mirror of
https://github.com/dlt-hub/dlt.git
synced 2025-12-17 19:31:30 +00:00
docs: LLM workflow update (#3422)
* working copy of docs * added diagram; wip * checkpoint * Misc docusaurus fixes * Remove placeholder text and whitespace * Move images to the gcp bucket * add data quality section * fixed linting * Escape curly braces --------- Co-authored-by: Marcin Rudolf <rudolfix@rudolfix.org> Co-authored-by: Anton Burnashev <anton.burnashev@gmail.com>
This commit is contained in:
@@ -1,74 +1,52 @@
|
||||
---
|
||||
title: Build pipelines and reports with LLMs
|
||||
description: How to extract and explore data from REST API with AI editors/agents
|
||||
title: REST API source in 10min
|
||||
description: Build a custom REST API connector in 10min
|
||||
keywords: [cursor, llm, restapi, ai]
|
||||
---
|
||||
|
||||
# Build dlt pipelines and reports with LLMs
|
||||
# REST API source in 10min
|
||||
|
||||
## Overview
|
||||
|
||||
This guide walks you through a collaborative AI-human workflow for extracting and exploring data from REST API sources using an AI editor/agent of your choice and dlt. It introduces the first workflow available in dltHub workspace — an LLM-native development environment for data engineering tasks.
|
||||
The Python library `dlt` provides a powerful [REST API toolkit](../../dlt-ecosystem/verified-sources/rest_api/basic.md) to ingest data. Combined with our [LLM scaffolds](https://dlthub.com/workspace) and [MCP server](../../hub/features/mcp-server.md), you can build a custom connector for any of the 8k+ available sources in 10 minutes by following this guide.
|
||||
|
||||
You will learn:
|
||||
1. How to initialize a dltHub workspace for your source using dltHub’s [LLM-context database](https://dlthub.com/workspace).
|
||||
2. How to build a REST API source in minutes with AI assistance.
|
||||
3. How to debug a pipeline and explore data using the workspace dashboard.
|
||||
4. How to start a new notebook and work with the pipeline’s dataset in it.
|
||||
Building with LLMs is an iterative process. We will follow this general workflow and give practical tips for each step.
|
||||
|
||||
## Prerequisites
|
||||
```mermaid
|
||||
stateDiagram-v2
|
||||
setup: setup workspace
|
||||
instructions: initial instructions
|
||||
codegen: generate code
|
||||
run: run pipeline
|
||||
context: manage context
|
||||
data: check data
|
||||
commit: commit working code
|
||||
|
||||
Have one of the following AI editors/agents installed:
|
||||
- [Cursor IDE](https://cursor.com/)
|
||||
- [Continue](https://www.continue.dev/)
|
||||
- [Cody](https://sourcegraph.com/cody)
|
||||
- [Claude](https://docs.anthropic.com/en/docs/claude-code/ide-integrations)
|
||||
- [Cline](https://cline.bot/)
|
||||
- [Codex](https://openai.com/codex/)
|
||||
- [Copilot](https://github.com/features/copilot)
|
||||
- [Amp](https://ampcode.com/)
|
||||
- [Windsurf](https://windsurf.com/)
|
||||
[*] --> setup: start
|
||||
setup --> instructions: workspace is ready
|
||||
instructions --> codegen: ask to ingest endpoint
|
||||
codegen --> run: code generated
|
||||
run --> context: fails
|
||||
run --> data: completes
|
||||
context --> codegen: context updated
|
||||
data --> context: is incorrect
|
||||
data --> commit: is correct
|
||||
commit --> instructions: add endpoint / refine config
|
||||
commit --> [*]
|
||||
```
|
||||
|
||||
## Concepts used in this guide
|
||||
:::note
|
||||
You will need an AI-enabled IDE or agent, such as Copilot, Claude Code, Cursor, Continue, etc.
|
||||
:::
|
||||
|
||||
Before diving into the workflow, here’s a quick overview of key terms you’ll encounter:
|
||||
|
||||
1. **dlt workspace** - An environment where all data engineering tasks, from writing code to maintenance in production, can be executed by a single developer:
|
||||
- Develop and test data pipelines locally
|
||||
- Run dlt pipelines, transformations, and notebooks with one command
|
||||
- Deliver live, production-ready reports with streamlined access to the dataset
|
||||
|
||||
We plan to support more functionality in the future, such as:
|
||||
- Deploy and run your data workflows in the cloud without any changes to code and schemas
|
||||
- Maintain pipelines with a Runtime Agent, customizable dashboards, and validation tests
|
||||
- Deploy live reports without worrying about schema drift or silent failures
|
||||
|
||||
2. **[Cursor](https://cursor.com/)** - An AI-powered code editor that lets you express tasks in natural language for an LLM agent to implement. Cursor is the first AI code editor we’ve integrated with, so the examples use Cursor, but the same workflow applies to Continue, Copilot, Cody, Windsurf, Cline, Claude, Amp, and Codex (only the UI/shortcuts differ).
|
||||
|
||||
3. **LLM-context** - A curated collection of prompts, rules, docs, and examples provided to an LLM for specific tasks. A rich context leads to more accurate, bug-free code generation. dltHub provides tailored [LLM-contexts for 1,000+ REST API sources](https://dlthub.com/workspace), so you can go from idea to working pipeline in under 10 minutes.
|
||||
|
||||
## Setup
|
||||
Before starting to build our connector, we need to initialize our [dltHub workspace](../../hub/workspace/overview.md) and configure our IDE.
|
||||
|
||||
### Setup your AI editor/agent
|
||||
|
||||
#### 1. Use the right model
|
||||
### Python dependencies
|
||||
|
||||
For best results, use newer models. For example, in Cursor we’ve found that Claude-4-sonnet performs best (available in the paid version). Older or weaker models often struggle with context comprehension and workflows.
|
||||
|
||||
#### 2. Add documentation
|
||||
|
||||
AI code editors let you upload documentation and code examples to provide additional context. The exact steps vary by tool, but here are two examples:
|
||||
|
||||
1. Cursor ([guide](https://docs.cursor.com/context/@-symbols/@-docs)): Go to `Settings > Indexing & Docs` to add documentation.
|
||||
2. Continue ([guide](https://docs.continue.dev/customize/context/documentation)): In chat, type `@Docs` and press `Enter`, then click `Add Docs`.
|
||||
|
||||
For any editor or agent, we recommend adding documentation scoped to a specific task.
|
||||
At minimum, include:
|
||||
|
||||
* [REST API source](../verified-sources/rest_api/) as `@dlt_rest_api`
|
||||
* [Core dlt concepts & usage](../../general-usage/) as `@dlt_docs`
|
||||
|
||||
### Install dlt workspace
|
||||
Run this command to install the Python library `dlt` with the `workspace` extra.
|
||||
|
||||
```sh
|
||||
pip install "dlt[workspace]"
|
||||
@@ -76,135 +54,405 @@ pip install "dlt[workspace]"
|
||||
|
||||
### Initialize workspace
|
||||
|
||||
We provide LLM context from over 5,000 sources, available at [https://dlthub.com/workspace](https://dlthub.com/workspace). To get started, search for your API and follow the tailored instructions.
|
||||
|
||||
<div style={{textAlign: 'center'}}>
|
||||

|
||||
</div>
|
||||
|
||||
To initialize a dltHub workspace, execute the following:
|
||||
To initialize your workspace, you will run a command of this shape:
|
||||
|
||||
```sh
|
||||
dlt init dlthub:{source_name} duckdb
|
||||
dlt init dlthub:{source} {destination}
|
||||
```
|
||||
|
||||
This command will first prompt you to choose an AI editor/agent. If you pick the wrong one, no problem. After initializing the workspace, you can delete the incorrect editor rules and run `dlt ai setup` to select the editor again. This time it will only load the rules.
|
||||
For the destination, `duckdb` is recommend for local development.
|
||||
Once you have a working pipeline, you easily change the destination to your
|
||||
data warehouse.
|
||||
|
||||
The dltHub workspace will be initialized with:
|
||||
- Files and folder structure you know from [dlt init](../../walkthroughs/create-a-pipeline.md)
|
||||
- Documentation scaffold for the specific source (typically a `yaml` file) optimized for LLMs
|
||||
- Rules for `dlt`, configured for your selected AI editor/agent
|
||||
- Pipeline script and REST API source (`{source_name}_pipeline.py`) definition that you'll customize in the next step
|
||||
For the source, select one of the 8k+ REST API sources available
|
||||
at [https://dlthub.com/workspace](https://dlthub.com/workspace). The source's page includes a command you can copy-paste to initialize your workspace.
|
||||
|
||||
:::tip
|
||||
If you can't find the source you need, start with a generic REST API source template. Choose a source name you need i.e.
|
||||
For example, this command setups ingestion from GitHub to local DuckDB.
|
||||
```sh
|
||||
dlt init dlthub:my_internal_fast_api duckdb
|
||||
dlt init dlthub:github duckdb
|
||||
```
|
||||
This will generate the full pipeline setup, including the script (`my_internal_fast_api_pipeline.py`) and all the files and folders you’d normally get with a standard [dlt init](../../walkthroughs/create-a-pipeline.md).
|
||||
To make your source available to the LLM, be sure to [include the documentation](#addon-bring-your-own-llm-scaffold) in the context so the model can understand how to use it.
|
||||
:::
|
||||
|
||||
## Create dlt pipeline
|
||||
|
||||
### Generate code
|
||||
|
||||
To get started quickly, we recommend using our pre-defined prompts tailored for each API. Visit [https://dlthub.com/workspace](https://dlthub.com/workspace) and copy the prompt for your selected source.
|
||||
Prompts are adjusted per API to provide the most accurate and relevant context.
|
||||
|
||||
Here's a general prompt template you can adapt:
|
||||
Several files will be added to your directory, similar to this:
|
||||
|
||||
```text
|
||||
Please generate a REST API source for {source} API, as specified in @{source}-docs.yaml
|
||||
Start with endpoints {endpoints you want} and skip incremental loading for now.
|
||||
my_project/
|
||||
├── .cursor/ # rules for Cursor IDE
|
||||
│ ├── rules.mdc
|
||||
│ └── ... # more rules
|
||||
├── .dlt/
|
||||
│ ├── config.toml # dlt configuration
|
||||
│ └── secrets.toml # dlt secrets
|
||||
├── .cursorignore
|
||||
├── .gitignore
|
||||
├── github_pipeline.py # pipeline template
|
||||
├── requirements.txt
|
||||
└── github-docs.yaml # GitHub LLM scaffold
|
||||
```
|
||||
|
||||
### Configure IDE
|
||||
|
||||
When running `dlt init`, you will be prompted to select the IDE or agent that you want to use.
|
||||
|
||||
```sh
|
||||
❯ dlt init dlthub:github duckdb
|
||||
dlt will generate useful project rules tailored to your assistant/IDE.
|
||||
Press Enter to accept the default (cursor), or type a name:
|
||||
```
|
||||
|
||||
Run this command to manually setup another IDE.
|
||||
|
||||
```sh
|
||||
dlt ai setup {IDE}
|
||||
```
|
||||
|
||||
### Choose an LLM
|
||||
|
||||
Your experience will greatly depend on the capabilities of the LLM you use. We suggest minimally using `GPT-4.1` from OpenAI or `Claude Sonnet 4` from Anthropic.
|
||||
|
||||
|
||||
### Install MCP server (optional)
|
||||
|
||||
You can install the [dlt MCP server ](https://github.com/dlt-hub/dlt-mcp) by adding this snippet to your IDE's configuration.
|
||||
|
||||
This default configuration will support local DuckDB destination
|
||||
```json
|
||||
{
|
||||
"name": "dlt",
|
||||
"command": "uv",
|
||||
"args": [
|
||||
"run",
|
||||
"--with",
|
||||
"dlt-mcp[search]",
|
||||
"python",
|
||||
"-m",
|
||||
"dlt_mcp"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
:::note
|
||||
The configuration file format varies slightly across IDEs
|
||||
:::
|
||||
|
||||
## Initial instructions
|
||||
|
||||
To get good result and make progress, it's best to implement one REST endpoint at a time.
|
||||
|
||||
The source's page on dlthub.com/workspace includes a prompt to get you started that looks
|
||||
like this:
|
||||
|
||||
```text
|
||||
Generate a REST API Source for {source}, as specified in @{source}-docs.yaml
|
||||
Start with endpoint {endpoint_name} and skip incremental loading for now.
|
||||
Place the code in {source}_pipeline.py and name the pipeline {source}_pipeline.
|
||||
If the file exists, use it as a starting point.
|
||||
Do not add or modify any other files.
|
||||
Use @dlt_rest_api as a tutorial.
|
||||
After adding the endpoints, allow the user to run the pipeline with python {source}_pipeline.py and await further instructions.
|
||||
```
|
||||
|
||||
In this prompt, we use `@` references to link source specifications and documentation. Make sure Cursor (or whichevert AI editor/agent you use) recognizes the referenced docs.
|
||||
For example, see [Cursor’s guide](https://docs.cursor.com/context/@-symbols/overview) to @ references.
|
||||
|
||||
* `@{source}-docs.yaml` contains the source specification and describes the source with endpoints, parameters, and other details.
|
||||
* `@dlt_rest_api` contains the documentation for dlt's REST API source.
|
||||
|
||||
### Add credentials
|
||||
|
||||
Prompt the LLM for credential setup instructions and add them to your workspace secrets file `.dlt/secrets.toml`.
|
||||
|
||||
## Run the pipeline
|
||||
|
||||
Run your pipeline:
|
||||
|
||||
```sh
|
||||
python {source}_pipeline.py
|
||||
```
|
||||
|
||||
Expected output:
|
||||
```sh
|
||||
Pipeline {source} load step completed in 0.26 seconds
|
||||
1 load package(s) were loaded to destination duckdb and into dataset {source}_data
|
||||
The duckdb destination used duckdb:/{source}.duckdb location to store data
|
||||
Load package 1749667187.541553 is LOADED and contains no failed jobs
|
||||
After adding the endpoint, allow the user to run the pipeline with
|
||||
`python {source}_pipeline.py`
|
||||
and await further instructions.
|
||||
```
|
||||
|
||||
:::tip
|
||||
If the pipeline fails, pass error messages to the LLM. Restart after 4-8 failed attempts.
|
||||
Reference `{'{'}source{'}'}-docs.yaml` and ask what the available endpoints are.
|
||||
:::
|
||||
|
||||
### Validate with workspace dashboard
|
||||
## Generate code
|
||||
|
||||
Launch the dashboard to validate your pipeline:
|
||||
The LLM can quickly produce a lot of code. When reviewing its proposed changes, your role is to nudge it in the right direction.
|
||||
|
||||
```sh
|
||||
dlt pipeline {source}_pipeline show
|
||||
### Anatomy of a REST API source
|
||||
Before practical tips, let's look at a minimal REST API source:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
from dlt.sources.rest_api import rest_api_resources
|
||||
from dlt.sources.rest_api.typing import RESTAPIConfig
|
||||
|
||||
# decorator indicates that this function produces a source
|
||||
@dlt.source
|
||||
def github_source(
|
||||
# the `access_token` will be retrieved from `.dlt/secrets.toml` by default
|
||||
access_token: str = dlt.secrets.value
|
||||
):
|
||||
config: RESTAPIConfig = {
|
||||
# client section
|
||||
"client": {
|
||||
"base_url": "https://api.github.com/v3/",
|
||||
# access token will be passed via headers
|
||||
"auth": {"type": "bearer", "token": access_token},
|
||||
},
|
||||
# endpoint section
|
||||
"resources": [
|
||||
# refers to GET endpoint `/issues`
|
||||
"issues",
|
||||
],
|
||||
}
|
||||
# returns a list of resources
|
||||
return rest_api_resources(config)
|
||||
```
|
||||
|
||||
The dashboard shows:
|
||||
- Pipeline overview with state and metrics
|
||||
- Data schema (tables, columns, types)
|
||||
- Data itself, you can even write custom queries
|
||||
For now, it's best to delete all the code you don't understand (e.g., paginator, incremental, data selector). This keeps the LLM focused and reduces the surface for bugs. After generating a working pipeline and committing code, you can go back configure endpoints more precisely.
|
||||
|
||||
The dashboard helps detect silent failures due to pagination errors, schema drift, or incremental load misconfigurations.
|
||||
:::tip
|
||||
Reference `{'{'}source{'}'}-docs.yaml` and ask what the available endpoints parameters are.
|
||||
:::
|
||||
|
||||
### Leveraging the IDE
|
||||
|
||||
`dlt` provides extensive validation and completion suggestions inside the IDE.
|
||||
|
||||
Invalid code generated by the LLM produce red error lines, simplifying code review.
|
||||
|
||||
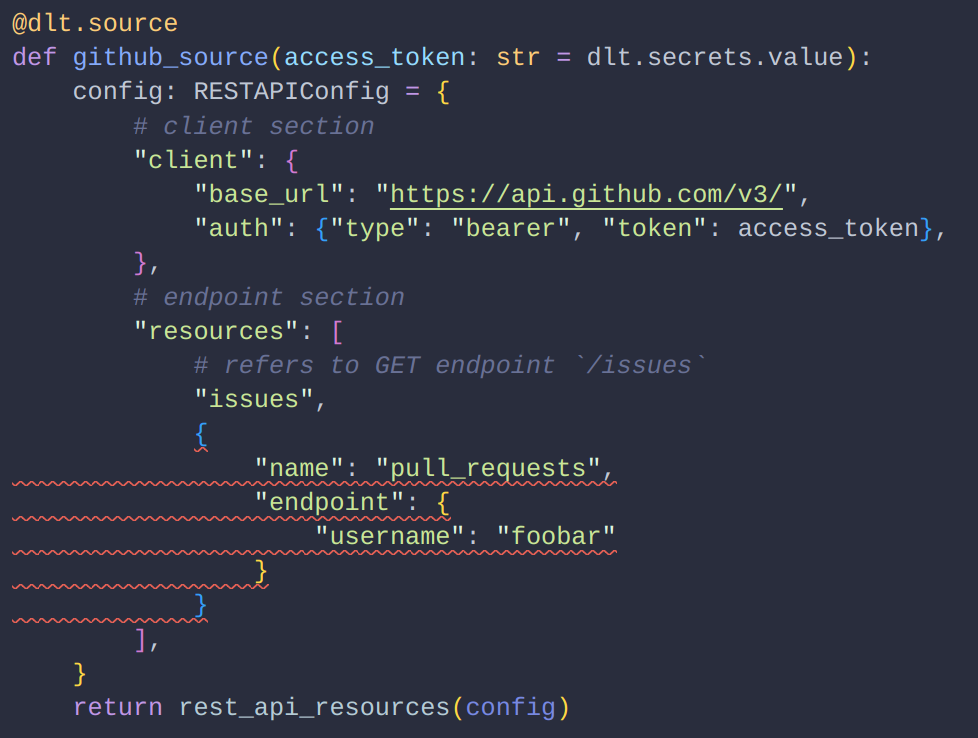
|
||||
|
||||
Completion suggestions makes it easy to fix LLM errors or set configuration options.
|
||||
|
||||
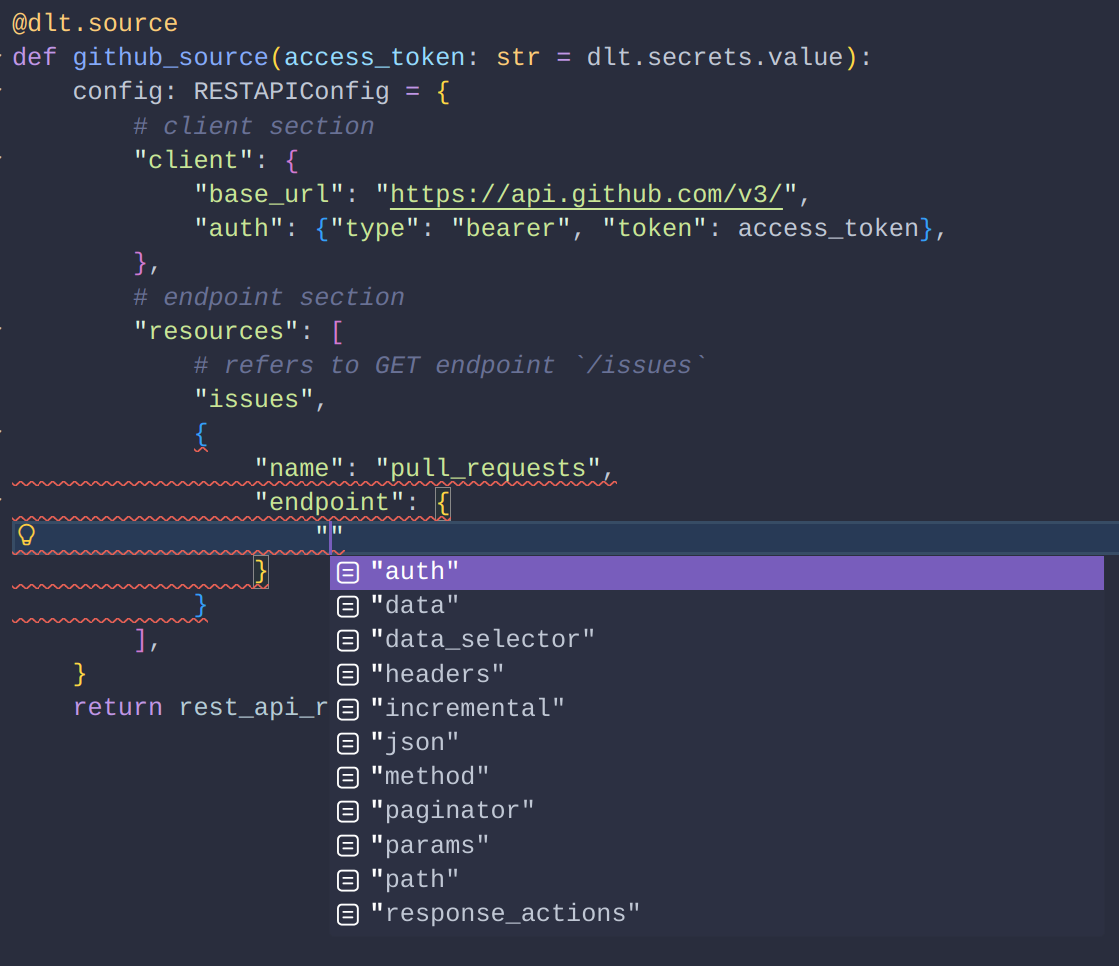
|
||||
|
||||
## Run pipeline
|
||||
### Agent running the pipeline
|
||||
Typically, the agent will ask permission to run the pipeline via the chat:
|
||||
|
||||
```sh
|
||||
python github_pipeline.py
|
||||
```
|
||||
|
||||
If you accept, it will run the pipeline and directly receive the output of the command (success or error).
|
||||
Then, it can automatically start fixing things or ask follow-up questions.
|
||||
|
||||
:::note
|
||||
Depending on the IDE, the pipeline may fail because of missing Python dependencies. In this case,
|
||||
you should run the pipeline manually.
|
||||
:::
|
||||
|
||||
### Manually running the pipeline
|
||||
You can manually run this command in the terminal to run the pipeline.
|
||||
|
||||
```sh
|
||||
python github_pipeline.py
|
||||
```
|
||||
|
||||
Then, use `@terminal` inside the chat window to add the success / error message to the LLM context.
|
||||
|
||||
### Success: pipeline completed without error
|
||||
A successful execution should print a message similar to this one:
|
||||
|
||||
```sh
|
||||
Pipeline github_source load step completed in 0.26 seconds
|
||||
1 load package(s) were loaded to destination duckdb and into dataset github_source_data
|
||||
The duckdb destination used duckdb:/github_source.duckdb location to store data
|
||||
Load package 1749667187.541553 is LOADED and contains no failed jobs
|
||||
```
|
||||
|
||||
### Failure: source credentials
|
||||
|
||||
Your first iterations will likely trigger credentials errors similar to the one below. The error message indicates how you can set credential values using `.dlt/config.toml` and `.dlt/secrets.toml` or environment variables ([learn more](../../general-usage/credentials/setup))
|
||||
|
||||
```text
|
||||
dlt.common.configuration.exceptions.ConfigFieldMissingException: Missing 1 field(s) in configuration `GithubRestApiSourceConfiguration`: `access_token`
|
||||
for field `access_token` the following (config provider, key) were tried in order:
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__GITHUB_PIPELINE__GITHUB_REST_API_SOURCE__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(secrets.toml, github_pipeline.sources.github_pipeline.github_rest_api_source.access_token)
|
||||
(secrets.toml, github_pipeline.sources.github_pipeline.access_token)
|
||||
(secrets.toml, github_pipeline.sources.access_token)
|
||||
(secrets.toml, github_pipeline.access_token)
|
||||
(Environment Variables, SOURCES__GITHUB_PIPELINE__GITHUB_REST_API_SOURCE__ACCESS_TOKEN)
|
||||
(Environment Variables, SOURCES__GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(Environment Variables, SOURCES__ACCESS_TOKEN)
|
||||
(Environment Variables, ACCESS_TOKEN)
|
||||
(secrets.toml, sources.github_pipeline.github_rest_api_source.access_token)
|
||||
(secrets.toml, sources.github_pipeline.access_token)
|
||||
(secrets.toml, sources.access_token)
|
||||
(secrets.toml, access_token)
|
||||
Provider `secrets.toml` loaded values from locations:
|
||||
- /home/user/path/to/my_project/.dlt/secrets.toml
|
||||
- /home/user/.dlt/secrets.toml
|
||||
Provider `config.toml` loaded values from locations:
|
||||
- /home/user/path/to/my_project/.dlt/config.toml
|
||||
- /home/user/.dlt/config.toml
|
||||
```
|
||||
|
||||
:::tip
|
||||
Getting credentials or API keys from a source system can be tedious. For popular sources, LLMs can provide step-by-step instructions
|
||||
:::
|
||||
|
||||
|
||||
### Failure: destination credentials
|
||||
|
||||
Destination credentials are similar to source credentials errors and can be fixed via `.dlt/config.toml` and `.dlt/secrets.toml` or environment variables ([learn more](../../general-usage/credentials/setup)). Destination-specific information can be found in [the documentation](../../dlt-ecosystem/destinations).
|
||||
|
||||
Alternatively, you can point the LLM to the Python code that defines the configuration. It's typically found in `from dlt.destinations.impl.{'{'}destination{'}'}.configuration`. For example, this retrieves the Snowflake configuration and credentials
|
||||
|
||||
```py
|
||||
from dlt.destinations.impl.snowflake.configuration import SnowflakeCredentials, SnowflakeClientConfiguration
|
||||
```
|
||||
|
||||
Credentials are what you typically put in `secrets.toml` and configuration in `config.toml`.
|
||||
|
||||
## Manage context
|
||||
|
||||
"Managing context" is about providing the right information to the LLM and help it focus on the right task. Below is a list of practical tips:
|
||||
|
||||
- Specify: "I'm a data engineer using the Python library `dlt` to ingest data from {'{'}source{'}'} to {'{'}destination{'}'}. I'm also using the Python libraries X,Y,Z."
|
||||
- Specify: "Focus on a single REST API endpoint `X`."
|
||||
- In later iteration when you're tuning your pipeline, specify "The current Python code works as expected. Make minimal and focused changes to do X"
|
||||
- Use the `@` symbol to reference the terminal output after running the pipeline
|
||||
- Use the `@` symbol to reference to the LLM scaffolds
|
||||
- Ingest documentation and index your code using your IDE. Refer to it explicitly using `@`
|
||||
- Ask the LLM to list available tools and explain them.
|
||||
- If the LLM goes on a tangent, trim the conversation history or create a new conversation
|
||||
|
||||
:::note
|
||||
These tips will differ slightly across IDEs
|
||||
:::
|
||||
|
||||
## Check data
|
||||
|
||||
### dlt Dashboard
|
||||
|
||||
Lauch the local [dlt Dashboard](../../general-usage/dashboard) to inspect your pipeline execution including:
|
||||
- pipeline state and metrics
|
||||
- data schema
|
||||
- SQL data explorer
|
||||
|
||||
```sh
|
||||
dlt pipeline github_pipeline show
|
||||
```
|
||||
|
||||
<div style={{textAlign: 'center'}}>
|
||||

|
||||
</div>
|
||||
|
||||
## Use the data in a notebook
|
||||
|
||||
With the pipeline and data validated, you can continue with custom data explorations and reports. You can use your preferred environment, for example, [Jupyter Notebook](https://jupyter.org/), [Marimo Notebook](https://marimo.io/), or a plain Python file.
|
||||
The dashboard helps detect silent failures due to pagination errors, schema drift, or incremental load misconfigurations.
|
||||
|
||||
:::tip
|
||||
For an optimized data exploration experience, we recommend using a Marimo notebook. Check out the [detailed guide on using dlt with Marimo](../../general-usage/dataset-access/marimo).
|
||||
Inside Cursor 2.0, you can open the [dashboard's web page inside the IDE](https://cursor.com/docs/agent/browser) and directly reference visual elements inside the chat.
|
||||
:::
|
||||
|
||||
To access the data, you can use the `dataset()` method:
|
||||
|
||||
### Ask the dlt MCP server
|
||||
If the [dlt MCP server](https://github.com/dlt-hub/dlt-mcp) is connected, you can directly ask in the IDE chat window if the data was successfully loaded. Based on your MCP configuration, it can have access to:
|
||||
- pipeline metadata
|
||||
- loaded data
|
||||
- dlt documentation and source code
|
||||
|
||||
It can answer questions such as:
|
||||
- What are the available pipelines?
|
||||
- What are the available tables?
|
||||
- What's table X's schema?
|
||||
- When was data last loaded?
|
||||
- Did schema change last run?
|
||||
- Display the pipeline's schema
|
||||
- How many rows are in table X?
|
||||
- Give me a data sample of table X
|
||||
|
||||
|
||||
### Python data exploration
|
||||
|
||||
Running a `dlt` pipeline creates a dataset, which can be accessed via Python code:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
|
||||
my_data = dlt.pipeline("{source}_pipeline").dataset()
|
||||
# get any table as Pandas frame
|
||||
my_data.table("table_name").df().head()
|
||||
# this refers to my previously ran pipeline
|
||||
github_pipeline = dlt.pipeline("github_pipeline")
|
||||
github_dataset = github_pipeline.dataset()
|
||||
# list tables
|
||||
github_dataset.tables
|
||||
# list columns
|
||||
github_dataset.table("pull_requests").columns
|
||||
# load the results as a pandas dataframe
|
||||
github_dataset.table("pull_requests").df()
|
||||
```
|
||||
|
||||
For more, see the [dataset access guide](../../general-usage/dataset-access).
|
||||
This shines in interactive environments like [marimo](../../general-usage/dataset-access/marimo) and Jupyter for data explorations. It's a great way to add data quality checks.
|
||||
|
||||
## Next steps: production deployment
|
||||
### Automated data quality
|
||||
|
||||
- [Prepare production deployment](../../walkthroughs/share-a-dataset.md)
|
||||
- [Deploy a pipeline](../../walkthroughs/deploy-a-pipeline/)
|
||||
Once you're familiar with the data, you can write expectations about the data in code. This section is an introduction to deep topics with their own documentation page.
|
||||
|
||||
:::tip
|
||||
Instead of asking the LLM to make data a certain way, you can ask the LLM to help you write automated data quality. Then, you can feedback the data quality information back to the LLM after each pipeline run.
|
||||
:::
|
||||
|
||||
#### Schema contract
|
||||
Enabling [schema contracts](../../general-usage/schema-contracts) lets you configure what aspect of the data can change or not between pipeline runs.
|
||||
|
||||
For example, this configuration allows to add new tables, raises on new columns, and drops records with incorrect data type:
|
||||
|
||||
```py
|
||||
@dlt.source(
|
||||
schema_contract={
|
||||
"tables": "evolve",
|
||||
"columns": "freeze",
|
||||
"data_type": "discard_row",
|
||||
}
|
||||
)
|
||||
def github_source(): ...
|
||||
```
|
||||
|
||||
#### Data validation
|
||||
Using [Pydantic](https://docs.pydantic.dev), you can define extend schema contract features and validate individual records one-by-one ([learn more](../../general-usage/resource#define-a-schema-with-pydantic)).
|
||||
|
||||
This allows to catch invalid data early, cancel the pipeline run, and prevent data being written to the destination
|
||||
|
||||
Data validation needs to be set on the **resource** rather than the **source**. We need a few more lines of code to retrieve them.
|
||||
|
||||
```py
|
||||
import dlt
|
||||
from pydantic import BaseModel
|
||||
|
||||
class PullRequestModel(BaseModel):
|
||||
...
|
||||
|
||||
@dlt.source
|
||||
def github_source(): ...
|
||||
|
||||
if __name__ == "__main__":
|
||||
source = github_source()
|
||||
# "pull_requests" would be one of the endpoints defined by `github_source`
|
||||
source.resources["pull_requests"].apply_hints(columns=PullRequestModel)
|
||||
|
||||
pipeline = dlt.pipeline("github_pipeline")
|
||||
pipeline.run(source)
|
||||
```
|
||||
|
||||
#### Data quality checks
|
||||
A [data quality check](../../hub/features/quality/data-quality) declares how the data on the destination should look like. It can be executed on the destination and efficiently process large data volume.
|
||||
|
||||
```py
|
||||
from dlt.hub import data_quality as dq
|
||||
|
||||
pipeline = dlt.pipeline("github_pipeline")
|
||||
pipeline.run(github_source())
|
||||
|
||||
dataset = pipeline.dataset()
|
||||
|
||||
pull_requests_checks = [
|
||||
dq.checks.is_not_null("id"),
|
||||
dq.checks.is_in("author", ["Romeo", "Foxtrot", "Tango"]),
|
||||
dq.checks.case("created_at > 2025-01-01"),
|
||||
]
|
||||
|
||||
dq.run_checks(dataset, checks={"pull_requests": pull_requests_checks})
|
||||
```
|
||||
|
||||
:::tip
|
||||
Data quality checks write results to the destination, which can be inspected via the dashboard, MCP server, and manual exploration
|
||||
:::
|
||||
|
||||
|
||||
## Addon: bring your own LLM scaffold
|
||||
## Conclusion
|
||||
By the end of this guide, you should have:
|
||||
- a local workspace
|
||||
- a working REST API source
|
||||
- a working pipeline
|
||||
- a local dataset
|
||||
|
||||
LLMs can infer a REST API source definition from various types of input, and in many cases, it’s easy to provide what’s needed.
|
||||
|
||||
Here are a few effective ways to scaffold your source:
|
||||
|
||||
1. **FastAPI (Internal APIs)**. If you're using FastAPI, simply add a file with the autogenerated OpenAPI spec to your workspace and reference it in your prompt.
|
||||
2. **Legacy code in any programming language**. Add the relevant code files to your workspace and reference them directly in your prompt. LLMs can extract useful structure even from older codebases.
|
||||
3. **Human-readable documentation**. Well-written documentation works too. You can add it to your AI editor docs and reference it in your prompt for context.
|
||||
Next steps:
|
||||
- [explore the dataset and build a data product](../../general-usage/dataset-access/dataset)
|
||||
- [replace the local destination with your data warehouse](../../walkthroughs/share-a-dataset)
|
||||
- [deploy the pipeline](../../walkthroughs/deploy-a-pipeline/)
|
||||
|
||||
@@ -65,7 +65,7 @@ A collaborative AI-human workflow that integrates `dlt` with AI editors and agen
|
||||
- **Cursor**,
|
||||
- **Continue**,
|
||||
- **Copilot**,
|
||||
- [the full list](../../dlt-ecosystem/llm-tooling/llm-native-workflow#prerequisites)
|
||||
- [the full list](../../dlt-ecosystem/llm-tooling/llm-native-workflow#configure-ide)
|
||||
|
||||
|
||||
**Initialize your first workspace pipeline**
|
||||
|
||||
Reference in New Issue
Block a user