mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-19 17:11:27 +00:00
Compare commits
1 Commits
test-docs-
...
fix/docker
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e93a8720a4 |
@@ -1,5 +1,5 @@
|
||||
[bumpversion]
|
||||
current_version = 1.3.0a1
|
||||
current_version = 1.0.1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
@@ -24,16 +24,16 @@ values =
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
|
||||
[bumpversion:file:core/setup.py]
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/dbt/adapters/postgres/__version__.py]
|
||||
|
||||
[bumpversion:file:docker/Dockerfile]
|
||||
|
||||
[bumpversion:file:tests/adapter/setup.py]
|
||||
|
||||
[bumpversion:file:tests/adapter/dbt/tests/adapter/__version__.py]
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
## Previous Releases
|
||||
|
||||
For information on prior major and minor releases, see their changelogs:
|
||||
|
||||
|
||||
* [1.2](https://github.com/dbt-labs/dbt-core/blob/1.2.latest/CHANGELOG.md)
|
||||
* [1.1](https://github.com/dbt-labs/dbt-core/blob/1.1.latest/CHANGELOG.md)
|
||||
* [1.0](https://github.com/dbt-labs/dbt-core/blob/1.0.latest/CHANGELOG.md)
|
||||
* [0.21](https://github.com/dbt-labs/dbt-core/blob/0.21.latest/CHANGELOG.md)
|
||||
* [0.20](https://github.com/dbt-labs/dbt-core/blob/0.20.latest/CHANGELOG.md)
|
||||
* [0.19](https://github.com/dbt-labs/dbt-core/blob/0.19.latest/CHANGELOG.md)
|
||||
* [0.18](https://github.com/dbt-labs/dbt-core/blob/0.18.latest/CHANGELOG.md)
|
||||
* [0.17](https://github.com/dbt-labs/dbt-core/blob/0.17.latest/CHANGELOG.md)
|
||||
* [0.16](https://github.com/dbt-labs/dbt-core/blob/0.16.latest/CHANGELOG.md)
|
||||
* [0.15](https://github.com/dbt-labs/dbt-core/blob/0.15.latest/CHANGELOG.md)
|
||||
* [0.14](https://github.com/dbt-labs/dbt-core/blob/0.14.latest/CHANGELOG.md)
|
||||
* [0.13](https://github.com/dbt-labs/dbt-core/blob/0.13.latest/CHANGELOG.md)
|
||||
* [0.12](https://github.com/dbt-labs/dbt-core/blob/0.12.latest/CHANGELOG.md)
|
||||
* [0.11 and earlier](https://github.com/dbt-labs/dbt-core/blob/0.11.latest/CHANGELOG.md)
|
||||
@@ -1,53 +0,0 @@
|
||||
# CHANGELOG Automation
|
||||
|
||||
We use [changie](https://changie.dev/) to automate `CHANGELOG` generation. For installation and format/command specifics, see the documentation.
|
||||
|
||||
### Quick Tour
|
||||
|
||||
- All new change entries get generated under `/.changes/unreleased` as a yaml file
|
||||
- `header.tpl.md` contains the contents of the entire CHANGELOG file
|
||||
- `0.0.0.md` contains the contents of the footer for the entire CHANGELOG file. changie looks to be in the process of supporting a footer file the same as it supports a header file. Switch to that when available. For now, the 0.0.0 in the file name forces it to the bottom of the changelog no matter what version we are releasing.
|
||||
- `.changie.yaml` contains the fields in a change, the format of a single change, as well as the format of the Contributors section for each version.
|
||||
|
||||
### Workflow
|
||||
|
||||
#### Daily workflow
|
||||
Almost every code change we make associated with an issue will require a `CHANGELOG` entry. After you have created the PR in GitHub, run `changie new` and follow the command prompts to generate a yaml file with your change details. This only needs to be done once per PR.
|
||||
|
||||
The `changie new` command will ensure correct file format and file name. There is a one to one mapping of issues to changes. Multiple issues cannot be lumped into a single entry. If you make a mistake, the yaml file may be directly modified and saved as long as the format is preserved.
|
||||
|
||||
Note: If your PR has been cleared by the Core Team as not needing a changelog entry, the `Skip Changelog` label may be put on the PR to bypass the GitHub action that blacks PRs from being merged when they are missing a `CHANGELOG` entry.
|
||||
|
||||
#### Prerelease Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` to be included in this prerelease and move those files to a directory named for the release version. The `--move-dir` will be created if it does not exist and is created in `/.changes`.
|
||||
|
||||
```
|
||||
changie batch <version> --move-dir '<version>' --prerelease 'rc1'
|
||||
changie merge
|
||||
```
|
||||
|
||||
Example
|
||||
```
|
||||
changie batch 1.0.5 --move-dir '1.0.5' --prerelease 'rc1'
|
||||
changie merge
|
||||
```
|
||||
|
||||
#### Final Release Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` as well as `/.changes/<version>` to be included in this final release and delete all prereleases. This rolls all prereleases up into a single final release. All `yaml` files in `/unreleased` and `<version>` will be deleted at this point.
|
||||
|
||||
```
|
||||
changie batch <version> --include '<version>' --remove-prereleases
|
||||
changie merge
|
||||
```
|
||||
|
||||
Example
|
||||
```
|
||||
changie batch 1.0.5 --include '1.0.5' --remove-prereleases
|
||||
changie merge
|
||||
```
|
||||
|
||||
### A Note on Manual Edits & Gotchas
|
||||
- Changie generates markdown files in the `.changes` directory that are parsed together with the `changie merge` command. Every time `changie merge` is run, it regenerates the entire file. For this reason, any changes made directly to `CHANGELOG.md` will be overwritten on the next run of `changie merge`.
|
||||
- If changes need to be made to the `CHANGELOG.md`, make the changes to the relevant `<version>.md` file located in the `/.changes` directory. You will then run `changie merge` to regenerate the `CHANGELOG.MD`.
|
||||
- Do not run `changie batch` again on released versions. Our final release workflow deletes all of the yaml files associated with individual changes. If for some reason modifications to the `CHANGELOG.md` are required after we've generated the final release `CHANGELOG.md`, the modifications need to be done manually to the `<version>.md` file in the `/.changes` directory.
|
||||
- changie can modify, create and delete files depending on the command you run. This is expected. Be sure to commit everything that has been modified and deleted.
|
||||
@@ -1,6 +0,0 @@
|
||||
# dbt Core Changelog
|
||||
|
||||
- This file provides a full account of all changes to `dbt-core` and `dbt-postgres`
|
||||
- Changes are listed under the (pre)release in which they first appear. Subsequent releases include changes from previous releases.
|
||||
- "Breaking changes" listed under a version may require action from end users or external maintainers when upgrading to that version.
|
||||
- Do not edit this file directly. This file is auto-generated using [changie](https://github.com/miniscruff/changie). For details on how to document a change, see [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#adding-changelog-entry)
|
||||
@@ -1,8 +0,0 @@
|
||||
kind: Features
|
||||
body: Add reusable function for retrying adapter connections. Utilize said function
|
||||
to add retries for Postgres (and Redshift).
|
||||
time: 2022-07-15T03:55:55.270637265+02:00
|
||||
custom:
|
||||
Author: tomasfarias
|
||||
Issue: "5022"
|
||||
PR: "5432"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Rename try to strict for more intuitiveness
|
||||
time: 2022-07-15T23:11:48.327928+12:00
|
||||
custom:
|
||||
Author: jeremyyeo
|
||||
Issue: "5475"
|
||||
PR: "5477"
|
||||
@@ -1,61 +0,0 @@
|
||||
changesDir: .changes
|
||||
unreleasedDir: unreleased
|
||||
headerPath: header.tpl.md
|
||||
versionHeaderPath: ""
|
||||
changelogPath: CHANGELOG.md
|
||||
versionExt: md
|
||||
versionFormat: '## dbt-core {{.Version}} - {{.Time.Format "January 02, 2006"}}'
|
||||
kindFormat: '### {{.Kind}}'
|
||||
changeFormat: '- {{.Body}} ([#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-core/issues/{{.Custom.Issue}}), [#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-core/pull/{{.Custom.PR}}))'
|
||||
kinds:
|
||||
- label: Breaking Changes
|
||||
- label: Features
|
||||
- label: Fixes
|
||||
- label: Docs
|
||||
- label: Under the Hood
|
||||
- label: Dependencies
|
||||
- label: Security
|
||||
custom:
|
||||
- key: Author
|
||||
label: GitHub Username(s) (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 3
|
||||
- key: Issue
|
||||
label: GitHub Issue Number
|
||||
type: int
|
||||
minLength: 4
|
||||
- key: PR
|
||||
label: GitHub Pull Request Number
|
||||
type: int
|
||||
minLength: 4
|
||||
footerFormat: |
|
||||
{{- $contributorDict := dict }}
|
||||
{{- /* any names added to this list should be all lowercase for later matching purposes */}}
|
||||
{{- $core_team := list "emmyoop" "nathaniel-may" "gshank" "leahwicz" "chenyulinx" "stu-k" "iknox-fa" "versusfacit" "mcknight-42" "jtcohen6" "dependabot" }}
|
||||
{{- range $change := .Changes }}
|
||||
{{- $authorList := splitList " " $change.Custom.Author }}
|
||||
{{- /* loop through all authors for a PR */}}
|
||||
{{- range $author := $authorList }}
|
||||
{{- $authorLower := lower $author }}
|
||||
{{- /* we only want to include non-core team contributors */}}
|
||||
{{- if not (has $authorLower $core_team)}}
|
||||
{{- $pr := $change.Custom.PR }}
|
||||
{{- /* check if this contributor has other PRs associated with them already */}}
|
||||
{{- if hasKey $contributorDict $author }}
|
||||
{{- $prList := get $contributorDict $author }}
|
||||
{{- $prList = append $prList $pr }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- else }}
|
||||
{{- $prList := list $change.Custom.PR }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- end }}
|
||||
{{- end}}
|
||||
{{- end}}
|
||||
{{- end }}
|
||||
{{- /* no indentation here for formatting so the final markdown doesn't have unneeded indentations */}}
|
||||
{{- if $contributorDict}}
|
||||
### Contributors
|
||||
{{- range $k,$v := $contributorDict }}
|
||||
- [@{{$k}}](https://github.com/{{$k}}) ({{ range $index, $element := $v }}{{if $index}}, {{end}}[#{{$element}}](https://github.com/dbt-labs/dbt-core/pull/{{$element}}){{end}})
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
2
.flake8
2
.flake8
@@ -8,5 +8,5 @@ ignore =
|
||||
W504
|
||||
E203 # makes Flake8 work like black
|
||||
E741
|
||||
E501 # long line checking is done in black
|
||||
max-line-length = 99
|
||||
exclude = test
|
||||
|
||||
@@ -1,2 +0,0 @@
|
||||
# Reformatting dbt-core via black, flake8, mypy, and assorted pre-commit hooks.
|
||||
43e3fc22c4eae4d3d901faba05e33c40f1f1dc5a
|
||||
6
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
6
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
@@ -6,7 +6,7 @@ body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this feature request!
|
||||
Thanks for taking the time to fill out this feature requests!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing feature request for this?
|
||||
@@ -14,10 +14,6 @@ body:
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
label: Is this your first time opening an issue?
|
||||
options:
|
||||
- label: I have read the [expectations for open source contributors](https://docs.getdbt.com/docs/contributing/oss-expectations)
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe the Feature
|
||||
|
||||
4
.github/pull_request_template.md
vendored
4
.github/pull_request_template.md
vendored
@@ -15,9 +15,7 @@ resolves #
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] I have read [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md) and understand what's expected of me
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have [opened an issue to add/update docs](https://github.com/dbt-labs/docs.getdbt.com/issues/new/choose), or docs changes are not required/relevant for this PR
|
||||
- [ ] I have run `changie new` to [create a changelog entry](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#Adding-CHANGELOG-Entry)
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change
|
||||
|
||||
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
module.exports = ({ context }) => {
|
||||
const defaultPythonVersion = "3.8";
|
||||
const supportedPythonVersions = ["3.7", "3.8", "3.9"];
|
||||
const supportedAdapters = ["postgres"];
|
||||
|
||||
// if PR, generate matrix based on files changed and PR labels
|
||||
if (context.eventName.includes("pull_request")) {
|
||||
// `changes` is a list of adapter names that have related
|
||||
// file changes in the PR
|
||||
// ex: ['postgres', 'snowflake']
|
||||
const changes = JSON.parse(process.env.CHANGES);
|
||||
const labels = context.payload.pull_request.labels.map(({ name }) => name);
|
||||
console.log("labels", labels);
|
||||
console.log("changes", changes);
|
||||
const testAllLabel = labels.includes("test all");
|
||||
const include = [];
|
||||
|
||||
for (const adapter of supportedAdapters) {
|
||||
if (
|
||||
changes.includes(adapter) ||
|
||||
testAllLabel ||
|
||||
labels.includes(`test ${adapter}`)
|
||||
) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
if (
|
||||
pythonVersion === defaultPythonVersion ||
|
||||
labels.includes(`test python${pythonVersion}`) ||
|
||||
testAllLabel
|
||||
) {
|
||||
// always run tests on ubuntu by default
|
||||
include.push({
|
||||
os: "ubuntu-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
|
||||
if (labels.includes("test windows") || testAllLabel) {
|
||||
include.push({
|
||||
os: "windows-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
|
||||
if (labels.includes("test macos") || testAllLabel) {
|
||||
include.push({
|
||||
os: "macos-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
}
|
||||
// if not PR, generate matrix of python version, adapter, and operating
|
||||
// system to run integration tests on
|
||||
|
||||
const include = [];
|
||||
// run for all adapters and python versions on ubuntu
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
include.push({
|
||||
os: 'ubuntu-latest',
|
||||
adapter: adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
// additionally include runs for all adapters, on macos and windows,
|
||||
// but only for the default python version
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const operatingSystem of ["windows-latest", "macos-latest"]) {
|
||||
include.push({
|
||||
os: operatingSystem,
|
||||
adapter: adapter,
|
||||
"python-version": defaultPythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
};
|
||||
18
.github/workflows/backport.yml
vendored
18
.github/workflows/backport.yml
vendored
@@ -13,28 +13,22 @@
|
||||
# This automates the backporting process
|
||||
|
||||
# **when?**
|
||||
# Once a PR is "Squash and merge"'d, by adding a backport label, this is triggered
|
||||
# Once a PR is "Squash and merge"'d and it has been correctly labeled
|
||||
# according to the naming convention.
|
||||
|
||||
name: Backport
|
||||
on:
|
||||
pull_request:
|
||||
types:
|
||||
- closed
|
||||
- labeled
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
backport:
|
||||
runs-on: ubuntu-18.04
|
||||
name: Backport
|
||||
runs-on: ubuntu-latest
|
||||
# Only react to merged PRs for security reasons.
|
||||
# See https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#pull_request_target.
|
||||
if: >
|
||||
github.event.pull_request.merged
|
||||
&& contains(github.event.label.name, 'backport')
|
||||
steps:
|
||||
- uses: tibdex/backport@v2.0.2
|
||||
- name: Backport
|
||||
uses: tibdex/backport@v1.1.1
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
78
.github/workflows/changelog-check.yml
vendored
78
.github/workflows/changelog-check.yml
vendored
@@ -1,78 +0,0 @@
|
||||
# **what?**
|
||||
# Checks that a file has been committed under the /.changes directory
|
||||
# as a new CHANGELOG entry. Cannot check for a specific filename as
|
||||
# it is dynamically generated by change type and timestamp.
|
||||
# This workflow should not require any secrets since it runs for PRs
|
||||
# from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code change gets reflected in the CHANGELOG.
|
||||
|
||||
# **when?**
|
||||
# This will run for all PRs going into main and *.latest. It will
|
||||
# run when they are opened, reopened, when any label is added or removed
|
||||
# and when new code is pushed to the branch. The action will then get
|
||||
# skipped if the 'Skip Changelog' label is present is any of the labels.
|
||||
|
||||
name: Check Changelog Entry
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [opened, reopened, labeled, unlabeled, synchronize]
|
||||
workflow_dispatch:
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: write
|
||||
|
||||
env:
|
||||
changelog_comment: 'Thank you for your pull request! We could not find a changelog entry for this change. For details on how to document a change, see [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#adding-changelog-entry).'
|
||||
|
||||
jobs:
|
||||
changelog:
|
||||
name: changelog
|
||||
if: "!contains(github.event.pull_request.labels.*.name, 'Skip Changelog')"
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check if changelog file was added
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: filter
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
changelog:
|
||||
- added: '.changes/unreleased/**.yaml'
|
||||
- name: Check if comment already exists
|
||||
uses: peter-evans/find-comment@v1
|
||||
id: changelog_comment
|
||||
with:
|
||||
issue-number: ${{ github.event.pull_request.number }}
|
||||
comment-author: 'github-actions[bot]'
|
||||
body-includes: ${{ env.changelog_comment }}
|
||||
- name: Create PR comment if changelog entry is missing, required, and does not exist
|
||||
if: |
|
||||
steps.filter.outputs.changelog == 'false' &&
|
||||
steps.changelog_comment.outputs.comment-body == ''
|
||||
uses: peter-evans/create-or-update-comment@v1
|
||||
with:
|
||||
issue-number: ${{ github.event.pull_request.number }}
|
||||
body: ${{ env.changelog_comment }}
|
||||
- name: Fail job if changelog entry is missing and required
|
||||
if: steps.filter.outputs.changelog == 'false'
|
||||
uses: actions/github-script@v6
|
||||
with:
|
||||
script: core.setFailed('Changelog entry required to merge.')
|
||||
114
.github/workflows/dependency-changelog.yml
vendored
114
.github/workflows/dependency-changelog.yml
vendored
@@ -1,114 +0,0 @@
|
||||
# **what?**
|
||||
# When dependabot create a PR, it always adds the `dependencies` label. This
|
||||
# action will add a corresponding changie yaml file to that PR when that label is added.
|
||||
# The file is created off a template:
|
||||
#
|
||||
# kind: Dependencies
|
||||
# body: <PR title>
|
||||
# time: <current timestamp>
|
||||
# custom:
|
||||
# Author: dependabot
|
||||
# Issue: 4904
|
||||
# PR: <PR number>
|
||||
#
|
||||
# **why?**
|
||||
# Automate changelog generation for more visability with automated dependency updates via dependabot.
|
||||
|
||||
# **when?**
|
||||
# Once a PR is created and it has been correctly labeled with `dependencies`. The intended use
|
||||
# is for the PRs created by dependabot. You can also manually trigger this by adding the
|
||||
# `dependencies` label at any time.
|
||||
|
||||
name: Dependency Changelog
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
# catch when the PR is opened with the label or when the label is added
|
||||
types: [opened, labeled]
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: read
|
||||
|
||||
jobs:
|
||||
dependency_changelog:
|
||||
if: "contains(github.event.pull_request.labels.*.name, 'dependencies')"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
# timestamp changes the order the changelog entries are listed in the final Changelog.md file. Precision is not
|
||||
# important here.
|
||||
# The timestamp on the filename and the timestamp in the contents of the file have different expected formats.
|
||||
- name: Get File Name Timestamp
|
||||
id: filename_time
|
||||
uses: nanzm/get-time-action@v1.1
|
||||
with:
|
||||
format: 'YYYYMMDD-HHmmss'
|
||||
|
||||
- name: Get File Content Timestamp
|
||||
id: file_content_time
|
||||
uses: nanzm/get-time-action@v1.1
|
||||
with:
|
||||
format: 'YYYY-MM-DDTHH:mm:ss.000000-05:00'
|
||||
|
||||
# changie expects files to be named in a specific pattern.
|
||||
- name: Generate Filepath
|
||||
id: fp
|
||||
run: |
|
||||
FILEPATH=.changes/unreleased/Dependencies-${{ steps.filename_time.outputs.time }}.yaml
|
||||
echo "::set-output name=FILEPATH::$FILEPATH"
|
||||
|
||||
- name: Check if changelog file exists already
|
||||
# if there's already a changelog entry, don't add another one!
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: changelog_check
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
exists:
|
||||
- added: '.changes/unreleased/**.yaml'
|
||||
|
||||
- name: Checkout Branch
|
||||
if: steps.changelog_check.outputs.exists == 'false'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
# specifying the ref avoids checking out the repository in a detached state
|
||||
ref: ${{ github.event.pull_request.head.ref }}
|
||||
# If this is not set to false, Git push is performed with github.token and not the token
|
||||
# configured using the env: GITHUB_TOKEN in commit step
|
||||
persist-credentials: false
|
||||
|
||||
- name: Create file from template
|
||||
if: steps.changelog_check.outputs.exists == 'false'
|
||||
run: |
|
||||
echo kind: Dependencies > "${{ steps.fp.outputs.FILEPATH }}"
|
||||
echo 'body: "${{ github.event.pull_request.title }}"' >> "${{ steps.fp.outputs.FILEPATH }}"
|
||||
echo time: "${{ steps.file_content_time.outputs.time }}" >> "${{ steps.fp.outputs.FILEPATH }}"
|
||||
echo custom: >> "${{ steps.fp.outputs.FILEPATH }}"
|
||||
echo ' Author: ${{ github.event.pull_request.user.login }}' >> "${{ steps.fp.outputs.FILEPATH }}"
|
||||
echo ' Issue: "4904"' >> "${{ steps.fp.outputs.FILEPATH }}" # github.event.pull_request.issue for auto id?
|
||||
echo ' PR: "${{ github.event.pull_request.number }}"' >> "${{ steps.fp.outputs.FILEPATH }}"
|
||||
|
||||
- name: Commit Changelog File
|
||||
if: steps.changelog_check.outputs.exists == 'false'
|
||||
uses: gr2m/create-or-update-pull-request-action@v1
|
||||
env:
|
||||
# When using the GITHUB_TOKEN, the resulting commit will not trigger another GitHub Actions
|
||||
# Workflow run. This is due to limitations set by GitHub.
|
||||
# See: https://docs.github.com/en/actions/security-guides/automatic-token-authentication#using-the-github_token-in-a-workflow
|
||||
# When you use the repository's GITHUB_TOKEN to perform tasks on behalf of the GitHub Actions
|
||||
# app, events triggered by the GITHUB_TOKEN will not create a new workflow run. This prevents
|
||||
# you from accidentally creating recursive workflow runs. To get around this, use a Personal
|
||||
# Access Token to commit changes.
|
||||
GITHUB_TOKEN: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
with:
|
||||
branch: ${{ github.event.pull_request.head.ref }}
|
||||
# author expected in the format "Lorem J. Ipsum <lorem@example.com>"
|
||||
author: "Github Build Bot <buildbot@fishtownanalytics.com>"
|
||||
commit-message: "Add automated changelog yaml from template"
|
||||
222
.github/workflows/integration.yml
vendored
Normal file
222
.github/workflows/integration.yml
vendored
Normal file
@@ -0,0 +1,222 @@
|
||||
# **what?**
|
||||
# This workflow runs all integration tests for supported OS
|
||||
# and python versions and core adapters. If triggered by PR,
|
||||
# the workflow will only run tests for adapters related
|
||||
# to code changes. Use the `test all` and `test ${adapter}`
|
||||
# label to run all or additional tests. Use `ok to test`
|
||||
# label to mark PRs from forked repositories that are safe
|
||||
# to run integration tests for. Requires secrets to run
|
||||
# against different warehouses.
|
||||
|
||||
# **why?**
|
||||
# This checks the functionality of dbt from a user's perspective
|
||||
# and attempts to catch functional regressions.
|
||||
|
||||
# **when?**
|
||||
# This workflow will run on every push to a protected branch
|
||||
# and when manually triggered. It will also run for all PRs, including
|
||||
# PRs from forks. The workflow will be skipped until there is a label
|
||||
# to mark the PR as safe to run.
|
||||
|
||||
name: Adapter Integration Tests
|
||||
|
||||
on:
|
||||
# pushes to release branches
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
# all PRs, important to note that `pull_request_target` workflows
|
||||
# will run in the context of the target branch of a PR
|
||||
pull_request_target:
|
||||
# manual tigger
|
||||
workflow_dispatch:
|
||||
|
||||
# explicitly turn off permissions for `GITHUB_TOKEN`
|
||||
permissions: read-all
|
||||
|
||||
# will cancel previous workflows triggered by the same event and for the same ref for PRs or same SHA otherwise
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(github.event_name, 'pull_request') && github.event.pull_request.head.ref || github.sha }}
|
||||
cancel-in-progress: true
|
||||
|
||||
# sets default shell to bash, for all operating systems
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
# generate test metadata about what files changed and the testing matrix to use
|
||||
test-metadata:
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
if: >-
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
outputs:
|
||||
matrix: ${{ steps.generate-matrix.outputs.result }}
|
||||
|
||||
steps:
|
||||
- name: Check out the repository (non-PR)
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Check if relevant files changed
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: get-changes
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
postgres:
|
||||
- 'core/**'
|
||||
- 'plugins/postgres/**'
|
||||
- 'dev-requirements.txt'
|
||||
|
||||
- name: Generate integration test matrix
|
||||
id: generate-matrix
|
||||
uses: actions/github-script@v4
|
||||
env:
|
||||
CHANGES: ${{ steps.get-changes.outputs.changes }}
|
||||
with:
|
||||
script: |
|
||||
const script = require('./.github/scripts/integration-test-matrix.js')
|
||||
const matrix = script({ context })
|
||||
console.log(matrix)
|
||||
return matrix
|
||||
|
||||
test:
|
||||
name: ${{ matrix.adapter }} / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
# also checks that the matrix generated is not empty
|
||||
if: >-
|
||||
needs.test-metadata.outputs.matrix &&
|
||||
fromJSON( needs.test-metadata.outputs.matrix ).include[0] &&
|
||||
(
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
)
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
needs: test-metadata
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix: ${{ fromJSON(needs.test-metadata.outputs.matrix) }}
|
||||
|
||||
env:
|
||||
TOXENV: integration-${{ matrix.adapter }}
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
# explicity checkout the branch for the PR,
|
||||
# this is necessary for the `pull_request_target` event
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox (postgres)
|
||||
if: matrix.adapter == 'postgres'
|
||||
run: tox
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs
|
||||
path: ./logs
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y-%m-%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ matrix.adapter }}-${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
require-label-comment:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
needs: test
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- name: Needs permission PR comment
|
||||
if: >-
|
||||
needs.test.result == 'skipped' &&
|
||||
github.event_name == 'pull_request_target' &&
|
||||
github.event.pull_request.head.repo.full_name != github.repository
|
||||
uses: unsplash/comment-on-pr@master
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
with:
|
||||
msg: |
|
||||
"You do not have permissions to run integration tests, @dbt-labs/core "\
|
||||
"needs to label this PR with `ok to test` in order to run integration tests!"
|
||||
check_for_duplicate_msg: true
|
||||
158
.github/workflows/main.yml
vendored
158
.github/workflows/main.yml
vendored
@@ -1,8 +1,9 @@
|
||||
# **what?**
|
||||
# Runs code quality checks, unit tests, integration tests and
|
||||
# verifies python build on all code commited to the repository. This workflow
|
||||
# should not require any secrets since it runs for PRs from forked repos. By
|
||||
# default, secrets are not passed to workflows running from a forked repos.
|
||||
# Runs code quality checks, unit tests, and verifies python build on
|
||||
# all code commited to the repository. This workflow should not
|
||||
# require any secrets since it runs for PRs from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code for dbt meets a certain quality standard.
|
||||
@@ -17,6 +18,7 @@ on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
@@ -38,25 +40,25 @@ jobs:
|
||||
name: code-quality
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 10
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install pre-commit
|
||||
pip install --user --upgrade pip
|
||||
pip install pre-commit
|
||||
pip install mypy==0.782
|
||||
pip install -r editable-requirements.txt
|
||||
pip --version
|
||||
pre-commit --version
|
||||
python -m pip install mypy==0.942
|
||||
mypy --version
|
||||
python -m pip install -r requirements.txt
|
||||
python -m pip install -r dev-requirements.txt
|
||||
dbt --version
|
||||
|
||||
- name: Run pre-commit hooks
|
||||
@@ -66,12 +68,11 @@ jobs:
|
||||
name: unit test / python ${{ matrix.python-version }}
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 10
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.7", "3.8", "3.9", "3.10"]
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
@@ -80,6 +81,8 @@ jobs:
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
@@ -88,9 +91,9 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
@@ -107,79 +110,6 @@ jobs:
|
||||
name: unit_results_${{ matrix.python-version }}-${{ steps.date.outputs.date }}.csv
|
||||
path: unit_results.csv
|
||||
|
||||
integration:
|
||||
name: integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
timeout-minutes: 45
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.7", "3.8", "3.9", "3.10"]
|
||||
os: [ubuntu-latest]
|
||||
include:
|
||||
- python-version: 3.8
|
||||
os: windows-latest
|
||||
- python-version: 3.8
|
||||
os: macos-latest
|
||||
|
||||
env:
|
||||
TOXENV: integration
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python tools
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
tox --version
|
||||
|
||||
- name: Run tests
|
||||
run: tox
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y_%m_%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}
|
||||
path: ./logs
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
build:
|
||||
name: build packages
|
||||
|
||||
@@ -188,6 +118,8 @@ jobs:
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
@@ -196,9 +128,9 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
python -m pip --version
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
- name: Build distributions
|
||||
run: ./scripts/build-dist.sh
|
||||
@@ -214,9 +146,47 @@ jobs:
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
test-build:
|
||||
name: verify packages / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
needs: build
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
os: [ubuntu-latest, macos-latest, windows-latest]
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
|
||||
steps:
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade wheel
|
||||
pip --version
|
||||
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
@@ -225,7 +195,7 @@ jobs:
|
||||
- name: Install source distributions
|
||||
# ignore dbt-1.0.0, which intentionally raises an error when installed from source
|
||||
run: |
|
||||
find ./dist/dbt-[a-z]*.gz -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
find ./dist/dbt-[a-z]*.gz -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
|
||||
176
.github/workflows/performance.yml
vendored
Normal file
176
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,176 @@
|
||||
name: Performance Regression Tests
|
||||
# Schedule triggers
|
||||
on:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
schedule:
|
||||
- cron: "5 10,22 * * *"
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: "0.20.latest"
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: make results directory
|
||||
run: mkdir ./final-output/
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./ -o ./final-output/
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final-output/*
|
||||
62
.github/workflows/release-branch-tests.yml
vendored
62
.github/workflows/release-branch-tests.yml
vendored
@@ -1,62 +0,0 @@
|
||||
# **what?**
|
||||
# The purpose of this workflow is to trigger CI to run for each
|
||||
# release branch and main branch on a regular cadence. If the CI workflow
|
||||
# fails for a branch, it will post to dev-core-alerts to raise awareness.
|
||||
# The 'aurelien-baudet/workflow-dispatch' Action triggers the existing
|
||||
# CI worklow file on the given branch to run so that even if we change the
|
||||
# CI workflow file in the future, the one that is tailored for the given
|
||||
# release branch will be used.
|
||||
|
||||
# **why?**
|
||||
# Ensures release branches and main are always shippable and not broken.
|
||||
# Also, can catch any dependencies shifting beneath us that might
|
||||
# introduce breaking changes (could also impact Cloud).
|
||||
|
||||
# **when?**
|
||||
# Mainly on a schedule of 9:00, 13:00, 18:00 UTC everyday.
|
||||
# Manual trigger can also test on demand
|
||||
|
||||
name: Release branch scheduled testing
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '0 9,13,18 * * *' # 9:00, 13:00, 18:00 UTC
|
||||
|
||||
workflow_dispatch: # for manual triggering
|
||||
|
||||
# no special access is needed
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
kick-off-ci:
|
||||
name: Kick-off CI
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
# must run CI 1 branch at a time b/c the workflow-dispatch Action polls for
|
||||
# latest run for results and it gets confused when we kick off multiple runs
|
||||
# at once. There is a race condition so we will just run in sequential order.
|
||||
max-parallel: 1
|
||||
fail-fast: false
|
||||
matrix:
|
||||
branch: [1.0.latest, 1.1.latest, main]
|
||||
|
||||
steps:
|
||||
- name: Call CI workflow for ${{ matrix.branch }} branch
|
||||
id: trigger-step
|
||||
uses: aurelien-baudet/workflow-dispatch@v2.1.1
|
||||
with:
|
||||
workflow: main.yml
|
||||
ref: ${{ matrix.branch }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: Post failure to Slack
|
||||
uses: ravsamhq/notify-slack-action@v1
|
||||
if: ${{ always() && !contains(steps.trigger-step.outputs.workflow-conclusion,'success') }}
|
||||
with:
|
||||
status: ${{ job.status }}
|
||||
notification_title: 'dbt-core scheduled run of "${{ matrix.branch }}" branch not successful'
|
||||
message_format: ':x: CI on branch "${{ matrix.branch }}" ${{ steps.trigger-step.outputs.workflow-conclusion }}'
|
||||
footer: 'Linked failed CI run ${{ steps.trigger-step.outputs.workflow-url }}'
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_DEV_CORE_ALERTS }}
|
||||
@@ -12,9 +12,6 @@
|
||||
|
||||
name: Docker release
|
||||
|
||||
permissions:
|
||||
packages: write
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
@@ -77,7 +74,7 @@ jobs:
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.actor }}
|
||||
username: USERNAME
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Build and push MAJOR.MINOR.PATCH tag
|
||||
3
.github/workflows/stale.yml
vendored
3
.github/workflows/stale.yml
vendored
@@ -12,6 +12,7 @@ jobs:
|
||||
with:
|
||||
stale-issue-message: "This issue has been marked as Stale because it has been open for 180 days with no activity. If you would like the issue to remain open, please remove the stale label or comment on the issue, or it will be closed in 7 days."
|
||||
stale-pr-message: "This PR has been marked as Stale because it has been open for 180 days with no activity. If you would like the PR to remain open, please remove the stale label or comment on the PR, or it will be closed in 7 days."
|
||||
close-issue-message: "Although we are closing this issue as stale, it's not gone forever. Issues can be reopened if there is renewed community interest; add a comment to notify the maintainers."
|
||||
# mark issues/PRs stale when they haven't seen activity in 180 days
|
||||
days-before-stale: 180
|
||||
# ignore checking issues with the following labels
|
||||
exempt-issue-labels: "epic,discussion"
|
||||
|
||||
@@ -6,6 +6,7 @@
|
||||
# version of our structured logging and add new documentation to
|
||||
# communicate these changes.
|
||||
|
||||
|
||||
name: Structured Logging Schema Check
|
||||
on:
|
||||
push:
|
||||
@@ -29,13 +30,9 @@ jobs:
|
||||
# points tests to the log file
|
||||
LOG_DIR: "/home/runner/work/dbt-core/dbt-core/logs"
|
||||
# tells integration tests to output into json format
|
||||
DBT_LOG_FORMAT: "json"
|
||||
# Additional test users
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
|
||||
DBT_LOG_FORMAT: 'json'
|
||||
steps:
|
||||
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
@@ -52,12 +49,8 @@ jobs:
|
||||
toolchain: stable
|
||||
override: true
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
|
||||
- name: Set up postgres
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
@@ -68,7 +61,7 @@ jobs:
|
||||
# integration tests generate a ton of logs in different files. the next step will find them all.
|
||||
# we actually care if these pass, because the normal test run doesn't usually include many json log outputs
|
||||
- name: Run integration tests
|
||||
run: tox -e integration -- -nauto
|
||||
run: tox -e py38-postgres -- -nauto
|
||||
|
||||
# apply our schema tests to every log event from the previous step
|
||||
# skips any output that isn't valid json
|
||||
|
||||
33
.github/workflows/triage-labels.yml
vendored
33
.github/workflows/triage-labels.yml
vendored
@@ -1,33 +0,0 @@
|
||||
# **what?**
|
||||
# When the core team triages, we sometimes need more information from the issue creator. In
|
||||
# those cases we remove the `triage` label and add the `awaiting_response` label. Once we
|
||||
# recieve a response in the form of a comment, we want the `awaiting_response` label removed
|
||||
# in favor of the `triage` label so we are aware that the issue needs action.
|
||||
|
||||
# **why?**
|
||||
# To help with out team triage issue tracking
|
||||
|
||||
# **when?**
|
||||
# This will run when a comment is added to an issue and that issue has to `awaiting_response` label.
|
||||
|
||||
name: Update Triage Label
|
||||
|
||||
on: issue_comment
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
|
||||
jobs:
|
||||
triage_label:
|
||||
if: contains(github.event.issue.labels.*.name, 'awaiting_response')
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: initial labeling
|
||||
uses: andymckay/labeler@master
|
||||
with:
|
||||
add-labels: "triage"
|
||||
remove-labels: "awaiting_response"
|
||||
2
.github/workflows/version-bump.yml
vendored
2
.github/workflows/version-bump.yml
vendored
@@ -107,5 +107,3 @@ jobs:
|
||||
base: ${{github.ref}}
|
||||
title: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
labels: |
|
||||
Skip Changelog
|
||||
|
||||
@@ -21,7 +21,7 @@ repos:
|
||||
- "markdown"
|
||||
- id: check-case-conflict
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 22.3.0
|
||||
rev: 21.12b0
|
||||
hooks:
|
||||
- id: black
|
||||
args:
|
||||
@@ -43,7 +43,7 @@ repos:
|
||||
alias: flake8-check
|
||||
stages: [manual]
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
rev: v0.942
|
||||
rev: v0.782
|
||||
hooks:
|
||||
- id: mypy
|
||||
# N.B.: Mypy is... a bit fragile.
|
||||
|
||||
3553
CHANGELOG.md
Executable file → Normal file
3553
CHANGELOG.md
Executable file → Normal file
File diff suppressed because it is too large
Load Diff
171
CONTRIBUTING.md
171
CONTRIBUTING.md
@@ -1,27 +1,79 @@
|
||||
# Contributing to `dbt-core`
|
||||
|
||||
`dbt-core` is open source software. It is what it is today because community members have opened issues, provided feedback, and [contributed to the knowledge loop](https://www.getdbt.com/dbt-labs/values/). Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
# Contributing to `dbt`
|
||||
|
||||
1. [About this document](#about-this-document)
|
||||
2. [Getting the code](#getting-the-code)
|
||||
3. [Setting up an environment](#setting-up-an-environment)
|
||||
4. [Running `dbt` in development](#running-dbt-core-in-development)
|
||||
5. [Testing dbt-core](#testing)
|
||||
6. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
2. [Proposing a change](#proposing-a-change)
|
||||
3. [Getting the code](#getting-the-code)
|
||||
4. [Setting up an environment](#setting-up-an-environment)
|
||||
5. [Running `dbt` in development](#running-dbt-in-development)
|
||||
6. [Testing](#testing)
|
||||
7. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
|
||||
## About this document
|
||||
|
||||
There are many ways to contribute to the ongoing development of `dbt-core`, such as by participating in discussions and issues. We encourage you to first read our higher-level document: ["Expectations for Open Source Contributors"](https://docs.getdbt.com/docs/contributing/oss-expectations).
|
||||
This document is a guide intended for folks interested in contributing to `dbt-core`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt-core`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
The rest of this document serves as a more granular guide for contributing code changes to `dbt-core` (this repository). It is not intended as a guide for using `dbt-core`, and some pieces assume a level of familiarity with Python development (virtualenvs, `pip`, etc). Specific code snippets in this guide assume you are using macOS or Linux and are comfortable with the command line.
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
If you get stuck, we're happy to help! Drop us a line in the `#dbt-core-development` channel in the [dbt Community Slack](https://community.getdbt.com).
|
||||
#### Adapters
|
||||
|
||||
### Notes
|
||||
If you have an issue or code change suggestion related to a specific database [adapter](https://docs.getdbt.com/docs/available-adapters); please refer to that supported databases seperate repo for those contributions.
|
||||
|
||||
- **Adapters:** Is your issue or proposed code change related to a specific [database adapter](https://docs.getdbt.com/docs/available-adapters)? If so, please open issues, PRs, and discussions in that adapter's repository instead. The sole exception is Postgres; the `dbt-postgres` plugin lives in this repository (`dbt-core`).
|
||||
- **CLA:** Please note that anyone contributing code to `dbt-core` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements). If you are unable to sign the CLA, the `dbt-core` maintainers will unfortunately be unable to merge any of your Pull Requests. We welcome you to participate in discussions, open issues, and comment on existing ones.
|
||||
- **Branches:** All pull requests from community contributors should target the `main` branch (default). If the change is needed as a patch for a minor version of dbt that has already been released (or is already a release candidate), a maintainer will backport the changes in your PR to the relevant "latest" release branch (`1.0.latest`, `1.1.latest`, ...)
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to `dbt-core` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt-core` codebase. If you are unable to sign the CLA, then the `dbt-core` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
|
||||
## Proposing a change
|
||||
|
||||
`dbt-core` is Apache 2.0-licensed open source software. `dbt-core` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt-core`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt-core/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt-core` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
### Discussing the idea
|
||||
|
||||
After you open an issue, a `dbt-core` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt-core` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
|
||||
### Submitting a change
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt-core` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The `dbt-core` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt-core/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
- Outline your planned implementation. If you want help getting started, ask!
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt-core` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt-core`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Check your formatting and linting with [Flake8](https://flake8.pycqa.org/en/latest/#), [Black](https://github.com/psf/black), and the rest of the hooks we have in our [pre-commit](https://pre-commit.com/) [config](https://github.com/dbt-labs/dbt-core/blob/75201be9db1cb2c6c01fa7e71a314f5e5beb060a/.pre-commit-config.yaml).
|
||||
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt-core` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt-core` maintainers are unwilling or unable to incorporate into the `dbt-core` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt-core` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
|
||||
### Using issue labels
|
||||
|
||||
The `dbt-core` maintainers use labels to categorize open issues. Most labels describe the domain in the `dbt-core` codebase germane to the discussion.
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/dbt-labs/dbt-core/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt-core` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt-core/labels/bug) | This issue represents a defect or regression in `dbt-core` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt-core/labels/enhancement) | This issue represents net-new functionality in `dbt-core` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt-core/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt-core` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt-core/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt-core/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt-core/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt-core` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt-core/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt-core` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt-core/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt-core` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt-core/labels/wontfix) | This issue does not require a code change in the `dbt-core` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
`dbt-core` has three types of branches:
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `main` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt-core`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt-core`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk branch or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
@@ -33,11 +85,11 @@ You will need `git` in order to download and modify the `dbt-core` source code.
|
||||
|
||||
If you are not a member of the `dbt-labs` GitHub organization, you can contribute to `dbt-core` by forking the `dbt-core` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
|
||||
1. Fork the `dbt-core` repository
|
||||
2. Clone your fork locally
|
||||
3. Check out a new branch for your proposed changes
|
||||
4. Push changes to your fork
|
||||
5. Open a pull request against `dbt-labs/dbt-core` from your forked repository
|
||||
1. fork the `dbt-core` repository
|
||||
2. clone your fork locally
|
||||
3. check out a new branch for your proposed changes
|
||||
4. push changes to your fork
|
||||
5. open a pull request against `dbt-labs/dbt` from your forked repository
|
||||
|
||||
### dbt Labs contributors
|
||||
|
||||
@@ -49,21 +101,19 @@ There are some tools that will be helpful to you in developing locally. While th
|
||||
|
||||
### Tools
|
||||
|
||||
These are the tools used in `dbt-core` development and testing:
|
||||
A short list of tools used in `dbt-core` testing that will be helpful to your understanding:
|
||||
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.7, 3.8, 3.9, and 3.10
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to define, discover, and run tests
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`black`](https://github.com/psf/black) for code formatting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [`pre-commit`](https://pre-commit.com) to easily run those checks
|
||||
- [`changie`](https://changie.dev/) to create changelog entries, without merge conflicts
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) to run multiple setup or test steps in combination. Don't worry too much, nobody _really_ understands how `make` works, and our Makefile aims to be super simple.
|
||||
- [GitHub Actions](https://github.com/features/actions) for automating tests and checks, once a PR is pushed to the `dbt-core` repository
|
||||
- [Github Actions](https://github.com/features/actions)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about each one.
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
#### Virtual environments
|
||||
#### virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in `dbt-core`. We recommend creating this virtualenv
|
||||
in the root of the `dbt-core` repository. To create a new virtualenv, run:
|
||||
@@ -74,12 +124,12 @@ source env/bin/activate
|
||||
|
||||
This will create and activate a new Python virtual environment.
|
||||
|
||||
#### Docker and `docker-compose`
|
||||
#### docker and docker-compose
|
||||
|
||||
Docker and `docker-compose` are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
Docker and docker-compose are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
|
||||
|
||||
#### Postgres (optional)
|
||||
#### postgres (optional)
|
||||
|
||||
For testing, and later in the examples in this document, you may want to have `psql` available so you can poke around in the database and see what happened. We recommend that you use [homebrew](https://brew.sh/) for that on macOS, and your package manager on Linux. You can install any version of the postgres client that you'd like. On macOS, with homebrew setup, you can run:
|
||||
|
||||
@@ -99,26 +149,24 @@ make dev
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
```
|
||||
|
||||
When installed in this way, any changes you make to your local copy of the source code will be reflected immediately in your next `dbt` run.
|
||||
When `dbt-core` is installed this way, any changes you make to the `dbt-core` source code will be reflected immediately in your next `dbt-core` run.
|
||||
|
||||
|
||||
### Running `dbt-core`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
With your virtualenv activated, the `dbt-core` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local Postgres instance, or a specific test sandbox within your data warehouse if appropriate.
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local postgres instance, or a specific test sandbox within your data warehouse if appropriate.
|
||||
|
||||
## Testing
|
||||
|
||||
Once you're able to manually test that your code change is working as expected, it's important to run existing automated tests, as well as adding some new ones. These tests will ensure that:
|
||||
- Your code changes do not unexpectedly break other established functionality
|
||||
- Your code changes can handle all known edge cases
|
||||
- The functionality you're adding will _keep_ working in the future
|
||||
Getting the `dbt-core` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt-core`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
Although `dbt-core` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead, you can test most `dbt-core` code changes with Python and Postgres.
|
||||
Although `dbt-core` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead you can test all dbt-core code changes with Python and Postgres.
|
||||
|
||||
### Initial setup
|
||||
|
||||
Postgres offers the easiest way to test most `dbt-core` functionality today. They are the fastest to run, and the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
We recommend starting with `dbt-core`'s Postgres tests. These tests cover most of the functionality in `dbt-core`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
@@ -144,50 +192,39 @@ make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a local installation of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> These make targets assume you have a local install of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
|
||||
#### `pre-commit`
|
||||
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
[`pre-commit`](https.pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.7, Python 3.8, Python 3.9, and Python 3.10 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py37`. The configuration for these tests in located in `tox.ini`.
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.7, Python 3.8, and Python 3.9 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py37`. The configuration for these tests in located in `tox.ini`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv active and dev dependencies installed you can do things like:
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv
|
||||
active and dev dependencies installed you can do things like:
|
||||
```sh
|
||||
# run specific postgres integration tests
|
||||
python -m pytest -m profile_postgres test/integration/001_simple_copy_test
|
||||
# run all unit tests in a file
|
||||
python3 -m pytest test/unit/test_graph.py
|
||||
python -m pytest test/unit/test_graph.py
|
||||
# run a specific unit test
|
||||
python3 -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
# run specific Postgres integration tests (old way)
|
||||
python3 -m pytest -m profile_postgres test/integration/074_postgres_unlogged_table_tests
|
||||
# run specific Postgres integration tests (new way)
|
||||
python3 -m pytest tests/functional/sources
|
||||
python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
```
|
||||
|
||||
> See [pytest usage docs](https://docs.pytest.org/en/6.2.x/usage.html) for an overview of useful command-line options.
|
||||
|
||||
## Adding CHANGELOG Entry
|
||||
|
||||
We use [changie](https://changie.dev) to generate `CHANGELOG` entries. **Note:** Do not edit the `CHANGELOG.md` directly. Your modifications will be lost.
|
||||
|
||||
Follow the steps to [install `changie`](https://changie.dev/guide/installation/) for your system.
|
||||
|
||||
Once changie is installed and your PR is created, simply run `changie new` and changie will walk you through the process of creating a changelog entry. Commit the file that's created and your changelog entry is complete!
|
||||
|
||||
You don't need to worry about which `dbt-core` version your change will go into. Just create the changelog entry with `changie`, and open your PR against the `main` branch. All merged changes will be included in the next minor version of `dbt-core`. The Core maintainers _may_ choose to "backport" specific changes in order to patch older minor versions. In that case, a maintainer will take care of that backport after merging your PR, before releasing the new version of `dbt-core`.
|
||||
|
||||
> [Here](https://docs.pytest.org/en/reorganize-docs/new-docs/user/commandlineuseful.html)
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
## Submitting a Pull Request
|
||||
|
||||
A `dbt-core` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
dbt Labs provides a CI environment to test changes to specific adapters, and periodic maintenance checks of `dbt-core` through Github Actions. For example, if you submit a pull request to the `dbt-redshift` repo, GitHub will trigger automated code checks and tests against Redshift.
|
||||
|
||||
A `dbt-core` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
- First time contributors should note code checks + unit tests require a maintainer to approve.
|
||||
|
||||
Automated tests run via GitHub Actions. If you're a first-time contributor, all tests (including code checks and unit tests) will require a maintainer to approve. Changes in the `dbt-core` repository trigger integration tests against Postgres. dbt Labs also provides CI environments in which to test changes to other adapters, triggered by PRs in those adapters' repositories, as well as periodic maintenance checks of each adapter in concert with the latest `dbt-core` code changes.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a `dbt-core` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
# See `/docker` for a generic and production-ready docker file
|
||||
##
|
||||
|
||||
FROM ubuntu:22.04
|
||||
FROM ubuntu:20.04
|
||||
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
@@ -46,9 +46,6 @@ RUN apt-get update \
|
||||
python3.9 \
|
||||
python3.9-dev \
|
||||
python3.9-venv \
|
||||
python3.10 \
|
||||
python3.10-dev \
|
||||
python3.10-venv \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
|
||||
|
||||
|
||||
27
Makefile
27
Makefile
@@ -9,7 +9,8 @@ endif
|
||||
.PHONY: dev
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies.
|
||||
@\
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt && \
|
||||
pre-commit install
|
||||
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy against staged changes for static type checking.
|
||||
@@ -33,27 +34,33 @@ lint: .env ## Runs flake8 and mypy code checks against staged changes.
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py
|
||||
unit: .env ## Runs unit tests with py38.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py
|
||||
$(DOCKER_CMD) tox -e py38
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py and code checks against staged changes.
|
||||
test: .env ## Runs unit tests with py38 and code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py; \
|
||||
$(DOCKER_CMD) tox -p -e py38; \
|
||||
$(DOCKER_CMD) pre-commit run black-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env ## Runs postgres integration tests with py-integration
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py-integration -- -nauto
|
||||
integration: .env integration-postgres ## Alias for integration-postgres.
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env ## Runs postgres integration tests with py-integration in "fail fast" mode.
|
||||
integration-fail-fast: .env integration-postgres-fail-fast ## Alias for integration-postgres-fail-fast.
|
||||
|
||||
.PHONY: integration-postgres
|
||||
integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py-integration -- -x -nauto
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -nauto
|
||||
|
||||
.PHONY: integration-postgres-fail-fast
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
|
||||
@@ -3,13 +3,16 @@
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||

|
||||
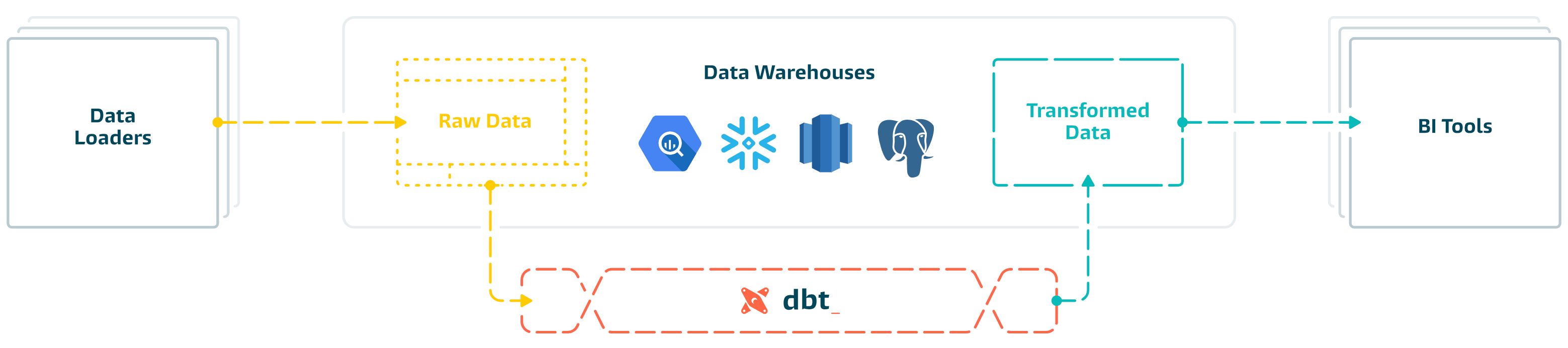
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
|
||||
@@ -3,7 +3,10 @@
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
# N.B.
|
||||
# This will add to the package’s __path__ all subdirectories of directories on sys.path named after the package which effectively combines both modules into a single namespace (dbt.adapters)
|
||||
# The matching statement is in plugins/postgres/dbt/__init__.py
|
||||
|
||||
from pkgutil import extend_path
|
||||
|
||||
__path__ = extend_path(__path__, __name__)
|
||||
@@ -1,30 +1 @@
|
||||
# Adapters README
|
||||
|
||||
The Adapters module is responsible for defining database connection methods, caching information from databases, how relations are defined, and the two major connection types we have - base and sql.
|
||||
|
||||
# Directories
|
||||
|
||||
## `base`
|
||||
|
||||
Defines the base implementation Adapters can use to build out full functionality.
|
||||
|
||||
## `sql`
|
||||
|
||||
Defines a sql implementation for adapters that initially inherits the above base implementation and comes with some premade methods and macros that can be overwritten as needed per adapter. (most common type of adapter.)
|
||||
|
||||
# Files
|
||||
|
||||
## `cache.py`
|
||||
|
||||
Cached information from the database.
|
||||
|
||||
## `factory.py`
|
||||
Defines how we generate adapter objects
|
||||
|
||||
## `protocol.py`
|
||||
|
||||
Defines various interfaces for various adapter objects. Helps mypy correctly resolve methods.
|
||||
|
||||
## `reference_keys.py`
|
||||
|
||||
Configures naming scheme for cache elements to be universal.
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
# N.B.
|
||||
# This will add to the package’s __path__ all subdirectories of directories on sys.path named after the package which effectively combines both modules into a single namespace (dbt.adapters)
|
||||
# The matching statement is in plugins/postgres/dbt/adapters/__init__.py
|
||||
|
||||
from pkgutil import extend_path
|
||||
|
||||
__path__ = extend_path(__path__, __name__)
|
||||
@@ -1,24 +1,10 @@
|
||||
import abc
|
||||
import os
|
||||
from time import sleep
|
||||
import sys
|
||||
|
||||
# multiprocessing.RLock is a function returning this type
|
||||
from multiprocessing.synchronize import RLock
|
||||
from threading import get_ident
|
||||
from typing import (
|
||||
Any,
|
||||
Dict,
|
||||
Tuple,
|
||||
Hashable,
|
||||
Optional,
|
||||
ContextManager,
|
||||
List,
|
||||
Type,
|
||||
Union,
|
||||
Iterable,
|
||||
Callable,
|
||||
)
|
||||
from typing import Dict, Tuple, Hashable, Optional, ContextManager, List, Union
|
||||
|
||||
import agate
|
||||
|
||||
@@ -35,7 +21,6 @@ from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.adapters.base.query_headers import (
|
||||
MacroQueryStringSetter,
|
||||
)
|
||||
from dbt.events import AdapterLogger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
NewConnection,
|
||||
@@ -49,9 +34,6 @@ from dbt.events.types import (
|
||||
)
|
||||
from dbt import flags
|
||||
|
||||
SleepTime = Union[int, float] # As taken by time.sleep.
|
||||
AdapterHandle = Any # Adapter connection handle objects can be any class.
|
||||
|
||||
|
||||
class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
"""Methods to implement:
|
||||
@@ -177,94 +159,6 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
conn.name = conn_name
|
||||
return conn
|
||||
|
||||
@classmethod
|
||||
def retry_connection(
|
||||
cls,
|
||||
connection: Connection,
|
||||
connect: Callable[[], AdapterHandle],
|
||||
logger: AdapterLogger,
|
||||
retryable_exceptions: Iterable[Type[Exception]],
|
||||
retry_limit: int = 1,
|
||||
retry_timeout: Union[Callable[[int], SleepTime], SleepTime] = 1,
|
||||
_attempts: int = 0,
|
||||
) -> Connection:
|
||||
"""Given a Connection, set its handle by calling connect.
|
||||
|
||||
The calls to connect will be retried up to retry_limit times to deal with transient
|
||||
connection errors. By default, one retry will be attempted if retryable_exceptions is set.
|
||||
|
||||
:param Connection connection: An instance of a Connection that needs a handle to be set,
|
||||
usually when attempting to open it.
|
||||
:param connect: A callable that returns the appropiate connection handle for a
|
||||
given adapter. This callable will be retried retry_limit times if a subclass of any
|
||||
Exception in retryable_exceptions is raised by connect.
|
||||
:type connect: Callable[[], AdapterHandle]
|
||||
:param AdapterLogger logger: A logger to emit messages on retry attempts or errors. When
|
||||
handling expected errors, we call debug, and call warning on unexpected errors or when
|
||||
all retry attempts have been exhausted.
|
||||
:param retryable_exceptions: An iterable of exception classes that if raised by
|
||||
connect should trigger a retry.
|
||||
:type retryable_exceptions: Iterable[Type[Exception]]
|
||||
:param int retry_limit: How many times to retry the call to connect. If this limit
|
||||
is exceeded before a successful call, a FailedToConnectException will be raised.
|
||||
Must be non-negative.
|
||||
:param retry_timeout: Time to wait between attempts to connect. Can also take a
|
||||
Callable that takes the number of attempts so far, beginning at 0, and returns an int
|
||||
or float to be passed to time.sleep.
|
||||
:type retry_timeout: Union[Callable[[int], SleepTime], SleepTime] = 1
|
||||
:param int _attempts: Parameter used to keep track of the number of attempts in calling the
|
||||
connect function across recursive calls. Passed as an argument to retry_timeout if it
|
||||
is a Callable. This parameter should not be set by the initial caller.
|
||||
:raises dbt.exceptions.FailedToConnectException: Upon exhausting all retry attempts without
|
||||
successfully acquiring a handle.
|
||||
:return: The given connection with its appropriate state and handle attributes set
|
||||
depending on whether we successfully acquired a handle or not.
|
||||
"""
|
||||
timeout = retry_timeout(_attempts) if callable(retry_timeout) else retry_timeout
|
||||
if timeout < 0:
|
||||
raise dbt.exceptions.FailedToConnectException(
|
||||
"retry_timeout cannot be negative or return a negative time."
|
||||
)
|
||||
|
||||
if retry_limit < 0 or retry_limit > sys.getrecursionlimit():
|
||||
# This guard is not perfect others may add to the recursion limit (e.g. built-ins).
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException("retry_limit cannot be negative")
|
||||
|
||||
try:
|
||||
connection.handle = connect()
|
||||
connection.state = ConnectionState.OPEN
|
||||
return connection
|
||||
|
||||
except tuple(retryable_exceptions) as e:
|
||||
if retry_limit <= 0:
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException(str(e))
|
||||
|
||||
logger.debug(
|
||||
f"Got a retryable error when attempting to open a {cls.TYPE} connection.\n"
|
||||
f"{retry_limit} attempts remaining. Retrying in {timeout} seconds.\n"
|
||||
f"Error:\n{e}"
|
||||
)
|
||||
|
||||
sleep(timeout)
|
||||
return cls.retry_connection(
|
||||
connection=connection,
|
||||
connect=connect,
|
||||
logger=logger,
|
||||
retry_limit=retry_limit - 1,
|
||||
retry_timeout=retry_timeout,
|
||||
retryable_exceptions=retryable_exceptions,
|
||||
_attempts=_attempts + 1,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException(str(e))
|
||||
|
||||
@abc.abstractmethod
|
||||
def cancel_open(self) -> Optional[List[str]]:
|
||||
"""Cancel all open connections on the adapter. (passable)"""
|
||||
@@ -272,8 +166,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
"`cancel_open` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def open(cls, connection: Connection) -> Connection:
|
||||
"""Open the given connection on the adapter and return it.
|
||||
|
||||
@@ -388,15 +281,15 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@abc.abstractmethod
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL.
|
||||
|
||||
:param str sql: The sql to execute.
|
||||
:param bool auto_begin: If set, and dbt is not currently inside a
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the query status and results (empty if fetch=False).
|
||||
:rtype: Tuple[AdapterResponse, agate.Table]
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
"`execute` is not implemented for this adapter!"
|
||||
|
||||
@@ -130,15 +130,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
methods are marked with a (passable) in their docstrings. Check docstrings
|
||||
for type information, etc.
|
||||
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}" in the
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}". in the
|
||||
adapter's internal project.
|
||||
|
||||
To invoke a method in an adapter macro, call it on the 'adapter' Jinja
|
||||
object using dot syntax.
|
||||
|
||||
To invoke a method in model code, add the @available decorator atop a method
|
||||
declaration. Methods are invoked as macros.
|
||||
|
||||
Methods:
|
||||
- exception_handler
|
||||
- date_function
|
||||
@@ -159,7 +153,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
- convert_datetime_type
|
||||
- convert_date_type
|
||||
- convert_time_type
|
||||
- standardize_grants_dict
|
||||
|
||||
Macros:
|
||||
- get_catalog
|
||||
@@ -228,7 +221,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
@available.parse(lambda *a, **k: ("", empty_table()))
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL. This is a thin wrapper around
|
||||
ConnectionManager.execute.
|
||||
|
||||
@@ -236,8 +229,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
:param bool auto_begin: If set, and dbt is not currently inside a
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the query status and results (empty if fetch=False).
|
||||
:rtype: Tuple[AdapterResponse, agate.Table]
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
return self.connections.execute(sql=sql, auto_begin=auto_begin, fetch=fetch)
|
||||
|
||||
@@ -277,15 +270,12 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
return self._macro_manifest_lazy
|
||||
|
||||
def load_macro_manifest(self, base_macros_only=False) -> MacroManifest:
|
||||
# base_macros_only is for the test framework
|
||||
def load_macro_manifest(self) -> MacroManifest:
|
||||
if self._macro_manifest_lazy is None:
|
||||
# avoid a circular import
|
||||
from dbt.parser.manifest import ManifestLoader
|
||||
|
||||
manifest = ManifestLoader.load_macros(
|
||||
self.config, self.connections.set_query_header, base_macros_only=base_macros_only
|
||||
)
|
||||
manifest = ManifestLoader.load_macros(self.config, self.connections.set_query_header)
|
||||
# TODO CT-211
|
||||
self._macro_manifest_lazy = manifest # type: ignore[assignment]
|
||||
# TODO CT-211
|
||||
@@ -347,14 +337,11 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
# databases
|
||||
return info_schema_name_map
|
||||
|
||||
def _relations_cache_for_schemas(
|
||||
self, manifest: Manifest, cache_schemas: Set[BaseRelation] = None
|
||||
) -> None:
|
||||
def _relations_cache_for_schemas(self, manifest: Manifest) -> None:
|
||||
"""Populate the relations cache for the given schemas. Returns an
|
||||
iterable of the schemas populated, as strings.
|
||||
"""
|
||||
if not cache_schemas:
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
with executor(self.config) as tpe:
|
||||
futures: List[Future[List[BaseRelation]]] = []
|
||||
for cache_schema in cache_schemas:
|
||||
@@ -380,16 +367,14 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
cache_update.add((relation.database, relation.schema))
|
||||
self.cache.update_schemas(cache_update)
|
||||
|
||||
def set_relations_cache(
|
||||
self, manifest: Manifest, clear: bool = False, required_schemas: Set[BaseRelation] = None
|
||||
) -> None:
|
||||
def set_relations_cache(self, manifest: Manifest, clear: bool = False) -> None:
|
||||
"""Run a query that gets a populated cache of the relations in the
|
||||
database and set the cache on this adapter.
|
||||
"""
|
||||
with self.cache.lock:
|
||||
if clear:
|
||||
self.cache.clear()
|
||||
self._relations_cache_for_schemas(manifest, required_schemas)
|
||||
self._relations_cache_for_schemas(manifest)
|
||||
|
||||
@available
|
||||
def cache_added(self, relation: Optional[BaseRelation]) -> str:
|
||||
@@ -435,14 +420,12 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
###
|
||||
# Abstract methods for database-specific values, attributes, and types
|
||||
###
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def date_function(cls) -> str:
|
||||
"""Get the date function used by this adapter's database."""
|
||||
raise NotImplementedException("`date_function` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def is_cancelable(cls) -> bool:
|
||||
raise NotImplementedException("`is_cancelable` is not implemented for this adapter!")
|
||||
|
||||
@@ -539,33 +522,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"`list_relations_without_caching` is not implemented for this " "adapter!"
|
||||
)
|
||||
|
||||
###
|
||||
# Methods about grants
|
||||
###
|
||||
@available
|
||||
def standardize_grants_dict(self, grants_table: agate.Table) -> dict:
|
||||
"""Translate the result of `show grants` (or equivalent) to match the
|
||||
grants which a user would configure in their project.
|
||||
|
||||
Ideally, the SQL to show grants should also be filtering:
|
||||
filter OUT any grants TO the current user/role (e.g. OWNERSHIP).
|
||||
If that's not possible in SQL, it can be done in this method instead.
|
||||
|
||||
:param grants_table: An agate table containing the query result of
|
||||
the SQL returned by get_show_grant_sql
|
||||
:return: A standardized dictionary matching the `grants` config
|
||||
:rtype: dict
|
||||
"""
|
||||
grants_dict: Dict[str, List[str]] = {}
|
||||
for row in grants_table:
|
||||
grantee = row["grantee"]
|
||||
privilege = row["privilege_type"]
|
||||
if privilege in grants_dict.keys():
|
||||
grants_dict[privilege].append(grantee)
|
||||
else:
|
||||
grants_dict.update({privilege: [grantee]})
|
||||
return grants_dict
|
||||
|
||||
###
|
||||
# Provided methods about relations
|
||||
###
|
||||
@@ -764,8 +720,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise NotImplementedException("`drop_schema` is not implemented for this adapter!")
|
||||
|
||||
@available
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def quote(cls, identifier: str) -> str:
|
||||
"""Quote the given identifier, as appropriate for the database."""
|
||||
raise NotImplementedException("`quote` is not implemented for this adapter!")
|
||||
@@ -811,8 +766,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
# Conversions: These must be implemented by concrete implementations, for
|
||||
# converting agate types into their sql equivalents.
|
||||
###
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_text_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Text
|
||||
type for the given agate table and column index.
|
||||
@@ -823,8 +777,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_text_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_number_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Number
|
||||
type for the given agate table and column index.
|
||||
@@ -835,8 +788,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_number_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_boolean_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Boolean
|
||||
type for the given agate table and column index.
|
||||
@@ -849,8 +801,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"`convert_boolean_type` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_datetime_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.DateTime
|
||||
type for the given agate table and column index.
|
||||
@@ -863,8 +814,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"`convert_datetime_type` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_date_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Date
|
||||
type for the given agate table and column index.
|
||||
@@ -875,8 +825,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_date_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_time_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the
|
||||
agate.TimeDelta type for the given agate table and column index.
|
||||
|
||||
@@ -140,6 +140,8 @@ class AdapterContainer:
|
||||
raise InternalException(f"No plugin found for {plugin_name}") from None
|
||||
plugins.append(plugin)
|
||||
seen.add(plugin_name)
|
||||
if plugin.dependencies is None:
|
||||
continue
|
||||
for dep in plugin.dependencies:
|
||||
if dep not in seen:
|
||||
plugin_names.append(dep)
|
||||
@@ -175,10 +177,6 @@ def get_adapter(config: AdapterRequiredConfig):
|
||||
return FACTORY.lookup_adapter(config.credentials.type)
|
||||
|
||||
|
||||
def get_adapter_by_type(adapter_type):
|
||||
return FACTORY.lookup_adapter(adapter_type)
|
||||
|
||||
|
||||
def reset_adapters():
|
||||
"""Clear the adapters. This is useful for tests, which change configs."""
|
||||
FACTORY.reset_adapters()
|
||||
|
||||
@@ -7,6 +7,7 @@ from typing import (
|
||||
List,
|
||||
Generic,
|
||||
TypeVar,
|
||||
ClassVar,
|
||||
Tuple,
|
||||
Union,
|
||||
Dict,
|
||||
@@ -87,13 +88,10 @@ class AdapterProtocol( # type: ignore[misc]
|
||||
Compiler_T,
|
||||
],
|
||||
):
|
||||
# N.B. Technically these are ClassVars, but mypy doesn't support putting type vars in a
|
||||
# ClassVar due to the restirctiveness of PEP-526
|
||||
# See: https://github.com/python/mypy/issues/5144
|
||||
AdapterSpecificConfigs: Type[AdapterConfig_T]
|
||||
Column: Type[Column_T]
|
||||
Relation: Type[Relation_T]
|
||||
ConnectionManager: Type[ConnectionManager_T]
|
||||
AdapterSpecificConfigs: ClassVar[Type[AdapterConfig_T]]
|
||||
Column: ClassVar[Type[Column_T]]
|
||||
Relation: ClassVar[Type[Relation_T]]
|
||||
ConnectionManager: ClassVar[Type[ConnectionManager_T]]
|
||||
connections: ConnectionManager_T
|
||||
|
||||
def __init__(self, config: AdapterRequiredConfig):
|
||||
@@ -157,7 +155,7 @@ class AdapterProtocol( # type: ignore[misc]
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
...
|
||||
|
||||
def get_compiler(self) -> Compiler_T:
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# this module exists to resolve circular imports with the events module
|
||||
|
||||
from collections import namedtuple
|
||||
from typing import Any, Optional
|
||||
from typing import Optional
|
||||
|
||||
|
||||
_ReferenceKey = namedtuple("_ReferenceKey", "database schema identifier")
|
||||
@@ -14,7 +14,7 @@ def lowercase(value: Optional[str]) -> Optional[str]:
|
||||
return value.lower()
|
||||
|
||||
|
||||
def _make_key(relation: Any) -> _ReferenceKey:
|
||||
def _make_key(relation) -> _ReferenceKey:
|
||||
"""Make _ReferenceKeys with lowercase values for the cache so we don't have
|
||||
to keep track of quoting
|
||||
"""
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import abc
|
||||
import time
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict, Union
|
||||
|
||||
import agate
|
||||
|
||||
@@ -77,9 +77,8 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
return connection, cursor
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
def get_response(cls, cursor: Any) -> AdapterResponse:
|
||||
@abc.abstractclassmethod
|
||||
def get_response(cls, cursor: Any) -> Union[AdapterResponse, str]:
|
||||
"""Get the status of the cursor."""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
"`get_response` is not implemented for this adapter!"
|
||||
@@ -118,7 +117,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[AdapterResponse, str], agate.Table]:
|
||||
sql = self._add_query_comment(sql)
|
||||
_, cursor = self.add_query(sql, auto_begin)
|
||||
response = self.get_response(cursor)
|
||||
|
||||
@@ -27,7 +27,7 @@ ALTER_COLUMN_TYPE_MACRO_NAME = "alter_column_type"
|
||||
|
||||
class SQLAdapter(BaseAdapter):
|
||||
"""The default adapter with the common agate conversions and some SQL
|
||||
methods was implemented. This adapter has a different much shorter list of
|
||||
methods implemented. This adapter has a different much shorter list of
|
||||
methods to implement, but some more macros that must be implemented.
|
||||
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}". in the
|
||||
@@ -171,7 +171,6 @@ class SQLAdapter(BaseAdapter):
|
||||
"relation": relation,
|
||||
}
|
||||
self.execute_macro(DROP_SCHEMA_MACRO_NAME, kwargs=kwargs)
|
||||
self.commit_if_has_connection()
|
||||
# we can update the cache here
|
||||
self.cache.drop_schema(relation.database, relation.schema)
|
||||
|
||||
@@ -219,25 +218,3 @@ class SQLAdapter(BaseAdapter):
|
||||
kwargs = {"information_schema": information_schema, "schema": schema}
|
||||
results = self.execute_macro(CHECK_SCHEMA_EXISTS_MACRO_NAME, kwargs=kwargs)
|
||||
return results[0][0] > 0
|
||||
|
||||
# This is for use in the test suite
|
||||
def run_sql_for_tests(self, sql, fetch, conn):
|
||||
cursor = conn.handle.cursor()
|
||||
try:
|
||||
cursor.execute(sql)
|
||||
if hasattr(conn.handle, "commit"):
|
||||
conn.handle.commit()
|
||||
if fetch == "one":
|
||||
return cursor.fetchone()
|
||||
elif fetch == "all":
|
||||
return cursor.fetchall()
|
||||
else:
|
||||
return
|
||||
except BaseException as e:
|
||||
if conn.handle and not getattr(conn.handle, "closed", True):
|
||||
conn.handle.rollback()
|
||||
print(sql)
|
||||
print(e)
|
||||
raise
|
||||
finally:
|
||||
conn.transaction_open = False
|
||||
|
||||
@@ -80,7 +80,7 @@ def table_from_rows(
|
||||
|
||||
|
||||
def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert a list of dictionaries into an Agate table"
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
|
||||
# The agate table is generated from a list of dicts, so the column order
|
||||
# from `data` is not preserved. We can use `select` to reorder the columns
|
||||
|
||||
@@ -28,7 +28,7 @@ def _is_commit(revision: str) -> bool:
|
||||
|
||||
|
||||
def _raise_git_cloning_error(repo, revision, error):
|
||||
stderr = error.stderr.strip()
|
||||
stderr = error.stderr.decode("utf-8").strip()
|
||||
if "usage: git" in stderr:
|
||||
stderr = stderr.split("\nusage: git")[0]
|
||||
if re.match("fatal: destination path '(.+)' already exists", stderr):
|
||||
@@ -115,8 +115,8 @@ def checkout(cwd, repo, revision=None):
|
||||
try:
|
||||
return _checkout(cwd, repo, revision)
|
||||
except CommandResultError as exc:
|
||||
stderr = exc.stderr.strip()
|
||||
bad_package_spec(repo, revision, stderr)
|
||||
stderr = exc.stderr.decode("utf-8").strip()
|
||||
bad_package_spec(repo, revision, stderr)
|
||||
|
||||
|
||||
def get_current_sha(cwd):
|
||||
@@ -142,7 +142,7 @@ def clone_and_checkout(
|
||||
subdirectory=subdirectory,
|
||||
)
|
||||
except CommandResultError as exc:
|
||||
err = exc.stderr
|
||||
err = exc.stderr.decode("utf-8")
|
||||
exists = re.match("fatal: destination path '(.+)' already exists", err)
|
||||
if not exists:
|
||||
raise_git_cloning_problem(repo)
|
||||
|
||||
@@ -103,7 +103,7 @@ class NativeSandboxEnvironment(MacroFuzzEnvironment):
|
||||
|
||||
|
||||
class TextMarker(str):
|
||||
"""A special native-env marker that indicates a value is text and is
|
||||
"""A special native-env marker that indicates that a value is text and is
|
||||
not to be evaluated. Use this to prevent your numbery-strings from becoming
|
||||
numbers!
|
||||
"""
|
||||
@@ -580,7 +580,7 @@ def extract_toplevel_blocks(
|
||||
allowed_blocks: Optional[Set[str]] = None,
|
||||
collect_raw_data: bool = True,
|
||||
) -> List[Union[BlockData, BlockTag]]:
|
||||
"""Extract the top-level blocks with matching block types from a jinja
|
||||
"""Extract the top level blocks with matching block types from a jinja
|
||||
file, with some special handling for block nesting.
|
||||
|
||||
:param data: The data to extract blocks from.
|
||||
|
||||
@@ -1,17 +1,7 @@
|
||||
import functools
|
||||
from typing import Any, Dict, List
|
||||
import requests
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
RegistryProgressMakingGETRequest,
|
||||
RegistryProgressGETResponse,
|
||||
RegistryIndexProgressMakingGETRequest,
|
||||
RegistryIndexProgressGETResponse,
|
||||
RegistryResponseUnexpectedType,
|
||||
RegistryResponseMissingTopKeys,
|
||||
RegistryResponseMissingNestedKeys,
|
||||
RegistryResponseExtraNestedKeys,
|
||||
)
|
||||
from dbt.events.types import RegistryProgressMakingGETRequest, RegistryProgressGETResponse
|
||||
from dbt.utils import memoized, _connection_exception_retry as connection_exception_retry
|
||||
from dbt import deprecations
|
||||
import os
|
||||
@@ -22,86 +12,55 @@ else:
|
||||
DEFAULT_REGISTRY_BASE_URL = "https://hub.getdbt.com/"
|
||||
|
||||
|
||||
def _get_url(name, registry_base_url=None):
|
||||
def _get_url(url, registry_base_url=None):
|
||||
if registry_base_url is None:
|
||||
registry_base_url = DEFAULT_REGISTRY_BASE_URL
|
||||
url = "api/v1/{}.json".format(name)
|
||||
|
||||
return "{}{}".format(registry_base_url, url)
|
||||
|
||||
|
||||
def _get_with_retries(package_name, registry_base_url=None):
|
||||
get_fn = functools.partial(_get, package_name, registry_base_url)
|
||||
def _get_with_retries(path, registry_base_url=None):
|
||||
get_fn = functools.partial(_get, path, registry_base_url)
|
||||
return connection_exception_retry(get_fn, 5)
|
||||
|
||||
|
||||
def _get(package_name, registry_base_url=None):
|
||||
url = _get_url(package_name, registry_base_url)
|
||||
def _get(path, registry_base_url=None):
|
||||
url = _get_url(path, registry_base_url)
|
||||
fire_event(RegistryProgressMakingGETRequest(url=url))
|
||||
# all exceptions from requests get caught in the retry logic so no need to wrap this here
|
||||
resp = requests.get(url, timeout=30)
|
||||
fire_event(RegistryProgressGETResponse(url=url, resp_code=resp.status_code))
|
||||
resp.raise_for_status()
|
||||
|
||||
# The response should always be a dictionary. Anything else is unexpected, raise error.
|
||||
# Raising this error will cause this function to retry (if called within _get_with_retries)
|
||||
# and hopefully get a valid response. This seems to happen when there's an issue with the Hub.
|
||||
# Since we control what we expect the HUB to return, this is safe.
|
||||
# It is unexpected for the content of the response to be None so if it is, raising this error
|
||||
# will cause this function to retry (if called within _get_with_retries) and hopefully get
|
||||
# a response. This seems to happen when there's an issue with the Hub.
|
||||
# See https://github.com/dbt-labs/dbt-core/issues/4577
|
||||
# and https://github.com/dbt-labs/dbt-core/issues/4849
|
||||
response = resp.json()
|
||||
|
||||
if not isinstance(response, dict): # This will also catch Nonetype
|
||||
error_msg = (
|
||||
f"Request error: Expected a response type of <dict> but got {type(response)} instead"
|
||||
if resp.json() is None:
|
||||
raise requests.exceptions.ContentDecodingError(
|
||||
"Request error: The response is None", response=resp
|
||||
)
|
||||
fire_event(RegistryResponseUnexpectedType(response=response))
|
||||
raise requests.exceptions.ContentDecodingError(error_msg, response=resp)
|
||||
|
||||
# check for expected top level keys
|
||||
expected_keys = {"name", "versions"}
|
||||
if not expected_keys.issubset(response):
|
||||
error_msg = (
|
||||
f"Request error: Expected the response to contain keys {expected_keys} "
|
||||
f"but is missing {expected_keys.difference(set(response))}"
|
||||
)
|
||||
fire_event(RegistryResponseMissingTopKeys(response=response))
|
||||
raise requests.exceptions.ContentDecodingError(error_msg, response=resp)
|
||||
|
||||
# check for the keys we need nested under each version
|
||||
expected_version_keys = {"name", "packages", "downloads"}
|
||||
all_keys = set().union(*(response["versions"][d] for d in response["versions"]))
|
||||
if not expected_version_keys.issubset(all_keys):
|
||||
error_msg = (
|
||||
"Request error: Expected the response for the version to contain keys "
|
||||
f"{expected_version_keys} but is missing {expected_version_keys.difference(all_keys)}"
|
||||
)
|
||||
fire_event(RegistryResponseMissingNestedKeys(response=response))
|
||||
raise requests.exceptions.ContentDecodingError(error_msg, response=resp)
|
||||
|
||||
# all version responses should contain identical keys.
|
||||
has_extra_keys = set().difference(*(response["versions"][d] for d in response["versions"]))
|
||||
if has_extra_keys:
|
||||
error_msg = (
|
||||
"Request error: Keys for all versions do not match. Found extra key(s) "
|
||||
f"of {has_extra_keys}."
|
||||
)
|
||||
fire_event(RegistryResponseExtraNestedKeys(response=response))
|
||||
raise requests.exceptions.ContentDecodingError(error_msg, response=resp)
|
||||
|
||||
return response
|
||||
return resp.json()
|
||||
|
||||
|
||||
_get_cached = memoized(_get_with_retries)
|
||||
def index(registry_base_url=None):
|
||||
return _get_with_retries("api/v1/index.json", registry_base_url)
|
||||
|
||||
|
||||
def package(package_name, registry_base_url=None) -> Dict[str, Any]:
|
||||
# returns a dictionary of metadata for all versions of a package
|
||||
response = _get_cached(package_name, registry_base_url)
|
||||
index_cached = memoized(index)
|
||||
|
||||
|
||||
def packages(registry_base_url=None):
|
||||
return _get_with_retries("api/v1/packages.json", registry_base_url)
|
||||
|
||||
|
||||
def package(name, registry_base_url=None):
|
||||
response = _get_with_retries("api/v1/{}.json".format(name), registry_base_url)
|
||||
|
||||
# Either redirectnamespace or redirectname in the JSON response indicate a redirect
|
||||
# redirectnamespace redirects based on package ownership
|
||||
# redirectname redirects based on package name
|
||||
# Both can be present at the same time, or neither. Fails gracefully to old name
|
||||
|
||||
if ("redirectnamespace" in response) or ("redirectname" in response):
|
||||
|
||||
if ("redirectnamespace" in response) and response["redirectnamespace"] is not None:
|
||||
@@ -115,49 +74,15 @@ def package(package_name, registry_base_url=None) -> Dict[str, Any]:
|
||||
use_name = response["name"]
|
||||
|
||||
new_nwo = use_namespace + "/" + use_name
|
||||
deprecations.warn("package-redirect", old_name=package_name, new_name=new_nwo)
|
||||
return response["versions"]
|
||||
|
||||
|
||||
def package_version(package_name, version, registry_base_url=None) -> Dict[str, Any]:
|
||||
# returns the metadata of a specific version of a package
|
||||
response = package(package_name, registry_base_url)
|
||||
return response[version]
|
||||
|
||||
|
||||
def get_available_versions(package_name) -> List["str"]:
|
||||
# returns a list of all available versions of a package
|
||||
response = package(package_name)
|
||||
return list(response)
|
||||
|
||||
|
||||
def _get_index(registry_base_url=None):
|
||||
|
||||
url = _get_url("index", registry_base_url)
|
||||
fire_event(RegistryIndexProgressMakingGETRequest(url=url))
|
||||
# all exceptions from requests get caught in the retry logic so no need to wrap this here
|
||||
resp = requests.get(url, timeout=30)
|
||||
fire_event(RegistryIndexProgressGETResponse(url=url, resp_code=resp.status_code))
|
||||
resp.raise_for_status()
|
||||
|
||||
# The response should be a list. Anything else is unexpected, raise an error.
|
||||
# Raising this error will cause this function to retry and hopefully get a valid response.
|
||||
|
||||
response = resp.json()
|
||||
|
||||
if not isinstance(response, list): # This will also catch Nonetype
|
||||
error_msg = (
|
||||
f"Request error: The response type of {type(response)} is not valid: {resp.text}"
|
||||
)
|
||||
raise requests.exceptions.ContentDecodingError(error_msg, response=resp)
|
||||
deprecations.warn("package-redirect", old_name=name, new_name=new_nwo)
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def index(registry_base_url=None) -> List[str]:
|
||||
# this returns a list of all packages on the Hub
|
||||
get_index_fn = functools.partial(_get_index, registry_base_url)
|
||||
return connection_exception_retry(get_index_fn, 5)
|
||||
def package_version(name, version, registry_base_url=None):
|
||||
return _get_with_retries("api/v1/{}/{}.json".format(name, version), registry_base_url)
|
||||
|
||||
|
||||
index_cached = memoized(index)
|
||||
def get_available_versions(name):
|
||||
response = package(name)
|
||||
return list(response["versions"])
|
||||
|
||||
@@ -246,17 +246,16 @@ def _supports_long_paths() -> bool:
|
||||
# https://stackoverflow.com/a/35097999/11262881
|
||||
# I don't know exaclty what he means, but I am inclined to believe him as
|
||||
# he's pretty active on Python windows bugs!
|
||||
else:
|
||||
try:
|
||||
dll = WinDLL("ntdll")
|
||||
except OSError: # I don't think this happens? you need ntdll to run python
|
||||
return False
|
||||
# not all windows versions have it at all
|
||||
if not hasattr(dll, "RtlAreLongPathsEnabled"):
|
||||
return False
|
||||
# tell windows we want to get back a single unsigned byte (a bool).
|
||||
dll.RtlAreLongPathsEnabled.restype = c_bool
|
||||
return dll.RtlAreLongPathsEnabled()
|
||||
try:
|
||||
dll = WinDLL("ntdll")
|
||||
except OSError: # I don't think this happens? you need ntdll to run python
|
||||
return False
|
||||
# not all windows versions have it at all
|
||||
if not hasattr(dll, "RtlAreLongPathsEnabled"):
|
||||
return False
|
||||
# tell windows we want to get back a single unsigned byte (a bool).
|
||||
dll.RtlAreLongPathsEnabled.restype = c_bool
|
||||
return dll.RtlAreLongPathsEnabled()
|
||||
|
||||
|
||||
def convert_path(path: str) -> str:
|
||||
@@ -336,7 +335,7 @@ def _handle_posix_cmd_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
|
||||
|
||||
def _handle_posix_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
"""OSError handling for POSIX systems.
|
||||
"""OSError handling for posix systems.
|
||||
|
||||
Some things that could happen to trigger an OSError:
|
||||
- cwd could not exist
|
||||
@@ -387,7 +386,7 @@ def _handle_windows_error(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
|
||||
|
||||
def _interpret_oserror(exc: OSError, cwd: str, cmd: List[str]) -> NoReturn:
|
||||
"""Interpret an OSError exception and raise the appropriate dbt exception."""
|
||||
"""Interpret an OSError exc and raise the appropriate dbt exception."""
|
||||
if len(cmd) == 0:
|
||||
raise dbt.exceptions.CommandError(cwd, cmd)
|
||||
|
||||
@@ -444,11 +443,7 @@ def download_with_retries(
|
||||
connection_exception_retry(download_fn, 5)
|
||||
|
||||
|
||||
def download(
|
||||
url: str,
|
||||
path: str,
|
||||
timeout: Optional[Union[float, Tuple[float, float], Tuple[float, None]]] = None,
|
||||
) -> None:
|
||||
def download(url: str, path: str, timeout: Optional[Union[float, tuple]] = None) -> None:
|
||||
path = convert_path(path)
|
||||
connection_timeout = timeout or float(os.getenv("DBT_HTTP_TIMEOUT", 10))
|
||||
response = requests.get(url, timeout=connection_timeout)
|
||||
@@ -506,7 +501,7 @@ def move(src, dst):
|
||||
directory on windows when it has read-only files in it and the move is
|
||||
between two drives.
|
||||
|
||||
This is almost identical to the real shutil.move, except it, uses our rmtree
|
||||
This is almost identical to the real shutil.move, except it uses our rmtree
|
||||
and skips handling non-windows OSes since the existing one works ok there.
|
||||
"""
|
||||
src = convert_path(src)
|
||||
@@ -541,7 +536,7 @@ def move(src, dst):
|
||||
|
||||
|
||||
def rmtree(path):
|
||||
"""Recursively remove the path. On permissions errors on windows, try to remove
|
||||
"""Recursively remove path. On permissions errors on windows, try to remove
|
||||
the read-only flag and try again.
|
||||
"""
|
||||
path = convert_path(path)
|
||||
|
||||
@@ -51,7 +51,7 @@ def safe_load(contents) -> Optional[Dict[str, Any]]:
|
||||
return yaml.load(contents, Loader=SafeLoader)
|
||||
|
||||
|
||||
def load_yaml_text(contents, path=None):
|
||||
def load_yaml_text(contents):
|
||||
try:
|
||||
return safe_load(contents)
|
||||
except (yaml.scanner.ScannerError, yaml.YAMLError) as e:
|
||||
|
||||
@@ -397,8 +397,6 @@ class Compiler:
|
||||
linker.dependency(node.unique_id, (manifest.nodes[dependency].unique_id))
|
||||
elif dependency in manifest.sources:
|
||||
linker.dependency(node.unique_id, (manifest.sources[dependency].unique_id))
|
||||
elif dependency in manifest.metrics:
|
||||
linker.dependency(node.unique_id, (manifest.metrics[dependency].unique_id))
|
||||
else:
|
||||
dependency_not_found(node, dependency)
|
||||
|
||||
|
||||
@@ -15,7 +15,7 @@ from typing_extensions import Protocol, runtime_checkable
|
||||
import hashlib
|
||||
import os
|
||||
|
||||
from dbt import flags, deprecations
|
||||
from dbt import deprecations
|
||||
from dbt.clients.system import resolve_path_from_base
|
||||
from dbt.clients.system import path_exists
|
||||
from dbt.clients.system import load_file_contents
|
||||
@@ -132,23 +132,12 @@ def _all_source_paths(
|
||||
analysis_paths: List[str],
|
||||
macro_paths: List[str],
|
||||
) -> List[str]:
|
||||
# We need to turn a list of lists into just a list, then convert to a set to
|
||||
# get only unique elements, then back to a list
|
||||
return list(
|
||||
set(list(chain(model_paths, seed_paths, snapshot_paths, analysis_paths, macro_paths)))
|
||||
)
|
||||
return list(chain(model_paths, seed_paths, snapshot_paths, analysis_paths, macro_paths))
|
||||
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
def flag_or(flag: Optional[T], value: Optional[T], default: T) -> T:
|
||||
if flag is None:
|
||||
return value_or(value, default)
|
||||
else:
|
||||
return flag
|
||||
|
||||
|
||||
def value_or(value: Optional[T], default: T) -> T:
|
||||
if value is None:
|
||||
return default
|
||||
@@ -363,9 +352,9 @@ class PartialProject(RenderComponents):
|
||||
|
||||
docs_paths: List[str] = value_or(cfg.docs_paths, all_source_paths)
|
||||
asset_paths: List[str] = value_or(cfg.asset_paths, [])
|
||||
target_path: str = flag_or(flags.TARGET_PATH, cfg.target_path, "target")
|
||||
target_path: str = value_or(cfg.target_path, "target")
|
||||
clean_targets: List[str] = value_or(cfg.clean_targets, [target_path])
|
||||
log_path: str = flag_or(flags.LOG_PATH, cfg.log_path, "logs")
|
||||
log_path: str = value_or(cfg.log_path, "logs")
|
||||
packages_install_path: str = value_or(cfg.packages_install_path, "dbt_packages")
|
||||
# in the default case we'll populate this once we know the adapter type
|
||||
# It would be nice to just pass along a Quoting here, but that would
|
||||
|
||||
@@ -1,15 +1,12 @@
|
||||
from typing import Dict, Any, Tuple, Optional, Union, Callable
|
||||
import re
|
||||
import os
|
||||
|
||||
from dbt.clients.jinja import get_rendered, catch_jinja
|
||||
from dbt.context.target import TargetContext
|
||||
from dbt.context.secret import SecretContext, SECRET_PLACEHOLDER
|
||||
from dbt.context.secret import SecretContext
|
||||
from dbt.context.base import BaseContext
|
||||
from dbt.contracts.connection import HasCredentials
|
||||
from dbt.exceptions import DbtProjectError, CompilationException, RecursionException
|
||||
from dbt.utils import deep_map_render
|
||||
from dbt.logger import SECRET_ENV_PREFIX
|
||||
|
||||
|
||||
Keypath = Tuple[Union[str, int], ...]
|
||||
@@ -117,9 +114,11 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
def name(self):
|
||||
"Project config"
|
||||
|
||||
# Uses SecretRenderer
|
||||
def get_package_renderer(self) -> BaseRenderer:
|
||||
return PackageRenderer(self.ctx_obj.cli_vars)
|
||||
return PackageRenderer(self.context)
|
||||
|
||||
def get_selector_renderer(self) -> BaseRenderer:
|
||||
return SelectorRenderer(self.context)
|
||||
|
||||
def render_project(
|
||||
self,
|
||||
@@ -137,7 +136,8 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
return package_renderer.render_data(packages)
|
||||
|
||||
def render_selectors(self, selectors: Dict[str, Any]):
|
||||
return self.render_data(selectors)
|
||||
selector_renderer = self.get_selector_renderer()
|
||||
return selector_renderer.render_data(selectors)
|
||||
|
||||
def render_entry(self, value: Any, keypath: Keypath) -> Any:
|
||||
result = super().render_entry(value, keypath)
|
||||
@@ -165,10 +165,18 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
return True
|
||||
|
||||
|
||||
class SelectorRenderer(BaseRenderer):
|
||||
@property
|
||||
def name(self):
|
||||
return "Selector config"
|
||||
|
||||
|
||||
class SecretRenderer(BaseRenderer):
|
||||
def __init__(self, cli_vars: Dict[str, Any] = {}) -> None:
|
||||
def __init__(self, cli_vars: Optional[Dict[str, Any]] = None) -> None:
|
||||
# Generate contexts here because we want to save the context
|
||||
# object in order to retrieve the env_vars.
|
||||
if cli_vars is None:
|
||||
cli_vars = {}
|
||||
self.ctx_obj = SecretContext(cli_vars)
|
||||
context = self.ctx_obj.to_dict()
|
||||
super().__init__(context)
|
||||
@@ -177,28 +185,6 @@ class SecretRenderer(BaseRenderer):
|
||||
def name(self):
|
||||
return "Secret"
|
||||
|
||||
def render_value(self, value: Any, keypath: Optional[Keypath] = None) -> Any:
|
||||
# First, standard Jinja rendering, with special handling for 'secret' environment variables
|
||||
# "{{ env_var('DBT_SECRET_ENV_VAR') }}" -> "$$$DBT_SECRET_START$$$DBT_SECRET_ENV_{VARIABLE_NAME}$$$DBT_SECRET_END$$$"
|
||||
# This prevents Jinja manipulation of secrets via macros/filters that might leak partial/modified values in logs
|
||||
rendered = super().render_value(value, keypath)
|
||||
# Now, detect instances of the placeholder value ($$$DBT_SECRET_START...DBT_SECRET_END$$$)
|
||||
# and replace them with the actual secret value
|
||||
if SECRET_ENV_PREFIX in str(rendered):
|
||||
search_group = f"({SECRET_ENV_PREFIX}(.*))"
|
||||
pattern = SECRET_PLACEHOLDER.format(search_group).replace("$", r"\$")
|
||||
m = re.search(
|
||||
pattern,
|
||||
rendered,
|
||||
)
|
||||
if m:
|
||||
found = m.group(1)
|
||||
value = os.environ[found]
|
||||
replace_this = SECRET_PLACEHOLDER.format(found)
|
||||
return rendered.replace(replace_this, value)
|
||||
else:
|
||||
return rendered
|
||||
|
||||
|
||||
class ProfileRenderer(SecretRenderer):
|
||||
@property
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import itertools
|
||||
import os
|
||||
from copy import deepcopy
|
||||
from dataclasses import dataclass, field
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from typing import Dict, Any, Optional, Mapping, Iterator, Iterable, Tuple, List, MutableSet, Type
|
||||
|
||||
@@ -11,7 +11,7 @@ from .renderer import DbtProjectYamlRenderer, ProfileRenderer
|
||||
from .utils import parse_cli_vars
|
||||
from dbt import flags
|
||||
from dbt.adapters.factory import get_relation_class_by_name, get_include_paths
|
||||
from dbt.helper_types import FQNPath, PathSet, DictDefaultEmptyStr
|
||||
from dbt.helper_types import FQNPath, PathSet
|
||||
from dbt.config.profile import read_user_config
|
||||
from dbt.contracts.connection import AdapterRequiredConfig, Credentials
|
||||
from dbt.contracts.graph.manifest import ManifestMetadata
|
||||
@@ -312,26 +312,22 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
|
||||
warn_or_error(msg, log_fmt=warning_tag("{}"))
|
||||
|
||||
def load_dependencies(self, base_only=False) -> Mapping[str, "RuntimeConfig"]:
|
||||
def load_dependencies(self) -> Mapping[str, "RuntimeConfig"]:
|
||||
if self.dependencies is None:
|
||||
all_projects = {self.project_name: self}
|
||||
internal_packages = get_include_paths(self.credentials.type)
|
||||
if base_only:
|
||||
# Test setup -- we want to load macros without dependencies
|
||||
project_paths = itertools.chain(internal_packages)
|
||||
else:
|
||||
# raise exception if fewer installed packages than in packages.yml
|
||||
count_packages_specified = len(self.packages.packages) # type: ignore
|
||||
count_packages_installed = len(tuple(self._get_project_directories()))
|
||||
if count_packages_specified > count_packages_installed:
|
||||
raise_compiler_error(
|
||||
f"dbt found {count_packages_specified} package(s) "
|
||||
f"specified in packages.yml, but only "
|
||||
f"{count_packages_installed} package(s) installed "
|
||||
f'in {self.packages_install_path}. Run "dbt deps" to '
|
||||
f"install package dependencies."
|
||||
)
|
||||
project_paths = itertools.chain(internal_packages, self._get_project_directories())
|
||||
# raise exception if fewer installed packages than in packages.yml
|
||||
count_packages_specified = len(self.packages.packages) # type: ignore
|
||||
count_packages_installed = len(tuple(self._get_project_directories()))
|
||||
if count_packages_specified > count_packages_installed:
|
||||
raise_compiler_error(
|
||||
f"dbt found {count_packages_specified} package(s) "
|
||||
f"specified in packages.yml, but only "
|
||||
f"{count_packages_installed} package(s) installed "
|
||||
f'in {self.packages_install_path}. Run "dbt deps" to '
|
||||
f"install package dependencies."
|
||||
)
|
||||
project_paths = itertools.chain(internal_packages, self._get_project_directories())
|
||||
for project_name, project in self.load_projects(project_paths):
|
||||
if project_name in all_projects:
|
||||
raise_compiler_error(
|
||||
@@ -400,7 +396,7 @@ class UnsetProfile(Profile):
|
||||
self.threads = -1
|
||||
|
||||
def to_target_dict(self):
|
||||
return DictDefaultEmptyStr({})
|
||||
return {}
|
||||
|
||||
def __getattribute__(self, name):
|
||||
if name in {"profile_name", "target_name", "threads"}:
|
||||
@@ -417,9 +413,6 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
missing, any access to profile members results in an exception.
|
||||
"""
|
||||
|
||||
profile_name: str = field(repr=False)
|
||||
target_name: str = field(repr=False)
|
||||
|
||||
def __post_init__(self):
|
||||
# instead of futzing with InitVar overrides or rewriting __init__, just
|
||||
# `del` the attrs we don't want users touching.
|
||||
@@ -438,57 +431,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
|
||||
def to_target_dict(self):
|
||||
# re-override the poisoned profile behavior
|
||||
return DictDefaultEmptyStr({})
|
||||
|
||||
def to_project_config(self, with_packages=False):
|
||||
"""Return a dict representation of the config that could be written to
|
||||
disk with `yaml.safe_dump` to get this configuration.
|
||||
|
||||
Overrides dbt.config.Project.to_project_config to omit undefined profile
|
||||
attributes.
|
||||
|
||||
:param with_packages bool: If True, include the serialized packages
|
||||
file in the root.
|
||||
:returns dict: The serialized profile.
|
||||
"""
|
||||
result = deepcopy(
|
||||
{
|
||||
"name": self.project_name,
|
||||
"version": self.version,
|
||||
"project-root": self.project_root,
|
||||
"profile": "",
|
||||
"model-paths": self.model_paths,
|
||||
"macro-paths": self.macro_paths,
|
||||
"seed-paths": self.seed_paths,
|
||||
"test-paths": self.test_paths,
|
||||
"analysis-paths": self.analysis_paths,
|
||||
"docs-paths": self.docs_paths,
|
||||
"asset-paths": self.asset_paths,
|
||||
"target-path": self.target_path,
|
||||
"snapshot-paths": self.snapshot_paths,
|
||||
"clean-targets": self.clean_targets,
|
||||
"log-path": self.log_path,
|
||||
"quoting": self.quoting,
|
||||
"models": self.models,
|
||||
"on-run-start": self.on_run_start,
|
||||
"on-run-end": self.on_run_end,
|
||||
"dispatch": self.dispatch,
|
||||
"seeds": self.seeds,
|
||||
"snapshots": self.snapshots,
|
||||
"sources": self.sources,
|
||||
"tests": self.tests,
|
||||
"vars": self.vars.to_dict(),
|
||||
"require-dbt-version": [v.to_version_string() for v in self.dbt_version],
|
||||
"config-version": self.config_version,
|
||||
}
|
||||
)
|
||||
if self.query_comment:
|
||||
result["query-comment"] = self.query_comment.to_dict(omit_none=True)
|
||||
|
||||
if with_packages:
|
||||
result.update(self.packages.to_dict(omit_none=True))
|
||||
|
||||
return result
|
||||
return {}
|
||||
|
||||
@classmethod
|
||||
def from_parts(
|
||||
|
||||
@@ -1,10 +1,9 @@
|
||||
from pathlib import Path
|
||||
from copy import deepcopy
|
||||
from typing import Dict, Any, Union
|
||||
from dbt.clients.yaml_helper import yaml, Loader, Dumper, load_yaml_text # noqa: F401
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from .renderer import BaseRenderer
|
||||
from .renderer import SelectorRenderer
|
||||
|
||||
from dbt.clients.system import (
|
||||
load_file_contents,
|
||||
@@ -58,7 +57,7 @@ class SelectorConfig(Dict[str, Dict[str, Union[SelectionSpec, bool]]]):
|
||||
def render_from_dict(
|
||||
cls,
|
||||
data: Dict[str, Any],
|
||||
renderer: BaseRenderer,
|
||||
renderer: SelectorRenderer,
|
||||
) -> "SelectorConfig":
|
||||
try:
|
||||
rendered = renderer.render_data(data)
|
||||
@@ -73,7 +72,7 @@ class SelectorConfig(Dict[str, Dict[str, Union[SelectionSpec, bool]]]):
|
||||
def from_path(
|
||||
cls,
|
||||
path: Path,
|
||||
renderer: BaseRenderer,
|
||||
renderer: SelectorRenderer,
|
||||
) -> "SelectorConfig":
|
||||
try:
|
||||
data = load_yaml_text(load_file_contents(str(path)))
|
||||
@@ -141,33 +140,28 @@ def validate_selector_default(selector_file: SelectorFile) -> None:
|
||||
# good to combine the two flows into one at some point.
|
||||
class SelectorDict:
|
||||
@classmethod
|
||||
def parse_dict_definition(cls, definition, selector_dict={}):
|
||||
def parse_dict_definition(cls, definition):
|
||||
key = list(definition)[0]
|
||||
value = definition[key]
|
||||
if isinstance(value, list):
|
||||
new_values = []
|
||||
for sel_def in value:
|
||||
new_value = cls.parse_from_definition(sel_def, selector_dict=selector_dict)
|
||||
new_value = cls.parse_from_definition(sel_def)
|
||||
new_values.append(new_value)
|
||||
value = new_values
|
||||
if key == "exclude":
|
||||
definition = {key: value}
|
||||
elif len(definition) == 1:
|
||||
definition = {"method": key, "value": value}
|
||||
elif key == "method" and value == "selector":
|
||||
sel_def = definition.get("value")
|
||||
if sel_def not in selector_dict:
|
||||
raise DbtSelectorsError(f"Existing selector definition for {sel_def} not found.")
|
||||
return selector_dict[definition["value"]]["definition"]
|
||||
return definition
|
||||
|
||||
@classmethod
|
||||
def parse_a_definition(cls, def_type, definition, selector_dict={}):
|
||||
def parse_a_definition(cls, def_type, definition):
|
||||
# this definition must be a list
|
||||
new_dict = {def_type: []}
|
||||
for sel_def in definition[def_type]:
|
||||
if isinstance(sel_def, dict):
|
||||
sel_def = cls.parse_from_definition(sel_def, selector_dict=selector_dict)
|
||||
sel_def = cls.parse_from_definition(sel_def)
|
||||
new_dict[def_type].append(sel_def)
|
||||
elif isinstance(sel_def, str):
|
||||
sel_def = SelectionCriteria.dict_from_single_spec(sel_def)
|
||||
@@ -177,17 +171,15 @@ class SelectorDict:
|
||||
return new_dict
|
||||
|
||||
@classmethod
|
||||
def parse_from_definition(cls, definition, selector_dict={}):
|
||||
def parse_from_definition(cls, definition):
|
||||
if isinstance(definition, str):
|
||||
definition = SelectionCriteria.dict_from_single_spec(definition)
|
||||
elif "union" in definition:
|
||||
definition = cls.parse_a_definition("union", definition, selector_dict=selector_dict)
|
||||
definition = cls.parse_a_definition("union", definition)
|
||||
elif "intersection" in definition:
|
||||
definition = cls.parse_a_definition(
|
||||
"intersection", definition, selector_dict=selector_dict
|
||||
)
|
||||
definition = cls.parse_a_definition("intersection", definition)
|
||||
elif isinstance(definition, dict):
|
||||
definition = cls.parse_dict_definition(definition, selector_dict=selector_dict)
|
||||
definition = cls.parse_dict_definition(definition)
|
||||
return definition
|
||||
|
||||
# This is the normal entrypoint of this code. Give it the
|
||||
@@ -198,8 +190,6 @@ class SelectorDict:
|
||||
for selector in selectors:
|
||||
sel_name = selector["name"]
|
||||
selector_dict[sel_name] = selector
|
||||
definition = cls.parse_from_definition(
|
||||
selector["definition"], selector_dict=deepcopy(selector_dict)
|
||||
)
|
||||
definition = cls.parse_from_definition(selector["definition"])
|
||||
selector_dict[sel_name]["definition"] = definition
|
||||
return selector_dict
|
||||
|
||||
@@ -1,15 +1,9 @@
|
||||
from argparse import Namespace
|
||||
from typing import Any, Dict, Optional, Union
|
||||
from xmlrpc.client import Boolean
|
||||
from dbt.contracts.project import UserConfig
|
||||
from typing import Dict, Any
|
||||
|
||||
import dbt.flags as flags
|
||||
from dbt.clients import yaml_helper
|
||||
from dbt.config import Profile, Project, read_user_config
|
||||
from dbt.config.renderer import DbtProjectYamlRenderer, ProfileRenderer
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.exceptions import raise_compiler_error, ValidationException
|
||||
from dbt.events.types import InvalidVarsYAML
|
||||
from dbt.exceptions import ValidationException, raise_compiler_error
|
||||
|
||||
|
||||
def parse_cli_vars(var_string: str) -> Dict[str, Any]:
|
||||
@@ -27,49 +21,3 @@ def parse_cli_vars(var_string: str) -> Dict[str, Any]:
|
||||
except ValidationException:
|
||||
fire_event(InvalidVarsYAML())
|
||||
raise
|
||||
|
||||
|
||||
def get_project_config(
|
||||
project_path: str,
|
||||
profile_name: str,
|
||||
args: Namespace = Namespace(),
|
||||
cli_vars: Optional[Dict[str, Any]] = None,
|
||||
profile: Optional[Profile] = None,
|
||||
user_config: Optional[UserConfig] = None,
|
||||
return_dict: Boolean = True,
|
||||
) -> Union[Project, Dict]:
|
||||
"""Returns a project config (dict or object) from a given project path and profile name.
|
||||
|
||||
Args:
|
||||
project_path: Path to project
|
||||
profile_name: Name of profile
|
||||
args: An argparse.Namespace that represents what would have been passed in on the
|
||||
command line (optional)
|
||||
cli_vars: A dict of any vars that would have been passed in on the command line (optional)
|
||||
(see parse_cli_vars above for formatting details)
|
||||
profile: A dbt.config.profile.Profile object (optional)
|
||||
user_config: A dbt.contracts.project.UserConfig object (optional)
|
||||
return_dict: Return a dict if true, return the full dbt.config.project.Project object if false
|
||||
|
||||
Returns:
|
||||
A full project config
|
||||
|
||||
"""
|
||||
# Generate a profile if not provided
|
||||
if profile is None:
|
||||
# Generate user_config if not provided
|
||||
if user_config is None:
|
||||
user_config = read_user_config(flags.PROFILES_DIR)
|
||||
# Update flags
|
||||
flags.set_from_args(args, user_config)
|
||||
if cli_vars is None:
|
||||
cli_vars = {}
|
||||
profile = Profile.render_from_args(args, ProfileRenderer(cli_vars), profile_name)
|
||||
# Generate a project
|
||||
project = Project.from_project_root(
|
||||
project_path,
|
||||
DbtProjectYamlRenderer(profile),
|
||||
verify_version=bool(flags.VERSION_CHECK),
|
||||
)
|
||||
# Return
|
||||
return project.to_project_config() if return_dict else project
|
||||
|
||||
@@ -1,51 +1 @@
|
||||
# Contexts and Jinja rendering
|
||||
|
||||
Contexts are used for Jinja rendering. They include context methods, executable macros, and various settings that are available in Jinja.
|
||||
|
||||
The most common entrypoint to Jinja rendering in dbt is a method named `get_rendered`, which takes two arguments: templated code (string), and a context used to render it (dictionary).
|
||||
|
||||
The context is the bundle of information that is in "scope" when rendering Jinja-templated code. For instance, imagine a simple Jinja template:
|
||||
```
|
||||
{% set new_value = some_macro(some_variable) %}
|
||||
```
|
||||
Both `some_macro()` and `some_variable` must be defined in that context. Otherwise, it will raise an error when rendering.
|
||||
|
||||
Different contexts are used in different places because we allow access to different methods and data in different places. Executable SQL, for example, includes all available macros and the model being run. The variables and macros in scope for Jinja defined in yaml files is much more limited.
|
||||
|
||||
### Implementation
|
||||
|
||||
The context that is passed to Jinja is always in a dictionary format, not an actual class, so a `to_dict()` is executed on a context class before it is used for rendering.
|
||||
|
||||
Each context has a `generate_<name>_context` function to create the context. `ProviderContext` subclasses have different generate functions for parsing and for execution, so that certain functions (notably `ref`, `source`, and `config`) can return different results
|
||||
|
||||
### Hierarchy
|
||||
|
||||
All contexts inherit from the `BaseContext`, which includes "pure" methods (e.g. `tojson`), `env_var()`, and `var()` (but only CLI values, passed via `--vars`).
|
||||
|
||||
Methods available in parent contexts are also available in child contexts.
|
||||
|
||||
```
|
||||
BaseContext -- core/dbt/context/base.py
|
||||
SecretContext -- core/dbt/context/secret.py
|
||||
TargetContext -- core/dbt/context/target.py
|
||||
ConfiguredContext -- core/dbt/context/configured.py
|
||||
SchemaYamlContext -- core/dbt/context/configured.py
|
||||
DocsRuntimeContext -- core/dbt/context/configured.py
|
||||
MacroResolvingContext -- core/dbt/context/configured.py
|
||||
ManifestContext -- core/dbt/context/manifest.py
|
||||
QueryHeaderContext -- core/dbt/context/manifest.py
|
||||
ProviderContext -- core/dbt/context/provider.py
|
||||
MacroContext -- core/dbt/context/provider.py
|
||||
ModelContext -- core/dbt/context/provider.py
|
||||
TestContext -- core/dbt/context/provider.py
|
||||
```
|
||||
|
||||
### Contexts for configuration
|
||||
|
||||
Contexts for rendering "special" `.yml` (configuration) files:
|
||||
- `SecretContext`: Supports "secret" env vars, which are prefixed with `DBT_ENV_SECRET_`. Used for rendering in `profiles.yml` and `packages.yml` ONLY. Secrets defined elsewhere will raise explicit errors.
|
||||
- `TargetContext`: The same as `Base`, plus `target` (connection profile). Used most notably in `dbt_project.yml` and `selectors.yml`.
|
||||
|
||||
Contexts for other `.yml` files in the project:
|
||||
- `SchemaYamlContext`: Supports `vars` declared on the CLI and in `dbt_project.yml`. Does not support custom macros, beyond `var()` + `env_var()` methods. Used for all `.yml` files, to define properties and configuration.
|
||||
- `DocsRuntimeContext`: Standard `.yml` file context, plus `doc()` method (with all `docs` blocks in scope). Used to resolve `description` properties.
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import json
|
||||
import os
|
||||
from typing import Any, Dict, NoReturn, Optional, Mapping, Iterable, Set, List
|
||||
from typing import Any, Dict, NoReturn, Optional, Mapping
|
||||
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
@@ -8,9 +8,8 @@ from dbt.clients.jinja import get_rendered
|
||||
from dbt.clients.yaml_helper import yaml, safe_load, SafeLoader, Loader, Dumper # noqa: F401
|
||||
from dbt.contracts.graph.compiled import CompiledResource
|
||||
from dbt.exceptions import (
|
||||
CompilationException,
|
||||
MacroReturn,
|
||||
raise_compiler_error,
|
||||
MacroReturn,
|
||||
raise_parsing_error,
|
||||
disallow_secret_env_var,
|
||||
)
|
||||
@@ -24,9 +23,39 @@ from dbt.version import __version__ as dbt_version
|
||||
import pytz
|
||||
import datetime
|
||||
import re
|
||||
import itertools
|
||||
|
||||
# See the `contexts` module README for more information on how contexts work
|
||||
# Contexts in dbt Core
|
||||
# Contexts are used for Jinja rendering. They include context methods,
|
||||
# executable macros, and various settings that are available in Jinja.
|
||||
#
|
||||
# Different contexts are used in different places because we allow access
|
||||
# to different methods and data in different places. Executable SQL, for
|
||||
# example, includes the available macros and the model, while Jinja in
|
||||
# yaml files is more limited.
|
||||
#
|
||||
# The context that is passed to Jinja is always in a dictionary format,
|
||||
# not an actual class, so a 'to_dict()' is executed on a context class
|
||||
# before it is used for rendering.
|
||||
#
|
||||
# Each context has a generate_<name>_context function to create the context.
|
||||
# ProviderContext subclasses have different generate functions for
|
||||
# parsing and for execution.
|
||||
#
|
||||
# Context class hierarchy
|
||||
#
|
||||
# BaseContext -- core/dbt/context/base.py
|
||||
# SecretContext -- core/dbt/context/secret.py
|
||||
# TargetContext -- core/dbt/context/target.py
|
||||
# ConfiguredContext -- core/dbt/context/configured.py
|
||||
# SchemaYamlContext -- core/dbt/context/configured.py
|
||||
# DocsRuntimeContext -- core/dbt/context/configured.py
|
||||
# MacroResolvingContext -- core/dbt/context/configured.py
|
||||
# ManifestContext -- core/dbt/context/manifest.py
|
||||
# QueryHeaderContext -- core/dbt/context/manifest.py
|
||||
# ProviderContext -- core/dbt/context/provider.py
|
||||
# MacroContext -- core/dbt/context/provider.py
|
||||
# ModelContext -- core/dbt/context/provider.py
|
||||
# TestContext -- core/dbt/context/provider.py
|
||||
|
||||
|
||||
def get_pytz_module_context() -> Dict[str, Any]:
|
||||
@@ -48,35 +77,11 @@ def get_re_module_context() -> Dict[str, Any]:
|
||||
return {name: getattr(re, name) for name in context_exports}
|
||||
|
||||
|
||||
def get_itertools_module_context() -> Dict[str, Any]:
|
||||
# Excluded dropwhile, filterfalse, takewhile and groupby;
|
||||
# first 3 illogical for Jinja and last redundant.
|
||||
context_exports = [
|
||||
"count",
|
||||
"cycle",
|
||||
"repeat",
|
||||
"accumulate",
|
||||
"chain",
|
||||
"compress",
|
||||
"islice",
|
||||
"starmap",
|
||||
"tee",
|
||||
"zip_longest",
|
||||
"product",
|
||||
"permutations",
|
||||
"combinations",
|
||||
"combinations_with_replacement",
|
||||
]
|
||||
|
||||
return {name: getattr(itertools, name) for name in context_exports}
|
||||
|
||||
|
||||
def get_context_modules() -> Dict[str, Dict[str, Any]]:
|
||||
return {
|
||||
"pytz": get_pytz_module_context(),
|
||||
"datetime": get_datetime_module_context(),
|
||||
"re": get_re_module_context(),
|
||||
"itertools": get_itertools_module_context(),
|
||||
}
|
||||
|
||||
|
||||
@@ -452,90 +457,6 @@ class BaseContext(metaclass=ContextMeta):
|
||||
except (ValueError, yaml.YAMLError):
|
||||
return default
|
||||
|
||||
@contextmember("set")
|
||||
@staticmethod
|
||||
def _set(value: Iterable[Any], default: Any = None) -> Optional[Set[Any]]:
|
||||
"""The `set` context method can be used to convert any iterable
|
||||
to a sequence of iterable elements that are unique (a set).
|
||||
|
||||
:param value: The iterable
|
||||
:param default: A default value to return if the `value` argument
|
||||
is not an iterable
|
||||
|
||||
Usage:
|
||||
{% set my_list = [1, 2, 2, 3] %}
|
||||
{% set my_set = set(my_list) %}
|
||||
{% do log(my_set) %} {# {1, 2, 3} #}
|
||||
"""
|
||||
try:
|
||||
return set(value)
|
||||
except TypeError:
|
||||
return default
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def set_strict(value: Iterable[Any]) -> Set[Any]:
|
||||
"""The `set_strict` context method can be used to convert any iterable
|
||||
to a sequence of iterable elements that are unique (a set). The
|
||||
difference to the `set` context method is that the `set_strict` method
|
||||
will raise an exception on a TypeError.
|
||||
|
||||
:param value: The iterable
|
||||
|
||||
Usage:
|
||||
{% set my_list = [1, 2, 2, 3] %}
|
||||
{% set my_set = set_strict(my_list) %}
|
||||
{% do log(my_set) %} {# {1, 2, 3} #}
|
||||
"""
|
||||
try:
|
||||
return set(value)
|
||||
except TypeError as e:
|
||||
raise CompilationException(e)
|
||||
|
||||
@contextmember("zip")
|
||||
@staticmethod
|
||||
def _zip(*args: Iterable[Any], default: Any = None) -> Optional[Iterable[Any]]:
|
||||
"""The `zip` context method can be used to used to return
|
||||
an iterator of tuples, where the i-th tuple contains the i-th
|
||||
element from each of the argument iterables.
|
||||
|
||||
:param *args: Any number of iterables
|
||||
:param default: A default value to return if `*args` is not
|
||||
iterable
|
||||
|
||||
Usage:
|
||||
{% set my_list_a = [1, 2] %}
|
||||
{% set my_list_b = ['alice', 'bob'] %}
|
||||
{% set my_zip = zip(my_list_a, my_list_b) | list %}
|
||||
{% do log(my_set) %} {# [(1, 'alice'), (2, 'bob')] #}
|
||||
"""
|
||||
try:
|
||||
return zip(*args)
|
||||
except TypeError:
|
||||
return default
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def zip_strict(*args: Iterable[Any]) -> Iterable[Any]:
|
||||
"""The `zip_strict` context method can be used to used to return
|
||||
an iterator of tuples, where the i-th tuple contains the i-th
|
||||
element from each of the argument iterables. The difference to the
|
||||
`zip` context method is that the `zip_strict` method will raise an
|
||||
exception on a TypeError.
|
||||
|
||||
:param *args: Any number of iterables
|
||||
|
||||
Usage:
|
||||
{% set my_list_a = [1, 2] %}
|
||||
{% set my_list_b = ['alice', 'bob'] %}
|
||||
{% set my_zip = zip_strict(my_list_a, my_list_b) | list %}
|
||||
{% do log(my_set) %} {# [(1, 'alice'), (2, 'bob')] #}
|
||||
"""
|
||||
try:
|
||||
return zip(*args)
|
||||
except TypeError as e:
|
||||
raise CompilationException(e)
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def log(msg: str, info: bool = False) -> str:
|
||||
@@ -648,40 +569,9 @@ class BaseContext(metaclass=ContextMeta):
|
||||
{{ print("Running some_macro: " ~ arg1 ~ ", " ~ arg2) }}
|
||||
{% endmacro %}"
|
||||
"""
|
||||
|
||||
if not flags.NO_PRINT:
|
||||
print(msg)
|
||||
print(msg)
|
||||
return ""
|
||||
|
||||
@contextmember
|
||||
@staticmethod
|
||||
def diff_of_two_dicts(
|
||||
dict_a: Dict[str, List[str]], dict_b: Dict[str, List[str]]
|
||||
) -> Dict[str, List[str]]:
|
||||
"""
|
||||
Given two dictionaries of type Dict[str, List[str]]:
|
||||
dict_a = {'key_x': ['value_1', 'VALUE_2'], 'KEY_Y': ['value_3']}
|
||||
dict_b = {'key_x': ['value_1'], 'key_z': ['value_4']}
|
||||
Return the same dictionary representation of dict_a MINUS dict_b,
|
||||
performing a case-insensitive comparison between the strings in each.
|
||||
All keys returned will be in the original case of dict_a.
|
||||
returns {'key_x': ['VALUE_2'], 'KEY_Y': ['value_3']}
|
||||
"""
|
||||
|
||||
dict_diff = {}
|
||||
dict_b_lowered = {k.casefold(): [x.casefold() for x in v] for k, v in dict_b.items()}
|
||||
for k in dict_a:
|
||||
if k.casefold() in dict_b_lowered.keys():
|
||||
diff = []
|
||||
for v in dict_a[k]:
|
||||
if v.casefold() not in dict_b_lowered[k.casefold()]:
|
||||
diff.append(v)
|
||||
if diff:
|
||||
dict_diff.update({k: diff})
|
||||
else:
|
||||
dict_diff.update({k: dict_a[k]})
|
||||
return dict_diff
|
||||
|
||||
|
||||
def generate_base_context(cli_vars: Dict[str, Any]) -> Dict[str, Any]:
|
||||
ctx = BaseContext(cli_vars)
|
||||
|
||||
@@ -4,7 +4,7 @@ from dataclasses import dataclass
|
||||
from typing import List, Iterator, Dict, Any, TypeVar, Generic
|
||||
|
||||
from dbt.config import RuntimeConfig, Project, IsFQNResource
|
||||
from dbt.contracts.graph.model_config import BaseConfig, get_config_for, _listify
|
||||
from dbt.contracts.graph.model_config import BaseConfig, get_config_for
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import fqn_search
|
||||
@@ -264,49 +264,18 @@ class ContextConfig:
|
||||
|
||||
@classmethod
|
||||
def _add_config_call(cls, config_call_dict, opts: Dict[str, Any]) -> None:
|
||||
# config_call_dict is already encountered configs, opts is new
|
||||
# This mirrors code in _merge_field_value in model_config.py which is similar but
|
||||
# operates on config objects.
|
||||
for k, v in opts.items():
|
||||
# MergeBehavior for post-hook and pre-hook is to collect all
|
||||
# values, instead of overwriting
|
||||
if k in BaseConfig.mergebehavior["append"]:
|
||||
if not isinstance(v, list):
|
||||
v = [v]
|
||||
if k in config_call_dict: # should always be a list here
|
||||
config_call_dict[k].extend(v)
|
||||
else:
|
||||
config_call_dict[k] = v
|
||||
|
||||
elif k in BaseConfig.mergebehavior["update"]:
|
||||
if not isinstance(v, dict):
|
||||
raise InternalException(f"expected dict, got {v}")
|
||||
if k in config_call_dict and isinstance(config_call_dict[k], dict):
|
||||
config_call_dict[k].update(v)
|
||||
else:
|
||||
config_call_dict[k] = v
|
||||
elif k in BaseConfig.mergebehavior["dict_key_append"]:
|
||||
if not isinstance(v, dict):
|
||||
raise InternalException(f"expected dict, got {v}")
|
||||
if k in config_call_dict: # should always be a dict
|
||||
for key, value in v.items():
|
||||
extend = False
|
||||
# This might start with a +, to indicate we should extend the list
|
||||
# instead of just clobbering it
|
||||
if key.startswith("+"):
|
||||
extend = True
|
||||
if key in config_call_dict[k] and extend:
|
||||
# extend the list
|
||||
config_call_dict[k][key].extend(_listify(value))
|
||||
else:
|
||||
# clobber the list
|
||||
config_call_dict[k][key] = _listify(value)
|
||||
else:
|
||||
# This is always a dictionary
|
||||
config_call_dict[k] = v
|
||||
# listify everything
|
||||
for key, value in config_call_dict[k].items():
|
||||
config_call_dict[k][key] = _listify(value)
|
||||
if k in BaseConfig.mergebehavior["update"] and not isinstance(v, dict):
|
||||
raise InternalException(f"expected dict, got {v}")
|
||||
if k in config_call_dict and isinstance(config_call_dict[k], list):
|
||||
config_call_dict[k].extend(v)
|
||||
elif k in config_call_dict and isinstance(config_call_dict[k], dict):
|
||||
config_call_dict[k].update(v)
|
||||
else:
|
||||
config_call_dict[k] = v
|
||||
|
||||
|
||||
@@ -40,7 +40,6 @@ from dbt.contracts.graph.parsed import (
|
||||
ParsedSeedNode,
|
||||
ParsedSourceDefinition,
|
||||
)
|
||||
from dbt.contracts.graph.metrics import MetricReference, ResolvedMetricReference
|
||||
from dbt.exceptions import (
|
||||
CompilationException,
|
||||
ParsingException,
|
||||
@@ -51,9 +50,7 @@ from dbt.exceptions import (
|
||||
missing_config,
|
||||
raise_compiler_error,
|
||||
ref_invalid_args,
|
||||
metric_invalid_args,
|
||||
ref_target_not_found,
|
||||
metric_target_not_found,
|
||||
ref_bad_context,
|
||||
source_target_not_found,
|
||||
wrapped_exports,
|
||||
@@ -65,8 +62,6 @@ from dbt.node_types import NodeType
|
||||
|
||||
from dbt.utils import merge, AttrDict, MultiDict
|
||||
|
||||
from dbt import selected_resources
|
||||
|
||||
import agate
|
||||
|
||||
|
||||
@@ -202,7 +197,7 @@ class BaseResolver(metaclass=abc.ABCMeta):
|
||||
return self.db_wrapper.Relation
|
||||
|
||||
@abc.abstractmethod
|
||||
def __call__(self, *args: str) -> Union[str, RelationProxy, MetricReference]:
|
||||
def __call__(self, *args: str) -> Union[str, RelationProxy]:
|
||||
pass
|
||||
|
||||
|
||||
@@ -268,41 +263,6 @@ class BaseSourceResolver(BaseResolver):
|
||||
return self.resolve(args[0], args[1])
|
||||
|
||||
|
||||
class BaseMetricResolver(BaseResolver):
|
||||
def resolve(self, name: str, package: Optional[str] = None) -> MetricReference:
|
||||
...
|
||||
|
||||
def _repack_args(self, name: str, package: Optional[str]) -> List[str]:
|
||||
if package is None:
|
||||
return [name]
|
||||
else:
|
||||
return [package, name]
|
||||
|
||||
def validate_args(self, name: str, package: Optional[str]):
|
||||
if not isinstance(name, str):
|
||||
raise CompilationException(
|
||||
f"The name argument to metric() must be a string, got {type(name)}"
|
||||
)
|
||||
|
||||
if package is not None and not isinstance(package, str):
|
||||
raise CompilationException(
|
||||
f"The package argument to metric() must be a string or None, got {type(package)}"
|
||||
)
|
||||
|
||||
def __call__(self, *args: str) -> MetricReference:
|
||||
name: str
|
||||
package: Optional[str] = None
|
||||
|
||||
if len(args) == 1:
|
||||
name = args[0]
|
||||
elif len(args) == 2:
|
||||
package, name = args
|
||||
else:
|
||||
metric_invalid_args(self.model, args)
|
||||
self.validate_args(name, package)
|
||||
return self.resolve(name, package)
|
||||
|
||||
|
||||
class Config(Protocol):
|
||||
def __init__(self, model, context_config: Optional[ContextConfig]):
|
||||
...
|
||||
@@ -549,34 +509,6 @@ class RuntimeSourceResolver(BaseSourceResolver):
|
||||
return self.Relation.create_from_source(target_source)
|
||||
|
||||
|
||||
# metric` implementations
|
||||
class ParseMetricResolver(BaseMetricResolver):
|
||||
def resolve(self, name: str, package: Optional[str] = None) -> MetricReference:
|
||||
self.model.metrics.append(self._repack_args(name, package))
|
||||
|
||||
return MetricReference(name, package)
|
||||
|
||||
|
||||
class RuntimeMetricResolver(BaseMetricResolver):
|
||||
def resolve(self, target_name: str, target_package: Optional[str] = None) -> MetricReference:
|
||||
target_metric = self.manifest.resolve_metric(
|
||||
target_name,
|
||||
target_package,
|
||||
self.current_project,
|
||||
self.model.package_name,
|
||||
)
|
||||
|
||||
if target_metric is None or isinstance(target_metric, Disabled):
|
||||
# TODO : Use a different exception!!
|
||||
metric_target_not_found(
|
||||
self.model,
|
||||
target_name,
|
||||
target_package,
|
||||
)
|
||||
|
||||
return ResolvedMetricReference(target_metric, self.manifest, self.Relation)
|
||||
|
||||
|
||||
# `var` implementations.
|
||||
class ModelConfiguredVar(Var):
|
||||
def __init__(
|
||||
@@ -634,7 +566,6 @@ class Provider(Protocol):
|
||||
Var: Type[ModelConfiguredVar]
|
||||
ref: Type[BaseRefResolver]
|
||||
source: Type[BaseSourceResolver]
|
||||
metric: Type[BaseMetricResolver]
|
||||
|
||||
|
||||
class ParseProvider(Provider):
|
||||
@@ -644,7 +575,6 @@ class ParseProvider(Provider):
|
||||
Var = ParseVar
|
||||
ref = ParseRefResolver
|
||||
source = ParseSourceResolver
|
||||
metric = ParseMetricResolver
|
||||
|
||||
|
||||
class GenerateNameProvider(Provider):
|
||||
@@ -654,7 +584,6 @@ class GenerateNameProvider(Provider):
|
||||
Var = RuntimeVar
|
||||
ref = ParseRefResolver
|
||||
source = ParseSourceResolver
|
||||
metric = ParseMetricResolver
|
||||
|
||||
|
||||
class RuntimeProvider(Provider):
|
||||
@@ -664,7 +593,6 @@ class RuntimeProvider(Provider):
|
||||
Var = RuntimeVar
|
||||
ref = RuntimeRefResolver
|
||||
source = RuntimeSourceResolver
|
||||
metric = RuntimeMetricResolver
|
||||
|
||||
|
||||
class OperationProvider(RuntimeProvider):
|
||||
@@ -848,10 +776,6 @@ class ProviderContext(ManifestContext):
|
||||
def source(self) -> Callable:
|
||||
return self.provider.source(self.db_wrapper, self.model, self.config, self.manifest)
|
||||
|
||||
@contextproperty
|
||||
def metric(self) -> Callable:
|
||||
return self.provider.metric(self.db_wrapper, self.model, self.config, self.manifest)
|
||||
|
||||
@contextproperty("config")
|
||||
def ctx_config(self) -> Config:
|
||||
"""The `config` variable exists to handle end-user configuration for
|
||||
@@ -1219,20 +1143,11 @@ class ProviderContext(ManifestContext):
|
||||
msg = f"Env var required but not provided: '{var}'"
|
||||
raise_parsing_error(msg)
|
||||
|
||||
@contextproperty
|
||||
def selected_resources(self) -> List[str]:
|
||||
"""The `selected_resources` variable contains a list of the resources
|
||||
selected based on the parameters provided to the dbt command.
|
||||
Currently, is not populated for the command `run-operation` that
|
||||
doesn't support `--select`.
|
||||
"""
|
||||
return selected_resources.SELECTED_RESOURCES
|
||||
|
||||
|
||||
class MacroContext(ProviderContext):
|
||||
"""Internally, macros can be executed like nodes, with some restrictions:
|
||||
|
||||
- they don't have all values available that nodes do:
|
||||
- they don't have have all values available that nodes do:
|
||||
- 'this', 'pre_hooks', 'post_hooks', and 'sql' are missing
|
||||
- 'schema' does not use any 'model' information
|
||||
- they can't be configured with config() directives
|
||||
@@ -1429,7 +1344,7 @@ class MetricRefResolver(BaseResolver):
|
||||
if not isinstance(name, str):
|
||||
raise ParsingException(
|
||||
f"In a metrics section in {self.model.original_file_path} "
|
||||
"the name argument to ref() must be a string"
|
||||
f"the name argument to ref() must be a string"
|
||||
)
|
||||
|
||||
|
||||
@@ -1447,12 +1362,6 @@ def generate_parse_metrics(
|
||||
project,
|
||||
manifest,
|
||||
),
|
||||
"metric": ParseMetricResolver(
|
||||
None,
|
||||
metric,
|
||||
project,
|
||||
manifest,
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
|
||||
@@ -7,9 +7,6 @@ from dbt.exceptions import raise_parsing_error
|
||||
from dbt.logger import SECRET_ENV_PREFIX
|
||||
|
||||
|
||||
SECRET_PLACEHOLDER = "$$$DBT_SECRET_START$$${}$$$DBT_SECRET_END$$$"
|
||||
|
||||
|
||||
class SecretContext(BaseContext):
|
||||
"""This context is used in profiles.yml + packages.yml. It can render secret
|
||||
env vars that aren't usable elsewhere"""
|
||||
@@ -21,29 +18,21 @@ class SecretContext(BaseContext):
|
||||
|
||||
If the default is None, raise an exception for an undefined variable.
|
||||
|
||||
In this context *only*, env_var will accept env vars prefixed with DBT_ENV_SECRET_.
|
||||
It will return the name of the secret env var, wrapped in 'start' and 'end' identifiers.
|
||||
The actual value will be subbed in later in SecretRenderer.render_value()
|
||||
In this context *only*, env_var will return the actual values of
|
||||
env vars prefixed with DBT_ENV_SECRET_
|
||||
"""
|
||||
return_value = None
|
||||
|
||||
# if this is a 'secret' env var, just return the name of the env var
|
||||
# instead of rendering the actual value here, to avoid any risk of
|
||||
# Jinja manipulation. it will be subbed out later, in SecretRenderer.render_value
|
||||
if var in os.environ and var.startswith(SECRET_ENV_PREFIX):
|
||||
return SECRET_PLACEHOLDER.format(var)
|
||||
|
||||
elif var in os.environ:
|
||||
if var in os.environ:
|
||||
return_value = os.environ[var]
|
||||
elif default is not None:
|
||||
return_value = default
|
||||
|
||||
if return_value is not None:
|
||||
# store env vars in the internal manifest to power partial parsing
|
||||
# if it's a 'secret' env var, we shouldn't even get here
|
||||
# but just to be safe — don't save secrets
|
||||
# do not save secret environment variables
|
||||
if not var.startswith(SECRET_ENV_PREFIX):
|
||||
self.env_vars[var] = return_value
|
||||
|
||||
# return the value even if its a secret
|
||||
return return_value
|
||||
else:
|
||||
msg = f"Env var required but not provided: '{var}'"
|
||||
|
||||
@@ -104,7 +104,7 @@ class Connection(ExtensibleDbtClassMixin, Replaceable):
|
||||
|
||||
|
||||
class LazyHandle:
|
||||
"""The opener must be a callable that takes a Connection object and opens the
|
||||
"""Opener must be a callable that takes a Connection object and opens the
|
||||
connection, updating the handle on the Connection.
|
||||
"""
|
||||
|
||||
|
||||
@@ -183,39 +183,6 @@ class RefableLookup(dbtClassMixin):
|
||||
return manifest.nodes[unique_id]
|
||||
|
||||
|
||||
class MetricLookup(dbtClassMixin):
|
||||
def __init__(self, manifest: "Manifest"):
|
||||
self.storage: Dict[str, Dict[PackageName, UniqueID]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def get_unique_id(self, search_name, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, search_name, package)
|
||||
|
||||
def find(self, search_name, package: Optional[PackageName], manifest: "Manifest"):
|
||||
unique_id = self.get_unique_id(search_name, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id, manifest)
|
||||
return None
|
||||
|
||||
def add_metric(self, metric: ParsedMetric):
|
||||
if metric.search_name not in self.storage:
|
||||
self.storage[metric.search_name] = {}
|
||||
|
||||
self.storage[metric.search_name][metric.package_name] = metric.unique_id
|
||||
|
||||
def populate(self, manifest):
|
||||
for metric in manifest.metrics.values():
|
||||
if hasattr(metric, "name"):
|
||||
self.add_metric(metric)
|
||||
|
||||
def perform_lookup(self, unique_id: UniqueID, manifest: "Manifest") -> ParsedMetric:
|
||||
if unique_id not in manifest.metrics:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f"Metric {unique_id} found in cache but not found in manifest"
|
||||
)
|
||||
return manifest.metrics[unique_id]
|
||||
|
||||
|
||||
# This handles both models/seeds/snapshots and sources
|
||||
class DisabledLookup(dbtClassMixin):
|
||||
def __init__(self, manifest: "Manifest"):
|
||||
@@ -361,6 +328,11 @@ class Locality(enum.IntEnum):
|
||||
Root = 3
|
||||
|
||||
|
||||
class Specificity(enum.IntEnum):
|
||||
Default = 1
|
||||
Adapter = 2
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroCandidate:
|
||||
locality: Locality
|
||||
@@ -383,14 +355,12 @@ class MacroCandidate:
|
||||
|
||||
@dataclass
|
||||
class MaterializationCandidate(MacroCandidate):
|
||||
# specificity describes where in the inheritance chain this materialization candidate is
|
||||
# a specificity of 0 means a materialization defined by the current adapter
|
||||
# the highest the specificity describes a default materialization. the value itself depends on
|
||||
# how many adapters there are in the inheritance chain
|
||||
specificity: int
|
||||
specificity: Specificity
|
||||
|
||||
@classmethod
|
||||
def from_macro(cls, candidate: MacroCandidate, specificity: int) -> "MaterializationCandidate":
|
||||
def from_macro(
|
||||
cls, candidate: MacroCandidate, specificity: Specificity
|
||||
) -> "MaterializationCandidate":
|
||||
return cls(
|
||||
locality=candidate.locality,
|
||||
macro=candidate.macro,
|
||||
@@ -414,9 +384,9 @@ class MaterializationCandidate(MacroCandidate):
|
||||
def __lt__(self, other: object) -> bool:
|
||||
if not isinstance(other, MaterializationCandidate):
|
||||
return NotImplemented
|
||||
if self.specificity > other.specificity:
|
||||
return True
|
||||
if self.specificity < other.specificity:
|
||||
return True
|
||||
if self.specificity > other.specificity:
|
||||
return False
|
||||
if self.locality < other.locality:
|
||||
return True
|
||||
@@ -464,9 +434,6 @@ class Disabled(Generic[D]):
|
||||
target: D
|
||||
|
||||
|
||||
MaybeMetricNode = Optional[ParsedMetric]
|
||||
|
||||
|
||||
MaybeDocumentation = Optional[ParsedDocumentation]
|
||||
|
||||
|
||||
@@ -486,7 +453,7 @@ T = TypeVar("T", bound=GraphMemberNode)
|
||||
|
||||
def _update_into(dest: MutableMapping[str, T], new_item: T):
|
||||
"""Update dest to overwrite whatever is at dest[new_item.unique_id] with
|
||||
new_itme. There must be an existing value to overwrite, and the two nodes
|
||||
new_itme. There must be an existing value to overwrite, and they two nodes
|
||||
must have the same original file path.
|
||||
"""
|
||||
unique_id = new_item.unique_id
|
||||
@@ -628,9 +595,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
_ref_lookup: Optional[RefableLookup] = field(
|
||||
default=None, metadata={"serialize": lambda x: None, "deserialize": lambda x: None}
|
||||
)
|
||||
_metric_lookup: Optional[MetricLookup] = field(
|
||||
default=None, metadata={"serialize": lambda x: None, "deserialize": lambda x: None}
|
||||
)
|
||||
_disabled_lookup: Optional[DisabledLookup] = field(
|
||||
default=None, metadata={"serialize": lambda x: None, "deserialize": lambda x: None}
|
||||
)
|
||||
@@ -707,24 +671,18 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
disabled_by_file_id[node.file_id] = node
|
||||
return disabled_by_file_id
|
||||
|
||||
def _get_parent_adapter_types(self, adapter_type: str) -> List[str]:
|
||||
# This is duplicated logic from core/dbt/context/providers.py
|
||||
# Ideally this would instead be incorporating actual dispatch logic
|
||||
from dbt.adapters.factory import get_adapter_type_names
|
||||
|
||||
# order matters for dispatch:
|
||||
# 1. current adapter
|
||||
# 2. any parent adapters (dependencies)
|
||||
# 3. 'default'
|
||||
return get_adapter_type_names(adapter_type) + ["default"]
|
||||
|
||||
def _materialization_candidates_for(
|
||||
self,
|
||||
project_name: str,
|
||||
materialization_name: str,
|
||||
adapter_type: str,
|
||||
specificity: int,
|
||||
adapter_type: Optional[str],
|
||||
) -> CandidateList:
|
||||
|
||||
if adapter_type is None:
|
||||
specificity = Specificity.Default
|
||||
else:
|
||||
specificity = Specificity.Adapter
|
||||
|
||||
full_name = dbt.utils.get_materialization_macro_name(
|
||||
materialization_name=materialization_name,
|
||||
adapter_type=adapter_type,
|
||||
@@ -744,9 +702,8 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
project_name=project_name,
|
||||
materialization_name=materialization_name,
|
||||
adapter_type=atype,
|
||||
specificity=specificity, # where in the inheritance chain this candidate is
|
||||
)
|
||||
for specificity, atype in enumerate(self._get_parent_adapter_types(adapter_type))
|
||||
for atype in (adapter_type, None)
|
||||
)
|
||||
)
|
||||
return candidates.last()
|
||||
@@ -876,12 +833,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
self._ref_lookup = RefableLookup(self)
|
||||
return self._ref_lookup
|
||||
|
||||
@property
|
||||
def metric_lookup(self) -> MetricLookup:
|
||||
if self._metric_lookup is None:
|
||||
self._metric_lookup = MetricLookup(self)
|
||||
return self._metric_lookup
|
||||
|
||||
def rebuild_ref_lookup(self):
|
||||
self._ref_lookup = RefableLookup(self)
|
||||
|
||||
@@ -957,22 +908,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
return Disabled(disabled[0])
|
||||
return None
|
||||
|
||||
def resolve_metric(
|
||||
self,
|
||||
target_metric_name: str,
|
||||
target_metric_package: Optional[str],
|
||||
current_project: str,
|
||||
node_package: str,
|
||||
) -> MaybeMetricNode:
|
||||
metric: Optional[ParsedMetric] = None
|
||||
|
||||
candidates = _search_packages(current_project, node_package, target_metric_package)
|
||||
for pkg in candidates:
|
||||
metric = self.metric_lookup.find(target_metric_name, pkg, self)
|
||||
if metric is not None:
|
||||
return metric
|
||||
return None
|
||||
|
||||
# Called by DocsRuntimeContext.doc
|
||||
def resolve_doc(
|
||||
self,
|
||||
@@ -1137,7 +1072,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
self._doc_lookup,
|
||||
self._source_lookup,
|
||||
self._ref_lookup,
|
||||
self._metric_lookup,
|
||||
self._disabled_lookup,
|
||||
self._analysis_lookup,
|
||||
)
|
||||
@@ -1157,7 +1091,7 @@ AnyManifest = Union[Manifest, MacroManifest]
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version("manifest", 6)
|
||||
@schema_version("manifest", 4)
|
||||
class WritableManifest(ArtifactMixin):
|
||||
nodes: Mapping[UniqueID, ManifestNode] = field(
|
||||
metadata=dict(description=("The nodes defined in the dbt project and its dependencies"))
|
||||
@@ -1201,16 +1135,6 @@ class WritableManifest(ArtifactMixin):
|
||||
)
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def compatible_previous_versions(self):
|
||||
return [("manifest", 4), ("manifest", 5)]
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
for unique_id, node in dct["nodes"].items():
|
||||
if "config_call_dict" in node:
|
||||
del node["config_call_dict"]
|
||||
return dct
|
||||
|
||||
|
||||
def _check_duplicates(value: HasUniqueID, src: Mapping[str, HasUniqueID]):
|
||||
if value.unique_id in src:
|
||||
|
||||
@@ -1,70 +0,0 @@
|
||||
from dbt.node_types import NodeType
|
||||
|
||||
|
||||
class MetricReference(object):
|
||||
def __init__(self, metric_name, package_name=None):
|
||||
self.metric_name = metric_name
|
||||
self.package_name = package_name
|
||||
|
||||
def __str__(self):
|
||||
return f"{self.metric_name}"
|
||||
|
||||
|
||||
class ResolvedMetricReference(MetricReference):
|
||||
"""
|
||||
Simple proxy over a ParsedMetric which delegates property
|
||||
lookups to the underlying node. Also adds helper functions
|
||||
for working with metrics (ie. __str__ and templating functions)
|
||||
"""
|
||||
|
||||
def __init__(self, node, manifest, Relation):
|
||||
super().__init__(node.name, node.package_name)
|
||||
self.node = node
|
||||
self.manifest = manifest
|
||||
self.Relation = Relation
|
||||
|
||||
def __getattr__(self, key):
|
||||
return getattr(self.node, key)
|
||||
|
||||
def __str__(self):
|
||||
return f"{self.node.name}"
|
||||
|
||||
@classmethod
|
||||
def parent_metrics(cls, metric_node, manifest):
|
||||
yield metric_node
|
||||
|
||||
for parent_unique_id in metric_node.depends_on.nodes:
|
||||
node = manifest.metrics.get(parent_unique_id)
|
||||
if node and node.resource_type == NodeType.Metric:
|
||||
yield from cls.parent_metrics(node, manifest)
|
||||
|
||||
def parent_models(self):
|
||||
in_scope_metrics = list(self.parent_metrics(self.node, self.manifest))
|
||||
|
||||
to_return = {
|
||||
"base": [],
|
||||
"derived": [],
|
||||
}
|
||||
for metric in in_scope_metrics:
|
||||
if metric.type == "expression":
|
||||
to_return["derived"].append(
|
||||
{"metric_source": None, "metric": metric, "is_derived": True}
|
||||
)
|
||||
else:
|
||||
for node_unique_id in metric.depends_on.nodes:
|
||||
node = self.manifest.nodes.get(node_unique_id)
|
||||
if node and node.resource_type in NodeType.refable():
|
||||
to_return["base"].append(
|
||||
{
|
||||
"metric_relation_node": node,
|
||||
"metric_relation": self.Relation.create(
|
||||
database=node.database,
|
||||
schema=node.schema,
|
||||
identifier=node.alias,
|
||||
),
|
||||
"metric": metric,
|
||||
"is_derived": False,
|
||||
}
|
||||
)
|
||||
|
||||
return to_return
|
||||
@@ -7,8 +7,7 @@ from dbt.dataclass_schema import (
|
||||
ValidationError,
|
||||
register_pattern,
|
||||
)
|
||||
from dbt.contracts.graph.unparsed import AdditionalPropertiesAllowed, Docs
|
||||
from dbt.contracts.graph.utils import validate_color
|
||||
from dbt.contracts.graph.unparsed import AdditionalPropertiesAllowed
|
||||
from dbt.exceptions import InternalException, CompilationException
|
||||
from dbt.contracts.util import Replaceable, list_str
|
||||
from dbt import hooks
|
||||
@@ -67,7 +66,6 @@ class MergeBehavior(Metadata):
|
||||
Append = 1
|
||||
Update = 2
|
||||
Clobber = 3
|
||||
DictKeyAppend = 4
|
||||
|
||||
@classmethod
|
||||
def default_field(cls) -> "MergeBehavior":
|
||||
@@ -126,9 +124,6 @@ def _listify(value: Any) -> List:
|
||||
return [value]
|
||||
|
||||
|
||||
# There are two versions of this code. The one here is for config
|
||||
# objects, the one in _add_config_call in context_config.py is for
|
||||
# config_call_dict dictionaries.
|
||||
def _merge_field_value(
|
||||
merge_behavior: MergeBehavior,
|
||||
self_value: Any,
|
||||
@@ -146,31 +141,6 @@ def _merge_field_value(
|
||||
value = self_value.copy()
|
||||
value.update(other_value)
|
||||
return value
|
||||
elif merge_behavior == MergeBehavior.DictKeyAppend:
|
||||
if not isinstance(self_value, dict):
|
||||
raise InternalException(f"expected dict, got {self_value}")
|
||||
if not isinstance(other_value, dict):
|
||||
raise InternalException(f"expected dict, got {other_value}")
|
||||
new_dict = {}
|
||||
for key in self_value.keys():
|
||||
new_dict[key] = _listify(self_value[key])
|
||||
for key in other_value.keys():
|
||||
extend = False
|
||||
new_key = key
|
||||
# This might start with a +, to indicate we should extend the list
|
||||
# instead of just clobbering it
|
||||
if new_key.startswith("+"):
|
||||
new_key = key.lstrip("+")
|
||||
extend = True
|
||||
if new_key in new_dict and extend:
|
||||
# extend the list
|
||||
value = other_value[key]
|
||||
new_dict[new_key].extend(_listify(value))
|
||||
else:
|
||||
# clobber the list
|
||||
new_dict[new_key] = _listify(other_value[key])
|
||||
return new_dict
|
||||
|
||||
else:
|
||||
raise InternalException(f"Got an invalid merge_behavior: {merge_behavior}")
|
||||
|
||||
@@ -286,8 +256,7 @@ class BaseConfig(AdditionalPropertiesAllowed, Replaceable):
|
||||
# 'meta' moved here from node
|
||||
mergebehavior = {
|
||||
"append": ["pre-hook", "pre_hook", "post-hook", "post_hook", "tags"],
|
||||
"update": ["quoting", "column_types", "meta", "docs"],
|
||||
"dict_key_append": ["grants"],
|
||||
"update": ["quoting", "column_types", "meta"],
|
||||
}
|
||||
|
||||
@classmethod
|
||||
@@ -366,40 +335,6 @@ class BaseConfig(AdditionalPropertiesAllowed, Replaceable):
|
||||
@dataclass
|
||||
class SourceConfig(BaseConfig):
|
||||
enabled: bool = True
|
||||
# to be implmented to complete CT-201
|
||||
# quoting: Dict[str, Any] = field(
|
||||
# default_factory=dict,
|
||||
# metadata=MergeBehavior.Update.meta(),
|
||||
# )
|
||||
# freshness: Optional[Dict[str, Any]] = field(
|
||||
# default=None,
|
||||
# metadata=CompareBehavior.Exclude.meta(),
|
||||
# )
|
||||
# loader: Optional[str] = field(
|
||||
# default=None,
|
||||
# metadata=CompareBehavior.Exclude.meta(),
|
||||
# )
|
||||
# # TODO what type is this? docs say: "<column_name_or_expression>"
|
||||
# loaded_at_field: Optional[str] = field(
|
||||
# default=None,
|
||||
# metadata=CompareBehavior.Exclude.meta(),
|
||||
# )
|
||||
# database: Optional[str] = field(
|
||||
# default=None,
|
||||
# metadata=CompareBehavior.Exclude.meta(),
|
||||
# )
|
||||
# schema: Optional[str] = field(
|
||||
# default=None,
|
||||
# metadata=CompareBehavior.Exclude.meta(),
|
||||
# )
|
||||
# meta: Dict[str, Any] = field(
|
||||
# default_factory=dict,
|
||||
# metadata=MergeBehavior.Update.meta(),
|
||||
# )
|
||||
# tags: Union[List[str], str] = field(
|
||||
# default_factory=list_str,
|
||||
# metadata=metas(ShowBehavior.Hide, MergeBehavior.Append, CompareBehavior.Exclude),
|
||||
# )
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -454,27 +389,8 @@ class NodeConfig(NodeAndTestConfig):
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
full_refresh: Optional[bool] = None
|
||||
# 'unique_key' doesn't use 'Optional' because typing.get_type_hints was
|
||||
# sometimes getting the Union order wrong, causing serialization failures.
|
||||
unique_key: Union[str, List[str], None] = None
|
||||
unique_key: Optional[Union[str, List[str]]] = None
|
||||
on_schema_change: Optional[str] = "ignore"
|
||||
grants: Dict[str, Any] = field(
|
||||
default_factory=dict, metadata=MergeBehavior.DictKeyAppend.meta()
|
||||
)
|
||||
docs: Docs = field(
|
||||
default_factory=lambda: Docs(show=True),
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
|
||||
# we validate that node_color has a suitable value to prevent dbt-docs from crashing
|
||||
def __post_init__(self):
|
||||
if self.docs.node_color:
|
||||
node_color = self.docs.node_color
|
||||
if not validate_color(node_color):
|
||||
raise ValidationError(
|
||||
f"Invalid color name for docs.node_color: {node_color}. "
|
||||
"It is neither a valid HTML color name nor a valid HEX code."
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
@@ -567,8 +483,7 @@ class SnapshotConfig(EmptySnapshotConfig):
|
||||
target_schema: Optional[str] = None
|
||||
target_database: Optional[str] = None
|
||||
updated_at: Optional[str] = None
|
||||
# Not using Optional because of serialization issues with a Union of str and List[str]
|
||||
check_cols: Union[str, List[str], None] = None
|
||||
check_cols: Optional[Union[str, List[str]]] = None
|
||||
|
||||
@classmethod
|
||||
def validate(cls, data):
|
||||
|
||||
@@ -157,6 +157,7 @@ class ParsedNodeMixins(dbtClassMixin):
|
||||
self.created_at = time.time()
|
||||
self.description = patch.description
|
||||
self.columns = patch.columns
|
||||
self.docs = patch.docs
|
||||
|
||||
def get_materialization(self):
|
||||
return self.config.materialized
|
||||
@@ -197,12 +198,11 @@ class ParsedNodeDefaults(NodeInfoMixin, ParsedNodeMandatory):
|
||||
tags: List[str] = field(default_factory=list)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
metrics: List[List[str]] = field(default_factory=list)
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
description: str = field(default="")
|
||||
columns: Dict[str, ColumnInfo] = field(default_factory=dict)
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
docs: Docs = field(default_factory=lambda: Docs(show=True))
|
||||
docs: Docs = field(default_factory=Docs)
|
||||
patch_path: Optional[str] = None
|
||||
compiled_path: Optional[str] = None
|
||||
build_path: Optional[str] = None
|
||||
@@ -233,6 +233,8 @@ class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins, SerializableType):
|
||||
return self.to_dict()
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
if "config_call_dict" in dct:
|
||||
del dct["config_call_dict"]
|
||||
if "_event_status" in dct:
|
||||
del dct["_event_status"]
|
||||
return dct
|
||||
@@ -584,7 +586,10 @@ class UnpatchedSourceDefinition(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
|
||||
@property
|
||||
def columns(self) -> Sequence[UnparsedColumn]:
|
||||
return [] if self.table.columns is None else self.table.columns
|
||||
if self.table.columns is None:
|
||||
return []
|
||||
else:
|
||||
return self.table.columns
|
||||
|
||||
def get_tests(self) -> Iterator[Tuple[Dict[str, Any], Optional[UnparsedColumn]]]:
|
||||
for test in self.tests:
|
||||
@@ -793,32 +798,24 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class MetricReference(dbtClassMixin, Replaceable):
|
||||
sql: Optional[Union[str, int]]
|
||||
unique_id: Optional[str]
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedMetric(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
model: str
|
||||
name: str
|
||||
description: str
|
||||
label: str
|
||||
type: str
|
||||
sql: str
|
||||
sql: Optional[str]
|
||||
timestamp: Optional[str]
|
||||
filters: List[MetricFilter]
|
||||
time_grains: List[str]
|
||||
dimensions: List[str]
|
||||
model: Optional[str] = None
|
||||
model_unique_id: Optional[str] = None
|
||||
resource_type: NodeType = NodeType.Metric
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
metrics: List[List[str]] = field(default_factory=list)
|
||||
created_at: float = field(default_factory=lambda: time.time())
|
||||
|
||||
@property
|
||||
|
||||
@@ -1,11 +1,15 @@
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.contracts.util import AdditionalPropertiesMixin, Mergeable, Replaceable
|
||||
from dbt.contracts.util import (
|
||||
AdditionalPropertiesMixin,
|
||||
Mergeable,
|
||||
Replaceable,
|
||||
)
|
||||
|
||||
# trigger the PathEncoder
|
||||
import dbt.helper_types # noqa:F401
|
||||
from dbt.exceptions import CompilationException, ParsingException
|
||||
from dbt.exceptions import CompilationException
|
||||
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum, ExtensibleDbtClassMixin, ValidationError
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum, ExtensibleDbtClassMixin
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import timedelta
|
||||
@@ -76,7 +80,6 @@ class UnparsedRunHook(UnparsedNode):
|
||||
@dataclass
|
||||
class Docs(dbtClassMixin, Replaceable):
|
||||
show: bool = True
|
||||
node_color: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -239,7 +242,6 @@ class Quoting(dbtClassMixin, Mergeable):
|
||||
|
||||
@dataclass
|
||||
class UnparsedSourceTableDefinition(HasColumnTests, HasTests):
|
||||
config: Dict[str, Any] = field(default_factory=dict)
|
||||
loaded_at_field: Optional[str] = None
|
||||
identifier: Optional[str] = None
|
||||
quoting: Quoting = field(default_factory=Quoting)
|
||||
@@ -320,7 +322,6 @@ class SourcePatch(dbtClassMixin, Replaceable):
|
||||
path: Path = field(
|
||||
metadata=dict(description="The path to the patch-defining yml file"),
|
||||
)
|
||||
config: Dict[str, Any] = field(default_factory=dict)
|
||||
description: Optional[str] = None
|
||||
meta: Optional[Dict[str, Any]] = None
|
||||
database: Optional[str] = None
|
||||
@@ -445,33 +446,15 @@ class MetricFilter(dbtClassMixin, Replaceable):
|
||||
|
||||
@dataclass
|
||||
class UnparsedMetric(dbtClassMixin, Replaceable):
|
||||
# TODO : verify that this disallows metric names with spaces
|
||||
# TODO: fix validation that you broke :p
|
||||
# name: Identifier
|
||||
model: str
|
||||
name: str
|
||||
label: str
|
||||
type: str
|
||||
model: Optional[str] = None
|
||||
description: str = ""
|
||||
sql: Union[str, int] = ""
|
||||
sql: Optional[str] = None
|
||||
timestamp: Optional[str] = None
|
||||
time_grains: List[str] = field(default_factory=list)
|
||||
dimensions: List[str] = field(default_factory=list)
|
||||
filters: List[MetricFilter] = field(default_factory=list)
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
@classmethod
|
||||
def validate(cls, data):
|
||||
# super().validate(data)
|
||||
# TODO: putting this back for now to get tests passing. Do we want to implement name: Identifier?
|
||||
super(UnparsedMetric, cls).validate(data)
|
||||
if "name" in data and " " in data["name"]:
|
||||
raise ParsingException(f"Metrics name '{data['name']}' cannot contain spaces")
|
||||
|
||||
# TODO: Expressions _cannot_ have `model` properties
|
||||
if data.get("model") is None and data.get("type") != "expression":
|
||||
raise ValidationError("Non-expression metrics require a 'model' property")
|
||||
|
||||
if data.get("model") is not None and data.get("type") == "expression":
|
||||
raise ValidationError("Expression metrics cannot have a 'model' property")
|
||||
|
||||
@@ -1,153 +0,0 @@
|
||||
import re
|
||||
|
||||
HTML_COLORS = [
|
||||
"aliceblue",
|
||||
"antiquewhite",
|
||||
"aqua",
|
||||
"aquamarine",
|
||||
"azure",
|
||||
"beige",
|
||||
"bisque",
|
||||
"black",
|
||||
"blanchedalmond",
|
||||
"blue",
|
||||
"blueviolet",
|
||||
"brown",
|
||||
"burlywood",
|
||||
"cadetblue",
|
||||
"chartreuse",
|
||||
"chocolate",
|
||||
"coral",
|
||||
"cornflowerblue",
|
||||
"cornsilk",
|
||||
"crimson",
|
||||
"cyan",
|
||||
"darkblue",
|
||||
"darkcyan",
|
||||
"darkgoldenrod",
|
||||
"darkgray",
|
||||
"darkgreen",
|
||||
"darkkhaki",
|
||||
"darkmagenta",
|
||||
"darkolivegreen",
|
||||
"darkorange",
|
||||
"darkorchid",
|
||||
"darkred",
|
||||
"darksalmon",
|
||||
"darkseagreen",
|
||||
"darkslateblue",
|
||||
"darkslategray",
|
||||
"darkturquoise",
|
||||
"darkviolet",
|
||||
"deeppink",
|
||||
"deepskyblue",
|
||||
"dimgray",
|
||||
"dodgerblue",
|
||||
"firebrick",
|
||||
"floralwhite",
|
||||
"forestgreen",
|
||||
"fuchsia",
|
||||
"gainsboro",
|
||||
"ghostwhite",
|
||||
"gold",
|
||||
"goldenrod",
|
||||
"gray",
|
||||
"green",
|
||||
"greenyellow",
|
||||
"honeydew",
|
||||
"hotpink",
|
||||
"indianred",
|
||||
"indigo",
|
||||
"ivory",
|
||||
"khaki",
|
||||
"lavender",
|
||||
"lavenderblush",
|
||||
"lawngreen",
|
||||
"lemonchiffon",
|
||||
"lightblue",
|
||||
"lightcoral",
|
||||
"lightcyan",
|
||||
"lightgoldenrodyellow",
|
||||
"lightgray",
|
||||
"lightgreen",
|
||||
"lightpink",
|
||||
"lightsalmon",
|
||||
"lightsalmon",
|
||||
"lightseagreen",
|
||||
"lightskyblue",
|
||||
"lightslategray",
|
||||
"lightsteelblue",
|
||||
"lightyellow",
|
||||
"lime",
|
||||
"limegreen",
|
||||
"linen",
|
||||
"magenta",
|
||||
"maroon",
|
||||
"mediumaquamarine",
|
||||
"mediumblue",
|
||||
"mediumorchid",
|
||||
"mediumpurple",
|
||||
"mediumseagreen",
|
||||
"mediumslateblue",
|
||||
"mediumslateblue",
|
||||
"mediumspringgreen",
|
||||
"mediumturquoise",
|
||||
"mediumvioletred",
|
||||
"midnightblue",
|
||||
"mintcream",
|
||||
"mistyrose",
|
||||
"moccasin",
|
||||
"navajowhite",
|
||||
"navy",
|
||||
"oldlace",
|
||||
"olive",
|
||||
"olivedrab",
|
||||
"orange",
|
||||
"orangered",
|
||||
"orchid",
|
||||
"palegoldenrod",
|
||||
"palegreen",
|
||||
"paleturquoise",
|
||||
"palevioletred",
|
||||
"papayawhip",
|
||||
"peachpuff",
|
||||
"peru",
|
||||
"pink",
|
||||
"plum",
|
||||
"powderblue",
|
||||
"purple",
|
||||
"rebeccapurple",
|
||||
"red",
|
||||
"rosybrown",
|
||||
"royalblue",
|
||||
"saddlebrown",
|
||||
"salmon",
|
||||
"sandybrown",
|
||||
"seagreen",
|
||||
"seashell",
|
||||
"sienna",
|
||||
"silver",
|
||||
"skyblue",
|
||||
"slateblue",
|
||||
"slategray",
|
||||
"snow",
|
||||
"springgreen",
|
||||
"steelblue",
|
||||
"tan",
|
||||
"teal",
|
||||
"thistle",
|
||||
"tomato",
|
||||
"turquoise",
|
||||
"violet",
|
||||
"wheat",
|
||||
"white",
|
||||
"whitesmoke",
|
||||
"yellow",
|
||||
"yellowgreen",
|
||||
]
|
||||
|
||||
|
||||
def validate_color(color: str) -> bool:
|
||||
match_hex = re.search(r"^#(?:[0-9a-f]{3}){1,2}$", color.lower())
|
||||
match_html_color_name = color.lower() in HTML_COLORS
|
||||
return bool(match_hex or match_html_color_name)
|
||||
@@ -1,4 +1,4 @@
|
||||
from dbt.contracts.util import Replaceable, Mergeable, list_str, Identifier
|
||||
from dbt.contracts.util import Replaceable, Mergeable, list_str
|
||||
from dbt.contracts.connection import QueryComment, UserConfigContract
|
||||
from dbt.helper_types import NoValue
|
||||
from dbt.dataclass_schema import (
|
||||
@@ -7,6 +7,7 @@ from dbt.dataclass_schema import (
|
||||
HyphenatedDbtClassMixin,
|
||||
ExtensibleDbtClassMixin,
|
||||
register_pattern,
|
||||
ValidatedStringMixin,
|
||||
)
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional, List, Dict, Union, Any
|
||||
@@ -18,6 +19,25 @@ PIN_PACKAGE_URL = (
|
||||
DEFAULT_SEND_ANONYMOUS_USAGE_STATS = True
|
||||
|
||||
|
||||
class Name(ValidatedStringMixin):
|
||||
ValidationRegex = r"^[^\d\W]\w*$"
|
||||
|
||||
@classmethod
|
||||
def is_valid(cls, value: Any) -> bool:
|
||||
if not isinstance(value, str):
|
||||
return False
|
||||
|
||||
try:
|
||||
cls.validate(value)
|
||||
except ValidationError:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
register_pattern(Name, r"^[^\d\W]\w*$")
|
||||
|
||||
|
||||
class SemverString(str, SerializableType):
|
||||
def _serialize(self) -> str:
|
||||
return self
|
||||
@@ -162,7 +182,7 @@ BANNED_PROJECT_NAMES = {
|
||||
|
||||
@dataclass
|
||||
class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
name: Identifier
|
||||
name: Name
|
||||
version: Union[SemverString, float]
|
||||
config_version: int
|
||||
project_root: Optional[str] = None
|
||||
@@ -233,7 +253,6 @@ class UserConfig(ExtensibleDbtClassMixin, Replaceable, UserConfigContract):
|
||||
use_experimental_parser: Optional[bool] = None
|
||||
static_parser: Optional[bool] = None
|
||||
indirect_selection: Optional[str] = None
|
||||
cache_selected_only: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -85,7 +85,6 @@ class RunStatus(StrEnum):
|
||||
|
||||
|
||||
class TestStatus(StrEnum):
|
||||
__test__ = False
|
||||
Pass = NodeStatus.Pass
|
||||
Error = NodeStatus.Error
|
||||
Fail = NodeStatus.Fail
|
||||
|
||||
@@ -1,23 +1,20 @@
|
||||
from pathlib import Path
|
||||
from .graph.manifest import WritableManifest
|
||||
from .results import RunResultsArtifact
|
||||
from .results import FreshnessExecutionResultArtifact
|
||||
from typing import Optional
|
||||
from dbt.exceptions import IncompatibleSchemaException
|
||||
|
||||
|
||||
class PreviousState:
|
||||
def __init__(self, path: Path, current_path: Path):
|
||||
def __init__(self, path: Path):
|
||||
self.path: Path = path
|
||||
self.current_path: Path = current_path
|
||||
self.manifest: Optional[WritableManifest] = None
|
||||
self.results: Optional[RunResultsArtifact] = None
|
||||
self.sources: Optional[FreshnessExecutionResultArtifact] = None
|
||||
self.sources_current: Optional[FreshnessExecutionResultArtifact] = None
|
||||
|
||||
manifest_path = self.path / "manifest.json"
|
||||
if manifest_path.exists() and manifest_path.is_file():
|
||||
try:
|
||||
# we want to bail with an error if schema versions don't match
|
||||
self.manifest = WritableManifest.read_and_check_versions(str(manifest_path))
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(manifest_path))
|
||||
@@ -26,27 +23,8 @@ class PreviousState:
|
||||
results_path = self.path / "run_results.json"
|
||||
if results_path.exists() and results_path.is_file():
|
||||
try:
|
||||
# we want to bail with an error if schema versions don't match
|
||||
self.results = RunResultsArtifact.read_and_check_versions(str(results_path))
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(results_path))
|
||||
raise
|
||||
|
||||
sources_path = self.path / "sources.json"
|
||||
if sources_path.exists() and sources_path.is_file():
|
||||
try:
|
||||
self.sources = FreshnessExecutionResultArtifact.read_and_check_versions(
|
||||
str(sources_path)
|
||||
)
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(sources_path))
|
||||
raise
|
||||
|
||||
sources_current_path = self.current_path / "sources.json"
|
||||
if sources_current_path.exists() and sources_current_path.is_file():
|
||||
try:
|
||||
self.sources_current = FreshnessExecutionResultArtifact.read_and_check_versions(
|
||||
str(sources_current_path)
|
||||
)
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(sources_current_path))
|
||||
raise
|
||||
|
||||
@@ -9,13 +9,6 @@ from dbt.version import __version__
|
||||
from dbt.events.functions import get_invocation_id
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
|
||||
from dbt.dataclass_schema import (
|
||||
ValidatedStringMixin,
|
||||
ValidationError,
|
||||
register_pattern,
|
||||
)
|
||||
|
||||
|
||||
SourceKey = Tuple[str, str]
|
||||
|
||||
|
||||
@@ -208,14 +201,6 @@ class VersionedSchema(dbtClassMixin):
|
||||
result["$id"] = str(cls.dbt_schema_version)
|
||||
return result
|
||||
|
||||
@classmethod
|
||||
def is_compatible_version(cls, schema_version):
|
||||
compatible_versions = [str(cls.dbt_schema_version)]
|
||||
if hasattr(cls, "compatible_previous_versions"):
|
||||
for name, version in cls.compatible_previous_versions():
|
||||
compatible_versions.append(str(SchemaVersion(name, version)))
|
||||
return str(schema_version) in compatible_versions
|
||||
|
||||
@classmethod
|
||||
def read_and_check_versions(cls, path: str):
|
||||
try:
|
||||
@@ -232,7 +217,7 @@ class VersionedSchema(dbtClassMixin):
|
||||
if "metadata" in data and "dbt_schema_version" in data["metadata"]:
|
||||
previous_schema_version = data["metadata"]["dbt_schema_version"]
|
||||
# cls.dbt_schema_version is a SchemaVersion object
|
||||
if not cls.is_compatible_version(previous_schema_version):
|
||||
if str(cls.dbt_schema_version) != previous_schema_version:
|
||||
raise IncompatibleSchemaException(
|
||||
expected=str(cls.dbt_schema_version), found=previous_schema_version
|
||||
)
|
||||
@@ -257,22 +242,3 @@ class ArtifactMixin(VersionedSchema, Writable, Readable):
|
||||
super().validate(data)
|
||||
if cls.dbt_schema_version is None:
|
||||
raise InternalException("Cannot call from_dict with no schema version!")
|
||||
|
||||
|
||||
class Identifier(ValidatedStringMixin):
|
||||
ValidationRegex = r"^[^\d\W]\w*$"
|
||||
|
||||
@classmethod
|
||||
def is_valid(cls, value: Any) -> bool:
|
||||
if not isinstance(value, str):
|
||||
return False
|
||||
|
||||
try:
|
||||
cls.validate(value)
|
||||
except ValidationError:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
register_pattern(Identifier, r"^[^\d\W]\w*$")
|
||||
|
||||
@@ -35,7 +35,7 @@ class DateTimeSerialization(SerializationStrategy):
|
||||
# jsonschemas for every class and the 'validate' method
|
||||
# come from Hologram.
|
||||
class dbtClassMixin(DataClassDictMixin, JsonSchemaMixin):
|
||||
"""The Mixin adds methods to generate a JSON schema and
|
||||
"""Mixin which adds methods to generate a JSON schema and
|
||||
convert to and from JSON encodable dicts with validation
|
||||
against the schema
|
||||
"""
|
||||
|
||||
@@ -103,8 +103,7 @@ SomeUnpinned = TypeVar("SomeUnpinned", bound="UnpinnedPackage")
|
||||
|
||||
|
||||
class UnpinnedPackage(Generic[SomePinned], BasePackage):
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def from_contract(cls, contract):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
@@ -64,7 +64,7 @@ class Event(metaclass=ABCMeta):
|
||||
|
||||
# in theory threads can change so we don't cache them.
|
||||
def get_thread_name(self) -> str:
|
||||
return threading.current_thread().name
|
||||
return threading.current_thread().getName()
|
||||
|
||||
@classmethod
|
||||
def get_invocation_id(cls) -> str:
|
||||
|
||||
@@ -15,7 +15,7 @@ def format_fancy_output_line(
|
||||
progress = ""
|
||||
else:
|
||||
progress = "{} of {} ".format(index, total)
|
||||
prefix = "{progress}{message} ".format(progress=progress, message=msg)
|
||||
prefix = "{progress}{message}".format(progress=progress, message=msg)
|
||||
|
||||
truncate_width = ui.printer_width() - 3
|
||||
justified = prefix.ljust(ui.printer_width(), ".")
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
import colorama
|
||||
from colorama import Style
|
||||
import dbt.events.functions as this # don't worry I hate it too.
|
||||
from dbt.events.base_types import NoStdOut, Event, NoFile, ShowException, Cache
|
||||
@@ -49,6 +50,25 @@ format_color = True
|
||||
format_json = False
|
||||
invocation_id: Optional[str] = None
|
||||
|
||||
# Colorama needs some help on windows because we're using logger.info
|
||||
# intead of print(). If the Windows env doesn't have a TERM var set,
|
||||
# then we should override the logging stream to use the colorama
|
||||
# converter. If the TERM var is set (as with Git Bash), then it's safe
|
||||
# to send escape characters and no log handler injection is needed.
|
||||
colorama_stdout = sys.stdout
|
||||
colorama_wrap = True
|
||||
|
||||
colorama.init(wrap=colorama_wrap)
|
||||
|
||||
if sys.platform == "win32" and not os.getenv("TERM"):
|
||||
colorama_wrap = False
|
||||
colorama_stdout = colorama.AnsiToWin32(sys.stdout).stream
|
||||
|
||||
elif sys.platform == "win32":
|
||||
colorama_wrap = False
|
||||
|
||||
colorama.init(wrap=colorama_wrap)
|
||||
|
||||
|
||||
def setup_event_logger(log_path, level_override=None):
|
||||
# flags have been resolved, and log_path is known
|
||||
@@ -166,12 +186,8 @@ def event_to_serializable_dict(
|
||||
|
||||
# translates an Event to a completely formatted text-based log line
|
||||
# type hinting everything as strings so we don't get any unintentional string conversions via str()
|
||||
def reset_color() -> str:
|
||||
return "" if not this.format_color else Style.RESET_ALL
|
||||
|
||||
|
||||
def create_info_text_log_line(e: T_Event) -> str:
|
||||
color_tag: str = reset_color()
|
||||
color_tag: str = "" if this.format_color else Style.RESET_ALL
|
||||
ts: str = get_ts().strftime("%H:%M:%S")
|
||||
scrubbed_msg: str = scrub_secrets(e.message(), env_secrets())
|
||||
log_line: str = f"{color_tag}{ts} {scrubbed_msg}"
|
||||
@@ -184,13 +200,13 @@ def create_debug_text_log_line(e: T_Event) -> str:
|
||||
if type(e) == MainReportVersion:
|
||||
separator = 30 * "="
|
||||
log_line = f"\n\n{separator} {get_ts()} | {get_invocation_id()} {separator}\n"
|
||||
color_tag: str = reset_color()
|
||||
color_tag: str = "" if this.format_color else Style.RESET_ALL
|
||||
ts: str = get_ts().strftime("%H:%M:%S.%f")
|
||||
scrubbed_msg: str = scrub_secrets(e.message(), env_secrets())
|
||||
level: str = e.level_tag() if len(e.level_tag()) == 5 else f"{e.level_tag()} "
|
||||
thread = ""
|
||||
if threading.current_thread().name:
|
||||
thread_name = threading.current_thread().name
|
||||
if threading.current_thread().getName():
|
||||
thread_name = threading.current_thread().getName()
|
||||
thread_name = thread_name[:10]
|
||||
thread_name = thread_name.ljust(10, " ")
|
||||
thread = f" [{thread_name}]:"
|
||||
|
||||
@@ -291,25 +291,6 @@ class GitProgressCheckedOutAt(DebugLevel):
|
||||
return f" Checked out at {self.end_sha}."
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryIndexProgressMakingGETRequest(DebugLevel):
|
||||
url: str
|
||||
code: str = "M022"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"Making package index registry request: GET {self.url}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryIndexProgressGETResponse(DebugLevel):
|
||||
url: str
|
||||
resp_code: int
|
||||
code: str = "M023"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"Response from registry index: GET {self.url} {self.resp_code}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryProgressMakingGETRequest(DebugLevel):
|
||||
url: str
|
||||
@@ -329,45 +310,6 @@ class RegistryProgressGETResponse(DebugLevel):
|
||||
return f"Response from registry: GET {self.url} {self.resp_code}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryResponseUnexpectedType(DebugLevel):
|
||||
response: str
|
||||
code: str = "M024"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"Response was None: {self.response}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryResponseMissingTopKeys(DebugLevel):
|
||||
response: str
|
||||
code: str = "M025"
|
||||
|
||||
def message(self) -> str:
|
||||
# expected/actual keys logged in exception
|
||||
return f"Response missing top level keys: {self.response}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryResponseMissingNestedKeys(DebugLevel):
|
||||
response: str
|
||||
code: str = "M026"
|
||||
|
||||
def message(self) -> str:
|
||||
# expected/actual keys logged in exception
|
||||
return f"Response missing nested keys: {self.response}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryResponseExtraNestedKeys(DebugLevel):
|
||||
response: str
|
||||
code: str = "M027"
|
||||
|
||||
def message(self) -> str:
|
||||
# expected/actual keys logged in exception
|
||||
return f"Response contained inconsistent keys: {self.response}"
|
||||
|
||||
|
||||
# TODO this was actually `logger.exception(...)` not `logger.error(...)`
|
||||
@dataclass
|
||||
class SystemErrorRetrievingModTime(ErrorLevel):
|
||||
@@ -1501,11 +1443,10 @@ class HooksRunning(InfoLevel):
|
||||
class HookFinished(InfoLevel):
|
||||
stat_line: str
|
||||
execution: str
|
||||
execution_time: float
|
||||
code: str = "E040"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"Finished running {self.stat_line}{self.execution} ({self.execution_time:0.2f}s)."
|
||||
return f"Finished running {self.stat_line}{self.execution}."
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -2353,15 +2294,11 @@ class WritingInjectedSQLForNode(DebugLevel):
|
||||
|
||||
|
||||
@dataclass
|
||||
class DisableTracking(DebugLevel):
|
||||
class DisableTracking(WarnLevel):
|
||||
code: str = "Z039"
|
||||
|
||||
def message(self) -> str:
|
||||
return (
|
||||
"Error sending anonymous usage statistics. Disabling tracking for this execution. "
|
||||
"If you wish to permanently disable tracking, see: "
|
||||
"https://docs.getdbt.com/reference/global-configs#send-anonymous-usage-stats."
|
||||
)
|
||||
return "Error sending message, disabling tracking"
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -2409,7 +2346,7 @@ class TrackingInitializeFailure(ShowException, DebugLevel):
|
||||
class RetryExternalCall(DebugLevel):
|
||||
attempt: int
|
||||
max: int
|
||||
code: str = "M020"
|
||||
code: str = "Z045"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"Retrying external call. Attempt: {self.attempt} Max attempts: {self.max}"
|
||||
@@ -2422,7 +2359,9 @@ class GeneralWarningMsg(WarnLevel):
|
||||
code: str = "Z046"
|
||||
|
||||
def message(self) -> str:
|
||||
return self.log_fmt.format(self.msg) if self.log_fmt is not None else self.msg
|
||||
if self.log_fmt is not None:
|
||||
return self.log_fmt.format(self.msg)
|
||||
return self.msg
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -2432,7 +2371,9 @@ class GeneralWarningException(WarnLevel):
|
||||
code: str = "Z047"
|
||||
|
||||
def message(self) -> str:
|
||||
return self.log_fmt.format(str(self.exc)) if self.log_fmt is not None else str(self.exc)
|
||||
if self.log_fmt is not None:
|
||||
return self.log_fmt.format(str(self.exc))
|
||||
return str(self.exc)
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -2440,19 +2381,7 @@ class EventBufferFull(WarnLevel):
|
||||
code: str = "Z048"
|
||||
|
||||
def message(self) -> str:
|
||||
return (
|
||||
"Internal logging/event buffer full."
|
||||
"Earliest logs/events will be dropped as new ones are fired (FIFO)."
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class RecordRetryException(DebugLevel):
|
||||
exc: Exception
|
||||
code: str = "M021"
|
||||
|
||||
def message(self) -> str:
|
||||
return f"External call exception: {self.exc}"
|
||||
return "Internal event buffer full. Earliest events will be dropped (FIFO)."
|
||||
|
||||
|
||||
# since mypy doesn't run on every file we need to suggest to mypy that every
|
||||
@@ -2484,14 +2413,6 @@ if 1 == 0:
|
||||
GitNothingToDo(sha="")
|
||||
GitProgressUpdatedCheckoutRange(start_sha="", end_sha="")
|
||||
GitProgressCheckedOutAt(end_sha="")
|
||||
RegistryIndexProgressMakingGETRequest(url="")
|
||||
RegistryIndexProgressGETResponse(url="", resp_code=1234)
|
||||
RegistryProgressMakingGETRequest(url="")
|
||||
RegistryProgressGETResponse(url="", resp_code=1234)
|
||||
RegistryResponseUnexpectedType(response=""),
|
||||
RegistryResponseMissingTopKeys(response=""),
|
||||
RegistryResponseMissingNestedKeys(response=""),
|
||||
RegistryResponseExtraNestedKeys(response=""),
|
||||
SystemErrorRetrievingModTime(path="")
|
||||
SystemCouldNotWrite(path="", reason="", exc=Exception(""))
|
||||
SystemExecutingCmd(cmd=[""])
|
||||
@@ -2621,7 +2542,7 @@ if 1 == 0:
|
||||
DatabaseErrorRunning(hook_type="")
|
||||
EmptyLine()
|
||||
HooksRunning(num_hooks=0, hook_type="")
|
||||
HookFinished(stat_line="", execution="", execution_time=0)
|
||||
HookFinished(stat_line="", execution="")
|
||||
WriteCatalogFailure(num_exceptions=0)
|
||||
CatalogWritten(path="")
|
||||
CannotGenerateDocs()
|
||||
@@ -2816,4 +2737,3 @@ if 1 == 0:
|
||||
GeneralWarningMsg(msg="", log_fmt="")
|
||||
GeneralWarningException(exc=Exception(""), log_fmt="")
|
||||
EventBufferFull()
|
||||
RecordRetryException(exc=Exception(""))
|
||||
|
||||
@@ -383,11 +383,10 @@ class FailedToConnectException(DatabaseException):
|
||||
|
||||
class CommandError(RuntimeException):
|
||||
def __init__(self, cwd, cmd, message="Error running command"):
|
||||
cmd_scrubbed = list(scrub_secrets(cmd_txt, env_secrets()) for cmd_txt in cmd)
|
||||
super().__init__(message)
|
||||
self.cwd = cwd
|
||||
self.cmd = cmd_scrubbed
|
||||
self.args = (cwd, cmd_scrubbed, message)
|
||||
self.cmd = cmd
|
||||
self.args = (cwd, cmd, message)
|
||||
|
||||
def __str__(self):
|
||||
if len(self.cmd) == 0:
|
||||
@@ -412,9 +411,9 @@ class CommandResultError(CommandError):
|
||||
def __init__(self, cwd, cmd, returncode, stdout, stderr, message="Got a non-zero returncode"):
|
||||
super().__init__(cwd, cmd, message)
|
||||
self.returncode = returncode
|
||||
self.stdout = scrub_secrets(stdout.decode("utf-8"), env_secrets())
|
||||
self.stderr = scrub_secrets(stderr.decode("utf-8"), env_secrets())
|
||||
self.args = (cwd, self.cmd, returncode, self.stdout, self.stderr, message)
|
||||
self.stdout = stdout
|
||||
self.stderr = stderr
|
||||
self.args = (cwd, cmd, returncode, stdout, stderr, message)
|
||||
|
||||
def __str__(self):
|
||||
return "{} running: {}".format(self.msg, self.cmd)
|
||||
@@ -437,10 +436,6 @@ class InvalidSelectorException(RuntimeException):
|
||||
super().__init__(name)
|
||||
|
||||
|
||||
class DuplicateYamlKeyException(CompilationException):
|
||||
pass
|
||||
|
||||
|
||||
def raise_compiler_error(msg, node=None) -> NoReturn:
|
||||
raise CompilationException(msg, node)
|
||||
|
||||
@@ -506,7 +501,7 @@ def invalid_type_error(
|
||||
|
||||
|
||||
def invalid_bool_error(got_value, macro_name) -> NoReturn:
|
||||
"""Raise a CompilationException when a macro expects a boolean but gets some
|
||||
"""Raise a CompilationException when an macro expects a boolean but gets some
|
||||
other value.
|
||||
"""
|
||||
msg = (
|
||||
@@ -520,12 +515,6 @@ def ref_invalid_args(model, args) -> NoReturn:
|
||||
raise_compiler_error("ref() takes at most two arguments ({} given)".format(len(args)), model)
|
||||
|
||||
|
||||
def metric_invalid_args(model, args) -> NoReturn:
|
||||
raise_compiler_error(
|
||||
"metric() takes at most two arguments ({} given)".format(len(args)), model
|
||||
)
|
||||
|
||||
|
||||
def ref_bad_context(model, args) -> NoReturn:
|
||||
ref_args = ", ".join("'{}'".format(a) for a in args)
|
||||
ref_string = "{{{{ ref({}) }}}}".format(ref_args)
|
||||
@@ -656,23 +645,6 @@ def source_target_not_found(
|
||||
raise_compiler_error(msg, model)
|
||||
|
||||
|
||||
def get_metric_not_found_msg(
|
||||
model,
|
||||
target_name: str,
|
||||
target_package: Optional[str],
|
||||
) -> str:
|
||||
reason = "was not found"
|
||||
return _get_target_failure_msg(
|
||||
model, target_name, target_package, include_path=True, reason=reason, target_kind="metric"
|
||||
)
|
||||
|
||||
|
||||
def metric_target_not_found(metric, target_name: str, target_package: Optional[str]) -> NoReturn:
|
||||
msg = get_metric_not_found_msg(metric, target_name, target_package)
|
||||
|
||||
raise_compiler_error(msg, metric)
|
||||
|
||||
|
||||
def dependency_not_found(model, target_model_name):
|
||||
raise_compiler_error(
|
||||
"'{}' depends on '{}' which is not in the graph!".format(
|
||||
@@ -732,6 +704,7 @@ def missing_materialization(model, adapter_type):
|
||||
|
||||
def bad_package_spec(repo, spec, error_message):
|
||||
msg = "Error checking out spec='{}' for repo {}\n{}".format(spec, repo, error_message)
|
||||
|
||||
raise InternalException(scrub_secrets(msg, env_secrets()))
|
||||
|
||||
|
||||
@@ -865,47 +838,31 @@ def raise_duplicate_macro_name(node_1, node_2, namespace) -> NoReturn:
|
||||
|
||||
def raise_duplicate_resource_name(node_1, node_2):
|
||||
duped_name = node_1.name
|
||||
node_type = NodeType(node_1.resource_type)
|
||||
pluralized = (
|
||||
node_type.pluralize()
|
||||
if node_1.resource_type == node_2.resource_type
|
||||
else "resources" # still raise if ref() collision, e.g. model + seed
|
||||
)
|
||||
|
||||
action = "looking for"
|
||||
# duplicate 'ref' targets
|
||||
if node_type in NodeType.refable():
|
||||
formatted_name = f'ref("{duped_name}")'
|
||||
# duplicate sources
|
||||
elif node_type == NodeType.Source:
|
||||
if node_1.resource_type in NodeType.refable():
|
||||
get_func = 'ref("{}")'.format(duped_name)
|
||||
elif node_1.resource_type == NodeType.Source:
|
||||
duped_name = node_1.get_full_source_name()
|
||||
formatted_name = node_1.get_source_representation()
|
||||
# duplicate docs blocks
|
||||
elif node_type == NodeType.Documentation:
|
||||
formatted_name = f'doc("{duped_name}")'
|
||||
# duplicate generic tests
|
||||
elif node_type == NodeType.Test and hasattr(node_1, "test_metadata"):
|
||||
column_name = f'column "{node_1.column_name}" in ' if node_1.column_name else ""
|
||||
model_name = node_1.file_key_name
|
||||
duped_name = f'{node_1.name}" defined on {column_name}"{model_name}'
|
||||
action = "running"
|
||||
formatted_name = "tests"
|
||||
# all other resource types
|
||||
get_func = node_1.get_source_representation()
|
||||
elif node_1.resource_type == NodeType.Documentation:
|
||||
get_func = 'doc("{}")'.format(duped_name)
|
||||
elif node_1.resource_type == NodeType.Test and "schema" in node_1.tags:
|
||||
return
|
||||
else:
|
||||
formatted_name = duped_name
|
||||
get_func = '"{}"'.format(duped_name)
|
||||
|
||||
# should this be raise_parsing_error instead?
|
||||
raise_compiler_error(
|
||||
f"""
|
||||
dbt found two {pluralized} with the name "{duped_name}".
|
||||
|
||||
Since these resources have the same name, dbt will be unable to find the correct resource
|
||||
when {action} {formatted_name}.
|
||||
|
||||
To fix this, change the name of one of these resources:
|
||||
- {node_1.unique_id} ({node_1.original_file_path})
|
||||
- {node_2.unique_id} ({node_2.original_file_path})
|
||||
""".strip()
|
||||
'dbt found two resources with the name "{}". Since these resources '
|
||||
"have the same name,\ndbt will be unable to find the correct resource "
|
||||
"when {} is used. To fix this,\nchange the name of one of "
|
||||
"these resources:\n- {} ({})\n- {} ({})".format(
|
||||
duped_name,
|
||||
get_func,
|
||||
node_1.unique_id,
|
||||
node_1.original_file_path,
|
||||
node_2.unique_id,
|
||||
node_2.original_file_path,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@@ -930,8 +887,7 @@ def raise_ambiguous_alias(node_1, node_2, duped_name=None):
|
||||
def raise_ambiguous_catalog_match(unique_id, match_1, match_2):
|
||||
def get_match_string(match):
|
||||
return "{}.{}".format(
|
||||
match.get("metadata", {}).get("schema"),
|
||||
match.get("metadata", {}).get("name"),
|
||||
match.get("metadata", {}).get("schema"), match.get("metadata", {}).get("name")
|
||||
)
|
||||
|
||||
raise_compiler_error(
|
||||
@@ -1010,11 +966,11 @@ def raise_duplicate_source_patch_name(patch_1, patch_2):
|
||||
)
|
||||
|
||||
|
||||
def raise_invalid_property_yml_version(path, issue):
|
||||
def raise_invalid_schema_yml_version(path, issue):
|
||||
raise_compiler_error(
|
||||
"The yml property file at {} is invalid because {}. Please consult the "
|
||||
"documentation for more information on yml property file syntax:\n\n"
|
||||
"https://docs.getdbt.com/reference/configs-and-properties".format(path, issue)
|
||||
"The schema file at {} is invalid because {}. Please consult the "
|
||||
"documentation for more information on schema.yml syntax:\n\n"
|
||||
"https://docs.getdbt.com/docs/schemayml-files".format(path, issue)
|
||||
)
|
||||
|
||||
|
||||
@@ -1092,7 +1048,7 @@ CONTEXT_EXPORTS = {
|
||||
raise_dependency_error,
|
||||
raise_duplicate_patch_name,
|
||||
raise_duplicate_resource_name,
|
||||
raise_invalid_property_yml_version,
|
||||
raise_invalid_schema_yml_version,
|
||||
raise_not_implemented,
|
||||
relation_wrong_type,
|
||||
]
|
||||
|
||||
@@ -35,22 +35,6 @@ INDIRECT_SELECTION = None
|
||||
LOG_CACHE_EVENTS = None
|
||||
EVENT_BUFFER_SIZE = 100000
|
||||
QUIET = None
|
||||
NO_PRINT = None
|
||||
CACHE_SELECTED_ONLY = None
|
||||
TARGET_PATH = None
|
||||
LOG_PATH = None
|
||||
|
||||
_NON_BOOLEAN_FLAGS = [
|
||||
"LOG_FORMAT",
|
||||
"PRINTER_WIDTH",
|
||||
"PROFILES_DIR",
|
||||
"INDIRECT_SELECTION",
|
||||
"EVENT_BUFFER_SIZE",
|
||||
"TARGET_PATH",
|
||||
"LOG_PATH",
|
||||
]
|
||||
|
||||
_NON_DBT_ENV_FLAGS = ["DO_NOT_TRACK"]
|
||||
|
||||
# Global CLI defaults. These flags are set from three places:
|
||||
# CLI args, environment variables, and user_config (profiles.yml).
|
||||
@@ -73,15 +57,11 @@ flag_defaults = {
|
||||
"LOG_CACHE_EVENTS": False,
|
||||
"EVENT_BUFFER_SIZE": 100000,
|
||||
"QUIET": False,
|
||||
"NO_PRINT": False,
|
||||
"CACHE_SELECTED_ONLY": False,
|
||||
"TARGET_PATH": None,
|
||||
"LOG_PATH": None,
|
||||
}
|
||||
|
||||
|
||||
def env_set_truthy(key: str) -> Optional[str]:
|
||||
"""Return the value if it was set to a "truthy" string value or None
|
||||
"""Return the value if it was set to a "truthy" string value, or None
|
||||
otherwise.
|
||||
"""
|
||||
value = os.getenv(key)
|
||||
@@ -126,8 +106,7 @@ def set_from_args(args, user_config):
|
||||
global STRICT_MODE, FULL_REFRESH, WARN_ERROR, USE_EXPERIMENTAL_PARSER, STATIC_PARSER
|
||||
global WRITE_JSON, PARTIAL_PARSE, USE_COLORS, STORE_FAILURES, PROFILES_DIR, DEBUG, LOG_FORMAT
|
||||
global INDIRECT_SELECTION, VERSION_CHECK, FAIL_FAST, SEND_ANONYMOUS_USAGE_STATS
|
||||
global PRINTER_WIDTH, WHICH, LOG_CACHE_EVENTS, EVENT_BUFFER_SIZE, QUIET, NO_PRINT, CACHE_SELECTED_ONLY
|
||||
global TARGET_PATH, LOG_PATH
|
||||
global PRINTER_WIDTH, WHICH, LOG_CACHE_EVENTS, EVENT_BUFFER_SIZE, QUIET
|
||||
|
||||
STRICT_MODE = False # backwards compatibility
|
||||
# cli args without user_config or env var option
|
||||
@@ -153,27 +132,32 @@ def set_from_args(args, user_config):
|
||||
LOG_CACHE_EVENTS = get_flag_value("LOG_CACHE_EVENTS", args, user_config)
|
||||
EVENT_BUFFER_SIZE = get_flag_value("EVENT_BUFFER_SIZE", args, user_config)
|
||||
QUIET = get_flag_value("QUIET", args, user_config)
|
||||
NO_PRINT = get_flag_value("NO_PRINT", args, user_config)
|
||||
CACHE_SELECTED_ONLY = get_flag_value("CACHE_SELECTED_ONLY", args, user_config)
|
||||
TARGET_PATH = get_flag_value("TARGET_PATH", args, user_config)
|
||||
LOG_PATH = get_flag_value("LOG_PATH", args, user_config)
|
||||
|
||||
_set_overrides_from_env()
|
||||
|
||||
|
||||
def _set_overrides_from_env():
|
||||
global SEND_ANONYMOUS_USAGE_STATS
|
||||
|
||||
flag_value = _get_flag_value_from_env("DO_NOT_TRACK")
|
||||
if flag_value is None:
|
||||
return
|
||||
|
||||
SEND_ANONYMOUS_USAGE_STATS = not flag_value
|
||||
|
||||
|
||||
def get_flag_value(flag, args, user_config):
|
||||
flag_value = _load_flag_value(flag, args, user_config)
|
||||
|
||||
lc_flag = flag.lower()
|
||||
flag_value = getattr(args, lc_flag, None)
|
||||
if flag_value is None:
|
||||
# Environment variables use pattern 'DBT_{flag name}'
|
||||
env_flag = f"DBT_{flag}"
|
||||
env_value = os.getenv(env_flag)
|
||||
if env_value is not None and env_value != "":
|
||||
env_value = env_value.lower()
|
||||
# non Boolean values
|
||||
if flag in [
|
||||
"LOG_FORMAT",
|
||||
"PRINTER_WIDTH",
|
||||
"PROFILES_DIR",
|
||||
"INDIRECT_SELECTION",
|
||||
"EVENT_BUFFER_SIZE",
|
||||
]:
|
||||
flag_value = env_value
|
||||
else:
|
||||
flag_value = env_set_bool(env_value)
|
||||
elif user_config is not None and getattr(user_config, lc_flag, None) is not None:
|
||||
flag_value = getattr(user_config, lc_flag)
|
||||
else:
|
||||
flag_value = flag_defaults[flag]
|
||||
if flag in ["PRINTER_WIDTH", "EVENT_BUFFER_SIZE"]: # must be ints
|
||||
flag_value = int(flag_value)
|
||||
if flag == "PROFILES_DIR":
|
||||
@@ -182,42 +166,6 @@ def get_flag_value(flag, args, user_config):
|
||||
return flag_value
|
||||
|
||||
|
||||
def _load_flag_value(flag, args, user_config):
|
||||
lc_flag = flag.lower()
|
||||
flag_value = getattr(args, lc_flag, None)
|
||||
if flag_value is not None:
|
||||
return flag_value
|
||||
|
||||
flag_value = _get_flag_value_from_env(flag)
|
||||
if flag_value is not None:
|
||||
return flag_value
|
||||
|
||||
if user_config is not None and getattr(user_config, lc_flag, None) is not None:
|
||||
return getattr(user_config, lc_flag)
|
||||
|
||||
return flag_defaults[flag]
|
||||
|
||||
|
||||
def _get_flag_value_from_env(flag):
|
||||
# Environment variables use pattern 'DBT_{flag name}'
|
||||
env_flag = _get_env_flag(flag)
|
||||
env_value = os.getenv(env_flag)
|
||||
if env_value is None or env_value == "":
|
||||
return None
|
||||
|
||||
env_value = env_value.lower()
|
||||
if flag in _NON_BOOLEAN_FLAGS:
|
||||
flag_value = env_value
|
||||
else:
|
||||
flag_value = env_set_bool(env_value)
|
||||
|
||||
return flag_value
|
||||
|
||||
|
||||
def _get_env_flag(flag):
|
||||
return flag if flag in _NON_DBT_ENV_FLAGS else f"DBT_{flag}"
|
||||
|
||||
|
||||
def get_flag_dict():
|
||||
return {
|
||||
"use_experimental_parser": USE_EXPERIMENTAL_PARSER,
|
||||
@@ -237,5 +185,4 @@ def get_flag_dict():
|
||||
"log_cache_events": LOG_CACHE_EVENTS,
|
||||
"event_buffer_size": EVENT_BUFFER_SIZE,
|
||||
"quiet": QUIET,
|
||||
"no_print": NO_PRINT,
|
||||
}
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
# special support for CLI argument parsing.
|
||||
from dbt import flags
|
||||
from copy import deepcopy
|
||||
import itertools
|
||||
from dbt.clients.yaml_helper import yaml, Loader, Dumper # noqa: F401
|
||||
|
||||
@@ -113,9 +112,9 @@ def _get_list_dicts(dct: Dict[str, Any], key: str) -> List[RawDefinition]:
|
||||
return result
|
||||
|
||||
|
||||
def _parse_exclusions(definition, result={}) -> Optional[SelectionSpec]:
|
||||
def _parse_exclusions(definition) -> Optional[SelectionSpec]:
|
||||
exclusions = _get_list_dicts(definition, "exclude")
|
||||
parsed_exclusions = [parse_from_definition(excl, result=result) for excl in exclusions]
|
||||
parsed_exclusions = [parse_from_definition(excl) for excl in exclusions]
|
||||
if len(parsed_exclusions) == 1:
|
||||
return parsed_exclusions[0]
|
||||
elif len(parsed_exclusions) > 1:
|
||||
@@ -125,7 +124,7 @@ def _parse_exclusions(definition, result={}) -> Optional[SelectionSpec]:
|
||||
|
||||
|
||||
def _parse_include_exclude_subdefs(
|
||||
definitions: List[RawDefinition], result={}
|
||||
definitions: List[RawDefinition],
|
||||
) -> Tuple[List[SelectionSpec], Optional[SelectionSpec]]:
|
||||
include_parts: List[SelectionSpec] = []
|
||||
diff_arg: Optional[SelectionSpec] = None
|
||||
@@ -139,16 +138,16 @@ def _parse_include_exclude_subdefs(
|
||||
f"You cannot provide multiple exclude arguments to the "
|
||||
f"same selector set operator:\n{yaml_sel_cfg}"
|
||||
)
|
||||
diff_arg = _parse_exclusions(definition, result=result)
|
||||
diff_arg = _parse_exclusions(definition)
|
||||
else:
|
||||
include_parts.append(parse_from_definition(definition, result=result))
|
||||
include_parts.append(parse_from_definition(definition))
|
||||
|
||||
return (include_parts, diff_arg)
|
||||
|
||||
|
||||
def parse_union_definition(definition: Dict[str, Any], result={}) -> SelectionSpec:
|
||||
def parse_union_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
union_def_parts = _get_list_dicts(definition, "union")
|
||||
include, exclude = _parse_include_exclude_subdefs(union_def_parts, result=result)
|
||||
include, exclude = _parse_include_exclude_subdefs(union_def_parts)
|
||||
|
||||
union = SelectionUnion(components=include)
|
||||
|
||||
@@ -159,9 +158,9 @@ def parse_union_definition(definition: Dict[str, Any], result={}) -> SelectionSp
|
||||
return SelectionDifference(components=[union, exclude], raw=definition)
|
||||
|
||||
|
||||
def parse_intersection_definition(definition: Dict[str, Any], result={}) -> SelectionSpec:
|
||||
def parse_intersection_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
intersection_def_parts = _get_list_dicts(definition, "intersection")
|
||||
include, exclude = _parse_include_exclude_subdefs(intersection_def_parts, result=result)
|
||||
include, exclude = _parse_include_exclude_subdefs(intersection_def_parts)
|
||||
intersection = SelectionIntersection(components=include)
|
||||
|
||||
if exclude is None:
|
||||
@@ -171,7 +170,7 @@ def parse_intersection_definition(definition: Dict[str, Any], result={}) -> Sele
|
||||
return SelectionDifference(components=[intersection, exclude], raw=definition)
|
||||
|
||||
|
||||
def parse_dict_definition(definition: Dict[str, Any], result={}) -> SelectionSpec:
|
||||
def parse_dict_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
diff_arg: Optional[SelectionSpec] = None
|
||||
if len(definition) == 1:
|
||||
key = list(definition)[0]
|
||||
@@ -184,15 +183,10 @@ def parse_dict_definition(definition: Dict[str, Any], result={}) -> SelectionSpe
|
||||
"method": key,
|
||||
"value": value,
|
||||
}
|
||||
elif definition.get("method") == "selector":
|
||||
sel_def = definition.get("value")
|
||||
if sel_def not in result:
|
||||
raise ValidationException(f"Existing selector definition for {sel_def} not found.")
|
||||
return result[definition["value"]]["definition"]
|
||||
elif "method" in definition and "value" in definition:
|
||||
dct = definition
|
||||
if "exclude" in definition:
|
||||
diff_arg = _parse_exclusions(definition, result=result)
|
||||
diff_arg = _parse_exclusions(definition)
|
||||
dct = {k: v for k, v in dct.items() if k != "exclude"}
|
||||
else:
|
||||
raise ValidationException(
|
||||
@@ -208,11 +202,7 @@ def parse_dict_definition(definition: Dict[str, Any], result={}) -> SelectionSpe
|
||||
return SelectionDifference(components=[base, diff_arg])
|
||||
|
||||
|
||||
def parse_from_definition(
|
||||
definition: RawDefinition,
|
||||
rootlevel=False,
|
||||
result: Dict[str, Dict[str, Union[SelectionSpec, bool]]] = {},
|
||||
) -> SelectionSpec:
|
||||
def parse_from_definition(definition: RawDefinition, rootlevel=False) -> SelectionSpec:
|
||||
|
||||
if (
|
||||
isinstance(definition, dict)
|
||||
@@ -228,11 +218,11 @@ def parse_from_definition(
|
||||
if isinstance(definition, str):
|
||||
return SelectionCriteria.from_single_spec(definition)
|
||||
elif "union" in definition:
|
||||
return parse_union_definition(definition, result=result)
|
||||
return parse_union_definition(definition)
|
||||
elif "intersection" in definition:
|
||||
return parse_intersection_definition(definition, result=result)
|
||||
return parse_intersection_definition(definition)
|
||||
elif isinstance(definition, dict):
|
||||
return parse_dict_definition(definition, result=result)
|
||||
return parse_dict_definition(definition)
|
||||
else:
|
||||
raise ValidationException(
|
||||
f"Expected to find union, intersection, str or dict, instead "
|
||||
@@ -248,8 +238,6 @@ def parse_from_selectors_definition(
|
||||
for selector in source.selectors:
|
||||
result[selector.name] = {
|
||||
"default": selector.default,
|
||||
"definition": parse_from_definition(
|
||||
selector.definition, rootlevel=True, result=deepcopy(result)
|
||||
),
|
||||
"definition": parse_from_definition(selector.definition, rootlevel=True),
|
||||
}
|
||||
return result
|
||||
|
||||
@@ -28,16 +28,20 @@ class Graph:
|
||||
"""Returns all nodes having a path to `node` in `graph`"""
|
||||
if not self.graph.has_node(node):
|
||||
raise InternalException(f"Node {node} not found in the graph!")
|
||||
return {
|
||||
child
|
||||
for _, child in nx.bfs_edges(self.graph, node, reverse=True, depth_limit=max_depth)
|
||||
}
|
||||
# This used to use nx.utils.reversed(self.graph), but that is deprecated,
|
||||
# so changing to use self.graph.reverse(copy=False) as recommeneded
|
||||
G = self.graph.reverse(copy=False) if self.graph.is_directed() else self.graph
|
||||
anc = nx.single_source_shortest_path_length(G=G, source=node, cutoff=max_depth).keys()
|
||||
return anc - {node}
|
||||
|
||||
def descendants(self, node: UniqueId, max_depth: Optional[int] = None) -> Set[UniqueId]:
|
||||
"""Returns all nodes reachable from `node` in `graph`"""
|
||||
if not self.graph.has_node(node):
|
||||
raise InternalException(f"Node {node} not found in the graph!")
|
||||
return {child for _, child in nx.bfs_edges(self.graph, node, depth_limit=max_depth)}
|
||||
des = nx.single_source_shortest_path_length(
|
||||
G=self.graph, source=node, cutoff=max_depth
|
||||
).keys()
|
||||
return des - {node}
|
||||
|
||||
def select_childrens_parents(self, selected: Set[UniqueId]) -> Set[UniqueId]:
|
||||
ancestors_for = self.select_children(selected) | selected
|
||||
|
||||
@@ -17,8 +17,6 @@ from dbt.contracts.graph.compiled import GraphMemberNode
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.state import PreviousState
|
||||
|
||||
from dbt import selected_resources
|
||||
|
||||
|
||||
def get_package_names(nodes):
|
||||
return set([node.split(".")[1] for node in nodes])
|
||||
@@ -271,7 +269,6 @@ class NodeSelector(MethodManager):
|
||||
dependecies.
|
||||
"""
|
||||
selected_nodes = self.get_selected(spec)
|
||||
selected_resources.set_selected_resources(selected_nodes)
|
||||
new_graph = self.full_graph.get_subset_graph(selected_nodes)
|
||||
# should we give a way here for consumers to mutate the graph?
|
||||
return GraphQueue(new_graph.graph, self.manifest, selected_nodes)
|
||||
|
||||
@@ -39,7 +39,6 @@ class MethodName(StrEnum):
|
||||
Tag = "tag"
|
||||
Source = "source"
|
||||
Path = "path"
|
||||
File = "file"
|
||||
Package = "package"
|
||||
Config = "config"
|
||||
TestName = "test_name"
|
||||
@@ -49,7 +48,6 @@ class MethodName(StrEnum):
|
||||
Exposure = "exposure"
|
||||
Metric = "metric"
|
||||
Result = "result"
|
||||
SourceStatus = "source_status"
|
||||
|
||||
|
||||
def is_selected_node(fqn: List[str], node_selector: str):
|
||||
@@ -281,7 +279,7 @@ class MetricSelectorMethod(SelectorMethod):
|
||||
|
||||
class PathSelectorMethod(SelectorMethod):
|
||||
def search(self, included_nodes: Set[UniqueId], selector: str) -> Iterator[UniqueId]:
|
||||
"""Yields nodes from included that match the given path."""
|
||||
"""Yields nodes from inclucded that match the given path."""
|
||||
# use '.' and not 'root' for easy comparison
|
||||
root = Path.cwd()
|
||||
paths = set(p.relative_to(root) for p in root.glob(selector))
|
||||
@@ -295,14 +293,6 @@ class PathSelectorMethod(SelectorMethod):
|
||||
yield node
|
||||
|
||||
|
||||
class FileSelectorMethod(SelectorMethod):
|
||||
def search(self, included_nodes: Set[UniqueId], selector: str) -> Iterator[UniqueId]:
|
||||
"""Yields nodes from included that match the given file name."""
|
||||
for node, real_node in self.all_nodes(included_nodes):
|
||||
if Path(real_node.original_file_path).name == selector:
|
||||
yield node
|
||||
|
||||
|
||||
class PackageSelectorMethod(SelectorMethod):
|
||||
def search(self, included_nodes: Set[UniqueId], selector: str) -> Iterator[UniqueId]:
|
||||
"""Yields nodes from included that have the specified package"""
|
||||
@@ -424,32 +414,22 @@ class StateSelectorMethod(SelectorMethod):
|
||||
|
||||
return modified
|
||||
|
||||
def recursively_check_macros_modified(self, node, visited_macros):
|
||||
def recursively_check_macros_modified(self, node, previous_macros):
|
||||
# loop through all macros that this node depends on
|
||||
for macro_uid in node.depends_on.macros:
|
||||
if macro_uid in visited_macros:
|
||||
# avoid infinite recursion if we've already seen this macro
|
||||
if macro_uid in previous_macros:
|
||||
continue
|
||||
visited_macros.append(macro_uid)
|
||||
|
||||
previous_macros.append(macro_uid)
|
||||
# is this macro one of the modified macros?
|
||||
if macro_uid in self.modified_macros:
|
||||
return True
|
||||
|
||||
# this macro hasn't been modified, but depends on other
|
||||
# macros which each need to be tested for modification
|
||||
# if not, and this macro depends on other macros, keep looping
|
||||
macro_node = self.manifest.macros[macro_uid]
|
||||
if len(macro_node.depends_on.macros) > 0:
|
||||
upstream_macros_changed = self.recursively_check_macros_modified(
|
||||
macro_node, visited_macros
|
||||
)
|
||||
if upstream_macros_changed:
|
||||
return True
|
||||
continue
|
||||
|
||||
# this macro hasn't been modified, but we haven't checked
|
||||
# the other macros the node depends on, so keep looking
|
||||
if len(node.depends_on.macros) > len(visited_macros):
|
||||
continue
|
||||
|
||||
return False
|
||||
return self.recursively_check_macros_modified(macro_node, previous_macros)
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_macros_modified(self, node):
|
||||
# check if there are any changes in macros the first time
|
||||
@@ -460,8 +440,8 @@ class StateSelectorMethod(SelectorMethod):
|
||||
return False
|
||||
# recursively loop through upstream macros to see if any is modified
|
||||
else:
|
||||
visited_macros = []
|
||||
return self.recursively_check_macros_modified(node, visited_macros)
|
||||
previous_macros = []
|
||||
return self.recursively_check_macros_modified(node, previous_macros)
|
||||
|
||||
# TODO check modifed_content and check_modified macro seems a bit redundent
|
||||
def check_modified_content(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
@@ -542,69 +522,12 @@ class ResultSelectorMethod(SelectorMethod):
|
||||
yield node
|
||||
|
||||
|
||||
class SourceStatusSelectorMethod(SelectorMethod):
|
||||
def search(self, included_nodes: Set[UniqueId], selector: str) -> Iterator[UniqueId]:
|
||||
|
||||
if self.previous_state is None or self.previous_state.sources is None:
|
||||
raise InternalException(
|
||||
"No previous state comparison freshness results in sources.json"
|
||||
)
|
||||
elif self.previous_state.sources_current is None:
|
||||
raise InternalException(
|
||||
"No current state comparison freshness results in sources.json"
|
||||
)
|
||||
|
||||
current_state_sources = {
|
||||
result.unique_id: getattr(result, "max_loaded_at", 0)
|
||||
for result in self.previous_state.sources_current.results
|
||||
if hasattr(result, "max_loaded_at")
|
||||
}
|
||||
|
||||
current_state_sources_runtime_error = {
|
||||
result.unique_id
|
||||
for result in self.previous_state.sources_current.results
|
||||
if not hasattr(result, "max_loaded_at")
|
||||
}
|
||||
|
||||
previous_state_sources = {
|
||||
result.unique_id: getattr(result, "max_loaded_at", 0)
|
||||
for result in self.previous_state.sources.results
|
||||
if hasattr(result, "max_loaded_at")
|
||||
}
|
||||
|
||||
previous_state_sources_runtime_error = {
|
||||
result.unique_id
|
||||
for result in self.previous_state.sources_current.results
|
||||
if not hasattr(result, "max_loaded_at")
|
||||
}
|
||||
|
||||
matches = set()
|
||||
if selector == "fresher":
|
||||
for unique_id in current_state_sources:
|
||||
if unique_id not in previous_state_sources:
|
||||
matches.add(unique_id)
|
||||
elif current_state_sources[unique_id] > previous_state_sources[unique_id]:
|
||||
matches.add(unique_id)
|
||||
|
||||
for unique_id in matches:
|
||||
if (
|
||||
unique_id in previous_state_sources_runtime_error
|
||||
or unique_id in current_state_sources_runtime_error
|
||||
):
|
||||
matches.remove(unique_id)
|
||||
|
||||
for node, real_node in self.all_nodes(included_nodes):
|
||||
if node in matches:
|
||||
yield node
|
||||
|
||||
|
||||
class MethodManager:
|
||||
SELECTOR_METHODS: Dict[MethodName, Type[SelectorMethod]] = {
|
||||
MethodName.FQN: QualifiedNameSelectorMethod,
|
||||
MethodName.Tag: TagSelectorMethod,
|
||||
MethodName.Source: SourceSelectorMethod,
|
||||
MethodName.Path: PathSelectorMethod,
|
||||
MethodName.File: FileSelectorMethod,
|
||||
MethodName.Package: PackageSelectorMethod,
|
||||
MethodName.Config: ConfigSelectorMethod,
|
||||
MethodName.TestName: TestNameSelectorMethod,
|
||||
@@ -614,7 +537,6 @@ class MethodManager:
|
||||
MethodName.Exposure: ExposureSelectorMethod,
|
||||
MethodName.Metric: MetricSelectorMethod,
|
||||
MethodName.Result: ResultSelectorMethod,
|
||||
MethodName.SourceStatus: SourceStatusSelectorMethod,
|
||||
}
|
||||
|
||||
def __init__(
|
||||
|
||||
@@ -2,7 +2,7 @@ import os
|
||||
import re
|
||||
from abc import ABCMeta, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
from dbt.dataclass_schema import StrEnum, dbtClassMixin
|
||||
from dbt.dataclass_schema import StrEnum
|
||||
|
||||
from typing import Set, Iterator, List, Optional, Dict, Union, Any, Iterable, Tuple
|
||||
from .graph import UniqueId
|
||||
@@ -27,7 +27,7 @@ class IndirectSelection(StrEnum):
|
||||
|
||||
|
||||
def _probably_path(value: str):
|
||||
"""Decide if the value is probably a path. Windows has two path separators, so
|
||||
"""Decide if value is probably a path. Windows has two path separators, so
|
||||
we should check both sep ('\\') and altsep ('/') there.
|
||||
"""
|
||||
if os.path.sep in value:
|
||||
@@ -80,8 +80,6 @@ class SelectionCriteria:
|
||||
def default_method(cls, value: str) -> MethodName:
|
||||
if _probably_path(value):
|
||||
return MethodName.Path
|
||||
elif value.lower().endswith(".sql"):
|
||||
return MethodName.File
|
||||
else:
|
||||
return MethodName.FQN
|
||||
|
||||
@@ -169,7 +167,7 @@ class SelectionCriteria:
|
||||
)
|
||||
|
||||
|
||||
class BaseSelectionGroup(dbtClassMixin, Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
class BaseSelectionGroup(Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
def __init__(
|
||||
self,
|
||||
components: Iterable[SelectionSpec],
|
||||
|
||||
@@ -131,10 +131,3 @@ class Lazy(Generic[T]):
|
||||
if self.memo is None:
|
||||
self.memo = self._typed_eval_f()
|
||||
return self.memo
|
||||
|
||||
|
||||
# This class is used in to_target_dict, so that accesses to missing keys
|
||||
# will return an empty string instead of Undefined
|
||||
class DictDefaultEmptyStr(dict):
|
||||
def __getitem__(self, key):
|
||||
return dict.get(self, key, "")
|
||||
|
||||
@@ -1,15 +1 @@
|
||||
# Include Module
|
||||
|
||||
The Include module is reponsible for housing default macro definitions, starter project scaffold, and the html file used to generate the docs page.
|
||||
|
||||
# Directories
|
||||
|
||||
## `global_project`
|
||||
Defines the default implementations of jinja2 macros for `dbt-core` which can be overwritten in each adapter repo to work more in line with those adapter plugins. To view adapter specific jinja2 changes please check the relevant adapter repo [`adapter.sql` ](https://github.com/dbt-labs/dbt-bigquery/blob/main/dbt/include/bigquery/macros/adapters.sql) file in the `include` directory or in the [`impl.py`](https://github.com/dbt-labs/dbt-bigquery/blob/main/dbt/adapters/bigquery/impl.py) file for some ex. BigQuery (truncate_relation).
|
||||
|
||||
## `starter_project`
|
||||
Produces the default project after running the `dbt init` command for the CLI. `dbt-cloud` initializes the project by using [dbt-starter-project](https://github.com/dbt-labs/dbt-starter-project).
|
||||
|
||||
|
||||
# Files
|
||||
- `index.html` a file generated from [dbt-docs](https://github.com/dbt-labs/dbt-docs) prior to new releases and replaced in the `dbt-core` directory. It is used to generate the docs page after using the `generate docs` command in dbt.
|
||||
# Include README
|
||||
|
||||
@@ -1,167 +0,0 @@
|
||||
{# ------- BOOLEAN MACROS --------- #}
|
||||
|
||||
{#
|
||||
-- COPY GRANTS
|
||||
-- When a relational object (view or table) is replaced in this database,
|
||||
-- do previous grants carry over to the new object? This may depend on:
|
||||
-- whether we use alter-rename-swap versus CREATE OR REPLACE
|
||||
-- user-supplied configuration (e.g. copy_grants on Snowflake)
|
||||
-- By default, play it safe, assume TRUE: that grants ARE copied over.
|
||||
-- This means dbt will first "show" current grants and then calculate diffs.
|
||||
-- It may require an additional query than is strictly necessary,
|
||||
-- but better safe than sorry.
|
||||
#}
|
||||
|
||||
{% macro copy_grants() %}
|
||||
{{ return(adapter.dispatch('copy_grants', 'dbt')()) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__copy_grants() %}
|
||||
{{ return(True) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{#
|
||||
-- SUPPORT MULTIPLE GRANTEES PER DCL STATEMENT
|
||||
-- Does this database support 'grant {privilege} to {grantee_1}, {grantee_2}, ...'
|
||||
-- Or must these be separate statements:
|
||||
-- `grant {privilege} to {grantee_1}`;
|
||||
-- `grant {privilege} to {grantee_2}`;
|
||||
-- By default, pick the former, because it's what we prefer when available.
|
||||
#}
|
||||
|
||||
{% macro support_multiple_grantees_per_dcl_statement() %}
|
||||
{{ return(adapter.dispatch('support_multiple_grantees_per_dcl_statement', 'dbt')()) }}
|
||||
{% endmacro %}
|
||||
|
||||
{%- macro default__support_multiple_grantees_per_dcl_statement() -%}
|
||||
{{ return(True) }}
|
||||
{%- endmacro -%}
|
||||
|
||||
|
||||
{% macro should_revoke(existing_relation, full_refresh_mode=True) %}
|
||||
|
||||
{% if not existing_relation %}
|
||||
{#-- The table doesn't already exist, so no grants to copy over --#}
|
||||
{{ return(False) }}
|
||||
{% elif full_refresh_mode %}
|
||||
{#-- The object is being REPLACED -- whether grants are copied over depends on the value of user config --#}
|
||||
{{ return(copy_grants()) }}
|
||||
{% else %}
|
||||
{#-- The table is being merged/upserted/inserted -- grants will be carried over --#}
|
||||
{{ return(True) }}
|
||||
{% endif %}
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
{# ------- DCL STATEMENT TEMPLATES --------- #}
|
||||
|
||||
{% macro get_show_grant_sql(relation) %}
|
||||
{{ return(adapter.dispatch("get_show_grant_sql", "dbt")(relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_show_grant_sql(relation) %}
|
||||
show grants on {{ relation }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro get_grant_sql(relation, privilege, grantees) %}
|
||||
{{ return(adapter.dispatch('get_grant_sql', 'dbt')(relation, privilege, grantees)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{%- macro default__get_grant_sql(relation, privilege, grantees) -%}
|
||||
grant {{ privilege }} on {{ relation }} to {{ grantees | join(', ') }}
|
||||
{%- endmacro -%}
|
||||
|
||||
|
||||
{% macro get_revoke_sql(relation, privilege, grantees) %}
|
||||
{{ return(adapter.dispatch('get_revoke_sql', 'dbt')(relation, privilege, grantees)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{%- macro default__get_revoke_sql(relation, privilege, grantees) -%}
|
||||
revoke {{ privilege }} on {{ relation }} from {{ grantees | join(', ') }}
|
||||
{%- endmacro -%}
|
||||
|
||||
|
||||
{# ------- RUNTIME APPLICATION --------- #}
|
||||
|
||||
{% macro get_dcl_statement_list(relation, grant_config, get_dcl_macro) %}
|
||||
{{ return(adapter.dispatch('get_dcl_statement_list', 'dbt')(relation, grant_config, get_dcl_macro)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{%- macro default__get_dcl_statement_list(relation, grant_config, get_dcl_macro) -%}
|
||||
{#
|
||||
-- Unpack grant_config into specific privileges and the set of users who need them granted/revoked.
|
||||
-- Depending on whether this database supports multiple grantees per statement, pass in the list of
|
||||
-- all grantees per privilege, or (if not) template one statement per privilege-grantee pair.
|
||||
-- `get_dcl_macro` will be either `get_grant_sql` or `get_revoke_sql`
|
||||
#}
|
||||
{%- set dcl_statements = [] -%}
|
||||
{%- for privilege, grantees in grant_config.items() %}
|
||||
{%- if support_multiple_grantees_per_dcl_statement() and grantees -%}
|
||||
{%- set dcl = get_dcl_macro(relation, privilege, grantees) -%}
|
||||
{%- do dcl_statements.append(dcl) -%}
|
||||
{%- else -%}
|
||||
{%- for grantee in grantees -%}
|
||||
{% set dcl = get_dcl_macro(relation, privilege, [grantee]) %}
|
||||
{%- do dcl_statements.append(dcl) -%}
|
||||
{% endfor -%}
|
||||
{%- endif -%}
|
||||
{%- endfor -%}
|
||||
{{ return(dcl_statements) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{% macro call_dcl_statements(dcl_statement_list) %}
|
||||
{{ return(adapter.dispatch("call_dcl_statements", "dbt")(dcl_statement_list)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__call_dcl_statements(dcl_statement_list) %}
|
||||
{#
|
||||
-- By default, supply all grant + revoke statements in a single semicolon-separated block,
|
||||
-- so that they're all processed together.
|
||||
|
||||
-- Some databases do not support this. Those adapters will need to override this macro
|
||||
-- to run each statement individually.
|
||||
#}
|
||||
{% call statement('grants') %}
|
||||
{% for dcl_statement in dcl_statement_list %}
|
||||
{{ dcl_statement }};
|
||||
{% endfor %}
|
||||
{% endcall %}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro apply_grants(relation, grant_config, should_revoke) %}
|
||||
{{ return(adapter.dispatch("apply_grants", "dbt")(relation, grant_config, should_revoke)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__apply_grants(relation, grant_config, should_revoke=True) %}
|
||||
{#-- If grant_config is {} or None, this is a no-op --#}
|
||||
{% if grant_config %}
|
||||
{% if should_revoke %}
|
||||
{#-- We think previous grants may have carried over --#}
|
||||
{#-- Show current grants and calculate diffs --#}
|
||||
{% set current_grants_table = run_query(get_show_grant_sql(relation)) %}
|
||||
{% set current_grants_dict = adapter.standardize_grants_dict(current_grants_table) %}
|
||||
{% set needs_granting = diff_of_two_dicts(grant_config, current_grants_dict) %}
|
||||
{% set needs_revoking = diff_of_two_dicts(current_grants_dict, grant_config) %}
|
||||
{% if not (needs_granting or needs_revoking) %}
|
||||
{{ log('On ' ~ relation ~': All grants are in place, no revocation or granting needed.')}}
|
||||
{% endif %}
|
||||
{% else %}
|
||||
{#-- We don't think there's any chance of previous grants having carried over. --#}
|
||||
{#-- Jump straight to granting what the user has configured. --#}
|
||||
{% set needs_revoking = {} %}
|
||||
{% set needs_granting = grant_config %}
|
||||
{% endif %}
|
||||
{% if needs_granting or needs_revoking %}
|
||||
{% set revoke_statement_list = get_dcl_statement_list(relation, needs_revoking, get_revoke_sql) %}
|
||||
{% set grant_statement_list = get_dcl_statement_list(relation, needs_granting, get_grant_sql) %}
|
||||
{% set dcl_statement_list = revoke_statement_list + grant_statement_list %}
|
||||
{% if dcl_statement_list %}
|
||||
{{ call_dcl_statements(dcl_statement_list) }}
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
{% endmacro %}
|
||||
@@ -1,35 +1,15 @@
|
||||
{% macro make_intermediate_relation(base_relation, suffix='__dbt_tmp') %}
|
||||
{{ return(adapter.dispatch('make_intermediate_relation', 'dbt')(base_relation, suffix)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__make_intermediate_relation(base_relation, suffix) %}
|
||||
{{ return(default__make_temp_relation(base_relation, suffix)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro make_temp_relation(base_relation, suffix='__dbt_tmp') %}
|
||||
{{ return(adapter.dispatch('make_temp_relation', 'dbt')(base_relation, suffix)) }}
|
||||
{{ return(adapter.dispatch('make_temp_relation', 'dbt')(base_relation, suffix))}}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__make_temp_relation(base_relation, suffix) %}
|
||||
{%- set temp_identifier = base_relation.identifier ~ suffix -%}
|
||||
{%- set temp_relation = base_relation.incorporate(
|
||||
path={"identifier": temp_identifier}) -%}
|
||||
{% set tmp_identifier = base_relation.identifier ~ suffix %}
|
||||
{% set tmp_relation = base_relation.incorporate(
|
||||
path={"identifier": tmp_identifier}) -%}
|
||||
|
||||
{{ return(temp_relation) }}
|
||||
{% do return(tmp_relation) %}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro make_backup_relation(base_relation, backup_relation_type, suffix='__dbt_backup') %}
|
||||
{{ return(adapter.dispatch('make_backup_relation', 'dbt')(base_relation, backup_relation_type, suffix)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__make_backup_relation(base_relation, backup_relation_type, suffix) %}
|
||||
{%- set backup_identifier = base_relation.identifier ~ suffix -%}
|
||||
{%- set backup_relation = base_relation.incorporate(
|
||||
path={"identifier": backup_identifier},
|
||||
type=backup_relation_type
|
||||
) -%}
|
||||
{{ return(backup_relation) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro drop_relation(relation) -%}
|
||||
{{ return(adapter.dispatch('drop_relation', 'dbt')(relation)) }}
|
||||
@@ -86,8 +66,8 @@
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
-- a user-friendly interface into adapter.get_relation
|
||||
{% macro load_cached_relation(relation) %}
|
||||
{# a user-friendly interface into adapter.get_relation #}
|
||||
{% macro load_relation(relation) %}
|
||||
{% do return(adapter.get_relation(
|
||||
database=relation.database,
|
||||
schema=relation.schema,
|
||||
@@ -95,12 +75,8 @@
|
||||
)) -%}
|
||||
{% endmacro %}
|
||||
|
||||
-- old name for backwards compatibility
|
||||
{% macro load_relation(relation) %}
|
||||
{{ return(load_cached_relation(relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{# not used much, here for backwards compatibility #}
|
||||
{% macro drop_relation_if_exists(relation) %}
|
||||
{% if relation is not none %}
|
||||
{{ adapter.drop_relation(relation) }}
|
||||
|
||||
@@ -1,8 +1,6 @@
|
||||
{% macro default__test_not_null(model, column_name) %}
|
||||
|
||||
{% set column_list = '*' if should_store_failures() else column_name %}
|
||||
|
||||
select {{ column_list }}
|
||||
select *
|
||||
from {{ model }}
|
||||
where {{ column_name }} is null
|
||||
|
||||
|
||||
@@ -1,27 +1,28 @@
|
||||
|
||||
{% materialization incremental, default -%}
|
||||
|
||||
-- relations
|
||||
{%- set existing_relation = load_cached_relation(this) -%}
|
||||
{%- set target_relation = this.incorporate(type='table') -%}
|
||||
{%- set temp_relation = make_temp_relation(target_relation)-%}
|
||||
{%- set intermediate_relation = make_intermediate_relation(target_relation)-%}
|
||||
{%- set backup_relation_type = 'table' if existing_relation is none else existing_relation.type -%}
|
||||
{%- set backup_relation = make_backup_relation(target_relation, backup_relation_type) -%}
|
||||
{% set unique_key = config.get('unique_key') %}
|
||||
|
||||
-- configs
|
||||
{%- set unique_key = config.get('unique_key') -%}
|
||||
{%- set full_refresh_mode = (should_full_refresh() or existing_relation.is_view) -%}
|
||||
{%- set on_schema_change = incremental_validate_on_schema_change(config.get('on_schema_change'), default='ignore') -%}
|
||||
{% set target_relation = this.incorporate(type='table') %}
|
||||
{% set existing_relation = load_relation(this) %}
|
||||
{% set tmp_relation = make_temp_relation(target_relation) %}
|
||||
{%- set full_refresh_mode = (should_full_refresh()) -%}
|
||||
|
||||
-- the temp_ and backup_ relations should not already exist in the database; get_relation
|
||||
{% set on_schema_change = incremental_validate_on_schema_change(config.get('on_schema_change'), default='ignore') %}
|
||||
|
||||
{% set tmp_identifier = model['name'] + '__dbt_tmp' %}
|
||||
{% set backup_identifier = model['name'] + "__dbt_backup" %}
|
||||
|
||||
-- the intermediate_ and backup_ relations should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation. This has to happen before
|
||||
-- BEGIN, in a separate transaction
|
||||
{%- set preexisting_intermediate_relation = load_cached_relation(intermediate_relation)-%}
|
||||
{%- set preexisting_backup_relation = load_cached_relation(backup_relation) -%}
|
||||
-- grab current tables grants config for comparision later on
|
||||
{% set grant_config = config.get('grants') %}
|
||||
{% set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{% set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) %}
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
{{ drop_relation_if_exists(preexisting_backup_relation) }}
|
||||
|
||||
@@ -32,22 +33,32 @@
|
||||
|
||||
{% set to_drop = [] %}
|
||||
|
||||
{# -- first check whether we want to full refresh for source view or config reasons #}
|
||||
{% set trigger_full_refresh = (full_refresh_mode or existing_relation.is_view) %}
|
||||
|
||||
{% if existing_relation is none %}
|
||||
{% set build_sql = get_create_table_as_sql(False, target_relation, sql) %}
|
||||
{% elif full_refresh_mode %}
|
||||
{% set build_sql = get_create_table_as_sql(False, intermediate_relation, sql) %}
|
||||
{% set build_sql = create_table_as(False, target_relation, sql) %}
|
||||
{% elif trigger_full_refresh %}
|
||||
{#-- Make sure the backup doesn't exist so we don't encounter issues with the rename below #}
|
||||
{% set tmp_identifier = model['name'] + '__dbt_tmp' %}
|
||||
{% set backup_identifier = model['name'] + '__dbt_backup' %}
|
||||
{% set intermediate_relation = existing_relation.incorporate(path={"identifier": tmp_identifier}) %}
|
||||
{% set backup_relation = existing_relation.incorporate(path={"identifier": backup_identifier}) %}
|
||||
|
||||
{% set build_sql = create_table_as(False, intermediate_relation, sql) %}
|
||||
{% set need_swap = true %}
|
||||
{% do to_drop.append(backup_relation) %}
|
||||
{% else %}
|
||||
{% do run_query(get_create_table_as_sql(True, temp_relation, sql)) %}
|
||||
{% do run_query(create_table_as(True, tmp_relation, sql)) %}
|
||||
{% do adapter.expand_target_column_types(
|
||||
from_relation=temp_relation,
|
||||
from_relation=tmp_relation,
|
||||
to_relation=target_relation) %}
|
||||
{#-- Process schema changes. Returns dict of changes if successful. Use source columns for upserting/merging --#}
|
||||
{% set dest_columns = process_schema_changes(on_schema_change, temp_relation, existing_relation) %}
|
||||
{% set dest_columns = process_schema_changes(on_schema_change, tmp_relation, existing_relation) %}
|
||||
{% if not dest_columns %}
|
||||
{% set dest_columns = adapter.get_columns_in_relation(existing_relation) %}
|
||||
{% endif %}
|
||||
{% set build_sql = get_delete_insert_merge_sql(target_relation, temp_relation, unique_key, dest_columns) %}
|
||||
{% set build_sql = get_delete_insert_merge_sql(target_relation, tmp_relation, unique_key, dest_columns) %}
|
||||
|
||||
{% endif %}
|
||||
|
||||
@@ -58,12 +69,8 @@
|
||||
{% if need_swap %}
|
||||
{% do adapter.rename_relation(target_relation, backup_relation) %}
|
||||
{% do adapter.rename_relation(intermediate_relation, target_relation) %}
|
||||
{% do to_drop.append(backup_relation) %}
|
||||
{% endif %}
|
||||
|
||||
{% set should_revoke = should_revoke(existing_relation, full_refresh_mode) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if existing_relation is none or existing_relation.is_view or should_full_refresh() %}
|
||||
|
||||
@@ -56,26 +56,13 @@
|
||||
|
||||
{%- set dest_cols_csv = get_quoted_csv(dest_columns | map(attribute="name")) -%}
|
||||
|
||||
{% if unique_key %}
|
||||
{% if unique_key is sequence and unique_key is not string %}
|
||||
delete from {{target }}
|
||||
using {{ source }}
|
||||
where (
|
||||
{% for key in unique_key %}
|
||||
{{ source }}.{{ key }} = {{ target }}.{{ key }}
|
||||
{{ "and " if not loop.last }}
|
||||
{% endfor %}
|
||||
);
|
||||
{% else %}
|
||||
delete from {{ target }}
|
||||
where (
|
||||
{{ unique_key }}) in (
|
||||
select ({{ unique_key }})
|
||||
from {{ source }}
|
||||
);
|
||||
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
{% if unique_key is not none %}
|
||||
delete from {{ target }}
|
||||
where ({{ unique_key }}) in (
|
||||
select ({{ unique_key }})
|
||||
from {{ source }}
|
||||
);
|
||||
{% endif %}
|
||||
|
||||
insert into {{ target }} ({{ dest_cols_csv }})
|
||||
(
|
||||
|
||||
@@ -1,21 +1,36 @@
|
||||
{% materialization table, default %}
|
||||
{%- set identifier = model['alias'] -%}
|
||||
{%- set tmp_identifier = model['name'] + '__dbt_tmp' -%}
|
||||
{%- set backup_identifier = model['name'] + '__dbt_backup' -%}
|
||||
|
||||
{%- set existing_relation = load_cached_relation(this) -%}
|
||||
{%- set target_relation = this.incorporate(type='table') %}
|
||||
{%- set intermediate_relation = make_intermediate_relation(target_relation) -%}
|
||||
{%- set old_relation = adapter.get_relation(database=database, schema=schema, identifier=identifier) -%}
|
||||
{%- set target_relation = api.Relation.create(identifier=identifier,
|
||||
schema=schema,
|
||||
database=database,
|
||||
type='table') -%}
|
||||
{%- set intermediate_relation = api.Relation.create(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database,
|
||||
type='table') -%}
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = load_cached_relation(intermediate_relation) -%}
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
See ../view/view.sql for more information about this relation.
|
||||
*/
|
||||
{%- set backup_relation_type = 'table' if existing_relation is none else existing_relation.type -%}
|
||||
{%- set backup_relation = make_backup_relation(target_relation, backup_relation_type) -%}
|
||||
{%- set backup_relation_type = 'table' if old_relation is none else old_relation.type -%}
|
||||
{%- set backup_relation = api.Relation.create(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database,
|
||||
type=backup_relation_type) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = load_cached_relation(backup_relation) -%}
|
||||
-- grab current tables grants config for comparision later on
|
||||
{% set grant_config = config.get('grants') %}
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
|
||||
-- drop the temp relations if they exist already in the database
|
||||
{{ drop_relation_if_exists(preexisting_intermediate_relation) }}
|
||||
@@ -32,8 +47,8 @@
|
||||
{%- endcall %}
|
||||
|
||||
-- cleanup
|
||||
{% if existing_relation is not none %}
|
||||
{{ adapter.rename_relation(existing_relation, backup_relation) }}
|
||||
{% if old_relation is not none %}
|
||||
{{ adapter.rename_relation(old_relation, backup_relation) }}
|
||||
{% endif %}
|
||||
|
||||
{{ adapter.rename_relation(intermediate_relation, target_relation) }}
|
||||
@@ -42,9 +57,6 @@
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
{% set should_revoke = should_revoke(existing_relation, full_refresh_mode=True) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
-- `COMMIT` happens here
|
||||
|
||||
@@ -13,12 +13,12 @@
|
||||
{%- set identifier = model['alias'] -%}
|
||||
|
||||
{%- set old_relation = adapter.get_relation(database=database, schema=schema, identifier=identifier) -%}
|
||||
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
|
||||
{%- set target_relation = api.Relation.create(
|
||||
identifier=identifier, schema=schema, database=database,
|
||||
type='view') -%}
|
||||
{% set grant_config = config.get('grants') %}
|
||||
|
||||
{{ run_hooks(pre_hooks) }}
|
||||
|
||||
@@ -34,9 +34,6 @@
|
||||
{{ get_create_view_as_sql(target_relation, sql) }}
|
||||
{%- endcall %}
|
||||
|
||||
{% set should_revoke = should_revoke(exists_as_view, full_refresh_mode=True) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=True) %}
|
||||
|
||||
{{ run_hooks(post_hooks) }}
|
||||
|
||||
{{ return({'relations': [target_relation]}) }}
|
||||
|
||||
@@ -1,32 +1,41 @@
|
||||
{%- materialization view, default -%}
|
||||
|
||||
{%- set existing_relation = load_cached_relation(this) -%}
|
||||
{%- set target_relation = this.incorporate(type='view') -%}
|
||||
{%- set intermediate_relation = make_intermediate_relation(target_relation) -%}
|
||||
{%- set identifier = model['alias'] -%}
|
||||
{%- set tmp_identifier = model['name'] + '__dbt_tmp' -%}
|
||||
{%- set backup_identifier = model['name'] + '__dbt_backup' -%}
|
||||
|
||||
{%- set old_relation = adapter.get_relation(database=database, schema=schema, identifier=identifier) -%}
|
||||
{%- set target_relation = api.Relation.create(identifier=identifier, schema=schema, database=database,
|
||||
type='view') -%}
|
||||
{%- set intermediate_relation = api.Relation.create(identifier=tmp_identifier,
|
||||
schema=schema, database=database, type='view') -%}
|
||||
-- the intermediate_relation should not already exist in the database; get_relation
|
||||
-- will return None in that case. Otherwise, we get a relation that we can drop
|
||||
-- later, before we try to use this name for the current operation
|
||||
{%- set preexisting_intermediate_relation = load_cached_relation(intermediate_relation) -%}
|
||||
{%- set preexisting_intermediate_relation = adapter.get_relation(identifier=tmp_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
/*
|
||||
This relation (probably) doesn't exist yet. If it does exist, it's a leftover from
|
||||
a previous run, and we're going to try to drop it immediately. At the end of this
|
||||
materialization, we're going to rename the "existing_relation" to this identifier,
|
||||
materialization, we're going to rename the "old_relation" to this identifier,
|
||||
and then we're going to drop it. In order to make sure we run the correct one of:
|
||||
- drop view ...
|
||||
- drop table ...
|
||||
|
||||
We need to set the type of this relation to be the type of the existing_relation, if it exists,
|
||||
or else "view" as a sane default if it does not. Note that if the existing_relation does not
|
||||
We need to set the type of this relation to be the type of the old_relation, if it exists,
|
||||
or else "view" as a sane default if it does not. Note that if the old_relation does not
|
||||
exist, then there is nothing to move out of the way and subsequentally drop. In that case,
|
||||
this relation will be effectively unused.
|
||||
*/
|
||||
{%- set backup_relation_type = 'view' if existing_relation is none else existing_relation.type -%}
|
||||
{%- set backup_relation = make_backup_relation(target_relation, backup_relation_type) -%}
|
||||
{%- set backup_relation_type = 'view' if old_relation is none else old_relation.type -%}
|
||||
{%- set backup_relation = api.Relation.create(identifier=backup_identifier,
|
||||
schema=schema, database=database,
|
||||
type=backup_relation_type) -%}
|
||||
-- as above, the backup_relation should not already exist
|
||||
{%- set preexisting_backup_relation = load_cached_relation(backup_relation) -%}
|
||||
-- grab current tables grants config for comparision later on
|
||||
{% set grant_config = config.get('grants') %}
|
||||
{%- set preexisting_backup_relation = adapter.get_relation(identifier=backup_identifier,
|
||||
schema=schema,
|
||||
database=database) -%}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
|
||||
@@ -39,19 +48,16 @@
|
||||
|
||||
-- build model
|
||||
{% call statement('main') -%}
|
||||
{{ get_create_view_as_sql(intermediate_relation, sql) }}
|
||||
{{ create_view_as(intermediate_relation, sql) }}
|
||||
{%- endcall %}
|
||||
|
||||
-- cleanup
|
||||
-- move the existing view out of the way
|
||||
{% if existing_relation is not none %}
|
||||
{{ adapter.rename_relation(existing_relation, backup_relation) }}
|
||||
{% if old_relation is not none %}
|
||||
{{ adapter.rename_relation(old_relation, backup_relation) }}
|
||||
{% endif %}
|
||||
{{ adapter.rename_relation(intermediate_relation, target_relation) }}
|
||||
|
||||
{% set should_revoke = should_revoke(existing_relation, full_refresh_mode=True) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{{ run_hooks(post_hooks, inside_transaction=True) }}
|
||||
|
||||
@@ -44,17 +44,6 @@
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro get_csv_sql(create_or_truncate_sql, insert_sql) %}
|
||||
{{ adapter.dispatch('get_csv_sql', 'dbt')(create_or_truncate_sql, insert_sql) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_csv_sql(create_or_truncate_sql, insert_sql) %}
|
||||
{{ create_or_truncate_sql }};
|
||||
-- dbt seed --
|
||||
{{ insert_sql }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro get_binding_char() -%}
|
||||
{{ adapter.dispatch('get_binding_char', 'dbt')() }}
|
||||
{%- endmacro %}
|
||||
|
||||
@@ -8,10 +8,7 @@
|
||||
{%- set exists_as_table = (old_relation is not none and old_relation.is_table) -%}
|
||||
{%- set exists_as_view = (old_relation is not none and old_relation.is_view) -%}
|
||||
|
||||
{%- set grant_config = config.get('grants') -%}
|
||||
{%- set agate_table = load_agate_table() -%}
|
||||
-- grab current tables grants config for comparision later on
|
||||
|
||||
{%- do store_result('agate_table', response='OK', agate_table=agate_table) -%}
|
||||
|
||||
{{ run_hooks(pre_hooks, inside_transaction=False) }}
|
||||
@@ -34,14 +31,12 @@
|
||||
{% set sql = load_csv_rows(model, agate_table) %}
|
||||
|
||||
{% call noop_statement('main', code ~ ' ' ~ rows_affected, code, rows_affected) %}
|
||||
{{ get_csv_sql(create_table_sql, sql) }};
|
||||
{{ create_table_sql }};
|
||||
-- dbt seed --
|
||||
{{ sql }}
|
||||
{% endcall %}
|
||||
|
||||
{% set target_relation = this.incorporate(type='table') %}
|
||||
|
||||
{% set should_revoke = should_revoke(old_relation, full_refresh_mode) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if full_refresh_mode or not exists_as_table %}
|
||||
|
||||
@@ -22,13 +22,6 @@
|
||||
{# no-op #}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro get_true_sql() %}
|
||||
{{ adapter.dispatch('get_true_sql', 'dbt')() }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_true_sql() %}
|
||||
{{ return('TRUE') }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro snapshot_staging_table(strategy, source_sql, target_relation) -%}
|
||||
{{ adapter.dispatch('snapshot_staging_table', 'dbt')(strategy, source_sql, target_relation) }}
|
||||
@@ -169,13 +162,13 @@
|
||||
|
||||
|
||||
{% macro build_snapshot_staging_table(strategy, sql, target_relation) %}
|
||||
{% set temp_relation = make_temp_relation(target_relation) %}
|
||||
{% set tmp_relation = make_temp_relation(target_relation) %}
|
||||
|
||||
{% set select = snapshot_staging_table(strategy, sql, target_relation) %}
|
||||
|
||||
{% call statement('build_snapshot_staging_relation') %}
|
||||
{{ create_table_as(True, temp_relation, select) }}
|
||||
{{ create_table_as(True, tmp_relation, select) }}
|
||||
{% endcall %}
|
||||
|
||||
{% do return(temp_relation) %}
|
||||
{% do return(tmp_relation) %}
|
||||
{% endmacro %}
|
||||
|
||||
@@ -5,8 +5,10 @@
|
||||
|
||||
{%- set strategy_name = config.get('strategy') -%}
|
||||
{%- set unique_key = config.get('unique_key') %}
|
||||
-- grab current tables grants config for comparision later on
|
||||
{%- set grant_config = config.get('grants') -%}
|
||||
|
||||
{% if not adapter.check_schema_exists(model.database, model.schema) %}
|
||||
{% do create_schema(model.database, model.schema) %}
|
||||
{% endif %}
|
||||
|
||||
{% set target_relation_exists, target_relation = get_or_create_relation(
|
||||
database=model.database,
|
||||
@@ -75,9 +77,6 @@
|
||||
{{ final_sql }}
|
||||
{% endcall %}
|
||||
|
||||
{% set should_revoke = should_revoke(target_relation_exists, full_refresh_mode=False) %}
|
||||
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
|
||||
|
||||
{% do persist_docs(target_relation, model) %}
|
||||
|
||||
{% if not target_relation_exists %}
|
||||
|
||||
@@ -103,42 +103,28 @@
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
{% macro snapshot_check_all_get_existing_columns(node, target_exists, check_cols_config) -%}
|
||||
{% macro snapshot_check_all_get_existing_columns(node, target_exists) -%}
|
||||
{%- set query_columns = get_columns_in_query(node['compiled_sql']) -%}
|
||||
{%- if not target_exists -%}
|
||||
{#-- no table yet -> return whatever the query does --#}
|
||||
{{ return((false, query_columns)) }}
|
||||
{# no table yet -> return whatever the query does #}
|
||||
{{ return([false, query_columns]) }}
|
||||
{%- endif -%}
|
||||
|
||||
{#-- handle any schema changes --#}
|
||||
{%- set target_relation = adapter.get_relation(database=node.database, schema=node.schema, identifier=node.alias) -%}
|
||||
|
||||
{% if check_cols_config == 'all' %}
|
||||
{%- set query_columns = get_columns_in_query(node['compiled_sql']) -%}
|
||||
|
||||
{% elif check_cols_config is iterable and (check_cols_config | length) > 0 %}
|
||||
{#-- query for proper casing/quoting, to support comparison below --#}
|
||||
{%- set select_check_cols_from_target -%}
|
||||
select {{ check_cols_config | join(', ') }} from ({{ node['compiled_sql'] }}) subq
|
||||
{%- endset -%}
|
||||
{% set query_columns = get_columns_in_query(select_check_cols_from_target) %}
|
||||
|
||||
{% else %}
|
||||
{% do exceptions.raise_compiler_error("Invalid value for 'check_cols': " ~ check_cols_config) %}
|
||||
{% endif %}
|
||||
|
||||
{%- set existing_cols = adapter.get_columns_in_relation(target_relation) | map(attribute = 'name') | list -%}
|
||||
{%- set ns = namespace() -%} {#-- handle for-loop scoping with a namespace --#}
|
||||
{# handle any schema changes #}
|
||||
{%- set target_table = node.get('alias', node.get('name')) -%}
|
||||
{%- set target_relation = adapter.get_relation(database=node.database, schema=node.schema, identifier=target_table) -%}
|
||||
{%- set existing_cols = get_columns_in_query('select * from ' ~ target_relation) -%}
|
||||
{%- set ns = namespace() -%} {# handle for-loop scoping with a namespace #}
|
||||
{%- set ns.column_added = false -%}
|
||||
|
||||
{%- set intersection = [] -%}
|
||||
{%- for col in query_columns -%}
|
||||
{%- if col in existing_cols -%}
|
||||
{%- do intersection.append(adapter.quote(col)) -%}
|
||||
{%- do intersection.append(col) -%}
|
||||
{%- else -%}
|
||||
{% set ns.column_added = true %}
|
||||
{%- endif -%}
|
||||
{%- endfor -%}
|
||||
{{ return((ns.column_added, intersection)) }}
|
||||
{{ return([ns.column_added, intersection]) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
@@ -146,16 +132,32 @@
|
||||
{% set check_cols_config = config['check_cols'] %}
|
||||
{% set primary_key = config['unique_key'] %}
|
||||
{% set invalidate_hard_deletes = config.get('invalidate_hard_deletes', false) %}
|
||||
{% set updated_at = config.get('updated_at', snapshot_get_time()) %}
|
||||
|
||||
{% set select_current_time -%}
|
||||
select {{ snapshot_get_time() }} as snapshot_start
|
||||
{%- endset %}
|
||||
|
||||
{#-- don't access the column by name, to avoid dealing with casing issues on snowflake #}
|
||||
{%- set now = run_query(select_current_time)[0][0] -%}
|
||||
{% if now is none or now is undefined -%}
|
||||
{%- do exceptions.raise_compiler_error('Could not get a snapshot start time from the database') -%}
|
||||
{%- endif %}
|
||||
{% set updated_at = config.get('updated_at', snapshot_string_as_time(now)) %}
|
||||
|
||||
{% set column_added = false %}
|
||||
|
||||
{% set column_added, check_cols = snapshot_check_all_get_existing_columns(node, target_exists, check_cols_config) %}
|
||||
{% if check_cols_config == 'all' %}
|
||||
{% set column_added, check_cols = snapshot_check_all_get_existing_columns(node, target_exists) %}
|
||||
{% elif check_cols_config is iterable and (check_cols_config | length) > 0 %}
|
||||
{% set check_cols = check_cols_config %}
|
||||
{% else %}
|
||||
{% do exceptions.raise_compiler_error("Invalid value for 'check_cols': " ~ check_cols_config) %}
|
||||
{% endif %}
|
||||
|
||||
{%- set row_changed_expr -%}
|
||||
(
|
||||
{%- if column_added -%}
|
||||
{{ get_true_sql() }}
|
||||
TRUE
|
||||
{%- else -%}
|
||||
{%- for col in check_cols -%}
|
||||
{{ snapshotted_rel }}.{{ col }} != {{ current_rel }}.{{ col }}
|
||||
|
||||
@@ -1,9 +0,0 @@
|
||||
{% macro any_value(expression) -%}
|
||||
{{ return(adapter.dispatch('any_value', 'dbt') (expression)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__any_value(expression) -%}
|
||||
|
||||
any_value({{ expression }})
|
||||
|
||||
{%- endmacro %}
|
||||
@@ -1,9 +0,0 @@
|
||||
{% macro bool_or(expression) -%}
|
||||
{{ return(adapter.dispatch('bool_or', 'dbt') (expression)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__bool_or(expression) -%}
|
||||
|
||||
bool_or({{ expression }})
|
||||
|
||||
{%- endmacro %}
|
||||
@@ -1,7 +0,0 @@
|
||||
{% macro cast_bool_to_text(field) %}
|
||||
{{ adapter.dispatch('cast_bool_to_text', 'dbt') (field) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__cast_bool_to_text(field) %}
|
||||
cast({{ field }} as {{ api.Column.translate_type('string') }})
|
||||
{% endmacro %}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user