||||
time: 2025-11-21T14:05:15.838252-05:00
|
time: 2025-11-21T14:05:15.838252-05:00
|
||||||
custom:
|
custom:
|
||||||
Author: emmyoop
|
Author: emmyoop
|
||||||
|
|||||||
6
.changes/unreleased/Under the Hood-20251209-131857.yaml
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
kind: Under the Hood
|
||||||
|
body: Add add_catalog_integration call even if we have a pre-existing manifest
|
||||||
|
time: 2025-12-09T13:18:57.043254-08:00
|
||||||
|
custom:
|
||||||
|
Author: colin-rogers-dbt
|
||||||
|
Issue: "12262"
|
||||||
@@ -41,32 +41,26 @@ newlines:
|
|||||||
endOfVersion: 1
|
endOfVersion: 1
|
||||||
|
|
||||||
custom:
|
custom:
|
||||||
- key: Author
|
- key: Author
|
||||||
label: GitHub Username(s) (separated by a single space if multiple)
|
label: GitHub Username(s) (separated by a single space if multiple)
|
||||||
type: string
|
type: string
|
||||||
minLength: 3
|
minLength: 3
|
||||||
- key: Issue
|
- key: Issue
|
||||||
label: GitHub Issue Number (separated by a single space if multiple)
|
label: GitHub Issue Number (separated by a single space if multiple)
|
||||||
type: string
|
type: string
|
||||||
minLength: 1
|
minLength: 1
|
||||||
|
|
||||||
footerFormat: |
|
footerFormat: |
|
||||||
{{- $contributorDict := dict }}
|
{{- $contributorDict := dict }}
|
||||||
{{- /* ensure all names in this list are all lowercase for later matching purposes */}}
|
{{- /* ensure we always skip snyk and dependabot */}}
|
||||||
{{- $core_team := splitList " " .Env.CORE_TEAM }}
|
{{- $bots := list "dependabot[bot]" "snyk-bot"}}
|
||||||
{{- /* ensure we always skip snyk and dependabot in addition to the core team */}}
|
|
||||||
{{- $maintainers := list "dependabot[bot]" "snyk-bot"}}
|
|
||||||
{{- range $team_member := $core_team }}
|
|
||||||
{{- $team_member_lower := lower $team_member }}
|
|
||||||
{{- $maintainers = append $maintainers $team_member_lower }}
|
|
||||||
{{- end }}
|
|
||||||
{{- range $change := .Changes }}
|
{{- range $change := .Changes }}
|
||||||
{{- $authorList := splitList " " $change.Custom.Author }}
|
{{- $authorList := splitList " " $change.Custom.Author }}
|
||||||
{{- /* loop through all authors for a single changelog */}}
|
{{- /* loop through all authors for a single changelog */}}
|
||||||
{{- range $author := $authorList }}
|
{{- range $author := $authorList }}
|
||||||
{{- $authorLower := lower $author }}
|
{{- $authorLower := lower $author }}
|
||||||
{{- /* we only want to include non-core team contributors */}}
|
{{- /* we only want to include non-bot contributors */}}
|
||||||
{{- if not (has $authorLower $maintainers)}}
|
{{- if not (has $authorLower $bots)}}
|
||||||
{{- $changeList := splitList " " $change.Custom.Author }}
|
{{- $changeList := splitList " " $change.Custom.Author }}
|
||||||
{{- $IssueList := list }}
|
{{- $IssueList := list }}
|
||||||
{{- $changeLink := $change.Kind }}
|
{{- $changeLink := $change.Kind }}
|
||||||
|
|||||||
1
.flake8
@@ -10,6 +10,5 @@ ignore =
|
|||||||
E704 # makes Flake8 work like black
|
E704 # makes Flake8 work like black
|
||||||
E741
|
E741
|
||||||
E501 # long line checking is done in black
|
E501 # long line checking is done in black
|
||||||
exclude = test/
|
|
||||||
per-file-ignores =
|
per-file-ignores =
|
||||||
*/__init__.py: F401
|
*/__init__.py: F401
|
||||||
|
|||||||
@@ -1 +1 @@
|
|||||||
../../../test/setup_db.sh
|
../../../scripts/setup_db.sh
|
||||||
169
.github/dbt-postgres-testing.yml
vendored
Normal file
@@ -0,0 +1,169 @@
|
|||||||
|
# **what?**
|
||||||
|
# Runs all tests in dbt-postgres with this branch of dbt-core to ensure nothing is broken
|
||||||
|
|
||||||
|
# **why?**
|
||||||
|
# Ensure dbt-core changes do not break dbt-postgres, as a basic proxy for other adapters
|
||||||
|
|
||||||
|
# **when?**
|
||||||
|
# This will run when trying to merge a PR into main.
|
||||||
|
# It can also be manually triggered.
|
||||||
|
|
||||||
|
# This workflow can be skipped by adding the "Skip Postgres Testing" label to the PR. This is
|
||||||
|
# useful when making a change in both `dbt-postgres` and `dbt-core` where the changes are dependant
|
||||||
|
# and cause the other repository to break.
|
||||||
|
|
||||||
|
name: "dbt-postgres Tests"
|
||||||
|
run-name: >-
|
||||||
|
${{ (github.event_name == 'workflow_dispatch' || github.event_name == 'workflow_call')
|
||||||
|
&& format('dbt-postgres@{0} with dbt-core@{1}', inputs.dbt-postgres-ref, inputs.dbt-core-ref)
|
||||||
|
|| 'dbt-postgres@main with dbt-core branch' }}
|
||||||
|
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches:
|
||||||
|
- "main"
|
||||||
|
- "*.latest"
|
||||||
|
- "releases/*"
|
||||||
|
pull_request:
|
||||||
|
merge_group:
|
||||||
|
types: [checks_requested]
|
||||||
|
workflow_dispatch:
|
||||||
|
inputs:
|
||||||
|
dbt-postgres-ref:
|
||||||
|
description: "The branch of dbt-postgres to test against"
|
||||||
|
default: "main"
|
||||||
|
dbt-core-ref:
|
||||||
|
description: "The branch of dbt-core to test against"
|
||||||
|
default: "main"
|
||||||
|
workflow_call:
|
||||||
|
inputs:
|
||||||
|
dbt-postgres-ref:
|
||||||
|
description: "The branch of dbt-postgres to test against"
|
||||||
|
type: string
|
||||||
|
required: true
|
||||||
|
default: "main"
|
||||||
|
dbt-core-ref:
|
||||||
|
description: "The branch of dbt-core to test against"
|
||||||
|
type: string
|
||||||
|
required: true
|
||||||
|
default: "main"
|
||||||
|
|
||||||
|
permissions: read-all
|
||||||
|
|
||||||
|
# will cancel previous workflows triggered by the same event
|
||||||
|
# and for the same ref for PRs/merges or same SHA otherwise
|
||||||
|
# and for the same inputs on workflow_dispatch or workflow_call
|
||||||
|
concurrency:
|
||||||
|
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(fromJson('["pull_request", "merge_group"]'), github.event_name) && github.event.pull_request.head.ref || github.sha }}-${{ contains(fromJson('["workflow_call", "workflow_dispatch"]'), github.event_name) && github.event.inputs.dbt-postgres-ref && github.event.inputs.dbt-core-ref || github.sha }}
|
||||||
|
cancel-in-progress: true
|
||||||
|
|
||||||
|
defaults:
|
||||||
|
run:
|
||||||
|
shell: bash
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
job-prep:
|
||||||
|
# This allow us to run the workflow on pull_requests as well so we can always run unit tests
|
||||||
|
# and only run integration tests on merge for time purposes
|
||||||
|
name: Setup Repo Refs
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
outputs:
|
||||||
|
dbt-postgres-ref: ${{ steps.core-ref.outputs.ref }}
|
||||||
|
dbt-core-ref: ${{ steps.common-ref.outputs.ref }}
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- name: "Input Refs"
|
||||||
|
id: job-inputs
|
||||||
|
run: |
|
||||||
|
echo "inputs.dbt-postgres-ref=${{ inputs.dbt-postgres-ref }}"
|
||||||
|
echo "inputs.dbt-core-ref=${{ inputs.dbt-core-ref }}"
|
||||||
|
|
||||||
|
- name: "Determine dbt-postgres ref"
|
||||||
|
id: core-ref
|
||||||
|
run: |
|
||||||
|
if [[ -z "${{ inputs.dbt-postgres-ref }}" ]]; then
|
||||||
|
REF="main"
|
||||||
|
else
|
||||||
|
REF=${{ inputs.dbt-postgres-ref }}
|
||||||
|
fi
|
||||||
|
echo "ref=$REF" >> $GITHUB_OUTPUT
|
||||||
|
|
||||||
|
- name: "Determine dbt-core ref"
|
||||||
|
id: common-ref
|
||||||
|
run: |
|
||||||
|
if [[ -z "${{ inputs.dbt-core-ref }}" ]]; then
|
||||||
|
# these will be commits instead of branches
|
||||||
|
if [[ "${{ github.event_name }}" == "merge_group" ]]; then
|
||||||
|
REF=${{ github.event.merge_group.head_sha }}
|
||||||
|
else
|
||||||
|
REF=${{ github.event.pull_request.base.sha }}
|
||||||
|
fi
|
||||||
|
else
|
||||||
|
REF=${{ inputs.dbt-core-ref }}
|
||||||
|
fi
|
||||||
|
echo "ref=$REF" >> $GITHUB_OUTPUT
|
||||||
|
|
||||||
|
- name: "Final Refs"
|
||||||
|
run: |
|
||||||
|
echo "dbt-postgres-ref=${{ steps.core-ref.outputs.ref }}"
|
||||||
|
echo "dbt-core-ref=${{ steps.common-ref.outputs.ref }}"
|
||||||
|
|
||||||
|
integration-tests-postgres:
|
||||||
|
name: "dbt-postgres integration tests"
|
||||||
|
needs: [job-prep]
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
defaults:
|
||||||
|
run:
|
||||||
|
working-directory: "./dbt-postgres"
|
||||||
|
environment:
|
||||||
|
name: "dbt-postgres"
|
||||||
|
env:
|
||||||
|
POSTGRES_TEST_HOST: ${{ vars.POSTGRES_TEST_HOST }}
|
||||||
|
POSTGRES_TEST_PORT: ${{ vars.POSTGRES_TEST_PORT }}
|
||||||
|
POSTGRES_TEST_USER: ${{ vars.POSTGRES_TEST_USER }}
|
||||||
|
POSTGRES_TEST_PASS: ${{ secrets.POSTGRES_TEST_PASS }}
|
||||||
|
POSTGRES_TEST_DATABASE: ${{ vars.POSTGRES_TEST_DATABASE }}
|
||||||
|
POSTGRES_TEST_THREADS: ${{ vars.POSTGRES_TEST_THREADS }}
|
||||||
|
services:
|
||||||
|
postgres:
|
||||||
|
image: postgres
|
||||||
|
env:
|
||||||
|
POSTGRES_PASSWORD: postgres
|
||||||
|
options: >-
|
||||||
|
--health-cmd pg_isready
|
||||||
|
--health-interval 10s
|
||||||
|
--health-timeout 5s
|
||||||
|
--health-retries 5
|
||||||
|
ports:
|
||||||
|
- ${{ vars.POSTGRES_TEST_PORT }}:5432
|
||||||
|
steps:
|
||||||
|
- name: "Check out dbt-adapters@${{ needs.job-prep.outputs.dbt-postgres-ref }}"
|
||||||
|
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||||
|
with:
|
||||||
|
repository: dbt-labs/dbt-adapters
|
||||||
|
ref: ${{ needs.job-prep.outputs.dbt-postgres-ref }}
|
||||||
|
|
||||||
|
- name: "Set up Python"
|
||||||
|
uses: actions/setup-python@a26af69be951a213d495a4c3e4e4022e16d87065 # actions/setup-python@v5
|
||||||
|
with:
|
||||||
|
python-version: ${{ inputs.python-version }}
|
||||||
|
|
||||||
|
- name: "Set environment variables"
|
||||||
|
run: |
|
||||||
|
echo "HATCH_PYTHON=${{ inputs.python-version }}" >> $GITHUB_ENV
|
||||||
|
echo "PIP_ONLY_BINARY=psycopg2-binary" >> $GITHUB_ENV
|
||||||
|
|
||||||
|
- name: "Setup test database"
|
||||||
|
run: psql -f ./scripts/setup_test_database.sql
|
||||||
|
env:
|
||||||
|
PGHOST: ${{ vars.POSTGRES_TEST_HOST }}
|
||||||
|
PGPORT: ${{ vars.POSTGRES_TEST_PORT }}
|
||||||
|
PGUSER: postgres
|
||||||
|
PGPASSWORD: postgres
|
||||||
|
PGDATABASE: postgres
|
||||||
|
|
||||||
|
- name: "Install hatch"
|
||||||
|
uses: pypa/hatch@257e27e51a6a5616ed08a39a408a21c35c9931bc # pypa/hatch@install
|
||||||
|
|
||||||
|
- name: "Run integration tests"
|
||||||
|
run: hatch run ${{ inputs.hatch-env }}:integration-tests
|
||||||
10
.github/workflows/cut-release-branch.yml
vendored
@@ -201,13 +201,13 @@ jobs:
|
|||||||
- name: "Install Python Dependencies"
|
- name: "Install Python Dependencies"
|
||||||
run: |
|
run: |
|
||||||
python -m pip install --upgrade pip
|
python -m pip install --upgrade pip
|
||||||
python -m pip install hatch bumpversion
|
python -m pip install hatch
|
||||||
|
|
||||||
- name: "Bump Version To ${{ needs.cleanup_changelog.outputs.next-version }}"
|
- name: "Bump Version To ${{ needs.cleanup_changelog.outputs.next-version }}"
|
||||||
run: |
|
run: |
|
||||||
cd core
|
cd core
|
||||||
hatch run setup
|
hatch version ${{ needs.cleanup_changelog.outputs.next-version }}
|
||||||
bumpversion --allow-dirty --new-version ${{ needs.cleanup_changelog.outputs.next-version }} major
|
hatch run dev-req
|
||||||
dbt --version
|
dbt --version
|
||||||
|
|
||||||
- name: "Commit Version Bump to Branch"
|
- name: "Commit Version Bump to Branch"
|
||||||
@@ -249,13 +249,13 @@ jobs:
|
|||||||
- name: "Cleanup - Remove Trailing Whitespace Via Pre-commit"
|
- name: "Cleanup - Remove Trailing Whitespace Via Pre-commit"
|
||||||
continue-on-error: true
|
continue-on-error: true
|
||||||
run: |
|
run: |
|
||||||
pre-commit run trailing-whitespace --files .bumpversion.cfg CHANGELOG.md .changes/* || true
|
pre-commit run trailing-whitespace --files CHANGELOG.md .changes/* || true
|
||||||
|
|
||||||
# this step will fail on newline errors but also correct them
|
# this step will fail on newline errors but also correct them
|
||||||
- name: "Cleanup - Remove Extra Newlines Via Pre-commit"
|
- name: "Cleanup - Remove Extra Newlines Via Pre-commit"
|
||||||
continue-on-error: true
|
continue-on-error: true
|
||||||
run: |
|
run: |
|
||||||
pre-commit run end-of-file-fixer --files .bumpversion.cfg CHANGELOG.md .changes/* || true
|
pre-commit run end-of-file-fixer --files CHANGELOG.md .changes/* || true
|
||||||
|
|
||||||
- name: "Commit Version Bump to Branch"
|
- name: "Commit Version Bump to Branch"
|
||||||
run: |
|
run: |
|
||||||
|
|||||||
24
.github/workflows/main.yml
vendored
@@ -75,7 +75,7 @@ jobs:
|
|||||||
hatch run code-quality
|
hatch run code-quality
|
||||||
|
|
||||||
unit:
|
unit:
|
||||||
name: unit test / python ${{ matrix.python-version }}
|
name: "unit test / python ${{ matrix.python-version }}"
|
||||||
|
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
timeout-minutes: 10
|
timeout-minutes: 10
|
||||||
@@ -85,9 +85,6 @@ jobs:
|
|||||||
matrix:
|
matrix:
|
||||||
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
||||||
|
|
||||||
env:
|
|
||||||
TOXENV: "unit"
|
|
||||||
|
|
||||||
steps:
|
steps:
|
||||||
- name: Check out the repository
|
- name: Check out the repository
|
||||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
||||||
@@ -124,6 +121,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
token: ${{ secrets.CODECOV_TOKEN }}
|
token: ${{ secrets.CODECOV_TOKEN }}
|
||||||
flags: unit
|
flags: unit
|
||||||
|
fail_ci_if_error: false
|
||||||
|
|
||||||
integration-metadata:
|
integration-metadata:
|
||||||
name: integration test metadata generation
|
name: integration test metadata generation
|
||||||
@@ -161,7 +159,7 @@ jobs:
|
|||||||
echo "include=${INCLUDE_GROUPS}" >> $GITHUB_OUTPUT
|
echo "include=${INCLUDE_GROUPS}" >> $GITHUB_OUTPUT
|
||||||
|
|
||||||
integration-postgres:
|
integration-postgres:
|
||||||
name: (${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
name: "(${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}"
|
||||||
|
|
||||||
runs-on: ${{ matrix.os }}
|
runs-on: ${{ matrix.os }}
|
||||||
timeout-minutes: 30
|
timeout-minutes: 30
|
||||||
@@ -174,7 +172,6 @@ jobs:
|
|||||||
os: ["ubuntu-latest"]
|
os: ["ubuntu-latest"]
|
||||||
split-group: ${{ fromJson(needs.integration-metadata.outputs.split-groups) }}
|
split-group: ${{ fromJson(needs.integration-metadata.outputs.split-groups) }}
|
||||||
env:
|
env:
|
||||||
TOXENV: integration
|
|
||||||
DBT_INVOCATION_ENV: github-actions
|
DBT_INVOCATION_ENV: github-actions
|
||||||
DBT_TEST_USER_1: dbt_test_user_1
|
DBT_TEST_USER_1: dbt_test_user_1
|
||||||
DBT_TEST_USER_2: dbt_test_user_2
|
DBT_TEST_USER_2: dbt_test_user_2
|
||||||
@@ -214,7 +211,7 @@ jobs:
|
|||||||
|
|
||||||
- name: Run postgres setup script
|
- name: Run postgres setup script
|
||||||
run: |
|
run: |
|
||||||
./test/setup_db.sh
|
./scripts/setup_db.sh
|
||||||
env:
|
env:
|
||||||
PGHOST: localhost
|
PGHOST: localhost
|
||||||
PGPORT: 5432
|
PGPORT: 5432
|
||||||
@@ -233,9 +230,7 @@ jobs:
|
|||||||
timeout_minutes: 30
|
timeout_minutes: 30
|
||||||
max_attempts: 3
|
max_attempts: 3
|
||||||
shell: bash
|
shell: bash
|
||||||
command: cd core && hatch run ci:integration-tests -- --ddtrace
|
command: cd core && hatch run ci:integration-tests -- --ddtrace --splits ${{ env.PYTHON_INTEGRATION_TEST_WORKERS }} --group ${{ matrix.split-group }}
|
||||||
env:
|
|
||||||
PYTEST_ADDOPTS: ${{ format('--splits {0} --group {1}', env.PYTHON_INTEGRATION_TEST_WORKERS, matrix.split-group) }}
|
|
||||||
|
|
||||||
- name: Get current date
|
- name: Get current date
|
||||||
if: always()
|
if: always()
|
||||||
@@ -256,6 +251,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
token: ${{ secrets.CODECOV_TOKEN }}
|
token: ${{ secrets.CODECOV_TOKEN }}
|
||||||
flags: integration
|
flags: integration
|
||||||
|
fail_ci_if_error: false
|
||||||
|
|
||||||
integration-mac-windows:
|
integration-mac-windows:
|
||||||
name: (${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
name: (${{ matrix.split-group }}) integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||||
@@ -270,7 +266,6 @@ jobs:
|
|||||||
# already includes split group and runs mac + windows
|
# already includes split group and runs mac + windows
|
||||||
include: ${{ fromJson(needs.integration-metadata.outputs.include) }}
|
include: ${{ fromJson(needs.integration-metadata.outputs.include) }}
|
||||||
env:
|
env:
|
||||||
TOXENV: integration
|
|
||||||
DBT_INVOCATION_ENV: github-actions
|
DBT_INVOCATION_ENV: github-actions
|
||||||
DBT_TEST_USER_1: dbt_test_user_1
|
DBT_TEST_USER_1: dbt_test_user_1
|
||||||
DBT_TEST_USER_2: dbt_test_user_2
|
DBT_TEST_USER_2: dbt_test_user_2
|
||||||
@@ -297,7 +292,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
timeout_minutes: 10
|
timeout_minutes: 10
|
||||||
max_attempts: 3
|
max_attempts: 3
|
||||||
command: ./test/setup_db.sh
|
command: ./scripts/setup_db.sh
|
||||||
|
|
||||||
- name: Set up postgres (windows)
|
- name: Set up postgres (windows)
|
||||||
if: runner.os == 'Windows'
|
if: runner.os == 'Windows'
|
||||||
@@ -316,9 +311,7 @@ jobs:
|
|||||||
timeout_minutes: 30
|
timeout_minutes: 30
|
||||||
max_attempts: 3
|
max_attempts: 3
|
||||||
shell: bash
|
shell: bash
|
||||||
command: cd core && hatch run ci:integration-tests -- --ddtrace
|
command: cd core && hatch run ci:integration-tests -- --ddtrace --splits ${{ env.PYTHON_INTEGRATION_TEST_WORKERS }} --group ${{ matrix.split-group }}
|
||||||
env:
|
|
||||||
PYTEST_ADDOPTS: ${{ format('--splits {0} --group {1}', env.PYTHON_INTEGRATION_TEST_WORKERS, matrix.split-group) }}
|
|
||||||
|
|
||||||
- name: Get current date
|
- name: Get current date
|
||||||
if: always()
|
if: always()
|
||||||
@@ -339,6 +332,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
token: ${{ secrets.CODECOV_TOKEN }}
|
token: ${{ secrets.CODECOV_TOKEN }}
|
||||||
flags: integration
|
flags: integration
|
||||||
|
fail_ci_if_error: false
|
||||||
|
|
||||||
integration-report:
|
integration-report:
|
||||||
if: ${{ always() }}
|
if: ${{ always() }}
|
||||||
|
|||||||
265
.github/workflows/model_performance.yml
vendored
@@ -1,265 +0,0 @@
|
|||||||
# **what?**
|
|
||||||
# This workflow models the performance characteristics of a point in time in dbt.
|
|
||||||
# It runs specific dbt commands on committed projects multiple times to create and
|
|
||||||
# commit information about the distribution to the current branch. For more information
|
|
||||||
# see the readme in the performance module at /performance/README.md.
|
|
||||||
#
|
|
||||||
# **why?**
|
|
||||||
# When developing new features, we can take quick performance samples and compare
|
|
||||||
# them against the commited baseline measurements produced by this workflow to detect
|
|
||||||
# some performance regressions at development time before they reach users.
|
|
||||||
#
|
|
||||||
# **when?**
|
|
||||||
# This is only run once directly after each release (for non-prereleases). If for some
|
|
||||||
# reason the results of a run are not satisfactory, it can also be triggered manually.
|
|
||||||
|
|
||||||
name: Model Performance Characteristics
|
|
||||||
|
|
||||||
on:
|
|
||||||
# runs after non-prereleases are published.
|
|
||||||
release:
|
|
||||||
types: [released]
|
|
||||||
# run manually from the actions tab
|
|
||||||
workflow_dispatch:
|
|
||||||
inputs:
|
|
||||||
release_id:
|
|
||||||
description: 'dbt version to model (must be non-prerelease in Pypi)'
|
|
||||||
type: string
|
|
||||||
required: true
|
|
||||||
|
|
||||||
env:
|
|
||||||
RUNNER_CACHE_PATH: performance/runner/target/release/runner
|
|
||||||
|
|
||||||
# both jobs need to write
|
|
||||||
permissions:
|
|
||||||
contents: write
|
|
||||||
pull-requests: write
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
set-variables:
|
|
||||||
name: Setting Variables
|
|
||||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
|
||||||
outputs:
|
|
||||||
cache_key: ${{ steps.variables.outputs.cache_key }}
|
|
||||||
release_id: ${{ steps.semver.outputs.base-version }}
|
|
||||||
release_branch: ${{ steps.variables.outputs.release_branch }}
|
|
||||||
steps:
|
|
||||||
|
|
||||||
# explicitly checkout the performance runner from main regardless of which
|
|
||||||
# version we are modeling.
|
|
||||||
- name: Checkout
|
|
||||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
|
||||||
with:
|
|
||||||
ref: main
|
|
||||||
|
|
||||||
- name: Parse version into parts
|
|
||||||
id: semver
|
|
||||||
uses: dbt-labs/actions/parse-semver@v1
|
|
||||||
with:
|
|
||||||
version: ${{ github.event.inputs.release_id || github.event.release.tag_name }}
|
|
||||||
|
|
||||||
# collect all the variables that need to be used in subsequent jobs
|
|
||||||
- name: Set variables
|
|
||||||
id: variables
|
|
||||||
run: |
|
|
||||||
# create a cache key that will be used in the next job. without this the
|
|
||||||
# next job would have to checkout from main and hash the files itself.
|
|
||||||
echo "cache_key=${{ runner.os }}-${{ hashFiles('performance/runner/Cargo.toml')}}-${{ hashFiles('performance/runner/src/*') }}" >> $GITHUB_OUTPUT
|
|
||||||
|
|
||||||
branch_name="${{steps.semver.outputs.major}}.${{steps.semver.outputs.minor}}.latest"
|
|
||||||
echo "release_branch=$branch_name" >> $GITHUB_OUTPUT
|
|
||||||
echo "release branch is inferred to be ${branch_name}"
|
|
||||||
|
|
||||||
latest-runner:
|
|
||||||
name: Build or Fetch Runner
|
|
||||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
|
||||||
needs: [set-variables]
|
|
||||||
env:
|
|
||||||
RUSTFLAGS: "-D warnings"
|
|
||||||
steps:
|
|
||||||
- name: '[DEBUG] print variables'
|
|
||||||
run: |
|
|
||||||
echo "all variables defined in set-variables"
|
|
||||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
|
||||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
|
||||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
|
||||||
|
|
||||||
# explicitly checkout the performance runner from main regardless of which
|
|
||||||
# version we are modeling.
|
|
||||||
- name: Checkout
|
|
||||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
|
||||||
with:
|
|
||||||
ref: main
|
|
||||||
|
|
||||||
# attempts to access a previously cached runner
|
|
||||||
- uses: actions/cache@0057852bfaa89a56745cba8c7296529d2fc39830 # actions/cache@v4
|
|
||||||
id: cache
|
|
||||||
with:
|
|
||||||
path: ${{ env.RUNNER_CACHE_PATH }}
|
|
||||||
key: ${{ needs.set-variables.outputs.cache_key }}
|
|
||||||
|
|
||||||
- name: Fetch Rust Toolchain
|
|
||||||
if: steps.cache.outputs.cache-hit != 'true'
|
|
||||||
uses: actions-rs/toolchain@16499b5e05bf2e26879000db0c1d13f7e13fa3af # actions-rs/toolchain@v1
|
|
||||||
with:
|
|
||||||
profile: minimal
|
|
||||||
toolchain: stable
|
|
||||||
override: true
|
|
||||||
|
|
||||||
- name: Add fmt
|
|
||||||
if: steps.cache.outputs.cache-hit != 'true'
|
|
||||||
run: rustup component add rustfmt
|
|
||||||
|
|
||||||
- name: Cargo fmt
|
|
||||||
if: steps.cache.outputs.cache-hit != 'true'
|
|
||||||
uses: actions-rs/cargo@844f36862e911db73fe0815f00a4a2602c279505 # actions-rs/cargo@v1
|
|
||||||
with:
|
|
||||||
command: fmt
|
|
||||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
|
||||||
|
|
||||||
- name: Test
|
|
||||||
if: steps.cache.outputs.cache-hit != 'true'
|
|
||||||
uses: actions-rs/cargo@844f36862e911db73fe0815f00a4a2602c279505 # actions-rs/cargo@v1
|
|
||||||
with:
|
|
||||||
command: test
|
|
||||||
args: --manifest-path performance/runner/Cargo.toml
|
|
||||||
|
|
||||||
- name: Build (optimized)
|
|
||||||
if: steps.cache.outputs.cache-hit != 'true'
|
|
||||||
uses: actions-rs/cargo@844f36862e911db73fe0815f00a4a2602c279505 # actions-rs/cargo@v1
|
|
||||||
with:
|
|
||||||
command: build
|
|
||||||
args: --release --manifest-path performance/runner/Cargo.toml
|
|
||||||
# the cache action automatically caches this binary at the end of the job
|
|
||||||
|
|
||||||
model:
|
|
||||||
# depends on `latest-runner` as a separate job so that failures in this job do not prevent
|
|
||||||
# a successfully tested and built binary from being cached.
|
|
||||||
needs: [set-variables, latest-runner]
|
|
||||||
name: Model a release
|
|
||||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
|
||||||
steps:
|
|
||||||
|
|
||||||
- name: '[DEBUG] print variables'
|
|
||||||
run: |
|
|
||||||
echo "all variables defined in set-variables"
|
|
||||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
|
||||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
|
||||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
|
||||||
|
|
||||||
- name: Setup Python
|
|
||||||
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # actions/setup-python@v6
|
|
||||||
with:
|
|
||||||
python-version: "3.10"
|
|
||||||
|
|
||||||
- name: Install dbt
|
|
||||||
run: pip install dbt-postgres==${{ needs.set-variables.outputs.release_id }}
|
|
||||||
|
|
||||||
- name: Install Hyperfine
|
|
||||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
|
||||||
|
|
||||||
# explicitly checkout main to get the latest project definitions
|
|
||||||
- name: Checkout
|
|
||||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
|
||||||
with:
|
|
||||||
ref: main
|
|
||||||
|
|
||||||
# this was built in the previous job so it will be there.
|
|
||||||
- name: Fetch Runner
|
|
||||||
uses: actions/cache@0057852bfaa89a56745cba8c7296529d2fc39830 # actions/cache@v4
|
|
||||||
id: cache
|
|
||||||
with:
|
|
||||||
path: ${{ env.RUNNER_CACHE_PATH }}
|
|
||||||
key: ${{ needs.set-variables.outputs.cache_key }}
|
|
||||||
|
|
||||||
- name: Move Runner
|
|
||||||
run: mv performance/runner/target/release/runner performance/app
|
|
||||||
|
|
||||||
- name: Change Runner Permissions
|
|
||||||
run: chmod +x ./performance/app
|
|
||||||
|
|
||||||
- name: '[DEBUG] ls baseline directory before run'
|
|
||||||
run: ls -R performance/baselines/
|
|
||||||
|
|
||||||
# `${{ github.workspace }}` is used to pass the absolute path
|
|
||||||
- name: Create directories
|
|
||||||
run: |
|
|
||||||
mkdir ${{ github.workspace }}/performance/tmp/
|
|
||||||
mkdir -p performance/baselines/${{ needs.set-variables.outputs.release_id }}/
|
|
||||||
|
|
||||||
# Run modeling with taking 20 samples
|
|
||||||
- name: Run Measurement
|
|
||||||
run: |
|
|
||||||
performance/app model -v ${{ needs.set-variables.outputs.release_id }} -b ${{ github.workspace }}/performance/baselines/ -p ${{ github.workspace }}/performance/projects/ -t ${{ github.workspace }}/performance/tmp/ -n 20
|
|
||||||
|
|
||||||
- name: '[DEBUG] ls baseline directory after run'
|
|
||||||
run: ls -R performance/baselines/
|
|
||||||
|
|
||||||
- uses: actions/upload-artifact@ea165f8d65b6e75b540449e92b4886f43607fa02 # actions/upload-artifact@v4
|
|
||||||
with:
|
|
||||||
name: baseline
|
|
||||||
path: performance/baselines/${{ needs.set-variables.outputs.release_id }}/
|
|
||||||
|
|
||||||
create-pr:
|
|
||||||
name: Open PR for ${{ matrix.base-branch }}
|
|
||||||
|
|
||||||
# depends on `model` as a separate job so that the baseline can be committed to more than one branch
|
|
||||||
# i.e. release branch and main
|
|
||||||
needs: [set-variables, latest-runner, model]
|
|
||||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
|
||||||
|
|
||||||
strategy:
|
|
||||||
matrix:
|
|
||||||
include:
|
|
||||||
- base-branch: refs/heads/main
|
|
||||||
target-branch: performance-bot/main_${{ needs.set-variables.outputs.release_id }}_${{GITHUB.RUN_ID}}
|
|
||||||
- base-branch: refs/heads/${{ needs.set-variables.outputs.release_branch }}
|
|
||||||
target-branch: performance-bot/release_${{ needs.set-variables.outputs.release_id }}_${{GITHUB.RUN_ID}}
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- name: '[DEBUG] print variables'
|
|
||||||
run: |
|
|
||||||
echo "all variables defined in set-variables"
|
|
||||||
echo "cache_key: ${{ needs.set-variables.outputs.cache_key }}"
|
|
||||||
echo "release_id: ${{ needs.set-variables.outputs.release_id }}"
|
|
||||||
echo "release_branch: ${{ needs.set-variables.outputs.release_branch }}"
|
|
||||||
|
|
||||||
- name: Checkout
|
|
||||||
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
|
|
||||||
with:
|
|
||||||
ref: ${{ matrix.base-branch }}
|
|
||||||
|
|
||||||
- name: Create PR branch
|
|
||||||
run: |
|
|
||||||
git checkout -b ${{ matrix.target-branch }}
|
|
||||||
git push origin ${{ matrix.target-branch }}
|
|
||||||
git branch --set-upstream-to=origin/${{ matrix.target-branch }} ${{ matrix.target-branch }}
|
|
||||||
|
|
||||||
- uses: actions/download-artifact@d3f86a106a0bac45b974a628896c90dbdf5c8093 # actions/download-artifact@v4
|
|
||||||
with:
|
|
||||||
name: baseline
|
|
||||||
path: performance/baselines/${{ needs.set-variables.outputs.release_id }}
|
|
||||||
|
|
||||||
- name: '[DEBUG] ls baselines after artifact download'
|
|
||||||
run: ls -R performance/baselines/
|
|
||||||
|
|
||||||
- name: Commit baseline
|
|
||||||
uses: EndBug/add-and-commit@a94899bca583c204427a224a7af87c02f9b325d5 # EndBug/add-and-commit@v9
|
|
||||||
with:
|
|
||||||
add: 'performance/baselines/*'
|
|
||||||
author_name: 'Github Build Bot'
|
|
||||||
author_email: 'buildbot@fishtownanalytics.com'
|
|
||||||
message: 'adding performance baseline for ${{ needs.set-variables.outputs.release_id }}'
|
|
||||||
push: 'origin origin/${{ matrix.target-branch }}'
|
|
||||||
|
|
||||||
- name: Create Pull Request
|
|
||||||
uses: peter-evans/create-pull-request@271a8d0340265f705b14b6d32b9829c1cb33d45e # peter-evans/create-pull-request@v7
|
|
||||||
with:
|
|
||||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
|
||||||
base: ${{ matrix.base-branch }}
|
|
||||||
branch: '${{ matrix.target-branch }}'
|
|
||||||
title: 'Adding performance modeling for ${{needs.set-variables.outputs.release_id}} to ${{ matrix.base-branch }}'
|
|
||||||
body: 'Committing perf results for tracking for the ${{needs.set-variables.outputs.release_id}}'
|
|
||||||
labels: |
|
|
||||||
Skip Changelog
|
|
||||||
Performance
|
|
||||||
2
.github/workflows/nightly-release.yml
vendored
@@ -46,7 +46,7 @@ jobs:
|
|||||||
- name: "Get Current Version Number"
|
- name: "Get Current Version Number"
|
||||||
id: version-number-sources
|
id: version-number-sources
|
||||||
run: |
|
run: |
|
||||||
current_version=`awk -F"current_version = " '{print $2}' .bumpversion.cfg | tr '\n' ' '`
|
current_version=$(grep '^version = ' core/dbt/__version__.py | sed 's/version = "\(.*\)"/\1/')
|
||||||
echo "current_version=$current_version" >> $GITHUB_OUTPUT
|
echo "current_version=$current_version" >> $GITHUB_OUTPUT
|
||||||
|
|
||||||
- name: "Audit Version And Parse Into Parts"
|
- name: "Audit Version And Parse Into Parts"
|
||||||
|
|||||||
47
.github/workflows/release.yml
vendored
@@ -72,10 +72,15 @@ defaults:
|
|||||||
run:
|
run:
|
||||||
shell: bash
|
shell: bash
|
||||||
|
|
||||||
|
env:
|
||||||
|
MIN_HATCH_VERSION: "1.11.0"
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
job-setup:
|
job-setup:
|
||||||
name: Log Inputs
|
name: Log Inputs
|
||||||
runs-on: ${{ vars.UBUNTU_LATEST }}
|
runs-on: ${{ vars.UBUNTU_LATEST }}
|
||||||
|
outputs:
|
||||||
|
use_hatch: ${{ steps.use_hatch.outputs.use_hatch }}
|
||||||
steps:
|
steps:
|
||||||
- name: "[DEBUG] Print Variables"
|
- name: "[DEBUG] Print Variables"
|
||||||
run: |
|
run: |
|
||||||
@@ -86,12 +91,36 @@ jobs:
|
|||||||
echo Nightly release: ${{ inputs.nightly_release }}
|
echo Nightly release: ${{ inputs.nightly_release }}
|
||||||
echo Only Docker: ${{ inputs.only_docker }}
|
echo Only Docker: ${{ inputs.only_docker }}
|
||||||
|
|
||||||
|
# In version env.HATCH_VERSION we started to use hatch for build tooling. Before that we used setuptools.
|
||||||
|
# This needs to check if we're using hatch or setuptools based on the version being released. We should
|
||||||
|
# check if the version is greater than or equal to env.HATCH_VERSION. If it is, we use hatch, otherwise we use setuptools.
|
||||||
|
- name: "Check if using hatch"
|
||||||
|
id: use_hatch
|
||||||
|
run: |
|
||||||
|
# Extract major.minor from versions like 1.11.0a1 -> 1.11
|
||||||
|
INPUT_MAJ_MIN=$(echo "${{ inputs.version_number }}" | sed -E 's/^([0-9]+\.[0-9]+).*/\1/')
|
||||||
|
HATCH_MAJ_MIN=$(echo "${{ env.MIN_HATCH_VERSION }}" | sed -E 's/^([0-9]+\.[0-9]+).*/\1/')
|
||||||
|
|
||||||
|
if [ $(echo "$INPUT_MAJ_MIN >= $HATCH_MAJ_MIN" | bc) -eq 1 ]; then
|
||||||
|
echo "use_hatch=true" >> $GITHUB_OUTPUT
|
||||||
|
else
|
||||||
|
echo "use_hatch=false" >> $GITHUB_OUTPUT
|
||||||
|
fi
|
||||||
|
|
||||||
|
- name: "Notify if using hatch"
|
||||||
|
run: |
|
||||||
|
if [ ${{ steps.use_hatch.outputs.use_hatch }} = "true" ]; then
|
||||||
|
echo "::notice title="Using Hatch": $title::Using Hatch for release"
|
||||||
|
else
|
||||||
|
echo "::notice title="Using Setuptools": $title::Using Setuptools for release"
|
||||||
|
fi
|
||||||
|
|
||||||
bump-version-generate-changelog:
|
bump-version-generate-changelog:
|
||||||
name: Bump package version, Generate changelog
|
name: Bump package version, Generate changelog
|
||||||
needs: [job-setup]
|
needs: [job-setup]
|
||||||
if: ${{ !inputs.only_docker }}
|
if: ${{ !inputs.only_docker }}
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/release-prep.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/release-prep.yml@main
|
||||||
|
|
||||||
with:
|
with:
|
||||||
version_number: ${{ inputs.version_number }}
|
version_number: ${{ inputs.version_number }}
|
||||||
@@ -100,7 +129,7 @@ jobs:
|
|||||||
env_setup_script_path: "scripts/env-setup.sh"
|
env_setup_script_path: "scripts/env-setup.sh"
|
||||||
test_run: ${{ inputs.test_run }}
|
test_run: ${{ inputs.test_run }}
|
||||||
nightly_release: ${{ inputs.nightly_release }}
|
nightly_release: ${{ inputs.nightly_release }}
|
||||||
use_hatch: true
|
use_hatch: ${{ needs.job-setup.outputs.use_hatch == 'true' }} # workflow outputs are strings...
|
||||||
|
|
||||||
secrets: inherit
|
secrets: inherit
|
||||||
|
|
||||||
@@ -123,7 +152,7 @@ jobs:
|
|||||||
if: ${{ !failure() && !cancelled() && !inputs.only_docker }}
|
if: ${{ !failure() && !cancelled() && !inputs.only_docker }}
|
||||||
needs: [job-setup, bump-version-generate-changelog]
|
needs: [job-setup, bump-version-generate-changelog]
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/build.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/build.yml@main
|
||||||
|
|
||||||
with:
|
with:
|
||||||
sha: ${{ needs.bump-version-generate-changelog.outputs.final_sha }}
|
sha: ${{ needs.bump-version-generate-changelog.outputs.final_sha }}
|
||||||
@@ -134,7 +163,7 @@ jobs:
|
|||||||
package_test_command: "dbt --version"
|
package_test_command: "dbt --version"
|
||||||
test_run: ${{ inputs.test_run }}
|
test_run: ${{ inputs.test_run }}
|
||||||
nightly_release: ${{ inputs.nightly_release }}
|
nightly_release: ${{ inputs.nightly_release }}
|
||||||
use_hatch: true
|
use_hatch: ${{ needs.job-setup.outputs.use_hatch == 'true' }} # workflow outputs are strings...
|
||||||
|
|
||||||
github-release:
|
github-release:
|
||||||
name: GitHub Release
|
name: GitHub Release
|
||||||
@@ -142,7 +171,7 @@ jobs:
|
|||||||
|
|
||||||
needs: [bump-version-generate-changelog, build-test-package]
|
needs: [bump-version-generate-changelog, build-test-package]
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/github-release.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/github-release.yml@main
|
||||||
|
|
||||||
with:
|
with:
|
||||||
sha: ${{ needs.bump-version-generate-changelog.outputs.final_sha }}
|
sha: ${{ needs.bump-version-generate-changelog.outputs.final_sha }}
|
||||||
@@ -155,7 +184,7 @@ jobs:
|
|||||||
|
|
||||||
needs: [github-release]
|
needs: [github-release]
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/pypi-release.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/pypi-release.yml@main
|
||||||
|
|
||||||
with:
|
with:
|
||||||
version_number: ${{ inputs.version_number }}
|
version_number: ${{ inputs.version_number }}
|
||||||
@@ -204,7 +233,7 @@ jobs:
|
|||||||
permissions:
|
permissions:
|
||||||
packages: write
|
packages: write
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/release-docker.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/release-docker.yml@main
|
||||||
with:
|
with:
|
||||||
package: ${{ matrix.package }}
|
package: ${{ matrix.package }}
|
||||||
version_number: ${{ inputs.version_number }}
|
version_number: ${{ inputs.version_number }}
|
||||||
@@ -223,7 +252,7 @@ jobs:
|
|||||||
docker-release,
|
docker-release,
|
||||||
]
|
]
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/slack-post-notification.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/slack-post-notification.yml@main
|
||||||
with:
|
with:
|
||||||
status: "failure"
|
status: "failure"
|
||||||
|
|
||||||
@@ -244,7 +273,7 @@ jobs:
|
|||||||
docker-release,
|
docker-release,
|
||||||
]
|
]
|
||||||
|
|
||||||
uses: dbt-labs/dbt-release/.github/workflows/slack-post-notification.yml@er/hatch-release
|
uses: dbt-labs/dbt-release/.github/workflows/slack-post-notification.yml@main
|
||||||
with:
|
with:
|
||||||
status: "failure"
|
status: "failure"
|
||||||
|
|
||||||
|
|||||||
@@ -107,7 +107,7 @@ jobs:
|
|||||||
|
|
||||||
- name: Run postgres setup script
|
- name: Run postgres setup script
|
||||||
run: |
|
run: |
|
||||||
./test/setup_db.sh
|
./scripts/setup_db.sh
|
||||||
env:
|
env:
|
||||||
PGHOST: localhost
|
PGHOST: localhost
|
||||||
PGPORT: 5432
|
PGPORT: 5432
|
||||||
|
|||||||
2
.github/workflows/test-repeater.yml
vendored
@@ -111,7 +111,7 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
timeout_minutes: 10
|
timeout_minutes: 10
|
||||||
max_attempts: 3
|
max_attempts: 3
|
||||||
command: ./test/setup_db.sh
|
command: ./scripts/setup_db.sh
|
||||||
|
|
||||||
- name: "Set up postgres (windows)"
|
- name: "Set up postgres (windows)"
|
||||||
if: inputs.os == 'windows-latest'
|
if: inputs.os == 'windows-latest'
|
||||||
|
|||||||
@@ -84,7 +84,7 @@ repos:
|
|||||||
types: [python]
|
types: [python]
|
||||||
- id: no_versioned_artifact_resource_imports
|
- id: no_versioned_artifact_resource_imports
|
||||||
name: no_versioned_artifact_resource_imports
|
name: no_versioned_artifact_resource_imports
|
||||||
entry: python custom-hooks/no_versioned_artifact_resource_imports.py
|
entry: python scripts/pre-commit-hooks/no_versioned_artifact_resource_imports.py
|
||||||
language: system
|
language: system
|
||||||
files: ^core/dbt/
|
files: ^core/dbt/
|
||||||
types: [python]
|
types: [python]
|
||||||
|
|||||||
@@ -17,10 +17,6 @@ The main subdirectories of core/dbt:
|
|||||||
- [`parser`](core/dbt/parser/README.md): Read project files, validate, construct python objects
|
- [`parser`](core/dbt/parser/README.md): Read project files, validate, construct python objects
|
||||||
- [`task`](core/dbt/task/README.md): Set forth the actions that dbt can perform when invoked
|
- [`task`](core/dbt/task/README.md): Set forth the actions that dbt can perform when invoked
|
||||||
|
|
||||||
Legacy tests are found in the 'test' directory:
|
|
||||||
- [`unit tests`](core/dbt/test/unit/README.md): Unit tests
|
|
||||||
- [`integration tests`](core/dbt/test/integration/README.md): Integration tests
|
|
||||||
|
|
||||||
### Invoking dbt
|
### Invoking dbt
|
||||||
|
|
||||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||||
@@ -45,10 +41,9 @@ The Postgres adapter code is the most central, and many of its implementations a
|
|||||||
|
|
||||||
## Testing dbt
|
## Testing dbt
|
||||||
|
|
||||||
The [`test/`](test/) subdirectory includes unit and integration tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Integration tests perform end-to-end dbt invocations against real adapters (Postgres, Redshift, Snowflake, BigQuery) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
The [`tests/`](tests/) subdirectory includes unit and fuctional tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Functional tests perform end-to-end dbt invocations against real adapters (Postgres) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
||||||
|
|
||||||
## Everything else
|
## Everything else
|
||||||
|
|
||||||
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
||||||
- [etc](etc/): Images for README
|
|
||||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, nor are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, nor are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||||
|
|||||||
@@ -20,9 +20,8 @@
|
|||||||
- [Testing](#testing)
|
- [Testing](#testing)
|
||||||
- [Initial setup](#initial-setup)
|
- [Initial setup](#initial-setup)
|
||||||
- [Test commands](#test-commands)
|
- [Test commands](#test-commands)
|
||||||
- [Makefile](#makefile)
|
- [Hatch scripts](#hatch-scripts)
|
||||||
- [`pre-commit`](#pre-commit)
|
- [`pre-commit`](#pre-commit)
|
||||||
- [`tox`](#tox)
|
|
||||||
- [`pytest`](#pytest)
|
- [`pytest`](#pytest)
|
||||||
- [Unit, Integration, Functional?](#unit-integration-functional)
|
- [Unit, Integration, Functional?](#unit-integration-functional)
|
||||||
- [Debugging](#debugging)
|
- [Debugging](#debugging)
|
||||||
@@ -74,15 +73,13 @@ There are some tools that will be helpful to you in developing locally. While th
|
|||||||
|
|
||||||
These are the tools used in `dbt-core` development and testing:
|
These are the tools used in `dbt-core` development and testing:
|
||||||
|
|
||||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage isolated test environments across python versions. We currently target the latest patch releases for Python 3.10, 3.11, 3.12, and 3.13
|
- [`hatch`](https://hatch.pypa.io/) for build backend, environment management, and running tests across Python versions (3.10, 3.11, 3.12, and 3.13)
|
||||||
- [`pytest`](https://docs.pytest.org/en/latest/) to define, discover, and run tests
|
- [`pytest`](https://docs.pytest.org/en/latest/) to define, discover, and run tests
|
||||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||||
- [`black`](https://github.com/psf/black) for code formatting
|
- [`black`](https://github.com/psf/black) for code formatting
|
||||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||||
- [`pre-commit`](https://pre-commit.com) to easily run those checks
|
- [`pre-commit`](https://pre-commit.com) to easily run those checks
|
||||||
- [`changie`](https://changie.dev/) to create changelog entries, without merge conflicts
|
- [`changie`](https://changie.dev/) to create changelog entries, without merge conflicts
|
||||||
- [`hatchling`](https://hatch.pypa.io/) as the build backend for creating distribution packages
|
|
||||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) to run multiple setup or test steps in combination. Don't worry too much, nobody _really_ understands how `make` works, and our Makefile aims to be super simple.
|
|
||||||
- [GitHub Actions](https://github.com/features/actions) for automating tests and checks, once a PR is pushed to the `dbt-core` repository
|
- [GitHub Actions](https://github.com/features/actions) for automating tests and checks, once a PR is pushed to the `dbt-core` repository
|
||||||
|
|
||||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about each one.
|
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about each one.
|
||||||
@@ -117,13 +114,17 @@ cd core
|
|||||||
hatch run setup
|
hatch run setup
|
||||||
```
|
```
|
||||||
|
|
||||||
This will install all development dependencies and set up pre-commit hooks. Alternatively, you can install dependencies directly:
|
This will install all development dependencies and set up pre-commit hooks.
|
||||||
|
|
||||||
|
By default, hatch will use whatever Python version is active in your environment. To specify a particular Python version, set the `HATCH_PYTHON` environment variable:
|
||||||
|
|
||||||
```sh
|
```sh
|
||||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
export HATCH_PYTHON=3.12
|
||||||
pre-commit install
|
hatch env create
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Or add it to your shell profile (e.g., `~/.zshrc` or `~/.bashrc`) for persistence.
|
||||||
|
|
||||||
When installed in this way, any changes you make to your local copy of the source code will be reflected immediately in your next `dbt` run.
|
When installed in this way, any changes you make to your local copy of the source code will be reflected immediately in your next `dbt` run.
|
||||||
|
|
||||||
#### Building dbt-core
|
#### Building dbt-core
|
||||||
@@ -167,7 +168,7 @@ Alternatively, you can run the setup commands directly:
|
|||||||
|
|
||||||
```sh
|
```sh
|
||||||
docker-compose up -d database
|
docker-compose up -d database
|
||||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash scripts/setup_db.sh
|
||||||
```
|
```
|
||||||
|
|
||||||
### Test commands
|
### Test commands
|
||||||
@@ -176,7 +177,7 @@ There are a few methods for running tests locally.
|
|||||||
|
|
||||||
#### Hatch scripts
|
#### Hatch scripts
|
||||||
|
|
||||||
The primary way to run tests and checks is using hatch scripts (defined in `core/pyproject.toml`):
|
The primary way to run tests and checks is using hatch scripts (defined in `core/hatch.toml`):
|
||||||
|
|
||||||
```sh
|
```sh
|
||||||
cd core
|
cd core
|
||||||
@@ -206,15 +207,27 @@ hatch run code-quality
|
|||||||
hatch run clean
|
hatch run clean
|
||||||
```
|
```
|
||||||
|
|
||||||
> These hatch scripts handle virtualenv management and dependency installation automatically via [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and `pre-commit` for code quality checks.
|
Hatch manages isolated environments and dependencies automatically. The commands above use the `default` environment which is recommended for most local development.
|
||||||
|
|
||||||
|
**Using the `ci` environment (optional)**
|
||||||
|
|
||||||
|
If you need to replicate exactly what runs in GitHub Actions (e.g., with coverage reporting), use the `ci` environment:
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd core
|
||||||
|
|
||||||
|
# Run unit tests with coverage
|
||||||
|
hatch run ci:unit-tests
|
||||||
|
|
||||||
|
# Run unit tests with a specific Python version
|
||||||
|
hatch run +py=3.11 ci:unit-tests
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Note:** Most developers should use the default environment (`hatch run unit-tests`). The `ci` environment is primarily for debugging CI failures or running tests with coverage.
|
||||||
|
|
||||||
#### `pre-commit`
|
#### `pre-commit`
|
||||||
|
|
||||||
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `hatch run setup` (or `pip install -r dev-requirements.txt && pre-commit install`) to install `pre-commit` in your local environment (we recommend running this command with a python virtual environment active). This installs several pip executables including black, mypy, and flake8. Once installed, hooks will run automatically on `git commit`, or you can run them manually with `hatch run code-quality`.
|
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `hatch run setup` to install `pre-commit` in your local environment (we recommend running this command with a python virtual environment active). This installs several pip executables including black, mypy, and flake8. Once installed, hooks will run automatically on `git commit`, or you can run them manually with `hatch run code-quality`.
|
||||||
|
|
||||||
#### `tox`
|
|
||||||
|
|
||||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing isolated test environments and installing dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.10, Python 3.11, Python 3.12 and Python 3.13 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py310`. The configuration for these tests is located in `tox.ini`.
|
|
||||||
|
|
||||||
#### `pytest`
|
#### `pytest`
|
||||||
|
|
||||||
|
|||||||
@@ -47,7 +47,7 @@ RUN curl -LO https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_V
|
|||||||
&& tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
&& tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
||||||
&& rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
&& rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
||||||
|
|
||||||
RUN pip3 install -U tox wheel six setuptools pre-commit
|
RUN pip3 install -U hatch wheel pre-commit
|
||||||
|
|
||||||
# These args are passed in via docker-compose, which reads then from the .env file.
|
# These args are passed in via docker-compose, which reads then from the .env file.
|
||||||
# On Linux, run `make .env` to create the .env file for the current user.
|
# On Linux, run `make .env` to create the .env file for the current user.
|
||||||
@@ -62,7 +62,6 @@ RUN if [ ${USER_ID:-0} -ne 0 ] && [ ${GROUP_ID:-0} -ne 0 ]; then \
|
|||||||
useradd -mU -l dbt_test_user; \
|
useradd -mU -l dbt_test_user; \
|
||||||
fi
|
fi
|
||||||
RUN mkdir /usr/app && chown dbt_test_user /usr/app
|
RUN mkdir /usr/app && chown dbt_test_user /usr/app
|
||||||
RUN mkdir /home/tox && chown dbt_test_user /home/tox
|
|
||||||
|
|
||||||
WORKDIR /usr/app
|
WORKDIR /usr/app
|
||||||
VOLUME /usr/app
|
VOLUME /usr/app
|
||||||
|
|||||||
201
LICENSE
@@ -1,201 +0,0 @@
|
|||||||
Apache License
|
|
||||||
Version 2.0, January 2004
|
|
||||||
http://www.apache.org/licenses/
|
|
||||||
|
|
||||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
|
||||||
|
|
||||||
1. Definitions.
|
|
||||||
|
|
||||||
"License" shall mean the terms and conditions for use, reproduction,
|
|
||||||
and distribution as defined by Sections 1 through 9 of this document.
|
|
||||||
|
|
||||||
"Licensor" shall mean the copyright owner or entity authorized by
|
|
||||||
the copyright owner that is granting the License.
|
|
||||||
|
|
||||||
"Legal Entity" shall mean the union of the acting entity and all
|
|
||||||
other entities that control, are controlled by, or are under common
|
|
||||||
control with that entity. For the purposes of this definition,
|
|
||||||
"control" means (i) the power, direct or indirect, to cause the
|
|
||||||
direction or management of such entity, whether by contract or
|
|
||||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
|
||||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
|
||||||
|
|
||||||
"You" (or "Your") shall mean an individual or Legal Entity
|
|
||||||
exercising permissions granted by this License.
|
|
||||||
|
|
||||||
"Source" form shall mean the preferred form for making modifications,
|
|
||||||
including but not limited to software source code, documentation
|
|
||||||
source, and configuration files.
|
|
||||||
|
|
||||||
"Object" form shall mean any form resulting from mechanical
|
|
||||||
transformation or translation of a Source form, including but
|
|
||||||
not limited to compiled object code, generated documentation,
|
|
||||||
and conversions to other media types.
|
|
||||||
|
|
||||||
"Work" shall mean the work of authorship, whether in Source or
|
|
||||||
Object form, made available under the License, as indicated by a
|
|
||||||
copyright notice that is included in or attached to the work
|
|
||||||
(an example is provided in the Appendix below).
|
|
||||||
|
|
||||||
"Derivative Works" shall mean any work, whether in Source or Object
|
|
||||||
form, that is based on (or derived from) the Work and for which the
|
|
||||||
editorial revisions, annotations, elaborations, or other modifications
|
|
||||||
represent, as a whole, an original work of authorship. For the purposes
|
|
||||||
of this License, Derivative Works shall not include works that remain
|
|
||||||
separable from, or merely link (or bind by name) to the interfaces of,
|
|
||||||
the Work and Derivative Works thereof.
|
|
||||||
|
|
||||||
"Contribution" shall mean any work of authorship, including
|
|
||||||
the original version of the Work and any modifications or additions
|
|
||||||
to that Work or Derivative Works thereof, that is intentionally
|
|
||||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
|
||||||
or by an individual or Legal Entity authorized to submit on behalf of
|
|
||||||
the copyright owner. For the purposes of this definition, "submitted"
|
|
||||||
means any form of electronic, verbal, or written communication sent
|
|
||||||
to the Licensor or its representatives, including but not limited to
|
|
||||||
communication on electronic mailing lists, source code control systems,
|
|
||||||
and issue tracking systems that are managed by, or on behalf of, the
|
|
||||||
Licensor for the purpose of discussing and improving the Work, but
|
|
||||||
excluding communication that is conspicuously marked or otherwise
|
|
||||||
designated in writing by the copyright owner as "Not a Contribution."
|
|
||||||
|
|
||||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
|
||||||
on behalf of whom a Contribution has been received by Licensor and
|
|
||||||
subsequently incorporated within the Work.
|
|
||||||
|
|
||||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
|
||||||
this License, each Contributor hereby grants to You a perpetual,
|
|
||||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
|
||||||
copyright license to reproduce, prepare Derivative Works of,
|
|
||||||
publicly display, publicly perform, sublicense, and distribute the
|
|
||||||
Work and such Derivative Works in Source or Object form.
|
|
||||||
|
|
||||||
3. Grant of Patent License. Subject to the terms and conditions of
|
|
||||||
this License, each Contributor hereby grants to You a perpetual,
|
|
||||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
|
||||||
(except as stated in this section) patent license to make, have made,
|
|
||||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
|
||||||
where such license applies only to those patent claims licensable
|
|
||||||
by such Contributor that are necessarily infringed by their
|
|
||||||
Contribution(s) alone or by combination of their Contribution(s)
|
|
||||||
with the Work to which such Contribution(s) was submitted. If You
|
|
||||||
institute patent litigation against any entity (including a
|
|
||||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
|
||||||
or a Contribution incorporated within the Work constitutes direct
|
|
||||||
or contributory patent infringement, then any patent licenses
|
|
||||||
granted to You under this License for that Work shall terminate
|
|
||||||
as of the date such litigation is filed.
|
|
||||||
|
|
||||||
4. Redistribution. You may reproduce and distribute copies of the
|
|
||||||
Work or Derivative Works thereof in any medium, with or without
|
|
||||||
modifications, and in Source or Object form, provided that You
|
|
||||||
meet the following conditions:
|
|
||||||
|
|
||||||
(a) You must give any other recipients of the Work or
|
|
||||||
Derivative Works a copy of this License; and
|
|
||||||
|
|
||||||
(b) You must cause any modified files to carry prominent notices
|
|
||||||
stating that You changed the files; and
|
|
||||||
|
|
||||||
(c) You must retain, in the Source form of any Derivative Works
|
|
||||||
that You distribute, all copyright, patent, trademark, and
|
|
||||||
attribution notices from the Source form of the Work,
|
|
||||||
excluding those notices that do not pertain to any part of
|
|
||||||
the Derivative Works; and
|
|
||||||
|
|
||||||
(d) If the Work includes a "NOTICE" text file as part of its
|
|
||||||
distribution, then any Derivative Works that You distribute must
|
|
||||||
include a readable copy of the attribution notices contained
|
|
||||||
within such NOTICE file, excluding those notices that do not
|
|
||||||
pertain to any part of the Derivative Works, in at least one
|
|
||||||
of the following places: within a NOTICE text file distributed
|
|
||||||
as part of the Derivative Works; within the Source form or
|
|
||||||
documentation, if provided along with the Derivative Works; or,
|
|
||||||
within a display generated by the Derivative Works, if and
|
|
||||||
wherever such third-party notices normally appear. The contents
|
|
||||||
of the NOTICE file are for informational purposes only and
|
|
||||||
do not modify the License. You may add Your own attribution
|
|
||||||
notices within Derivative Works that You distribute, alongside
|
|
||||||
or as an addendum to the NOTICE text from the Work, provided
|
|
||||||
that such additional attribution notices cannot be construed
|
|
||||||
as modifying the License.
|
|
||||||
|
|
||||||
You may add Your own copyright statement to Your modifications and
|
|
||||||
may provide additional or different license terms and conditions
|
|
||||||
for use, reproduction, or distribution of Your modifications, or
|
|
||||||
for any such Derivative Works as a whole, provided Your use,
|
|
||||||
reproduction, and distribution of the Work otherwise complies with
|
|
||||||
the conditions stated in this License.
|
|
||||||
|
|
||||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
|
||||||
any Contribution intentionally submitted for inclusion in the Work
|
|
||||||
by You to the Licensor shall be under the terms and conditions of
|
|
||||||
this License, without any additional terms or conditions.
|
|
||||||
Notwithstanding the above, nothing herein shall supersede or modify
|
|
||||||
the terms of any separate license agreement you may have executed
|
|
||||||
with Licensor regarding such Contributions.
|
|
||||||
|
|
||||||
6. Trademarks. This License does not grant permission to use the trade
|
|
||||||
names, trademarks, service marks, or product names of the Licensor,
|
|
||||||
except as required for reasonable and customary use in describing the
|
|
||||||
origin of the Work and reproducing the content of the NOTICE file.
|
|
||||||
|
|
||||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
|
||||||
agreed to in writing, Licensor provides the Work (and each
|
|
||||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
|
||||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
|
||||||
implied, including, without limitation, any warranties or conditions
|
|
||||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
|
||||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
|
||||||
appropriateness of using or redistributing the Work and assume any
|
|
||||||
risks associated with Your exercise of permissions under this License.
|
|
||||||
|
|
||||||
8. Limitation of Liability. In no event and under no legal theory,
|
|
||||||
whether in tort (including negligence), contract, or otherwise,
|
|
||||||
unless required by applicable law (such as deliberate and grossly
|
|
||||||
negligent acts) or agreed to in writing, shall any Contributor be
|
|
||||||
liable to You for damages, including any direct, indirect, special,
|
|
||||||
incidental, or consequential damages of any character arising as a
|
|
||||||
result of this License or out of the use or inability to use the
|
|
||||||
Work (including but not limited to damages for loss of goodwill,
|
|
||||||
work stoppage, computer failure or malfunction, or any and all
|
|
||||||
other commercial damages or losses), even if such Contributor
|
|
||||||
has been advised of the possibility of such damages.
|
|
||||||
|
|
||||||
9. Accepting Warranty or Additional Liability. While redistributing
|
|
||||||
the Work or Derivative Works thereof, You may choose to offer,
|
|
||||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
|
||||||
or other liability obligations and/or rights consistent with this
|
|
||||||
License. However, in accepting such obligations, You may act only
|
|
||||||
on Your own behalf and on Your sole responsibility, not on behalf
|
|
||||||
of any other Contributor, and only if You agree to indemnify,
|
|
||||||
defend, and hold each Contributor harmless for any liability
|
|
||||||
incurred by, or claims asserted against, such Contributor by reason
|
|
||||||
of your accepting any such warranty or additional liability.
|
|
||||||
|
|
||||||
END OF TERMS AND CONDITIONS
|
|
||||||
|
|
||||||
APPENDIX: How to apply the Apache License to your work.
|
|
||||||
|
|
||||||
To apply the Apache License to your work, attach the following
|
|
||||||
boilerplate notice, with the fields enclosed by brackets "{}"
|
|
||||||
replaced with your own identifying information. (Don't include
|
|
||||||
the brackets!) The text should be enclosed in the appropriate
|
|
||||||
comment syntax for the file format. We also recommend that a
|
|
||||||
file or class name and description of purpose be included on the
|
|
||||||
same "printed page" as the copyright notice for easier
|
|
||||||
identification within third-party archives.
|
|
||||||
|
|
||||||
Copyright 2021 dbt Labs, Inc.
|
|
||||||
|
|
||||||
Licensed under the Apache License, Version 2.0 (the "License");
|
|
||||||
you may not use this file except in compliance with the License.
|
|
||||||
You may obtain a copy of the License at
|
|
||||||
|
|
||||||
http://www.apache.org/licenses/LICENSE-2.0
|
|
||||||
|
|
||||||
Unless required by applicable law or agreed to in writing, software
|
|
||||||
distributed under the License is distributed on an "AS IS" BASIS,
|
|
||||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
|
||||||
See the License for the specific language governing permissions and
|
|
||||||
limitations under the License.
|
|
||||||
27
codecov.yml
@@ -2,39 +2,22 @@ ignore:
|
|||||||
- ".github"
|
- ".github"
|
||||||
- ".changes"
|
- ".changes"
|
||||||
|
|
||||||
|
# Disable all status checks to prevent red X's in CI
|
||||||
|
# Coverage data is still uploaded and PR comments are still posted
|
||||||
coverage:
|
coverage:
|
||||||
status:
|
status:
|
||||||
project:
|
project: off
|
||||||
default:
|
patch: off
|
||||||
target: auto
|
|
||||||
threshold: 0.1% # Reduce noise by ignoring rounding errors in coverage drops
|
|
||||||
informational: true
|
|
||||||
patch:
|
|
||||||
default:
|
|
||||||
target: auto
|
|
||||||
threshold: 80%
|
|
||||||
informational: true
|
|
||||||
|
|
||||||
comment:
|
comment:
|
||||||
layout: "header, diff, flags, components" # show component info in the PR comment
|
layout: "header, diff, flags, components" # show component info in the PR comment
|
||||||
|
|
||||||
component_management:
|
component_management:
|
||||||
default_rules: # default rules that will be inherited by all components
|
|
||||||
statuses:
|
|
||||||
- type: project # in this case every component that doens't have a status defined will have a project type one
|
|
||||||
target: auto
|
|
||||||
threshold: 0.1%
|
|
||||||
- type: patch
|
|
||||||
target: 80%
|
|
||||||
individual_components:
|
individual_components:
|
||||||
- component_id: unittests
|
- component_id: unittests
|
||||||
name: "Unit Tests"
|
name: "Unit Tests"
|
||||||
flag_regexes:
|
flag_regexes:
|
||||||
- "unit"
|
- "unit"
|
||||||
statuses:
|
|
||||||
- type: patch
|
|
||||||
target: 80%
|
|
||||||
threshold: 5%
|
|
||||||
- component_id: integrationtests
|
- component_id: integrationtests
|
||||||
name: "Integration Tests"
|
name: "Integration Tests"
|
||||||
flag_regexes:
|
flag_regexes:
|
||||||
|
|||||||
201
core/LICENSE
Normal file
@@ -0,0 +1,201 @@
|
|||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "{}"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright 2021 dbt Labs, Inc.
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
@@ -1,5 +1,5 @@
|
|||||||
<p align="center">
|
<p align="center">
|
||||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/docs/images/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||||
</p>
|
</p>
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||||
@@ -9,7 +9,7 @@
|
|||||||
|
|
||||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||||
|
|
||||||
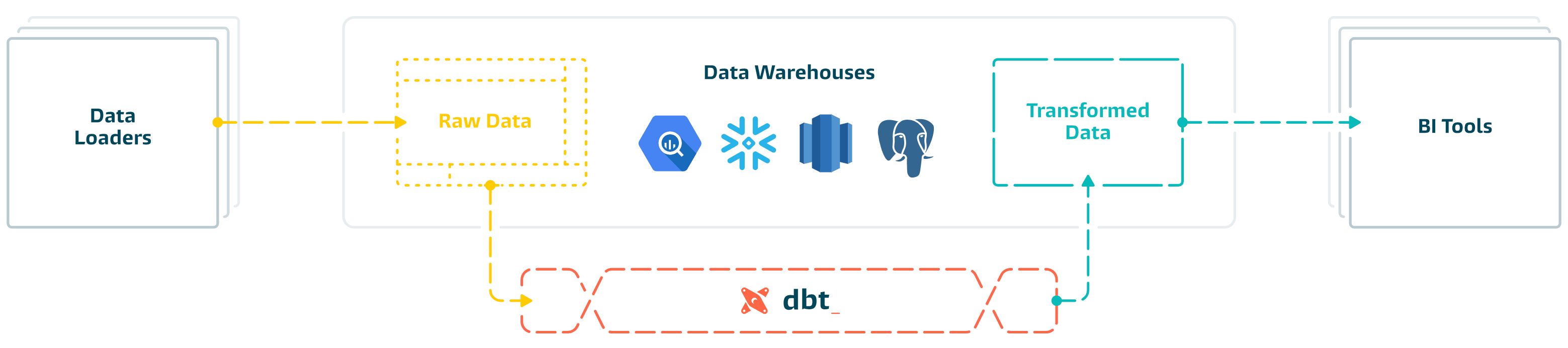
|

|
||||||
|
|
||||||
## Understanding dbt
|
## Understanding dbt
|
||||||
|
|
||||||
@@ -17,7 +17,7 @@ Analysts using dbt can transform their data by simply writing select statements,
|
|||||||
|
|
||||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||||
|
|
||||||
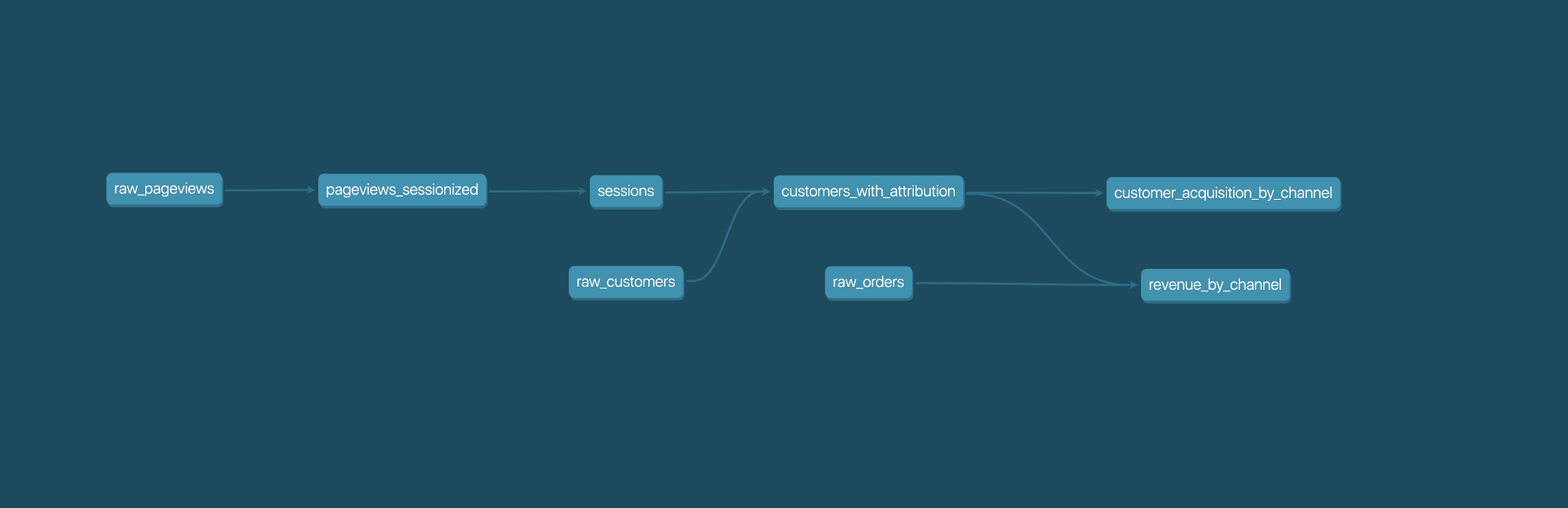
|

|
||||||
|
|
||||||
## Getting started
|
## Getting started
|
||||||
|
|
||||||
|
|||||||
@@ -2,11 +2,13 @@ import inspect
|
|||||||
import typing as t
|
import typing as t
|
||||||
|
|
||||||
import click
|
import click
|
||||||
from click import Context
|
|
||||||
from click.parser import _OptionParser, _ParsingState
|
|
||||||
|
|
||||||
from dbt.cli.option_types import ChoiceTuple
|
from dbt.cli.option_types import ChoiceTuple
|
||||||
|
|
||||||
|
if t.TYPE_CHECKING:
|
||||||
|
from click import Context
|
||||||
|
from click.parser import _OptionParser, _ParsingState
|
||||||
|
|
||||||
|
|
||||||
# Implementation from: https://stackoverflow.com/a/48394004
|
# Implementation from: https://stackoverflow.com/a/48394004
|
||||||
# Note MultiOption options must be specified with type=tuple or type=ChoiceTuple (https://github.com/pallets/click/issues/2012)
|
# Note MultiOption options must be specified with type=tuple or type=ChoiceTuple (https://github.com/pallets/click/issues/2012)
|
||||||
@@ -33,8 +35,8 @@ class MultiOption(click.Option):
|
|||||||
else:
|
else:
|
||||||
assert isinstance(option_type, ChoiceTuple), msg
|
assert isinstance(option_type, ChoiceTuple), msg
|
||||||
|
|
||||||
def add_to_parser(self, parser: _OptionParser, ctx: Context):
|
def add_to_parser(self, parser: "_OptionParser", ctx: "Context"):
|
||||||
def parser_process(value: str, state: _ParsingState):
|
def parser_process(value: str, state: "_ParsingState"):
|
||||||
# method to hook to the parser.process
|
# method to hook to the parser.process
|
||||||
done = False
|
done = False
|
||||||
value_list = str.split(value, " ")
|
value_list = str.split(value, " ")
|
||||||
@@ -65,7 +67,7 @@ class MultiOption(click.Option):
|
|||||||
break
|
break
|
||||||
return retval
|
return retval
|
||||||
|
|
||||||
def type_cast_value(self, ctx: Context, value: t.Any) -> t.Any:
|
def type_cast_value(self, ctx: "Context", value: t.Any) -> t.Any:
|
||||||
def flatten(data):
|
def flatten(data):
|
||||||
if isinstance(data, tuple):
|
if isinstance(data, tuple):
|
||||||
for x in data:
|
for x in data:
|
||||||
|
|||||||
@@ -291,8 +291,22 @@ def project(func):
|
|||||||
flags = ctx.obj["flags"]
|
flags = ctx.obj["flags"]
|
||||||
# TODO deprecations warnings fired from loading the project will lack
|
# TODO deprecations warnings fired from loading the project will lack
|
||||||
# the project_id in the snowplow event.
|
# the project_id in the snowplow event.
|
||||||
|
|
||||||
|
# Determine if vars should be required during project loading.
|
||||||
|
# Commands that don't need vars evaluated (like 'deps', 'clean')
|
||||||
|
# should use lenient mode (require_vars=False) to allow missing vars.
|
||||||
|
# Commands that validate or execute (like 'run', 'compile', 'build', 'debug') should use
|
||||||
|
# strict mode (require_vars=True) to show helpful "Required var X not found" errors.
|
||||||
|
# If adding more commands to lenient mode, update this condition.
|
||||||
|
require_vars = flags.WHICH != "deps"
|
||||||
|
|
||||||
project = load_project(
|
project = load_project(
|
||||||
flags.PROJECT_DIR, flags.VERSION_CHECK, ctx.obj["profile"], flags.VARS, validate=True
|
flags.PROJECT_DIR,
|
||||||
|
flags.VERSION_CHECK,
|
||||||
|
ctx.obj["profile"],
|
||||||
|
flags.VARS,
|
||||||
|
validate=True,
|
||||||
|
require_vars=require_vars,
|
||||||
)
|
)
|
||||||
ctx.obj["project"] = project
|
ctx.obj["project"] = project
|
||||||
|
|
||||||
@@ -432,3 +446,5 @@ def setup_manifest(ctx: Context, write: bool = True, write_perf_info: bool = Fal
|
|||||||
adapter.set_macro_resolver(ctx.obj["manifest"])
|
adapter.set_macro_resolver(ctx.obj["manifest"])
|
||||||
query_header_context = generate_query_header_context(adapter.config, ctx.obj["manifest"]) # type: ignore[attr-defined]
|
query_header_context = generate_query_header_context(adapter.config, ctx.obj["manifest"]) # type: ignore[attr-defined]
|
||||||
adapter.connections.set_query_header(query_header_context)
|
adapter.connections.set_query_header(query_header_context)
|
||||||
|
for integration in active_integrations:
|
||||||
|
adapter.add_catalog_integration(integration)
|
||||||
|
|||||||
@@ -26,6 +26,7 @@ from dbt.contracts.graph.nodes import (
|
|||||||
SeedNode,
|
SeedNode,
|
||||||
UnitTestDefinition,
|
UnitTestDefinition,
|
||||||
UnitTestNode,
|
UnitTestNode,
|
||||||
|
UnitTestSourceDefinition,
|
||||||
)
|
)
|
||||||
from dbt.events.types import FoundStats, WritingInjectedSQLForNode
|
from dbt.events.types import FoundStats, WritingInjectedSQLForNode
|
||||||
from dbt.exceptions import (
|
from dbt.exceptions import (
|
||||||
@@ -566,7 +567,12 @@ class Compiler:
|
|||||||
|
|
||||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||||
|
|
||||||
new_cte_name = self.add_ephemeral_prefix(cte_model.identifier)
|
cte_name = (
|
||||||
|
cte_model.cte_name
|
||||||
|
if isinstance(cte_model, UnitTestSourceDefinition)
|
||||||
|
else cte_model.identifier
|
||||||
|
)
|
||||||
|
new_cte_name = self.add_ephemeral_prefix(cte_name)
|
||||||
rendered_sql = cte_model._pre_injected_sql or cte_model.compiled_code
|
rendered_sql = cte_model._pre_injected_sql or cte_model.compiled_code
|
||||||
sql = f" {new_cte_name} as (\n{rendered_sql}\n)"
|
sql = f" {new_cte_name} as (\n{rendered_sql}\n)"
|
||||||
|
|
||||||
@@ -654,8 +660,15 @@ class Compiler:
|
|||||||
raise GraphDependencyNotFoundError(node, to_expression)
|
raise GraphDependencyNotFoundError(node, to_expression)
|
||||||
|
|
||||||
adapter = get_adapter(self.config)
|
adapter = get_adapter(self.config)
|
||||||
relation_name = str(adapter.Relation.create_from(self.config, foreign_key_node))
|
|
||||||
return relation_name
|
if (
|
||||||
|
hasattr(foreign_key_node, "defer_relation")
|
||||||
|
and foreign_key_node.defer_relation
|
||||||
|
and self.config.args.defer
|
||||||
|
):
|
||||||
|
return str(adapter.Relation.create_from(self.config, foreign_key_node.defer_relation))
|
||||||
|
else:
|
||||||
|
return str(adapter.Relation.create_from(self.config, foreign_key_node))
|
||||||
|
|
||||||
# This method doesn't actually "compile" any of the nodes. That is done by the
|
# This method doesn't actually "compile" any of the nodes. That is done by the
|
||||||
# "compile_node" method. This creates a Linker and builds the networkx graph,
|
# "compile_node" method. This creates a Linker and builds the networkx graph,
|
||||||
|
|||||||
@@ -101,7 +101,10 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
|||||||
_KEYPATH_HANDLERS = ProjectPostprocessor()
|
_KEYPATH_HANDLERS = ProjectPostprocessor()
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self, profile: Optional[HasCredentials] = None, cli_vars: Optional[Dict[str, Any]] = None
|
self,
|
||||||
|
profile: Optional[HasCredentials] = None,
|
||||||
|
cli_vars: Optional[Dict[str, Any]] = None,
|
||||||
|
require_vars: bool = True,
|
||||||
) -> None:
|
) -> None:
|
||||||
# Generate contexts here because we want to save the context
|
# Generate contexts here because we want to save the context
|
||||||
# object in order to retrieve the env_vars. This is almost always
|
# object in order to retrieve the env_vars. This is almost always
|
||||||
@@ -109,10 +112,19 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
|||||||
# even when we don't have a profile.
|
# even when we don't have a profile.
|
||||||
if cli_vars is None:
|
if cli_vars is None:
|
||||||
cli_vars = {}
|
cli_vars = {}
|
||||||
|
# Store profile and cli_vars for creating strict context later
|
||||||
|
self.profile = profile
|
||||||
|
self.cli_vars = cli_vars
|
||||||
|
|
||||||
|
# By default, require vars (strict mode) for proper error messages.
|
||||||
|
# Commands that don't need vars (like 'deps') should explicitly pass
|
||||||
|
# require_vars=False for lenient loading.
|
||||||
if profile:
|
if profile:
|
||||||
self.ctx_obj = TargetContext(profile.to_target_dict(), cli_vars)
|
self.ctx_obj = TargetContext(
|
||||||
|
profile.to_target_dict(), cli_vars, require_vars=require_vars
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
self.ctx_obj = BaseContext(cli_vars) # type:ignore
|
self.ctx_obj = BaseContext(cli_vars, require_vars=require_vars) # type:ignore
|
||||||
context = self.ctx_obj.to_dict()
|
context = self.ctx_obj.to_dict()
|
||||||
super().__init__(context)
|
super().__init__(context)
|
||||||
|
|
||||||
|
|||||||
@@ -52,9 +52,10 @@ def load_project(
|
|||||||
profile: HasCredentials,
|
profile: HasCredentials,
|
||||||
cli_vars: Optional[Dict[str, Any]] = None,
|
cli_vars: Optional[Dict[str, Any]] = None,
|
||||||
validate: bool = False,
|
validate: bool = False,
|
||||||
|
require_vars: bool = True,
|
||||||
) -> Project:
|
) -> Project:
|
||||||
# get the project with all of the provided information
|
# get the project with all of the provided information
|
||||||
project_renderer = DbtProjectYamlRenderer(profile, cli_vars)
|
project_renderer = DbtProjectYamlRenderer(profile, cli_vars, require_vars=require_vars)
|
||||||
project = Project.from_project_root(
|
project = Project.from_project_root(
|
||||||
project_root, project_renderer, verify_version=version_check, validate=validate
|
project_root, project_renderer, verify_version=version_check, validate=validate
|
||||||
)
|
)
|
||||||
@@ -267,7 +268,14 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
|||||||
args,
|
args,
|
||||||
)
|
)
|
||||||
flags = get_flags()
|
flags = get_flags()
|
||||||
project = load_project(project_root, bool(flags.VERSION_CHECK), profile, cli_vars)
|
# For dbt deps, use lenient var validation to allow missing vars
|
||||||
|
# For all other commands, use strict validation for helpful error messages
|
||||||
|
# If command is not set (e.g., during test setup), default to strict mode
|
||||||
|
# unless the command is explicitly "deps"
|
||||||
|
require_vars = getattr(flags, "WHICH", None) != "deps"
|
||||||
|
project = load_project(
|
||||||
|
project_root, bool(flags.VERSION_CHECK), profile, cli_vars, require_vars=require_vars
|
||||||
|
)
|
||||||
return project, profile
|
return project, profile
|
||||||
|
|
||||||
# Called in task/base.py, in BaseTask.from_args
|
# Called in task/base.py, in BaseTask.from_args
|
||||||
|
|||||||
@@ -152,10 +152,12 @@ class Var:
|
|||||||
context: Mapping[str, Any],
|
context: Mapping[str, Any],
|
||||||
cli_vars: Mapping[str, Any],
|
cli_vars: Mapping[str, Any],
|
||||||
node: Optional[Resource] = None,
|
node: Optional[Resource] = None,
|
||||||
|
require_vars: bool = True,
|
||||||
) -> None:
|
) -> None:
|
||||||
self._context: Mapping[str, Any] = context
|
self._context: Mapping[str, Any] = context
|
||||||
self._cli_vars: Mapping[str, Any] = cli_vars
|
self._cli_vars: Mapping[str, Any] = cli_vars
|
||||||
self._node: Optional[Resource] = node
|
self._node: Optional[Resource] = node
|
||||||
|
self._require_vars: bool = require_vars
|
||||||
self._merged: Mapping[str, Any] = self._generate_merged()
|
self._merged: Mapping[str, Any] = self._generate_merged()
|
||||||
|
|
||||||
def _generate_merged(self) -> Mapping[str, Any]:
|
def _generate_merged(self) -> Mapping[str, Any]:
|
||||||
@@ -168,9 +170,11 @@ class Var:
|
|||||||
else:
|
else:
|
||||||
return "<Configuration>"
|
return "<Configuration>"
|
||||||
|
|
||||||
def get_missing_var(self, var_name: str) -> NoReturn:
|
def get_missing_var(self, var_name: str) -> None:
|
||||||
# TODO function name implies a non exception resolution
|
# Only raise an error if vars are _required_
|
||||||
raise RequiredVarNotFoundError(var_name, dict(self._merged), self._node)
|
if self._require_vars:
|
||||||
|
# TODO function name implies a non exception resolution
|
||||||
|
raise RequiredVarNotFoundError(var_name, dict(self._merged), self._node)
|
||||||
|
|
||||||
def has_var(self, var_name: str) -> bool:
|
def has_var(self, var_name: str) -> bool:
|
||||||
return var_name in self._merged
|
return var_name in self._merged
|
||||||
@@ -198,10 +202,11 @@ class BaseContext(metaclass=ContextMeta):
|
|||||||
_context_attrs_: Dict[str, Any]
|
_context_attrs_: Dict[str, Any]
|
||||||
|
|
||||||
# subclass is TargetContext
|
# subclass is TargetContext
|
||||||
def __init__(self, cli_vars: Dict[str, Any]) -> None:
|
def __init__(self, cli_vars: Dict[str, Any], require_vars: bool = True) -> None:
|
||||||
self._ctx: Dict[str, Any] = {}
|
self._ctx: Dict[str, Any] = {}
|
||||||
self.cli_vars: Dict[str, Any] = cli_vars
|
self.cli_vars: Dict[str, Any] = cli_vars
|
||||||
self.env_vars: Dict[str, Any] = {}
|
self.env_vars: Dict[str, Any] = {}
|
||||||
|
self.require_vars: bool = require_vars
|
||||||
|
|
||||||
def generate_builtins(self) -> Dict[str, Any]:
|
def generate_builtins(self) -> Dict[str, Any]:
|
||||||
builtins: Dict[str, Any] = {}
|
builtins: Dict[str, Any] = {}
|
||||||
@@ -307,7 +312,7 @@ class BaseContext(metaclass=ContextMeta):
|
|||||||
from events
|
from events
|
||||||
where event_type = '{{ var("event_type", "activation") }}'
|
where event_type = '{{ var("event_type", "activation") }}'
|
||||||
"""
|
"""
|
||||||
return Var(self._ctx, self.cli_vars)
|
return Var(self._ctx, self.cli_vars, require_vars=self.require_vars)
|
||||||
|
|
||||||
@contextmember()
|
@contextmember()
|
||||||
def env_var(self, var: str, default: Optional[str] = None) -> str:
|
def env_var(self, var: str, default: Optional[str] = None) -> str:
|
||||||
|
|||||||
@@ -15,8 +15,8 @@ class ConfiguredContext(TargetContext):
|
|||||||
# subclasses are SchemaYamlContext, MacroResolvingContext, ManifestContext
|
# subclasses are SchemaYamlContext, MacroResolvingContext, ManifestContext
|
||||||
config: AdapterRequiredConfig
|
config: AdapterRequiredConfig
|
||||||
|
|
||||||
def __init__(self, config: AdapterRequiredConfig) -> None:
|
def __init__(self, config: AdapterRequiredConfig, require_vars: bool = True) -> None:
|
||||||
super().__init__(config.to_target_dict(), config.cli_vars)
|
super().__init__(config.to_target_dict(), config.cli_vars, require_vars=require_vars)
|
||||||
self.config = config
|
self.config = config
|
||||||
|
|
||||||
@contextproperty()
|
@contextproperty()
|
||||||
|
|||||||
@@ -544,9 +544,15 @@ class ParseConfigObject(Config):
|
|||||||
def require(self, name, validator=None):
|
def require(self, name, validator=None):
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
|
def meta_require(self, name, validator=None):
|
||||||
|
return ""
|
||||||
|
|
||||||
def get(self, name, default=None, validator=None):
|
def get(self, name, default=None, validator=None):
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
|
def meta_get(self, name, default=None, validator=None):
|
||||||
|
return ""
|
||||||
|
|
||||||
def persist_relation_docs(self) -> bool:
|
def persist_relation_docs(self) -> bool:
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@@ -578,6 +584,16 @@ class RuntimeConfigObject(Config):
|
|||||||
raise MissingConfigError(unique_id=self.model.unique_id, name=name)
|
raise MissingConfigError(unique_id=self.model.unique_id, name=name)
|
||||||
return result
|
return result
|
||||||
|
|
||||||
|
def _lookup_meta(self, name, default=_MISSING):
|
||||||
|
# if this is a macro, there might be no `model.config`.
|
||||||
|
if not hasattr(self.model, "config"):
|
||||||
|
result = default
|
||||||
|
else:
|
||||||
|
result = self.model.config.meta_get(name, default)
|
||||||
|
if result is _MISSING:
|
||||||
|
raise MissingConfigError(unique_id=self.model.unique_id, name=name)
|
||||||
|
return result
|
||||||
|
|
||||||
def require(self, name, validator=None):
|
def require(self, name, validator=None):
|
||||||
to_return = self._lookup(name)
|
to_return = self._lookup(name)
|
||||||
|
|
||||||
@@ -586,6 +602,12 @@ class RuntimeConfigObject(Config):
|
|||||||
|
|
||||||
return to_return
|
return to_return
|
||||||
|
|
||||||
|
def meta_require(self, name, validator=None):
|
||||||
|
to_return = self._lookup_meta(name)
|
||||||
|
|
||||||
|
if validator is not None:
|
||||||
|
self._validate(validator, to_return)
|
||||||
|
|
||||||
def get(self, name, default=None, validator=None):
|
def get(self, name, default=None, validator=None):
|
||||||
to_return = self._lookup(name, default)
|
to_return = self._lookup(name, default)
|
||||||
|
|
||||||
@@ -594,6 +616,14 @@ class RuntimeConfigObject(Config):
|
|||||||
|
|
||||||
return to_return
|
return to_return
|
||||||
|
|
||||||
|
def meta_get(self, name, default=None, validator=None):
|
||||||
|
to_return = self._lookup_meta(name, default)
|
||||||
|
|
||||||
|
if validator is not None and default is not None:
|
||||||
|
self._validate(validator, to_return)
|
||||||
|
|
||||||
|
return to_return
|
||||||
|
|
||||||
def persist_relation_docs(self) -> bool:
|
def persist_relation_docs(self) -> bool:
|
||||||
persist_docs = self.get("persist_docs", default={})
|
persist_docs = self.get("persist_docs", default={})
|
||||||
if not isinstance(persist_docs, dict):
|
if not isinstance(persist_docs, dict):
|
||||||
@@ -854,7 +884,12 @@ class RuntimeUnitTestSourceResolver(BaseSourceResolver):
|
|||||||
# we just need to set_cte, but skipping it confuses typing. We *do* need
|
# we just need to set_cte, but skipping it confuses typing. We *do* need
|
||||||
# the relation in the "this" property.
|
# the relation in the "this" property.
|
||||||
self.model.set_cte(target_source.unique_id, None)
|
self.model.set_cte(target_source.unique_id, None)
|
||||||
return self.Relation.create_ephemeral_from(target_source)
|
|
||||||
|
identifier = self.Relation.add_ephemeral_prefix(target_source.cte_name)
|
||||||
|
return self.Relation.create(
|
||||||
|
type=self.Relation.CTE,
|
||||||
|
identifier=identifier,
|
||||||
|
).quote(identifier=False)
|
||||||
|
|
||||||
|
|
||||||
# metric` implementations
|
# metric` implementations
|
||||||
|
|||||||
@@ -5,8 +5,10 @@ from dbt.context.base import BaseContext, contextproperty
|
|||||||
|
|
||||||
class TargetContext(BaseContext):
|
class TargetContext(BaseContext):
|
||||||
# subclass is ConfiguredContext
|
# subclass is ConfiguredContext
|
||||||
def __init__(self, target_dict: Dict[str, Any], cli_vars: Dict[str, Any]):
|
def __init__(
|
||||||
super().__init__(cli_vars=cli_vars)
|
self, target_dict: Dict[str, Any], cli_vars: Dict[str, Any], require_vars: bool = True
|
||||||
|
):
|
||||||
|
super().__init__(cli_vars=cli_vars, require_vars=require_vars)
|
||||||
self.target_dict = target_dict
|
self.target_dict = target_dict
|
||||||
|
|
||||||
@contextproperty()
|
@contextproperty()
|
||||||
|
|||||||
@@ -161,6 +161,7 @@ class SourceFile(BaseSourceFile):
|
|||||||
docs: List[str] = field(default_factory=list)
|
docs: List[str] = field(default_factory=list)
|
||||||
macros: List[str] = field(default_factory=list)
|
macros: List[str] = field(default_factory=list)
|
||||||
env_vars: List[str] = field(default_factory=list)
|
env_vars: List[str] = field(default_factory=list)
|
||||||
|
functions: List[str] = field(default_factory=list)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def big_seed(cls, path: FilePath) -> "SourceFile":
|
def big_seed(cls, path: FilePath) -> "SourceFile":
|
||||||
|
|||||||
@@ -1715,9 +1715,10 @@ class Manifest(MacroMethods, dbtClassMixin):
|
|||||||
self.exposures[exposure.unique_id] = exposure
|
self.exposures[exposure.unique_id] = exposure
|
||||||
source_file.exposures.append(exposure.unique_id)
|
source_file.exposures.append(exposure.unique_id)
|
||||||
|
|
||||||
def add_function(self, function: FunctionNode):
|
def add_function(self, source_file: SourceFile, function: FunctionNode):
|
||||||
_check_duplicates(function, self.functions)
|
_check_duplicates(function, self.functions)
|
||||||
self.functions[function.unique_id] = function
|
self.functions[function.unique_id] = function
|
||||||
|
source_file.functions.append(function.unique_id)
|
||||||
|
|
||||||
def add_metric(
|
def add_metric(
|
||||||
self, source_file: SchemaSourceFile, metric: Metric, generated_from: Optional[str] = None
|
self, source_file: SchemaSourceFile, metric: Metric, generated_from: Optional[str] = None
|
||||||
|
|||||||
@@ -697,6 +697,36 @@ class ModelNode(ModelResource, CompiledNode):
|
|||||||
)
|
)
|
||||||
)
|
)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _normalize_data_type_for_comparison(data_type: Optional[str]) -> Optional[str]:
|
||||||
|
"""
|
||||||
|
Normalize a data type string by removing size, precision, and scale parameters.
|
||||||
|
This allows comparison of base types while ignoring non-breaking parameter changes.
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
varchar(10) -> varchar
|
||||||
|
VARCHAR(5) -> varchar
|
||||||
|
numeric(10,2) -> numeric
|
||||||
|
text -> text
|
||||||
|
decimal(5) -> decimal
|
||||||
|
None -> None
|
||||||
|
|
||||||
|
Per dbt documentation, changes to size/precision/scale should not be
|
||||||
|
considered breaking changes for contracts.
|
||||||
|
See: https://docs.getdbt.com/reference/resource-configs/contract#size-precision-and-scale
|
||||||
|
|
||||||
|
Note: Comparison is case-insensitive. Type aliases (e.g., 'varchar' vs
|
||||||
|
'character varying') are not automatically resolved - users should use
|
||||||
|
consistent type names in their contracts to avoid false positives.
|
||||||
|
"""
|
||||||
|
if not data_type:
|
||||||
|
return data_type
|
||||||
|
|
||||||
|
# Split on the first '(' to get the base type without parameters
|
||||||
|
# Convert to lowercase for case-insensitive comparison
|
||||||
|
base_type, _, _ = data_type.partition("(")
|
||||||
|
return base_type.strip().lower()
|
||||||
|
|
||||||
def same_contract(self, old, adapter_type=None) -> bool:
|
def same_contract(self, old, adapter_type=None) -> bool:
|
||||||
# If the contract wasn't previously enforced:
|
# If the contract wasn't previously enforced:
|
||||||
if old.contract.enforced is False and self.contract.enforced is False:
|
if old.contract.enforced is False and self.contract.enforced is False:
|
||||||
@@ -738,14 +768,24 @@ class ModelNode(ModelResource, CompiledNode):
|
|||||||
columns_removed.append(old_value.name)
|
columns_removed.append(old_value.name)
|
||||||
# Has this column's data type changed?
|
# Has this column's data type changed?
|
||||||
elif old_value.data_type != self.columns[old_key].data_type:
|
elif old_value.data_type != self.columns[old_key].data_type:
|
||||||
column_type_changes.append(
|
# Compare normalized data types (without size/precision/scale)
|
||||||
{
|
# to determine if this is a breaking change
|
||||||
"column_name": str(old_value.name),
|
old_normalized = self._normalize_data_type_for_comparison(old_value.data_type)
|
||||||
"previous_column_type": str(old_value.data_type),
|
new_normalized = self._normalize_data_type_for_comparison(
|
||||||
"current_column_type": str(self.columns[old_key].data_type),
|
self.columns[old_key].data_type
|
||||||
}
|
|
||||||
)
|
)
|
||||||
|
|
||||||
|
# Only consider it a breaking change if the base types differ
|
||||||
|
# Changes like varchar(3) -> varchar(10) are not breaking
|
||||||
|
if old_normalized != new_normalized:
|
||||||
|
column_type_changes.append(
|
||||||
|
{
|
||||||
|
"column_name": str(old_value.name),
|
||||||
|
"previous_column_type": str(old_value.data_type),
|
||||||
|
"current_column_type": str(self.columns[old_key].data_type),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
# track if there are any column level constraints for the materialization check late
|
# track if there are any column level constraints for the materialization check late
|
||||||
if old_value.constraints:
|
if old_value.constraints:
|
||||||
column_constraints_exist = True
|
column_constraints_exist = True
|
||||||
@@ -1058,6 +1098,10 @@ class UnitTestSourceDefinition(ModelNode):
|
|||||||
source_name: str = "undefined"
|
source_name: str = "undefined"
|
||||||
quoting: QuotingResource = field(default_factory=QuotingResource)
|
quoting: QuotingResource = field(default_factory=QuotingResource)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def cte_name(self):
|
||||||
|
return self.unique_id.split(".")[-1]
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def search_name(self):
|
def search_name(self):
|
||||||
return f"{self.source_name}.{self.name}"
|
return f"{self.source_name}.{self.name}"
|
||||||
|
|||||||
@@ -366,6 +366,7 @@ class ProjectFlags(ExtensibleDbtClassMixin):
|
|||||||
validate_macro_args: bool = False
|
validate_macro_args: bool = False
|
||||||
require_all_warnings_handled_by_warn_error: bool = False
|
require_all_warnings_handled_by_warn_error: bool = False
|
||||||
require_generic_test_arguments_property: bool = True
|
require_generic_test_arguments_property: bool = True
|
||||||
|
require_unique_project_resource_names: bool = False
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def project_only_flags(self) -> Dict[str, Any]:
|
def project_only_flags(self) -> Dict[str, Any]:
|
||||||
@@ -382,6 +383,7 @@ class ProjectFlags(ExtensibleDbtClassMixin):
|
|||||||
"validate_macro_args": self.validate_macro_args,
|
"validate_macro_args": self.validate_macro_args,
|
||||||
"require_all_warnings_handled_by_warn_error": self.require_all_warnings_handled_by_warn_error,
|
"require_all_warnings_handled_by_warn_error": self.require_all_warnings_handled_by_warn_error,
|
||||||
"require_generic_test_arguments_property": self.require_generic_test_arguments_property,
|
"require_generic_test_arguments_property": self.require_generic_test_arguments_property,
|
||||||
|
"require_unique_project_resource_names": self.require_unique_project_resource_names,
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -230,6 +230,11 @@ class ModulesItertoolsUsageDeprecation(DBTDeprecation):
|
|||||||
_event = "ModulesItertoolsUsageDeprecation"
|
_event = "ModulesItertoolsUsageDeprecation"
|
||||||
|
|
||||||
|
|
||||||
|
class DuplicateNameDistinctNodeTypesDeprecation(DBTDeprecation):
|
||||||
|
_name = "duplicate-name-distinct-node-types-deprecation"
|
||||||
|
_event = "DuplicateNameDistinctNodeTypesDeprecation"
|
||||||
|
|
||||||
|
|
||||||
def renamed_env_var(old_name: str, new_name: str):
|
def renamed_env_var(old_name: str, new_name: str):
|
||||||
class EnvironmentVariableRenamed(DBTDeprecation):
|
class EnvironmentVariableRenamed(DBTDeprecation):
|
||||||
_name = f"environment-variable-renamed:{old_name}"
|
_name = f"environment-variable-renamed:{old_name}"
|
||||||
@@ -266,7 +271,7 @@ def show_deprecations_summary() -> None:
|
|||||||
deprecation_event = deprecations[deprecation].event()
|
deprecation_event = deprecations[deprecation].event()
|
||||||
summaries.append(
|
summaries.append(
|
||||||
DeprecationSummary(
|
DeprecationSummary(
|
||||||
event_name=deprecation_event.__name__,
|
event_name=type(deprecation_event).__name__,
|
||||||
event_code=deprecation_event.code(),
|
event_code=deprecation_event.code(),
|
||||||
occurrences=occurrences,
|
occurrences=occurrences,
|
||||||
).to_msg_dict()
|
).to_msg_dict()
|
||||||
@@ -316,6 +321,7 @@ deprecations_list: List[DBTDeprecation] = [
|
|||||||
ArgumentsPropertyInGenericTestDeprecation(),
|
ArgumentsPropertyInGenericTestDeprecation(),
|
||||||
MissingArgumentsPropertyInGenericTestDeprecation(),
|
MissingArgumentsPropertyInGenericTestDeprecation(),
|
||||||
ModulesItertoolsUsageDeprecation(),
|
ModulesItertoolsUsageDeprecation(),
|
||||||
|
DuplicateNameDistinctNodeTypesDeprecation(),
|
||||||
]
|
]
|
||||||
|
|
||||||
deprecations: Dict[str, DBTDeprecation] = {d.name: d for d in deprecations_list}
|
deprecations: Dict[str, DBTDeprecation] = {d.name: d for d in deprecations_list}
|
||||||
|
|||||||
@@ -16,15 +16,14 @@ from dbt_common.events.format import (
|
|||||||
pluralize,
|
pluralize,
|
||||||
timestamp_to_datetime_string,
|
timestamp_to_datetime_string,
|
||||||
)
|
)
|
||||||
from dbt_common.ui import (
|
from dbt_common.ui import deprecation_tag as deprecation_tag_less_strict
|
||||||
deprecation_tag,
|
from dbt_common.ui import error_tag, green, line_wrap_message, red, warning_tag, yellow
|
||||||
error_tag,
|
|
||||||
green,
|
|
||||||
line_wrap_message,
|
# This makes it so that mypy will complain if a deprecation tag is used without an event name
|
||||||
red,
|
def _deprecation_tag(description: str, event_name: str) -> str:
|
||||||
warning_tag,
|
return deprecation_tag_less_strict(description, event_name)
|
||||||
yellow,
|
|
||||||
)
|
|
||||||
|
|
||||||
# Event codes have prefixes which follow this table
|
# Event codes have prefixes which follow this table
|
||||||
#
|
#
|
||||||
@@ -260,7 +259,7 @@ class DeprecatedModel(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(msg, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(msg, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return warning_tag(msg)
|
return warning_tag(msg)
|
||||||
|
|
||||||
@@ -276,9 +275,9 @@ class PackageRedirectDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class PackageInstallPathDeprecation(WarnLevel):
|
class PackageInstallPathDeprecation(WarnLevel):
|
||||||
@@ -293,9 +292,9 @@ class PackageInstallPathDeprecation(WarnLevel):
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class ConfigSourcePathDeprecation(WarnLevel):
|
class ConfigSourcePathDeprecation(WarnLevel):
|
||||||
@@ -309,9 +308,9 @@ class ConfigSourcePathDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class ConfigDataPathDeprecation(WarnLevel):
|
class ConfigDataPathDeprecation(WarnLevel):
|
||||||
@@ -325,9 +324,9 @@ class ConfigDataPathDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class MetricAttributesRenamed(WarnLevel):
|
class MetricAttributesRenamed(WarnLevel):
|
||||||
@@ -345,9 +344,9 @@ class MetricAttributesRenamed(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return deprecation_tag(description)
|
return deprecation_tag_less_strict(description)
|
||||||
|
|
||||||
|
|
||||||
class ExposureNameDeprecation(WarnLevel):
|
class ExposureNameDeprecation(WarnLevel):
|
||||||
@@ -364,9 +363,9 @@ class ExposureNameDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class InternalDeprecation(WarnLevel):
|
class InternalDeprecation(WarnLevel):
|
||||||
@@ -383,7 +382,7 @@ class InternalDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return deprecation_tag(msg, self.__class__.__name__)
|
return _deprecation_tag(msg, self.__class__.__name__)
|
||||||
else:
|
else:
|
||||||
return warning_tag(msg)
|
return warning_tag(msg)
|
||||||
|
|
||||||
@@ -401,9 +400,9 @@ class EnvironmentVariableRenamed(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class ConfigLogPathDeprecation(WarnLevel):
|
class ConfigLogPathDeprecation(WarnLevel):
|
||||||
@@ -422,9 +421,9 @@ class ConfigLogPathDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class ConfigTargetPathDeprecation(WarnLevel):
|
class ConfigTargetPathDeprecation(WarnLevel):
|
||||||
@@ -443,9 +442,9 @@ class ConfigTargetPathDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
# Note: this deprecation has been removed, but we are leaving
|
# Note: this deprecation has been removed, but we are leaving
|
||||||
@@ -462,9 +461,9 @@ class TestsConfigDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(deprecation_tag_less_strict(description))
|
||||||
|
|
||||||
|
|
||||||
class ProjectFlagsMovedDeprecation(WarnLevel):
|
class ProjectFlagsMovedDeprecation(WarnLevel):
|
||||||
@@ -478,9 +477,9 @@ class ProjectFlagsMovedDeprecation(WarnLevel):
|
|||||||
)
|
)
|
||||||
# Can't use line_wrap_message here because flags.printer_width isn't available yet
|
# Can't use line_wrap_message here because flags.printer_width isn't available yet
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return deprecation_tag(description, self.__class__.__name__)
|
return _deprecation_tag(description, self.__class__.__name__)
|
||||||
else:
|
else:
|
||||||
return deprecation_tag(description)
|
return deprecation_tag_less_strict(description)
|
||||||
|
|
||||||
|
|
||||||
class SpacesInResourceNameDeprecation(DynamicLevel):
|
class SpacesInResourceNameDeprecation(DynamicLevel):
|
||||||
@@ -496,7 +495,7 @@ class SpacesInResourceNameDeprecation(DynamicLevel):
|
|||||||
description = warning_tag(description)
|
description = warning_tag(description)
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(description)
|
return line_wrap_message(description)
|
||||||
|
|
||||||
@@ -514,7 +513,7 @@ class ResourceNamesWithSpacesDeprecation(WarnLevel):
|
|||||||
description += " For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
description += " For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -527,7 +526,7 @@ class PackageMaterializationOverrideDeprecation(WarnLevel):
|
|||||||
description = f"Installed package '{self.package_name}' is overriding the built-in materialization '{self.materialization_name}'. Overrides of built-in materializations from installed packages will be deprecated in future versions of dbt. For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
description = f"Installed package '{self.package_name}' is overriding the built-in materialization '{self.materialization_name}'. Overrides of built-in materializations from installed packages will be deprecated in future versions of dbt. For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -540,7 +539,7 @@ class SourceFreshnessProjectHooksNotRun(WarnLevel):
|
|||||||
description = "In a future version of dbt, the `source freshness` command will start running `on-run-start` and `on-run-end` hooks by default. For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
description = "In a future version of dbt, the `source freshness` command will start running `on-run-start` and `on-run-end` hooks by default. For more information: https://docs.getdbt.com/reference/global-configs/legacy-behaviors"
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -553,7 +552,7 @@ class MFTimespineWithoutYamlConfigurationDeprecation(WarnLevel):
|
|||||||
description = "Time spines without YAML configuration are in the process of deprecation. Please add YAML configuration for your 'metricflow_time_spine' model. See documentation on MetricFlow time spines: https://docs.getdbt.com/docs/build/metricflow-time-spine and behavior change documentation: https://docs.getdbt.com/reference/global-configs/behavior-changes."
|
description = "Time spines without YAML configuration are in the process of deprecation. Please add YAML configuration for your 'metricflow_time_spine' model. See documentation on MetricFlow time spines: https://docs.getdbt.com/docs/build/metricflow-time-spine and behavior change documentation: https://docs.getdbt.com/reference/global-configs/behavior-changes."
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -566,7 +565,7 @@ class MFCumulativeTypeParamsDeprecation(WarnLevel):
|
|||||||
description = "Cumulative fields `type_params.window` and `type_params.grain_to_date` have been moved and will soon be deprecated. Please nest those values under `type_params.cumulative_type_params.window` and `type_params.cumulative_type_params.grain_to_date`. See documentation on behavior changes: https://docs.getdbt.com/reference/global-configs/behavior-changes."
|
description = "Cumulative fields `type_params.window` and `type_params.grain_to_date` have been moved and will soon be deprecated. Please nest those values under `type_params.cumulative_type_params.window` and `type_params.cumulative_type_params.grain_to_date`. See documentation on behavior changes: https://docs.getdbt.com/reference/global-configs/behavior-changes."
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -579,7 +578,7 @@ class MicrobatchMacroOutsideOfBatchesDeprecation(WarnLevel):
|
|||||||
description = "The use of a custom microbatch macro outside of batched execution is deprecated. To use it with batched execution, set `flags.require_batched_execution_for_custom_microbatch_strategy` to `True` in `dbt_project.yml`. In the future this will be the default behavior."
|
description = "The use of a custom microbatch macro outside of batched execution is deprecated. To use it with batched execution, set `flags.require_batched_execution_for_custom_microbatch_strategy` to `True` in `dbt_project.yml`. In the future this will be the default behavior."
|
||||||
|
|
||||||
if require_event_names_in_deprecations():
|
if require_event_names_in_deprecations():
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
else:
|
else:
|
||||||
return line_wrap_message(warning_tag(description))
|
return line_wrap_message(warning_tag(description))
|
||||||
|
|
||||||
@@ -599,7 +598,7 @@ class GenericJSONSchemaValidationDeprecation(WarnLevel):
|
|||||||
else:
|
else:
|
||||||
description = f"{self.violation} in file `{self.file}` at path `{self.key_path}` is possibly a deprecation. {possible_causes}"
|
description = f"{self.violation} in file `{self.file}` at path `{self.key_path}` is possibly a deprecation. {possible_causes}"
|
||||||
|
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class UnexpectedJinjaBlockDeprecation(WarnLevel):
|
class UnexpectedJinjaBlockDeprecation(WarnLevel):
|
||||||
@@ -608,7 +607,7 @@ class UnexpectedJinjaBlockDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"{self.msg} in file `{self.file}`"
|
description = f"{self.msg} in file `{self.file}`"
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class DuplicateYAMLKeysDeprecation(WarnLevel):
|
class DuplicateYAMLKeysDeprecation(WarnLevel):
|
||||||
@@ -617,7 +616,7 @@ class DuplicateYAMLKeysDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"{self.duplicate_description} in file `{self.file}`"
|
description = f"{self.duplicate_description} in file `{self.file}`"
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class CustomTopLevelKeyDeprecation(WarnLevel):
|
class CustomTopLevelKeyDeprecation(WarnLevel):
|
||||||
@@ -626,7 +625,7 @@ class CustomTopLevelKeyDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"{self.msg} in file `{self.file}`"
|
description = f"{self.msg} in file `{self.file}`"
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class CustomKeyInConfigDeprecation(WarnLevel):
|
class CustomKeyInConfigDeprecation(WarnLevel):
|
||||||
@@ -639,7 +638,7 @@ class CustomKeyInConfigDeprecation(WarnLevel):
|
|||||||
path_specification = f" at path `{self.key_path}`"
|
path_specification = f" at path `{self.key_path}`"
|
||||||
|
|
||||||
description = f"Custom key `{self.key}` found in `config`{path_specification} in file `{self.file}`. Custom config keys should move into the `config.meta`."
|
description = f"Custom key `{self.key}` found in `config`{path_specification} in file `{self.file}`. Custom config keys should move into the `config.meta`."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class CustomKeyInObjectDeprecation(WarnLevel):
|
class CustomKeyInObjectDeprecation(WarnLevel):
|
||||||
@@ -648,7 +647,7 @@ class CustomKeyInObjectDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Custom key `{self.key}` found at `{self.key_path}` in file `{self.file}`. This may mean the key is a typo, or is simply not a key supported by the object."
|
description = f"Custom key `{self.key}` found at `{self.key_path}` in file `{self.file}`. This may mean the key is a typo, or is simply not a key supported by the object."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class DeprecationsSummary(WarnLevel):
|
class DeprecationsSummary(WarnLevel):
|
||||||
@@ -665,7 +664,7 @@ class DeprecationsSummary(WarnLevel):
|
|||||||
if self.show_all_hint:
|
if self.show_all_hint:
|
||||||
description += "\n\nTo see all deprecation instances instead of just the first occurrence of each, run command again with the `--show-all-deprecations` flag. You may also need to run with `--no-partial-parse` as some deprecations are only encountered during parsing."
|
description += "\n\nTo see all deprecation instances instead of just the first occurrence of each, run command again with the `--show-all-deprecations` flag. You may also need to run with `--no-partial-parse` as some deprecations are only encountered during parsing."
|
||||||
|
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class CustomOutputPathInSourceFreshnessDeprecation(WarnLevel):
|
class CustomOutputPathInSourceFreshnessDeprecation(WarnLevel):
|
||||||
@@ -674,7 +673,7 @@ class CustomOutputPathInSourceFreshnessDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Custom output path usage `--output {self.path}` usage detected in `dbt source freshness` command."
|
description = f"Custom output path usage `--output {self.path}` usage detected in `dbt source freshness` command."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class PropertyMovedToConfigDeprecation(WarnLevel):
|
class PropertyMovedToConfigDeprecation(WarnLevel):
|
||||||
@@ -683,7 +682,7 @@ class PropertyMovedToConfigDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Found `{self.key}` as a top-level property of `{self.key_path}` in file `{self.file}`. The `{self.key}` top-level property should be moved into the `config` of `{self.key_path}`."
|
description = f"Found `{self.key}` as a top-level property of `{self.key_path}` in file `{self.file}`. The `{self.key}` top-level property should be moved into the `config` of `{self.key_path}`."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class WEOIncludeExcludeDeprecation(WarnLevel):
|
class WEOIncludeExcludeDeprecation(WarnLevel):
|
||||||
@@ -703,7 +702,7 @@ class WEOIncludeExcludeDeprecation(WarnLevel):
|
|||||||
if self.found_exclude:
|
if self.found_exclude:
|
||||||
description += " Please use `warn` instead of `exclude`."
|
description += " Please use `warn` instead of `exclude`."
|
||||||
|
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class ModelParamUsageDeprecation(WarnLevel):
|
class ModelParamUsageDeprecation(WarnLevel):
|
||||||
@@ -712,7 +711,7 @@ class ModelParamUsageDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = "Usage of `--models`, `--model`, and `-m` is deprecated in favor of `--select` or `-s`."
|
description = "Usage of `--models`, `--model`, and `-m` is deprecated in favor of `--select` or `-s`."
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class ModulesItertoolsUsageDeprecation(WarnLevel):
|
class ModulesItertoolsUsageDeprecation(WarnLevel):
|
||||||
@@ -723,7 +722,7 @@ class ModulesItertoolsUsageDeprecation(WarnLevel):
|
|||||||
description = (
|
description = (
|
||||||
"Usage of itertools modules is deprecated. Please use the built-in functions instead."
|
"Usage of itertools modules is deprecated. Please use the built-in functions instead."
|
||||||
)
|
)
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class SourceOverrideDeprecation(WarnLevel):
|
class SourceOverrideDeprecation(WarnLevel):
|
||||||
@@ -732,7 +731,7 @@ class SourceOverrideDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"The source property `overrides` is deprecated but was found on source `{self.source_name}` in file `{self.file}`. Instead, `enabled` should be used to disable the unwanted source."
|
description = f"The source property `overrides` is deprecated but was found on source `{self.source_name}` in file `{self.file}`. Instead, `enabled` should be used to disable the unwanted source."
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class EnvironmentVariableNamespaceDeprecation(WarnLevel):
|
class EnvironmentVariableNamespaceDeprecation(WarnLevel):
|
||||||
@@ -741,7 +740,7 @@ class EnvironmentVariableNamespaceDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Found custom environment variable `{self.env_var}` in the environment. The prefix `{self.reserved_prefix}` is reserved for dbt engine environment variables. Custom environment variables with the prefix `{self.reserved_prefix}` may cause collisions and runtime errors."
|
description = f"Found custom environment variable `{self.env_var}` in the environment. The prefix `{self.reserved_prefix}` is reserved for dbt engine environment variables. Custom environment variables with the prefix `{self.reserved_prefix}` may cause collisions and runtime errors."
|
||||||
return line_wrap_message(deprecation_tag(description))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class MissingPlusPrefixDeprecation(WarnLevel):
|
class MissingPlusPrefixDeprecation(WarnLevel):
|
||||||
@@ -750,7 +749,7 @@ class MissingPlusPrefixDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Missing '+' prefix on `{self.key}` found at `{self.key_path}` in file `{self.file}`. Hierarchical config values without a '+' prefix are deprecated in dbt_project.yml."
|
description = f"Missing '+' prefix on `{self.key}` found at `{self.key_path}` in file `{self.file}`. Hierarchical config values without a '+' prefix are deprecated in dbt_project.yml."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class ArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
class ArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
||||||
@@ -759,7 +758,7 @@ class ArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Found `arguments` property in test definition of {self.test_name} without usage of `require_generic_test_arguments_property` behavior change flag. The `arguments` property is deprecated for custom usage and will be used to nest keyword arguments in future versions of dbt."
|
description = f"Found `arguments` property in test definition of {self.test_name} without usage of `require_generic_test_arguments_property` behavior change flag. The `arguments` property is deprecated for custom usage and will be used to nest keyword arguments in future versions of dbt."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
class MissingArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
class MissingArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
||||||
@@ -768,7 +767,16 @@ class MissingArgumentsPropertyInGenericTestDeprecation(WarnLevel):
|
|||||||
|
|
||||||
def message(self) -> str:
|
def message(self) -> str:
|
||||||
description = f"Found top-level arguments to test {self.test_name}. Arguments to generic tests should be nested under the `arguments` property."
|
description = f"Found top-level arguments to test {self.test_name}. Arguments to generic tests should be nested under the `arguments` property."
|
||||||
return line_wrap_message(deprecation_tag(description, self.__class__.__name__))
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
|
class DuplicateNameDistinctNodeTypesDeprecation(WarnLevel):
|
||||||
|
def code(self) -> str:
|
||||||
|
return "D040"
|
||||||
|
|
||||||
|
def message(self) -> str:
|
||||||
|
description = f"Found resources with the same name '{self.resource_name}' in package '{self.package_name}': '{self.unique_id1}' and '{self.unique_id2}'. Please update one of the resources to have a unique name."
|
||||||
|
return line_wrap_message(_deprecation_tag(description, self.__class__.__name__))
|
||||||
|
|
||||||
|
|
||||||
# =======================================================
|
# =======================================================
|
||||||
|
|||||||
@@ -80,7 +80,7 @@ class AliasError(DbtValidationError):
|
|||||||
pass
|
pass
|
||||||
|
|
||||||
|
|
||||||
class DependencyError(Exception):
|
class DependencyError(DbtRuntimeError):
|
||||||
CODE = 10006
|
CODE = 10006
|
||||||
MESSAGE = "Dependency Error"
|
MESSAGE = "Dependency Error"
|
||||||
|
|
||||||
|
|||||||
@@ -120,7 +120,9 @@ class NodeSelector(MethodManager):
|
|||||||
additional.update(self.graph.select_children(selected, depth))
|
additional.update(self.graph.select_children(selected, depth))
|
||||||
return additional
|
return additional
|
||||||
|
|
||||||
def select_nodes_recursively(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
def select_nodes_recursively(
|
||||||
|
self, spec: SelectionSpec, warn_on_no_nodes: bool = True
|
||||||
|
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||||
"""If the spec is a composite spec (a union, difference, or intersection),
|
"""If the spec is a composite spec (a union, difference, or intersection),
|
||||||
recurse into its selections and combine them. If the spec is a concrete
|
recurse into its selections and combine them. If the spec is a concrete
|
||||||
selection criteria, resolve that using the given graph.
|
selection criteria, resolve that using the given graph.
|
||||||
@@ -128,7 +130,10 @@ class NodeSelector(MethodManager):
|
|||||||
if isinstance(spec, SelectionCriteria):
|
if isinstance(spec, SelectionCriteria):
|
||||||
direct_nodes, indirect_nodes = self.get_nodes_from_criteria(spec)
|
direct_nodes, indirect_nodes = self.get_nodes_from_criteria(spec)
|
||||||
else:
|
else:
|
||||||
bundles = [self.select_nodes_recursively(component) for component in spec]
|
bundles = [
|
||||||
|
self.select_nodes_recursively(spec=component, warn_on_no_nodes=warn_on_no_nodes)
|
||||||
|
for component in spec.components
|
||||||
|
]
|
||||||
|
|
||||||
direct_sets = []
|
direct_sets = []
|
||||||
indirect_sets = []
|
indirect_sets = []
|
||||||
@@ -144,19 +149,23 @@ class NodeSelector(MethodManager):
|
|||||||
initial_direct, indirect_nodes, spec.indirect_selection
|
initial_direct, indirect_nodes, spec.indirect_selection
|
||||||
)
|
)
|
||||||
|
|
||||||
if spec.expect_exists and len(direct_nodes) == 0:
|
if spec.expect_exists and len(direct_nodes) == 0 and warn_on_no_nodes:
|
||||||
warn_or_error(NoNodesForSelectionCriteria(spec_raw=str(spec.raw)))
|
warn_or_error(NoNodesForSelectionCriteria(spec_raw=str(spec.raw)))
|
||||||
|
|
||||||
return direct_nodes, indirect_nodes
|
return direct_nodes, indirect_nodes
|
||||||
|
|
||||||
def select_nodes(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
def select_nodes(
|
||||||
|
self, spec: SelectionSpec, warn_on_no_nodes: bool = True
|
||||||
|
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||||
"""Select the nodes in the graph according to the spec.
|
"""Select the nodes in the graph according to the spec.
|
||||||
|
|
||||||
This is the main point of entry for turning a spec into a set of nodes:
|
This is the main point of entry for turning a spec into a set of nodes:
|
||||||
- Recurse through spec, select by criteria, combine by set operation
|
- Recurse through spec, select by criteria, combine by set operation
|
||||||
- Return final (unfiltered) selection set
|
- Return final (unfiltered) selection set
|
||||||
"""
|
"""
|
||||||
direct_nodes, indirect_nodes = self.select_nodes_recursively(spec)
|
direct_nodes, indirect_nodes = self.select_nodes_recursively(
|
||||||
|
spec=spec, warn_on_no_nodes=warn_on_no_nodes
|
||||||
|
)
|
||||||
indirect_only = indirect_nodes.difference(direct_nodes)
|
indirect_only = indirect_nodes.difference(direct_nodes)
|
||||||
return direct_nodes, indirect_only
|
return direct_nodes, indirect_only
|
||||||
|
|
||||||
@@ -324,7 +333,7 @@ class NodeSelector(MethodManager):
|
|||||||
|
|
||||||
return selected
|
return selected
|
||||||
|
|
||||||
def get_selected(self, spec: SelectionSpec) -> Set[UniqueId]:
|
def get_selected(self, spec: SelectionSpec, warn_on_no_nodes: bool = True) -> Set[UniqueId]:
|
||||||
"""get_selected runs through the node selection process:
|
"""get_selected runs through the node selection process:
|
||||||
|
|
||||||
- node selection. Based on the include/exclude sets, the set
|
- node selection. Based on the include/exclude sets, the set
|
||||||
@@ -334,7 +343,9 @@ class NodeSelector(MethodManager):
|
|||||||
- selectors can filter the nodes after all of them have been
|
- selectors can filter the nodes after all of them have been
|
||||||
selected
|
selected
|
||||||
"""
|
"""
|
||||||
selected_nodes, indirect_only = self.select_nodes(spec)
|
selected_nodes, indirect_only = self.select_nodes(
|
||||||
|
spec=spec, warn_on_no_nodes=warn_on_no_nodes
|
||||||
|
)
|
||||||
filtered_nodes = self.filter_selection(selected_nodes)
|
filtered_nodes = self.filter_selection(selected_nodes)
|
||||||
|
|
||||||
return filtered_nodes
|
return filtered_nodes
|
||||||
|
|||||||
@@ -35,7 +35,7 @@ from dbt.contracts.state import PreviousState
|
|||||||
from dbt.node_types import NodeType
|
from dbt.node_types import NodeType
|
||||||
from dbt_common.dataclass_schema import StrEnum
|
from dbt_common.dataclass_schema import StrEnum
|
||||||
from dbt_common.events.contextvars import get_project_root
|
from dbt_common.events.contextvars import get_project_root
|
||||||
from dbt_common.exceptions import DbtInternalError, DbtRuntimeError
|
from dbt_common.exceptions import CompilationError, DbtInternalError, DbtRuntimeError
|
||||||
|
|
||||||
from .graph import UniqueId
|
from .graph import UniqueId
|
||||||
|
|
||||||
@@ -655,6 +655,16 @@ class StateSelectorMethod(SelectorMethod):
|
|||||||
continue
|
continue
|
||||||
visited_macros.append(macro_uid)
|
visited_macros.append(macro_uid)
|
||||||
|
|
||||||
|
# If macro_uid is None, it means the macro/test was removed but is still referenced.
|
||||||
|
# Raise a clear error to match the behavior of regular dbt run.
|
||||||
|
if macro_uid is None:
|
||||||
|
raise CompilationError(
|
||||||
|
f"Node '{node.name}' (in {node.original_file_path}) depends on a macro or test "
|
||||||
|
f"that does not exist. This can happen when a macro or generic test is removed "
|
||||||
|
f"but is still referenced. Check for typos and/or install package dependencies "
|
||||||
|
f"with 'dbt deps'."
|
||||||
|
)
|
||||||
|
|
||||||
if macro_uid in self.modified_macros:
|
if macro_uid in self.modified_macros:
|
||||||
return True
|
return True
|
||||||
|
|
||||||
|
|||||||
@@ -1,5 +1,4 @@
|
|||||||
import json
|
import json
|
||||||
import os
|
|
||||||
import re
|
import re
|
||||||
from datetime import date, datetime
|
from datetime import date, datetime
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
@@ -141,9 +140,6 @@ def _get_allowed_config_fields_from_error_path(
|
|||||||
|
|
||||||
|
|
||||||
def _can_run_validations() -> bool:
|
def _can_run_validations() -> bool:
|
||||||
if not os.environ.get("DBT_ENV_PRIVATE_RUN_JSONSCHEMA_VALIDATIONS"):
|
|
||||||
return False
|
|
||||||
|
|
||||||
invocation_context = get_invocation_context()
|
invocation_context = get_invocation_context()
|
||||||
return invocation_context.adapter_types.issubset(_JSONSCHEMA_SUPPORTED_ADAPTERS)
|
return invocation_context.adapter_types.issubset(_JSONSCHEMA_SUPPORTED_ADAPTERS)
|
||||||
|
|
||||||
@@ -269,6 +265,11 @@ def validate_model_config(config: Dict[str, Any], file_path: str) -> None:
|
|||||||
if len(error.path) == 0:
|
if len(error.path) == 0:
|
||||||
key_path = error_path_to_string(error)
|
key_path = error_path_to_string(error)
|
||||||
for key in keys:
|
for key in keys:
|
||||||
|
# Special case for pre/post hook keys as they are updated during config parsing
|
||||||
|
# from the user-provided pre_hook/post_hook to pre-hook/post-hook keys.
|
||||||
|
# Avoids false positives as described in https://github.com/dbt-labs/dbt-core/issues/12087
|
||||||
|
if key in ("post-hook", "pre-hook"):
|
||||||
|
continue
|
||||||
deprecations.warn(
|
deprecations.warn(
|
||||||
"custom-key-in-config-deprecation",
|
"custom-key-in-config-deprecation",
|
||||||
key=key,
|
key=key,
|
||||||
|
|||||||
@@ -1,4 +1,5 @@
|
|||||||
from dbt.artifacts.resources.types import NodeType
|
from dbt.artifacts.resources.types import NodeType
|
||||||
|
from dbt.contracts.files import SourceFile
|
||||||
from dbt.contracts.graph.nodes import FunctionNode, ManifestNode
|
from dbt.contracts.graph.nodes import FunctionNode, ManifestNode
|
||||||
from dbt.parser.base import SimpleParser
|
from dbt.parser.base import SimpleParser
|
||||||
from dbt.parser.search import FileBlock
|
from dbt.parser.search import FileBlock
|
||||||
@@ -21,10 +22,12 @@ class FunctionParser(SimpleParser[FileBlock, FunctionNode]):
|
|||||||
# overrides SimpleSQLParser.add_result_node
|
# overrides SimpleSQLParser.add_result_node
|
||||||
def add_result_node(self, block: FileBlock, node: ManifestNode):
|
def add_result_node(self, block: FileBlock, node: ManifestNode):
|
||||||
assert isinstance(node, FunctionNode), "Got non FunctionNode in FunctionParser"
|
assert isinstance(node, FunctionNode), "Got non FunctionNode in FunctionParser"
|
||||||
|
file = block.file
|
||||||
|
assert isinstance(file, SourceFile)
|
||||||
if node.config.enabled:
|
if node.config.enabled:
|
||||||
self.manifest.add_function(node)
|
self.manifest.add_function(file, node)
|
||||||
else:
|
else:
|
||||||
self.manifest.add_disabled(block.file, node)
|
self.manifest.add_disabled(file, node)
|
||||||
|
|
||||||
def parse_file(self, file_block: FileBlock) -> None:
|
def parse_file(self, file_block: FileBlock) -> None:
|
||||||
self.parse_node(file_block)
|
self.parse_node(file_block)
|
||||||
|
|||||||
@@ -90,6 +90,7 @@ from dbt.events.types import (
|
|||||||
)
|
)
|
||||||
from dbt.exceptions import (
|
from dbt.exceptions import (
|
||||||
AmbiguousAliasError,
|
AmbiguousAliasError,
|
||||||
|
DuplicateResourceNameError,
|
||||||
InvalidAccessTypeError,
|
InvalidAccessTypeError,
|
||||||
TargetNotFoundError,
|
TargetNotFoundError,
|
||||||
scrub_secrets,
|
scrub_secrets,
|
||||||
@@ -537,6 +538,9 @@ class ManifestLoader:
|
|||||||
self.skip_parsing = self.partial_parser.skip_parsing()
|
self.skip_parsing = self.partial_parser.skip_parsing()
|
||||||
if self.skip_parsing:
|
if self.skip_parsing:
|
||||||
# nothing changed, so we don't need to generate project_parser_files
|
# nothing changed, so we don't need to generate project_parser_files
|
||||||
|
fire_event(
|
||||||
|
Note(msg="Nothing changed, skipping partial parsing."), level=EventLevel.DEBUG
|
||||||
|
)
|
||||||
self.manifest = self.saved_manifest # type: ignore[assignment]
|
self.manifest = self.saved_manifest # type: ignore[assignment]
|
||||||
else:
|
else:
|
||||||
# create child_map and parent_map
|
# create child_map and parent_map
|
||||||
@@ -631,23 +635,24 @@ class ManifestLoader:
|
|||||||
def check_for_spaces_in_resource_names(self):
|
def check_for_spaces_in_resource_names(self):
|
||||||
"""Validates that resource names do not contain spaces
|
"""Validates that resource names do not contain spaces
|
||||||
|
|
||||||
If `DEBUG` flag is `False`, logs only first bad model name
|
If `DEBUG` flag is `False`, logs only first bad model name, unless `REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES` is `True` as error will indicate all bad model names
|
||||||
If `DEBUG` flag is `True`, logs every bad model name
|
If `DEBUG` flag is `True`, logs every bad model name
|
||||||
If `REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES` is `True`, logs are `ERROR` level and an exception is raised if any names are bad
|
If `REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES` is `True`, logs are `ERROR` level and an exception is raised if any names are bad
|
||||||
If `REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES` is `False`, logs are `WARN` level
|
If `REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES` is `False`, logs are `WARN` level
|
||||||
"""
|
"""
|
||||||
improper_resource_names = 0
|
improper_resource_names_unique_ids = set()
|
||||||
level = (
|
error_on_invalid_resource_name = (
|
||||||
EventLevel.ERROR
|
self.root_project.args.REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES
|
||||||
if self.root_project.args.REQUIRE_RESOURCE_NAMES_WITHOUT_SPACES
|
|
||||||
else EventLevel.WARN
|
|
||||||
)
|
)
|
||||||
|
level = EventLevel.ERROR if error_on_invalid_resource_name else EventLevel.WARN
|
||||||
|
|
||||||
flags = get_flags()
|
flags = get_flags()
|
||||||
|
|
||||||
for node in self.manifest.nodes.values():
|
for node in self.manifest.nodes.values():
|
||||||
if " " in node.name:
|
if " " in node.name:
|
||||||
if improper_resource_names == 0 or flags.DEBUG:
|
if (
|
||||||
|
not improper_resource_names_unique_ids and not error_on_invalid_resource_name
|
||||||
|
) or flags.DEBUG:
|
||||||
fire_event(
|
fire_event(
|
||||||
SpacesInResourceNameDeprecation(
|
SpacesInResourceNameDeprecation(
|
||||||
unique_id=node.unique_id,
|
unique_id=node.unique_id,
|
||||||
@@ -655,17 +660,23 @@ class ManifestLoader:
|
|||||||
),
|
),
|
||||||
level=level,
|
level=level,
|
||||||
)
|
)
|
||||||
improper_resource_names += 1
|
improper_resource_names_unique_ids.add(node.unique_id)
|
||||||
|
|
||||||
if improper_resource_names > 0:
|
if improper_resource_names_unique_ids:
|
||||||
if level == EventLevel.WARN:
|
if level == EventLevel.WARN:
|
||||||
dbt.deprecations.warn(
|
dbt.deprecations.warn(
|
||||||
"resource-names-with-spaces",
|
"resource-names-with-spaces",
|
||||||
count_invalid_names=improper_resource_names,
|
count_invalid_names=len(improper_resource_names_unique_ids),
|
||||||
show_debug_hint=(not flags.DEBUG),
|
show_debug_hint=(not flags.DEBUG),
|
||||||
)
|
)
|
||||||
else: # ERROR level
|
else: # ERROR level
|
||||||
raise DbtValidationError("Resource names cannot contain spaces")
|
formatted_resources_with_spaces = "\n".join(
|
||||||
|
f" * '{unique_id}' ({self.manifest.nodes[unique_id].original_file_path})"
|
||||||
|
for unique_id in improper_resource_names_unique_ids
|
||||||
|
)
|
||||||
|
raise DbtValidationError(
|
||||||
|
f"Resource names cannot contain spaces:\n{formatted_resources_with_spaces}\nPlease rename the invalid model(s) so that their name(s) do not contain any spaces."
|
||||||
|
)
|
||||||
|
|
||||||
def check_for_microbatch_deprecations(self) -> None:
|
def check_for_microbatch_deprecations(self) -> None:
|
||||||
if not get_flags().require_batched_execution_for_custom_microbatch_strategy:
|
if not get_flags().require_batched_execution_for_custom_microbatch_strategy:
|
||||||
@@ -1647,12 +1658,26 @@ def _check_resource_uniqueness(
|
|||||||
alias_resources: Dict[str, ManifestNode] = {}
|
alias_resources: Dict[str, ManifestNode] = {}
|
||||||
name_resources: Dict[str, Dict] = {}
|
name_resources: Dict[str, Dict] = {}
|
||||||
|
|
||||||
for resource, node in manifest.nodes.items():
|
for _, node in manifest.nodes.items():
|
||||||
if not node.is_relational:
|
if not node.is_relational:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if node.package_name not in name_resources:
|
if node.package_name not in name_resources:
|
||||||
name_resources[node.package_name] = {"ver": {}, "unver": {}}
|
name_resources[node.package_name] = {"ver": {}, "unver": {}}
|
||||||
|
|
||||||
|
existing_unversioned_node = name_resources[node.package_name]["unver"].get(node.name)
|
||||||
|
if existing_unversioned_node is not None and not node.is_versioned:
|
||||||
|
if get_flags().require_unique_project_resource_names:
|
||||||
|
raise DuplicateResourceNameError(existing_unversioned_node, node)
|
||||||
|
else:
|
||||||
|
dbt.deprecations.warn(
|
||||||
|
"duplicate-name-distinct-node-types-deprecation",
|
||||||
|
resource_name=node.name,
|
||||||
|
unique_id1=existing_unversioned_node.unique_id,
|
||||||
|
unique_id2=node.unique_id,
|
||||||
|
package_name=node.package_name,
|
||||||
|
)
|
||||||
|
|
||||||
if node.is_versioned:
|
if node.is_versioned:
|
||||||
name_resources[node.package_name]["ver"][node.name] = node
|
name_resources[node.package_name]["ver"][node.name] = node
|
||||||
else:
|
else:
|
||||||
|
|||||||
@@ -11,7 +11,13 @@ from dbt.contracts.files import (
|
|||||||
parse_file_type_to_parser,
|
parse_file_type_to_parser,
|
||||||
)
|
)
|
||||||
from dbt.contracts.graph.manifest import Manifest
|
from dbt.contracts.graph.manifest import Manifest
|
||||||
from dbt.contracts.graph.nodes import AnalysisNode, ModelNode, SeedNode, SnapshotNode
|
from dbt.contracts.graph.nodes import (
|
||||||
|
AnalysisNode,
|
||||||
|
GenericTestNode,
|
||||||
|
ModelNode,
|
||||||
|
SeedNode,
|
||||||
|
SnapshotNode,
|
||||||
|
)
|
||||||
from dbt.events.types import PartialParsingEnabled, PartialParsingFile
|
from dbt.events.types import PartialParsingEnabled, PartialParsingFile
|
||||||
from dbt.node_types import NodeType
|
from dbt.node_types import NodeType
|
||||||
from dbt_common.context import get_invocation_context
|
from dbt_common.context import get_invocation_context
|
||||||
@@ -58,6 +64,7 @@ special_override_macros = [
|
|||||||
"generate_schema_name",
|
"generate_schema_name",
|
||||||
"generate_database_name",
|
"generate_database_name",
|
||||||
"generate_alias_name",
|
"generate_alias_name",
|
||||||
|
"function",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
|
||||||
@@ -295,6 +302,10 @@ class PartialParsing:
|
|||||||
if saved_source_file.parse_file_type == ParseFileType.Fixture:
|
if saved_source_file.parse_file_type == ParseFileType.Fixture:
|
||||||
self.delete_fixture_node(saved_source_file)
|
self.delete_fixture_node(saved_source_file)
|
||||||
|
|
||||||
|
# functions
|
||||||
|
if saved_source_file.parse_file_type == ParseFileType.Function:
|
||||||
|
self.delete_function_node(saved_source_file)
|
||||||
|
|
||||||
fire_event(PartialParsingFile(operation="deleted", file_id=file_id))
|
fire_event(PartialParsingFile(operation="deleted", file_id=file_id))
|
||||||
|
|
||||||
# Updates for non-schema files
|
# Updates for non-schema files
|
||||||
@@ -310,6 +321,8 @@ class PartialParsing:
|
|||||||
self.update_doc_in_saved(new_source_file, old_source_file)
|
self.update_doc_in_saved(new_source_file, old_source_file)
|
||||||
elif new_source_file.parse_file_type == ParseFileType.Fixture:
|
elif new_source_file.parse_file_type == ParseFileType.Fixture:
|
||||||
self.update_fixture_in_saved(new_source_file, old_source_file)
|
self.update_fixture_in_saved(new_source_file, old_source_file)
|
||||||
|
elif new_source_file.parse_file_type == ParseFileType.Function:
|
||||||
|
self.update_function_in_saved(new_source_file, old_source_file)
|
||||||
else:
|
else:
|
||||||
raise Exception(f"Invalid parse_file_type in source_file {file_id}")
|
raise Exception(f"Invalid parse_file_type in source_file {file_id}")
|
||||||
fire_event(PartialParsingFile(operation="updated", file_id=file_id))
|
fire_event(PartialParsingFile(operation="updated", file_id=file_id))
|
||||||
@@ -405,6 +418,15 @@ class PartialParsing:
|
|||||||
self.saved_files[new_source_file.file_id] = deepcopy(new_source_file)
|
self.saved_files[new_source_file.file_id] = deepcopy(new_source_file)
|
||||||
self.add_to_pp_files(new_source_file)
|
self.add_to_pp_files(new_source_file)
|
||||||
|
|
||||||
|
def update_function_in_saved(
|
||||||
|
self, new_source_file: SourceFile, old_source_file: SourceFile
|
||||||
|
) -> None:
|
||||||
|
if self.already_scheduled_for_parsing(old_source_file):
|
||||||
|
return
|
||||||
|
self.delete_function_node(old_source_file)
|
||||||
|
self.saved_files[new_source_file.file_id] = deepcopy(new_source_file)
|
||||||
|
self.add_to_pp_files(new_source_file)
|
||||||
|
|
||||||
def remove_mssat_file(self, source_file: AnySourceFile):
|
def remove_mssat_file(self, source_file: AnySourceFile):
|
||||||
# nodes [unique_ids] -- SQL files
|
# nodes [unique_ids] -- SQL files
|
||||||
# There should always be a node for a SQL file
|
# There should always be a node for a SQL file
|
||||||
@@ -630,6 +652,42 @@ class PartialParsing:
|
|||||||
source_file.unit_tests.remove(unique_id)
|
source_file.unit_tests.remove(unique_id)
|
||||||
self.saved_manifest.files.pop(source_file.file_id)
|
self.saved_manifest.files.pop(source_file.file_id)
|
||||||
|
|
||||||
|
def delete_function_node(self, source_file: SourceFile) -> None:
|
||||||
|
# There should always be a node for a Function file
|
||||||
|
if not isinstance(source_file, SourceFile) or not source_file.functions:
|
||||||
|
return
|
||||||
|
|
||||||
|
# There can only be one node of a function
|
||||||
|
function_unique_id = source_file.functions[0]
|
||||||
|
|
||||||
|
# Remove the function node from the saved manifest
|
||||||
|
function_node = self.saved_manifest.functions.pop(function_unique_id)
|
||||||
|
|
||||||
|
# Remove the function node from the source file so that it's not viewed as a
|
||||||
|
# duplicate when it's re-added
|
||||||
|
source_file.functions.remove(function_unique_id)
|
||||||
|
|
||||||
|
# If this function had a schema patch, schedule that schema element to be reapplied.
|
||||||
|
patch_path = function_node.patch_path
|
||||||
|
if (
|
||||||
|
patch_path is not None
|
||||||
|
and patch_path in self.saved_files
|
||||||
|
and patch_path not in self.file_diff["deleted_schema_files"]
|
||||||
|
):
|
||||||
|
schema_file = self.saved_files[patch_path]
|
||||||
|
# Only proceed if this is a schema file
|
||||||
|
if isinstance(schema_file, SchemaSourceFile):
|
||||||
|
elements = schema_file.dict_from_yaml.get("functions", [])
|
||||||
|
schema_element = self.get_schema_element(elements, function_node.name)
|
||||||
|
if schema_element:
|
||||||
|
# Remove any previous links and re-merge the patch to pp_dict so it gets reparsed
|
||||||
|
self.delete_schema_function(schema_file, schema_element)
|
||||||
|
self.merge_patch(schema_file, "functions", schema_element)
|
||||||
|
|
||||||
|
# Finally, remove the deleted function file from saved files
|
||||||
|
if source_file.file_id in self.saved_manifest.files:
|
||||||
|
self.saved_manifest.files.pop(source_file.file_id)
|
||||||
|
|
||||||
# Schema files -----------------------
|
# Schema files -----------------------
|
||||||
# Changed schema files
|
# Changed schema files
|
||||||
def change_schema_file(self, file_id):
|
def change_schema_file(self, file_id):
|
||||||
@@ -744,6 +802,7 @@ class PartialParsing:
|
|||||||
handle_change("unit_tests", self.delete_schema_unit_test)
|
handle_change("unit_tests", self.delete_schema_unit_test)
|
||||||
handle_change("saved_queries", self.delete_schema_saved_query)
|
handle_change("saved_queries", self.delete_schema_saved_query)
|
||||||
handle_change("data_tests", self.delete_schema_data_test_patch)
|
handle_change("data_tests", self.delete_schema_data_test_patch)
|
||||||
|
handle_change("functions", self.delete_schema_function)
|
||||||
|
|
||||||
def _handle_element_change(
|
def _handle_element_change(
|
||||||
self, schema_file, saved_yaml_dict, new_yaml_dict, env_var_changes, dict_key: str, delete
|
self, schema_file, saved_yaml_dict, new_yaml_dict, env_var_changes, dict_key: str, delete
|
||||||
@@ -917,7 +976,7 @@ class PartialParsing:
|
|||||||
for child_id in self.saved_manifest.child_map[unique_id]:
|
for child_id in self.saved_manifest.child_map[unique_id]:
|
||||||
if child_id.startswith("test") and child_id in self.saved_manifest.nodes:
|
if child_id.startswith("test") and child_id in self.saved_manifest.nodes:
|
||||||
child_test = self.saved_manifest.nodes[child_id]
|
child_test = self.saved_manifest.nodes[child_id]
|
||||||
if child_test.attached_node:
|
if isinstance(child_test, GenericTestNode) and child_test.attached_node:
|
||||||
if child_test.attached_node in self.saved_manifest.nodes:
|
if child_test.attached_node in self.saved_manifest.nodes:
|
||||||
attached_node = self.saved_manifest.nodes[child_test.attached_node]
|
attached_node = self.saved_manifest.nodes[child_test.attached_node]
|
||||||
self.update_in_saved(attached_node.file_id)
|
self.update_in_saved(attached_node.file_id)
|
||||||
@@ -1080,6 +1139,24 @@ class PartialParsing:
|
|||||||
schema_file.unit_tests.remove(unique_id)
|
schema_file.unit_tests.remove(unique_id)
|
||||||
# No disabled unit tests yet
|
# No disabled unit tests yet
|
||||||
|
|
||||||
|
def delete_schema_function(self, schema_file: SchemaSourceFile, function_dict: dict) -> None:
|
||||||
|
function_name = function_dict["name"]
|
||||||
|
functions = schema_file.node_patches.copy()
|
||||||
|
for unique_id in functions:
|
||||||
|
if unique_id in self.saved_manifest.functions:
|
||||||
|
function = self.saved_manifest.functions[unique_id]
|
||||||
|
if function.name == function_name:
|
||||||
|
removed_function = self.saved_manifest.functions.pop(unique_id)
|
||||||
|
# For schema patches, recorded unique_ids live in node_patches (ndp)
|
||||||
|
if unique_id in schema_file.node_patches:
|
||||||
|
schema_file.node_patches.remove(unique_id)
|
||||||
|
# Schedule the function's SQL file for reparsing so the node is re-added
|
||||||
|
file_id = removed_function.file_id
|
||||||
|
if file_id and file_id in self.new_files:
|
||||||
|
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||||
|
if file_id and file_id in self.saved_files:
|
||||||
|
self.add_to_pp_files(self.saved_files[file_id])
|
||||||
|
|
||||||
def get_schema_element(self, elem_list, elem_name):
|
def get_schema_element(self, elem_list, elem_name):
|
||||||
for element in elem_list:
|
for element in elem_list:
|
||||||
if "name" in element and element["name"] == elem_name:
|
if "name" in element and element["name"] == elem_name:
|
||||||
|
|||||||
@@ -168,6 +168,10 @@ class UnitTestManifestLoader:
|
|||||||
**common_fields,
|
**common_fields,
|
||||||
source_name=original_input_node.source_name, # needed for source lookup
|
source_name=original_input_node.source_name, # needed for source lookup
|
||||||
)
|
)
|
||||||
|
# In the case of multiple sources with the same name, we add the source schema name to the unique id.
|
||||||
|
# This additionally prevents duplicate CTE names during compilation.
|
||||||
|
input_node.unique_id = f"model.{original_input_node.package_name}.{original_input_node.source_name}__{input_name}"
|
||||||
|
|
||||||
# Sources need to go in the sources dictionary in order to create the right lookup
|
# Sources need to go in the sources dictionary in order to create the right lookup
|
||||||
self.unit_test_manifest.sources[input_node.unique_id] = input_node # type: ignore
|
self.unit_test_manifest.sources[input_node.unique_id] = input_node # type: ignore
|
||||||
|
|
||||||
@@ -286,8 +290,11 @@ class UnitTestParser(YamlReader):
|
|||||||
)
|
)
|
||||||
|
|
||||||
if tested_model_node:
|
if tested_model_node:
|
||||||
unit_test_definition.depends_on.nodes.append(tested_model_node.unique_id)
|
if tested_model_node.config.enabled:
|
||||||
unit_test_definition.schema = tested_model_node.schema
|
unit_test_definition.depends_on.nodes.append(tested_model_node.unique_id)
|
||||||
|
unit_test_definition.schema = tested_model_node.schema
|
||||||
|
else:
|
||||||
|
unit_test_definition.config.enabled = False
|
||||||
|
|
||||||
# Check that format and type of rows matches for each given input,
|
# Check that format and type of rows matches for each given input,
|
||||||
# convert rows to a list of dictionaries, and add the unique_id of
|
# convert rows to a list of dictionaries, and add the unique_id of
|
||||||
@@ -298,7 +305,7 @@ class UnitTestParser(YamlReader):
|
|||||||
# for calculating state:modified
|
# for calculating state:modified
|
||||||
unit_test_definition.build_unit_test_checksum()
|
unit_test_definition.build_unit_test_checksum()
|
||||||
assert isinstance(self.yaml.file, SchemaSourceFile)
|
assert isinstance(self.yaml.file, SchemaSourceFile)
|
||||||
if unit_test_config.enabled:
|
if unit_test_definition.config.enabled:
|
||||||
self.manifest.add_unit_test(self.yaml.file, unit_test_definition)
|
self.manifest.add_unit_test(self.yaml.file, unit_test_definition)
|
||||||
else:
|
else:
|
||||||
self.manifest.add_disabled(self.yaml.file, unit_test_definition)
|
self.manifest.add_disabled(self.yaml.file, unit_test_definition)
|
||||||
@@ -488,6 +495,13 @@ def find_tested_model_node(
|
|||||||
model_version = model_name_split[1] if len(model_name_split) == 2 else None
|
model_version = model_name_split[1] if len(model_name_split) == 2 else None
|
||||||
|
|
||||||
tested_node = manifest.ref_lookup.find(model_name, current_project, model_version, manifest)
|
tested_node = manifest.ref_lookup.find(model_name, current_project, model_version, manifest)
|
||||||
|
if not tested_node:
|
||||||
|
disabled_node = manifest.disabled_lookup.find(
|
||||||
|
model_name, current_project, model_version, [NodeType.Model]
|
||||||
|
)
|
||||||
|
if disabled_node:
|
||||||
|
tested_node = disabled_node[0]
|
||||||
|
|
||||||
return tested_node
|
return tested_node
|
||||||
|
|
||||||
|
|
||||||
@@ -505,22 +519,36 @@ def process_models_for_unit_test(
|
|||||||
f"Unable to find model '{current_project}.{unit_test_def.model}' for "
|
f"Unable to find model '{current_project}.{unit_test_def.model}' for "
|
||||||
f"unit test '{unit_test_def.name}' in {unit_test_def.original_file_path}"
|
f"unit test '{unit_test_def.name}' in {unit_test_def.original_file_path}"
|
||||||
)
|
)
|
||||||
unit_test_def.depends_on.nodes.append(tested_node.unique_id)
|
if tested_node.config.enabled:
|
||||||
unit_test_def.schema = tested_node.schema
|
unit_test_def.depends_on.nodes.append(tested_node.unique_id)
|
||||||
|
unit_test_def.schema = tested_node.schema
|
||||||
|
else:
|
||||||
|
# If the model is disabled, the unit test should be disabled
|
||||||
|
unit_test_def.config.enabled = False
|
||||||
|
|
||||||
# The UnitTestDefinition should only have one "depends_on" at this point,
|
# The UnitTestDefinition should only have one "depends_on" at this point,
|
||||||
# the one that's found by the "model" field.
|
# the one that's found by the "model" field.
|
||||||
target_model_id = unit_test_def.depends_on.nodes[0]
|
target_model_id = unit_test_def.depends_on.nodes[0]
|
||||||
if target_model_id not in manifest.nodes:
|
if target_model_id not in manifest.nodes:
|
||||||
if target_model_id in manifest.disabled:
|
if target_model_id in manifest.disabled:
|
||||||
# The model is disabled, so we don't need to do anything (#10540)
|
# If the model is disabled, the unit test should be disabled
|
||||||
return
|
unit_test_def.config.enabled = False
|
||||||
else:
|
else:
|
||||||
# If we've reached here and the model is not disabled, throw an error
|
# If we've reached here and the model is not disabled, throw an error
|
||||||
raise ParsingError(
|
raise ParsingError(
|
||||||
f"Unit test '{unit_test_def.name}' references a model that does not exist: {target_model_id}"
|
f"Unit test '{unit_test_def.name}' references a model that does not exist: {target_model_id}"
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if not unit_test_def.config.enabled:
|
||||||
|
# Ensure the unit test is disabled in the manifest
|
||||||
|
if unit_test_def.unique_id in manifest.unit_tests:
|
||||||
|
manifest.unit_tests.pop(unit_test_def.unique_id)
|
||||||
|
if unit_test_def.unique_id not in manifest.disabled:
|
||||||
|
manifest.add_disabled(manifest.files[unit_test_def.file_id], unit_test_def)
|
||||||
|
|
||||||
|
# The unit test is disabled, so we don't need to do any further processing (#10540)
|
||||||
|
return
|
||||||
|
|
||||||
target_model = manifest.nodes[target_model_id]
|
target_model = manifest.nodes[target_model_id]
|
||||||
assert isinstance(target_model, ModelNode)
|
assert isinstance(target_model, ModelNode)
|
||||||
|
|
||||||
|
|||||||
@@ -1,5 +1,6 @@
|
|||||||
from typing import Dict, List, Optional, Set, Type
|
from typing import Dict, Iterable, List, Optional, Set, Type
|
||||||
|
|
||||||
|
from dbt.adapters.base import BaseRelation
|
||||||
from dbt.artifacts.schemas.results import NodeStatus
|
from dbt.artifacts.schemas.results import NodeStatus
|
||||||
from dbt.artifacts.schemas.run import RunResult
|
from dbt.artifacts.schemas.run import RunResult
|
||||||
from dbt.cli.flags import Flags
|
from dbt.cli.flags import Flags
|
||||||
@@ -64,6 +65,22 @@ class BuildTask(RunTask):
|
|||||||
resource_types.remove(NodeType.Unit)
|
resource_types.remove(NodeType.Unit)
|
||||||
return list(resource_types)
|
return list(resource_types)
|
||||||
|
|
||||||
|
def get_model_schemas(self, adapter, selected_uids: Iterable[str]) -> Set[BaseRelation]:
|
||||||
|
|
||||||
|
# Get model schemas as usual
|
||||||
|
model_schemas = super().get_model_schemas(adapter, selected_uids)
|
||||||
|
|
||||||
|
# Get function schemas
|
||||||
|
function_schemas: Set[BaseRelation] = set()
|
||||||
|
for function in (
|
||||||
|
self.manifest.functions.values() if self.manifest else []
|
||||||
|
): # functionally the manifest will never be None as we do an assert in super().get_model_schemas(...)
|
||||||
|
if function.unique_id in selected_uids:
|
||||||
|
relation = adapter.Relation.create_from(self.config, function)
|
||||||
|
function_schemas.add(relation.without_identifier())
|
||||||
|
|
||||||
|
return model_schemas.union(function_schemas)
|
||||||
|
|
||||||
# overrides get_graph_queue in runnable.py
|
# overrides get_graph_queue in runnable.py
|
||||||
def get_graph_queue(self) -> GraphQueue:
|
def get_graph_queue(self) -> GraphQueue:
|
||||||
# Following uses self.selection_arg and self.exclusion_arg
|
# Following uses self.selection_arg and self.exclusion_arg
|
||||||
@@ -72,12 +89,14 @@ class BuildTask(RunTask):
|
|||||||
# selector including unit tests
|
# selector including unit tests
|
||||||
full_selector = self.get_node_selector(no_unit_tests=False)
|
full_selector = self.get_node_selector(no_unit_tests=False)
|
||||||
# selected node unique_ids with unit_tests
|
# selected node unique_ids with unit_tests
|
||||||
full_selected_nodes = full_selector.get_selected(spec)
|
full_selected_nodes = full_selector.get_selected(spec=spec, warn_on_no_nodes=False)
|
||||||
|
|
||||||
# This selector removes the unit_tests from the selector
|
# This selector removes the unit_tests from the selector
|
||||||
selector_wo_unit_tests = self.get_node_selector(no_unit_tests=True)
|
selector_wo_unit_tests = self.get_node_selector(no_unit_tests=True)
|
||||||
# selected node unique_ids without unit_tests
|
# selected node unique_ids without unit_tests
|
||||||
selected_nodes_wo_unit_tests = selector_wo_unit_tests.get_selected(spec)
|
selected_nodes_wo_unit_tests = selector_wo_unit_tests.get_selected(
|
||||||
|
spec=spec, warn_on_no_nodes=False
|
||||||
|
)
|
||||||
|
|
||||||
# Get the difference in the sets of nodes with and without unit tests and
|
# Get the difference in the sets of nodes with and without unit tests and
|
||||||
# save it
|
# save it
|
||||||
|
|||||||
@@ -119,23 +119,97 @@ class DepsTask(BaseTask):
|
|||||||
)
|
)
|
||||||
|
|
||||||
def check_for_duplicate_packages(self, packages_yml):
|
def check_for_duplicate_packages(self, packages_yml):
|
||||||
"""Loop through contents of `packages.yml` to ensure no duplicate package names + versions.
|
"""Loop through contents of `packages.yml` to remove entries that match the package being added.
|
||||||
|
|
||||||
This duplicate check will take into consideration exact match of a package name, as well as
|
This method is called only during `dbt deps --add-package` to check if the package
|
||||||
a check to see if a package name exists within a name (i.e. a package name inside a git URL).
|
being added already exists in packages.yml. It uses substring matching to identify
|
||||||
|
duplicates, which means it will match across different package sources. For example,
|
||||||
|
adding a hub package "dbt-labs/dbt_utils" will remove an existing git package
|
||||||
|
"https://github.com/dbt-labs/dbt-utils.git" since both contain "dbt_utils" or "dbt-utils".
|
||||||
|
|
||||||
|
The matching is flexible to handle both underscore and hyphen variants of package names,
|
||||||
|
as git repos often use hyphens (dbt-utils) while package names use underscores (dbt_utils).
|
||||||
|
Word boundaries (/, .) are enforced to prevent false matches like "dbt-core" matching
|
||||||
|
"dbt-core-utils".
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
packages_yml (dict): In-memory read of `packages.yml` contents
|
packages_yml (dict): In-memory read of `packages.yml` contents
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
dict: Updated or untouched packages_yml contents
|
dict: Updated packages_yml contents with matching packages removed
|
||||||
"""
|
"""
|
||||||
for i, pkg_entry in enumerate(packages_yml["packages"]):
|
# Extract the package name for matching
|
||||||
for val in pkg_entry.values():
|
package_name = self.args.add_package["name"]
|
||||||
if self.args.add_package["name"] in val:
|
|
||||||
del packages_yml["packages"][i]
|
|
||||||
|
|
||||||
fire_event(DepsFoundDuplicatePackage(removed_package=pkg_entry))
|
# Create variants for flexible matching (handle _ vs -)
|
||||||
|
# Check multiple variants to handle naming inconsistencies between hub and git
|
||||||
|
package_name_parts = [
|
||||||
|
package_name, # Original: "dbt-labs/dbt_utils"
|
||||||
|
package_name.replace("_", "-"), # Hyphens: "dbt-labs/dbt-utils"
|
||||||
|
package_name.replace("-", "_"), # Underscores: "dbt_labs/dbt_utils"
|
||||||
|
]
|
||||||
|
# Extract just the package name without org (after last /)
|
||||||
|
if "/" in package_name:
|
||||||
|
short_name = package_name.split("/")[-1]
|
||||||
|
package_name_parts.extend(
|
||||||
|
[
|
||||||
|
short_name, # "dbt_utils"
|
||||||
|
short_name.replace("_", "-"), # "dbt-utils"
|
||||||
|
short_name.replace("-", "_"), # "dbt_utils" (deduplicated)
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
# Remove duplicates from package_name_parts
|
||||||
|
package_name_parts = list(set(package_name_parts))
|
||||||
|
|
||||||
|
# Iterate backwards to safely delete items without index shifting issues
|
||||||
|
for i in range(len(packages_yml["packages"]) - 1, -1, -1):
|
||||||
|
pkg_entry = packages_yml["packages"][i]
|
||||||
|
|
||||||
|
# Get the package identifier key (package type determines which key exists)
|
||||||
|
# This avoids iterating over non-string values like warn-unpinned: false
|
||||||
|
package_identifier = (
|
||||||
|
pkg_entry.get("package") # hub/registry package
|
||||||
|
or pkg_entry.get("git") # git package
|
||||||
|
or pkg_entry.get("local") # local package
|
||||||
|
or pkg_entry.get("tarball") # tarball package
|
||||||
|
or pkg_entry.get("private") # private package
|
||||||
|
)
|
||||||
|
|
||||||
|
# Check if any variant of the package name appears in the identifier
|
||||||
|
# Use word boundaries to avoid false matches (e.g., "dbt-core" shouldn't match "dbt-core-utils")
|
||||||
|
# Word boundaries are: start/end of string, /, or .
|
||||||
|
# Note: - and _ are NOT boundaries since they're used within compound package names
|
||||||
|
if package_identifier:
|
||||||
|
is_duplicate = False
|
||||||
|
for name_variant in package_name_parts:
|
||||||
|
if name_variant in package_identifier:
|
||||||
|
# Found a match, now verify it's not a substring of a larger word
|
||||||
|
# Check characters before and after the match
|
||||||
|
idx = package_identifier.find(name_variant)
|
||||||
|
start_ok = idx == 0 or package_identifier[idx - 1] in "/."
|
||||||
|
end_idx = idx + len(name_variant)
|
||||||
|
end_ok = (
|
||||||
|
end_idx == len(package_identifier)
|
||||||
|
or package_identifier[end_idx] in "/."
|
||||||
|
)
|
||||||
|
|
||||||
|
if start_ok and end_ok:
|
||||||
|
is_duplicate = True
|
||||||
|
break
|
||||||
|
|
||||||
|
if is_duplicate:
|
||||||
|
del packages_yml["packages"][i]
|
||||||
|
# Filter out non-string values (like warn-unpinned boolean) before logging
|
||||||
|
# Note: Check for bool first since bool is a subclass of int in Python
|
||||||
|
loggable_package = {
|
||||||
|
k: v
|
||||||
|
for k, v in pkg_entry.items()
|
||||||
|
if not isinstance(v, bool)
|
||||||
|
and isinstance(v, (str, int, float))
|
||||||
|
and k != "unrendered"
|
||||||
|
}
|
||||||
|
fire_event(DepsFoundDuplicatePackage(removed_package=loggable_package))
|
||||||
|
|
||||||
return packages_yml
|
return packages_yml
|
||||||
|
|
||||||
|
|||||||
@@ -126,6 +126,7 @@ class RetryTask(ConfiguredTask):
|
|||||||
result.unique_id
|
result.unique_id
|
||||||
for result in self.previous_results.results
|
for result in self.previous_results.results
|
||||||
if result.status in RETRYABLE_STATUSES
|
if result.status in RETRYABLE_STATUSES
|
||||||
|
# Avoid retrying operation nodes unless we are retrying the run-operation command
|
||||||
and not (
|
and not (
|
||||||
self.previous_command_name != "run-operation"
|
self.previous_command_name != "run-operation"
|
||||||
and result.unique_id.startswith("operation.")
|
and result.unique_id.startswith("operation.")
|
||||||
@@ -150,6 +151,11 @@ class RetryTask(ConfiguredTask):
|
|||||||
)
|
)
|
||||||
}
|
}
|
||||||
|
|
||||||
|
# Tasks without get_graph_queue (e.g. run-operation) and no failed nodes to retry.
|
||||||
|
if not unique_ids and not hasattr(self.task_class, "get_graph_queue"):
|
||||||
|
# Return early with the previous results as the past invocation was successful
|
||||||
|
return self.previous_results
|
||||||
|
|
||||||
class TaskWrapper(self.task_class):
|
class TaskWrapper(self.task_class):
|
||||||
def get_graph_queue(self):
|
def get_graph_queue(self):
|
||||||
new_graph = self.graph.get_subset_graph(unique_ids)
|
new_graph = self.graph.get_subset_graph(unique_ids)
|
||||||
|
|||||||
127
core/hatch.toml
@@ -4,11 +4,26 @@ path = "dbt/__version__.py"
|
|||||||
[build.targets.wheel]
|
[build.targets.wheel]
|
||||||
packages = ["dbt"]
|
packages = ["dbt"]
|
||||||
only-packages = true
|
only-packages = true
|
||||||
|
exclude = [
|
||||||
|
"**/*.md",
|
||||||
|
]
|
||||||
artifacts = [
|
artifacts = [
|
||||||
"dbt/include/**/*",
|
"dbt/include/**/*.py",
|
||||||
|
"dbt/include/**/*.sql",
|
||||||
|
"dbt/include/**/*.yml",
|
||||||
|
"dbt/include/**/*.html",
|
||||||
|
"dbt/include/**/*.md",
|
||||||
|
"dbt/include/**/.gitkeep",
|
||||||
|
"dbt/include/**/.gitignore",
|
||||||
"dbt/task/docs/**/*.html",
|
"dbt/task/docs/**/*.html",
|
||||||
"dbt/jsonschemas/**/*.json",
|
"dbt/jsonschemas/**/*.json",
|
||||||
"dbt/py.typed",
|
"dbt/py.typed",
|
||||||
|
# Directories without __init__.py (namespace packages)
|
||||||
|
"dbt/artifacts/resources/v1/**/*.py",
|
||||||
|
"dbt/artifacts/utils/**/*.py",
|
||||||
|
"dbt/event_time/**/*.py",
|
||||||
|
"dbt/docs/source/**/*.py",
|
||||||
|
"dbt/tests/util.py",
|
||||||
]
|
]
|
||||||
|
|
||||||
[build.targets.sdist]
|
[build.targets.sdist]
|
||||||
@@ -18,34 +33,66 @@ include = [
|
|||||||
]
|
]
|
||||||
|
|
||||||
[build.targets.sdist.force-include]
|
[build.targets.sdist.force-include]
|
||||||
"../LICENSE" = "LICENSE"
|
|
||||||
"dbt/task/docs/index.html" = "dbt/task/docs/index.html"
|
"dbt/task/docs/index.html" = "dbt/task/docs/index.html"
|
||||||
|
|
||||||
[envs.default]
|
[envs.default]
|
||||||
|
# Python 3.10-3.11 required locally due to flake8==4.0.1 compatibility
|
||||||
|
# CI uses [envs.ci] which doesn't set python, allowing matrix testing
|
||||||
|
python = "3.11"
|
||||||
dependencies = [
|
dependencies = [
|
||||||
|
# Git dependencies for development against main branches
|
||||||
|
"dbt-adapters @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-adapters",
|
||||||
|
"dbt-tests-adapter @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-tests-adapter",
|
||||||
|
"dbt-common @ git+https://github.com/dbt-labs/dbt-common.git@main",
|
||||||
|
"dbt-postgres @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-postgres",
|
||||||
|
# Code quality
|
||||||
"pre-commit~=3.7.0",
|
"pre-commit~=3.7.0",
|
||||||
|
"black>=24.3,<25.0",
|
||||||
|
"flake8==4.0.1", # requires python <3.12
|
||||||
|
"mypy==1.4.1", # update requires code fixes
|
||||||
|
"isort==5.13.2",
|
||||||
|
# Testing
|
||||||
"pytest>=7.0,<8.0",
|
"pytest>=7.0,<8.0",
|
||||||
"pytest-xdist~=3.6",
|
"pytest-xdist~=3.6",
|
||||||
"pytest-csv~=3.0",
|
"pytest-csv~=3.0",
|
||||||
|
"pytest-cov",
|
||||||
|
"pytest-dotenv",
|
||||||
|
"pytest-mock",
|
||||||
|
"pytest-split",
|
||||||
"pytest-logbook~=1.2",
|
"pytest-logbook~=1.2",
|
||||||
"logbook<1.9",
|
"logbook<1.9",
|
||||||
"mypy>=1.9,<2.0",
|
"flaky",
|
||||||
"flake8>=6.0,<7.0",
|
"freezegun>=1.5.1",
|
||||||
"black>=24.3,<25.0",
|
"hypothesis",
|
||||||
"tox~=4.16",
|
"mocker",
|
||||||
|
# Debugging
|
||||||
|
"ipdb",
|
||||||
|
"ddtrace==2.21.3",
|
||||||
|
# Documentation
|
||||||
|
"docutils",
|
||||||
|
"sphinx",
|
||||||
|
# Type stubs
|
||||||
|
"types-docutils",
|
||||||
|
"types-PyYAML",
|
||||||
|
"types-Jinja2",
|
||||||
|
"types-jsonschema",
|
||||||
|
"types-mock",
|
||||||
|
"types-protobuf>=5.0,<6.0",
|
||||||
|
"types-python-dateutil",
|
||||||
|
"types-pytz",
|
||||||
|
"types-requests",
|
||||||
|
"types-setuptools",
|
||||||
|
# Other
|
||||||
|
"pip-tools",
|
||||||
|
"protobuf>=6.0,<7.0",
|
||||||
]
|
]
|
||||||
|
|
||||||
[envs.default.scripts]
|
[envs.default.scripts]
|
||||||
# Setup commands
|
# Setup commands
|
||||||
setup = [
|
setup = [
|
||||||
"pip install -r ../dev-requirements.txt",
|
|
||||||
"pip install -e .",
|
"pip install -e .",
|
||||||
"pre-commit install",
|
"pre-commit install",
|
||||||
]
|
]
|
||||||
dev-req = [
|
|
||||||
"pip install -r ../dev-requirements.txt",
|
|
||||||
"pip install -e .",
|
|
||||||
]
|
|
||||||
|
|
||||||
# Code quality commands
|
# Code quality commands
|
||||||
code-quality = "pre-commit run --all-files --show-diff-on-failure"
|
code-quality = "pre-commit run --all-files --show-diff-on-failure"
|
||||||
@@ -58,11 +105,11 @@ mypy = "pre-commit run mypy-check --hook-stage manual --all-files"
|
|||||||
black = "pre-commit run black-check --hook-stage manual --all-files"
|
black = "pre-commit run black-check --hook-stage manual --all-files"
|
||||||
|
|
||||||
# Testing commands
|
# Testing commands
|
||||||
unit-tests = "tox -e unit"
|
unit-tests = "python -m pytest {args} ../tests/unit"
|
||||||
integration-tests = "tox -e py-integration -- -nauto"
|
integration-tests = "python -m pytest -nauto {args} ../tests/functional"
|
||||||
integration-tests-fail-fast = "tox -e py-integration -- -x -nauto"
|
integration-tests-fail-fast = "python -m pytest -x -nauto {args} ../tests/functional"
|
||||||
test = [
|
test = [
|
||||||
"tox -e unit",
|
"python -m pytest ../tests/unit",
|
||||||
"pre-commit run black-check --hook-stage manual --all-files",
|
"pre-commit run black-check --hook-stage manual --all-files",
|
||||||
"pre-commit run flake8-check --hook-stage manual --all-files",
|
"pre-commit run flake8-check --hook-stage manual --all-files",
|
||||||
"pre-commit run mypy-check --hook-stage manual --all-files",
|
"pre-commit run mypy-check --hook-stage manual --all-files",
|
||||||
@@ -71,7 +118,7 @@ test = [
|
|||||||
# Database setup
|
# Database setup
|
||||||
setup-db = [
|
setup-db = [
|
||||||
"docker compose up -d database",
|
"docker compose up -d database",
|
||||||
"bash ../test/setup_db.sh",
|
"bash ../scripts/setup_db.sh",
|
||||||
]
|
]
|
||||||
|
|
||||||
# Utility commands
|
# Utility commands
|
||||||
@@ -79,7 +126,6 @@ clean = [
|
|||||||
"rm -f .coverage",
|
"rm -f .coverage",
|
||||||
"rm -f .coverage.*",
|
"rm -f .coverage.*",
|
||||||
"rm -rf .eggs/",
|
"rm -rf .eggs/",
|
||||||
"rm -rf .tox/",
|
|
||||||
"rm -rf build/",
|
"rm -rf build/",
|
||||||
"rm -rf dbt.egg-info/",
|
"rm -rf dbt.egg-info/",
|
||||||
"rm -f dbt_project.yml",
|
"rm -f dbt_project.yml",
|
||||||
@@ -90,6 +136,7 @@ clean = [
|
|||||||
json-schema = "python ../scripts/collect-artifact-schema.py --path ../schemas"
|
json-schema = "python ../scripts/collect-artifact-schema.py --path ../schemas"
|
||||||
|
|
||||||
[envs.build]
|
[envs.build]
|
||||||
|
python = "3.11"
|
||||||
detached = true
|
detached = true
|
||||||
dependencies = [
|
dependencies = [
|
||||||
"wheel",
|
"wheel",
|
||||||
@@ -115,23 +162,45 @@ check-sdist = [
|
|||||||
"dbt --version",
|
"dbt --version",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
# CI environment - isolated environment with test dependencies
|
||||||
[envs.ci]
|
[envs.ci]
|
||||||
dependencies = [
|
dependencies = [
|
||||||
|
# Git dependencies for development against main branches
|
||||||
|
"dbt-adapters @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-adapters",
|
||||||
|
"dbt-tests-adapter @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-tests-adapter",
|
||||||
|
"dbt-common @ git+https://github.com/dbt-labs/dbt-common.git@main",
|
||||||
|
"dbt-postgres @ git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-postgres",
|
||||||
|
# Testing
|
||||||
"pytest>=7.0,<8.0",
|
"pytest>=7.0,<8.0",
|
||||||
|
"pytest-cov",
|
||||||
"pytest-xdist~=3.6",
|
"pytest-xdist~=3.6",
|
||||||
"tox~=4.16",
|
"pytest-csv~=3.0",
|
||||||
|
"pytest-dotenv",
|
||||||
|
"pytest-mock",
|
||||||
|
"pytest-split",
|
||||||
|
"ddtrace==2.21.3",
|
||||||
|
"flaky",
|
||||||
|
"freezegun>=1.5.1",
|
||||||
|
"hypothesis",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
pre-install-commands = [
|
||||||
|
"pip install -e .",
|
||||||
|
]
|
||||||
|
|
||||||
|
[envs.ci.env-vars]
|
||||||
|
DBT_TEST_USER_1 = "dbt_test_user_1"
|
||||||
|
DBT_TEST_USER_2 = "dbt_test_user_2"
|
||||||
|
DBT_TEST_USER_3 = "dbt_test_user_3"
|
||||||
|
|
||||||
[envs.ci.scripts]
|
[envs.ci.scripts]
|
||||||
unit-tests = "tox -e unit"
|
unit-tests = "python -m pytest --cov=dbt --cov-report=xml {args} ../tests/unit"
|
||||||
integration-tests = "tox -- {args}"
|
# Run as single command to avoid pre-install-commands running twice
|
||||||
|
integration-tests = """
|
||||||
|
python -m pytest --cov=dbt --cov-append --cov-report=xml {args} ../tests/functional -k "not tests/functional/graph_selection" && \
|
||||||
|
python -m pytest --cov=dbt --cov-append --cov-report=xml {args} ../tests/functional/graph_selection
|
||||||
|
"""
|
||||||
|
|
||||||
[envs.cd]
|
# Note: Python version matrix is handled by GitHub Actions CI, not hatch.
|
||||||
dependencies = [
|
# This avoids running tests 4x per job. The CI sets up the Python version
|
||||||
"pytest>=7.0,<8.0",
|
# and hatch uses whatever Python is active.
|
||||||
"pytest-xdist~=3.6",
|
|
||||||
]
|
|
||||||
|
|
||||||
[envs.cd.scripts]
|
|
||||||
unit-tests = "python -m pytest tests/unit"
|
|
||||||
integration-tests = "python -m pytest tests/functional"
|
|
||||||
|
|||||||
@@ -6,7 +6,7 @@ description = "With dbt, data analysts and engineers can build analytics the way
|
|||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
requires-python = ">=3.10"
|
requires-python = ">=3.10"
|
||||||
license = "Apache-2.0"
|
license = "Apache-2.0"
|
||||||
license-files = { globs = ["../LICENSE"] }
|
license-files = { globs = ["LICENSE"] }
|
||||||
keywords = []
|
keywords = []
|
||||||
authors = [
|
authors = [
|
||||||
{ name = "dbt Labs", email = "info@dbtlabs.com" },
|
{ name = "dbt Labs", email = "info@dbtlabs.com" },
|
||||||
@@ -54,9 +54,9 @@ dependencies = [
|
|||||||
"dbt-extractor>=0.5.0,<=0.6",
|
"dbt-extractor>=0.5.0,<=0.6",
|
||||||
"dbt-semantic-interfaces>=0.9.0,<0.10",
|
"dbt-semantic-interfaces>=0.9.0,<0.10",
|
||||||
# Minor versions for these are expected to be backwards-compatible
|
# Minor versions for these are expected to be backwards-compatible
|
||||||
"dbt-common>=1.27.0,<2.0",
|
"dbt-common>=1.37.0,<2.0",
|
||||||
"dbt-adapters>=1.15.5,<2.0",
|
"dbt-adapters>=1.15.5,<2.0",
|
||||||
"dbt-protos>=1.0.375,<2.0",
|
"dbt-protos>=1.0.405,<2.0",
|
||||||
"pydantic<3",
|
"pydantic<3",
|
||||||
# ----
|
# ----
|
||||||
# Expect compatibility with all new versions of these packages, so lower bounds only.
|
# Expect compatibility with all new versions of these packages, so lower bounds only.
|
||||||
@@ -79,6 +79,7 @@ dbt = "dbt.cli.main:cli"
|
|||||||
[tool.hatch.version]
|
[tool.hatch.version]
|
||||||
path = "dbt/__version__.py"
|
path = "dbt/__version__.py"
|
||||||
|
|
||||||
|
|
||||||
[build-system]
|
[build-system]
|
||||||
requires = ["hatchling"]
|
requires = ["hatchling"]
|
||||||
build-backend = "hatchling.build"
|
build-backend = "hatchling.build"
|
||||||
|
|||||||
@@ -1,5 +0,0 @@
|
|||||||
# The create_adapter_plugins script is being replaced by a new interactive cookiecutter scaffold
|
|
||||||
# that can be found https://github.com/dbt-labs/dbt-database-adapter-scaffold
|
|
||||||
print(
|
|
||||||
"This script has been deprecated, to create a new adapter please visit https://github.com/dbt-labs/dbt-database-adapter-scaffold"
|
|
||||||
)
|
|
||||||
@@ -1,16 +0,0 @@
|
|||||||
#!/usr/bin/env python
|
|
||||||
|
|
||||||
"""
|
|
||||||
DEPRECATED: This setup.py is maintained for backwards compatibility only.
|
|
||||||
|
|
||||||
dbt-core now uses hatchling as its build backend (defined in pyproject.toml).
|
|
||||||
Please use `python -m build` or `pip install` directly instead of setup.py commands.
|
|
||||||
|
|
||||||
This file will be maintained indefinitely for legacy tooling support but is no
|
|
||||||
longer the primary build interface.
|
|
||||||
"""
|
|
||||||
|
|
||||||
from setuptools import setup
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
|
||||||
setup()
|
|
||||||
@@ -1,38 +0,0 @@
|
|||||||
git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-adapters
|
|
||||||
git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-tests-adapter
|
|
||||||
git+https://github.com/dbt-labs/dbt-common.git@main
|
|
||||||
git+https://github.com/dbt-labs/dbt-adapters.git@main#subdirectory=dbt-postgres
|
|
||||||
black==24.3.0
|
|
||||||
bumpversion
|
|
||||||
ddtrace==2.21.3
|
|
||||||
docutils
|
|
||||||
flake8==4.0.1
|
|
||||||
flaky
|
|
||||||
freezegun>=1.5.1
|
|
||||||
hypothesis
|
|
||||||
ipdb
|
|
||||||
isort==5.13.2
|
|
||||||
mypy==1.4.1
|
|
||||||
pip-tools
|
|
||||||
pre-commit
|
|
||||||
protobuf>=6.0,<7.0
|
|
||||||
pytest>=7.4,<8.0
|
|
||||||
pytest-cov
|
|
||||||
pytest-csv>=3.0,<4.0
|
|
||||||
pytest-dotenv
|
|
||||||
pytest-mock
|
|
||||||
pytest-split
|
|
||||||
pytest-xdist
|
|
||||||
sphinx
|
|
||||||
tox>=3.13
|
|
||||||
types-docutils
|
|
||||||
types-PyYAML
|
|
||||||
types-Jinja2
|
|
||||||
types-jsonschema
|
|
||||||
types-mock
|
|
||||||
types-protobuf>=5.0,<6.0
|
|
||||||
types-python-dateutil
|
|
||||||
types-pytz
|
|
||||||
types-requests
|
|
||||||
types-setuptools
|
|
||||||
mocker
|
|
||||||
@@ -23,7 +23,7 @@ services:
|
|||||||
# Run `make .env` to set $USER_ID and $GROUP_ID
|
# Run `make .env` to set $USER_ID and $GROUP_ID
|
||||||
USER_ID: ${USER_ID:-}
|
USER_ID: ${USER_ID:-}
|
||||||
GROUP_ID: ${GROUP_ID:-}
|
GROUP_ID: ${GROUP_ID:-}
|
||||||
command: "/root/.virtualenvs/dbt/bin/pytest"
|
command: "bash -c 'cd core && hatch run ci:unit-tests'"
|
||||||
environment:
|
environment:
|
||||||
POSTGRES_TEST_HOST: "database"
|
POSTGRES_TEST_HOST: "database"
|
||||||
volumes:
|
volumes:
|
||||||
|
|||||||
@@ -1,11 +0,0 @@
|
|||||||
## ADRs
|
|
||||||
|
|
||||||
For any architectural/engineering decisions we make, we will create an ADR (Architectural Design Record) to keep track of what decision we made and why. This allows us to refer back to decisions in the future and see if the reasons we made a choice still holds true. This also allows for others to more easily understand the code. ADRs will follow this process:
|
|
||||||
|
|
||||||
- They will live in the repo, under a directory `docs/arch`
|
|
||||||
- They will be written in markdown
|
|
||||||
- They will follow the naming convention [`adr-NNN-<decision-title>.md`](http://adr-nnn.md/)
|
|
||||||
- `NNN` will just be a counter starting at `001` and will allow us easily keep the records in chronological order.
|
|
||||||
- The common sections that each ADR should have are:
|
|
||||||
- Title, Context, Decision, Status, Consequences
|
|
||||||
- Use this article as a reference: [https://cognitect.com/blog/2011/11/15/documenting-architecture-decisions](https://cognitect.com/blog/2011/11/15/documenting-architecture-decisions)
|
|
||||||
@@ -1,35 +0,0 @@
|
|||||||
# Performance Regression Framework
|
|
||||||
|
|
||||||
## Context
|
|
||||||
We want the ability to benchmark our perfomance overtime with new changes going forward.
|
|
||||||
|
|
||||||
### Options
|
|
||||||
- Static Window: Compare the develop branch to fastest version and ensure it doesn't exceed a static window (i.e. time parse on develop and time parse on 0.20.latest and make sure it's not more than 5% slower)
|
|
||||||
- Pro: quick to run
|
|
||||||
- Pro: simple to implement
|
|
||||||
- Con: rerunning a failing test could get it to pass in a large number of changes.
|
|
||||||
- Con: several small regressions could press us up against the threshold requiring us to do unexpected additional performance work, or lower the threshold to get a release out.
|
|
||||||
- Variance-aware Testing: Run both the develop branch and our fastest version *many times* to collect a set of timing data. We can fail on a static window based on medians, confidence interval midpoints, and even variance magnitude.
|
|
||||||
- Pro: would catch more small performance regressions
|
|
||||||
- Con: would take much longer to run
|
|
||||||
- Con: Need to be very careful about making sure caching doesn't wreck the curve (or if it does, it wrecks the curve equally for all tests)
|
|
||||||
- Stateful Tracking: For example, the rust compiler team does some [bananas performance tracking](https://perf.rust-lang.org/). This option could be done in tandem with the above options, however it would require results be stored somewhere.
|
|
||||||
- Pro: we can graph our performance history and look really cool.
|
|
||||||
- Pro: Variance-aware testing would run in half the time since you can just reference old runs for comparison
|
|
||||||
- Con: state in tests sucks
|
|
||||||
- Con: longer to build
|
|
||||||
- Performance Profiling: Running a sampling-based profiler through a series of standardized test runs (test designed to hit as many/all of the code paths in the codebase) to determine if any particular function/class/other code has regressed in performance.
|
|
||||||
- Pro: easy to find the cause of the perf. regression
|
|
||||||
- Pro: should be able to run on a fairly small project size without losing much test resolution (a 5% change in a function should be evident with even a single case that runs that code path)
|
|
||||||
- Con: complex to build
|
|
||||||
- Con: compute intensive
|
|
||||||
- Con: requires stored results to compare against
|
|
||||||
|
|
||||||
## Decision
|
|
||||||
We decided to start with variance-aware testing with the ability to add stateful tracking by leveraging `hyperfine` which does all the variance work for us, and outputs clear json artifacts. Since we're running perfornace testing on a schedule it doesn't matter that as we add more tests it may take hours to run. The artifacts are all stored in the github action runs today, but could easily be changed to be sent somewhere in the action to track over time.
|
|
||||||
|
|
||||||
## Status
|
|
||||||
Completed
|
|
||||||
|
|
||||||
## Consequences
|
|
||||||
We now have the ability to more rigorously detect performance regressions, but we do not have a solid way to identify where that regression is coming from. Adding Performance Profiling cababilities will help with this, but for now just running it nightly should help us narrow it down to specific commits. As we add more performance tests, the testing matrix may take hours to run which consumes resources on GitHub Actions. Because performance testing is asynchronous, failures are easier to miss or ignore, and because it is non-deterministic it adds a non-trivial amount of complexity to our development process.
|
|
||||||
@@ -1,34 +0,0 @@
|
|||||||
# Structured Logging Arch
|
|
||||||
|
|
||||||
## Context
|
|
||||||
Consumers of dbt have been relying on log parsing well before this change. However, our logs were never optimized for programatic consumption, nor were logs treated like a formal interface between dbt and users. dbt's logging strategy was changed explicitly to address these two realities.
|
|
||||||
|
|
||||||
### Options
|
|
||||||
#### How to structure the data
|
|
||||||
- Using a library like structlog to represent log data with structural types like dictionaries. This would allow us to easily add data to a log event's context at each call site and have structlog do all the string formatting and io work.
|
|
||||||
- Creating our own nominal type layer that describes each event in source. This allows event fields to be enforced statically via mypy accross all call sites.
|
|
||||||
|
|
||||||
#### How to output the data
|
|
||||||
- Using structlog to output log lines regardless of if we used it to represent the data. The defaults for structlog are good, and it handles json vs text and formatting for us.
|
|
||||||
- Using the std lib logger to log our messages more manually. Easy to use, but does far less for us.
|
|
||||||
|
|
||||||
## Decision
|
|
||||||
#### How to structure the data
|
|
||||||
We decided to go with a custom nominal type layer even though this was going to be more work. This type layer centralizes our assumptions about what data each log event contains, and allows us to use mypy to enforce these centralized assumptions acrosss the codebase. This is all for the purpose for treating logs like a formal interface between dbt and users. Here are two concrete, practical examples of how this pattern is used:
|
|
||||||
|
|
||||||
1. On the abstract superclass of all events, there are abstract methods and fields that each concrete class must implement such as `level_tag()` and `code`. If you make a new concrete event type without those, mypy will fail and tell you that you need them, preventing lost log lines, and json log events without a computer-friendly code.
|
|
||||||
|
|
||||||
2. On each concrete event, the fields we need to construct the message are explicitly in the source of the class. At every call site if you construct an event without all the necessary data, mypy will fail and tell you which fields you are missing.
|
|
||||||
|
|
||||||
Using mypy to enforce these assumptions is a step better than testing becacuse we do not need to write tests to run through every branch of dbt that it could take. Because it is checked statically on every file, mypy will give us these guarantees as long as it is configured to run everywhere.
|
|
||||||
|
|
||||||
#### How to output the data
|
|
||||||
We decided to use the std lib logger because it was far more difficult than we expected to get to structlog to work properly. Documentation was lacking, and reading the source code wasn't a quick way to learn. The std lib logger was used mostly out of a necessity, and because many of the pleasantries you get from using a log library we had already chosen to do explicitly with functions in our nominal typing layer. Swapping out the std lib logger in the future should be an easy task should we choose to do it.
|
|
||||||
|
|
||||||
## Status
|
|
||||||
Completed
|
|
||||||
|
|
||||||
## Consequences
|
|
||||||
Adding a new log event is more cumbersome than it was previously: instead of writing the message at the log callsite, you must create a new concrete class in the event types. This is more opaque for new contributors. The json serialization approach we are using via `asdict` is fragile and unoptimized and should be replaced.
|
|
||||||
|
|
||||||
All user-facing log messages now live in one file which makes the job of conforming them much simpler. Because they are all nominally typed separately, it opens up the possibility to have log documentation generated from the type hints as well as outputting our logs in multiple human languages if we want to translate our messages.
|
|
||||||
@@ -1,68 +0,0 @@
|
|||||||
# Python Model Arch
|
|
||||||
|
|
||||||
## Context
|
|
||||||
We are thinking of supporting `python` ([roadmap](https://github.com/dbt-labs/dbt-core/blob/main/docs/roadmap/2022-05-dbt-a-core-story.md#scene-3-python-language-dbt-models), [discussion](https://github.com/dbt-labs/dbt-core/discussions/5261)) as a language other than SQL in dbt-core. This would allow users to express transformation logic that is tricky to do in SQL and have more libraries available to them.
|
|
||||||
|
|
||||||
### Options
|
|
||||||
|
|
||||||
#### Where to run the code
|
|
||||||
- running it locally where we run dbt core.
|
|
||||||
- running it in the cloud providers' environment.
|
|
||||||
|
|
||||||
#### What are the guardrails dbt would enforce for the python model
|
|
||||||
- None, users can write whatever code they like.
|
|
||||||
- focusing on data transformation logic where each python model should have a model function that returns a database object for dbt to materialize.
|
|
||||||
|
|
||||||
#### Where should the implementation live
|
|
||||||
Two places we need to consider are `dbt-core` and each individual adapter code-base. What are the pieces needed? How do we decide what goes where?
|
|
||||||
|
|
||||||
|
|
||||||
#### Are we going to allow writing macros in python
|
|
||||||
- Not allowing it.
|
|
||||||
- Allowing certain Jinja templating
|
|
||||||
- Allow everything
|
|
||||||
|
|
||||||
## Decisions
|
|
||||||
#### Where to run the code
|
|
||||||
In the same idea of dbt is not your query engine, we don't want dbt to be your python runtime. Instead, we want dbt to focus on being the place to express transformation logic. So python model will be following the existing pattern of the SQL model(parse and compile user written logic and submit it to your computation engine).
|
|
||||||
|
|
||||||
#### What are the guardrails dbt would enforce for the python model
|
|
||||||
We want dbt to focus on transformation logic, so we opt for setting up some tools and guardrails for the python model to focus on doing data transformation.
|
|
||||||
1. A `dbt` object would have functions including `dbt.ref`, `dbt.source` function to reference other models and sources in the dbt project, the return of the function will be a dataframe of referenced resources.
|
|
||||||
1. Code in the python model node should include a model function that takes a `dbt` object as an argument, do the data transformation logic inside, and return a dataframe in the end. We think folks should load their data into dataframes using the `dbt.ref`, `dbt.source` provided over raw data references. We also think logic to write dataframe to database objects should live in materialization logic instead of transformation code.
|
|
||||||
1. That `dbt` object should also have an attribute called `dbt.config` to allow users to define configurations of the current python model like materialization logic, a specific version of python libraries, etc. This `dbt.config` object should also provide a clear access function for variables defined in project YAML. This way user can access arbitrary configuration at runtime.
|
|
||||||
|
|
||||||
#### Where should the implementation live
|
|
||||||
|
|
||||||
Logic in core should be universal and carry the opionions we have for the feature, this includes but not limited to
|
|
||||||
1. parsing of python file in dbt-core to get the `ref`, `source`, and `config` information. This information is used to place the python model in the correct place in project DAG and generate the correct python code sent to compute engine.
|
|
||||||
1. `language` as a new top-level node property.
|
|
||||||
1. python template code that is not cloud provider-specific, this includes implementation for `dbt.ref`, `dbt.source`. We would use ast parser to parse out all of the `dbt.ref`, `dbt.source` inside python during parsing time, and generate what database resources those points to during compilation time. This should allow user to copy-paste the "compiled" code, and run it themselves against the data warehouse — just like with SQL models. A example of definition for `dbt.ref` could look like this
|
|
||||||
```python
|
|
||||||
def ref(*args):
|
|
||||||
refs = {"my_sql_model": "DBT_TEST.DBT_SOMESCHEMA.my_sql_model"}
|
|
||||||
key = ".".join(args)
|
|
||||||
return load_df_function(refs[key])
|
|
||||||
```
|
|
||||||
|
|
||||||
1. functional tests for the python model, these tests are expected to be inherited in the adapter code to make sure intended functions are met.
|
|
||||||
1. Generalizing the names of properties (`sql`, `raw_sql`, `compiled_sql`) for a future where it's not all SQL.
|
|
||||||
1. implementation of restrictions have for python model.
|
|
||||||
|
|
||||||
|
|
||||||
Computing engine specific logic should live in adapters, including but not limited to
|
|
||||||
- `load_df_function` of how to load a dataframe for a given database resource,
|
|
||||||
- `materialize` of how to save a dataframe to table or other materialization formats.
|
|
||||||
- some kind of `submit_python` function for submitting python code to compute engine.
|
|
||||||
- addition or modification `materialization` macro to add materialize the python model
|
|
||||||
|
|
||||||
|
|
||||||
#### Are we going to allow writing macros in python
|
|
||||||
|
|
||||||
We don't know yet. We use macros in SQL models because it allows us to achieve what SQL can't do. But with python being a programming language, we don't see a strong need for macros in python yet. So we plan to strictly disable that in the user-written code in the beginning, and potentially add more as we hear from the community.
|
|
||||||
|
|
||||||
## Status
|
|
||||||
Implementing
|
|
||||||
|
|
||||||
# Consequences
|
|
||||||
Users would be able to write python transformation models in dbt and run them as part of their data transformation workflow.
|
|
||||||
@@ -1,53 +0,0 @@
|
|||||||
# Use of betterproto package for generating Python message classes
|
|
||||||
|
|
||||||
## Context
|
|
||||||
We are providing proto definitions for our structured logging messages, and as part of that we need to also have Python classes for use in our Python codebase
|
|
||||||
|
|
||||||
### Options, August 30, 2022
|
|
||||||
|
|
||||||
#### Google protobuf package
|
|
||||||
|
|
||||||
You can use the google protobuf package to generate Python "classes", using the protobuf compiler, "protoc" with the "--python_out" option.
|
|
||||||
|
|
||||||
* It's not readable. There are no identifiable classes in the output.
|
|
||||||
* A "class" is generated using a metaclass when it is used.
|
|
||||||
* You can't subclass the generated classes, which don't act much like Python objects
|
|
||||||
* Since you can't put defaults or methods of any kind in these classes, and you can't subclass them, they aren't very usable in Python.
|
|
||||||
* Generated classes are not easily importable
|
|
||||||
* Serialization is via external utilities.
|
|
||||||
* Mypy and flake8 totally fail so you have to exclude the generated files in the pre-commit config.
|
|
||||||
|
|
||||||
#### betterproto package
|
|
||||||
|
|
||||||
* It generates readable "dataclass" classes.
|
|
||||||
* You can subclass the generated classes. (Though you still can't add additional attributes. But if we really needed to we might be able to modify the source code to do so.)
|
|
||||||
* Integrates much more easily with our codebase.
|
|
||||||
* Serialization (to_dict and to_json) is built in.
|
|
||||||
* Mypy and flake8 work on generated files.
|
|
||||||
|
|
||||||
* Additional benefits listed: [betterproto](https://github.com/danielgtaylor/python-betterproto)
|
|
||||||
|
|
||||||
|
|
||||||
## Revisited, March 21, 2023
|
|
||||||
|
|
||||||
We are switching away from using betterproto because of the following reasons:
|
|
||||||
* betterproto only suppports Optional fields in a beta release
|
|
||||||
* betterproto has had only beta releases for a few years
|
|
||||||
* betterproto doesn't support Struct, which we really need
|
|
||||||
* betterproto started changing our message names to be more "pythonic"
|
|
||||||
|
|
||||||
Steps taken to mitigate the drawbacks of Google protobuf from above:
|
|
||||||
* We are using a wrapping class around the logging events to enable a constructor that looks more like a Python constructor, as long as only keyword arguments are used.
|
|
||||||
* The generated file is skipped in the pre-commit config
|
|
||||||
* We can live with the awkward interfaces. It's just code.
|
|
||||||
|
|
||||||
Advantages of Google protobuf:
|
|
||||||
* Message can be constructed from a dictionary of all message values. With betterproto you had to pre-construct nested message objects, which kind of forced you to sprinkle generated message objects through the codebase.
|
|
||||||
* The Struct support works really well
|
|
||||||
* Type errors are caught much earlier and more consistently. Betterproto would accept fields of the wrong types, which was sometimes caught on serialization to a dictionary, and sometimes not until serialized to a binary string. Sometimes not at all.
|
|
||||||
|
|
||||||
Disadvantages of Google protobuf:
|
|
||||||
* You can't just set nested message objects, you have to use CopyFrom. Just code, again.
|
|
||||||
* If you try to stringify parts of the message (like in the constructed event message) it outputs in a bizarre "user friendly" format. Really bad for Struct, in particular.
|
|
||||||
* Python messages aren't really Python. You can't expect them to *act* like normal Python objects. So they are best kept isolated to the logging code only.
|
|
||||||
* As part of the not-really-Python, you can't use added classes to act like flags (Cache, NoFile, etc), since you can only use the bare generated message to construct other messages.
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 97 KiB After Width: | Height: | Size: 97 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.1 KiB After Width: | Height: | Size: 7.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 138 KiB After Width: | Height: | Size: 138 KiB |
{kind=link}
|
Before Width: | Height: | Size: 49 KiB After Width: | Height: | Size: 49 KiB |
@@ -1 +0,0 @@
|
|||||||
-e ./core
|
|
||||||
@@ -1,3 +0,0 @@
|
|||||||
The events outlined here exist to support "very very old versions of dbt-core, which expected to look directly at the HEAD branch of this github repo to find validation schemas".
|
|
||||||
|
|
||||||
Eventually these should go away (see https://github.com/dbt-labs/dbt-core/issues/7228)
|
|
||||||
@@ -1,10 +0,0 @@
|
|||||||
{
|
|
||||||
"type": "object",
|
|
||||||
"title": "invocation_env",
|
|
||||||
"description": "DBT invocation environment type",
|
|
||||||
"properties": {
|
|
||||||
"environment": {
|
|
||||||
"type": "string"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,43 +0,0 @@
|
|||||||
{
|
|
||||||
"type": "object",
|
|
||||||
"title": "invocation",
|
|
||||||
"description": "Schema for a dbt invocation",
|
|
||||||
"properties": {
|
|
||||||
"project_id": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"user_id": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"invocation_id": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"command": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"command_options": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"progress": {
|
|
||||||
"type": "string",
|
|
||||||
"enum": ["start", "end"]
|
|
||||||
},
|
|
||||||
"version": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"remote_ip": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"run_type": {
|
|
||||||
"type": "string",
|
|
||||||
"enum": ["dry", "test", "regular"]
|
|
||||||
},
|
|
||||||
"result_type": {
|
|
||||||
"type": "string",
|
|
||||||
"enum": ["ok", "error"]
|
|
||||||
},
|
|
||||||
"result": {
|
|
||||||
"type": "string"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,16 +0,0 @@
|
|||||||
{
|
|
||||||
"type": "object",
|
|
||||||
"title": "platform",
|
|
||||||
"description": "Schema for a dbt user's platform",
|
|
||||||
"properties": {
|
|
||||||
"platform": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"python": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"python_version": {
|
|
||||||
"type": "string"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,35 +0,0 @@
|
|||||||
{
|
|
||||||
"type": "object",
|
|
||||||
"title": "run_model",
|
|
||||||
"description": "Schema for the execution of a model",
|
|
||||||
"properties": {
|
|
||||||
"index": {
|
|
||||||
"type": "number"
|
|
||||||
},
|
|
||||||
"total": {
|
|
||||||
"type": "number"
|
|
||||||
},
|
|
||||||
"execution_time": {
|
|
||||||
"type": "number",
|
|
||||||
"multiple_of": 0.01
|
|
||||||
},
|
|
||||||
"run_status": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"run_skipped": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"run_error": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"model_materialization": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"model_id": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"hashed_contents": {
|
|
||||||
"type": "string"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@@ -1,118 +0,0 @@
|
|||||||
# Performance Regression Testing
|
|
||||||
|
|
||||||
## Attention!
|
|
||||||
|
|
||||||
PLEASE READ THIS README IN THE MAIN BRANCH
|
|
||||||
The performance runner is always pulled from main regardless of the version being modeled or sampled. If you are not in the main branch, this information may be stale.
|
|
||||||
|
|
||||||
## Description
|
|
||||||
|
|
||||||
This test suite samples the performance characteristics of individual commits against performance models for prior releases. Performance is measured in project-command pairs which are assumed to conform to a normal distribution. The sampling and comparison is effecient enough to run against PRs.
|
|
||||||
|
|
||||||
This collection of projects and commands should expand over time to reflect user feedback about poorly performing projects to protect against poor performance in these scenarios in future versions.
|
|
||||||
|
|
||||||
Here are all the components of the testing module:
|
|
||||||
|
|
||||||
- dbt project setups that are known performance bottlenecks which you can find in `/performance/projects/`, and a runner written in Rust that runs specific dbt commands on each of the projects.
|
|
||||||
- Performance characteristics called "baselines" from released dbt versions in `/performance/baselines/`. Each branch will only have the baselines for its ancestors because when we compare samples, we compare against the lastest baseline available in the branch.
|
|
||||||
- A GitHub action for modeling the performance distribution for a new release: `/.github/workflows/model_performance.yml`.
|
|
||||||
- A GitHub action for sampling performance of dbt at your commit and comparing it against a previous release: `/.github/workflows/sample_performance.yml`.
|
|
||||||
|
|
||||||
At this time, the biggest risk in the design of this project is how to account for the natural variation of GitHub Action runs. Typically, performance work is done on dedicated hardware to elimiate this factor. However, there are ways to integrate the variation in obeservation tools if it can be measured.
|
|
||||||
|
|
||||||
## Adding Test Scenarios
|
|
||||||
|
|
||||||
A clear process for maintainers and community members to add new performance testing targets will exist after the next stage of the test suite is complete. For details, see #4768.
|
|
||||||
|
|
||||||
## Investigating Regressions
|
|
||||||
|
|
||||||
If your commit has failed one of the performance regression tests, it does not necessarily mean your commit has a performance regression. However, the observed runtime value was so much slower than the expected value that it was unlikely to be random noise. If it is not due to random noise, this commit contains the code that is causing this performance regression. However, it may not be the commit that introduced that code. That code may have been introduced in the commit before even if it passed due to natural variation in sampling. When investigating a performance regression, start with the failing commit and working your way backwards.
|
|
||||||
|
|
||||||
Here's an example of how this could happen:
|
|
||||||
|
|
||||||
```
|
|
||||||
Commit
|
|
||||||
A <- last release
|
|
||||||
B
|
|
||||||
C <- perf regression
|
|
||||||
D
|
|
||||||
E
|
|
||||||
F <- the first failing commit
|
|
||||||
```
|
|
||||||
- Commit A is measured to have an expected value for one performance metric of 30 seconds with a standard deviation of 0.5 seconds.
|
|
||||||
- Commit B doesn't introduce a performance regression and passes the performance regression tests.
|
|
||||||
- Commit C introduces a performance regression such that the new expected value of the metric is 32 seconds with a standard deviation still at 0.5 seconds, but we don't know this because we don't estimate the whole performance distribution on every commit because that is far too much work to run on every commit. It passes the performance regression test because we happened to sample a value of 31 seconds which is within our threshold for the original model. It's also only 2 standard deviations away from the actual performance model of commit C so even though it's not going to be a super common situation, it is expected to happen sometimes.
|
|
||||||
- Commit D samples a value of 31.4 seconds and passes
|
|
||||||
- Commit E samples a value of 31.2 seconds and passes
|
|
||||||
- Commit F samples a value of 32.9 seconds and fails
|
|
||||||
|
|
||||||
Because these performance regression tests are non-deterministic, it is frequently going to be possible to rerun the test on a failing commit and get it to pass. The more often we do this, the farther down the commit history we will be punting detection.
|
|
||||||
|
|
||||||
If your PR is against `main` your commits will be compared against the latest baseline measurement found in `performance/baselines`. If this commit needs to be backported, that PR will be against the `.latest` branch and will also compare against the latest baseline measurement found in `performance/baselines` in that branch. These two versions may be the same or they may be different. For example, If the latest version of dbt is v1.99.0, the performance sample of your PR against main will compare against the baseline for v1.99.0. When those commits are backported to `1.98.latest` those commits will be compared against the baseline for v1.98.6 (or whatever the latest is at that time). Even if the compared baseline is the same, a different sample is taken for each PR. In this case, even though it should be rare, it is possible for a performance regression to be detected in one of the two PRs even with the same baseline due to variation in sampling.
|
|
||||||
|
|
||||||
## The Statistics
|
|
||||||
Particle physicists need to be confident in declaring new discoveries, snack manufacturers need to be sure each individual item is within the regulated margin of error for nutrition facts, and weight-rated climbing gear needs to be produced so you can trust your life to every unit that comes off the line. All of these use cases use the same kind of math to meet their needs: sigma-based p-values. This section will peel apart that math with the help of a physicist and walk through how we apply this approach to performance regression testing in this test suite.
|
|
||||||
|
|
||||||
You are likely familiar with forming a hypothesis of the form "A and B are correlated" which is known as _the research hypothesis_. Additionally, it follows that the hypothesis "A and B are not correlated" is relevant and is known as _the null hypothesis_. When looking at data, we commonly use a _p-value_ to determine the significance of the data. Formally, a _p-value_ is the probability of obtaining data at least as extreme as the ones observed, if the null hypothesis is true. To refine this definition, The experimental partical physicist [Dr. Tommaso Dorigo](https://userswww.pd.infn.it/~dorigo/#about) has an excellent [glossary](https://www.science20.com/quantum_diaries_survivor/fundamental_glossary_higgs_broadcast-85365) of these terms that helps clarify: "'Extreme' is quite tricky instead: it depends on what is your 'alternate hypothesis' of reference, and what kind of departure it would produce on the studied statistic derived from the data. So 'extreme' will mean 'departing from the typical values expected for the null hypothesis, toward the values expected from the alternate hypothesis.'" In the context of performance regression testing, our research hypothesis is that "after commit A, the codebase includes a performance regression" which means we expect the runtime of our measured processes to be _slower_, not faster than the expected value.
|
|
||||||
|
|
||||||
Given this definition of p-value, we need to explicitly call out the common tendancy to apply _probability inversion_ to our observations. To quote [Dr. Tommaso Dorigo](https://www.science20.com/quantum_diaries_survivor/fundamental_glossary_higgs_broadcast-85365) again, "If your ability on the long jump puts you in the 99.99% percentile, that does not mean that you are a kangaroo, and neither can one infer that the probability that you belong to the human race is 0.01%." Using our previously defined terms, the p-value is _not_ the probability that the null hypothesis _is true_.
|
|
||||||
|
|
||||||
This brings us to calculating sigma values. Sigma refers to the standard deviation of a statistical model, which is used as a measurement of how far away an observed value is from the expected value. When we say that we have a "3 sigma result" we are saying that if the null hypothesis is true, this is a particularly unlikely observation—not that the null hypothesis is false. Exactly how unlikely depends on what the expected values from our research hypothesis are. In the context of performance regression testing, if the null hypothesis is false, we are expecting the results to be _slower_ than the expected value not _slower or faster_. Looking at a normal distrubiton below, we can see that we only care about one _half_ of the distribution: the half where the values are slower than the expected value. This means that when we're calculating the p-value we are not including both sides of the normal distribution.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Because of this, the following table describes the significance of each sigma level for our _one-sided_ hypothesis:
|
|
||||||
|
|
||||||
| σ | p-value | scientific significance |
|
|
||||||
| --- | -------------- | ----------------------- |
|
|
||||||
| 1 σ | 1 in 6 | |
|
|
||||||
| 2 σ | 1 in 44 | |
|
|
||||||
| 3 σ | 1 in 741 | evidence |
|
|
||||||
| 4 σ | 1 in 31,574 | |
|
|
||||||
| 5 σ | 1 in 3,486,914 | discovery |
|
|
||||||
|
|
||||||
When detecting performance regressions that trigger alerts, block PRs, or delay releases we want to be conservative enough that detections are infrequently triggered by noise, but not so conservative as to miss most actual regressions. This test suite uses a 3 sigma standard so that only about 1 in every 700 runs is expected to fail the performance regression test suite due to expected variance in our measurements.
|
|
||||||
|
|
||||||
In practice, the number of performance regression failures due to random noise will be higher because we are not incorporating the variance of the tools we use to measure, namely GHA.
|
|
||||||
|
|
||||||
### Concrete Example: Performance Regression Detection
|
|
||||||
|
|
||||||
The following example data was collected by running the code in this repository in Github Actions.
|
|
||||||
|
|
||||||
In dbt v1.0.3, we have the following mean and standard deviation when parsing a dbt project with 2000 models:
|
|
||||||
|
|
||||||
μ (mean): 41.22<br/>
|
|
||||||
σ (stddev): 0.2525<br/>
|
|
||||||
|
|
||||||
The 2-sided 3 sigma range can be calculated with these two values via:
|
|
||||||
|
|
||||||
x < μ - 3 σ or x > μ + 3 σ<br/>
|
|
||||||
x < 41.22 - 3 * 0.2525 or x > 41.22 + 3 * 0.2525 <br/>
|
|
||||||
x < 40.46 or x > 41.98<br/>
|
|
||||||
|
|
||||||
It follows that the 1-sided 3 sigma range for performance regressions is just:<br/>
|
|
||||||
x > 41.98
|
|
||||||
|
|
||||||
If when we sample a single `dbt parse` of the same project with a commit slated to go into dbt v1.0.4, we observe a 42s parse time, then this observation is so unlikely if there were no code-induced performance regressions, that we should investigate if there is a performance regression in any of the commits between this failure and the commit where the initial distribution was measured.
|
|
||||||
|
|
||||||
Observations with 3 sigma significance that are _not_ performance regressions could be due to observing unlikely values (roughly 1 in every 750 observations), or variations in the instruments we use to take these measurements such as github actions. At this time we do not measure the variation in the instruments we use to account for these in our calculations which means failures due to random noise are more likely than they would be if we did take them into account.
|
|
||||||
|
|
||||||
### Concrete Example: Performance Modeling
|
|
||||||
|
|
||||||
Once a new dbt version is released (excluding pre-releases), the performance characteristics of that released version need to be measured. In this repository this measurement is referred to as a baseline.
|
|
||||||
|
|
||||||
After dbt v1.0.99 is released, a github action running from `main`, for the latest version of that action, takes the following steps:
|
|
||||||
- Checks out main for the latest performance runner
|
|
||||||
- pip installs dbt v1.0.99
|
|
||||||
- builds the runner if it's not already in the github actions cache
|
|
||||||
- uses the performance runner model sub command with `./runner model`.
|
|
||||||
- The model subcommand calls hyperfine to run all of the project-command pairs a large number of times (maybe 20 or so) and save the hyperfine outputs to files in `performance/baselines/1.0.99/` one file per command-project pair.
|
|
||||||
- The action opens two PRs with these files: one against `main` and one against `1.0.latest` so that future PRs against these branches will detect regressions against the performance characteristics of dbt v1.0.99 instead of v1.0.98.
|
|
||||||
- The release driver for dbt v1.0.99 reviews and merges these PRs which is the sole deliverable of the performance modeling work.
|
|
||||||
|
|
||||||
## Future work
|
|
||||||
- pin commands to projects by reading commands from a file defined in the project.
|
|
||||||
- add a postgres warehouse to run `dbt compile` and `dbt run` commands
|
|
||||||
- add more projects to test different configurations that have been known performance bottlenecks
|
|
||||||
- Account for github action variation: Either measure it, or eliminate it. To measure it we could set up another action that periodically samples the same version of dbt and use a 7 day rolling variation. To eliminate it we could run the action using something like [act](https://github.com/nektos/act) on dedicated hardware.
|
|
||||||
- build in a git-bisect run to automatically identify the commits that caused a performance regression by modeling each commit's expected value for the failing metric. Running this automatically, or even providing a script to do this locally would be useful.
|
|
||||||
1
performance/baselines/.gitignore
vendored
@@ -1 +0,0 @@
|
|||||||
# placeholder for baselines directory
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
{"version":"1.2.0","metric":{"name":"parse","project_name":"01_2000_simple_models"},"ts":"2023-05-09T13:49:21.773314639Z","measurement":{"command":"dbt parse --no-version-check --profiles-dir ../../project_config/","mean":44.19299478025,"stddev":0.2429047068802047,"median":44.17483035975,"user":43.4559033,"system":0.5913923200000001,"min":43.81193651175,"max":44.61466355675,"times":[44.597056272749995,43.96855886975,43.90405755675,44.14156308475,44.49939515775,44.11553658675,44.30173547275,43.932534850749995,43.843978513749995,44.08611205475,43.99133546975,44.39880287075,44.20809763475,44.10553540675,43.81193651175,44.24880915975,44.408731260749995,44.61466355675,44.31538149475,44.36607381875]}}
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
{"version":"1.3.0","metric":{"name":"parse","project_name":"01_2000_simple_models"},"ts":"2023-05-05T21:26:14.178981105Z","measurement":{"command":"dbt parse --no-version-check --profiles-dir ../../project_config/","mean":57.34703829679,"stddev":1.264070714183875,"median":57.16122855003999,"user":56.124171495,"system":0.6879409899999999,"min":56.03876437454,"max":62.15960342254,"times":[56.45744564454,56.27775436354,56.50617413654,57.34027474654,57.38757627154,57.17093026654,56.29133183054,56.89527107354,57.48466258854,56.87484084654,57.14306217354,57.13537045454,58.00688797954,57.15152683354,57.65667721054,56.03876437454,57.68217591654,58.03524921154,62.15960342254,57.24518659054]}}
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
{"version":"1.3.4","metric":{"name":"parse","project_name":"01_2000_simple_models"},"ts":"2023-05-05T21:21:13.216166358Z","measurement":{"command":"dbt parse --no-version-check --profiles-dir ../../project_config/","mean":43.251824134715,"stddev":0.2626902769638351,"median":43.195683199465,"user":42.82592822,"system":0.444670655,"min":42.988474644965,"max":44.268850566965,"times":[43.117288670965,43.276664016965,44.268850566965,43.175714899965,43.069990564965,43.353031152965,43.064902203965,43.104385867965,43.228237677965,43.151709868965,43.410496816965,43.139105498965,43.112643799965,43.19391977696501,43.303759563965,43.312242193965,43.197446621965,43.297804568965,42.988474644965,43.269813715965]}}
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
{"version":"1.4.0","metric":{"name":"parse","project_name":"01_2000_simple_models"},"ts":"2023-05-05T16:07:45.035878166Z","measurement":{"command":"dbt parse --no-version-check --profiles-dir ../../project_config/","mean":53.44691701517499,"stddev":1.9217109918352029,"median":54.31170254667501,"user":52.633288745,"system":0.636774385,"min":49.603911921675,"max":55.743179437675,"times":[55.021354517675,54.25164864567501,54.975722432675,52.635067164675,53.571658032675,51.382873180675,50.043912339675,49.603911921675,51.132099650675,54.615839302675,52.565473620675,51.152761771675,52.459746128675,55.743179437675,54.936982552675005,54.37175644767501,54.852100134675,55.048404930675,55.185989433675005,55.387858656675]}}
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
{"version":"1.4.1","metric":{"name":"parse","project_name":"01_2000_simple_models"},"ts":"2023-05-05T21:23:11.574110714Z","measurement":{"command":"dbt parse --no-version-check --profiles-dir ../../project_config/","mean":51.81799889823499,"stddev":0.49021827459557155,"median":51.877185231885,"user":50.937133405,"system":0.66050657,"min":50.713426685384995,"max":52.451290474385,"times":[51.868264556385,51.967490942385,52.321507218385,51.886105907385,52.451290474385,52.283930937385,51.818989812385,51.978303421385,51.213362656385,50.713426685384995,52.258454610385,51.758877730384995,51.082508232384995,51.128473688385,51.631421367384995,52.194084467385,52.240100726384995,51.64952270338499,51.49970049638499,52.414161330385]}}
|
|
||||||