mirror of
https://github.com/dlt-hub/dlt.git
synced 2025-12-17 19:31:30 +00:00
apply feedback
This commit is contained in:
@@ -6,7 +6,7 @@ keywords: [pipeline, schema, data, inspect]
|
||||
|
||||
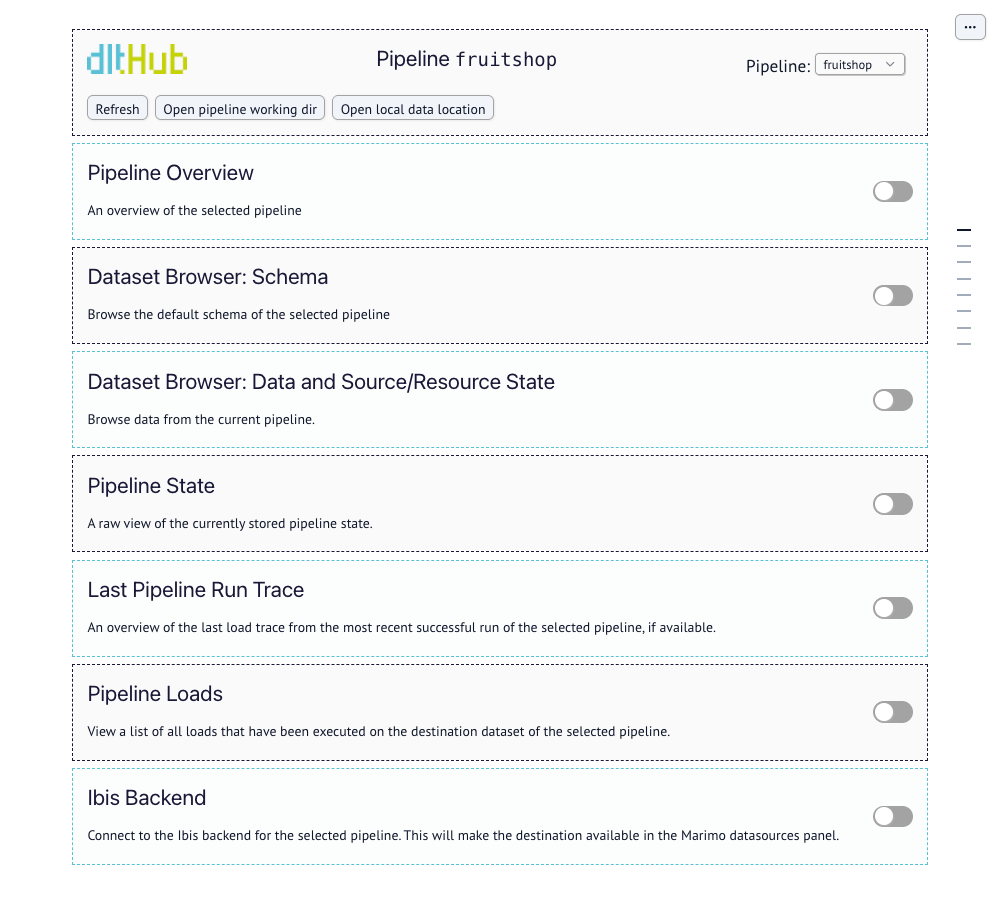
# Inspect your pipeline with the workspace dashboard
|
||||
|
||||
Once you have run a pipeline locally, you can launch a web app that displays detailed information about your pipeline. This app is built with the Marimo Python notebook framework. For this to work, you will need to have the `marimo` package installed.
|
||||
Once you have run a pipeline locally, you can launch a web app that displays detailed information about your pipeline. This app is built with the marimo Python notebook framework. For this to work, you will need to have the `marimo` package installed.
|
||||
|
||||
:::tip
|
||||
The workspace dashboard app works with all destinations that are supported by our dataset. Vector databases are generally unsupported at this point; however, you can still inspect metadata such as run traces, schemas, and pipeline state.
|
||||
@@ -24,14 +24,14 @@ You can use the dashboard app to:
|
||||
* Inspect the full run trace, including which configs were found and where; the results of the extract, normalize, and load steps (with timing and row counts); and information about the execution context (dlt version, platform, etc.)
|
||||
* See a history of load packages and associated table counts
|
||||
|
||||
You can even eject the code for the dashboard app into your current working directory and start editing it either in your code editor or in Marimo edit mode to create your own custom dashboard app!
|
||||
You can even eject the code for the dashboard app into your current working directory and start editing it either in your code editor or in marimo edit mode to create your own custom dashboard app!
|
||||
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
To install Marimo, run the following command:
|
||||
To install marimo, run the following command:
|
||||
```sh
|
||||
pip install marimo
|
||||
```
|
||||
@@ -116,7 +116,7 @@ Using `replace` write disposition is slower but simpler. If you are using it to
|
||||
SELECT _dlt_load_id, COUNT(*) FROM items GROUP BY 1
|
||||
```
|
||||
|
||||
- Optionally, check for continuity in the data. If you have a time axis or incremental IDs with normal distribution, plot them on a line chart to spot any anomalies. For easy plotting, we suggest using our integrated [Marimo notebook](./dataset-access/marimo.md).
|
||||
- Optionally, check for continuity in the data. If you have a time axis or incremental IDs with normal distribution, plot them on a line chart to spot any anomalies. For easy plotting, we suggest using our integrated [marimo notebook](./dataset-access/marimo.md).
|
||||
|
||||
### 3) Is my normalized schema the one I actually want?
|
||||
|
||||
@@ -203,7 +203,7 @@ SELECT * FROM {your_table} LIMIT 10
|
||||
2. Add additional endpoints to your source if you need related entities.
|
||||
3. Use [`add_map`](../dlt-ecosystem/transformations/add-map.md) to hash PII or reshape records before loading.
|
||||
|
||||
Use the Dataset Browser to explore the data, or the [Marimo notebook](./dataset-access/marimo.md) for more complex analysis.
|
||||
Use the Dataset Browser to explore the data, or the [marimo notebook](./dataset-access/marimo.md) for more complex analysis.
|
||||
|
||||
### 5) Are my data types correct?
|
||||
|
||||
@@ -295,7 +295,7 @@ dlt pipeline {pipeline_name} show --edit
|
||||
dlt dashboard --edit
|
||||
```
|
||||
|
||||
This will copy the dashboard code to the local folder and start Marimo in edit mode. If a local copy already exists, it will not overwrite it but will start it in edit mode. Once you have the local version, you can also use the regular Marimo commands to run or edit this notebook. This way, you can maintain multiple versions of your dashboard or other Marimo apps in your project:
|
||||
This will copy the dashboard code to the local folder and start marimo in edit mode. If a local copy already exists, it will not overwrite it but will start it in edit mode. Once you have the local version, you can also use the regular marimo commands to run or edit this notebook. This way, you can maintain multiple versions of your dashboard or other marimo apps in your project:
|
||||
|
||||
```sh
|
||||
# this will run a local dashboard
|
||||
|
||||
@@ -6,19 +6,24 @@ keywords: [data quality, validation, contracts, pydantic, schema, monitoring, go
|
||||
|
||||
# Data Quality Lifecycle
|
||||
|
||||
The data quality lifecycle has rarely been achievable in a single tool due to the runtime constraints of traditional ETL vendors.
|
||||
The data quality lifecycle has rarely been achievable
|
||||
in a single tool due to the runtime constraints of
|
||||
traditional ETL vendors.
|
||||
|
||||
## One library, end-to-end
|
||||
|
||||
Because `dlt` together with `dltHub` span the entire pipeline, starting from ingestion, passing through a portable staging layer, and extending into the transformation, it uniquely bridges these gaps.
|
||||
|
||||
This capability allows you to bring software engineering standards to your data infrastructure. `dlt` enables an end-to-end lifecycle that combines proactive "Shift Left" validation with reactive monitoring, ensuring production-grade quality and governance in one integrated solution.
|
||||
Instead of stitching together four or five separate tools, you write Python code that works across the entire pipeline. No glue scripts. No context lost between systems.
|
||||
|
||||
|
||||

|
||||
|
||||
**The three checkpoints for data quality:**
|
||||
|
||||
1. **In-Stream (Record Level):** Checking individual items in memory as they are extracted.
|
||||
2. **Staging Buffer (Batch Level):** Checking the aggregate properties of the current load before it merges.
|
||||
3. **Destination (Dataset Level):** Checking the holistic state of the data in the warehouse.
|
||||
1. **In-flight:** Check individual records as data is extracted, before loading it.
|
||||
2. **Staging:** We optionally load the data to an optionally transient staging area where we can test it without breaking production.
|
||||
3. **Destination:** Check properties of the full dataset currently written to the destination.
|
||||
|
||||
## The five pillars of data quality
|
||||
|
||||
@@ -111,25 +116,11 @@ Monitoring the reliability of the delivery mechanism itself. Even perfectly vali
|
||||
| Trace Lineage | **Load IDs:** Every row in your destination is tagged with `_dlt_load_id`. You can trace any specific record back to the exact pipeline run that produced it. | [Destination Tables](../general-usage/destination-tables.md#data-lineage) | dlt |
|
||||
| Alert on failures | **Slack Integration:** Send pipeline success/failure notifications via Slack incoming webhooks configured in `dlt.secrets`. | [Alerting](alerting.md) | dlt |
|
||||
|
||||
---
|
||||
|
||||
## Implementation matrix
|
||||
|
||||
Summary of which `dlt` features apply at each lifecycle stage.
|
||||
|
||||
| Dimension | In-Stream (Record) | Staging Buffer (Batch) | Destination (Dataset) |
|
||||
|-----------|-------------------|------------------------|----------------------|
|
||||
| **Structural** | Schema contracts, Type coercion | Batch schema validation | Schema drift audit |
|
||||
| **Semantic** | Pydantic models, `add_filter` | Aggregate checks (Ibis/DuckDB) | Cross-table consistency |
|
||||
| **Uniqueness** | In-memory dedup | Batch duplicate detection | Primary key enforcement |
|
||||
| **Privacy** | `add_map` masking, Hashing | — | Audit trail in `load_info` |
|
||||
| **Operational** | Extraction error handling | Row count assertions | `_dlt_loads` freshness monitoring |
|
||||
|
||||
---
|
||||
|
||||
## Validate data quality during development
|
||||
|
||||
Use the [Workspace Dashboard](../general-usage/dashboard.md) to interactively inspect your pipeline during development. The dashboard lets you:
|
||||
Use the [dlt Dashboard](../general-usage/dashboard.md) to interactively inspect your pipeline during development. The dashboard lets you:
|
||||
|
||||
- Query loaded data and verify row counts match expectations
|
||||
- Inspect schemas, columns, and all column hints
|
||||
@@ -145,7 +136,7 @@ dlt pipeline {pipeline_name} show
|
||||
|
||||
## Get the full lifecycle with dltHub
|
||||
|
||||
The features marked `dlt` in the tables above are available today in the open-source library. To unlock the complete data quality lifecycle, **dltHub** provides a managed runtime and additional capabilities:
|
||||
The features marked `dlt` in the tables above are available today in the open-source library. **dltHub** provides a managed runtime and additional data quality capabilities:
|
||||
|
||||
- **Run dlt on the dltHub runtime** — Execute all your existing dlt pipelines with managed infrastructure, scheduling, and observability built-in.
|
||||
- **Built-in data quality checks** — Use `is_in()`, `is_unique()`, `is_primary_key()`, and more with row-level and batch-level validation.
|
||||
@@ -163,16 +154,8 @@ Interested in the full data quality lifecycle? [Join dltHub early access](https:
|
||||
|
||||
## Related documentation
|
||||
|
||||
- [Workspace Dashboard](../general-usage/dashboard.md) — Inspect pipelines, schemas, and data during development
|
||||
- [Schema Contracts](../general-usage/schema-contracts.md) — Schema contracts, frozen mode, evolution strategies
|
||||
- [Schema](../general-usage/schema.md) — Type system, schema definition
|
||||
- [Schema Evolution](../general-usage/schema-evolution.md) — How schemas evolve over time
|
||||
- [Incremental Loading](../general-usage/incremental-loading.md) — Append, merge strategies
|
||||
- [Merge Loading](../general-usage/merge-loading.md) — SCD2, upserts, deduplication
|
||||
- [Destination Tables](../general-usage/destination-tables.md) — Parent-child relationships, system tables, lineage
|
||||
- [Transform with add_map](../dlt-ecosystem/transformations/add-map.md) — Masking, filtering, transformations
|
||||
- [Pseudonymizing Columns](../general-usage/customising-pipelines/pseudonymizing_columns.md) — PII hashing examples
|
||||
- [Removing Columns](../general-usage/customising-pipelines/removing_columns.md) — Dropping sensitive fields
|
||||
- [Running in Production](running.md) — Metrics, debugging failed loads
|
||||
- [dlt Dashboard](../general-usage/dashboard.md) — Inspect pipelines, schemas, and data during development
|
||||
- [Schema Contracts](../general-usage/schema-contracts.md) — Schema contracts and Pydantic validation
|
||||
- [Running in Production](running.md) — Metrics, load info, and debugging
|
||||
- [Monitoring](monitoring.md) — Run and data monitoring
|
||||
- [Alerting](alerting.md) — Setting up alerts for pipeline issues
|
||||
|
||||
Reference in New Issue
Block a user