mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-17 19:31:34 +00:00
Compare commits
607 Commits
v0.20.2
...
jerco/sql-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
feb37c55c7 | ||
|
|
9a0abc1bfc | ||
|
|
490d68e076 | ||
|
|
c45147fe6d | ||
|
|
bc3468e649 | ||
|
|
8fff6729a2 | ||
|
|
08f50acb9e | ||
|
|
436a5f5cd4 | ||
|
|
aca710048f | ||
|
|
673ad50e21 | ||
|
|
8ee86a61a0 | ||
|
|
0dda0a90cf | ||
|
|
220d8b888c | ||
|
|
42d5812577 | ||
|
|
dea4f5f8ff | ||
|
|
8f50eee330 | ||
|
|
8fd8dfcf74 | ||
|
|
10b27b9633 | ||
|
|
5808ee6dd7 | ||
|
|
a66fe7f467 | ||
|
|
18fef38702 | ||
|
|
3ad61d5d81 | ||
|
|
bb1f5b43be | ||
|
|
a642b20abc | ||
|
|
c112050455 | ||
|
|
43e3fc22c4 | ||
|
|
41c6177ae2 | ||
|
|
72ecd1ce74 | ||
|
|
2d0b975b6c | ||
|
|
8a0bc39a66 | ||
|
|
f3c7b6bfd1 | ||
|
|
0391e4e53a | ||
|
|
3ad3c21886 | ||
|
|
6e0ed751e1 | ||
|
|
c43c79a995 | ||
|
|
d6cc8b3042 | ||
|
|
2f4a6e33ec | ||
|
|
b9867e89cb | ||
|
|
13b18654f0 | ||
|
|
aafa1c7f47 | ||
|
|
638e3ad299 | ||
|
|
d9cfeb1ea3 | ||
|
|
e6786a2bc3 | ||
|
|
13571435a3 | ||
|
|
efb890db2d | ||
|
|
f3735187a6 | ||
|
|
3032594b26 | ||
|
|
1df7a029b4 | ||
|
|
f467fba151 | ||
|
|
8791313ec5 | ||
|
|
7798f932a0 | ||
|
|
a588607ec6 | ||
|
|
348764d99d | ||
|
|
5aeb088a73 | ||
|
|
e943b9fc84 | ||
|
|
892426eecb | ||
|
|
1d25b2b046 | ||
|
|
da70840be8 | ||
|
|
7632782ecd | ||
|
|
6fae647097 | ||
|
|
fc8b8c11d5 | ||
|
|
26a7922a34 | ||
|
|
c18b4f1f1a | ||
|
|
fa31a67499 | ||
|
|
742cd990ee | ||
|
|
8463af35c3 | ||
|
|
b34a4ab493 | ||
|
|
417ccdc3b4 | ||
|
|
7c46b784ef | ||
|
|
067b861d30 | ||
|
|
9f6ed3cec3 | ||
|
|
43edc887f9 | ||
|
|
6d4c64a436 | ||
|
|
0ed14fa236 | ||
|
|
51f2daf4b0 | ||
|
|
76f7bf9900 | ||
|
|
3fc715f066 | ||
|
|
b6811da84f | ||
|
|
1dffccd9da | ||
|
|
9ed9936c84 | ||
|
|
e75ae8c754 | ||
|
|
b68535b8cb | ||
|
|
5310498647 | ||
|
|
22b1a09aa2 | ||
|
|
6855fe06a7 | ||
|
|
affd8619c2 | ||
|
|
b67d5f396b | ||
|
|
b3039fdc76 | ||
|
|
9bdf5fe74a | ||
|
|
c675c2d318 | ||
|
|
2cd1f7d98e | ||
|
|
ce9ac8ea10 | ||
|
|
b90ab74975 | ||
|
|
6d3c3f1995 | ||
|
|
74fbaa18cd | ||
|
|
fc7c073691 | ||
|
|
29f504e201 | ||
|
|
eeb490ed15 | ||
|
|
c220b1e42c | ||
|
|
d973ae9ec6 | ||
|
|
f461683df5 | ||
|
|
41ed976941 | ||
|
|
e93ad5f118 | ||
|
|
d75ed964f8 | ||
|
|
284ac9b138 | ||
|
|
7448ec5adb | ||
|
|
caa6269bc7 | ||
|
|
31691c3b88 | ||
|
|
3a904a811f | ||
|
|
b927a31a53 | ||
|
|
d8dd75320c | ||
|
|
a613556246 | ||
|
|
8d2351d541 | ||
|
|
f72b603196 | ||
|
|
4eb17b57fb | ||
|
|
85a4b87267 | ||
|
|
0d320c58da | ||
|
|
ed1ff2caac | ||
|
|
d80646c258 | ||
|
|
a9b4316346 | ||
|
|
36776b96e7 | ||
|
|
7f2d3cd24f | ||
|
|
d046ae0606 | ||
|
|
e8c267275e | ||
|
|
a4951749a8 | ||
|
|
e1a2e8d9f5 | ||
|
|
f80c78e3a5 | ||
|
|
c541eca592 | ||
|
|
726aba0586 | ||
|
|
d300addee1 | ||
|
|
d5d16f01f4 | ||
|
|
2cb26e2699 | ||
|
|
b4793b4f9b | ||
|
|
045e70ccf1 | ||
|
|
ba23395c8e | ||
|
|
0aacd99168 | ||
|
|
e4b5d73dc4 | ||
|
|
bd950f687a | ||
|
|
aea23a488b | ||
|
|
22731df07b | ||
|
|
c55be164e6 | ||
|
|
9d73304c1a | ||
|
|
719b2026ab | ||
|
|
22416980d1 | ||
|
|
3d28b6704c | ||
|
|
5d1b104e1f | ||
|
|
4a8a68049d | ||
|
|
4b7fd1d46a | ||
|
|
0722922c03 | ||
|
|
40321d7966 | ||
|
|
434f3d2678 | ||
|
|
6dd9c2c5ba | ||
|
|
5e6be1660e | ||
|
|
31acb95d7a | ||
|
|
683190b711 | ||
|
|
ebb84c404f | ||
|
|
2ca6ce688b | ||
|
|
a40550b89d | ||
|
|
b2aea11cdb | ||
|
|
43b39fd1aa | ||
|
|
5cc8626e96 | ||
|
|
f95e9efbc0 | ||
|
|
25c974af8c | ||
|
|
b5c6f09a9e | ||
|
|
bd3e623240 | ||
|
|
63343653a9 | ||
|
|
d8b97c1077 | ||
|
|
e0b0edaeed | ||
|
|
3cafc9e13f | ||
|
|
13f31aed90 | ||
|
|
d513491046 | ||
|
|
281d2491a5 | ||
|
|
9857e1dd83 | ||
|
|
6b36b18029 | ||
|
|
d8868c5197 | ||
|
|
b141620125 | ||
|
|
51d8440dd4 | ||
|
|
5b2562a919 | ||
|
|
44a9da621e | ||
|
|
69aa6bf964 | ||
|
|
f9ef9da110 | ||
|
|
57ae9180c2 | ||
|
|
efe926d20c | ||
|
|
1081b8e720 | ||
|
|
8205921c4b | ||
|
|
da6c211611 | ||
|
|
354c1e0d4d | ||
|
|
855419d698 | ||
|
|
e94fd61b24 | ||
|
|
4cf9b73c3d | ||
|
|
8442fb66a5 | ||
|
|
f8cefa3eff | ||
|
|
d83e0fb8d8 | ||
|
|
3e9da06365 | ||
|
|
bda70c988e | ||
|
|
229e897070 | ||
|
|
f20e83a32b | ||
|
|
dd84f9a896 | ||
|
|
e6df4266f6 | ||
|
|
b591e1a2b7 | ||
|
|
3dab058c73 | ||
|
|
c7bc6eb812 | ||
|
|
c690ecc1fd | ||
|
|
73e272f06e | ||
|
|
95d087b51b | ||
|
|
40ae6b6bc8 | ||
|
|
fe20534a98 | ||
|
|
dd7af477ac | ||
|
|
178f74b753 | ||
|
|
a14f563ec8 | ||
|
|
ff109e1806 | ||
|
|
5e46694b68 | ||
|
|
73af9a56e5 | ||
|
|
d2aa920275 | ||
|
|
c34f3530c8 | ||
|
|
c019a94206 | ||
|
|
f9bdfa050b | ||
|
|
1b35d1aa21 | ||
|
|
420ef9cc7b | ||
|
|
02fdc2cb9f | ||
|
|
f82745fb0c | ||
|
|
3397bdc6a5 | ||
|
|
96e858ac0b | ||
|
|
f6a98b5674 | ||
|
|
824f0bf2c0 | ||
|
|
5648b1c622 | ||
|
|
bb1382e576 | ||
|
|
085ea9181f | ||
|
|
eace5b77a7 | ||
|
|
1c61bb18e6 | ||
|
|
f79a968a09 | ||
|
|
34c23fe650 | ||
|
|
3ae9475655 | ||
|
|
11436fed45 | ||
|
|
21a7b71657 | ||
|
|
280e9ad9c9 | ||
|
|
97f31c88e1 | ||
|
|
5f483a6b13 | ||
|
|
86f24e13db | ||
|
|
4bda8c8880 | ||
|
|
80a5d27127 | ||
|
|
4307a82058 | ||
|
|
5c01c42308 | ||
|
|
80ba71682b | ||
|
|
26625e9627 | ||
|
|
134e8423b7 | ||
|
|
04a9195297 | ||
|
|
8a10a69f59 | ||
|
|
fd7c95d1d2 | ||
|
|
79aa136301 | ||
|
|
3b5cec6cc6 | ||
|
|
0e9a67956d | ||
|
|
f9f0eab0b7 | ||
|
|
ed01b439cf | ||
|
|
a398ed1a3e | ||
|
|
a818e6551b | ||
|
|
0a7471ebdc | ||
|
|
1a5bc83598 | ||
|
|
6e2df00648 | ||
|
|
b338dfc99a | ||
|
|
47033c459f | ||
|
|
92a0930634 | ||
|
|
cad1a48eb0 | ||
|
|
b451f87e3c | ||
|
|
20756290bc | ||
|
|
f44c6ed136 | ||
|
|
b501f4317c | ||
|
|
91b43f71bb | ||
|
|
6fc64f0d3b | ||
|
|
ee5c697645 | ||
|
|
3caec08ccb | ||
|
|
f7680379fc | ||
|
|
3789acc5a7 | ||
|
|
8ae232abe8 | ||
|
|
332d23c5eb | ||
|
|
5799973474 | ||
|
|
3d816d56ec | ||
|
|
111f3c28f8 | ||
|
|
10aded793c | ||
|
|
b5cc7b8dff | ||
|
|
449f042742 | ||
|
|
66b70e025b | ||
|
|
578c6d6a20 | ||
|
|
64ce9d6aa4 | ||
|
|
213ddedb85 | ||
|
|
c96201c060 | ||
|
|
16b02f4f55 | ||
|
|
e0d2b02d46 | ||
|
|
65e76df6ec | ||
|
|
052a3060d4 | ||
|
|
b65ae1ddde | ||
|
|
a8246ab1f1 | ||
|
|
6854e67464 | ||
|
|
ca7c1fc4ad | ||
|
|
5dbc945f23 | ||
|
|
655ff85dc9 | ||
|
|
6a2ceaa073 | ||
|
|
e8fb29d185 | ||
|
|
8443142f27 | ||
|
|
7ebe21dccb | ||
|
|
c25b7a1143 | ||
|
|
38eb46dfc3 | ||
|
|
fe9ed9ccdd | ||
|
|
ff4e5219b1 | ||
|
|
04632a008f | ||
|
|
6925cebcf6 | ||
|
|
571beb13d9 | ||
|
|
69cd82f483 | ||
|
|
11e379280f | ||
|
|
0018eb7db6 | ||
|
|
154a682180 | ||
|
|
1b79a245e6 | ||
|
|
6b590122c7 | ||
|
|
d5f632e6fd | ||
|
|
2fc8e5e0b6 | ||
|
|
5ab07273ba | ||
|
|
19c9e5bfdf | ||
|
|
60794367a5 | ||
|
|
ea07729bbf | ||
|
|
c4370773f6 | ||
|
|
fda17b456e | ||
|
|
bc3e1a0a71 | ||
|
|
a06988706c | ||
|
|
ce73124bbf | ||
|
|
352c62f3c3 | ||
|
|
81a51d3942 | ||
|
|
64fc3a39a7 | ||
|
|
e5b6f4f293 | ||
|
|
d26e63ed9a | ||
|
|
f4f5d31959 | ||
|
|
e7e12075b9 | ||
|
|
74dda5aa19 | ||
|
|
092e96ce70 | ||
|
|
18102027ba | ||
|
|
f80825d63e | ||
|
|
9316e47b77 | ||
|
|
f99cf1218a | ||
|
|
5871915ce9 | ||
|
|
5ce290043f | ||
|
|
080d27321b | ||
|
|
1d0936bd14 | ||
|
|
706b8ca9df | ||
|
|
7dc491b7ba | ||
|
|
779c789a64 | ||
|
|
409b4ba109 | ||
|
|
59d131d3ac | ||
|
|
6563d09ba7 | ||
|
|
05dea18b62 | ||
|
|
d7177c7d89 | ||
|
|
35f0fea804 | ||
|
|
8953c7c533 | ||
|
|
76c59a5545 | ||
|
|
237048c7ac | ||
|
|
30ff395b7b | ||
|
|
5c0a31b829 | ||
|
|
243bc3d41d | ||
|
|
67b594a950 | ||
|
|
2493c21649 | ||
|
|
d3826e670f | ||
|
|
4b5b1696b7 | ||
|
|
abb59ef14f | ||
|
|
3b7c2816b9 | ||
|
|
484517416f | ||
|
|
39447055d3 | ||
|
|
95cca277c9 | ||
|
|
96083dcaf5 | ||
|
|
75b4cf691b | ||
|
|
7c9171b00b | ||
|
|
3effade266 | ||
|
|
44e7390526 | ||
|
|
c141798abc | ||
|
|
df7ec3fb37 | ||
|
|
90e5507d03 | ||
|
|
332d3494b3 | ||
|
|
6393f5a5d7 | ||
|
|
ce97a9ca7a | ||
|
|
9af071bfe4 | ||
|
|
45a41202f3 | ||
|
|
9768999ca1 | ||
|
|
fc0d11c0a5 | ||
|
|
e6344205bb | ||
|
|
9d7a6556ef | ||
|
|
15f4add0b8 | ||
|
|
464becacd0 | ||
|
|
51a76d0d63 | ||
|
|
052e54d43a | ||
|
|
9e796671dd | ||
|
|
a9a6254f52 | ||
|
|
8b3a09c7ae | ||
|
|
6aa4d812d4 | ||
|
|
07fa719fb0 | ||
|
|
650b34ae24 | ||
|
|
0a935855f3 | ||
|
|
d500aae4dc | ||
|
|
370d3e746d | ||
|
|
ab06149c81 | ||
|
|
e72895c7c9 | ||
|
|
fe4a67daa4 | ||
|
|
09ea989d81 | ||
|
|
7fa14b6948 | ||
|
|
d4974cd35c | ||
|
|
459178811b | ||
|
|
b37f6a010e | ||
|
|
e817164d31 | ||
|
|
09ce43edbf | ||
|
|
2980cd17df | ||
|
|
8c804de643 | ||
|
|
c8241b87e6 | ||
|
|
f204d24ed8 | ||
|
|
d5461ccd8b | ||
|
|
a20d2d93d3 | ||
|
|
57e1eec165 | ||
|
|
d2dbe6afe4 | ||
|
|
72eb163223 | ||
|
|
af16c74c3a | ||
|
|
664f6584b9 | ||
|
|
76fd3bdf8c | ||
|
|
b633adb881 | ||
|
|
b6e534cdd0 | ||
|
|
1dc4adb86f | ||
|
|
0a4d7c4831 | ||
|
|
ad67e55d74 | ||
|
|
2fae64a488 | ||
|
|
1a984601ee | ||
|
|
454168204c | ||
|
|
43642956a2 | ||
|
|
1fe53750fa | ||
|
|
8609c02383 | ||
|
|
355b0c496e | ||
|
|
cd6894acf4 | ||
|
|
b90b3a9c19 | ||
|
|
e7b8488be8 | ||
|
|
06cc0c57e8 | ||
|
|
87072707ed | ||
|
|
ef63319733 | ||
|
|
2068dd5510 | ||
|
|
3e1e171c66 | ||
|
|
5f9ed1a83c | ||
|
|
3d9e54d970 | ||
|
|
52a0fdef6c | ||
|
|
d9b02fb0a0 | ||
|
|
6c8de62b24 | ||
|
|
2d3d1b030a | ||
|
|
88acf0727b | ||
|
|
02839ec779 | ||
|
|
44a8f6a3bf | ||
|
|
751ea92576 | ||
|
|
02007b3619 | ||
|
|
fe0b9e7ef5 | ||
|
|
4b1c6b51f9 | ||
|
|
0b4689f311 | ||
|
|
b77eff8f6f | ||
|
|
2782a33ecf | ||
|
|
94c6cf1b3c | ||
|
|
3c8daacd3e | ||
|
|
2f9907b072 | ||
|
|
287c4d2b03 | ||
|
|
ba9d76b3f9 | ||
|
|
0efaaf7daf | ||
|
|
9ae7d68260 | ||
|
|
486afa9fcd | ||
|
|
1f189f5225 | ||
|
|
580b1fdd68 | ||
|
|
bad0198a36 | ||
|
|
252280b56e | ||
|
|
64bf9c8885 | ||
|
|
935c138736 | ||
|
|
5891b59790 | ||
|
|
4e020c3878 | ||
|
|
3004969a93 | ||
|
|
873e9714f8 | ||
|
|
fe24dd43d4 | ||
|
|
ed91ded2c1 | ||
|
|
757614d57f | ||
|
|
faff8c00b3 | ||
|
|
45fe76eef4 | ||
|
|
80244a09fe | ||
|
|
ea772ae419 | ||
|
|
c68fca7937 | ||
|
|
37e86257f5 | ||
|
|
c182c05c2f | ||
|
|
b02875a12b | ||
|
|
03332b2955 | ||
|
|
f1f99a2371 | ||
|
|
95116dbb5b | ||
|
|
868fd64adf | ||
|
|
2f7ab2d038 | ||
|
|
159e79ee6b | ||
|
|
3d4a82cca2 | ||
|
|
6ba837d73d | ||
|
|
f4775d7673 | ||
|
|
429396aa02 | ||
|
|
8a5e9b71a5 | ||
|
|
fa78102eaf | ||
|
|
5466d474c5 | ||
|
|
80951ae973 | ||
|
|
d5662ef34c | ||
|
|
57783bb5f6 | ||
|
|
d73ee588e5 | ||
|
|
40089d710b | ||
|
|
6ec61950eb | ||
|
|
72c831a80a | ||
|
|
929931a26a | ||
|
|
577e2438c1 | ||
|
|
2679792199 | ||
|
|
2adf982991 | ||
|
|
1fb4a7f428 | ||
|
|
30e72bc5e2 | ||
|
|
35645a7233 | ||
|
|
d583c8d737 | ||
|
|
a83f00c594 | ||
|
|
45bb955b55 | ||
|
|
c448702c1b | ||
|
|
558a6a03ac | ||
|
|
52ec7907d3 | ||
|
|
792f39a888 | ||
|
|
16264f58c1 | ||
|
|
2317c0c3c8 | ||
|
|
3c09ab9736 | ||
|
|
f10dc0e1b3 | ||
|
|
634bc41d8a | ||
|
|
d7ea3648c6 | ||
|
|
e5c8e19ff2 | ||
|
|
4ddba7e44c | ||
|
|
37b31d10c8 | ||
|
|
93cf1f085f | ||
|
|
a84f824a44 | ||
|
|
9c58f3465b | ||
|
|
0e3778132b | ||
|
|
72722635f2 | ||
|
|
a4c7c7fc55 | ||
|
|
2bad73eead | ||
|
|
c8bc25d11a | ||
|
|
4c06689ff5 | ||
|
|
a45c9d0192 | ||
|
|
34e2c4f90b | ||
|
|
c0e2023c81 | ||
|
|
108b55bdc3 | ||
|
|
a29367b7fe | ||
|
|
1d7e8349ed | ||
|
|
67c194dcd1 | ||
|
|
75d3d87d64 | ||
|
|
4ff3f6d4e8 | ||
|
|
d0773f3346 | ||
|
|
ee58d27d94 | ||
|
|
9e3da391a7 | ||
|
|
bd7010678a | ||
|
|
9f716b31b3 | ||
|
|
3dd486d8fa | ||
|
|
33217891ca | ||
|
|
1d37c4e555 | ||
|
|
9f62ec2153 | ||
|
|
372eca76b8 | ||
|
|
e3cb050bbc | ||
|
|
0ae93c7f54 | ||
|
|
1f6386d760 | ||
|
|
66eb3964e2 | ||
|
|
f460d275ba | ||
|
|
fb91bad800 | ||
|
|
eaec22ae53 | ||
|
|
b7c1768cca | ||
|
|
387b26a202 | ||
|
|
8a1e6438f1 | ||
|
|
aaac5ff2e6 | ||
|
|
4dc29630b5 | ||
|
|
f716631439 | ||
|
|
648a780850 | ||
|
|
de0919ff88 | ||
|
|
8b1ea5fb6c | ||
|
|
85627aafcd | ||
|
|
49065158f5 | ||
|
|
bdb3049218 | ||
|
|
e10d1b0f86 | ||
|
|
83b98c8ebf | ||
|
|
b9d5123aa3 | ||
|
|
c09300bfd2 | ||
|
|
fc490cee7b | ||
|
|
3baa3d7fe8 | ||
|
|
764c7c0fdc | ||
|
|
c97ebbbf35 | ||
|
|
85fe32bd08 | ||
|
|
eba3fd2255 | ||
|
|
e2f2c07873 | ||
|
|
70850cd362 | ||
|
|
16992e6391 | ||
|
|
fd0d95140e | ||
|
|
ac65fcd557 | ||
|
|
4d246567b9 | ||
|
|
1ad1c834f3 | ||
|
|
41610b822c | ||
|
|
c794600242 | ||
|
|
9d414f6ec3 | ||
|
|
552e831306 | ||
|
|
c712c96a0b | ||
|
|
eb46bfc3d6 | ||
|
|
f52537b606 | ||
|
|
762419d2fe | ||
|
|
4feb7cb15b | ||
|
|
eb47b85148 | ||
|
|
9faa019a07 | ||
|
|
9589dc91fa | ||
|
|
14507a283e | ||
|
|
af0fe120ec | ||
|
|
16501ec1c6 | ||
|
|
bf867f6aff | ||
|
|
eb4ad4444f | ||
|
|
8fdba17ac6 |
@@ -1,23 +1,27 @@
|
||||
[bumpversion]
|
||||
current_version = 0.20.0rc1
|
||||
current_version = 1.0.1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
((?P<prerelease>[a-z]+)(?P<num>\d+))?
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prerelease}{num}
|
||||
((?P<prekind>a|b|rc)
|
||||
(?P<pre>\d+) # pre-release version num
|
||||
)?
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prekind}{pre}
|
||||
{major}.{minor}.{patch}
|
||||
commit = False
|
||||
tag = False
|
||||
|
||||
[bumpversion:part:prerelease]
|
||||
[bumpversion:part:prekind]
|
||||
first_value = a
|
||||
values =
|
||||
optional_value = final
|
||||
values =
|
||||
a
|
||||
b
|
||||
rc
|
||||
final
|
||||
|
||||
[bumpversion:part:num]
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
@@ -26,19 +30,10 @@ first_value = 1
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/dbt/adapters/postgres/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/dbt/adapters/redshift/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/dbt/adapters/snowflake/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/dbt/adapters/bigquery/__version__.py]
|
||||
|
||||
[bumpversion:file:docker/Dockerfile]
|
||||
|
||||
16
.changes/0.0.0.md
Normal file
16
.changes/0.0.0.md
Normal file
@@ -0,0 +1,16 @@
|
||||
## Previous Releases
|
||||
|
||||
For information on prior major and minor releases, see their changelogs:
|
||||
|
||||
* [1.0](https://github.com/dbt-labs/dbt-core/blob/1.0.latest/CHANGELOG.md)
|
||||
* [0.21](https://github.com/dbt-labs/dbt-core/blob/0.21.latest/CHANGELOG.md)
|
||||
* [0.20](https://github.com/dbt-labs/dbt-core/blob/0.20.latest/CHANGELOG.md)
|
||||
* [0.19](https://github.com/dbt-labs/dbt-core/blob/0.19.latest/CHANGELOG.md)
|
||||
* [0.18](https://github.com/dbt-labs/dbt-core/blob/0.18.latest/CHANGELOG.md)
|
||||
* [0.17](https://github.com/dbt-labs/dbt-core/blob/0.17.latest/CHANGELOG.md)
|
||||
* [0.16](https://github.com/dbt-labs/dbt-core/blob/0.16.latest/CHANGELOG.md)
|
||||
* [0.15](https://github.com/dbt-labs/dbt-core/blob/0.15.latest/CHANGELOG.md)
|
||||
* [0.14](https://github.com/dbt-labs/dbt-core/blob/0.14.latest/CHANGELOG.md)
|
||||
* [0.13](https://github.com/dbt-labs/dbt-core/blob/0.13.latest/CHANGELOG.md)
|
||||
* [0.12](https://github.com/dbt-labs/dbt-core/blob/0.12.latest/CHANGELOG.md)
|
||||
* [0.11 and earlier](https://github.com/dbt-labs/dbt-core/blob/0.11.latest/CHANGELOG.md)
|
||||
31
.changes/1.0.1.md
Normal file
31
.changes/1.0.1.md
Normal file
@@ -0,0 +1,31 @@
|
||||
## dbt-core 1.1.0 (TBD)
|
||||
|
||||
### Features
|
||||
- Added Support for Semantic Versioning ([#4644](https://github.com/dbt-labs/dbt-core/pull/4644))
|
||||
- New Dockerfile to support specific db adapters and platforms. See docker/README.md for details ([#4495](https://github.com/dbt-labs/dbt-core/issues/4495), [#4487](https://github.com/dbt-labs/dbt-core/pull/4487))
|
||||
- Allow unique_key to take a list ([#2479](https://github.com/dbt-labs/dbt-core/issues/2479), [#4618](https://github.com/dbt-labs/dbt-core/pull/4618))
|
||||
- Add `--quiet` global flag and `print` Jinja function ([#3451](https://github.com/dbt-labs/dbt-core/issues/3451), [#4701](https://github.com/dbt-labs/dbt-core/pull/4701))
|
||||
|
||||
### Fixes
|
||||
- User wasn't asked for permission to overwite a profile entry when running init inside an existing project ([#4375](https://github.com/dbt-labs/dbt-core/issues/4375), [#4447](https://github.com/dbt-labs/dbt-core/pull/4447))
|
||||
- Add project name validation to `dbt init` ([#4490](https://github.com/dbt-labs/dbt-core/issues/4490),[#4536](https://github.com/dbt-labs/dbt-core/pull/4536))
|
||||
- Allow override of string and numeric types for adapters. ([#4603](https://github.com/dbt-labs/dbt-core/issues/4603))
|
||||
- A change in secret environment variables won't trigger a full reparse [#4650](https://github.com/dbt-labs/dbt-core/issues/4650) [4665](https://github.com/dbt-labs/dbt-core/pull/4665)
|
||||
- Fix misspellings and typos in docstrings ([#4545](https://github.com/dbt-labs/dbt-core/pull/4545))
|
||||
|
||||
### Under the hood
|
||||
- Testing cleanup ([#4496](https://github.com/dbt-labs/dbt-core/pull/4496), [#4509](https://github.com/dbt-labs/dbt-core/pull/4509))
|
||||
- Clean up test deprecation warnings ([#3988](https://github.com/dbt-labs/dbt-core/issue/3988), [#4556](https://github.com/dbt-labs/dbt-core/pull/4556))
|
||||
- Use mashumaro for serialization in event logging ([#4504](https://github.com/dbt-labs/dbt-core/issues/4504), [#4505](https://github.com/dbt-labs/dbt-core/pull/4505))
|
||||
- Drop support for Python 3.7.0 + 3.7.1 ([#4584](https://github.com/dbt-labs/dbt-core/issues/4584), [#4585](https://github.com/dbt-labs/dbt-core/pull/4585), [#4643](https://github.com/dbt-labs/dbt-core/pull/4643))
|
||||
- Re-format codebase (except tests) using pre-commit hooks ([#3195](https://github.com/dbt-labs/dbt-core/issues/3195), [#4697](https://github.com/dbt-labs/dbt-core/pull/4697))
|
||||
- Add deps module README ([#4686](https://github.com/dbt-labs/dbt-core/pull/4686/))
|
||||
- Initial conversion of tests to pytest ([#4690](https://github.com/dbt-labs/dbt-core/issues/4690), [#4691](https://github.com/dbt-labs/dbt-core/pull/4691))
|
||||
- Fix errors in Windows for tests/functions ([#4781](https://github.com/dbt-labs/dbt-core/issues/4781), [#4767](https://github.com/dbt-labs/dbt-core/pull/4767))
|
||||
|
||||
Contributors:
|
||||
- [@NiallRees](https://github.com/NiallRees) ([#4447](https://github.com/dbt-labs/dbt-core/pull/4447))
|
||||
- [@alswang18](https://github.com/alswang18) ([#4644](https://github.com/dbt-labs/dbt-core/pull/4644))
|
||||
- [@emartens](https://github.com/ehmartens) ([#4701](https://github.com/dbt-labs/dbt-core/pull/4701))
|
||||
- [@mdesmet](https://github.com/mdesmet) ([#4604](https://github.com/dbt-labs/dbt-core/pull/4604))
|
||||
- [@kazanzhy](https://github.com/kazanzhy) ([#4545](https://github.com/dbt-labs/dbt-core/pull/4545))
|
||||
40
.changes/README.md
Normal file
40
.changes/README.md
Normal file
@@ -0,0 +1,40 @@
|
||||
# CHANGELOG Automation
|
||||
|
||||
We use [changie](https://changie.dev/) to automate `CHANGELOG` generation. For installation and format/command specifics, see the documentation.
|
||||
|
||||
### Quick Tour
|
||||
|
||||
- All new change entries get generated under `/.changes/unreleased` as a yaml file
|
||||
- `header.tpl.md` contains the contents of the entire CHANGELOG file
|
||||
- `0.0.0.md` contains the contents of the footer for the entire CHANGELOG file. changie looks to be in the process of supporting a footer file the same as it supports a header file. Switch to that when available. For now, the 0.0.0 in the file name forces it to the bottom of the changelog no matter what version we are releasing.
|
||||
- `.changie.yaml` contains the fields in a change, the format of a single change, as well as the format of the Contributors section for each version.
|
||||
|
||||
### Workflow
|
||||
|
||||
#### Daily workflow
|
||||
Almost every code change we make associated with an issue will require a `CHANGELOG` entry. After you have created the PR in GitHub, run `changie new` and follow the command prompts to generate a yaml file with your change details. This only needs to be done once per PR.
|
||||
|
||||
The `changie new` command will ensure correct file format and file name. There is a one to one mapping of issues to changes. Multiple issues cannot be lumped into a single entry. If you make a mistake, the yaml file may be directly modified and saved as long as the format is preserved.
|
||||
|
||||
Note: If your PR has been cleared by the Core Team as not needing a changelog entry, the `Skip Changelog` label may be put on the PR to bypass the GitHub action that blacks PRs from being merged when they are missing a `CHANGELOG` entry.
|
||||
|
||||
#### Prerelease Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` to be included in this prerelease and move those files to a directory named for the release version. The `--move-dir` will be created if it does not exist and is created in `/.changes`.
|
||||
|
||||
```
|
||||
changie batch <version> --move-dir '<version>' --prerelease 'rc1'
|
||||
changie merge
|
||||
```
|
||||
|
||||
#### Final Release Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` as well as `/.changes/<version>` to be included in this final release and delete all prereleases. This rolls all prereleases up into a single final release. All `yaml` files in `/unreleased` and `<version>` will be deleted at this point.
|
||||
|
||||
```
|
||||
changie batch <version> --include '<version>' --remove-prereleases
|
||||
changie merge
|
||||
```
|
||||
|
||||
### A Note on Manual Edits & Gotchas
|
||||
- Changie generates markdown files in the `.changes` directory that are parsed together with the `changie merge` command. Every time `changie merge` is run, it regenerates the entire file. For this reason, any changes made directly to `CHANGELOG.md` will be overwritten on the next run of `changie merge`.
|
||||
- If changes need to be made to the `CHANGELOG.md`, make the changes to the relevant `<version>.md` file located in the `/.changes` directory. You will then run `changie merge` to regenerate the `CHANGELOG.MD`.
|
||||
- Do not run `changie batch` again on released versions. Our final release workflow deletes all of the yaml files associated with individual changes. If for some reason modifications to the `CHANGELOG.md` are required after we've generated the final release `CHANGELOG.md`, the modifications need to be done manually to the `<version>.md` file in the `/.changes` directory.
|
||||
6
.changes/header.tpl.md
Executable file
6
.changes/header.tpl.md
Executable file
@@ -0,0 +1,6 @@
|
||||
# dbt Core Changelog
|
||||
|
||||
- This file provides a full account of all changes to `dbt-core` and `dbt-postgres`
|
||||
- Changes are listed under the (pre)release in which they first appear. Subsequent releases include changes from previous releases.
|
||||
- "Breaking changes" listed under a version may require action from end users or external maintainers when upgrading to that version.
|
||||
- Do not edit this file directly. This file is auto-generated using [changie](https://github.com/miniscruff/changie). For details on how to document a change, see [the contributing guide](CONTRIBUTING.md)
|
||||
0
test/integration/004_simple_snapshot_test/models/.gitkeep → .changes/unreleased/.gitkeep
Normal file → Executable file
0
test/integration/004_simple_snapshot_test/models/.gitkeep → .changes/unreleased/.gitkeep
Normal file → Executable file
7
.changes/unreleased/Under the Hood-20220218-161319.yaml
Normal file
7
.changes/unreleased/Under the Hood-20220218-161319.yaml
Normal file
@@ -0,0 +1,7 @@
|
||||
kind: Under the Hood
|
||||
body: Automate changelog generation with changie
|
||||
time: 2022-02-18T16:13:19.882436-06:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "4652"
|
||||
PR: "4743"
|
||||
50
.changie.yaml
Executable file
50
.changie.yaml
Executable file
@@ -0,0 +1,50 @@
|
||||
changesDir: .changes
|
||||
unreleasedDir: unreleased
|
||||
headerPath: header.tpl.md
|
||||
versionHeaderPath: ""
|
||||
changelogPath: CHANGELOG.md
|
||||
versionExt: md
|
||||
versionFormat: '## dbt-core {{.Version}} - {{.Time.Format "January 02, 2006"}}'
|
||||
kindFormat: '### {{.Kind}}'
|
||||
changeFormat: '- {{.Body}} ([#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-core/issues/{{.Custom.Issue}}), [#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-core/pull/{{.Custom.PR}}))'
|
||||
kinds:
|
||||
- label: Fixes
|
||||
- label: Features
|
||||
- label: Under the Hood
|
||||
- label: Breaking Changes
|
||||
- label: Docs
|
||||
- label: Dependencies
|
||||
custom:
|
||||
- key: Author
|
||||
label: GitHub Name
|
||||
type: string
|
||||
minLength: 3
|
||||
- key: Issue
|
||||
label: GitHub Issue Number
|
||||
type: int
|
||||
minLength: 4
|
||||
- key: PR
|
||||
label: GitHub Pull Request Number
|
||||
type: int
|
||||
minLength: 4
|
||||
footerFormat: |
|
||||
Contributors:
|
||||
{{- $contributorDict := dict }}
|
||||
{{- $core_team := list "emmyoop" "nathaniel-may" "gshank" "leahwicz" "ChenyuLInx" "stu-k" "iknox-fa" "VersusFacit" "McKnight-42" "jtcohen6" }}
|
||||
{{- range $change := .Changes }}
|
||||
{{- $author := $change.Custom.Author }}
|
||||
{{- if not (has $author $core_team)}}
|
||||
{{- $pr := $change.Custom.PR }}
|
||||
{{- if hasKey $contributorDict $author }}
|
||||
{{- $prList := get $contributorDict $author }}
|
||||
{{- $prList = append $prList $pr }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- else }}
|
||||
{{- $prList := list $change.Custom.PR }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- end }}
|
||||
{{- end}}
|
||||
{{- end }}
|
||||
{{- range $k,$v := $contributorDict }}
|
||||
- [{{$k}}](https://github.com/{{$k}}) ({{ range $index, $element := $v }}{{if $index}}, {{end}}[#{{$element}}](https://github.com/dbt-labs/dbt-core/pull/{{$element}}){{end}})
|
||||
{{- end }}
|
||||
@@ -1,123 +0,0 @@
|
||||
version: 2.1
|
||||
jobs:
|
||||
unit:
|
||||
docker: &test_only
|
||||
- image: fishtownanalytics/test-container:12
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
DOCKER_TEST_DATABASE_HOST: "database"
|
||||
TOX_PARALLEL_NO_SPINNER: 1
|
||||
steps:
|
||||
- checkout
|
||||
- run: tox -p -e py36,py37,py38
|
||||
lint:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run: tox -e mypy,flake8 -- -v
|
||||
build-wheels:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Build wheels
|
||||
command: |
|
||||
python3.8 -m venv "${PYTHON_ENV}"
|
||||
export PYTHON_BIN="${PYTHON_ENV}/bin/python"
|
||||
$PYTHON_BIN -m pip install -U pip setuptools
|
||||
$PYTHON_BIN -m pip install -r requirements.txt
|
||||
$PYTHON_BIN -m pip install -r dev-requirements.txt
|
||||
/bin/bash ./scripts/build-wheels.sh
|
||||
$PYTHON_BIN ./scripts/collect-dbt-contexts.py > ./dist/context_metadata.json
|
||||
$PYTHON_BIN ./scripts/collect-artifact-schema.py > ./dist/artifact_schemas.json
|
||||
environment:
|
||||
PYTHON_ENV: /home/tox/build_venv/
|
||||
- store_artifacts:
|
||||
path: ./dist
|
||||
destination: dist
|
||||
integration-postgres:
|
||||
docker:
|
||||
- image: fishtownanalytics/test-container:12
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
DOCKER_TEST_DATABASE_HOST: "database"
|
||||
TOX_PARALLEL_NO_SPINNER: 1
|
||||
- image: postgres
|
||||
name: database
|
||||
environment:
|
||||
POSTGRES_USER: "root"
|
||||
POSTGRES_PASSWORD: "password"
|
||||
POSTGRES_DB: "dbt"
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Setup postgres
|
||||
command: bash test/setup_db.sh
|
||||
environment:
|
||||
PGHOST: database
|
||||
PGUSER: root
|
||||
PGPASSWORD: password
|
||||
PGDATABASE: postgres
|
||||
- run:
|
||||
name: Postgres integration tests
|
||||
command: tox -p -e py36-postgres,py38-postgres -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Snowflake integration tests
|
||||
command: tox -p -e py36-snowflake,py38-snowflake -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Redshift integration tests
|
||||
command: tox -p -e py36-redshift,py38-redshift -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Bigquery integration test
|
||||
command: tox -p -e py36-bigquery,py38-bigquery -- -v -n4
|
||||
no_output_timeout: 30m
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
|
||||
workflows:
|
||||
version: 2
|
||||
test-everything:
|
||||
jobs:
|
||||
- lint
|
||||
- unit
|
||||
- integration-postgres:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift:
|
||||
requires:
|
||||
- unit
|
||||
- integration-bigquery:
|
||||
requires:
|
||||
- unit
|
||||
- integration-snowflake:
|
||||
requires:
|
||||
- unit
|
||||
- build-wheels:
|
||||
requires:
|
||||
- lint
|
||||
- unit
|
||||
- integration-postgres
|
||||
- integration-redshift
|
||||
- integration-bigquery
|
||||
- integration-snowflake
|
||||
12
.flake8
Normal file
12
.flake8
Normal file
@@ -0,0 +1,12 @@
|
||||
[flake8]
|
||||
select =
|
||||
E
|
||||
W
|
||||
F
|
||||
ignore =
|
||||
W503 # makes Flake8 work like black
|
||||
W504
|
||||
E203 # makes Flake8 work like black
|
||||
E741
|
||||
E501 # long line checking is done in black
|
||||
exclude = test
|
||||
43
.github/CODEOWNERS
vendored
Normal file
43
.github/CODEOWNERS
vendored
Normal file
@@ -0,0 +1,43 @@
|
||||
# This file contains the code owners for the dbt-core repo.
|
||||
# PRs will be automatically assigned for review to the associated
|
||||
# team(s) or person(s) that touches any files that are mapped to them.
|
||||
#
|
||||
# A statement takes precedence over the statements above it so more general
|
||||
# assignments are found at the top with specific assignments being lower in
|
||||
# the ordering (i.e. catch all assignment should be the first item)
|
||||
#
|
||||
# Consult GitHub documentation for formatting guidelines:
|
||||
# https://docs.github.com/en/repositories/managing-your-repositorys-settings-and-features/customizing-your-repository/about-code-owners#example-of-a-codeowners-file
|
||||
|
||||
# As a default for areas with no assignment,
|
||||
# the core team as a whole will be assigned
|
||||
* @dbt-labs/core
|
||||
|
||||
# Changes to GitHub configurations including Actions
|
||||
/.github/ @leahwicz
|
||||
|
||||
# Language core modules
|
||||
/core/dbt/config/ @dbt-labs/core-language
|
||||
/core/dbt/context/ @dbt-labs/core-language
|
||||
/core/dbt/contracts/ @dbt-labs/core-language
|
||||
/core/dbt/deps/ @dbt-labs/core-language
|
||||
/core/dbt/parser/ @dbt-labs/core-language
|
||||
|
||||
# Execution core modules
|
||||
/core/dbt/events/ @dbt-labs/core-execution @dbt-labs/core-language # eventually remove language but they have knowledge here now
|
||||
/core/dbt/graph/ @dbt-labs/core-execution
|
||||
/core/dbt/task/ @dbt-labs/core-execution
|
||||
|
||||
# Adapter interface, scaffold, Postgres plugin
|
||||
/core/dbt/adapters @dbt-labs/core-adapters
|
||||
/core/scripts/create_adapter_plugin.py @dbt-labs/core-adapters
|
||||
/plugins/ @dbt-labs/core-adapters
|
||||
|
||||
# Global project: default macros, including generic tests + materializations
|
||||
/core/dbt/include/global_project @dbt-labs/core-execution @dbt-labs/core-adapters
|
||||
|
||||
# Perf regression testing framework
|
||||
# This excludes the test project files itself since those aren't specific
|
||||
# framework changes (excluded by not setting an owner next to it- no owner)
|
||||
/performance @nathaniel-may
|
||||
/performance/projects
|
||||
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
@@ -0,0 +1,85 @@
|
||||
name: 🐞 Bug
|
||||
description: Report a bug or an issue you've found with dbt
|
||||
title: "[Bug] <title>"
|
||||
labels: ["bug", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing issue for this?
|
||||
description: Please search to see if an issue already exists for the bug you encountered.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Current Behavior
|
||||
description: A concise description of what you're experiencing.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Expected Behavior
|
||||
description: A concise description of what you expected to happen.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Steps To Reproduce
|
||||
description: Steps to reproduce the behavior.
|
||||
placeholder: |
|
||||
1. In this environment...
|
||||
2. With this config...
|
||||
3. Run '...'
|
||||
4. See error...
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Relevant log output
|
||||
description: |
|
||||
If applicable, log output to help explain your problem.
|
||||
render: shell
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.7.2 (`python --version`)
|
||||
- **dbt**: 0.21.0 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
- Python:
|
||||
- dbt:
|
||||
render: markdown
|
||||
validations:
|
||||
required: false
|
||||
- type: dropdown
|
||||
id: database
|
||||
attributes:
|
||||
label: What database are you using dbt with?
|
||||
multiple: true
|
||||
options:
|
||||
- postgres
|
||||
- redshift
|
||||
- snowflake
|
||||
- bigquery
|
||||
- other (mention it in "Additional Context")
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Additional Context
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the issue you are encountering!
|
||||
|
||||
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
||||
validations:
|
||||
required: false
|
||||
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -1,41 +0,0 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Report a bug or an issue you've found with dbt
|
||||
title: ''
|
||||
labels: bug, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the bug
|
||||
A clear and concise description of what the bug is. What command did you run? What happened?
|
||||
|
||||
### Steps To Reproduce
|
||||
In as much detail as possible, please provide steps to reproduce the issue. Sample data that triggers the issue, example model code, etc is all very helpful here.
|
||||
|
||||
### Expected behavior
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
### Screenshots and log output
|
||||
If applicable, add screenshots or log output to help explain your problem.
|
||||
|
||||
### System information
|
||||
**Which database are you using dbt with?**
|
||||
- [ ] postgres
|
||||
- [ ] redshift
|
||||
- [ ] bigquery
|
||||
- [ ] snowflake
|
||||
- [ ] other (specify: ____________)
|
||||
|
||||
|
||||
**The output of `dbt --version`:**
|
||||
```
|
||||
<output goes here>
|
||||
```
|
||||
|
||||
**The operating system you're using:**
|
||||
|
||||
**The output of `python --version`:**
|
||||
|
||||
### Additional context
|
||||
Add any other context about the problem here.
|
||||
16
.github/ISSUE_TEMPLATE/config.yml
vendored
Normal file
16
.github/ISSUE_TEMPLATE/config.yml
vendored
Normal file
@@ -0,0 +1,16 @@
|
||||
contact_links:
|
||||
- name: Create an issue for dbt-redshift
|
||||
url: https://github.com/dbt-labs/dbt-redshift/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-redshift
|
||||
- name: Create an issue for dbt-bigquery
|
||||
url: https://github.com/dbt-labs/dbt-bigquery/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-bigquery
|
||||
- name: Create an issue for dbt-snowflake
|
||||
url: https://github.com/dbt-labs/dbt-snowflake/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-snowflake
|
||||
- name: Ask a question or get support
|
||||
url: https://docs.getdbt.com/docs/guides/getting-help
|
||||
about: Ask a question or request support
|
||||
- name: Questions on Stack Overflow
|
||||
url: https://stackoverflow.com/questions/tagged/dbt
|
||||
about: Look at questions/answers at Stack Overflow
|
||||
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
name: ✨ Feature
|
||||
description: Suggest an idea for dbt
|
||||
title: "[Feature] <title>"
|
||||
labels: ["enhancement", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this feature requests!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing feature request for this?
|
||||
description: Please search to see if an issue already exists for the feature you would like.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe the Feature
|
||||
description: A clear and concise description of what you want to happen.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe alternatives you've considered
|
||||
description: |
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Who will this benefit?
|
||||
description: |
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
validations:
|
||||
required: false
|
||||
- type: input
|
||||
attributes:
|
||||
label: Are you interested in contributing this feature?
|
||||
description: Let us know if you want to write some code, and how we can help.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Anything else?
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the feature you are suggesting!
|
||||
validations:
|
||||
required: false
|
||||
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -1,23 +0,0 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for dbt
|
||||
title: ''
|
||||
labels: enhancement, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the feature
|
||||
A clear and concise description of what you want to happen.
|
||||
|
||||
### Describe alternatives you've considered
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
|
||||
### Additional context
|
||||
Is this feature database-specific? Which database(s) is/are relevant? Please include any other relevant context here.
|
||||
|
||||
### Who will this benefit?
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
|
||||
### Are you interested in contributing this feature?
|
||||
Let us know if you want to write some code, and how we can help.
|
||||
14
.github/actions/latest-wrangler/Dockerfile
vendored
Normal file
14
.github/actions/latest-wrangler/Dockerfile
vendored
Normal file
@@ -0,0 +1,14 @@
|
||||
FROM python:3-slim AS builder
|
||||
ADD . /app
|
||||
WORKDIR /app
|
||||
|
||||
# We are installing a dependency here directly into our app source dir
|
||||
RUN pip install --target=/app requests packaging
|
||||
|
||||
# A distroless container image with Python and some basics like SSL certificates
|
||||
# https://github.com/GoogleContainerTools/distroless
|
||||
FROM gcr.io/distroless/python3-debian10
|
||||
COPY --from=builder /app /app
|
||||
WORKDIR /app
|
||||
ENV PYTHONPATH /app
|
||||
CMD ["/app/main.py"]
|
||||
50
.github/actions/latest-wrangler/README.md
vendored
Normal file
50
.github/actions/latest-wrangler/README.md
vendored
Normal file
@@ -0,0 +1,50 @@
|
||||
# Github package 'latest' tag wrangler for containers
|
||||
## Usage
|
||||
|
||||
Plug in the necessary inputs to determine if the container being built should be tagged 'latest; at the package level, for example `dbt-redshift:latest`.
|
||||
|
||||
## Inputs
|
||||
| Input | Description |
|
||||
| - | - |
|
||||
| `package` | Name of the GH package to check against |
|
||||
| `new_version` | Semver of new container |
|
||||
| `gh_token` | GH token with package read scope|
|
||||
| `halt_on_missing` | Return non-zero exit code if requested package does not exist. (defaults to false)|
|
||||
|
||||
|
||||
## Outputs
|
||||
| Output | Description |
|
||||
| - | - |
|
||||
| `latest` | Wether or not the new container should be tagged 'latest'|
|
||||
| `minor_latest` | Wether or not the new container should be tagged major.minor.latest |
|
||||
|
||||
## Example workflow
|
||||
```yaml
|
||||
name: Ship it!
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
description: The package to publish
|
||||
required: true
|
||||
version_number:
|
||||
description: The version number
|
||||
required: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v1
|
||||
- name: Wrangle latest tag
|
||||
id: is_latest
|
||||
uses: ./.github/actions/latest-wrangler
|
||||
with:
|
||||
package: ${{ github.event.inputs.package }}
|
||||
new_version: ${{ github.event.inputs.new_version }}
|
||||
gh_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Print the results
|
||||
run: |
|
||||
echo "Is it latest? Survey says: ${{ steps.is_latest.outputs.latest }} !"
|
||||
echo "Is it minor.latest? Survey says: ${{ steps.is_latest.outputs.minor_latest }} !"
|
||||
```
|
||||
20
.github/actions/latest-wrangler/action.yml
vendored
Normal file
20
.github/actions/latest-wrangler/action.yml
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
name: "Github package 'latest' tag wrangler for containers"
|
||||
description: "Determines wether or not a given dbt container should be given a bare 'latest' tag (I.E. dbt-core:latest)"
|
||||
inputs:
|
||||
package_name:
|
||||
description: "Package to check (I.E. dbt-core, dbt-redshift, etc)"
|
||||
required: true
|
||||
new_version:
|
||||
description: "Semver of the container being built (I.E. 1.0.4)"
|
||||
required: true
|
||||
gh_token:
|
||||
description: "Auth token for github (must have view packages scope)"
|
||||
required: true
|
||||
outputs:
|
||||
latest:
|
||||
description: "Wether or not built container should be tagged latest (bool)"
|
||||
minor_latest:
|
||||
description: "Wether or not built container should be tagged minor.latest (bool)"
|
||||
runs:
|
||||
using: "docker"
|
||||
image: "Dockerfile"
|
||||
26
.github/actions/latest-wrangler/examples/example_workflow.yml
vendored
Normal file
26
.github/actions/latest-wrangler/examples/example_workflow.yml
vendored
Normal file
@@ -0,0 +1,26 @@
|
||||
name: Ship it!
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
description: The package to publish
|
||||
required: true
|
||||
version_number:
|
||||
description: The version number
|
||||
required: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v1
|
||||
- name: Wrangle latest tag
|
||||
id: is_latest
|
||||
uses: ./.github/actions/latest-wrangler
|
||||
with:
|
||||
package: ${{ github.event.inputs.package }}
|
||||
new_version: ${{ github.event.inputs.new_version }}
|
||||
gh_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
- name: Print the results
|
||||
run: |
|
||||
echo "Is it latest? Survey says: ${{ steps.is_latest.outputs.latest }} !"
|
||||
6
.github/actions/latest-wrangler/examples/example_workflow_dispatch.json
vendored
Normal file
6
.github/actions/latest-wrangler/examples/example_workflow_dispatch.json
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"inputs": {
|
||||
"version_number": "1.0.1",
|
||||
"package": "dbt-redshift"
|
||||
}
|
||||
}
|
||||
95
.github/actions/latest-wrangler/main.py
vendored
Normal file
95
.github/actions/latest-wrangler/main.py
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
import os
|
||||
import sys
|
||||
import requests
|
||||
from distutils.util import strtobool
|
||||
from typing import Union
|
||||
from packaging.version import parse, Version
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# get inputs
|
||||
package = os.environ["INPUT_PACKAGE"]
|
||||
new_version = parse(os.environ["INPUT_NEW_VERSION"])
|
||||
gh_token = os.environ["INPUT_GH_TOKEN"]
|
||||
halt_on_missing = strtobool(os.environ.get("INPUT_HALT_ON_MISSING", "False"))
|
||||
|
||||
# get package metadata from github
|
||||
package_request = requests.get(
|
||||
f"https://api.github.com/orgs/dbt-labs/packages/container/{package}/versions",
|
||||
auth=("", gh_token),
|
||||
)
|
||||
package_meta = package_request.json()
|
||||
|
||||
# Log info if we don't get a 200
|
||||
if package_request.status_code != 200:
|
||||
print(f"Call to GH API failed: {package_request.status_code} {package_meta['message']}")
|
||||
|
||||
# Make an early exit if there is no matching package in github
|
||||
if package_request.status_code == 404:
|
||||
if halt_on_missing:
|
||||
sys.exit(1)
|
||||
else:
|
||||
# everything is the latest if the package doesn't exist
|
||||
print(f"::set-output name=latest::{True}")
|
||||
print(f"::set-output name=minor_latest::{True}")
|
||||
sys.exit(0)
|
||||
|
||||
# TODO: verify package meta is "correct"
|
||||
# https://github.com/dbt-labs/dbt-core/issues/4640
|
||||
|
||||
# map versions and tags
|
||||
version_tag_map = {
|
||||
version["id"]: version["metadata"]["container"]["tags"] for version in package_meta
|
||||
}
|
||||
|
||||
# is pre-release
|
||||
pre_rel = True if any(x in str(new_version) for x in ["a", "b", "rc"]) else False
|
||||
|
||||
# semver of current latest
|
||||
for version, tags in version_tag_map.items():
|
||||
if "latest" in tags:
|
||||
# N.B. This seems counterintuitive, but we expect any version tagged
|
||||
# 'latest' to have exactly three associated tags:
|
||||
# latest, major.minor.latest, and major.minor.patch.
|
||||
# Subtracting everything that contains the string 'latest' gets us
|
||||
# the major.minor.patch which is what's needed for comparison.
|
||||
current_latest = parse([tag for tag in tags if "latest" not in tag][0])
|
||||
else:
|
||||
current_latest = False
|
||||
|
||||
# semver of current_minor_latest
|
||||
for version, tags in version_tag_map.items():
|
||||
if f"{new_version.major}.{new_version.minor}.latest" in tags:
|
||||
# Similar to above, only now we expect exactly two tags:
|
||||
# major.minor.patch and major.minor.latest
|
||||
current_minor_latest = parse([tag for tag in tags if "latest" not in tag][0])
|
||||
else:
|
||||
current_minor_latest = False
|
||||
|
||||
def is_latest(
|
||||
pre_rel: bool, new_version: Version, remote_latest: Union[bool, Version]
|
||||
) -> bool:
|
||||
"""Determine if a given contaier should be tagged 'latest' based on:
|
||||
- it's pre-release status
|
||||
- it's version
|
||||
- the version of a previously identified container tagged 'latest'
|
||||
|
||||
:param pre_rel: Wether or not the version of the new container is a pre-release
|
||||
:param new_version: The version of the new container
|
||||
:param remote_latest: The version of the previously identified container that's
|
||||
already tagged latest or False
|
||||
"""
|
||||
# is a pre-release = not latest
|
||||
if pre_rel:
|
||||
return False
|
||||
# + no latest tag found = is latest
|
||||
if not remote_latest:
|
||||
return True
|
||||
# + if remote version is lower than current = is latest, else not latest
|
||||
return True if remote_latest <= new_version else False
|
||||
|
||||
latest = is_latest(pre_rel, new_version, current_latest)
|
||||
minor_latest = is_latest(pre_rel, new_version, current_minor_latest)
|
||||
|
||||
print(f"::set-output name=latest::{latest}")
|
||||
print(f"::set-output name=minor_latest::{minor_latest}")
|
||||
10
.github/actions/setup-postgres-linux/action.yml
vendored
Normal file
10
.github/actions/setup-postgres-linux/action.yml
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
name: "Set up postgres (linux)"
|
||||
description: "Set up postgres service on linux vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
sudo systemctl start postgresql.service
|
||||
pg_isready
|
||||
sudo -u postgres bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-linux/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-linux/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
24
.github/actions/setup-postgres-macos/action.yml
vendored
Normal file
24
.github/actions/setup-postgres-macos/action.yml
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
name: "Set up postgres (macos)"
|
||||
description: "Set up postgres service on macos vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
brew services start postgresql
|
||||
echo "Check PostgreSQL service is running"
|
||||
i=10
|
||||
COMMAND='pg_isready'
|
||||
while [ $i -gt -1 ]; do
|
||||
if [ $i == 0 ]; then
|
||||
echo "PostgreSQL service not ready, all attempts exhausted"
|
||||
exit 1
|
||||
fi
|
||||
echo "Check PostgreSQL service status"
|
||||
eval $COMMAND && break
|
||||
echo "PostgreSQL service not ready, wait 10 more sec, attempts left: $i"
|
||||
sleep 10
|
||||
((i--))
|
||||
done
|
||||
createuser -s postgres
|
||||
bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-macos/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-macos/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
12
.github/actions/setup-postgres-windows/action.yml
vendored
Normal file
12
.github/actions/setup-postgres-windows/action.yml
vendored
Normal file
@@ -0,0 +1,12 @@
|
||||
name: "Set up postgres (windows)"
|
||||
description: "Set up postgres service on windows vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: pwsh
|
||||
run: |
|
||||
$pgService = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $pgService -Status running -StartupType automatic
|
||||
Start-Process -FilePath "$env:PGBIN\pg_isready" -Wait -PassThru
|
||||
$env:Path += ";$env:PGBIN"
|
||||
bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-windows/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-windows/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
15
.github/dependabot.yml
vendored
15
.github/dependabot.yml
vendored
@@ -11,26 +11,11 @@ updates:
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/bigquery"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/postgres"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/redshift"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/snowflake"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
|
||||
# docker dependencies
|
||||
- package-ecosystem: "docker"
|
||||
|
||||
19
.github/pull_request_template.md
vendored
19
.github/pull_request_template.md
vendored
@@ -4,19 +4,18 @@ resolves #
|
||||
Include the number of the issue addressed by this PR above if applicable.
|
||||
PRs for code changes without an associated issue *will not be merged*.
|
||||
See CONTRIBUTING.md for more information.
|
||||
|
||||
Example:
|
||||
resolves #1234
|
||||
-->
|
||||
|
||||
|
||||
### Description
|
||||
|
||||
<!--- Describe the Pull Request here -->
|
||||
|
||||
<!---
|
||||
Describe the Pull Request here. Add any references and info to help reviewers
|
||||
understand your changes. Include any tradeoffs you considered.
|
||||
-->
|
||||
|
||||
### Checklist
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change to the "dbt next" section.
|
||||
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have added information about my change to be included in the [CHANGELOG](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#Adding-CHANGELOG-Entry).
|
||||
|
||||
34
.github/workflows/backport.yml
vendored
Normal file
34
.github/workflows/backport.yml
vendored
Normal file
@@ -0,0 +1,34 @@
|
||||
# **what?**
|
||||
# When a PR is merged, if it has the backport label, it will create
|
||||
# a new PR to backport those changes to the given branch. If it can't
|
||||
# cleanly do a backport, it will comment on the merged PR of the failure.
|
||||
#
|
||||
# Label naming convention: "backport <branch name to backport to>"
|
||||
# Example: backport 1.0.latest
|
||||
#
|
||||
# You MUST "Squash and merge" the original PR or this won't work.
|
||||
|
||||
# **why?**
|
||||
# Changes sometimes need to be backported to release branches.
|
||||
# This automates the backporting process
|
||||
|
||||
# **when?**
|
||||
# Once a PR is "Squash and merge"'d and it has been correctly labeled
|
||||
# according to the naming convention.
|
||||
|
||||
name: Backport
|
||||
on:
|
||||
pull_request:
|
||||
types:
|
||||
- closed
|
||||
- labeled
|
||||
|
||||
jobs:
|
||||
backport:
|
||||
runs-on: ubuntu-18.04
|
||||
name: Backport
|
||||
steps:
|
||||
- name: Backport
|
||||
uses: tibdex/backport@v1.1.1
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
62
.github/workflows/changelog-check.yml
vendored
Normal file
62
.github/workflows/changelog-check.yml
vendored
Normal file
@@ -0,0 +1,62 @@
|
||||
# **what?**
|
||||
# Checks that a file has been committed under the /.changes directory
|
||||
# as a new CHANGELOG entry. Cannot check for a specific filename as
|
||||
# it is dynamically generated by change type and timestamp.
|
||||
# This workflow should not require any secrets since it runs for PRs
|
||||
# from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code change gets reflected in the CHANGELOG.
|
||||
|
||||
# **when?**
|
||||
# This will run for all PRs going into main and *.latest.
|
||||
|
||||
name: Check Changelog Entry
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
workflow_dispatch:
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
changelog:
|
||||
name: changelog
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check if changelog file was added
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: filter
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
changelog:
|
||||
- added: '.changes/unreleased/**.yaml'
|
||||
- name: Check a file has been added to .changes/unreleased if required
|
||||
uses: actions/github-script@v6
|
||||
if: steps.filter.outputs.changelog == 'false' && !contains( github.event.pull_request.labels.*.name, 'Skip Changelog')
|
||||
with:
|
||||
script: |
|
||||
github.rest.issues.createComment({
|
||||
issue_number: context.issue.number,
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
body: "Thank you for your pull request! We could not find a changelog entry for this change. For details on how to document a change, see [the contributing guide](CONTRIBUTING.md)."
|
||||
})
|
||||
core.setFailed('Changelog entry required to merge.')
|
||||
26
.github/workflows/jira-creation.yml
vendored
Normal file
26
.github/workflows/jira-creation.yml
vendored
Normal file
@@ -0,0 +1,26 @@
|
||||
# **what?**
|
||||
# Mirrors issues into Jira. Includes the information: title,
|
||||
# GitHub Issue ID and URL
|
||||
|
||||
# **why?**
|
||||
# Jira is our tool for tracking and we need to see these issues in there
|
||||
|
||||
# **when?**
|
||||
# On issue creation or when an issue is labeled `Jira`
|
||||
|
||||
name: Jira Issue Creation
|
||||
|
||||
on:
|
||||
issues:
|
||||
types: [opened, labeled]
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
|
||||
jobs:
|
||||
call-label-action:
|
||||
uses: dbt-labs/jira-actions/.github/workflows/jira-creation.yml@main
|
||||
secrets:
|
||||
JIRA_BASE_URL: ${{ secrets.JIRA_BASE_URL }}
|
||||
JIRA_USER_EMAIL: ${{ secrets.JIRA_USER_EMAIL }}
|
||||
JIRA_API_TOKEN: ${{ secrets.JIRA_API_TOKEN }}
|
||||
26
.github/workflows/jira-label.yml
vendored
Normal file
26
.github/workflows/jira-label.yml
vendored
Normal file
@@ -0,0 +1,26 @@
|
||||
# **what?**
|
||||
# Calls mirroring Jira label Action. Includes adding a new label
|
||||
# to an existing issue or removing a label as well
|
||||
|
||||
# **why?**
|
||||
# Jira is our tool for tracking and we need to see these labels in there
|
||||
|
||||
# **when?**
|
||||
# On labels being added or removed from issues
|
||||
|
||||
name: Jira Label Mirroring
|
||||
|
||||
on:
|
||||
issues:
|
||||
types: [labeled, unlabeled]
|
||||
|
||||
permissions:
|
||||
issues: read
|
||||
|
||||
jobs:
|
||||
call-label-action:
|
||||
uses: dbt-labs/jira-actions/.github/workflows/jira-label.yml@main
|
||||
secrets:
|
||||
JIRA_BASE_URL: ${{ secrets.JIRA_BASE_URL }}
|
||||
JIRA_USER_EMAIL: ${{ secrets.JIRA_USER_EMAIL }}
|
||||
JIRA_API_TOKEN: ${{ secrets.JIRA_API_TOKEN }}
|
||||
24
.github/workflows/jira-transition.yml
vendored
Normal file
24
.github/workflows/jira-transition.yml
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
# **what?**
|
||||
# Transition a Jira issue to a new state
|
||||
# Only supports these GitHub Issue transitions:
|
||||
# closed, deleted, reopened
|
||||
|
||||
# **why?**
|
||||
# Jira needs to be kept up-to-date
|
||||
|
||||
# **when?**
|
||||
# On issue closing, deletion, reopened
|
||||
|
||||
name: Jira Issue Transition
|
||||
|
||||
on:
|
||||
issues:
|
||||
types: [closed, deleted, reopened]
|
||||
|
||||
jobs:
|
||||
call-label-action:
|
||||
uses: dbt-labs/jira-actions/.github/workflows/jira-transition.yml@main
|
||||
secrets:
|
||||
JIRA_BASE_URL: ${{ secrets.JIRA_BASE_URL }}
|
||||
JIRA_USER_EMAIL: ${{ secrets.JIRA_USER_EMAIL }}
|
||||
JIRA_API_TOKEN: ${{ secrets.JIRA_API_TOKEN }}
|
||||
225
.github/workflows/main.yml
vendored
Normal file
225
.github/workflows/main.yml
vendored
Normal file
@@ -0,0 +1,225 @@
|
||||
# **what?**
|
||||
# Runs code quality checks, unit tests, integration tests and
|
||||
# verifies python build on all code commited to the repository. This workflow
|
||||
# should not require any secrets since it runs for PRs from forked repos. By
|
||||
# default, secrets are not passed to workflows running from a forked repos.
|
||||
|
||||
# **why?**
|
||||
# Ensure code for dbt meets a certain quality standard.
|
||||
|
||||
# **when?**
|
||||
# This will run for all PRs, when code is pushed to a release
|
||||
# branch, and when manually triggered.
|
||||
|
||||
name: Tests and Code Checks
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
workflow_dispatch:
|
||||
|
||||
permissions: read-all
|
||||
|
||||
# will cancel previous workflows triggered by the same event and for the same ref for PRs or same SHA otherwise
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(github.event_name, 'pull_request') && github.event.pull_request.head.ref || github.sha }}
|
||||
cancel-in-progress: true
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
code-quality:
|
||||
name: code-quality
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install pre-commit
|
||||
pre-commit --version
|
||||
pip install mypy==0.782
|
||||
mypy --version
|
||||
pip install -r editable-requirements.txt
|
||||
dbt --version
|
||||
|
||||
- name: Run pre-commit hooks
|
||||
run: pre-commit run --all-files --show-diff-on-failure
|
||||
|
||||
unit:
|
||||
name: unit test / python ${{ matrix.python-version }}
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
PYTEST_ADDOPTS: "-v --color=yes --csv unit_results.csv"
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
run: tox
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y-%m-%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: unit_results_${{ matrix.python-version }}-${{ steps.date.outputs.date }}.csv
|
||||
path: unit_results.csv
|
||||
|
||||
integration:
|
||||
name: integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
os: [ubuntu-latest]
|
||||
include:
|
||||
- python-version: 3.8
|
||||
os: windows-latest
|
||||
- python-version: 3.8
|
||||
os: macos-latest
|
||||
|
||||
env:
|
||||
TOXENV: integration
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python tools
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
|
||||
- name: Run tests
|
||||
run: tox
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y_%m_%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}
|
||||
path: ./logs
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
build:
|
||||
name: build packages
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
- name: Build distributions
|
||||
run: ./scripts/build-dist.sh
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Check distribution descriptions
|
||||
run: |
|
||||
twine check dist/*
|
||||
|
||||
- name: Check wheel contents
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
dbt --version
|
||||
|
||||
- name: Install source distributions
|
||||
# ignore dbt-1.0.0, which intentionally raises an error when installed from source
|
||||
run: |
|
||||
find ./dist/dbt-[a-z]*.gz -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
dbt --version
|
||||
176
.github/workflows/performance.yml
vendored
Normal file
176
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,176 @@
|
||||
name: Performance Regression Tests
|
||||
# Schedule triggers
|
||||
on:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
schedule:
|
||||
- cron: "5 10,22 * * *"
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: "0.20.latest"
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: make results directory
|
||||
run: mkdir ./final-output/
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./ -o ./final-output/
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final-output/*
|
||||
113
.github/workflows/release-docker.yml
vendored
Normal file
113
.github/workflows/release-docker.yml
vendored
Normal file
@@ -0,0 +1,113 @@
|
||||
# **what?**
|
||||
# This workflow will generate a series of docker images for dbt and push them to the github container registry
|
||||
|
||||
# **why?**
|
||||
# Docker images for dbt are used in a number of important places throughout the dbt ecosystem. This is how we keep those images up-to-date.
|
||||
|
||||
# **when?**
|
||||
# This is triggered manually
|
||||
|
||||
# **next steps**
|
||||
# - build this into the release workflow (or conversly, break out the different release methods into their own workflow files)
|
||||
|
||||
name: Docker release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
description: The package to release. _One_ of [dbt-core, dbt-redshift, dbt-bigquery, dbt-snowflake, dbt-spark, dbt-postgres]
|
||||
required: true
|
||||
version_number:
|
||||
description: The release version number (i.e. 1.0.0b1). Do not include `latest` tags or a leading `v`!
|
||||
required: true
|
||||
|
||||
jobs:
|
||||
get_version_meta:
|
||||
name: Get version meta
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
major: ${{ steps.version.outputs.major }}
|
||||
minor: ${{ steps.version.outputs.minor }}
|
||||
patch: ${{ steps.version.outputs.patch }}
|
||||
latest: ${{ steps.latest.outputs.latest }}
|
||||
minor_latest: ${{ steps.latest.outputs.minor_latest }}
|
||||
steps:
|
||||
- uses: actions/checkout@v1
|
||||
- name: Split version
|
||||
id: version
|
||||
run: |
|
||||
IFS="." read -r MAJOR MINOR PATCH <<< ${{ github.event.inputs.version_number }}
|
||||
echo "::set-output name=major::$MAJOR"
|
||||
echo "::set-output name=minor::$MINOR"
|
||||
echo "::set-output name=patch::$PATCH"
|
||||
|
||||
- name: Is pkg 'latest'
|
||||
id: latest
|
||||
uses: ./.github/actions/latest-wrangler
|
||||
with:
|
||||
package: ${{ github.event.inputs.package }}
|
||||
new_version: ${{ github.event.inputs.version_number }}
|
||||
gh_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
halt_on_missing: False
|
||||
|
||||
setup_image_builder:
|
||||
name: Set up docker image builder
|
||||
runs-on: ubuntu-latest
|
||||
needs: [get_version_meta]
|
||||
steps:
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
|
||||
build_and_push:
|
||||
name: Build images and push to GHCR
|
||||
runs-on: ubuntu-latest
|
||||
needs: [setup_image_builder, get_version_meta]
|
||||
steps:
|
||||
- name: Get docker build arg
|
||||
id: build_arg
|
||||
run: |
|
||||
echo "::set-output name=build_arg_name::"$(echo ${{ github.event.inputs.package }} | sed 's/\-/_/g')
|
||||
echo "::set-output name=build_arg_value::"$(echo ${{ github.event.inputs.package }} | sed 's/postgres/core/g')
|
||||
|
||||
- name: Log in to the GHCR
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.actor }}
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Build and push MAJOR.MINOR.PATCH tag
|
||||
uses: docker/build-push-action@v2
|
||||
with:
|
||||
file: docker/Dockerfile
|
||||
push: True
|
||||
target: ${{ github.event.inputs.package }}
|
||||
build-args: |
|
||||
${{ steps.build_arg.outputs.build_arg_name }}_ref=${{ steps.build_arg.outputs.build_arg_value }}@v${{ github.event.inputs.version_number }}
|
||||
tags: |
|
||||
ghcr.io/dbt-labs/${{ github.event.inputs.package }}:${{ github.event.inputs.version_number }}
|
||||
|
||||
- name: Build and push MINOR.latest tag
|
||||
uses: docker/build-push-action@v2
|
||||
if: ${{ needs.get_version_meta.outputs.minor_latest == 'True' }}
|
||||
with:
|
||||
file: docker/Dockerfile
|
||||
push: True
|
||||
target: ${{ github.event.inputs.package }}
|
||||
build-args: |
|
||||
${{ steps.build_arg.outputs.build_arg_name }}_ref=${{ steps.build_arg.outputs.build_arg_value }}@v${{ github.event.inputs.version_number }}
|
||||
tags: |
|
||||
ghcr.io/dbt-labs/${{ github.event.inputs.package }}:${{ needs.get_version_meta.outputs.major }}.${{ needs.get_version_meta.outputs.minor }}.latest
|
||||
|
||||
- name: Build and push latest tag
|
||||
uses: docker/build-push-action@v2
|
||||
if: ${{ needs.get_version_meta.outputs.latest == 'True' }}
|
||||
with:
|
||||
file: docker/Dockerfile
|
||||
push: True
|
||||
target: ${{ github.event.inputs.package }}
|
||||
build-args: |
|
||||
${{ steps.build_arg.outputs.build_arg_name }}_ref=${{ steps.build_arg.outputs.build_arg_value }}@v${{ github.event.inputs.version_number }}
|
||||
tags: |
|
||||
ghcr.io/dbt-labs/${{ github.event.inputs.package }}:latest
|
||||
199
.github/workflows/release.yml
vendored
Normal file
199
.github/workflows/release.yml
vendored
Normal file
@@ -0,0 +1,199 @@
|
||||
# **what?**
|
||||
# Take the given commit, run unit tests specifically on that sha, build and
|
||||
# package it, and then release to GitHub and PyPi with that specific build
|
||||
|
||||
# **why?**
|
||||
# Ensure an automated and tested release process
|
||||
|
||||
# **when?**
|
||||
# This will only run manually with a given sha and version
|
||||
|
||||
name: Release to GitHub and PyPi
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
sha:
|
||||
description: 'The last commit sha in the release'
|
||||
required: true
|
||||
version_number:
|
||||
description: 'The release version number (i.e. 1.0.0b1)'
|
||||
required: true
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
unit:
|
||||
name: Unit test
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.inputs.sha }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
run: tox
|
||||
|
||||
build:
|
||||
name: build packages
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.inputs.sha }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
- name: Build distributions
|
||||
run: ./scripts/build-dist.sh
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Check distribution descriptions
|
||||
run: |
|
||||
twine check dist/*
|
||||
|
||||
- name: Check wheel contents
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: |
|
||||
dist/
|
||||
!dist/dbt-${{github.event.inputs.version_number}}.tar.gz
|
||||
|
||||
test-build:
|
||||
name: verify packages
|
||||
|
||||
needs: [build, unit]
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade wheel
|
||||
pip --version
|
||||
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
dbt --version
|
||||
|
||||
- name: Install source distributions
|
||||
run: |
|
||||
find ./dist/*.gz -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
dbt --version
|
||||
|
||||
github-release:
|
||||
name: GitHub Release
|
||||
|
||||
needs: test-build
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: '.'
|
||||
|
||||
# Need to set an output variable because env variables can't be taken as input
|
||||
# This is needed for the next step with releasing to GitHub
|
||||
- name: Find release type
|
||||
id: release_type
|
||||
env:
|
||||
IS_PRERELEASE: ${{ contains(github.event.inputs.version_number, 'rc') || contains(github.event.inputs.version_number, 'b') }}
|
||||
run: |
|
||||
echo ::set-output name=isPrerelease::$IS_PRERELEASE
|
||||
|
||||
- name: Creating GitHub Release
|
||||
uses: softprops/action-gh-release@v1
|
||||
with:
|
||||
name: dbt-core v${{github.event.inputs.version_number}}
|
||||
tag_name: v${{github.event.inputs.version_number}}
|
||||
prerelease: ${{ steps.release_type.outputs.isPrerelease }}
|
||||
target_commitish: ${{github.event.inputs.sha}}
|
||||
body: |
|
||||
[Release notes](https://github.com/dbt-labs/dbt-core/blob/main/CHANGELOG.md)
|
||||
files: |
|
||||
dbt_postgres-${{github.event.inputs.version_number}}-py3-none-any.whl
|
||||
dbt_core-${{github.event.inputs.version_number}}-py3-none-any.whl
|
||||
dbt-postgres-${{github.event.inputs.version_number}}.tar.gz
|
||||
dbt-core-${{github.event.inputs.version_number}}.tar.gz
|
||||
|
||||
pypi-release:
|
||||
name: Pypi release
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
needs: github-release
|
||||
|
||||
environment: PypiProd
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: 'dist'
|
||||
|
||||
- name: Publish distribution to PyPI
|
||||
uses: pypa/gh-action-pypi-publish@v1.4.2
|
||||
with:
|
||||
password: ${{ secrets.PYPI_API_TOKEN }}
|
||||
87
.github/workflows/schema-check.yml
vendored
Normal file
87
.github/workflows/schema-check.yml
vendored
Normal file
@@ -0,0 +1,87 @@
|
||||
# **what?**
|
||||
# Compares the schema of the dbt version of the given ref vs
|
||||
# the latest official schema releases found in schemas.getdbt.com.
|
||||
# If there are differences, the workflow will fail and upload the
|
||||
# diff as an artifact. The metadata team should be alerted to the change.
|
||||
#
|
||||
# **why?**
|
||||
# Reaction work may need to be done if artifact schema changes
|
||||
# occur so we want to proactively alert to it.
|
||||
#
|
||||
# **when?**
|
||||
# On pushes to `develop` and release branches. Manual runs are also enabled.
|
||||
name: Artifact Schema Check
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
pull_request: #TODO: remove before merging
|
||||
push:
|
||||
branches:
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
|
||||
env:
|
||||
LATEST_SCHEMA_PATH: ${{ github.workspace }}/new_schemas
|
||||
SCHEMA_DIFF_ARTIFACT: ${{ github.workspace }}//schema_schanges.txt
|
||||
DBT_REPO_DIRECTORY: ${{ github.workspace }}/dbt
|
||||
SCHEMA_REPO_DIRECTORY: ${{ github.workspace }}/schemas.getdbt.com
|
||||
|
||||
jobs:
|
||||
checking-schemas:
|
||||
name: "Checking schemas"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Checkout dbt repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
path: ${{ env.DBT_REPO_DIRECTORY }}
|
||||
|
||||
- name: Checkout schemas.getdbt.com repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
repository: dbt-labs/schemas.getdbt.com
|
||||
ref: 'main'
|
||||
ssh-key: ${{ secrets.SCHEMA_SSH_PRIVATE_KEY }}
|
||||
path: ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
|
||||
- name: Generate current schema
|
||||
run: |
|
||||
cd ${{ env.DBT_REPO_DIRECTORY }}
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
python scripts/collect-artifact-schema.py --path ${{ env.LATEST_SCHEMA_PATH }}
|
||||
|
||||
# Copy generated schema files into the schemas.getdbt.com repo
|
||||
# Do a git diff to find any changes
|
||||
# Ignore any date or version changes though
|
||||
- name: Compare schemas
|
||||
run: |
|
||||
cp -r ${{ env.LATEST_SCHEMA_PATH }}/dbt ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
cd ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
diff_results=$(git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' --compact-summary)
|
||||
if [[ $(echo diff_results) ]]; then
|
||||
echo $diff_results
|
||||
echo "Schema changes detected!"
|
||||
git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' > ${{ env.SCHEMA_DIFF_ARTIFACT }}
|
||||
exit 1
|
||||
else
|
||||
echo "No schema changes detected"
|
||||
fi
|
||||
|
||||
- name: Upload schema diff
|
||||
uses: actions/upload-artifact@v2.2.4
|
||||
if: ${{ failure() }}
|
||||
with:
|
||||
name: 'schema_schanges.txt'
|
||||
path: '${{ env.SCHEMA_DIFF_ARTIFACT }}'
|
||||
18
.github/workflows/stale.yml
vendored
Normal file
18
.github/workflows/stale.yml
vendored
Normal file
@@ -0,0 +1,18 @@
|
||||
name: "Close stale issues and PRs"
|
||||
on:
|
||||
schedule:
|
||||
- cron: "30 1 * * *"
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
# pinned at v4 (https://github.com/actions/stale/releases/tag/v4.0.0)
|
||||
- uses: actions/stale@cdf15f641adb27a71842045a94023bef6945e3aa
|
||||
with:
|
||||
stale-issue-message: "This issue has been marked as Stale because it has been open for 180 days with no activity. If you would like the issue to remain open, please remove the stale label or comment on the issue, or it will be closed in 7 days."
|
||||
stale-pr-message: "This PR has been marked as Stale because it has been open for 180 days with no activity. If you would like the PR to remain open, please remove the stale label or comment on the PR, or it will be closed in 7 days."
|
||||
# mark issues/PRs stale when they haven't seen activity in 180 days
|
||||
days-before-stale: 180
|
||||
# ignore checking issues with the following labels
|
||||
exempt-issue-labels: "epic,discussion"
|
||||
73
.github/workflows/structured-logging-schema-check.yml
vendored
Normal file
73
.github/workflows/structured-logging-schema-check.yml
vendored
Normal file
@@ -0,0 +1,73 @@
|
||||
# This Action checks makes a dbt run to sample json structured logs
|
||||
# and checks that they conform to the currently documented schema.
|
||||
#
|
||||
# If this action fails it either means we have unintentionally deviated
|
||||
# from our documented structured logging schema, or we need to bump the
|
||||
# version of our structured logging and add new documentation to
|
||||
# communicate these changes.
|
||||
|
||||
name: Structured Logging Schema Check
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
workflow_dispatch:
|
||||
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
# run the performance measurements on the current or default branch
|
||||
test-schema:
|
||||
name: Test Log Schema
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns warnings into errors
|
||||
RUSTFLAGS: "-D warnings"
|
||||
# points tests to the log file
|
||||
LOG_DIR: "/home/runner/work/dbt-core/dbt-core/logs"
|
||||
# tells integration tests to output into json format
|
||||
DBT_LOG_FORMAT: "json"
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
|
||||
- name: Set up postgres
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: ls
|
||||
run: ls
|
||||
|
||||
# integration tests generate a ton of logs in different files. the next step will find them all.
|
||||
# we actually care if these pass, because the normal test run doesn't usually include many json log outputs
|
||||
- name: Run integration tests
|
||||
run: tox -e integration -- -nauto
|
||||
|
||||
# apply our schema tests to every log event from the previous step
|
||||
# skips any output that isn't valid json
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: run
|
||||
args: --manifest-path test/interop/log_parsing/Cargo.toml
|
||||
1
.github/workflows/test/.actrc
vendored
Normal file
1
.github/workflows/test/.actrc
vendored
Normal file
@@ -0,0 +1 @@
|
||||
-P ubuntu-latest=ghcr.io/catthehacker/ubuntu:act-latest
|
||||
1
.github/workflows/test/.gitignore
vendored
Normal file
1
.github/workflows/test/.gitignore
vendored
Normal file
@@ -0,0 +1 @@
|
||||
.secrets
|
||||
1
.github/workflows/test/.secrets.EXAMPLE
vendored
Normal file
1
.github/workflows/test/.secrets.EXAMPLE
vendored
Normal file
@@ -0,0 +1 @@
|
||||
GITHUB_TOKEN=GH_PERSONAL_ACCESS_TOKEN_GOES_HERE
|
||||
6
.github/workflows/test/inputs/release_docker.json
vendored
Normal file
6
.github/workflows/test/inputs/release_docker.json
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"inputs": {
|
||||
"version_number": "1.0.1",
|
||||
"package": "dbt-postgres"
|
||||
}
|
||||
}
|
||||
178
.github/workflows/tests.yml
vendored
178
.github/workflows/tests.yml
vendored
@@ -1,178 +0,0 @@
|
||||
# This is a workflow to run our unit and integration tests for windows and mac
|
||||
|
||||
name: dbt Tests
|
||||
|
||||
# Triggers
|
||||
on:
|
||||
# Triggers the workflow on push or pull request events and also adds a manual trigger
|
||||
push:
|
||||
branches:
|
||||
- 'develop'
|
||||
- '*.latest'
|
||||
- 'releases/*'
|
||||
pull_request_target:
|
||||
branches:
|
||||
- 'develop'
|
||||
- '*.latest'
|
||||
- 'pr/*'
|
||||
- 'releases/*'
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
Linting:
|
||||
runs-on: ubuntu-latest #no need to run on every OS
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Linting'
|
||||
run: tox -e mypy,flake8 -- -v
|
||||
|
||||
UnitTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, ubuntu-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run unit tests'
|
||||
run: python -m tox -e py -- -v
|
||||
|
||||
PostgresIntegrationTest:
|
||||
runs-on: 'windows-latest' #TODO: Add Mac support
|
||||
environment: 'Postgres'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: 'Install postgresql and set up database'
|
||||
shell: pwsh
|
||||
run: |
|
||||
$serviceName = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $serviceName -StartupType Automatic
|
||||
Start-Service -InputObject $serviceName
|
||||
& $env:PGBIN\createdb.exe -U postgres dbt
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE root WITH PASSWORD '$env:ROOT_PASSWORD';"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE root WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CREATE, CONNECT ON DATABASE dbt TO root WITH GRANT OPTION;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE noaccess WITH PASSWORD '$env:NOACCESS_PASSWORD' NOSUPERUSER;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE noaccess WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CONNECT ON DATABASE dbt TO noaccess;"
|
||||
env:
|
||||
ROOT_PASSWORD: ${{ secrets.ROOT_PASSWORD }}
|
||||
NOACCESS_PASSWORD: ${{ secrets.NOACCESS_PASSWORD }}
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-postgres -- -v -n4
|
||||
|
||||
# These three are all similar except secure environment variables, which MUST be passed along to their tasks,
|
||||
# but there's probably a better way to do this!
|
||||
SnowflakeIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Snowflake'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-snowflake -- -v -n4
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: ${{ secrets.SNOWFLAKE_TEST_ACCOUNT }}
|
||||
SNOWFLAKE_TEST_PASSWORD: ${{ secrets.SNOWFLAKE_TEST_PASSWORD }}
|
||||
SNOWFLAKE_TEST_USER: ${{ secrets.SNOWFLAKE_TEST_USER }}
|
||||
SNOWFLAKE_TEST_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN: ${{ secrets.SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_ID: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_ID }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET }}
|
||||
SNOWFLAKE_TEST_ALT_DATABASE: ${{ secrets.SNOWFLAKE_TEST_ALT_DATABASE }}
|
||||
SNOWFLAKE_TEST_ALT_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_ALT_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_DATABASE: ${{ secrets.SNOWFLAKE_TEST_DATABASE }}
|
||||
SNOWFLAKE_TEST_QUOTED_DATABASE: ${{ secrets.SNOWFLAKE_TEST_QUOTED_DATABASE }}
|
||||
SNOWFLAKE_TEST_ROLE: ${{ secrets.SNOWFLAKE_TEST_ROLE }}
|
||||
|
||||
BigQueryIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Bigquery'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-bigquery -- -v -n4
|
||||
env:
|
||||
BIGQUERY_SERVICE_ACCOUNT_JSON: ${{ secrets.BIGQUERY_SERVICE_ACCOUNT_JSON }}
|
||||
BIGQUERY_TEST_ALT_DATABASE: ${{ secrets.BIGQUERY_TEST_ALT_DATABASE }}
|
||||
|
||||
RedshiftIntegrationTest:
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest]
|
||||
runs-on: ${{ matrix.os }}
|
||||
environment: 'Redshift'
|
||||
needs: UnitTest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- name: 'Install dependencies'
|
||||
run: python -m pip install --upgrade pip && pip install tox
|
||||
|
||||
- name: 'Run integration tests'
|
||||
run: python -m tox -e py-redshift -- -v -n4
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: ${{ secrets.REDSHIFT_TEST_DBNAME }}
|
||||
REDSHIFT_TEST_PASS: ${{ secrets.REDSHIFT_TEST_PASS }}
|
||||
REDSHIFT_TEST_USER: ${{ secrets.REDSHIFT_TEST_USER }}
|
||||
REDSHIFT_TEST_PORT: ${{ secrets.REDSHIFT_TEST_PORT }}
|
||||
REDSHIFT_TEST_HOST: ${{ secrets.REDSHIFT_TEST_HOST }}
|
||||
109
.github/workflows/version-bump.yml
vendored
Normal file
109
.github/workflows/version-bump.yml
vendored
Normal file
@@ -0,0 +1,109 @@
|
||||
# **what?**
|
||||
# This workflow will take a version number and a dry run flag. With that
|
||||
# it will run versionbump to update the version number everywhere in the
|
||||
# code base and then generate an update Docker requirements file. If this
|
||||
# is a dry run, a draft PR will open with the changes. If this isn't a dry
|
||||
# run, the changes will be committed to the branch this is run on.
|
||||
|
||||
# **why?**
|
||||
# This is to aid in releasing dbt and making sure we have updated
|
||||
# the versions and Docker requirements in all places.
|
||||
|
||||
# **when?**
|
||||
# This is triggered either manually OR
|
||||
# from the repository_dispatch event "version-bump" which is sent from
|
||||
# the dbt-release repo Action
|
||||
|
||||
name: Version Bump
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version_number:
|
||||
description: 'The version number to bump to'
|
||||
required: true
|
||||
is_dry_run:
|
||||
description: 'Creates a draft PR to allow testing instead of committing to a branch'
|
||||
required: true
|
||||
default: 'true'
|
||||
repository_dispatch:
|
||||
types: [version-bump]
|
||||
|
||||
jobs:
|
||||
bump:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set version and dry run values
|
||||
id: variables
|
||||
env:
|
||||
VERSION_NUMBER: "${{ github.event.client_payload.version_number == '' && github.event.inputs.version_number || github.event.client_payload.version_number }}"
|
||||
IS_DRY_RUN: "${{ github.event.client_payload.is_dry_run == '' && github.event.inputs.is_dry_run || github.event.client_payload.is_dry_run }}"
|
||||
run: |
|
||||
echo Repository dispatch event version: ${{ github.event.client_payload.version_number }}
|
||||
echo Repository dispatch event dry run: ${{ github.event.client_payload.is_dry_run }}
|
||||
echo Workflow dispatch event version: ${{ github.event.inputs.version_number }}
|
||||
echo Workflow dispatch event dry run: ${{ github.event.inputs.is_dry_run }}
|
||||
echo ::set-output name=VERSION_NUMBER::$VERSION_NUMBER
|
||||
echo ::set-output name=IS_DRY_RUN::$IS_DRY_RUN
|
||||
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
|
||||
- name: Create PR branch
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
run: |
|
||||
git checkout -b bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git push origin bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git branch --set-upstream-to=origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
|
||||
# - name: Generate Docker requirements
|
||||
# run: |
|
||||
# source env/bin/activate
|
||||
# pip install -r requirements.txt
|
||||
# pip freeze -l > docker/requirements/requirements.txt
|
||||
# git status
|
||||
|
||||
- name: Bump version
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r dev-requirements.txt
|
||||
env/bin/bumpversion --allow-dirty --new-version ${{steps.variables.outputs.VERSION_NUMBER}} major
|
||||
git status
|
||||
|
||||
- name: Commit version bump directly
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'false' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
|
||||
- name: Commit version bump to branch
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
push: 'origin origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v3
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
||||
draft: true
|
||||
base: ${{github.ref}}
|
||||
title: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
9
.gitignore
vendored
9
.gitignore
vendored
@@ -49,9 +49,8 @@ coverage.xml
|
||||
*,cover
|
||||
.hypothesis/
|
||||
test.env
|
||||
*.pytest_cache/
|
||||
|
||||
# Mypy
|
||||
.mypy_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
@@ -66,10 +65,10 @@ docs/_build/
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
#Ipython Notebook
|
||||
# Ipython Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
#Emacs
|
||||
# Emacs
|
||||
*~
|
||||
|
||||
# Sublime Text
|
||||
@@ -78,6 +77,7 @@ target/
|
||||
# Vim
|
||||
*.sw*
|
||||
|
||||
# Pyenv
|
||||
.python-version
|
||||
|
||||
# Vim
|
||||
@@ -90,6 +90,7 @@ venv/
|
||||
# AWS credentials
|
||||
.aws/
|
||||
|
||||
# MacOS
|
||||
.DS_Store
|
||||
|
||||
# vscode
|
||||
|
||||
68
.pre-commit-config.yaml
Normal file
68
.pre-commit-config.yaml
Normal file
@@ -0,0 +1,68 @@
|
||||
# Configuration for pre-commit hooks (see https://pre-commit.com/).
|
||||
# Eventually the hooks described here will be run as tests before merging each PR.
|
||||
|
||||
# TODO: remove global exclusion of tests when testing overhaul is complete
|
||||
exclude: ^test/
|
||||
|
||||
# Force all unspecified python hooks to run python 3.8
|
||||
default_language_version:
|
||||
python: python3.8
|
||||
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v3.2.0
|
||||
hooks:
|
||||
- id: check-yaml
|
||||
args: [--unsafe]
|
||||
- id: check-json
|
||||
- id: end-of-file-fixer
|
||||
- id: trailing-whitespace
|
||||
exclude_types:
|
||||
- "markdown"
|
||||
- id: check-case-conflict
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 21.12b0
|
||||
hooks:
|
||||
- id: black
|
||||
args:
|
||||
- "--line-length=99"
|
||||
- "--target-version=py38"
|
||||
- id: black
|
||||
alias: black-check
|
||||
stages: [manual]
|
||||
args:
|
||||
- "--line-length=99"
|
||||
- "--target-version=py38"
|
||||
- "--check"
|
||||
- "--diff"
|
||||
- repo: https://gitlab.com/pycqa/flake8
|
||||
rev: 4.0.1
|
||||
hooks:
|
||||
- id: flake8
|
||||
- id: flake8
|
||||
alias: flake8-check
|
||||
stages: [manual]
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
rev: v0.782
|
||||
hooks:
|
||||
- id: mypy
|
||||
# N.B.: Mypy is... a bit fragile.
|
||||
#
|
||||
# By using `language: system` we run this hook in the local
|
||||
# environment instead of a pre-commit isolated one. This is needed
|
||||
# to ensure mypy correctly parses the project.
|
||||
|
||||
# It may cause trouble
|
||||
# in that it adds environmental variables out of our control to the
|
||||
# mix. Unfortunately, there's nothing we can do about per pre-commit's
|
||||
# author.
|
||||
# See https://github.com/pre-commit/pre-commit/issues/730 for details.
|
||||
args: [--show-error-codes]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
- id: mypy
|
||||
alias: mypy-check
|
||||
stages: [manual]
|
||||
args: [--show-error-codes, --pretty]
|
||||
files: ^core/dbt/
|
||||
language: system
|
||||
@@ -1,34 +1,39 @@
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
|
||||
## dbt-core
|
||||
|
||||
Most of the python code in the repository is within the `core/dbt` directory. Currently the main subdirectories are:
|
||||
- [`adapters`](core/dbt/adapters): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
- [`context`](core/dbt/context): Build and expose dbt-specific Jinja functionality
|
||||
- [`contracts`](core/dbt/contracts): Define Python objects (dataclasses) that dbt expects to create and validate
|
||||
- [`deps`](core/dbt/deps): Package installation and dependency resolution
|
||||
- [`graph`](core/dbt/graph): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`parser`](core/dbt/parser): Read project files, validate, construct python objects
|
||||
- [`rpc`](core/dbt/rpc): Provide remote procedure call server for invoking dbt, following JSON-RPC 2.0 spec
|
||||
- [`task`](core/dbt/task): Set forth the actions that dbt can perform when invoked
|
||||
Most of the python code in the repository is within the `core/dbt` directory.
|
||||
- [`single python files`](core/dbt/README.md): A number of individual files, such as 'compilation.py' and 'exceptions.py'
|
||||
|
||||
The main subdirectories of core/dbt:
|
||||
- [`adapters`](core/dbt/adapters/README.md): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients/README.md): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config/README.md): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
- [`context`](core/dbt/context/README.md): Build and expose dbt-specific Jinja functionality
|
||||
- [`contracts`](core/dbt/contracts/README.md): Define Python objects (dataclasses) that dbt expects to create and validate
|
||||
- [`deps`](core/dbt/deps/README.md): Package installation and dependency resolution
|
||||
- [`events`](core/dbt/events/README.md): Logging events
|
||||
- [`graph`](core/dbt/graph/README.md): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include/README.md): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`parser`](core/dbt/parser/README.md): Read project files, validate, construct python objects
|
||||
- [`task`](core/dbt/task/README.md): Set forth the actions that dbt can perform when invoked
|
||||
|
||||
Legacy tests are found in the 'test' directory:
|
||||
- [`unit tests`](core/dbt/test/unit/README.md): Unit tests
|
||||
- [`integration tests`](core/dbt/test/integration/README.md): Integration tests
|
||||
|
||||
### Invoking dbt
|
||||
|
||||
There are two supported ways of invoking dbt: from the command line and using an RPC server.
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task/rpc should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
|
||||
core/dbt/include/index.html
|
||||
This is the docs website code. It comes from the dbt-docs repository, and is generated when a release is packaged.
|
||||
|
||||
## Adapters
|
||||
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. The four core adapters that are in the main repository, contained within the [`plugins`](plugins) subdirectory, are: Postgres Redshift, Snowflake and BigQuery. Other warehouses use adapter plugins defined in separate repositories (e.g. [dbt-spark](https://github.com/fishtown-analytics/dbt-spark), [dbt-presto](https://github.com/fishtown-analytics/dbt-presto)).
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. For testing and development purposes, the dbt-postgres plugin lives alongside the dbt-core codebase, in the [`plugins`](plugins) subdirectory. Like other adapter plugins, it is a self-contained codebase and package that builds on top of dbt-core.
|
||||
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
|
||||
Each adapter plugin is a standalone python package that includes:
|
||||
|
||||
@@ -46,4 +51,4 @@ The [`test/`](test/) subdirectory includes unit and integration tests that run a
|
||||
|
||||
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
||||
- [etc](etc/): Images for README
|
||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, not are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, nor are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||
|
||||
3055
CHANGELOG.md
Normal file → Executable file
3055
CHANGELOG.md
Normal file → Executable file
File diff suppressed because it is too large
Load Diff
134
CONTRIBUTING.md
134
CONTRIBUTING.md
@@ -10,107 +10,113 @@
|
||||
|
||||
## About this document
|
||||
|
||||
This document is a guide intended for folks interested in contributing to `dbt`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
This document is a guide intended for folks interested in contributing to `dbt-core`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt-core`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
#### Adapters
|
||||
|
||||
If you have an issue or code change suggestion related to a specific database [adapter](https://docs.getdbt.com/docs/available-adapters); please refer to that supported databases seperate repo for those contributions.
|
||||
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to `dbt` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt` codebase. If you are unable to sign the CLA, then the `dbt` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
Please note that all contributors to `dbt-core` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt-core` codebase. If you are unable to sign the CLA, then the `dbt-core` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
|
||||
## Proposing a change
|
||||
|
||||
`dbt` is Apache 2.0-licensed open source software. `dbt` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
`dbt-core` is Apache 2.0-licensed open source software. `dbt-core` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt`, the first step is to open an issue. Please check the list of [open issues](https://github.com/fishtown-analytics/dbt/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt-core`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt-core/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt-core` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
### Discussing the idea
|
||||
|
||||
After you open an issue, a `dbt` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
After you open an issue, a `dbt-core` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt-core` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
|
||||
### Submitting a change
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt-core` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The `dbt` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/fishtown-analytics/dbt/contribute) page.
|
||||
The `dbt-core` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt-core/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
- Outline your planned implementation. If you want help getting started, ask!
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt-core` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt-core`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Check your formatting and linting with [Flake8](https://flake8.pycqa.org/en/latest/#), [Black](https://github.com/psf/black), and the rest of the hooks we have in our [pre-commit](https://pre-commit.com/) [config](https://github.com/dbt-labs/dbt-core/blob/75201be9db1cb2c6c01fa7e71a314f5e5beb060a/.pre-commit-config.yaml).
|
||||
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt` maintainers are unwilling or unable to incorporate into the `dbt` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt-core` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt-core` maintainers are unwilling or unable to incorporate into the `dbt-core` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt-core` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
|
||||
### Using issue labels
|
||||
|
||||
The `dbt` maintainers use labels to categorize open issues. Some labels indicate the databases impacted by the issue, while others describe the domain in the `dbt` codebase germane to the discussion. While most of these labels are self-explanatory (eg. `snowflake` or `bigquery`), there are others that are worth describing.
|
||||
The `dbt-core` maintainers use labels to categorize open issues. Most labels describe the domain in the `dbt-core` codebase germane to the discussion.
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/fishtown-analytics/dbt/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/fishtown-analytics/dbt/labels/bug) | This issue represents a defect or regression in `dbt` |
|
||||
| [enhancement](https://github.com/fishtown-analytics/dbt/labels/enhancement) | This issue represents net-new functionality in `dbt` |
|
||||
| [good first issue](https://github.com/fishtown-analytics/dbt/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/fishtown-analytics/`dbt`/labels/help%20wanted) / [discussion](https://github.com/fishtown-analytics/dbt/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/fishtown-analytics/dbt/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/fishtown-analytics/dbt/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/fishtown-analytics/dbt/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/fishtown-analytics/dbt/labels/wontfix) | This issue does not require a code change in the `dbt` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
| [triage](https://github.com/dbt-labs/dbt-core/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt-core` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt-core/labels/bug) | This issue represents a defect or regression in `dbt-core` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt-core/labels/enhancement) | This issue represents net-new functionality in `dbt-core` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt-core/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt-core` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt-core/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt-core/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt-core/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt-core` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt-core/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt-core` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt-core/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt-core` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt-core/labels/wontfix) | This issue does not require a code change in the `dbt-core` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
`dbt` has three types of branches:
|
||||
`dbt-core` has three types of branches:
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `develop` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk brnach or a specific release branch.
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `main` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt-core`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt-core`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk branch or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
### Installing git
|
||||
|
||||
You will need `git` in order to download and modify the `dbt` source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
You will need `git` in order to download and modify the `dbt-core` source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
|
||||
### External contributors
|
||||
|
||||
If you are not a member of the `fishtown-analytics` GitHub organization, you can contribute to `dbt` by forking the `dbt` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
If you are not a member of the `dbt-labs` GitHub organization, you can contribute to `dbt-core` by forking the `dbt-core` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
|
||||
1. fork the `dbt` repository
|
||||
1. fork the `dbt-core` repository
|
||||
2. clone your fork locally
|
||||
3. check out a new branch for your proposed changes
|
||||
4. push changes to your fork
|
||||
5. open a pull request against `fishtown-analytics/dbt` from your forked repository
|
||||
5. open a pull request against `dbt-labs/dbt` from your forked repository
|
||||
|
||||
### Core contributors
|
||||
### dbt Labs contributors
|
||||
|
||||
If you are a member of the `fishtown-analytics` GitHub organization, you will have push access to the `dbt` repo. Rather than forking `dbt` to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
If you are a member of the `dbt-labs` GitHub organization, you will have push access to the `dbt-core` repo. Rather than forking `dbt-core` to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
## Setting up an environment
|
||||
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for `dbt` development, many of these tools are used commonly across open-source python projects.
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for `dbt-core` development, many of these tools are used commonly across open-source python projects.
|
||||
|
||||
### Tools
|
||||
|
||||
A short list of tools used in `dbt` testing that will be helpful to your understanding:
|
||||
A short list of tools used in `dbt-core` testing that will be helpful to your understanding:
|
||||
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.6, Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`black`](https://github.com/psf/black) for code formatting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [CircleCI](https://circleci.com/product/) and [Azure Pipelines](https://azure.microsoft.com/en-us/services/devops/pipelines/)
|
||||
- [Github Actions](https://github.com/features/actions)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
#### virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in `dbt`. We recommend creating this virtualenv
|
||||
in the root of the `dbt` repository. To create a new virtualenv, run:
|
||||
We strongly recommend using virtual environments when developing code in `dbt-core`. We recommend creating this virtualenv
|
||||
in the root of the `dbt-core` repository. To create a new virtualenv, run:
|
||||
```sh
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
@@ -131,11 +137,11 @@ For testing, and later in the examples in this document, you may want to have `p
|
||||
brew install postgresql
|
||||
```
|
||||
|
||||
## Running `dbt` in development
|
||||
## Running `dbt-core` in development
|
||||
|
||||
### Installation
|
||||
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Next, install `dbt` (and its dependencies) with:
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Also ensure you have the latest version of pip installed with `pip install --upgrade pip`. Next, install `dbt-core` (and its dependencies) with:
|
||||
|
||||
```sh
|
||||
make dev
|
||||
@@ -143,23 +149,24 @@ make dev
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
```
|
||||
|
||||
When `dbt` is installed this way, any changes you make to the `dbt` source code will be reflected immediately in your next `dbt` run.
|
||||
When `dbt-core` is installed this way, any changes you make to the `dbt-core` source code will be reflected immediately in your next `dbt-core` run.
|
||||
|
||||
### Running `dbt`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
### Running `dbt-core`
|
||||
|
||||
With your virtualenv activated, the `dbt-core` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local postgres instance, or a specific test sandbox within your data warehouse if appropriate.
|
||||
|
||||
## Testing
|
||||
|
||||
Getting the `dbt` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
Getting the `dbt-core` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt-core`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
Since `dbt` works with a number of different databases, you will need to supply credentials for one or more of these databases in your test environment. Most organizations don't have access to each of a BigQuery, Redshift, Snowflake, and Postgres database, so it's likely that you will be unable to run every integration test locally. Fortunately, Fishtown Analytics provides a CI environment with access to sandboxed Redshift, Snowflake, BigQuery, and Postgres databases. See the section on [_Submitting a Pull Request_](#submitting-a-pull-request) below for more information on this CI setup.
|
||||
Although `dbt-core` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead you can test all dbt-core code changes with Python and Postgres.
|
||||
|
||||
### Initial setup
|
||||
|
||||
We recommend starting with `dbt`'s Postgres tests. These tests cover most of the functionality in `dbt`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
We recommend starting with `dbt-core`'s Postgres tests. These tests cover most of the functionality in `dbt-core`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
@@ -170,15 +177,6 @@ docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
```
|
||||
|
||||
`dbt` uses test credentials specified in a `test.env` file in the root of the repository for non-Postgres databases. This `test.env` file is git-ignored, but please be _extra_ careful to never check in credentials or other sensitive information when developing against `dbt`. To create your `test.env` file, copy the provided sample file, then supply your relevant credentials. This step is only required to use non-Postgres databases.
|
||||
|
||||
```
|
||||
cp test.env.sample test.env
|
||||
$EDITOR test.env
|
||||
```
|
||||
|
||||
> In general, it's most important to have successful unit and Postgres tests. Once you open a PR, `dbt` will automatically run integration tests for the other three core database adapters. Of course, if you are a BigQuery user, contributing a BigQuery-only feature, it's important to run BigQuery tests as well.
|
||||
|
||||
### Test commands
|
||||
|
||||
There are a few methods for running tests locally.
|
||||
@@ -194,19 +192,18 @@ make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) installed locally,
|
||||
> These make targets assume you have a local install of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
|
||||
#### `pre-commit`
|
||||
[`pre-commit`](https.pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run
|
||||
tests. You can also run tests in parallel, for example, you can run unit tests
|
||||
for Python 3.6, Python 3.7, Python 3.8, `flake8` checks, and `mypy` checks in
|
||||
parallel with `tox -p`. Also, you can run unit tests for specific python versions
|
||||
with `tox -e py36`. The configuration for these tests in located in `tox.ini`.
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.7, Python 3.8, and Python 3.9 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py37`. The configuration for these tests in located in `tox.ini`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
@@ -222,10 +219,21 @@ python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
```
|
||||
> [Here](https://docs.pytest.org/en/reorganize-docs/new-docs/user/commandlineuseful.html)
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
|
||||
## Adding CHANGELOG Entry
|
||||
|
||||
We use [changie](https://changie.dev) to generate `CHANGELOG` entries. Do not edit the `CHANGELOG.md` directly. Your modifications will be lost.
|
||||
|
||||
Follow the steps to [install `changie`](https://changie.dev/guide/installation/) for your system.
|
||||
|
||||
Once changie is installed and your PR is created, simply run `changie new` and changie will walk you through the process of creating a changelog entry. Commit the file that's created and your changelog entry is complete!
|
||||
|
||||
## Submitting a Pull Request
|
||||
|
||||
Fishtown Analytics provides a sandboxed Redshift, Snowflake, and BigQuery database for use in a CI environment. When pull requests are submitted to the `fishtown-analytics/dbt` repo, GitHub will trigger automated tests in CircleCI and Azure Pipelines.
|
||||
dbt Labs provides a CI environment to test changes to specific adapters, and periodic maintenance checks of `dbt-core` through Github Actions. For example, if you submit a pull request to the `dbt-redshift` repo, GitHub will trigger automated code checks and tests against Redshift.
|
||||
|
||||
A `dbt` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
A `dbt-core` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
- First time contributors should note code checks + unit tests require a maintainer to approve.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a `dbt` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
Once all tests are passing and your PR has been approved, a `dbt-core` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
@@ -1,4 +1,9 @@
|
||||
FROM ubuntu:18.04
|
||||
##
|
||||
# This dockerfile is used for local development and adapter testing only.
|
||||
# See `/docker` for a generic and production-ready docker file
|
||||
##
|
||||
|
||||
FROM ubuntu:20.04
|
||||
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
@@ -27,7 +32,7 @@ RUN apt-get update \
|
||||
&& apt-get install -y \
|
||||
python \
|
||||
python-dev \
|
||||
python-pip \
|
||||
python3-pip \
|
||||
python3.6 \
|
||||
python3.6-dev \
|
||||
python3-pip \
|
||||
|
||||
@@ -186,7 +186,7 @@
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
Copyright 2021 dbt Labs, Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
|
||||
109
Makefile
109
Makefile
@@ -8,69 +8,58 @@ endif
|
||||
|
||||
.PHONY: dev
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies.
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
@\
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt && \
|
||||
pre-commit install
|
||||
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy for static type checking.
|
||||
$(DOCKER_CMD) tox -e mypy
|
||||
mypy: .env ## Runs mypy against staged changes for static type checking.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual mypy-check | grep -v "INFO"
|
||||
|
||||
.PHONY: flake8
|
||||
flake8: .env ## Runs flake8 to enforce style guide.
|
||||
$(DOCKER_CMD) tox -e flake8
|
||||
flake8: .env ## Runs flake8 against staged changes to enforce style guide.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual flake8-check | grep -v "INFO"
|
||||
|
||||
.PHONY: black
|
||||
black: .env ## Runs black against staged changes to enforce style guide.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run --hook-stage manual black-check -v | grep -v "INFO"
|
||||
|
||||
.PHONY: lint
|
||||
lint: .env ## Runs all code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e flake8,mypy
|
||||
lint: .env ## Runs flake8 and mypy code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py38.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py38 and code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e py38,flake8,mypy
|
||||
test: .env ## Runs unit tests with py38 and code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38; \
|
||||
$(DOCKER_CMD) pre-commit run black-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env integration-postgres ## Alias for integration-postgres.
|
||||
integration: .env ## Runs postgres integration tests with py38.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38-integration -- -nauto
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env integration-postgres-fail-fast ## Alias for integration-postgres-fail-fast.
|
||||
|
||||
.PHONY: integration-postgres
|
||||
integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -nauto
|
||||
|
||||
.PHONY: integration-postgres-fail-fast
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: integration-redshift
|
||||
integration-redshift: .env ## Runs redshift integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -nauto
|
||||
|
||||
.PHONY: integration-redshift-fail-fast
|
||||
integration-redshift-fail-fast: .env ## Runs redshift integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -x -nauto
|
||||
|
||||
.PHONY: integration-snowflake
|
||||
integration-snowflake: .env ## Runs snowflake integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -nauto
|
||||
|
||||
.PHONY: integration-snowflake-fail-fast
|
||||
integration-snowflake-fail-fast: .env ## Runs snowflake integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -x -nauto
|
||||
|
||||
.PHONY: integration-bigquery
|
||||
integration-bigquery: .env ## Runs bigquery integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -nauto
|
||||
|
||||
.PHONY: integration-bigquery-fail-fast
|
||||
integration-bigquery-fail-fast: .env ## Runs bigquery integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -x -nauto
|
||||
integration-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38-integration -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
docker-compose up -d database
|
||||
@\
|
||||
docker-compose up -d database && \
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
|
||||
# This rule creates a file named .env that is used by docker-compose for passing
|
||||
@@ -86,27 +75,29 @@ endif
|
||||
|
||||
.PHONY: clean
|
||||
clean: ## Resets development environment.
|
||||
rm -f .coverage
|
||||
rm -rf .eggs/
|
||||
rm -f .env
|
||||
rm -rf .tox/
|
||||
rm -rf build/
|
||||
rm -rf dbt.egg-info/
|
||||
rm -f dbt_project.yml
|
||||
rm -rf dist/
|
||||
rm -f htmlcov/*.{css,html,js,json,png}
|
||||
rm -rf logs/
|
||||
rm -rf target/
|
||||
find . -type f -name '*.pyc' -delete
|
||||
find . -type d -name '__pycache__' -depth -delete
|
||||
@echo 'cleaning repo...'
|
||||
@rm -f .coverage
|
||||
@rm -rf .eggs/
|
||||
@rm -f .env
|
||||
@rm -rf .tox/
|
||||
@rm -rf build/
|
||||
@rm -rf dbt.egg-info/
|
||||
@rm -f dbt_project.yml
|
||||
@rm -rf dist/
|
||||
@rm -f htmlcov/*.{css,html,js,json,png}
|
||||
@rm -rf logs/
|
||||
@rm -rf target/
|
||||
@find . -type f -name '*.pyc' -delete
|
||||
@find . -type d -name '__pycache__' -depth -delete
|
||||
@echo 'done.'
|
||||
|
||||
|
||||
.PHONY: help
|
||||
help: ## Show this help message.
|
||||
@echo 'usage: make [target] [USE_DOCKER=true]'
|
||||
@echo
|
||||
@echo 'targets:'
|
||||
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
@grep -E '^[8+a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
@echo
|
||||
@echo 'options:'
|
||||
@echo 'use USE_DOCKER=true to run target in a docker container'
|
||||
|
||||
|
||||
45
README.md
45
README.md
@@ -1,28 +1,15 @@
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/fishtown-analytics/dbt/6c6649f9129d5d108aa3b0526f634cd8f3a9d1ed/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://codeclimate.com/github/fishtown-analytics/dbt">
|
||||
<img src="https://codeclimate.com/github/fishtown-analytics/dbt/badges/gpa.svg" alt="Code Climate"/>
|
||||
</a>
|
||||
<a href="https://circleci.com/gh/fishtown-analytics/dbt/tree/master">
|
||||
<img src="https://circleci.com/gh/fishtown-analytics/dbt/tree/master.svg?style=svg" alt="CircleCI" />
|
||||
</a>
|
||||
<a href="https://ci.appveyor.com/project/DrewBanin/dbt/branch/development">
|
||||
<img src="https://ci.appveyor.com/api/projects/status/v01rwd3q91jnwp9m/branch/development?svg=true" alt="AppVeyor" />
|
||||
</a>
|
||||
<a href="https://community.getdbt.com">
|
||||
<img src="https://community.getdbt.com/badge.svg" alt="Slack" />
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** (data build tool) enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
dbt is the T in ELT. Organize, cleanse, denormalize, filter, rename, and pre-aggregate the raw data in your warehouse so that it's ready for analysis.
|
||||
|
||||
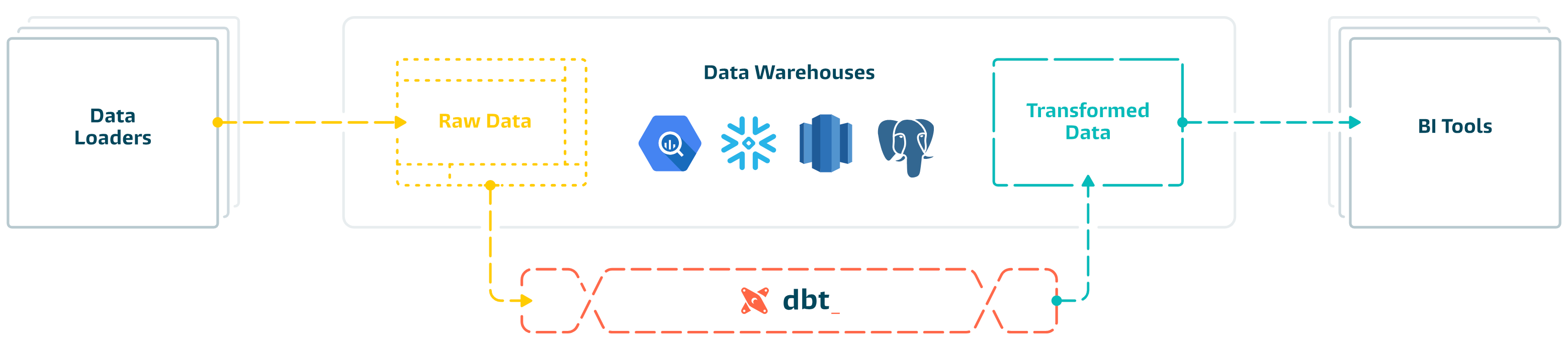
|
||||
|
||||
dbt can be used to [aggregate pageviews into sessions](https://github.com/fishtown-analytics/snowplow), calculate [ad spend ROI](https://github.com/fishtown-analytics/facebook-ads), or report on [email campaign performance](https://github.com/fishtown-analytics/mailchimp).
|
||||
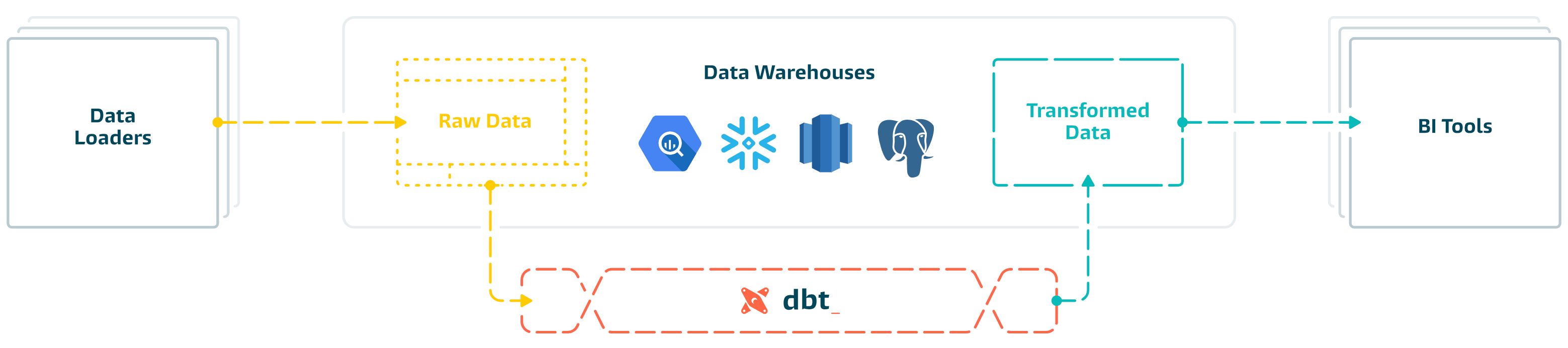
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -30,28 +17,22 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||
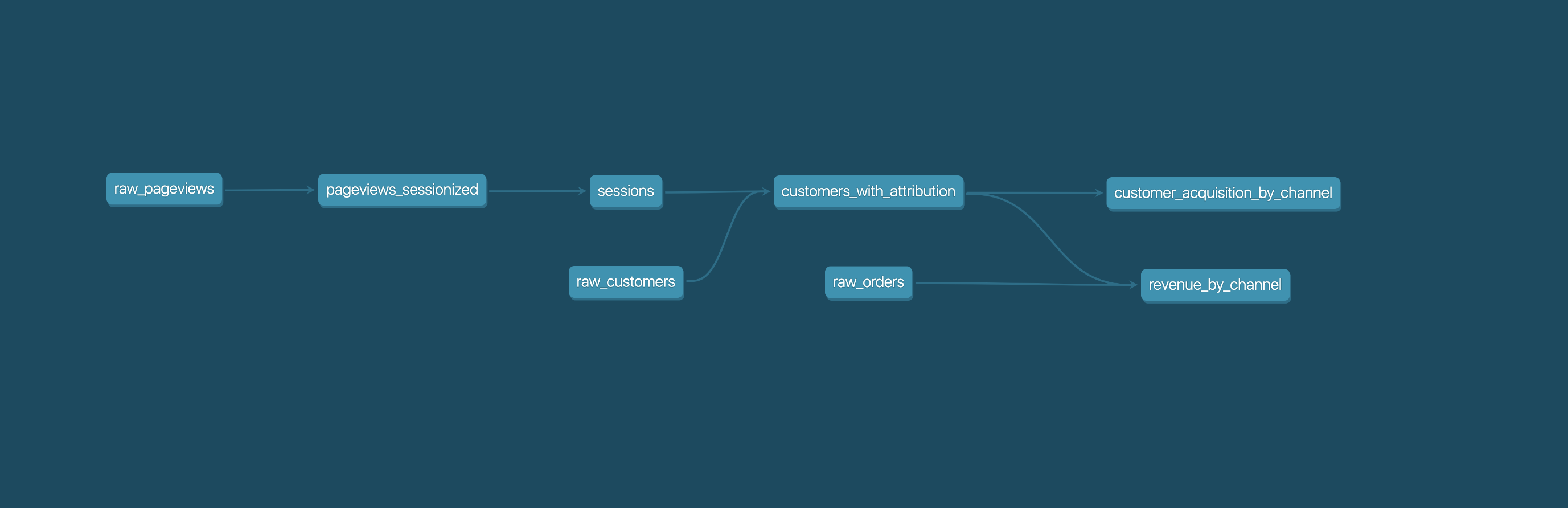
|
||||
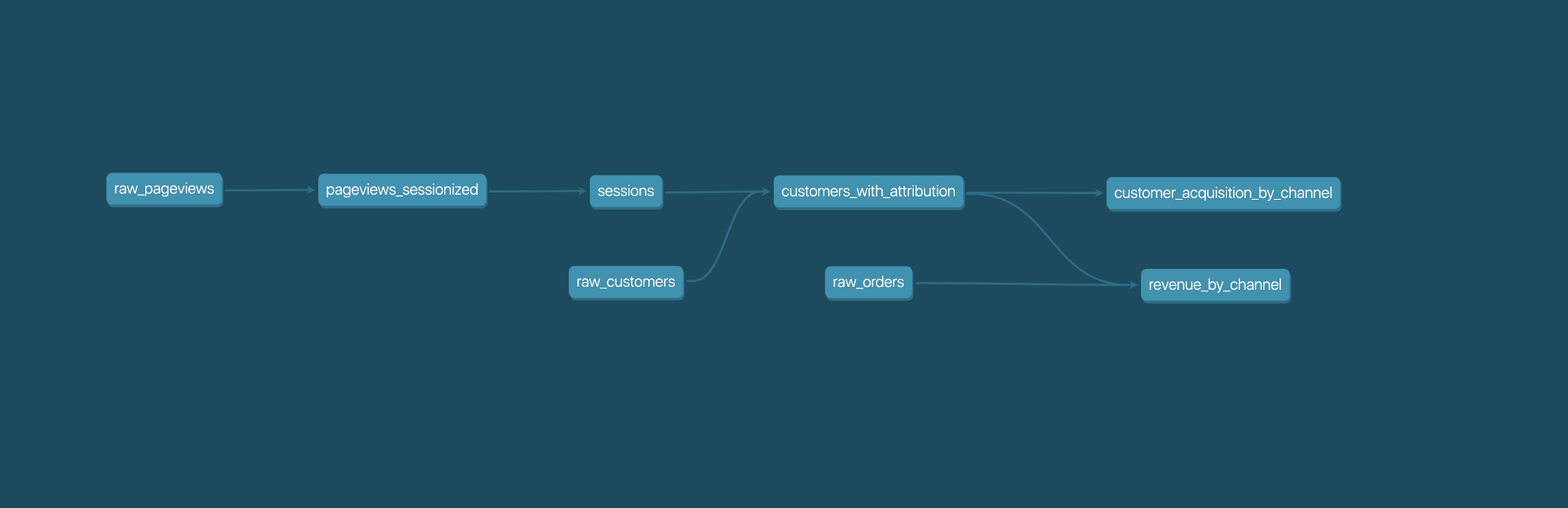
|
||||
|
||||
## Getting started
|
||||
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [documentation](https://docs.getdbt.com/).
|
||||
- Productionize your dbt project with [dbt Cloud](https://www.getdbt.com)
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
|
||||
|
||||
## Find out more
|
||||
## Join the dbt Community
|
||||
|
||||
- Check out the [Introduction to dbt](https://docs.getdbt.com/docs/introduction/).
|
||||
- Read the [dbt Viewpoint](https://docs.getdbt.com/docs/about/viewpoint/).
|
||||
|
||||
## Join thousands of analysts in the dbt community
|
||||
|
||||
- Join the [chat](http://community.getdbt.com/) on Slack.
|
||||
- Find community posts on [dbt Discourse](https://discourse.getdbt.com).
|
||||
- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
|
||||
- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/fishtown-analytics/dbt/issues/new).
|
||||
- Want to help us build dbt? Check out the [Contributing Getting Started Guide](https://github.com/fishtown-analytics/dbt/blob/HEAD/CONTRIBUTING.md)
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt-core/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt-core/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
@@ -1,154 +0,0 @@
|
||||
# Python package
|
||||
# Create and test a Python package on multiple Python versions.
|
||||
# Add steps that analyze code, save the dist with the build record, publish to a PyPI-compatible index, and more:
|
||||
# https://docs.microsoft.com/azure/devops/pipelines/languages/python
|
||||
|
||||
trigger:
|
||||
branches:
|
||||
include:
|
||||
- develop
|
||||
- '*.latest'
|
||||
- pr/*
|
||||
|
||||
jobs:
|
||||
- job: UnitTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e py -- -v
|
||||
displayName: Run unit tests
|
||||
|
||||
- job: PostgresIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: UnitTest
|
||||
|
||||
steps:
|
||||
- pwsh: |
|
||||
$serviceName = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $serviceName -StartupType Automatic
|
||||
Start-Service -InputObject $serviceName
|
||||
|
||||
& $env:PGBIN\createdb.exe -U postgres dbt
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE root WITH PASSWORD 'password';"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE root WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CREATE, CONNECT ON DATABASE dbt TO root WITH GRANT OPTION;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE noaccess WITH PASSWORD 'password' NOSUPERUSER;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE noaccess WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CONNECT ON DATABASE dbt TO noaccess;"
|
||||
displayName: Install postgresql and set up database
|
||||
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e py-postgres -- -v -n4
|
||||
displayName: Run integration tests
|
||||
|
||||
# These three are all similar except secure environment variables, which MUST be passed along to their tasks,
|
||||
# but there's probably a better way to do this!
|
||||
- job: SnowflakeIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e py-snowflake -- -v -n4
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: $(SNOWFLAKE_TEST_ACCOUNT)
|
||||
SNOWFLAKE_TEST_PASSWORD: $(SNOWFLAKE_TEST_PASSWORD)
|
||||
SNOWFLAKE_TEST_USER: $(SNOWFLAKE_TEST_USER)
|
||||
SNOWFLAKE_TEST_WAREHOUSE: $(SNOWFLAKE_TEST_WAREHOUSE)
|
||||
SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN: $(SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN)
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_ID: $(SNOWFLAKE_TEST_OAUTH_CLIENT_ID)
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET: $(SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: BigQueryIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
- script: python -m tox -e py-bigquery -- -v -n4
|
||||
env:
|
||||
BIGQUERY_SERVICE_ACCOUNT_JSON: $(BIGQUERY_SERVICE_ACCOUNT_JSON)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: RedshiftIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: UnitTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e py-redshift -- -v -n4
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: $(REDSHIFT_TEST_DBNAME)
|
||||
REDSHIFT_TEST_PASS: $(REDSHIFT_TEST_PASS)
|
||||
REDSHIFT_TEST_USER: $(REDSHIFT_TEST_USER)
|
||||
REDSHIFT_TEST_PORT: $(REDSHIFT_TEST_PORT)
|
||||
REDSHIFT_TEST_HOST: $(REDSHIFT_TEST_HOST)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: BuildWheel
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn:
|
||||
- UnitTest
|
||||
- PostgresIntegrationTest
|
||||
- RedshiftIntegrationTest
|
||||
- SnowflakeIntegrationTest
|
||||
- BigQueryIntegrationTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip setuptools && python -m pip install -r requirements.txt && python -m pip install -r dev-requirements.txt
|
||||
displayName: Install dependencies
|
||||
- task: ShellScript@2
|
||||
inputs:
|
||||
scriptPath: scripts/build-wheels.sh
|
||||
- task: CopyFiles@2
|
||||
inputs:
|
||||
contents: 'dist\?(*.whl|*.tar.gz)'
|
||||
TargetFolder: '$(Build.ArtifactStagingDirectory)'
|
||||
- task: PublishBuildArtifacts@1
|
||||
inputs:
|
||||
pathtoPublish: '$(Build.ArtifactStagingDirectory)'
|
||||
artifactName: dists
|
||||
73
converter.py
73
converter.py
@@ -1,73 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
import json
|
||||
import yaml
|
||||
import sys
|
||||
import argparse
|
||||
from datetime import datetime, timezone
|
||||
import dbt.clients.registry as registry
|
||||
|
||||
|
||||
def yaml_type(fname):
|
||||
with open(fname) as f:
|
||||
return yaml.load(f)
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--project", type=yaml_type, default="dbt_project.yml")
|
||||
parser.add_argument("--namespace", required=True)
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def get_full_name(args):
|
||||
return "{}/{}".format(args.namespace, args.project["name"])
|
||||
|
||||
|
||||
def init_project_in_packages(args, packages):
|
||||
full_name = get_full_name(args)
|
||||
if full_name not in packages:
|
||||
packages[full_name] = {
|
||||
"name": args.project["name"],
|
||||
"namespace": args.namespace,
|
||||
"latest": args.project["version"],
|
||||
"assets": {},
|
||||
"versions": {},
|
||||
}
|
||||
return packages[full_name]
|
||||
|
||||
|
||||
def add_version_to_package(args, project_json):
|
||||
project_json["versions"][args.project["version"]] = {
|
||||
"id": "{}/{}".format(get_full_name(args), args.project["version"]),
|
||||
"name": args.project["name"],
|
||||
"version": args.project["version"],
|
||||
"description": "",
|
||||
"published_at": datetime.now(timezone.utc).astimezone().isoformat(),
|
||||
"packages": args.project.get("packages") or [],
|
||||
"works_with": [],
|
||||
"_source": {
|
||||
"type": "github",
|
||||
"url": "",
|
||||
"readme": "",
|
||||
},
|
||||
"downloads": {
|
||||
"tarball": "",
|
||||
"format": "tgz",
|
||||
"sha1": "",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
packages = registry.packages()
|
||||
project_json = init_project_in_packages(args, packages)
|
||||
if args.project["version"] in project_json["versions"]:
|
||||
raise Exception("Version {} already in packages JSON"
|
||||
.format(args.project["version"]),
|
||||
file=sys.stderr)
|
||||
add_version_to_package(args, project_json)
|
||||
print(json.dumps(packages, indent=2))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1 +1 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
|
||||
39
core/README.md
Normal file
39
core/README.md
Normal file
@@ -0,0 +1,39 @@
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||

|
||||
|
||||
## Understanding dbt
|
||||
|
||||
Analysts using dbt can transform their data by simply writing select statements, while dbt handles turning these statements into tables and views in a data warehouse.
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||

|
||||
|
||||
## Getting started
|
||||
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
|
||||
|
||||
## Join the dbt Community
|
||||
|
||||
- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
|
||||
- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt-core/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt-core/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
Everyone interacting in the dbt project's codebases, issue trackers, chat rooms, and mailing lists is expected to follow the [dbt Code of Conduct](https://community.getdbt.com/code-of-conduct).
|
||||
51
core/dbt/README.md
Normal file
51
core/dbt/README.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# core/dbt directory README
|
||||
|
||||
## The following are individual files in this directory.
|
||||
|
||||
### deprecations.py
|
||||
|
||||
### flags.py
|
||||
|
||||
### main.py
|
||||
|
||||
### tracking.py
|
||||
|
||||
### version.py
|
||||
|
||||
### lib.py
|
||||
|
||||
### node_types.py
|
||||
|
||||
### helper_types.py
|
||||
|
||||
### links.py
|
||||
|
||||
### semver.py
|
||||
|
||||
### ui.py
|
||||
|
||||
### compilation.py
|
||||
|
||||
### dataclass_schema.py
|
||||
|
||||
### exceptions.py
|
||||
|
||||
### hooks.py
|
||||
|
||||
### logger.py
|
||||
|
||||
### profiler.py
|
||||
|
||||
### utils.py
|
||||
|
||||
|
||||
## The subdirectories will be documented in a README in the subdirectory
|
||||
* config
|
||||
* include
|
||||
* adapters
|
||||
* context
|
||||
* deps
|
||||
* graph
|
||||
* task
|
||||
* clients
|
||||
* events
|
||||
1
core/dbt/adapters/README.md
Normal file
1
core/dbt/adapters/README.md
Normal file
@@ -0,0 +1 @@
|
||||
# Adapters README
|
||||
@@ -8,10 +8,10 @@ from dbt.exceptions import RuntimeException
|
||||
@dataclass
|
||||
class Column:
|
||||
TYPE_LABELS: ClassVar[Dict[str, str]] = {
|
||||
'STRING': 'TEXT',
|
||||
'TIMESTAMP': 'TIMESTAMP',
|
||||
'FLOAT': 'FLOAT',
|
||||
'INTEGER': 'INT'
|
||||
"STRING": "TEXT",
|
||||
"TIMESTAMP": "TIMESTAMP",
|
||||
"FLOAT": "FLOAT",
|
||||
"INTEGER": "INT",
|
||||
}
|
||||
column: str
|
||||
dtype: str
|
||||
@@ -24,7 +24,7 @@ class Column:
|
||||
return cls.TYPE_LABELS.get(dtype.upper(), dtype)
|
||||
|
||||
@classmethod
|
||||
def create(cls, name, label_or_dtype: str) -> 'Column':
|
||||
def create(cls, name, label_or_dtype: str) -> "Column":
|
||||
column_type = cls.translate_type(label_or_dtype)
|
||||
return cls(name, column_type)
|
||||
|
||||
@@ -39,16 +39,14 @@ class Column:
|
||||
@property
|
||||
def data_type(self) -> str:
|
||||
if self.is_string():
|
||||
return Column.string_type(self.string_size())
|
||||
return self.string_type(self.string_size())
|
||||
elif self.is_numeric():
|
||||
return Column.numeric_type(self.dtype, self.numeric_precision,
|
||||
self.numeric_scale)
|
||||
return self.numeric_type(self.dtype, self.numeric_precision, self.numeric_scale)
|
||||
else:
|
||||
return self.dtype
|
||||
|
||||
def is_string(self) -> bool:
|
||||
return self.dtype.lower() in ['text', 'character varying', 'character',
|
||||
'varchar']
|
||||
return self.dtype.lower() in ["text", "character varying", "character", "varchar"]
|
||||
|
||||
def is_number(self):
|
||||
return any([self.is_integer(), self.is_numeric(), self.is_float()])
|
||||
@@ -56,33 +54,45 @@ class Column:
|
||||
def is_float(self):
|
||||
return self.dtype.lower() in [
|
||||
# floats
|
||||
'real', 'float4', 'float', 'double precision', 'float8'
|
||||
"real",
|
||||
"float4",
|
||||
"float",
|
||||
"double precision",
|
||||
"float8",
|
||||
]
|
||||
|
||||
def is_integer(self) -> bool:
|
||||
return self.dtype.lower() in [
|
||||
# real types
|
||||
'smallint', 'integer', 'bigint',
|
||||
'smallserial', 'serial', 'bigserial',
|
||||
"smallint",
|
||||
"integer",
|
||||
"bigint",
|
||||
"smallserial",
|
||||
"serial",
|
||||
"bigserial",
|
||||
# aliases
|
||||
'int2', 'int4', 'int8',
|
||||
'serial2', 'serial4', 'serial8',
|
||||
"int2",
|
||||
"int4",
|
||||
"int8",
|
||||
"serial2",
|
||||
"serial4",
|
||||
"serial8",
|
||||
]
|
||||
|
||||
def is_numeric(self) -> bool:
|
||||
return self.dtype.lower() in ['numeric', 'decimal']
|
||||
return self.dtype.lower() in ["numeric", "decimal"]
|
||||
|
||||
def string_size(self) -> int:
|
||||
if not self.is_string():
|
||||
raise RuntimeException("Called string_size() on non-string field!")
|
||||
|
||||
if self.dtype == 'text' or self.char_size is None:
|
||||
if self.dtype == "text" or self.char_size is None:
|
||||
# char_size should never be None. Handle it reasonably just in case
|
||||
return 256
|
||||
else:
|
||||
return int(self.char_size)
|
||||
|
||||
def can_expand_to(self, other_column: 'Column') -> bool:
|
||||
def can_expand_to(self, other_column: "Column") -> bool:
|
||||
"""returns True if this column can be expanded to the size of the
|
||||
other column"""
|
||||
if not self.is_string() or not other_column.is_string():
|
||||
@@ -110,12 +120,10 @@ class Column:
|
||||
return "<Column {} ({})>".format(self.name, self.data_type)
|
||||
|
||||
@classmethod
|
||||
def from_description(cls, name: str, raw_data_type: str) -> 'Column':
|
||||
match = re.match(r'([^(]+)(\([^)]+\))?', raw_data_type)
|
||||
def from_description(cls, name: str, raw_data_type: str) -> "Column":
|
||||
match = re.match(r"([^(]+)(\([^)]+\))?", raw_data_type)
|
||||
if match is None:
|
||||
raise RuntimeException(
|
||||
f'Could not interpret data type "{raw_data_type}"'
|
||||
)
|
||||
raise RuntimeException(f'Could not interpret data type "{raw_data_type}"')
|
||||
data_type, size_info = match.groups()
|
||||
char_size = None
|
||||
numeric_precision = None
|
||||
@@ -123,7 +131,7 @@ class Column:
|
||||
if size_info is not None:
|
||||
# strip out the parentheses
|
||||
size_info = size_info[1:-1]
|
||||
parts = size_info.split(',')
|
||||
parts = size_info.split(",")
|
||||
if len(parts) == 1:
|
||||
try:
|
||||
char_size = int(parts[0])
|
||||
@@ -148,6 +156,4 @@ class Column:
|
||||
f'could not convert "{parts[1]}" to an integer'
|
||||
)
|
||||
|
||||
return cls(
|
||||
name, data_type, char_size, numeric_precision, numeric_scale
|
||||
)
|
||||
return cls(name, data_type, char_size, numeric_precision, numeric_scale)
|
||||
|
||||
@@ -1,24 +1,37 @@
|
||||
import abc
|
||||
import os
|
||||
|
||||
# multiprocessing.RLock is a function returning this type
|
||||
from multiprocessing.synchronize import RLock
|
||||
from threading import get_ident
|
||||
from typing import (
|
||||
Dict, Tuple, Hashable, Optional, ContextManager, List, Union
|
||||
)
|
||||
from typing import Dict, Tuple, Hashable, Optional, ContextManager, List, Union
|
||||
|
||||
import agate
|
||||
|
||||
import dbt.exceptions
|
||||
from dbt.contracts.connection import (
|
||||
Connection, Identifier, ConnectionState,
|
||||
AdapterRequiredConfig, LazyHandle, AdapterResponse
|
||||
Connection,
|
||||
Identifier,
|
||||
ConnectionState,
|
||||
AdapterRequiredConfig,
|
||||
LazyHandle,
|
||||
AdapterResponse,
|
||||
)
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.adapters.base.query_headers import (
|
||||
MacroQueryStringSetter,
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
NewConnection,
|
||||
ConnectionReused,
|
||||
ConnectionLeftOpen,
|
||||
ConnectionLeftOpen2,
|
||||
ConnectionClosed,
|
||||
ConnectionClosed2,
|
||||
Rollback,
|
||||
RollbackFailed,
|
||||
)
|
||||
from dbt import flags
|
||||
|
||||
|
||||
@@ -35,6 +48,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
You must also set the 'TYPE' class attribute with a class-unique constant
|
||||
string.
|
||||
"""
|
||||
|
||||
TYPE: str = NotImplemented
|
||||
|
||||
def __init__(self, profile: AdapterRequiredConfig):
|
||||
@@ -56,16 +70,14 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
key = self.get_thread_identifier()
|
||||
with self.lock:
|
||||
if key not in self.thread_connections:
|
||||
raise dbt.exceptions.InvalidConnectionException(
|
||||
key, list(self.thread_connections)
|
||||
)
|
||||
raise dbt.exceptions.InvalidConnectionException(key, list(self.thread_connections))
|
||||
return self.thread_connections[key]
|
||||
|
||||
def set_thread_connection(self, conn: Connection) -> None:
|
||||
key = self.get_thread_identifier()
|
||||
if key in self.thread_connections:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'In set_thread_connection, existing connection exists for {}'
|
||||
"In set_thread_connection, existing connection exists for {}"
|
||||
)
|
||||
self.thread_connections[key] = conn
|
||||
|
||||
@@ -105,18 +117,19 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
underlying database.
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`exception_handler` is not implemented for this adapter!')
|
||||
"`exception_handler` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
def set_connection_name(self, name: Optional[str] = None) -> Connection:
|
||||
conn_name: str
|
||||
if name is None:
|
||||
# if a name isn't specified, we'll re-use a single handle
|
||||
# named 'master'
|
||||
conn_name = 'master'
|
||||
conn_name = "master"
|
||||
else:
|
||||
if not isinstance(name, str):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'For connection name, got {name} - not a string!'
|
||||
f"For connection name, got {name} - not a string!"
|
||||
)
|
||||
assert isinstance(name, str)
|
||||
conn_name = name
|
||||
@@ -129,21 +142,17 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
state=ConnectionState.INIT,
|
||||
transaction_open=False,
|
||||
handle=None,
|
||||
credentials=self.profile.credentials
|
||||
credentials=self.profile.credentials,
|
||||
)
|
||||
self.set_thread_connection(conn)
|
||||
|
||||
if conn.name == conn_name and conn.state == 'open':
|
||||
if conn.name == conn_name and conn.state == "open":
|
||||
return conn
|
||||
|
||||
logger.debug(
|
||||
'Acquiring new {} connection "{}".'.format(self.TYPE, conn_name))
|
||||
fire_event(NewConnection(conn_name=conn_name, conn_type=self.TYPE))
|
||||
|
||||
if conn.state == 'open':
|
||||
logger.debug(
|
||||
'Re-using an available connection from the pool (formerly {}).'
|
||||
.format(conn.name)
|
||||
)
|
||||
if conn.state == "open":
|
||||
fire_event(ConnectionReused(conn_name=conn_name))
|
||||
else:
|
||||
conn.handle = LazyHandle(self.open)
|
||||
|
||||
@@ -154,7 +163,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
def cancel_open(self) -> Optional[List[str]]:
|
||||
"""Cancel all open connections on the adapter. (passable)"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`cancel_open` is not implemented for this adapter!'
|
||||
"`cancel_open` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@abc.abstractclassmethod
|
||||
@@ -167,9 +176,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
This should be thread-safe, or hold the lock if necessary. The given
|
||||
connection should not be in either in_use or available.
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`open` is not implemented for this adapter!'
|
||||
)
|
||||
raise dbt.exceptions.NotImplementedException("`open` is not implemented for this adapter!")
|
||||
|
||||
def release(self) -> None:
|
||||
with self.lock:
|
||||
@@ -189,12 +196,10 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
def cleanup_all(self) -> None:
|
||||
with self.lock:
|
||||
for connection in self.thread_connections.values():
|
||||
if connection.state not in {'closed', 'init'}:
|
||||
logger.debug("Connection '{}' was left open."
|
||||
.format(connection.name))
|
||||
if connection.state not in {"closed", "init"}:
|
||||
fire_event(ConnectionLeftOpen(conn_name=connection.name))
|
||||
else:
|
||||
logger.debug("Connection '{}' was properly closed."
|
||||
.format(connection.name))
|
||||
fire_event(ConnectionClosed(conn_name=connection.name))
|
||||
self.close(connection)
|
||||
|
||||
# garbage collect these connections
|
||||
@@ -204,14 +209,14 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
def begin(self) -> None:
|
||||
"""Begin a transaction. (passable)"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`begin` is not implemented for this adapter!'
|
||||
"`begin` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@abc.abstractmethod
|
||||
def commit(self) -> None:
|
||||
"""Commit a transaction. (passable)"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`commit` is not implemented for this adapter!'
|
||||
"`commit` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -220,55 +225,40 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
try:
|
||||
connection.handle.rollback()
|
||||
except Exception:
|
||||
logger.debug(
|
||||
'Failed to rollback {}'.format(connection.name),
|
||||
exc_info=True
|
||||
)
|
||||
fire_event(RollbackFailed(conn_name=connection.name))
|
||||
|
||||
@classmethod
|
||||
def _close_handle(cls, connection: Connection) -> None:
|
||||
"""Perform the actual close operation."""
|
||||
# On windows, sometimes connection handles don't have a close() attr.
|
||||
if hasattr(connection.handle, 'close'):
|
||||
logger.debug(f'On {connection.name}: Close')
|
||||
if hasattr(connection.handle, "close"):
|
||||
fire_event(ConnectionClosed2(conn_name=connection.name))
|
||||
connection.handle.close()
|
||||
else:
|
||||
logger.debug(f'On {connection.name}: No close available on handle')
|
||||
fire_event(ConnectionLeftOpen2(conn_name=connection.name))
|
||||
|
||||
@classmethod
|
||||
def _rollback(cls, connection: Connection) -> None:
|
||||
"""Roll back the given connection."""
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In _rollback, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Tried to rollback transaction on connection '
|
||||
f"Tried to rollback transaction on connection "
|
||||
f'"{connection.name}", but it does not have one open!'
|
||||
)
|
||||
|
||||
logger.debug(f'On {connection.name}: ROLLBACK')
|
||||
fire_event(Rollback(conn_name=connection.name))
|
||||
cls._rollback_handle(connection)
|
||||
|
||||
connection.transaction_open = False
|
||||
|
||||
@classmethod
|
||||
def close(cls, connection: Connection) -> Connection:
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In close, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
# if the connection is in closed or init, there's nothing to do
|
||||
if connection.state in {ConnectionState.CLOSED, ConnectionState.INIT}:
|
||||
return connection
|
||||
|
||||
if connection.transaction_open and connection.handle:
|
||||
logger.debug('On {}: ROLLBACK'.format(connection.name))
|
||||
fire_event(Rollback(conn_name=connection.name))
|
||||
cls._rollback_handle(connection)
|
||||
connection.transaction_open = False
|
||||
|
||||
@@ -302,5 +292,5 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`execute` is not implemented for this adapter!'
|
||||
"`execute` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -30,9 +30,11 @@ class _Available:
|
||||
x.update(big_expensive_db_query())
|
||||
return x
|
||||
"""
|
||||
|
||||
def inner(func):
|
||||
func._parse_replacement_ = parse_replacement
|
||||
return self(func)
|
||||
|
||||
return inner
|
||||
|
||||
def deprecated(
|
||||
@@ -57,13 +59,14 @@ class _Available:
|
||||
The optional parse_replacement, if provided, will provide a parse-time
|
||||
replacement for the actual method (see `available.parse`).
|
||||
"""
|
||||
|
||||
def wrapper(func):
|
||||
func_name = func.__name__
|
||||
renamed_method(func_name, supported_name)
|
||||
|
||||
@wraps(func)
|
||||
def inner(*args, **kwargs):
|
||||
warn('adapter:{}'.format(func_name))
|
||||
warn("adapter:{}".format(func_name))
|
||||
return func(*args, **kwargs)
|
||||
|
||||
if parse_replacement:
|
||||
@@ -71,6 +74,7 @@ class _Available:
|
||||
else:
|
||||
available_function = self
|
||||
return available_function(inner)
|
||||
|
||||
return wrapper
|
||||
|
||||
def parse_none(self, func: Callable) -> Callable:
|
||||
@@ -95,9 +99,7 @@ class AdapterMeta(abc.ABCMeta):
|
||||
# I'm not sure there is any benefit to it after poking around a bit,
|
||||
# but having it doesn't hurt on the python side (and omitting it could
|
||||
# hurt for obscure metaclass reasons, for all I know)
|
||||
cls = abc.ABCMeta.__new__( # type: ignore
|
||||
mcls, name, bases, namespace, **kwargs
|
||||
)
|
||||
cls = abc.ABCMeta.__new__(mcls, name, bases, namespace, **kwargs) # type: ignore
|
||||
|
||||
# this is very much inspired by ABCMeta's own implementation
|
||||
|
||||
@@ -109,14 +111,14 @@ class AdapterMeta(abc.ABCMeta):
|
||||
|
||||
# collect base class data first
|
||||
for base in bases:
|
||||
available.update(getattr(base, '_available_', set()))
|
||||
replacements.update(getattr(base, '_parse_replacements_', set()))
|
||||
available.update(getattr(base, "_available_", set()))
|
||||
replacements.update(getattr(base, "_parse_replacements_", set()))
|
||||
|
||||
# override with local data if it exists
|
||||
for name, value in namespace.items():
|
||||
if getattr(value, '_is_available_', False):
|
||||
if getattr(value, "_is_available_", False):
|
||||
available.add(name)
|
||||
parse_replacement = getattr(value, '_parse_replacement_', None)
|
||||
parse_replacement = getattr(value, "_parse_replacement_", None)
|
||||
if parse_replacement is not None:
|
||||
replacements[name] = parse_replacement
|
||||
|
||||
|
||||
@@ -8,11 +8,10 @@ from dbt.adapters.protocol import AdapterProtocol
|
||||
def project_name_from_path(include_path: str) -> str:
|
||||
# avoid an import cycle
|
||||
from dbt.config.project import Project
|
||||
|
||||
partial = Project.partial_load(include_path)
|
||||
if partial.project_name is None:
|
||||
raise CompilationException(
|
||||
f'Invalid project at {include_path}: name not set!'
|
||||
)
|
||||
raise CompilationException(f"Invalid project at {include_path}: name not set!")
|
||||
return partial.project_name
|
||||
|
||||
|
||||
@@ -23,12 +22,13 @@ class AdapterPlugin:
|
||||
:param dependencies: A list of adapter names that this adapter depends
|
||||
upon.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
adapter: Type[AdapterProtocol],
|
||||
credentials: Type[Credentials],
|
||||
include_path: str,
|
||||
dependencies: Optional[List[str]] = None
|
||||
dependencies: Optional[List[str]] = None,
|
||||
):
|
||||
|
||||
self.adapter: Type[AdapterProtocol] = adapter
|
||||
|
||||
@@ -15,7 +15,7 @@ class NodeWrapper:
|
||||
self._inner_node = node
|
||||
|
||||
def __getattr__(self, name):
|
||||
return getattr(self._inner_node, name, '')
|
||||
return getattr(self._inner_node, name, "")
|
||||
|
||||
|
||||
class _QueryComment(local):
|
||||
@@ -24,6 +24,7 @@ class _QueryComment(local):
|
||||
- the current thread's query comment.
|
||||
- a source_name indicating what set the current thread's query comment
|
||||
"""
|
||||
|
||||
def __init__(self, initial):
|
||||
self.query_comment: Optional[str] = initial
|
||||
self.append = False
|
||||
@@ -35,21 +36,19 @@ class _QueryComment(local):
|
||||
if self.append:
|
||||
# replace last ';' with '<comment>;'
|
||||
sql = sql.rstrip()
|
||||
if sql[-1] == ';':
|
||||
if sql[-1] == ";":
|
||||
sql = sql[:-1]
|
||||
return '{}\n/* {} */;'.format(sql, self.query_comment.strip())
|
||||
return "{}\n/* {} */;".format(sql, self.query_comment.strip())
|
||||
|
||||
return '{}\n/* {} */'.format(sql, self.query_comment.strip())
|
||||
return "{}\n/* {} */".format(sql, self.query_comment.strip())
|
||||
|
||||
return '/* {} */\n{}'.format(self.query_comment.strip(), sql)
|
||||
return "/* {} */\n{}".format(self.query_comment.strip(), sql)
|
||||
|
||||
def set(self, comment: Optional[str], append: bool):
|
||||
if isinstance(comment, str) and '*/' in comment:
|
||||
if isinstance(comment, str) and "*/" in comment:
|
||||
# tell the user "no" so they don't hurt themselves by writing
|
||||
# garbage
|
||||
raise RuntimeException(
|
||||
f'query comment contains illegal value "*/": {comment}'
|
||||
)
|
||||
raise RuntimeException(f'query comment contains illegal value "*/": {comment}')
|
||||
self.query_comment = comment
|
||||
self.append = append
|
||||
|
||||
@@ -63,15 +62,17 @@ class MacroQueryStringSetter:
|
||||
self.config = config
|
||||
|
||||
comment_macro = self._get_comment_macro()
|
||||
self.generator: QueryStringFunc = lambda name, model: ''
|
||||
self.generator: QueryStringFunc = lambda name, model: ""
|
||||
# if the comment value was None or the empty string, just skip it
|
||||
if comment_macro:
|
||||
assert isinstance(comment_macro, str)
|
||||
macro = '\n'.join((
|
||||
'{%- macro query_comment_macro(connection_name, node) -%}',
|
||||
comment_macro,
|
||||
'{% endmacro %}'
|
||||
))
|
||||
macro = "\n".join(
|
||||
(
|
||||
"{%- macro query_comment_macro(connection_name, node) -%}",
|
||||
comment_macro,
|
||||
"{% endmacro %}",
|
||||
)
|
||||
)
|
||||
ctx = self._get_context()
|
||||
self.generator = QueryStringGenerator(macro, ctx)
|
||||
self.comment = _QueryComment(None)
|
||||
@@ -87,7 +88,7 @@ class MacroQueryStringSetter:
|
||||
return self.comment.add(sql)
|
||||
|
||||
def reset(self):
|
||||
self.set('master', None)
|
||||
self.set("master", None)
|
||||
|
||||
def set(self, name: str, node: Optional[CompileResultNode]):
|
||||
wrapped: Optional[NodeWrapper] = None
|
||||
|
||||
@@ -1,13 +1,16 @@
|
||||
from collections.abc import Hashable
|
||||
from dataclasses import dataclass
|
||||
from typing import (
|
||||
Optional, TypeVar, Any, Type, Dict, Union, Iterator, Tuple, Set
|
||||
)
|
||||
from typing import Optional, TypeVar, Any, Type, Dict, Union, Iterator, Tuple, Set
|
||||
|
||||
from dbt.contracts.graph.compiled import CompiledNode
|
||||
from dbt.contracts.graph.parsed import ParsedSourceDefinition, ParsedNode
|
||||
from dbt.contracts.relation import (
|
||||
RelationType, ComponentName, HasQuoting, FakeAPIObject, Policy, Path
|
||||
RelationType,
|
||||
ComponentName,
|
||||
HasQuoting,
|
||||
FakeAPIObject,
|
||||
Policy,
|
||||
Path,
|
||||
)
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.node_types import NodeType
|
||||
@@ -16,7 +19,7 @@ from dbt.utils import filter_null_values, deep_merge, classproperty
|
||||
import dbt.exceptions
|
||||
|
||||
|
||||
Self = TypeVar('Self', bound='BaseRelation')
|
||||
Self = TypeVar("Self", bound="BaseRelation")
|
||||
|
||||
|
||||
@dataclass(frozen=True, eq=False, repr=False)
|
||||
@@ -40,7 +43,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
if field.name == field_name:
|
||||
return field
|
||||
# this should be unreachable
|
||||
raise ValueError(f'BaseRelation has no {field_name} field!')
|
||||
raise ValueError(f"BaseRelation has no {field_name} field!")
|
||||
|
||||
def __eq__(self, other):
|
||||
if not isinstance(other, self.__class__):
|
||||
@@ -49,20 +52,18 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
|
||||
@classmethod
|
||||
def get_default_quote_policy(cls) -> Policy:
|
||||
return cls._get_field_named('quote_policy').default
|
||||
return cls._get_field_named("quote_policy").default
|
||||
|
||||
@classmethod
|
||||
def get_default_include_policy(cls) -> Policy:
|
||||
return cls._get_field_named('include_policy').default
|
||||
return cls._get_field_named("include_policy").default
|
||||
|
||||
def get(self, key, default=None):
|
||||
"""Override `.get` to return a metadata object so we don't break
|
||||
dbt_utils.
|
||||
"""
|
||||
if key == 'metadata':
|
||||
return {
|
||||
'type': self.__class__.__name__
|
||||
}
|
||||
if key == "metadata":
|
||||
return {"type": self.__class__.__name__}
|
||||
return super().get(key, default)
|
||||
|
||||
def matches(
|
||||
@@ -71,16 +72,19 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
schema: Optional[str] = None,
|
||||
identifier: Optional[str] = None,
|
||||
) -> bool:
|
||||
search = filter_null_values({
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier
|
||||
})
|
||||
search = filter_null_values(
|
||||
{
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier,
|
||||
}
|
||||
)
|
||||
|
||||
if not search:
|
||||
# nothing was passed in
|
||||
raise dbt.exceptions.RuntimeException(
|
||||
"Tried to match relation, but no search path was passed!")
|
||||
"Tried to match relation, but no search path was passed!"
|
||||
)
|
||||
|
||||
exact_match = True
|
||||
approximate_match = True
|
||||
@@ -88,14 +92,13 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
for k, v in search.items():
|
||||
if not self._is_exactish_match(k, v):
|
||||
exact_match = False
|
||||
|
||||
if self.path.get_lowered_part(k) != v.lower():
|
||||
approximate_match = False
|
||||
if str(self.path.get_lowered_part(k)).strip(self.quote_character) != v.lower().strip(
|
||||
self.quote_character
|
||||
):
|
||||
approximate_match = False # type: ignore[union-attr]
|
||||
|
||||
if approximate_match and not exact_match:
|
||||
target = self.create(
|
||||
database=database, schema=schema, identifier=identifier
|
||||
)
|
||||
target = self.create(database=database, schema=schema, identifier=identifier)
|
||||
dbt.exceptions.approximate_relation_match(target, self)
|
||||
|
||||
return exact_match
|
||||
@@ -109,11 +112,13 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
schema: Optional[bool] = None,
|
||||
identifier: Optional[bool] = None,
|
||||
) -> Self:
|
||||
policy = filter_null_values({
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier
|
||||
})
|
||||
policy = filter_null_values(
|
||||
{
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier,
|
||||
}
|
||||
)
|
||||
|
||||
new_quote_policy = self.quote_policy.replace_dict(policy)
|
||||
return self.replace(quote_policy=new_quote_policy)
|
||||
@@ -124,16 +129,18 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
schema: Optional[bool] = None,
|
||||
identifier: Optional[bool] = None,
|
||||
) -> Self:
|
||||
policy = filter_null_values({
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier
|
||||
})
|
||||
policy = filter_null_values(
|
||||
{
|
||||
ComponentName.Database: database,
|
||||
ComponentName.Schema: schema,
|
||||
ComponentName.Identifier: identifier,
|
||||
}
|
||||
)
|
||||
|
||||
new_include_policy = self.include_policy.replace_dict(policy)
|
||||
return self.replace(include_policy=new_include_policy)
|
||||
|
||||
def information_schema(self, view_name=None) -> 'InformationSchema':
|
||||
def information_schema(self, view_name=None) -> "InformationSchema":
|
||||
# some of our data comes from jinja, where things can be `Undefined`.
|
||||
if not isinstance(view_name, str):
|
||||
view_name = None
|
||||
@@ -143,10 +150,10 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
info_schema = InformationSchema.from_relation(self, view_name)
|
||||
return info_schema.incorporate(path={"schema": None})
|
||||
|
||||
def information_schema_only(self) -> 'InformationSchema':
|
||||
def information_schema_only(self) -> "InformationSchema":
|
||||
return self.information_schema()
|
||||
|
||||
def without_identifier(self) -> 'BaseRelation':
|
||||
def without_identifier(self) -> "BaseRelation":
|
||||
"""Return a form of this relation that only has the database and schema
|
||||
set to included. To get the appropriately-quoted form the schema out of
|
||||
the result (for use as part of a query), use `.render()`. To get the
|
||||
@@ -156,9 +163,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
"""
|
||||
return self.include(identifier=False).replace_path(identifier=None)
|
||||
|
||||
def _render_iterator(
|
||||
self
|
||||
) -> Iterator[Tuple[Optional[ComponentName], Optional[str]]]:
|
||||
def _render_iterator(self) -> Iterator[Tuple[Optional[ComponentName], Optional[str]]]:
|
||||
|
||||
for key in ComponentName:
|
||||
path_part: Optional[str] = None
|
||||
@@ -170,27 +175,22 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
|
||||
def render(self) -> str:
|
||||
# if there is nothing set, this will return the empty string.
|
||||
return '.'.join(
|
||||
part for _, part in self._render_iterator()
|
||||
if part is not None
|
||||
)
|
||||
return ".".join(part for _, part in self._render_iterator() if part is not None)
|
||||
|
||||
def quoted(self, identifier):
|
||||
return '{quote_char}{identifier}{quote_char}'.format(
|
||||
return "{quote_char}{identifier}{quote_char}".format(
|
||||
quote_char=self.quote_character,
|
||||
identifier=identifier,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def create_from_source(
|
||||
cls: Type[Self], source: ParsedSourceDefinition, **kwargs: Any
|
||||
) -> Self:
|
||||
def create_from_source(cls: Type[Self], source: ParsedSourceDefinition, **kwargs: Any) -> Self:
|
||||
source_quoting = source.quoting.to_dict(omit_none=True)
|
||||
source_quoting.pop('column', None)
|
||||
source_quoting.pop("column", None)
|
||||
quote_policy = deep_merge(
|
||||
cls.get_default_quote_policy().to_dict(omit_none=True),
|
||||
source_quoting,
|
||||
kwargs.get('quote_policy', {}),
|
||||
kwargs.get("quote_policy", {}),
|
||||
)
|
||||
|
||||
return cls.create(
|
||||
@@ -198,12 +198,12 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
schema=source.schema,
|
||||
identifier=source.identifier,
|
||||
quote_policy=quote_policy,
|
||||
**kwargs
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def add_ephemeral_prefix(name: str):
|
||||
return f'__dbt__cte__{name}'
|
||||
return f"__dbt__cte__{name}"
|
||||
|
||||
@classmethod
|
||||
def create_ephemeral_from_node(
|
||||
@@ -236,7 +236,8 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
schema=node.schema,
|
||||
identifier=node.alias,
|
||||
quote_policy=quote_policy,
|
||||
**kwargs)
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def create_from(
|
||||
@@ -248,15 +249,14 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
if node.resource_type == NodeType.Source:
|
||||
if not isinstance(node, ParsedSourceDefinition):
|
||||
raise InternalException(
|
||||
'type mismatch, expected ParsedSourceDefinition but got {}'
|
||||
.format(type(node))
|
||||
"type mismatch, expected ParsedSourceDefinition but got {}".format(type(node))
|
||||
)
|
||||
return cls.create_from_source(node, **kwargs)
|
||||
else:
|
||||
if not isinstance(node, (ParsedNode, CompiledNode)):
|
||||
raise InternalException(
|
||||
'type mismatch, expected ParsedNode or CompiledNode but '
|
||||
'got {}'.format(type(node))
|
||||
"type mismatch, expected ParsedNode or CompiledNode but "
|
||||
"got {}".format(type(node))
|
||||
)
|
||||
return cls.create_from_node(config, node, **kwargs)
|
||||
|
||||
@@ -269,14 +269,16 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
type: Optional[RelationType] = None,
|
||||
**kwargs,
|
||||
) -> Self:
|
||||
kwargs.update({
|
||||
'path': {
|
||||
'database': database,
|
||||
'schema': schema,
|
||||
'identifier': identifier,
|
||||
},
|
||||
'type': type,
|
||||
})
|
||||
kwargs.update(
|
||||
{
|
||||
"path": {
|
||||
"database": database,
|
||||
"schema": schema,
|
||||
"identifier": identifier,
|
||||
},
|
||||
"type": type,
|
||||
}
|
||||
)
|
||||
return cls.from_dict(kwargs)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
@@ -342,7 +344,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
return RelationType
|
||||
|
||||
|
||||
Info = TypeVar('Info', bound='InformationSchema')
|
||||
Info = TypeVar("Info", bound="InformationSchema")
|
||||
|
||||
|
||||
@dataclass(frozen=True, eq=False, repr=False)
|
||||
@@ -352,17 +354,15 @@ class InformationSchema(BaseRelation):
|
||||
def __post_init__(self):
|
||||
if not isinstance(self.information_schema_view, (type(None), str)):
|
||||
raise dbt.exceptions.CompilationException(
|
||||
'Got an invalid name: {}'.format(self.information_schema_view)
|
||||
"Got an invalid name: {}".format(self.information_schema_view)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_path(
|
||||
cls, relation: BaseRelation, information_schema_view: Optional[str]
|
||||
) -> Path:
|
||||
def get_path(cls, relation: BaseRelation, information_schema_view: Optional[str]) -> Path:
|
||||
return Path(
|
||||
database=relation.database,
|
||||
schema=relation.schema,
|
||||
identifier='INFORMATION_SCHEMA',
|
||||
identifier="INFORMATION_SCHEMA",
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -393,9 +393,7 @@ class InformationSchema(BaseRelation):
|
||||
relation: BaseRelation,
|
||||
information_schema_view: Optional[str],
|
||||
) -> Info:
|
||||
include_policy = cls.get_include_policy(
|
||||
relation, information_schema_view
|
||||
)
|
||||
include_policy = cls.get_include_policy(relation, information_schema_view)
|
||||
quote_policy = cls.get_quote_policy(relation, information_schema_view)
|
||||
path = cls.get_path(relation, information_schema_view)
|
||||
return cls(
|
||||
@@ -417,6 +415,7 @@ class SchemaSearchMap(Dict[InformationSchema, Set[Optional[str]]]):
|
||||
search for what schemas. The schema values are all lowercased to avoid
|
||||
duplication.
|
||||
"""
|
||||
|
||||
def add(self, relation: BaseRelation):
|
||||
key = relation.information_schema_only()
|
||||
if key not in self:
|
||||
@@ -426,30 +425,28 @@ class SchemaSearchMap(Dict[InformationSchema, Set[Optional[str]]]):
|
||||
schema = relation.schema.lower()
|
||||
self[key].add(schema)
|
||||
|
||||
def search(
|
||||
self
|
||||
) -> Iterator[Tuple[InformationSchema, Optional[str]]]:
|
||||
def search(self) -> Iterator[Tuple[InformationSchema, Optional[str]]]:
|
||||
for information_schema_name, schemas in self.items():
|
||||
for schema in schemas:
|
||||
yield information_schema_name, schema
|
||||
|
||||
def flatten(self):
|
||||
def flatten(self, allow_multiple_databases: bool = False):
|
||||
new = self.__class__()
|
||||
|
||||
# make sure we don't have duplicates
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
# make sure we don't have multiple databases if allow_multiple_databases is set to False
|
||||
if not allow_multiple_databases:
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
|
||||
for information_schema_name, schema in self.search():
|
||||
path = {
|
||||
'database': information_schema_name.database,
|
||||
'schema': schema
|
||||
}
|
||||
new.add(information_schema_name.incorporate(
|
||||
path=path,
|
||||
quote_policy={'database': False},
|
||||
include_policy={'database': False},
|
||||
))
|
||||
path = {"database": information_schema_name.database, "schema": schema}
|
||||
new.add(
|
||||
information_schema_name.incorporate(
|
||||
path=path,
|
||||
quote_policy={"database": False},
|
||||
include_policy={"database": False},
|
||||
)
|
||||
)
|
||||
|
||||
return new
|
||||
|
||||
@@ -1,23 +1,27 @@
|
||||
from collections import namedtuple
|
||||
from copy import deepcopy
|
||||
from typing import List, Iterable, Optional, Dict, Set, Tuple, Any
|
||||
import threading
|
||||
from copy import deepcopy
|
||||
from typing import Any, Dict, Iterable, List, Optional, Set, Tuple
|
||||
|
||||
from dbt.logger import CACHE_LOGGER as logger
|
||||
from dbt.utils import lowercase
|
||||
from dbt.adapters.reference_keys import _make_key, _ReferenceKey
|
||||
import dbt.exceptions
|
||||
|
||||
_ReferenceKey = namedtuple('_ReferenceKey', 'database schema identifier')
|
||||
|
||||
|
||||
def _make_key(relation) -> _ReferenceKey:
|
||||
"""Make _ReferenceKeys with lowercase values for the cache so we don't have
|
||||
to keep track of quoting
|
||||
"""
|
||||
# databases and schemas can both be None
|
||||
return _ReferenceKey(lowercase(relation.database),
|
||||
lowercase(relation.schema),
|
||||
lowercase(relation.identifier))
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
AddLink,
|
||||
AddRelation,
|
||||
DropCascade,
|
||||
DropMissingRelation,
|
||||
DropRelation,
|
||||
DumpAfterAddGraph,
|
||||
DumpAfterRenameSchema,
|
||||
DumpBeforeAddGraph,
|
||||
DumpBeforeRenameSchema,
|
||||
RenameSchema,
|
||||
TemporaryRelation,
|
||||
UncachedRelation,
|
||||
UpdateReference,
|
||||
)
|
||||
from dbt.utils import lowercase
|
||||
from dbt.helper_types import Lazy
|
||||
|
||||
|
||||
def dot_separated(key: _ReferenceKey) -> str:
|
||||
@@ -25,7 +29,7 @@ def dot_separated(key: _ReferenceKey) -> str:
|
||||
|
||||
:param _ReferenceKey key: The key to stringify.
|
||||
"""
|
||||
return '.'.join(map(str, key))
|
||||
return ".".join(map(str, key))
|
||||
|
||||
|
||||
class _CachedRelation:
|
||||
@@ -37,14 +41,15 @@ class _CachedRelation:
|
||||
that refer to this relation.
|
||||
:attr BaseRelation inner: The underlying dbt relation.
|
||||
"""
|
||||
|
||||
def __init__(self, inner):
|
||||
self.referenced_by = {}
|
||||
self.inner = inner
|
||||
|
||||
def __str__(self) -> str:
|
||||
return (
|
||||
'_CachedRelation(database={}, schema={}, identifier={}, inner={})'
|
||||
).format(self.database, self.schema, self.identifier, self.inner)
|
||||
return ("_CachedRelation(database={}, schema={}, identifier={}, inner={})").format(
|
||||
self.database, self.schema, self.identifier, self.inner
|
||||
)
|
||||
|
||||
@property
|
||||
def database(self) -> Optional[str]:
|
||||
@@ -78,7 +83,7 @@ class _CachedRelation:
|
||||
"""
|
||||
return _make_key(self)
|
||||
|
||||
def add_reference(self, referrer: '_CachedRelation'):
|
||||
def add_reference(self, referrer: "_CachedRelation"):
|
||||
"""Add a reference from referrer to self, indicating that if this node
|
||||
were drop...cascaded, the referrer would be dropped as well.
|
||||
|
||||
@@ -122,9 +127,9 @@ class _CachedRelation:
|
||||
# table_name is ever anything but the identifier (via .create())
|
||||
self.inner = self.inner.incorporate(
|
||||
path={
|
||||
'database': new_relation.inner.database,
|
||||
'schema': new_relation.inner.schema,
|
||||
'identifier': new_relation.inner.identifier
|
||||
"database": new_relation.inner.database,
|
||||
"schema": new_relation.inner.schema,
|
||||
"identifier": new_relation.inner.identifier,
|
||||
},
|
||||
)
|
||||
|
||||
@@ -140,8 +145,9 @@ class _CachedRelation:
|
||||
"""
|
||||
if new_key in self.referenced_by:
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
'in rename of "{}" -> "{}", new name is in the cache already'
|
||||
.format(old_key, new_key)
|
||||
'in rename of "{}" -> "{}", new name is in the cache already'.format(
|
||||
old_key, new_key
|
||||
)
|
||||
)
|
||||
|
||||
if old_key not in self.referenced_by:
|
||||
@@ -157,12 +163,6 @@ class _CachedRelation:
|
||||
return [dot_separated(r) for r in self.referenced_by]
|
||||
|
||||
|
||||
def lazy_log(msg, func):
|
||||
if logger.disabled:
|
||||
return
|
||||
logger.debug(msg.format(func()))
|
||||
|
||||
|
||||
class RelationsCache:
|
||||
"""A cache of the relations known to dbt. Keeps track of relationships
|
||||
declared between tables and handles renames/drops as a real database would.
|
||||
@@ -172,13 +172,16 @@ class RelationsCache:
|
||||
The adapters also hold this lock while filling the cache.
|
||||
:attr Set[str] schemas: The set of known/cached schemas, all lowercased.
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.relations: Dict[_ReferenceKey, _CachedRelation] = {}
|
||||
self.lock = threading.RLock()
|
||||
self.schemas: Set[Tuple[Optional[str], Optional[str]]] = set()
|
||||
|
||||
def add_schema(
|
||||
self, database: Optional[str], schema: Optional[str],
|
||||
self,
|
||||
database: Optional[str],
|
||||
schema: Optional[str],
|
||||
) -> None:
|
||||
"""Add a schema to the set of known schemas (case-insensitive)
|
||||
|
||||
@@ -188,7 +191,9 @@ class RelationsCache:
|
||||
self.schemas.add((lowercase(database), lowercase(schema)))
|
||||
|
||||
def drop_schema(
|
||||
self, database: Optional[str], schema: Optional[str],
|
||||
self,
|
||||
database: Optional[str],
|
||||
schema: Optional[str],
|
||||
) -> None:
|
||||
"""Drop the given schema and remove it from the set of known schemas.
|
||||
|
||||
@@ -232,10 +237,7 @@ class RelationsCache:
|
||||
# self.relations or any cache entry's referenced_by during iteration
|
||||
# it's a runtime error!
|
||||
with self.lock:
|
||||
return {
|
||||
dot_separated(k): v.dump_graph_entry()
|
||||
for k, v in self.relations.items()
|
||||
}
|
||||
return {dot_separated(k): v.dump_graph_entry() for k, v in self.relations.items()}
|
||||
|
||||
def _setdefault(self, relation: _CachedRelation):
|
||||
"""Add a relation to the cache, or return it if it already exists.
|
||||
@@ -263,21 +265,20 @@ class RelationsCache:
|
||||
return
|
||||
if referenced is None:
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
'in add_link, referenced link key {} not in cache!'
|
||||
.format(referenced_key)
|
||||
"in add_link, referenced link key {} not in cache!".format(referenced_key)
|
||||
)
|
||||
|
||||
dependent = self.relations.get(dependent_key)
|
||||
if dependent is None:
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
'in add_link, dependent link key {} not in cache!'
|
||||
.format(dependent_key)
|
||||
"in add_link, dependent link key {} not in cache!".format(dependent_key)
|
||||
)
|
||||
|
||||
assert dependent is not None # we just raised!
|
||||
|
||||
referenced.add_reference(dependent)
|
||||
|
||||
# TODO: Is this dead code? I can't seem to find it grepping the codebase.
|
||||
def add_link(self, referenced, dependent):
|
||||
"""Add a link between two relations to the database. If either relation
|
||||
does not exist, it will be added as an "external" relation.
|
||||
@@ -293,33 +294,22 @@ class RelationsCache:
|
||||
:raises InternalError: If either entry does not exist.
|
||||
"""
|
||||
ref_key = _make_key(referenced)
|
||||
dep_key = _make_key(dependent)
|
||||
if (ref_key.database, ref_key.schema) not in self:
|
||||
# if we have not cached the referenced schema at all, we must be
|
||||
# referring to a table outside our control. There's no need to make
|
||||
# a link - we will never drop the referenced relation during a run.
|
||||
logger.debug(
|
||||
'{dep!s} references {ref!s} but {ref.database}.{ref.schema} '
|
||||
'is not in the cache, skipping assumed external relation'
|
||||
.format(dep=dependent, ref=ref_key)
|
||||
)
|
||||
fire_event(UncachedRelation(dep_key=dep_key, ref_key=ref_key))
|
||||
return
|
||||
if ref_key not in self.relations:
|
||||
# Insert a dummy "external" relation.
|
||||
referenced = referenced.replace(
|
||||
type=referenced.External
|
||||
)
|
||||
referenced = referenced.replace(type=referenced.External)
|
||||
self.add(referenced)
|
||||
|
||||
dep_key = _make_key(dependent)
|
||||
if dep_key not in self.relations:
|
||||
# Insert a dummy "external" relation.
|
||||
dependent = dependent.replace(
|
||||
type=referenced.External
|
||||
)
|
||||
dependent = dependent.replace(type=referenced.External)
|
||||
self.add(dependent)
|
||||
logger.debug(
|
||||
'adding link, {!s} references {!s}'.format(dep_key, ref_key)
|
||||
)
|
||||
fire_event(AddLink(dep_key=dep_key, ref_key=ref_key))
|
||||
with self.lock:
|
||||
self._add_link(ref_key, dep_key)
|
||||
|
||||
@@ -330,14 +320,12 @@ class RelationsCache:
|
||||
:param BaseRelation relation: The underlying relation.
|
||||
"""
|
||||
cached = _CachedRelation(relation)
|
||||
logger.debug('Adding relation: {!s}'.format(cached))
|
||||
|
||||
lazy_log('before adding: {!s}', self.dump_graph)
|
||||
fire_event(AddRelation(relation=_make_key(cached)))
|
||||
fire_event(DumpBeforeAddGraph(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
with self.lock:
|
||||
self._setdefault(cached)
|
||||
|
||||
lazy_log('after adding: {!s}', self.dump_graph)
|
||||
fire_event(DumpAfterAddGraph(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
def _remove_refs(self, keys):
|
||||
"""Removes all references to all entries in keys. This does not
|
||||
@@ -352,20 +340,17 @@ class RelationsCache:
|
||||
for cached in self.relations.values():
|
||||
cached.release_references(keys)
|
||||
|
||||
def _drop_cascade_relation(self, dropped):
|
||||
def _drop_cascade_relation(self, dropped_key):
|
||||
"""Drop the given relation and cascade it appropriately to all
|
||||
dependent relations.
|
||||
|
||||
:param _CachedRelation dropped: An existing _CachedRelation to drop.
|
||||
"""
|
||||
if dropped not in self.relations:
|
||||
logger.debug('dropped a nonexistent relationship: {!s}'
|
||||
.format(dropped))
|
||||
if dropped_key not in self.relations:
|
||||
fire_event(DropMissingRelation(relation=dropped_key))
|
||||
return
|
||||
consequences = self.relations[dropped].collect_consequences()
|
||||
logger.debug(
|
||||
'drop {} is cascading to {}'.format(dropped, consequences)
|
||||
)
|
||||
consequences = self.relations[dropped_key].collect_consequences()
|
||||
fire_event(DropCascade(dropped=dropped_key, consequences=consequences))
|
||||
self._remove_refs(consequences)
|
||||
|
||||
def drop(self, relation):
|
||||
@@ -379,10 +364,10 @@ class RelationsCache:
|
||||
:param str schema: The schema of the relation to drop.
|
||||
:param str identifier: The identifier of the relation to drop.
|
||||
"""
|
||||
dropped = _make_key(relation)
|
||||
logger.debug('Dropping relation: {!s}'.format(dropped))
|
||||
dropped_key = _make_key(relation)
|
||||
fire_event(DropRelation(dropped=dropped_key))
|
||||
with self.lock:
|
||||
self._drop_cascade_relation(dropped)
|
||||
self._drop_cascade_relation(dropped_key)
|
||||
|
||||
def _rename_relation(self, old_key, new_relation):
|
||||
"""Rename a relation named old_key to new_key, updating references.
|
||||
@@ -403,9 +388,8 @@ class RelationsCache:
|
||||
# update all the relations that refer to it
|
||||
for cached in self.relations.values():
|
||||
if cached.is_referenced_by(old_key):
|
||||
logger.debug(
|
||||
'updated reference from {0} -> {2} to {1} -> {2}'
|
||||
.format(old_key, new_key, cached.key())
|
||||
fire_event(
|
||||
UpdateReference(old_key=old_key, new_key=new_key, cached_key=cached.key())
|
||||
)
|
||||
cached.rename_key(old_key, new_key)
|
||||
|
||||
@@ -430,15 +414,13 @@ class RelationsCache:
|
||||
"""
|
||||
if new_key in self.relations:
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
'in rename, new key {} already in cache: {}'
|
||||
.format(new_key, list(self.relations.keys()))
|
||||
"in rename, new key {} already in cache: {}".format(
|
||||
new_key, list(self.relations.keys())
|
||||
)
|
||||
)
|
||||
|
||||
if old_key not in self.relations:
|
||||
logger.debug(
|
||||
'old key {} not found in self.relations, assuming temporary'
|
||||
.format(old_key)
|
||||
)
|
||||
fire_event(TemporaryRelation(key=old_key))
|
||||
return False
|
||||
return True
|
||||
|
||||
@@ -456,11 +438,9 @@ class RelationsCache:
|
||||
"""
|
||||
old_key = _make_key(old)
|
||||
new_key = _make_key(new)
|
||||
logger.debug('Renaming relation {!s} to {!s}'.format(
|
||||
old_key, new_key
|
||||
))
|
||||
fire_event(RenameSchema(old_key=old_key, new_key=new_key))
|
||||
|
||||
lazy_log('before rename: {!s}', self.dump_graph)
|
||||
fire_event(DumpBeforeRenameSchema(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
with self.lock:
|
||||
if self._check_rename_constraints(old_key, new_key):
|
||||
@@ -468,11 +448,9 @@ class RelationsCache:
|
||||
else:
|
||||
self._setdefault(_CachedRelation(new))
|
||||
|
||||
lazy_log('after rename: {!s}', self.dump_graph)
|
||||
fire_event(DumpAfterRenameSchema(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
def get_relations(
|
||||
self, database: Optional[str], schema: Optional[str]
|
||||
) -> List[Any]:
|
||||
def get_relations(self, database: Optional[str], schema: Optional[str]) -> List[Any]:
|
||||
"""Case-insensitively yield all relations matching the given schema.
|
||||
|
||||
:param str schema: The case-insensitive schema name to list from.
|
||||
@@ -483,14 +461,14 @@ class RelationsCache:
|
||||
schema = lowercase(schema)
|
||||
with self.lock:
|
||||
results = [
|
||||
r.inner for r in self.relations.values()
|
||||
if (lowercase(r.schema) == schema and
|
||||
lowercase(r.database) == database)
|
||||
r.inner
|
||||
for r in self.relations.values()
|
||||
if (lowercase(r.schema) == schema and lowercase(r.database) == database)
|
||||
]
|
||||
|
||||
if None in results:
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
'in get_relations, a None relation was found in the cache!'
|
||||
"in get_relations, a None relation was found in the cache!"
|
||||
)
|
||||
return results
|
||||
|
||||
|
||||
@@ -8,10 +8,9 @@ from dbt.include.global_project import (
|
||||
PACKAGE_PATH as GLOBAL_PROJECT_PATH,
|
||||
PROJECT_NAME as GLOBAL_PROJECT_NAME,
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import AdapterImportError, PluginLoadError
|
||||
from dbt.contracts.connection import Credentials, AdapterRequiredConfig
|
||||
|
||||
|
||||
from dbt.adapters.protocol import (
|
||||
AdapterProtocol,
|
||||
AdapterConfig,
|
||||
@@ -50,9 +49,7 @@ class AdapterContainer:
|
||||
adapter = self.get_adapter_class_by_name(name)
|
||||
return adapter.Relation
|
||||
|
||||
def get_config_class_by_name(
|
||||
self, name: str
|
||||
) -> Type[AdapterConfig]:
|
||||
def get_config_class_by_name(self, name: str) -> Type[AdapterConfig]:
|
||||
adapter = self.get_adapter_class_by_name(name)
|
||||
return adapter.AdapterSpecificConfigs
|
||||
|
||||
@@ -62,24 +59,25 @@ class AdapterContainer:
|
||||
# singletons
|
||||
try:
|
||||
# mypy doesn't think modules have any attributes.
|
||||
mod: Any = import_module('.' + name, 'dbt.adapters')
|
||||
mod: Any = import_module("." + name, "dbt.adapters")
|
||||
except ModuleNotFoundError as exc:
|
||||
# if we failed to import the target module in particular, inform
|
||||
# the user about it via a runtime error
|
||||
if exc.name == 'dbt.adapters.' + name:
|
||||
raise RuntimeException(f'Could not find adapter type {name}!')
|
||||
logger.info(f'Error importing adapter: {exc}')
|
||||
if exc.name == "dbt.adapters." + name:
|
||||
fire_event(AdapterImportError(exc=exc))
|
||||
raise RuntimeException(f"Could not find adapter type {name}!")
|
||||
# otherwise, the error had to have come from some underlying
|
||||
# library. Log the stack trace.
|
||||
logger.debug('', exc_info=True)
|
||||
|
||||
fire_event(PluginLoadError())
|
||||
raise
|
||||
plugin: AdapterPlugin = mod.Plugin
|
||||
plugin_type = plugin.adapter.type()
|
||||
|
||||
if plugin_type != name:
|
||||
raise RuntimeException(
|
||||
f'Expected to find adapter with type named {name}, got '
|
||||
f'adapter with type {plugin_type}'
|
||||
f"Expected to find adapter with type named {name}, got "
|
||||
f"adapter with type {plugin_type}"
|
||||
)
|
||||
|
||||
with self.lock:
|
||||
@@ -109,8 +107,7 @@ class AdapterContainer:
|
||||
return self.adapters[adapter_name]
|
||||
|
||||
def reset_adapters(self):
|
||||
"""Clear the adapters. This is useful for tests, which change configs.
|
||||
"""
|
||||
"""Clear the adapters. This is useful for tests, which change configs."""
|
||||
with self.lock:
|
||||
for adapter in self.adapters.values():
|
||||
adapter.cleanup_connections()
|
||||
@@ -140,9 +137,7 @@ class AdapterContainer:
|
||||
try:
|
||||
plugin = self.plugins[plugin_name]
|
||||
except KeyError:
|
||||
raise InternalException(
|
||||
f'No plugin found for {plugin_name}'
|
||||
) from None
|
||||
raise InternalException(f"No plugin found for {plugin_name}") from None
|
||||
plugins.append(plugin)
|
||||
seen.add(plugin_name)
|
||||
if plugin.dependencies is None:
|
||||
@@ -153,9 +148,7 @@ class AdapterContainer:
|
||||
return plugins
|
||||
|
||||
def get_adapter_package_names(self, name: Optional[str]) -> List[str]:
|
||||
package_names: List[str] = [
|
||||
p.project_name for p in self.get_adapter_plugins(name)
|
||||
]
|
||||
package_names: List[str] = [p.project_name for p in self.get_adapter_plugins(name)]
|
||||
package_names.append(GLOBAL_PROJECT_NAME)
|
||||
return package_names
|
||||
|
||||
@@ -165,9 +158,7 @@ class AdapterContainer:
|
||||
try:
|
||||
path = self.packages[package_name]
|
||||
except KeyError:
|
||||
raise InternalException(
|
||||
f'No internal package listing found for {package_name}'
|
||||
)
|
||||
raise InternalException(f"No internal package listing found for {package_name}")
|
||||
paths.append(path)
|
||||
return paths
|
||||
|
||||
@@ -186,9 +177,12 @@ def get_adapter(config: AdapterRequiredConfig):
|
||||
return FACTORY.lookup_adapter(config.credentials.type)
|
||||
|
||||
|
||||
def get_adapter_by_type(adapter_type):
|
||||
return FACTORY.lookup_adapter(adapter_type)
|
||||
|
||||
|
||||
def reset_adapters():
|
||||
"""Clear the adapters. This is useful for tests, which change configs.
|
||||
"""
|
||||
"""Clear the adapters. This is useful for tests, which change configs."""
|
||||
FACTORY.reset_adapters()
|
||||
|
||||
|
||||
|
||||
@@ -1,18 +1,24 @@
|
||||
from dataclasses import dataclass
|
||||
from typing import (
|
||||
Type, Hashable, Optional, ContextManager, List, Generic, TypeVar, ClassVar,
|
||||
Tuple, Union, Dict, Any
|
||||
Type,
|
||||
Hashable,
|
||||
Optional,
|
||||
ContextManager,
|
||||
List,
|
||||
Generic,
|
||||
TypeVar,
|
||||
ClassVar,
|
||||
Tuple,
|
||||
Union,
|
||||
Dict,
|
||||
Any,
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
|
||||
import agate
|
||||
|
||||
from dbt.contracts.connection import (
|
||||
Connection, AdapterRequiredConfig, AdapterResponse
|
||||
)
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledNode, ManifestNode, NonSourceCompiledNode
|
||||
)
|
||||
from dbt.contracts.connection import Connection, AdapterRequiredConfig, AdapterResponse
|
||||
from dbt.contracts.graph.compiled import CompiledNode, ManifestNode, NonSourceCompiledNode
|
||||
from dbt.contracts.graph.parsed import ParsedNode, ParsedSourceDefinition
|
||||
from dbt.contracts.graph.model_config import BaseConfig
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
@@ -34,7 +40,7 @@ class ColumnProtocol(Protocol):
|
||||
pass
|
||||
|
||||
|
||||
Self = TypeVar('Self', bound='RelationProtocol')
|
||||
Self = TypeVar("Self", bound="RelationProtocol")
|
||||
|
||||
|
||||
class RelationProtocol(Protocol):
|
||||
@@ -64,22 +70,15 @@ class CompilerProtocol(Protocol):
|
||||
...
|
||||
|
||||
|
||||
AdapterConfig_T = TypeVar(
|
||||
'AdapterConfig_T', bound=AdapterConfig
|
||||
)
|
||||
ConnectionManager_T = TypeVar(
|
||||
'ConnectionManager_T', bound=ConnectionManagerProtocol
|
||||
)
|
||||
Relation_T = TypeVar(
|
||||
'Relation_T', bound=RelationProtocol
|
||||
)
|
||||
Column_T = TypeVar(
|
||||
'Column_T', bound=ColumnProtocol
|
||||
)
|
||||
Compiler_T = TypeVar('Compiler_T', bound=CompilerProtocol)
|
||||
AdapterConfig_T = TypeVar("AdapterConfig_T", bound=AdapterConfig)
|
||||
ConnectionManager_T = TypeVar("ConnectionManager_T", bound=ConnectionManagerProtocol)
|
||||
Relation_T = TypeVar("Relation_T", bound=RelationProtocol)
|
||||
Column_T = TypeVar("Column_T", bound=ColumnProtocol)
|
||||
Compiler_T = TypeVar("Compiler_T", bound=CompilerProtocol)
|
||||
|
||||
|
||||
class AdapterProtocol(
|
||||
# TODO CT-211
|
||||
class AdapterProtocol( # type: ignore[misc]
|
||||
Protocol,
|
||||
Generic[
|
||||
AdapterConfig_T,
|
||||
@@ -87,7 +86,7 @@ class AdapterProtocol(
|
||||
Relation_T,
|
||||
Column_T,
|
||||
Compiler_T,
|
||||
]
|
||||
],
|
||||
):
|
||||
AdapterSpecificConfigs: ClassVar[Type[AdapterConfig_T]]
|
||||
Column: ClassVar[Type[Column_T]]
|
||||
|
||||
24
core/dbt/adapters/reference_keys.py
Normal file
24
core/dbt/adapters/reference_keys.py
Normal file
@@ -0,0 +1,24 @@
|
||||
# this module exists to resolve circular imports with the events module
|
||||
|
||||
from collections import namedtuple
|
||||
from typing import Optional
|
||||
|
||||
|
||||
_ReferenceKey = namedtuple("_ReferenceKey", "database schema identifier")
|
||||
|
||||
|
||||
def lowercase(value: Optional[str]) -> Optional[str]:
|
||||
if value is None:
|
||||
return None
|
||||
else:
|
||||
return value.lower()
|
||||
|
||||
|
||||
def _make_key(relation) -> _ReferenceKey:
|
||||
"""Make _ReferenceKeys with lowercase values for the cache so we don't have
|
||||
to keep track of quoting
|
||||
"""
|
||||
# databases and schemas can both be None
|
||||
return _ReferenceKey(
|
||||
lowercase(relation.database), lowercase(relation.schema), lowercase(relation.identifier)
|
||||
)
|
||||
@@ -7,11 +7,9 @@ import agate
|
||||
import dbt.clients.agate_helper
|
||||
import dbt.exceptions
|
||||
from dbt.adapters.base import BaseConnectionManager
|
||||
from dbt.contracts.connection import (
|
||||
Connection, ConnectionState, AdapterResponse
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt import flags
|
||||
from dbt.contracts.connection import Connection, ConnectionState, AdapterResponse
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import ConnectionUsed, SQLQuery, SQLCommit, SQLQueryStatus
|
||||
|
||||
|
||||
class SQLConnectionManager(BaseConnectionManager):
|
||||
@@ -23,11 +21,12 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
- get_response
|
||||
- open
|
||||
"""
|
||||
|
||||
@abc.abstractmethod
|
||||
def cancel(self, connection: Connection):
|
||||
"""Cancel the given connection."""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`cancel` is not implemented for this adapter!'
|
||||
"`cancel` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
def cancel_open(self) -> List[str]:
|
||||
@@ -40,10 +39,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
# if the connection failed, the handle will be None so we have
|
||||
# nothing to cancel.
|
||||
if (
|
||||
connection.handle is not None and
|
||||
connection.state == ConnectionState.OPEN
|
||||
):
|
||||
if connection.handle is not None and connection.state == ConnectionState.OPEN:
|
||||
self.cancel(connection)
|
||||
if connection.name is not None:
|
||||
names.append(connection.name)
|
||||
@@ -54,34 +50,29 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
sql: str,
|
||||
auto_begin: bool = True,
|
||||
bindings: Optional[Any] = None,
|
||||
abridge_sql_log: bool = False
|
||||
abridge_sql_log: bool = False,
|
||||
) -> Tuple[Connection, Any]:
|
||||
connection = self.get_thread_connection()
|
||||
if auto_begin and connection.transaction_open is False:
|
||||
self.begin()
|
||||
|
||||
logger.debug('Using {} connection "{}".'
|
||||
.format(self.TYPE, connection.name))
|
||||
fire_event(ConnectionUsed(conn_type=self.TYPE, conn_name=connection.name))
|
||||
|
||||
with self.exception_handler(sql):
|
||||
if abridge_sql_log:
|
||||
log_sql = '{}...'.format(sql[:512])
|
||||
log_sql = "{}...".format(sql[:512])
|
||||
else:
|
||||
log_sql = sql
|
||||
|
||||
logger.debug(
|
||||
'On {connection_name}: {sql}',
|
||||
connection_name=connection.name,
|
||||
sql=log_sql,
|
||||
)
|
||||
fire_event(SQLQuery(conn_name=connection.name, sql=log_sql))
|
||||
pre = time.time()
|
||||
|
||||
cursor = connection.handle.cursor()
|
||||
cursor.execute(sql, bindings)
|
||||
logger.debug(
|
||||
"SQL status: {status} in {elapsed:0.2f} seconds",
|
||||
status=self.get_response(cursor),
|
||||
elapsed=(time.time() - pre)
|
||||
|
||||
fire_event(
|
||||
SQLQueryStatus(
|
||||
status=str(self.get_response(cursor)), elapsed=round((time.time() - pre), 2)
|
||||
)
|
||||
)
|
||||
|
||||
return connection, cursor
|
||||
@@ -90,23 +81,26 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
def get_response(cls, cursor: Any) -> Union[AdapterResponse, str]:
|
||||
"""Get the status of the cursor."""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`get_response` is not implemented for this adapter!'
|
||||
"`get_response` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def process_results(
|
||||
cls,
|
||||
column_names: Iterable[str],
|
||||
rows: Iterable[Any]
|
||||
cls, column_names: Iterable[str], rows: Iterable[Any]
|
||||
) -> List[Dict[str, Any]]:
|
||||
unique_col_names = dict()
|
||||
for idx in range(len(column_names)):
|
||||
col_name = column_names[idx]
|
||||
# TODO CT-211
|
||||
unique_col_names = dict() # type: ignore[var-annotated]
|
||||
# TODO CT-211
|
||||
for idx in range(len(column_names)): # type: ignore[arg-type]
|
||||
# TODO CT-211
|
||||
col_name = column_names[idx] # type: ignore[index]
|
||||
if col_name in unique_col_names:
|
||||
unique_col_names[col_name] += 1
|
||||
column_names[idx] = f'{col_name}_{unique_col_names[col_name]}'
|
||||
# TODO CT-211
|
||||
column_names[idx] = f"{col_name}_{unique_col_names[col_name]}" # type: ignore[index] # noqa
|
||||
else:
|
||||
unique_col_names[column_names[idx]] = 1
|
||||
# TODO CT-211
|
||||
unique_col_names[column_names[idx]] = 1 # type: ignore[index]
|
||||
return [dict(zip(column_names, row)) for row in rows]
|
||||
|
||||
@classmethod
|
||||
@@ -119,10 +113,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
rows = cursor.fetchall()
|
||||
data = cls.process_results(column_names, rows)
|
||||
|
||||
return dbt.clients.agate_helper.table_from_data_flat(
|
||||
data,
|
||||
column_names
|
||||
)
|
||||
return dbt.clients.agate_helper.table_from_data_flat(data, column_names)
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
@@ -137,24 +128,18 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
return response, table
|
||||
|
||||
def add_begin_query(self):
|
||||
return self.add_query('BEGIN', auto_begin=False)
|
||||
return self.add_query("BEGIN", auto_begin=False)
|
||||
|
||||
def add_commit_query(self):
|
||||
return self.add_query('COMMIT', auto_begin=False)
|
||||
return self.add_query("COMMIT", auto_begin=False)
|
||||
|
||||
def begin(self):
|
||||
connection = self.get_thread_connection()
|
||||
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In begin, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is True:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to begin a new transaction on connection "{}", but '
|
||||
'it already had one open!'.format(connection.name))
|
||||
"it already had one open!".format(connection.name)
|
||||
)
|
||||
|
||||
self.add_begin_query()
|
||||
|
||||
@@ -163,18 +148,13 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def commit(self):
|
||||
connection = self.get_thread_connection()
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In commit, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to commit transaction on connection "{}", but '
|
||||
'it does not have one open!'.format(connection.name))
|
||||
"it does not have one open!".format(connection.name)
|
||||
)
|
||||
|
||||
logger.debug('On {}: COMMIT'.format(connection.name))
|
||||
fire_event(SQLCommit(conn_name=connection.name))
|
||||
self.add_commit_query()
|
||||
|
||||
connection.transaction_open = False
|
||||
|
||||
@@ -5,26 +5,29 @@ import dbt.clients.agate_helper
|
||||
from dbt.contracts.connection import Connection
|
||||
import dbt.exceptions
|
||||
from dbt.adapters.base import BaseAdapter, available
|
||||
from dbt.adapters.cache import _make_key
|
||||
from dbt.adapters.sql import SQLConnectionManager
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import ColTypeChange, SchemaCreation, SchemaDrop
|
||||
|
||||
|
||||
from dbt.adapters.base.relation import BaseRelation
|
||||
|
||||
LIST_RELATIONS_MACRO_NAME = 'list_relations_without_caching'
|
||||
GET_COLUMNS_IN_RELATION_MACRO_NAME = 'get_columns_in_relation'
|
||||
LIST_SCHEMAS_MACRO_NAME = 'list_schemas'
|
||||
CHECK_SCHEMA_EXISTS_MACRO_NAME = 'check_schema_exists'
|
||||
CREATE_SCHEMA_MACRO_NAME = 'create_schema'
|
||||
DROP_SCHEMA_MACRO_NAME = 'drop_schema'
|
||||
RENAME_RELATION_MACRO_NAME = 'rename_relation'
|
||||
TRUNCATE_RELATION_MACRO_NAME = 'truncate_relation'
|
||||
DROP_RELATION_MACRO_NAME = 'drop_relation'
|
||||
ALTER_COLUMN_TYPE_MACRO_NAME = 'alter_column_type'
|
||||
LIST_RELATIONS_MACRO_NAME = "list_relations_without_caching"
|
||||
GET_COLUMNS_IN_RELATION_MACRO_NAME = "get_columns_in_relation"
|
||||
LIST_SCHEMAS_MACRO_NAME = "list_schemas"
|
||||
CHECK_SCHEMA_EXISTS_MACRO_NAME = "check_schema_exists"
|
||||
CREATE_SCHEMA_MACRO_NAME = "create_schema"
|
||||
DROP_SCHEMA_MACRO_NAME = "drop_schema"
|
||||
RENAME_RELATION_MACRO_NAME = "rename_relation"
|
||||
TRUNCATE_RELATION_MACRO_NAME = "truncate_relation"
|
||||
DROP_RELATION_MACRO_NAME = "drop_relation"
|
||||
ALTER_COLUMN_TYPE_MACRO_NAME = "alter_column_type"
|
||||
|
||||
|
||||
class SQLAdapter(BaseAdapter):
|
||||
"""The default adapter with the common agate conversions and some SQL
|
||||
methods implemented. This adapter has a different much shorter list of
|
||||
methods was implemented. This adapter has a different much shorter list of
|
||||
methods to implement, but some more macros that must be implemented.
|
||||
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}". in the
|
||||
@@ -60,30 +63,24 @@ class SQLAdapter(BaseAdapter):
|
||||
:param abridge_sql_log: If set, limit the raw sql logged to 512
|
||||
characters
|
||||
"""
|
||||
return self.connections.add_query(sql, auto_begin, bindings,
|
||||
abridge_sql_log)
|
||||
return self.connections.add_query(sql, auto_begin, bindings, abridge_sql_log)
|
||||
|
||||
@classmethod
|
||||
def convert_text_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
return "text"
|
||||
|
||||
@classmethod
|
||||
def convert_number_type(
|
||||
cls, agate_table: agate.Table, col_idx: int
|
||||
) -> str:
|
||||
decimals = agate_table.aggregate(agate.MaxPrecision(col_idx))
|
||||
def convert_number_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
# TODO CT-211
|
||||
decimals = agate_table.aggregate(agate.MaxPrecision(col_idx)) # type: ignore[attr-defined]
|
||||
return "float8" if decimals else "integer"
|
||||
|
||||
@classmethod
|
||||
def convert_boolean_type(
|
||||
cls, agate_table: agate.Table, col_idx: int
|
||||
) -> str:
|
||||
def convert_boolean_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
return "boolean"
|
||||
|
||||
@classmethod
|
||||
def convert_datetime_type(
|
||||
cls, agate_table: agate.Table, col_idx: int
|
||||
) -> str:
|
||||
def convert_datetime_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
return "timestamp without time zone"
|
||||
|
||||
@classmethod
|
||||
@@ -99,31 +96,27 @@ class SQLAdapter(BaseAdapter):
|
||||
return True
|
||||
|
||||
def expand_column_types(self, goal, current):
|
||||
reference_columns = {
|
||||
c.name: c for c in
|
||||
self.get_columns_in_relation(goal)
|
||||
}
|
||||
reference_columns = {c.name: c for c in self.get_columns_in_relation(goal)}
|
||||
|
||||
target_columns = {
|
||||
c.name: c for c
|
||||
in self.get_columns_in_relation(current)
|
||||
}
|
||||
target_columns = {c.name: c for c in self.get_columns_in_relation(current)}
|
||||
|
||||
for column_name, reference_column in reference_columns.items():
|
||||
target_column = target_columns.get(column_name)
|
||||
|
||||
if target_column is not None and \
|
||||
target_column.can_expand_to(reference_column):
|
||||
if target_column is not None and target_column.can_expand_to(reference_column):
|
||||
col_string_size = reference_column.string_size()
|
||||
new_type = self.Column.string_type(col_string_size)
|
||||
logger.debug("Changing col type from {} to {} in table {}",
|
||||
target_column.data_type, new_type, current)
|
||||
fire_event(
|
||||
ColTypeChange(
|
||||
orig_type=target_column.data_type,
|
||||
new_type=new_type,
|
||||
table=_make_key(current),
|
||||
)
|
||||
)
|
||||
|
||||
self.alter_column_type(current, column_name, new_type)
|
||||
|
||||
def alter_column_type(
|
||||
self, relation, column_name, new_column_type
|
||||
) -> None:
|
||||
def alter_column_type(self, relation, column_name, new_column_type) -> None:
|
||||
"""
|
||||
1. Create a new column (w/ temp name and correct type)
|
||||
2. Copy data over to it
|
||||
@@ -131,53 +124,40 @@ class SQLAdapter(BaseAdapter):
|
||||
4. Rename the new column to existing column
|
||||
"""
|
||||
kwargs = {
|
||||
'relation': relation,
|
||||
'column_name': column_name,
|
||||
'new_column_type': new_column_type,
|
||||
"relation": relation,
|
||||
"column_name": column_name,
|
||||
"new_column_type": new_column_type,
|
||||
}
|
||||
self.execute_macro(
|
||||
ALTER_COLUMN_TYPE_MACRO_NAME,
|
||||
kwargs=kwargs
|
||||
)
|
||||
self.execute_macro(ALTER_COLUMN_TYPE_MACRO_NAME, kwargs=kwargs)
|
||||
|
||||
def drop_relation(self, relation):
|
||||
if relation.type is None:
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
'Tried to drop relation {}, but its type is null.'
|
||||
.format(relation))
|
||||
"Tried to drop relation {}, but its type is null.".format(relation)
|
||||
)
|
||||
|
||||
self.cache_dropped(relation)
|
||||
self.execute_macro(
|
||||
DROP_RELATION_MACRO_NAME,
|
||||
kwargs={'relation': relation}
|
||||
)
|
||||
self.execute_macro(DROP_RELATION_MACRO_NAME, kwargs={"relation": relation})
|
||||
|
||||
def truncate_relation(self, relation):
|
||||
self.execute_macro(
|
||||
TRUNCATE_RELATION_MACRO_NAME,
|
||||
kwargs={'relation': relation}
|
||||
)
|
||||
self.execute_macro(TRUNCATE_RELATION_MACRO_NAME, kwargs={"relation": relation})
|
||||
|
||||
def rename_relation(self, from_relation, to_relation):
|
||||
self.cache_renamed(from_relation, to_relation)
|
||||
|
||||
kwargs = {'from_relation': from_relation, 'to_relation': to_relation}
|
||||
self.execute_macro(
|
||||
RENAME_RELATION_MACRO_NAME,
|
||||
kwargs=kwargs
|
||||
)
|
||||
kwargs = {"from_relation": from_relation, "to_relation": to_relation}
|
||||
self.execute_macro(RENAME_RELATION_MACRO_NAME, kwargs=kwargs)
|
||||
|
||||
def get_columns_in_relation(self, relation):
|
||||
return self.execute_macro(
|
||||
GET_COLUMNS_IN_RELATION_MACRO_NAME,
|
||||
kwargs={'relation': relation}
|
||||
GET_COLUMNS_IN_RELATION_MACRO_NAME, kwargs={"relation": relation}
|
||||
)
|
||||
|
||||
def create_schema(self, relation: BaseRelation) -> None:
|
||||
relation = relation.without_identifier()
|
||||
logger.debug('Creating schema "{}"', relation)
|
||||
fire_event(SchemaCreation(relation=_make_key(relation)))
|
||||
kwargs = {
|
||||
'relation': relation,
|
||||
"relation": relation,
|
||||
}
|
||||
self.execute_macro(CREATE_SCHEMA_MACRO_NAME, kwargs=kwargs)
|
||||
self.commit_if_has_connection()
|
||||
@@ -186,51 +166,44 @@ class SQLAdapter(BaseAdapter):
|
||||
|
||||
def drop_schema(self, relation: BaseRelation) -> None:
|
||||
relation = relation.without_identifier()
|
||||
logger.debug('Dropping schema "{}".', relation)
|
||||
fire_event(SchemaDrop(relation=_make_key(relation)))
|
||||
kwargs = {
|
||||
'relation': relation,
|
||||
"relation": relation,
|
||||
}
|
||||
self.execute_macro(DROP_SCHEMA_MACRO_NAME, kwargs=kwargs)
|
||||
# we can update the cache here
|
||||
self.cache.drop_schema(relation.database, relation.schema)
|
||||
|
||||
def list_relations_without_caching(
|
||||
self, schema_relation: BaseRelation,
|
||||
self,
|
||||
schema_relation: BaseRelation,
|
||||
) -> List[BaseRelation]:
|
||||
kwargs = {'schema_relation': schema_relation}
|
||||
results = self.execute_macro(
|
||||
LIST_RELATIONS_MACRO_NAME,
|
||||
kwargs=kwargs
|
||||
)
|
||||
kwargs = {"schema_relation": schema_relation}
|
||||
results = self.execute_macro(LIST_RELATIONS_MACRO_NAME, kwargs=kwargs)
|
||||
|
||||
relations = []
|
||||
quote_policy = {
|
||||
'database': True,
|
||||
'schema': True,
|
||||
'identifier': True
|
||||
}
|
||||
quote_policy = {"database": True, "schema": True, "identifier": True}
|
||||
for _database, name, _schema, _type in results:
|
||||
try:
|
||||
_type = self.Relation.get_relation_type(_type)
|
||||
except ValueError:
|
||||
_type = self.Relation.External
|
||||
relations.append(self.Relation.create(
|
||||
database=_database,
|
||||
schema=_schema,
|
||||
identifier=name,
|
||||
quote_policy=quote_policy,
|
||||
type=_type
|
||||
))
|
||||
relations.append(
|
||||
self.Relation.create(
|
||||
database=_database,
|
||||
schema=_schema,
|
||||
identifier=name,
|
||||
quote_policy=quote_policy,
|
||||
type=_type,
|
||||
)
|
||||
)
|
||||
return relations
|
||||
|
||||
def quote(self, identifier):
|
||||
return '"{}"'.format(identifier)
|
||||
|
||||
def list_schemas(self, database: str) -> List[str]:
|
||||
results = self.execute_macro(
|
||||
LIST_SCHEMAS_MACRO_NAME,
|
||||
kwargs={'database': database}
|
||||
)
|
||||
results = self.execute_macro(LIST_SCHEMAS_MACRO_NAME, kwargs={"database": database})
|
||||
|
||||
return [row[0] for row in results]
|
||||
|
||||
@@ -238,13 +211,10 @@ class SQLAdapter(BaseAdapter):
|
||||
information_schema = self.Relation.create(
|
||||
database=database,
|
||||
schema=schema,
|
||||
identifier='INFORMATION_SCHEMA',
|
||||
quote_policy=self.config.quoting
|
||||
identifier="INFORMATION_SCHEMA",
|
||||
quote_policy=self.config.quoting,
|
||||
).information_schema()
|
||||
|
||||
kwargs = {'information_schema': information_schema, 'schema': schema}
|
||||
results = self.execute_macro(
|
||||
CHECK_SCHEMA_EXISTS_MACRO_NAME,
|
||||
kwargs=kwargs
|
||||
)
|
||||
kwargs = {"information_schema": information_schema, "schema": schema}
|
||||
results = self.execute_macro(CHECK_SCHEMA_EXISTS_MACRO_NAME, kwargs=kwargs)
|
||||
return results[0][0] > 0
|
||||
|
||||
1
core/dbt/clients/README.md
Normal file
1
core/dbt/clients/README.md
Normal file
@@ -0,0 +1 @@
|
||||
# Clients README
|
||||
@@ -10,79 +10,83 @@ def regex(pat):
|
||||
|
||||
class BlockData:
|
||||
"""raw plaintext data from the top level of the file."""
|
||||
|
||||
def __init__(self, contents):
|
||||
self.block_type_name = '__dbt__data'
|
||||
self.block_type_name = "__dbt__data"
|
||||
self.contents = contents
|
||||
self.full_block = contents
|
||||
|
||||
|
||||
class BlockTag:
|
||||
def __init__(self, block_type_name, block_name, contents=None,
|
||||
full_block=None, **kw):
|
||||
def __init__(self, block_type_name, block_name, contents=None, full_block=None, **kw):
|
||||
self.block_type_name = block_type_name
|
||||
self.block_name = block_name
|
||||
self.contents = contents
|
||||
self.full_block = full_block
|
||||
|
||||
def __str__(self):
|
||||
return 'BlockTag({!r}, {!r})'.format(self.block_type_name,
|
||||
self.block_name)
|
||||
return "BlockTag({!r}, {!r})".format(self.block_type_name, self.block_name)
|
||||
|
||||
def __repr__(self):
|
||||
return str(self)
|
||||
|
||||
@property
|
||||
def end_block_type_name(self):
|
||||
return 'end{}'.format(self.block_type_name)
|
||||
return "end{}".format(self.block_type_name)
|
||||
|
||||
def end_pat(self):
|
||||
# we don't want to use string formatting here because jinja uses most
|
||||
# of the string formatting operators in its syntax...
|
||||
pattern = ''.join((
|
||||
r'(?P<endblock>((?:\s*\{\%\-|\{\%)\s*',
|
||||
self.end_block_type_name,
|
||||
r'\s*(?:\-\%\}\s*|\%\})))',
|
||||
))
|
||||
pattern = "".join(
|
||||
(
|
||||
r"(?P<endblock>((?:\s*\{\%\-|\{\%)\s*",
|
||||
self.end_block_type_name,
|
||||
r"\s*(?:\-\%\}\s*|\%\})))",
|
||||
)
|
||||
)
|
||||
return regex(pattern)
|
||||
|
||||
|
||||
Tag = namedtuple('Tag', 'block_type_name block_name start end')
|
||||
Tag = namedtuple("Tag", "block_type_name block_name start end")
|
||||
|
||||
|
||||
_NAME_PATTERN = r'[A-Za-z_][A-Za-z_0-9]*'
|
||||
_NAME_PATTERN = r"[A-Za-z_][A-Za-z_0-9]*"
|
||||
|
||||
COMMENT_START_PATTERN = regex(r'(?:(?P<comment_start>(\s*\{\#)))')
|
||||
COMMENT_END_PATTERN = regex(r'(.*?)(\s*\#\})')
|
||||
RAW_START_PATTERN = regex(
|
||||
r'(?:\s*\{\%\-|\{\%)\s*(?P<raw_start>(raw))\s*(?:\-\%\}\s*|\%\})'
|
||||
COMMENT_START_PATTERN = regex(r"(?:(?P<comment_start>(\s*\{\#)))")
|
||||
COMMENT_END_PATTERN = regex(r"(.*?)(\s*\#\})")
|
||||
RAW_START_PATTERN = regex(r"(?:\s*\{\%\-|\{\%)\s*(?P<raw_start>(raw))\s*(?:\-\%\}\s*|\%\})")
|
||||
EXPR_START_PATTERN = regex(r"(?P<expr_start>(\{\{\s*))")
|
||||
EXPR_END_PATTERN = regex(r"(?P<expr_end>(\s*\}\}))")
|
||||
|
||||
BLOCK_START_PATTERN = regex(
|
||||
"".join(
|
||||
(
|
||||
r"(?:\s*\{\%\-|\{\%)\s*",
|
||||
r"(?P<block_type_name>({}))".format(_NAME_PATTERN),
|
||||
# some blocks have a 'block name'.
|
||||
r"(?:\s+(?P<block_name>({})))?".format(_NAME_PATTERN),
|
||||
)
|
||||
)
|
||||
)
|
||||
EXPR_START_PATTERN = regex(r'(?P<expr_start>(\{\{\s*))')
|
||||
EXPR_END_PATTERN = regex(r'(?P<expr_end>(\s*\}\}))')
|
||||
|
||||
BLOCK_START_PATTERN = regex(''.join((
|
||||
r'(?:\s*\{\%\-|\{\%)\s*',
|
||||
r'(?P<block_type_name>({}))'.format(_NAME_PATTERN),
|
||||
# some blocks have a 'block name'.
|
||||
r'(?:\s+(?P<block_name>({})))?'.format(_NAME_PATTERN),
|
||||
)))
|
||||
|
||||
|
||||
RAW_BLOCK_PATTERN = regex(''.join((
|
||||
r'(?:\s*\{\%\-|\{\%)\s*raw\s*(?:\-\%\}\s*|\%\})',
|
||||
r'(?:.*?)',
|
||||
r'(?:\s*\{\%\-|\{\%)\s*endraw\s*(?:\-\%\}\s*|\%\})',
|
||||
)))
|
||||
RAW_BLOCK_PATTERN = regex(
|
||||
"".join(
|
||||
(
|
||||
r"(?:\s*\{\%\-|\{\%)\s*raw\s*(?:\-\%\}\s*|\%\})",
|
||||
r"(?:.*?)",
|
||||
r"(?:\s*\{\%\-|\{\%)\s*endraw\s*(?:\-\%\}\s*|\%\})",
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
TAG_CLOSE_PATTERN = regex(r'(?:(?P<tag_close>(\-\%\}\s*|\%\})))')
|
||||
TAG_CLOSE_PATTERN = regex(r"(?:(?P<tag_close>(\-\%\}\s*|\%\})))")
|
||||
|
||||
# stolen from jinja's lexer. Note that we've consumed all prefix whitespace by
|
||||
# the time we want to use this.
|
||||
STRING_PATTERN = regex(
|
||||
r"(?P<string>('([^'\\]*(?:\\.[^'\\]*)*)'|"
|
||||
r'"([^"\\]*(?:\\.[^"\\]*)*)"))'
|
||||
)
|
||||
STRING_PATTERN = regex(r"(?P<string>('([^'\\]*(?:\\.[^'\\]*)*)'|" r'"([^"\\]*(?:\\.[^"\\]*)*)"))')
|
||||
|
||||
QUOTE_START_PATTERN = regex(r'''(?P<quote>(['"]))''')
|
||||
QUOTE_START_PATTERN = regex(r"""(?P<quote>(['"]))""")
|
||||
|
||||
|
||||
class TagIterator:
|
||||
@@ -99,10 +103,10 @@ class TagIterator:
|
||||
end_val: int = self.pos if end is None else end
|
||||
data = self.data[:end_val]
|
||||
# if not found, rfind returns -1, and -1+1=0, which is perfect!
|
||||
last_line_start = data.rfind('\n') + 1
|
||||
last_line_start = data.rfind("\n") + 1
|
||||
# it's easy to forget this, but line numbers are 1-indexed
|
||||
line_number = data.count('\n') + 1
|
||||
return f'{line_number}:{end_val - last_line_start}'
|
||||
line_number = data.count("\n") + 1
|
||||
return f"{line_number}:{end_val - last_line_start}"
|
||||
|
||||
def advance(self, new_position):
|
||||
self.pos = new_position
|
||||
@@ -120,7 +124,7 @@ class TagIterator:
|
||||
matches = []
|
||||
for pattern in patterns:
|
||||
# default to 'search', but sometimes we want to 'match'.
|
||||
if kwargs.get('method', 'search') == 'search':
|
||||
if kwargs.get("method", "search") == "search":
|
||||
match = self._search(pattern)
|
||||
else:
|
||||
match = self._match(pattern)
|
||||
@@ -136,7 +140,7 @@ class TagIterator:
|
||||
match = self._first_match(*patterns, **kwargs)
|
||||
if match is None:
|
||||
msg = 'unexpected EOF, expected {}, got "{}"'.format(
|
||||
expected_name, self.data[self.pos:]
|
||||
expected_name, self.data[self.pos :]
|
||||
)
|
||||
dbt.exceptions.raise_compiler_error(msg)
|
||||
return match
|
||||
@@ -156,22 +160,20 @@ class TagIterator:
|
||||
"""
|
||||
self.advance(match.end())
|
||||
while True:
|
||||
match = self._expect_match('}}',
|
||||
EXPR_END_PATTERN,
|
||||
QUOTE_START_PATTERN)
|
||||
if match.groupdict().get('expr_end') is not None:
|
||||
match = self._expect_match("}}", EXPR_END_PATTERN, QUOTE_START_PATTERN)
|
||||
if match.groupdict().get("expr_end") is not None:
|
||||
break
|
||||
else:
|
||||
# it's a quote. we haven't advanced for this match yet, so
|
||||
# just slurp up the whole string, no need to rewind.
|
||||
match = self._expect_match('string', STRING_PATTERN)
|
||||
match = self._expect_match("string", STRING_PATTERN)
|
||||
self.advance(match.end())
|
||||
|
||||
self.advance(match.end())
|
||||
|
||||
def handle_comment(self, match):
|
||||
self.advance(match.end())
|
||||
match = self._expect_match('#}', COMMENT_END_PATTERN)
|
||||
match = self._expect_match("#}", COMMENT_END_PATTERN)
|
||||
self.advance(match.end())
|
||||
|
||||
def _expect_block_close(self):
|
||||
@@ -188,22 +190,19 @@ class TagIterator:
|
||||
"""
|
||||
while True:
|
||||
end_match = self._expect_match(
|
||||
'tag close ("%}")',
|
||||
QUOTE_START_PATTERN,
|
||||
TAG_CLOSE_PATTERN
|
||||
'tag close ("%}")', QUOTE_START_PATTERN, TAG_CLOSE_PATTERN
|
||||
)
|
||||
self.advance(end_match.end())
|
||||
if end_match.groupdict().get('tag_close') is not None:
|
||||
if end_match.groupdict().get("tag_close") is not None:
|
||||
return
|
||||
# must be a string. Rewind to its start and advance past it.
|
||||
self.rewind()
|
||||
string_match = self._expect_match('string', STRING_PATTERN)
|
||||
string_match = self._expect_match("string", STRING_PATTERN)
|
||||
self.advance(string_match.end())
|
||||
|
||||
def handle_raw(self):
|
||||
# raw blocks are super special, they are a single complete regex
|
||||
match = self._expect_match('{% raw %}...{% endraw %}',
|
||||
RAW_BLOCK_PATTERN)
|
||||
match = self._expect_match("{% raw %}...{% endraw %}", RAW_BLOCK_PATTERN)
|
||||
self.advance(match.end())
|
||||
return match.end()
|
||||
|
||||
@@ -220,30 +219,24 @@ class TagIterator:
|
||||
"""
|
||||
groups = match.groupdict()
|
||||
# always a value
|
||||
block_type_name = groups['block_type_name']
|
||||
block_type_name = groups["block_type_name"]
|
||||
# might be None
|
||||
block_name = groups.get('block_name')
|
||||
block_name = groups.get("block_name")
|
||||
start_pos = self.pos
|
||||
if block_type_name == 'raw':
|
||||
match = self._expect_match('{% raw %}...{% endraw %}',
|
||||
RAW_BLOCK_PATTERN)
|
||||
if block_type_name == "raw":
|
||||
match = self._expect_match("{% raw %}...{% endraw %}", RAW_BLOCK_PATTERN)
|
||||
self.advance(match.end())
|
||||
else:
|
||||
self.advance(match.end())
|
||||
self._expect_block_close()
|
||||
return Tag(
|
||||
block_type_name=block_type_name,
|
||||
block_name=block_name,
|
||||
start=start_pos,
|
||||
end=self.pos
|
||||
block_type_name=block_type_name, block_name=block_name, start=start_pos, end=self.pos
|
||||
)
|
||||
|
||||
def find_tags(self):
|
||||
while True:
|
||||
match = self._first_match(
|
||||
BLOCK_START_PATTERN,
|
||||
COMMENT_START_PATTERN,
|
||||
EXPR_START_PATTERN
|
||||
BLOCK_START_PATTERN, COMMENT_START_PATTERN, EXPR_START_PATTERN
|
||||
)
|
||||
if match is None:
|
||||
break
|
||||
@@ -252,9 +245,9 @@ class TagIterator:
|
||||
# start = self.pos
|
||||
|
||||
groups = match.groupdict()
|
||||
comment_start = groups.get('comment_start')
|
||||
expr_start = groups.get('expr_start')
|
||||
block_type_name = groups.get('block_type_name')
|
||||
comment_start = groups.get("comment_start")
|
||||
expr_start = groups.get("expr_start")
|
||||
block_type_name = groups.get("block_type_name")
|
||||
|
||||
if comment_start is not None:
|
||||
self.handle_comment(match)
|
||||
@@ -264,8 +257,8 @@ class TagIterator:
|
||||
yield self.handle_tag(match)
|
||||
else:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Invalid regex match in next_block, expected block start, '
|
||||
'expr start, or comment start'
|
||||
"Invalid regex match in next_block, expected block start, "
|
||||
"expr start, or comment start"
|
||||
)
|
||||
|
||||
def __iter__(self):
|
||||
@@ -273,21 +266,18 @@ class TagIterator:
|
||||
|
||||
|
||||
duplicate_tags = (
|
||||
'Got nested tags: {outer.block_type_name} (started at {outer.start}) did '
|
||||
'not have a matching {{% end{outer.block_type_name} %}} before a '
|
||||
'subsequent {inner.block_type_name} was found (started at {inner.start})'
|
||||
"Got nested tags: {outer.block_type_name} (started at {outer.start}) did "
|
||||
"not have a matching {{% end{outer.block_type_name} %}} before a "
|
||||
"subsequent {inner.block_type_name} was found (started at {inner.start})"
|
||||
)
|
||||
|
||||
|
||||
_CONTROL_FLOW_TAGS = {
|
||||
'if': 'endif',
|
||||
'for': 'endfor',
|
||||
"if": "endif",
|
||||
"for": "endfor",
|
||||
}
|
||||
|
||||
_CONTROL_FLOW_END_TAGS = {
|
||||
v: k
|
||||
for k, v in _CONTROL_FLOW_TAGS.items()
|
||||
}
|
||||
_CONTROL_FLOW_END_TAGS = {v: k for k, v in _CONTROL_FLOW_TAGS.items()}
|
||||
|
||||
|
||||
class BlockIterator:
|
||||
@@ -310,15 +300,15 @@ class BlockIterator:
|
||||
|
||||
def is_current_end(self, tag):
|
||||
return (
|
||||
tag.block_type_name.startswith('end') and
|
||||
self.current is not None and
|
||||
tag.block_type_name[3:] == self.current.block_type_name
|
||||
tag.block_type_name.startswith("end")
|
||||
and self.current is not None
|
||||
and tag.block_type_name[3:] == self.current.block_type_name
|
||||
)
|
||||
|
||||
def find_blocks(self, allowed_blocks=None, collect_raw_data=True):
|
||||
"""Find all top-level blocks in the data."""
|
||||
if allowed_blocks is None:
|
||||
allowed_blocks = {'snapshot', 'macro', 'materialization', 'docs'}
|
||||
allowed_blocks = {"snapshot", "macro", "materialization", "docs"}
|
||||
|
||||
for tag in self.tag_parser.find_tags():
|
||||
if tag.block_type_name in _CONTROL_FLOW_TAGS:
|
||||
@@ -329,37 +319,35 @@ class BlockIterator:
|
||||
found = self.stack.pop()
|
||||
else:
|
||||
expected = _CONTROL_FLOW_END_TAGS[tag.block_type_name]
|
||||
dbt.exceptions.raise_compiler_error((
|
||||
'Got an unexpected control flow end tag, got {} but '
|
||||
'never saw a preceeding {} (@ {})'
|
||||
).format(
|
||||
tag.block_type_name,
|
||||
expected,
|
||||
self.tag_parser.linepos(tag.start)
|
||||
))
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
(
|
||||
"Got an unexpected control flow end tag, got {} but "
|
||||
"never saw a preceeding {} (@ {})"
|
||||
).format(tag.block_type_name, expected, self.tag_parser.linepos(tag.start))
|
||||
)
|
||||
expected = _CONTROL_FLOW_TAGS[found]
|
||||
if expected != tag.block_type_name:
|
||||
dbt.exceptions.raise_compiler_error((
|
||||
'Got an unexpected control flow end tag, got {} but '
|
||||
'expected {} next (@ {})'
|
||||
).format(
|
||||
tag.block_type_name,
|
||||
expected,
|
||||
self.tag_parser.linepos(tag.start)
|
||||
))
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
(
|
||||
"Got an unexpected control flow end tag, got {} but "
|
||||
"expected {} next (@ {})"
|
||||
).format(tag.block_type_name, expected, self.tag_parser.linepos(tag.start))
|
||||
)
|
||||
|
||||
if tag.block_type_name in allowed_blocks:
|
||||
if self.stack:
|
||||
dbt.exceptions.raise_compiler_error((
|
||||
'Got a block definition inside control flow at {}. '
|
||||
'All dbt block definitions must be at the top level'
|
||||
).format(self.tag_parser.linepos(tag.start)))
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
(
|
||||
"Got a block definition inside control flow at {}. "
|
||||
"All dbt block definitions must be at the top level"
|
||||
).format(self.tag_parser.linepos(tag.start))
|
||||
)
|
||||
if self.current is not None:
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
duplicate_tags.format(outer=self.current, inner=tag)
|
||||
)
|
||||
if collect_raw_data:
|
||||
raw_data = self.data[self.last_position:tag.start]
|
||||
raw_data = self.data[self.last_position : tag.start]
|
||||
self.last_position = tag.start
|
||||
if raw_data:
|
||||
yield BlockData(raw_data)
|
||||
@@ -371,23 +359,25 @@ class BlockIterator:
|
||||
yield BlockTag(
|
||||
block_type_name=self.current.block_type_name,
|
||||
block_name=self.current.block_name,
|
||||
contents=self.data[self.current.end:tag.start],
|
||||
full_block=self.data[self.current.start:tag.end]
|
||||
contents=self.data[self.current.end : tag.start],
|
||||
full_block=self.data[self.current.start : tag.end],
|
||||
)
|
||||
self.current = None
|
||||
|
||||
if self.current:
|
||||
linecount = self.data[:self.current.end].count('\n') + 1
|
||||
dbt.exceptions.raise_compiler_error((
|
||||
'Reached EOF without finding a close tag for '
|
||||
'{} (searched from line {})'
|
||||
).format(self.current.block_type_name, linecount))
|
||||
linecount = self.data[: self.current.end].count("\n") + 1
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
(
|
||||
"Reached EOF without finding a close tag for " "{} (searched from line {})"
|
||||
).format(self.current.block_type_name, linecount)
|
||||
)
|
||||
|
||||
if collect_raw_data:
|
||||
raw_data = self.data[self.last_position:]
|
||||
raw_data = self.data[self.last_position :]
|
||||
if raw_data:
|
||||
yield BlockData(raw_data)
|
||||
|
||||
def lex_for_blocks(self, allowed_blocks=None, collect_raw_data=True):
|
||||
return list(self.find_blocks(allowed_blocks=allowed_blocks,
|
||||
collect_raw_data=collect_raw_data))
|
||||
return list(
|
||||
self.find_blocks(allowed_blocks=allowed_blocks, collect_raw_data=collect_raw_data)
|
||||
)
|
||||
|
||||
@@ -10,7 +10,17 @@ from typing import Iterable, List, Dict, Union, Optional, Any
|
||||
from dbt.exceptions import RuntimeException
|
||||
|
||||
|
||||
BOM = BOM_UTF8.decode('utf-8') # '\ufeff'
|
||||
BOM = BOM_UTF8.decode("utf-8") # '\ufeff'
|
||||
|
||||
|
||||
class Number(agate.data_types.Number):
|
||||
# undo the change in https://github.com/wireservice/agate/pull/733
|
||||
# i.e. do not cast True and False to numeric 1 and 0
|
||||
def cast(self, d):
|
||||
if type(d) == bool:
|
||||
raise agate.exceptions.CastError("Do not cast True to 1 or False to 0.")
|
||||
else:
|
||||
return super().cast(d)
|
||||
|
||||
|
||||
class ISODateTime(agate.data_types.DateTime):
|
||||
@@ -30,28 +40,24 @@ class ISODateTime(agate.data_types.DateTime):
|
||||
except: # noqa
|
||||
pass
|
||||
|
||||
raise agate.exceptions.CastError(
|
||||
'Can not parse value "%s" as datetime.' % d
|
||||
)
|
||||
raise agate.exceptions.CastError('Can not parse value "%s" as datetime.' % d)
|
||||
|
||||
|
||||
def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
def build_type_tester(
|
||||
text_columns: Iterable[str], string_null_values: Optional[Iterable[str]] = ("null", "")
|
||||
) -> agate.TypeTester:
|
||||
|
||||
types = [
|
||||
agate.data_types.Number(null_values=('null', '')),
|
||||
agate.data_types.Date(null_values=('null', ''),
|
||||
date_format='%Y-%m-%d'),
|
||||
agate.data_types.DateTime(null_values=('null', ''),
|
||||
datetime_format='%Y-%m-%d %H:%M:%S'),
|
||||
ISODateTime(null_values=('null', '')),
|
||||
agate.data_types.Boolean(true_values=('true',),
|
||||
false_values=('false',),
|
||||
null_values=('null', '')),
|
||||
agate.data_types.Text(null_values=('null', ''))
|
||||
Number(null_values=("null", "")),
|
||||
agate.data_types.Date(null_values=("null", ""), date_format="%Y-%m-%d"),
|
||||
agate.data_types.DateTime(null_values=("null", ""), datetime_format="%Y-%m-%d %H:%M:%S"),
|
||||
ISODateTime(null_values=("null", "")),
|
||||
agate.data_types.Boolean(
|
||||
true_values=("true",), false_values=("false",), null_values=("null", "")
|
||||
),
|
||||
agate.data_types.Text(null_values=string_null_values),
|
||||
]
|
||||
force = {
|
||||
k: agate.data_types.Text(null_values=('null', ''))
|
||||
for k in text_columns
|
||||
}
|
||||
force = {k: agate.data_types.Text(null_values=string_null_values) for k in text_columns}
|
||||
return agate.TypeTester(force=force, types=types)
|
||||
|
||||
|
||||
@@ -66,12 +72,15 @@ def table_from_rows(
|
||||
if text_only_columns is None:
|
||||
column_types = DEFAULT_TYPE_TESTER
|
||||
else:
|
||||
column_types = build_type_tester(text_only_columns)
|
||||
# If text_only_columns are present, prevent coercing empty string or
|
||||
# literal 'null' strings to a None representation.
|
||||
column_types = build_type_tester(text_only_columns, string_null_values=())
|
||||
|
||||
return agate.Table(rows, column_names, column_types=column_types)
|
||||
|
||||
|
||||
def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
"Convert a list of dictionaries into an Agate table"
|
||||
|
||||
# The agate table is generated from a list of dicts, so the column order
|
||||
# from `data` is not preserved. We can use `select` to reorder the columns
|
||||
@@ -86,19 +95,32 @@ def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
|
||||
|
||||
def table_from_data_flat(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
"""
|
||||
Convert a list of dictionaries into an Agate table. This method does not
|
||||
coerce string values into more specific types (eg. '005' will not be
|
||||
coerced to '5'). Additionally, this method does not coerce values to
|
||||
None (eg. '' or 'null' will retain their string literal representations).
|
||||
"""
|
||||
|
||||
rows = []
|
||||
text_only_columns = set()
|
||||
for _row in data:
|
||||
row = []
|
||||
for value in list(_row.values()):
|
||||
for col_name in column_names:
|
||||
value = _row[col_name]
|
||||
if isinstance(value, (dict, list, tuple)):
|
||||
row.append(json.dumps(value, cls=dbt.utils.JSONEncoder))
|
||||
else:
|
||||
row.append(value)
|
||||
# Represent container types as json strings
|
||||
value = json.dumps(value, cls=dbt.utils.JSONEncoder)
|
||||
text_only_columns.add(col_name)
|
||||
elif isinstance(value, str):
|
||||
text_only_columns.add(col_name)
|
||||
row.append(value)
|
||||
|
||||
rows.append(row)
|
||||
|
||||
return table_from_rows(rows=rows, column_names=column_names)
|
||||
return table_from_rows(
|
||||
rows=rows, column_names=column_names, text_only_columns=text_only_columns
|
||||
)
|
||||
|
||||
|
||||
def empty_table():
|
||||
@@ -115,7 +137,7 @@ def as_matrix(table):
|
||||
|
||||
def from_csv(abspath, text_columns):
|
||||
type_tester = build_type_tester(text_columns=text_columns)
|
||||
with open(abspath, encoding='utf-8') as fp:
|
||||
with open(abspath, encoding="utf-8") as fp:
|
||||
if fp.read(1) != BOM:
|
||||
fp.seek(0)
|
||||
return agate.Table.from_csv(fp, column_types=type_tester)
|
||||
@@ -147,8 +169,8 @@ class ColumnTypeBuilder(Dict[str, NullableAgateType]):
|
||||
elif not isinstance(value, type(existing_type)):
|
||||
# actual type mismatch!
|
||||
raise RuntimeException(
|
||||
f'Tables contain columns with the same names ({key}), '
|
||||
f'but different types ({value} vs {existing_type})'
|
||||
f"Tables contain columns with the same names ({key}), "
|
||||
f"but different types ({value} vs {existing_type})"
|
||||
)
|
||||
|
||||
def finalize(self) -> Dict[str, agate.data_types.DataType]:
|
||||
@@ -162,9 +184,7 @@ class ColumnTypeBuilder(Dict[str, NullableAgateType]):
|
||||
return result
|
||||
|
||||
|
||||
def _merged_column_types(
|
||||
tables: List[agate.Table]
|
||||
) -> Dict[str, agate.data_types.DataType]:
|
||||
def _merged_column_types(tables: List[agate.Table]) -> Dict[str, agate.data_types.DataType]:
|
||||
# this is a lot like agate.Table.merge, but with handling for all-null
|
||||
# rows being "any type".
|
||||
new_columns: ColumnTypeBuilder = ColumnTypeBuilder()
|
||||
@@ -190,10 +210,7 @@ def merge_tables(tables: List[agate.Table]) -> agate.Table:
|
||||
|
||||
rows: List[agate.Row] = []
|
||||
for table in tables:
|
||||
if (
|
||||
table.column_names == column_names and
|
||||
table.column_types == column_types
|
||||
):
|
||||
if table.column_names == column_names and table.column_types == column_types:
|
||||
rows.extend(table.rows)
|
||||
else:
|
||||
for row in table.rows:
|
||||
|
||||
@@ -1,26 +0,0 @@
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from dbt.clients.system import run_cmd
|
||||
|
||||
NOT_INSTALLED_MSG = """
|
||||
dbt requires the gcloud SDK to be installed to authenticate with BigQuery.
|
||||
Please download and install the SDK, or use a Service Account instead.
|
||||
|
||||
https://cloud.google.com/sdk/
|
||||
"""
|
||||
|
||||
|
||||
def gcloud_installed():
|
||||
try:
|
||||
run_cmd('.', ['gcloud', '--version'])
|
||||
return True
|
||||
except OSError as e:
|
||||
logger.debug(e)
|
||||
return False
|
||||
|
||||
|
||||
def setup_default_credentials():
|
||||
if gcloud_installed():
|
||||
run_cmd('.', ["gcloud", "auth", "application-default", "login"])
|
||||
else:
|
||||
raise dbt.exceptions.RuntimeException(NOT_INSTALLED_MSG)
|
||||
@@ -2,8 +2,23 @@ import re
|
||||
import os.path
|
||||
|
||||
from dbt.clients.system import run_cmd, rmdir
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
GitSparseCheckoutSubdirectory,
|
||||
GitProgressCheckoutRevision,
|
||||
GitProgressUpdatingExistingDependency,
|
||||
GitProgressPullingNewDependency,
|
||||
GitNothingToDo,
|
||||
GitProgressUpdatedCheckoutRange,
|
||||
GitProgressCheckedOutAt,
|
||||
)
|
||||
from dbt.exceptions import (
|
||||
CommandResultError,
|
||||
RuntimeException,
|
||||
bad_package_spec,
|
||||
raise_git_cloning_error,
|
||||
raise_git_cloning_problem,
|
||||
)
|
||||
from packaging import version
|
||||
|
||||
|
||||
@@ -12,14 +27,24 @@ def _is_commit(revision: str) -> bool:
|
||||
return bool(re.match(r"\b[0-9a-f]{40}\b", revision))
|
||||
|
||||
|
||||
def _raise_git_cloning_error(repo, revision, error):
|
||||
stderr = error.stderr.decode("utf-8").strip()
|
||||
if "usage: git" in stderr:
|
||||
stderr = stderr.split("\nusage: git")[0]
|
||||
if re.match("fatal: destination path '(.+)' already exists", stderr):
|
||||
raise_git_cloning_error(error)
|
||||
|
||||
bad_package_spec(repo, revision, stderr)
|
||||
|
||||
|
||||
def clone(repo, cwd, dirname=None, remove_git_dir=False, revision=None, subdirectory=None):
|
||||
has_revision = revision is not None
|
||||
is_commit = _is_commit(revision or "")
|
||||
|
||||
clone_cmd = ['git', 'clone', '--depth', '1']
|
||||
clone_cmd = ["git", "clone", "--depth", "1"]
|
||||
if subdirectory:
|
||||
logger.debug(' Subdirectory specified: {}, using sparse checkout.'.format(subdirectory))
|
||||
out, _ = run_cmd(cwd, ['git', '--version'], env={'LC_ALL': 'C'})
|
||||
fire_event(GitSparseCheckoutSubdirectory(subdir=subdirectory))
|
||||
out, _ = run_cmd(cwd, ["git", "--version"], env={"LC_ALL": "C"})
|
||||
git_version = version.parse(re.search(r"\d+\.\d+\.\d+", out.decode("utf-8")).group(0))
|
||||
if not git_version >= version.parse("2.25.0"):
|
||||
# 2.25.0 introduces --sparse
|
||||
@@ -27,78 +52,86 @@ def clone(repo, cwd, dirname=None, remove_git_dir=False, revision=None, subdirec
|
||||
"Please update your git version to pull a dbt package "
|
||||
"from a subdirectory: your version is {}, >= 2.25.0 needed".format(git_version)
|
||||
)
|
||||
clone_cmd.extend(['--filter=blob:none', '--sparse'])
|
||||
clone_cmd.extend(["--filter=blob:none", "--sparse"])
|
||||
|
||||
if has_revision and not is_commit:
|
||||
clone_cmd.extend(['--branch', revision])
|
||||
clone_cmd.extend(["--branch", revision])
|
||||
|
||||
clone_cmd.append(repo)
|
||||
|
||||
if dirname is not None:
|
||||
clone_cmd.append(dirname)
|
||||
result = run_cmd(cwd, clone_cmd, env={'LC_ALL': 'C'})
|
||||
try:
|
||||
result = run_cmd(cwd, clone_cmd, env={"LC_ALL": "C"})
|
||||
except CommandResultError as exc:
|
||||
_raise_git_cloning_error(repo, revision, exc)
|
||||
|
||||
if subdirectory:
|
||||
run_cmd(os.path.join(cwd, dirname or ''), ['git', 'sparse-checkout', 'set', subdirectory])
|
||||
cwd_subdir = os.path.join(cwd, dirname or "")
|
||||
clone_cmd_subdir = ["git", "sparse-checkout", "set", subdirectory]
|
||||
try:
|
||||
run_cmd(cwd_subdir, clone_cmd_subdir)
|
||||
except CommandResultError as exc:
|
||||
_raise_git_cloning_error(repo, revision, exc)
|
||||
|
||||
if remove_git_dir:
|
||||
rmdir(os.path.join(dirname, '.git'))
|
||||
rmdir(os.path.join(dirname, ".git"))
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def list_tags(cwd):
|
||||
out, err = run_cmd(cwd, ['git', 'tag', '--list'], env={'LC_ALL': 'C'})
|
||||
tags = out.decode('utf-8').strip().split("\n")
|
||||
out, err = run_cmd(cwd, ["git", "tag", "--list"], env={"LC_ALL": "C"})
|
||||
tags = out.decode("utf-8").strip().split("\n")
|
||||
return tags
|
||||
|
||||
|
||||
def _checkout(cwd, repo, revision):
|
||||
logger.debug(' Checking out revision {}.'.format(revision))
|
||||
fire_event(GitProgressCheckoutRevision(revision=revision))
|
||||
|
||||
fetch_cmd = ["git", "fetch", "origin", "--depth", "1"]
|
||||
|
||||
if _is_commit(revision):
|
||||
run_cmd(cwd, fetch_cmd + [revision])
|
||||
else:
|
||||
run_cmd(cwd, ['git', 'remote', 'set-branches', 'origin', revision])
|
||||
run_cmd(cwd, ["git", "remote", "set-branches", "origin", revision])
|
||||
run_cmd(cwd, fetch_cmd + ["--tags", revision])
|
||||
|
||||
if _is_commit(revision):
|
||||
spec = revision
|
||||
# Prefer tags to branches if one exists
|
||||
elif revision in list_tags(cwd):
|
||||
spec = 'tags/{}'.format(revision)
|
||||
spec = "tags/{}".format(revision)
|
||||
else:
|
||||
spec = 'origin/{}'.format(revision)
|
||||
spec = "origin/{}".format(revision)
|
||||
|
||||
out, err = run_cmd(cwd, ['git', 'reset', '--hard', spec],
|
||||
env={'LC_ALL': 'C'})
|
||||
out, err = run_cmd(cwd, ["git", "reset", "--hard", spec], env={"LC_ALL": "C"})
|
||||
return out, err
|
||||
|
||||
|
||||
def checkout(cwd, repo, revision=None):
|
||||
if revision is None:
|
||||
revision = 'HEAD'
|
||||
revision = "HEAD"
|
||||
try:
|
||||
return _checkout(cwd, repo, revision)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
stderr = exc.stderr.decode('utf-8').strip()
|
||||
dbt.exceptions.bad_package_spec(repo, revision, stderr)
|
||||
except CommandResultError as exc:
|
||||
stderr = exc.stderr.decode("utf-8").strip()
|
||||
bad_package_spec(repo, revision, stderr)
|
||||
|
||||
|
||||
def get_current_sha(cwd):
|
||||
out, err = run_cmd(cwd, ['git', 'rev-parse', 'HEAD'], env={'LC_ALL': 'C'})
|
||||
out, err = run_cmd(cwd, ["git", "rev-parse", "HEAD"], env={"LC_ALL": "C"})
|
||||
|
||||
return out.decode('utf-8')
|
||||
return out.decode("utf-8")
|
||||
|
||||
|
||||
def remove_remote(cwd):
|
||||
return run_cmd(cwd, ['git', 'remote', 'rm', 'origin'], env={'LC_ALL': 'C'})
|
||||
return run_cmd(cwd, ["git", "remote", "rm", "origin"], env={"LC_ALL": "C"})
|
||||
|
||||
|
||||
def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
revision=None, subdirectory=None):
|
||||
def clone_and_checkout(
|
||||
repo, cwd, dirname=None, remove_git_dir=False, revision=None, subdirectory=None
|
||||
):
|
||||
exists = None
|
||||
try:
|
||||
_, err = clone(
|
||||
@@ -108,35 +141,34 @@ def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
remove_git_dir=remove_git_dir,
|
||||
subdirectory=subdirectory,
|
||||
)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
err = exc.stderr.decode('utf-8')
|
||||
except CommandResultError as exc:
|
||||
err = exc.stderr.decode("utf-8")
|
||||
exists = re.match("fatal: destination path '(.+)' already exists", err)
|
||||
if not exists: # something else is wrong, raise it
|
||||
raise
|
||||
if not exists:
|
||||
raise_git_cloning_problem(repo)
|
||||
|
||||
directory = None
|
||||
start_sha = None
|
||||
if exists:
|
||||
directory = exists.group(1)
|
||||
logger.debug('Updating existing dependency {}.', directory)
|
||||
fire_event(GitProgressUpdatingExistingDependency(dir=directory))
|
||||
else:
|
||||
matches = re.match("Cloning into '(.+)'", err.decode('utf-8'))
|
||||
matches = re.match("Cloning into '(.+)'", err.decode("utf-8"))
|
||||
if matches is None:
|
||||
raise dbt.exceptions.RuntimeException(
|
||||
f'Error cloning {repo} - never saw "Cloning into ..." from git'
|
||||
)
|
||||
raise RuntimeException(f'Error cloning {repo} - never saw "Cloning into ..." from git')
|
||||
directory = matches.group(1)
|
||||
logger.debug('Pulling new dependency {}.', directory)
|
||||
fire_event(GitProgressPullingNewDependency(dir=directory))
|
||||
full_path = os.path.join(cwd, directory)
|
||||
start_sha = get_current_sha(full_path)
|
||||
checkout(full_path, repo, revision)
|
||||
end_sha = get_current_sha(full_path)
|
||||
if exists:
|
||||
if start_sha == end_sha:
|
||||
logger.debug(' Already at {}, nothing to do.', start_sha[:7])
|
||||
fire_event(GitNothingToDo(sha=start_sha[:7]))
|
||||
else:
|
||||
logger.debug(' Updated checkout from {} to {}.',
|
||||
start_sha[:7], end_sha[:7])
|
||||
fire_event(
|
||||
GitProgressUpdatedCheckoutRange(start_sha=start_sha[:7], end_sha=end_sha[:7])
|
||||
)
|
||||
else:
|
||||
logger.debug(' Checked out at {}.', end_sha[:7])
|
||||
return os.path.join(directory, subdirectory or '')
|
||||
fire_event(GitProgressCheckedOutAt(end_sha=end_sha[:7]))
|
||||
return os.path.join(directory, subdirectory or "")
|
||||
|
||||
@@ -7,10 +7,7 @@ import threading
|
||||
from ast import literal_eval
|
||||
from contextlib import contextmanager
|
||||
from itertools import chain, islice
|
||||
from typing import (
|
||||
List, Union, Set, Optional, Dict, Any, Iterator, Type, NoReturn, Tuple,
|
||||
Callable
|
||||
)
|
||||
from typing import List, Union, Set, Optional, Dict, Any, Iterator, Type, NoReturn, Tuple, Callable
|
||||
|
||||
import jinja2
|
||||
import jinja2.ext
|
||||
@@ -20,20 +17,26 @@ import jinja2.parser
|
||||
import jinja2.sandbox
|
||||
|
||||
from dbt.utils import (
|
||||
get_dbt_macro_name, get_docs_macro_name, get_materialization_macro_name,
|
||||
get_test_macro_name, deep_map
|
||||
get_dbt_macro_name,
|
||||
get_docs_macro_name,
|
||||
get_materialization_macro_name,
|
||||
get_test_macro_name,
|
||||
deep_map_render,
|
||||
)
|
||||
|
||||
from dbt.clients._jinja_blocks import BlockIterator, BlockData, BlockTag
|
||||
from dbt.contracts.graph.compiled import CompiledSchemaTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedSchemaTestNode
|
||||
from dbt.contracts.graph.compiled import CompiledGenericTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedGenericTestNode
|
||||
from dbt.exceptions import (
|
||||
InternalException, raise_compiler_error, CompilationException,
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException,
|
||||
UndefinedMacroException
|
||||
InternalException,
|
||||
raise_compiler_error,
|
||||
CompilationException,
|
||||
invalid_materialization_argument,
|
||||
MacroReturn,
|
||||
JinjaRenderingException,
|
||||
UndefinedMacroException,
|
||||
)
|
||||
from dbt import flags
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
|
||||
|
||||
def _linecache_inject(source, write):
|
||||
@@ -41,27 +44,22 @@ def _linecache_inject(source, write):
|
||||
# this is the only reliable way to accomplish this. Obviously, it's
|
||||
# really darn noisy and will fill your temporary directory
|
||||
tmp_file = tempfile.NamedTemporaryFile(
|
||||
prefix='dbt-macro-compiled-',
|
||||
suffix='.py',
|
||||
prefix="dbt-macro-compiled-",
|
||||
suffix=".py",
|
||||
delete=False,
|
||||
mode='w+',
|
||||
encoding='utf-8',
|
||||
mode="w+",
|
||||
encoding="utf-8",
|
||||
)
|
||||
tmp_file.write(source)
|
||||
filename = tmp_file.name
|
||||
else:
|
||||
# `codecs.encode` actually takes a `bytes` as the first argument if
|
||||
# the second argument is 'hex' - mypy does not know this.
|
||||
rnd = codecs.encode(os.urandom(12), 'hex') # type: ignore
|
||||
filename = rnd.decode('ascii')
|
||||
rnd = codecs.encode(os.urandom(12), "hex") # type: ignore
|
||||
filename = rnd.decode("ascii")
|
||||
|
||||
# put ourselves in the cache
|
||||
cache_entry = (
|
||||
len(source),
|
||||
None,
|
||||
[line + '\n' for line in source.splitlines()],
|
||||
filename
|
||||
)
|
||||
cache_entry = (len(source), None, [line + "\n" for line in source.splitlines()], filename)
|
||||
# linecache does in fact have an attribute `cache`, thanks
|
||||
linecache.cache[filename] = cache_entry # type: ignore
|
||||
return filename
|
||||
@@ -74,12 +72,10 @@ class MacroFuzzParser(jinja2.parser.Parser):
|
||||
# modified to fuzz macros defined in the same file. this way
|
||||
# dbt can understand the stack of macros being called.
|
||||
# - @cmcarthur
|
||||
node.name = get_dbt_macro_name(
|
||||
self.parse_assign_target(name_only=True).name)
|
||||
node.name = get_dbt_macro_name(self.parse_assign_target(name_only=True).name)
|
||||
|
||||
self.parse_signature(node)
|
||||
node.body = self.parse_statements(('name:endmacro',),
|
||||
drop_needle=True)
|
||||
node.body = self.parse_statements(("name:endmacro",), drop_needle=True)
|
||||
return node
|
||||
|
||||
|
||||
@@ -95,8 +91,8 @@ class MacroFuzzEnvironment(jinja2.sandbox.SandboxedEnvironment):
|
||||
If the value is 'write', also write the files to disk.
|
||||
WARNING: This can write a ton of data if you aren't careful.
|
||||
"""
|
||||
if filename == '<template>' and flags.MACRO_DEBUGGING:
|
||||
write = flags.MACRO_DEBUGGING == 'write'
|
||||
if filename == "<template>" and flags.MACRO_DEBUGGING:
|
||||
write = flags.MACRO_DEBUGGING == "write"
|
||||
filename = _linecache_inject(source, write)
|
||||
|
||||
return super()._compile(source, filename) # type: ignore
|
||||
@@ -107,7 +103,7 @@ class NativeSandboxEnvironment(MacroFuzzEnvironment):
|
||||
|
||||
|
||||
class TextMarker(str):
|
||||
"""A special native-env marker that indicates that a value is text and is
|
||||
"""A special native-env marker that indicates a value is text and is
|
||||
not to be evaluated. Use this to prevent your numbery-strings from becoming
|
||||
numbers!
|
||||
"""
|
||||
@@ -139,7 +135,7 @@ def quoted_native_concat(nodes):
|
||||
head = list(islice(nodes, 2))
|
||||
|
||||
if not head:
|
||||
return ''
|
||||
return ""
|
||||
|
||||
if len(head) == 1:
|
||||
raw = head[0]
|
||||
@@ -157,13 +153,9 @@ def quoted_native_concat(nodes):
|
||||
except (ValueError, SyntaxError, MemoryError):
|
||||
result = raw
|
||||
if isinstance(raw, BoolMarker) and not isinstance(result, bool):
|
||||
raise JinjaRenderingException(
|
||||
f"Could not convert value '{raw!s}' into type 'bool'"
|
||||
)
|
||||
raise JinjaRenderingException(f"Could not convert value '{raw!s}' into type 'bool'")
|
||||
if isinstance(raw, NumberMarker) and not _is_number(result):
|
||||
raise JinjaRenderingException(
|
||||
f"Could not convert value '{raw!s}' into type 'number'"
|
||||
)
|
||||
raise JinjaRenderingException(f"Could not convert value '{raw!s}' into type 'number'")
|
||||
|
||||
return result
|
||||
|
||||
@@ -181,9 +173,7 @@ class NativeSandboxTemplate(jinja2.nativetypes.NativeTemplate): # mypy: ignore
|
||||
vars = dict(*args, **kwargs)
|
||||
|
||||
try:
|
||||
return quoted_native_concat(
|
||||
self.root_render_func(self.new_context(vars))
|
||||
)
|
||||
return quoted_native_concat(self.root_render_func(self.new_context(vars)))
|
||||
except Exception:
|
||||
return self.environment.handle_exception()
|
||||
|
||||
@@ -222,10 +212,10 @@ class BaseMacroGenerator:
|
||||
self.context: Optional[Dict[str, Any]] = context
|
||||
|
||||
def get_template(self):
|
||||
raise NotImplementedError('get_template not implemented!')
|
||||
raise NotImplementedError("get_template not implemented!")
|
||||
|
||||
def get_name(self) -> str:
|
||||
raise NotImplementedError('get_name not implemented!')
|
||||
raise NotImplementedError("get_name not implemented!")
|
||||
|
||||
def get_macro(self):
|
||||
name = self.get_name()
|
||||
@@ -248,9 +238,7 @@ class BaseMacroGenerator:
|
||||
def call_macro(self, *args, **kwargs):
|
||||
# called from __call__ methods
|
||||
if self.context is None:
|
||||
raise InternalException(
|
||||
'Context is still None in call_macro!'
|
||||
)
|
||||
raise InternalException("Context is still None in call_macro!")
|
||||
assert self.context is not None
|
||||
|
||||
macro = self.get_macro()
|
||||
@@ -277,7 +265,7 @@ class MacroStack(threading.local):
|
||||
def pop(self, name):
|
||||
got = self.call_stack.pop()
|
||||
if got != name:
|
||||
raise InternalException(f'popped {got}, expected {name}')
|
||||
raise InternalException(f"popped {got}, expected {name}")
|
||||
|
||||
|
||||
class MacroGenerator(BaseMacroGenerator):
|
||||
@@ -286,7 +274,7 @@ class MacroGenerator(BaseMacroGenerator):
|
||||
macro,
|
||||
context: Optional[Dict[str, Any]] = None,
|
||||
node: Optional[Any] = None,
|
||||
stack: Optional[MacroStack] = None
|
||||
stack: Optional[MacroStack] = None,
|
||||
) -> None:
|
||||
super().__init__(context)
|
||||
self.macro = macro
|
||||
@@ -334,9 +322,7 @@ class MacroGenerator(BaseMacroGenerator):
|
||||
|
||||
|
||||
class QueryStringGenerator(BaseMacroGenerator):
|
||||
def __init__(
|
||||
self, template_str: str, context: Dict[str, Any]
|
||||
) -> None:
|
||||
def __init__(self, template_str: str, context: Dict[str, Any]) -> None:
|
||||
super().__init__(context)
|
||||
self.template_str: str = template_str
|
||||
env = get_environment()
|
||||
@@ -346,7 +332,7 @@ class QueryStringGenerator(BaseMacroGenerator):
|
||||
)
|
||||
|
||||
def get_name(self) -> str:
|
||||
return 'query_comment_macro'
|
||||
return "query_comment_macro"
|
||||
|
||||
def get_template(self):
|
||||
"""Don't use the template cache, we don't have a node"""
|
||||
@@ -357,45 +343,39 @@ class QueryStringGenerator(BaseMacroGenerator):
|
||||
|
||||
|
||||
class MaterializationExtension(jinja2.ext.Extension):
|
||||
tags = ['materialization']
|
||||
tags = ["materialization"]
|
||||
|
||||
def parse(self, parser):
|
||||
node = jinja2.nodes.Macro(lineno=next(parser.stream).lineno)
|
||||
materialization_name = \
|
||||
parser.parse_assign_target(name_only=True).name
|
||||
materialization_name = parser.parse_assign_target(name_only=True).name
|
||||
|
||||
adapter_name = 'default'
|
||||
adapter_name = "default"
|
||||
node.args = []
|
||||
node.defaults = []
|
||||
|
||||
while parser.stream.skip_if('comma'):
|
||||
while parser.stream.skip_if("comma"):
|
||||
target = parser.parse_assign_target(name_only=True)
|
||||
|
||||
if target.name == 'default':
|
||||
if target.name == "default":
|
||||
pass
|
||||
|
||||
elif target.name == 'adapter':
|
||||
parser.stream.expect('assign')
|
||||
elif target.name == "adapter":
|
||||
parser.stream.expect("assign")
|
||||
value = parser.parse_expression()
|
||||
adapter_name = value.value
|
||||
|
||||
else:
|
||||
invalid_materialization_argument(
|
||||
materialization_name, target.name
|
||||
)
|
||||
invalid_materialization_argument(materialization_name, target.name)
|
||||
|
||||
node.name = get_materialization_macro_name(
|
||||
materialization_name, adapter_name
|
||||
)
|
||||
node.name = get_materialization_macro_name(materialization_name, adapter_name)
|
||||
|
||||
node.body = parser.parse_statements(('name:endmaterialization',),
|
||||
drop_needle=True)
|
||||
node.body = parser.parse_statements(("name:endmaterialization",), drop_needle=True)
|
||||
|
||||
return node
|
||||
|
||||
|
||||
class DocumentationExtension(jinja2.ext.Extension):
|
||||
tags = ['docs']
|
||||
tags = ["docs"]
|
||||
|
||||
def parse(self, parser):
|
||||
node = jinja2.nodes.Macro(lineno=next(parser.stream).lineno)
|
||||
@@ -404,13 +384,12 @@ class DocumentationExtension(jinja2.ext.Extension):
|
||||
node.args = []
|
||||
node.defaults = []
|
||||
node.name = get_docs_macro_name(docs_name)
|
||||
node.body = parser.parse_statements(('name:enddocs',),
|
||||
drop_needle=True)
|
||||
node.body = parser.parse_statements(("name:enddocs",), drop_needle=True)
|
||||
return node
|
||||
|
||||
|
||||
class TestExtension(jinja2.ext.Extension):
|
||||
tags = ['test']
|
||||
tags = ["test"]
|
||||
|
||||
def parse(self, parser):
|
||||
node = jinja2.nodes.Macro(lineno=next(parser.stream).lineno)
|
||||
@@ -418,13 +397,12 @@ class TestExtension(jinja2.ext.Extension):
|
||||
|
||||
parser.parse_signature(node)
|
||||
node.name = get_test_macro_name(test_name)
|
||||
node.body = parser.parse_statements(('name:endtest',),
|
||||
drop_needle=True)
|
||||
node.body = parser.parse_statements(("name:endtest",), drop_needle=True)
|
||||
return node
|
||||
|
||||
|
||||
def _is_dunder_name(name):
|
||||
return name.startswith('__') and name.endswith('__')
|
||||
return name.startswith("__") and name.endswith("__")
|
||||
|
||||
|
||||
def create_undefined(node=None):
|
||||
@@ -445,10 +423,9 @@ def create_undefined(node=None):
|
||||
return self
|
||||
|
||||
def __getattr__(self, name):
|
||||
if name == 'name' or _is_dunder_name(name):
|
||||
if name == "name" or _is_dunder_name(name):
|
||||
raise AttributeError(
|
||||
"'{}' object has no attribute '{}'"
|
||||
.format(type(self).__name__, name)
|
||||
"'{}' object has no attribute '{}'".format(type(self).__name__, name)
|
||||
)
|
||||
|
||||
self.name = name
|
||||
@@ -459,24 +436,24 @@ def create_undefined(node=None):
|
||||
return self
|
||||
|
||||
def __reduce__(self):
|
||||
raise_compiler_error(f'{self.name} is undefined', node=node)
|
||||
raise_compiler_error(f"{self.name} is undefined", node=node)
|
||||
|
||||
return Undefined
|
||||
|
||||
|
||||
NATIVE_FILTERS: Dict[str, Callable[[Any], Any]] = {
|
||||
'as_text': TextMarker,
|
||||
'as_bool': BoolMarker,
|
||||
'as_native': NativeMarker,
|
||||
'as_number': NumberMarker,
|
||||
"as_text": TextMarker,
|
||||
"as_bool": BoolMarker,
|
||||
"as_native": NativeMarker,
|
||||
"as_number": NumberMarker,
|
||||
}
|
||||
|
||||
|
||||
TEXT_FILTERS: Dict[str, Callable[[Any], Any]] = {
|
||||
'as_text': lambda x: x,
|
||||
'as_bool': lambda x: x,
|
||||
'as_native': lambda x: x,
|
||||
'as_number': lambda x: x,
|
||||
"as_text": lambda x: x,
|
||||
"as_bool": lambda x: x,
|
||||
"as_native": lambda x: x,
|
||||
"as_number": lambda x: x,
|
||||
}
|
||||
|
||||
|
||||
@@ -486,15 +463,15 @@ def get_environment(
|
||||
native: bool = False,
|
||||
) -> jinja2.Environment:
|
||||
args: Dict[str, List[Union[str, Type[jinja2.ext.Extension]]]] = {
|
||||
'extensions': ['jinja2.ext.do']
|
||||
"extensions": ["jinja2.ext.do"]
|
||||
}
|
||||
|
||||
if capture_macros:
|
||||
args['undefined'] = create_undefined(node)
|
||||
args["undefined"] = create_undefined(node)
|
||||
|
||||
args['extensions'].append(MaterializationExtension)
|
||||
args['extensions'].append(DocumentationExtension)
|
||||
args['extensions'].append(TestExtension)
|
||||
args["extensions"].append(MaterializationExtension)
|
||||
args["extensions"].append(DocumentationExtension)
|
||||
args["extensions"].append(TestExtension)
|
||||
|
||||
env_cls: Type[jinja2.Environment]
|
||||
text_filter: Type
|
||||
@@ -557,8 +534,8 @@ def _requote_result(raw_value: str, rendered: str) -> str:
|
||||
elif single_quoted:
|
||||
quote_char = "'"
|
||||
else:
|
||||
quote_char = ''
|
||||
return f'{quote_char}{rendered}{quote_char}'
|
||||
quote_char = ""
|
||||
return f"{quote_char}{rendered}{quote_char}"
|
||||
|
||||
|
||||
# performance note: Local benmcharking (so take it with a big grain of salt!)
|
||||
@@ -566,7 +543,7 @@ def _requote_result(raw_value: str, rendered: str) -> str:
|
||||
# checking two separate patterns, but the standard deviation is smaller with
|
||||
# one pattern. The time difference between the two was ~2 std deviations, which
|
||||
# is small enough that I've just chosen the more readable option.
|
||||
_HAS_RENDER_CHARS_PAT = re.compile(r'({[{%#]|[#}%]})')
|
||||
_HAS_RENDER_CHARS_PAT = re.compile(r"({[{%#]|[#}%]})")
|
||||
|
||||
|
||||
def get_rendered(
|
||||
@@ -582,11 +559,7 @@ def get_rendered(
|
||||
# If this is desirable in the native env as well, we could handle the
|
||||
# native=True case by passing the input string to ast.literal_eval, like
|
||||
# the native renderer does.
|
||||
if (
|
||||
not native and
|
||||
isinstance(string, str) and
|
||||
_HAS_RENDER_CHARS_PAT.search(string) is None
|
||||
):
|
||||
if not native and isinstance(string, str) and _HAS_RENDER_CHARS_PAT.search(string) is None:
|
||||
return string
|
||||
template = get_template(
|
||||
string,
|
||||
@@ -607,7 +580,7 @@ def extract_toplevel_blocks(
|
||||
allowed_blocks: Optional[Set[str]] = None,
|
||||
collect_raw_data: bool = True,
|
||||
) -> List[Union[BlockData, BlockTag]]:
|
||||
"""Extract the top level blocks with matching block types from a jinja
|
||||
"""Extract the top-level blocks with matching block types from a jinja
|
||||
file, with some special handling for block nesting.
|
||||
|
||||
:param data: The data to extract blocks from.
|
||||
@@ -622,44 +595,40 @@ def extract_toplevel_blocks(
|
||||
`collect_raw_data` is `True`) `BlockData` objects.
|
||||
"""
|
||||
return BlockIterator(data).lex_for_blocks(
|
||||
allowed_blocks=allowed_blocks,
|
||||
collect_raw_data=collect_raw_data
|
||||
allowed_blocks=allowed_blocks, collect_raw_data=collect_raw_data
|
||||
)
|
||||
|
||||
|
||||
SCHEMA_TEST_KWARGS_NAME = '_dbt_schema_test_kwargs'
|
||||
GENERIC_TEST_KWARGS_NAME = "_dbt_generic_test_kwargs"
|
||||
|
||||
|
||||
def add_rendered_test_kwargs(
|
||||
context: Dict[str, Any],
|
||||
node: Union[ParsedSchemaTestNode, CompiledSchemaTestNode],
|
||||
node: Union[ParsedGenericTestNode, CompiledGenericTestNode],
|
||||
capture_macros: bool = False,
|
||||
) -> None:
|
||||
"""Render each of the test kwargs in the given context using the native
|
||||
renderer, then insert that value into the given context as the special test
|
||||
keyword arguments member.
|
||||
"""
|
||||
looks_like_func = r'^\s*(env_var|ref|var|source|doc)\s*\(.+\)\s*$'
|
||||
looks_like_func = r"^\s*(env_var|ref|var|source|doc)\s*\(.+\)\s*$"
|
||||
|
||||
def _convert_function(
|
||||
value: Any, keypath: Tuple[Union[str, int], ...]
|
||||
) -> Any:
|
||||
def _convert_function(value: Any, keypath: Tuple[Union[str, int], ...]) -> Any:
|
||||
if isinstance(value, str):
|
||||
if keypath == ('column_name',):
|
||||
if keypath == ("column_name",):
|
||||
# special case: Don't render column names as native, make them
|
||||
# be strings
|
||||
return value
|
||||
|
||||
if re.match(looks_like_func, value) is not None:
|
||||
# curly braces to make rendering happy
|
||||
value = f'{{{{ {value} }}}}'
|
||||
value = f"{{{{ {value} }}}}"
|
||||
|
||||
value = get_rendered(
|
||||
value, context, node, capture_macros=capture_macros,
|
||||
native=True
|
||||
)
|
||||
value = get_rendered(value, context, node, capture_macros=capture_macros, native=True)
|
||||
|
||||
return value
|
||||
|
||||
kwargs = deep_map(_convert_function, node.test_metadata.kwargs)
|
||||
context[SCHEMA_TEST_KWARGS_NAME] = kwargs
|
||||
# The test_metadata.kwargs come from the test builder, and were set
|
||||
# when the test node was created in _parse_generic_test.
|
||||
kwargs = deep_map_render(_convert_function, node.test_metadata.kwargs)
|
||||
context[GENERIC_TEST_KWARGS_NAME] = kwargs
|
||||
|
||||
@@ -8,11 +8,11 @@ def statically_extract_macro_calls(string, ctx, db_wrapper=None):
|
||||
env = get_environment(None, capture_macros=True)
|
||||
parsed = env.parse(string)
|
||||
|
||||
standard_calls = ['source', 'ref', 'config']
|
||||
standard_calls = ["source", "ref", "config"]
|
||||
possible_macro_calls = []
|
||||
for func_call in parsed.find_all(jinja2.nodes.Call):
|
||||
func_name = None
|
||||
if hasattr(func_call, 'node') and hasattr(func_call.node, 'name'):
|
||||
if hasattr(func_call, "node") and hasattr(func_call.node, "name"):
|
||||
func_name = func_call.node.name
|
||||
else:
|
||||
# func_call for dbt_utils.current_timestamp macro
|
||||
@@ -30,22 +30,25 @@ def statically_extract_macro_calls(string, ctx, db_wrapper=None):
|
||||
# dyn_args=None,
|
||||
# dyn_kwargs=None
|
||||
# )
|
||||
if (hasattr(func_call, 'node') and
|
||||
hasattr(func_call.node, 'node') and
|
||||
type(func_call.node.node).__name__ == 'Name' and
|
||||
hasattr(func_call.node, 'attr')):
|
||||
if (
|
||||
hasattr(func_call, "node")
|
||||
and hasattr(func_call.node, "node")
|
||||
and type(func_call.node.node).__name__ == "Name"
|
||||
and hasattr(func_call.node, "attr")
|
||||
):
|
||||
package_name = func_call.node.node.name
|
||||
macro_name = func_call.node.attr
|
||||
if package_name == 'adapter':
|
||||
if macro_name == 'dispatch':
|
||||
if package_name == "adapter":
|
||||
if macro_name == "dispatch":
|
||||
ad_macro_calls = statically_parse_adapter_dispatch(
|
||||
func_call, ctx, db_wrapper)
|
||||
func_call, ctx, db_wrapper
|
||||
)
|
||||
possible_macro_calls.extend(ad_macro_calls)
|
||||
else:
|
||||
# This skips calls such as adapter.parse_index
|
||||
continue
|
||||
else:
|
||||
func_name = f'{package_name}.{macro_name}'
|
||||
func_name = f"{package_name}.{macro_name}"
|
||||
else:
|
||||
continue
|
||||
if not func_name:
|
||||
@@ -96,7 +99,6 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
# packages positional argument
|
||||
packages = None
|
||||
macro_namespace = None
|
||||
packages_arg = None
|
||||
packages_arg_type = None
|
||||
@@ -109,117 +111,48 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
# keyword arguments
|
||||
if func_call.kwargs:
|
||||
for kwarg in func_call.kwargs:
|
||||
if kwarg.key == 'packages':
|
||||
# The packages keyword will be deprecated and
|
||||
# eventually removed
|
||||
packages_arg = kwarg.value
|
||||
# This can be a List or a Call
|
||||
packages_arg_type = type(kwarg.value).__name__
|
||||
elif kwarg.key == 'macro_name':
|
||||
if kwarg.key == "macro_name":
|
||||
# This will remain to enable static resolution
|
||||
if type(kwarg.value).__name__ == 'Const':
|
||||
if type(kwarg.value).__name__ == "Const":
|
||||
func_name = kwarg.value.value
|
||||
possible_macro_calls.append(func_name)
|
||||
else:
|
||||
raise_compiler_error(f"The macro_name parameter ({kwarg.value.value}) "
|
||||
"to adapter.dispatch was not a string")
|
||||
elif kwarg.key == 'macro_namespace':
|
||||
raise_compiler_error(
|
||||
f"The macro_name parameter ({kwarg.value.value}) "
|
||||
"to adapter.dispatch was not a string"
|
||||
)
|
||||
elif kwarg.key == "macro_namespace":
|
||||
# This will remain to enable static resolution
|
||||
kwarg_type = type(kwarg.value).__name__
|
||||
if kwarg_type == 'Const':
|
||||
if kwarg_type == "Const":
|
||||
macro_namespace = kwarg.value.value
|
||||
else:
|
||||
raise_compiler_error("The macro_namespace parameter to adapter.dispatch "
|
||||
f"is a {kwarg_type}, not a string")
|
||||
raise_compiler_error(
|
||||
"The macro_namespace parameter to adapter.dispatch "
|
||||
f"is a {kwarg_type}, not a string"
|
||||
)
|
||||
|
||||
# positional arguments
|
||||
if packages_arg:
|
||||
if packages_arg_type == 'List':
|
||||
if packages_arg_type == "List":
|
||||
# This will remain to enable static resolution
|
||||
packages = []
|
||||
for item in packages_arg.items:
|
||||
packages.append(item.value)
|
||||
elif packages_arg_type == 'Const':
|
||||
elif packages_arg_type == "Const":
|
||||
# This will remain to enable static resolution
|
||||
macro_namespace = packages_arg.value
|
||||
elif packages_arg_type == 'Call':
|
||||
# This is deprecated and should be removed eventually.
|
||||
# It is here to support (hackily) common ways of providing
|
||||
# a packages list to adapter.dispatch
|
||||
if (hasattr(packages_arg, 'node') and
|
||||
hasattr(packages_arg.node, 'node') and
|
||||
hasattr(packages_arg.node.node, 'name') and
|
||||
hasattr(packages_arg.node, 'attr')):
|
||||
package_name = packages_arg.node.node.name
|
||||
macro_name = packages_arg.node.attr
|
||||
if (macro_name.startswith('_get') and 'namespaces' in macro_name):
|
||||
# noqa: https://github.com/fishtown-analytics/dbt-utils/blob/9e9407b/macros/cross_db_utils/_get_utils_namespaces.sql
|
||||
var_name = f'{package_name}_dispatch_list'
|
||||
# hard code compatibility for fivetran_utils, just a teensy bit different
|
||||
# noqa: https://github.com/fivetran/dbt_fivetran_utils/blob/0978ba2/macros/_get_utils_namespaces.sql
|
||||
if package_name == 'fivetran_utils':
|
||||
default_packages = ['dbt_utils', 'fivetran_utils']
|
||||
else:
|
||||
default_packages = [package_name]
|
||||
|
||||
namespace_names = get_dispatch_list(ctx, var_name, default_packages)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
else:
|
||||
msg = (
|
||||
f"As of v0.19.2, custom macros, such as '{macro_name}', are no longer "
|
||||
"supported in the 'packages' argument of 'adapter.dispatch()'.\n"
|
||||
f"See https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch "
|
||||
"for details."
|
||||
).strip()
|
||||
raise_compiler_error(msg)
|
||||
elif packages_arg_type == 'Add':
|
||||
# This logic is for when there is a variable and an addition of a list,
|
||||
# like: packages = (var('local_utils_dispatch_list', []) + ['local_utils2'])
|
||||
# This is deprecated and should be removed eventually.
|
||||
namespace_var = None
|
||||
default_namespaces = []
|
||||
# This might be a single call or it might be the 'left' piece in an addition
|
||||
for var_call in packages_arg.find_all(jinja2.nodes.Call):
|
||||
if (hasattr(var_call, 'node') and
|
||||
var_call.node.name == 'var' and
|
||||
hasattr(var_call, 'args')):
|
||||
namespace_var = var_call.args[0].value
|
||||
if hasattr(packages_arg, 'right'): # we have a default list of namespaces
|
||||
for item in packages_arg.right.items:
|
||||
default_namespaces.append(item.value)
|
||||
if namespace_var:
|
||||
namespace_names = get_dispatch_list(ctx, namespace_var, default_namespaces)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
|
||||
if db_wrapper:
|
||||
macro = db_wrapper.dispatch(
|
||||
func_name,
|
||||
packages=packages,
|
||||
macro_namespace=macro_namespace
|
||||
).macro
|
||||
func_name = f'{macro.package_name}.{macro.name}'
|
||||
macro = db_wrapper.dispatch(func_name, macro_namespace=macro_namespace).macro
|
||||
func_name = f"{macro.package_name}.{macro.name}"
|
||||
possible_macro_calls.append(func_name)
|
||||
else: # this is only for test/unit/test_macro_calls.py
|
||||
if macro_namespace:
|
||||
packages = [macro_namespace]
|
||||
if packages is None:
|
||||
else:
|
||||
packages = []
|
||||
for package_name in packages:
|
||||
possible_macro_calls.append(f'{package_name}.{func_name}')
|
||||
possible_macro_calls.append(f"{package_name}.{func_name}")
|
||||
|
||||
return possible_macro_calls
|
||||
|
||||
|
||||
def get_dispatch_list(ctx, var_name, default_packages):
|
||||
namespace_list = None
|
||||
try:
|
||||
# match the logic currently used in package _get_namespaces() macro
|
||||
namespace_list = ctx['var'](var_name) + default_packages
|
||||
except Exception:
|
||||
pass
|
||||
namespace_list = namespace_list if namespace_list else default_packages
|
||||
return namespace_list
|
||||
|
||||
@@ -1,73 +1,88 @@
|
||||
from functools import wraps
|
||||
import functools
|
||||
import requests
|
||||
from dbt.exceptions import RegistryException
|
||||
from dbt.utils import memoized
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import RegistryProgressMakingGETRequest, RegistryProgressGETResponse
|
||||
from dbt.utils import memoized, _connection_exception_retry as connection_exception_retry
|
||||
from dbt import deprecations
|
||||
import os
|
||||
import time
|
||||
|
||||
if os.getenv('DBT_PACKAGE_HUB_URL'):
|
||||
DEFAULT_REGISTRY_BASE_URL = os.getenv('DBT_PACKAGE_HUB_URL')
|
||||
if os.getenv("DBT_PACKAGE_HUB_URL"):
|
||||
DEFAULT_REGISTRY_BASE_URL = os.getenv("DBT_PACKAGE_HUB_URL")
|
||||
else:
|
||||
DEFAULT_REGISTRY_BASE_URL = 'https://hub.getdbt.com/'
|
||||
DEFAULT_REGISTRY_BASE_URL = "https://hub.getdbt.com/"
|
||||
|
||||
|
||||
def _get_url(url, registry_base_url=None):
|
||||
if registry_base_url is None:
|
||||
registry_base_url = DEFAULT_REGISTRY_BASE_URL
|
||||
|
||||
return '{}{}'.format(registry_base_url, url)
|
||||
return "{}{}".format(registry_base_url, url)
|
||||
|
||||
|
||||
def _wrap_exceptions(fn):
|
||||
@wraps(fn)
|
||||
def wrapper(*args, **kwargs):
|
||||
max_attempts = 5
|
||||
attempt = 0
|
||||
while True:
|
||||
attempt += 1
|
||||
try:
|
||||
return fn(*args, **kwargs)
|
||||
except (requests.exceptions.ConnectionError, requests.exceptions.Timeout) as exc:
|
||||
if attempt < max_attempts:
|
||||
time.sleep(1)
|
||||
continue
|
||||
raise RegistryException(
|
||||
'Unable to connect to registry hub'
|
||||
) from exc
|
||||
return wrapper
|
||||
def _get_with_retries(path, registry_base_url=None):
|
||||
get_fn = functools.partial(_get, path, registry_base_url)
|
||||
return connection_exception_retry(get_fn, 5)
|
||||
|
||||
|
||||
@_wrap_exceptions
|
||||
def _get(path, registry_base_url=None):
|
||||
url = _get_url(path, registry_base_url)
|
||||
logger.debug('Making package registry request: GET {}'.format(url))
|
||||
fire_event(RegistryProgressMakingGETRequest(url=url))
|
||||
resp = requests.get(url, timeout=30)
|
||||
logger.debug('Response from registry: GET {} {}'.format(url,
|
||||
resp.status_code))
|
||||
fire_event(RegistryProgressGETResponse(url=url, resp_code=resp.status_code))
|
||||
resp.raise_for_status()
|
||||
|
||||
# It is unexpected for the content of the response to be None so if it is, raising this error
|
||||
# will cause this function to retry (if called within _get_with_retries) and hopefully get
|
||||
# a response. This seems to happen when there's an issue with the Hub.
|
||||
# See https://github.com/dbt-labs/dbt-core/issues/4577
|
||||
if resp.json() is None:
|
||||
raise requests.exceptions.ContentDecodingError(
|
||||
"Request error: The response is None", response=resp
|
||||
)
|
||||
return resp.json()
|
||||
|
||||
|
||||
def index(registry_base_url=None):
|
||||
return _get('api/v1/index.json', registry_base_url)
|
||||
return _get_with_retries("api/v1/index.json", registry_base_url)
|
||||
|
||||
|
||||
index_cached = memoized(index)
|
||||
|
||||
|
||||
def packages(registry_base_url=None):
|
||||
return _get('api/v1/packages.json', registry_base_url)
|
||||
return _get_with_retries("api/v1/packages.json", registry_base_url)
|
||||
|
||||
|
||||
def package(name, registry_base_url=None):
|
||||
return _get('api/v1/{}.json'.format(name), registry_base_url)
|
||||
response = _get_with_retries("api/v1/{}.json".format(name), registry_base_url)
|
||||
|
||||
# Either redirectnamespace or redirectname in the JSON response indicate a redirect
|
||||
# redirectnamespace redirects based on package ownership
|
||||
# redirectname redirects based on package name
|
||||
# Both can be present at the same time, or neither. Fails gracefully to old name
|
||||
|
||||
if ("redirectnamespace" in response) or ("redirectname" in response):
|
||||
|
||||
if ("redirectnamespace" in response) and response["redirectnamespace"] is not None:
|
||||
use_namespace = response["redirectnamespace"]
|
||||
else:
|
||||
use_namespace = response["namespace"]
|
||||
|
||||
if ("redirectname" in response) and response["redirectname"] is not None:
|
||||
use_name = response["redirectname"]
|
||||
else:
|
||||
use_name = response["name"]
|
||||
|
||||
new_nwo = use_namespace + "/" + use_name
|
||||
deprecations.warn("package-redirect", old_name=name, new_name=new_nwo)
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def package_version(name, version, registry_base_url=None):
|
||||
return _get('api/v1/{}/{}.json'.format(name, version), registry_base_url)
|
||||
return _get_with_retries("api/v1/{}/{}.json".format(name, version), registry_base_url)
|
||||
|
||||
|
||||
def get_available_versions(name):
|
||||
response = package(name)
|
||||
return list(response['versions'])
|
||||
return list(response["versions"])
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import errno
|
||||
import functools
|
||||
import fnmatch
|
||||
import json
|
||||
import os
|
||||
@@ -10,16 +11,21 @@ import sys
|
||||
import tarfile
|
||||
import requests
|
||||
import stat
|
||||
from typing import (
|
||||
Type, NoReturn, List, Optional, Dict, Any, Tuple, Callable, Union
|
||||
from typing import Type, NoReturn, List, Optional, Dict, Any, Tuple, Callable, Union
|
||||
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
SystemErrorRetrievingModTime,
|
||||
SystemCouldNotWrite,
|
||||
SystemExecutingCmd,
|
||||
SystemStdOutMsg,
|
||||
SystemStdErrMsg,
|
||||
SystemReportReturnCode,
|
||||
)
|
||||
|
||||
import dbt.exceptions
|
||||
import dbt.utils
|
||||
from dbt.utils import _connection_exception_retry as connection_exception_retry
|
||||
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
|
||||
if sys.platform == 'win32':
|
||||
if sys.platform == "win32":
|
||||
from ctypes import WinDLL, c_bool
|
||||
else:
|
||||
WinDLL = None
|
||||
@@ -30,7 +36,7 @@ def find_matching(
|
||||
root_path: str,
|
||||
relative_paths_to_search: List[str],
|
||||
file_pattern: str,
|
||||
) -> List[Dict[str, str]]:
|
||||
) -> List[Dict[str, Any]]:
|
||||
"""
|
||||
Given an absolute `root_path`, a list of relative paths to that
|
||||
absolute root path (`relative_paths_to_search`), and a `file_pattern`
|
||||
@@ -51,30 +57,35 @@ def find_matching(
|
||||
reobj = re.compile(regex, re.IGNORECASE)
|
||||
|
||||
for relative_path_to_search in relative_paths_to_search:
|
||||
absolute_path_to_search = os.path.join(
|
||||
root_path, relative_path_to_search)
|
||||
absolute_path_to_search = os.path.join(root_path, relative_path_to_search)
|
||||
walk_results = os.walk(absolute_path_to_search)
|
||||
|
||||
for current_path, subdirectories, local_files in walk_results:
|
||||
for local_file in local_files:
|
||||
absolute_path = os.path.join(current_path, local_file)
|
||||
relative_path = os.path.relpath(
|
||||
absolute_path, absolute_path_to_search
|
||||
)
|
||||
relative_path = os.path.relpath(absolute_path, absolute_path_to_search)
|
||||
modification_time = 0.0
|
||||
try:
|
||||
modification_time = os.path.getmtime(absolute_path)
|
||||
except OSError:
|
||||
fire_event(SystemErrorRetrievingModTime(path=absolute_path))
|
||||
if reobj.match(local_file):
|
||||
matching.append({
|
||||
'searched_path': relative_path_to_search,
|
||||
'absolute_path': absolute_path,
|
||||
'relative_path': relative_path,
|
||||
})
|
||||
matching.append(
|
||||
{
|
||||
"searched_path": relative_path_to_search,
|
||||
"absolute_path": absolute_path,
|
||||
"relative_path": relative_path,
|
||||
"modification_time": modification_time,
|
||||
}
|
||||
)
|
||||
|
||||
return matching
|
||||
|
||||
|
||||
def load_file_contents(path: str, strip: bool = True) -> str:
|
||||
path = convert_path(path)
|
||||
with open(path, 'rb') as handle:
|
||||
to_return = handle.read().decode('utf-8')
|
||||
with open(path, "rb") as handle:
|
||||
to_return = handle.read().decode("utf-8")
|
||||
|
||||
if strip:
|
||||
to_return = to_return.strip()
|
||||
@@ -101,14 +112,14 @@ def make_directory(path: str) -> None:
|
||||
raise e
|
||||
|
||||
|
||||
def make_file(path: str, contents: str = '', overwrite: bool = False) -> bool:
|
||||
def make_file(path: str, contents: str = "", overwrite: bool = False) -> bool:
|
||||
"""
|
||||
Make a file at `path` assuming that the directory it resides in already
|
||||
exists. The file is saved with contents `contents`
|
||||
"""
|
||||
if overwrite or not os.path.exists(path):
|
||||
path = convert_path(path)
|
||||
with open(path, 'w') as fh:
|
||||
with open(path, "w") as fh:
|
||||
fh.write(contents)
|
||||
return True
|
||||
|
||||
@@ -120,7 +131,7 @@ def make_symlink(source: str, link_path: str) -> None:
|
||||
Create a symlink at `link_path` referring to `source`.
|
||||
"""
|
||||
if not supports_symlinks():
|
||||
dbt.exceptions.system_error('create a symbolic link')
|
||||
dbt.exceptions.system_error("create a symbolic link")
|
||||
|
||||
os.symlink(source, link_path)
|
||||
|
||||
@@ -129,11 +140,11 @@ def supports_symlinks() -> bool:
|
||||
return getattr(os, "symlink", None) is not None
|
||||
|
||||
|
||||
def write_file(path: str, contents: str = '') -> bool:
|
||||
def write_file(path: str, contents: str = "") -> bool:
|
||||
path = convert_path(path)
|
||||
try:
|
||||
make_directory(os.path.dirname(path))
|
||||
with open(path, 'w', encoding='utf-8') as f:
|
||||
with open(path, "w", encoding="utf-8") as f:
|
||||
f.write(str(contents))
|
||||
except Exception as exc:
|
||||
# note that you can't just catch FileNotFound, because sometimes
|
||||
@@ -142,21 +153,18 @@ def write_file(path: str, contents: str = '') -> bool:
|
||||
# sometimes windows fails to write paths that are less than the length
|
||||
# limit. So on windows, suppress all errors that happen from writing
|
||||
# to disk.
|
||||
if os.name == 'nt':
|
||||
if os.name == "nt":
|
||||
# sometimes we get a winerror of 3 which means the path was
|
||||
# definitely too long, but other times we don't and it means the
|
||||
# path was just probably too long. This is probably based on the
|
||||
# windows/python version.
|
||||
if getattr(exc, 'winerror', 0) == 3:
|
||||
reason = 'Path was too long'
|
||||
if getattr(exc, "winerror", 0) == 3:
|
||||
reason = "Path was too long"
|
||||
else:
|
||||
reason = 'Path was possibly too long'
|
||||
reason = "Path was possibly too long"
|
||||
# all our hard work and the path was still too long. Log and
|
||||
# continue.
|
||||
logger.debug(
|
||||
f'Could not write to path {path}({len(path)} characters): '
|
||||
f'{reason}\nexception: {exc}'
|
||||
)
|
||||
fire_event(SystemCouldNotWrite(path=path, reason=reason, exc=exc))
|
||||
else:
|
||||
raise
|
||||
return True
|
||||
@@ -170,9 +178,7 @@ def write_json(path: str, data: Dict[str, Any]) -> bool:
|
||||
return write_file(path, json.dumps(data, cls=dbt.utils.JSONEncoder))
|
||||
|
||||
|
||||
def _windows_rmdir_readonly(
|
||||
func: Callable[[str], Any], path: str, exc: Tuple[Any, OSError, Any]
|
||||
):
|
||||
def _windows_rmdir_readonly(func: Callable[[str], Any], path: str, exc: Tuple[Any, OSError, Any]):
|
||||
exception_val = exc[1]
|
||||
if exception_val.errno == errno.EACCES:
|
||||
os.chmod(path, stat.S_IWUSR)
|
||||
@@ -189,10 +195,7 @@ def resolve_path_from_base(path_to_resolve: str, base_path: str) -> str:
|
||||
If path_to_resolve is an absolute path or a user path (~), just
|
||||
resolve it to an absolute path and return.
|
||||
"""
|
||||
return os.path.abspath(
|
||||
os.path.join(
|
||||
base_path,
|
||||
os.path.expanduser(path_to_resolve)))
|
||||
return os.path.abspath(os.path.join(base_path, os.path.expanduser(path_to_resolve)))
|
||||
|
||||
|
||||
def rmdir(path: str) -> None:
|
||||
@@ -202,7 +205,7 @@ def rmdir(path: str) -> None:
|
||||
cloned via git) can cause rmtree to throw a PermissionError exception
|
||||
"""
|
||||
path = convert_path(path)
|
||||
if sys.platform == 'win32':
|
||||
if sys.platform == "win32":
|
||||
onerror = _windows_rmdir_readonly
|
||||
else:
|
||||
onerror = None
|
||||
@@ -221,7 +224,7 @@ def _win_prepare_path(path: str) -> str:
|
||||
# letter back in.
|
||||
# Unless it starts with '\\'. In that case, the path is a UNC mount point
|
||||
# and splitdrive will be fine.
|
||||
if not path.startswith('\\\\') and path.startswith('\\'):
|
||||
if not path.startswith("\\\\") and path.startswith("\\"):
|
||||
curdrive = os.path.splitdrive(os.getcwd())[0]
|
||||
path = curdrive + path
|
||||
|
||||
@@ -236,7 +239,7 @@ def _win_prepare_path(path: str) -> str:
|
||||
|
||||
|
||||
def _supports_long_paths() -> bool:
|
||||
if sys.platform != 'win32':
|
||||
if sys.platform != "win32":
|
||||
return True
|
||||
# Eryk Sun says to use `WinDLL('ntdll')` instead of `windll.ntdll` because
|
||||
# of pointer caching in a comment here:
|
||||
@@ -244,11 +247,11 @@ def _supports_long_paths() -> bool:
|
||||
# I don't know exaclty what he means, but I am inclined to believe him as
|
||||
# he's pretty active on Python windows bugs!
|
||||
try:
|
||||
dll = WinDLL('ntdll')
|
||||
dll = WinDLL("ntdll")
|
||||
except OSError: # I don't think this happens? you need ntdll to run python
|
||||
return False
|
||||
# not all windows versions have it at all
|
||||
if not hasattr(dll, 'RtlAreLongPathsEnabled'):
|
||||
if not hasattr(dll, "RtlAreLongPathsEnabled"):
|
||||
return False
|
||||
# tell windows we want to get back a single unsigned byte (a bool).
|
||||
dll.RtlAreLongPathsEnabled.restype = c_bool
|
||||
@@ -268,7 +271,7 @@ def convert_path(path: str) -> str:
|
||||
if _supports_long_paths():
|
||||
return path
|
||||
|
||||
prefix = '\\\\?\\'
|
||||
prefix = "\\\\?\\"
|
||||
# Nothing to do
|
||||
if path.startswith(prefix):
|
||||
return path
|
||||
@@ -299,44 +302,40 @@ def path_is_symlink(path: str) -> bool:
|
||||
|
||||
def open_dir_cmd() -> str:
|
||||
# https://docs.python.org/2/library/sys.html#sys.platform
|
||||
if sys.platform == 'win32':
|
||||
return 'start'
|
||||
if sys.platform == "win32":
|
||||
return "start"
|
||||
|
||||
elif sys.platform == 'darwin':
|
||||
return 'open'
|
||||
elif sys.platform == "darwin":
|
||||
return "open"
|
||||
|
||||
else:
|
||||
return 'xdg-open'
|
||||
return "xdg-open"
|
||||
|
||||
|
||||
def _handle_posix_cwd_error(
|
||||
exc: OSError, cwd: str, cmd: List[str]
|
||||
) -> NoReturn:
|
||||
def _handle_posix_cwd_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
if exc.errno == errno.ENOENT:
|
||||
message = 'Directory does not exist'
|
||||
message = "Directory does not exist"
|
||||
elif exc.errno == errno.EACCES:
|
||||
message = 'Current user cannot access directory, check permissions'
|
||||
message = "Current user cannot access directory, check permissions"
|
||||
elif exc.errno == errno.ENOTDIR:
|
||||
message = 'Not a directory'
|
||||
message = "Not a directory"
|
||||
else:
|
||||
message = 'Unknown OSError: {} - cwd'.format(str(exc))
|
||||
message = "Unknown OSError: {} - cwd".format(str(exc))
|
||||
raise dbt.exceptions.WorkingDirectoryError(cwd, cmd, message)
|
||||
|
||||
|
||||
def _handle_posix_cmd_error(
|
||||
exc: OSError, cwd: str, cmd: List[str]
|
||||
) -> NoReturn:
|
||||
def _handle_posix_cmd_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
if exc.errno == errno.ENOENT:
|
||||
message = "Could not find command, ensure it is in the user's PATH"
|
||||
elif exc.errno == errno.EACCES:
|
||||
message = 'User does not have permissions for this command'
|
||||
message = "User does not have permissions for this command"
|
||||
else:
|
||||
message = 'Unknown OSError: {} - cmd'.format(str(exc))
|
||||
message = "Unknown OSError: {} - cmd".format(str(exc))
|
||||
raise dbt.exceptions.ExecutableError(cwd, cmd, message)
|
||||
|
||||
|
||||
def _handle_posix_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
"""OSError handling for posix systems.
|
||||
"""OSError handling for POSIX systems.
|
||||
|
||||
Some things that could happen to trigger an OSError:
|
||||
- cwd could not exist
|
||||
@@ -356,7 +355,7 @@ def _handle_posix_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
- exc.errno == EACCES
|
||||
- exc.filename == None(?)
|
||||
"""
|
||||
if getattr(exc, 'filename', None) == cwd:
|
||||
if getattr(exc, "filename", None) == cwd:
|
||||
_handle_posix_cwd_error(exc, cwd, cmd)
|
||||
else:
|
||||
_handle_posix_cmd_error(exc, cwd, cmd)
|
||||
@@ -365,46 +364,46 @@ def _handle_posix_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
def _handle_windows_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
cls: Type[dbt.exceptions.Exception] = dbt.exceptions.CommandError
|
||||
if exc.errno == errno.ENOENT:
|
||||
message = ("Could not find command, ensure it is in the user's PATH "
|
||||
"and that the user has permissions to run it")
|
||||
message = (
|
||||
"Could not find command, ensure it is in the user's PATH "
|
||||
"and that the user has permissions to run it"
|
||||
)
|
||||
cls = dbt.exceptions.ExecutableError
|
||||
elif exc.errno == errno.ENOEXEC:
|
||||
message = ('Command was not executable, ensure it is valid')
|
||||
message = "Command was not executable, ensure it is valid"
|
||||
cls = dbt.exceptions.ExecutableError
|
||||
elif exc.errno == errno.ENOTDIR:
|
||||
message = ('Unable to cd: path does not exist, user does not have'
|
||||
' permissions, or not a directory')
|
||||
message = (
|
||||
"Unable to cd: path does not exist, user does not have"
|
||||
" permissions, or not a directory"
|
||||
)
|
||||
cls = dbt.exceptions.WorkingDirectoryError
|
||||
else:
|
||||
message = 'Unknown error: {} (errno={}: "{}")'.format(
|
||||
str(exc), exc.errno, errno.errorcode.get(exc.errno, '<Unknown!>')
|
||||
str(exc), exc.errno, errno.errorcode.get(exc.errno, "<Unknown!>")
|
||||
)
|
||||
raise cls(cwd, cmd, message)
|
||||
|
||||
|
||||
def _interpret_oserror(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
"""Interpret an OSError exc and raise the appropriate dbt exception.
|
||||
|
||||
"""
|
||||
"""Interpret an OSError exception and raise the appropriate dbt exception."""
|
||||
if len(cmd) == 0:
|
||||
raise dbt.exceptions.CommandError(cwd, cmd)
|
||||
|
||||
# all of these functions raise unconditionally
|
||||
if os.name == 'nt':
|
||||
if os.name == "nt":
|
||||
_handle_windows_error(exc, cwd, cmd)
|
||||
else:
|
||||
_handle_posix_error(exc, cwd, cmd)
|
||||
|
||||
# this should not be reachable, raise _something_ at least!
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Unhandled exception in _interpret_oserror: {}'.format(exc)
|
||||
"Unhandled exception in _interpret_oserror: {}".format(exc)
|
||||
)
|
||||
|
||||
|
||||
def run_cmd(
|
||||
cwd: str, cmd: List[str], env: Optional[Dict[str, Any]] = None
|
||||
) -> Tuple[bytes, bytes]:
|
||||
logger.debug('Executing "{}"'.format(' '.join(cmd)))
|
||||
def run_cmd(cwd: str, cmd: List[str], env: Optional[Dict[str, Any]] = None) -> Tuple[bytes, bytes]:
|
||||
fire_event(SystemExecutingCmd(cmd=cmd))
|
||||
if len(cmd) == 0:
|
||||
raise dbt.exceptions.CommandError(cwd, cmd)
|
||||
|
||||
@@ -420,34 +419,35 @@ def run_cmd(
|
||||
if exe_pth:
|
||||
cmd = [os.path.abspath(exe_pth)] + list(cmd[1:])
|
||||
proc = subprocess.Popen(
|
||||
cmd,
|
||||
cwd=cwd,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
env=full_env)
|
||||
cmd, cwd=cwd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=full_env
|
||||
)
|
||||
|
||||
out, err = proc.communicate()
|
||||
except OSError as exc:
|
||||
_interpret_oserror(exc, cwd, cmd)
|
||||
|
||||
logger.debug('STDOUT: "{!s}"'.format(out))
|
||||
logger.debug('STDERR: "{!s}"'.format(err))
|
||||
fire_event(SystemStdOutMsg(bmsg=out))
|
||||
fire_event(SystemStdErrMsg(bmsg=err))
|
||||
|
||||
if proc.returncode != 0:
|
||||
logger.debug('command return code={}'.format(proc.returncode))
|
||||
raise dbt.exceptions.CommandResultError(cwd, cmd, proc.returncode,
|
||||
out, err)
|
||||
fire_event(SystemReportReturnCode(returncode=proc.returncode))
|
||||
raise dbt.exceptions.CommandResultError(cwd, cmd, proc.returncode, out, err)
|
||||
|
||||
return out, err
|
||||
|
||||
|
||||
def download(
|
||||
def download_with_retries(
|
||||
url: str, path: str, timeout: Optional[Union[float, tuple]] = None
|
||||
) -> None:
|
||||
download_fn = functools.partial(download, url, path, timeout)
|
||||
connection_exception_retry(download_fn, 5)
|
||||
|
||||
|
||||
def download(url: str, path: str, timeout: Optional[Union[float, tuple]] = None) -> None:
|
||||
path = convert_path(path)
|
||||
connection_timeout = timeout or float(os.getenv('DBT_HTTP_TIMEOUT', 10))
|
||||
connection_timeout = timeout or float(os.getenv("DBT_HTTP_TIMEOUT", 10))
|
||||
response = requests.get(url, timeout=connection_timeout)
|
||||
with open(path, 'wb') as handle:
|
||||
with open(path, "wb") as handle:
|
||||
for block in response.iter_content(1024 * 64):
|
||||
handle.write(block)
|
||||
|
||||
@@ -466,12 +466,10 @@ def rename(from_path: str, to_path: str, force: bool = False) -> None:
|
||||
shutil.move(from_path, to_path)
|
||||
|
||||
|
||||
def untar_package(
|
||||
tar_path: str, dest_dir: str, rename_to: Optional[str] = None
|
||||
) -> None:
|
||||
def untar_package(tar_path: str, dest_dir: str, rename_to: Optional[str] = None) -> None:
|
||||
tar_path = convert_path(tar_path)
|
||||
tar_dir_name = None
|
||||
with tarfile.open(tar_path, 'r') as tarball:
|
||||
with tarfile.open(tar_path, "r:gz") as tarball:
|
||||
tarball.extractall(dest_dir)
|
||||
tar_dir_name = os.path.commonprefix(tarball.getnames())
|
||||
if rename_to:
|
||||
@@ -487,7 +485,7 @@ def chmod_and_retry(func, path, exc_info):
|
||||
We want to retry most operations here, but listdir is one that we know will
|
||||
be useless.
|
||||
"""
|
||||
if func is os.listdir or os.name != 'nt':
|
||||
if func is os.listdir or os.name != "nt":
|
||||
raise
|
||||
os.chmod(path, stat.S_IREAD | stat.S_IWRITE)
|
||||
# on error,this will raise.
|
||||
@@ -503,12 +501,12 @@ def move(src, dst):
|
||||
directory on windows when it has read-only files in it and the move is
|
||||
between two drives.
|
||||
|
||||
This is almost identical to the real shutil.move, except it uses our rmtree
|
||||
This is almost identical to the real shutil.move, except it, uses our rmtree
|
||||
and skips handling non-windows OSes since the existing one works ok there.
|
||||
"""
|
||||
src = convert_path(src)
|
||||
dst = convert_path(dst)
|
||||
if os.name != 'nt':
|
||||
if os.name != "nt":
|
||||
return shutil.move(src, dst)
|
||||
|
||||
if os.path.isdir(dst):
|
||||
@@ -516,7 +514,7 @@ def move(src, dst):
|
||||
os.rename(src, dst)
|
||||
return
|
||||
|
||||
dst = os.path.join(dst, os.path.basename(src.rstrip('/\\')))
|
||||
dst = os.path.join(dst, os.path.basename(src.rstrip("/\\")))
|
||||
if os.path.exists(dst):
|
||||
raise EnvironmentError("Path '{}' already exists".format(dst))
|
||||
|
||||
@@ -525,11 +523,10 @@ def move(src, dst):
|
||||
except OSError:
|
||||
# probably different drives
|
||||
if os.path.isdir(src):
|
||||
if _absnorm(dst + '\\').startswith(_absnorm(src + '\\')):
|
||||
if _absnorm(dst + "\\").startswith(_absnorm(src + "\\")):
|
||||
# dst is inside src
|
||||
raise EnvironmentError(
|
||||
"Cannot move a directory '{}' into itself '{}'"
|
||||
.format(src, dst)
|
||||
"Cannot move a directory '{}' into itself '{}'".format(src, dst)
|
||||
)
|
||||
shutil.copytree(src, dst, symlinks=True)
|
||||
rmtree(src)
|
||||
@@ -539,7 +536,7 @@ def move(src, dst):
|
||||
|
||||
|
||||
def rmtree(path):
|
||||
"""Recursively remove path. On permissions errors on windows, try to remove
|
||||
"""Recursively remove the path. On permissions errors on windows, try to remove
|
||||
the read-only flag and try again.
|
||||
"""
|
||||
path = convert_path(path)
|
||||
|
||||
@@ -1,19 +1,12 @@
|
||||
import dbt.exceptions
|
||||
|
||||
from typing import Any, Dict, Optional
|
||||
import yaml
|
||||
import yaml.scanner
|
||||
|
||||
# the C version is faster, but it doesn't always exist
|
||||
try:
|
||||
from yaml import (
|
||||
CLoader as Loader,
|
||||
CSafeLoader as SafeLoader,
|
||||
CDumper as Dumper
|
||||
)
|
||||
from yaml import CLoader as Loader, CSafeLoader as SafeLoader, CDumper as Dumper
|
||||
except ImportError:
|
||||
from yaml import ( # type: ignore # noqa: F401
|
||||
Loader, SafeLoader, Dumper
|
||||
)
|
||||
from yaml import Loader, SafeLoader, Dumper # type: ignore # noqa: F401
|
||||
|
||||
|
||||
YAML_ERROR_MESSAGE = """
|
||||
@@ -33,14 +26,12 @@ def line_no(i, line, width=3):
|
||||
|
||||
|
||||
def prefix_with_line_numbers(string, no_start, no_end):
|
||||
line_list = string.split('\n')
|
||||
line_list = string.split("\n")
|
||||
|
||||
numbers = range(no_start, no_end)
|
||||
relevant_lines = line_list[no_start:no_end]
|
||||
|
||||
return "\n".join([
|
||||
line_no(i + 1, line) for (i, line) in zip(numbers, relevant_lines)
|
||||
])
|
||||
return "\n".join([line_no(i + 1, line) for (i, line) in zip(numbers, relevant_lines)])
|
||||
|
||||
|
||||
def contextualized_yaml_error(raw_contents, error):
|
||||
@@ -51,12 +42,12 @@ def contextualized_yaml_error(raw_contents, error):
|
||||
|
||||
nice_error = prefix_with_line_numbers(raw_contents, min_line, max_line)
|
||||
|
||||
return YAML_ERROR_MESSAGE.format(line_number=mark.line + 1,
|
||||
nice_error=nice_error,
|
||||
raw_error=error)
|
||||
return YAML_ERROR_MESSAGE.format(
|
||||
line_number=mark.line + 1, nice_error=nice_error, raw_error=error
|
||||
)
|
||||
|
||||
|
||||
def safe_load(contents):
|
||||
def safe_load(contents) -> Optional[Dict[str, Any]]:
|
||||
return yaml.load(contents, Loader=SafeLoader)
|
||||
|
||||
|
||||
@@ -64,7 +55,7 @@ def load_yaml_text(contents):
|
||||
try:
|
||||
return safe_load(contents)
|
||||
except (yaml.scanner.ScannerError, yaml.YAMLError) as e:
|
||||
if hasattr(e, 'problem_mark'):
|
||||
if hasattr(e, "problem_mark"):
|
||||
error = contextualized_yaml_error(contents, e)
|
||||
else:
|
||||
error = str(e)
|
||||
|
||||
@@ -3,21 +3,24 @@ from collections import defaultdict
|
||||
from typing import List, Dict, Any, Tuple, cast, Optional
|
||||
|
||||
import networkx as nx # type: ignore
|
||||
import pickle
|
||||
import sqlparse
|
||||
|
||||
from dbt import flags
|
||||
from dbt.adapters.factory import get_adapter
|
||||
from dbt.clients import jinja
|
||||
from dbt.clients.system import make_directory
|
||||
from dbt.context.providers import generate_runtime_model
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.context.providers import generate_runtime_model_context, generate_runtime_sql_operation_context
|
||||
from dbt.contracts.graph.manifest import Manifest, UniqueID
|
||||
from dbt.contracts.graph.compiled import (
|
||||
COMPILED_TYPES,
|
||||
CompiledSchemaTestNode,
|
||||
CompiledGenericTestNode,
|
||||
GraphMemberNode,
|
||||
InjectedCTE,
|
||||
ManifestNode,
|
||||
NonSourceCompiledNode,
|
||||
CompiledSqlNode,
|
||||
CompiledRPCNode,
|
||||
)
|
||||
from dbt.contracts.graph.parsed import ParsedNode
|
||||
from dbt.exceptions import (
|
||||
@@ -26,33 +29,35 @@ from dbt.exceptions import (
|
||||
RuntimeException,
|
||||
)
|
||||
from dbt.graph import Graph
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import FoundStats, CompilingNode, WritingInjectedSQLForNode
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import pluralize
|
||||
from dbt.events.format import pluralize
|
||||
import dbt.tracking
|
||||
|
||||
graph_file_name = 'graph.gpickle'
|
||||
graph_file_name = "graph.gpickle"
|
||||
|
||||
|
||||
def _compiled_type_for(model: ParsedNode):
|
||||
if type(model) not in COMPILED_TYPES:
|
||||
raise InternalException(
|
||||
f'Asked to compile {type(model)} node, but it has no compiled form'
|
||||
f"Asked to compile {type(model)} node, but it has no compiled form"
|
||||
)
|
||||
return COMPILED_TYPES[type(model)]
|
||||
|
||||
|
||||
def print_compile_stats(stats):
|
||||
names = {
|
||||
NodeType.Model: 'model',
|
||||
NodeType.Test: 'test',
|
||||
NodeType.Snapshot: 'snapshot',
|
||||
NodeType.Analysis: 'analysis',
|
||||
NodeType.Macro: 'macro',
|
||||
NodeType.Operation: 'operation',
|
||||
NodeType.Seed: 'seed file',
|
||||
NodeType.Source: 'source',
|
||||
NodeType.Exposure: 'exposure',
|
||||
NodeType.Model: "model",
|
||||
NodeType.Test: "test",
|
||||
NodeType.Snapshot: "snapshot",
|
||||
NodeType.Analysis: "analysis",
|
||||
NodeType.Macro: "macro",
|
||||
NodeType.Operation: "operation",
|
||||
NodeType.Seed: "seed file",
|
||||
NodeType.Source: "source",
|
||||
NodeType.Exposure: "exposure",
|
||||
NodeType.Metric: "metric",
|
||||
}
|
||||
|
||||
results = {k: 0 for k in names.keys()}
|
||||
@@ -63,12 +68,9 @@ def print_compile_stats(stats):
|
||||
resource_counts = {k.pluralize(): v for k, v in results.items()}
|
||||
dbt.tracking.track_resource_counts(resource_counts)
|
||||
|
||||
stat_line = ", ".join([
|
||||
pluralize(ct, names.get(t)) for t, ct in results.items()
|
||||
if t in names
|
||||
])
|
||||
stat_line = ", ".join([pluralize(ct, names.get(t)) for t, ct in results.items() if t in names])
|
||||
|
||||
logger.info("Found {}".format(stat_line))
|
||||
fire_event(FoundStats(stat_line=stat_line))
|
||||
|
||||
|
||||
def _node_enabled(node: ManifestNode):
|
||||
@@ -89,6 +91,8 @@ def _generate_stats(manifest: Manifest):
|
||||
stats[source.resource_type] += 1
|
||||
for exposure in manifest.exposures.values():
|
||||
stats[exposure.resource_type] += 1
|
||||
for metric in manifest.metrics.values():
|
||||
stats[metric.resource_type] += 1
|
||||
for macro in manifest.macros.values():
|
||||
stats[macro.resource_type] += 1
|
||||
return stats
|
||||
@@ -107,6 +111,19 @@ def _extend_prepended_ctes(prepended_ctes, new_prepended_ctes):
|
||||
_add_prepended_cte(prepended_ctes, new_cte)
|
||||
|
||||
|
||||
def _get_tests_for_node(manifest: Manifest, unique_id: UniqueID) -> List[UniqueID]:
|
||||
"""Get a list of tests that depend on the node with the
|
||||
provided unique id"""
|
||||
|
||||
tests = []
|
||||
if unique_id in manifest.child_map:
|
||||
for child_unique_id in manifest.child_map[unique_id]:
|
||||
if child_unique_id.startswith("test."):
|
||||
tests.append(child_unique_id)
|
||||
|
||||
return tests
|
||||
|
||||
|
||||
class Linker:
|
||||
def __init__(self, data=None):
|
||||
if data is None:
|
||||
@@ -142,10 +159,11 @@ class Linker:
|
||||
include all nodes in their corresponding graph entries.
|
||||
"""
|
||||
out_graph = self.graph.copy()
|
||||
for node_id in self.graph.nodes():
|
||||
for node_id in self.graph:
|
||||
data = manifest.expect(node_id).to_dict(omit_none=True)
|
||||
out_graph.add_node(node_id, **data)
|
||||
nx.write_gpickle(out_graph, outfile)
|
||||
with open(outfile, "wb") as outfh:
|
||||
pickle.dump(out_graph, outfh, protocol=pickle.HIGHEST_PROTOCOL)
|
||||
|
||||
|
||||
class Compiler:
|
||||
@@ -154,7 +172,7 @@ class Compiler:
|
||||
|
||||
def initialize(self):
|
||||
make_directory(self.config.target_path)
|
||||
make_directory(self.config.modules_path)
|
||||
make_directory(self.config.packages_install_path)
|
||||
|
||||
# creates a ModelContext which is converted to
|
||||
# a dict for jinja rendering of SQL
|
||||
@@ -164,12 +182,14 @@ class Compiler:
|
||||
manifest: Manifest,
|
||||
extra_context: Dict[str, Any],
|
||||
) -> Dict[str, Any]:
|
||||
|
||||
context = generate_runtime_model(
|
||||
node, self.config, manifest
|
||||
)
|
||||
|
||||
if isinstance(node, CompiledSqlNode) or isinstance(node, CompiledRPCNode):
|
||||
# or node.resource_type in ('SqlOperation', 'RPCCall'):
|
||||
context = generate_runtime_sql_operation_context(node, self.config, manifest)
|
||||
else:
|
||||
context = generate_runtime_model_context(node, self.config, manifest)
|
||||
context.update(extra_context)
|
||||
if isinstance(node, CompiledSchemaTestNode):
|
||||
if isinstance(node, CompiledGenericTestNode):
|
||||
# for test nodes, add a special keyword args value to the context
|
||||
jinja.add_rendered_test_kwargs(context, node)
|
||||
|
||||
@@ -225,26 +245,21 @@ class Compiler:
|
||||
|
||||
with_stmt = None
|
||||
for token in parsed.tokens:
|
||||
if token.is_keyword and token.normalized == 'WITH':
|
||||
if token.is_keyword and token.normalized == "WITH":
|
||||
with_stmt = token
|
||||
break
|
||||
|
||||
if with_stmt is None:
|
||||
# no with stmt, add one, and inject CTEs right at the beginning
|
||||
first_token = parsed.token_first()
|
||||
with_stmt = sqlparse.sql.Token(sqlparse.tokens.Keyword, 'with')
|
||||
with_stmt = sqlparse.sql.Token(sqlparse.tokens.Keyword, "with")
|
||||
parsed.insert_before(first_token, with_stmt)
|
||||
else:
|
||||
# stmt exists, add a comma (which will come after injected CTEs)
|
||||
trailing_comma = sqlparse.sql.Token(
|
||||
sqlparse.tokens.Punctuation, ','
|
||||
)
|
||||
trailing_comma = sqlparse.sql.Token(sqlparse.tokens.Punctuation, ",")
|
||||
parsed.insert_after(with_stmt, trailing_comma)
|
||||
|
||||
token = sqlparse.sql.Token(
|
||||
sqlparse.tokens.Keyword,
|
||||
", ".join(c.sql for c in ctes)
|
||||
)
|
||||
token = sqlparse.sql.Token(sqlparse.tokens.Keyword, ", ".join(c.sql for c in ctes))
|
||||
parsed.insert_after(with_stmt, token)
|
||||
|
||||
return str(parsed)
|
||||
@@ -263,9 +278,7 @@ class Compiler:
|
||||
inserting CTEs into the SQL.
|
||||
"""
|
||||
if model.compiled_sql is None:
|
||||
raise RuntimeException(
|
||||
'Cannot inject ctes into an unparsed node', model
|
||||
)
|
||||
raise RuntimeException("Cannot inject ctes into an unparsed node", model)
|
||||
if model.extra_ctes_injected:
|
||||
return (model, model.extra_ctes)
|
||||
|
||||
@@ -286,17 +299,17 @@ class Compiler:
|
||||
for cte in model.extra_ctes:
|
||||
if cte.id not in manifest.nodes:
|
||||
raise InternalException(
|
||||
f'During compilation, found a cte reference that '
|
||||
f'could not be resolved: {cte.id}'
|
||||
f"During compilation, found a cte reference that "
|
||||
f"could not be resolved: {cte.id}"
|
||||
)
|
||||
cte_model = manifest.nodes[cte.id]
|
||||
|
||||
if not cte_model.is_ephemeral_model:
|
||||
raise InternalException(f'{cte.id} is not ephemeral')
|
||||
raise InternalException(f"{cte.id} is not ephemeral")
|
||||
|
||||
# This model has already been compiled, so it's been
|
||||
# through here before
|
||||
if getattr(cte_model, 'compiled', False):
|
||||
if getattr(cte_model, "compiled", False):
|
||||
assert isinstance(cte_model, tuple(COMPILED_TYPES.values()))
|
||||
cte_model = cast(NonSourceCompiledNode, cte_model)
|
||||
new_prepended_ctes = cte_model.extra_ctes
|
||||
@@ -305,13 +318,11 @@ class Compiler:
|
||||
else:
|
||||
# This is an ephemeral parsed model that we can compile.
|
||||
# Compile and update the node
|
||||
cte_model = self._compile_node(
|
||||
cte_model, manifest, extra_context)
|
||||
cte_model = self._compile_node(cte_model, manifest, extra_context)
|
||||
# recursively call this method
|
||||
cte_model, new_prepended_ctes = \
|
||||
self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
cte_model, new_prepended_ctes = self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
# Save compiled SQL file and sync manifest
|
||||
self._write_node(cte_model)
|
||||
manifest.sync_update_node(cte_model)
|
||||
@@ -319,10 +330,8 @@ class Compiler:
|
||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||
|
||||
new_cte_name = self.add_ephemeral_prefix(cte_model.name)
|
||||
rendered_sql = (
|
||||
cte_model._pre_injected_sql or cte_model.compiled_sql
|
||||
)
|
||||
sql = f' {new_cte_name} as (\n{rendered_sql}\n)'
|
||||
rendered_sql = cte_model._pre_injected_sql or cte_model.compiled_sql
|
||||
sql = f" {new_cte_name} as (\n{rendered_sql}\n)"
|
||||
|
||||
_add_prepended_cte(prepended_ctes, InjectedCTE(id=cte.id, sql=sql))
|
||||
|
||||
@@ -353,20 +362,20 @@ class Compiler:
|
||||
if extra_context is None:
|
||||
extra_context = {}
|
||||
|
||||
logger.debug("Compiling {}".format(node.unique_id))
|
||||
fire_event(CompilingNode(unique_id=node.unique_id))
|
||||
|
||||
data = node.to_dict(omit_none=True)
|
||||
data.update({
|
||||
'compiled': False,
|
||||
'compiled_sql': None,
|
||||
'extra_ctes_injected': False,
|
||||
'extra_ctes': [],
|
||||
})
|
||||
data.update(
|
||||
{
|
||||
"compiled": False,
|
||||
"compiled_sql": None,
|
||||
"extra_ctes_injected": False,
|
||||
"extra_ctes": [],
|
||||
}
|
||||
)
|
||||
compiled_node = _compiled_type_for(node).from_dict(data)
|
||||
|
||||
context = self._create_node_context(
|
||||
compiled_node, manifest, extra_context
|
||||
)
|
||||
context = self._create_node_context(compiled_node, manifest, extra_context)
|
||||
|
||||
compiled_node.compiled_sql = jinja.get_rendered(
|
||||
node.raw_sql,
|
||||
@@ -386,44 +395,93 @@ class Compiler:
|
||||
if flags.WRITE_JSON:
|
||||
linker.write_graph(graph_path, manifest)
|
||||
|
||||
def link_node(
|
||||
self, linker: Linker, node: GraphMemberNode, manifest: Manifest
|
||||
):
|
||||
def link_node(self, linker: Linker, node: GraphMemberNode, manifest: Manifest):
|
||||
linker.add_node(node.unique_id)
|
||||
|
||||
for dependency in node.depends_on_nodes:
|
||||
if dependency in manifest.nodes:
|
||||
linker.dependency(
|
||||
node.unique_id,
|
||||
(manifest.nodes[dependency].unique_id)
|
||||
)
|
||||
linker.dependency(node.unique_id, (manifest.nodes[dependency].unique_id))
|
||||
elif dependency in manifest.sources:
|
||||
linker.dependency(
|
||||
node.unique_id,
|
||||
(manifest.sources[dependency].unique_id)
|
||||
)
|
||||
linker.dependency(node.unique_id, (manifest.sources[dependency].unique_id))
|
||||
else:
|
||||
dependency_not_found(node, dependency)
|
||||
|
||||
def link_graph(self, linker: Linker, manifest: Manifest):
|
||||
def link_graph(self, linker: Linker, manifest: Manifest, add_test_edges: bool = False):
|
||||
for source in manifest.sources.values():
|
||||
linker.add_node(source.unique_id)
|
||||
for node in manifest.nodes.values():
|
||||
self.link_node(linker, node, manifest)
|
||||
for exposure in manifest.exposures.values():
|
||||
self.link_node(linker, exposure, manifest)
|
||||
# linker.add_node(exposure.unique_id)
|
||||
for metric in manifest.metrics.values():
|
||||
self.link_node(linker, metric, manifest)
|
||||
|
||||
cycle = linker.find_cycles()
|
||||
|
||||
if cycle:
|
||||
raise RuntimeError("Found a cycle: {}".format(cycle))
|
||||
|
||||
def compile(self, manifest: Manifest, write=True) -> Graph:
|
||||
if add_test_edges:
|
||||
manifest.build_parent_and_child_maps()
|
||||
self.add_test_edges(linker, manifest)
|
||||
|
||||
def add_test_edges(self, linker: Linker, manifest: Manifest) -> None:
|
||||
"""This method adds additional edges to the DAG. For a given non-test
|
||||
executable node, add an edge from an upstream test to the given node if
|
||||
the set of nodes the test depends on is a subset of the upstream nodes
|
||||
for the given node."""
|
||||
|
||||
# Given a graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | |
|
||||
# | \/
|
||||
# \/ test 2
|
||||
# test1
|
||||
#
|
||||
# Produce the following graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | /\ | /\ /\
|
||||
# | | \/ | |
|
||||
# \/ | test2 ----| |
|
||||
# test1 ----|---------------|
|
||||
|
||||
for node_id in linker.graph:
|
||||
# If node is executable (in manifest.nodes) and does _not_
|
||||
# represent a test, continue.
|
||||
if (
|
||||
node_id in manifest.nodes
|
||||
and manifest.nodes[node_id].resource_type != NodeType.Test
|
||||
):
|
||||
# Get *everything* upstream of the node
|
||||
all_upstream_nodes = nx.traversal.bfs_tree(linker.graph, node_id, reverse=True)
|
||||
# Get the set of upstream nodes not including the current node.
|
||||
upstream_nodes = set([n for n in all_upstream_nodes if n != node_id])
|
||||
|
||||
# Get all tests that depend on any upstream nodes.
|
||||
upstream_tests = []
|
||||
for upstream_node in upstream_nodes:
|
||||
upstream_tests += _get_tests_for_node(manifest, upstream_node)
|
||||
|
||||
for upstream_test in upstream_tests:
|
||||
# Get the set of all nodes that the test depends on
|
||||
# including the upstream_node itself. This is necessary
|
||||
# because tests can depend on multiple nodes (ex:
|
||||
# relationship tests). Test nodes do not distinguish
|
||||
# between what node the test is "testing" and what
|
||||
# node(s) it depends on.
|
||||
test_depends_on = set(manifest.nodes[upstream_test].depends_on_nodes)
|
||||
|
||||
# If the set of nodes that an upstream test depends on
|
||||
# is a subset of all upstream nodes of the current node,
|
||||
# add an edge from the upstream test to the current node.
|
||||
if test_depends_on.issubset(upstream_nodes):
|
||||
linker.graph.add_edge(upstream_test, node_id)
|
||||
|
||||
def compile(self, manifest: Manifest, write=True, add_test_edges=False) -> Graph:
|
||||
self.initialize()
|
||||
linker = Linker()
|
||||
|
||||
self.link_graph(linker, manifest)
|
||||
self.link_graph(linker, manifest, add_test_edges)
|
||||
|
||||
stats = _generate_stats(manifest)
|
||||
|
||||
@@ -435,16 +493,13 @@ class Compiler:
|
||||
|
||||
# writes the "compiled_sql" into the target/compiled directory
|
||||
def _write_node(self, node: NonSourceCompiledNode) -> ManifestNode:
|
||||
if (not node.extra_ctes_injected or
|
||||
node.resource_type == NodeType.Snapshot):
|
||||
if not node.extra_ctes_injected or node.resource_type == NodeType.Snapshot:
|
||||
return node
|
||||
logger.debug(f'Writing injected SQL for node "{node.unique_id}"')
|
||||
fire_event(WritingInjectedSQLForNode(unique_id=node.unique_id))
|
||||
|
||||
if node.compiled_sql:
|
||||
node.compiled_path = node.write_node(
|
||||
self.config.target_path,
|
||||
'compiled',
|
||||
node.compiled_sql
|
||||
self.config.target_path, "compiled", node.compiled_sql
|
||||
)
|
||||
return node
|
||||
|
||||
@@ -463,9 +518,7 @@ class Compiler:
|
||||
"""
|
||||
node = self._compile_node(node, manifest, extra_context)
|
||||
|
||||
node, _ = self._recursively_prepend_ctes(
|
||||
node, manifest, extra_context
|
||||
)
|
||||
node, _ = self._recursively_prepend_ctes(node, manifest, extra_context)
|
||||
if write:
|
||||
self._write_node(node)
|
||||
return node
|
||||
|
||||
1
core/dbt/config/README.md
Normal file
1
core/dbt/config/README.md
Normal file
@@ -0,0 +1 @@
|
||||
# Config README
|
||||
@@ -1,4 +1,4 @@
|
||||
# all these are just exports, they need "noqa" so flake8 will not complain.
|
||||
from .profile import Profile, PROFILES_DIR, read_user_config # noqa
|
||||
from .profile import Profile, read_user_config # noqa
|
||||
from .project import Project, IsFQNResource # noqa
|
||||
from .runtime import RuntimeConfig, UnsetProfileConfig # noqa
|
||||
|
||||
@@ -4,6 +4,7 @@ import os
|
||||
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from dbt import flags
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.clients.yaml_helper import load_yaml_text
|
||||
from dbt.contracts.connection import Credentials, HasCredentials
|
||||
@@ -14,16 +15,15 @@ from dbt.exceptions import DbtProjectError
|
||||
from dbt.exceptions import ValidationException
|
||||
from dbt.exceptions import RuntimeException
|
||||
from dbt.exceptions import validator_error_message
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.types import MissingProfileTarget
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.utils import coerce_dict_str
|
||||
|
||||
from .renderer import ProfileRenderer
|
||||
|
||||
DEFAULT_THREADS = 1
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser('~'), '.dbt')
|
||||
PROFILES_DIR = os.path.expanduser(
|
||||
os.getenv('DBT_PROFILES_DIR', DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser("~"), ".dbt")
|
||||
|
||||
INVALID_PROFILE_MESSAGE = """
|
||||
dbt encountered an error while trying to read your profiles.yml file.
|
||||
@@ -43,11 +43,13 @@ Here, [profile name] should be replaced with a profile name
|
||||
defined in your profiles.yml file. You can find profiles.yml here:
|
||||
|
||||
{profiles_file}/profiles.yml
|
||||
""".format(profiles_file=PROFILES_DIR)
|
||||
""".format(
|
||||
profiles_file=DEFAULT_PROFILES_DIR
|
||||
)
|
||||
|
||||
|
||||
def read_profile(profiles_dir: str) -> Dict[str, Any]:
|
||||
path = os.path.join(profiles_dir, 'profiles.yml')
|
||||
path = os.path.join(profiles_dir, "profiles.yml")
|
||||
|
||||
contents = None
|
||||
if os.path.isfile(path):
|
||||
@@ -55,12 +57,8 @@ def read_profile(profiles_dir: str) -> Dict[str, Any]:
|
||||
contents = load_file_contents(path, strip=False)
|
||||
yaml_content = load_yaml_text(contents)
|
||||
if not yaml_content:
|
||||
msg = f'The profiles.yml file at {path} is empty'
|
||||
raise DbtProfileError(
|
||||
INVALID_PROFILE_MESSAGE.format(
|
||||
error_string=msg
|
||||
)
|
||||
)
|
||||
msg = f"The profiles.yml file at {path} is empty"
|
||||
raise DbtProfileError(INVALID_PROFILE_MESSAGE.format(error_string=msg))
|
||||
return yaml_content
|
||||
except ValidationException as e:
|
||||
msg = INVALID_PROFILE_MESSAGE.format(error_string=e)
|
||||
@@ -73,10 +71,10 @@ def read_user_config(directory: str) -> UserConfig:
|
||||
try:
|
||||
profile = read_profile(directory)
|
||||
if profile:
|
||||
user_cfg = coerce_dict_str(profile.get('config', {}))
|
||||
if user_cfg is not None:
|
||||
UserConfig.validate(user_cfg)
|
||||
return UserConfig.from_dict(user_cfg)
|
||||
user_config = coerce_dict_str(profile.get("config", {}))
|
||||
if user_config is not None:
|
||||
UserConfig.validate(user_config)
|
||||
return UserConfig.from_dict(user_config)
|
||||
except (RuntimeException, ValidationError):
|
||||
pass
|
||||
return UserConfig()
|
||||
@@ -84,17 +82,35 @@ def read_user_config(directory: str) -> UserConfig:
|
||||
|
||||
# The Profile class is included in RuntimeConfig, so any attribute
|
||||
# additions must also be set where the RuntimeConfig class is created
|
||||
@dataclass
|
||||
# `init=False` is a workaround for https://bugs.python.org/issue45081
|
||||
@dataclass(init=False)
|
||||
class Profile(HasCredentials):
|
||||
profile_name: str
|
||||
target_name: str
|
||||
config: UserConfig
|
||||
user_config: UserConfig
|
||||
threads: int
|
||||
credentials: Credentials
|
||||
profile_env_vars: Dict[str, Any]
|
||||
|
||||
def to_profile_info(
|
||||
self, serialize_credentials: bool = False
|
||||
) -> Dict[str, Any]:
|
||||
def __init__(
|
||||
self,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_config: UserConfig,
|
||||
threads: int,
|
||||
credentials: Credentials,
|
||||
):
|
||||
"""Explicitly defining `__init__` to work around bug in Python 3.9.7
|
||||
https://bugs.python.org/issue45081
|
||||
"""
|
||||
self.profile_name = profile_name
|
||||
self.target_name = target_name
|
||||
self.user_config = user_config
|
||||
self.threads = threads
|
||||
self.credentials = credentials
|
||||
self.profile_env_vars = {} # never available on init
|
||||
|
||||
def to_profile_info(self, serialize_credentials: bool = False) -> Dict[str, Any]:
|
||||
"""Unlike to_project_config, this dict is not a mirror of any existing
|
||||
on-disk data structure. It's used when creating a new profile from an
|
||||
existing one.
|
||||
@@ -104,34 +120,33 @@ class Profile(HasCredentials):
|
||||
:returns dict: The serialized profile.
|
||||
"""
|
||||
result = {
|
||||
'profile_name': self.profile_name,
|
||||
'target_name': self.target_name,
|
||||
'config': self.config,
|
||||
'threads': self.threads,
|
||||
'credentials': self.credentials,
|
||||
"profile_name": self.profile_name,
|
||||
"target_name": self.target_name,
|
||||
"user_config": self.user_config,
|
||||
"threads": self.threads,
|
||||
"credentials": self.credentials,
|
||||
}
|
||||
if serialize_credentials:
|
||||
result['config'] = self.config.to_dict(omit_none=True)
|
||||
result['credentials'] = self.credentials.to_dict(omit_none=True)
|
||||
result["user_config"] = self.user_config.to_dict(omit_none=True)
|
||||
result["credentials"] = self.credentials.to_dict(omit_none=True)
|
||||
return result
|
||||
|
||||
def to_target_dict(self) -> Dict[str, Any]:
|
||||
target = dict(
|
||||
self.credentials.connection_info(with_aliases=True)
|
||||
target = dict(self.credentials.connection_info(with_aliases=True))
|
||||
target.update(
|
||||
{
|
||||
"type": self.credentials.type,
|
||||
"threads": self.threads,
|
||||
"name": self.target_name,
|
||||
"target_name": self.target_name,
|
||||
"profile_name": self.profile_name,
|
||||
"config": self.user_config.to_dict(omit_none=True),
|
||||
}
|
||||
)
|
||||
target.update({
|
||||
'type': self.credentials.type,
|
||||
'threads': self.threads,
|
||||
'name': self.target_name,
|
||||
'target_name': self.target_name,
|
||||
'profile_name': self.profile_name,
|
||||
'config': self.config.to_dict(omit_none=True),
|
||||
})
|
||||
return target
|
||||
|
||||
def __eq__(self, other: object) -> bool:
|
||||
if not (isinstance(other, self.__class__) and
|
||||
isinstance(self, other.__class__)):
|
||||
if not (isinstance(other, self.__class__) and isinstance(self, other.__class__)):
|
||||
return NotImplemented
|
||||
return self.to_profile_info() == other.to_profile_info()
|
||||
|
||||
@@ -151,14 +166,17 @@ class Profile(HasCredentials):
|
||||
) -> Credentials:
|
||||
# avoid an import cycle
|
||||
from dbt.adapters.factory import load_plugin
|
||||
|
||||
# credentials carry their 'type' in their actual type, not their
|
||||
# attributes. We do want this in order to pick our Credentials class.
|
||||
if 'type' not in profile:
|
||||
if "type" not in profile:
|
||||
raise DbtProfileError(
|
||||
'required field "type" not found in profile {} and target {}'
|
||||
.format(profile_name, target_name))
|
||||
'required field "type" not found in profile {} and target {}'.format(
|
||||
profile_name, target_name
|
||||
)
|
||||
)
|
||||
|
||||
typename = profile.pop('type')
|
||||
typename = profile.pop("type")
|
||||
try:
|
||||
cls = load_plugin(typename)
|
||||
data = cls.translate_aliases(profile)
|
||||
@@ -167,8 +185,9 @@ class Profile(HasCredentials):
|
||||
except (RuntimeException, ValidationError) as e:
|
||||
msg = str(e) if isinstance(e, RuntimeException) else e.message
|
||||
raise DbtProfileError(
|
||||
'Credentials in profile "{}", target "{}" invalid: {}'
|
||||
.format(profile_name, target_name, msg)
|
||||
'Credentials in profile "{}", target "{}" invalid: {}'.format(
|
||||
profile_name, target_name, msg
|
||||
)
|
||||
) from e
|
||||
|
||||
return credentials
|
||||
@@ -189,19 +208,19 @@ class Profile(HasCredentials):
|
||||
def _get_profile_data(
|
||||
profile: Dict[str, Any], profile_name: str, target_name: str
|
||||
) -> Dict[str, Any]:
|
||||
if 'outputs' not in profile:
|
||||
raise DbtProfileError(
|
||||
"outputs not specified in profile '{}'".format(profile_name)
|
||||
)
|
||||
outputs = profile['outputs']
|
||||
if "outputs" not in profile:
|
||||
raise DbtProfileError("outputs not specified in profile '{}'".format(profile_name))
|
||||
outputs = profile["outputs"]
|
||||
|
||||
if target_name not in outputs:
|
||||
outputs = '\n'.join(' - {}'.format(output)
|
||||
for output in outputs)
|
||||
msg = ("The profile '{}' does not have a target named '{}'. The "
|
||||
"valid target names for this profile are:\n{}"
|
||||
.format(profile_name, target_name, outputs))
|
||||
raise DbtProfileError(msg, result_type='invalid_target')
|
||||
outputs = "\n".join(" - {}".format(output) for output in outputs)
|
||||
msg = (
|
||||
"The profile '{}' does not have a target named '{}'. The "
|
||||
"valid target names for this profile are:\n{}".format(
|
||||
profile_name, target_name, outputs
|
||||
)
|
||||
)
|
||||
raise DbtProfileError(msg, result_type="invalid_target")
|
||||
profile_data = outputs[target_name]
|
||||
|
||||
if not isinstance(profile_data, dict):
|
||||
@@ -209,7 +228,7 @@ class Profile(HasCredentials):
|
||||
f"output '{target_name}' of profile '{profile_name}' is "
|
||||
f"misconfigured in profiles.yml"
|
||||
)
|
||||
raise DbtProfileError(msg, result_type='invalid_target')
|
||||
raise DbtProfileError(msg, result_type="invalid_target")
|
||||
|
||||
return profile_data
|
||||
|
||||
@@ -220,8 +239,8 @@ class Profile(HasCredentials):
|
||||
threads: int,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_cfg: Optional[Dict[str, Any]] = None
|
||||
) -> 'Profile':
|
||||
user_config: Optional[Dict[str, Any]] = None,
|
||||
) -> "Profile":
|
||||
"""Create a profile from an existing set of Credentials and the
|
||||
remaining information.
|
||||
|
||||
@@ -229,22 +248,22 @@ class Profile(HasCredentials):
|
||||
:param threads: The number of threads to use for connections.
|
||||
:param profile_name: The profile name used for this profile.
|
||||
:param target_name: The target name used for this profile.
|
||||
:param user_cfg: The user-level config block from the
|
||||
:param user_config: The user-level config block from the
|
||||
raw profiles, if specified.
|
||||
:raises DbtProfileError: If the profile is invalid.
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
if user_cfg is None:
|
||||
user_cfg = {}
|
||||
UserConfig.validate(user_cfg)
|
||||
config = UserConfig.from_dict(user_cfg)
|
||||
if user_config is None:
|
||||
user_config = {}
|
||||
UserConfig.validate(user_config)
|
||||
user_config_obj: UserConfig = UserConfig.from_dict(user_config)
|
||||
|
||||
profile = cls(
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
config=config,
|
||||
user_config=user_config_obj,
|
||||
threads=threads,
|
||||
credentials=credentials
|
||||
credentials=credentials,
|
||||
)
|
||||
profile.validate()
|
||||
return profile
|
||||
@@ -269,19 +288,14 @@ class Profile(HasCredentials):
|
||||
# name to extract a profile that we can render.
|
||||
if target_override is not None:
|
||||
target_name = target_override
|
||||
elif 'target' in raw_profile:
|
||||
elif "target" in raw_profile:
|
||||
# render the target if it was parsed from yaml
|
||||
target_name = renderer.render_value(raw_profile['target'])
|
||||
target_name = renderer.render_value(raw_profile["target"])
|
||||
else:
|
||||
target_name = 'default'
|
||||
logger.debug(
|
||||
"target not specified in profile '{}', using '{}'"
|
||||
.format(profile_name, target_name)
|
||||
)
|
||||
target_name = "default"
|
||||
fire_event(MissingProfileTarget(profile_name=profile_name, target_name=target_name))
|
||||
|
||||
raw_profile_data = cls._get_profile_data(
|
||||
raw_profile, profile_name, target_name
|
||||
)
|
||||
raw_profile_data = cls._get_profile_data(raw_profile, profile_name, target_name)
|
||||
|
||||
try:
|
||||
profile_data = renderer.render_data(raw_profile_data)
|
||||
@@ -295,10 +309,10 @@ class Profile(HasCredentials):
|
||||
raw_profile: Dict[str, Any],
|
||||
profile_name: str,
|
||||
renderer: ProfileRenderer,
|
||||
user_cfg: Optional[Dict[str, Any]] = None,
|
||||
user_config: Optional[Dict[str, Any]] = None,
|
||||
target_override: Optional[str] = None,
|
||||
threads_override: Optional[int] = None,
|
||||
) -> 'Profile':
|
||||
) -> "Profile":
|
||||
"""Create a profile from its raw profile information.
|
||||
|
||||
(this is an intermediate step, mostly useful for unit testing)
|
||||
@@ -307,7 +321,7 @@ class Profile(HasCredentials):
|
||||
disk as yaml and its values rendered with jinja.
|
||||
:param profile_name: The profile name used.
|
||||
:param renderer: The config renderer.
|
||||
:param user_cfg: The global config for the user, if it
|
||||
:param user_config: The global config for the user, if it
|
||||
was present.
|
||||
:param target_override: The target to use, if provided on
|
||||
the command line.
|
||||
@@ -317,9 +331,9 @@ class Profile(HasCredentials):
|
||||
target could not be found
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
# user_cfg is not rendered.
|
||||
if user_cfg is None:
|
||||
user_cfg = raw_profile.get('config')
|
||||
# user_config is not rendered.
|
||||
if user_config is None:
|
||||
user_config = raw_profile.get("config")
|
||||
# TODO: should it be, and the values coerced to bool?
|
||||
target_name, profile_data = cls.render_profile(
|
||||
raw_profile, profile_name, target_override, renderer
|
||||
@@ -327,7 +341,7 @@ class Profile(HasCredentials):
|
||||
|
||||
# valid connections never include the number of threads, but it's
|
||||
# stored on a per-connection level in the raw configs
|
||||
threads = profile_data.pop('threads', DEFAULT_THREADS)
|
||||
threads = profile_data.pop("threads", DEFAULT_THREADS)
|
||||
if threads_override is not None:
|
||||
threads = threads_override
|
||||
|
||||
@@ -340,7 +354,7 @@ class Profile(HasCredentials):
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
threads=threads,
|
||||
user_cfg=user_cfg
|
||||
user_config=user_config,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -351,7 +365,7 @@ class Profile(HasCredentials):
|
||||
renderer: ProfileRenderer,
|
||||
target_override: Optional[str] = None,
|
||||
threads_override: Optional[int] = None,
|
||||
) -> 'Profile':
|
||||
) -> "Profile":
|
||||
"""
|
||||
:param raw_profiles: The profile data, from disk as yaml.
|
||||
:param profile_name: The profile name to use.
|
||||
@@ -367,29 +381,21 @@ class Profile(HasCredentials):
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
if profile_name not in raw_profiles:
|
||||
raise DbtProjectError(
|
||||
"Could not find profile named '{}'".format(profile_name)
|
||||
)
|
||||
raise DbtProjectError("Could not find profile named '{}'".format(profile_name))
|
||||
|
||||
# First, we've already got our final decision on profile name, and we
|
||||
# don't render keys, so we can pluck that out
|
||||
raw_profile = raw_profiles[profile_name]
|
||||
if not raw_profile:
|
||||
msg = (
|
||||
f'Profile {profile_name} in profiles.yml is empty'
|
||||
)
|
||||
raise DbtProfileError(
|
||||
INVALID_PROFILE_MESSAGE.format(
|
||||
error_string=msg
|
||||
)
|
||||
)
|
||||
user_cfg = raw_profiles.get('config')
|
||||
msg = f"Profile {profile_name} in profiles.yml is empty"
|
||||
raise DbtProfileError(INVALID_PROFILE_MESSAGE.format(error_string=msg))
|
||||
user_config = raw_profiles.get("config")
|
||||
|
||||
return cls.from_raw_profile_info(
|
||||
raw_profile=raw_profile,
|
||||
profile_name=profile_name,
|
||||
renderer=renderer,
|
||||
user_cfg=user_cfg,
|
||||
user_config=user_config,
|
||||
target_override=target_override,
|
||||
threads_override=threads_override,
|
||||
)
|
||||
@@ -400,7 +406,7 @@ class Profile(HasCredentials):
|
||||
args: Any,
|
||||
renderer: ProfileRenderer,
|
||||
project_profile_name: Optional[str],
|
||||
) -> 'Profile':
|
||||
) -> "Profile":
|
||||
"""Given the raw profiles as read from disk and the name of the desired
|
||||
profile if specified, return the profile component of the runtime
|
||||
config.
|
||||
@@ -415,15 +421,14 @@ class Profile(HasCredentials):
|
||||
target could not be found.
|
||||
:returns Profile: The new Profile object.
|
||||
"""
|
||||
threads_override = getattr(args, 'threads', None)
|
||||
target_override = getattr(args, 'target', None)
|
||||
raw_profiles = read_profile(args.profiles_dir)
|
||||
profile_name = cls.pick_profile_name(getattr(args, 'profile', None),
|
||||
project_profile_name)
|
||||
threads_override = getattr(args, "threads", None)
|
||||
target_override = getattr(args, "target", None)
|
||||
raw_profiles = read_profile(flags.PROFILES_DIR)
|
||||
profile_name = cls.pick_profile_name(getattr(args, "profile", None), project_profile_name)
|
||||
return cls.from_raw_profiles(
|
||||
raw_profiles=raw_profiles,
|
||||
profile_name=profile_name,
|
||||
renderer=renderer,
|
||||
target_override=target_override,
|
||||
threads_override=threads_override
|
||||
threads_override=threads_override,
|
||||
)
|
||||
|
||||
@@ -2,13 +2,20 @@ from copy import deepcopy
|
||||
from dataclasses import dataclass, field
|
||||
from itertools import chain
|
||||
from typing import (
|
||||
List, Dict, Any, Optional, TypeVar, Union, Mapping,
|
||||
List,
|
||||
Dict,
|
||||
Any,
|
||||
Optional,
|
||||
TypeVar,
|
||||
Union,
|
||||
Mapping,
|
||||
)
|
||||
from typing_extensions import Protocol, runtime_checkable
|
||||
|
||||
import hashlib
|
||||
import os
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.clients.system import resolve_path_from_base
|
||||
from dbt.clients.system import path_exists
|
||||
from dbt.clients.system import load_file_contents
|
||||
@@ -44,7 +51,7 @@ INVALID_VERSION_ERROR = """\
|
||||
This version of dbt is not supported with the '{package}' package.
|
||||
Installed version of dbt: {installed}
|
||||
Required version of dbt for '{package}': {version_spec}
|
||||
Check the requirements for the '{package}' package, or run dbt again with \
|
||||
Check for a different version of the '{package}' package, or run dbt again with \
|
||||
--no-version-check
|
||||
"""
|
||||
|
||||
@@ -53,7 +60,7 @@ IMPOSSIBLE_VERSION_ERROR = """\
|
||||
The package version requirement can never be satisfied for the '{package}
|
||||
package.
|
||||
Required versions of dbt for '{package}': {version_spec}
|
||||
Check the requirements for the '{package}' package, or run dbt again with \
|
||||
Check for a different version of the '{package}' package, or run dbt again with \
|
||||
--no-version-check
|
||||
"""
|
||||
|
||||
@@ -82,9 +89,7 @@ def _load_yaml(path):
|
||||
|
||||
|
||||
def package_data_from_root(project_root):
|
||||
package_filepath = resolve_path_from_base(
|
||||
'packages.yml', project_root
|
||||
)
|
||||
package_filepath = resolve_path_from_base("packages.yml", project_root)
|
||||
|
||||
if path_exists(package_filepath):
|
||||
packages_dict = _load_yaml(package_filepath)
|
||||
@@ -95,15 +100,13 @@ def package_data_from_root(project_root):
|
||||
|
||||
def package_config_from_data(packages_data: Dict[str, Any]):
|
||||
if not packages_data:
|
||||
packages_data = {'packages': []}
|
||||
packages_data = {"packages": []}
|
||||
|
||||
try:
|
||||
PackageConfig.validate(packages_data)
|
||||
packages = PackageConfig.from_dict(packages_data)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(
|
||||
MALFORMED_PACKAGE_ERROR.format(error=str(e.message))
|
||||
) from e
|
||||
raise DbtProjectError(MALFORMED_PACKAGE_ERROR.format(error=str(e.message))) from e
|
||||
return packages
|
||||
|
||||
|
||||
@@ -118,22 +121,21 @@ def _parse_versions(versions: Union[List[str], str]) -> List[VersionSpecifier]:
|
||||
Regardless, this will return a list of VersionSpecifiers
|
||||
"""
|
||||
if isinstance(versions, str):
|
||||
versions = versions.split(',')
|
||||
versions = versions.split(",")
|
||||
return [VersionSpecifier.from_version_string(v) for v in versions]
|
||||
|
||||
|
||||
def _all_source_paths(
|
||||
source_paths: List[str],
|
||||
data_paths: List[str],
|
||||
model_paths: List[str],
|
||||
seed_paths: List[str],
|
||||
snapshot_paths: List[str],
|
||||
analysis_paths: List[str],
|
||||
macro_paths: List[str],
|
||||
) -> List[str]:
|
||||
return list(chain(source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths))
|
||||
return list(chain(model_paths, seed_paths, snapshot_paths, analysis_paths, macro_paths))
|
||||
|
||||
|
||||
T = TypeVar('T')
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def value_or(value: Optional[T], default: T) -> T:
|
||||
@@ -146,30 +148,27 @@ def value_or(value: Optional[T], default: T) -> T:
|
||||
def _raw_project_from(project_root: str) -> Dict[str, Any]:
|
||||
|
||||
project_root = os.path.normpath(project_root)
|
||||
project_yaml_filepath = os.path.join(project_root, 'dbt_project.yml')
|
||||
project_yaml_filepath = os.path.join(project_root, "dbt_project.yml")
|
||||
|
||||
# get the project.yml contents
|
||||
if not path_exists(project_yaml_filepath):
|
||||
raise DbtProjectError(
|
||||
'no dbt_project.yml found at expected path {}'
|
||||
.format(project_yaml_filepath)
|
||||
"no dbt_project.yml found at expected path {}".format(project_yaml_filepath)
|
||||
)
|
||||
|
||||
project_dict = _load_yaml(project_yaml_filepath)
|
||||
|
||||
if not isinstance(project_dict, dict):
|
||||
raise DbtProjectError(
|
||||
'dbt_project.yml does not parse to a dictionary'
|
||||
)
|
||||
raise DbtProjectError("dbt_project.yml does not parse to a dictionary")
|
||||
|
||||
return project_dict
|
||||
|
||||
|
||||
def _query_comment_from_cfg(
|
||||
cfg_query_comment: Union[QueryComment, NoValue, str, None]
|
||||
cfg_query_comment: Union[QueryComment, NoValue, str, None]
|
||||
) -> QueryComment:
|
||||
if not cfg_query_comment:
|
||||
return QueryComment(comment='')
|
||||
return QueryComment(comment="")
|
||||
|
||||
if isinstance(cfg_query_comment, str):
|
||||
return QueryComment(comment=cfg_query_comment)
|
||||
@@ -185,10 +184,7 @@ def validate_version(dbt_version: List[VersionSpecifier], project_name: str):
|
||||
installed = get_installed_version()
|
||||
if not versions_compatible(*dbt_version):
|
||||
msg = IMPOSSIBLE_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
version_spec=[
|
||||
x.to_version_string() for x in dbt_version
|
||||
]
|
||||
package=project_name, version_spec=[x.to_version_string() for x in dbt_version]
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
@@ -196,9 +192,7 @@ def validate_version(dbt_version: List[VersionSpecifier], project_name: str):
|
||||
msg = INVALID_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
installed=installed.to_version_string(),
|
||||
version_spec=[
|
||||
x.to_version_string() for x in dbt_version
|
||||
]
|
||||
version_spec=[x.to_version_string() for x in dbt_version],
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
@@ -207,8 +201,8 @@ def _get_required_version(
|
||||
project_dict: Dict[str, Any],
|
||||
verify_version: bool,
|
||||
) -> List[VersionSpecifier]:
|
||||
dbt_raw_version: Union[List[str], str] = '>=0.0.0'
|
||||
required = project_dict.get('require-dbt-version')
|
||||
dbt_raw_version: Union[List[str], str] = ">=0.0.0"
|
||||
required = project_dict.get("require-dbt-version")
|
||||
if required is not None:
|
||||
dbt_raw_version = required
|
||||
|
||||
@@ -219,46 +213,39 @@ def _get_required_version(
|
||||
|
||||
if verify_version:
|
||||
# no name is also an error that we want to raise
|
||||
if 'name' not in project_dict:
|
||||
if "name" not in project_dict:
|
||||
raise DbtProjectError(
|
||||
'Required "name" field not present in project',
|
||||
)
|
||||
validate_version(dbt_version, project_dict['name'])
|
||||
validate_version(dbt_version, project_dict["name"])
|
||||
|
||||
return dbt_version
|
||||
|
||||
|
||||
@dataclass
|
||||
class RenderComponents:
|
||||
project_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The project dictionary')
|
||||
)
|
||||
packages_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The packages dictionary')
|
||||
)
|
||||
selectors_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The selectors dictionary')
|
||||
)
|
||||
project_dict: Dict[str, Any] = field(metadata=dict(description="The project dictionary"))
|
||||
packages_dict: Dict[str, Any] = field(metadata=dict(description="The packages dictionary"))
|
||||
selectors_dict: Dict[str, Any] = field(metadata=dict(description="The selectors dictionary"))
|
||||
|
||||
|
||||
@dataclass
|
||||
class PartialProject(RenderComponents):
|
||||
profile_name: Optional[str] = field(metadata=dict(
|
||||
description='The unrendered profile name in the project, if set'
|
||||
))
|
||||
project_name: Optional[str] = field(metadata=dict(
|
||||
description=(
|
||||
'The name of the project. This should always be set and will not '
|
||||
'be rendered'
|
||||
profile_name: Optional[str] = field(
|
||||
metadata=dict(description="The unrendered profile name in the project, if set")
|
||||
)
|
||||
project_name: Optional[str] = field(
|
||||
metadata=dict(
|
||||
description=(
|
||||
"The name of the project. This should always be set and will not " "be rendered"
|
||||
)
|
||||
)
|
||||
))
|
||||
)
|
||||
project_root: str = field(
|
||||
metadata=dict(description='The root directory of the project'),
|
||||
metadata=dict(description="The root directory of the project"),
|
||||
)
|
||||
verify_version: bool = field(
|
||||
metadata=dict(description=(
|
||||
'If True, verify the dbt version matches the required version'
|
||||
))
|
||||
metadata=dict(description=("If True, verify the dbt version matches the required version"))
|
||||
)
|
||||
|
||||
def render_profile_name(self, renderer) -> Optional[str]:
|
||||
@@ -271,9 +258,7 @@ class PartialProject(RenderComponents):
|
||||
renderer: DbtProjectYamlRenderer,
|
||||
) -> RenderComponents:
|
||||
|
||||
rendered_project = renderer.render_project(
|
||||
self.project_dict, self.project_root
|
||||
)
|
||||
rendered_project = renderer.render_project(self.project_dict, self.project_root)
|
||||
rendered_packages = renderer.render_packages(self.packages_dict)
|
||||
rendered_selectors = renderer.render_selectors(self.selectors_dict)
|
||||
|
||||
@@ -283,16 +268,35 @@ class PartialProject(RenderComponents):
|
||||
selectors_dict=rendered_selectors,
|
||||
)
|
||||
|
||||
def render(self, renderer: DbtProjectYamlRenderer) -> 'Project':
|
||||
# Called by 'collect_parts' in RuntimeConfig
|
||||
def render(self, renderer: DbtProjectYamlRenderer) -> "Project":
|
||||
try:
|
||||
rendered = self.get_rendered(renderer)
|
||||
return self.create_project(rendered)
|
||||
except DbtProjectError as exc:
|
||||
if exc.path is None:
|
||||
exc.path = os.path.join(self.project_root, 'dbt_project.yml')
|
||||
exc.path = os.path.join(self.project_root, "dbt_project.yml")
|
||||
raise
|
||||
|
||||
def create_project(self, rendered: RenderComponents) -> 'Project':
|
||||
def check_config_path(self, project_dict, deprecated_path, exp_path):
|
||||
if deprecated_path in project_dict:
|
||||
if exp_path in project_dict:
|
||||
msg = (
|
||||
"{deprecated_path} and {exp_path} cannot both be defined. The "
|
||||
"`{deprecated_path}` config has been deprecated in favor of `{exp_path}`. "
|
||||
"Please update your `dbt_project.yml` configuration to reflect this "
|
||||
"change."
|
||||
)
|
||||
raise DbtProjectError(
|
||||
msg.format(deprecated_path=deprecated_path, exp_path=exp_path)
|
||||
)
|
||||
deprecations.warn(
|
||||
f"project-config-{deprecated_path}",
|
||||
deprecated_path=deprecated_path,
|
||||
exp_path=exp_path,
|
||||
)
|
||||
|
||||
def create_project(self, rendered: RenderComponents) -> "Project":
|
||||
unrendered = RenderComponents(
|
||||
project_dict=self.project_dict,
|
||||
packages_dict=self.packages_dict,
|
||||
@@ -303,11 +307,12 @@ class PartialProject(RenderComponents):
|
||||
verify_version=self.verify_version,
|
||||
)
|
||||
|
||||
self.check_config_path(rendered.project_dict, "source-paths", "model-paths")
|
||||
self.check_config_path(rendered.project_dict, "data-paths", "seed-paths")
|
||||
|
||||
try:
|
||||
ProjectContract.validate(rendered.project_dict)
|
||||
cfg = ProjectContract.from_dict(
|
||||
rendered.project_dict
|
||||
)
|
||||
cfg = ProjectContract.from_dict(rendered.project_dict)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
# name/version are required in the Project definition, so we can assume
|
||||
@@ -317,31 +322,40 @@ class PartialProject(RenderComponents):
|
||||
# this is added at project_dict parse time and should always be here
|
||||
# once we see it.
|
||||
if cfg.project_root is None:
|
||||
raise DbtProjectError('cfg must have a project root!')
|
||||
raise DbtProjectError("cfg must have a project root!")
|
||||
else:
|
||||
project_root = cfg.project_root
|
||||
# this is only optional in the sense that if it's not present, it needs
|
||||
# to have been a cli argument.
|
||||
profile_name = cfg.profile
|
||||
# these are all the defaults
|
||||
source_paths: List[str] = value_or(cfg.source_paths, ['models'])
|
||||
macro_paths: List[str] = value_or(cfg.macro_paths, ['macros'])
|
||||
data_paths: List[str] = value_or(cfg.data_paths, ['data'])
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ['test'])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, [])
|
||||
snapshot_paths: List[str] = value_or(cfg.snapshot_paths, ['snapshots'])
|
||||
|
||||
# `source_paths` is deprecated but still allowed. Copy it into
|
||||
# `model_paths` to simlify logic throughout the rest of the system.
|
||||
model_paths: List[str] = value_or(
|
||||
cfg.model_paths if "model-paths" in rendered.project_dict else cfg.source_paths,
|
||||
["models"],
|
||||
)
|
||||
macro_paths: List[str] = value_or(cfg.macro_paths, ["macros"])
|
||||
# `data_paths` is deprecated but still allowed. Copy it into
|
||||
# `seed_paths` to simlify logic throughout the rest of the system.
|
||||
seed_paths: List[str] = value_or(
|
||||
cfg.seed_paths if "seed-paths" in rendered.project_dict else cfg.data_paths, ["seeds"]
|
||||
)
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ["tests"])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, ["analyses"])
|
||||
snapshot_paths: List[str] = value_or(cfg.snapshot_paths, ["snapshots"])
|
||||
|
||||
all_source_paths: List[str] = _all_source_paths(
|
||||
source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths
|
||||
model_paths, seed_paths, snapshot_paths, analysis_paths, macro_paths
|
||||
)
|
||||
|
||||
docs_paths: List[str] = value_or(cfg.docs_paths, all_source_paths)
|
||||
asset_paths: List[str] = value_or(cfg.asset_paths, [])
|
||||
target_path: str = value_or(cfg.target_path, 'target')
|
||||
target_path: str = value_or(cfg.target_path, "target")
|
||||
clean_targets: List[str] = value_or(cfg.clean_targets, [target_path])
|
||||
log_path: str = value_or(cfg.log_path, 'logs')
|
||||
modules_path: str = value_or(cfg.modules_path, 'dbt_modules')
|
||||
log_path: str = value_or(cfg.log_path, "logs")
|
||||
packages_install_path: str = value_or(cfg.packages_install_path, "dbt_packages")
|
||||
# in the default case we'll populate this once we know the adapter type
|
||||
# It would be nice to just pass along a Quoting here, but that would
|
||||
# break many things
|
||||
@@ -369,6 +383,8 @@ class PartialProject(RenderComponents):
|
||||
vars_dict = cfg.vars
|
||||
|
||||
vars_value = VarProvider(vars_dict)
|
||||
# There will never be any project_env_vars when it's first created
|
||||
project_env_vars: Dict[str, Any] = {}
|
||||
on_run_start: List[str] = value_or(cfg.on_run_start, [])
|
||||
on_run_end: List[str] = value_or(cfg.on_run_end, [])
|
||||
|
||||
@@ -377,20 +393,20 @@ class PartialProject(RenderComponents):
|
||||
packages = package_config_from_data(rendered.packages_dict)
|
||||
selectors = selector_config_from_data(rendered.selectors_dict)
|
||||
manifest_selectors: Dict[str, Any] = {}
|
||||
if rendered.selectors_dict and rendered.selectors_dict['selectors']:
|
||||
if rendered.selectors_dict and rendered.selectors_dict["selectors"]:
|
||||
# this is a dict with a single key 'selectors' pointing to a list
|
||||
# of dicts.
|
||||
manifest_selectors = SelectorDict.parse_from_selectors_list(
|
||||
rendered.selectors_dict['selectors'])
|
||||
|
||||
rendered.selectors_dict["selectors"]
|
||||
)
|
||||
project = Project(
|
||||
project_name=name,
|
||||
version=version,
|
||||
project_root=project_root,
|
||||
profile_name=profile_name,
|
||||
source_paths=source_paths,
|
||||
model_paths=model_paths,
|
||||
macro_paths=macro_paths,
|
||||
data_paths=data_paths,
|
||||
seed_paths=seed_paths,
|
||||
test_paths=test_paths,
|
||||
analysis_paths=analysis_paths,
|
||||
docs_paths=docs_paths,
|
||||
@@ -399,7 +415,7 @@ class PartialProject(RenderComponents):
|
||||
snapshot_paths=snapshot_paths,
|
||||
clean_targets=clean_targets,
|
||||
log_path=log_path,
|
||||
modules_path=modules_path,
|
||||
packages_install_path=packages_install_path,
|
||||
quoting=quoting,
|
||||
models=models,
|
||||
on_run_start=on_run_start,
|
||||
@@ -417,6 +433,7 @@ class PartialProject(RenderComponents):
|
||||
vars=vars_value,
|
||||
config_version=cfg.config_version,
|
||||
unrendered=unrendered,
|
||||
project_env_vars=project_env_vars,
|
||||
)
|
||||
# sanity check - this means an internal issue
|
||||
project.validate()
|
||||
@@ -432,10 +449,9 @@ class PartialProject(RenderComponents):
|
||||
*,
|
||||
verify_version: bool = False,
|
||||
):
|
||||
"""Construct a partial project from its constituent dicts.
|
||||
"""
|
||||
project_name = project_dict.get('name')
|
||||
profile_name = project_dict.get('profile')
|
||||
"""Construct a partial project from its constituent dicts."""
|
||||
project_name = project_dict.get("name")
|
||||
profile_name = project_dict.get("profile")
|
||||
|
||||
return cls(
|
||||
profile_name=profile_name,
|
||||
@@ -450,14 +466,14 @@ class PartialProject(RenderComponents):
|
||||
@classmethod
|
||||
def from_project_root(
|
||||
cls, project_root: str, *, verify_version: bool = False
|
||||
) -> 'PartialProject':
|
||||
) -> "PartialProject":
|
||||
project_root = os.path.normpath(project_root)
|
||||
project_dict = _raw_project_from(project_root)
|
||||
config_version = project_dict.get('config-version', 1)
|
||||
config_version = project_dict.get("config-version", 1)
|
||||
if config_version != 2:
|
||||
raise DbtProjectError(
|
||||
f'Invalid config version: {config_version}, expected 2',
|
||||
path=os.path.join(project_root, 'dbt_project.yml')
|
||||
f"Invalid config version: {config_version}, expected 2",
|
||||
path=os.path.join(project_root, "dbt_project.yml"),
|
||||
)
|
||||
|
||||
packages_dict = package_data_from_root(project_root)
|
||||
@@ -474,15 +490,10 @@ class PartialProject(RenderComponents):
|
||||
class VarProvider:
|
||||
"""Var providers are tied to a particular Project."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vars: Dict[str, Dict[str, Any]]
|
||||
) -> None:
|
||||
def __init__(self, vars: Dict[str, Dict[str, Any]]) -> None:
|
||||
self.vars = vars
|
||||
|
||||
def vars_for(
|
||||
self, node: IsFQNResource, adapter_type: str
|
||||
) -> Mapping[str, Any]:
|
||||
def vars_for(self, node: IsFQNResource, adapter_type: str) -> Mapping[str, Any]:
|
||||
# in v2, vars are only either project or globally scoped
|
||||
merged = MultiDict([self.vars])
|
||||
merged.add(self.vars.get(node.package_name, {}))
|
||||
@@ -500,9 +511,9 @@ class Project:
|
||||
version: Union[SemverString, float]
|
||||
project_root: str
|
||||
profile_name: Optional[str]
|
||||
source_paths: List[str]
|
||||
model_paths: List[str]
|
||||
macro_paths: List[str]
|
||||
data_paths: List[str]
|
||||
seed_paths: List[str]
|
||||
test_paths: List[str]
|
||||
analysis_paths: List[str]
|
||||
docs_paths: List[str]
|
||||
@@ -511,7 +522,7 @@ class Project:
|
||||
snapshot_paths: List[str]
|
||||
clean_targets: List[str]
|
||||
log_path: str
|
||||
modules_path: str
|
||||
packages_install_path: str
|
||||
quoting: Dict[str, Any]
|
||||
models: Dict[str, Any]
|
||||
on_run_start: List[str]
|
||||
@@ -529,24 +540,35 @@ class Project:
|
||||
query_comment: QueryComment
|
||||
config_version: int
|
||||
unrendered: RenderComponents
|
||||
project_env_vars: Dict[str, Any]
|
||||
|
||||
@property
|
||||
def all_source_paths(self) -> List[str]:
|
||||
return _all_source_paths(
|
||||
self.source_paths, self.data_paths, self.snapshot_paths,
|
||||
self.analysis_paths, self.macro_paths
|
||||
self.model_paths,
|
||||
self.seed_paths,
|
||||
self.snapshot_paths,
|
||||
self.analysis_paths,
|
||||
self.macro_paths,
|
||||
)
|
||||
|
||||
@property
|
||||
def generic_test_paths(self):
|
||||
generic_test_paths = []
|
||||
for test_path in self.test_paths:
|
||||
generic_test_paths.append(os.path.join(test_path, "generic"))
|
||||
return generic_test_paths
|
||||
|
||||
def __str__(self):
|
||||
cfg = self.to_project_config(with_packages=True)
|
||||
return str(cfg)
|
||||
|
||||
def __eq__(self, other):
|
||||
if not (isinstance(other, self.__class__) and
|
||||
isinstance(self, other.__class__)):
|
||||
if not (isinstance(other, self.__class__) and isinstance(self, other.__class__)):
|
||||
return False
|
||||
return self.to_project_config(with_packages=True) == \
|
||||
other.to_project_config(with_packages=True)
|
||||
return self.to_project_config(with_packages=True) == other.to_project_config(
|
||||
with_packages=True
|
||||
)
|
||||
|
||||
def to_project_config(self, with_packages=False):
|
||||
"""Return a dict representation of the config that could be written to
|
||||
@@ -556,40 +578,39 @@ class Project:
|
||||
file in the root.
|
||||
:returns dict: The serialized profile.
|
||||
"""
|
||||
result = deepcopy({
|
||||
'name': self.project_name,
|
||||
'version': self.version,
|
||||
'project-root': self.project_root,
|
||||
'profile': self.profile_name,
|
||||
'source-paths': self.source_paths,
|
||||
'macro-paths': self.macro_paths,
|
||||
'data-paths': self.data_paths,
|
||||
'test-paths': self.test_paths,
|
||||
'analysis-paths': self.analysis_paths,
|
||||
'docs-paths': self.docs_paths,
|
||||
'asset-paths': self.asset_paths,
|
||||
'target-path': self.target_path,
|
||||
'snapshot-paths': self.snapshot_paths,
|
||||
'clean-targets': self.clean_targets,
|
||||
'log-path': self.log_path,
|
||||
'quoting': self.quoting,
|
||||
'models': self.models,
|
||||
'on-run-start': self.on_run_start,
|
||||
'on-run-end': self.on_run_end,
|
||||
'dispatch': self.dispatch,
|
||||
'seeds': self.seeds,
|
||||
'snapshots': self.snapshots,
|
||||
'sources': self.sources,
|
||||
'tests': self.tests,
|
||||
'vars': self.vars.to_dict(),
|
||||
'require-dbt-version': [
|
||||
v.to_version_string() for v in self.dbt_version
|
||||
],
|
||||
'config-version': self.config_version,
|
||||
})
|
||||
result = deepcopy(
|
||||
{
|
||||
"name": self.project_name,
|
||||
"version": self.version,
|
||||
"project-root": self.project_root,
|
||||
"profile": self.profile_name,
|
||||
"model-paths": self.model_paths,
|
||||
"macro-paths": self.macro_paths,
|
||||
"seed-paths": self.seed_paths,
|
||||
"test-paths": self.test_paths,
|
||||
"analysis-paths": self.analysis_paths,
|
||||
"docs-paths": self.docs_paths,
|
||||
"asset-paths": self.asset_paths,
|
||||
"target-path": self.target_path,
|
||||
"snapshot-paths": self.snapshot_paths,
|
||||
"clean-targets": self.clean_targets,
|
||||
"log-path": self.log_path,
|
||||
"quoting": self.quoting,
|
||||
"models": self.models,
|
||||
"on-run-start": self.on_run_start,
|
||||
"on-run-end": self.on_run_end,
|
||||
"dispatch": self.dispatch,
|
||||
"seeds": self.seeds,
|
||||
"snapshots": self.snapshots,
|
||||
"sources": self.sources,
|
||||
"tests": self.tests,
|
||||
"vars": self.vars.to_dict(),
|
||||
"require-dbt-version": [v.to_version_string() for v in self.dbt_version],
|
||||
"config-version": self.config_version,
|
||||
}
|
||||
)
|
||||
if self.query_comment:
|
||||
result['query-comment'] = \
|
||||
self.query_comment.to_dict(omit_none=True)
|
||||
result["query-comment"] = self.query_comment.to_dict(omit_none=True)
|
||||
|
||||
if with_packages:
|
||||
result.update(self.packages.to_dict(omit_none=True))
|
||||
@@ -603,34 +624,12 @@ class Project:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
@classmethod
|
||||
def partial_load(
|
||||
cls, project_root: str, *, verify_version: bool = False
|
||||
) -> PartialProject:
|
||||
def partial_load(cls, project_root: str, *, verify_version: bool = False) -> PartialProject:
|
||||
return PartialProject.from_project_root(
|
||||
project_root,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def render_from_dict(
|
||||
cls,
|
||||
project_root: str,
|
||||
project_dict: Dict[str, Any],
|
||||
packages_dict: Dict[str, Any],
|
||||
selectors_dict: Dict[str, Any],
|
||||
renderer: DbtProjectYamlRenderer,
|
||||
*,
|
||||
verify_version: bool = False
|
||||
) -> 'Project':
|
||||
partial = PartialProject.from_dicts(
|
||||
project_root=project_root,
|
||||
project_dict=project_dict,
|
||||
packages_dict=packages_dict,
|
||||
selectors_dict=selectors_dict,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
return partial.render(renderer)
|
||||
|
||||
@classmethod
|
||||
def from_project_root(
|
||||
cls,
|
||||
@@ -638,23 +637,33 @@ class Project:
|
||||
renderer: DbtProjectYamlRenderer,
|
||||
*,
|
||||
verify_version: bool = False,
|
||||
) -> 'Project':
|
||||
) -> "Project":
|
||||
partial = cls.partial_load(project_root, verify_version=verify_version)
|
||||
return partial.render(renderer)
|
||||
|
||||
def hashed_name(self):
|
||||
return hashlib.md5(self.project_name.encode('utf-8')).hexdigest()
|
||||
return hashlib.md5(self.project_name.encode("utf-8")).hexdigest()
|
||||
|
||||
def get_selector(self, name: str) -> SelectionSpec:
|
||||
def get_selector(self, name: str) -> Union[SelectionSpec, bool]:
|
||||
if name not in self.selectors:
|
||||
raise RuntimeException(
|
||||
f'Could not find selector named {name}, expected one of '
|
||||
f'{list(self.selectors)}'
|
||||
f"Could not find selector named {name}, expected one of " f"{list(self.selectors)}"
|
||||
)
|
||||
return self.selectors[name]
|
||||
return self.selectors[name]["definition"]
|
||||
|
||||
def get_default_selector_name(self) -> Union[str, None]:
|
||||
"""This function fetch the default selector to use on `dbt run` (if any)
|
||||
:return: either a selector if default is set or None
|
||||
:rtype: Union[SelectionSpec, None]
|
||||
"""
|
||||
for selector_name, selector in self.selectors.items():
|
||||
if selector["default"] is True:
|
||||
return selector_name
|
||||
|
||||
return None
|
||||
|
||||
def get_macro_search_order(self, macro_namespace: str):
|
||||
for dispatch_entry in self.dispatch:
|
||||
if dispatch_entry['macro_namespace'] == macro_namespace:
|
||||
return dispatch_entry['search_order']
|
||||
if dispatch_entry["macro_namespace"] == macro_namespace:
|
||||
return dispatch_entry["search_order"]
|
||||
return None
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
from typing import Dict, Any, Tuple, Optional, Union, Callable
|
||||
|
||||
from dbt.clients.jinja import get_rendered, catch_jinja
|
||||
|
||||
from dbt.exceptions import (
|
||||
DbtProjectError, CompilationException, RecursionException
|
||||
)
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import deep_map
|
||||
from dbt.context.target import TargetContext
|
||||
from dbt.context.secret import SecretContext
|
||||
from dbt.context.base import BaseContext
|
||||
from dbt.contracts.connection import HasCredentials
|
||||
from dbt.exceptions import DbtProjectError, CompilationException, RecursionException
|
||||
from dbt.utils import deep_map_render
|
||||
|
||||
|
||||
Keypath = Tuple[Union[str, int], ...]
|
||||
@@ -18,7 +18,7 @@ class BaseRenderer:
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return 'Rendering'
|
||||
return "Rendering"
|
||||
|
||||
def should_render_keypath(self, keypath: Keypath) -> bool:
|
||||
return True
|
||||
@@ -29,9 +29,7 @@ class BaseRenderer:
|
||||
|
||||
return self.render_value(value, keypath)
|
||||
|
||||
def render_value(
|
||||
self, value: Any, keypath: Optional[Keypath] = None
|
||||
) -> Any:
|
||||
def render_value(self, value: Any, keypath: Optional[Keypath] = None) -> Any:
|
||||
# keypath is ignored.
|
||||
# if it wasn't read as a string, ignore it
|
||||
if not isinstance(value, str):
|
||||
@@ -40,18 +38,15 @@ class BaseRenderer:
|
||||
with catch_jinja():
|
||||
return get_rendered(value, self.context, native=True)
|
||||
except CompilationException as exc:
|
||||
msg = f'Could not render {value}: {exc.msg}'
|
||||
msg = f"Could not render {value}: {exc.msg}"
|
||||
raise CompilationException(msg) from exc
|
||||
|
||||
def render_data(
|
||||
self, data: Dict[str, Any]
|
||||
) -> Dict[str, Any]:
|
||||
def render_data(self, data: Dict[str, Any]) -> Dict[str, Any]:
|
||||
try:
|
||||
return deep_map(self.render_entry, data)
|
||||
return deep_map_render(self.render_entry, data)
|
||||
except RecursionException:
|
||||
raise DbtProjectError(
|
||||
f'Cycle detected: {self.name} input has a reference to itself',
|
||||
project=data
|
||||
f"Cycle detected: {self.name} input has a reference to itself", project=data
|
||||
)
|
||||
|
||||
|
||||
@@ -78,15 +73,15 @@ class ProjectPostprocessor(Dict[Keypath, Callable[[Any], Any]]):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
self[('on-run-start',)] = _list_if_none_or_string
|
||||
self[('on-run-end',)] = _list_if_none_or_string
|
||||
self[("on-run-start",)] = _list_if_none_or_string
|
||||
self[("on-run-end",)] = _list_if_none_or_string
|
||||
|
||||
for k in ('models', 'seeds', 'snapshots'):
|
||||
for k in ("models", "seeds", "snapshots"):
|
||||
self[(k,)] = _dict_if_none
|
||||
self[(k, 'vars')] = _dict_if_none
|
||||
self[(k, 'pre-hook')] = _list_if_none_or_string
|
||||
self[(k, 'post-hook')] = _list_if_none_or_string
|
||||
self[('seeds', 'column_types')] = _dict_if_none
|
||||
self[(k, "vars")] = _dict_if_none
|
||||
self[(k, "pre-hook")] = _list_if_none_or_string
|
||||
self[(k, "post-hook")] = _list_if_none_or_string
|
||||
self[("seeds", "column_types")] = _dict_if_none
|
||||
|
||||
def postprocess(self, value: Any, key: Keypath) -> Any:
|
||||
if key in self:
|
||||
@@ -99,9 +94,25 @@ class ProjectPostprocessor(Dict[Keypath, Callable[[Any], Any]]):
|
||||
class DbtProjectYamlRenderer(BaseRenderer):
|
||||
_KEYPATH_HANDLERS = ProjectPostprocessor()
|
||||
|
||||
def __init__(
|
||||
self, profile: Optional[HasCredentials] = None, cli_vars: Optional[Dict[str, Any]] = None
|
||||
) -> None:
|
||||
# Generate contexts here because we want to save the context
|
||||
# object in order to retrieve the env_vars. This is almost always
|
||||
# a TargetContext, but in the debug task we want a project
|
||||
# even when we don't have a profile.
|
||||
if cli_vars is None:
|
||||
cli_vars = {}
|
||||
if profile:
|
||||
self.ctx_obj = TargetContext(profile, cli_vars)
|
||||
else:
|
||||
self.ctx_obj = BaseContext(cli_vars) # type:ignore
|
||||
context = self.ctx_obj.to_dict()
|
||||
super().__init__(context)
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
'Project config'
|
||||
"Project config"
|
||||
|
||||
def get_package_renderer(self) -> BaseRenderer:
|
||||
return PackageRenderer(self.context)
|
||||
@@ -116,7 +127,7 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
) -> Dict[str, Any]:
|
||||
"""Render the project and insert the project root after rendering."""
|
||||
rendered_project = self.render_data(project)
|
||||
rendered_project['project-root'] = project_root
|
||||
rendered_project["project-root"] = project_root
|
||||
return rendered_project
|
||||
|
||||
def render_packages(self, packages: Dict[str, Any]):
|
||||
@@ -138,101 +149,50 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
|
||||
first = keypath[0]
|
||||
# run hooks are not rendered
|
||||
if first in {'on-run-start', 'on-run-end', 'query-comment'}:
|
||||
if first in {"on-run-start", "on-run-end", "query-comment"}:
|
||||
return False
|
||||
|
||||
# don't render vars blocks until runtime
|
||||
if first == 'vars':
|
||||
if first == "vars":
|
||||
return False
|
||||
|
||||
if first in {'seeds', 'models', 'snapshots', 'tests'}:
|
||||
keypath_parts = {
|
||||
(k.lstrip('+') if isinstance(k, str) else k)
|
||||
for k in keypath
|
||||
}
|
||||
if first in {"seeds", "models", "snapshots", "tests"}:
|
||||
keypath_parts = {(k.lstrip("+ ") if isinstance(k, str) else k) for k in keypath}
|
||||
# model-level hooks
|
||||
if 'pre-hook' in keypath_parts or 'post-hook' in keypath_parts:
|
||||
if "pre-hook" in keypath_parts or "post-hook" in keypath_parts:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
class ProfileRenderer(BaseRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
'Profile'
|
||||
|
||||
|
||||
class SchemaYamlRenderer(BaseRenderer):
|
||||
DOCUMENTABLE_NODES = frozenset(
|
||||
n.pluralize() for n in NodeType.documentable()
|
||||
)
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return 'Rendering yaml'
|
||||
|
||||
def _is_norender_key(self, keypath: Keypath) -> bool:
|
||||
"""
|
||||
models:
|
||||
- name: blah
|
||||
- description: blah
|
||||
tests: ...
|
||||
- columns:
|
||||
- name:
|
||||
- description: blah
|
||||
tests: ...
|
||||
|
||||
Return True if it's tests or description - those aren't rendered
|
||||
"""
|
||||
if len(keypath) >= 2 and keypath[1] in ('tests', 'description'):
|
||||
return True
|
||||
|
||||
if (
|
||||
len(keypath) >= 4 and
|
||||
keypath[1] == 'columns' and
|
||||
keypath[3] in ('tests', 'description')
|
||||
):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
# don't render descriptions or test keyword arguments
|
||||
def should_render_keypath(self, keypath: Keypath) -> bool:
|
||||
if len(keypath) < 2:
|
||||
return True
|
||||
|
||||
if keypath[0] not in self.DOCUMENTABLE_NODES:
|
||||
return True
|
||||
|
||||
if len(keypath) < 3:
|
||||
return True
|
||||
|
||||
if keypath[0] == NodeType.Source.pluralize():
|
||||
if keypath[2] == 'description':
|
||||
return False
|
||||
if keypath[2] == 'tables':
|
||||
if self._is_norender_key(keypath[3:]):
|
||||
return False
|
||||
elif keypath[0] == NodeType.Macro.pluralize():
|
||||
if keypath[2] == 'arguments':
|
||||
if self._is_norender_key(keypath[3:]):
|
||||
return False
|
||||
elif self._is_norender_key(keypath[1:]):
|
||||
return False
|
||||
else: # keypath[0] in self.DOCUMENTABLE_NODES:
|
||||
if self._is_norender_key(keypath[1:]):
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
class PackageRenderer(BaseRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
return 'Packages config'
|
||||
|
||||
|
||||
class SelectorRenderer(BaseRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
return 'Selector config'
|
||||
return "Selector config"
|
||||
|
||||
|
||||
class SecretRenderer(BaseRenderer):
|
||||
def __init__(self, cli_vars: Optional[Dict[str, Any]] = None) -> None:
|
||||
# Generate contexts here because we want to save the context
|
||||
# object in order to retrieve the env_vars.
|
||||
if cli_vars is None:
|
||||
cli_vars = {}
|
||||
self.ctx_obj = SecretContext(cli_vars)
|
||||
context = self.ctx_obj.to_dict()
|
||||
super().__init__(context)
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return "Secret"
|
||||
|
||||
|
||||
class ProfileRenderer(SecretRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
return "Profile"
|
||||
|
||||
|
||||
class PackageRenderer(SecretRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
return "Packages config"
|
||||
|
||||
@@ -1,44 +1,36 @@
|
||||
import itertools
|
||||
import os
|
||||
from copy import deepcopy
|
||||
from dataclasses import dataclass, fields
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import (
|
||||
Dict, Any, Optional, Mapping, Iterator, Iterable, Tuple, List, MutableSet,
|
||||
Type
|
||||
)
|
||||
from typing import Dict, Any, Optional, Mapping, Iterator, Iterable, Tuple, List, MutableSet, Type
|
||||
|
||||
from .profile import Profile
|
||||
from .project import Project
|
||||
from .renderer import DbtProjectYamlRenderer, ProfileRenderer
|
||||
from .utils import parse_cli_vars
|
||||
from dbt import tracking
|
||||
from dbt import flags
|
||||
from dbt.adapters.factory import get_relation_class_by_name, get_include_paths
|
||||
from dbt.helper_types import FQNPath, PathSet
|
||||
from dbt.context.base import generate_base_context
|
||||
from dbt.context.target import generate_target_context
|
||||
from dbt.helper_types import FQNPath, PathSet, DictDefaultEmptyStr
|
||||
from dbt.config.profile import read_user_config
|
||||
from dbt.contracts.connection import AdapterRequiredConfig, Credentials
|
||||
from dbt.contracts.graph.manifest import ManifestMetadata
|
||||
from dbt.contracts.relation import ComponentName
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.ui import warning_tag
|
||||
|
||||
from dbt.contracts.project import Configuration, UserConfig
|
||||
from dbt.exceptions import (
|
||||
RuntimeException,
|
||||
DbtProfileError,
|
||||
DbtProjectError,
|
||||
validator_error_message,
|
||||
warn_or_error,
|
||||
raise_compiler_error
|
||||
raise_compiler_error,
|
||||
)
|
||||
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
|
||||
def _project_quoting_dict(
|
||||
proj: Project, profile: Profile
|
||||
) -> Dict[ComponentName, bool]:
|
||||
def _project_quoting_dict(proj: Project, profile: Profile) -> Dict[ComponentName, bool]:
|
||||
src: Dict[str, Any] = profile.credentials.translate_aliases(proj.quoting)
|
||||
result: Dict[ComponentName, bool] = {}
|
||||
for key in ComponentName:
|
||||
@@ -54,19 +46,20 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
args: Any
|
||||
profile_name: str
|
||||
cli_vars: Dict[str, Any]
|
||||
dependencies: Optional[Mapping[str, 'RuntimeConfig']] = None
|
||||
dependencies: Optional[Mapping[str, "RuntimeConfig"]] = None
|
||||
|
||||
def __post_init__(self):
|
||||
self.validate()
|
||||
|
||||
# Called by 'new_project' and 'from_args'
|
||||
@classmethod
|
||||
def from_parts(
|
||||
cls,
|
||||
project: Project,
|
||||
profile: Profile,
|
||||
args: Any,
|
||||
dependencies: Optional[Mapping[str, 'RuntimeConfig']] = None,
|
||||
) -> 'RuntimeConfig':
|
||||
dependencies: Optional[Mapping[str, "RuntimeConfig"]] = None,
|
||||
) -> "RuntimeConfig":
|
||||
"""Instantiate a RuntimeConfig from its components.
|
||||
|
||||
:param profile: A parsed dbt Profile.
|
||||
@@ -80,15 +73,15 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
.replace_dict(_project_quoting_dict(project, profile))
|
||||
).to_dict(omit_none=True)
|
||||
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, 'vars', '{}'))
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, "vars", "{}"))
|
||||
|
||||
return cls(
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
source_paths=project.source_paths,
|
||||
model_paths=project.model_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
data_paths=project.data_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -97,7 +90,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
modules_path=project.modules_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
quoting=quoting,
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
@@ -115,9 +108,11 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
project_env_vars=project.project_env_vars,
|
||||
profile_env_vars=profile.profile_env_vars,
|
||||
profile_name=profile.profile_name,
|
||||
target_name=profile.target_name,
|
||||
config=profile.config,
|
||||
user_config=profile.user_config,
|
||||
threads=profile.threads,
|
||||
credentials=profile.credentials,
|
||||
args=args,
|
||||
@@ -125,7 +120,8 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
dependencies=dependencies,
|
||||
)
|
||||
|
||||
def new_project(self, project_root: str) -> 'RuntimeConfig':
|
||||
# Called by 'load_projects' in this class
|
||||
def new_project(self, project_root: str) -> "RuntimeConfig":
|
||||
"""Given a new project root, read in its project dictionary, supply the
|
||||
existing project's profile info, and create a new project file.
|
||||
|
||||
@@ -139,22 +135,22 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
profile.validate()
|
||||
|
||||
# load the new project and its packages. Don't pass cli variables.
|
||||
renderer = DbtProjectYamlRenderer(generate_target_context(profile, {}))
|
||||
renderer = DbtProjectYamlRenderer(profile)
|
||||
|
||||
project = Project.from_project_root(
|
||||
project_root,
|
||||
renderer,
|
||||
verify_version=getattr(self.args, 'version_check', False),
|
||||
verify_version=bool(flags.VERSION_CHECK),
|
||||
)
|
||||
|
||||
cfg = self.from_parts(
|
||||
runtime_config = self.from_parts(
|
||||
project=project,
|
||||
profile=profile,
|
||||
args=deepcopy(self.args),
|
||||
)
|
||||
# force our quoting back onto the new project.
|
||||
cfg.quoting = deepcopy(self.quoting)
|
||||
return cfg
|
||||
runtime_config.quoting = deepcopy(self.quoting)
|
||||
return runtime_config
|
||||
|
||||
def serialize(self) -> Dict[str, Any]:
|
||||
"""Serialize the full configuration to a single dictionary. For any
|
||||
@@ -167,7 +163,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
"""
|
||||
result = self.to_project_config(with_packages=True)
|
||||
result.update(self.to_profile_info(serialize_credentials=True))
|
||||
result['cli_vars'] = deepcopy(self.cli_vars)
|
||||
result["cli_vars"] = deepcopy(self.cli_vars)
|
||||
return result
|
||||
|
||||
def validate(self):
|
||||
@@ -187,40 +183,37 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
profile_renderer: ProfileRenderer,
|
||||
profile_name: Optional[str],
|
||||
) -> Profile:
|
||||
return Profile.render_from_args(
|
||||
args, profile_renderer, profile_name
|
||||
)
|
||||
|
||||
return Profile.render_from_args(args, profile_renderer, profile_name)
|
||||
|
||||
@classmethod
|
||||
def collect_parts(
|
||||
cls: Type['RuntimeConfig'], args: Any
|
||||
) -> Tuple[Project, Profile]:
|
||||
def collect_parts(cls: Type["RuntimeConfig"], args: Any) -> Tuple[Project, Profile]:
|
||||
# profile_name from the project
|
||||
project_root = args.project_dir if args.project_dir else os.getcwd()
|
||||
version_check = getattr(args, 'version_check', False)
|
||||
partial = Project.partial_load(
|
||||
project_root,
|
||||
verify_version=version_check
|
||||
)
|
||||
version_check = bool(flags.VERSION_CHECK)
|
||||
partial = Project.partial_load(project_root, verify_version=version_check)
|
||||
|
||||
# build the profile using the base renderer and the one fact we know
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, 'vars', '{}'))
|
||||
profile_renderer = ProfileRenderer(generate_base_context(cli_vars))
|
||||
# Note: only the named profile section is rendered. The rest of the
|
||||
# profile is ignored.
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, "vars", "{}"))
|
||||
profile_renderer = ProfileRenderer(cli_vars)
|
||||
profile_name = partial.render_profile_name(profile_renderer)
|
||||
|
||||
profile = cls._get_rendered_profile(
|
||||
args, profile_renderer, profile_name
|
||||
)
|
||||
profile = cls._get_rendered_profile(args, profile_renderer, profile_name)
|
||||
# Save env_vars encountered in rendering for partial parsing
|
||||
profile.profile_env_vars = profile_renderer.ctx_obj.env_vars
|
||||
|
||||
# get a new renderer using our target information and render the
|
||||
# project
|
||||
ctx = generate_target_context(profile, cli_vars)
|
||||
project_renderer = DbtProjectYamlRenderer(ctx)
|
||||
project_renderer = DbtProjectYamlRenderer(profile, cli_vars)
|
||||
project = partial.render(project_renderer)
|
||||
# Save env_vars encountered in rendering for partial parsing
|
||||
project.project_env_vars = project_renderer.ctx_obj.env_vars
|
||||
return (project, profile)
|
||||
|
||||
# Called in main.py, lib.py, task/base.py
|
||||
@classmethod
|
||||
def from_args(cls, args: Any) -> 'RuntimeConfig':
|
||||
def from_args(cls, args: Any) -> "RuntimeConfig":
|
||||
"""Given arguments, read in dbt_project.yml from the current directory,
|
||||
read in packages.yml if it exists, and use them to find the profile to
|
||||
load.
|
||||
@@ -239,10 +232,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
)
|
||||
|
||||
def get_metadata(self) -> ManifestMetadata:
|
||||
return ManifestMetadata(
|
||||
project_id=self.hashed_name(),
|
||||
adapter_type=self.credentials.type
|
||||
)
|
||||
return ManifestMetadata(project_id=self.hashed_name(), adapter_type=self.credentials.type)
|
||||
|
||||
def _get_v2_config_paths(
|
||||
self,
|
||||
@@ -251,8 +241,8 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
paths: MutableSet[FQNPath],
|
||||
) -> PathSet:
|
||||
for key, value in config.items():
|
||||
if isinstance(value, dict) and not key.startswith('+'):
|
||||
self._get_v2_config_paths(value, path + (key,), paths)
|
||||
if isinstance(value, dict) and not key.startswith("+"):
|
||||
self._get_config_paths(value, path + (key,), paths)
|
||||
else:
|
||||
paths.add(path)
|
||||
return frozenset(paths)
|
||||
@@ -267,7 +257,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
paths = set()
|
||||
|
||||
for key, value in config.items():
|
||||
if isinstance(value, dict) and not key.startswith('+'):
|
||||
if isinstance(value, dict) and not key.startswith("+"):
|
||||
self._get_v2_config_paths(value, path + (key,), paths)
|
||||
else:
|
||||
paths.add(path)
|
||||
@@ -279,11 +269,11 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
a configured path in the resource.
|
||||
"""
|
||||
return {
|
||||
'models': self._get_config_paths(self.models),
|
||||
'seeds': self._get_config_paths(self.seeds),
|
||||
'snapshots': self._get_config_paths(self.snapshots),
|
||||
'sources': self._get_config_paths(self.sources),
|
||||
'tests': self._get_config_paths(self.tests),
|
||||
"models": self._get_config_paths(self.models),
|
||||
"seeds": self._get_config_paths(self.seeds),
|
||||
"snapshots": self._get_config_paths(self.snapshots),
|
||||
"sources": self._get_config_paths(self.sources),
|
||||
"tests": self._get_config_paths(self.tests),
|
||||
}
|
||||
|
||||
def get_unused_resource_config_paths(
|
||||
@@ -304,9 +294,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
|
||||
for config_path in config_paths:
|
||||
if not _is_config_used(config_path, fqns):
|
||||
unused_resource_config_paths.append(
|
||||
(resource_type,) + config_path
|
||||
)
|
||||
unused_resource_config_paths.append((resource_type,) + config_path)
|
||||
return unused_resource_config_paths
|
||||
|
||||
def warn_for_unused_resource_config_paths(
|
||||
@@ -319,13 +307,12 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
return
|
||||
|
||||
msg = UNUSED_RESOURCE_CONFIGURATION_PATH_MESSAGE.format(
|
||||
len(unused),
|
||||
'\n'.join('- {}'.format('.'.join(u)) for u in unused)
|
||||
len(unused), "\n".join("- {}".format(".".join(u)) for u in unused)
|
||||
)
|
||||
|
||||
warn_or_error(msg, log_fmt=warning_tag('{}'))
|
||||
warn_or_error(msg, log_fmt=warning_tag("{}"))
|
||||
|
||||
def load_dependencies(self) -> Mapping[str, 'RuntimeConfig']:
|
||||
def load_dependencies(self) -> Mapping[str, "RuntimeConfig"]:
|
||||
if self.dependencies is None:
|
||||
all_projects = {self.project_name: self}
|
||||
internal_packages = get_include_paths(self.credentials.type)
|
||||
@@ -334,23 +321,20 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
count_packages_installed = len(tuple(self._get_project_directories()))
|
||||
if count_packages_specified > count_packages_installed:
|
||||
raise_compiler_error(
|
||||
f'dbt found {count_packages_specified} package(s) '
|
||||
f'specified in packages.yml, but only '
|
||||
f'{count_packages_installed} package(s) installed '
|
||||
f'in {self.modules_path}. Run "dbt deps" to '
|
||||
f'install package dependencies.'
|
||||
f"dbt found {count_packages_specified} package(s) "
|
||||
f"specified in packages.yml, but only "
|
||||
f"{count_packages_installed} package(s) installed "
|
||||
f'in {self.packages_install_path}. Run "dbt deps" to '
|
||||
f"install package dependencies."
|
||||
)
|
||||
project_paths = itertools.chain(
|
||||
internal_packages,
|
||||
self._get_project_directories()
|
||||
)
|
||||
project_paths = itertools.chain(internal_packages, self._get_project_directories())
|
||||
for project_name, project in self.load_projects(project_paths):
|
||||
if project_name in all_projects:
|
||||
raise_compiler_error(
|
||||
f'dbt found more than one package with the name '
|
||||
f"dbt found more than one package with the name "
|
||||
f'"{project_name}" included in this project. Package '
|
||||
f'names must be unique in a project. Please rename '
|
||||
f'one of these packages.'
|
||||
f"names must be unique in a project. Please rename "
|
||||
f"one of these packages."
|
||||
)
|
||||
all_projects[project_name] = project
|
||||
self.dependencies = all_projects
|
||||
@@ -359,38 +343,41 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
def clear_dependencies(self):
|
||||
self.dependencies = None
|
||||
|
||||
def load_projects(
|
||||
self, paths: Iterable[Path]
|
||||
) -> Iterator[Tuple[str, 'RuntimeConfig']]:
|
||||
# Called by 'load_dependencies' in this class
|
||||
def load_projects(self, paths: Iterable[Path]) -> Iterator[Tuple[str, "RuntimeConfig"]]:
|
||||
for path in paths:
|
||||
try:
|
||||
project = self.new_project(str(path))
|
||||
except DbtProjectError as e:
|
||||
raise DbtProjectError(
|
||||
f'Failed to read package: {e}',
|
||||
result_type='invalid_project',
|
||||
f"Failed to read package: {e}",
|
||||
result_type="invalid_project",
|
||||
path=path,
|
||||
) from e
|
||||
else:
|
||||
yield project.project_name, project
|
||||
|
||||
def _get_project_directories(self) -> Iterator[Path]:
|
||||
root = Path(self.project_root) / self.modules_path
|
||||
root = Path(self.project_root) / self.packages_install_path
|
||||
|
||||
if root.exists():
|
||||
for path in root.iterdir():
|
||||
if path.is_dir() and not path.name.startswith('__'):
|
||||
if path.is_dir() and not path.name.startswith("__"):
|
||||
yield path
|
||||
|
||||
|
||||
class UnsetCredentials(Credentials):
|
||||
def __init__(self):
|
||||
super().__init__('', '')
|
||||
super().__init__("", "")
|
||||
|
||||
@property
|
||||
def type(self):
|
||||
return None
|
||||
|
||||
@property
|
||||
def unique_field(self):
|
||||
return None
|
||||
|
||||
def connection_info(self, *args, **kwargs):
|
||||
return {}
|
||||
|
||||
@@ -398,37 +385,28 @@ class UnsetCredentials(Credentials):
|
||||
return ()
|
||||
|
||||
|
||||
class UnsetConfig(UserConfig):
|
||||
def __getattribute__(self, name):
|
||||
if name in {f.name for f in fields(UserConfig)}:
|
||||
raise AttributeError(
|
||||
f"'UnsetConfig' object has no attribute {name}"
|
||||
)
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
return {}
|
||||
|
||||
|
||||
# This is used by UnsetProfileConfig, for commands which do
|
||||
# not require a profile, i.e. dbt deps and clean
|
||||
class UnsetProfile(Profile):
|
||||
def __init__(self):
|
||||
self.credentials = UnsetCredentials()
|
||||
self.config = UnsetConfig()
|
||||
self.profile_name = ''
|
||||
self.target_name = ''
|
||||
self.user_config = UserConfig() # This will be read in _get_rendered_profile
|
||||
self.profile_name = ""
|
||||
self.target_name = ""
|
||||
self.threads = -1
|
||||
|
||||
def to_target_dict(self):
|
||||
return {}
|
||||
return DictDefaultEmptyStr({})
|
||||
|
||||
def __getattribute__(self, name):
|
||||
if name in {'profile_name', 'target_name', 'threads'}:
|
||||
raise RuntimeException(
|
||||
f'Error: disallowed attribute "{name}" - no profile!'
|
||||
)
|
||||
if name in {"profile_name", "target_name", "threads"}:
|
||||
raise RuntimeException(f'Error: disallowed attribute "{name}" - no profile!')
|
||||
|
||||
return Profile.__getattribute__(self, name)
|
||||
|
||||
|
||||
# This class is used by the dbt deps and clean commands, because they don't
|
||||
# require a functioning profile.
|
||||
@dataclass
|
||||
class UnsetProfileConfig(RuntimeConfig):
|
||||
"""This class acts a lot _like_ a RuntimeConfig, except if your profile is
|
||||
@@ -445,17 +423,15 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
|
||||
def __getattribute__(self, name):
|
||||
# Override __getattribute__ to check that the attribute isn't 'banned'.
|
||||
if name in {'profile_name', 'target_name'}:
|
||||
raise RuntimeException(
|
||||
f'Error: disallowed attribute "{name}" - no profile!'
|
||||
)
|
||||
if name in {"profile_name", "target_name"}:
|
||||
raise RuntimeException(f'Error: disallowed attribute "{name}" - no profile!')
|
||||
|
||||
# avoid every attribute access triggering infinite recursion
|
||||
return RuntimeConfig.__getattribute__(self, name)
|
||||
|
||||
def to_target_dict(self):
|
||||
# re-override the poisoned profile behavior
|
||||
return {}
|
||||
return DictDefaultEmptyStr({})
|
||||
|
||||
@classmethod
|
||||
def from_parts(
|
||||
@@ -463,8 +439,8 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
project: Project,
|
||||
profile: Profile,
|
||||
args: Any,
|
||||
dependencies: Optional[Mapping[str, 'RuntimeConfig']] = None,
|
||||
) -> 'RuntimeConfig':
|
||||
dependencies: Optional[Mapping[str, "RuntimeConfig"]] = None,
|
||||
) -> "RuntimeConfig":
|
||||
"""Instantiate a RuntimeConfig from its components.
|
||||
|
||||
:param profile: Ignored.
|
||||
@@ -472,15 +448,15 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
:param args: The parsed command-line arguments.
|
||||
:returns RuntimeConfig: The new configuration.
|
||||
"""
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, 'vars', '{}'))
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, "vars", "{}"))
|
||||
|
||||
return cls(
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
source_paths=project.source_paths,
|
||||
model_paths=project.model_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
data_paths=project.data_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -489,7 +465,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
modules_path=project.modules_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
quoting=project.quoting, # we never use this anyway.
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
@@ -507,10 +483,12 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
profile_name='',
|
||||
target_name='',
|
||||
config=UnsetConfig(),
|
||||
threads=getattr(args, 'threads', 1),
|
||||
project_env_vars=project.project_env_vars,
|
||||
profile_env_vars=profile.profile_env_vars,
|
||||
profile_name="",
|
||||
target_name="",
|
||||
user_config=UserConfig(),
|
||||
threads=getattr(args, "threads", 1),
|
||||
credentials=UnsetCredentials(),
|
||||
args=args,
|
||||
cli_vars=cli_vars,
|
||||
@@ -524,26 +502,16 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
profile_renderer: ProfileRenderer,
|
||||
profile_name: Optional[str],
|
||||
) -> Profile:
|
||||
try:
|
||||
profile = Profile.render_from_args(
|
||||
args, profile_renderer, profile_name
|
||||
)
|
||||
except (DbtProjectError, DbtProfileError) as exc:
|
||||
logger.debug(
|
||||
'Profile not loaded due to error: {}', exc, exc_info=True
|
||||
)
|
||||
logger.info(
|
||||
'No profile "{}" found, continuing with no target',
|
||||
profile_name
|
||||
)
|
||||
# return the poisoned form
|
||||
profile = UnsetProfile()
|
||||
# disable anonymous usage statistics
|
||||
tracking.disable_tracking()
|
||||
|
||||
profile = UnsetProfile()
|
||||
# The profile (for warehouse connection) is not needed, but we want
|
||||
# to get the UserConfig, which is also in profiles.yml
|
||||
user_config = read_user_config(flags.PROFILES_DIR)
|
||||
profile.user_config = user_config
|
||||
return profile
|
||||
|
||||
@classmethod
|
||||
def from_args(cls: Type[RuntimeConfig], args: Any) -> 'RuntimeConfig':
|
||||
def from_args(cls: Type[RuntimeConfig], args: Any) -> "RuntimeConfig":
|
||||
"""Given arguments, read in dbt_project.yml from the current directory,
|
||||
read in packages.yml if it exists, and use them to find the profile to
|
||||
load.
|
||||
@@ -554,15 +522,8 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
:raises ValidationException: If the cli variables are invalid.
|
||||
"""
|
||||
project, profile = cls.collect_parts(args)
|
||||
if not isinstance(profile, UnsetProfile):
|
||||
# if it's a real profile, return a real config
|
||||
cls = RuntimeConfig
|
||||
|
||||
return cls.from_parts(
|
||||
project=project,
|
||||
profile=profile,
|
||||
args=args
|
||||
)
|
||||
return cls.from_parts(project=project, profile=profile, args=args)
|
||||
|
||||
|
||||
UNUSED_RESOURCE_CONFIGURATION_PATH_MESSAGE = """\
|
||||
@@ -576,6 +537,6 @@ There are {} unused configuration paths:
|
||||
def _is_config_used(path, fqns):
|
||||
if fqns:
|
||||
for fqn in fqns:
|
||||
if len(path) <= len(fqn) and fqn[:len(path)] == path:
|
||||
if len(path) <= len(fqn) and fqn[: len(path)] == path:
|
||||
return True
|
||||
return False
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
from pathlib import Path
|
||||
from typing import Dict, Any
|
||||
from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
yaml, Loader, Dumper, load_yaml_text
|
||||
)
|
||||
from typing import Dict, Any, Union
|
||||
from dbt.clients.yaml_helper import yaml, Loader, Dumper, load_yaml_text # noqa: F401
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from .renderer import SelectorRenderer
|
||||
@@ -29,13 +27,13 @@ Validator Error:
|
||||
"""
|
||||
|
||||
|
||||
class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
|
||||
class SelectorConfig(Dict[str, Dict[str, Union[SelectionSpec, bool]]]):
|
||||
@classmethod
|
||||
def selectors_from_dict(cls, data: Dict[str, Any]) -> 'SelectorConfig':
|
||||
def selectors_from_dict(cls, data: Dict[str, Any]) -> "SelectorConfig":
|
||||
try:
|
||||
SelectorFile.validate(data)
|
||||
selector_file = SelectorFile.from_dict(data)
|
||||
validate_selector_default(selector_file)
|
||||
selectors = parse_from_selectors_definition(selector_file)
|
||||
except ValidationError as exc:
|
||||
yaml_sel_cfg = yaml.dump(exc.instance)
|
||||
@@ -45,12 +43,12 @@ class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
f"union, intersection, string, dictionary. No lists. "
|
||||
f"\nhttps://docs.getdbt.com/reference/node-selection/"
|
||||
f"yaml-selectors",
|
||||
result_type='invalid_selector'
|
||||
result_type="invalid_selector",
|
||||
) from exc
|
||||
except RuntimeException as exc:
|
||||
raise DbtSelectorsError(
|
||||
f'Could not read selector file data: {exc}',
|
||||
result_type='invalid_selector',
|
||||
f"Could not read selector file data: {exc}",
|
||||
result_type="invalid_selector",
|
||||
) from exc
|
||||
|
||||
return cls(selectors)
|
||||
@@ -60,26 +58,28 @@ class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
cls,
|
||||
data: Dict[str, Any],
|
||||
renderer: SelectorRenderer,
|
||||
) -> 'SelectorConfig':
|
||||
) -> "SelectorConfig":
|
||||
try:
|
||||
rendered = renderer.render_data(data)
|
||||
except (ValidationError, RuntimeException) as exc:
|
||||
raise DbtSelectorsError(
|
||||
f'Could not render selector data: {exc}',
|
||||
result_type='invalid_selector',
|
||||
f"Could not render selector data: {exc}",
|
||||
result_type="invalid_selector",
|
||||
) from exc
|
||||
return cls.selectors_from_dict(rendered)
|
||||
|
||||
@classmethod
|
||||
def from_path(
|
||||
cls, path: Path, renderer: SelectorRenderer,
|
||||
) -> 'SelectorConfig':
|
||||
cls,
|
||||
path: Path,
|
||||
renderer: SelectorRenderer,
|
||||
) -> "SelectorConfig":
|
||||
try:
|
||||
data = load_yaml_text(load_file_contents(str(path)))
|
||||
except (ValidationError, RuntimeException) as exc:
|
||||
raise DbtSelectorsError(
|
||||
f'Could not read selector file: {exc}',
|
||||
result_type='invalid_selector',
|
||||
f"Could not read selector file: {exc}",
|
||||
result_type="invalid_selector",
|
||||
path=path,
|
||||
) from exc
|
||||
|
||||
@@ -91,9 +91,7 @@ class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
|
||||
|
||||
def selector_data_from_root(project_root: str) -> Dict[str, Any]:
|
||||
selector_filepath = resolve_path_from_base(
|
||||
'selectors.yml', project_root
|
||||
)
|
||||
selector_filepath = resolve_path_from_base("selectors.yml", project_root)
|
||||
|
||||
if path_exists(selector_filepath):
|
||||
selectors_dict = load_yaml_text(load_file_contents(selector_filepath))
|
||||
@@ -102,22 +100,38 @@ def selector_data_from_root(project_root: str) -> Dict[str, Any]:
|
||||
return selectors_dict
|
||||
|
||||
|
||||
def selector_config_from_data(
|
||||
selectors_data: Dict[str, Any]
|
||||
) -> SelectorConfig:
|
||||
def selector_config_from_data(selectors_data: Dict[str, Any]) -> SelectorConfig:
|
||||
if not selectors_data:
|
||||
selectors_data = {'selectors': []}
|
||||
selectors_data = {"selectors": []}
|
||||
|
||||
try:
|
||||
selectors = SelectorConfig.selectors_from_dict(selectors_data)
|
||||
except ValidationError as e:
|
||||
raise DbtSelectorsError(
|
||||
MALFORMED_SELECTOR_ERROR.format(error=str(e.message)),
|
||||
result_type='invalid_selector',
|
||||
result_type="invalid_selector",
|
||||
) from e
|
||||
return selectors
|
||||
|
||||
|
||||
def validate_selector_default(selector_file: SelectorFile) -> None:
|
||||
"""Check if a selector.yml file has more than 1 default key set to true"""
|
||||
default_set: bool = False
|
||||
default_selector_name: Union[str, None] = None
|
||||
|
||||
for selector in selector_file.selectors:
|
||||
if selector.default is True and default_set is False:
|
||||
default_set = True
|
||||
default_selector_name = selector.name
|
||||
continue
|
||||
if selector.default is True and default_set is True:
|
||||
raise DbtSelectorsError(
|
||||
"Error when parsing the selector file. "
|
||||
"Found multiple selectors with `default: true`:"
|
||||
f"{default_selector_name} and {selector.name}"
|
||||
)
|
||||
|
||||
|
||||
# These are utilities to clean up the dictionary created from
|
||||
# selectors.yml by turning the cli-string format entries into
|
||||
# normalized dictionary entries. It parallels the flow in
|
||||
@@ -125,7 +139,6 @@ def selector_config_from_data(
|
||||
# be necessary to make changes here. Ideally it would be
|
||||
# good to combine the two flows into one at some point.
|
||||
class SelectorDict:
|
||||
|
||||
@classmethod
|
||||
def parse_dict_definition(cls, definition):
|
||||
key = list(definition)[0]
|
||||
@@ -136,10 +149,10 @@ class SelectorDict:
|
||||
new_value = cls.parse_from_definition(sel_def)
|
||||
new_values.append(new_value)
|
||||
value = new_values
|
||||
if key == 'exclude':
|
||||
if key == "exclude":
|
||||
definition = {key: value}
|
||||
elif len(definition) == 1:
|
||||
definition = {'method': key, 'value': value}
|
||||
definition = {"method": key, "value": value}
|
||||
return definition
|
||||
|
||||
@classmethod
|
||||
@@ -161,10 +174,10 @@ class SelectorDict:
|
||||
def parse_from_definition(cls, definition):
|
||||
if isinstance(definition, str):
|
||||
definition = SelectionCriteria.dict_from_single_spec(definition)
|
||||
elif 'union' in definition:
|
||||
definition = cls.parse_a_definition('union', definition)
|
||||
elif 'intersection' in definition:
|
||||
definition = cls.parse_a_definition('intersection', definition)
|
||||
elif "union" in definition:
|
||||
definition = cls.parse_a_definition("union", definition)
|
||||
elif "intersection" in definition:
|
||||
definition = cls.parse_a_definition("intersection", definition)
|
||||
elif isinstance(definition, dict):
|
||||
definition = cls.parse_dict_definition(definition)
|
||||
return definition
|
||||
@@ -175,8 +188,8 @@ class SelectorDict:
|
||||
def parse_from_selectors_list(cls, selectors):
|
||||
selector_dict = {}
|
||||
for selector in selectors:
|
||||
sel_name = selector['name']
|
||||
sel_name = selector["name"]
|
||||
selector_dict[sel_name] = selector
|
||||
definition = cls.parse_from_definition(selector['definition'])
|
||||
selector_dict[sel_name]['definition'] = definition
|
||||
definition = cls.parse_from_definition(selector["definition"])
|
||||
selector_dict[sel_name]["definition"] = definition
|
||||
return selector_dict
|
||||
|
||||
@@ -1,8 +1,9 @@
|
||||
from typing import Dict, Any
|
||||
|
||||
from dbt.clients import yaml_helper
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.exceptions import raise_compiler_error, ValidationException
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.types import InvalidVarsYAML
|
||||
|
||||
|
||||
def parse_cli_vars(var_string: str) -> Dict[str, Any]:
|
||||
@@ -15,9 +16,8 @@ def parse_cli_vars(var_string: str) -> Dict[str, Any]:
|
||||
type_name = var_type.__name__
|
||||
raise_compiler_error(
|
||||
"The --vars argument must be a YAML dictionary, but was "
|
||||
"of type '{}'".format(type_name))
|
||||
"of type '{}'".format(type_name)
|
||||
)
|
||||
except ValidationException:
|
||||
logger.error(
|
||||
"The YAML provided in the --vars argument is not valid.\n"
|
||||
)
|
||||
fire_event(InvalidVarsYAML())
|
||||
raise
|
||||
|
||||
1
core/dbt/context/README.md
Normal file
1
core/dbt/context/README.md
Normal file
@@ -0,0 +1 @@
|
||||
# Contexts and Jinja rendering
|
||||
@@ -1,18 +1,21 @@
|
||||
import json
|
||||
import os
|
||||
from typing import (
|
||||
Any, Dict, NoReturn, Optional, Mapping
|
||||
)
|
||||
from typing import Any, Dict, NoReturn, Optional, Mapping
|
||||
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
from dbt.clients.jinja import undefined_error, get_rendered
|
||||
from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
yaml, safe_load, SafeLoader, Loader, Dumper
|
||||
)
|
||||
from dbt.clients.jinja import get_rendered
|
||||
from dbt.clients.yaml_helper import yaml, safe_load, SafeLoader, Loader, Dumper # noqa: F401
|
||||
from dbt.contracts.graph.compiled import CompiledResource
|
||||
from dbt.exceptions import raise_compiler_error, MacroReturn
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.exceptions import (
|
||||
raise_compiler_error,
|
||||
MacroReturn,
|
||||
raise_parsing_error,
|
||||
disallow_secret_env_var,
|
||||
)
|
||||
from dbt.logger import SECRET_ENV_PREFIX
|
||||
from dbt.events.functions import fire_event, get_invocation_id
|
||||
from dbt.events.types import MacroEventInfo, MacroEventDebug
|
||||
from dbt.version import __version__ as dbt_version
|
||||
|
||||
# These modules are added to the context. Consider alternative
|
||||
@@ -21,42 +24,64 @@ import pytz
|
||||
import datetime
|
||||
import re
|
||||
|
||||
# Contexts in dbt Core
|
||||
# Contexts are used for Jinja rendering. They include context methods,
|
||||
# executable macros, and various settings that are available in Jinja.
|
||||
#
|
||||
# Different contexts are used in different places because we allow access
|
||||
# to different methods and data in different places. Executable SQL, for
|
||||
# example, includes the available macros and the model, while Jinja in
|
||||
# yaml files is more limited.
|
||||
#
|
||||
# The context that is passed to Jinja is always in a dictionary format,
|
||||
# not an actual class, so a 'to_dict()' is executed on a context class
|
||||
# before it is used for rendering.
|
||||
#
|
||||
# Each context has a generate_<name>_context function to create the context.
|
||||
# ProviderContext subclasses have different generate functions for
|
||||
# parsing and for execution.
|
||||
#
|
||||
# Context class hierarchy
|
||||
#
|
||||
# BaseContext -- core/dbt/context/base.py
|
||||
# SecretContext -- core/dbt/context/secret.py
|
||||
# TargetContext -- core/dbt/context/target.py
|
||||
# ConfiguredContext -- core/dbt/context/configured.py
|
||||
# SchemaYamlContext -- core/dbt/context/configured.py
|
||||
# DocsRuntimeContext -- core/dbt/context/configured.py
|
||||
# MacroResolvingContext -- core/dbt/context/configured.py
|
||||
# ManifestContext -- core/dbt/context/manifest.py
|
||||
# QueryHeaderContext -- core/dbt/context/manifest.py
|
||||
# ProviderContext -- core/dbt/context/provider.py
|
||||
# MacroContext -- core/dbt/context/provider.py
|
||||
# ModelContext -- core/dbt/context/provider.py
|
||||
# TestContext -- core/dbt/context/provider.py
|
||||
|
||||
|
||||
def get_pytz_module_context() -> Dict[str, Any]:
|
||||
context_exports = pytz.__all__ # type: ignore
|
||||
|
||||
return {
|
||||
name: getattr(pytz, name) for name in context_exports
|
||||
}
|
||||
return {name: getattr(pytz, name) for name in context_exports}
|
||||
|
||||
|
||||
def get_datetime_module_context() -> Dict[str, Any]:
|
||||
context_exports = [
|
||||
'date',
|
||||
'datetime',
|
||||
'time',
|
||||
'timedelta',
|
||||
'tzinfo'
|
||||
]
|
||||
context_exports = ["date", "datetime", "time", "timedelta", "tzinfo"]
|
||||
|
||||
return {
|
||||
name: getattr(datetime, name) for name in context_exports
|
||||
}
|
||||
return {name: getattr(datetime, name) for name in context_exports}
|
||||
|
||||
|
||||
def get_re_module_context() -> Dict[str, Any]:
|
||||
context_exports = re.__all__
|
||||
# TODO CT-211
|
||||
context_exports = re.__all__ # type: ignore[attr-defined]
|
||||
|
||||
return {
|
||||
name: getattr(re, name) for name in context_exports
|
||||
}
|
||||
return {name: getattr(re, name) for name in context_exports}
|
||||
|
||||
|
||||
def get_context_modules() -> Dict[str, Dict[str, Any]]:
|
||||
return {
|
||||
'pytz': get_pytz_module_context(),
|
||||
'datetime': get_datetime_module_context(),
|
||||
're': get_re_module_context(),
|
||||
"pytz": get_pytz_module_context(),
|
||||
"datetime": get_datetime_module_context(),
|
||||
"re": get_re_module_context(),
|
||||
}
|
||||
|
||||
|
||||
@@ -90,8 +115,8 @@ class ContextMeta(type):
|
||||
new_dct = {}
|
||||
|
||||
for base in bases:
|
||||
context_members.update(getattr(base, '_context_members_', {}))
|
||||
context_attrs.update(getattr(base, '_context_attrs_', {}))
|
||||
context_members.update(getattr(base, "_context_members_", {}))
|
||||
context_attrs.update(getattr(base, "_context_attrs_", {}))
|
||||
|
||||
for key, value in dct.items():
|
||||
if isinstance(value, ContextMember):
|
||||
@@ -100,21 +125,20 @@ class ContextMeta(type):
|
||||
context_attrs[context_key] = key
|
||||
value = value.inner
|
||||
new_dct[key] = value
|
||||
new_dct['_context_members_'] = context_members
|
||||
new_dct['_context_attrs_'] = context_attrs
|
||||
new_dct["_context_members_"] = context_members
|
||||
new_dct["_context_attrs_"] = context_attrs
|
||||
return type.__new__(mcls, name, bases, new_dct)
|
||||
|
||||
|
||||
class Var:
|
||||
UndefinedVarError = "Required var '{}' not found in config:\nVars "\
|
||||
"supplied to {} = {}"
|
||||
UndefinedVarError = "Required var '{}' not found in config:\nVars " "supplied to {} = {}"
|
||||
_VAR_NOTSET = object()
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
context: Mapping[str, Any],
|
||||
cli_vars: Mapping[str, Any],
|
||||
node: Optional[CompiledResource] = None
|
||||
node: Optional[CompiledResource] = None,
|
||||
) -> None:
|
||||
self._context: Mapping[str, Any] = context
|
||||
self._cli_vars: Mapping[str, Any] = cli_vars
|
||||
@@ -129,14 +153,12 @@ class Var:
|
||||
if self._node is not None:
|
||||
return self._node.name
|
||||
else:
|
||||
return '<Configuration>'
|
||||
return "<Configuration>"
|
||||
|
||||
def get_missing_var(self, var_name):
|
||||
dct = {k: self._merged[k] for k in self._merged}
|
||||
pretty_vars = json.dumps(dct, sort_keys=True, indent=4)
|
||||
msg = self.UndefinedVarError.format(
|
||||
var_name, self.node_name, pretty_vars
|
||||
)
|
||||
msg = self.UndefinedVarError.format(var_name, self.node_name, pretty_vars)
|
||||
raise_compiler_error(msg, self._node)
|
||||
|
||||
def has_var(self, var_name: str):
|
||||
@@ -160,14 +182,16 @@ class Var:
|
||||
|
||||
|
||||
class BaseContext(metaclass=ContextMeta):
|
||||
# subclass is TargetContext
|
||||
def __init__(self, cli_vars):
|
||||
self._ctx = {}
|
||||
self.cli_vars = cli_vars
|
||||
self.env_vars = {}
|
||||
|
||||
def generate_builtins(self):
|
||||
builtins: Dict[str, Any] = {}
|
||||
for key, value in self._context_members_.items():
|
||||
if hasattr(value, '__get__'):
|
||||
if hasattr(value, "__get__"):
|
||||
# handle properties, bound methods, etc
|
||||
value = value.__get__(self)
|
||||
builtins[key] = value
|
||||
@@ -175,9 +199,9 @@ class BaseContext(metaclass=ContextMeta):
|
||||
|
||||
# no dbtClassMixin so this is not an actual override
|
||||
def to_dict(self):
|
||||
self._ctx['context'] = self._ctx
|
||||
self._ctx["context"] = self._ctx
|
||||
builtins = self.generate_builtins()
|
||||
self._ctx['builtins'] = builtins
|
||||
self._ctx["builtins"] = builtins
|
||||
self._ctx.update(builtins)
|
||||
return self._ctx
|
||||
|
||||
@@ -271,33 +295,41 @@ class BaseContext(metaclass=ContextMeta):
|
||||
return Var(self._ctx, self.cli_vars)
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def env_var(var: str, default: Optional[str] = None) -> str:
|
||||
def env_var(self, var: str, default: Optional[str] = None) -> str:
|
||||
"""The env_var() function. Return the environment variable named 'var'.
|
||||
If there is no such environment variable set, return the default.
|
||||
|
||||
If the default is None, raise an exception for an undefined variable.
|
||||
"""
|
||||
return_value = None
|
||||
if var.startswith(SECRET_ENV_PREFIX):
|
||||
disallow_secret_env_var(var)
|
||||
if var in os.environ:
|
||||
return os.environ[var]
|
||||
return_value = os.environ[var]
|
||||
elif default is not None:
|
||||
return default
|
||||
return_value = default
|
||||
|
||||
if return_value is not None:
|
||||
self.env_vars[var] = return_value
|
||||
return return_value
|
||||
else:
|
||||
msg = f"Env var required but not provided: '{var}'"
|
||||
undefined_error(msg)
|
||||
raise_parsing_error(msg)
|
||||
|
||||
if os.environ.get("DBT_MACRO_DEBUGGING"):
|
||||
|
||||
if os.environ.get('DBT_MACRO_DEBUGGING'):
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def debug():
|
||||
"""Enter a debugger at this line in the compiled jinja code."""
|
||||
import sys
|
||||
import ipdb # type: ignore
|
||||
|
||||
frame = sys._getframe(3)
|
||||
ipdb.set_trace(frame)
|
||||
return ''
|
||||
return ""
|
||||
|
||||
@contextmember('return')
|
||||
@contextmember("return")
|
||||
@staticmethod
|
||||
def _return(data: Any) -> NoReturn:
|
||||
"""The `return` function can be used in macros to return data to the
|
||||
@@ -348,9 +380,7 @@ class BaseContext(metaclass=ContextMeta):
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def tojson(
|
||||
value: Any, default: Any = None, sort_keys: bool = False
|
||||
) -> Any:
|
||||
def tojson(value: Any, default: Any = None, sort_keys: bool = False) -> Any:
|
||||
"""The `tojson` context method can be used to serialize a Python
|
||||
object primitive, eg. a `dict` or `list` to a json string.
|
||||
|
||||
@@ -443,10 +473,10 @@ class BaseContext(metaclass=ContextMeta):
|
||||
{% endmacro %}"
|
||||
"""
|
||||
if info:
|
||||
logger.info(msg)
|
||||
fire_event(MacroEventInfo(msg=msg))
|
||||
else:
|
||||
logger.debug(msg)
|
||||
return ''
|
||||
fire_event(MacroEventDebug(msg=msg))
|
||||
return ""
|
||||
|
||||
@contextproperty
|
||||
def run_started_at(self) -> Optional[datetime.datetime]:
|
||||
@@ -481,10 +511,7 @@ class BaseContext(metaclass=ContextMeta):
|
||||
"""invocation_id outputs a UUID generated for this dbt run (useful for
|
||||
auditing)
|
||||
"""
|
||||
if tracking.active_user is not None:
|
||||
return tracking.active_user.invocation_id
|
||||
else:
|
||||
return None
|
||||
return get_invocation_id()
|
||||
|
||||
@contextproperty
|
||||
def modules(self) -> Dict[str, Any]:
|
||||
@@ -524,17 +551,27 @@ class BaseContext(metaclass=ContextMeta):
|
||||
-- no-op
|
||||
{% endif %}
|
||||
|
||||
The list of valid flags are:
|
||||
|
||||
- `flags.STRICT_MODE`: True if `--strict` (or `-S`) was provided on the
|
||||
command line
|
||||
- `flags.FULL_REFRESH`: True if `--full-refresh` was provided on the
|
||||
command line
|
||||
- `flags.NON_DESTRUCTIVE`: True if `--non-destructive` was provided on
|
||||
the command line
|
||||
This supports all flags defined in flags submodule (core/dbt/flags.py)
|
||||
TODO: Replace with object that provides read-only access to flag values
|
||||
"""
|
||||
return flags
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def print(msg: str) -> str:
|
||||
"""Prints a line to stdout.
|
||||
|
||||
:param msg: The message to print
|
||||
|
||||
> macros/my_log_macro.sql
|
||||
|
||||
{% macro some_macro(arg1, arg2) %}
|
||||
{{ print("Running some_macro: " ~ arg1 ~ ", " ~ arg2) }}
|
||||
{% endmacro %}"
|
||||
"""
|
||||
print(msg)
|
||||
return ""
|
||||
|
||||
|
||||
def generate_base_context(cli_vars: Dict[str, Any]) -> Dict[str, Any]:
|
||||
ctx = BaseContext(cli_vars)
|
||||
|
||||
@@ -1,19 +1,21 @@
|
||||
from typing import Any, Dict
|
||||
import os
|
||||
from typing import Any, Dict, Optional
|
||||
|
||||
from dbt.contracts.connection import AdapterRequiredConfig
|
||||
from dbt.logger import SECRET_ENV_PREFIX
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import MultiDict
|
||||
|
||||
from dbt.context.base import contextproperty, Var
|
||||
from dbt.context.base import contextproperty, contextmember, Var
|
||||
from dbt.context.target import TargetContext
|
||||
from dbt.exceptions import raise_parsing_error, disallow_secret_env_var
|
||||
|
||||
|
||||
class ConfiguredContext(TargetContext):
|
||||
# subclasses are SchemaYamlContext, MacroResolvingContext, ManifestContext
|
||||
config: AdapterRequiredConfig
|
||||
|
||||
def __init__(
|
||||
self, config: AdapterRequiredConfig
|
||||
) -> None:
|
||||
def __init__(self, config: AdapterRequiredConfig) -> None:
|
||||
super().__init__(config, config.cli_vars)
|
||||
|
||||
@contextproperty
|
||||
@@ -63,16 +65,40 @@ class ConfiguredVar(Var):
|
||||
return self.get_missing_var(var_name)
|
||||
|
||||
|
||||
class SchemaYamlVars:
|
||||
def __init__(self):
|
||||
self.env_vars = {}
|
||||
self.vars = {}
|
||||
|
||||
|
||||
class SchemaYamlContext(ConfiguredContext):
|
||||
def __init__(self, config, project_name: str):
|
||||
# subclass is DocsRuntimeContext
|
||||
def __init__(self, config, project_name: str, schema_yaml_vars: Optional[SchemaYamlVars]):
|
||||
super().__init__(config)
|
||||
self._project_name = project_name
|
||||
self.schema_yaml_vars = schema_yaml_vars
|
||||
|
||||
@contextproperty
|
||||
def var(self) -> ConfiguredVar:
|
||||
return ConfiguredVar(
|
||||
self._ctx, self.config, self._project_name
|
||||
)
|
||||
return ConfiguredVar(self._ctx, self.config, self._project_name)
|
||||
|
||||
@contextmember
|
||||
def env_var(self, var: str, default: Optional[str] = None) -> str:
|
||||
return_value = None
|
||||
if var.startswith(SECRET_ENV_PREFIX):
|
||||
disallow_secret_env_var(var)
|
||||
if var in os.environ:
|
||||
return_value = os.environ[var]
|
||||
elif default is not None:
|
||||
return_value = default
|
||||
|
||||
if return_value is not None:
|
||||
if self.schema_yaml_vars:
|
||||
self.schema_yaml_vars.env_vars[var] = return_value
|
||||
return return_value
|
||||
else:
|
||||
msg = f"Env var required but not provided: '{var}'"
|
||||
raise_parsing_error(msg)
|
||||
|
||||
|
||||
class MacroResolvingContext(ConfiguredContext):
|
||||
@@ -81,15 +107,13 @@ class MacroResolvingContext(ConfiguredContext):
|
||||
|
||||
@contextproperty
|
||||
def var(self) -> ConfiguredVar:
|
||||
return ConfiguredVar(
|
||||
self._ctx, self.config, self.config.project_name
|
||||
)
|
||||
return ConfiguredVar(self._ctx, self.config, self.config.project_name)
|
||||
|
||||
|
||||
def generate_schema_yml(
|
||||
config: AdapterRequiredConfig, project_name: str
|
||||
def generate_schema_yml_context(
|
||||
config: AdapterRequiredConfig, project_name: str, schema_yaml_vars: SchemaYamlVars = None
|
||||
) -> Dict[str, Any]:
|
||||
ctx = SchemaYamlContext(config, project_name)
|
||||
ctx = SchemaYamlContext(config, project_name, schema_yaml_vars)
|
||||
return ctx.to_dict()
|
||||
|
||||
|
||||
|
||||
@@ -17,8 +17,8 @@ class ModelParts(IsFQNResource):
|
||||
package_name: str
|
||||
|
||||
|
||||
T = TypeVar('T') # any old type
|
||||
C = TypeVar('C', bound=BaseConfig)
|
||||
T = TypeVar("T") # any old type
|
||||
C = TypeVar("C", bound=BaseConfig)
|
||||
|
||||
|
||||
class ConfigSource:
|
||||
@@ -36,15 +36,15 @@ class UnrenderedConfig(ConfigSource):
|
||||
def get_config_dict(self, resource_type: NodeType) -> Dict[str, Any]:
|
||||
unrendered = self.project.unrendered.project_dict
|
||||
if resource_type == NodeType.Seed:
|
||||
model_configs = unrendered.get('seeds')
|
||||
model_configs = unrendered.get("seeds")
|
||||
elif resource_type == NodeType.Snapshot:
|
||||
model_configs = unrendered.get('snapshots')
|
||||
model_configs = unrendered.get("snapshots")
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = unrendered.get('sources')
|
||||
model_configs = unrendered.get("sources")
|
||||
elif resource_type == NodeType.Test:
|
||||
model_configs = unrendered.get('tests')
|
||||
model_configs = unrendered.get("tests")
|
||||
else:
|
||||
model_configs = unrendered.get('models')
|
||||
model_configs = unrendered.get("models")
|
||||
|
||||
if model_configs is None:
|
||||
return {}
|
||||
@@ -83,8 +83,8 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
dependencies = self._active_project.load_dependencies()
|
||||
if project_name not in dependencies:
|
||||
raise InternalException(
|
||||
f'Project name {project_name} not found in dependencies '
|
||||
f'(found {list(dependencies)})'
|
||||
f"Project name {project_name} not found in dependencies "
|
||||
f"(found {list(dependencies)})"
|
||||
)
|
||||
return dependencies[project_name]
|
||||
|
||||
@@ -96,8 +96,8 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
for level_config in fqn_search(model_configs, fqn):
|
||||
result = {}
|
||||
for key, value in level_config.items():
|
||||
if key.startswith('+'):
|
||||
result[key[1:]] = deepcopy(value)
|
||||
if key.startswith("+"):
|
||||
result[key[1:].strip()] = deepcopy(value)
|
||||
elif not isinstance(value, dict):
|
||||
result[key] = deepcopy(value)
|
||||
|
||||
@@ -109,9 +109,7 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
return self._project_configs(self._active_project, fqn, resource_type)
|
||||
|
||||
@abstractmethod
|
||||
def _update_from_config(
|
||||
self, result: T, partial: Dict[str, Any], validate: bool = False
|
||||
) -> T:
|
||||
def _update_from_config(self, result: T, partial: Dict[str, Any], validate: bool = False) -> T:
|
||||
...
|
||||
|
||||
@abstractmethod
|
||||
@@ -120,11 +118,12 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
|
||||
def calculate_node_config(
|
||||
self,
|
||||
config_calls: List[Dict[str, Any]],
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: Dict[str, Any] = None,
|
||||
) -> BaseConfig:
|
||||
own_config = self.get_node_project(project_name)
|
||||
|
||||
@@ -134,24 +133,33 @@ class BaseContextConfigGenerator(Generic[T]):
|
||||
for fqn_config in project_configs:
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
|
||||
for config_call in config_calls:
|
||||
result = self._update_from_config(result, config_call)
|
||||
# When schema files patch config, it has lower precedence than
|
||||
# config in the models (config_call_dict), so we add the patch_config_dict
|
||||
# before the config_call_dict
|
||||
if patch_config_dict:
|
||||
result = self._update_from_config(result, patch_config_dict)
|
||||
|
||||
# config_calls are created in the 'experimental' model parser and
|
||||
# the ParseConfigObject (via add_config_call)
|
||||
result = self._update_from_config(result, config_call_dict)
|
||||
|
||||
if own_config.project_name != self._active_project.project_name:
|
||||
for fqn_config in self._active_project_configs(fqn, resource_type):
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
|
||||
# this is mostly impactful in the snapshot config case
|
||||
return result
|
||||
# TODO CT-211
|
||||
return result # type: ignore[return-value]
|
||||
|
||||
@abstractmethod
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_calls: List[Dict[str, Any]],
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: Dict[str, Any],
|
||||
) -> Dict[str, Any]:
|
||||
...
|
||||
|
||||
@@ -172,32 +180,28 @@ class ContextConfigGenerator(BaseContextConfigGenerator[C]):
|
||||
result = config_cls.from_dict({})
|
||||
return result
|
||||
|
||||
def _update_from_config(
|
||||
self, result: C, partial: Dict[str, Any], validate: bool = False
|
||||
) -> C:
|
||||
translated = self._active_project.credentials.translate_aliases(
|
||||
partial
|
||||
)
|
||||
def _update_from_config(self, result: C, partial: Dict[str, Any], validate: bool = False) -> C:
|
||||
translated = self._active_project.credentials.translate_aliases(partial)
|
||||
return result.update_from(
|
||||
translated,
|
||||
self._active_project.credentials.type,
|
||||
validate=validate
|
||||
translated, self._active_project.credentials.type, validate=validate
|
||||
)
|
||||
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_calls: List[Dict[str, Any]],
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: dict = None,
|
||||
) -> Dict[str, Any]:
|
||||
config = self.calculate_node_config(
|
||||
config_calls=config_calls,
|
||||
config_call_dict=config_call_dict,
|
||||
fqn=fqn,
|
||||
resource_type=resource_type,
|
||||
project_name=project_name,
|
||||
base=base,
|
||||
patch_config_dict=patch_config_dict,
|
||||
)
|
||||
finalized = config.finalize_and_validate()
|
||||
return finalized.to_dict(omit_none=True)
|
||||
@@ -209,25 +213,24 @@ class UnrenderedConfigGenerator(BaseContextConfigGenerator[Dict[str, Any]]):
|
||||
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_calls: List[Dict[str, Any]],
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: dict = None,
|
||||
) -> Dict[str, Any]:
|
||||
# TODO CT-211
|
||||
return self.calculate_node_config(
|
||||
config_calls=config_calls,
|
||||
config_call_dict=config_call_dict,
|
||||
fqn=fqn,
|
||||
resource_type=resource_type,
|
||||
project_name=project_name,
|
||||
base=base,
|
||||
)
|
||||
patch_config_dict=patch_config_dict,
|
||||
) # type: ignore[return-value]
|
||||
|
||||
def initial_result(
|
||||
self,
|
||||
resource_type: NodeType,
|
||||
base: bool
|
||||
) -> Dict[str, Any]:
|
||||
def initial_result(self, resource_type: NodeType, base: bool) -> Dict[str, Any]:
|
||||
return {}
|
||||
|
||||
def _update_from_config(
|
||||
@@ -236,9 +239,7 @@ class UnrenderedConfigGenerator(BaseContextConfigGenerator[Dict[str, Any]]):
|
||||
partial: Dict[str, Any],
|
||||
validate: bool = False,
|
||||
) -> Dict[str, Any]:
|
||||
translated = self._active_project.credentials.translate_aliases(
|
||||
partial
|
||||
)
|
||||
translated = self._active_project.credentials.translate_aliases(partial)
|
||||
result.update(translated)
|
||||
return result
|
||||
|
||||
@@ -251,30 +252,48 @@ class ContextConfig:
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
) -> None:
|
||||
self._config_calls: List[Dict[str, Any]] = []
|
||||
self._config_call_dict: Dict[str, Any] = {}
|
||||
self._active_project = active_project
|
||||
self._fqn = fqn
|
||||
self._resource_type = resource_type
|
||||
self._project_name = project_name
|
||||
|
||||
def update_in_model_config(self, opts: Dict[str, Any]) -> None:
|
||||
self._config_calls.append(opts)
|
||||
def add_config_call(self, opts: Dict[str, Any]) -> None:
|
||||
dct = self._config_call_dict
|
||||
self._add_config_call(dct, opts)
|
||||
|
||||
@classmethod
|
||||
def _add_config_call(cls, config_call_dict, opts: Dict[str, Any]) -> None:
|
||||
for k, v in opts.items():
|
||||
# MergeBehavior for post-hook and pre-hook is to collect all
|
||||
# values, instead of overwriting
|
||||
if k in BaseConfig.mergebehavior["append"]:
|
||||
if not isinstance(v, list):
|
||||
v = [v]
|
||||
if k in BaseConfig.mergebehavior["update"] and not isinstance(v, dict):
|
||||
raise InternalException(f"expected dict, got {v}")
|
||||
if k in config_call_dict and isinstance(config_call_dict[k], list):
|
||||
config_call_dict[k].extend(v)
|
||||
elif k in config_call_dict and isinstance(config_call_dict[k], dict):
|
||||
config_call_dict[k].update(v)
|
||||
else:
|
||||
config_call_dict[k] = v
|
||||
|
||||
def build_config_dict(
|
||||
self,
|
||||
base: bool = False,
|
||||
*,
|
||||
rendered: bool = True,
|
||||
self, base: bool = False, *, rendered: bool = True, patch_config_dict: dict = None
|
||||
) -> Dict[str, Any]:
|
||||
if rendered:
|
||||
src = ContextConfigGenerator(self._active_project)
|
||||
# TODO CT-211
|
||||
src = ContextConfigGenerator(self._active_project) # type: ignore[var-annotated]
|
||||
else:
|
||||
src = UnrenderedConfigGenerator(self._active_project)
|
||||
# TODO CT-211
|
||||
src = UnrenderedConfigGenerator(self._active_project) # type: ignore[assignment]
|
||||
|
||||
return src.calculate_node_config_dict(
|
||||
config_calls=self._config_calls,
|
||||
config_call_dict=self._config_call_dict,
|
||||
fqn=self._fqn,
|
||||
resource_type=self._resource_type,
|
||||
project_name=self._project_name,
|
||||
base=base,
|
||||
patch_config_dict=patch_config_dict,
|
||||
)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user