mirror of
https://github.com/dlt-hub/dlt.git
synced 2025-12-17 19:31:30 +00:00
Merge pull request #3458 from dlt-hub/devel
master merge for 1.20.0 release
This commit is contained in:
2
.github/workflows/lint.yml
vendored
2
.github/workflows/lint.yml
vendored
@@ -42,7 +42,7 @@ jobs:
|
||||
run: uv lock --check
|
||||
|
||||
- name: Install dependencies
|
||||
run: uv sync --all-extras --group airflow --group providers --group pipeline --group sources --group sentry-sdk --group dbt --group streamlit
|
||||
run: uv sync --all-extras --no-extra hub --group airflow --group providers --group pipeline --group sources --group sentry-sdk --group dbt --group streamlit
|
||||
|
||||
- name: Run make lint
|
||||
run: |
|
||||
|
||||
2
.github/workflows/test_docs.yml
vendored
2
.github/workflows/test_docs.yml
vendored
@@ -83,7 +83,7 @@ jobs:
|
||||
run: cd docs && make dev
|
||||
|
||||
- name: Install dlthub incl alpha releases
|
||||
run: cd docs && uv run pip install --pre dlthub
|
||||
run: cd docs
|
||||
|
||||
- name: lint docs
|
||||
run: cd docs && make lint
|
||||
|
||||
24
.github/workflows/test_hub.yml
vendored
24
.github/workflows/test_hub.yml
vendored
@@ -19,7 +19,7 @@ jobs:
|
||||
matrix:
|
||||
os: ["ubuntu-latest", "macos-latest", "windows-latest"]
|
||||
python-version: ["3.10", "3.11", "3.12", "3.13"]
|
||||
dlthub_dep: ["dlthub", "https://dlt-packages.fra1.digitaloceanspaces.com/dlthub/dlthub-0.0.0+nightly-py3-none-any.whl"]
|
||||
dlthub_dep: ["", "https://dlt-packages.fra1.digitaloceanspaces.com/dlthub/dlthub-0.0.0+nightly-py3-none-any.whl"]
|
||||
# Test all python versions on ubuntu only
|
||||
exclude:
|
||||
- os: "macos-latest"
|
||||
@@ -56,6 +56,12 @@ jobs:
|
||||
activate-environment: true
|
||||
enable-cache: true
|
||||
|
||||
- name: Install min dependencies
|
||||
run: uv sync
|
||||
|
||||
- name: run import tests
|
||||
run: uv run pytest tests/hub/test_plugin_import.py
|
||||
|
||||
# NOTE: needed for mssql source tests in plus
|
||||
- name: Install ODBC driver for SQL Server
|
||||
run: |
|
||||
@@ -78,15 +84,27 @@ jobs:
|
||||
# odbcinst -q -d || true
|
||||
|
||||
- name: Install all dependencies
|
||||
run: make dev
|
||||
run: make dev-hub
|
||||
|
||||
- name: Install dlthub
|
||||
run: uv run pip install --upgrade --force-reinstall --no-cache-dir ${{ matrix.dlthub_dep }}
|
||||
if: matrix.dlthub_dep != ''
|
||||
run: uv run pip install --upgrade --force-reinstall --pre --no-cache-dir ${{ matrix.dlthub_dep }}
|
||||
|
||||
- name: Run tests
|
||||
run: pytest tests/hub
|
||||
# if: matrix.os != 'macos-latest'
|
||||
|
||||
- name: Test runtime client
|
||||
run: |
|
||||
mkdir .dlt && touch .dlt/.workspace
|
||||
dlt runtime --help
|
||||
|
||||
# DISABLED: because docs rendering happens in non-deterministic order (of plugin discovery)
|
||||
# must be fixed
|
||||
# - name: Check that dlthub cli docs are up to date
|
||||
# run: cd docs/tools/dlthub_cli && make check-cli-docs
|
||||
# if: ${{ matrix.python-version == '3.11' && matrix.os == 'ubuntu-latest' }}
|
||||
|
||||
matrix_job_required_check:
|
||||
name: hub | dlthub features tests
|
||||
needs: run_hub_features
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -149,4 +149,4 @@ local_cache/
|
||||
|
||||
# test file for examples are generated and should not be committed
|
||||
docs/examples/**/test*.py
|
||||
compiled_requirements.txt
|
||||
compiled_requirements.txt
|
||||
|
||||
7
Makefile
7
Makefile
@@ -44,10 +44,13 @@ has-uv:
|
||||
uv --version
|
||||
|
||||
dev: has-uv
|
||||
uv sync --all-extras --group dev --group providers --group pipeline --group sources --group sentry-sdk --group ibis --group adbc --group dashboard-tests
|
||||
uv sync --all-extras --no-extra hub --group dev --group providers --group pipeline --group sources --group sentry-sdk --group ibis --group adbc --group dashboard-tests
|
||||
|
||||
dev-airflow: has-uv
|
||||
uv sync --all-extras --group providers --group pipeline --group sources --group sentry-sdk --group ibis --group airflow
|
||||
uv sync --all-extras --no-extra hub --group providers --group pipeline --group sources --group sentry-sdk --group ibis --group airflow
|
||||
|
||||
dev-hub: has-uv
|
||||
uv sync --all-extras --group dev --group providers --group pipeline --group sources --group sentry-sdk --group ibis --group adbc --group dashboard-tests
|
||||
|
||||
lint: lint-core lint-security lint-docstrings
|
||||
|
||||
|
||||
@@ -34,7 +34,7 @@ COPY dist/dlt-${IMAGE_VERSION}.tar.gz .
|
||||
RUN mkdir -p /app
|
||||
WORKDIR /app
|
||||
RUN uv venv && uv pip install /tmp/pydlt/dlt-${IMAGE_VERSION}.tar.gz --resolution lowest-direct && uv pip install typing-extensions==4.8.0
|
||||
RUN rm -r /tmp/pydlt
|
||||
# RUN rm -r /tmp/pydlt
|
||||
|
||||
# make sure dlt can be actually imported
|
||||
RUN uv run python -c 'import dlt;import pendulum;'
|
||||
@@ -50,7 +50,12 @@ RUN uv run dlt pipeline fruit_pipeline info
|
||||
|
||||
# enable workspace
|
||||
RUN mkdir -p .dlt && touch .dlt/.workspace
|
||||
# RUN dlt pipeline fruit_pipeline info
|
||||
RUN uv run dlt workspace info
|
||||
RUN uv run dlt workspace -v info
|
||||
RUN uv run python minimal_pipeline.py
|
||||
RUN uv run dlt pipeline fruit_pipeline info
|
||||
RUN uv run dlt pipeline fruit_pipeline info
|
||||
|
||||
# install hub
|
||||
RUN uv pip install /tmp/pydlt/dlt-${IMAGE_VERSION}.tar.gz[hub] --resolution lowest-direct && uv pip install typing-extensions==4.8.0
|
||||
RUN uv run python minimal_pipeline.py
|
||||
RUN uv run dlt --non-interactive license issue dlthub.transformation
|
||||
RUN uv run dlt runtime --help
|
||||
@@ -1,4 +1,5 @@
|
||||
# ignore secrets, virtual environments and typical python compilation artifacts
|
||||
# dlt-specific ignores
|
||||
# secrets and credentials
|
||||
secrets.toml
|
||||
*.secrets.toml
|
||||
# ignore pinned profile name
|
||||
@@ -7,11 +8,199 @@ secrets.toml
|
||||
.dlt/.var
|
||||
# ignore default local dir (loaded data)
|
||||
_local
|
||||
# ignore basic python artifacts
|
||||
.env
|
||||
**/__pycache__/
|
||||
**/*.py[cod]
|
||||
**/*$py.class
|
||||
# ignore duckdb
|
||||
*.duckdb
|
||||
*.wal
|
||||
*.wal
|
||||
|
||||
# Git repository
|
||||
.git/
|
||||
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[codz]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py.cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
.pybuilder/
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# pipenv
|
||||
Pipfile.lock
|
||||
|
||||
# UV
|
||||
uv.lock
|
||||
|
||||
# poetry
|
||||
poetry.lock
|
||||
poetry.toml
|
||||
|
||||
# pdm
|
||||
pdm.lock
|
||||
pdm.toml
|
||||
.pdm-python
|
||||
.pdm-build/
|
||||
|
||||
# pixi
|
||||
pixi.lock
|
||||
.pixi
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# Redis
|
||||
*.rdb
|
||||
*.aof
|
||||
*.pid
|
||||
|
||||
# RabbitMQ
|
||||
mnesia/
|
||||
rabbitmq/
|
||||
rabbitmq-data/
|
||||
|
||||
# ActiveMQ
|
||||
activemq-data/
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.envrc
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# pytype static type analyzer
|
||||
.pytype/
|
||||
|
||||
# Cython debug symbols
|
||||
cython_debug/
|
||||
|
||||
# PyCharm
|
||||
.idea/
|
||||
|
||||
# Abstra
|
||||
.abstra/
|
||||
|
||||
# Visual Studio Code
|
||||
.vscode/
|
||||
|
||||
# Ruff stuff:
|
||||
.ruff_cache/
|
||||
|
||||
# PyPI configuration file
|
||||
.pypirc
|
||||
|
||||
# Marimo
|
||||
marimo/_static/
|
||||
marimo/_lsp/
|
||||
__marimo__/
|
||||
|
||||
# Streamlit
|
||||
.streamlit/secrets.toml
|
||||
|
||||
# macOS
|
||||
.DS_Store
|
||||
|
||||
@@ -83,12 +83,7 @@ class WorkspaceRunContext(ProfilesRunContext):
|
||||
return os.environ.get(known_env.DLT_DATA_DIR, self._data_dir)
|
||||
|
||||
def initial_providers(self) -> List[ConfigProvider]:
|
||||
providers = [
|
||||
EnvironProvider(),
|
||||
ProfileSecretsTomlProvider(self.settings_dir, self.profile, self.global_dir),
|
||||
ProfileConfigTomlProvider(self.settings_dir, self.profile, self.global_dir),
|
||||
]
|
||||
return providers
|
||||
return self._initial_providers(self.profile)
|
||||
|
||||
def initialize_runtime(self, runtime_config: RuntimeConfiguration = None) -> None:
|
||||
if runtime_config is not None:
|
||||
@@ -98,9 +93,17 @@ class WorkspaceRunContext(ProfilesRunContext):
|
||||
# this also resolves workspace config if necessary
|
||||
initialize_runtime(self.name, self.config.runtime)
|
||||
|
||||
# if on runtime, add additional tracker
|
||||
if self.runtime_config.run_id:
|
||||
from dlt._workspace.helpers.runtime import runtime_artifacts
|
||||
from dlt.pipeline import trace
|
||||
|
||||
if runtime_artifacts not in trace.TRACKING_MODULES:
|
||||
trace.TRACKING_MODULES.append(runtime_artifacts)
|
||||
|
||||
@property
|
||||
def runtime_config(self) -> WorkspaceRuntimeConfiguration:
|
||||
return self._config.runtime
|
||||
return self.config.runtime
|
||||
|
||||
@property
|
||||
def config(self) -> WorkspaceConfiguration:
|
||||
@@ -119,11 +122,8 @@ class WorkspaceRunContext(ProfilesRunContext):
|
||||
if self._config.settings.name:
|
||||
self._name = self._config.settings.name
|
||||
|
||||
self._data_dir = _to_run_dir(self._config.settings.working_dir) or default_working_dir(
|
||||
self.settings_dir,
|
||||
self.name,
|
||||
self.profile,
|
||||
DEFAULT_WORKSPACE_WORKING_FOLDER,
|
||||
self._data_dir = (
|
||||
_to_run_dir(self._config.settings.working_dir) or self._make_default_working_dir()
|
||||
)
|
||||
self._local_dir = _to_run_dir(self._config.settings.local_dir) or default_working_dir(
|
||||
self.run_dir,
|
||||
@@ -162,6 +162,11 @@ class WorkspaceRunContext(ProfilesRunContext):
|
||||
def unplug(self) -> None:
|
||||
pass
|
||||
|
||||
def reset_config(self) -> None:
|
||||
# Drop resolved configuration to force re-resolve with refreshed providers
|
||||
self._config = None
|
||||
# no need to initialize the _config anew as it's done in .config property
|
||||
|
||||
# SupportsProfilesOnContext
|
||||
|
||||
@property
|
||||
@@ -179,6 +184,85 @@ class WorkspaceRunContext(ProfilesRunContext):
|
||||
profiles.append(pinned_profile)
|
||||
return profiles
|
||||
|
||||
def configured_profiles(self) -> List[str]:
|
||||
"""Returns profiles that have configuration or pipelines.
|
||||
|
||||
A profile is considered configured if:
|
||||
- It is the current profile
|
||||
- It is the pinned profile
|
||||
- It has any toml configuration files (config.toml or secrets.toml with profile prefix)
|
||||
- It has pipelines in its working directory
|
||||
|
||||
NOTE: calling this function is relatively expensive as it probes all available profiles
|
||||
"""
|
||||
configured: set[str] = set()
|
||||
|
||||
# current profile is always configured
|
||||
configured.add(self.profile)
|
||||
|
||||
# pinned profile is always configured
|
||||
if pinned := read_profile_pin(self):
|
||||
configured.add(pinned)
|
||||
|
||||
# probe all available profiles
|
||||
for profile_name in self.available_profiles():
|
||||
if profile_name in configured:
|
||||
continue
|
||||
|
||||
# Check if profile has any toml config files
|
||||
if self._profile_has_config(profile_name):
|
||||
configured.add(profile_name)
|
||||
continue
|
||||
|
||||
# Check if profile has any pipelines
|
||||
if self._profile_has_pipelines(profile_name):
|
||||
configured.add(profile_name)
|
||||
|
||||
return list(configured)
|
||||
|
||||
def _initial_providers(self, profile_name: str) -> List[ConfigProvider]:
|
||||
providers = [
|
||||
EnvironProvider(),
|
||||
ProfileSecretsTomlProvider(self.settings_dir, profile_name, self.global_dir),
|
||||
ProfileConfigTomlProvider(self.settings_dir, profile_name, self.global_dir),
|
||||
]
|
||||
return providers
|
||||
|
||||
def _make_default_working_dir(self, profile_name: str = None) -> str:
|
||||
return default_working_dir(
|
||||
self.settings_dir,
|
||||
self.name,
|
||||
profile_name or self.profile,
|
||||
DEFAULT_WORKSPACE_WORKING_FOLDER,
|
||||
)
|
||||
|
||||
def _has_default_working_dir(self) -> bool:
|
||||
"""Checks if current working dir has default layout that includes profiles"""
|
||||
return self._data_dir == self._make_default_working_dir()
|
||||
|
||||
def _profile_has_config(self, profile_name: str) -> bool:
|
||||
"""Check if a profile has any configuration files."""
|
||||
# check if any profile-specific files were found
|
||||
for provider in self._initial_providers(profile_name):
|
||||
for location in provider.present_locations:
|
||||
# check if it's a profile-specific file (starts with profile name)
|
||||
if os.path.basename(location).startswith(f"{profile_name}."):
|
||||
return True
|
||||
return False
|
||||
|
||||
def _profile_has_pipelines(self, profile_name: str) -> bool:
|
||||
"""Check if a profile has any pipelines in its data directory."""
|
||||
# non default layouts can be probed
|
||||
if not self._has_default_working_dir():
|
||||
return False
|
||||
|
||||
working_dir = self._make_default_working_dir(profile_name)
|
||||
pipelines_dir = os.path.join(working_dir, "pipelines")
|
||||
try:
|
||||
return os.path.isdir(pipelines_dir) and bool(os.listdir(pipelines_dir))
|
||||
except OSError:
|
||||
return False
|
||||
|
||||
def switch_profile(self, new_profile: str) -> "WorkspaceRunContext":
|
||||
return switch_context(self.run_dir, new_profile, required="WorkspaceRunContext")
|
||||
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
import os
|
||||
from pathlib import Path
|
||||
import yaml
|
||||
from typing import Any, Sequence, Tuple
|
||||
from typing import Any, Dict, List, Sequence, Tuple, cast
|
||||
from inspect import signature
|
||||
import dlt
|
||||
|
||||
from dlt.common.json import json
|
||||
from dlt.common.pendulum import pendulum
|
||||
from dlt.common.pipeline import get_dlt_pipelines_dir, TSourceState
|
||||
from dlt.common.destination.reference import TDestinationReferenceArg
|
||||
from dlt.common.runners import Venv
|
||||
@@ -29,6 +31,41 @@ DLT_PIPELINE_COMMAND_DOCS_URL = (
|
||||
)
|
||||
|
||||
|
||||
def list_pipelines(pipelines_dir: str = None, verbosity: int = 1) -> None:
|
||||
"""List all pipelines in the given directory, sorted by last run time.
|
||||
|
||||
Args:
|
||||
pipelines_dir: Directory containing pipeline folders. If None, uses the default
|
||||
dlt pipelines directory.
|
||||
verbosity: Controls output detail level:
|
||||
- 0: Only show count summary
|
||||
- 1+: Show full list with last run times
|
||||
"""
|
||||
pipelines_dir, pipelines = utils.list_local_pipelines(pipelines_dir)
|
||||
|
||||
if len(pipelines) > 0:
|
||||
if verbosity == 0:
|
||||
fmt.echo(
|
||||
"%s pipelines found in %s. Use %s to see the full list."
|
||||
% (len(pipelines), fmt.bold(pipelines_dir), fmt.bold("-v"))
|
||||
)
|
||||
return
|
||||
else:
|
||||
fmt.echo("%s pipelines found in %s" % (len(pipelines), fmt.bold(pipelines_dir)))
|
||||
else:
|
||||
fmt.echo("No pipelines found in %s" % fmt.bold(pipelines_dir))
|
||||
return
|
||||
|
||||
# pipelines are already sorted by timestamp (newest first) from get_local_pipelines
|
||||
for pipeline_info in pipelines:
|
||||
name = pipeline_info["name"]
|
||||
timestamp = pipeline_info["timestamp"]
|
||||
time_str = utils.date_from_timestamp_with_ago(timestamp)
|
||||
fmt.echo(
|
||||
"%s %s" % (fmt.style(name, fg="green"), fmt.style(f"(last run: {time_str})", fg="cyan"))
|
||||
)
|
||||
|
||||
|
||||
def pipeline_command(
|
||||
operation: str,
|
||||
pipeline_name: str,
|
||||
@@ -39,19 +76,7 @@ def pipeline_command(
|
||||
**command_kwargs: Any,
|
||||
) -> None:
|
||||
if operation == "list":
|
||||
pipelines_dir = pipelines_dir or get_dlt_pipelines_dir()
|
||||
storage = FileStorage(pipelines_dir)
|
||||
dirs = []
|
||||
try:
|
||||
dirs = storage.list_folder_dirs(".", to_root=False)
|
||||
except FileNotFoundError:
|
||||
pass
|
||||
if len(dirs) > 0:
|
||||
fmt.echo("%s pipelines found in %s" % (len(dirs), fmt.bold(pipelines_dir)))
|
||||
else:
|
||||
fmt.echo("No pipelines found in %s" % fmt.bold(pipelines_dir))
|
||||
for _dir in dirs:
|
||||
fmt.secho(_dir, fg="green")
|
||||
list_pipelines(pipelines_dir)
|
||||
return
|
||||
|
||||
# we may open the dashboard for a pipeline without checking if it exists
|
||||
|
||||
@@ -20,9 +20,20 @@ def print_profile_info(workspace_run_context: WorkspaceRunContext) -> None:
|
||||
@utils.track_command("profile", track_before=False, operation="list")
|
||||
def list_profiles(workspace_run_context: WorkspaceRunContext) -> None:
|
||||
fmt.echo("Available profiles:")
|
||||
current_profile = workspace_run_context.profile
|
||||
configured_profiles = workspace_run_context.configured_profiles()
|
||||
for profile in workspace_run_context.available_profiles():
|
||||
desc = BUILT_IN_PROFILES.get(profile, "Pinned custom profile")
|
||||
fmt.echo("* %s - %s" % (fmt.bold(profile), desc))
|
||||
markers = []
|
||||
if profile == current_profile:
|
||||
markers.append(fmt.bold("(current)"))
|
||||
if profile in configured_profiles:
|
||||
markers.append(fmt.bold("(configured)"))
|
||||
marker_str = " ".join(markers)
|
||||
if marker_str:
|
||||
fmt.echo("* %s %s - %s" % (fmt.bold(profile), marker_str, desc))
|
||||
else:
|
||||
fmt.echo("* %s - %s" % (fmt.bold(profile), desc))
|
||||
|
||||
|
||||
@utils.track_command("profile", track_before=False, operation="pin")
|
||||
@@ -39,7 +50,4 @@ def pin_profile(workspace_run_context: WorkspaceRunContext, profile_name: str) -
|
||||
fmt.echo("No pinned profile.")
|
||||
else:
|
||||
fmt.echo("Will pin the profile %s to current Workspace." % fmt.bold(profile_name))
|
||||
if not fmt.confirm("Do you want to proceed?", default=True):
|
||||
# TODO: raise exception that will exit with all required cleanups
|
||||
exit(0)
|
||||
save_profile_pin(workspace_run_context, profile_name)
|
||||
|
||||
@@ -9,11 +9,12 @@ from dlt.common.configuration.specs.pluggable_run_context import (
|
||||
from dlt._workspace.cli import echo as fmt, utils
|
||||
from dlt._workspace._workspace_context import WorkspaceRunContext
|
||||
from dlt._workspace.cli.utils import check_delete_local_data, delete_local_data
|
||||
from dlt._workspace.cli._pipeline_command import list_pipelines
|
||||
from dlt._workspace.profile import read_profile_pin
|
||||
|
||||
|
||||
@utils.track_command("workspace", track_before=False, operation="info")
|
||||
def print_workspace_info(run_context: WorkspaceRunContext) -> None:
|
||||
def print_workspace_info(run_context: WorkspaceRunContext, verbosity: int = 0) -> None:
|
||||
fmt.echo("Workspace %s:" % fmt.bold(run_context.name))
|
||||
fmt.echo("Workspace dir: %s" % fmt.bold(run_context.run_dir))
|
||||
fmt.echo("Settings dir: %s" % fmt.bold(run_context.settings_dir))
|
||||
@@ -24,16 +25,41 @@ def print_workspace_info(run_context: WorkspaceRunContext) -> None:
|
||||
fmt.echo(" Locally loaded data: %s" % fmt.bold(run_context.local_dir))
|
||||
if run_context.profile == read_profile_pin(run_context):
|
||||
fmt.echo(" Profile is %s" % fmt.bold("pinned"))
|
||||
configured_profiles = run_context.configured_profiles()
|
||||
if configured_profiles:
|
||||
fmt.echo(
|
||||
"Profiles with configs or pipelines: %s" % fmt.bold(", ".join(configured_profiles))
|
||||
)
|
||||
|
||||
# provider info
|
||||
providers_context = Container()[PluggableRunContext].providers
|
||||
fmt.echo()
|
||||
fmt.echo("dlt reads configuration from following locations:")
|
||||
fmt.echo("dlt found configuration in following locations:")
|
||||
total_not_found_count = 0
|
||||
for provider in providers_context.providers:
|
||||
fmt.echo("* %s" % fmt.bold(provider.name))
|
||||
for location in provider.locations:
|
||||
for location in provider.present_locations:
|
||||
fmt.echo(" %s" % location)
|
||||
if provider.is_empty:
|
||||
fmt.echo(" provider is empty")
|
||||
# check for locations that were not found
|
||||
not_found_locations = set(provider.locations).difference(provider.present_locations)
|
||||
if not_found_locations:
|
||||
if verbosity > 0:
|
||||
# display details of not found locations
|
||||
for location in not_found_locations:
|
||||
fmt.echo(" %s (not found)" % fmt.style(location, fg="yellow"))
|
||||
else:
|
||||
total_not_found_count += len(not_found_locations)
|
||||
# at verbosity 0, show summary of not found locations
|
||||
if verbosity == 0 and total_not_found_count > 0:
|
||||
fmt.echo(
|
||||
"%s location(s) were probed but not found. Use %s to see details."
|
||||
% (fmt.bold(str(total_not_found_count)), fmt.bold("-v"))
|
||||
)
|
||||
# list pipelines in the workspace
|
||||
fmt.echo()
|
||||
list_pipelines(run_context.get_data_entity("pipelines"), verbosity)
|
||||
|
||||
|
||||
@utils.track_command("workspace", track_before=False, operation="clean")
|
||||
|
||||
@@ -431,8 +431,13 @@ list of all tables and columns created at the destination during the loading of
|
||||
def execute(self, args: argparse.Namespace) -> None:
|
||||
from dlt._workspace.cli._pipeline_command import pipeline_command_wrapper
|
||||
|
||||
if args.list_pipelines:
|
||||
pipeline_command_wrapper("list", "-", args.pipelines_dir, args.verbosity)
|
||||
if (
|
||||
args.list_pipelines
|
||||
or args.operation == "list"
|
||||
or (not args.pipeline_name and not args.operation)
|
||||
):
|
||||
# Always use max verbosity (1) for dlt pipeline list - show full details
|
||||
pipeline_command_wrapper("list", "-", args.pipelines_dir, 1)
|
||||
else:
|
||||
command_kwargs = dict(args._get_kwargs())
|
||||
if not command_kwargs.get("pipeline_name"):
|
||||
@@ -785,6 +790,15 @@ workspace info.
|
||||
def configure_parser(self, parser: argparse.ArgumentParser) -> None:
|
||||
self.parser = parser
|
||||
|
||||
parser.add_argument(
|
||||
"--verbose",
|
||||
"-v",
|
||||
action="count",
|
||||
default=0,
|
||||
help="Provides more information for certain commands.",
|
||||
dest="verbosity",
|
||||
)
|
||||
|
||||
subparsers = parser.add_subparsers(
|
||||
title="Available subcommands", dest="workspace_command", required=False
|
||||
)
|
||||
@@ -844,7 +858,7 @@ workspace info.
|
||||
workspace_context = active()
|
||||
|
||||
if args.workspace_command == "info" or not args.workspace_command:
|
||||
print_workspace_info(workspace_context)
|
||||
print_workspace_info(workspace_context, args.verbosity)
|
||||
elif args.workspace_command == "clean":
|
||||
clean_workspace(workspace_context, args)
|
||||
elif args.workspace_command == "show":
|
||||
|
||||
@@ -1,10 +1,12 @@
|
||||
import ast
|
||||
import os
|
||||
import shutil
|
||||
from typing import Any, Callable, List
|
||||
from typing import Any, Callable, Dict, List, Tuple, cast
|
||||
|
||||
import dlt
|
||||
from dlt.common.typing import TFun
|
||||
from dlt.common.pipeline import get_dlt_pipelines_dir
|
||||
from dlt.common.time import ensure_pendulum_datetime_non_utc
|
||||
from dlt.common.typing import TAnyDateTime, TFun
|
||||
from dlt.common.configuration.resolve import resolve_configuration
|
||||
from dlt.common.configuration.specs.pluggable_run_context import (
|
||||
RunContextBase,
|
||||
@@ -19,6 +21,7 @@ from dlt.common.storages.file_storage import FileStorage
|
||||
from dlt._workspace.cli.exceptions import CliCommandException, CliCommandInnerException
|
||||
from dlt._workspace.cli import echo as fmt
|
||||
|
||||
from dlt.pipeline.trace import get_trace_file_path
|
||||
from dlt.reflection.script_visitor import PipelineScriptVisitor
|
||||
|
||||
REQUIREMENTS_TXT = "requirements.txt"
|
||||
@@ -27,6 +30,64 @@ GITHUB_WORKFLOWS_DIR = os.path.join(".github", "workflows")
|
||||
AIRFLOW_DAGS_FOLDER = os.path.join("dags")
|
||||
AIRFLOW_BUILD_FOLDER = os.path.join("build")
|
||||
MODULE_INIT = "__init__.py"
|
||||
DATETIME_FORMAT = "YYYY-MM-DD HH:mm:ss"
|
||||
|
||||
|
||||
def get_pipeline_trace_mtime(pipelines_dir: str, pipeline_name: str) -> float:
|
||||
"""Get mtime of the trace saved by pipeline, which approximates run time"""
|
||||
trace_file = get_trace_file_path(pipelines_dir, pipeline_name)
|
||||
if os.path.isfile(trace_file):
|
||||
return os.path.getmtime(trace_file)
|
||||
return 0
|
||||
|
||||
|
||||
def list_local_pipelines(
|
||||
pipelines_dir: str = None, sort_by_trace: bool = True, additional_pipelines: List[str] = None
|
||||
) -> Tuple[str, List[Dict[str, Any]]]:
|
||||
"""Get the local pipelines directory and the list of pipeline names in it.
|
||||
|
||||
Args:
|
||||
pipelines_dir (str, optional): The local pipelines directory. Defaults to get_dlt_pipelines_dir().
|
||||
sort_by_trace (bool, optional): Whether to sort the pipelines by the latest timestamp of trace. Defaults to True.
|
||||
Returns:
|
||||
Tuple[str, List[str]]: The local pipelines directory and the list of pipeline names in it.
|
||||
"""
|
||||
pipelines_dir = pipelines_dir or get_dlt_pipelines_dir()
|
||||
storage = FileStorage(pipelines_dir)
|
||||
|
||||
try:
|
||||
pipelines = storage.list_folder_dirs(".", to_root=False)
|
||||
except Exception:
|
||||
pipelines = []
|
||||
|
||||
if additional_pipelines:
|
||||
for pipeline in additional_pipelines:
|
||||
if pipeline and pipeline not in pipelines:
|
||||
pipelines.append(pipeline)
|
||||
|
||||
# check last trace timestamp and create dict
|
||||
pipelines_with_timestamps = []
|
||||
for pipeline in pipelines:
|
||||
pipelines_with_timestamps.append(
|
||||
{"name": pipeline, "timestamp": get_pipeline_trace_mtime(pipelines_dir, pipeline)}
|
||||
)
|
||||
|
||||
if sort_by_trace:
|
||||
pipelines_with_timestamps.sort(key=lambda x: cast(float, x["timestamp"]), reverse=True)
|
||||
|
||||
return pipelines_dir, pipelines_with_timestamps
|
||||
|
||||
|
||||
def date_from_timestamp_with_ago(
|
||||
timestamp: TAnyDateTime, datetime_format: str = DATETIME_FORMAT
|
||||
) -> str:
|
||||
"""Return a date with ago section"""
|
||||
if not timestamp or timestamp == 0:
|
||||
return "never"
|
||||
timestamp = ensure_pendulum_datetime_non_utc(timestamp)
|
||||
time_formatted = timestamp.format(datetime_format)
|
||||
ago = timestamp.diff_for_humans()
|
||||
return f"{ago} ({time_formatted})"
|
||||
|
||||
|
||||
def display_run_context_info() -> None:
|
||||
|
||||
@@ -2,6 +2,7 @@ from typing import ClassVar, Optional, Sequence
|
||||
from dlt.common.configuration.specs import known_sections
|
||||
from dlt.common.configuration.specs.base_configuration import BaseConfiguration, configspec
|
||||
from dlt.common.configuration.specs.runtime_configuration import RuntimeConfiguration
|
||||
from dlt.common.typing import TSecretStrValue
|
||||
|
||||
|
||||
@configspec
|
||||
@@ -21,8 +22,18 @@ class WorkspaceSettings(BaseConfiguration):
|
||||
class WorkspaceRuntimeConfiguration(RuntimeConfiguration):
|
||||
"""Extends runtime configuration with dlthub runtime"""
|
||||
|
||||
# TODO: connect workspace to runtime here
|
||||
# TODO: optionally define scripts and other runtime settings
|
||||
workspace_id: Optional[str] = None
|
||||
"""Id of the remote workspace that local one should be connected to"""
|
||||
auth_token: Optional[TSecretStrValue] = None
|
||||
"""JWT token for Runtime API"""
|
||||
auth_base_url: Optional[str] = "https://dlthub.app/api/auth"
|
||||
"""Base URL for the dltHub Runtime authentication API"""
|
||||
api_base_url: Optional[str] = "https://dlthub.app/api/api"
|
||||
"""Base URL for the dltHub Runtime API"""
|
||||
invite_code: Optional[str] = None
|
||||
"""Invite code for dltHub Runtime"""
|
||||
|
||||
__section__: ClassVar[str] = "runtime"
|
||||
|
||||
|
||||
@configspec
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import Iterator, Optional, List
|
||||
from typing import Iterable, Iterator, Optional, List, Tuple
|
||||
from pathlib import Path
|
||||
from pathspec import PathSpec
|
||||
from pathspec.util import iter_tree_files
|
||||
@@ -6,7 +6,16 @@ from pathspec.util import iter_tree_files
|
||||
from dlt._workspace._workspace_context import WorkspaceRunContext
|
||||
|
||||
|
||||
class WorkspaceFileSelector:
|
||||
class BaseFileSelector(Iterable[Tuple[Path, Path]]):
|
||||
"""
|
||||
Base class for file selectors. For every file yields 2 paths: absolute path in the filesystem
|
||||
and relative path of the file in the resulting tarball
|
||||
"""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
class WorkspaceFileSelector(BaseFileSelector):
|
||||
"""Iterates files in workspace respecting ignore patterns and excluding workspace internals.
|
||||
|
||||
Uses gitignore-style patterns from a configurable ignore file (default .gitignore). Additional
|
||||
@@ -22,7 +31,7 @@ class WorkspaceFileSelector:
|
||||
self.root_path: Path = Path(context.run_dir).resolve()
|
||||
self.settings_dir: Path = Path(context.settings_dir).resolve()
|
||||
self.ignore_file: str = ignore_file
|
||||
self.spec: PathSpec = self._build_pathspec(additional_excludes or [])
|
||||
self.ignore_spec: PathSpec = self._build_pathspec(additional_excludes or [])
|
||||
|
||||
def _build_pathspec(self, additional_excludes: List[str]) -> PathSpec:
|
||||
"""Build PathSpec from ignore file + defaults + additional excludes"""
|
||||
@@ -39,8 +48,25 @@ class WorkspaceFileSelector:
|
||||
|
||||
return PathSpec.from_lines("gitwildmatch", patterns)
|
||||
|
||||
def __iter__(self) -> Iterator[Path]:
|
||||
def __iter__(self) -> Iterator[Tuple[Path, Path]]:
|
||||
"""Yield paths of files eligible for deployment"""
|
||||
root_path = Path(self.root_path)
|
||||
for file_path in iter_tree_files(self.root_path):
|
||||
if not self.spec.match_file(file_path):
|
||||
yield Path(file_path)
|
||||
if not self.ignore_spec.match_file(file_path):
|
||||
yield root_path / file_path, Path(file_path)
|
||||
|
||||
|
||||
class ConfigurationFileSelector(BaseFileSelector):
|
||||
"""Iterates config and secrets files in workspace"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
context: WorkspaceRunContext,
|
||||
) -> None:
|
||||
self.settings_dir: Path = Path(context.settings_dir).resolve()
|
||||
|
||||
def __iter__(self) -> Iterator[Tuple[Path, Path]]:
|
||||
"""Yield paths of config and secrets paths"""
|
||||
for file_path in iter_tree_files(self.settings_dir):
|
||||
if file_path.endswith("config.toml") or file_path.endswith("secrets.toml"):
|
||||
yield self.settings_dir / file_path, Path(file_path)
|
||||
|
||||
@@ -7,7 +7,7 @@ import yaml
|
||||
from dlt.common.time import precise_time
|
||||
from dlt.common.utils import digest256_tar_stream
|
||||
|
||||
from dlt._workspace.deployment.file_selector import WorkspaceFileSelector
|
||||
from dlt._workspace.deployment.file_selector import BaseFileSelector, WorkspaceFileSelector
|
||||
from dlt._workspace.deployment.manifest import (
|
||||
TDeploymentFileItem,
|
||||
TDeploymentManifest,
|
||||
@@ -22,33 +22,32 @@ DEFAULT_MANIFEST_FILE_NAME = "manifest.yaml"
|
||||
DEFAULT_DEPLOYMENT_PACKAGE_LAYOUT = "deployment-{timestamp}.tar.gz"
|
||||
|
||||
|
||||
class DeploymentPackageBuilder:
|
||||
class PackageBuilder:
|
||||
"""Builds gzipped deployment package from file selectors"""
|
||||
|
||||
def __init__(self, context: WorkspaceRunContext):
|
||||
self.run_context: WorkspaceRunContext = context
|
||||
|
||||
def write_package_to_stream(
|
||||
self, file_selector: WorkspaceFileSelector, output_stream: BinaryIO
|
||||
self, file_selector: BaseFileSelector, output_stream: BinaryIO
|
||||
) -> str:
|
||||
"""Write deployment package to output stream, return content hash"""
|
||||
manifest_files: List[TDeploymentFileItem] = []
|
||||
|
||||
# Add files to the archive
|
||||
with tarfile.open(fileobj=output_stream, mode="w|gz") as tar:
|
||||
for file_path in file_selector:
|
||||
full_path = self.run_context.run_dir / file_path
|
||||
for abs_path, rel_path in file_selector:
|
||||
# Use POSIX paths for tar archives (cross-platform compatibility)
|
||||
posix_path = file_path.as_posix()
|
||||
posix_path = rel_path.as_posix()
|
||||
tar.add(
|
||||
full_path,
|
||||
abs_path,
|
||||
arcname=f"{DEFAULT_DEPLOYMENT_FILES_FOLDER}/{posix_path}",
|
||||
recursive=False,
|
||||
)
|
||||
manifest_files.append(
|
||||
{
|
||||
"relative_path": posix_path,
|
||||
"size_in_bytes": full_path.stat().st_size,
|
||||
"size_in_bytes": abs_path.stat().st_size,
|
||||
}
|
||||
)
|
||||
# Create and add manifest with file metadata at the end
|
||||
@@ -65,9 +64,12 @@ class DeploymentPackageBuilder:
|
||||
manifest_info.size = len(manifest_yaml)
|
||||
tar.addfile(manifest_info, BytesIO(manifest_yaml))
|
||||
|
||||
return digest256_tar_stream(output_stream)
|
||||
content_hash, _ = digest256_tar_stream(
|
||||
output_stream, filter_file_names=lambda x: x != DEFAULT_MANIFEST_FILE_NAME
|
||||
)
|
||||
return content_hash
|
||||
|
||||
def build_package(self, file_selector: WorkspaceFileSelector) -> Tuple[Path, str]:
|
||||
def build_package(self, file_selector: BaseFileSelector) -> Tuple[Path, str]:
|
||||
"""Create deployment package file, return (path, content_hash)"""
|
||||
package_name = DEFAULT_DEPLOYMENT_PACKAGE_LAYOUT.format(timestamp=str(precise_time()))
|
||||
package_path = Path(self.run_context.get_data_entity(package_name))
|
||||
|
||||
@@ -33,6 +33,12 @@ class DashboardConfiguration(BaseConfiguration):
|
||||
datetime_format: str = "YYYY-MM-DD HH:mm:ss Z"
|
||||
"""The format of the datetime strings"""
|
||||
|
||||
sync_from_runtime: bool = False
|
||||
"""
|
||||
Whether to sync the pipeline states and traces from the runtime backup.
|
||||
Needs to be run inside a dlt workspace with runtime artifacts credentials set.
|
||||
"""
|
||||
|
||||
# this is needed for using this as a param in the cache
|
||||
def __hash__(self) -> int:
|
||||
return hash(
|
||||
|
||||
@@ -38,6 +38,14 @@ def build_header_controls(dlt_profile_select: mo.ui.dropdown) -> Union[List[Any]
|
||||
return None
|
||||
|
||||
|
||||
@app.function(hide_code=True)
|
||||
def detect_dlt_hub():
|
||||
try:
|
||||
return dlt.hub.__found__
|
||||
except ImportError:
|
||||
return False
|
||||
|
||||
|
||||
@app.function
|
||||
def build_home_header_row(
|
||||
dlt_profile_select: mo.ui.dropdown,
|
||||
@@ -86,6 +94,7 @@ def render_workspace_home(
|
||||
) -> List[Any]:
|
||||
"""Render the workspace-level home view (no pipeline selected)."""
|
||||
return [
|
||||
ui.section_marker(strings.app_section_name, has_content=True),
|
||||
build_home_header_row(dlt_profile_select, dlt_pipeline_select),
|
||||
mo.md(strings.app_title).center(),
|
||||
mo.md(strings.app_intro).center(),
|
||||
@@ -185,7 +194,7 @@ def render_pipeline_home(
|
||||
)
|
||||
_pipeline_execution_exception = utils.build_exception_section(dlt_pipeline)
|
||||
|
||||
_stack = [ui.section_marker(strings.home_section_name)]
|
||||
_stack = [ui.section_marker(strings.home_section_name, has_content=dlt_pipeline is not None)]
|
||||
_stack.extend(
|
||||
render_pipeline_header_row(
|
||||
dlt_pipeline_name, dlt_profile_select, dlt_pipeline_select, _buttons
|
||||
@@ -304,7 +313,9 @@ def section_info(
|
||||
Overview page of currently selected pipeline
|
||||
"""
|
||||
|
||||
_result = [ui.section_marker(strings.overview_section_name)]
|
||||
_result = [
|
||||
ui.section_marker(strings.overview_section_name, has_content=dlt_pipeline is not None)
|
||||
]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -363,7 +374,7 @@ def section_schema(
|
||||
Show schema of the currently selected pipeline
|
||||
"""
|
||||
|
||||
_result = [ui.section_marker(strings.schema_section_name)]
|
||||
_result = [ui.section_marker(strings.schema_section_name, has_content=dlt_pipeline is not None)]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -443,6 +454,223 @@ def section_schema(
|
||||
return
|
||||
|
||||
|
||||
@app.cell(hide_code=True)
|
||||
def ui_data_quality_controls(
|
||||
dlt_pipeline: dlt.Pipeline,
|
||||
dlt_section_data_quality_switch: mo.ui.switch,
|
||||
):
|
||||
"""
|
||||
Create data quality filter controls (separate cell for marimo reactivity)
|
||||
|
||||
Import the function from the dashboard module and call it.
|
||||
"""
|
||||
dlt_data_quality_show_failed_filter: mo.ui.checkbox = None
|
||||
dlt_data_quality_table_filter: mo.ui.dropdown = None
|
||||
dlt_data_quality_rate_filter: mo.ui.slider = None
|
||||
dlt_data_quality_checks_arrow = None
|
||||
|
||||
# Create controls whenever dlthub is detected and pipeline exists
|
||||
# The switch controls whether widget content is shown, not whether controls exist
|
||||
if detect_dlt_hub() and dlt_pipeline:
|
||||
try:
|
||||
# Import the function from the dashboard module
|
||||
from dlthub.data_quality._dashboard import create_data_quality_controls
|
||||
|
||||
# Call the function - returns (checkbox, dropdown, slider, checks_arrow)
|
||||
(
|
||||
dlt_data_quality_show_failed_filter,
|
||||
dlt_data_quality_table_filter,
|
||||
dlt_data_quality_rate_filter,
|
||||
dlt_data_quality_checks_arrow,
|
||||
) = create_data_quality_controls(dlt_pipeline)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return (
|
||||
dlt_data_quality_show_failed_filter,
|
||||
dlt_data_quality_table_filter,
|
||||
dlt_data_quality_rate_filter,
|
||||
dlt_data_quality_checks_arrow,
|
||||
)
|
||||
|
||||
|
||||
@app.cell(hide_code=True)
|
||||
def section_data_quality(
|
||||
dlt_pipeline: dlt.Pipeline,
|
||||
dlt_section_data_quality_switch: mo.ui.switch,
|
||||
dlt_data_quality_show_failed_filter: mo.ui.checkbox,
|
||||
dlt_data_quality_table_filter: mo.ui.dropdown,
|
||||
dlt_data_quality_rate_filter: mo.ui.slider,
|
||||
dlt_data_quality_checks_arrow,
|
||||
):
|
||||
"""
|
||||
Show data quality of the currently selected pipeline
|
||||
only if dlt.hub is installed
|
||||
|
||||
Import the widget function from the dashboard module and call it.
|
||||
"""
|
||||
if not detect_dlt_hub():
|
||||
_result = None
|
||||
else:
|
||||
_result = [
|
||||
ui.section_marker(
|
||||
strings.data_quality_section_name, has_content=dlt_pipeline is not None
|
||||
)
|
||||
]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
strings.data_quality_title,
|
||||
strings.data_quality_subtitle,
|
||||
strings.data_quality_subtitle,
|
||||
dlt_section_data_quality_switch,
|
||||
)
|
||||
)
|
||||
if dlt_pipeline and dlt_section_data_quality_switch.value:
|
||||
try:
|
||||
# Import the widget function from the dashboard module
|
||||
from dlthub.data_quality._dashboard import data_quality_widget
|
||||
|
||||
# Extract values from controls (must be in separate cell from where controls are created)
|
||||
show_failed_value = (
|
||||
dlt_data_quality_show_failed_filter.value
|
||||
if dlt_data_quality_show_failed_filter is not None
|
||||
else False
|
||||
)
|
||||
table_value = None
|
||||
if (
|
||||
dlt_data_quality_table_filter is not None
|
||||
and dlt_data_quality_table_filter.value != "All"
|
||||
):
|
||||
table_value = dlt_data_quality_table_filter.value
|
||||
rate_value = (
|
||||
dlt_data_quality_rate_filter.value
|
||||
if dlt_data_quality_rate_filter is not None
|
||||
else None
|
||||
)
|
||||
|
||||
# Call the widget function
|
||||
widget_output = data_quality_widget(
|
||||
dlt_pipeline=dlt_pipeline,
|
||||
failure_rate_slider=dlt_data_quality_rate_filter,
|
||||
failure_rate_filter_value=rate_value,
|
||||
show_only_failed_checkbox=dlt_data_quality_show_failed_filter,
|
||||
show_only_failed_value=show_failed_value,
|
||||
table_dropdown=dlt_data_quality_table_filter,
|
||||
table_name_filter_value=table_value,
|
||||
checks_arrow=dlt_data_quality_checks_arrow,
|
||||
)
|
||||
if widget_output is not None:
|
||||
_result.append(widget_output)
|
||||
|
||||
# Only show raw table switch if there is data to display
|
||||
if (
|
||||
dlt_data_quality_checks_arrow is not None
|
||||
and dlt_data_quality_checks_arrow.num_rows > 0
|
||||
):
|
||||
dlt_data_quality_show_raw_table_switch: mo.ui.switch = mo.ui.switch(
|
||||
value=False,
|
||||
label="<small>Show Raw Table</small>",
|
||||
)
|
||||
_result.append(
|
||||
mo.hstack([dlt_data_quality_show_raw_table_switch], justify="start")
|
||||
)
|
||||
else:
|
||||
dlt_data_quality_show_raw_table_switch = None
|
||||
except ImportError:
|
||||
_result.append(mo.md("**DLT Hub data quality module is not available.**"))
|
||||
dlt_data_quality_show_raw_table_switch = None
|
||||
except Exception as exc:
|
||||
_result.append(
|
||||
ui.build_error_callout(
|
||||
f"Error loading data quality checks: {exc}",
|
||||
traceback_string=traceback.format_exc(),
|
||||
)
|
||||
)
|
||||
dlt_data_quality_show_raw_table_switch = None
|
||||
else:
|
||||
dlt_data_quality_show_raw_table_switch = None
|
||||
mo.vstack(_result) if _result else None
|
||||
return dlt_data_quality_show_raw_table_switch
|
||||
|
||||
|
||||
@app.cell(hide_code=True)
|
||||
def section_data_quality_raw_table(
|
||||
dlt_pipeline: dlt.Pipeline,
|
||||
dlt_section_data_quality_switch: mo.ui.switch,
|
||||
dlt_data_quality_show_raw_table_switch: mo.ui.switch,
|
||||
dlt_get_last_query_result,
|
||||
dlt_set_last_query_result,
|
||||
):
|
||||
"""
|
||||
Display the raw data quality checks table with _dlt_load_id column
|
||||
"""
|
||||
_result = []
|
||||
|
||||
if (
|
||||
dlt_pipeline
|
||||
and dlt_section_data_quality_switch.value
|
||||
and dlt_data_quality_show_raw_table_switch is not None
|
||||
and dlt_data_quality_show_raw_table_switch.value
|
||||
):
|
||||
try:
|
||||
# Import constants from data_quality module (using private names to avoid conflicts)
|
||||
from dlthub.data_quality.storage import (
|
||||
DLT_CHECKS_RESULTS_TABLE_NAME as _DLT_CHECKS_RESULTS_TABLE_NAME,
|
||||
DLT_DATA_QUALITY_SCHEMA_NAME as _DLT_DATA_QUALITY_SCHEMA_NAME,
|
||||
)
|
||||
|
||||
_error_message: str = None
|
||||
with mo.status.spinner(title="Loading raw data quality checks table..."):
|
||||
try:
|
||||
# Build query to select all columns including _dlt_load_id
|
||||
_raw_dataset = dlt_pipeline.dataset(schema=_DLT_DATA_QUALITY_SCHEMA_NAME)
|
||||
_raw_sql_query = (
|
||||
_raw_dataset.table(_DLT_CHECKS_RESULTS_TABLE_NAME)
|
||||
.limit(1000)
|
||||
.to_sql(pretty=True, _raw_query=True)
|
||||
)
|
||||
|
||||
# Execute query
|
||||
_raw_query_result, _error_message, _traceback_string = utils.get_query_result(
|
||||
dlt_pipeline, _raw_sql_query
|
||||
)
|
||||
dlt_set_last_query_result(_raw_query_result)
|
||||
except Exception as exc:
|
||||
_error_message = str(exc)
|
||||
_traceback_string = traceback.format_exc()
|
||||
|
||||
# Display error message if encountered
|
||||
if _error_message:
|
||||
_result.append(
|
||||
ui.build_error_callout(
|
||||
f"Error loading raw table: {_error_message}",
|
||||
traceback_string=_traceback_string,
|
||||
)
|
||||
)
|
||||
|
||||
# Always display result table
|
||||
_last_result = dlt_get_last_query_result()
|
||||
if _last_result is not None:
|
||||
_result.append(mo.ui.table(_last_result, selection=None))
|
||||
except ImportError:
|
||||
_result.append(
|
||||
mo.callout(
|
||||
mo.md("DLT Hub data quality module is not available."),
|
||||
kind="warn",
|
||||
)
|
||||
)
|
||||
except Exception as exc:
|
||||
_result.append(
|
||||
ui.build_error_callout(
|
||||
f"Error loading raw table: {exc}",
|
||||
traceback_string=traceback.format_exc(),
|
||||
)
|
||||
)
|
||||
mo.vstack(_result) if _result else None
|
||||
return
|
||||
|
||||
|
||||
@app.cell(hide_code=True)
|
||||
def section_browse_data_table_list(
|
||||
dlt_clear_query_cache: mo.ui.run_button,
|
||||
@@ -460,7 +688,9 @@ def section_browse_data_table_list(
|
||||
Show data of the currently selected pipeline
|
||||
"""
|
||||
|
||||
_result = [ui.section_marker(strings.browse_data_section_name)]
|
||||
_result = [
|
||||
ui.section_marker(strings.browse_data_section_name, has_content=dlt_pipeline is not None)
|
||||
]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -493,7 +723,7 @@ def section_browse_data_table_list(
|
||||
|
||||
# we only show resource state if the table has resource set, child tables do not have a resource set
|
||||
_resource_name, _source_state, _resource_state = (
|
||||
utils.get_source_and_resouce_state_for_table(
|
||||
utils.get_source_and_resource_state_for_table(
|
||||
_schema_table, dlt_pipeline, dlt_selected_schema_name
|
||||
)
|
||||
)
|
||||
@@ -705,7 +935,7 @@ def section_state(
|
||||
"""
|
||||
Show state of the currently selected pipeline
|
||||
"""
|
||||
_result = [ui.section_marker(strings.state_section_name)]
|
||||
_result = [ui.section_marker(strings.state_section_name, has_content=dlt_pipeline is not None)]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -737,7 +967,7 @@ def section_trace(
|
||||
Show last trace of the currently selected pipeline
|
||||
"""
|
||||
|
||||
_result = [ui.section_marker(strings.trace_section_name)]
|
||||
_result = [ui.section_marker(strings.trace_section_name, has_content=dlt_pipeline is not None)]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -851,7 +1081,7 @@ def section_loads(
|
||||
Show loads of the currently selected pipeline
|
||||
"""
|
||||
|
||||
_result = [ui.section_marker(strings.loads_section_name)]
|
||||
_result = [ui.section_marker(strings.loads_section_name, has_content=dlt_pipeline is not None)]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -964,7 +1194,9 @@ def section_ibis_backend(
|
||||
"""
|
||||
Connects to ibis backend and makes it available in the datasources panel
|
||||
"""
|
||||
_result = [ui.section_marker(strings.ibis_backend_section_name)]
|
||||
_result = [
|
||||
ui.section_marker(strings.ibis_backend_section_name, has_content=dlt_pipeline is not None)
|
||||
]
|
||||
_result.extend(
|
||||
ui.build_page_header(
|
||||
dlt_pipeline,
|
||||
@@ -998,6 +1230,15 @@ def utils_discover_pipelines(
|
||||
"""
|
||||
Discovers local pipelines and returns a multiselect widget to select one of the pipelines
|
||||
"""
|
||||
from dlt._workspace.cli.utils import list_local_pipelines
|
||||
|
||||
# sync from runtime if enabled
|
||||
_tmp_config = utils.resolve_dashboard_config(None)
|
||||
if _tmp_config.sync_from_runtime:
|
||||
from dlt._workspace.helpers.runtime.runtime_artifacts import sync_from_runtime
|
||||
|
||||
with mo.status.spinner(title="Syncing pipeline list from runtime"):
|
||||
sync_from_runtime()
|
||||
|
||||
_run_context = dlt.current.run_context()
|
||||
if (
|
||||
@@ -1009,9 +1250,9 @@ def utils_discover_pipelines(
|
||||
# discover pipelines and build selector
|
||||
dlt_pipelines_dir: str = ""
|
||||
dlt_all_pipelines: List[Dict[str, Any]] = []
|
||||
dlt_pipelines_dir, dlt_all_pipelines = utils.get_local_pipelines(
|
||||
dlt_pipelines_dir, dlt_all_pipelines = list_local_pipelines(
|
||||
mo_cli_arg_pipelines_dir,
|
||||
addtional_pipelines=[mo_cli_arg_pipeline, mo_query_var_pipeline_name],
|
||||
additional_pipelines=[mo_cli_arg_pipeline, mo_query_var_pipeline_name],
|
||||
)
|
||||
|
||||
dlt_pipeline_select: mo.ui.multiselect = mo.ui.multiselect(
|
||||
@@ -1039,7 +1280,7 @@ def utils_discover_profiles(mo_query_var_profile: str, mo_cli_arg_profile: str):
|
||||
selected_profile = None
|
||||
|
||||
if isinstance(run_context, ProfilesRunContext):
|
||||
options = run_context.available_profiles() or []
|
||||
options = run_context.configured_profiles() or []
|
||||
current = run_context.profile if options and run_context.profile in options else None
|
||||
|
||||
selected_profile = current
|
||||
@@ -1135,13 +1376,16 @@ def ui_controls(mo_cli_arg_with_test_identifiers: bool):
|
||||
dlt_section_ibis_browser_switch: mo.ui.switch = mo.ui.switch(
|
||||
value=False, label="ibis" if mo_cli_arg_with_test_identifiers else ""
|
||||
)
|
||||
dlt_section_data_quality_switch: mo.ui.switch = mo.ui.switch(
|
||||
value=False, label="data_quality" if mo_cli_arg_with_test_identifiers else ""
|
||||
)
|
||||
|
||||
# other switches
|
||||
dlt_schema_show_dlt_tables: mo.ui.switch = mo.ui.switch(
|
||||
label=f"<small>{strings.ui_show_dlt_tables}</small>"
|
||||
)
|
||||
dlt_schema_show_child_tables: mo.ui.switch = mo.ui.switch(
|
||||
label=f"<small>{strings.ui_show_child_tables}</small>", value=False
|
||||
label=f"<small>{strings.ui_show_child_tables}</small>", value=True
|
||||
)
|
||||
dlt_schema_show_row_counts: mo.ui.run_button = mo.ui.run_button(
|
||||
label=f"<small>{strings.ui_load_row_counts}</small>"
|
||||
@@ -1175,6 +1419,7 @@ def ui_controls(mo_cli_arg_with_test_identifiers: bool):
|
||||
dlt_schema_show_row_counts,
|
||||
dlt_schema_show_type_hints,
|
||||
dlt_section_browse_data_switch,
|
||||
dlt_section_data_quality_switch,
|
||||
dlt_section_ibis_browser_switch,
|
||||
dlt_section_loads_switch,
|
||||
dlt_section_info_switch,
|
||||
@@ -1193,15 +1438,15 @@ def watch_changes(
|
||||
"""
|
||||
Watch changes in the trace file and trigger reload in the home cell and all following cells on change
|
||||
"""
|
||||
from dlt.pipeline.trace import get_trace_file_path
|
||||
|
||||
# provide pipeline object to the following cells
|
||||
dlt_pipeline_name: str = (
|
||||
str(dlt_pipeline_select.value[0]) if dlt_pipeline_select.value else None
|
||||
)
|
||||
dlt_file_watcher = None
|
||||
if dlt_pipeline_name:
|
||||
dlt_file_watcher = mo.watch.file(
|
||||
utils.get_trace_file_path(dlt_pipeline_name, dlt_pipelines_dir)
|
||||
)
|
||||
dlt_file_watcher = mo.watch.file(get_trace_file_path(dlt_pipelines_dir, dlt_pipeline_name))
|
||||
return dlt_pipeline_name, dlt_file_watcher
|
||||
|
||||
|
||||
|
||||
@@ -56,22 +56,26 @@
|
||||
|
||||
/* add colors to cells */
|
||||
|
||||
/* Default: all sections get purple border and background */
|
||||
#App .marimo-cell .output-area {
|
||||
/* Default: all sections that have content get purple border and background */
|
||||
#App .marimo-cell .output-area:has(.section-marker.has-content) {
|
||||
border: 1px dashed var(--dlt-color-purple);
|
||||
background-color: var(--dlt-color-purple-background);
|
||||
}
|
||||
|
||||
/* All cells with section markers get margin-top */
|
||||
#App .marimo-cell .output-area:has(.section-marker) {
|
||||
|
||||
/* All cells with section markers and have content get margin-top */
|
||||
#App .marimo-cell .output-area:has(.section-marker.has-content) {
|
||||
margin-top: 0.5rem;
|
||||
}
|
||||
|
||||
/* Aqua sections - identified by section name in strings.py */
|
||||
#App .marimo-cell .output-area:has([data-section="home_section"]),
|
||||
#App .marimo-cell .output-area:has([data-section="schema_section"]),
|
||||
#App .marimo-cell .output-area:has([data-section="state_section"]),
|
||||
#App .marimo-cell .output-area:has([data-section="loads_section"]) {
|
||||
|
||||
/* Aqua sections - identified by section name in strings.py and the availability of content */
|
||||
#App .marimo-cell .output-area:has([data-section="workspace_home"].has-content),
|
||||
#App .marimo-cell .output-area:has([data-section="home_section"].has-content),
|
||||
#App .marimo-cell .output-area:has([data-section="schema_section"].has-content),
|
||||
#App .marimo-cell .output-area:has([data-section="state_section"].has-content),
|
||||
#App .marimo-cell .output-area:has([data-section="loads_section"].has-content),
|
||||
#App .marimo-cell .output-area:has([data-section="data_quality_section"].has-content) {
|
||||
background-color: var(--dlt-color-aqua-background);
|
||||
border: 1px dashed var(--dlt-color-aqua);
|
||||
}
|
||||
@@ -154,4 +158,4 @@ marimo-callout-output .border {
|
||||
.status-badge-grey {
|
||||
background-color: var(--grey-bg);
|
||||
color: var(--grey-text);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -19,7 +19,7 @@ try:
|
||||
except ModuleNotFoundError:
|
||||
raise MissingDependencyException(
|
||||
"Workspace Dashboard",
|
||||
['dlt["workspace"]'],
|
||||
["dlt[workspace]"],
|
||||
"to install the dlt workspace extra.",
|
||||
)
|
||||
|
||||
|
||||
@@ -18,6 +18,7 @@ _credentials_info = (
|
||||
#
|
||||
# App general
|
||||
#
|
||||
app_section_name = "workspace_home"
|
||||
app_title = """
|
||||
# Welcome to the dltHub workspace dashboard...
|
||||
"""
|
||||
@@ -124,7 +125,7 @@ schema_raw_yaml_title = "Raw Schema as YAML"
|
||||
schema_show_raw_yaml_text = "Show raw schema as YAML"
|
||||
|
||||
# Schema UI controls
|
||||
ui_show_dlt_tables = "Show `_dlt` tables"
|
||||
ui_show_dlt_tables = "Show internal tables"
|
||||
ui_show_child_tables = "Show child tables"
|
||||
ui_load_row_counts = "Load row counts"
|
||||
ui_show_dlt_columns = "Show `_dlt` columns"
|
||||
@@ -179,6 +180,12 @@ state_section_name = "state_section"
|
||||
state_title = "Pipeline State"
|
||||
state_subtitle = "A raw view of the currently stored pipeline state."
|
||||
|
||||
#
|
||||
# Data quality page
|
||||
#
|
||||
data_quality_section_name = "data_quality_section"
|
||||
data_quality_title = "Data Quality"
|
||||
data_quality_subtitle = "View the results of your data quality checks"
|
||||
|
||||
#
|
||||
# Last trace page
|
||||
|
||||
@@ -78,6 +78,18 @@ def build_page_header(
|
||||
]
|
||||
|
||||
|
||||
def section_marker(section_name: str) -> mo.Html:
|
||||
"""Create an invisible marker element to identify sections for CSS styling."""
|
||||
return mo.Html(f'<div class="section-marker" data-section="{section_name}" hidden"></div>')
|
||||
def section_marker(section_name: str, has_content: bool = False) -> mo.Html:
|
||||
"""Create an invisible marker element to identify sections for CSS styling.
|
||||
|
||||
Args:
|
||||
section_name: Name identifier for the section (e.g., "home_section", "schema_section")
|
||||
has_content: If True, adds 'has-content' class to enable CSS styling (borders, backgrounds).
|
||||
Should be True only when the section has actual content and is displayed.
|
||||
|
||||
Returns:
|
||||
Hidden HTML div element with section marker classes for CSS targeting.
|
||||
"""
|
||||
content_class = "has-content" if has_content else ""
|
||||
return mo.Html(
|
||||
f'<div class="section-marker {content_class}" data-section="{section_name}" hidden"></div>'
|
||||
)
|
||||
|
||||
@@ -9,7 +9,6 @@ from typing import (
|
||||
List,
|
||||
Mapping,
|
||||
Optional,
|
||||
Set,
|
||||
Tuple,
|
||||
Union,
|
||||
cast,
|
||||
@@ -33,47 +32,31 @@ from dlt.common.configuration.specs import known_sections
|
||||
from dlt.common.destination.client import WithStateSync
|
||||
from dlt.common.json import json
|
||||
from dlt.common.pendulum import pendulum
|
||||
from dlt.common.pipeline import get_dlt_pipelines_dir, LoadInfo
|
||||
from dlt.common.pipeline import LoadInfo
|
||||
from dlt.common.schema import Schema
|
||||
from dlt.common.schema.typing import TTableSchema
|
||||
from dlt.common.storages import FileStorage, LoadPackageInfo
|
||||
from dlt.common.storages import LoadPackageInfo
|
||||
from dlt.common.storages.load_package import PackageStorage, TLoadPackageStatus
|
||||
from dlt.common.destination.client import DestinationClientConfiguration
|
||||
from dlt.common.destination.exceptions import SqlClientNotAvailable
|
||||
from dlt.common.storages.configuration import WithLocalFiles
|
||||
from dlt.common.configuration.exceptions import ConfigFieldMissingException
|
||||
from dlt.common.typing import DictStrAny, TypedDict
|
||||
from dlt.common.typing import DictStrAny
|
||||
from dlt.common.utils import map_nested_keys_in_place
|
||||
|
||||
from dlt._workspace.helpers.dashboard import ui_elements as ui
|
||||
from dlt._workspace.helpers.dashboard.config import DashboardConfiguration
|
||||
from dlt._workspace.cli import utils as cli_utils
|
||||
from dlt.destinations.exceptions import DatabaseUndefinedRelation, DestinationUndefinedEntity
|
||||
from dlt.pipeline.exceptions import PipelineConfigMissing
|
||||
from dlt.pipeline.exceptions import CannotRestorePipelineException
|
||||
from dlt.pipeline.trace import PipelineTrace, PipelineStepTrace
|
||||
|
||||
PICKLE_TRACE_FILE = "trace.pickle"
|
||||
|
||||
|
||||
#
|
||||
# App helpers
|
||||
#
|
||||
|
||||
|
||||
def _exception_to_string(exception: Exception) -> str:
|
||||
"""Convert an exception to a string"""
|
||||
if isinstance(exception, (PipelineConfigMissing, ConfigFieldMissingException)):
|
||||
return "Could not connect to destination, configuration values are missing."
|
||||
elif isinstance(exception, (SqlClientNotAvailable)):
|
||||
return "The destination of this pipeline does not support querying data with sql."
|
||||
elif isinstance(exception, (DestinationUndefinedEntity, DatabaseUndefinedRelation)):
|
||||
return (
|
||||
"Could connect to destination, but the required table or dataset does not exist in the"
|
||||
" destination."
|
||||
)
|
||||
return str(exception)
|
||||
|
||||
|
||||
def get_dashboard_config_sections(p: Optional[dlt.Pipeline]) -> Tuple[str, ...]:
|
||||
"""Find dashboard config section layout for a particular pipeline or for active
|
||||
run context type.
|
||||
@@ -102,55 +85,6 @@ def resolve_dashboard_config(p: Optional[dlt.Pipeline]) -> DashboardConfiguratio
|
||||
)
|
||||
|
||||
|
||||
def get_trace_file_path(pipeline_name: str, pipelines_dir: str) -> Path:
|
||||
"""Get the path to the pickle file for a pipeline"""
|
||||
return Path(pipelines_dir) / pipeline_name / PICKLE_TRACE_FILE
|
||||
|
||||
|
||||
def get_pipeline_last_run(pipeline_name: str, pipelines_dir: str) -> float:
|
||||
"""Get the last run of a pipeline"""
|
||||
trace_file = get_trace_file_path(pipeline_name, pipelines_dir)
|
||||
if trace_file.exists():
|
||||
return os.path.getmtime(trace_file)
|
||||
return 0
|
||||
|
||||
|
||||
def get_local_pipelines(
|
||||
pipelines_dir: str = None, sort_by_trace: bool = True, addtional_pipelines: List[str] = None
|
||||
) -> Tuple[str, List[Dict[str, Any]]]:
|
||||
"""Get the local pipelines directory and the list of pipeline names in it.
|
||||
|
||||
Args:
|
||||
pipelines_dir (str, optional): The local pipelines directory. Defaults to get_dlt_pipelines_dir().
|
||||
sort_by_trace (bool, optional): Whether to sort the pipelines by the latet timestamp of trace. Defaults to True.
|
||||
Returns:
|
||||
Tuple[str, List[str]]: The local pipelines directory and the list of pipeline names in it.
|
||||
"""
|
||||
pipelines_dir = pipelines_dir or get_dlt_pipelines_dir()
|
||||
storage = FileStorage(pipelines_dir)
|
||||
|
||||
try:
|
||||
pipelines = storage.list_folder_dirs(".", to_root=False)
|
||||
except Exception:
|
||||
pipelines = []
|
||||
|
||||
if addtional_pipelines:
|
||||
for pipeline in addtional_pipelines:
|
||||
if pipeline and pipeline not in pipelines:
|
||||
pipelines.append(pipeline)
|
||||
|
||||
# check last trace timestamp and create dict
|
||||
pipelines_with_timestamps = []
|
||||
for pipeline in pipelines:
|
||||
pipelines_with_timestamps.append(
|
||||
{"name": pipeline, "timestamp": get_pipeline_last_run(pipeline, pipelines_dir)}
|
||||
)
|
||||
|
||||
pipelines_with_timestamps.sort(key=lambda x: cast(float, x["timestamp"]), reverse=True)
|
||||
|
||||
return pipelines_dir, pipelines_with_timestamps
|
||||
|
||||
|
||||
def get_pipeline(pipeline_name: str, pipelines_dir: str) -> dlt.Pipeline:
|
||||
"""Get a pipeline by name. Attach exceptions must be handled by the caller
|
||||
|
||||
@@ -215,7 +149,11 @@ def pipeline_details(
|
||||
credentials = "Could not resolve credentials."
|
||||
|
||||
# find the pipeline in all_pipelines and get the timestamp
|
||||
pipeline_timestamp = get_pipeline_last_run(pipeline.pipeline_name, pipeline.pipelines_dir)
|
||||
trace = pipeline.last_trace
|
||||
|
||||
last_executed = "No trace found"
|
||||
if trace and hasattr(trace, "started_at"):
|
||||
last_executed = cli_utils.date_from_timestamp_with_ago(trace.started_at, c.datetime_format)
|
||||
|
||||
details_dict = {
|
||||
"pipeline_name": pipeline.pipeline_name,
|
||||
@@ -224,7 +162,7 @@ def pipeline_details(
|
||||
if pipeline.destination
|
||||
else "No destination set"
|
||||
),
|
||||
"last executed": _date_from_timestamp_with_ago(c, pipeline_timestamp),
|
||||
"last executed": last_executed,
|
||||
"credentials": credentials,
|
||||
"dataset_name": pipeline.dataset_name,
|
||||
"working_dir": pipeline.working_dir,
|
||||
@@ -357,7 +295,7 @@ def create_column_list(
|
||||
return _align_dict_keys(column_list)
|
||||
|
||||
|
||||
def get_source_and_resouce_state_for_table(
|
||||
def get_source_and_resource_state_for_table(
|
||||
table: TTableSchema, pipeline: dlt.Pipeline, schema_name: str
|
||||
) -> Tuple[str, DictStrAny, DictStrAny]:
|
||||
if "resource" not in table:
|
||||
@@ -663,13 +601,17 @@ def build_pipeline_link_list(
|
||||
) -> str:
|
||||
"""Build a list of links to the pipeline."""
|
||||
if not pipelines:
|
||||
return "No local pipelines found."
|
||||
return "No pipelines found."
|
||||
|
||||
count = 0
|
||||
link_list: str = ""
|
||||
for _p in pipelines:
|
||||
link = f"* [{_p['name']}](?pipeline={_p['name']})"
|
||||
link = link + " - last executed: " + _date_from_timestamp_with_ago(config, _p["timestamp"])
|
||||
link = (
|
||||
link
|
||||
+ " - last executed: "
|
||||
+ cli_utils.date_from_timestamp_with_ago(_p["timestamp"], config.datetime_format)
|
||||
)
|
||||
|
||||
link_list += f"{link}\n"
|
||||
count += 1
|
||||
@@ -745,16 +687,18 @@ def build_exception_section(p: dlt.Pipeline) -> List[Any]:
|
||||
#
|
||||
|
||||
|
||||
def _date_from_timestamp_with_ago(
|
||||
config: DashboardConfiguration, timestamp: Union[int, float]
|
||||
) -> str:
|
||||
"""Return a date with ago section"""
|
||||
if not timestamp or timestamp == 0:
|
||||
return "never"
|
||||
p_ts = pendulum.from_timestamp(timestamp)
|
||||
time_formatted = p_ts.format(config.datetime_format)
|
||||
ago = p_ts.diff_for_humans()
|
||||
return f"{ago} ({time_formatted})"
|
||||
def _exception_to_string(exception: Exception) -> str:
|
||||
"""Convert an exception to a string"""
|
||||
if isinstance(exception, (PipelineConfigMissing, ConfigFieldMissingException)):
|
||||
return "Could not connect to destination, configuration values are missing."
|
||||
elif isinstance(exception, (SqlClientNotAvailable)):
|
||||
return "The destination of this pipeline does not support querying data with sql."
|
||||
elif isinstance(exception, (DestinationUndefinedEntity, DatabaseUndefinedRelation)):
|
||||
return (
|
||||
"Could connect to destination, but the required table or dataset does not exist in the"
|
||||
" destination."
|
||||
)
|
||||
return str(exception)
|
||||
|
||||
|
||||
def _without_none_or_empty_string(d: Mapping[Any, Any]) -> Mapping[Any, Any]:
|
||||
|
||||
0
dlt/_workspace/helpers/runtime/__init__.py
Normal file
0
dlt/_workspace/helpers/runtime/__init__.py
Normal file
192
dlt/_workspace/helpers/runtime/runtime_artifacts.py
Normal file
192
dlt/_workspace/helpers/runtime/runtime_artifacts.py
Normal file
@@ -0,0 +1,192 @@
|
||||
"""Implements SupportsTracking"""
|
||||
from typing import Any, ClassVar, List, Optional, Tuple, Union
|
||||
import fsspec
|
||||
import pickle
|
||||
import os
|
||||
|
||||
import dlt
|
||||
from dlt.common import logger
|
||||
from dlt.common.configuration.exceptions import ConfigurationException
|
||||
from dlt.common.configuration.resolve import resolve_configuration
|
||||
from dlt.common.configuration.specs.base_configuration import BaseConfiguration, configspec
|
||||
from dlt.common.storages.configuration import FilesystemConfiguration
|
||||
from dlt.common.storages.fsspec_filesystem import FileItemDict, fsspec_from_config, glob_files
|
||||
from dlt.common.versioned_state import json_encode_state
|
||||
|
||||
from dlt.pipeline.trace import PipelineTrace, PipelineStepTrace, TPipelineStep, SupportsPipeline
|
||||
from dlt._workspace.run_context import DEFAULT_WORKSPACE_WORKING_FOLDER
|
||||
from dlt._workspace._workspace_context import WorkspaceRunContext
|
||||
|
||||
|
||||
@configspec
|
||||
class RuntimeArtifactsConfiguration(BaseConfiguration):
|
||||
artifacts: FilesystemConfiguration = None
|
||||
|
||||
|
||||
def sync_from_runtime() -> None:
|
||||
"""Sync the pipeline states and traces from the runtime backup, recursively."""
|
||||
from dlt._workspace.helpers.runtime.runtime_artifacts import _get_runtime_artifacts_fs
|
||||
|
||||
def sync_dir(fs: fsspec.AbstractFileSystem, src_root: str, dst_root: str) -> None:
|
||||
"""Recursively sync src_root on fs into dst_root locally, always using fs.walk."""
|
||||
|
||||
os.makedirs(dst_root, exist_ok=True)
|
||||
|
||||
for file_dict in glob_files(fs, src_root):
|
||||
file_item = FileItemDict(file_dict, fs)
|
||||
|
||||
relative_dir = os.path.dirname(file_dict["relative_path"])
|
||||
local_dir = dst_root if relative_dir == "." else os.path.join(dst_root, relative_dir)
|
||||
os.makedirs(local_dir, exist_ok=True)
|
||||
|
||||
local_file = os.path.join(dst_root, file_dict["relative_path"])
|
||||
|
||||
logger.info(f"Restoring artifact {local_file}")
|
||||
with open(local_file, "wb") as lf:
|
||||
lf.write(file_item.read_bytes())
|
||||
|
||||
ts = file_dict["modification_date"].timestamp()
|
||||
os.utime(local_file, (ts, ts)) # (atime, mtime)
|
||||
|
||||
context = dlt.current.run_context()
|
||||
|
||||
if not context.runtime_config.run_id:
|
||||
return
|
||||
|
||||
if not isinstance(context, WorkspaceRunContext):
|
||||
return
|
||||
|
||||
fs, config = _get_runtime_artifacts_fs(section="sync")
|
||||
if not fs:
|
||||
return
|
||||
|
||||
# TODO: there's no good way to get this value on sync.
|
||||
data_dir_root = os.path.join(
|
||||
context.settings_dir, DEFAULT_WORKSPACE_WORKING_FOLDER
|
||||
) # the local .var folder
|
||||
|
||||
# Just sync the whole base folder into the local pipelines dir
|
||||
sync_dir(fs, config.bucket_url, data_dir_root)
|
||||
|
||||
|
||||
def _get_runtime_artifacts_fs(
|
||||
section: str,
|
||||
) -> Tuple[fsspec.AbstractFileSystem, FilesystemConfiguration]:
|
||||
try:
|
||||
config = resolve_configuration(RuntimeArtifactsConfiguration(), sections=(section,))
|
||||
except ConfigurationException:
|
||||
logger.info(f"No artifact storage credentials found for {section}")
|
||||
return None, None
|
||||
|
||||
return fsspec_from_config(config.artifacts)[0], config.artifacts
|
||||
|
||||
|
||||
def _write_to_bucket(
|
||||
fs: fsspec.AbstractFileSystem,
|
||||
bucket_url: str,
|
||||
pipeline_name: str,
|
||||
paths: List[str],
|
||||
data: Union[str, bytes],
|
||||
mode: str = "w",
|
||||
) -> None:
|
||||
# write to bucket using the config, same object may be written to multiple paths
|
||||
|
||||
logger.info(f"Will send run artifact to {bucket_url}: {paths}")
|
||||
for path in paths:
|
||||
with fs.open(f"{bucket_url}/{pipeline_name}/{path}", mode=mode) as f:
|
||||
f.write(data)
|
||||
|
||||
|
||||
def _send_trace_to_bucket(
|
||||
fs: fsspec.AbstractFileSystem, bucket_url: str, trace: PipelineTrace, pipeline: SupportsPipeline
|
||||
) -> None:
|
||||
"""
|
||||
Send the full trace pickled to the runtime bucket
|
||||
"""
|
||||
pickled_trace = pickle.dumps(trace)
|
||||
_write_to_bucket(
|
||||
fs,
|
||||
bucket_url,
|
||||
pipeline.pipeline_name,
|
||||
[
|
||||
"trace.pickle",
|
||||
], # save current and by start time
|
||||
pickled_trace,
|
||||
mode="wb",
|
||||
)
|
||||
|
||||
|
||||
def _send_state_to_bucket(
|
||||
fs: fsspec.AbstractFileSystem, bucket_url: str, pipeline: SupportsPipeline
|
||||
) -> None:
|
||||
encoded_state = json_encode_state(pipeline.state)
|
||||
_write_to_bucket(
|
||||
fs,
|
||||
bucket_url,
|
||||
pipeline.pipeline_name,
|
||||
[
|
||||
"state.json",
|
||||
], # save current and by start time
|
||||
encoded_state,
|
||||
mode="w",
|
||||
)
|
||||
|
||||
|
||||
def _send_schemas_to_bucket(
|
||||
fs: fsspec.AbstractFileSystem, bucket_url: str, pipeline: SupportsPipeline
|
||||
) -> None:
|
||||
schema_dir = os.path.join(pipeline.working_dir, "schemas")
|
||||
for schema_file in os.listdir(schema_dir):
|
||||
_write_to_bucket(
|
||||
fs,
|
||||
bucket_url,
|
||||
pipeline.pipeline_name,
|
||||
[f"schemas/{schema_file}"],
|
||||
open(os.path.join(schema_dir, schema_file), "rb").read(),
|
||||
mode="wb",
|
||||
)
|
||||
|
||||
|
||||
def on_start_trace(trace: PipelineTrace, step: TPipelineStep, pipeline: SupportsPipeline) -> None:
|
||||
pass
|
||||
|
||||
|
||||
def on_start_trace_step(
|
||||
trace: PipelineTrace, step: TPipelineStep, pipeline: SupportsPipeline
|
||||
) -> None:
|
||||
pass
|
||||
|
||||
|
||||
def on_end_trace_step(
|
||||
trace: PipelineTrace,
|
||||
step: PipelineStepTrace,
|
||||
pipeline: SupportsPipeline,
|
||||
step_info: Any,
|
||||
send_state: bool,
|
||||
) -> None:
|
||||
pass
|
||||
|
||||
|
||||
def on_end_trace(trace: PipelineTrace, pipeline: SupportsPipeline, send_state: bool) -> None:
|
||||
# skip if runtime not running
|
||||
if pipeline.run_context.runtime_config.run_id is None:
|
||||
return
|
||||
|
||||
fs, config = _get_runtime_artifacts_fs(section="send")
|
||||
if fs:
|
||||
logger.info(
|
||||
f"Sending run artifacts from pipeline `{pipeline.pipeline_name}` to"
|
||||
f" `{config.bucket_url}`"
|
||||
)
|
||||
try:
|
||||
_send_trace_to_bucket(fs, config.bucket_url, trace, pipeline)
|
||||
_send_state_to_bucket(fs, config.bucket_url, pipeline)
|
||||
_send_schemas_to_bucket(fs, config.bucket_url, pipeline)
|
||||
except Exception:
|
||||
logger.exception(
|
||||
f"Sending run artifacts from pipeline `{pipeline.pipeline_name}` to"
|
||||
f" `{config.bucket_url}`"
|
||||
)
|
||||
raise
|
||||
else:
|
||||
logger.info("Pipeline results reported to runtime")
|
||||
@@ -126,10 +126,23 @@ class ConfigFieldMissingException(KeyError, ConfigurationException):
|
||||
# print locations for config providers
|
||||
providers = Container()[PluggableRunContext].providers
|
||||
for provider in providers.providers:
|
||||
if provider.locations:
|
||||
locations = "\n".join([f"\t- {os.path.abspath(loc)}" for loc in provider.locations])
|
||||
if provider.present_locations:
|
||||
locations = "\n".join(
|
||||
[f"\t- {os.path.abspath(loc)}" for loc in provider.present_locations]
|
||||
)
|
||||
msg += f"Provider `{provider.name}` loaded values from locations:\n{locations}\n"
|
||||
|
||||
# inform on locations that were not found
|
||||
not_found_locations = set(provider.locations).difference(provider.present_locations)
|
||||
if not_found_locations:
|
||||
locations = "\n".join(
|
||||
[f"\t- {os.path.abspath(loc)}" for loc in not_found_locations]
|
||||
)
|
||||
msg += (
|
||||
f"Provider `{provider.name}` probed but not found the following"
|
||||
f" locations:\n{locations}\n"
|
||||
)
|
||||
|
||||
if provider.is_empty:
|
||||
msg += (
|
||||
f"WARNING: provider `{provider.name}` is empty. Locations (i.e., files) are"
|
||||
|
||||
@@ -51,9 +51,14 @@ class ConfigProvider(abc.ABC):
|
||||
|
||||
@property
|
||||
def locations(self) -> Sequence[str]:
|
||||
"""Returns a list of locations where secrets are stored, human readable"""
|
||||
"""Returns a all possible locations where secrets may be stored, human readable"""
|
||||
return []
|
||||
|
||||
@property
|
||||
def present_locations(self) -> Sequence[str]:
|
||||
"""Returns a list of locations that were present and contained secrets, human readable"""
|
||||
return self.locations
|
||||
|
||||
def __repr__(self) -> str:
|
||||
kwargs = {
|
||||
"is_empty": self.is_empty,
|
||||
|
||||
@@ -74,7 +74,8 @@ class SettingsTomlProvider(CustomLoaderDocProvider):
|
||||
self._toml_paths = self._resolve_toml_paths(
|
||||
file_name, [d for d in resolvable_dirs if d is not None]
|
||||
)
|
||||
|
||||
# read toml files and set present locations
|
||||
self._present_locations: List[str] = []
|
||||
self._config_toml = self._read_toml_files(name, file_name, self._toml_paths)
|
||||
|
||||
super().__init__(
|
||||
@@ -115,6 +116,10 @@ class SettingsTomlProvider(CustomLoaderDocProvider):
|
||||
def is_empty(self) -> bool:
|
||||
return len(self._config_toml.body) == 0 and super().is_empty
|
||||
|
||||
@property
|
||||
def present_locations(self) -> List[str]:
|
||||
return self._present_locations
|
||||
|
||||
def set_fragment(
|
||||
self, key: Optional[str], value_or_fragment: str, pipeline_name: str, *sections: str
|
||||
) -> None:
|
||||
@@ -207,6 +212,8 @@ class SettingsTomlProvider(CustomLoaderDocProvider):
|
||||
result_toml = loaded_toml
|
||||
else:
|
||||
result_toml = update_dict_nested(loaded_toml, result_toml)
|
||||
# store as present location
|
||||
self._present_locations.append(path)
|
||||
|
||||
# if nothing was found, try to load from google colab or streamlit
|
||||
if result_toml is None:
|
||||
|
||||
@@ -607,8 +607,8 @@ def _emit_placeholder_warning(
|
||||
"Most likely, this comes from `init`-command, which creates basic templates for "
|
||||
f"non-complex configs and secrets. The provider to adjust is {provider.name}"
|
||||
)
|
||||
if bool(provider.locations):
|
||||
locations = "\n".join([f"\t- {os.path.abspath(loc)}" for loc in provider.locations])
|
||||
if bool(provider.present_locations):
|
||||
locations = "\n".join([f"\t- {os.path.abspath(loc)}" for loc in provider.present_locations])
|
||||
msg += f" at one of these locations:\n{locations}"
|
||||
logger.warning(msg=msg)
|
||||
|
||||
|
||||
@@ -137,6 +137,10 @@ class RunContextBase(ABC):
|
||||
f"`{run_dir=:}` doesn't belong to module `{m_.__file__}` which seems unrelated."
|
||||
)
|
||||
|
||||
@abstractmethod
|
||||
def reset_config(self) -> None:
|
||||
"""Hook for contexts that store resolved configuration to reset it"""
|
||||
|
||||
|
||||
class ProfilesRunContext(RunContextBase):
|
||||
"""Adds profile support on run context. Note: runtime checkable protocols are slow on isinstance"""
|
||||
@@ -155,6 +159,10 @@ class ProfilesRunContext(RunContextBase):
|
||||
def available_profiles(self) -> List[str]:
|
||||
"""Returns available profiles"""
|
||||
|
||||
def configured_profiles(self) -> List[str]:
|
||||
"""Returns profiles with configurations or dlt entities, same as available by default"""
|
||||
return self.available_profiles()
|
||||
|
||||
@abstractmethod
|
||||
def switch_profile(self, new_profile: str) -> Self:
|
||||
"""Switches current profile and returns new run context"""
|
||||
@@ -206,7 +214,10 @@ class PluggableRunContext(ContainerInjectableContext):
|
||||
|
||||
def reload_providers(self) -> None:
|
||||
self.providers = ConfigProvidersContainer(self.context.initial_providers())
|
||||
# Re-add extras and re-initialize runtime so changes take effect
|
||||
self.providers.add_extras()
|
||||
# Invalidate any cached configuration on the context so it re-resolves using new providers
|
||||
self.context.reset_config()
|
||||
|
||||
def after_add(self) -> None:
|
||||
super().after_add()
|
||||
|
||||
@@ -33,6 +33,7 @@ class RuntimeConfiguration(BaseConfiguration):
|
||||
config_files_storage_path: str = "/run/config/"
|
||||
"""Platform connection"""
|
||||
dlthub_dsn: Optional[TSecretStrValue] = None
|
||||
run_id: Optional[str] = None
|
||||
http_show_error_body: bool = False
|
||||
"""Include HTTP response body in raised exceptions/logs. Default is False"""
|
||||
http_max_error_body_length: int = 8192
|
||||
|
||||
@@ -337,7 +337,12 @@ class LoadJob(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def exception(self) -> str:
|
||||
def failed_message(self) -> str:
|
||||
"""The error message in failed or retry states"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def exception(self) -> BaseException:
|
||||
"""The exception associated with failed or retry states"""
|
||||
pass
|
||||
|
||||
@@ -450,10 +455,12 @@ class RunnableLoadJob(LoadJob, ABC):
|
||||
"""Returns current state. Should poll external resource if necessary."""
|
||||
return self._state
|
||||
|
||||
def exception(self) -> str:
|
||||
"""The exception associated with failed or retry states"""
|
||||
def failed_message(self) -> str:
|
||||
return str(self._exception)
|
||||
|
||||
def exception(self) -> BaseException:
|
||||
return self._exception
|
||||
|
||||
|
||||
class FollowupJobRequest:
|
||||
"""Base class for follow up jobs that should be created"""
|
||||
|
||||
@@ -195,6 +195,14 @@ class UnsupportedDataType(DestinationTerminalException):
|
||||
super().__init__(msg)
|
||||
|
||||
|
||||
class WithJobError:
|
||||
"""A mixin for exceptions raised on failed jobs"""
|
||||
|
||||
load_id: str
|
||||
job_id: str
|
||||
failed_message: str
|
||||
|
||||
|
||||
class DestinationHasFailedJobs(DestinationTerminalException):
|
||||
def __init__(self, destination_name: str, load_id: str, failed_jobs: List[Any]) -> None:
|
||||
self.destination_name = destination_name
|
||||
|
||||
@@ -89,9 +89,9 @@ class LoadJobMetrics(NamedTuple):
|
||||
table_name: str
|
||||
started_at: datetime.datetime
|
||||
finished_at: Optional[datetime.datetime]
|
||||
state: Optional[str]
|
||||
state: str
|
||||
remote_url: Optional[str]
|
||||
retry_count: Optional[int] = 0
|
||||
retry_count: int = 0
|
||||
|
||||
|
||||
class LoadMetrics(StepMetrics):
|
||||
|
||||
@@ -432,11 +432,11 @@ class WithStepInfo(ABC, Generic[TStepMetrics, TStepInfo]):
|
||||
# metrics must be present
|
||||
metrics = self._load_id_metrics[load_id][-1]
|
||||
# update finished at
|
||||
assert metrics["finished_at"] is None
|
||||
assert self._current_load_id is not None
|
||||
if finished:
|
||||
metrics["finished_at"] = ensure_pendulum_datetime_utc(precise_time())
|
||||
self._current_load_id = None
|
||||
self._current_load_started = None
|
||||
self._current_load_id = None
|
||||
self._current_load_started = None
|
||||
|
||||
def _step_info_metrics(self, load_id: str) -> List[TStepMetrics]:
|
||||
return self._load_id_metrics[load_id]
|
||||
@@ -530,6 +530,10 @@ class SupportsPipeline(Protocol):
|
||||
collector: Collector
|
||||
"""A collector that tracks the progress of the pipeline"""
|
||||
|
||||
@property
|
||||
def has_pending_data(self) -> bool:
|
||||
""" "Tells if pipeline contains any pending packages"""
|
||||
|
||||
@property
|
||||
def state(self) -> TPipelineState:
|
||||
"""Returns dictionary with current pipeline state
|
||||
|
||||
@@ -6,6 +6,8 @@ from types import ModuleType
|
||||
from typing import Any, Dict, Iterator, List, Optional
|
||||
from urllib.parse import urlencode
|
||||
|
||||
from packaging.specifiers import SpecifierSet
|
||||
|
||||
from dlt.common import known_env
|
||||
from dlt.common.configuration.container import Container
|
||||
from dlt.common.configuration.providers import (
|
||||
@@ -81,6 +83,8 @@ class RunContext(RunContextBase):
|
||||
|
||||
@property
|
||||
def runtime_config(self) -> RuntimeConfiguration:
|
||||
if self._runtime_config is None:
|
||||
self.initialize_runtime()
|
||||
return self._runtime_config
|
||||
|
||||
@property
|
||||
@@ -114,6 +118,9 @@ class RunContext(RunContextBase):
|
||||
def unplug(self) -> None:
|
||||
pass
|
||||
|
||||
def reset_config(self) -> None:
|
||||
self._runtime_config = None
|
||||
|
||||
@property
|
||||
def name(self) -> str:
|
||||
return "dlt"
|
||||
@@ -233,6 +240,63 @@ def get_plugin_modules() -> List[str]:
|
||||
return plugin_modules
|
||||
|
||||
|
||||
def ensure_plugin_version_match(
|
||||
pkg_name: str,
|
||||
dlt_version: str,
|
||||
plugin_version: str,
|
||||
plugin_module_name: str,
|
||||
dlt_extra: str,
|
||||
dlt_version_specifier: Optional[SpecifierSet] = None,
|
||||
) -> None:
|
||||
"""Ensures that installed plugin version matches dlt requirements. Plugins are tightly bound
|
||||
to `dlt` and released together.
|
||||
|
||||
If `dlt_version_specifier` is provided, it is used to check if the plugin version satisfies
|
||||
the specifier. Otherwise, the specifier is read from dlt's package metadata (Requires-Dist).
|
||||
If specifier cannot be determined, the function returns without checking.
|
||||
|
||||
Args:
|
||||
pkg_name: Name of the plugin package (e.g., "dlthub")
|
||||
dlt_version: The installed dlt version string
|
||||
plugin_version: The installed plugin version string
|
||||
plugin_module_name: The module name for MissingDependencyException (e.g., "dlthub")
|
||||
dlt_extra: The dlt extra to install the plugin (e.g., "hub")
|
||||
dlt_version_specifier: Optional version specifier for the plugin. If not provided,
|
||||
reads from dlt's package metadata.
|
||||
|
||||
Raises:
|
||||
MissingDependencyException: If version mismatch is detected
|
||||
"""
|
||||
# Get specifier from dlt's package metadata if not provided
|
||||
if dlt_version_specifier is None:
|
||||
from dlt.version import get_dependency_requirement
|
||||
|
||||
req = get_dependency_requirement(pkg_name)
|
||||
if req is not None:
|
||||
dlt_version_specifier = req.specifier
|
||||
|
||||
# If specifier still not available, exit without checking
|
||||
if dlt_version_specifier is None or len(dlt_version_specifier) == 0:
|
||||
return
|
||||
|
||||
# Use specifier.contains() for proper version check (allowing prereleases)
|
||||
if not dlt_version_specifier.contains(plugin_version, prereleases=True):
|
||||
from dlt.common.exceptions import MissingDependencyException
|
||||
|
||||
custom_msg = (
|
||||
f"`{pkg_name}` is a `dlt` plugin and must satisfy version requirement "
|
||||
f"`{dlt_version_specifier}` but you have {plugin_version}. "
|
||||
f"Please install the right version of {pkg_name} with:\n\n"
|
||||
f'pip install "dlt[{dlt_extra}]=={dlt_version}"\n\n'
|
||||
"or if you are upgrading the plugin:\n\n"
|
||||
f'pip install "dlt[{dlt_extra}]=={dlt_version}" -U {pkg_name}'
|
||||
)
|
||||
missing_dep_ex = MissingDependencyException(plugin_module_name, [])
|
||||
missing_dep_ex.args = (custom_msg,)
|
||||
missing_dep_ex.msg = custom_msg
|
||||
raise missing_dep_ex
|
||||
|
||||
|
||||
def context_uri(name: str, run_dir: str, runtime_kwargs: Optional[Dict[str, Any]]) -> str:
|
||||
from dlt.common.storages.configuration import FilesystemConfiguration
|
||||
|
||||
|
||||
@@ -50,7 +50,7 @@ def _signal_receiver(sig: int, frame: FrameType) -> None:
|
||||
sig_desc = f"Signal {sig}"
|
||||
msg = (
|
||||
f"{sig_desc} received. Trying to shut down gracefully. It may take time to drain"
|
||||
f" job pools. Send {sig_desc} again to force stop."
|
||||
f" job pools. Send {sig_desc} again to force stop.\n"
|
||||
)
|
||||
try:
|
||||
os.write(sys.stderr.fileno(), msg.encode(encoding="utf-8"))
|
||||
@@ -87,7 +87,13 @@ def set_received_signal(sig: int) -> None:
|
||||
def raise_if_signalled() -> None:
|
||||
"""Raises `SignalReceivedException` if signal was received."""
|
||||
if was_signal_received():
|
||||
raise SignalReceivedException(_received_signal)
|
||||
raise exception_for_signal()
|
||||
|
||||
|
||||
def exception_for_signal() -> BaseException:
|
||||
if not was_signal_received():
|
||||
raise RuntimeError("no signal received")
|
||||
return SignalReceivedException(_received_signal)
|
||||
|
||||
|
||||
def was_signal_received() -> bool:
|
||||
|
||||
@@ -182,6 +182,7 @@ class DataValidationError(SchemaException):
|
||||
and table_schema
|
||||
and hasattr(table_schema, "get")
|
||||
):
|
||||
# TODO: use get_columns_names_with_prop!
|
||||
identifier_columns = [
|
||||
x.get("name")
|
||||
for x in table_schema.get("columns", {}).values()
|
||||
|
||||
@@ -108,11 +108,8 @@ def migrate_schema(schema_dict: DictStrAny, from_engine: int, to_engine: int) ->
|
||||
if from_engine == 6 and to_engine > 6:
|
||||
# migrate from sealed properties to schema evolution settings
|
||||
schema_dict["settings"].pop("schema_sealed", None)
|
||||
schema_dict["settings"]["schema_contract"] = {}
|
||||
for table in schema_dict["tables"].values():
|
||||
table.pop("table_sealed", None)
|
||||
if not table.get("parent"):
|
||||
table["schema_contract"] = {}
|
||||
from_engine = 7
|
||||
if from_engine == 7 and to_engine > 7:
|
||||
schema_dict["previous_hashes"] = []
|
||||
|
||||
@@ -101,6 +101,12 @@ class LoadPackageNotFound(LoadStorageException, FileNotFoundError):
|
||||
super().__init__(f"Package with `{load_id=:}` could not be found")
|
||||
|
||||
|
||||
class LoadPackageCancelled(LoadStorageException):
|
||||
def __init__(self, load_id: str) -> None:
|
||||
self.load_id = load_id
|
||||
super().__init__(f"Package with `{load_id=:}` is cancelled")
|
||||
|
||||
|
||||
class LoadPackageAlreadyCompleted(LoadStorageException):
|
||||
def __init__(self, load_id: str) -> None:
|
||||
self.load_id = load_id
|
||||
|
||||
@@ -113,6 +113,27 @@ class FileStorage:
|
||||
return FileStorage.open_zipsafe_ro(self.make_full_path(relative_path), mode)
|
||||
return open(self.make_full_path(relative_path), mode, encoding=encoding_for_mode(mode))
|
||||
|
||||
def touch_file(self, relative_path: str) -> None:
|
||||
"""Touch file, assumes single writer"""
|
||||
file_path = self.make_full_path(relative_path)
|
||||
try:
|
||||
os.utime(file_path, None)
|
||||
return
|
||||
except OSError as ex:
|
||||
if isinstance(ex, FileNotFoundError):
|
||||
# File does not exist, create it
|
||||
flags = os.O_CREAT | os.O_EXCL | os.O_WRONLY
|
||||
fd = None
|
||||
try:
|
||||
fd = os.open(file_path, flags, 0o666)
|
||||
return
|
||||
finally:
|
||||
if fd is not None:
|
||||
os.close(fd)
|
||||
else:
|
||||
# utime does not work
|
||||
pass
|
||||
|
||||
# def open_temp(self, delete: bool = False, mode: str = "w", file_type: str = None) -> IO[Any]:
|
||||
# mode = mode + file_type or self.file_type
|
||||
# return tempfile.NamedTemporaryFile(
|
||||
|
||||
@@ -65,10 +65,16 @@ MTIME_DISPATCH = {
|
||||
"az": lambda f: ensure_pendulum_datetime_utc(f["last_modified"]),
|
||||
"gcs": lambda f: ensure_pendulum_datetime_utc(f["updated"]),
|
||||
"https": lambda f: cast(
|
||||
pendulum.DateTime, pendulum.parse(f["Last-Modified"], exact=True, strict=False)
|
||||
pendulum.DateTime,
|
||||
pendulum.parse(
|
||||
f.get("Last-Modified", pendulum.now().isoformat()), exact=True, strict=False
|
||||
),
|
||||
),
|
||||
"http": lambda f: cast(
|
||||
pendulum.DateTime, pendulum.parse(f["Last-Modified"], exact=True, strict=False)
|
||||
pendulum.DateTime,
|
||||
pendulum.parse(
|
||||
f.get("Last-Modified", pendulum.now().isoformat()), exact=True, strict=False
|
||||
),
|
||||
),
|
||||
"file": lambda f: ensure_pendulum_datetime_utc(f["mtime"]),
|
||||
"memory": lambda f: ensure_pendulum_datetime_utc(f["created"]),
|
||||
|
||||
@@ -38,6 +38,7 @@ from dlt.common.schema.typing import TStoredSchema, TTableSchemaColumns, TTableS
|
||||
from dlt.common.storages import FileStorage
|
||||
from dlt.common.storages.exceptions import (
|
||||
LoadPackageAlreadyCompleted,
|
||||
LoadPackageCancelled,
|
||||
LoadPackageNotCompleted,
|
||||
LoadPackageNotFound,
|
||||
CurrentLoadPackageStateNotAvailable,
|
||||
@@ -333,6 +334,7 @@ class PackageStorage:
|
||||
LOAD_PACKAGE_STATE_FILE_NAME = ( # internal state of the load package, will not be synced to the destination
|
||||
"load_package_state.json"
|
||||
)
|
||||
CANCEL_PACKAGE_FILE_NAME = "_cancelled"
|
||||
|
||||
def __init__(self, storage: FileStorage, initial_state: TLoadPackageStatus) -> None:
|
||||
"""Creates storage that manages load packages with root at `storage` and initial package state `initial_state`"""
|
||||
@@ -484,7 +486,9 @@ class PackageStorage:
|
||||
# Create and drop entities
|
||||
#
|
||||
|
||||
def create_package(self, load_id: str, initial_state: TLoadPackageState = None) -> None:
|
||||
def create_package(
|
||||
self, load_id: str, initial_state: TLoadPackageState = None, schema: Schema = None
|
||||
) -> None:
|
||||
self.storage.create_folder(load_id)
|
||||
# create processing directories
|
||||
self.storage.create_folder(os.path.join(load_id, PackageStorage.NEW_JOBS_FOLDER))
|
||||
@@ -501,6 +505,8 @@ class PackageStorage:
|
||||
created_at = precise_time()
|
||||
state["created_at"] = pendulum.from_timestamp(created_at)
|
||||
self.save_load_package_state(load_id, state)
|
||||
if schema:
|
||||
self.save_schema(load_id, schema)
|
||||
|
||||
def complete_loading_package(self, load_id: str, load_state: TLoadPackageStatus) -> str:
|
||||
"""Completes loading the package by writing marker file with`package_state. Returns path to the completed package"""
|
||||
@@ -551,9 +557,25 @@ class PackageStorage:
|
||||
) as f:
|
||||
json.dump(schema_update, f)
|
||||
|
||||
def cancel(self, load_id: str) -> None:
|
||||
"""Sets cancel flag currently used for inter-process signalling"""
|
||||
package_path = self.get_package_path(load_id)
|
||||
if not self.storage.has_folder(package_path):
|
||||
raise LoadPackageNotFound(load_id)
|
||||
self.storage.touch_file(os.path.join(package_path, self.CANCEL_PACKAGE_FILE_NAME))
|
||||
|
||||
def raise_if_cancelled(self, load_id: str) -> None:
|
||||
"""Raise an exception if package is cancelled"""
|
||||
package_path = self.get_package_path(load_id)
|
||||
if not self.storage.has_folder(package_path):
|
||||
raise LoadPackageNotFound(load_id)
|
||||
if self.storage.has_file(os.path.join(package_path, self.CANCEL_PACKAGE_FILE_NAME)):
|
||||
raise LoadPackageCancelled(load_id)
|
||||
|
||||
#
|
||||
# Loadpackage state
|
||||
# Load package state
|
||||
#
|
||||
|
||||
def get_load_package_state(self, load_id: str) -> TLoadPackageState:
|
||||
package_path = self.get_package_path(load_id)
|
||||
if not self.storage.has_folder(package_path):
|
||||
|
||||
@@ -92,6 +92,8 @@ class LoadStorage(VersionedStorage):
|
||||
self.new_packages.create_package(
|
||||
load_id, extract_package_storage.get_load_package_state(load_id)
|
||||
)
|
||||
# import schema
|
||||
self.new_packages.save_schema(load_id, extract_package_storage.load_schema(load_id))
|
||||
|
||||
def list_new_jobs(self, load_id: str) -> Sequence[str]:
|
||||
"""Lists all jobs in new jobs folder of normalized package storage and checks if file formats are supported"""
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import re
|
||||
from typing import TYPE_CHECKING, Any, BinaryIO, Literal
|
||||
from typing import TYPE_CHECKING, Any, BinaryIO, IO
|
||||
import os
|
||||
from pathlib import Path
|
||||
import sys
|
||||
@@ -131,33 +131,50 @@ def digest256_file_stream(stream: BinaryIO, chunk_size: int = 4096) -> str:
|
||||
return base64.b64encode(digest).decode("ascii")
|
||||
|
||||
|
||||
def digest256_tar_stream(stream: BinaryIO, chunk_size: int = 8192) -> str:
|
||||
"""Returns a base64 encoded sha3_256 hash of tar archive contents.
|
||||
def digest256_tar_stream(
|
||||
stream: IO[bytes],
|
||||
filter_file_names: Callable[[str], bool] = lambda x: True,
|
||||
chunk_size: int = 8192,
|
||||
) -> Tuple[str, List[str]]:
|
||||
"""Calculates hash and collects file names from tar archive in a single pass.
|
||||
|
||||
Hashes only filenames and file contents, ignoring timestamps and other metadata.
|
||||
Members are sorted by name before hashing, so tar member order doesn't affect
|
||||
the hash.
|
||||
Hashes only file names and file contents of filtered members, ignoring timestamps
|
||||
and other tar metadata. Members are sorted by name before hashing for consistency.
|
||||
Operates entirely in-memory to prevent leakage of sensitive data.
|
||||
|
||||
Note: This function operates entirely in-memory using tar.extractfile() which reads
|
||||
from the archive stream. No files are written to disk, preventing leakage of sensitive
|
||||
data that may be contained in the archive.
|
||||
Args:
|
||||
stream: Binary stream containing the tar archive
|
||||
filter_file_names: Callable that returns True for members to include in hash
|
||||
and file names list. Default includes all members. Use this to exclude
|
||||
metadata files (e.g., manifest.yaml) from the hash calculation.
|
||||
chunk_size: Size of chunks to read when hashing file contents. Default 8192.
|
||||
|
||||
Returns:
|
||||
tuple: (content_hash, file_names)
|
||||
"""
|
||||
stream.seek(0)
|
||||
hash_obj = hashlib.sha3_256()
|
||||
file_names = []
|
||||
|
||||
with tarfile.open(fileobj=stream, mode="r:*") as tar:
|
||||
members = sorted(tar.getmembers(), key=lambda m: m.name)
|
||||
|
||||
for member in members:
|
||||
if not filter_file_names(member.name):
|
||||
continue
|
||||
|
||||
hash_obj.update(member.name.encode())
|
||||
if member.isfile():
|
||||
file_names.append(member.name)
|
||||
f = tar.extractfile(member)
|
||||
if f:
|
||||
while chunk := f.read(chunk_size):
|
||||
hash_obj.update(chunk)
|
||||
|
||||
digest = hash_obj.digest()
|
||||
return base64.b64encode(digest).decode("ascii")
|
||||
content_hash = base64.b64encode(digest).decode("ascii")
|
||||
|
||||
return content_hash, file_names
|
||||
|
||||
|
||||
def str2bool(v: str) -> bool:
|
||||
|
||||
@@ -128,7 +128,7 @@ class BigQueryLoadJob(RunnableLoadJob, HasFollowupJobs):
|
||||
)
|
||||
)
|
||||
|
||||
def exception(self) -> str:
|
||||
def failed_message(self) -> str:
|
||||
if self._bq_load_job:
|
||||
return json.dumps(
|
||||
{
|
||||
@@ -139,6 +139,11 @@ class BigQueryLoadJob(RunnableLoadJob, HasFollowupJobs):
|
||||
"job_id": self._bq_load_job.job_id,
|
||||
}
|
||||
)
|
||||
return super().failed_message()
|
||||
|
||||
def exception(self) -> BaseException:
|
||||
if self._bq_load_job:
|
||||
return self._bq_load_job.exception() # type: ignore[no-any-return]
|
||||
return super().exception()
|
||||
|
||||
@staticmethod
|
||||
|
||||
@@ -37,10 +37,12 @@ class FinalizedLoadJob(LoadJob):
|
||||
started_at: pendulum.DateTime = None,
|
||||
finished_at: pendulum.DateTime = None,
|
||||
status: TLoadJobState = "completed",
|
||||
exception: str = None,
|
||||
failed_message: str = None,
|
||||
exception: BaseException = None,
|
||||
) -> None:
|
||||
super().__init__(file_path)
|
||||
self._status = status
|
||||
self._failed_message = failed_message
|
||||
self._exception = exception
|
||||
self._started_at = started_at or pendulum.now()
|
||||
self._finished_at = finished_at or (
|
||||
@@ -58,19 +60,24 @@ class FinalizedLoadJob(LoadJob):
|
||||
finished_at: pendulum.DateTime = None,
|
||||
status: TLoadJobState = "completed",
|
||||
message: str = None,
|
||||
exception: BaseException = None,
|
||||
) -> "FinalizedLoadJob":
|
||||
return cls(
|
||||
file_path,
|
||||
started_at=started_at,
|
||||
finished_at=finished_at,
|
||||
status=status,
|
||||
exception=message,
|
||||
failed_message=message,
|
||||
exception=exception,
|
||||
)
|
||||
|
||||
def state(self) -> TLoadJobState:
|
||||
return self._status
|
||||
|
||||
def exception(self) -> str:
|
||||
def failed_message(self) -> str:
|
||||
return self._failed_message
|
||||
|
||||
def exception(self) -> BaseException:
|
||||
return self._exception
|
||||
|
||||
|
||||
|
||||
@@ -193,6 +193,7 @@ def data_to_sources(
|
||||
for resource in source.resources.extracted:
|
||||
apply_hint_args(resource)
|
||||
|
||||
# TODO: order source by schema so packages are extracted in order
|
||||
return sources
|
||||
|
||||
|
||||
|
||||
@@ -102,52 +102,6 @@ class HintsMeta:
|
||||
self.create_table_variant = create_table_variant
|
||||
|
||||
|
||||
class SqlModel:
|
||||
"""
|
||||
A SqlModel is a named tuple that contains a query and a dialect.
|
||||
It is used to represent a SQL query and the dialect to use for parsing it.
|
||||
"""
|
||||
|
||||
__slots__ = ("_query", "_dialect")
|
||||
|
||||
def __init__(self, query: str, dialect: Optional[str] = None) -> None:
|
||||
self._query = query
|
||||
self._dialect = dialect
|
||||
|
||||
def to_sql(self) -> str:
|
||||
return self._query
|
||||
|
||||
@property
|
||||
def query_dialect(self) -> str:
|
||||
return self._dialect
|
||||
|
||||
@classmethod
|
||||
def from_query_string(cls, query: str, dialect: Optional[str] = None) -> "SqlModel":
|
||||
"""
|
||||
Creates a SqlModel from a raw SQL query string using sqlglot.
|
||||
Ensures that the parsed query is an instance of sqlglot.exp.Select.
|
||||
|
||||
Args:
|
||||
query (str): The raw SQL query string.
|
||||
dialect (Optional[str]): The SQL dialect to use for parsing.
|
||||
|
||||
Returns:
|
||||
SqlModel: An instance of SqlModel with the normalized query and dialect.
|
||||
|
||||
Raises:
|
||||
ValueError: If the parsed query is not an instance of sqlglot.exp.Select.
|
||||
"""
|
||||
|
||||
parsed_query = sqlglot.parse_one(query, read=dialect)
|
||||
|
||||
# Ensure the parsed query is a SELECT statement
|
||||
if not isinstance(parsed_query, sqlglot.exp.Select):
|
||||
raise ValueError("Only SELECT statements are allowed to create a `SqlModel`.")
|
||||
|
||||
normalized_query = parsed_query.sql(dialect=dialect)
|
||||
return cls(query=normalized_query, dialect=dialect)
|
||||
|
||||
|
||||
NATURAL_CALLABLES = ["incremental", "validator", "original_columns"]
|
||||
|
||||
|
||||
|
||||
@@ -199,6 +199,10 @@ class LimitItem(ItemTransform[TDataItem, Dict[str, Any]]):
|
||||
if item is None:
|
||||
return None
|
||||
|
||||
# do not return any late arriving items
|
||||
if self.exhausted:
|
||||
return None
|
||||
|
||||
if self.count_rows:
|
||||
self.count += count_rows_in_items(item)
|
||||
else:
|
||||
@@ -219,9 +223,6 @@ class LimitItem(ItemTransform[TDataItem, Dict[str, Any]]):
|
||||
# otherwise never return anything
|
||||
if self.max_items != 0:
|
||||
return item
|
||||
|
||||
# do not return any late arriving items
|
||||
if self.exhausted:
|
||||
return None
|
||||
|
||||
return item
|
||||
|
||||
@@ -11,7 +11,6 @@ from dlt.destinations.impl.athena.configuration import AthenaClientConfiguration
|
||||
from dlt.destinations.impl.duckdb.configuration import DuckDbClientConfiguration
|
||||
from dlt.destinations.impl.databricks.configuration import DatabricksClientConfiguration
|
||||
from dlt.destinations.impl.ducklake.configuration import DuckLakeClientConfiguration
|
||||
from dlt.destinations.impl.ducklake.ducklake import DuckLakeClient
|
||||
from dlt.destinations.impl.motherduck.configuration import MotherDuckClientConfiguration
|
||||
from dlt.destinations.impl.postgres.configuration import PostgresClientConfiguration
|
||||
from dlt.destinations.impl.redshift.configuration import RedshiftClientConfiguration
|
||||
@@ -74,6 +73,8 @@ def create_ibis_backend(
|
||||
# move main connection ownership to ibis
|
||||
con = ibis.duckdb.from_connection(client.config.credentials.conn_pool.move_conn())
|
||||
elif issubclass(destination.spec, DuckLakeClientConfiguration):
|
||||
from dlt.destinations.impl.ducklake.ducklake import DuckLakeClient
|
||||
|
||||
assert isinstance(client, DuckLakeClient)
|
||||
# open connection but do not close it, ducklake always creates a separate connection
|
||||
# and will not close it in destructor
|
||||
|
||||
@@ -1,11 +1,39 @@
|
||||
"""A collection of dltHub Features"""
|
||||
from typing import Any
|
||||
|
||||
|
||||
__found__ = False
|
||||
__exception__ = None
|
||||
|
||||
|
||||
try:
|
||||
from dlthub import transformation, runner, data_quality
|
||||
from dlthub import transformation, runner
|
||||
from . import current
|
||||
from . import data_quality
|
||||
|
||||
__found__ = True
|
||||
__all__ = ("transformation", "current", "runner", "data_quality")
|
||||
except ImportError:
|
||||
pass
|
||||
except ImportError as import_exc:
|
||||
__exception__ = import_exc
|
||||
|
||||
|
||||
def __getattr__(name: str) -> Any:
|
||||
"""Provide useful info on missing attributes"""
|
||||
|
||||
# hub was found this is just regular missing attribute
|
||||
if __found__:
|
||||
raise AttributeError(f"module 'dlt.hub' has no attribute '{name}'")
|
||||
|
||||
from dlt.common.exceptions import MissingDependencyException
|
||||
|
||||
if isinstance(__exception__, MissingDependencyException):
|
||||
# plugins will MissingDependencyException if they are not installed with a right version
|
||||
# in that case just re-raise original message
|
||||
raise __exception__
|
||||
|
||||
raise MissingDependencyException(
|
||||
"dlt.hub",
|
||||
["dlt[hub]"],
|
||||
"This will install `dlthub` plugin package in with a matching "
|
||||
f"version.\nfrom:\n({str(__exception__)})",
|
||||
)
|
||||
|
||||
@@ -1,3 +1 @@
|
||||
"""A collection of dltHub Features"""
|
||||
|
||||
from dlthub.current import * # noqa
|
||||
|
||||
1
dlt/hub/data_quality.py
Normal file
1
dlt/hub/data_quality.py
Normal file
@@ -0,0 +1 @@
|
||||
from dlthub.data_quality import * # noqa
|
||||
@@ -2,19 +2,22 @@ from typing import Sequence
|
||||
from dlt.common.destination.exceptions import (
|
||||
DestinationTerminalException,
|
||||
DestinationTransientException,
|
||||
WithJobError,
|
||||
)
|
||||
|
||||
|
||||
class LoadClientJobException(Exception):
|
||||
load_id: str
|
||||
job_id: str
|
||||
class LoadClientJobException(Exception, WithJobError):
|
||||
client_exception: BaseException
|
||||
|
||||
|
||||
class LoadClientJobFailed(DestinationTerminalException, LoadClientJobException):
|
||||
def __init__(self, load_id: str, job_id: str, failed_message: str) -> None:
|
||||
def __init__(
|
||||
self, load_id: str, job_id: str, failed_message: str, exception: BaseException
|
||||
) -> None:
|
||||
self.load_id = load_id
|
||||
self.job_id = job_id
|
||||
self.failed_message = failed_message
|
||||
self.client_exception = exception
|
||||
super().__init__(
|
||||
f"Job with `{job_id=:}` and `{load_id=:}` failed terminally with message:"
|
||||
f" {failed_message}. The package is aborted and cannot be retried."
|
||||
@@ -23,17 +26,24 @@ class LoadClientJobFailed(DestinationTerminalException, LoadClientJobException):
|
||||
|
||||
class LoadClientJobRetry(DestinationTransientException, LoadClientJobException):
|
||||
def __init__(
|
||||
self, load_id: str, job_id: str, retry_count: int, max_retry_count: int, retry_message: str
|
||||
self,
|
||||
load_id: str,
|
||||
job_id: str,
|
||||
retry_count: int,
|
||||
max_retry_count: int,
|
||||
failed_message: str,
|
||||
exception: BaseException,
|
||||
) -> None:
|
||||
self.load_id = load_id
|
||||
self.job_id = job_id
|
||||
self.retry_count = retry_count
|
||||
self.max_retry_count = max_retry_count
|
||||
self.retry_message = retry_message
|
||||
self.failed_message = failed_message
|
||||
self.client_exception = exception
|
||||
super().__init__(
|
||||
f"Job with `{job_id=:}` had {retry_count} retries which is a multiple of"
|
||||
f" `{max_retry_count=:}`. Exiting retry loop. You can still rerun the load package to"
|
||||
f" retry this job. Last failure message was: {retry_message}"
|
||||
f" retry this job. Last failure message was: {failed_message}"
|
||||
)
|
||||
|
||||
|
||||
|
||||
@@ -201,13 +201,21 @@ class Load(Runnable[Executor], WithStepInfo[LoadMetrics, LoadInfo]):
|
||||
" extension could not be associated with job type and that indicates an error"
|
||||
" in the code."
|
||||
)
|
||||
except (TerminalException, AssertionError):
|
||||
except (TerminalException, AssertionError) as term_ex:
|
||||
job = FinalizedLoadJobWithFollowupJobs.from_file_path(
|
||||
file_path, started_at=started_at, status="failed", message=pretty_format_exception()
|
||||
file_path,
|
||||
started_at=started_at,
|
||||
status="failed",
|
||||
message=pretty_format_exception(),
|
||||
exception=term_ex,
|
||||
)
|
||||
except Exception:
|
||||
except Exception as retry_ex:
|
||||
job = FinalizedLoadJobWithFollowupJobs.from_file_path(
|
||||
file_path, started_at=started_at, status="retry", message=pretty_format_exception()
|
||||
file_path,
|
||||
started_at=started_at,
|
||||
status="retry",
|
||||
message=pretty_format_exception(),
|
||||
exception=retry_ex,
|
||||
)
|
||||
|
||||
# move to started jobs in case this is not a restored job
|
||||
@@ -427,7 +435,7 @@ class Load(Runnable[Executor], WithStepInfo[LoadMetrics, LoadInfo]):
|
||||
# create followup jobs
|
||||
self.create_followup_jobs(load_id, state, job, schema)
|
||||
# try to get exception message from job
|
||||
failed_message = job.exception()
|
||||
failed_message = job.failed_message()
|
||||
self.load_storage.normalized_packages.fail_job(
|
||||
load_id, job.file_name(), failed_message
|
||||
)
|
||||
@@ -441,11 +449,12 @@ class Load(Runnable[Executor], WithStepInfo[LoadMetrics, LoadInfo]):
|
||||
load_id,
|
||||
job.job_file_info().job_id(),
|
||||
failed_message,
|
||||
job.exception(),
|
||||
)
|
||||
finalized_jobs.append(job)
|
||||
elif state == "retry":
|
||||
# try to get exception message from job
|
||||
retry_message = job.exception()
|
||||
retry_message = job.failed_message()
|
||||
# move back to new folder to try again
|
||||
self.load_storage.normalized_packages.retry_job(load_id, job.file_name())
|
||||
logger.warning(
|
||||
@@ -460,7 +469,8 @@ class Load(Runnable[Executor], WithStepInfo[LoadMetrics, LoadInfo]):
|
||||
job.job_id(),
|
||||
r_c,
|
||||
self.config.raise_on_max_retries,
|
||||
retry_message=retry_message,
|
||||
failed_message=retry_message,
|
||||
exception=job.exception(),
|
||||
)
|
||||
elif state == "completed":
|
||||
# create followup jobs
|
||||
@@ -640,7 +650,8 @@ class Load(Runnable[Executor], WithStepInfo[LoadMetrics, LoadInfo]):
|
||||
f"Package {load_id} was not fully loaded. Load job pool is successfully drained"
|
||||
f" but {len(remaining_jobs)} new jobs are left in the package."
|
||||
)
|
||||
raise pending_exception
|
||||
# raise exception with continuous backtrace into client exception
|
||||
raise pending_exception from pending_exception.client_exception
|
||||
|
||||
# pool is drained
|
||||
if not remaining_jobs:
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
from typing import Any, List
|
||||
from typing import List
|
||||
|
||||
from dlt.common.exceptions import DltException
|
||||
from dlt.common.metrics import DataWriterMetrics
|
||||
from dlt.common.destination.exceptions import WithJobError
|
||||
|
||||
|
||||
class NormalizeException(DltException):
|
||||
@@ -7,9 +10,13 @@ class NormalizeException(DltException):
|
||||
super().__init__(msg)
|
||||
|
||||
|
||||
class NormalizeJobFailed(NormalizeException):
|
||||
class NormalizeJobFailed(NormalizeException, WithJobError):
|
||||
def __init__(
|
||||
self, load_id: str, job_id: str, failed_message: str, writer_metrics: List[Any]
|
||||
self,
|
||||
load_id: str,
|
||||
job_id: str,
|
||||
failed_message: str,
|
||||
writer_metrics: List[DataWriterMetrics],
|
||||
) -> None:
|
||||
self.load_id = load_id
|
||||
self.job_id = job_id
|
||||
|
||||
@@ -16,7 +16,7 @@ from dlt.common.json import custom_pua_decode, may_have_pua
|
||||
from dlt.common.metrics import DataWriterMetrics
|
||||
from dlt.common.normalizers.json.relational import DataItemNormalizer as RelationalNormalizer
|
||||
from dlt.common.normalizers.json.helpers import get_root_row_id_type
|
||||
from dlt.common.runtime import signals
|
||||
from dlt.common.schema import utils
|
||||
from dlt.common.schema.typing import (
|
||||
C_DLT_ID,
|
||||
C_DLT_LOAD_ID,
|
||||
@@ -37,6 +37,7 @@ from dlt.common.schema.utils import (
|
||||
)
|
||||
from dlt.common.schema import utils
|
||||
from dlt.common.schema.exceptions import CannotCoerceColumnException, CannotCoerceNullException
|
||||
from dlt.common.storages.load_storage import LoadStorage
|
||||
from dlt.common.time import normalize_timezone
|
||||
from dlt.common.utils import read_dialect_and_sql
|
||||
from dlt.common.storages import NormalizeStorage
|
||||
@@ -46,9 +47,8 @@ from dlt.common.typing import VARIANT_FIELD_FORMAT, DictStrAny, REPattern, StrAn
|
||||
from dlt.common.schema import TSchemaUpdate, Schema
|
||||
from dlt.common.exceptions import MissingDependencyException
|
||||
from dlt.common.normalizers.utils import generate_dlt_ids
|
||||
from dlt.extract.hints import SqlModel
|
||||
from dlt.normalize.exceptions import NormalizeException
|
||||
|
||||
from dlt.normalize.exceptions import NormalizeException
|
||||
from dlt.normalize.configuration import NormalizeConfiguration
|
||||
|
||||
try:
|
||||
@@ -62,22 +62,73 @@ except MissingDependencyException:
|
||||
DLT_SUBQUERY_NAME = "_dlt_subquery"
|
||||
|
||||
|
||||
class SqlModel:
|
||||
"""
|
||||
A SqlModel is a named tuple that contains a query and a dialect.
|
||||
It is used to represent a SQL query and the dialect to use for parsing it.
|
||||
"""
|
||||
|
||||
__slots__ = ("_query", "_dialect")
|
||||
|
||||
def __init__(self, query: str, dialect: Optional[str] = None) -> None:
|
||||
self._query = query
|
||||
self._dialect = dialect
|
||||
|
||||
def to_sql(self) -> str:
|
||||
return self._query
|
||||
|
||||
@property
|
||||
def query_dialect(self) -> str:
|
||||
return self._dialect
|
||||
|
||||
@classmethod
|
||||
def from_query_string(cls, query: str, dialect: Optional[str] = None) -> "SqlModel":
|
||||
"""
|
||||
Creates a SqlModel from a raw SQL query string using sqlglot.
|
||||
Ensures that the parsed query is an instance of sqlglot.exp.Select.
|
||||
|
||||
Args:
|
||||
query (str): The raw SQL query string.
|
||||
dialect (Optional[str]): The SQL dialect to use for parsing.
|
||||
|
||||
Returns:
|
||||
SqlModel: An instance of SqlModel with the normalized query and dialect.
|
||||
|
||||
Raises:
|
||||
ValueError: If the parsed query is not an instance of sqlglot.exp.Select.
|
||||
"""
|
||||
|
||||
parsed_query = sqlglot.parse_one(query, read=dialect)
|
||||
|
||||
# Ensure the parsed query is a SELECT statement
|
||||
if not isinstance(parsed_query, sqlglot.exp.Select):
|
||||
raise ValueError("Only SELECT statements are allowed to create a `SqlModel`.")
|
||||
|
||||
normalized_query = parsed_query.sql(dialect=dialect)
|
||||
return cls(query=normalized_query, dialect=dialect)
|
||||
|
||||
|
||||
class ItemsNormalizer:
|
||||
def __init__(
|
||||
self,
|
||||
item_storage: DataItemStorage,
|
||||
load_storage: LoadStorage,
|
||||
normalize_storage: NormalizeStorage,
|
||||
schema: Schema,
|
||||
load_id: str,
|
||||
config: NormalizeConfiguration,
|
||||
) -> None:
|
||||
self.item_storage = item_storage
|
||||
self.load_storage = load_storage
|
||||
self.normalize_storage = normalize_storage
|
||||
self.schema = schema
|
||||
self.load_id = load_id
|
||||
self.config = config
|
||||
self.naming = self.schema.naming
|
||||
|
||||
def _maybe_cancel(self) -> None:
|
||||
self.load_storage.new_packages.raise_if_cancelled(self.load_id)
|
||||
|
||||
@abstractmethod
|
||||
def __call__(self, extracted_items_file: str, root_table_name: str) -> List[TSchemaUpdate]: ...
|
||||
|
||||
@@ -317,6 +368,7 @@ class ModelItemsNormalizer(ItemsNormalizer):
|
||||
return outer_select, needs_reordering
|
||||
|
||||
def __call__(self, extracted_items_file: str, root_table_name: str) -> List[TSchemaUpdate]:
|
||||
self._maybe_cancel()
|
||||
with self.normalize_storage.extracted_packages.storage.open_file(
|
||||
extracted_items_file, "r"
|
||||
) as f:
|
||||
@@ -380,12 +432,13 @@ class JsonLItemsNormalizer(ItemsNormalizer):
|
||||
def __init__(
|
||||
self,
|
||||
item_storage: DataItemStorage,
|
||||
load_storage: LoadStorage,
|
||||
normalize_storage: NormalizeStorage,
|
||||
schema: Schema,
|
||||
load_id: str,
|
||||
config: NormalizeConfiguration,
|
||||
) -> None:
|
||||
super().__init__(item_storage, normalize_storage, schema, load_id, config)
|
||||
super().__init__(item_storage, load_storage, normalize_storage, schema, load_id, config)
|
||||
self._table_contracts: Dict[str, TSchemaContractDict] = {}
|
||||
self._filtered_tables: Set[str] = set()
|
||||
self._filtered_tables_columns: Dict[str, Dict[str, TSchemaEvolutionMode]] = {}
|
||||
@@ -522,11 +575,8 @@ class JsonLItemsNormalizer(ItemsNormalizer):
|
||||
)
|
||||
except StopIteration:
|
||||
pass
|
||||
# kill job if signalled
|
||||
signals.raise_if_signalled()
|
||||
|
||||
self._clean_seen_null_first_hint(schema_update)
|
||||
|
||||
return schema_update
|
||||
|
||||
def _clean_seen_null_first_hint(self, schema_update: TSchemaUpdate) -> None:
|
||||
@@ -874,6 +924,7 @@ class JsonLItemsNormalizer(ItemsNormalizer):
|
||||
extracted_items_file: str,
|
||||
root_table_name: str,
|
||||
) -> List[TSchemaUpdate]:
|
||||
self._maybe_cancel()
|
||||
schema_updates: List[TSchemaUpdate] = []
|
||||
with self.normalize_storage.extracted_packages.storage.open_file(
|
||||
extracted_items_file, "rb"
|
||||
@@ -881,6 +932,7 @@ class JsonLItemsNormalizer(ItemsNormalizer):
|
||||
# enumerate jsonl file line by line
|
||||
line: bytes = None
|
||||
for line_no, line in enumerate(f):
|
||||
self._maybe_cancel()
|
||||
items: List[TDataItem] = json.loadb(line)
|
||||
partial_update = self._normalize_chunk(
|
||||
root_table_name, items, may_have_pua(line), skip_write=False
|
||||
@@ -951,12 +1003,14 @@ class ArrowItemsNormalizer(ItemsNormalizer):
|
||||
# if we use adapter to convert arrow to dicts, then normalization is not necessary
|
||||
is_native_arrow_writer = not issubclass(self.item_storage.writer_cls, ArrowToObjectAdapter)
|
||||
should_normalize: bool = None
|
||||
self._maybe_cancel()
|
||||
with self.normalize_storage.extracted_packages.storage.open_file(
|
||||
extracted_items_file, "rb"
|
||||
) as f:
|
||||
for batch in pyarrow.pq_stream_with_new_columns(
|
||||
f, new_columns, row_groups_per_read=self.REWRITE_ROW_GROUPS
|
||||
):
|
||||
self._maybe_cancel()
|
||||
items_count += batch.num_rows
|
||||
# we may need to normalize
|
||||
if is_native_arrow_writer and should_normalize is None:
|
||||
@@ -993,6 +1047,7 @@ class ArrowItemsNormalizer(ItemsNormalizer):
|
||||
return [schema_update]
|
||||
|
||||
def __call__(self, extracted_items_file: str, root_table_name: str) -> List[TSchemaUpdate]:
|
||||
self._maybe_cancel()
|
||||
# read schema and counts from file metadata
|
||||
from dlt.common.libs.pyarrow import get_parquet_metadata
|
||||
|
||||
@@ -1041,6 +1096,7 @@ class ArrowItemsNormalizer(ItemsNormalizer):
|
||||
|
||||
class FileImportNormalizer(ItemsNormalizer):
|
||||
def __call__(self, extracted_items_file: str, root_table_name: str) -> List[TSchemaUpdate]:
|
||||
self._maybe_cancel()
|
||||
logger.info(
|
||||
f"Table {root_table_name} {self.item_storage.writer_spec.file_format} file"
|
||||
f" {extracted_items_file} will be directly imported without normalization"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
import itertools
|
||||
from typing import List, Dict, Sequence, Optional, Callable
|
||||
from typing import List, Dict, NamedTuple, Sequence, Optional, Callable
|
||||
from concurrent.futures import Future, Executor
|
||||
|
||||
from dlt.common import logger
|
||||
@@ -12,7 +12,7 @@ from dlt.common.data_writers.writers import EMPTY_DATA_WRITER_METRICS
|
||||
from dlt.common.runners import TRunMetrics, Runnable, NullExecutor
|
||||
from dlt.common.runtime import signals
|
||||
from dlt.common.runtime.collector import Collector, NULL_COLLECTOR
|
||||
from dlt.common.schema.typing import TStoredSchema, TTableSchema
|
||||
from dlt.common.schema.typing import TSchemaUpdate, TStoredSchema, TTableSchema
|
||||
from dlt.common.schema.utils import (
|
||||
merge_schema_updates,
|
||||
has_seen_null_first_hint,
|
||||
@@ -41,12 +41,24 @@ from dlt.normalize.worker import w_normalize_files, group_worker_files, TWorkerR
|
||||
from dlt.normalize.validate import validate_and_update_schema, verify_normalized_table
|
||||
|
||||
|
||||
class SubmitRV(NamedTuple):
|
||||
schema_updates: List[TSchemaUpdate]
|
||||
file_metrics: List[DataWriterMetrics]
|
||||
pending_exc: BaseException
|
||||
|
||||
|
||||
# normalize worker wrapping function signature
|
||||
TMapFuncType = Callable[
|
||||
[Schema, str, Sequence[str]], TWorkerRV
|
||||
[Schema, str, Sequence[str]], SubmitRV
|
||||
] # input parameters: (schema name, load_id, list of files to process)
|
||||
|
||||
|
||||
def remove_files_from_metrics(file_metrics: List[DataWriterMetrics]) -> None:
|
||||
"""Deletes files in a list of metrics"""
|
||||
for metrics in file_metrics:
|
||||
os.remove(metrics.file_path)
|
||||
|
||||
|
||||
class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo]):
|
||||
pool: Executor
|
||||
|
||||
@@ -84,8 +96,10 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
config=self.config._load_storage_config,
|
||||
)
|
||||
|
||||
def map_parallel(self, schema: Schema, load_id: str, files: Sequence[str]) -> TWorkerRV:
|
||||
def map_parallel(self, schema: Schema, load_id: str, files: Sequence[str]) -> SubmitRV:
|
||||
workers: int = getattr(self.pool, "_max_workers", 1)
|
||||
# group files to process into as many groups as there are workers. prefer to send same tables
|
||||
# to the same worker
|
||||
chunk_files = group_worker_files(files, workers)
|
||||
schema_dict: TStoredSchema = schema.to_dict()
|
||||
param_chunk = [
|
||||
@@ -103,6 +117,8 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
summary = TWorkerRV([], [])
|
||||
# push all tasks to queue
|
||||
tasks = [(self.pool.submit(w_normalize_files, *params), params) for params in param_chunk]
|
||||
pending_exc: BaseException = None
|
||||
logger.info(f"Filled {len(tasks)} out of {len(files)} files")
|
||||
|
||||
while len(tasks) > 0:
|
||||
sleep(0.3)
|
||||
@@ -110,58 +126,78 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
for task in list(tasks):
|
||||
pending, params = task
|
||||
if pending.done():
|
||||
# collect metrics from the exception (if any)
|
||||
if isinstance(pending.exception(), NormalizeJobFailed):
|
||||
summary.file_metrics.extend(pending.exception().writer_metrics) # type: ignore[attr-defined]
|
||||
# Exception in task (if any) is raised here
|
||||
result: TWorkerRV = pending.result()
|
||||
try:
|
||||
# gather schema from all manifests, validate consistency and combine
|
||||
validate_and_update_schema(schema, result[0])
|
||||
summary.schema_updates.extend(result.schema_updates)
|
||||
summary.file_metrics.extend(result.file_metrics)
|
||||
# update metrics
|
||||
self.collector.update("Files", len(result.file_metrics))
|
||||
self.collector.update(
|
||||
"Items", sum(result.file_metrics, EMPTY_DATA_WRITER_METRICS).items_count
|
||||
)
|
||||
except CannotCoerceColumnException as exc:
|
||||
# schema conflicts resulting from parallel executing
|
||||
logger.warning(
|
||||
f"Parallel schema update conflict, retrying task ({str(exc)}"
|
||||
)
|
||||
# delete all files produced by the task
|
||||
for metrics in result.file_metrics:
|
||||
os.remove(metrics.file_path)
|
||||
# schedule the task again
|
||||
schema_dict = schema.to_dict()
|
||||
# TODO: it's time for a named tuple
|
||||
params = params[:3] + (schema_dict,) + params[4:]
|
||||
retry_pending: Future[TWorkerRV] = self.pool.submit(
|
||||
w_normalize_files, *params
|
||||
)
|
||||
tasks.append((retry_pending, params))
|
||||
exc = pending.exception()
|
||||
if exc is not None:
|
||||
# collect metrics from NormalizeJobFailed (if any), then cancel others and propagate
|
||||
if isinstance(exc, NormalizeJobFailed):
|
||||
summary.file_metrics.extend(exc.writer_metrics)
|
||||
logger.warning("Received exception from worker: %s" % str(exc))
|
||||
if not pending_exc:
|
||||
# store to raise when pool is drained
|
||||
pending_exc = exc
|
||||
# cancel workers on any error
|
||||
logger.warning(f"Cancelling package {load_id}")
|
||||
self.load_storage.new_packages.cancel(load_id)
|
||||
else:
|
||||
result: TWorkerRV = pending.result()
|
||||
try:
|
||||
# gather schema from all manifests, validate consistency and combine
|
||||
validate_and_update_schema(schema, result[0])
|
||||
summary.schema_updates.extend(result.schema_updates)
|
||||
summary.file_metrics.extend(result.file_metrics)
|
||||
# update metrics
|
||||
self.collector.update("Files", len(result.file_metrics))
|
||||
self.collector.update(
|
||||
"Items",
|
||||
sum(result.file_metrics, EMPTY_DATA_WRITER_METRICS).items_count,
|
||||
)
|
||||
except CannotCoerceColumnException as exc:
|
||||
# schema conflicts resulting from parallel executing
|
||||
logger.warning(
|
||||
f"Parallel schema update conflict, retrying task ({str(exc)}"
|
||||
)
|
||||
# delete all files produced by the task
|
||||
remove_files_from_metrics(result.file_metrics)
|
||||
# schedule the task again with the schema updated by other workers
|
||||
schema_dict = schema.to_dict()
|
||||
# TODO: it's time for a named tuple
|
||||
params = params[:3] + (schema_dict,) + params[4:]
|
||||
retry_pending: Future[TWorkerRV] = self.pool.submit(
|
||||
w_normalize_files, *params
|
||||
)
|
||||
tasks.append((retry_pending, params))
|
||||
# remove finished tasks
|
||||
tasks.remove(task)
|
||||
logger.debug(f"{len(tasks)} tasks still remaining for {load_id}...")
|
||||
logger.debug(f"{len(tasks)} tasks still remaining for {load_id}...")
|
||||
# raise on signal
|
||||
if signals.was_signal_received() and not pending_exc:
|
||||
pending_exc = signals.exception_for_signal()
|
||||
logger.warning(f"Cancelling package {load_id} due to signal")
|
||||
self.load_storage.new_packages.cancel(load_id)
|
||||
|
||||
return summary
|
||||
return SubmitRV(summary.schema_updates, summary.file_metrics, pending_exc)
|
||||
|
||||
def map_single(self, schema: Schema, load_id: str, files: Sequence[str]) -> TWorkerRV:
|
||||
result = w_normalize_files(
|
||||
self.config,
|
||||
self.normalize_storage.config,
|
||||
self.load_storage.config,
|
||||
schema.to_dict(),
|
||||
load_id,
|
||||
files,
|
||||
)
|
||||
validate_and_update_schema(schema, result.schema_updates)
|
||||
self.collector.update("Files", len(result.file_metrics))
|
||||
self.collector.update(
|
||||
"Items", sum(result.file_metrics, EMPTY_DATA_WRITER_METRICS).items_count
|
||||
)
|
||||
return result
|
||||
def map_single(self, schema: Schema, load_id: str, files: Sequence[str]) -> SubmitRV:
|
||||
pending_exc: Exception = None
|
||||
try:
|
||||
result = w_normalize_files(
|
||||
self.config,
|
||||
self.normalize_storage.config,
|
||||
self.load_storage.config,
|
||||
schema.to_dict(),
|
||||
load_id,
|
||||
files,
|
||||
)
|
||||
validate_and_update_schema(schema, result.schema_updates)
|
||||
self.collector.update("Files", len(result.file_metrics))
|
||||
self.collector.update(
|
||||
"Items", sum(result.file_metrics, EMPTY_DATA_WRITER_METRICS).items_count
|
||||
)
|
||||
except NormalizeJobFailed as job_failed_ex:
|
||||
pending_exc = job_failed_ex
|
||||
result = TWorkerRV(None, job_failed_ex.writer_metrics)
|
||||
|
||||
return SubmitRV(result.schema_updates, result.file_metrics, pending_exc)
|
||||
|
||||
def clean_x_normalizer(
|
||||
self, load_id: str, table_name: str, table_schema: TTableSchema, path_separator: str
|
||||
@@ -197,7 +233,7 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
self, load_id: str, schema: Schema, map_f: TMapFuncType, files: Sequence[str]
|
||||
) -> None:
|
||||
# process files in parallel or in single thread, depending on map_f
|
||||
schema_updates, writer_metrics = map_f(schema, load_id, files)
|
||||
schema_updates, writer_metrics, pending_exc = map_f(schema, load_id, files)
|
||||
# compute metrics
|
||||
job_metrics = {ParsedLoadJobFileName.parse(m.file_path): m for m in writer_metrics}
|
||||
table_metrics: Dict[str, DataWriterMetrics] = {
|
||||
@@ -206,6 +242,19 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
job_metrics.items(), lambda pair: pair[0].table_name
|
||||
)
|
||||
}
|
||||
self._step_info_update_metrics(
|
||||
load_id,
|
||||
{
|
||||
"started_at": None,
|
||||
"finished_at": None,
|
||||
"job_metrics": {job.job_id(): metrics for job, metrics in job_metrics.items()},
|
||||
"table_metrics": table_metrics,
|
||||
},
|
||||
)
|
||||
# raise pending exception after computing metrics
|
||||
if pending_exc:
|
||||
raise pending_exc
|
||||
|
||||
# update normalizer specific info
|
||||
for table_name in table_metrics:
|
||||
table = schema.tables[table_name]
|
||||
@@ -238,15 +287,6 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
self.normalize_storage.extracted_packages.delete_package(load_id)
|
||||
# log and update metrics
|
||||
logger.info(f"Extracted package {load_id} processed")
|
||||
self._step_info_update_metrics(
|
||||
load_id,
|
||||
{
|
||||
"started_at": None,
|
||||
"finished_at": None,
|
||||
"job_metrics": {job.job_id(): metrics for job, metrics in job_metrics.items()},
|
||||
"table_metrics": table_metrics,
|
||||
},
|
||||
)
|
||||
self._step_info_complete_load_id(load_id)
|
||||
|
||||
def spool_schema_files(self, load_id: str, schema: Schema, files: Sequence[str]) -> str:
|
||||
@@ -256,7 +296,7 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
self.load_storage.import_extracted_package(
|
||||
load_id, self.normalize_storage.extracted_packages
|
||||
)
|
||||
logger.info(f"Created new load package {load_id} on loading volume with ")
|
||||
logger.info(f"Created new load package {load_id} on loading volume with {len(files)} files")
|
||||
# get number of workers with default == 1 if not set (ie. NullExecutor)
|
||||
workers: int = getattr(self.pool, "_max_workers", 1)
|
||||
map_f: TMapFuncType = self.map_parallel if workers > 1 else self.map_single
|
||||
@@ -321,7 +361,13 @@ class Normalize(Runnable[Executor], WithStepInfo[NormalizeMetrics, NormalizeInfo
|
||||
try:
|
||||
return self.load_storage.get_load_package_info(load_id)
|
||||
except LoadPackageNotFound:
|
||||
return self.normalize_storage.extracted_packages.get_load_package_info(load_id)
|
||||
# combine new extracted package and new load package that will be discarded
|
||||
new_package = self.load_storage.new_packages.get_load_package_info(load_id)
|
||||
extracted_package = self.normalize_storage.extracted_packages.get_load_package_info(
|
||||
load_id
|
||||
)
|
||||
extracted_package.jobs["completed_jobs"] = new_package.jobs["new_jobs"]
|
||||
return extracted_package
|
||||
|
||||
def get_step_info(
|
||||
self,
|
||||
|
||||
@@ -186,6 +186,7 @@ def w_normalize_files(
|
||||
|
||||
norm = item_normalizers[normalizer_key] = cls(
|
||||
item_storage,
|
||||
load_storage,
|
||||
normalize_storage,
|
||||
schema,
|
||||
load_id,
|
||||
|
||||
@@ -1,6 +1,9 @@
|
||||
from typing import Any, Dict, Union, Literal
|
||||
|
||||
from dlt.common.exceptions import PipelineException
|
||||
from dlt.common.pipeline import StepInfo, StepMetrics, SupportsPipeline
|
||||
from dlt.common.pipeline import LoadInfo, NormalizeInfo, StepInfo, StepMetrics, SupportsPipeline
|
||||
|
||||
from dlt.common.storages.load_package import PackageStorage
|
||||
from dlt.pipeline.typing import TPipelineStep
|
||||
|
||||
|
||||
@@ -58,13 +61,46 @@ class PipelineStepFailed(PipelineException):
|
||||
self.load_id = load_id
|
||||
self.exception = exception
|
||||
self.step_info = step_info
|
||||
self.has_pending_data = pipeline.has_pending_data
|
||||
self.is_package_partially_loaded = False
|
||||
|
||||
package_str = f" when processing package with `{load_id=:}`" if load_id else ""
|
||||
super().__init__(
|
||||
pipeline.pipeline_name,
|
||||
msg = (
|
||||
f"Pipeline execution failed at `{step=:}`{package_str} with"
|
||||
f" exception:\n\n{type(exception)}\n{exception}",
|
||||
f" exception:\n\n{type(exception)}\n{exception}"
|
||||
)
|
||||
if isinstance(step_info, (NormalizeInfo, LoadInfo)):
|
||||
if self.has_pending_data:
|
||||
msg += (
|
||||
"\n\nPending packages are left in the pipeline and will be re-tried on the"
|
||||
" next pipeline run."
|
||||
" If you pass new data to extract to next run, it will be ignored. Run "
|
||||
f"`dlt pipeline {pipeline.pipeline_name} info` for more information or `dlt"
|
||||
f" pipeline {pipeline.pipeline_name} drop-pending-packages` to drop pending"
|
||||
" packages."
|
||||
)
|
||||
if load_id and step_info and load_id in step_info.loads_ids and step == "load":
|
||||
# get package info
|
||||
package_info = next(
|
||||
(p for p in step_info.load_packages if p.load_id == load_id), None
|
||||
)
|
||||
if package_info:
|
||||
self.is_package_partially_loaded = PackageStorage.is_package_partially_loaded(
|
||||
package_info
|
||||
)
|
||||
if self.is_package_partially_loaded:
|
||||
msg += (
|
||||
f"\nWARNING: package `{load_id}` is partially loaded. Data in"
|
||||
" destination could be modified by one of completed load jobs while"
|
||||
" others were not yet executed or were retried. Data in the"
|
||||
" destination may be in inconsistent state. We recommend that you"
|
||||
" retry the load or review the incident before dropping pending"
|
||||
" packages. See"
|
||||
" https://dlthub.com/docs/running-in-production/running#partially-loaded-packages"
|
||||
" for details"
|
||||
)
|
||||
|
||||
super().__init__(pipeline.pipeline_name, msg)
|
||||
|
||||
def attrs(self) -> Dict[str, Any]:
|
||||
# remove attr that should not be published
|
||||
|
||||
@@ -25,7 +25,6 @@ from dlt.common.json import json
|
||||
from dlt.common.pendulum import pendulum
|
||||
from dlt.common.exceptions import ValueErrorWithKnownValues
|
||||
from dlt.common.configuration import inject_section, known_sections
|
||||
from dlt.common.configuration.specs import RuntimeConfiguration
|
||||
from dlt.common.configuration.container import Container
|
||||
from dlt.common.configuration.exceptions import (
|
||||
ContextDefaultCannotBeCreated,
|
||||
@@ -35,6 +34,7 @@ from dlt.common.destination.exceptions import (
|
||||
DestinationIncompatibleLoaderFileFormatException,
|
||||
DestinationNoStagingMode,
|
||||
DestinationUndefinedEntity,
|
||||
WithJobError,
|
||||
)
|
||||
from dlt.common.runtime import signals
|
||||
from dlt.common.schema.typing import (
|
||||
@@ -539,11 +539,15 @@ class Pipeline(SupportsPipeline):
|
||||
runner.run_pool(normalize_step.config, normalize_step)
|
||||
return self._get_step_info(normalize_step)
|
||||
except (Exception, KeyboardInterrupt) as n_ex:
|
||||
if isinstance(n_ex, WithJobError):
|
||||
err_load_id = n_ex.load_id
|
||||
else:
|
||||
err_load_id = normalize_step.current_load_id
|
||||
step_info = self._get_step_info(normalize_step)
|
||||
raise PipelineStepFailed(
|
||||
self,
|
||||
"normalize",
|
||||
normalize_step.current_load_id,
|
||||
err_load_id,
|
||||
n_ex,
|
||||
step_info,
|
||||
) from n_ex
|
||||
@@ -600,10 +604,12 @@ class Pipeline(SupportsPipeline):
|
||||
self._update_last_run_context()
|
||||
return info
|
||||
except (Exception, KeyboardInterrupt) as l_ex:
|
||||
if isinstance(l_ex, WithJobError):
|
||||
err_load_id = l_ex.load_id
|
||||
else:
|
||||
err_load_id = load_step.current_load_id
|
||||
step_info = self._get_step_info(load_step)
|
||||
raise PipelineStepFailed(
|
||||
self, "load", load_step.current_load_id, l_ex, step_info
|
||||
) from l_ex
|
||||
raise PipelineStepFailed(self, "load", err_load_id, l_ex, step_info) from l_ex
|
||||
|
||||
@with_runtime_trace()
|
||||
@with_config_section(("run",))
|
||||
@@ -708,18 +714,20 @@ class Pipeline(SupportsPipeline):
|
||||
self._sync_destination(destination, staging, dataset_name)
|
||||
# sync only once
|
||||
self._state_restored = True
|
||||
# normalize and load pending data
|
||||
if self.list_extracted_load_packages():
|
||||
self.normalize()
|
||||
if self.list_normalized_load_packages():
|
||||
# if there were any pending loads, load them and **exit**
|
||||
|
||||
if self.has_pending_data:
|
||||
if data is not None:
|
||||
logger.warn(
|
||||
"The pipeline `run` method will now load the pending load packages. The data"
|
||||
" you passed to the run function will not be loaded. In order to do that you"
|
||||
" you passed to the run function will not be extracted. In order to do that you"
|
||||
" must run the pipeline again"
|
||||
)
|
||||
return self.load(destination, dataset_name, credentials=credentials)
|
||||
# normalize and load pending data
|
||||
if self.list_extracted_load_packages():
|
||||
self.normalize()
|
||||
if self.list_normalized_load_packages():
|
||||
# if there were any pending loads, load them and **exit**
|
||||
return self.load(destination, dataset_name, credentials=credentials)
|
||||
|
||||
# extract from the source
|
||||
if data is not None:
|
||||
@@ -1197,10 +1205,9 @@ class Pipeline(SupportsPipeline):
|
||||
return NormalizeStorage(True, self._normalize_storage_config())
|
||||
|
||||
def _get_load_storage(self) -> LoadStorage:
|
||||
caps = self._get_destination_capabilities()
|
||||
return LoadStorage(
|
||||
True,
|
||||
caps.supported_loader_file_formats,
|
||||
[],
|
||||
self._load_storage_config(),
|
||||
)
|
||||
|
||||
|
||||
@@ -347,6 +347,11 @@ def load_trace(trace_dir: str, ignore_errors: bool = True) -> PipelineTrace:
|
||||
return None
|
||||
|
||||
|
||||
def get_trace_file_path(pipelines_dir: str, pipeline_name: str) -> str:
|
||||
"""Get the path to the pickle file for a pipeline"""
|
||||
return os.path.join(pipelines_dir, pipeline_name, TRACE_FILE_NAME)
|
||||
|
||||
|
||||
def get_exception_traces(exc: BaseException, container: Container = None) -> List[ExceptionTrace]:
|
||||
"""Gets exception trace chain and extend it with data available in Container context"""
|
||||
traces = get_exception_trace_chain(exc)
|
||||
|
||||
@@ -846,6 +846,9 @@ class JSONResponseCursorPaginator(BaseReferencePaginator):
|
||||
cursor_path: jsonpath.TJsonPath = "cursors.next",
|
||||
cursor_param: Optional[str] = None,
|
||||
cursor_body_path: Optional[str] = None,
|
||||
*,
|
||||
stop_after_empty_page: bool = False,
|
||||
has_more_path: Optional[jsonpath.TJsonPath] = None,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
@@ -854,6 +857,10 @@ class JSONResponseCursorPaginator(BaseReferencePaginator):
|
||||
cursor_param: The name of the query parameter to be used in
|
||||
the request to get the next page.
|
||||
cursor_body_path: The dot-separated path where to place the cursor in the request body.
|
||||
stop_after_empty_page: Whether pagination should stop when
|
||||
a page contains no result items. Defaults to `False`.
|
||||
has_more_path: The JSON path to a boolean value in the response
|
||||
indicating whether there are more items to fetch.
|
||||
"""
|
||||
super().__init__()
|
||||
self.cursor_path = jsonpath.compile_path(cursor_path)
|
||||
@@ -869,12 +876,48 @@ class JSONResponseCursorPaginator(BaseReferencePaginator):
|
||||
|
||||
self.cursor_param = cursor_param
|
||||
self.cursor_body_path = cursor_body_path
|
||||
self.stop_after_empty_page = stop_after_empty_page
|
||||
self.has_more_path = jsonpath.compile_path(has_more_path) if has_more_path else None
|
||||
|
||||
def update_state(self, response: Response, data: Optional[List[Any]] = None) -> None:
|
||||
"""Extracts the cursor value from the JSON response."""
|
||||
values = jsonpath.find_values(self.cursor_path, response.json())
|
||||
response_json = response.json()
|
||||
values = jsonpath.find_values(self.cursor_path, response_json)
|
||||
self._next_reference = values[0] if values and values[0] else None
|
||||
|
||||
if self.stop_after_empty_page and not data:
|
||||
self._has_next_page = False
|
||||
return
|
||||
|
||||
has_more = None
|
||||
if self.has_more_path:
|
||||
values = jsonpath.find_values(self.has_more_path, response_json)
|
||||
has_more = values[0] if values else None
|
||||
if has_more is None:
|
||||
self._handle_missing_has_more(response_json)
|
||||
elif isinstance(has_more, str):
|
||||
try:
|
||||
has_more = str2bool(has_more)
|
||||
except ValueError:
|
||||
self._handle_invalid_has_more(has_more)
|
||||
elif not isinstance(has_more, bool):
|
||||
self._handle_invalid_has_more(has_more)
|
||||
|
||||
self._has_next_page = has_more
|
||||
|
||||
def _handle_invalid_has_more(self, has_more: Any) -> None:
|
||||
raise ValueError(
|
||||
f"'{self.has_more_path}' is not a `bool` in the response in"
|
||||
f" `{self.__class__.__name__}`. Expected a boolean, got `{has_more}`"
|
||||
)
|
||||
|
||||
def _handle_missing_has_more(self, response_json: Dict[str, Any]) -> None:
|
||||
raise ValueError(
|
||||
f"Has more value not found in the response in `{self.__class__.__name__}`. "
|
||||
f"Expected a response with a `{self.has_more_path}` key, got"
|
||||
f" `{response_json}`."
|
||||
)
|
||||
|
||||
def update_request(self, request: Request) -> None:
|
||||
"""Updates the request with the cursor value either in query parameters
|
||||
or in the request JSON body."""
|
||||
|
||||
@@ -76,7 +76,9 @@ class OffsetPaginatorConfig(PaginatorTypeConfig, total=False):
|
||||
limit: int
|
||||
offset: Optional[int]
|
||||
offset_param: Optional[str]
|
||||
offset_body_path: Optional[str]
|
||||
limit_param: Optional[str]
|
||||
limit_body_path: Optional[str]
|
||||
total_path: Optional[jsonpath.TJsonPath]
|
||||
maximum_offset: Optional[int]
|
||||
stop_after_empty_page: Optional[bool]
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
from importlib.metadata import version as pkg_version, distribution as pkg_distribution
|
||||
from typing import Optional
|
||||
from urllib.request import url2pathname
|
||||
from urllib.parse import urlparse
|
||||
from packaging.requirements import Requirement
|
||||
|
||||
DLT_IMPORT_NAME = "dlt"
|
||||
PKG_NAME = DLT_PKG_NAME = "dlt"
|
||||
@@ -30,3 +32,19 @@ def get_installed_requirement_string(
|
||||
else:
|
||||
package_requirement = f"{package}{ver_selector}{pkg_version(package)}"
|
||||
return package_requirement
|
||||
|
||||
|
||||
def get_dependency_requirement(
|
||||
dependency_name: str, package: str = DLT_PKG_NAME
|
||||
) -> Optional[Requirement]:
|
||||
"""Find a specific dependency requirement from package metadata"""
|
||||
dist = pkg_distribution(package)
|
||||
|
||||
if dist.requires is None:
|
||||
return None
|
||||
|
||||
for req_str in dist.requires:
|
||||
req = Requirement(req_str)
|
||||
if req.name == dependency_name:
|
||||
return req
|
||||
return None
|
||||
|
||||
@@ -13,9 +13,30 @@ EXAMPLES_DIR = "./examples"
|
||||
# settings
|
||||
SKIP_FOLDERS = ["archive", ".", "_", "local_cache"]
|
||||
# @pytest.mark.rfam
|
||||
SKIP_EXAMPLES: List[str] = ["backfill_in_chunks", "connector_x_arrow", "transformers"]
|
||||
SKIP_EXAMPLES: List[str] = [
|
||||
"backfill_in_chunks",
|
||||
"connector_x_arrow",
|
||||
"transformers",
|
||||
]
|
||||
# Examples will be skipped from forked subprocesses
|
||||
SKIP_FORK_EXAMPLES: List[str] = ["custom_destination_lancedb"]
|
||||
|
||||
# Examples that require external secrets (cloud credentials, API keys, etc.)
|
||||
# These will be skipped when running on fork PRs where secrets are not available
|
||||
EXAMPLES_REQUIRING_SECRETS: List[str] = [
|
||||
"chess",
|
||||
"chess_production",
|
||||
"custom_destination_bigquery",
|
||||
"custom_destination_lancedb",
|
||||
"custom_naming",
|
||||
"google_sheets",
|
||||
"incremental_loading",
|
||||
"nested_data",
|
||||
"pdf_to_weaviate",
|
||||
"postgres_to_postgres",
|
||||
"qdrant_zendesk",
|
||||
]
|
||||
|
||||
|
||||
# the entry point for the script
|
||||
MAIN_CLAUSE = 'if __name__ == "__main__":'
|
||||
@@ -40,7 +61,11 @@ def main() -> None:
|
||||
# get args
|
||||
args = parser.parse_args()
|
||||
|
||||
# Check if CI is running on a fork pull request
|
||||
is_fork = os.environ.get("IS_FORK") == "true"
|
||||
|
||||
count = 0
|
||||
skipped_for_fork = 0
|
||||
for example in next(os.walk(EXAMPLES_DIR))[1]:
|
||||
# skip some
|
||||
if any(map(lambda skip: example.startswith(skip), SKIP_FOLDERS)):
|
||||
@@ -49,6 +74,12 @@ def main() -> None:
|
||||
if example in SKIP_EXAMPLES:
|
||||
continue
|
||||
|
||||
# Skip examples requiring secrets when running on fork PRs
|
||||
if is_fork and example in EXAMPLES_REQUIRING_SECRETS:
|
||||
skipped_for_fork += 1
|
||||
fmt.note(f"Skipping {example} (requires secrets, running on fork PR)")
|
||||
continue
|
||||
|
||||
count += 1
|
||||
example_file = f"{EXAMPLES_DIR}/{example}/{example}.py"
|
||||
test_example_file = f"{EXAMPLES_DIR}/{example}/test_{example}.py"
|
||||
@@ -89,4 +120,7 @@ def main() -> None:
|
||||
if args.clear:
|
||||
fmt.note("Cleared generated test files.")
|
||||
else:
|
||||
fmt.note(f"Prepared {count} examples for testing.")
|
||||
msg = f"Prepared {count} examples for testing."
|
||||
if skipped_for_fork > 0:
|
||||
msg += f" Skipped {skipped_for_fork} examples requiring secrets (fork PR)."
|
||||
fmt.note(msg)
|
||||
|
||||
@@ -7,7 +7,7 @@ requires-python = ">=3.10, <3.13" # databind not available over 3.10, we need t
|
||||
|
||||
# NOTE: working here is always dev enviroment, so we don't need a dev group
|
||||
dependencies = [
|
||||
"dlt[duckdb,postgres,bigquery,mssql,databricks,qdrant,sql_database,workspace,weaviate]",
|
||||
"dlt[duckdb,postgres,bigquery,mssql,databricks,qdrant,sql_database,workspace,weaviate,hub]",
|
||||
"docstring-parser>=0.11",
|
||||
"flake8>=7.0.0,<8",
|
||||
"modal>=1.2.1",
|
||||
|
||||
@@ -1,11 +1,14 @@
|
||||
.PHONY: install-dlthub, update-cli-docs, check-cli-docs
|
||||
.PHONY: update-cli-docs, check-cli-docs, dev
|
||||
# this must be run from `dlthub_cli` to see workspace commands
|
||||
# it will use dlthub and dlt-runtime versions from dlt/docs/pyproject.toml to generate docs
|
||||
|
||||
install-dlthub:
|
||||
uv pip install dlthub
|
||||
dev:
|
||||
uv sync
|
||||
|
||||
update-cli-docs: install-dlthub
|
||||
uv run dlt --debug render-docs ../../website/docs/hub/command-line-interface.md --commands license workspace profile
|
||||
update-cli-docs: dev
|
||||
# generate as there's no license
|
||||
RUNTIME__LICENSE="" uv run dlt --debug render-docs ../../website/docs/hub/command-line-interface.md --commands license workspace profile runtime
|
||||
|
||||
check-cli-docs: install-dlthub
|
||||
uv run dlt --debug render-docs ../../website/docs/hub/command-line-interface.md --compare --commands license workspace profile
|
||||
check-cli-docs: dev
|
||||
# generate as there's no license
|
||||
RUNTIME__LICENSE="" uv run dlt --debug render-docs ../../website/docs/hub/command-line-interface.md --compare --commands license workspace profile runtime
|
||||
|
||||
145
docs/uv.lock
generated
145
docs/uv.lock
generated
@@ -473,6 +473,18 @@ wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/08/d0/2af09c4077e0d357f33384e4d6fc2c34a3d33e473ae7f939a6c58769774d/connectorx-0.4.4-cp312-none-win_amd64.whl", hash = "sha256:dcf4fb9d1e94ebe0bb4b72a18aeba119895d2fa66b4fe69a8ece97942748c3b0", size = 34561589, upload-time = "2025-08-19T05:38:14.81Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "cron-descriptor"
|
||||
version = "2.0.6"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "typing-extensions" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/7c/31/0b21d1599656b2ffa6043e51ca01041cd1c0f6dacf5a3e2b620ed120e7d8/cron_descriptor-2.0.6.tar.gz", hash = "sha256:e39d2848e1d8913cfb6e3452e701b5eec662ee18bea8cc5aa53ee1a7bb217157", size = 49456, upload-time = "2025-09-03T16:30:22.434Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/21/cc/361326a54ad92e2e12845ad15e335a4e14b8953665007fb514d3393dfb0f/cron_descriptor-2.0.6-py3-none-any.whl", hash = "sha256:3a1c0d837c0e5a32e415f821b36cf758eb92d510e6beff8fbfe4fa16573d93d6", size = 74446, upload-time = "2025-09-03T16:30:21.397Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "cryptography"
|
||||
version = "46.0.3"
|
||||
@@ -822,7 +834,7 @@ wheels = [
|
||||
|
||||
[[package]]
|
||||
name = "dlt"
|
||||
version = "1.19.0"
|
||||
version = "1.20.0"
|
||||
source = { editable = "../" }
|
||||
dependencies = [
|
||||
{ name = "click" },
|
||||
@@ -868,6 +880,10 @@ databricks = [
|
||||
duckdb = [
|
||||
{ name = "duckdb" },
|
||||
]
|
||||
hub = [
|
||||
{ name = "dlt-runtime" },
|
||||
{ name = "dlthub" },
|
||||
]
|
||||
mssql = [
|
||||
{ name = "pyodbc" },
|
||||
]
|
||||
@@ -912,11 +928,13 @@ requires-dist = [
|
||||
{ name = "db-dtypes", marker = "extra == 'bigquery'", specifier = ">=1.2.0" },
|
||||
{ name = "db-dtypes", marker = "extra == 'gcp'", specifier = ">=1.2.0" },
|
||||
{ name = "deltalake", marker = "extra == 'deltalake'", specifier = ">=0.25.1" },
|
||||
{ name = "dlt-runtime", marker = "python_full_version >= '3.10' and extra == 'hub'", specifier = ">=0.20.0a0,<0.21" },
|
||||
{ name = "dlthub", marker = "python_full_version >= '3.10' and extra == 'hub'", specifier = ">=0.20.0a1,<0.21" },
|
||||
{ name = "duckdb", marker = "extra == 'duckdb'", specifier = ">=0.9" },
|
||||
{ name = "duckdb", marker = "extra == 'ducklake'", specifier = ">=1.2.0" },
|
||||
{ name = "duckdb", marker = "extra == 'motherduck'", specifier = ">=0.9" },
|
||||
{ name = "duckdb", marker = "extra == 'workspace'", specifier = ">=0.9" },
|
||||
{ name = "fsspec", specifier = ">=2025.9.0" },
|
||||
{ name = "fsspec", specifier = ">=2022.4.0" },
|
||||
{ name = "gcsfs", marker = "extra == 'bigquery'", specifier = ">=2022.4.0" },
|
||||
{ name = "gcsfs", marker = "extra == 'clickhouse'", specifier = ">=2022.4.0" },
|
||||
{ name = "gcsfs", marker = "extra == 'gcp'", specifier = ">=2022.4.0" },
|
||||
@@ -983,7 +1001,7 @@ requires-dist = [
|
||||
{ name = "sqlalchemy", marker = "extra == 'pyiceberg'", specifier = ">=1.4" },
|
||||
{ name = "sqlalchemy", marker = "extra == 'sql-database'", specifier = ">=1.4" },
|
||||
{ name = "sqlalchemy", marker = "extra == 'sqlalchemy'", specifier = ">=1.4" },
|
||||
{ name = "sqlglot", specifier = ">=25.4.0" },
|
||||
{ name = "sqlglot", specifier = ">=25.4.0,!=28.1" },
|
||||
{ name = "tantivy", marker = "extra == 'lancedb'", specifier = ">=0.22.0" },
|
||||
{ name = "tenacity", specifier = ">=8.0.2" },
|
||||
{ name = "tomlkit", specifier = ">=0.11.3" },
|
||||
@@ -992,7 +1010,7 @@ requires-dist = [
|
||||
{ name = "weaviate-client", marker = "extra == 'weaviate'", specifier = ">=3.26.7,<4.0.0" },
|
||||
{ name = "win-precise-time", marker = "python_full_version < '3.13' and os_name == 'nt'", specifier = ">=1.4.2" },
|
||||
]
|
||||
provides-extras = ["gcp", "bigquery", "postgres", "redshift", "parquet", "duckdb", "ducklake", "filesystem", "s3", "gs", "az", "sftp", "http", "snowflake", "motherduck", "cli", "athena", "weaviate", "mssql", "synapse", "qdrant", "databricks", "clickhouse", "dremio", "lancedb", "deltalake", "sql-database", "sqlalchemy", "pyiceberg", "postgis", "workspace", "dbml"]
|
||||
provides-extras = ["gcp", "bigquery", "postgres", "redshift", "parquet", "duckdb", "ducklake", "filesystem", "s3", "gs", "az", "sftp", "http", "snowflake", "motherduck", "cli", "athena", "weaviate", "mssql", "synapse", "qdrant", "databricks", "clickhouse", "dremio", "lancedb", "deltalake", "sql-database", "sqlalchemy", "pyiceberg", "postgis", "workspace", "hub", "dbml"]
|
||||
|
||||
[package.metadata.requires-dev]
|
||||
adbc = [
|
||||
@@ -1097,7 +1115,7 @@ dependencies = [
|
||||
{ name = "databind" },
|
||||
{ name = "dbt-core" },
|
||||
{ name = "dbt-duckdb" },
|
||||
{ name = "dlt", extra = ["bigquery", "databricks", "duckdb", "mssql", "postgres", "qdrant", "sql-database", "weaviate", "workspace"] },
|
||||
{ name = "dlt", extra = ["bigquery", "databricks", "duckdb", "hub", "mssql", "postgres", "qdrant", "sql-database", "weaviate", "workspace"] },
|
||||
{ name = "docstring-parser" },
|
||||
{ name = "flake8" },
|
||||
{ name = "google-api-python-client" },
|
||||
@@ -1136,7 +1154,7 @@ requires-dist = [
|
||||
{ name = "databind", specifier = ">=4.5.2" },
|
||||
{ name = "dbt-core", specifier = ">=1.5.0" },
|
||||
{ name = "dbt-duckdb", specifier = ">=1.5.0" },
|
||||
{ name = "dlt", extras = ["duckdb", "postgres", "bigquery", "mssql", "databricks", "qdrant", "sql-database", "workspace", "weaviate"], editable = "../" },
|
||||
{ name = "dlt", extras = ["duckdb", "postgres", "bigquery", "mssql", "databricks", "qdrant", "sql-database", "workspace", "weaviate", "hub"], editable = "../" },
|
||||
{ name = "docstring-parser", specifier = ">=0.11" },
|
||||
{ name = "flake8", specifier = ">=7.0.0,<8" },
|
||||
{ name = "google-api-python-client", specifier = ">=1.7.11" },
|
||||
@@ -1169,6 +1187,36 @@ requires-dist = [
|
||||
{ name = "weaviate-client", specifier = ">=3.26.7,<4.0.0" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "dlt-runtime"
|
||||
version = "0.20.0"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "attrs" },
|
||||
{ name = "cron-descriptor" },
|
||||
{ name = "httpx" },
|
||||
{ name = "pathspec" },
|
||||
{ name = "python-jose" },
|
||||
{ name = "tabulate" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/d0/86/d7f057d8bdf2f3ada28bf1277b7f24a7abbb221d72788bd682176126a75c/dlt_runtime-0.20.0.tar.gz", hash = "sha256:753c7522bc01c92a453459640e482f87b647b14cc5734d754133a91968acc79f", size = 49532, upload-time = "2025-12-09T14:32:33.708Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/4c/b0/02a6c846d89e3c27a592a929d95526036be1d607e48fca214dcbf3b7bf58/dlt_runtime-0.20.0-py3-none-any.whl", hash = "sha256:0969165672b2b3938a618ddd263e0cf8ec356d289253f58134e325e222753056", size = 119573, upload-time = "2025-12-09T14:32:32.119Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "dlthub"
|
||||
version = "0.20.1"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "python-jose" },
|
||||
{ name = "ruamel-yaml" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/77/1b/2c079f22243462e914026172094411ed7ef1fc96c8089e0ca66d1a14038a/dlthub-0.20.1.tar.gz", hash = "sha256:7b3a188abc28601fd4bdf8f17e7925ef729d4f91fb67a6b4eb5c5dc5a04ac3a2", size = 158432, upload-time = "2025-12-09T15:18:10.813Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/21/94/b2a87853102c6aa08606b2708d8f678b1e39855e8227fe111e37c32631b6/dlthub-0.20.1-py3-none-any.whl", hash = "sha256:c4d4e0c4515cd68f316ccd02c9ecc007332c861ae6f92a488f7e961935e7f1a0", size = 209767, upload-time = "2025-12-09T15:18:09.067Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "dnspython"
|
||||
version = "2.8.0"
|
||||
@@ -1247,6 +1295,18 @@ wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/c0/21/08f10706d30252753349ec545833fc0cea67c11abd0b5223acf2827f1056/duckdb-1.4.1-cp312-cp312-win_amd64.whl", hash = "sha256:567f3b3a785a9e8650612461893c49ca799661d2345a6024dda48324ece89ded", size = 12336422, upload-time = "2025-10-07T10:36:57.521Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ecdsa"
|
||||
version = "0.19.1"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "six" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/c0/1f/924e3caae75f471eae4b26bd13b698f6af2c44279f67af317439c2f4c46a/ecdsa-0.19.1.tar.gz", hash = "sha256:478cba7b62555866fcb3bb3fe985e06decbdb68ef55713c4e5ab98c57d508e61", size = 201793, upload-time = "2025-03-13T11:52:43.25Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/cb/a3/460c57f094a4a165c84a1341c373b0a4f5ec6ac244b998d5021aade89b77/ecdsa-0.19.1-py2.py3-none-any.whl", hash = "sha256:30638e27cf77b7e15c4c4cc1973720149e1033827cfd00661ca5c8cc0cdb24c3", size = 150607, upload-time = "2025-03-13T11:52:41.757Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "et-xmlfile"
|
||||
version = "2.0.0"
|
||||
@@ -3825,6 +3885,20 @@ wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/14/1b/a298b06749107c305e1fe0f814c6c74aea7b2f1e10989cb30f544a1b3253/python_dotenv-1.2.1-py3-none-any.whl", hash = "sha256:b81ee9561e9ca4004139c6cbba3a238c32b03e4894671e181b671e8cb8425d61", size = 21230, upload-time = "2025-10-26T15:12:09.109Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "python-jose"
|
||||
version = "3.5.0"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "ecdsa" },
|
||||
{ name = "pyasn1" },
|
||||
{ name = "rsa" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/c6/77/3a1c9039db7124eb039772b935f2244fbb73fc8ee65b9acf2375da1c07bf/python_jose-3.5.0.tar.gz", hash = "sha256:fb4eaa44dbeb1c26dcc69e4bd7ec54a1cb8dd64d3b4d81ef08d90ff453f2b01b", size = 92726, upload-time = "2025-05-28T17:31:54.288Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/d9/c3/0bd11992072e6a1c513b16500a5d07f91a24017c5909b02c72c62d7ad024/python_jose-3.5.0-py2.py3-none-any.whl", hash = "sha256:abd1202f23d34dfad2c3d28cb8617b90acf34132c7afd60abd0b0b7d3cb55771", size = 34624, upload-time = "2025-05-28T17:31:52.802Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "python-multipart"
|
||||
version = "0.0.20"
|
||||
@@ -4145,6 +4219,56 @@ wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/64/8d/0133e4eb4beed9e425d9a98ed6e081a55d195481b7632472be1af08d2f6b/rsa-4.9.1-py3-none-any.whl", hash = "sha256:68635866661c6836b8d39430f97a996acbd61bfa49406748ea243539fe239762", size = 34696, upload-time = "2025-04-16T09:51:17.142Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ruamel-yaml"
|
||||
version = "0.18.16"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
dependencies = [
|
||||
{ name = "ruamel-yaml-clib", marker = "platform_python_implementation == 'CPython'" },
|
||||
]
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/9f/c7/ee630b29e04a672ecfc9b63227c87fd7a37eb67c1bf30fe95376437f897c/ruamel.yaml-0.18.16.tar.gz", hash = "sha256:a6e587512f3c998b2225d68aa1f35111c29fad14aed561a26e73fab729ec5e5a", size = 147269, upload-time = "2025-10-22T17:54:02.346Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/0f/73/bb1bc2529f852e7bf64a2dec885e89ff9f5cc7bbf6c9340eed30ff2c69c5/ruamel.yaml-0.18.16-py3-none-any.whl", hash = "sha256:048f26d64245bae57a4f9ef6feb5b552a386830ef7a826f235ffb804c59efbba", size = 119858, upload-time = "2025-10-22T17:53:59.012Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ruamel-yaml-clib"
|
||||
version = "0.2.15"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/ea/97/60fda20e2fb54b83a61ae14648b0817c8f5d84a3821e40bfbdae1437026a/ruamel_yaml_clib-0.2.15.tar.gz", hash = "sha256:46e4cc8c43ef6a94885f72512094e482114a8a706d3c555a34ed4b0d20200600", size = 225794, upload-time = "2025-11-16T16:12:59.761Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/f7/5a/4ab767cd42dcd65b83c323e1620d7c01ee60a52f4032fb7b61501f45f5c2/ruamel_yaml_clib-0.2.15-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:88eea8baf72f0ccf232c22124d122a7f26e8a24110a0273d9bcddcb0f7e1fa03", size = 147454, upload-time = "2025-11-16T16:13:02.54Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/40/44/184173ac1e74fd35d308108bcbf83904d6ef8439c70763189225a166b238/ruamel_yaml_clib-0.2.15-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:9b6f7d74d094d1f3a4e157278da97752f16ee230080ae331fcc219056ca54f77", size = 132467, upload-time = "2025-11-16T16:13:03.539Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/49/1b/2d2077a25fe682ae335007ca831aff42e3cbc93c14066675cf87a6c7fc3e/ruamel_yaml_clib-0.2.15-cp310-cp310-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:4be366220090d7c3424ac2b71c90d1044ea34fca8c0b88f250064fd06087e614", size = 693454, upload-time = "2025-11-16T20:22:41.083Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/90/16/e708059c4c429ad2e33be65507fc1730641e5f239fb2964efc1ba6edea94/ruamel_yaml_clib-0.2.15-cp310-cp310-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1f66f600833af58bea694d5892453f2270695b92200280ee8c625ec5a477eed3", size = 700345, upload-time = "2025-11-16T16:13:04.771Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/d9/79/0e8ef51df1f0950300541222e3332f20707a9c210b98f981422937d1278c/ruamel_yaml_clib-0.2.15-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:da3d6adadcf55a93c214d23941aef4abfd45652110aed6580e814152f385b862", size = 731306, upload-time = "2025-11-16T16:13:06.312Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/a6/f4/2cdb54b142987ddfbd01fc45ac6bd882695fbcedb9d8bbf796adc3fc3746/ruamel_yaml_clib-0.2.15-cp310-cp310-musllinux_1_2_aarch64.whl", hash = "sha256:e9fde97ecb7bb9c41261c2ce0da10323e9227555c674989f8d9eb7572fc2098d", size = 692415, upload-time = "2025-11-16T16:13:07.465Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/a0/07/40b5fc701cce8240a3e2d26488985d3bbdc446e9fe397c135528d412fea6/ruamel_yaml_clib-0.2.15-cp310-cp310-musllinux_1_2_i686.whl", hash = "sha256:05c70f7f86be6f7bee53794d80050a28ae7e13e4a0087c1839dcdefd68eb36b6", size = 705007, upload-time = "2025-11-16T20:22:42.856Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/82/19/309258a1df6192fb4a77ffa8eae3e8150e8d0ffa56c1b6fa92e450ba2740/ruamel_yaml_clib-0.2.15-cp310-cp310-musllinux_1_2_x86_64.whl", hash = "sha256:6f1d38cbe622039d111b69e9ca945e7e3efebb30ba998867908773183357f3ed", size = 723974, upload-time = "2025-11-16T16:13:08.72Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/67/3a/d6ee8263b521bfceb5cd2faeb904a15936480f2bb01c7ff74a14ec058ca4/ruamel_yaml_clib-0.2.15-cp310-cp310-win32.whl", hash = "sha256:fe239bdfdae2302e93bd6e8264bd9b71290218fff7084a9db250b55caaccf43f", size = 102836, upload-time = "2025-11-16T16:13:10.27Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/ed/03/92aeb5c69018387abc49a8bb4f83b54a0471d9ef48e403b24bac68f01381/ruamel_yaml_clib-0.2.15-cp310-cp310-win_amd64.whl", hash = "sha256:468858e5cbde0198337e6a2a78eda8c3fb148bdf4c6498eaf4bc9ba3f8e780bd", size = 121917, upload-time = "2025-11-16T16:13:12.145Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/2c/80/8ce7b9af532aa94dd83360f01ce4716264db73de6bc8efd22c32341f6658/ruamel_yaml_clib-0.2.15-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:c583229f336682b7212a43d2fa32c30e643d3076178fb9f7a6a14dde85a2d8bd", size = 147998, upload-time = "2025-11-16T16:13:13.241Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/53/09/de9d3f6b6701ced5f276d082ad0f980edf08ca67114523d1b9264cd5e2e0/ruamel_yaml_clib-0.2.15-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:56ea19c157ed8c74b6be51b5fa1c3aff6e289a041575f0556f66e5fb848bb137", size = 132743, upload-time = "2025-11-16T16:13:14.265Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/0e/f7/73a9b517571e214fe5c246698ff3ed232f1ef863c8ae1667486625ec688a/ruamel_yaml_clib-0.2.15-cp311-cp311-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:5fea0932358e18293407feb921d4f4457db837b67ec1837f87074667449f9401", size = 731459, upload-time = "2025-11-16T20:22:44.338Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/9b/a2/0dc0013169800f1c331a6f55b1282c1f4492a6d32660a0cf7b89e6684919/ruamel_yaml_clib-0.2.15-cp311-cp311-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:ef71831bd61fbdb7aa0399d5c4da06bea37107ab5c79ff884cc07f2450910262", size = 749289, upload-time = "2025-11-16T16:13:15.633Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/aa/ed/3fb20a1a96b8dc645d88c4072df481fe06e0289e4d528ebbdcc044ebc8b3/ruamel_yaml_clib-0.2.15-cp311-cp311-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:617d35dc765715fa86f8c3ccdae1e4229055832c452d4ec20856136acc75053f", size = 777630, upload-time = "2025-11-16T16:13:16.898Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/60/50/6842f4628bc98b7aa4733ab2378346e1441e150935ad3b9f3c3c429d9408/ruamel_yaml_clib-0.2.15-cp311-cp311-musllinux_1_2_aarch64.whl", hash = "sha256:1b45498cc81a4724a2d42273d6cfc243c0547ad7c6b87b4f774cb7bcc131c98d", size = 744368, upload-time = "2025-11-16T16:13:18.117Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/d3/b0/128ae8e19a7d794c2e36130a72b3bb650ce1dd13fb7def6cf10656437dcf/ruamel_yaml_clib-0.2.15-cp311-cp311-musllinux_1_2_i686.whl", hash = "sha256:def5663361f6771b18646620fca12968aae730132e104688766cf8a3b1d65922", size = 745233, upload-time = "2025-11-16T20:22:45.833Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/75/05/91130633602d6ba7ce3e07f8fc865b40d2a09efd4751c740df89eed5caf9/ruamel_yaml_clib-0.2.15-cp311-cp311-musllinux_1_2_x86_64.whl", hash = "sha256:014181cdec565c8745b7cbc4de3bf2cc8ced05183d986e6d1200168e5bb59490", size = 770963, upload-time = "2025-11-16T16:13:19.344Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/fd/4b/fd4542e7f33d7d1bc64cc9ac9ba574ce8cf145569d21f5f20133336cdc8c/ruamel_yaml_clib-0.2.15-cp311-cp311-win32.whl", hash = "sha256:d290eda8f6ada19e1771b54e5706b8f9807e6bb08e873900d5ba114ced13e02c", size = 102640, upload-time = "2025-11-16T16:13:20.498Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/bb/eb/00ff6032c19c7537371e3119287999570867a0eafb0154fccc80e74bf57a/ruamel_yaml_clib-0.2.15-cp311-cp311-win_amd64.whl", hash = "sha256:bdc06ad71173b915167702f55d0f3f027fc61abd975bd308a0968c02db4a4c3e", size = 121996, upload-time = "2025-11-16T16:13:21.855Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/72/4b/5fde11a0722d676e469d3d6f78c6a17591b9c7e0072ca359801c4bd17eee/ruamel_yaml_clib-0.2.15-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:cb15a2e2a90c8475df45c0949793af1ff413acfb0a716b8b94e488ea95ce7cff", size = 149088, upload-time = "2025-11-16T16:13:22.836Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/85/82/4d08ac65ecf0ef3b046421985e66301a242804eb9a62c93ca3437dc94ee0/ruamel_yaml_clib-0.2.15-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:64da03cbe93c1e91af133f5bec37fd24d0d4ba2418eaf970d7166b0a26a148a2", size = 134553, upload-time = "2025-11-16T16:13:24.151Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/b9/cb/22366d68b280e281a932403b76da7a988108287adff2bfa5ce881200107a/ruamel_yaml_clib-0.2.15-cp312-cp312-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:f6d3655e95a80325b84c4e14c080b2470fe4f33b6846f288379ce36154993fb1", size = 737468, upload-time = "2025-11-16T20:22:47.335Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/71/73/81230babf8c9e33770d43ed9056f603f6f5f9665aea4177a2c30ae48e3f3/ruamel_yaml_clib-0.2.15-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:71845d377c7a47afc6592aacfea738cc8a7e876d586dfba814501d8c53c1ba60", size = 753349, upload-time = "2025-11-16T16:13:26.269Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/61/62/150c841f24cda9e30f588ef396ed83f64cfdc13b92d2f925bb96df337ba9/ruamel_yaml_clib-0.2.15-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:11e5499db1ccbc7f4b41f0565e4f799d863ea720e01d3e99fa0b7b5fcd7802c9", size = 788211, upload-time = "2025-11-16T16:13:27.441Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/30/93/e79bd9cbecc3267499d9ead919bd61f7ddf55d793fb5ef2b1d7d92444f35/ruamel_yaml_clib-0.2.15-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:4b293a37dc97e2b1e8a1aec62792d1e52027087c8eea4fc7b5abd2bdafdd6642", size = 743203, upload-time = "2025-11-16T16:13:28.671Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/8d/06/1eb640065c3a27ce92d76157f8efddb184bd484ed2639b712396a20d6dce/ruamel_yaml_clib-0.2.15-cp312-cp312-musllinux_1_2_i686.whl", hash = "sha256:512571ad41bba04eac7268fe33f7f4742210ca26a81fe0c75357fa682636c690", size = 747292, upload-time = "2025-11-16T20:22:48.584Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/a5/21/ee353e882350beab65fcc47a91b6bdc512cace4358ee327af2962892ff16/ruamel_yaml_clib-0.2.15-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:e5e9f630c73a490b758bf14d859a39f375e6999aea5ddd2e2e9da89b9953486a", size = 771624, upload-time = "2025-11-16T16:13:29.853Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/57/34/cc1b94057aa867c963ecf9ea92ac59198ec2ee3a8d22a126af0b4d4be712/ruamel_yaml_clib-0.2.15-cp312-cp312-win32.whl", hash = "sha256:f4421ab780c37210a07d138e56dd4b51f8642187cdfb433eb687fe8c11de0144", size = 100342, upload-time = "2025-11-16T16:13:31.067Z" },
|
||||
{ url = "https://files.pythonhosted.org/packages/b3/e5/8925a4208f131b218f9a7e459c0d6fcac8324ae35da269cb437894576366/ruamel_yaml_clib-0.2.15-cp312-cp312-win_amd64.whl", hash = "sha256:2b216904750889133d9222b7b873c199d48ecbb12912aca78970f84a5aa1a4bc", size = 119013, upload-time = "2025-11-16T16:13:32.164Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ruff"
|
||||
version = "0.3.7"
|
||||
@@ -4415,6 +4539,15 @@ wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/f8/f9/ce041b9531022a0b5999a47e6da14485239f7bce9c595d1bfb387fe60e89/synchronicity-0.10.2-py3-none-any.whl", hash = "sha256:4ba1f8c02ca582ef068033300201e3c403e08d81e42553554f4e67b27f0d9bb1", size = 38766, upload-time = "2025-07-30T20:23:18.04Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "tabulate"
|
||||
version = "0.9.0"
|
||||
source = { registry = "https://pypi.org/simple" }
|
||||
sdist = { url = "https://files.pythonhosted.org/packages/ec/fe/802052aecb21e3797b8f7902564ab6ea0d60ff8ca23952079064155d1ae1/tabulate-0.9.0.tar.gz", hash = "sha256:0095b12bf5966de529c0feb1fa08671671b3368eec77d7ef7ab114be2c068b3c", size = 81090, upload-time = "2022-10-06T17:21:48.54Z" }
|
||||
wheels = [
|
||||
{ url = "https://files.pythonhosted.org/packages/40/44/4a5f08c96eb108af5cb50b41f76142f0afa346dfa99d5296fe7202a11854/tabulate-0.9.0-py3-none-any.whl", hash = "sha256:024ca478df22e9340661486f85298cff5f6dcdba14f3813e8830015b9ed1948f", size = 35252, upload-time = "2022-10-06T17:21:44.262Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "tenacity"
|
||||
version = "9.1.2"
|
||||
|
||||
@@ -1,74 +1,52 @@
|
||||
---
|
||||
title: Build pipelines and reports with LLMs
|
||||
description: How to extract and explore data from REST API with AI editors/agents
|
||||
title: REST API source in 10min
|
||||
description: Build a custom REST API connector in 10min
|
||||
keywords: [cursor, llm, restapi, ai]
|
||||
---
|
||||
|
||||
# Build dlt pipelines and reports with LLMs
|
||||
# REST API source in 10min
|
||||
|
||||
## Overview
|
||||
|
||||
This guide walks you through a collaborative AI-human workflow for extracting and exploring data from REST API sources using an AI editor/agent of your choice and dlt. It introduces the first workflow available in dltHub workspace — an LLM-native development environment for data engineering tasks.
|
||||
The Python library `dlt` provides a powerful [REST API toolkit](../../dlt-ecosystem/verified-sources/rest_api/basic.md) to ingest data. Combined with our [LLM scaffolds](https://dlthub.com/workspace) and [MCP server](../../hub/features/mcp-server.md), you can build a custom connector for any of the 8k+ available sources in 10 minutes by following this guide.
|
||||
|
||||
You will learn:
|
||||
1. How to initialize a dltHub workspace for your source using dltHub’s [LLM-context database](https://dlthub.com/workspace).
|
||||
2. How to build a REST API source in minutes with AI assistance.
|
||||
3. How to debug a pipeline and explore data using the workspace dashboard.
|
||||
4. How to start a new notebook and work with the pipeline’s dataset in it.
|
||||
Building with LLMs is an iterative process. We will follow this general workflow and give practical tips for each step.
|
||||
|
||||
## Prerequisites
|
||||
```mermaid
|
||||
stateDiagram-v2
|
||||
setup: setup workspace
|
||||
instructions: initial instructions
|
||||
codegen: generate code
|
||||
run: run pipeline
|
||||
context: manage context
|
||||
data: check data
|
||||
commit: commit working code
|
||||
|
||||
Have one of the following AI editors/agents installed:
|
||||
- [Cursor IDE](https://cursor.com/)
|
||||
- [Continue](https://www.continue.dev/)
|
||||
- [Cody](https://sourcegraph.com/cody)
|
||||
- [Claude](https://docs.anthropic.com/en/docs/claude-code/ide-integrations)
|
||||
- [Cline](https://cline.bot/)
|
||||
- [Codex](https://openai.com/codex/)
|
||||
- [Copilot](https://github.com/features/copilot)
|
||||
- [Amp](https://ampcode.com/)
|
||||
- [Windsurf](https://windsurf.com/)
|
||||
[*] --> setup: start
|
||||
setup --> instructions: workspace is ready
|
||||
instructions --> codegen: ask to ingest endpoint
|
||||
codegen --> run: code generated
|
||||
run --> context: fails
|
||||
run --> data: completes
|
||||
context --> codegen: context updated
|
||||
data --> context: is incorrect
|
||||
data --> commit: is correct
|
||||
commit --> instructions: add endpoint / refine config
|
||||
commit --> [*]
|
||||
```
|
||||
|
||||
## Concepts used in this guide
|
||||
:::note
|
||||
You will need an AI-enabled IDE or agent, such as Copilot, Claude Code, Cursor, Continue, etc.
|
||||
:::
|
||||
|
||||
Before diving into the workflow, here’s a quick overview of key terms you’ll encounter:
|
||||
|
||||
1. **dlt workspace** - An environment where all data engineering tasks, from writing code to maintenance in production, can be executed by a single developer:
|
||||
- Develop and test data pipelines locally
|
||||
- Run dlt pipelines, transformations, and notebooks with one command
|
||||
- Deliver live, production-ready reports with streamlined access to the dataset
|
||||
|
||||
We plan to support more functionality in the future, such as:
|
||||
- Deploy and run your data workflows in the cloud without any changes to code and schemas
|
||||
- Maintain pipelines with a Runtime Agent, customizable dashboards, and validation tests
|
||||
- Deploy live reports without worrying about schema drift or silent failures
|
||||
|
||||
2. **[Cursor](https://cursor.com/)** - An AI-powered code editor that lets you express tasks in natural language for an LLM agent to implement. Cursor is the first AI code editor we’ve integrated with, so the examples use Cursor, but the same workflow applies to Continue, Copilot, Cody, Windsurf, Cline, Claude, Amp, and Codex (only the UI/shortcuts differ).
|
||||
|
||||
3. **LLM-context** - A curated collection of prompts, rules, docs, and examples provided to an LLM for specific tasks. A rich context leads to more accurate, bug-free code generation. dltHub provides tailored [LLM-contexts for 1,000+ REST API sources](https://dlthub.com/workspace), so you can go from idea to working pipeline in under 10 minutes.
|
||||
|
||||
## Setup
|
||||
Before starting to build our connector, we need to initialize our [dltHub workspace](../../hub/workspace/overview.md) and configure our IDE.
|
||||
|
||||
### Setup your AI editor/agent
|
||||
|
||||
#### 1. Use the right model
|
||||
### Python dependencies
|
||||
|
||||
For best results, use newer models. For example, in Cursor we’ve found that Claude-4-sonnet performs best (available in the paid version). Older or weaker models often struggle with context comprehension and workflows.
|
||||
|
||||
#### 2. Add documentation
|
||||
|
||||
AI code editors let you upload documentation and code examples to provide additional context. The exact steps vary by tool, but here are two examples:
|
||||
|
||||
1. Cursor ([guide](https://docs.cursor.com/context/@-symbols/@-docs)): Go to `Settings > Indexing & Docs` to add documentation.
|
||||
2. Continue ([guide](https://docs.continue.dev/customize/context/documentation)): In chat, type `@Docs` and press `Enter`, then click `Add Docs`.
|
||||
|
||||
For any editor or agent, we recommend adding documentation scoped to a specific task.
|
||||
At minimum, include:
|
||||
|
||||
* [REST API source](../verified-sources/rest_api/) as `@dlt_rest_api`
|
||||
* [Core dlt concepts & usage](../../general-usage/) as `@dlt_docs`
|
||||
|
||||
### Install dlt workspace
|
||||
Run this command to install the Python library `dlt` with the `workspace` extra.
|
||||
|
||||
```sh
|
||||
pip install "dlt[workspace]"
|
||||
@@ -76,135 +54,405 @@ pip install "dlt[workspace]"
|
||||
|
||||
### Initialize workspace
|
||||
|
||||
We provide LLM context from over 5,000 sources, available at [https://dlthub.com/workspace](https://dlthub.com/workspace). To get started, search for your API and follow the tailored instructions.
|
||||
|
||||
<div style={{textAlign: 'center'}}>
|
||||

|
||||
</div>
|
||||
|
||||
To initialize a dltHub workspace, execute the following:
|
||||
To initialize your workspace, you will run a command of this shape:
|
||||
|
||||
```sh
|
||||
dlt init dlthub:{source_name} duckdb
|
||||
dlt init dlthub:{source} {destination}
|
||||
```
|
||||
|
||||
This command will first prompt you to choose an AI editor/agent. If you pick the wrong one, no problem. After initializing the workspace, you can delete the incorrect editor rules and run `dlt ai setup` to select the editor again. This time it will only load the rules.
|
||||
For the destination, `duckdb` is recommend for local development.
|
||||
Once you have a working pipeline, you easily change the destination to your
|
||||
data warehouse.
|
||||
|
||||
The dltHub workspace will be initialized with:
|
||||
- Files and folder structure you know from [dlt init](../../walkthroughs/create-a-pipeline.md)
|
||||
- Documentation scaffold for the specific source (typically a `yaml` file) optimized for LLMs
|
||||
- Rules for `dlt`, configured for your selected AI editor/agent
|
||||
- Pipeline script and REST API source (`{source_name}_pipeline.py`) definition that you'll customize in the next step
|
||||
For the source, select one of the 8k+ REST API sources available
|
||||
at [https://dlthub.com/workspace](https://dlthub.com/workspace). The source's page includes a command you can copy-paste to initialize your workspace.
|
||||
|
||||
:::tip
|
||||
If you can't find the source you need, start with a generic REST API source template. Choose a source name you need i.e.
|
||||
For example, this command setups ingestion from GitHub to local DuckDB.
|
||||
```sh
|
||||
dlt init dlthub:my_internal_fast_api duckdb
|
||||
dlt init dlthub:github duckdb
|
||||
```
|
||||
This will generate the full pipeline setup, including the script (`my_internal_fast_api_pipeline.py`) and all the files and folders you’d normally get with a standard [dlt init](../../walkthroughs/create-a-pipeline.md).
|
||||
To make your source available to the LLM, be sure to [include the documentation](#addon-bring-your-own-llm-scaffold) in the context so the model can understand how to use it.
|
||||
:::
|
||||
|
||||
## Create dlt pipeline
|
||||
|
||||
### Generate code
|
||||
|
||||
To get started quickly, we recommend using our pre-defined prompts tailored for each API. Visit [https://dlthub.com/workspace](https://dlthub.com/workspace) and copy the prompt for your selected source.
|
||||
Prompts are adjusted per API to provide the most accurate and relevant context.
|
||||
|
||||
Here's a general prompt template you can adapt:
|
||||
Several files will be added to your directory, similar to this:
|
||||
|
||||
```text
|
||||
Please generate a REST API source for {source} API, as specified in @{source}-docs.yaml
|
||||
Start with endpoints {endpoints you want} and skip incremental loading for now.
|
||||
my_project/
|
||||
├── .cursor/ # rules for Cursor IDE
|
||||
│ ├── rules.mdc
|
||||
│ └── ... # more rules
|
||||
├── .dlt/
|
||||
│ ├── config.toml # dlt configuration
|
||||
│ └── secrets.toml # dlt secrets
|
||||
├── .cursorignore
|
||||
├── .gitignore
|
||||
├── github_pipeline.py # pipeline template
|
||||
├── requirements.txt
|
||||
└── github-docs.yaml # GitHub LLM scaffold
|
||||
```
|
||||
|
||||
### Configure IDE
|
||||
|
||||
When running `dlt init`, you will be prompted to select the IDE or agent that you want to use.
|
||||
|
||||
```sh
|
||||
❯ dlt init dlthub:github duckdb
|
||||
dlt will generate useful project rules tailored to your assistant/IDE.
|
||||
Press Enter to accept the default (cursor), or type a name:
|
||||
```
|
||||
|
||||
Run this command to manually setup another IDE.
|
||||
|
||||
```sh
|
||||
dlt ai setup {IDE}
|
||||
```
|
||||
|
||||
### Choose an LLM
|
||||
|
||||
Your experience will greatly depend on the capabilities of the LLM you use. We suggest minimally using `GPT-4.1` from OpenAI or `Claude Sonnet 4` from Anthropic.
|
||||
|
||||
|
||||
### Install MCP server (optional)
|
||||
|
||||
You can install the [dlt MCP server ](https://github.com/dlt-hub/dlt-mcp) by adding this snippet to your IDE's configuration.
|
||||
|
||||
This default configuration will support local DuckDB destination
|
||||
```json
|
||||
{
|
||||
"name": "dlt",
|
||||
"command": "uv",
|
||||
"args": [
|
||||
"run",
|
||||
"--with",
|
||||
"dlt-mcp[search]",
|
||||
"python",
|
||||
"-m",
|
||||
"dlt_mcp"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
:::note
|
||||
The configuration file format varies slightly across IDEs
|
||||
:::
|
||||
|
||||
## Initial instructions
|
||||
|
||||
To get good result and make progress, it's best to implement one REST endpoint at a time.
|
||||
|
||||
The source's page on dlthub.com/workspace includes a prompt to get you started that looks
|
||||
like this:
|
||||
|
||||
```text
|
||||
Generate a REST API Source for {source}, as specified in @{source}-docs.yaml
|
||||
Start with endpoint {endpoint_name} and skip incremental loading for now.
|
||||
Place the code in {source}_pipeline.py and name the pipeline {source}_pipeline.
|
||||
If the file exists, use it as a starting point.
|
||||
Do not add or modify any other files.
|
||||
Use @dlt_rest_api as a tutorial.
|
||||
After adding the endpoints, allow the user to run the pipeline with python {source}_pipeline.py and await further instructions.
|
||||
```
|
||||
|
||||
In this prompt, we use `@` references to link source specifications and documentation. Make sure Cursor (or whichevert AI editor/agent you use) recognizes the referenced docs.
|
||||
For example, see [Cursor’s guide](https://docs.cursor.com/context/@-symbols/overview) to @ references.
|
||||
|
||||
* `@{source}-docs.yaml` contains the source specification and describes the source with endpoints, parameters, and other details.
|
||||
* `@dlt_rest_api` contains the documentation for dlt's REST API source.
|
||||
|
||||
### Add credentials
|
||||
|
||||
Prompt the LLM for credential setup instructions and add them to your workspace secrets file `.dlt/secrets.toml`.
|
||||
|
||||
## Run the pipeline
|
||||
|
||||
Run your pipeline:
|
||||
|
||||
```sh
|
||||
python {source}_pipeline.py
|
||||
```
|
||||
|
||||
Expected output:
|
||||
```sh
|
||||
Pipeline {source} load step completed in 0.26 seconds
|
||||
1 load package(s) were loaded to destination duckdb and into dataset {source}_data
|
||||
The duckdb destination used duckdb:/{source}.duckdb location to store data
|
||||
Load package 1749667187.541553 is LOADED and contains no failed jobs
|
||||
After adding the endpoint, allow the user to run the pipeline with
|
||||
`python {source}_pipeline.py`
|
||||
and await further instructions.
|
||||
```
|
||||
|
||||
:::tip
|
||||
If the pipeline fails, pass error messages to the LLM. Restart after 4-8 failed attempts.
|
||||
Reference `{'{'}source{'}'}-docs.yaml` and ask what the available endpoints are.
|
||||
:::
|
||||
|
||||
### Validate with workspace dashboard
|
||||
## Generate code
|
||||
|
||||
Launch the dashboard to validate your pipeline:
|
||||
The LLM can quickly produce a lot of code. When reviewing its proposed changes, your role is to nudge it in the right direction.
|
||||
|
||||
```sh
|
||||
dlt pipeline {source}_pipeline show
|
||||
### Anatomy of a REST API source
|
||||
Before practical tips, let's look at a minimal REST API source:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
from dlt.sources.rest_api import rest_api_resources
|
||||
from dlt.sources.rest_api.typing import RESTAPIConfig
|
||||
|
||||
# decorator indicates that this function produces a source
|
||||
@dlt.source
|
||||
def github_source(
|
||||
# the `access_token` will be retrieved from `.dlt/secrets.toml` by default
|
||||
access_token: str = dlt.secrets.value
|
||||
):
|
||||
config: RESTAPIConfig = {
|
||||
# client section
|
||||
"client": {
|
||||
"base_url": "https://api.github.com/v3/",
|
||||
# access token will be passed via headers
|
||||
"auth": {"type": "bearer", "token": access_token},
|
||||
},
|
||||
# endpoint section
|
||||
"resources": [
|
||||
# refers to GET endpoint `/issues`
|
||||
"issues",
|
||||
],
|
||||
}
|
||||
# returns a list of resources
|
||||
return rest_api_resources(config)
|
||||
```
|
||||
|
||||
The dashboard shows:
|
||||
- Pipeline overview with state and metrics
|
||||
- Data schema (tables, columns, types)
|
||||
- Data itself, you can even write custom queries
|
||||
For now, it's best to delete all the code you don't understand (e.g., paginator, incremental, data selector). This keeps the LLM focused and reduces the surface for bugs. After generating a working pipeline and committing code, you can go back configure endpoints more precisely.
|
||||
|
||||
The dashboard helps detect silent failures due to pagination errors, schema drift, or incremental load misconfigurations.
|
||||
:::tip
|
||||
Reference `{'{'}source{'}'}-docs.yaml` and ask what the available endpoints parameters are.
|
||||
:::
|
||||
|
||||
### Leveraging the IDE
|
||||
|
||||
`dlt` provides extensive validation and completion suggestions inside the IDE.
|
||||
|
||||
Invalid code generated by the LLM produce red error lines, simplifying code review.
|
||||
|
||||
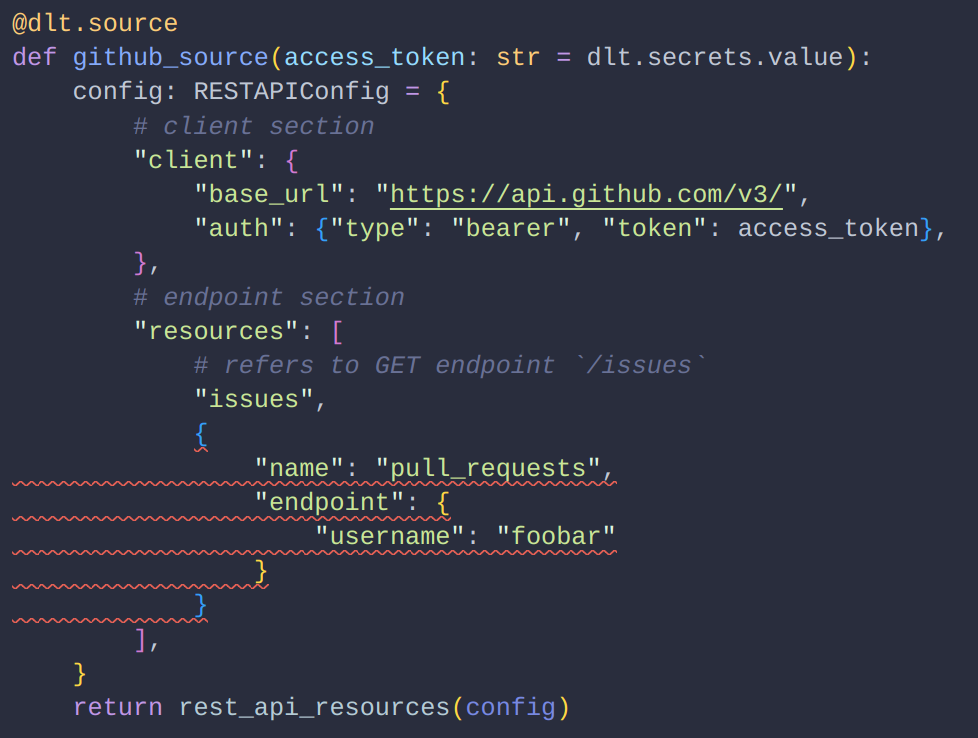
|
||||
|
||||
Completion suggestions makes it easy to fix LLM errors or set configuration options.
|
||||
|
||||
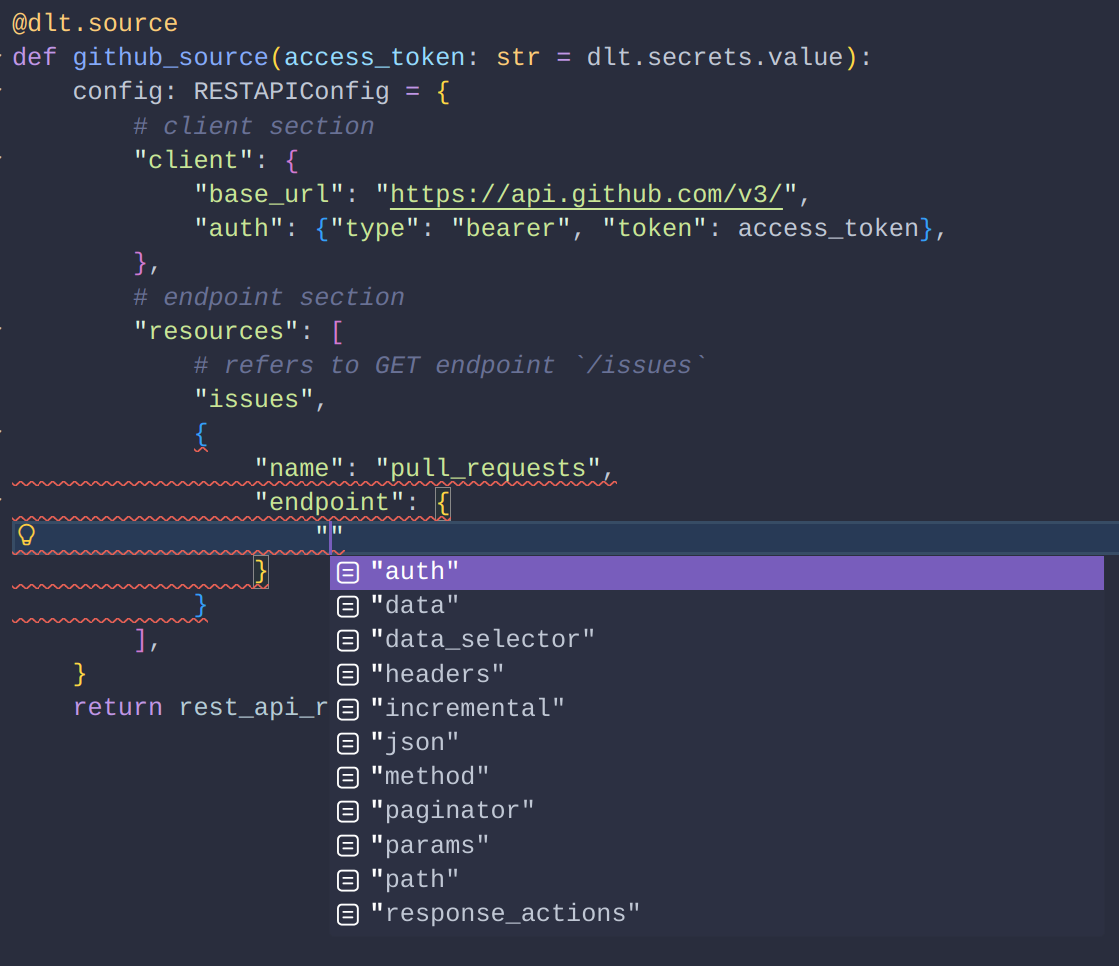
|
||||
|
||||
## Run pipeline
|
||||
### Agent running the pipeline
|
||||
Typically, the agent will ask permission to run the pipeline via the chat:
|
||||
|
||||
```sh
|
||||
python github_pipeline.py
|
||||
```
|
||||
|
||||
If you accept, it will run the pipeline and directly receive the output of the command (success or error).
|
||||
Then, it can automatically start fixing things or ask follow-up questions.
|
||||
|
||||
:::note
|
||||
Depending on the IDE, the pipeline may fail because of missing Python dependencies. In this case,
|
||||
you should run the pipeline manually.
|
||||
:::
|
||||
|
||||
### Manually running the pipeline
|
||||
You can manually run this command in the terminal to run the pipeline.
|
||||
|
||||
```sh
|
||||
python github_pipeline.py
|
||||
```
|
||||
|
||||
Then, use `@terminal` inside the chat window to add the success / error message to the LLM context.
|
||||
|
||||
### Success: pipeline completed without error
|
||||
A successful execution should print a message similar to this one:
|
||||
|
||||
```sh
|
||||
Pipeline github_source load step completed in 0.26 seconds
|
||||
1 load package(s) were loaded to destination duckdb and into dataset github_source_data
|
||||
The duckdb destination used duckdb:/github_source.duckdb location to store data
|
||||
Load package 1749667187.541553 is LOADED and contains no failed jobs
|
||||
```
|
||||
|
||||
### Failure: source credentials
|
||||
|
||||
Your first iterations will likely trigger credentials errors similar to the one below. The error message indicates how you can set credential values using `.dlt/config.toml` and `.dlt/secrets.toml` or environment variables ([learn more](../../general-usage/credentials/setup))
|
||||
|
||||
```text
|
||||
dlt.common.configuration.exceptions.ConfigFieldMissingException: Missing 1 field(s) in configuration `GithubRestApiSourceConfiguration`: `access_token`
|
||||
for field `access_token` the following (config provider, key) were tried in order:
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__GITHUB_PIPELINE__GITHUB_REST_API_SOURCE__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__SOURCES__ACCESS_TOKEN)
|
||||
(Environment Variables, GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(secrets.toml, github_pipeline.sources.github_pipeline.github_rest_api_source.access_token)
|
||||
(secrets.toml, github_pipeline.sources.github_pipeline.access_token)
|
||||
(secrets.toml, github_pipeline.sources.access_token)
|
||||
(secrets.toml, github_pipeline.access_token)
|
||||
(Environment Variables, SOURCES__GITHUB_PIPELINE__GITHUB_REST_API_SOURCE__ACCESS_TOKEN)
|
||||
(Environment Variables, SOURCES__GITHUB_PIPELINE__ACCESS_TOKEN)
|
||||
(Environment Variables, SOURCES__ACCESS_TOKEN)
|
||||
(Environment Variables, ACCESS_TOKEN)
|
||||
(secrets.toml, sources.github_pipeline.github_rest_api_source.access_token)
|
||||
(secrets.toml, sources.github_pipeline.access_token)
|
||||
(secrets.toml, sources.access_token)
|
||||
(secrets.toml, access_token)
|
||||
Provider `secrets.toml` loaded values from locations:
|
||||
- /home/user/path/to/my_project/.dlt/secrets.toml
|
||||
- /home/user/.dlt/secrets.toml
|
||||
Provider `config.toml` loaded values from locations:
|
||||
- /home/user/path/to/my_project/.dlt/config.toml
|
||||
- /home/user/.dlt/config.toml
|
||||
```
|
||||
|
||||
:::tip
|
||||
Getting credentials or API keys from a source system can be tedious. For popular sources, LLMs can provide step-by-step instructions
|
||||
:::
|
||||
|
||||
|
||||
### Failure: destination credentials
|
||||
|
||||
Destination credentials are similar to source credentials errors and can be fixed via `.dlt/config.toml` and `.dlt/secrets.toml` or environment variables ([learn more](../../general-usage/credentials/setup)). Destination-specific information can be found in [the documentation](../../dlt-ecosystem/destinations).
|
||||
|
||||
Alternatively, you can point the LLM to the Python code that defines the configuration. It's typically found in `from dlt.destinations.impl.{'{'}destination{'}'}.configuration`. For example, this retrieves the Snowflake configuration and credentials
|
||||
|
||||
```py
|
||||
from dlt.destinations.impl.snowflake.configuration import SnowflakeCredentials, SnowflakeClientConfiguration
|
||||
```
|
||||
|
||||
Credentials are what you typically put in `secrets.toml` and configuration in `config.toml`.
|
||||
|
||||
## Manage context
|
||||
|
||||
"Managing context" is about providing the right information to the LLM and help it focus on the right task. Below is a list of practical tips:
|
||||
|
||||
- Specify: "I'm a data engineer using the Python library `dlt` to ingest data from {'{'}source{'}'} to {'{'}destination{'}'}. I'm also using the Python libraries X,Y,Z."
|
||||
- Specify: "Focus on a single REST API endpoint `X`."
|
||||
- In later iteration when you're tuning your pipeline, specify "The current Python code works as expected. Make minimal and focused changes to do X"
|
||||
- Use the `@` symbol to reference the terminal output after running the pipeline
|
||||
- Use the `@` symbol to reference to the LLM scaffolds
|
||||
- Ingest documentation and index your code using your IDE. Refer to it explicitly using `@`
|
||||
- Ask the LLM to list available tools and explain them.
|
||||
- If the LLM goes on a tangent, trim the conversation history or create a new conversation
|
||||
|
||||
:::note
|
||||
These tips will differ slightly across IDEs
|
||||
:::
|
||||
|
||||
## Check data
|
||||
|
||||
### dlt Dashboard
|
||||
|
||||
Lauch the local [dlt Dashboard](../../general-usage/dashboard) to inspect your pipeline execution including:
|
||||
- pipeline state and metrics
|
||||
- data schema
|
||||
- SQL data explorer
|
||||
|
||||
```sh
|
||||
dlt pipeline github_pipeline show
|
||||
```
|
||||
|
||||
<div style={{textAlign: 'center'}}>
|
||||

|
||||
</div>
|
||||
|
||||
## Use the data in a notebook
|
||||
|
||||
With the pipeline and data validated, you can continue with custom data explorations and reports. You can use your preferred environment, for example, [Jupyter Notebook](https://jupyter.org/), [Marimo Notebook](https://marimo.io/), or a plain Python file.
|
||||
The dashboard helps detect silent failures due to pagination errors, schema drift, or incremental load misconfigurations.
|
||||
|
||||
:::tip
|
||||
For an optimized data exploration experience, we recommend using a Marimo notebook. Check out the [detailed guide on using dlt with Marimo](../../general-usage/dataset-access/marimo).
|
||||
Inside Cursor 2.0, you can open the [dashboard's web page inside the IDE](https://cursor.com/docs/agent/browser) and directly reference visual elements inside the chat.
|
||||
:::
|
||||
|
||||
To access the data, you can use the `dataset()` method:
|
||||
|
||||
### Ask the dlt MCP server
|
||||
If the [dlt MCP server](https://github.com/dlt-hub/dlt-mcp) is connected, you can directly ask in the IDE chat window if the data was successfully loaded. Based on your MCP configuration, it can have access to:
|
||||
- pipeline metadata
|
||||
- loaded data
|
||||
- dlt documentation and source code
|
||||
|
||||
It can answer questions such as:
|
||||
- What are the available pipelines?
|
||||
- What are the available tables?
|
||||
- What's table X's schema?
|
||||
- When was data last loaded?
|
||||
- Did schema change last run?
|
||||
- Display the pipeline's schema
|
||||
- How many rows are in table X?
|
||||
- Give me a data sample of table X
|
||||
|
||||
|
||||
### Python data exploration
|
||||
|
||||
Running a `dlt` pipeline creates a dataset, which can be accessed via Python code:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
|
||||
my_data = dlt.pipeline("{source}_pipeline").dataset()
|
||||
# get any table as Pandas frame
|
||||
my_data.table("table_name").df().head()
|
||||
# this refers to my previously ran pipeline
|
||||
github_pipeline = dlt.pipeline("github_pipeline")
|
||||
github_dataset = github_pipeline.dataset()
|
||||
# list tables
|
||||
github_dataset.tables
|
||||
# list columns
|
||||
github_dataset.table("pull_requests").columns
|
||||
# load the results as a pandas dataframe
|
||||
github_dataset.table("pull_requests").df()
|
||||
```
|
||||
|
||||
For more, see the [dataset access guide](../../general-usage/dataset-access).
|
||||
This shines in interactive environments like [marimo](../../general-usage/dataset-access/marimo) and Jupyter for data explorations. It's a great way to add data quality checks.
|
||||
|
||||
## Next steps: production deployment
|
||||
### Automated data quality
|
||||
|
||||
- [Prepare production deployment](../../walkthroughs/share-a-dataset.md)
|
||||
- [Deploy a pipeline](../../walkthroughs/deploy-a-pipeline/)
|
||||
Once you're familiar with the data, you can write expectations about the data in code. This section is an introduction to deep topics with their own documentation page.
|
||||
|
||||
:::tip
|
||||
Instead of asking the LLM to make data a certain way, you can ask the LLM to help you write automated data quality. Then, you can feedback the data quality information back to the LLM after each pipeline run.
|
||||
:::
|
||||
|
||||
#### Schema contract
|
||||
Enabling [schema contracts](../../general-usage/schema-contracts) lets you configure what aspect of the data can change or not between pipeline runs.
|
||||
|
||||
For example, this configuration allows to add new tables, raises on new columns, and drops records with incorrect data type:
|
||||
|
||||
```py
|
||||
@dlt.source(
|
||||
schema_contract={
|
||||
"tables": "evolve",
|
||||
"columns": "freeze",
|
||||
"data_type": "discard_row",
|
||||
}
|
||||
)
|
||||
def github_source(): ...
|
||||
```
|
||||
|
||||
#### Data validation
|
||||
Using [Pydantic](https://docs.pydantic.dev), you can define extend schema contract features and validate individual records one-by-one ([learn more](../../general-usage/resource#define-a-schema-with-pydantic)).
|
||||
|
||||
This allows to catch invalid data early, cancel the pipeline run, and prevent data being written to the destination
|
||||
|
||||
Data validation needs to be set on the **resource** rather than the **source**. We need a few more lines of code to retrieve them.
|
||||
|
||||
```py
|
||||
import dlt
|
||||
from pydantic import BaseModel
|
||||
|
||||
class PullRequestModel(BaseModel):
|
||||
...
|
||||
|
||||
@dlt.source
|
||||
def github_source(): ...
|
||||
|
||||
if __name__ == "__main__":
|
||||
source = github_source()
|
||||
# "pull_requests" would be one of the endpoints defined by `github_source`
|
||||
source.resources["pull_requests"].apply_hints(columns=PullRequestModel)
|
||||
|
||||
pipeline = dlt.pipeline("github_pipeline")
|
||||
pipeline.run(source)
|
||||
```
|
||||
|
||||
#### Data quality checks
|
||||
A [data quality check](../../hub/features/quality/data-quality) declares how the data on the destination should look like. It can be executed on the destination and efficiently process large data volume.
|
||||
|
||||
```py
|
||||
from dlt.hub import data_quality as dq
|
||||
|
||||
pipeline = dlt.pipeline("github_pipeline")
|
||||
pipeline.run(github_source())
|
||||
|
||||
dataset = pipeline.dataset()
|
||||
|
||||
pull_requests_checks = [
|
||||
dq.checks.is_not_null("id"),
|
||||
dq.checks.is_in("author", ["Romeo", "Foxtrot", "Tango"]),
|
||||
dq.checks.case("created_at > 2025-01-01"),
|
||||
]
|
||||
|
||||
dq.run_checks(dataset, checks={"pull_requests": pull_requests_checks})
|
||||
```
|
||||
|
||||
:::tip
|
||||
Data quality checks write results to the destination, which can be inspected via the dashboard, MCP server, and manual exploration
|
||||
:::
|
||||
|
||||
|
||||
## Addon: bring your own LLM scaffold
|
||||
## Conclusion
|
||||
By the end of this guide, you should have:
|
||||
- a local workspace
|
||||
- a working REST API source
|
||||
- a working pipeline
|
||||
- a local dataset
|
||||
|
||||
LLMs can infer a REST API source definition from various types of input, and in many cases, it’s easy to provide what’s needed.
|
||||
|
||||
Here are a few effective ways to scaffold your source:
|
||||
|
||||
1. **FastAPI (Internal APIs)**. If you're using FastAPI, simply add a file with the autogenerated OpenAPI spec to your workspace and reference it in your prompt.
|
||||
2. **Legacy code in any programming language**. Add the relevant code files to your workspace and reference them directly in your prompt. LLMs can extract useful structure even from older codebases.
|
||||
3. **Human-readable documentation**. Well-written documentation works too. You can add it to your AI editor docs and reference it in your prompt for context.
|
||||
Next steps:
|
||||
- [explore the dataset and build a data product](../../general-usage/dataset-access/dataset)
|
||||
- [replace the local destination with your data warehouse](../../walkthroughs/share-a-dataset)
|
||||
- [deploy the pipeline](../../walkthroughs/deploy-a-pipeline/)
|
||||
|
||||
@@ -452,7 +452,7 @@ These are the available paginators:
|
||||
| `json_link` | [JSONLinkPaginator](../../../general-usage/http/rest-client.md#jsonlinkpaginator) | The link to the next page is in the body (JSON) of the response.<br/>*Parameters:*<ul><li>`next_url_path` (str) - the JSONPath to the next page URL</li></ul> |
|
||||
| `header_link` | [HeaderLinkPaginator](../../../general-usage/http/rest-client.md#headerlinkpaginator) | The links to the next page are in the response headers.<br/>*Parameters:*<ul><li>`links_next_key` (str) - the name of the header containing the links. Default is "next".</li></ul> |
|
||||
| `header_cursor` | [HeaderCursorPaginator](../../../general-usage/http/rest-client.md#headercursorpaginator) | The cursor for the next page is in the response headers.<br/>*Parameters:*<ul><li>`cursor_key` (str) - the name of the header containing the cursor. Defaults to "next"</li><li>`cursor_param` (str) - the query parameter name for the cursor. Defaults to "cursor"</li></ul> |
|
||||
| `offset` | [OffsetPaginator](../../../general-usage/http/rest-client.md#offsetpaginator) | The pagination is based on an offset parameter, with the total items count either in the response body or explicitly provided.<br/>*Parameters:*<ul><li>`limit` (int) - the maximum number of items to retrieve in each request</li><li>`offset` (int) - the initial offset for the first request. Defaults to `0`</li><li>`offset_param` (str) - the name of the query parameter used to specify the offset. Defaults to "offset"</li><li>`limit_param` (str) - the name of the query parameter used to specify the limit. Defaults to "limit"</li><li>`total_path` (str) - a JSONPath expression for the total number of items. If not provided, pagination is controlled by `maximum_offset` and `stop_after_empty_page`</li><li>`maximum_offset` (int) - optional maximum offset value. Limits pagination even without total count</li><li>`stop_after_empty_page` (bool) - Whether pagination should stop when a page contains no result items. Defaults to `True`</li><li>`has_more_path` (str) - a JSONPath expression for the boolean value indicating whether there are more items to fetch. Defaults to `None`.</li></ul> |
|
||||
| `offset` | [OffsetPaginator](../../../general-usage/http/rest-client.md#offsetpaginator) | The pagination is based on an offset parameter, with the total items count either in the response body or explicitly provided.<br/>*Parameters:*<ul><li>`limit` (int) - the maximum number of items to retrieve in each request</li><li>`offset` (int) - the initial offset for the first request. Defaults to `0`</li><li>`offset_param` (str) - the name of the query parameter used to specify the offset. Defaults to "offset"</li><li>`offset_body_path` (str) - a dot-separated path specifying where to place the offset in the request JSON body. Defaults to `None`</li><li>`limit_param` (str) - the name of the query parameter used to specify the limit. Defaults to "limit"</li><li>`limit_body_path` (str) - a dot-separated path specifying where to place the limit in the request JSON body. Defaults to `None`</li><li>`total_path` (str) - a JSONPath expression for the total number of items. If not provided, pagination is controlled by `maximum_offset` and `stop_after_empty_page`</li><li>`maximum_offset` (int) - optional maximum offset value. Limits pagination even without total count</li><li>`stop_after_empty_page` (bool) - Whether pagination should stop when a page contains no result items. Defaults to `True`</li><li>`has_more_path` (str) - a JSONPath expression for the boolean value indicating whether there are more items to fetch. Defaults to `None`.</li></ul> |
|
||||
| `page_number` | [PageNumberPaginator](../../../general-usage/http/rest-client.md#pagenumberpaginator) | The pagination is based on a page number parameter, with the total pages count either in the response body or explicitly provided.<br/>*Parameters:*<ul><li>`base_page` (int) - the starting page number. Defaults to `0`</li><li>`page_param` (str) - the query parameter name for the page number. Defaults to "page"</li><li>`total_path` (str) - a JSONPath expression for the total number of pages. If not provided, pagination is controlled by `maximum_page` and `stop_after_empty_page`</li><li>`maximum_page` (int) - optional maximum page number. Stops pagination once this page is reached</li><li>`stop_after_empty_page` (bool) - Whether pagination should stop when a page contains no result items. Defaults to `True`</li><li>`has_more_path` (str) - a JSONPath expression for the boolean value indicating whether there are more items to fetch. Defaults to `None`.</li></ul> |
|
||||
| `cursor` | [JSONResponseCursorPaginator](../../../general-usage/http/rest-client.md#jsonresponsecursorpaginator) | The pagination is based on a cursor parameter, with the value of the cursor in the response body (JSON).<br/>*Parameters:*<ul><li>`cursor_path` (str) - the JSONPath to the cursor value. Defaults to "cursors.next"</li><li>`cursor_param` (str) - the query parameter name for the cursor. Defaults to "cursor" if neither `cursor_param` nor `cursor_body_path` is provided.</li><li>`cursor_body_path` (str, optional) - the JSONPath to place the cursor in the request body.</li></ul>Note: You must provide either `cursor_param` or `cursor_body_path`, but not both. If neither is provided, `cursor_param` will default to "cursor". |
|
||||
| `single_page` | SinglePagePaginator | The response will be interpreted as a single-page response, ignoring possible pagination metadata. |
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -9,26 +9,21 @@ keywords: [dltHub, profiles, workspace, configuration, secrets, environments]
|
||||
Profiles in `dlt` define **environment-specific configurations and secrets**.
|
||||
They allow you to manage separate settings for development, testing, and production using the same codebase.
|
||||
|
||||
Each profile provides isolated configuration, credentials, and working directories, ensuring your pipelines are secure and environment-aware.
|
||||
Each profile provides isolated configuration, credentials, and working directories for dlt pipelines, datasets, transformations, and notebooks. You don't need to write any additional code to benefit from profiles.
|
||||
|
||||
## Overview
|
||||
|
||||
A **profile** is a named configuration context that controls how and where your pipelines run.
|
||||
Profiles are defined and managed through [**TOML files**](../../general-usage/credentials) located in the `.dlt` directory.
|
||||
They are compatible with the `secrets.toml` and `config.toml` files you may already know from OSS dlt.
|
||||
|
||||
Profiles let you:
|
||||
dltHub Runtime automatically uses certain profiles to deploy and run pipelines and notebooks.
|
||||
|
||||
* Securely manage credentials for multiple environments.
|
||||
* Isolate pipeline state, configuration, and local data storage.
|
||||
* Switch between environments without changing code.
|
||||
|
||||
## Enable the workspace and profiles
|
||||
|
||||
Before you start, make sure that you followed [installation instructions](../getting-started/installation.md) and enabled [additional Workspace features](../getting-started/installation.md#enable-dlthub-free-tier-features) (which also include Profiles)
|
||||
Before you start, make sure you have followed the [installation instructions](../getting-started/installation.md) and enabled [additional Workspace features](../getting-started/installation.md#enable-dlthub-free-and-paid-features) (which also include Profiles).
|
||||
|
||||
**dltHub Workspace** is a unified environment for developing, running, and maintaining data pipelines — from local development to production.
|
||||
**dltHub Workspace** is a unified environment for developing, running, and maintaining data pipelines—from local development to production.
|
||||
|
||||
[More about dlt Workspace ->](../workspace/overview.md)
|
||||
[More about dlt Workspace →](../workspace/overview.md)
|
||||
|
||||
[Initialize](../workspace/init) a project:
|
||||
|
||||
@@ -43,23 +38,24 @@ dlt profile
|
||||
dlt workspace
|
||||
```
|
||||
|
||||
## Default profiles
|
||||
## Define profiles
|
||||
|
||||
When you initialize a project with `dlt init`, it creates a complete project structure — including configuration and secrets directories (`.dlt/`), a sample pipeline script, and a default `dev` profile.
|
||||
This setup lets you start developing and running pipelines immediately, with environment-specific configurations ready to extend or customize.
|
||||
If you use `dlt init`, you'll have two familiar `toml` files in `.dlt`: `secrets.toml` and `config.toml`. They work exactly the same way as in OSS `dlt`. You can run your OSS dlt code without modifications.
|
||||
|
||||
The **dltHub Workspace** adds predefined profiles that isolate environments and simplify transitions between them:
|
||||
**Anything you place in those files is visible to all profiles**. For example, if you place
|
||||
`log_level="INFO"` in `config.toml`, it applies to all profiles. Only when you want certain settings to vary across profiles (e.g., `INFO` level for development, `WARNING` for production) do you need to create profile-specific `toml` files.
|
||||
|
||||
| Profile | Description |
|
||||
|---------|-------------------------------------------------------------------------------------------------------------|
|
||||
| **`dev`** | Default profile for local development. Pipelines store data in `_local/dev/` and state in `.dlt/.var/dev/`. |
|
||||
| **`prod`** | Production profile, used by pipelines deployed in Runtime. |
|
||||
| **`tests`** | Profile for automated test runs and CI/CD. |
|
||||
| **`access`** | Read-only production profile for interactive notebooks in Runtime. |
|
||||
**dltHub Workspace** predefines several profiles, and together with **dltHub Runtime**, assigns them specific functions:
|
||||
|
||||
| Profile | Description |
|
||||
| ------------ | ----------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **`dev`** | Default profile for local development. |
|
||||
| **`prod`** | Production profile, [used by Runtime to run pipelines](../runtime/overview.md#understanding-workspace-profiles). |
|
||||
| **`tests`** | Profile for automated test runs and CI/CD. |
|
||||
| **`access`** | Read-only production profile [for interactive notebooks in Runtime](../runtime/overview.md#understanding-workspace-profiles). |
|
||||
|
||||
:::note
|
||||
Only the `dev` profile is active by default when you create a workspace.
|
||||
The others become active when pinned or automatically selected by Runtime.
|
||||
The `dev` profile is active by default when you create a workspace. The others become active when pinned or automatically selected by Runtime.
|
||||
:::
|
||||
|
||||
View available profiles:
|
||||
@@ -68,20 +64,11 @@ View available profiles:
|
||||
dlt profile list
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```text
|
||||
Available profiles:
|
||||
* dev - dev profile, workspace default
|
||||
* prod - production profile, assumed by pipelines deployed in Runtime
|
||||
* tests - profile assumed when running tests
|
||||
* access - production profile, assumed by interactive notebooks
|
||||
```
|
||||
|
||||
## Switching profiles
|
||||
|
||||
To change environments, **pin the desired profile**.
|
||||
This makes it the default for all commands and runs:
|
||||
This makes it the default for all dlt commands:
|
||||
|
||||
```sh
|
||||
dlt profile prod pin
|
||||
@@ -99,28 +86,56 @@ To unpin:
|
||||
rm .dlt/profile-name
|
||||
```
|
||||
|
||||
:::tip
|
||||
You can pin a profile with any name, not just those from the predefined list. This allows you to create as many profiles as you need.
|
||||
You can also pin a profile that doesn't yet have profile-specific TOML files and add those files later.
|
||||
```sh
|
||||
dlt workspace -v info
|
||||
```
|
||||
This command lists all expected file locations from which `dlt` reads profile settings.
|
||||
:::
|
||||
|
||||
Once pinned, you can simply run your pipeline as usual:
|
||||
|
||||
```sh
|
||||
python pokemon_api_pipeline.py
|
||||
```
|
||||
|
||||
The workspace automatically uses the active profile’s configuration and secrets.
|
||||
The workspace automatically uses the active profile's configuration, secrets, and data locations to run the pipeline.
|
||||
|
||||
## Example: Switching between environments
|
||||
:::tip
|
||||
Profiles isolate not only configuration but also pipeline runs. Each profile has a separate pipeline directory (`.dlt/var/$profile/pipelines`) and
|
||||
storage location for locally stored data (e.g., local `filesystem`, `ducklake`, or `duckdb`). This makes it easy to:
|
||||
1. Clean up your workspace and start over (`dlt workspace clean`)
|
||||
2. Switch to the `test` profile when running `pytest` (e.g., using a fixture) so you can develop on the `dev` profile interactively while running tests in parallel in isolation
|
||||
:::
|
||||
|
||||
### Switching profiles in code
|
||||
|
||||
You can interact with the workspace run context, switch profiles, and inspect workspace configuration using code:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
|
||||
workspace = dlt.current.workspace()
|
||||
|
||||
workspace.switch_profile("test")
|
||||
```
|
||||
|
||||
## Example: Switch destinations using profiles
|
||||
|
||||
Let's walk through a setup that switches between **local DuckDB** (`dev`) and **MotherDuck** (`prod`).
|
||||
|
||||
### Step 1. Configure the development profile
|
||||
|
||||
In `.dlt/dev.secrets.toml` (to fully split profiles), define your local destination:
|
||||
In `.dlt/dev.secrets.toml` (to fully separate profiles), define your local destination:
|
||||
|
||||
```toml
|
||||
[destination.warehouse]
|
||||
destination_type = "duckdb"
|
||||
```
|
||||
|
||||
Then, in your pipeline script, change the code `(destination="warehouse")`:
|
||||
Then, in your pipeline script, use `destination="warehouse"`:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
@@ -139,6 +154,7 @@ python pokemon_api_pipeline.py
|
||||
```
|
||||
|
||||
Data will be stored in `_local/dev/warehouse.duckdb`.
|
||||
Pipeline state will be stored in `.dlt/.var/dev/`.
|
||||
|
||||
|
||||
### Step 2. Configure the production profile
|
||||
@@ -166,29 +182,38 @@ dlt --debug pipeline pokemon_api_pipeline sync --destination warehouse --dataset
|
||||
```
|
||||
|
||||
This command performs a **dry run**, checking the connection to your destination and validating credentials without loading any data.
|
||||
If your credentials are invalid or there’s another configuration issue, `dlt` will raise a detailed exception with a full stack trace — helping you debug before deployment.
|
||||
If your credentials are invalid or there's another configuration issue, `dlt` will raise a detailed exception with a full stack trace—helping you debug before deployment.
|
||||
|
||||
If the connection succeeds but the dataset doesn’t yet exist in **MotherDuck**, you’ll see a message like:
|
||||
If the connection succeeds but the dataset doesn't yet exist in **MotherDuck**, you'll see a message like:
|
||||
|
||||
```text
|
||||
ERROR: Pipeline pokemon_api_pipeline was not found in dataset pokemon_api_data in warehouse
|
||||
```
|
||||
|
||||
This simply means the target dataset hasn’t been created yet — no action is required.
|
||||
Now, run your pipeline script to load data into MotherDuck:
|
||||
This simply means the target dataset hasn't been created yet—no action is required.
|
||||
Now run your pipeline script to load data into MotherDuck:
|
||||
|
||||
#### Run the pipeline with the `prod` profile
|
||||
|
||||
```sh
|
||||
python pokemon_api_pipeline.py
|
||||
```
|
||||
|
||||
Data will be stored in MotherDuck.
|
||||
Pipeline state will be stored in `.dlt/.var/prod/`.
|
||||
|
||||
Once the pipeline completes, open the **Workspace Dashboard** with:
|
||||
|
||||
```sh
|
||||
dlt workspace show
|
||||
```
|
||||
|
||||
You’ll see your pipeline connected to the remote MotherDuck dataset and ready for further exploration.
|
||||
You'll see your pipeline connected to the remote MotherDuck dataset and ready for further exploration.
|
||||
|
||||
#### Schedule the pipeline to run on Runtime
|
||||
|
||||
Now you're ready to deploy your Workspace to Runtime and [schedule your pipeline to run](../getting-started/runtime-tutorial.md#7-schedule-a-pipeline).
|
||||
Note that Runtime will automatically use the `prod` profile you just created.
|
||||
|
||||
## Inspecting and managing profiles
|
||||
|
||||
@@ -204,7 +229,7 @@ You’ll see your pipeline connected to the remote MotherDuck dataset and ready
|
||||
dlt profile
|
||||
```
|
||||
|
||||
* **Clean workspace (useful in dev)**
|
||||
* **Clean the workspace (useful in dev)**
|
||||
|
||||
```sh
|
||||
dlt workspace clean
|
||||
@@ -214,13 +239,13 @@ You’ll see your pipeline connected to the remote MotherDuck dataset and ready
|
||||
|
||||
* Use **`dev`** for local testing and experimentation.
|
||||
* Use **`prod`** for production jobs and runtime environments.
|
||||
* Keep secrets in separate `<profile>.secrets.toml` files — never in code.
|
||||
* Keep secrets in separate `<profile>.secrets.toml` files—never in code.
|
||||
* Use **named destinations** (like `warehouse`) to simplify switching.
|
||||
* Commit `config.toml`, but exclude all `.secrets.toml` files.
|
||||
|
||||
|
||||
## Next steps
|
||||
|
||||
* [Configure the workspace.](../workspace/overview.md)
|
||||
* [Deploy your pipeline.](../../walkthroughs/deploy-a-pipeline)
|
||||
* [Monitor and debug pipelines.](../../general-usage/pipeline#monitor-the-loading-progress)
|
||||
* [Configure the workspace](../workspace/overview.md)
|
||||
* [Deploy your pipeline](../getting-started/runtime-tutorial.md#5-run-your-first-pipeline-on-runtime)
|
||||
* [Monitor and debug pipelines](../../general-usage/pipeline#monitor-the-loading-progress)
|
||||
|
||||
@@ -5,23 +5,50 @@ description: Installation information for the dlthub package
|
||||
|
||||
:::info Supported Python versions
|
||||
|
||||
dltHub currently supports Python versions 3.9-3.13.
|
||||
dltHub currently supports Python versions 3.10-3.13.
|
||||
|
||||
:::
|
||||
|
||||
## Quickstart
|
||||
|
||||
To install the `dlt[workspace]` package, create a new [Python virtual environment](#setting-up-your-environment) and run:
|
||||
To install the `dlt[hub]` package, create a new [Python virtual environment](#setting-up-your-environment) and run:
|
||||
```sh
|
||||
uv pip install "dlt[hub]"
|
||||
```
|
||||
This will install `dlt` with two additional extras:
|
||||
* `dlthub` which enables features that require a [license](#self-licensing)
|
||||
* `dlt-runtime` which enables access to [dltHub Runtime](../runtime/overview.md)
|
||||
|
||||
When working with locally you'll need several dependencies like `duckdb`, `marimo`, `pyarrow` or `fastmcp`. You can install them all with:
|
||||
```sh
|
||||
uv pip install "dlt[workspace]"
|
||||
```
|
||||
This will install `dlt` with several additional dependencies you'll need for local development: `arrow`, `marimo`, `mcp`, and a few others.
|
||||
|
||||
If you need to install `uv` (a modern package manager), [please refer to the next section](#configuration-of-the-python-environment).
|
||||
|
||||
### Enable dltHub Free tier features
|
||||
### Upgrade existing installation
|
||||
|
||||
To upgrade just the `hub` extra without upgrading `dlt` itself run:
|
||||
```sh
|
||||
uv pip install -U "dlt[hub]==1.20.0"
|
||||
```
|
||||
This will keep current `1.20.0` `dlt` and upgrade `dlthub` and `dlt-runtime` to their newest matching versions.
|
||||
|
||||
:::tip
|
||||
Note that particular `dlt` version expects `dlthub` and `dlt-runtime` versions in a matching range. For example: `1.20.x` versions expects
|
||||
`0.20.x` version of a plugin. This is enforced via dependencies in `hub` extra and at import time. Installing plugin directly will not affect
|
||||
installed `dlt` version to prevent unwanted upgrades. For example if you run:
|
||||
```sh
|
||||
uv pip install dlthub
|
||||
```
|
||||
and it downloads `0.21.0` version of a plugin, `dlt` `1.20.0` will still be there but it will report a wrong plugin version on import (with instructions
|
||||
how to install valid plugin version).
|
||||
:::
|
||||
|
||||
### Enable dltHub Free and Paid features
|
||||
|
||||
:::info
|
||||
The most recent [dltHub Free tier features](../intro.md#tiers--licensing) like profiles are hidden behind a feature flag,
|
||||
The most recent [dltHub features](../intro.md#tiers--licensing) like profiles and runtime access are hidden behind a feature flag,
|
||||
which means you need to manually enable them before use.
|
||||
|
||||
To activate these features, create an empty `.dlt/.workspace` file in your project directory; this tells `dlt` to switch from the classic project mode to the Workspace mode.
|
||||
@@ -53,16 +80,6 @@ type nul > .dlt\.workspace
|
||||
|
||||
:::
|
||||
|
||||
### Enable features that require a license
|
||||
|
||||
Licensed features come with a commercial Python `dlthub` package:
|
||||
|
||||
```sh
|
||||
uv pip install -U dlthub
|
||||
```
|
||||
|
||||
Please install a valid license before proceeding, as described under [licensing](#self-licensing).
|
||||
|
||||
## Setting up your environment
|
||||
|
||||
### Configuration of the Python environment
|
||||
@@ -127,6 +144,7 @@ export DLT_LICENSE_KEY="your-dlthub-license-key"
|
||||
- [@dlt.hub.transformation](../features/transformations/index.md) - a powerful Python decorator to build transformation pipelines and notebooks
|
||||
- [dbt transformations](../features/transformations/dbt-transformations.md) - a staging layer for data transformations, combining a local cache with schema enforcement, debugging tools, and integration with existing data workflows.
|
||||
- [Iceberg support](../ecosystem/iceberg.md).
|
||||
- [Data Checks](../features/quality/data-quality.md).
|
||||
- [MSSQL Change Tracking source](../ecosystem/ms-sql.md).
|
||||
|
||||
For more information about the feature scopes, see [Scopes](#scopes).
|
||||
|
||||
383
docs/website/docs/hub/getting-started/runtime-tutorial.md
Normal file
383
docs/website/docs/hub/getting-started/runtime-tutorial.md
Normal file
@@ -0,0 +1,383 @@
|
||||
---
|
||||
title: Deploy trusted dlt pipelines and dashboards
|
||||
description: Tutorial walking through deployment on dltHub Runtime
|
||||
keywords: [deployment, runtime, dashboard, dlt pipeline]
|
||||
---
|
||||
|
||||
With the dltHub you can not only build data ingestion pipelines and dashboards, but also **run and manage them on a fully managed dltHub Runtime**.
|
||||
See the [Runtime overview](../runtime/overview.md) for more details. You get:
|
||||
|
||||
- the flexibility and developer experience of dlt
|
||||
- the simplicity and reliability of managed infrastructure
|
||||
|
||||
## What you will learn
|
||||
|
||||
In this tutorial you will:
|
||||
|
||||
- Deploy a dlt pipeline on the dltHub managed Runtime
|
||||
- Deploy an always-fresh dashboard on the dltHub managed Runtime
|
||||
- Add Python transformations to your ELT jobs
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Python 3.13+
|
||||
- A [MotherDuck](https://motherduck.com) account (for the starter pack example)
|
||||
- [uv](https://docs.astral.sh/uv/) package manager (recommended for dependency management)
|
||||
|
||||
## Quickstart
|
||||
|
||||
To make things easier, we provide a starter repository with a preconfigured dltHub project. It contains a working source, pipeline, transformations, and a small dashboard so you can focus on learning the Runtime rather than setting everything up from scratch.
|
||||
|
||||
This starter pack includes:
|
||||
|
||||
1. A dlt pipeline that loads data from the jaffle shop API into a local DuckDB destination.
|
||||
2. A remote destination configured as MotherDuck. You can swap it for any other cloud destination you prefer (for example
|
||||
[BigQuery](../../dlt-ecosystem/destinations/bigquery.md),
|
||||
[Snowflake](../../dlt-ecosystem/destinations/snowflake.md),
|
||||
[AWS S3](../../dlt-ecosystem/destinations/filesystem.md), …).
|
||||
3. A simple Marimo dashboard that you can use to explore and analyze the data.
|
||||
4. A set of custom transformations that are executed after the raw data is loaded.
|
||||
|
||||
We’ll walk through cloning the repo, installing dependencies, connecting to Runtime, and then deploying both pipelines and dashboards.
|
||||
|
||||
### 1. Clone the starter pack
|
||||
|
||||
```sh
|
||||
git clone https://github.com/dlt-hub/runtime-starter-pack.git
|
||||
cd runtime-starter-pack
|
||||
```
|
||||
|
||||
### 2. Install dependencies and activate the environment
|
||||
|
||||
The starter pack comes with a `pyproject.toml` that defines all required dependencies:
|
||||
|
||||
```toml
|
||||
[project]
|
||||
name = "runtime-starter-pack"
|
||||
version = "0.1.0"
|
||||
requires-python = ">=3.13"
|
||||
dependencies = [
|
||||
"dlt[motherduck,workspace,hub]==1.20.0a0",
|
||||
"marimo>=0.18.2",
|
||||
"numpy>=2.3.5",
|
||||
]
|
||||
```
|
||||
|
||||
Install everything with uv:
|
||||
|
||||
```sh
|
||||
uv sync
|
||||
```
|
||||
|
||||
Activate the environment:
|
||||
|
||||
```sh
|
||||
source .venv/bin/activate
|
||||
```
|
||||
|
||||
### 3. Configure your credentials
|
||||
|
||||
If you are running this tutorial as part of the early access program, you need to create `.dlt/secrets.toml` file and add your Runtime invite code there:
|
||||
|
||||
```toml
|
||||
[runtime]
|
||||
invite_code="xxx-yyy"
|
||||
```
|
||||
|
||||
Next, configure your destination credentials. The starter pack uses MotherDuck as the destination, but you can switch to any other destination you prefer.
|
||||
Details on configuring credentials for Runtime are available [here](../runtime/overview.md#credentials-and-configs).
|
||||
Make sure your destination credentials are valid before running pipelines remotely. Below you can find instructions for configuring credentials for MotherDuck destination.
|
||||
|
||||
**`prod.config.toml`** (for batch jobs running on Runtime):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination]
|
||||
destination_type = "motherduck"
|
||||
```
|
||||
|
||||
**`prod.secrets.toml`** (for batch jobs - read/write credentials):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination.credentials]
|
||||
database = "your_database"
|
||||
password = "your-motherduck-service-token" # Read/write token
|
||||
```
|
||||
|
||||
**`access.config.toml`** (for interactive notebooks):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination]
|
||||
destination_type = "motherduck"
|
||||
```
|
||||
|
||||
**`access.secrets.toml`** (for interactive notebooks - read-only credentials):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination.credentials]
|
||||
database = "your_database"
|
||||
password = "your-motherduck-read-only-token" # Read-only token
|
||||
```
|
||||
|
||||
:::tip Getting MotherDuck Credentials
|
||||
1. Sign up at [motherduck.com](https://motherduck.com)
|
||||
2. Go to Settings > Service Tokens
|
||||
3. Create two tokens:
|
||||
- A **read/write** token for the `prod` profile
|
||||
- A **read-only** token for the `access` profile
|
||||
:::
|
||||
|
||||
:::warning Security
|
||||
Files matching `*.secrets.toml` and `secrets.toml` are gitignored by default. Never commit secrets to version control. The Runtime securely stores your secrets when you sync your configuration.
|
||||
:::
|
||||
|
||||
### 4. Log in to dltHub Runtime
|
||||
|
||||
Authenticate your local workspace with the managed Runtime:
|
||||
|
||||
```sh
|
||||
uv run dlt runtime login
|
||||
```
|
||||
|
||||
This will:
|
||||
|
||||
1. Open a browser window.
|
||||
2. Use GitHub OAuth for authentication.
|
||||
3. Link your local workspace to your dltHub Runtime account through automatically generated workspace id. You can find this id in your `config.toml`.
|
||||
|
||||
Currently, GitHub-based authentication is the only supported method. Additional authentication options will be added later.
|
||||
|
||||
:::tip
|
||||
For a full list of available commands and options, see the [Runtime CLI reference](../runtime/overview.md#common-commands).
|
||||
:::
|
||||
|
||||
### Job types in dltHub Runtime
|
||||
|
||||
dltHub Runtime supports two types of jobs:
|
||||
|
||||
- **Batch jobs** – Python scripts that are meant to be run once or on a schedule.
|
||||
- Created with commands like `dlt runtime launch <script>` (and scheduled with `dlt runtime schedule <script>`).
|
||||
- Typical use cases: ELT pipelines, transformation runs, backfills.
|
||||
- Runs with the `prod` profile.
|
||||
|
||||
- **Interactive jobs** – long-running jobs that serve an interactive notebook or app.
|
||||
- Started with `dlt runtime <script>`.
|
||||
- Typical use cases: Marimo notebooks, dashboards, and (in the future) apps like Streamlit.
|
||||
- Runs with the `access` profile.
|
||||
|
||||
### 5. Run your first pipeline on Runtime
|
||||
|
||||
Now let’s deploy and run a pipeline remotely:
|
||||
|
||||
```sh
|
||||
uv run dlt runtime launch fruitshop_pipeline.py
|
||||
```
|
||||
|
||||
This single command:
|
||||
|
||||
1. Uploads your code and configuration to Runtime.
|
||||
2. Creates and starts a batch job.
|
||||
3. Streams logs and status, so you can follow the run from your terminal. To run it in deatached mode, use `uv run dlt runtime launch fruitshop_pipeline.py -d`
|
||||
|
||||
dltHub supports two types of jobs:
|
||||
* batch job, which are Python scripts, which are supposed to be run once or scheduled
|
||||
* interactive job, which basically serves the interactive notebook
|
||||
|
||||
### 6. Open an interactive notebook
|
||||
|
||||
```sh
|
||||
uv run dlt runtime serve fruitshop_notebook.py
|
||||
```
|
||||
|
||||
This command:
|
||||
|
||||
1. Uploads your code and configuration.
|
||||
2. Starts an interactive notebook session using the access profile.
|
||||
3. Opens the notebook in your browser.
|
||||
|
||||
:::note
|
||||
Interactive notebooks use the `access` profile with read-only credentials, so they are safe for data exploration and dashboarding without the risk of accidental writes.
|
||||
Read more about profiles in the [Runtime profiles docs](../runtime/overview.md#profiles).
|
||||
:::
|
||||
|
||||
Interactive jobs are the building block for serving notebooks, dashboards , streamlit or similar apps (in the future).
|
||||
At the moment, only Marimo is supported. You can share links to these interactive jobs with your colleagues for collaborative exploration.
|
||||
|
||||
### 7. Schedule a pipeline
|
||||
|
||||
To run a pipeline on a schedule, use:
|
||||
|
||||
```sh
|
||||
uv run dlt runtime schedule fruitshop_pipeline.py "*/10 * * * *"
|
||||
```
|
||||
|
||||
This example schedules the pipeline to run every 10 minutes. Use [crontab.guru](https://crontab.guru) to build and test your cron expressions.
|
||||
|
||||
To cancel an existing schedule:
|
||||
|
||||
```sh
|
||||
uv run dlt runtime schedule fruitshop_pipeline.py cancel
|
||||
```
|
||||
|
||||
## Review and manage jobs in the UI
|
||||
|
||||
The command line is great for development, but the dltHub web UI gives you a bird’s-eye view of everything running on Runtime.
|
||||
Visit [dlthub.app](https://dlthub.app) to access the dashboard. You will find:
|
||||
|
||||
1. A list of existing jobs.
|
||||
2. An overview of scheduled runs.
|
||||
3. Visibility into interactive sessions.
|
||||
4. Management actions and workspace settings
|
||||
|
||||
Visit [dlthub.app](https://dlthub.app) to access the web dashboard. The dashboard provides overview of your existing jobs, scheduled and interactive runs and some management and settings.
|
||||
|
||||
### Pipelines and data access in the Dashboard
|
||||
|
||||
The dltHub Dashboard lets you see all your pipelines and job runs, inspect job metadata (status, start time, duration, logs, etc.), and access the data in your destination via a SQL interface.
|
||||
This makes it easy to debug issues, check the health of your pipelines, and quickly validate the data that has been loaded.
|
||||
|
||||
### Public links for interactive jobs
|
||||
|
||||
Interactive jobs such as notebooks and dashboards can be shared via public links. To manage public links:
|
||||
|
||||
1. Open the context menu of a job in the job list or navigate to the job detail page.
|
||||
2. Click "Manage Public Link".
|
||||
3. Enable the link to generate a shareable URL, or disable it to revoke access.
|
||||
|
||||
Anyone with an active public link can view the running notebook or dashboard, even if they don’t have direct Runtime access. This is ideal for sharing dashboards with stakeholders, business users, or other teams.
|
||||
|
||||
## Add transformations
|
||||
|
||||
Raw ingested data is rarely enough. Transformations let you reshape, enrich, and prepare data for analytics and downstream tools. Transformations are useful when you want to
|
||||
aggregate raw data into reporting tables, join multiple tables into enriched datasets, create dimensional models for analytics, and apply business logic to normalize or clean data.
|
||||
|
||||
dltHub Transformations let you build new tables or entire datasets from data that has already been ingested using dlt.
|
||||
|
||||
Key characteristics:
|
||||
|
||||
1. Defined in Python functions decorated with `@dlt.hub.transformation`.
|
||||
2. Can use Python (via Ibis) or pure SQL
|
||||
3. Operate on the destination dataset (`dlt.Dataset`)
|
||||
4. Executed on the destination compute or locally via DuckDB
|
||||
|
||||
You can find full details in the [Transformations](../features/transformations/index.md) documentation. Below are a few core patterns to get you started.
|
||||
|
||||
### Basic example with Ibis
|
||||
|
||||
Use the `@dlt.hub.transformation` decorator to define transformations. The function must accept a `dlt.Dataset` parameter and yield an Ibis table expression or SQL query.
|
||||
|
||||
```py
|
||||
import dlt
|
||||
import typing
|
||||
from ibis import ir
|
||||
|
||||
@dlt.hub.transformation
|
||||
def customer_orders(dataset: dlt.Dataset) -> typing.Iterator[ir.Table]:
|
||||
"""Aggregate statistics about previous customer orders"""
|
||||
orders = dataset.table("orders").to_ibis()
|
||||
yield orders.group_by("customer_id").aggregate(
|
||||
first_order=orders.ordered_at.min(),
|
||||
most_recent_order=orders.ordered_at.max(),
|
||||
number_of_orders=orders.id.count(),
|
||||
)
|
||||
```
|
||||
|
||||
This transformation reads the `orders` table from the destination, aggregates per customer, and yields a result that can be materialized as a new table.
|
||||
|
||||
### Joining multiple tables
|
||||
|
||||
You can join multiple tables and then aggregate or reshape the data:
|
||||
|
||||
```py
|
||||
import dlt
|
||||
import typing
|
||||
import ibis
|
||||
from ibis import ir
|
||||
|
||||
@dlt.hub.transformation
|
||||
def customer_payments(dataset: dlt.Dataset) -> typing.Iterator[ir.Table]:
|
||||
"""Customer order and payment info"""
|
||||
orders = dataset.table("orders").to_ibis()
|
||||
payments = dataset.table("payments").to_ibis()
|
||||
yield (
|
||||
payments.left_join(orders, payments.order_id == orders.id)
|
||||
.group_by(orders.customer_id)
|
||||
.aggregate(total_amount=ibis._.amount.sum())
|
||||
)
|
||||
```
|
||||
Here, we join `payments` with `orders` and aggregate total payment amounts per customer.
|
||||
|
||||
### Using Pure SQL
|
||||
|
||||
If you prefer, you can also write transformations as raw SQL:
|
||||
|
||||
```py
|
||||
@dlt.hub.transformation
|
||||
def enriched_purchases(dataset: dlt.Dataset) -> typing.Any:
|
||||
yield dataset(
|
||||
"""
|
||||
SELECT customers.name, purchases.quantity
|
||||
FROM purchases
|
||||
JOIN customers
|
||||
ON purchases.customer_id = customers.id
|
||||
"""
|
||||
)
|
||||
```
|
||||
|
||||
This is a good option if your team is more comfortable with SQL or you want to port existing SQL models.
|
||||
|
||||
### Running transformations locally
|
||||
|
||||
The starter pack includes a predefined `jaffle_transformations.py` script that:
|
||||
|
||||
1. Combines two resources: data from the jaffle shop API and payments stored in parquet files.
|
||||
2. Loads them into a local DuckDB (default dev profile).
|
||||
3. Creates aggregations and loads them into the remote destination.
|
||||
|
||||
:::tip
|
||||
Before running transformations locally, you need to issue a license for the transformations feature:
|
||||
|
||||
```sh
|
||||
dlt license issue dlthub.transformation
|
||||
```
|
||||
You can find more details in the [license section](../getting-started/installation.md#self-licensing) of the docs.
|
||||
:::
|
||||
|
||||
To run transformations locally (using the default `dev` profile):
|
||||
|
||||
```sh
|
||||
uv run python jaffle_transformations.py
|
||||
```
|
||||
|
||||
### Running with the production profile
|
||||
|
||||
To run the same transformations against your production destination:
|
||||
|
||||
```sh
|
||||
uv run dlt profile prod pin
|
||||
uv run python jaffle_transformations.py
|
||||
```
|
||||
|
||||
* `dlt profile prod pin` sets prod as the active profile.
|
||||
* The script will now read from and write to the production dataset and credentials.
|
||||
|
||||
### Deploying transformations to Runtime
|
||||
|
||||
You can deploy and orchestrate transformations on dltHub Runtime just like any other pipeline:
|
||||
|
||||
```sh
|
||||
uv run dlt runtime launch jaffle_transformations.py
|
||||
```
|
||||
|
||||
This uploads the transformation script, runs it on managed infrastructure, and streams logs back to your terminal. You can also schedule this job and monitor it via the dltHub UI.
|
||||
|
||||
## Next steps
|
||||
|
||||
You’ve completed the introductory tutorial for dltHub Runtime: you’ve learned how to deploy pipelines, run interactive notebooks, and add transformations.
|
||||
|
||||
As next steps, we recommend:
|
||||
|
||||
1. Take one of your existing dlt pipelines and schedule it on the managed Runtime.
|
||||
2. Explore our [MCP](../features/mcp-server.md) integration for connecting Runtime to tools and agents.
|
||||
3. Add [data checks](../features/quality/data-quality.md) to your pipelines to monitor data quality and catch issues early.
|
||||
|
||||
This gives you a trusted, managed environment for both ingestion and analytics, built on dlt and powered by dltHub Runtime.
|
||||
@@ -52,7 +52,7 @@ To get started quickly, follow the [installation instructions](getting-started/i
|
||||
3. **[Data quality](features/quality/data-quality.md)**: define correctness rules, run checks, and fail fast with actionable messages.
|
||||
4. **[Data apps & sharing](../general-usage/dataset-access/marimo)**: build lightweight, shareable data apps and notebooks for consumers.
|
||||
5. **[AI agentic support](features/mcp-server.md)**: use MCP servers to analyze pipelines and datasets.
|
||||
6. **Managed runtime**: deploy and run with a single command—no infra to provision or patch.
|
||||
6. **[Managed runtime](runtime/overview.md)**: deploy and run with a single command—no infra to provision or patch.
|
||||
7. **[Storage choice](ecosystem/iceberg.md)**: pick managed Iceberg-based lakehouse, DuckLake, or bring your own storage.
|
||||
|
||||
### How dltHub fits with dlt (OSS)
|
||||
@@ -81,7 +81,7 @@ dltHub consists of three main products. You can use them together or compose the
|
||||
|
||||
### Runtime
|
||||
|
||||
**Runtime [Private preview]** - a managed cloud runtime operated by dltHub:
|
||||
**[Runtime](runtime/overview.md)** - a managed cloud runtime operated by dltHub:
|
||||
|
||||
* Scalable execution for pipelines and transformations.
|
||||
* APIs, web interfaces, and auxiliary services.
|
||||
|
||||
315
docs/website/docs/hub/runtime/overview.md
Normal file
315
docs/website/docs/hub/runtime/overview.md
Normal file
@@ -0,0 +1,315 @@
|
||||
---
|
||||
title: Overview
|
||||
description: Deploy and run dlt pipelines and notebooks in the cloud
|
||||
keywords: [runtime, deployment, cloud, scheduling, notebooks, dashboard]
|
||||
---
|
||||
|
||||
# dltHub Runtime
|
||||
|
||||
dltHub Runtime is a managed cloud platform for running your `dlt` pipelines and notebooks. It provides:
|
||||
|
||||
- Cloud execution of batch pipelines and interactive notebooks
|
||||
- Scheduling with cron expressions
|
||||
- A web dashboard for monitoring runs, viewing logs, and managing jobs
|
||||
- Secure secrets management with multiple profiles
|
||||
|
||||
dltHub Runtime creates a mirror of your local workspace (called a **workspace deployment**). You continue working with your familiar dlt pipelines, datasets, notebooks, and dashboards - they just run remotely instead of on your machine.
|
||||
|
||||
:::caution
|
||||
Each GitHub account can have only one remote workspace. When you run `dlt runtime login`, it connects your current local workspace to this remote workspace. If you later connect a different local repository and deploy or launch a job, it will replace your existing [**deployment** and **configuration**](#deployments-and-configurations), making any previously scheduled jobs defunct.
|
||||
|
||||
Support for multiple remote workspaces (mirroring multiple local repositories) is planned for next year.
|
||||
:::
|
||||
|
||||
## Credentials and configs
|
||||
|
||||
### Understanding workspace profiles
|
||||
|
||||
dlt Runtime uses **profiles** to manage different configurations for different environments. The two main profiles are:
|
||||
|
||||
| Profile | Purpose | Credentials |
|
||||
|---------|---------|-------------|
|
||||
| `prod` | Production/batch jobs | Read/write access to your destination |
|
||||
| `access` | Interactive notebooks and dashboards | Read-only access (for safe data exploration) |
|
||||
|
||||
### Setting up configuration files
|
||||
|
||||
Configuration files live in the `.dlt/` directory:
|
||||
|
||||
```text
|
||||
.dlt/
|
||||
├── config.toml # Default config (local development)
|
||||
├── secrets.toml # Default secrets (gitignored, local only)
|
||||
├── prod.config.toml # Production profile config
|
||||
├── prod.secrets.toml # Production secrets (gitignored)
|
||||
├── access.config.toml # Access profile config
|
||||
└── access.secrets.toml # Access secrets (gitignored)
|
||||
```
|
||||
|
||||
Below you will find an example with the credentials set for the MotherDuck destination. You can swap it for any other cloud destination you prefer (for example
|
||||
[BigQuery](../../dlt-ecosystem/destinations/bigquery.md),
|
||||
[Snowflake](../../dlt-ecosystem/destinations/snowflake.md),
|
||||
[AWS S3](../../dlt-ecosystem/destinations/filesystem.md), …).
|
||||
|
||||
**Default `config.toml`** (for local development with DuckDB):
|
||||
|
||||
```toml
|
||||
[runtime]
|
||||
log_level = "WARNING"
|
||||
dlthub_telemetry = true
|
||||
|
||||
# Runtime connection settings (set after login)
|
||||
auth_base_url = "https://dlthub.app/api/auth"
|
||||
api_base_url = "https://dlthub.app/api/api"
|
||||
workspace_id = "your-workspace-id" # will be set by the runtime cli automatically
|
||||
|
||||
[destination.fruitshop_destination]
|
||||
destination_type = "duckdb"
|
||||
```
|
||||
|
||||
**`prod.config.toml`** (for batch jobs running on Runtime):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination]
|
||||
destination_type = "motherduck"
|
||||
```
|
||||
|
||||
**`prod.secrets.toml`** (for batch jobs - read/write credentials):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination.credentials]
|
||||
database = "your_database"
|
||||
password = "your-motherduck-service-token" # Read/write token
|
||||
```
|
||||
|
||||
**`access.config.toml`** (for interactive notebooks):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination]
|
||||
destination_type = "motherduck"
|
||||
```
|
||||
|
||||
**`access.secrets.toml`** (for interactive notebooks - read-only credentials):
|
||||
|
||||
```toml
|
||||
[destination.fruitshop_destination.credentials]
|
||||
database = "your_database"
|
||||
password = "your-motherduck-read-only-token" # Read-only token
|
||||
```
|
||||
|
||||
:::warning Security
|
||||
Files matching `*.secrets.toml` and `secrets.toml` are gitignored by default. Never commit secrets to version control. The Runtime securely stores your secrets when you sync your configuration.
|
||||
:::
|
||||
|
||||
## Web UI
|
||||
|
||||
Visit [dlthub.app](https://dlthub.app) to access the web dashboard. The dashboard provides:
|
||||
|
||||
### Overview
|
||||
The workspace overview shows all your jobs and recent runs at a glance. Lists auto-refresh every 10 seconds.
|
||||
|
||||
### Jobs
|
||||
View and manage all jobs in your workspace. A **job** represents a script that can be run on demand or on a schedule.
|
||||
|
||||
From the Jobs page you can:
|
||||
- View job details and run history
|
||||
- Change or cancel schedules for batch jobs
|
||||
- Create and manage **public links** for interactive jobs (notebooks/dashboards)
|
||||
|
||||
#### Public kinks for interactive jobs
|
||||
|
||||
Interactive jobs like notebooks and dashboards can be shared via public links. To manage public links:
|
||||
1. Open the context menu on a job in the job list, or go to the job detail page
|
||||
2. Click "Manage Public Link"
|
||||
3. Enable the link to generate a shareable URL, or disable it to revoke access
|
||||
|
||||
Anyone with an active public link can view the running notebook or dashboard. This is useful for sharing dashboards with stakeholders who don't have Runtime access.
|
||||
|
||||
### Runs
|
||||
Monitor all job runs with:
|
||||
- Run status (pending, running, completed, failed, cancelled)
|
||||
- Start time and duration
|
||||
- Trigger type (manual, scheduled, API)
|
||||
|
||||
### Run details
|
||||
Click on any run to see:
|
||||
- Full execution logs
|
||||
- Run metadata
|
||||
- Pipeline information
|
||||
|
||||
### Deployment & config
|
||||
View the files deployed to Runtime:
|
||||
- Current deployment version
|
||||
- Configuration profiles
|
||||
- File listing
|
||||
|
||||
### Dashboard
|
||||
Access the dlt pipeline dashboard to visualize:
|
||||
- Pipeline schemas
|
||||
- Load information
|
||||
- Data lineage
|
||||
|
||||
### Settings
|
||||
Manage workspace settings and view workspace metadata.
|
||||
|
||||
## CLI reference
|
||||
|
||||
For detailed CLI documentation, see [CLI](../command-line-interface.md).
|
||||
|
||||
### Common commands
|
||||
|
||||
| Command | Description |
|
||||
|---------|-------------|
|
||||
| `dlt runtime login` | Authenticate with GitHub OAuth |
|
||||
| `dlt runtime logout` | Clear local credentials |
|
||||
| `dlt runtime launch <script>` | Deploy and run a batch script |
|
||||
| `dlt runtime serve <script>` | Deploy and run an interactive notebook |
|
||||
| `dlt runtime schedule <script> "<cron>"` | Schedule a script with cron expression |
|
||||
| `dlt runtime schedule <script> cancel` | Cancel a scheduled script |
|
||||
| `dlt runtime logs <script> [run_number]` | View logs for a run |
|
||||
| `dlt runtime cancel <script> [run_number]` | Cancel a running job |
|
||||
| `dlt runtime dashboard` | Open the web dashboard |
|
||||
| `dlt runtime deploy` | Sync code and config without running |
|
||||
| `dlt runtime info` | Show workspace overview |
|
||||
|
||||
### Deployment Commands
|
||||
|
||||
```sh
|
||||
# Sync only code (deployment)
|
||||
dlt runtime deployment sync
|
||||
|
||||
# Sync only configuration (secrets and config)
|
||||
dlt runtime configuration sync
|
||||
|
||||
# List all deployments
|
||||
dlt runtime deployment list
|
||||
|
||||
# Get deployment details
|
||||
dlt runtime deployment info [version_number]
|
||||
```
|
||||
|
||||
### Job commands
|
||||
|
||||
```sh
|
||||
# List all jobs
|
||||
dlt runtime job list
|
||||
|
||||
# Get job details
|
||||
dlt runtime job info <script_path_or_job_name>
|
||||
|
||||
# Create a job without running it
|
||||
dlt runtime job create <script_path> [--name NAME] [--schedule "CRON"] [--interactive]
|
||||
```
|
||||
|
||||
### Job run commands
|
||||
|
||||
```sh
|
||||
# List all runs
|
||||
dlt runtime job-run list [script_path_or_job_name]
|
||||
|
||||
# Get run details
|
||||
dlt runtime job-run info <script_path_or_job_name> [run_number]
|
||||
|
||||
# Create a new run
|
||||
dlt runtime job-run create <script_path_or_job_name>
|
||||
|
||||
# View run logs
|
||||
dlt runtime job-run logs <script_path_or_job_name> [run_number] [-f/--follow]
|
||||
|
||||
# Cancel a run
|
||||
dlt runtime job-run cancel <script_path_or_job_name> [run_number]
|
||||
```
|
||||
|
||||
### Configuration commands
|
||||
|
||||
```sh
|
||||
# List configuration versions
|
||||
dlt runtime configuration list
|
||||
|
||||
# Get configuration details
|
||||
dlt runtime configuration info [version_number]
|
||||
|
||||
# Sync local configuration to Runtime
|
||||
dlt runtime configuration sync
|
||||
```
|
||||
|
||||
## Development workflow
|
||||
|
||||
A typical development flow:
|
||||
|
||||
1. **Develop locally** with DuckDB (`dev` profile):
|
||||
```sh
|
||||
uv run python fruitshop_pipeline.py
|
||||
```
|
||||
|
||||
2. **Test your notebook locally**:
|
||||
```sh
|
||||
uv run marimo edit fruitshop_notebook.py
|
||||
```
|
||||
|
||||
3. **Run pipeline in Runtime** (`prod` profile):
|
||||
```sh
|
||||
uv run dlt runtime launch fruitshop_pipeline.py
|
||||
```
|
||||
|
||||
4. **Run notebook in Runtime** (`access` profile):
|
||||
```sh
|
||||
uv run dlt runtime serve fruitshop_notebook.py
|
||||
```
|
||||
|
||||
5. **Check run status and logs**:
|
||||
```sh
|
||||
uv run dlt runtime logs fruitshop_pipeline.py
|
||||
```
|
||||
|
||||
## Key concepts
|
||||
|
||||
### Jobs vs runs
|
||||
|
||||
- A **Job** is a script registered in your workspace. It defines what code to run and optionally a schedule.
|
||||
- A **Run** is a single execution of a job. Each run has its own logs, status, and metadata.
|
||||
|
||||
### Batch vs interactive
|
||||
|
||||
- **Batch jobs** run with the `prod` profile and are meant for scheduled data loading
|
||||
- **Interactive jobs** run with the `access` profile and are meant for notebooks and dashboards
|
||||
|
||||
### Profiles
|
||||
|
||||
Profiles allow you to have different configurations for different environments:
|
||||
|
||||
- Local development can use DuckDB with no credentials needed
|
||||
- Production runs use MotherDuck (or other destinations) with full read/write access
|
||||
- Interactive sessions use read-only credentials for safety
|
||||
|
||||
### Deployments and configurations
|
||||
|
||||
- **Deployment**: Your code files (`.py` scripts, notebooks)
|
||||
- **Configuration**: Your `.dlt/*.toml` files (settings and secrets)
|
||||
|
||||
Both are versioned separately, allowing you to update code without changing secrets and vice versa.
|
||||
|
||||
## Current limitations
|
||||
|
||||
- **Runtime limits**: Jobs are limited to 120 minutes maximum execution time
|
||||
- **Interactive timeout**: Notebooks are killed after about 5 minutes of inactivity (no open browser tab)
|
||||
- **UI operations**: Creating jobs must currently be done via CLI (schedules can be changed in the WebUI)
|
||||
- **Pagination**: List views show the top 100 items
|
||||
- **Log latency**: Logs may lag 20-30 seconds during execution; they are guaranteed complete after run finishes (completed or failed state)
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### No 'access' profile detected
|
||||
If you see this warning, your interactive notebooks will use the default configuration. Create `access.config.toml` and `access.secrets.toml` files with read-only credentials.
|
||||
|
||||
### No 'prod' profile detected
|
||||
Batch jobs will use the default configuration. Create `prod.config.toml` and `prod.secrets.toml` files with read/write credentials.
|
||||
|
||||
### Job not using latest code
|
||||
The CLI does not yet detect whether local code differs from remote. Run `dlt runtime deployment sync` to ensure your latest code is deployed.
|
||||
|
||||
### Logs not appearing
|
||||
Logs may lag 20-30 seconds during execution. Wait for the run to complete for guaranteed complete logs, or use `--follow` to tail logs in real-time:
|
||||
```sh
|
||||
dlt runtime logs my_pipeline.py --follow
|
||||
```
|
||||
@@ -24,7 +24,7 @@ You can create one in three CLI-based ways:
|
||||
|
||||
## Step 0: Install dlt with workspace support
|
||||
|
||||
Before you start, make sure that you followed [installation instructions](../getting-started/installation.md) and enabled [additional Workspace features](../getting-started/installation.md#enable-dlthub-free-tier-features)
|
||||
Before you start, make sure that you followed [installation instructions](../getting-started/installation.md) and enabled [additional Workspace features](../getting-started/installation.md#enable-dlthub-free-and-paid-features)
|
||||
|
||||
**dltHub Workspace** is a unified environment for developing, running, and maintaining data pipelines — from local development to production.
|
||||
|
||||
@@ -65,7 +65,7 @@ A collaborative AI-human workflow that integrates `dlt` with AI editors and agen
|
||||
- **Cursor**,
|
||||
- **Continue**,
|
||||
- **Copilot**,
|
||||
- [the full list](../../dlt-ecosystem/llm-tooling/llm-native-workflow#prerequisites)
|
||||
- [the full list](../../dlt-ecosystem/llm-tooling/llm-native-workflow#configure-ide)
|
||||
|
||||
|
||||
**Initialize your first workspace pipeline**
|
||||
@@ -301,4 +301,4 @@ dlt pipeline {pipeline_name} trace # last run trace & errors
|
||||
Once your pipeline runs locally:
|
||||
* [Monitor via the workspace dashboard](../../general-usage/dataset-access/data-quality-dashboard)
|
||||
* Set up [Profiles](../core-concepts/profiles-dlthub.md) to manage separate dev, prod, and test environments
|
||||
* [Deploy a pipeline](../../walkthroughs/deploy-a-pipeline/)
|
||||
* [Deploy to runtime](../getting-started/runtime-tutorial.md#5-run-your-first-pipeline-on-runtime)
|
||||
|
||||
@@ -14,6 +14,7 @@ It provides:
|
||||
* powerful transformation with [`@dlt.hub.transformation`](../features/transformations/index.md) and [dbt integration](../features/transformations/dbt-transformations.md)
|
||||
* [dashboard](../../general-usage/dashboard.md) as a comprehensive observability tool
|
||||
* [MCP](../features/mcp-server.md) for data exploration and semantic modeling
|
||||
* [dltHub Runtime Integration](../runtime/overview.md) for easy deployment of pipelines, transformations and notebooks with no configuration
|
||||
|
||||
It automates essential tasks like data loading, quality checks, and governance while enabling seamless collaboration across teams and providing a consistent development-to-production workflow.
|
||||
|
||||
|
||||
@@ -51,7 +51,6 @@ const config = {
|
||||
url: 'https://dlthub.com',
|
||||
baseUrl: '/docs',
|
||||
onBrokenLinks: 'throw',
|
||||
onBrokenMarkdownLinks: 'throw',
|
||||
onBrokenAnchors: 'throw',
|
||||
favicon: 'img/favicon.ico',
|
||||
staticDirectories: ['public', 'static'],
|
||||
@@ -79,7 +78,12 @@ const config = {
|
||||
},
|
||||
},
|
||||
|
||||
markdown: { mermaid: true },
|
||||
markdown: {
|
||||
mermaid: true,
|
||||
hooks: {
|
||||
onBrokenMarkdownLinks: 'throw',
|
||||
},
|
||||
},
|
||||
themes: ['@docusaurus/theme-mermaid'],
|
||||
|
||||
presets: [
|
||||
|
||||
@@ -390,14 +390,11 @@ const sidebars = {
|
||||
type: "category",
|
||||
label: "Run in Snowflake",
|
||||
link: {
|
||||
type: "generated-index",
|
||||
title: "Run in Snwoflake",
|
||||
description: "How to run dlt in Snowflake.",
|
||||
slug: "walkthroughs/run-in-snowflake",
|
||||
keywords: ["snowflake"]
|
||||
type: "doc",
|
||||
id: "walkthroughs/run-in-snowflake/index",
|
||||
},
|
||||
items: [
|
||||
"walkthroughs/run-in-snowflake/run-in-snowflake"
|
||||
"walkthroughs/run-in-snowflake/application-architecture"
|
||||
]
|
||||
}
|
||||
]
|
||||
@@ -502,6 +499,7 @@ const sidebars = {
|
||||
'hub/intro',
|
||||
'hub/getting-started/installation',
|
||||
{ type: 'ref', id: 'dlt-ecosystem/llm-tooling/llm-native-workflow' },
|
||||
'hub/getting-started/runtime-tutorial',
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -553,7 +551,7 @@ const sidebars = {
|
||||
type: 'category',
|
||||
label: 'Runtime',
|
||||
items: [
|
||||
'hub/production/observability',
|
||||
'hub/runtime/overview',
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[project]
|
||||
name = "dlt"
|
||||
version = "1.19.1"
|
||||
version = "1.20.0"
|
||||
description = "dlt is an open-source python-first scalable data loading library that does not require any backend to run."
|
||||
authors = [{ name = "dltHub Inc.", email = "services@dlthub.com" }]
|
||||
requires-python = ">=3.9.2, <3.15"
|
||||
@@ -52,7 +52,7 @@ dependencies = [
|
||||
"orjson>=3.11.0 ; python_version > '3.13'",
|
||||
"tenacity>=8.0.2",
|
||||
"jsonpath-ng>=1.5.3",
|
||||
"fsspec>=2025.9.0",
|
||||
"fsspec>=2022.4.0",
|
||||
"packaging>=21.1",
|
||||
"pluggy>=1.3.0",
|
||||
"win-precise-time>=1.4.2 ; os_name == 'nt' and python_version < '3.13'",
|
||||
@@ -187,6 +187,11 @@ workspace = [
|
||||
"mcp>=1.2.1 ; python_version >= '3.10'",
|
||||
"pathspec>=0.11.2",
|
||||
]
|
||||
hub = [
|
||||
"dlthub>=0.20.0a1,<0.21 ; python_version >= '3.10'",
|
||||
"dlt-runtime>=0.20.0a0,<0.21 ; python_version >= '3.10'",
|
||||
]
|
||||
|
||||
dbml = [
|
||||
"pydbml"
|
||||
]
|
||||
@@ -309,6 +314,7 @@ dlt = "dlt.__plugins__"
|
||||
|
||||
[tool.uv.sources]
|
||||
flake8-encodings = { git = "https://github.com/dlt-hub/flake8-encodings.git", branch = "disable_jedi_support" }
|
||||
# dlthub = { path = "../dlt-plus/packages/dlthub", editable = true }
|
||||
|
||||
[tool.hatch.build.targets.sdist]
|
||||
packages = ["dlt"]
|
||||
|
||||
@@ -753,6 +753,7 @@ def test_configuration_is_mutable_mapping(environment: Any, env_provider: Config
|
||||
"request_max_retry_delay": 300,
|
||||
"config_files_storage_path": "storage",
|
||||
"dlthub_dsn": None,
|
||||
"run_id": None,
|
||||
"http_show_error_body": False,
|
||||
"http_max_error_body_length": 8192,
|
||||
"secret_value": None,
|
||||
|
||||
@@ -286,18 +286,25 @@ def test_toml_global_config() -> None:
|
||||
# project overwrites
|
||||
v, _ = config.get_value("param1", bool, None, "api", "params")
|
||||
assert v == "a"
|
||||
# verify locations
|
||||
# verify global location
|
||||
assert os.path.join(global_dir, "config.toml") in config.locations
|
||||
assert os.path.join(global_dir, "config.toml") in config.present_locations
|
||||
# verify local location
|
||||
assert os.path.join(settings_dir, "config.toml") in config.locations
|
||||
assert os.path.join(settings_dir, "config.toml") in config.present_locations
|
||||
|
||||
secrets = SecretsTomlProvider(settings_dir=settings_dir, global_dir=global_dir)
|
||||
assert secrets._toml_paths[1] == os.path.join(global_dir, SECRETS_TOML)
|
||||
# check if values from project exist
|
||||
secrets_project = SecretsTomlProvider(settings_dir=settings_dir)
|
||||
assert secrets._config_doc == secrets_project._config_doc
|
||||
# verify locations
|
||||
# verify global location (secrets not present)
|
||||
assert os.path.join(global_dir, "secrets.toml") in secrets.locations
|
||||
assert os.path.join(global_dir, "secrets.toml") not in secrets.present_locations
|
||||
# verify local location (secrets not present)
|
||||
assert os.path.join(settings_dir, "secrets.toml") in secrets.locations
|
||||
# CI creates secrets.toml so actually those are sometimes present
|
||||
# assert os.path.join(settings_dir, "secrets.toml") not in secrets.present_locations
|
||||
|
||||
|
||||
def test_write_value(toml_providers: ConfigProvidersContainer) -> None:
|
||||
|
||||
22
tests/common/runtime/test_known_plugins.py
Normal file
22
tests/common/runtime/test_known_plugins.py
Normal file
@@ -0,0 +1,22 @@
|
||||
"""Tests behavior of know plugins when they are not installed"""
|
||||
import pytest
|
||||
|
||||
from dlt.common.exceptions import MissingDependencyException
|
||||
|
||||
|
||||
def test_hub_fallback() -> None:
|
||||
import dlt.hub
|
||||
|
||||
if dlt.hub.__found__ or not isinstance(dlt.hub.__exception__, ModuleNotFoundError):
|
||||
pytest.skip(
|
||||
"Skip test due to hub being present or partially loaded: " + str(dlt.hub.__exception__)
|
||||
)
|
||||
|
||||
assert isinstance(dlt.hub.__exception__, ModuleNotFoundError)
|
||||
|
||||
# accessing attributes generates import error
|
||||
|
||||
with pytest.raises(MissingDependencyException) as missing_ex:
|
||||
dlt.hub.transformation
|
||||
|
||||
assert missing_ex.value.dependencies[0] == "dlt[hub]"
|
||||
@@ -10,10 +10,12 @@ from dlt.common.runtime.init import restore_run_context
|
||||
from dlt.common.runtime.run_context import (
|
||||
DOT_DLT,
|
||||
RunContext,
|
||||
ensure_plugin_version_match,
|
||||
get_plugin_modules,
|
||||
is_folder_writable,
|
||||
switched_run_context,
|
||||
)
|
||||
from dlt.common.exceptions import MissingDependencyException
|
||||
from dlt.common.storages.configuration import _make_file_url
|
||||
from dlt.common.utils import set_working_dir
|
||||
|
||||
@@ -46,11 +48,6 @@ def test_run_context() -> None:
|
||||
# check config providers
|
||||
assert len(run_context.initial_providers()) == 3
|
||||
|
||||
assert ctx.context.runtime_config is None
|
||||
ctx.add_extras()
|
||||
# still not applied - must be in container
|
||||
assert ctx.context.runtime_config is None
|
||||
|
||||
with Container().injectable_context(ctx):
|
||||
ctx.initialize_runtime()
|
||||
assert ctx.context.runtime_config is not None
|
||||
@@ -173,3 +170,102 @@ def test_context_with_xdg_dir(mocker) -> None:
|
||||
ctx = PluggableRunContext()
|
||||
run_context = ctx.context
|
||||
assert run_context.global_dir == dlt_home
|
||||
|
||||
|
||||
def test_ensure_plugin_version_match_same_versions() -> None:
|
||||
"""test that matching versions pass without error."""
|
||||
from packaging.specifiers import SpecifierSet
|
||||
|
||||
# Use explicit specifier to test specific version matching scenarios
|
||||
# PEP 440 ordering: .devN < .aN < .bN < .rcN < final < .postN
|
||||
# So we use .dev0 as lower bound to include all pre-releases
|
||||
specifier_1_19 = SpecifierSet(">=1.19.0.dev0,<1.20.0") # includes all prereleases
|
||||
specifier_2_5 = SpecifierSet(">=2.5.0.dev0,<2.6.0")
|
||||
|
||||
# exact same version
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0", "1.19.0", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.5", "1.19.2", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
# different patch versions are ok
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "2.5.0", "2.5.10", "fake-plugin", "hub", specifier_2_5
|
||||
)
|
||||
# alpha specifiers (e.g. 1.19.0a1) - these are LESS than 1.19.0
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0a1", "1.19.0a2", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0a1", "1.19.0", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
# dev specifiers (e.g. 1.19.0.dev1) - these are LESS than 1.19.0a0
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0.dev1", "1.19.0.dev2", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0.dev1", "1.19.0", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
# post release specifiers
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0.post1", "1.19.0.post2", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0.post1", "1.19.0", "fake-plugin", "hub", specifier_1_19
|
||||
)
|
||||
|
||||
|
||||
def test_ensure_plugin_version_match_alpha_plugin() -> None:
|
||||
"""test that alpha plugins (major=0) match specifier."""
|
||||
from packaging.specifiers import SpecifierSet
|
||||
|
||||
# specifier for 0.19.x versions (including all pre-releases)
|
||||
# PEP 440 ordering: .devN < .aN < .bN < .rcN < final < .postN
|
||||
specifier_0_19 = SpecifierSet(">=0.19.0.dev0,<0.20.0")
|
||||
|
||||
# alpha plugin (0.x.y) should match specifier
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0", "0.19.0", "fake-plugin", "hub", specifier_0_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.5", "0.19.2", "fake-plugin", "hub", specifier_0_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "2.19.0", "0.19.0", "fake-plugin", "hub", specifier_0_19
|
||||
)
|
||||
# alpha plugin with alpha/dev specifiers
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0a1", "0.19.0a2", "fake-plugin", "hub", specifier_0_19
|
||||
)
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", "1.19.0.dev1", "0.19.0.dev2", "fake-plugin", "hub", specifier_0_19
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.parametrize(
|
||||
"dlt_version,plugin_version",
|
||||
[
|
||||
# minor mismatch
|
||||
("1.19.0", "1.18.0"),
|
||||
("1.19.0", "0.18.0"),
|
||||
("1.19.0a1", "1.18.0a1"),
|
||||
("1.19.0.dev1", "1.18.0.dev1"),
|
||||
# major mismatch (non-alpha plugin)
|
||||
("1.19.0", "2.19.0"),
|
||||
("1.19.0a1", "2.19.0a1"),
|
||||
("1.19.0.dev1", "2.19.0.dev1"),
|
||||
],
|
||||
)
|
||||
def test_ensure_plugin_version_match_mismatch(dlt_version: str, plugin_version: str) -> None:
|
||||
"""test that mismatched versions raise MissingDependencyException."""
|
||||
from packaging.specifiers import SpecifierSet
|
||||
|
||||
# Use explicit specifier that requires 1.19.x versions
|
||||
specifier = SpecifierSet(">=1.19.0,<1.20.0")
|
||||
|
||||
with pytest.raises(MissingDependencyException) as exc_info:
|
||||
ensure_plugin_version_match(
|
||||
"fake-plugin", dlt_version, plugin_version, "fake-plugin", "hub", specifier
|
||||
)
|
||||
assert "fake-plugin" in str(exc_info.value)
|
||||
|
||||
@@ -92,18 +92,19 @@ def test_save_load_schema(load_storage: LoadStorage) -> None:
|
||||
schema = Schema("event")
|
||||
schema._stored_version = 762171
|
||||
|
||||
load_storage.new_packages.create_package("copy")
|
||||
load_storage.new_packages.create_package("copy", schema=schema)
|
||||
assert load_storage.new_packages.storage.has_file(
|
||||
os.path.join("copy", PackageStorage.SCHEMA_FILE_NAME)
|
||||
)
|
||||
schema_copy = load_storage.new_packages.load_schema("copy")
|
||||
assert schema.stored_version == schema_copy.stored_version
|
||||
# also check file name
|
||||
saved_file_name = load_storage.new_packages.save_schema("copy", schema)
|
||||
assert saved_file_name.endswith(
|
||||
os.path.join(
|
||||
load_storage.new_packages.storage.storage_path, "copy", PackageStorage.SCHEMA_FILE_NAME
|
||||
)
|
||||
)
|
||||
assert load_storage.new_packages.storage.has_file(
|
||||
os.path.join("copy", PackageStorage.SCHEMA_FILE_NAME)
|
||||
)
|
||||
schema_copy = load_storage.new_packages.load_schema("copy")
|
||||
assert schema.stored_version == schema_copy.stored_version
|
||||
|
||||
|
||||
def test_create_package(load_storage: LoadStorage) -> None:
|
||||
@@ -434,8 +435,7 @@ def create_load_package(
|
||||
) -> str:
|
||||
schema = Schema("test")
|
||||
load_id = create_load_id()
|
||||
package_storage.create_package(load_id)
|
||||
package_storage.save_schema(load_id, schema)
|
||||
package_storage.create_package(load_id, schema=schema)
|
||||
add_new_jobs(package_storage, load_id, new_jobs, table_name)
|
||||
return load_id
|
||||
|
||||
|
||||
@@ -3,6 +3,7 @@ import pytest
|
||||
|
||||
from dlt.common import json, pendulum
|
||||
from dlt.common.schema import TSchemaTables
|
||||
from dlt.common.schema.schema import Schema
|
||||
from dlt.common.storages import PackageStorage, LoadStorage
|
||||
from dlt.common.storages.exceptions import LoadPackageNotFound, NoMigrationPathException
|
||||
|
||||
@@ -171,7 +172,7 @@ def test_import_extracted_package(load_storage: LoadStorage) -> None:
|
||||
FileStorage(os.path.join(load_storage.config.load_volume_path, "extracted")), "new"
|
||||
)
|
||||
load_id = create_load_id()
|
||||
extracted.create_package(load_id)
|
||||
extracted.create_package(load_id, schema=Schema("package"))
|
||||
extracted_state = extracted.get_load_package_state(load_id)
|
||||
load_storage.import_extracted_package(load_id, extracted)
|
||||
# make sure state was imported
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
import os
|
||||
import pytest
|
||||
from importlib.metadata import PackageNotFoundError
|
||||
from packaging.requirements import Requirement
|
||||
|
||||
from dlt.version import get_installed_requirement_string
|
||||
from dlt.version import get_installed_requirement_string, get_dependency_requirement
|
||||
|
||||
|
||||
def test_installed_requirement_string() -> None:
|
||||
@@ -15,3 +16,24 @@ def test_installed_requirement_string() -> None:
|
||||
# this is not installed
|
||||
with pytest.raises(PackageNotFoundError):
|
||||
get_installed_requirement_string("requests-X")
|
||||
|
||||
|
||||
def test_get_dependency_requirement() -> None:
|
||||
# dlt depends on dlthub, so this should return a Requirement
|
||||
req = get_dependency_requirement("dlthub")
|
||||
assert req is not None
|
||||
assert isinstance(req, Requirement)
|
||||
assert req.name == "dlthub"
|
||||
# click has a version specifier
|
||||
assert str(req.specifier) != ""
|
||||
|
||||
# dlt depends on fsspec with a version constraint
|
||||
req = get_dependency_requirement("fsspec")
|
||||
assert req is not None
|
||||
assert req.name == "fsspec"
|
||||
# verify we can check version satisfaction
|
||||
assert "2022.4.0" in req.specifier
|
||||
|
||||
# non-existent dependency returns None
|
||||
req = get_dependency_requirement("non-existent-package-xyz")
|
||||
assert req is None
|
||||
|
||||
@@ -2,6 +2,7 @@ import pathlib
|
||||
import sys
|
||||
from typing import Any
|
||||
import pickle
|
||||
import os
|
||||
|
||||
import pytest
|
||||
|
||||
@@ -11,6 +12,7 @@ from dlt._workspace._templates._single_file_templates.fruitshop_pipeline import
|
||||
fruitshop as fruitshop_source,
|
||||
)
|
||||
from dlt._workspace.helpers.dashboard import utils as dashboard_utils
|
||||
from dlt.pipeline.trace import get_trace_file_path
|
||||
|
||||
|
||||
def _normpath(path: str) -> str:
|
||||
@@ -94,9 +96,9 @@ def broken_trace_pipeline() -> Any:
|
||||
)
|
||||
bp.run(fruitshop_source())
|
||||
|
||||
trace_file = dashboard_utils.get_trace_file_path(bp.pipeline_name, bp.pipelines_dir)
|
||||
trace_file.parent.mkdir(parents=True, exist_ok=True)
|
||||
with trace_file.open("wb") as f:
|
||||
trace_file = get_trace_file_path(bp.pipelines_dir, bp.pipeline_name)
|
||||
os.makedirs(os.path.dirname(trace_file), exist_ok=True)
|
||||
with open(trace_file, mode="wb") as f:
|
||||
pickle.dump({"not": "a real PipelineTrace"}, f)
|
||||
|
||||
return bp
|
||||
|
||||
@@ -193,7 +193,7 @@ def test_simple_incremental_pipeline(page: Page, simple_incremental_pipeline: An
|
||||
page.get_by_role("button", name="Run Query").click()
|
||||
|
||||
# enable dlt tables
|
||||
page.get_by_role("switch", name="Show _dlt tables").check()
|
||||
page.get_by_role("switch", name="Show internal tables").check()
|
||||
|
||||
# state page
|
||||
_open_section(page, "state")
|
||||
@@ -367,7 +367,7 @@ def test_workspace_profile_dev(page: Page):
|
||||
|
||||
page.goto(f"http://localhost:{test_port}/?profile=dev&pipeline=fruit_pipeline")
|
||||
|
||||
expect(page.get_by_role("switch", name="overview")).to_be_visible()
|
||||
expect(page.get_by_role("switch", name="overview")).to_be_visible(timeout=20000)
|
||||
page.get_by_role("switch", name="loads").check()
|
||||
expect(page.get_by_role("row", name="fruitshop").first).to_be_visible()
|
||||
|
||||
|
||||
@@ -1,12 +1,11 @@
|
||||
import pytest
|
||||
|
||||
import dlt
|
||||
|
||||
|
||||
def test_direct_module_import():
|
||||
"""It's currently not possible to import the module directly"""
|
||||
with pytest.raises(ModuleNotFoundError):
|
||||
import dlt.hub.data_quality # type: ignore[import-not-found]
|
||||
# NOTE: this is still re-import so submodule structure is not importable
|
||||
from dlt.hub import data_quality as dq
|
||||
|
||||
dq.checks.is_in("payment_methods", ["card", "cash", "voucher"]) # type: ignore[attr-defined,unused-ignore]
|
||||
|
||||
|
||||
def test_from_module_import():
|
||||
@@ -18,8 +17,8 @@ def test_data_quality_entrypoints():
|
||||
import dlthub.data_quality as dq
|
||||
|
||||
# access a single check
|
||||
assert dlt.hub.data_quality is dq
|
||||
assert dlt.hub.data_quality.checks is dq.checks
|
||||
assert dlt.hub.data_quality.checks.is_not_null is dq.checks.is_not_null
|
||||
assert dlt.hub.data_quality.CheckSuite is dq.CheckSuite
|
||||
assert dlt.hub.data_quality.prepare_checks is dq.prepare_checks
|
||||
assert dlt.hub.data_quality is not dq
|
||||
assert dlt.hub.data_quality.checks is dq.checks # type: ignore[attr-defined,unused-ignore]
|
||||
assert dlt.hub.data_quality.checks.is_not_null is dq.checks.is_not_null # type: ignore[attr-defined,unused-ignore]
|
||||
assert dlt.hub.data_quality.CheckSuite is dq.CheckSuite # type: ignore[attr-defined,unused-ignore]
|
||||
assert dlt.hub.data_quality.prepare_checks is dq.prepare_checks # type: ignore[attr-defined,unused-ignore]
|
||||
|
||||
36
tests/hub/test_plugin_import.py
Normal file
36
tests/hub/test_plugin_import.py
Normal file
@@ -0,0 +1,36 @@
|
||||
import pytest
|
||||
from pytest_console_scripts import ScriptRunner
|
||||
|
||||
from tests.workspace.utils import isolated_workspace
|
||||
|
||||
|
||||
def test_import_props() -> None:
|
||||
import dlt.hub
|
||||
|
||||
# hub plugin found
|
||||
assert dlt.hub.__found__
|
||||
assert len(dlt.hub.__all__) > 0
|
||||
|
||||
# no exception
|
||||
assert dlt.hub.__exception__ is None
|
||||
|
||||
# regular attribute error raised
|
||||
|
||||
with pytest.raises(AttributeError) as attr_err:
|
||||
dlt.hub._unknown_feature
|
||||
|
||||
assert "_unknown_feature" in str(attr_err.value)
|
||||
|
||||
|
||||
def test_runtime_client_imports(script_runner: ScriptRunner) -> None:
|
||||
pytest.importorskip("dlt_runtime")
|
||||
|
||||
import dlt_runtime # type: ignore[import-untyped,import-not-found,unused-ignore]
|
||||
|
||||
print(dlt_runtime.__version__)
|
||||
|
||||
# check command activation
|
||||
|
||||
with isolated_workspace("pipelines"):
|
||||
result = script_runner.run(["dlt", "runtime", "-h"])
|
||||
assert result.returncode == 0
|
||||
@@ -378,7 +378,8 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
job = expect_load_file(
|
||||
client, file_storage, json.dumps(insert_json), user_table_name, status="failed"
|
||||
)
|
||||
assert "No such field: _unk_" in job.exception()
|
||||
assert "No such field: _unk_" in job.failed_message()
|
||||
assert job.exception() is not None
|
||||
|
||||
# insert null value
|
||||
insert_json = copy(load_json)
|
||||
@@ -386,7 +387,8 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
job = expect_load_file(
|
||||
client, file_storage, json.dumps(insert_json), user_table_name, status="failed"
|
||||
)
|
||||
assert "Only optional fields can be set to NULL. Field: timestamp;" in job.exception()
|
||||
assert "Only optional fields can be set to NULL. Field: timestamp;" in job.failed_message()
|
||||
assert job.exception() is not None
|
||||
|
||||
# insert a wrong type
|
||||
insert_json = copy(load_json)
|
||||
@@ -394,7 +396,8 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
job = expect_load_file(
|
||||
client, file_storage, json.dumps(insert_json), user_table_name, status="failed"
|
||||
)
|
||||
assert "Could not parse 'AA' as a timestamp" in job.exception()
|
||||
assert "Could not parse 'AA' as a timestamp" in job.failed_message()
|
||||
assert job.exception() is not None
|
||||
|
||||
# numeric overflow on bigint
|
||||
insert_json = copy(load_json)
|
||||
@@ -403,7 +406,8 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
job = expect_load_file(
|
||||
client, file_storage, json.dumps(insert_json), user_table_name, status="failed"
|
||||
)
|
||||
assert "Could not convert value" in job.exception()
|
||||
assert "Could not convert value" in job.failed_message()
|
||||
assert job.exception() is not None
|
||||
|
||||
# numeric overflow on NUMERIC
|
||||
insert_json = copy(load_json)
|
||||
@@ -421,8 +425,9 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
)
|
||||
assert (
|
||||
"Invalid NUMERIC value: 100000000000000000000000000000 Field: parse_data__intent__id;"
|
||||
in job.exception()
|
||||
in job.failed_message()
|
||||
)
|
||||
assert job.exception() is not None
|
||||
|
||||
# max bigquery decimal is (76, 76) (256 bit) = 5.7896044618658097711785492504343953926634992332820282019728792003956564819967E+38
|
||||
insert_json = copy(load_json)
|
||||
@@ -436,8 +441,9 @@ def test_loading_errors(client: BigQueryClient, file_storage: FileStorage) -> No
|
||||
"Invalid BIGNUMERIC value:"
|
||||
" 578960446186580977117854925043439539266.34992332820282019728792003956564819968 Field:"
|
||||
" parse_data__metadata__rasa_x_id;"
|
||||
in job.exception()
|
||||
in job.failed_message()
|
||||
)
|
||||
assert job.exception() is not None
|
||||
|
||||
|
||||
def prepare_oauth_json() -> Tuple[str, str]:
|
||||
|
||||
@@ -58,7 +58,7 @@ def perform_load(
|
||||
job = load.submit_job(f, load_id, schema)
|
||||
# job execution failed
|
||||
if isinstance(job, FinalizedLoadJobWithFollowupJobs):
|
||||
raise RuntimeError(job.exception())
|
||||
raise RuntimeError(job.failed_message())
|
||||
jobs.append(job)
|
||||
|
||||
yield client, jobs, root_path, load_id # type: ignore
|
||||
|
||||
@@ -519,7 +519,7 @@ def test_table_format_partitioning(
|
||||
with pytest.raises(PipelineStepFailed) as pip_ex:
|
||||
pipeline.run(zero_part())
|
||||
assert isinstance(pip_ex.value.__context__, LoadClientJobRetry)
|
||||
assert "partitioning" in pip_ex.value.__context__.retry_message
|
||||
assert "partitioning" in pip_ex.value.__context__.failed_message
|
||||
elif destination_config.table_format == "iceberg":
|
||||
# while Iceberg supports partition evolution, we don't apply it
|
||||
pipeline.run(zero_part())
|
||||
|
||||
@@ -6,6 +6,7 @@ import pytest
|
||||
from unittest.mock import patch
|
||||
from typing import List, Tuple
|
||||
|
||||
from dlt.common.destination.exceptions import DestinationTerminalException
|
||||
from dlt.common.exceptions import TerminalException, TerminalValueError
|
||||
from dlt.common.storages import FileStorage, PackageStorage, ParsedLoadJobFileName
|
||||
from dlt.common.storages.configuration import FilesystemConfiguration
|
||||
@@ -240,6 +241,8 @@ def test_spool_job_failed_and_package_completed() -> None:
|
||||
load_id, schema = prepare_load_package(load.load_storage, NORMALIZED_FILES)
|
||||
run_all(load)
|
||||
|
||||
# not loading
|
||||
assert load.current_load_id is None
|
||||
package_info = load.load_storage.get_load_package_info(load_id)
|
||||
assert package_info.state == "loaded"
|
||||
# all jobs failed
|
||||
@@ -259,7 +262,10 @@ def test_spool_job_failed_terminally_exception_init() -> None:
|
||||
with patch.object(dummy_impl.DummyClient, "complete_load") as complete_load:
|
||||
with pytest.raises(LoadClientJobFailed) as py_ex:
|
||||
run_all(load)
|
||||
assert isinstance(py_ex.value.client_exception, DestinationTerminalException)
|
||||
assert py_ex.value.load_id == load_id
|
||||
# not loading - package aborted
|
||||
assert load.current_load_id is None
|
||||
package_info = load.load_storage.get_load_package_info(load_id)
|
||||
assert package_info.state == "aborted"
|
||||
# both failed - we wait till the current loop is completed and then raise
|
||||
@@ -281,6 +287,8 @@ def test_spool_job_failed_transiently_exception_init() -> None:
|
||||
with pytest.raises(LoadClientJobRetry) as py_ex:
|
||||
run_all(load)
|
||||
assert py_ex.value.load_id == load_id
|
||||
# loading - can be retried
|
||||
assert load.current_load_id is not None
|
||||
package_info = load.load_storage.get_load_package_info(load_id)
|
||||
assert package_info.state == "normalized"
|
||||
# both failed - we wait till the current loop is completed and then raise
|
||||
@@ -316,6 +324,7 @@ def test_spool_job_failed_exception_complete() -> None:
|
||||
load_id, _ = prepare_load_package(load.load_storage, NORMALIZED_FILES)
|
||||
with pytest.raises(LoadClientJobFailed) as py_ex:
|
||||
run_all(load)
|
||||
assert load.current_load_id is None
|
||||
assert py_ex.value.load_id == load_id
|
||||
package_info = load.load_storage.get_load_package_info(load_id)
|
||||
assert package_info.state == "aborted"
|
||||
|
||||
@@ -259,7 +259,7 @@ def test_complete_load(naming: str, client: SqlJobClientBase) -> None:
|
||||
def test_schema_update_create_table(client: SqlJobClientBase) -> None:
|
||||
# infer typical rasa event schema
|
||||
schema = client.schema
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, schema, "load_id", None)
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, None, schema, "load_id", None)
|
||||
table_name = "event_test_table" + uniq_id()
|
||||
# this will be sort
|
||||
timestamp = item_normalizer._infer_column("timestamp", 182879721.182912)
|
||||
@@ -305,7 +305,7 @@ def test_schema_update_create_table_bigquery_hidden_dataset(
|
||||
|
||||
# infer typical rasa event schema
|
||||
schema = client.schema
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, schema, "load_id", None)
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, None, schema, "load_id", None)
|
||||
# this will be partition
|
||||
timestamp = item_normalizer._infer_column("timestamp", 182879721.182912)
|
||||
# this will be cluster
|
||||
@@ -333,7 +333,7 @@ def test_schema_update_alter_table(client: SqlJobClientBase) -> None:
|
||||
# force to update schema in chunks by setting the max query size to 10 bytes/chars
|
||||
with patch.object(client.capabilities, "max_query_length", new=10):
|
||||
schema = client.schema
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, schema, "load_id", None)
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, None, schema, "load_id", None)
|
||||
col1 = item_normalizer._infer_column("col1", "string")
|
||||
table_name = "event_test_table" + uniq_id()
|
||||
schema.update_table(new_table(table_name, columns=[col1]))
|
||||
@@ -1197,7 +1197,7 @@ def test_schema_retrieval(destination_config: DestinationTestConfiguration) -> N
|
||||
|
||||
def prepare_schema(client: SqlJobClientBase, case: str) -> Tuple[List[Dict[str, Any]], str]:
|
||||
client.update_stored_schema()
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, client.schema, "load_id", None)
|
||||
item_normalizer = JsonLItemsNormalizer(None, None, None, client.schema, "load_id", None)
|
||||
rows = load_json_case(case)
|
||||
# normalize rows
|
||||
normalize_rows(rows, client.schema.naming)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user