mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-17 19:31:34 +00:00
Compare commits
1037 Commits
dev/0.18.1
...
add-except
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
d342165f6d | ||
|
|
a3dc5efda7 | ||
|
|
1015b89dbf | ||
|
|
5c9fd07050 | ||
|
|
c019a94206 | ||
|
|
f9bdfa050b | ||
|
|
1b35d1aa21 | ||
|
|
420ef9cc7b | ||
|
|
02fdc2cb9f | ||
|
|
f82745fb0c | ||
|
|
3397bdc6a5 | ||
|
|
96e858ac0b | ||
|
|
f6a98b5674 | ||
|
|
824f0bf2c0 | ||
|
|
5648b1c622 | ||
|
|
bb1382e576 | ||
|
|
085ea9181f | ||
|
|
eace5b77a7 | ||
|
|
1c61bb18e6 | ||
|
|
f79a968a09 | ||
|
|
34c23fe650 | ||
|
|
3ae9475655 | ||
|
|
11436fed45 | ||
|
|
21a7b71657 | ||
|
|
280e9ad9c9 | ||
|
|
97f31c88e1 | ||
|
|
5f483a6b13 | ||
|
|
86f24e13db | ||
|
|
4bda8c8880 | ||
|
|
80a5d27127 | ||
|
|
4307a82058 | ||
|
|
5c01c42308 | ||
|
|
80ba71682b | ||
|
|
26625e9627 | ||
|
|
134e8423b7 | ||
|
|
04a9195297 | ||
|
|
8a10a69f59 | ||
|
|
fd7c95d1d2 | ||
|
|
79aa136301 | ||
|
|
3b5cec6cc6 | ||
|
|
0e9a67956d | ||
|
|
f9f0eab0b7 | ||
|
|
ed01b439cf | ||
|
|
a398ed1a3e | ||
|
|
a818e6551b | ||
|
|
0a7471ebdc | ||
|
|
1a5bc83598 | ||
|
|
6e2df00648 | ||
|
|
b338dfc99a | ||
|
|
47033c459f | ||
|
|
92a0930634 | ||
|
|
cad1a48eb0 | ||
|
|
b451f87e3c | ||
|
|
20756290bc | ||
|
|
f44c6ed136 | ||
|
|
b501f4317c | ||
|
|
91b43f71bb | ||
|
|
6fc64f0d3b | ||
|
|
ee5c697645 | ||
|
|
3caec08ccb | ||
|
|
f7680379fc | ||
|
|
3789acc5a7 | ||
|
|
8ae232abe8 | ||
|
|
332d23c5eb | ||
|
|
5799973474 | ||
|
|
3d816d56ec | ||
|
|
111f3c28f8 | ||
|
|
10aded793c | ||
|
|
b5cc7b8dff | ||
|
|
449f042742 | ||
|
|
66b70e025b | ||
|
|
578c6d6a20 | ||
|
|
64ce9d6aa4 | ||
|
|
213ddedb85 | ||
|
|
c96201c060 | ||
|
|
16b02f4f55 | ||
|
|
e0d2b02d46 | ||
|
|
65e76df6ec | ||
|
|
052a3060d4 | ||
|
|
b65ae1ddde | ||
|
|
a8246ab1f1 | ||
|
|
6854e67464 | ||
|
|
ca7c1fc4ad | ||
|
|
5dbc945f23 | ||
|
|
655ff85dc9 | ||
|
|
6a2ceaa073 | ||
|
|
e8fb29d185 | ||
|
|
8443142f27 | ||
|
|
7ebe21dccb | ||
|
|
c25b7a1143 | ||
|
|
38eb46dfc3 | ||
|
|
fe9ed9ccdd | ||
|
|
ff4e5219b1 | ||
|
|
04632a008f | ||
|
|
6925cebcf6 | ||
|
|
571beb13d9 | ||
|
|
69cd82f483 | ||
|
|
11e379280f | ||
|
|
0018eb7db6 | ||
|
|
154a682180 | ||
|
|
1b79a245e6 | ||
|
|
6b590122c7 | ||
|
|
d5f632e6fd | ||
|
|
2fc8e5e0b6 | ||
|
|
5ab07273ba | ||
|
|
19c9e5bfdf | ||
|
|
60794367a5 | ||
|
|
ea07729bbf | ||
|
|
c4370773f6 | ||
|
|
fda17b456e | ||
|
|
bc3e1a0a71 | ||
|
|
a06988706c | ||
|
|
ce73124bbf | ||
|
|
352c62f3c3 | ||
|
|
81a51d3942 | ||
|
|
64fc3a39a7 | ||
|
|
e5b6f4f293 | ||
|
|
d26e63ed9a | ||
|
|
f4f5d31959 | ||
|
|
e7e12075b9 | ||
|
|
74dda5aa19 | ||
|
|
092e96ce70 | ||
|
|
18102027ba | ||
|
|
f80825d63e | ||
|
|
9316e47b77 | ||
|
|
f99cf1218a | ||
|
|
5871915ce9 | ||
|
|
5ce290043f | ||
|
|
080d27321b | ||
|
|
1d0936bd14 | ||
|
|
706b8ca9df | ||
|
|
7dc491b7ba | ||
|
|
779c789a64 | ||
|
|
409b4ba109 | ||
|
|
59d131d3ac | ||
|
|
6563d09ba7 | ||
|
|
05dea18b62 | ||
|
|
d7177c7d89 | ||
|
|
35f0fea804 | ||
|
|
8953c7c533 | ||
|
|
76c59a5545 | ||
|
|
237048c7ac | ||
|
|
30ff395b7b | ||
|
|
5c0a31b829 | ||
|
|
243bc3d41d | ||
|
|
67b594a950 | ||
|
|
2493c21649 | ||
|
|
d3826e670f | ||
|
|
4b5b1696b7 | ||
|
|
abb59ef14f | ||
|
|
3b7c2816b9 | ||
|
|
484517416f | ||
|
|
39447055d3 | ||
|
|
95cca277c9 | ||
|
|
96083dcaf5 | ||
|
|
75b4cf691b | ||
|
|
7c9171b00b | ||
|
|
3effade266 | ||
|
|
44e7390526 | ||
|
|
c141798abc | ||
|
|
df7ec3fb37 | ||
|
|
90e5507d03 | ||
|
|
332d3494b3 | ||
|
|
6393f5a5d7 | ||
|
|
ce97a9ca7a | ||
|
|
9af071bfe4 | ||
|
|
45a41202f3 | ||
|
|
9768999ca1 | ||
|
|
fc0d11c0a5 | ||
|
|
e6344205bb | ||
|
|
9d7a6556ef | ||
|
|
15f4add0b8 | ||
|
|
464becacd0 | ||
|
|
51a76d0d63 | ||
|
|
052e54d43a | ||
|
|
9e796671dd | ||
|
|
a9a6254f52 | ||
|
|
8b3a09c7ae | ||
|
|
6aa4d812d4 | ||
|
|
07fa719fb0 | ||
|
|
650b34ae24 | ||
|
|
0a935855f3 | ||
|
|
d500aae4dc | ||
|
|
370d3e746d | ||
|
|
ab06149c81 | ||
|
|
e72895c7c9 | ||
|
|
fe4a67daa4 | ||
|
|
09ea989d81 | ||
|
|
7fa14b6948 | ||
|
|
d4974cd35c | ||
|
|
459178811b | ||
|
|
b37f6a010e | ||
|
|
e817164d31 | ||
|
|
09ce43edbf | ||
|
|
2980cd17df | ||
|
|
8c804de643 | ||
|
|
c8241b87e6 | ||
|
|
f204d24ed8 | ||
|
|
d5461ccd8b | ||
|
|
a20d2d93d3 | ||
|
|
57e1eec165 | ||
|
|
d2dbe6afe4 | ||
|
|
72eb163223 | ||
|
|
af16c74c3a | ||
|
|
664f6584b9 | ||
|
|
76fd3bdf8c | ||
|
|
b633adb881 | ||
|
|
b6e534cdd0 | ||
|
|
1dc4adb86f | ||
|
|
0a4d7c4831 | ||
|
|
ad67e55d74 | ||
|
|
2fae64a488 | ||
|
|
1a984601ee | ||
|
|
454168204c | ||
|
|
43642956a2 | ||
|
|
1fe53750fa | ||
|
|
8609c02383 | ||
|
|
355b0c496e | ||
|
|
cd6894acf4 | ||
|
|
b90b3a9c19 | ||
|
|
e7b8488be8 | ||
|
|
06cc0c57e8 | ||
|
|
87072707ed | ||
|
|
ef63319733 | ||
|
|
2068dd5510 | ||
|
|
3e1e171c66 | ||
|
|
5f9ed1a83c | ||
|
|
3d9e54d970 | ||
|
|
52a0fdef6c | ||
|
|
d9b02fb0a0 | ||
|
|
6c8de62b24 | ||
|
|
2d3d1b030a | ||
|
|
88acf0727b | ||
|
|
02839ec779 | ||
|
|
44a8f6a3bf | ||
|
|
751ea92576 | ||
|
|
02007b3619 | ||
|
|
fe0b9e7ef5 | ||
|
|
4b1c6b51f9 | ||
|
|
0b4689f311 | ||
|
|
b77eff8f6f | ||
|
|
2782a33ecf | ||
|
|
94c6cf1b3c | ||
|
|
3c8daacd3e | ||
|
|
2f9907b072 | ||
|
|
287c4d2b03 | ||
|
|
ba9d76b3f9 | ||
|
|
0efaaf7daf | ||
|
|
9ae7d68260 | ||
|
|
486afa9fcd | ||
|
|
1f189f5225 | ||
|
|
580b1fdd68 | ||
|
|
bad0198a36 | ||
|
|
252280b56e | ||
|
|
64bf9c8885 | ||
|
|
935c138736 | ||
|
|
5891b59790 | ||
|
|
4e020c3878 | ||
|
|
3004969a93 | ||
|
|
873e9714f8 | ||
|
|
fe24dd43d4 | ||
|
|
ed91ded2c1 | ||
|
|
757614d57f | ||
|
|
faff8c00b3 | ||
|
|
45fe76eef4 | ||
|
|
80244a09fe | ||
|
|
ea772ae419 | ||
|
|
c68fca7937 | ||
|
|
37e86257f5 | ||
|
|
c182c05c2f | ||
|
|
b02875a12b | ||
|
|
03332b2955 | ||
|
|
f1f99a2371 | ||
|
|
95116dbb5b | ||
|
|
868fd64adf | ||
|
|
2f7ab2d038 | ||
|
|
159e79ee6b | ||
|
|
3d4a82cca2 | ||
|
|
6ba837d73d | ||
|
|
f4775d7673 | ||
|
|
429396aa02 | ||
|
|
8a5e9b71a5 | ||
|
|
fa78102eaf | ||
|
|
5466d474c5 | ||
|
|
80951ae973 | ||
|
|
d5662ef34c | ||
|
|
57783bb5f6 | ||
|
|
d73ee588e5 | ||
|
|
40089d710b | ||
|
|
6ec61950eb | ||
|
|
72c831a80a | ||
|
|
929931a26a | ||
|
|
577e2438c1 | ||
|
|
2679792199 | ||
|
|
2adf982991 | ||
|
|
1fb4a7f428 | ||
|
|
30e72bc5e2 | ||
|
|
35645a7233 | ||
|
|
d583c8d737 | ||
|
|
a83f00c594 | ||
|
|
45bb955b55 | ||
|
|
c448702c1b | ||
|
|
558a6a03ac | ||
|
|
52ec7907d3 | ||
|
|
792f39a888 | ||
|
|
16264f58c1 | ||
|
|
2317c0c3c8 | ||
|
|
3c09ab9736 | ||
|
|
f10dc0e1b3 | ||
|
|
634bc41d8a | ||
|
|
d7ea3648c6 | ||
|
|
e5c8e19ff2 | ||
|
|
4ddba7e44c | ||
|
|
37b31d10c8 | ||
|
|
93cf1f085f | ||
|
|
a84f824a44 | ||
|
|
9c58f3465b | ||
|
|
0e3778132b | ||
|
|
72722635f2 | ||
|
|
a4c7c7fc55 | ||
|
|
2bad73eead | ||
|
|
c8bc25d11a | ||
|
|
4c06689ff5 | ||
|
|
a45c9d0192 | ||
|
|
34e2c4f90b | ||
|
|
c0e2023c81 | ||
|
|
108b55bdc3 | ||
|
|
a29367b7fe | ||
|
|
1d7e8349ed | ||
|
|
67c194dcd1 | ||
|
|
75d3d87d64 | ||
|
|
4ff3f6d4e8 | ||
|
|
d0773f3346 | ||
|
|
ee58d27d94 | ||
|
|
9e3da391a7 | ||
|
|
bd7010678a | ||
|
|
9f716b31b3 | ||
|
|
3dd486d8fa | ||
|
|
33217891ca | ||
|
|
1d37c4e555 | ||
|
|
9f62ec2153 | ||
|
|
372eca76b8 | ||
|
|
e3cb050bbc | ||
|
|
0ae93c7f54 | ||
|
|
1f6386d760 | ||
|
|
66eb3964e2 | ||
|
|
f460d275ba | ||
|
|
fb91bad800 | ||
|
|
eaec22ae53 | ||
|
|
b7c1768cca | ||
|
|
387b26a202 | ||
|
|
8a1e6438f1 | ||
|
|
aaac5ff2e6 | ||
|
|
4dc29630b5 | ||
|
|
f716631439 | ||
|
|
648a780850 | ||
|
|
de0919ff88 | ||
|
|
8b1ea5fb6c | ||
|
|
85627aafcd | ||
|
|
49065158f5 | ||
|
|
bdb3049218 | ||
|
|
e10d1b0f86 | ||
|
|
83b98c8ebf | ||
|
|
b9d5123aa3 | ||
|
|
c09300bfd2 | ||
|
|
fc490cee7b | ||
|
|
3baa3d7fe8 | ||
|
|
764c7c0fdc | ||
|
|
c97ebbbf35 | ||
|
|
85fe32bd08 | ||
|
|
eba3fd2255 | ||
|
|
e2f2c07873 | ||
|
|
70850cd362 | ||
|
|
16992e6391 | ||
|
|
fd0d95140e | ||
|
|
ac65fcd557 | ||
|
|
4d246567b9 | ||
|
|
1ad1c834f3 | ||
|
|
41610b822c | ||
|
|
c794600242 | ||
|
|
9d414f6ec3 | ||
|
|
552e831306 | ||
|
|
c712c96a0b | ||
|
|
eb46bfc3d6 | ||
|
|
f52537b606 | ||
|
|
762419d2fe | ||
|
|
4feb7cb15b | ||
|
|
eb47b85148 | ||
|
|
9faa019a07 | ||
|
|
9589dc91fa | ||
|
|
14507a283e | ||
|
|
af0fe120ec | ||
|
|
16501ec1c6 | ||
|
|
bf867f6aff | ||
|
|
eb4ad4444f | ||
|
|
8fdba17ac6 | ||
|
|
abe8e83945 | ||
|
|
02cbae1f9f | ||
|
|
65908b395f | ||
|
|
4971395d5d | ||
|
|
eeec2038aa | ||
|
|
4fac086556 | ||
|
|
8818061d59 | ||
|
|
b195778eb9 | ||
|
|
de1763618a | ||
|
|
7485066ed4 | ||
|
|
15ce956380 | ||
|
|
e5c63884e2 | ||
|
|
9fef62d83e | ||
|
|
7563b997c2 | ||
|
|
291ff3600b | ||
|
|
2c405304ee | ||
|
|
1e5a7878e5 | ||
|
|
d89e1d7f85 | ||
|
|
98c015b775 | ||
|
|
a56502688f | ||
|
|
c0d757ab19 | ||
|
|
e68fd6eb7f | ||
|
|
90edc38859 | ||
|
|
0f018ea5dd | ||
|
|
1be6254363 | ||
|
|
760af71ed2 | ||
|
|
82f5e9f5b2 | ||
|
|
988c187db3 | ||
|
|
b23129982c | ||
|
|
4d5d0e2150 | ||
|
|
c0c487bf77 | ||
|
|
835d805079 | ||
|
|
c2a767184c | ||
|
|
1e7c8802eb | ||
|
|
a76ec42586 | ||
|
|
7418f36932 | ||
|
|
f9ef5e7e8e | ||
|
|
dbfa351395 | ||
|
|
e775f2b38e | ||
|
|
6f27454be4 | ||
|
|
201723d506 | ||
|
|
17555faaca | ||
|
|
36e0ab9f42 | ||
|
|
6017bd6cba | ||
|
|
30fed8d421 | ||
|
|
8ac5cdd2e1 | ||
|
|
114ac0793a | ||
|
|
d0b750461a | ||
|
|
9693170eb9 | ||
|
|
bbab6c2361 | ||
|
|
cfe3636c78 | ||
|
|
aadf3c702e | ||
|
|
1eac726a07 | ||
|
|
85e2c89794 | ||
|
|
fffcd3b404 | ||
|
|
fbfef4b1a3 | ||
|
|
526a6c0d0c | ||
|
|
1f33b6a74a | ||
|
|
95fc6d43e7 | ||
|
|
d8c261ffcf | ||
|
|
66ea0a9e0f | ||
|
|
435b542e7b | ||
|
|
10cd06f515 | ||
|
|
9da1868c3b | ||
|
|
2649fac4a4 | ||
|
|
6e05226e3b | ||
|
|
c1c3397f66 | ||
|
|
2065db2383 | ||
|
|
08fb868b63 | ||
|
|
8d39ef16b6 | ||
|
|
66c5082aa7 | ||
|
|
26fb58bd1b | ||
|
|
fed8826043 | ||
|
|
9af78a3249 | ||
|
|
bf1ad6cd17 | ||
|
|
15e995f2f5 | ||
|
|
b3e73b0de8 | ||
|
|
dd2633dfcb | ||
|
|
29f0278451 | ||
|
|
f0f98be692 | ||
|
|
5956a64b01 | ||
|
|
5fb36e3e2a | ||
|
|
9d295a1d91 | ||
|
|
39f350fe89 | ||
|
|
8c55e744b8 | ||
|
|
a260d4e25b | ||
|
|
509797588f | ||
|
|
2eed20f1f3 | ||
|
|
1d7b4c0db2 | ||
|
|
ac8cd788cb | ||
|
|
33dc970859 | ||
|
|
f73202734c | ||
|
|
32bacdab4b | ||
|
|
6113c3b533 | ||
|
|
1c634af489 | ||
|
|
428cdea2dc | ||
|
|
f14b55f839 | ||
|
|
5934d263b8 | ||
|
|
3860d919e6 | ||
|
|
fd0b9434ae | ||
|
|
efb30d0262 | ||
|
|
cee0bfbfa2 | ||
|
|
dc684d31d3 | ||
|
|
bfdf7f01b5 | ||
|
|
2cc0579b6e | ||
|
|
bfc472dc0f | ||
|
|
ea4e3680ab | ||
|
|
f02139956d | ||
|
|
cacbd1c212 | ||
|
|
3f78bb7819 | ||
|
|
aa65b01fe3 | ||
|
|
4f0968d678 | ||
|
|
118973cf79 | ||
|
|
df7cc0521f | ||
|
|
40c02d2cc9 | ||
|
|
be70b1a0c1 | ||
|
|
7ec5c122e1 | ||
|
|
a10ab99efc | ||
|
|
9f4398c557 | ||
|
|
d60f6bc89b | ||
|
|
617eeb4ff7 | ||
|
|
5b55825638 | ||
|
|
103d524db5 | ||
|
|
babd084a9b | ||
|
|
749f87397e | ||
|
|
307d47ebaf | ||
|
|
6acd4b91c1 | ||
|
|
f4a9530894 | ||
|
|
ab65385a16 | ||
|
|
ebd761e3dc | ||
|
|
3b942ec790 | ||
|
|
b373486908 | ||
|
|
c8cd5502f6 | ||
|
|
d6dd968c4f | ||
|
|
b8d73d2197 | ||
|
|
17e57f1e0b | ||
|
|
e21bf9fbc7 | ||
|
|
12e281f076 | ||
|
|
a5ce658755 | ||
|
|
ce30dfa82d | ||
|
|
c04d1e9d5c | ||
|
|
80031d122c | ||
|
|
943b090c90 | ||
|
|
39fd53d1f9 | ||
|
|
777e7b3b6d | ||
|
|
2783fe2a9f | ||
|
|
f5880cb001 | ||
|
|
26e501008a | ||
|
|
2c67e3f5c7 | ||
|
|
033596021d | ||
|
|
f36c72e085 | ||
|
|
fefaf7b4be | ||
|
|
91431401ad | ||
|
|
59d96c08a1 | ||
|
|
f10447395b | ||
|
|
c2b6222798 | ||
|
|
3a58c49184 | ||
|
|
440a5e49e2 | ||
|
|
77c10713a3 | ||
|
|
48e367ce2f | ||
|
|
934c23bf39 | ||
|
|
e0febcb6c3 | ||
|
|
044a6c6ea4 | ||
|
|
8ebbc10572 | ||
|
|
7435828082 | ||
|
|
369b595e8a | ||
|
|
9a6d30f03d | ||
|
|
6bdd01d52b | ||
|
|
bae9767498 | ||
|
|
b0e50dedb8 | ||
|
|
96bfb3b259 | ||
|
|
909068dfa8 | ||
|
|
f4c74968be | ||
|
|
0e958f3704 | ||
|
|
a8b2942f93 | ||
|
|
564fe62400 | ||
|
|
5c5013191b | ||
|
|
31989b85d1 | ||
|
|
5ed4af2372 | ||
|
|
4d18e391aa | ||
|
|
2feeb5b927 | ||
|
|
2853f07875 | ||
|
|
4e6adc07a1 | ||
|
|
6a5ed4f418 | ||
|
|
ef25698d3d | ||
|
|
429dcc7000 | ||
|
|
ab3f994626 | ||
|
|
5f8235fcfc | ||
|
|
db325d0fde | ||
|
|
8dc1f49ac7 | ||
|
|
9fe2b651ed | ||
|
|
24e4b75c35 | ||
|
|
34174abf26 | ||
|
|
af778312cb | ||
|
|
280f5614ef | ||
|
|
8566a46793 | ||
|
|
af3c3f4cbe | ||
|
|
034a44e625 | ||
|
|
84155fdff7 | ||
|
|
8255c913a3 | ||
|
|
4d4d17669b | ||
|
|
540a0422f5 | ||
|
|
de4d7d6273 | ||
|
|
1345d95589 | ||
|
|
a5bc19dd69 | ||
|
|
25b143c8cc | ||
|
|
82cca959e4 | ||
|
|
d52374a0b6 | ||
|
|
c71a18ca07 | ||
|
|
8d73ae2cc0 | ||
|
|
7b0c74ca3e | ||
|
|
62be9f9064 | ||
|
|
2fdc113d93 | ||
|
|
b70fb543f5 | ||
|
|
31c88f9f5a | ||
|
|
af3a818f12 | ||
|
|
a07532d4c7 | ||
|
|
fb449ca4bc | ||
|
|
4da65643c0 | ||
|
|
bf64db474c | ||
|
|
344a14416d | ||
|
|
be47a0c5db | ||
|
|
808b980301 | ||
|
|
3528480562 | ||
|
|
6bd263d23f | ||
|
|
2b9aa3864b | ||
|
|
81155caf88 | ||
|
|
c7c057483d | ||
|
|
7f5170ae4d | ||
|
|
49b8693b11 | ||
|
|
d7b0a14eb5 | ||
|
|
8996cb1e18 | ||
|
|
38f278cce0 | ||
|
|
bb4e475044 | ||
|
|
4fbe36a8e9 | ||
|
|
a1a40b562a | ||
|
|
3a4a1bb005 | ||
|
|
4f8c10c1aa | ||
|
|
4833348769 | ||
|
|
ad07d59a78 | ||
|
|
e8aaabd1d3 | ||
|
|
d7d7396eeb | ||
|
|
41538860cd | ||
|
|
5c9f8a0cf0 | ||
|
|
11c997c3e9 | ||
|
|
1b1184a5e1 | ||
|
|
4ffcc43ed9 | ||
|
|
4ccaac46a6 | ||
|
|
ba88b84055 | ||
|
|
9086634c8f | ||
|
|
e88f1f1edb | ||
|
|
13c7486f0e | ||
|
|
8e811ba141 | ||
|
|
c5d86afed6 | ||
|
|
43a0cfbee1 | ||
|
|
8567d5f302 | ||
|
|
36d1bddc5b | ||
|
|
bf992680af | ||
|
|
e064298dfc | ||
|
|
e01a10ced5 | ||
|
|
2aa10fb1ed | ||
|
|
66f442ad76 | ||
|
|
11f1ecebcf | ||
|
|
e339cb27f6 | ||
|
|
bce3232b39 | ||
|
|
b08970ce39 | ||
|
|
533f88ceaf | ||
|
|
c8f0469a44 | ||
|
|
a1fc24e532 | ||
|
|
d80daa48df | ||
|
|
92aae2803f | ||
|
|
77cbbbfaf2 | ||
|
|
6c6649f912 | ||
|
|
55fbaabfda | ||
|
|
56c2518936 | ||
|
|
2b48152da6 | ||
|
|
e743e23d6b | ||
|
|
f846f921f2 | ||
|
|
e52a599be6 | ||
|
|
99744bd318 | ||
|
|
1060035838 | ||
|
|
69cc20013e | ||
|
|
3572bfd37d | ||
|
|
a6b82990f5 | ||
|
|
540c1fd9c6 | ||
|
|
46d36cd412 | ||
|
|
a170764fc5 | ||
|
|
f72873a1ce | ||
|
|
82496c30b1 | ||
|
|
cb3c007acd | ||
|
|
cb460a797c | ||
|
|
1b666d01cf | ||
|
|
df24c7d2f8 | ||
|
|
133c15c0e2 | ||
|
|
116e18a19e | ||
|
|
ec0af7c97b | ||
|
|
a34a877737 | ||
|
|
f018794465 | ||
|
|
d45f5e9791 | ||
|
|
04bd0d834c | ||
|
|
ed4f0c4713 | ||
|
|
c747068d4a | ||
|
|
aa0fbdc993 | ||
|
|
b50bfa7277 | ||
|
|
e91988f679 | ||
|
|
3ed1fce3fb | ||
|
|
e3ea0b511a | ||
|
|
c411c663de | ||
|
|
1c6f66fc14 | ||
|
|
1f927a374c | ||
|
|
07c4225aa8 | ||
|
|
42a85ac39f | ||
|
|
16e6d31ee3 | ||
|
|
a6db5b436d | ||
|
|
47675f2e28 | ||
|
|
0642bbefa7 | ||
|
|
43da603d52 | ||
|
|
f9e1f4d111 | ||
|
|
1508564e10 | ||
|
|
c14e6f4dcc | ||
|
|
75b6a20134 | ||
|
|
d82a07c221 | ||
|
|
c6f7dbcaa5 | ||
|
|
82cd099e48 | ||
|
|
546c011dd8 | ||
|
|
10b33ccaf6 | ||
|
|
bc01572176 | ||
|
|
ccd2064722 | ||
|
|
0fb42901dd | ||
|
|
a4280d7457 | ||
|
|
6966ede68b | ||
|
|
27dd14a5a2 | ||
|
|
2494301f1e | ||
|
|
f13143accb | ||
|
|
26d340a917 | ||
|
|
cc75cd4102 | ||
|
|
cf8615b231 | ||
|
|
30f473a2b1 | ||
|
|
4618709baa | ||
|
|
16b098ea42 | ||
|
|
b31c4d407a | ||
|
|
28c36cc5e2 | ||
|
|
6bfbcb842e | ||
|
|
a0eade4fdd | ||
|
|
ee24b7e88a | ||
|
|
c9baddf9a4 | ||
|
|
c5c780a685 | ||
|
|
421aaabf62 | ||
|
|
86788f034f | ||
|
|
232d3758cf | ||
|
|
71bcf9b31d | ||
|
|
bf4ee4f064 | ||
|
|
aa3bdfeb17 | ||
|
|
ce6967d396 | ||
|
|
330065f5e0 | ||
|
|
944db82553 | ||
|
|
c257361f05 | ||
|
|
ffdbfb018a | ||
|
|
cfa2bd6b08 | ||
|
|
51e90c3ce0 | ||
|
|
d69149f43e | ||
|
|
f261663f3d | ||
|
|
e5948dd1d3 | ||
|
|
5f13aab7d8 | ||
|
|
292d489592 | ||
|
|
0a01f20e35 | ||
|
|
2bd08d5c4c | ||
|
|
adae5126db | ||
|
|
dddf1bcb76 | ||
|
|
d23d4b0fd4 | ||
|
|
658f7550b3 | ||
|
|
cfb50ae21e | ||
|
|
9b0a365822 | ||
|
|
97ab130619 | ||
|
|
3578fde290 | ||
|
|
f382da69b8 | ||
|
|
2da3d215c6 | ||
|
|
43ed29c14c | ||
|
|
9df0283689 | ||
|
|
04b82cf4a5 | ||
|
|
274c3012b0 | ||
|
|
2b24a4934f | ||
|
|
692a423072 | ||
|
|
148f55335f | ||
|
|
2f752842a1 | ||
|
|
aff72996a1 | ||
|
|
08e425bcf6 | ||
|
|
454ddc601a | ||
|
|
b025f208a8 | ||
|
|
b60e533b9d | ||
|
|
37af0e0d59 | ||
|
|
ac1de5bce9 | ||
|
|
ef7ff55e07 | ||
|
|
608db5b982 | ||
|
|
8dd69efd48 | ||
|
|
73f7fba793 | ||
|
|
867e2402d2 | ||
|
|
a3b9e61967 | ||
|
|
cd149b68e8 | ||
|
|
cd3583c736 | ||
|
|
441f86f3ed | ||
|
|
f62bea65a1 | ||
|
|
886b574987 | ||
|
|
2888bac275 | ||
|
|
35c9206916 | ||
|
|
c4c5b59312 | ||
|
|
f25fb4e5ac | ||
|
|
868bfec5e6 | ||
|
|
e7c242213a | ||
|
|
862552ead4 | ||
|
|
9d90e0c167 | ||
|
|
a281f227cd | ||
|
|
5b981278db | ||
|
|
c1091ed3d1 | ||
|
|
08aed63455 | ||
|
|
90a550ee4f | ||
|
|
34869fc2a2 | ||
|
|
3deb10156d | ||
|
|
8c0e84de05 | ||
|
|
23be083c39 | ||
|
|
217aafce39 | ||
|
|
03210c63f4 | ||
|
|
a90510f6f2 | ||
|
|
36d91aded6 | ||
|
|
9afe8a1297 | ||
|
|
1e6f272034 | ||
|
|
a1aa2f81ef | ||
|
|
62899ef308 | ||
|
|
7f3396c002 | ||
|
|
453bc18196 | ||
|
|
dbb6b57b76 | ||
|
|
d7137db78c | ||
|
|
5ac4f2d80b | ||
|
|
5ba5271da9 | ||
|
|
b834e3015a | ||
|
|
c8721ded62 | ||
|
|
1e97372d24 | ||
|
|
fd4e111784 | ||
|
|
75094e7e21 | ||
|
|
8db2d674ed | ||
|
|
ffb140fab3 | ||
|
|
e93543983c | ||
|
|
0d066f80ff | ||
|
|
ccca1b2016 | ||
|
|
fec0e31a25 | ||
|
|
d246aa8f6d | ||
|
|
66bfba2258 | ||
|
|
b53b4373cb | ||
|
|
0810f93883 | ||
|
|
a4e696a252 | ||
|
|
0951d08f52 | ||
|
|
dbf367e070 | ||
|
|
6447ba8ec8 | ||
|
|
43e260966f | ||
|
|
b0e301b046 | ||
|
|
c8a9ea4979 | ||
|
|
afb7fc05da | ||
|
|
14124ccca8 | ||
|
|
df5022dbc3 | ||
|
|
015e798a31 | ||
|
|
c19125bb02 | ||
|
|
0e6ac5baf1 | ||
|
|
2c8d1b5b8c | ||
|
|
f7c0c1c21a | ||
|
|
4edd98f7ce | ||
|
|
df0abb7000 | ||
|
|
4f93da307f | ||
|
|
a8765d54aa | ||
|
|
bb834358d4 | ||
|
|
ec0f3d22e7 | ||
|
|
009b75cab6 | ||
|
|
d64668df1e | ||
|
|
72e808c9a7 | ||
|
|
96cc9223be | ||
|
|
13b099fbd0 | ||
|
|
1a8416c297 | ||
|
|
8538bec99e | ||
|
|
f983900597 | ||
|
|
3af02020ff | ||
|
|
8c71488757 | ||
|
|
74316bf702 | ||
|
|
7aa8c435c9 | ||
|
|
daeb51253d | ||
|
|
0ce2f41db4 | ||
|
|
02e5a962d7 | ||
|
|
dcc32dc69f | ||
|
|
af3d6681dd | ||
|
|
106968a3be | ||
|
|
2cd56ca044 | ||
|
|
eff198d079 | ||
|
|
c3b5b88cd2 | ||
|
|
4e19e87bbc | ||
|
|
6be6f6585d | ||
|
|
d7579f0c99 | ||
|
|
b741679c9c | ||
|
|
852990e967 | ||
|
|
21fd75b500 | ||
|
|
3e5d9010a3 | ||
|
|
784616ec29 | ||
|
|
6251d19946 | ||
|
|
17b1332a2a | ||
|
|
74eec3bdbe | ||
|
|
a9901c4ea7 | ||
|
|
348a2f91ee | ||
|
|
7115d862ea | ||
|
|
52ed4aa631 | ||
|
|
92cedf8931 | ||
|
|
e1097f11b5 | ||
|
|
eb34c0e46b | ||
|
|
ee2181b371 | ||
|
|
2a5d090e91 | ||
|
|
857bebe819 | ||
|
|
9728152768 | ||
|
|
2566a85429 | ||
|
|
46b3130198 | ||
|
|
8664516c8d | ||
|
|
0733c246ea | ||
|
|
4203985e3e | ||
|
|
900298bce7 | ||
|
|
09c37f508e | ||
|
|
c9e01bcc81 | ||
|
|
b079545e0f | ||
|
|
c3bf0f8cbf | ||
|
|
e945bca1d9 | ||
|
|
bf5835de5e | ||
|
|
7503f0cb10 | ||
|
|
3a751bcf9b | ||
|
|
c31ba101d6 | ||
|
|
ecadc74d44 | ||
|
|
63d25aaf19 | ||
|
|
5af82c3c05 | ||
|
|
8b4d74ed17 | ||
|
|
6a6a9064d5 | ||
|
|
b188a9488a | ||
|
|
7c2635f65d | ||
|
|
c67d0a0e1a | ||
|
|
7ee78e89c9 | ||
|
|
40370e104f | ||
|
|
a8809baa6c | ||
|
|
244d5d2c3b | ||
|
|
a0370a6617 | ||
|
|
eb077fcc75 | ||
|
|
c5adc50eed | ||
|
|
6e71b6fd31 | ||
|
|
278382589d | ||
|
|
6f0f6cf21a | ||
|
|
01331ed311 | ||
|
|
f638a3d50c | ||
|
|
512c41dbaf | ||
|
|
78bd7c9465 | ||
|
|
d74df8692b | ||
|
|
eda86412cc | ||
|
|
cce5945fd2 | ||
|
|
72038258ed | ||
|
|
056d8fa9ad | ||
|
|
3888e0066f | ||
|
|
ee6571d050 | ||
|
|
9472288304 | ||
|
|
fd5e10cfdf | ||
|
|
aeae18ec37 | ||
|
|
03d3943e99 | ||
|
|
214d137672 | ||
|
|
83db275ddf | ||
|
|
b8f16d081a | ||
|
|
675b01ed48 | ||
|
|
b20224a096 | ||
|
|
fd6edfccc4 | ||
|
|
4c58438e8a | ||
|
|
5ff383a025 | ||
|
|
dcb6854683 | ||
|
|
e4644bfe5a | ||
|
|
93168fef87 | ||
|
|
9832822bdf | ||
|
|
5d91aa3bcd | ||
|
|
354ab5229b | ||
|
|
00de0cd4b5 | ||
|
|
26210216da | ||
|
|
e29c14a22b | ||
|
|
a6990c8fb8 | ||
|
|
3e40e71b96 | ||
|
|
3f45abe331 | ||
|
|
6777c62789 | ||
|
|
1cf87c639b | ||
|
|
2cb3d92163 | ||
|
|
89b6e52a73 | ||
|
|
97407c10ff | ||
|
|
81222dadbc | ||
|
|
400555c391 | ||
|
|
9125b05809 | ||
|
|
41ae831d0e | ||
|
|
dbca540d70 | ||
|
|
dc7eca4bf9 | ||
|
|
fb07149cb7 | ||
|
|
46eadd54e5 | ||
|
|
19232f554f | ||
|
|
676af831c0 | ||
|
|
873d76d72c | ||
|
|
8ee490b881 | ||
|
|
ff31b277f6 | ||
|
|
120eb5b502 | ||
|
|
a32295e74a | ||
|
|
204b02de3e | ||
|
|
8379edce99 | ||
|
|
a4b80cc2e4 | ||
|
|
4994cc07a0 | ||
|
|
e96cf02561 | ||
|
|
764c9b2986 | ||
|
|
4cc1a4f74c | ||
|
|
540607086c | ||
|
|
7d929e98af | ||
|
|
0086097639 | ||
|
|
daff0badc8 | ||
|
|
c43873379c | ||
|
|
07d4020fca | ||
|
|
b9d502e2e6 | ||
|
|
8c80862c10 | ||
|
|
2356c7b63d | ||
|
|
b71b7e209e | ||
|
|
2581e98aff | ||
|
|
afc7136bae | ||
|
|
e489170558 | ||
|
|
50106f2bd3 | ||
|
|
9d00c00072 | ||
|
|
10c3118f9c | ||
|
|
1fa149dca2 | ||
|
|
60f4c963b5 | ||
|
|
ae542dce74 | ||
|
|
d31e82edfc | ||
|
|
5354e39e5f | ||
|
|
ca9293cbfb | ||
|
|
bcbf7c3b7b | ||
|
|
6a26cb280f | ||
|
|
fd658ace9d | ||
|
|
5e71a2aa3f | ||
|
|
e3fb923b34 | ||
|
|
1dd4187cd0 | ||
|
|
9e36ebdaab | ||
|
|
aaa0127354 | ||
|
|
e60280c4d6 | ||
|
|
aef7866e29 | ||
|
|
70694e3bb9 |
@@ -1,23 +1,27 @@
|
||||
[bumpversion]
|
||||
current_version = 0.18.1
|
||||
current_version = 1.0.0b2
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
((?P<prerelease>[a-z]+)(?P<num>\d+))?
|
||||
((?P<prekind>a|b|rc)
|
||||
(?P<pre>\d+) # pre-release version num
|
||||
)?
|
||||
serialize =
|
||||
{major}.{minor}.{patch}{prerelease}{num}
|
||||
{major}.{minor}.{patch}{prekind}{pre}
|
||||
{major}.{minor}.{patch}
|
||||
commit = False
|
||||
tag = False
|
||||
|
||||
[bumpversion:part:prerelease]
|
||||
[bumpversion:part:prekind]
|
||||
first_value = a
|
||||
optional_value = final
|
||||
values =
|
||||
a
|
||||
b
|
||||
rc
|
||||
final
|
||||
|
||||
[bumpversion:part:num]
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
@@ -26,19 +30,8 @@ first_value = 1
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/dbt/adapters/postgres/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/dbt/adapters/redshift/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/dbt/adapters/snowflake/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/dbt/adapters/bigquery/__version__.py]
|
||||
|
||||
|
||||
@@ -1,163 +0,0 @@
|
||||
version: 2.1
|
||||
jobs:
|
||||
unit:
|
||||
docker: &test_only
|
||||
- image: fishtownanalytics/test-container:9
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
steps:
|
||||
- checkout
|
||||
- run: tox -e flake8,mypy,unit-py36,unit-py38
|
||||
build-wheels:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Build wheels
|
||||
command: |
|
||||
python3.8 -m venv "${PYTHON_ENV}"
|
||||
export PYTHON_BIN="${PYTHON_ENV}/bin/python"
|
||||
$PYTHON_BIN -m pip install -U pip setuptools
|
||||
$PYTHON_BIN -m pip install -r requirements.txt
|
||||
$PYTHON_BIN -m pip install -r dev_requirements.txt
|
||||
/bin/bash ./scripts/build-wheels.sh
|
||||
$PYTHON_BIN ./scripts/collect-dbt-contexts.py > ./dist/context_metadata.json
|
||||
$PYTHON_BIN ./scripts/collect-artifact-schema.py > ./dist/artifact_schemas.json
|
||||
environment:
|
||||
PYTHON_ENV: /home/tox/build_venv/
|
||||
- store_artifacts:
|
||||
path: ./dist
|
||||
destination: dist
|
||||
integration-postgres-py36:
|
||||
docker: &test_and_postgres
|
||||
- image: fishtownanalytics/test-container:9
|
||||
environment:
|
||||
DBT_INVOCATION_ENV: circle
|
||||
- image: postgres
|
||||
name: database
|
||||
environment: &pgenv
|
||||
POSTGRES_USER: "root"
|
||||
POSTGRES_PASSWORD: "password"
|
||||
POSTGRES_DB: "dbt"
|
||||
steps:
|
||||
- checkout
|
||||
- run: &setupdb
|
||||
name: Setup postgres
|
||||
command: bash test/setup_db.sh
|
||||
environment:
|
||||
PGHOST: database
|
||||
PGUSER: root
|
||||
PGPASSWORD: password
|
||||
PGDATABASE: postgres
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-postgres-py36
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake-py36:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-snowflake-py36
|
||||
no_output_timeout: 1h
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift-py36:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-redshift-py36
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery-py36:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-bigquery-py36
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-postgres-py38:
|
||||
docker: *test_and_postgres
|
||||
steps:
|
||||
- checkout
|
||||
- run: *setupdb
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-postgres-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-snowflake-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-snowflake-py38
|
||||
no_output_timeout: 1h
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-redshift-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-redshift-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
integration-bigquery-py38:
|
||||
docker: *test_only
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
name: Run tests
|
||||
command: tox -e integration-bigquery-py38
|
||||
- store_artifacts:
|
||||
path: ./logs
|
||||
|
||||
workflows:
|
||||
version: 2
|
||||
test-everything:
|
||||
jobs:
|
||||
- unit
|
||||
- integration-postgres-py36:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-bigquery-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-snowflake-py36:
|
||||
requires:
|
||||
- integration-postgres-py36
|
||||
- integration-postgres-py38:
|
||||
requires:
|
||||
- unit
|
||||
- integration-redshift-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- integration-bigquery-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- integration-snowflake-py38:
|
||||
requires:
|
||||
- integration-postgres-py38
|
||||
- build-wheels:
|
||||
requires:
|
||||
- unit
|
||||
- integration-postgres-py36
|
||||
- integration-redshift-py36
|
||||
- integration-bigquery-py36
|
||||
- integration-snowflake-py36
|
||||
- integration-postgres-py38
|
||||
- integration-redshift-py38
|
||||
- integration-bigquery-py38
|
||||
- integration-snowflake-py38
|
||||
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
Normal file
@@ -0,0 +1,85 @@
|
||||
name: 🐞 Bug
|
||||
description: Report a bug or an issue you've found with dbt
|
||||
title: "[Bug] <title>"
|
||||
labels: ["bug", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing issue for this?
|
||||
description: Please search to see if an issue already exists for the bug you encountered.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Current Behavior
|
||||
description: A concise description of what you're experiencing.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Expected Behavior
|
||||
description: A concise description of what you expected to happen.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Steps To Reproduce
|
||||
description: Steps to reproduce the behavior.
|
||||
placeholder: |
|
||||
1. In this environment...
|
||||
2. With this config...
|
||||
3. Run '...'
|
||||
4. See error...
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Relevant log output
|
||||
description: |
|
||||
If applicable, log output to help explain your problem.
|
||||
render: shell
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.7.2 (`python --version`)
|
||||
- **dbt**: 0.21.0 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
- Python:
|
||||
- dbt:
|
||||
render: markdown
|
||||
validations:
|
||||
required: false
|
||||
- type: dropdown
|
||||
id: database
|
||||
attributes:
|
||||
label: What database are you using dbt with?
|
||||
multiple: true
|
||||
options:
|
||||
- postgres
|
||||
- redshift
|
||||
- snowflake
|
||||
- bigquery
|
||||
- other (mention it in "Additional Context")
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Additional Context
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the issue you are encountering!
|
||||
|
||||
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
||||
validations:
|
||||
required: false
|
||||
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -1,41 +0,0 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Report a bug or an issue you've found with dbt
|
||||
title: ''
|
||||
labels: bug, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the bug
|
||||
A clear and concise description of what the bug is. What command did you run? What happened?
|
||||
|
||||
### Steps To Reproduce
|
||||
In as much detail as possible, please provide steps to reproduce the issue. Sample data that triggers the issue, example model code, etc is all very helpful here.
|
||||
|
||||
### Expected behavior
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
### Screenshots and log output
|
||||
If applicable, add screenshots or log output to help explain your problem.
|
||||
|
||||
### System information
|
||||
**Which database are you using dbt with?**
|
||||
- [ ] postgres
|
||||
- [ ] redshift
|
||||
- [ ] bigquery
|
||||
- [ ] snowflake
|
||||
- [ ] other (specify: ____________)
|
||||
|
||||
|
||||
**The output of `dbt --version`:**
|
||||
```
|
||||
<output goes here>
|
||||
```
|
||||
|
||||
**The operating system you're using:**
|
||||
|
||||
**The output of `python --version`:**
|
||||
|
||||
### Additional context
|
||||
Add any other context about the problem here.
|
||||
16
.github/ISSUE_TEMPLATE/config.yml
vendored
Normal file
16
.github/ISSUE_TEMPLATE/config.yml
vendored
Normal file
@@ -0,0 +1,16 @@
|
||||
contact_links:
|
||||
- name: Create an issue for dbt-redshift
|
||||
url: https://github.com/dbt-labs/dbt-redshift/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-redshift
|
||||
- name: Create an issue for dbt-bigquery
|
||||
url: https://github.com/dbt-labs/dbt-bigquery/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-bigquery
|
||||
- name: Create an issue for dbt-snowflake
|
||||
url: https://github.com/dbt-labs/dbt-snowflake/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-snowflake
|
||||
- name: Ask a question or get support
|
||||
url: https://docs.getdbt.com/docs/guides/getting-help
|
||||
about: Ask a question or request support
|
||||
- name: Questions on Stack Overflow
|
||||
url: https://stackoverflow.com/questions/tagged/dbt
|
||||
about: Look at questions/answers at Stack Overflow
|
||||
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
name: ✨ Feature
|
||||
description: Suggest an idea for dbt
|
||||
title: "[Feature] <title>"
|
||||
labels: ["enhancement", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this feature requests!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing feature request for this?
|
||||
description: Please search to see if an issue already exists for the feature you would like.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe the Feature
|
||||
description: A clear and concise description of what you want to happen.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe alternatives you've considered
|
||||
description: |
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Who will this benefit?
|
||||
description: |
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
validations:
|
||||
required: false
|
||||
- type: input
|
||||
attributes:
|
||||
label: Are you interested in contributing this feature?
|
||||
description: Let us know if you want to write some code, and how we can help.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Anything else?
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the feature you are suggesting!
|
||||
validations:
|
||||
required: false
|
||||
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -1,23 +0,0 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for dbt
|
||||
title: ''
|
||||
labels: enhancement, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the feature
|
||||
A clear and concise description of what you want to happen.
|
||||
|
||||
### Describe alternatives you've considered
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
|
||||
### Additional context
|
||||
Is this feature database-specific? Which database(s) is/are relevant? Please include any other relevant context here.
|
||||
|
||||
### Who will this benefit?
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
|
||||
### Are you interested in contributing this feature?
|
||||
Let us know if you want to write some code, and how we can help.
|
||||
10
.github/actions/setup-postgres-linux/action.yml
vendored
Normal file
10
.github/actions/setup-postgres-linux/action.yml
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
name: "Set up postgres (linux)"
|
||||
description: "Set up postgres service on linux vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
sudo systemctl start postgresql.service
|
||||
pg_isready
|
||||
sudo -u postgres bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-linux/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-linux/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
24
.github/actions/setup-postgres-macos/action.yml
vendored
Normal file
24
.github/actions/setup-postgres-macos/action.yml
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
name: "Set up postgres (macos)"
|
||||
description: "Set up postgres service on macos vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: bash
|
||||
run: |
|
||||
brew services start postgresql
|
||||
echo "Check PostgreSQL service is running"
|
||||
i=10
|
||||
COMMAND='pg_isready'
|
||||
while [ $i -gt -1 ]; do
|
||||
if [ $i == 0 ]; then
|
||||
echo "PostgreSQL service not ready, all attempts exhausted"
|
||||
exit 1
|
||||
fi
|
||||
echo "Check PostgreSQL service status"
|
||||
eval $COMMAND && break
|
||||
echo "PostgreSQL service not ready, wait 10 more sec, attempts left: $i"
|
||||
sleep 10
|
||||
((i--))
|
||||
done
|
||||
createuser -s postgres
|
||||
bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-macos/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-macos/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
12
.github/actions/setup-postgres-windows/action.yml
vendored
Normal file
12
.github/actions/setup-postgres-windows/action.yml
vendored
Normal file
@@ -0,0 +1,12 @@
|
||||
name: "Set up postgres (windows)"
|
||||
description: "Set up postgres service on windows vm for dbt integration tests"
|
||||
runs:
|
||||
using: "composite"
|
||||
steps:
|
||||
- shell: pwsh
|
||||
run: |
|
||||
$pgService = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $pgService -Status running -StartupType automatic
|
||||
Start-Process -FilePath "$env:PGBIN\pg_isready" -Wait -PassThru
|
||||
$env:Path += ";$env:PGBIN"
|
||||
bash ${{ github.action_path }}/setup_db.sh
|
||||
1
.github/actions/setup-postgres-windows/setup_db.sh
vendored
Symbolic link
1
.github/actions/setup-postgres-windows/setup_db.sh
vendored
Symbolic link
@@ -0,0 +1 @@
|
||||
../../../test/setup_db.sh
|
||||
30
.github/dependabot.yml
vendored
Normal file
30
.github/dependabot.yml
vendored
Normal file
@@ -0,0 +1,30 @@
|
||||
version: 2
|
||||
updates:
|
||||
# python dependencies
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/core"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/postgres"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
|
||||
# docker dependencies
|
||||
- package-ecosystem: "docker"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "docker"
|
||||
directory: "/docker"
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
rebase-strategy: "disabled"
|
||||
19
.github/pull_request_template.md
vendored
19
.github/pull_request_template.md
vendored
@@ -4,19 +4,18 @@ resolves #
|
||||
Include the number of the issue addressed by this PR above if applicable.
|
||||
PRs for code changes without an associated issue *will not be merged*.
|
||||
See CONTRIBUTING.md for more information.
|
||||
|
||||
Example:
|
||||
resolves #1234
|
||||
-->
|
||||
|
||||
|
||||
### Description
|
||||
|
||||
<!--- Describe the Pull Request here -->
|
||||
|
||||
<!---
|
||||
Describe the Pull Request here. Add any references and info to help reviewers
|
||||
understand your changes. Include any tradeoffs you considered.
|
||||
-->
|
||||
|
||||
### Checklist
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change to the "dbt next" section.
|
||||
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change
|
||||
|
||||
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
module.exports = ({ context }) => {
|
||||
const defaultPythonVersion = "3.8";
|
||||
const supportedPythonVersions = ["3.6", "3.7", "3.8", "3.9"];
|
||||
const supportedAdapters = ["postgres"];
|
||||
|
||||
// if PR, generate matrix based on files changed and PR labels
|
||||
if (context.eventName.includes("pull_request")) {
|
||||
// `changes` is a list of adapter names that have related
|
||||
// file changes in the PR
|
||||
// ex: ['postgres', 'snowflake']
|
||||
const changes = JSON.parse(process.env.CHANGES);
|
||||
const labels = context.payload.pull_request.labels.map(({ name }) => name);
|
||||
console.log("labels", labels);
|
||||
console.log("changes", changes);
|
||||
const testAllLabel = labels.includes("test all");
|
||||
const include = [];
|
||||
|
||||
for (const adapter of supportedAdapters) {
|
||||
if (
|
||||
changes.includes(adapter) ||
|
||||
testAllLabel ||
|
||||
labels.includes(`test ${adapter}`)
|
||||
) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
if (
|
||||
pythonVersion === defaultPythonVersion ||
|
||||
labels.includes(`test python${pythonVersion}`) ||
|
||||
testAllLabel
|
||||
) {
|
||||
// always run tests on ubuntu by default
|
||||
include.push({
|
||||
os: "ubuntu-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
|
||||
if (labels.includes("test windows") || testAllLabel) {
|
||||
include.push({
|
||||
os: "windows-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
|
||||
if (labels.includes("test macos") || testAllLabel) {
|
||||
include.push({
|
||||
os: "macos-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
}
|
||||
// if not PR, generate matrix of python version, adapter, and operating
|
||||
// system to run integration tests on
|
||||
|
||||
const include = [];
|
||||
// run for all adapters and python versions on ubuntu
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
include.push({
|
||||
os: 'ubuntu-latest',
|
||||
adapter: adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
// additionally include runs for all adapters, on macos and windows,
|
||||
// but only for the default python version
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const operatingSystem of ["windows-latest", "macos-latest"]) {
|
||||
include.push({
|
||||
os: operatingSystem,
|
||||
adapter: adapter,
|
||||
"python-version": defaultPythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
};
|
||||
222
.github/workflows/integration.yml
vendored
Normal file
222
.github/workflows/integration.yml
vendored
Normal file
@@ -0,0 +1,222 @@
|
||||
# **what?**
|
||||
# This workflow runs all integration tests for supported OS
|
||||
# and python versions and core adapters. If triggered by PR,
|
||||
# the workflow will only run tests for adapters related
|
||||
# to code changes. Use the `test all` and `test ${adapter}`
|
||||
# label to run all or additional tests. Use `ok to test`
|
||||
# label to mark PRs from forked repositories that are safe
|
||||
# to run integration tests for. Requires secrets to run
|
||||
# against different warehouses.
|
||||
|
||||
# **why?**
|
||||
# This checks the functionality of dbt from a user's perspective
|
||||
# and attempts to catch functional regressions.
|
||||
|
||||
# **when?**
|
||||
# This workflow will run on every push to a protected branch
|
||||
# and when manually triggered. It will also run for all PRs, including
|
||||
# PRs from forks. The workflow will be skipped until there is a label
|
||||
# to mark the PR as safe to run.
|
||||
|
||||
name: Adapter Integration Tests
|
||||
|
||||
on:
|
||||
# pushes to release branches
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
# all PRs, important to note that `pull_request_target` workflows
|
||||
# will run in the context of the target branch of a PR
|
||||
pull_request_target:
|
||||
# manual tigger
|
||||
workflow_dispatch:
|
||||
|
||||
# explicitly turn off permissions for `GITHUB_TOKEN`
|
||||
permissions: read-all
|
||||
|
||||
# will cancel previous workflows triggered by the same event and for the same ref for PRs or same SHA otherwise
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(github.event_name, 'pull_request') && github.event.pull_request.head.ref || github.sha }}
|
||||
cancel-in-progress: true
|
||||
|
||||
# sets default shell to bash, for all operating systems
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
# generate test metadata about what files changed and the testing matrix to use
|
||||
test-metadata:
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
if: >-
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
outputs:
|
||||
matrix: ${{ steps.generate-matrix.outputs.result }}
|
||||
|
||||
steps:
|
||||
- name: Check out the repository (non-PR)
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Check if relevant files changed
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: get-changes
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
postgres:
|
||||
- 'core/**'
|
||||
- 'plugins/postgres/**'
|
||||
- 'dev-requirements.txt'
|
||||
|
||||
- name: Generate integration test matrix
|
||||
id: generate-matrix
|
||||
uses: actions/github-script@v4
|
||||
env:
|
||||
CHANGES: ${{ steps.get-changes.outputs.changes }}
|
||||
with:
|
||||
script: |
|
||||
const script = require('./.github/scripts/integration-test-matrix.js')
|
||||
const matrix = script({ context })
|
||||
console.log(matrix)
|
||||
return matrix
|
||||
|
||||
test:
|
||||
name: ${{ matrix.adapter }} / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
# also checks that the matrix generated is not empty
|
||||
if: >-
|
||||
needs.test-metadata.outputs.matrix &&
|
||||
fromJSON( needs.test-metadata.outputs.matrix ).include[0] &&
|
||||
(
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
)
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
needs: test-metadata
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix: ${{ fromJSON(needs.test-metadata.outputs.matrix) }}
|
||||
|
||||
env:
|
||||
TOXENV: integration-${{ matrix.adapter }}
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
# explicity checkout the branch for the PR,
|
||||
# this is necessary for the `pull_request_target` event
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox (postgres)
|
||||
if: matrix.adapter == 'postgres'
|
||||
run: tox
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs
|
||||
path: ./logs
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y-%m-%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ matrix.adapter }}-${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
require-label-comment:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
needs: test
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- name: Needs permission PR comment
|
||||
if: >-
|
||||
needs.test.result == 'skipped' &&
|
||||
github.event_name == 'pull_request_target' &&
|
||||
github.event.pull_request.head.repo.full_name != github.repository
|
||||
uses: unsplash/comment-on-pr@master
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
with:
|
||||
msg: |
|
||||
"You do not have permissions to run integration tests, @dbt-labs/core "\
|
||||
"needs to label this PR with `ok to test` in order to run integration tests!"
|
||||
check_for_duplicate_msg: true
|
||||
206
.github/workflows/main.yml
vendored
Normal file
206
.github/workflows/main.yml
vendored
Normal file
@@ -0,0 +1,206 @@
|
||||
# **what?**
|
||||
# Runs code quality checks, unit tests, and verifies python build on
|
||||
# all code commited to the repository. This workflow should not
|
||||
# require any secrets since it runs for PRs from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code for dbt meets a certain quality standard.
|
||||
|
||||
# **when?**
|
||||
# This will run for all PRs, when code is pushed to a release
|
||||
# branch, and when manually triggered.
|
||||
|
||||
name: Tests and Code Checks
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
workflow_dispatch:
|
||||
|
||||
permissions: read-all
|
||||
|
||||
# will cancel previous workflows triggered by the same event and for the same ref for PRs or same SHA otherwise
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(github.event_name, 'pull_request') && github.event.pull_request.head.ref || github.sha }}
|
||||
cancel-in-progress: true
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
code-quality:
|
||||
name: ${{ matrix.toxenv }}
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
toxenv: [flake8, mypy]
|
||||
|
||||
env:
|
||||
TOXENV: ${{ matrix.toxenv }}
|
||||
PYTEST_ADDOPTS: "-v --color=yes"
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
run: tox
|
||||
|
||||
unit:
|
||||
name: unit test / python ${{ matrix.python-version }}
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: [3.6, 3.7, 3.8] # TODO: support unit testing for python 3.9 (https://github.com/dbt-labs/dbt/issues/3689)
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
PYTEST_ADDOPTS: "-v --color=yes --csv unit_results.csv"
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
run: tox
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y-%m-%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: unit_results_${{ matrix.python-version }}-${{ steps.date.outputs.date }}.csv
|
||||
path: unit_results.csv
|
||||
|
||||
build:
|
||||
name: build packages
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
- name: Build distributions
|
||||
run: ./scripts/build-dist.sh
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Check distribution descriptions
|
||||
run: |
|
||||
twine check dist/*
|
||||
|
||||
- name: Check wheel contents
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
test-build:
|
||||
name: verify packages / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
needs: build
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
os: [ubuntu-latest, macos-latest, windows-latest]
|
||||
python-version: [3.6, 3.7, 3.8, 3.9]
|
||||
|
||||
steps:
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade wheel
|
||||
pip --version
|
||||
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
dbt --version
|
||||
|
||||
- name: Install source distributions
|
||||
run: |
|
||||
find ./dist/*.gz -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
dbt --version
|
||||
176
.github/workflows/performance.yml
vendored
Normal file
176
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,176 @@
|
||||
name: Performance Regression Tests
|
||||
# Schedule triggers
|
||||
on:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
schedule:
|
||||
- cron: "5 10,22 * * *"
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: "0.20.latest"
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: make results directory
|
||||
run: mkdir ./final-output/
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./ -o ./final-output/
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final-output/*
|
||||
87
.github/workflows/schema-check.yml
vendored
Normal file
87
.github/workflows/schema-check.yml
vendored
Normal file
@@ -0,0 +1,87 @@
|
||||
# **what?**
|
||||
# Compares the schema of the dbt version of the given ref vs
|
||||
# the latest official schema releases found in schemas.getdbt.com.
|
||||
# If there are differences, the workflow will fail and upload the
|
||||
# diff as an artifact. The metadata team should be alerted to the change.
|
||||
#
|
||||
# **why?**
|
||||
# Reaction work may need to be done if artifact schema changes
|
||||
# occur so we want to proactively alert to it.
|
||||
#
|
||||
# **when?**
|
||||
# On pushes to `develop` and release branches. Manual runs are also enabled.
|
||||
name: Artifact Schema Check
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
pull_request: #TODO: remove before merging
|
||||
push:
|
||||
branches:
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
|
||||
env:
|
||||
LATEST_SCHEMA_PATH: ${{ github.workspace }}/new_schemas
|
||||
SCHEMA_DIFF_ARTIFACT: ${{ github.workspace }}//schema_schanges.txt
|
||||
DBT_REPO_DIRECTORY: ${{ github.workspace }}/dbt
|
||||
SCHEMA_REPO_DIRECTORY: ${{ github.workspace }}/schemas.getdbt.com
|
||||
|
||||
jobs:
|
||||
checking-schemas:
|
||||
name: "Checking schemas"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Checkout dbt repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
path: ${{ env.DBT_REPO_DIRECTORY }}
|
||||
|
||||
- name: Checkout schemas.getdbt.com repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
repository: dbt-labs/schemas.getdbt.com
|
||||
ref: 'main'
|
||||
ssh-key: ${{ secrets.SCHEMA_SSH_PRIVATE_KEY }}
|
||||
path: ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
|
||||
- name: Generate current schema
|
||||
run: |
|
||||
cd ${{ env.DBT_REPO_DIRECTORY }}
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
python scripts/collect-artifact-schema.py --path ${{ env.LATEST_SCHEMA_PATH }}
|
||||
|
||||
# Copy generated schema files into the schemas.getdbt.com repo
|
||||
# Do a git diff to find any changes
|
||||
# Ignore any date or version changes though
|
||||
- name: Compare schemas
|
||||
run: |
|
||||
cp -r ${{ env.LATEST_SCHEMA_PATH }}/dbt ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
cd ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
diff_results=$(git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' --compact-summary)
|
||||
if [[ $(echo diff_results) ]]; then
|
||||
echo $diff_results
|
||||
echo "Schema changes detected!"
|
||||
git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' > ${{ env.SCHEMA_DIFF_ARTIFACT }}
|
||||
exit 1
|
||||
else
|
||||
echo "No schema changes detected"
|
||||
fi
|
||||
|
||||
- name: Upload schema diff
|
||||
uses: actions/upload-artifact@v2.2.4
|
||||
if: ${{ failure() }}
|
||||
with:
|
||||
name: 'schema_schanges.txt'
|
||||
path: '${{ env.SCHEMA_DIFF_ARTIFACT }}'
|
||||
18
.github/workflows/stale.yml
vendored
Normal file
18
.github/workflows/stale.yml
vendored
Normal file
@@ -0,0 +1,18 @@
|
||||
name: "Close stale issues and PRs"
|
||||
on:
|
||||
schedule:
|
||||
- cron: "30 1 * * *"
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
# pinned at v4 (https://github.com/actions/stale/releases/tag/v4.0.0)
|
||||
- uses: actions/stale@cdf15f641adb27a71842045a94023bef6945e3aa
|
||||
with:
|
||||
stale-issue-message: "This issue has been marked as Stale because it has been open for 180 days with no activity. If you would like the issue to remain open, please remove the stale label or comment on the issue, or it will be closed in 7 days."
|
||||
stale-pr-message: "This PR has been marked as Stale because it has been open for 180 days with no activity. If you would like the PR to remain open, please remove the stale label or comment on the PR, or it will be closed in 7 days."
|
||||
# mark issues/PRs stale when they haven't seen activity in 180 days
|
||||
days-before-stale: 180
|
||||
# ignore checking issues with the following labels
|
||||
exempt-issue-labels: "epic,discussion"
|
||||
109
.github/workflows/version-bump.yml
vendored
Normal file
109
.github/workflows/version-bump.yml
vendored
Normal file
@@ -0,0 +1,109 @@
|
||||
# **what?**
|
||||
# This workflow will take a version number and a dry run flag. With that
|
||||
# it will run versionbump to update the version number everywhere in the
|
||||
# code base and then generate an update Docker requirements file. If this
|
||||
# is a dry run, a draft PR will open with the changes. If this isn't a dry
|
||||
# run, the changes will be committed to the branch this is run on.
|
||||
|
||||
# **why?**
|
||||
# This is to aid in releasing dbt and making sure we have updated
|
||||
# the versions and Docker requirements in all places.
|
||||
|
||||
# **when?**
|
||||
# This is triggered either manually OR
|
||||
# from the repository_dispatch event "version-bump" which is sent from
|
||||
# the dbt-release repo Action
|
||||
|
||||
name: Version Bump
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version_number:
|
||||
description: 'The version number to bump to'
|
||||
required: true
|
||||
is_dry_run:
|
||||
description: 'Creates a draft PR to allow testing instead of committing to a branch'
|
||||
required: true
|
||||
default: 'true'
|
||||
repository_dispatch:
|
||||
types: [version-bump]
|
||||
|
||||
jobs:
|
||||
bump:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set version and dry run values
|
||||
id: variables
|
||||
env:
|
||||
VERSION_NUMBER: "${{ github.event.client_payload.version_number == '' && github.event.inputs.version_number || github.event.client_payload.version_number }}"
|
||||
IS_DRY_RUN: "${{ github.event.client_payload.is_dry_run == '' && github.event.inputs.is_dry_run || github.event.client_payload.is_dry_run }}"
|
||||
run: |
|
||||
echo Repository dispatch event version: ${{ github.event.client_payload.version_number }}
|
||||
echo Repository dispatch event dry run: ${{ github.event.client_payload.is_dry_run }}
|
||||
echo Workflow dispatch event version: ${{ github.event.inputs.version_number }}
|
||||
echo Workflow dispatch event dry run: ${{ github.event.inputs.is_dry_run }}
|
||||
echo ::set-output name=VERSION_NUMBER::$VERSION_NUMBER
|
||||
echo ::set-output name=IS_DRY_RUN::$IS_DRY_RUN
|
||||
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
|
||||
- name: Create PR branch
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
run: |
|
||||
git checkout -b bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git push origin bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git branch --set-upstream-to=origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
|
||||
- name: Generate Docker requirements
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r requirements.txt
|
||||
pip freeze -l > docker/requirements/requirements.txt
|
||||
git status
|
||||
|
||||
- name: Bump version
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r dev-requirements.txt
|
||||
env/bin/bumpversion --allow-dirty --new-version ${{steps.variables.outputs.VERSION_NUMBER}} major
|
||||
git status
|
||||
|
||||
- name: Commit version bump directly
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'false' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
|
||||
- name: Commit version bump to branch
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
push: 'origin origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v3
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
||||
draft: true
|
||||
base: ${{github.ref}}
|
||||
title: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -8,7 +8,7 @@ __pycache__/
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
env/
|
||||
env*/
|
||||
dbt_env/
|
||||
build/
|
||||
develop-eggs/
|
||||
@@ -85,6 +85,7 @@ target/
|
||||
|
||||
# pycharm
|
||||
.idea/
|
||||
venv/
|
||||
|
||||
# AWS credentials
|
||||
.aws/
|
||||
|
||||
47
ARCHITECTURE.md
Normal file
47
ARCHITECTURE.md
Normal file
@@ -0,0 +1,47 @@
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
|
||||
## dbt-core
|
||||
|
||||
Most of the python code in the repository is within the `core/dbt` directory. Currently the main subdirectories are:
|
||||
|
||||
- [`adapters`](core/dbt/adapters): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
- [`context`](core/dbt/context): Build and expose dbt-specific Jinja functionality
|
||||
- [`contracts`](core/dbt/contracts): Define Python objects (dataclasses) that dbt expects to create and validate
|
||||
- [`deps`](core/dbt/deps): Package installation and dependency resolution
|
||||
- [`graph`](core/dbt/graph): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`parser`](core/dbt/parser): Read project files, validate, construct python objects
|
||||
- [`task`](core/dbt/task): Set forth the actions that dbt can perform when invoked
|
||||
|
||||
### Invoking dbt
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
|
||||
core/dbt/include/index.html
|
||||
This is the docs website code. It comes from the dbt-docs repository, and is generated when a release is packaged.
|
||||
|
||||
## Adapters
|
||||
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. For testing and development purposes, the dbt-postgres plugin lives alongside the dbt-core codebase, in the [`plugins`](plugins) subdirectory. Like other adapter plugins, it is a self-contained codebase and package that builds on top of dbt-core.
|
||||
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
|
||||
Each adapter plugin is a standalone python package that includes:
|
||||
|
||||
- `dbt/include/[name]`: A "sub-global" dbt project, of YAML and SQL files, that reimplements Jinja macros to use the adapter's supported SQL syntax
|
||||
- `dbt/adapters/[name]`: Python modules that inherit, and optionally reimplement, the base adapter classes defined in dbt-core
|
||||
- `setup.py`
|
||||
|
||||
The Postgres adapter code is the most central, and many of its implementations are used as the default defined in the dbt-core global project. The greater the distance of a data technology from Postgres, the more its adapter plugin may need to reimplement.
|
||||
|
||||
## Testing dbt
|
||||
|
||||
The [`test/`](test/) subdirectory includes unit and integration tests that run as continuous integration checks against open pull requests. Unit tests check mock inputs and outputs of specific python functions. Integration tests perform end-to-end dbt invocations against real adapters (Postgres, Redshift, Snowflake, BigQuery) and assert that the results match expectations. See [the contributing guide](CONTRIBUTING.md) for a step-by-step walkthrough of setting up a local development and testing environment.
|
||||
|
||||
## Everything else
|
||||
|
||||
- [docker](docker/): All dbt versions are published as Docker images on DockerHub. This subfolder contains the `Dockerfile` (constant) and `requirements.txt` (one for each version).
|
||||
- [etc](etc/): Images for README
|
||||
- [scripts](scripts/): Helper scripts for testing, releasing, and producing JSON schemas. These are not included in distributions of dbt, not are they rigorously tested—they're just handy tools for the dbt maintainers :)
|
||||
2735
CHANGELOG.md
2735
CHANGELOG.md
File diff suppressed because it is too large
Load Diff
217
CONTRIBUTING.md
217
CONTRIBUTING.md
@@ -1,112 +1,121 @@
|
||||
# Contributing to dbt
|
||||
# Contributing to `dbt`
|
||||
|
||||
1. [About this document](#about-this-document)
|
||||
2. [Proposing a change](#proposing-a-change)
|
||||
3. [Getting the code](#getting-the-code)
|
||||
4. [Setting up an environment](#setting-up-an-environment)
|
||||
5. [Running dbt in development](#running-dbt-in-development)
|
||||
5. [Running `dbt` in development](#running-dbt-in-development)
|
||||
6. [Testing](#testing)
|
||||
7. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
|
||||
## About this document
|
||||
|
||||
This document is a guide intended for folks interested in contributing to dbt. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using dbt, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
This document is a guide intended for folks interested in contributing to `dbt`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the #development channel on [slack](community.getdbt.com).
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
#### Adapters
|
||||
|
||||
If you have an issue or code change suggestion related to a specific database [adapter](https://docs.getdbt.com/docs/available-adapters); please refer to that supported databases seperate repo for those contributions.
|
||||
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to dbt must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the dbt codebase. If you are unable to sign the CLA, then the dbt maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
Please note that all contributors to `dbt` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt` codebase. If you are unable to sign the CLA, then the `dbt` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
|
||||
## Proposing a change
|
||||
|
||||
dbt is Apache 2.0-licensed open source software. dbt is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
`dbt` is Apache 2.0-licensed open source software. `dbt` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in dbt, the first step is to open an issue. Please check the list of [open issues](https://github.com/fishtown-analytics/dbt/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The dbt maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt-core/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
**Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
### Discussing the idea
|
||||
|
||||
After you open an issue, a dbt maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The dbt maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
After you open an issue, a `dbt` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
|
||||
### Submitting a change
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the dbt codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The dbt maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/fishtown-analytics/dbt/contribute) page.
|
||||
The `dbt` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt-core/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
- Outline your planned implementation. If you want help getting started, ask!
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the dbt maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding dbt's [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
|
||||
In some cases, the right resolution to an open issue might be tangential to the dbt codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the dbt maintainers are unwilling or unable to incorporate into the dbt codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the dbt repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt` maintainers are unwilling or unable to incorporate into the `dbt` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
|
||||
### Using issue labels
|
||||
|
||||
The dbt maintainers use labels to categorize open issues. Some labels indicate the databases impacted by the issue, while others describe the domain in the dbt codebase germane to the discussion. While most of these labels are self-explanatory (eg. `snowflake` or `bigquery`), there are others that are worth describing.
|
||||
The `dbt` maintainers use labels to categorize open issues. Some labels indicate the databases impacted by the issue, while others describe the domain in the `dbt` codebase germane to the discussion. While most of these labels are self-explanatory (eg. `snowflake` or `bigquery`), there are others that are worth describing.
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/fishtown-analytics/dbt/labels/triage) | This is a new issue which has not yet been reviewed by a dbt maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/fishtown-analytics/dbt/labels/bug) | This issue represents a defect or regression in dbt |
|
||||
| [enhancement](https://github.com/fishtown-analytics/dbt/labels/enhancement) | This issue represents net-new functionality in dbt |
|
||||
| [good first issue](https://github.com/fishtown-analytics/dbt/labels/good%20first%20issue) | This issue does not require deep knowledge of the dbt codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/fishtown-analytics/dbt/labels/help%20wanted) / [discussion](https://github.com/fishtown-analytics/dbt/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/fishtown-analytics/dbt/issues/duplicate) | This issue is functionally identical to another open issue. The dbt maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/fishtown-analytics/dbt/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The dbt maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/fishtown-analytics/dbt/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by dbt maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/fishtown-analytics/dbt/labels/wontfix) | This issue does not require a code change in the dbt repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
| [triage](https://github.com/dbt-labs/dbt-core/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt-core/labels/bug) | This issue represents a defect or regression in `dbt` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt-core/labels/enhancement) | This issue represents net-new functionality in `dbt` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt-core/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt-core/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt-core/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt-core/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt-core/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt-core/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt-core/labels/wontfix) | This issue does not require a code change in the `dbt` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
`dbt` has three types of branches:
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `develop` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk branch or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
### Installing git
|
||||
|
||||
You will need `git` in order to download and modify the dbt source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
You will need `git` in order to download and modify the `dbt` source code. On macOS, the best way to download git is to just install [Xcode](https://developer.apple.com/support/xcode/).
|
||||
|
||||
### External contributors
|
||||
|
||||
If you are not a member of the `fishtown-analytics` GitHub organization, you can contribute to dbt by forking the dbt repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
If you are not a member of the `dbt-labs` GitHub organization, you can contribute to `dbt` by forking the `dbt` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
|
||||
1. fork the dbt repository
|
||||
1. fork the `dbt` repository
|
||||
2. clone your fork locally
|
||||
3. check out a new branch for your proposed changes
|
||||
4. push changes to your fork
|
||||
5. open a pull request against `fishtown-analytics/dbt` from your forked repository
|
||||
5. open a pull request against `dbt-labs/dbt` from your forked repository
|
||||
|
||||
### Core contributors
|
||||
|
||||
If you are a member of the `fishtown-analytics` GitHub organization, you will have push access to the dbt repo. Rather than
|
||||
forking dbt to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
If you are a member of the `dbt-labs` GitHub organization, you will have push access to the `dbt` repo. Rather than forking `dbt` to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
## Setting up an environment
|
||||
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for dbt development, many of these tools are used commonly across open-source python projects.
|
||||
There are some tools that will be helpful to you in developing locally. While this is the list relevant for `dbt` development, many of these tools are used commonly across open-source python projects.
|
||||
|
||||
### Tools
|
||||
|
||||
A short list of tools used in dbt testing that will be helpful to your understanding:
|
||||
A short list of tools used in `dbt` testing that will be helpful to your understanding:
|
||||
|
||||
- [virtualenv](https://virtualenv.pypa.io/en/stable/) to manage dependencies
|
||||
- [tox](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions
|
||||
- [pytest](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [make](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [flake8](https://gitlab.com/pycqa/flake8) for code linting
|
||||
- [CircleCI](https://circleci.com/product/) and [Azure Pipelines](https://azure.microsoft.com/en-us/services/devops/pipelines/)
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.6, Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [Github Actions](https://github.com/features/actions)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to dbt, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
#### virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in dbt. We recommend creating this virtualenv
|
||||
in the root of the dbt repository. To create a new virtualenv, run:
|
||||
```
|
||||
We strongly recommend using virtual environments when developing code in `dbt`. We recommend creating this virtualenv
|
||||
in the root of the `dbt` repository. To create a new virtualenv, run:
|
||||
```sh
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
```
|
||||
@@ -115,30 +124,32 @@ This will create and activate a new Python virtual environment.
|
||||
|
||||
#### docker and docker-compose
|
||||
|
||||
Docker and docker-compose are both used in testing. For macOS, the easiest thing to do is to [download docker for mac](https://store.docker.com/editions/community/docker-ce-desktop-mac). You'll need to make an account. On Linux, you can use one of the packages [here](https://docs.docker.com/install/#server). We recommend installing from docker.com instead of from your package manager. On Linux you also have to install docker-compose separately, following [these instructions](https://docs.docker.com/compose/install/#install-compose).
|
||||
Docker and docker-compose are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
|
||||
|
||||
#### postgres (optional)
|
||||
|
||||
For testing, and later in the examples in this document, you may want to have `psql` available so you can poke around in the database and see what happened. We recommend that you use [homebrew](https://brew.sh/) for that on macOS, and your package manager on Linux. You can install any version of the postgres client that you'd like. On macOS, with homebrew setup, you can run:
|
||||
|
||||
```
|
||||
```sh
|
||||
brew install postgresql
|
||||
```
|
||||
|
||||
## Running dbt in development
|
||||
## Running `dbt` in development
|
||||
|
||||
### Installation
|
||||
|
||||
First make sure that you set up your `virtualenv` as described in section _Setting up an environment_. Next, install dbt (and its dependencies) with:
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Also ensure you have the latest version of pip installed with `pip install --upgrade pip`. Next, install `dbt` (and its dependencies) with:
|
||||
|
||||
```
|
||||
pip install -r editable_requirements.txt
|
||||
```sh
|
||||
make dev
|
||||
# or
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
```
|
||||
|
||||
When dbt is installed from source in this way, any changes you make to the dbt source code will be reflected immediately in your next `dbt` run.
|
||||
When `dbt` is installed this way, any changes you make to the `dbt` source code will be reflected immediately in your next `dbt` run.
|
||||
|
||||
### Running dbt
|
||||
### Running `dbt`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
|
||||
@@ -146,77 +157,79 @@ Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as
|
||||
|
||||
## Testing
|
||||
|
||||
Getting the dbt integration tests set up in your local environment will be very helpful as you start to make changes to your local version of dbt. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
Getting the `dbt` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
### Running tests via Docker
|
||||
Although `dbt` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead you can test all dbt-core code changes with Python and Postgres.
|
||||
|
||||
dbt's unit and integration tests run in Docker. Because dbt works with a number of different databases, you will need to supply credentials for one or more of these databases in your test environment. Most organizations don't have access to each of a BigQuery, Redshift, Snowflake, and Postgres database, so it's likely that you will be unable to run every integration test locally. Fortunately, Fishtown Analytics provides a CI environment with access to sandboxed Redshift, Snowflake, BigQuery, and Postgres databases. See the section on [_Submitting a Pull Request_](#submitting-a-pull-request) below for more information on this CI setup.
|
||||
### Initial setup
|
||||
|
||||
We recommend starting with `dbt`'s Postgres tests. These tests cover most of the functionality in `dbt`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
### Specifying your test credentials
|
||||
|
||||
dbt uses test credentials specified in a `test.env` file in the root of the repository. This `test.env` file is git-ignored, but please be _extra_ careful to never check in credentials or other sensitive information when developing against dbt. To create your `test.env` file, copy the provided sample file, then supply your relevant credentials:
|
||||
|
||||
```
|
||||
cp test.env.sample test.env
|
||||
atom test.env # supply your credentials
|
||||
```
|
||||
|
||||
We recommend starting with dbt's Postgres tests. These tests cover most of the functionality in dbt, are the fastest to run, and are the easiest to set up. dbt's test suite runs Postgres in a Docker container, so no setup should be required to run these tests.
|
||||
|
||||
If you additionally want to test Snowflake, Bigquery, or Redshift, locally you'll need to get credentials and add them to the `test.env` file. In general, it's most important to have successful unit and Postgres tests. Once you open a PR, dbt will automatically run integration tests for the other three core database adapters. Of course, if you are a BigQuery user, contributing a BigQuery-only feature, it's important to run BigQuery tests as well.
|
||||
|
||||
### Test commands
|
||||
|
||||
dbt's unit tests and Python linter can be run with:
|
||||
|
||||
```
|
||||
make test-unit
|
||||
```
|
||||
|
||||
To run the Postgres + Python 3.6 integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
```
|
||||
or, alternatively:
|
||||
```sh
|
||||
docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
```
|
||||
|
||||
To run a quick test for Python3 integration tests on Postgres, you can run:
|
||||
`dbt` uses test credentials specified in a `test.env` file in the root of the repository for non-Postgres databases. This `test.env` file is git-ignored, but please be _extra_ careful to never check in credentials or other sensitive information when developing against `dbt`. To create your `test.env` file, copy the provided sample file, then supply your relevant credentials. This step is only required to use non-Postgres databases.
|
||||
|
||||
```
|
||||
make test-quick
|
||||
cp test.env.sample test.env
|
||||
$EDITOR test.env
|
||||
```
|
||||
|
||||
To run tests for a specific database, invoke `tox` directly with the required flags:
|
||||
```
|
||||
# Run Postgres py36 tests
|
||||
docker-compose run test tox -e integration-postgres-py36 -- -x
|
||||
> In general, it's most important to have successful unit and Postgres tests. Once you open a PR, `dbt` will automatically run integration tests for the other three core database adapters. Of course, if you are a BigQuery user, contributing a BigQuery-only feature, it's important to run BigQuery tests as well.
|
||||
|
||||
# Run Snowflake py36 tests
|
||||
docker-compose run test tox -e integration-snowflake-py36 -- -x
|
||||
### Test commands
|
||||
|
||||
# Run BigQuery py36 tests
|
||||
docker-compose run test tox -e integration-bigquery-py36 -- -x
|
||||
There are a few methods for running tests locally.
|
||||
|
||||
# Run Redshift py36 tests
|
||||
docker-compose run test tox -e integration-redshift-py36 -- -x
|
||||
```
|
||||
#### Makefile
|
||||
|
||||
To run a specific test by itself:
|
||||
```
|
||||
docker-compose run test tox -e explicit-py36 -- -s -x -m profile_{adapter} {path_to_test_file_or_folder}
|
||||
```
|
||||
E.g.
|
||||
```
|
||||
docker-compose run test tox -e explicit-py36 -- -s -x -m profile_snowflake test/integration/001_simple_copy_test
|
||||
```
|
||||
There are multiple targets in the Makefile to run common test suites and code
|
||||
checks, most notably:
|
||||
|
||||
See the `Makefile` contents for more some other examples of ways to run `tox`.
|
||||
```sh
|
||||
# Runs unit tests with py38 and code checks in parallel.
|
||||
make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) installed locally,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run
|
||||
tests. You can also run tests in parallel, for example, you can run unit tests
|
||||
for Python 3.6, Python 3.7, Python 3.8, `flake8` checks, and `mypy` checks in
|
||||
parallel with `tox -p`. Also, you can run unit tests for specific python versions
|
||||
with `tox -e py36`. The configuration for these tests in located in `tox.ini`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv
|
||||
active and dev dependencies installed you can do things like:
|
||||
```sh
|
||||
# run specific postgres integration tests
|
||||
python -m pytest -m profile_postgres test/integration/001_simple_copy_test
|
||||
# run all unit tests in a file
|
||||
python -m pytest test/unit/test_graph.py
|
||||
# run a specific unit test
|
||||
python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
```
|
||||
> [Here](https://docs.pytest.org/en/reorganize-docs/new-docs/user/commandlineuseful.html)
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
## Submitting a Pull Request
|
||||
|
||||
Fishtown Analytics provides a sandboxed Redshift, Snowflake, and BigQuery database for use in a CI environment. When pull requests are submitted to the `fishtown-analytics/dbt` repo, GitHub will trigger automated tests in CircleCI and Azure Pipelines.
|
||||
dbt Labs provides a CI environment to test changes to specific adapters, and periodic maintenance checks of `dbt-core` through Github Actions. For example, if you submit a pull request to the `dbt-redshift` repo, GitHub will trigger automated code checks and tests against Redshift.
|
||||
|
||||
A dbt maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
A `dbt` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a dbt maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
Once all tests are passing and your PR has been approved, a `dbt` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
51
Dockerfile
51
Dockerfile
@@ -1,51 +0,0 @@
|
||||
FROM ubuntu:18.04
|
||||
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get dist-upgrade -y && \
|
||||
apt-get install -y --no-install-recommends \
|
||||
netcat postgresql curl git ssh software-properties-common \
|
||||
make build-essential ca-certificates libpq-dev \
|
||||
libsasl2-dev libsasl2-2 libsasl2-modules-gssapi-mit libyaml-dev \
|
||||
&& \
|
||||
add-apt-repository ppa:deadsnakes/ppa && \
|
||||
apt-get install -y \
|
||||
python python-dev python-pip \
|
||||
python3.6 python3.6-dev python3-pip python3.6-venv \
|
||||
python3.7 python3.7-dev python3.7-venv \
|
||||
python3.8 python3.8-dev python3.8-venv \
|
||||
python3.9 python3.9-dev python3.9-venv && \
|
||||
apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
|
||||
|
||||
ARG DOCKERIZE_VERSION=v0.6.1
|
||||
RUN curl -LO https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz && \
|
||||
tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz && \
|
||||
rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
||||
|
||||
RUN pip3 install -U "tox==3.14.4" wheel "six>=1.14.0,<1.15.0" "virtualenv==20.0.3" setuptools
|
||||
# tox fails if the 'python' interpreter (python2) doesn't have `tox` installed
|
||||
RUN pip install -U "tox==3.14.4" "six>=1.14.0,<1.15.0" "virtualenv==20.0.3" setuptools
|
||||
|
||||
# These args are passed in via docker-compose, which reads then from the .env file.
|
||||
# On Linux, run `make .env` to create the .env file for the current user.
|
||||
# On MacOS and Windows, these can stay unset.
|
||||
ARG USER_ID
|
||||
ARG GROUP_ID
|
||||
|
||||
RUN if [ ${USER_ID:-0} -ne 0 ] && [ ${GROUP_ID:-0} -ne 0 ]; then \
|
||||
groupadd -g ${GROUP_ID} dbt_test_user && \
|
||||
useradd -m -l -u ${USER_ID} -g ${GROUP_ID} dbt_test_user; \
|
||||
else \
|
||||
useradd -mU -l dbt_test_user; \
|
||||
fi
|
||||
RUN mkdir /usr/app && chown dbt_test_user /usr/app
|
||||
RUN mkdir /home/tox && chown dbt_test_user /home/tox
|
||||
|
||||
WORKDIR /usr/app
|
||||
VOLUME /usr/app
|
||||
|
||||
USER dbt_test_user
|
||||
|
||||
ENV PYTHONIOENCODING=utf-8
|
||||
ENV LANG C.UTF-8
|
||||
75
Dockerfile.test
Normal file
75
Dockerfile.test
Normal file
@@ -0,0 +1,75 @@
|
||||
FROM ubuntu:20.04
|
||||
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
software-properties-common \
|
||||
&& add-apt-repository ppa:git-core/ppa -y \
|
||||
&& apt-get dist-upgrade -y \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
netcat \
|
||||
postgresql \
|
||||
curl \
|
||||
git \
|
||||
ssh \
|
||||
software-properties-common \
|
||||
make \
|
||||
build-essential \
|
||||
ca-certificates \
|
||||
libpq-dev \
|
||||
libsasl2-dev \
|
||||
libsasl2-2 \
|
||||
libsasl2-modules-gssapi-mit \
|
||||
libyaml-dev \
|
||||
unixodbc-dev \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa \
|
||||
&& apt-get install -y \
|
||||
python \
|
||||
python-dev \
|
||||
python3-pip \
|
||||
python3.6 \
|
||||
python3.6-dev \
|
||||
python3-pip \
|
||||
python3.6-venv \
|
||||
python3.7 \
|
||||
python3.7-dev \
|
||||
python3.7-venv \
|
||||
python3.8 \
|
||||
python3.8-dev \
|
||||
python3.8-venv \
|
||||
python3.9 \
|
||||
python3.9-dev \
|
||||
python3.9-venv \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
|
||||
|
||||
ARG DOCKERIZE_VERSION=v0.6.1
|
||||
RUN curl -LO https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
||||
&& tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
|
||||
&& rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
|
||||
|
||||
RUN pip3 install -U tox wheel six setuptools
|
||||
|
||||
# These args are passed in via docker-compose, which reads then from the .env file.
|
||||
# On Linux, run `make .env` to create the .env file for the current user.
|
||||
# On MacOS and Windows, these can stay unset.
|
||||
ARG USER_ID
|
||||
ARG GROUP_ID
|
||||
|
||||
RUN if [ ${USER_ID:-0} -ne 0 ] && [ ${GROUP_ID:-0} -ne 0 ]; then \
|
||||
groupadd -g ${GROUP_ID} dbt_test_user && \
|
||||
useradd -m -l -u ${USER_ID} -g ${GROUP_ID} dbt_test_user; \
|
||||
else \
|
||||
useradd -mU -l dbt_test_user; \
|
||||
fi
|
||||
RUN mkdir /usr/app && chown dbt_test_user /usr/app
|
||||
RUN mkdir /home/tox && chown dbt_test_user /home/tox
|
||||
|
||||
WORKDIR /usr/app
|
||||
VOLUME /usr/app
|
||||
|
||||
USER dbt_test_user
|
||||
|
||||
ENV PYTHONIOENCODING=utf-8
|
||||
ENV LANG C.UTF-8
|
||||
@@ -186,7 +186,7 @@
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright {yyyy} {name of copyright owner}
|
||||
Copyright 2021 dbt Labs, Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
|
||||
77
Makefile
77
Makefile
@@ -1,29 +1,57 @@
|
||||
.PHONY: install test test-unit test-integration
|
||||
.DEFAULT_GOAL:=help
|
||||
|
||||
changed_tests := `git status --porcelain | grep '^\(M\| M\|A\| A\)' | awk '{ print $$2 }' | grep '\/test_[a-zA-Z_\-\.]\+.py'`
|
||||
# Optional flag to run target in a docker container.
|
||||
# (example `make test USE_DOCKER=true`)
|
||||
ifeq ($(USE_DOCKER),true)
|
||||
DOCKER_CMD := docker-compose run --rm test
|
||||
endif
|
||||
|
||||
install:
|
||||
pip install -e .
|
||||
.PHONY: dev
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies.
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
|
||||
test: .env
|
||||
@echo "Full test run starting..."
|
||||
@time docker-compose run test tox
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy for static type checking.
|
||||
$(DOCKER_CMD) tox -e mypy
|
||||
|
||||
test-unit: .env
|
||||
@echo "Unit test run starting..."
|
||||
@time docker-compose run test tox -e unit-py36,flake8
|
||||
.PHONY: flake8
|
||||
flake8: .env ## Runs flake8 to enforce style guide.
|
||||
$(DOCKER_CMD) tox -e flake8
|
||||
|
||||
test-integration: .env
|
||||
@echo "Integration test run starting..."
|
||||
@time docker-compose run test tox -e integration-postgres-py36,integration-redshift-py36,integration-snowflake-py36,integration-bigquery-py36
|
||||
.PHONY: lint
|
||||
lint: .env ## Runs all code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e flake8,mypy
|
||||
|
||||
test-quick: .env
|
||||
@echo "Integration test run starting..."
|
||||
@time docker-compose run test tox -e integration-postgres-py36 -- -x
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py38 and code checks in parallel.
|
||||
$(DOCKER_CMD) tox -p -e py38,flake8,mypy
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env integration-postgres ## Alias for integration-postgres.
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env integration-postgres-fail-fast ## Alias for integration-postgres-fail-fast.
|
||||
|
||||
.PHONY: integration-postgres
|
||||
integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -nauto
|
||||
|
||||
.PHONY: integration-postgres-fail-fast
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
docker-compose up -d database
|
||||
PGHOST=localhost PGUSER=root PGPASSWORD=password PGDATABASE=postgres bash test/setup_db.sh
|
||||
|
||||
# This rule creates a file named .env that is used by docker-compose for passing
|
||||
# the USER_ID and GROUP_ID arguments to the Docker image.
|
||||
.env:
|
||||
.env: ## Setup step for using using docker-compose with make target.
|
||||
@touch .env
|
||||
ifneq ($(OS),Windows_NT)
|
||||
ifneq ($(shell uname -s), Darwin)
|
||||
@@ -31,9 +59,9 @@ ifneq ($(shell uname -s), Darwin)
|
||||
@echo GROUP_ID=$(shell id -g) >> .env
|
||||
endif
|
||||
endif
|
||||
@time docker-compose build
|
||||
|
||||
clean:
|
||||
.PHONY: clean
|
||||
clean: ## Resets development environment.
|
||||
rm -f .coverage
|
||||
rm -rf .eggs/
|
||||
rm -f .env
|
||||
@@ -47,3 +75,14 @@ clean:
|
||||
rm -rf target/
|
||||
find . -type f -name '*.pyc' -delete
|
||||
find . -type d -name '__pycache__' -depth -delete
|
||||
|
||||
.PHONY: help
|
||||
help: ## Show this help message.
|
||||
@echo 'usage: make [target] [USE_DOCKER=true]'
|
||||
@echo
|
||||
@echo 'targets:'
|
||||
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
@echo
|
||||
@echo 'options:'
|
||||
@echo 'use USE_DOCKER=true to run target in a docker container'
|
||||
|
||||
|
||||
46
README.md
46
README.md
@@ -1,28 +1,18 @@
|
||||
<p align="center">
|
||||
<img src="/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://codeclimate.com/github/fishtown-analytics/dbt">
|
||||
<img src="https://codeclimate.com/github/fishtown-analytics/dbt/badges/gpa.svg" alt="Code Climate"/>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://circleci.com/gh/fishtown-analytics/dbt/tree/master">
|
||||
<img src="https://circleci.com/gh/fishtown-analytics/dbt/tree/master.svg?style=svg" alt="CircleCI" />
|
||||
</a>
|
||||
<a href="https://ci.appveyor.com/project/DrewBanin/dbt/branch/development">
|
||||
<img src="https://ci.appveyor.com/api/projects/status/v01rwd3q91jnwp9m/branch/development?svg=true" alt="AppVeyor" />
|
||||
</a>
|
||||
<a href="https://community.getdbt.com">
|
||||
<img src="https://community.getdbt.com/badge.svg" alt="Slack" />
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** (data build tool) enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
dbt is the T in ELT. Organize, cleanse, denormalize, filter, rename, and pre-aggregate the raw data in your warehouse so that it's ready for analysis.
|
||||
|
||||

|
||||
|
||||
dbt can be used to [aggregate pageviews into sessions](https://github.com/fishtown-analytics/snowplow), calculate [ad spend ROI](https://github.com/fishtown-analytics/facebook-ads), or report on [email campaign performance](https://github.com/fishtown-analytics/mailchimp).
|
||||
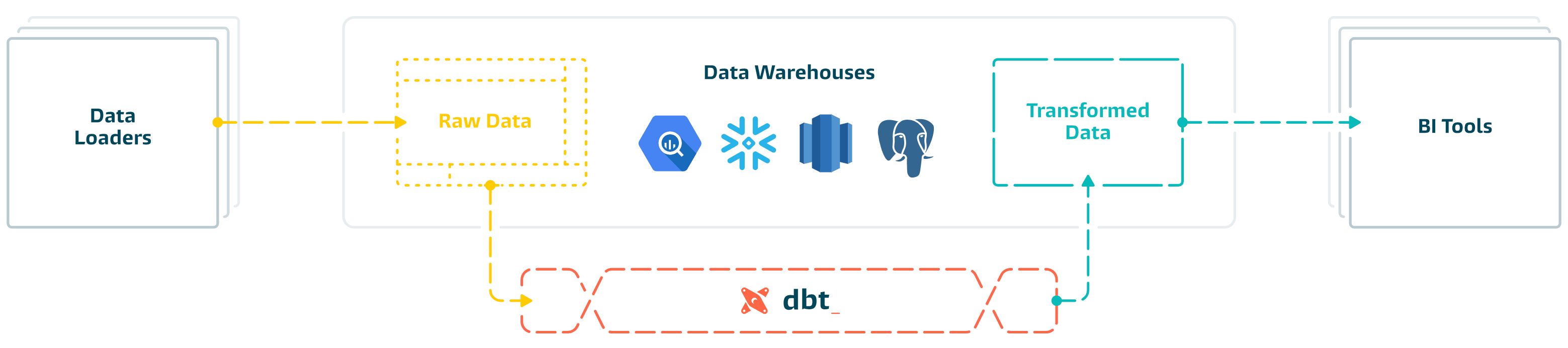
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -30,28 +20,22 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||

|
||||
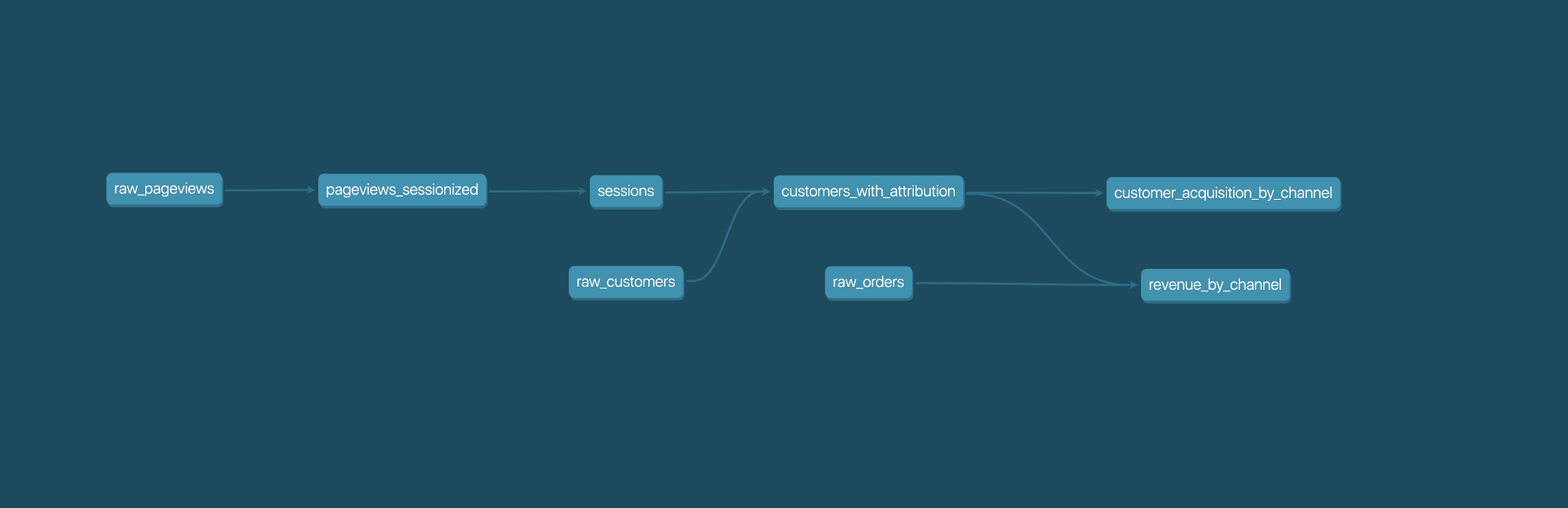
|
||||
|
||||
## Getting started
|
||||
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [documentation](https://docs.getdbt.com/).
|
||||
- Productionize your dbt project with [dbt Cloud](https://www.getdbt.com)
|
||||
- [Install dbt](https://docs.getdbt.com/docs/installation)
|
||||
- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
|
||||
|
||||
## Find out more
|
||||
## Join the dbt Community
|
||||
|
||||
- Check out the [Introduction to dbt](https://docs.getdbt.com/docs/introduction/).
|
||||
- Read the [dbt Viewpoint](https://docs.getdbt.com/docs/about/viewpoint/).
|
||||
|
||||
## Join thousands of analysts in the dbt community
|
||||
|
||||
- Join the [chat](http://community.getdbt.com/) on Slack.
|
||||
- Find community posts on [dbt Discourse](https://discourse.getdbt.com).
|
||||
- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
|
||||
- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/fishtown-analytics/dbt/issues/new).
|
||||
- Want to help us build dbt? Check out the [Contributing Getting Started Guide](/CONTRIBUTING.md)
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt-core/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt-core/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
92
RELEASE.md
92
RELEASE.md
@@ -1,92 +0,0 @@
|
||||
### Release Procedure :shipit:
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
dbt has three types of branches:
|
||||
|
||||
- **Trunks** track the latest release of a minor version of dbt. Historically, we used the `master` branch as the trunk. Each minor version release has a corresponding trunk. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of dbt.
|
||||
- **Release Branches** track a specific, not yet complete release of dbt. These releases are codenamed since we don't always know what their semantic version will be. Example: `dev/lucretia-mott` became `0.11.1`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into a release branch.
|
||||
|
||||
#### Git & PyPI
|
||||
|
||||
1. Update CHANGELOG.md with the most recent changes
|
||||
2. If this is a release candidate, you want to create it off of your release branch. If it's an actual release, you must first merge to a master branch. Open a Pull Request in Github to merge it into the appropriate trunk (`X.X.latest`)
|
||||
3. Bump the version using `bumpversion`:
|
||||
- Dry run first by running `bumpversion --new-version <desired-version> <part>` and checking the diff. If it looks correct, clean up the chanages and move on:
|
||||
- Alpha releases: `bumpversion --commit --no-tag --new-version 0.10.2a1 num`
|
||||
- Patch releases: `bumpversion --commit --no-tag --new-version 0.10.2 patch`
|
||||
- Minor releases: `bumpversion --commit --no-tag --new-version 0.11.0 minor`
|
||||
- Major releases: `bumpversion --commit --no-tag --new-version 1.0.0 major`
|
||||
4. (If this is a not a release candidate) Merge to `x.x.latest` and (optionally) `master`.
|
||||
5. Update the default branch to the next dev release branch.
|
||||
6. Build source distributions for all packages by running `./scripts/build-sdists.sh`. Note that this will clean out your `dist/` folder, so if you have important stuff in there, don't run it!!!
|
||||
7. Deploy to pypi
|
||||
- `twine upload dist/*`
|
||||
8. Deploy to homebrew (see below)
|
||||
9. Deploy to conda-forge (see below)
|
||||
10. Git release notes (points to changelog)
|
||||
11. Post to slack (point to changelog)
|
||||
|
||||
After releasing a new version, it's important to merge the changes back into the other outstanding release branches. This avoids merge conflicts moving forward.
|
||||
|
||||
In some cases, where the branches have diverged wildly, it's ok to skip this step. But this means that the changes you just released won't be included in future releases.
|
||||
|
||||
#### Homebrew Release Process
|
||||
|
||||
1. Clone the `homebrew-dbt` repository:
|
||||
|
||||
```
|
||||
git clone git@github.com:fishtown-analytics/homebrew-dbt.git
|
||||
```
|
||||
|
||||
2. For ALL releases (prereleases and version releases), copy the relevant formula. To copy from the latest version release of dbt, do:
|
||||
|
||||
```bash
|
||||
cp Formula/dbt.rb Formula/dbt@{NEW-VERSION}.rb
|
||||
```
|
||||
|
||||
To copy from a different version, simply copy the corresponding file.
|
||||
|
||||
3. Open the file, and edit the following:
|
||||
- the name of the ruby class: this is important, homebrew won't function properly if the class name is wrong. Check historical versions to figure out the right name.
|
||||
- under the `bottle` section, remove all of the hashes (lines starting with `sha256`)
|
||||
|
||||
4. Create a **Python 3.7** virtualenv, activate it, and then install two packages: `homebrew-pypi-poet`, and the version of dbt you are preparing. I use:
|
||||
|
||||
```
|
||||
pyenv virtualenv 3.7.0 homebrew-dbt-{VERSION}
|
||||
pyenv activate homebrew-dbt-{VERSION}
|
||||
pip install dbt=={VERSION} homebrew-pypi-poet
|
||||
```
|
||||
|
||||
homebrew-pypi-poet is a program that generates a valid homebrew formula for an installed pip package. You want to use it to generate a diff against the existing formula. Then you want to apply the diff for the dependency packages only -- e.g. it will tell you that `google-api-core` has been updated and that you need to use the latest version.
|
||||
|
||||
5. reinstall, test, and audit dbt. if the test or audit fails, fix the formula with step 1.
|
||||
|
||||
```bash
|
||||
brew uninstall --force Formula/{YOUR-FILE}.rb
|
||||
brew install Formula/{YOUR-FILE}.rb
|
||||
brew test dbt
|
||||
brew audit --strict dbt
|
||||
```
|
||||
|
||||
6. Ask Connor to bottle the change (only his laptop can do it!)
|
||||
|
||||
#### Conda Forge Release Process
|
||||
|
||||
1. Clone the fork of `conda-forge/dbt-feedstock` [here](https://github.com/fishtown-analytics/dbt-feedstock)
|
||||
```bash
|
||||
git clone git@github.com:fishtown-analytics/dbt-feedstock.git
|
||||
|
||||
```
|
||||
2. Update the version and sha256 in `recipe/meta.yml`. To calculate the sha256, run:
|
||||
|
||||
```bash
|
||||
wget https://github.com/fishtown-analytics/dbt/archive/v{version}.tar.gz
|
||||
openssl sha256 v{version}.tar.gz
|
||||
```
|
||||
|
||||
3. Push the changes and create a PR against `conda-forge/dbt-feedstock`
|
||||
|
||||
4. Confirm that all automated conda-forge tests are passing
|
||||
@@ -1,154 +0,0 @@
|
||||
# Python package
|
||||
# Create and test a Python package on multiple Python versions.
|
||||
# Add steps that analyze code, save the dist with the build record, publish to a PyPI-compatible index, and more:
|
||||
# https://docs.microsoft.com/azure/devops/pipelines/languages/python
|
||||
|
||||
trigger:
|
||||
branches:
|
||||
include:
|
||||
- master
|
||||
- dev/*
|
||||
- pr/*
|
||||
|
||||
jobs:
|
||||
- job: UnitTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-unit
|
||||
displayName: Run unit tests
|
||||
|
||||
- job: PostgresIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: UnitTest
|
||||
|
||||
steps:
|
||||
- pwsh: |
|
||||
$serviceName = Get-Service -Name postgresql*
|
||||
Set-Service -InputObject $serviceName -StartupType Automatic
|
||||
Start-Service -InputObject $serviceName
|
||||
|
||||
& $env:PGBIN\createdb.exe -U postgres dbt
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE root WITH PASSWORD 'password';"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE root WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CREATE, CONNECT ON DATABASE dbt TO root WITH GRANT OPTION;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "CREATE ROLE noaccess WITH PASSWORD 'password' NOSUPERUSER;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "ALTER ROLE noaccess WITH LOGIN;"
|
||||
& $env:PGBIN\psql.exe -U postgres -c "GRANT CONNECT ON DATABASE dbt TO noaccess;"
|
||||
displayName: Install postgresql and set up database
|
||||
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-postgres
|
||||
displayName: Run integration tests
|
||||
|
||||
# These three are all similar except secure environment variables, which MUST be passed along to their tasks,
|
||||
# but there's probably a better way to do this!
|
||||
- job: SnowflakeIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-snowflake
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: $(SNOWFLAKE_TEST_ACCOUNT)
|
||||
SNOWFLAKE_TEST_PASSWORD: $(SNOWFLAKE_TEST_PASSWORD)
|
||||
SNOWFLAKE_TEST_USER: $(SNOWFLAKE_TEST_USER)
|
||||
SNOWFLAKE_TEST_WAREHOUSE: $(SNOWFLAKE_TEST_WAREHOUSE)
|
||||
SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN: $(SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN)
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_ID: $(SNOWFLAKE_TEST_OAUTH_CLIENT_ID)
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET: $(SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: BigQueryIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
- script: python -m tox -e pywin-bigquery
|
||||
env:
|
||||
BIGQUERY_SERVICE_ACCOUNT_JSON: $(BIGQUERY_SERVICE_ACCOUNT_JSON)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: RedshiftIntegrationTest
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn: PostgresIntegrationTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
|
||||
- script: python -m pip install --upgrade pip && pip install tox
|
||||
displayName: 'Install dependencies'
|
||||
|
||||
- script: python -m tox -e pywin-redshift
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: $(REDSHIFT_TEST_DBNAME)
|
||||
REDSHIFT_TEST_PASS: $(REDSHIFT_TEST_PASS)
|
||||
REDSHIFT_TEST_USER: $(REDSHIFT_TEST_USER)
|
||||
REDSHIFT_TEST_PORT: $(REDSHIFT_TEST_PORT)
|
||||
REDSHIFT_TEST_HOST: $(REDSHIFT_TEST_HOST)
|
||||
displayName: Run integration tests
|
||||
|
||||
- job: BuildWheel
|
||||
pool:
|
||||
vmImage: 'vs2017-win2016'
|
||||
dependsOn:
|
||||
- UnitTest
|
||||
- PostgresIntegrationTest
|
||||
- RedshiftIntegrationTest
|
||||
- SnowflakeIntegrationTest
|
||||
- BigQueryIntegrationTest
|
||||
condition: succeeded()
|
||||
steps:
|
||||
- task: UsePythonVersion@0
|
||||
inputs:
|
||||
versionSpec: '3.7'
|
||||
architecture: 'x64'
|
||||
- script: python -m pip install --upgrade pip setuptools && python -m pip install -r requirements.txt && python -m pip install -r dev_requirements.txt
|
||||
displayName: Install dependencies
|
||||
- task: ShellScript@2
|
||||
inputs:
|
||||
scriptPath: scripts/build-wheels.sh
|
||||
- task: CopyFiles@2
|
||||
inputs:
|
||||
contents: 'dist\?(*.whl|*.tar.gz)'
|
||||
TargetFolder: '$(Build.ArtifactStagingDirectory)'
|
||||
- task: PublishBuildArtifacts@1
|
||||
inputs:
|
||||
pathtoPublish: '$(Build.ArtifactStagingDirectory)'
|
||||
artifactName: dists
|
||||
73
converter.py
73
converter.py
@@ -1,73 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
import json
|
||||
import yaml
|
||||
import sys
|
||||
import argparse
|
||||
from datetime import datetime, timezone
|
||||
import dbt.clients.registry as registry
|
||||
|
||||
|
||||
def yaml_type(fname):
|
||||
with open(fname) as f:
|
||||
return yaml.load(f)
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--project", type=yaml_type, default="dbt_project.yml")
|
||||
parser.add_argument("--namespace", required=True)
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def get_full_name(args):
|
||||
return "{}/{}".format(args.namespace, args.project["name"])
|
||||
|
||||
|
||||
def init_project_in_packages(args, packages):
|
||||
full_name = get_full_name(args)
|
||||
if full_name not in packages:
|
||||
packages[full_name] = {
|
||||
"name": args.project["name"],
|
||||
"namespace": args.namespace,
|
||||
"latest": args.project["version"],
|
||||
"assets": {},
|
||||
"versions": {},
|
||||
}
|
||||
return packages[full_name]
|
||||
|
||||
|
||||
def add_version_to_package(args, project_json):
|
||||
project_json["versions"][args.project["version"]] = {
|
||||
"id": "{}/{}".format(get_full_name(args), args.project["version"]),
|
||||
"name": args.project["name"],
|
||||
"version": args.project["version"],
|
||||
"description": "",
|
||||
"published_at": datetime.now(timezone.utc).astimezone().isoformat(),
|
||||
"packages": args.project.get("packages") or [],
|
||||
"works_with": [],
|
||||
"_source": {
|
||||
"type": "github",
|
||||
"url": "",
|
||||
"readme": "",
|
||||
},
|
||||
"downloads": {
|
||||
"tarball": "",
|
||||
"format": "tgz",
|
||||
"sha1": "",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
packages = registry.packages()
|
||||
project_json = init_project_in_packages(args, packages)
|
||||
if args.project["version"] in project_json["versions"]:
|
||||
raise Exception("Version {} already in packages JSON"
|
||||
.format(args.project["version"]),
|
||||
file=sys.stderr)
|
||||
add_version_to_package(args, project_json)
|
||||
print(json.dumps(packages, indent=2))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1 +1 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
|
||||
@@ -1,14 +1,12 @@
|
||||
from dataclasses import dataclass
|
||||
import re
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from dbt.exceptions import RuntimeException
|
||||
|
||||
from typing import Dict, ClassVar, Any, Optional
|
||||
|
||||
from dbt.exceptions import RuntimeException
|
||||
|
||||
|
||||
@dataclass
|
||||
class Column(JsonSchemaMixin):
|
||||
class Column:
|
||||
TYPE_LABELS: ClassVar[Dict[str, str]] = {
|
||||
'STRING': 'TEXT',
|
||||
'TIMESTAMP': 'TIMESTAMP',
|
||||
|
||||
@@ -4,14 +4,15 @@ import os
|
||||
from multiprocessing.synchronize import RLock
|
||||
from threading import get_ident
|
||||
from typing import (
|
||||
Dict, Tuple, Hashable, Optional, ContextManager, List
|
||||
Dict, Tuple, Hashable, Optional, ContextManager, List, Union
|
||||
)
|
||||
|
||||
import agate
|
||||
|
||||
import dbt.exceptions
|
||||
from dbt.contracts.connection import (
|
||||
Connection, Identifier, ConnectionState, AdapterRequiredConfig, LazyHandle
|
||||
Connection, Identifier, ConnectionState,
|
||||
AdapterRequiredConfig, LazyHandle, AdapterResponse
|
||||
)
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.adapters.base.query_headers import (
|
||||
@@ -237,12 +238,6 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@classmethod
|
||||
def _rollback(cls, connection: Connection) -> None:
|
||||
"""Roll back the given connection."""
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In _rollback, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Tried to rollback transaction on connection '
|
||||
@@ -256,12 +251,6 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
|
||||
@classmethod
|
||||
def close(cls, connection: Connection) -> Connection:
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In close, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
# if the connection is in closed or init, there's nothing to do
|
||||
if connection.state in {ConnectionState.CLOSED, ConnectionState.INIT}:
|
||||
return connection
|
||||
@@ -290,7 +279,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@abc.abstractmethod
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[str, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL.
|
||||
|
||||
:param str sql: The sql to execute.
|
||||
@@ -298,7 +287,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[str, agate.Table]
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`execute` is not implemented for this adapter!'
|
||||
|
||||
@@ -16,9 +16,7 @@ from dbt.exceptions import (
|
||||
get_relation_returned_multiple_results,
|
||||
InternalException, NotImplementedException, RuntimeException,
|
||||
)
|
||||
from dbt import flags
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.adapters.protocol import (
|
||||
AdapterConfig,
|
||||
ConnectionManagerProtocol,
|
||||
@@ -28,14 +26,13 @@ from dbt.clients.jinja import MacroGenerator
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompileResultNode, CompiledSeedNode
|
||||
)
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.graph.manifest import Manifest, MacroManifest
|
||||
from dbt.contracts.graph.parsed import ParsedSeedNode
|
||||
from dbt.exceptions import warn_or_error
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.utils import filter_null_values, executor
|
||||
|
||||
from dbt.adapters.base.connections import Connection
|
||||
from dbt.adapters.base.connections import Connection, AdapterResponse
|
||||
from dbt.adapters.base.meta import AdapterMeta, available
|
||||
from dbt.adapters.base.relation import (
|
||||
ComponentName, BaseRelation, InformationSchema, SchemaSearchMap
|
||||
@@ -160,7 +157,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
self.config = config
|
||||
self.cache = RelationsCache()
|
||||
self.connections = self.ConnectionManager(config)
|
||||
self._macro_manifest_lazy: Optional[Manifest] = None
|
||||
self._macro_manifest_lazy: Optional[MacroManifest] = None
|
||||
|
||||
###
|
||||
# Methods that pass through to the connection manager
|
||||
@@ -180,6 +177,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def commit_if_has_connection(self) -> None:
|
||||
self.connections.commit_if_has_connection()
|
||||
|
||||
def debug_query(self) -> None:
|
||||
self.execute('select 1 as id')
|
||||
|
||||
def nice_connection_name(self) -> str:
|
||||
conn = self.connections.get_if_exists()
|
||||
if conn is None or conn.name is None:
|
||||
@@ -210,7 +210,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
@available.parse(lambda *a, **k: ('', empty_table()))
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[str, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL. This is a thin wrapper around
|
||||
ConnectionManager.execute.
|
||||
|
||||
@@ -219,7 +219,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[str, agate.Table]
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
return self.connections.execute(
|
||||
sql=sql,
|
||||
@@ -227,6 +227,21 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
fetch=fetch
|
||||
)
|
||||
|
||||
@available.parse(lambda *a, **k: ('', empty_table()))
|
||||
def get_partitions_metadata(
|
||||
self, table: str
|
||||
) -> Tuple[agate.Table]:
|
||||
"""Obtain partitions metadata for a BigQuery partitioned table.
|
||||
|
||||
:param str table_id: a partitioned table id, in standard SQL format.
|
||||
:return: a partition metadata tuple, as described in
|
||||
https://cloud.google.com/bigquery/docs/creating-partitioned-tables#getting_partition_metadata_using_meta_tables.
|
||||
:rtype: agate.Table
|
||||
"""
|
||||
return self.connections.get_partitions_metadata(
|
||||
table=table
|
||||
)
|
||||
|
||||
###
|
||||
# Methods that should never be overridden
|
||||
###
|
||||
@@ -241,22 +256,22 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
return cls.ConnectionManager.TYPE
|
||||
|
||||
@property
|
||||
def _macro_manifest(self) -> Manifest:
|
||||
def _macro_manifest(self) -> MacroManifest:
|
||||
if self._macro_manifest_lazy is None:
|
||||
return self.load_macro_manifest()
|
||||
return self._macro_manifest_lazy
|
||||
|
||||
def check_macro_manifest(self) -> Optional[Manifest]:
|
||||
def check_macro_manifest(self) -> Optional[MacroManifest]:
|
||||
"""Return the internal manifest (used for executing macros) if it's
|
||||
been initialized, otherwise return None.
|
||||
"""
|
||||
return self._macro_manifest_lazy
|
||||
|
||||
def load_macro_manifest(self) -> Manifest:
|
||||
def load_macro_manifest(self) -> MacroManifest:
|
||||
if self._macro_manifest_lazy is None:
|
||||
# avoid a circular import
|
||||
from dbt.parser.manifest import load_macro_manifest
|
||||
manifest = load_macro_manifest(
|
||||
from dbt.parser.manifest import ManifestLoader
|
||||
manifest = ManifestLoader.load_macros(
|
||||
self.config, self.connections.set_query_header
|
||||
)
|
||||
self._macro_manifest_lazy = manifest
|
||||
@@ -272,9 +287,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def _schema_is_cached(self, database: Optional[str], schema: str) -> bool:
|
||||
"""Check if the schema is cached, and by default logs if it is not."""
|
||||
|
||||
if flags.USE_CACHE is False:
|
||||
return False
|
||||
elif (database, schema) not in self.cache:
|
||||
if (database, schema) not in self.cache:
|
||||
logger.debug(
|
||||
'On "{}": cache miss for schema "{}.{}", this is inefficient'
|
||||
.format(self.nice_connection_name(), database, schema)
|
||||
@@ -292,8 +305,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
self.Relation.create_from(self.config, node).without_identifier()
|
||||
for node in manifest.nodes.values()
|
||||
if (
|
||||
node.resource_type in NodeType.executable() and
|
||||
not node.is_ephemeral_model
|
||||
node.is_relational and not node.is_ephemeral_model
|
||||
)
|
||||
}
|
||||
|
||||
@@ -308,7 +320,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
info_schema_name_map = SchemaSearchMap()
|
||||
nodes: Iterator[CompileResultNode] = chain(
|
||||
manifest.nodes.values(),
|
||||
[node for node in manifest.nodes.values() if (
|
||||
node.is_relational and not node.is_ephemeral_model
|
||||
)],
|
||||
manifest.sources.values(),
|
||||
)
|
||||
for node in nodes:
|
||||
@@ -324,9 +338,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""Populate the relations cache for the given schemas. Returns an
|
||||
iterable of the schemas populated, as strings.
|
||||
"""
|
||||
if not flags.USE_CACHE:
|
||||
return
|
||||
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
with executor(self.config) as tpe:
|
||||
futures: List[Future[List[BaseRelation]]] = []
|
||||
@@ -359,9 +370,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""Run a query that gets a populated cache of the relations in the
|
||||
database and set the cache on this adapter.
|
||||
"""
|
||||
if not flags.USE_CACHE:
|
||||
return
|
||||
|
||||
with self.cache.lock:
|
||||
if clear:
|
||||
self.cache.clear()
|
||||
@@ -375,8 +383,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise_compiler_error(
|
||||
'Attempted to cache a null relation for {}'.format(name)
|
||||
)
|
||||
if flags.USE_CACHE:
|
||||
self.cache.add(relation)
|
||||
self.cache.add(relation)
|
||||
# so jinja doesn't render things
|
||||
return ''
|
||||
|
||||
@@ -390,8 +397,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise_compiler_error(
|
||||
'Attempted to drop a null relation for {}'.format(name)
|
||||
)
|
||||
if flags.USE_CACHE:
|
||||
self.cache.drop(relation)
|
||||
self.cache.drop(relation)
|
||||
return ''
|
||||
|
||||
@available
|
||||
@@ -412,8 +418,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
.format(src_name, dst_name, name)
|
||||
)
|
||||
|
||||
if flags.USE_CACHE:
|
||||
self.cache.rename(from_relation, to_relation)
|
||||
self.cache.rename(from_relation, to_relation)
|
||||
return ''
|
||||
|
||||
###
|
||||
@@ -495,7 +500,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def get_columns_in_relation(
|
||||
self, relation: BaseRelation
|
||||
) -> List[BaseColumn]:
|
||||
"""Get a list of the columns in the given Relation."""
|
||||
"""Get a list of the columns in the given Relation. """
|
||||
raise NotImplementedException(
|
||||
'`get_columns_in_relation` is not implemented for this adapter!'
|
||||
)
|
||||
@@ -791,12 +796,11 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def quote_seed_column(
|
||||
self, column: str, quote_config: Optional[bool]
|
||||
) -> str:
|
||||
# this is the default for now
|
||||
quote_columns: bool = False
|
||||
quote_columns: bool = True
|
||||
if isinstance(quote_config, bool):
|
||||
quote_columns = quote_config
|
||||
elif quote_config is None:
|
||||
deprecations.warn('column-quoting-unset')
|
||||
pass
|
||||
else:
|
||||
raise_compiler_error(
|
||||
f'The seed configuration value of "quote_columns" has an '
|
||||
@@ -928,7 +932,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
project: Optional[str] = None,
|
||||
context_override: Optional[Dict[str, Any]] = None,
|
||||
kwargs: Dict[str, Any] = None,
|
||||
release: bool = False,
|
||||
text_only_columns: Optional[Iterable[str]] = None,
|
||||
) -> agate.Table:
|
||||
"""Look macro_name up in the manifest and execute its results.
|
||||
@@ -942,10 +945,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
execution context.
|
||||
:param kwargs: An optional dict of keyword args used to pass to the
|
||||
macro.
|
||||
:param release: Ignored.
|
||||
"""
|
||||
if release is not False:
|
||||
deprecations.warn('execute-macro-release')
|
||||
|
||||
if kwargs is None:
|
||||
kwargs = {}
|
||||
if context_override is None:
|
||||
|
||||
@@ -21,8 +21,8 @@ Self = TypeVar('Self', bound='BaseRelation')
|
||||
|
||||
@dataclass(frozen=True, eq=False, repr=False)
|
||||
class BaseRelation(FakeAPIObject, Hashable):
|
||||
type: Optional[RelationType]
|
||||
path: Path
|
||||
type: Optional[RelationType] = None
|
||||
quote_character: str = '"'
|
||||
include_policy: Policy = Policy()
|
||||
quote_policy: Policy = Policy()
|
||||
@@ -45,7 +45,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
def __eq__(self, other):
|
||||
if not isinstance(other, self.__class__):
|
||||
return False
|
||||
return self.to_dict() == other.to_dict()
|
||||
return self.to_dict(omit_none=True) == other.to_dict(omit_none=True)
|
||||
|
||||
@classmethod
|
||||
def get_default_quote_policy(cls) -> Policy:
|
||||
@@ -185,10 +185,10 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
def create_from_source(
|
||||
cls: Type[Self], source: ParsedSourceDefinition, **kwargs: Any
|
||||
) -> Self:
|
||||
source_quoting = source.quoting.to_dict()
|
||||
source_quoting = source.quoting.to_dict(omit_none=True)
|
||||
source_quoting.pop('column', None)
|
||||
quote_policy = deep_merge(
|
||||
cls.get_default_quote_policy().to_dict(),
|
||||
cls.get_default_quote_policy().to_dict(omit_none=True),
|
||||
source_quoting,
|
||||
kwargs.get('quote_policy', {}),
|
||||
)
|
||||
@@ -203,7 +203,7 @@ class BaseRelation(FakeAPIObject, Hashable):
|
||||
|
||||
@staticmethod
|
||||
def add_ephemeral_prefix(name: str):
|
||||
return f'__dbt__CTE__{name}'
|
||||
return f'__dbt__cte__{name}'
|
||||
|
||||
@classmethod
|
||||
def create_ephemeral_from_node(
|
||||
@@ -433,13 +433,14 @@ class SchemaSearchMap(Dict[InformationSchema, Set[Optional[str]]]):
|
||||
for schema in schemas:
|
||||
yield information_schema_name, schema
|
||||
|
||||
def flatten(self):
|
||||
def flatten(self, allow_multiple_databases: bool = False):
|
||||
new = self.__class__()
|
||||
|
||||
# make sure we don't have duplicates
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
# make sure we don't have multiple databases if allow_multiple_databases is set to False
|
||||
if not allow_multiple_databases:
|
||||
seen = {r.database.lower() for r in self if r.database}
|
||||
if len(seen) > 1:
|
||||
dbt.exceptions.raise_compiler_error(str(seen))
|
||||
|
||||
for information_schema_name, schema in self.search():
|
||||
path = {
|
||||
|
||||
@@ -7,7 +7,9 @@ from typing_extensions import Protocol
|
||||
|
||||
import agate
|
||||
|
||||
from dbt.contracts.connection import Connection, AdapterRequiredConfig
|
||||
from dbt.contracts.connection import (
|
||||
Connection, AdapterRequiredConfig, AdapterResponse
|
||||
)
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledNode, ManifestNode, NonSourceCompiledNode
|
||||
)
|
||||
@@ -154,7 +156,7 @@ class AdapterProtocol(
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[str, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
...
|
||||
|
||||
def get_compiler(self) -> Compiler_T:
|
||||
|
||||
@@ -1,15 +1,16 @@
|
||||
import abc
|
||||
import time
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict, Union
|
||||
|
||||
import agate
|
||||
|
||||
import dbt.clients.agate_helper
|
||||
import dbt.exceptions
|
||||
from dbt.adapters.base import BaseConnectionManager
|
||||
from dbt.contracts.connection import Connection, ConnectionState
|
||||
from dbt.contracts.connection import (
|
||||
Connection, ConnectionState, AdapterResponse
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt import flags
|
||||
|
||||
|
||||
class SQLConnectionManager(BaseConnectionManager):
|
||||
@@ -18,7 +19,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
Methods to implement:
|
||||
- exception_handler
|
||||
- cancel
|
||||
- get_status
|
||||
- get_response
|
||||
- open
|
||||
"""
|
||||
@abc.abstractmethod
|
||||
@@ -76,20 +77,19 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
cursor = connection.handle.cursor()
|
||||
cursor.execute(sql, bindings)
|
||||
|
||||
logger.debug(
|
||||
"SQL status: {status} in {elapsed:0.2f} seconds",
|
||||
status=self.get_status(cursor),
|
||||
status=self.get_response(cursor),
|
||||
elapsed=(time.time() - pre)
|
||||
)
|
||||
|
||||
return connection, cursor
|
||||
|
||||
@abc.abstractclassmethod
|
||||
def get_status(cls, cursor: Any) -> str:
|
||||
def get_response(cls, cursor: Any) -> Union[AdapterResponse, str]:
|
||||
"""Get the status of the cursor."""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'`get_status` is not implemented for this adapter!'
|
||||
'`get_response` is not implemented for this adapter!'
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -98,7 +98,14 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
column_names: Iterable[str],
|
||||
rows: Iterable[Any]
|
||||
) -> List[Dict[str, Any]]:
|
||||
|
||||
unique_col_names = dict()
|
||||
for idx in range(len(column_names)):
|
||||
col_name = column_names[idx]
|
||||
if col_name in unique_col_names:
|
||||
unique_col_names[col_name] += 1
|
||||
column_names[idx] = f'{col_name}_{unique_col_names[col_name]}'
|
||||
else:
|
||||
unique_col_names[column_names[idx]] = 1
|
||||
return [dict(zip(column_names, row)) for row in rows]
|
||||
|
||||
@classmethod
|
||||
@@ -118,15 +125,15 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[str, agate.Table]:
|
||||
) -> Tuple[Union[AdapterResponse, str], agate.Table]:
|
||||
sql = self._add_query_comment(sql)
|
||||
_, cursor = self.add_query(sql, auto_begin)
|
||||
status = self.get_status(cursor)
|
||||
response = self.get_response(cursor)
|
||||
if fetch:
|
||||
table = self.get_result_from_cursor(cursor)
|
||||
else:
|
||||
table = dbt.clients.agate_helper.empty_table()
|
||||
return status, table
|
||||
return response, table
|
||||
|
||||
def add_begin_query(self):
|
||||
return self.add_query('BEGIN', auto_begin=False)
|
||||
@@ -136,13 +143,6 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def begin(self):
|
||||
connection = self.get_thread_connection()
|
||||
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In begin, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is True:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to begin a new transaction on connection "{}", but '
|
||||
@@ -155,12 +155,6 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def commit(self):
|
||||
connection = self.get_thread_connection()
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In commit, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to commit transaction on connection "{}", but '
|
||||
|
||||
@@ -35,7 +35,11 @@ class ISODateTime(agate.data_types.DateTime):
|
||||
)
|
||||
|
||||
|
||||
def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
def build_type_tester(
|
||||
text_columns: Iterable[str],
|
||||
string_null_values: Optional[Iterable[str]] = ('null', '')
|
||||
) -> agate.TypeTester:
|
||||
|
||||
types = [
|
||||
agate.data_types.Number(null_values=('null', '')),
|
||||
agate.data_types.Date(null_values=('null', ''),
|
||||
@@ -46,10 +50,10 @@ def build_type_tester(text_columns: Iterable[str]) -> agate.TypeTester:
|
||||
agate.data_types.Boolean(true_values=('true',),
|
||||
false_values=('false',),
|
||||
null_values=('null', '')),
|
||||
agate.data_types.Text(null_values=('null', ''))
|
||||
agate.data_types.Text(null_values=string_null_values)
|
||||
]
|
||||
force = {
|
||||
k: agate.data_types.Text(null_values=('null', ''))
|
||||
k: agate.data_types.Text(null_values=string_null_values)
|
||||
for k in text_columns
|
||||
}
|
||||
return agate.TypeTester(force=force, types=types)
|
||||
@@ -66,7 +70,13 @@ def table_from_rows(
|
||||
if text_only_columns is None:
|
||||
column_types = DEFAULT_TYPE_TESTER
|
||||
else:
|
||||
column_types = build_type_tester(text_only_columns)
|
||||
# If text_only_columns are present, prevent coercing empty string or
|
||||
# literal 'null' strings to a None representation.
|
||||
column_types = build_type_tester(
|
||||
text_only_columns,
|
||||
string_null_values=()
|
||||
)
|
||||
|
||||
return agate.Table(rows, column_names, column_types=column_types)
|
||||
|
||||
|
||||
@@ -86,19 +96,34 @@ def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
|
||||
|
||||
def table_from_data_flat(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
"""
|
||||
Convert a list of dictionaries into an Agate table. This method does not
|
||||
coerce string values into more specific types (eg. '005' will not be
|
||||
coerced to '5'). Additionally, this method does not coerce values to
|
||||
None (eg. '' or 'null' will retain their string literal representations).
|
||||
"""
|
||||
|
||||
rows = []
|
||||
text_only_columns = set()
|
||||
for _row in data:
|
||||
row = []
|
||||
for value in list(_row.values()):
|
||||
for col_name in column_names:
|
||||
value = _row[col_name]
|
||||
if isinstance(value, (dict, list, tuple)):
|
||||
row.append(json.dumps(value, cls=dbt.utils.JSONEncoder))
|
||||
else:
|
||||
row.append(value)
|
||||
# Represent container types as json strings
|
||||
value = json.dumps(value, cls=dbt.utils.JSONEncoder)
|
||||
text_only_columns.add(col_name)
|
||||
elif isinstance(value, str):
|
||||
text_only_columns.add(col_name)
|
||||
row.append(value)
|
||||
|
||||
rows.append(row)
|
||||
|
||||
return table_from_rows(rows=rows, column_names=column_names)
|
||||
return table_from_rows(
|
||||
rows=rows,
|
||||
column_names=column_names,
|
||||
text_only_columns=text_only_columns
|
||||
)
|
||||
|
||||
|
||||
def empty_table():
|
||||
|
||||
@@ -1,26 +0,0 @@
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from dbt.clients.system import run_cmd
|
||||
|
||||
NOT_INSTALLED_MSG = """
|
||||
dbt requires the gcloud SDK to be installed to authenticate with BigQuery.
|
||||
Please download and install the SDK, or use a Service Account instead.
|
||||
|
||||
https://cloud.google.com/sdk/
|
||||
"""
|
||||
|
||||
|
||||
def gcloud_installed():
|
||||
try:
|
||||
run_cmd('.', ['gcloud', '--version'])
|
||||
return True
|
||||
except OSError as e:
|
||||
logger.debug(e)
|
||||
return False
|
||||
|
||||
|
||||
def setup_default_credentials():
|
||||
if gcloud_installed():
|
||||
run_cmd('.', ["gcloud", "auth", "application-default", "login"])
|
||||
else:
|
||||
raise dbt.exceptions.RuntimeException(NOT_INSTALLED_MSG)
|
||||
@@ -4,21 +4,43 @@ import os.path
|
||||
from dbt.clients.system import run_cmd, rmdir
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from packaging import version
|
||||
|
||||
|
||||
def clone(repo, cwd, dirname=None, remove_git_dir=False, branch=None):
|
||||
def _is_commit(revision: str) -> bool:
|
||||
# match SHA-1 git commit
|
||||
return bool(re.match(r"\b[0-9a-f]{40}\b", revision))
|
||||
|
||||
|
||||
def clone(repo, cwd, dirname=None, remove_git_dir=False, revision=None, subdirectory=None):
|
||||
has_revision = revision is not None
|
||||
is_commit = _is_commit(revision or "")
|
||||
|
||||
clone_cmd = ['git', 'clone', '--depth', '1']
|
||||
if subdirectory:
|
||||
logger.debug(' Subdirectory specified: {}, using sparse checkout.'.format(subdirectory))
|
||||
out, _ = run_cmd(cwd, ['git', '--version'], env={'LC_ALL': 'C'})
|
||||
git_version = version.parse(re.search(r"\d+\.\d+\.\d+", out.decode("utf-8")).group(0))
|
||||
if not git_version >= version.parse("2.25.0"):
|
||||
# 2.25.0 introduces --sparse
|
||||
raise RuntimeError(
|
||||
"Please update your git version to pull a dbt package "
|
||||
"from a subdirectory: your version is {}, >= 2.25.0 needed".format(git_version)
|
||||
)
|
||||
clone_cmd.extend(['--filter=blob:none', '--sparse'])
|
||||
|
||||
if branch is not None:
|
||||
clone_cmd.extend(['--branch', branch])
|
||||
if has_revision and not is_commit:
|
||||
clone_cmd.extend(['--branch', revision])
|
||||
|
||||
clone_cmd.append(repo)
|
||||
|
||||
if dirname is not None:
|
||||
clone_cmd.append(dirname)
|
||||
|
||||
result = run_cmd(cwd, clone_cmd, env={'LC_ALL': 'C'})
|
||||
|
||||
if subdirectory:
|
||||
run_cmd(os.path.join(cwd, dirname or ''), ['git', 'sparse-checkout', 'set', subdirectory])
|
||||
|
||||
if remove_git_dir:
|
||||
rmdir(os.path.join(dirname, '.git'))
|
||||
|
||||
@@ -31,33 +53,38 @@ def list_tags(cwd):
|
||||
return tags
|
||||
|
||||
|
||||
def _checkout(cwd, repo, branch):
|
||||
logger.debug(' Checking out branch {}.'.format(branch))
|
||||
def _checkout(cwd, repo, revision):
|
||||
logger.debug(' Checking out revision {}.'.format(revision))
|
||||
|
||||
run_cmd(cwd, ['git', 'remote', 'set-branches', 'origin', branch])
|
||||
run_cmd(cwd, ['git', 'fetch', '--tags', '--depth', '1', 'origin', branch])
|
||||
fetch_cmd = ["git", "fetch", "origin", "--depth", "1"]
|
||||
|
||||
tags = list_tags(cwd)
|
||||
|
||||
# Prefer tags to branches if one exists
|
||||
if branch in tags:
|
||||
spec = 'tags/{}'.format(branch)
|
||||
if _is_commit(revision):
|
||||
run_cmd(cwd, fetch_cmd + [revision])
|
||||
else:
|
||||
spec = 'origin/{}'.format(branch)
|
||||
run_cmd(cwd, ['git', 'remote', 'set-branches', 'origin', revision])
|
||||
run_cmd(cwd, fetch_cmd + ["--tags", revision])
|
||||
|
||||
if _is_commit(revision):
|
||||
spec = revision
|
||||
# Prefer tags to branches if one exists
|
||||
elif revision in list_tags(cwd):
|
||||
spec = 'tags/{}'.format(revision)
|
||||
else:
|
||||
spec = 'origin/{}'.format(revision)
|
||||
|
||||
out, err = run_cmd(cwd, ['git', 'reset', '--hard', spec],
|
||||
env={'LC_ALL': 'C'})
|
||||
return out, err
|
||||
|
||||
|
||||
def checkout(cwd, repo, branch=None):
|
||||
if branch is None:
|
||||
branch = 'master'
|
||||
def checkout(cwd, repo, revision=None):
|
||||
if revision is None:
|
||||
revision = 'HEAD'
|
||||
try:
|
||||
return _checkout(cwd, repo, branch)
|
||||
return _checkout(cwd, repo, revision)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
stderr = exc.stderr.decode('utf-8').strip()
|
||||
dbt.exceptions.bad_package_spec(repo, branch, stderr)
|
||||
dbt.exceptions.bad_package_spec(repo, revision, stderr)
|
||||
|
||||
|
||||
def get_current_sha(cwd):
|
||||
@@ -71,11 +98,16 @@ def remove_remote(cwd):
|
||||
|
||||
|
||||
def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
branch=None):
|
||||
revision=None, subdirectory=None):
|
||||
exists = None
|
||||
try:
|
||||
_, err = clone(repo, cwd, dirname=dirname,
|
||||
remove_git_dir=remove_git_dir)
|
||||
_, err = clone(
|
||||
repo,
|
||||
cwd,
|
||||
dirname=dirname,
|
||||
remove_git_dir=remove_git_dir,
|
||||
subdirectory=subdirectory,
|
||||
)
|
||||
except dbt.exceptions.CommandResultError as exc:
|
||||
err = exc.stderr.decode('utf-8')
|
||||
exists = re.match("fatal: destination path '(.+)' already exists", err)
|
||||
@@ -97,7 +129,7 @@ def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
logger.debug('Pulling new dependency {}.', directory)
|
||||
full_path = os.path.join(cwd, directory)
|
||||
start_sha = get_current_sha(full_path)
|
||||
checkout(full_path, repo, branch)
|
||||
checkout(full_path, repo, revision)
|
||||
end_sha = get_current_sha(full_path)
|
||||
if exists:
|
||||
if start_sha == end_sha:
|
||||
@@ -107,4 +139,4 @@ def clone_and_checkout(repo, cwd, dirname=None, remove_git_dir=False,
|
||||
start_sha[:7], end_sha[:7])
|
||||
else:
|
||||
logger.debug(' Checked out at {}.', end_sha[:7])
|
||||
return directory
|
||||
return os.path.join(directory, subdirectory or '')
|
||||
|
||||
@@ -21,15 +21,16 @@ import jinja2.sandbox
|
||||
|
||||
from dbt.utils import (
|
||||
get_dbt_macro_name, get_docs_macro_name, get_materialization_macro_name,
|
||||
deep_map
|
||||
get_test_macro_name, deep_map
|
||||
)
|
||||
|
||||
from dbt.clients._jinja_blocks import BlockIterator, BlockData, BlockTag
|
||||
from dbt.contracts.graph.compiled import CompiledSchemaTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedSchemaTestNode
|
||||
from dbt.contracts.graph.compiled import CompiledGenericTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedGenericTestNode
|
||||
from dbt.exceptions import (
|
||||
InternalException, raise_compiler_error, CompilationException,
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException,
|
||||
UndefinedMacroException
|
||||
)
|
||||
from dbt import flags
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
@@ -231,6 +232,7 @@ class BaseMacroGenerator:
|
||||
template = self.get_template()
|
||||
# make the module. previously we set both vars and local, but that's
|
||||
# redundant: They both end up in the same place
|
||||
# make_module is in jinja2.environment. It returns a TemplateModule
|
||||
module = template.make_module(vars=self.context, shared=False)
|
||||
macro = module.__dict__[get_dbt_macro_name(name)]
|
||||
module.__dict__.update(self.context)
|
||||
@@ -244,6 +246,7 @@ class BaseMacroGenerator:
|
||||
raise_compiler_error(str(e))
|
||||
|
||||
def call_macro(self, *args, **kwargs):
|
||||
# called from __call__ methods
|
||||
if self.context is None:
|
||||
raise InternalException(
|
||||
'Context is still None in call_macro!'
|
||||
@@ -306,8 +309,10 @@ class MacroGenerator(BaseMacroGenerator):
|
||||
e.stack.append(self.macro)
|
||||
raise e
|
||||
|
||||
# This adds the macro's unique id to the node's 'depends_on'
|
||||
@contextmanager
|
||||
def track_call(self):
|
||||
# This is only called from __call__
|
||||
if self.stack is None or self.node is None:
|
||||
yield
|
||||
else:
|
||||
@@ -322,6 +327,7 @@ class MacroGenerator(BaseMacroGenerator):
|
||||
finally:
|
||||
self.stack.pop(unique_id)
|
||||
|
||||
# this makes MacroGenerator objects callable like functions
|
||||
def __call__(self, *args, **kwargs):
|
||||
with self.track_call():
|
||||
return self.call_macro(*args, **kwargs)
|
||||
@@ -403,6 +409,20 @@ class DocumentationExtension(jinja2.ext.Extension):
|
||||
return node
|
||||
|
||||
|
||||
class TestExtension(jinja2.ext.Extension):
|
||||
tags = ['test']
|
||||
|
||||
def parse(self, parser):
|
||||
node = jinja2.nodes.Macro(lineno=next(parser.stream).lineno)
|
||||
test_name = parser.parse_assign_target(name_only=True).name
|
||||
|
||||
parser.parse_signature(node)
|
||||
node.name = get_test_macro_name(test_name)
|
||||
node.body = parser.parse_statements(('name:endtest',),
|
||||
drop_needle=True)
|
||||
return node
|
||||
|
||||
|
||||
def _is_dunder_name(name):
|
||||
return name.startswith('__') and name.endswith('__')
|
||||
|
||||
@@ -474,6 +494,7 @@ def get_environment(
|
||||
|
||||
args['extensions'].append(MaterializationExtension)
|
||||
args['extensions'].append(DocumentationExtension)
|
||||
args['extensions'].append(TestExtension)
|
||||
|
||||
env_cls: Type[jinja2.Environment]
|
||||
text_filter: Type
|
||||
@@ -498,7 +519,7 @@ def catch_jinja(node=None) -> Iterator[None]:
|
||||
e.translated = False
|
||||
raise CompilationException(str(e), node) from e
|
||||
except jinja2.exceptions.UndefinedError as e:
|
||||
raise CompilationException(str(e), node) from e
|
||||
raise UndefinedMacroException(str(e), node) from e
|
||||
except CompilationException as exc:
|
||||
exc.add_node(node)
|
||||
raise
|
||||
@@ -606,12 +627,12 @@ def extract_toplevel_blocks(
|
||||
)
|
||||
|
||||
|
||||
SCHEMA_TEST_KWARGS_NAME = '_dbt_schema_test_kwargs'
|
||||
GENERIC_TEST_KWARGS_NAME = '_dbt_generic_test_kwargs'
|
||||
|
||||
|
||||
def add_rendered_test_kwargs(
|
||||
context: Dict[str, Any],
|
||||
node: Union[ParsedSchemaTestNode, CompiledSchemaTestNode],
|
||||
node: Union[ParsedGenericTestNode, CompiledGenericTestNode],
|
||||
capture_macros: bool = False,
|
||||
) -> None:
|
||||
"""Render each of the test kwargs in the given context using the native
|
||||
@@ -641,4 +662,4 @@ def add_rendered_test_kwargs(
|
||||
return value
|
||||
|
||||
kwargs = deep_map(_convert_function, node.test_metadata.kwargs)
|
||||
context[SCHEMA_TEST_KWARGS_NAME] = kwargs
|
||||
context[GENERIC_TEST_KWARGS_NAME] = kwargs
|
||||
|
||||
154
core/dbt/clients/jinja_static.py
Normal file
154
core/dbt/clients/jinja_static.py
Normal file
@@ -0,0 +1,154 @@
|
||||
import jinja2
|
||||
from dbt.clients.jinja import get_environment
|
||||
from dbt.exceptions import raise_compiler_error
|
||||
|
||||
|
||||
def statically_extract_macro_calls(string, ctx, db_wrapper=None):
|
||||
# set 'capture_macros' to capture undefined
|
||||
env = get_environment(None, capture_macros=True)
|
||||
parsed = env.parse(string)
|
||||
|
||||
standard_calls = ['source', 'ref', 'config']
|
||||
possible_macro_calls = []
|
||||
for func_call in parsed.find_all(jinja2.nodes.Call):
|
||||
func_name = None
|
||||
if hasattr(func_call, 'node') and hasattr(func_call.node, 'name'):
|
||||
func_name = func_call.node.name
|
||||
else:
|
||||
# func_call for dbt_utils.current_timestamp macro
|
||||
# Call(
|
||||
# node=Getattr(
|
||||
# node=Name(
|
||||
# name='dbt_utils',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# attr='current_timestamp',
|
||||
# ctx='load
|
||||
# ),
|
||||
# args=[],
|
||||
# kwargs=[],
|
||||
# dyn_args=None,
|
||||
# dyn_kwargs=None
|
||||
# )
|
||||
if (hasattr(func_call, 'node') and
|
||||
hasattr(func_call.node, 'node') and
|
||||
type(func_call.node.node).__name__ == 'Name' and
|
||||
hasattr(func_call.node, 'attr')):
|
||||
package_name = func_call.node.node.name
|
||||
macro_name = func_call.node.attr
|
||||
if package_name == 'adapter':
|
||||
if macro_name == 'dispatch':
|
||||
ad_macro_calls = statically_parse_adapter_dispatch(
|
||||
func_call, ctx, db_wrapper)
|
||||
possible_macro_calls.extend(ad_macro_calls)
|
||||
else:
|
||||
# This skips calls such as adapter.parse_index
|
||||
continue
|
||||
else:
|
||||
func_name = f'{package_name}.{macro_name}'
|
||||
else:
|
||||
continue
|
||||
if not func_name:
|
||||
continue
|
||||
if func_name in standard_calls:
|
||||
continue
|
||||
elif ctx.get(func_name):
|
||||
continue
|
||||
else:
|
||||
if func_name not in possible_macro_calls:
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
return possible_macro_calls
|
||||
|
||||
|
||||
# Call(
|
||||
# node=Getattr(
|
||||
# node=Name(
|
||||
# name='adapter',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# attr='dispatch',
|
||||
# ctx='load'
|
||||
# ),
|
||||
# args=[
|
||||
# Const(value='test_pkg_and_dispatch')
|
||||
# ],
|
||||
# kwargs=[
|
||||
# Keyword(
|
||||
# key='packages',
|
||||
# value=Call(node=Getattr(node=Name(name='local_utils', ctx='load'),
|
||||
# attr='_get_utils_namespaces', ctx='load'), args=[], kwargs=[],
|
||||
# dyn_args=None, dyn_kwargs=None)
|
||||
# )
|
||||
# ],
|
||||
# dyn_args=None,
|
||||
# dyn_kwargs=None
|
||||
# )
|
||||
def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
possible_macro_calls = []
|
||||
# This captures an adapter.dispatch('<macro_name>') call.
|
||||
|
||||
func_name = None
|
||||
# macro_name positional argument
|
||||
if len(func_call.args) > 0:
|
||||
func_name = func_call.args[0].value
|
||||
if func_name:
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
# packages positional argument
|
||||
macro_namespace = None
|
||||
packages_arg = None
|
||||
packages_arg_type = None
|
||||
|
||||
if len(func_call.args) > 1:
|
||||
packages_arg = func_call.args[1]
|
||||
# This can be a List or a Call
|
||||
packages_arg_type = type(func_call.args[1]).__name__
|
||||
|
||||
# keyword arguments
|
||||
if func_call.kwargs:
|
||||
for kwarg in func_call.kwargs:
|
||||
if kwarg.key == 'macro_name':
|
||||
# This will remain to enable static resolution
|
||||
if type(kwarg.value).__name__ == 'Const':
|
||||
func_name = kwarg.value.value
|
||||
possible_macro_calls.append(func_name)
|
||||
else:
|
||||
raise_compiler_error(f"The macro_name parameter ({kwarg.value.value}) "
|
||||
"to adapter.dispatch was not a string")
|
||||
elif kwarg.key == 'macro_namespace':
|
||||
# This will remain to enable static resolution
|
||||
kwarg_type = type(kwarg.value).__name__
|
||||
if kwarg_type == 'Const':
|
||||
macro_namespace = kwarg.value.value
|
||||
else:
|
||||
raise_compiler_error("The macro_namespace parameter to adapter.dispatch "
|
||||
f"is a {kwarg_type}, not a string")
|
||||
|
||||
# positional arguments
|
||||
if packages_arg:
|
||||
if packages_arg_type == 'List':
|
||||
# This will remain to enable static resolution
|
||||
packages = []
|
||||
for item in packages_arg.items:
|
||||
packages.append(item.value)
|
||||
elif packages_arg_type == 'Const':
|
||||
# This will remain to enable static resolution
|
||||
macro_namespace = packages_arg.value
|
||||
|
||||
if db_wrapper:
|
||||
macro = db_wrapper.dispatch(
|
||||
func_name,
|
||||
macro_namespace=macro_namespace
|
||||
).macro
|
||||
func_name = f'{macro.package_name}.{macro.name}'
|
||||
possible_macro_calls.append(func_name)
|
||||
else: # this is only for test/unit/test_macro_calls.py
|
||||
if macro_namespace:
|
||||
packages = [macro_namespace]
|
||||
else:
|
||||
packages = []
|
||||
for package_name in packages:
|
||||
possible_macro_calls.append(f'{package_name}.{func_name}')
|
||||
|
||||
return possible_macro_calls
|
||||
@@ -1,10 +1,9 @@
|
||||
from functools import wraps
|
||||
import functools
|
||||
import requests
|
||||
from dbt.exceptions import RegistryException
|
||||
from dbt.utils import memoized
|
||||
from dbt.utils import memoized, _connection_exception_retry as connection_exception_retry
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt import deprecations
|
||||
import os
|
||||
import time
|
||||
|
||||
if os.getenv('DBT_PACKAGE_HUB_URL'):
|
||||
DEFAULT_REGISTRY_BASE_URL = os.getenv('DBT_PACKAGE_HUB_URL')
|
||||
@@ -19,31 +18,15 @@ def _get_url(url, registry_base_url=None):
|
||||
return '{}{}'.format(registry_base_url, url)
|
||||
|
||||
|
||||
def _wrap_exceptions(fn):
|
||||
@wraps(fn)
|
||||
def wrapper(*args, **kwargs):
|
||||
max_attempts = 5
|
||||
attempt = 0
|
||||
while True:
|
||||
attempt += 1
|
||||
try:
|
||||
return fn(*args, **kwargs)
|
||||
except requests.exceptions.ConnectionError as exc:
|
||||
if attempt < max_attempts:
|
||||
time.sleep(1)
|
||||
continue
|
||||
|
||||
raise RegistryException(
|
||||
'Unable to connect to registry hub'
|
||||
) from exc
|
||||
return wrapper
|
||||
def _get_with_retries(path, registry_base_url=None):
|
||||
get_fn = functools.partial(_get, path, registry_base_url)
|
||||
return connection_exception_retry(get_fn, 5)
|
||||
|
||||
|
||||
@_wrap_exceptions
|
||||
def _get(path, registry_base_url=None):
|
||||
url = _get_url(path, registry_base_url)
|
||||
logger.debug('Making package registry request: GET {}'.format(url))
|
||||
resp = requests.get(url)
|
||||
resp = requests.get(url, timeout=30)
|
||||
logger.debug('Response from registry: GET {} {}'.format(url,
|
||||
resp.status_code))
|
||||
resp.raise_for_status()
|
||||
@@ -51,22 +34,44 @@ def _get(path, registry_base_url=None):
|
||||
|
||||
|
||||
def index(registry_base_url=None):
|
||||
return _get('api/v1/index.json', registry_base_url)
|
||||
return _get_with_retries('api/v1/index.json', registry_base_url)
|
||||
|
||||
|
||||
index_cached = memoized(index)
|
||||
|
||||
|
||||
def packages(registry_base_url=None):
|
||||
return _get('api/v1/packages.json', registry_base_url)
|
||||
return _get_with_retries('api/v1/packages.json', registry_base_url)
|
||||
|
||||
|
||||
def package(name, registry_base_url=None):
|
||||
return _get('api/v1/{}.json'.format(name), registry_base_url)
|
||||
response = _get_with_retries('api/v1/{}.json'.format(name), registry_base_url)
|
||||
|
||||
# Either redirectnamespace or redirectname in the JSON response indicate a redirect
|
||||
# redirectnamespace redirects based on package ownership
|
||||
# redirectname redirects based on package name
|
||||
# Both can be present at the same time, or neither. Fails gracefully to old name
|
||||
|
||||
if ('redirectnamespace' in response) or ('redirectname' in response):
|
||||
|
||||
if ('redirectnamespace' in response) and response['redirectnamespace'] is not None:
|
||||
use_namespace = response['redirectnamespace']
|
||||
else:
|
||||
use_namespace = response['namespace']
|
||||
|
||||
if ('redirectname' in response) and response['redirectname'] is not None:
|
||||
use_name = response['redirectname']
|
||||
else:
|
||||
use_name = response['name']
|
||||
|
||||
new_nwo = use_namespace + "/" + use_name
|
||||
deprecations.warn('package-redirect', old_name=name, new_name=new_nwo)
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def package_version(name, version, registry_base_url=None):
|
||||
return _get('api/v1/{}/{}.json'.format(name, version), registry_base_url)
|
||||
return _get_with_retries('api/v1/{}/{}.json'.format(name, version), registry_base_url)
|
||||
|
||||
|
||||
def get_available_versions(name):
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import errno
|
||||
import functools
|
||||
import fnmatch
|
||||
import json
|
||||
import os
|
||||
@@ -15,9 +16,8 @@ from typing import (
|
||||
)
|
||||
|
||||
import dbt.exceptions
|
||||
import dbt.utils
|
||||
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.utils import _connection_exception_retry as connection_exception_retry
|
||||
|
||||
if sys.platform == 'win32':
|
||||
from ctypes import WinDLL, c_bool
|
||||
@@ -30,7 +30,7 @@ def find_matching(
|
||||
root_path: str,
|
||||
relative_paths_to_search: List[str],
|
||||
file_pattern: str,
|
||||
) -> List[Dict[str, str]]:
|
||||
) -> List[Dict[str, Any]]:
|
||||
"""
|
||||
Given an absolute `root_path`, a list of relative paths to that
|
||||
absolute root path (`relative_paths_to_search`), and a `file_pattern`
|
||||
@@ -61,11 +61,19 @@ def find_matching(
|
||||
relative_path = os.path.relpath(
|
||||
absolute_path, absolute_path_to_search
|
||||
)
|
||||
modification_time = 0.0
|
||||
try:
|
||||
modification_time = os.path.getmtime(absolute_path)
|
||||
except OSError:
|
||||
logger.exception(
|
||||
f"Error retrieving modification time for file {absolute_path}"
|
||||
)
|
||||
if reobj.match(local_file):
|
||||
matching.append({
|
||||
'searched_path': relative_path_to_search,
|
||||
'absolute_path': absolute_path,
|
||||
'relative_path': relative_path,
|
||||
'modification_time': modification_time,
|
||||
})
|
||||
|
||||
return matching
|
||||
@@ -416,6 +424,9 @@ def run_cmd(
|
||||
full_env.update(env)
|
||||
|
||||
try:
|
||||
exe_pth = shutil.which(cmd[0])
|
||||
if exe_pth:
|
||||
cmd = [os.path.abspath(exe_pth)] + list(cmd[1:])
|
||||
proc = subprocess.Popen(
|
||||
cmd,
|
||||
cwd=cwd,
|
||||
@@ -438,7 +449,16 @@ def run_cmd(
|
||||
return out, err
|
||||
|
||||
|
||||
def download(url: str, path: str, timeout: Union[float, tuple] = None) -> None:
|
||||
def download_with_retries(
|
||||
url: str, path: str, timeout: Optional[Union[float, tuple]] = None
|
||||
) -> None:
|
||||
download_fn = functools.partial(download, url, path, timeout)
|
||||
connection_exception_retry(download_fn, 5)
|
||||
|
||||
|
||||
def download(
|
||||
url: str, path: str, timeout: Optional[Union[float, tuple]] = None
|
||||
) -> None:
|
||||
path = convert_path(path)
|
||||
connection_timeout = timeout or float(os.getenv('DBT_HTTP_TIMEOUT', 10))
|
||||
response = requests.get(url, timeout=connection_timeout)
|
||||
|
||||
@@ -1,16 +1,18 @@
|
||||
from typing import Any
|
||||
|
||||
import dbt.exceptions
|
||||
|
||||
from typing import Any, Dict, Optional
|
||||
import yaml
|
||||
import yaml.scanner
|
||||
|
||||
# the C version is faster, but it doesn't always exist
|
||||
YamlLoader: Any
|
||||
try:
|
||||
from yaml import CSafeLoader as YamlLoader
|
||||
from yaml import (
|
||||
CLoader as Loader,
|
||||
CSafeLoader as SafeLoader,
|
||||
CDumper as Dumper
|
||||
)
|
||||
except ImportError:
|
||||
from yaml import SafeLoader as YamlLoader
|
||||
from yaml import ( # type: ignore # noqa: F401
|
||||
Loader, SafeLoader, Dumper
|
||||
)
|
||||
|
||||
|
||||
YAML_ERROR_MESSAGE = """
|
||||
@@ -53,8 +55,8 @@ def contextualized_yaml_error(raw_contents, error):
|
||||
raw_error=error)
|
||||
|
||||
|
||||
def safe_load(contents):
|
||||
return yaml.load(contents, Loader=YamlLoader)
|
||||
def safe_load(contents) -> Optional[Dict[str, Any]]:
|
||||
return yaml.load(contents, Loader=SafeLoader)
|
||||
|
||||
|
||||
def load_yaml_text(contents):
|
||||
|
||||
@@ -10,11 +10,10 @@ from dbt.adapters.factory import get_adapter
|
||||
from dbt.clients import jinja
|
||||
from dbt.clients.system import make_directory
|
||||
from dbt.context.providers import generate_runtime_model
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.graph.manifest import Manifest, UniqueID
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledDataTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
COMPILED_TYPES,
|
||||
CompiledGenericTestNode,
|
||||
GraphMemberNode,
|
||||
InjectedCTE,
|
||||
ManifestNode,
|
||||
@@ -30,6 +29,7 @@ from dbt.graph import Graph
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import pluralize
|
||||
import dbt.tracking
|
||||
|
||||
graph_file_name = 'graph.gpickle'
|
||||
|
||||
@@ -52,11 +52,17 @@ def print_compile_stats(stats):
|
||||
NodeType.Operation: 'operation',
|
||||
NodeType.Seed: 'seed file',
|
||||
NodeType.Source: 'source',
|
||||
NodeType.Exposure: 'exposure',
|
||||
}
|
||||
|
||||
results = {k: 0 for k in names.keys()}
|
||||
results.update(stats)
|
||||
|
||||
# create tracking event for resource_counts
|
||||
if dbt.tracking.active_user is not None:
|
||||
resource_counts = {k.pluralize(): v for k, v in results.items()}
|
||||
dbt.tracking.track_resource_counts(resource_counts)
|
||||
|
||||
stat_line = ", ".join([
|
||||
pluralize(ct, names.get(t)) for t, ct in results.items()
|
||||
if t in names
|
||||
@@ -81,6 +87,8 @@ def _generate_stats(manifest: Manifest):
|
||||
|
||||
for source in manifest.sources.values():
|
||||
stats[source.resource_type] += 1
|
||||
for exposure in manifest.exposures.values():
|
||||
stats[exposure.resource_type] += 1
|
||||
for macro in manifest.macros.values():
|
||||
stats[macro.resource_type] += 1
|
||||
return stats
|
||||
@@ -99,6 +107,19 @@ def _extend_prepended_ctes(prepended_ctes, new_prepended_ctes):
|
||||
_add_prepended_cte(prepended_ctes, new_cte)
|
||||
|
||||
|
||||
def _get_tests_for_node(manifest: Manifest, unique_id: UniqueID) -> List[UniqueID]:
|
||||
""" Get a list of tests that depend on the node with the
|
||||
provided unique id """
|
||||
|
||||
tests = []
|
||||
if unique_id in manifest.child_map:
|
||||
for child_unique_id in manifest.child_map[unique_id]:
|
||||
if child_unique_id.startswith('test.'):
|
||||
tests.append(child_unique_id)
|
||||
|
||||
return tests
|
||||
|
||||
|
||||
class Linker:
|
||||
def __init__(self, data=None):
|
||||
if data is None:
|
||||
@@ -134,8 +155,8 @@ class Linker:
|
||||
include all nodes in their corresponding graph entries.
|
||||
"""
|
||||
out_graph = self.graph.copy()
|
||||
for node_id in self.graph.nodes():
|
||||
data = manifest.expect(node_id).to_dict()
|
||||
for node_id in self.graph:
|
||||
data = manifest.expect(node_id).to_dict(omit_none=True)
|
||||
out_graph.add_node(node_id, **data)
|
||||
nx.write_gpickle(out_graph, outfile)
|
||||
|
||||
@@ -146,19 +167,22 @@ class Compiler:
|
||||
|
||||
def initialize(self):
|
||||
make_directory(self.config.target_path)
|
||||
make_directory(self.config.modules_path)
|
||||
make_directory(self.config.packages_install_path)
|
||||
|
||||
# creates a ModelContext which is converted to
|
||||
# a dict for jinja rendering of SQL
|
||||
def _create_node_context(
|
||||
self,
|
||||
node: NonSourceCompiledNode,
|
||||
manifest: Manifest,
|
||||
extra_context: Dict[str, Any],
|
||||
) -> Dict[str, Any]:
|
||||
|
||||
context = generate_runtime_model(
|
||||
node, self.config, manifest
|
||||
)
|
||||
context.update(extra_context)
|
||||
if isinstance(node, CompiledSchemaTestNode):
|
||||
if isinstance(node, CompiledGenericTestNode):
|
||||
# for test nodes, add a special keyword args value to the context
|
||||
jinja.add_rendered_test_kwargs(context, node)
|
||||
|
||||
@@ -169,35 +193,13 @@ class Compiler:
|
||||
relation_cls = adapter.Relation
|
||||
return relation_cls.add_ephemeral_prefix(name)
|
||||
|
||||
def _get_compiled_model(
|
||||
self,
|
||||
manifest: Manifest,
|
||||
cte_id: str,
|
||||
extra_context: Dict[str, Any],
|
||||
) -> NonSourceCompiledNode:
|
||||
|
||||
if cte_id not in manifest.nodes:
|
||||
raise InternalException(
|
||||
f'During compilation, found a cte reference that could not be '
|
||||
f'resolved: {cte_id}'
|
||||
)
|
||||
cte_model = manifest.nodes[cte_id]
|
||||
if getattr(cte_model, 'compiled', False):
|
||||
assert isinstance(cte_model, tuple(COMPILED_TYPES.values()))
|
||||
return cast(NonSourceCompiledNode, cte_model)
|
||||
elif cte_model.is_ephemeral_model:
|
||||
# this must be some kind of parsed node that we can compile.
|
||||
# we know it's not a parsed source definition
|
||||
assert isinstance(cte_model, tuple(COMPILED_TYPES))
|
||||
# update the node so
|
||||
node = self.compile_node(cte_model, manifest, extra_context)
|
||||
manifest.sync_update_node(node)
|
||||
return node
|
||||
else:
|
||||
raise InternalException(
|
||||
f'During compilation, found an uncompiled cte that '
|
||||
f'was not an ephemeral model: {cte_id}'
|
||||
)
|
||||
def _get_relation_name(self, node: ParsedNode):
|
||||
relation_name = None
|
||||
if node.is_relational and not node.is_ephemeral_model:
|
||||
adapter = get_adapter(self.config)
|
||||
relation_cls = adapter.Relation
|
||||
relation_name = str(relation_cls.create_from(self.config, node))
|
||||
return relation_name
|
||||
|
||||
def _inject_ctes_into_sql(self, sql: str, ctes: List[InjectedCTE]) -> str:
|
||||
"""
|
||||
@@ -206,11 +208,11 @@ class Compiler:
|
||||
[
|
||||
InjectedCTE(
|
||||
id="cte_id_1",
|
||||
sql="__dbt__CTE__ephemeral as (select * from table)",
|
||||
sql="__dbt__cte__ephemeral as (select * from table)",
|
||||
),
|
||||
InjectedCTE(
|
||||
id="cte_id_2",
|
||||
sql="__dbt__CTE__events as (select id, type from events)",
|
||||
sql="__dbt__cte__events as (select id, type from events)",
|
||||
),
|
||||
]
|
||||
|
||||
@@ -221,8 +223,8 @@ class Compiler:
|
||||
|
||||
This will spit out:
|
||||
|
||||
"with __dbt__CTE__ephemeral as (select * from table),
|
||||
__dbt__CTE__events as (select id, type from events),
|
||||
"with __dbt__cte__ephemeral as (select * from table),
|
||||
__dbt__cte__events as (select id, type from events),
|
||||
with internal_cte as (select * from sessions)
|
||||
select * from internal_cte"
|
||||
|
||||
@@ -260,103 +262,101 @@ class Compiler:
|
||||
|
||||
return str(parsed)
|
||||
|
||||
def _model_prepend_ctes(
|
||||
self,
|
||||
model: NonSourceCompiledNode,
|
||||
prepended_ctes: List[InjectedCTE]
|
||||
) -> NonSourceCompiledNode:
|
||||
if model.compiled_sql is None:
|
||||
raise RuntimeException(
|
||||
'Cannot prepend ctes to an unparsed node', model
|
||||
)
|
||||
injected_sql = self._inject_ctes_into_sql(
|
||||
model.compiled_sql,
|
||||
prepended_ctes,
|
||||
)
|
||||
|
||||
model.extra_ctes_injected = True
|
||||
model.extra_ctes = prepended_ctes
|
||||
model.injected_sql = injected_sql
|
||||
model.validate(model.to_dict())
|
||||
return model
|
||||
|
||||
def _get_dbt_test_name(self) -> str:
|
||||
return 'dbt__CTE__INTERNAL_test'
|
||||
|
||||
def _recursively_prepend_ctes(
|
||||
self,
|
||||
model: NonSourceCompiledNode,
|
||||
manifest: Manifest,
|
||||
extra_context: Dict[str, Any],
|
||||
extra_context: Optional[Dict[str, Any]],
|
||||
) -> Tuple[NonSourceCompiledNode, List[InjectedCTE]]:
|
||||
"""This method is called by the 'compile_node' method. Starting
|
||||
from the node that it is passed in, it will recursively call
|
||||
itself using the 'extra_ctes'. The 'ephemeral' models do
|
||||
not produce SQL that is executed directly, instead they
|
||||
are rolled up into the models that refer to them by
|
||||
inserting CTEs into the SQL.
|
||||
"""
|
||||
if model.compiled_sql is None:
|
||||
raise RuntimeException(
|
||||
'Cannot inject ctes into an unparsed node', model
|
||||
)
|
||||
if model.extra_ctes_injected:
|
||||
return (model, model.extra_ctes)
|
||||
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(model, tuple(COMPILED_TYPES.values())):
|
||||
raise InternalException(
|
||||
f'Bad model type: {type(model)}'
|
||||
)
|
||||
# Just to make it plain that nothing is actually injected for this case
|
||||
if not model.extra_ctes:
|
||||
model.extra_ctes_injected = True
|
||||
manifest.update_node(model)
|
||||
return (model, model.extra_ctes)
|
||||
|
||||
# This stores the ctes which will all be recursively
|
||||
# gathered and then "injected" into the model.
|
||||
prepended_ctes: List[InjectedCTE] = []
|
||||
|
||||
dbt_test_name = self._get_dbt_test_name()
|
||||
|
||||
# extra_ctes are added to the model by
|
||||
# RuntimeRefResolver.create_relation, which adds an
|
||||
# extra_cte for every model relation which is an
|
||||
# ephemeral model.
|
||||
for cte in model.extra_ctes:
|
||||
if cte.id == dbt_test_name:
|
||||
sql = cte.sql
|
||||
else:
|
||||
cte_model = self._get_compiled_model(
|
||||
manifest,
|
||||
cte.id,
|
||||
extra_context,
|
||||
if cte.id not in manifest.nodes:
|
||||
raise InternalException(
|
||||
f'During compilation, found a cte reference that '
|
||||
f'could not be resolved: {cte.id}'
|
||||
)
|
||||
cte_model, new_prepended_ctes = self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||
cte_model = manifest.nodes[cte.id]
|
||||
|
||||
if not cte_model.is_ephemeral_model:
|
||||
raise InternalException(f'{cte.id} is not ephemeral')
|
||||
|
||||
# This model has already been compiled, so it's been
|
||||
# through here before
|
||||
if getattr(cte_model, 'compiled', False):
|
||||
assert isinstance(cte_model, tuple(COMPILED_TYPES.values()))
|
||||
cte_model = cast(NonSourceCompiledNode, cte_model)
|
||||
new_prepended_ctes = cte_model.extra_ctes
|
||||
|
||||
# if the cte_model isn't compiled, i.e. first time here
|
||||
else:
|
||||
# This is an ephemeral parsed model that we can compile.
|
||||
# Compile and update the node
|
||||
cte_model = self._compile_node(
|
||||
cte_model, manifest, extra_context)
|
||||
# recursively call this method
|
||||
cte_model, new_prepended_ctes = \
|
||||
self._recursively_prepend_ctes(
|
||||
cte_model, manifest, extra_context
|
||||
)
|
||||
# Save compiled SQL file and sync manifest
|
||||
self._write_node(cte_model)
|
||||
manifest.sync_update_node(cte_model)
|
||||
|
||||
_extend_prepended_ctes(prepended_ctes, new_prepended_ctes)
|
||||
|
||||
new_cte_name = self.add_ephemeral_prefix(cte_model.name)
|
||||
rendered_sql = (
|
||||
cte_model._pre_injected_sql or cte_model.compiled_sql
|
||||
)
|
||||
sql = f' {new_cte_name} as (\n{rendered_sql}\n)'
|
||||
|
||||
new_cte_name = self.add_ephemeral_prefix(cte_model.name)
|
||||
sql = f' {new_cte_name} as (\n{cte_model.compiled_sql}\n)'
|
||||
_add_prepended_cte(prepended_ctes, InjectedCTE(id=cte.id, sql=sql))
|
||||
|
||||
model = self._model_prepend_ctes(model, prepended_ctes)
|
||||
injected_sql = self._inject_ctes_into_sql(
|
||||
model.compiled_sql,
|
||||
prepended_ctes,
|
||||
)
|
||||
model._pre_injected_sql = model.compiled_sql
|
||||
model.compiled_sql = injected_sql
|
||||
model.extra_ctes_injected = True
|
||||
model.extra_ctes = prepended_ctes
|
||||
model.validate(model.to_dict(omit_none=True))
|
||||
|
||||
manifest.update_node(model)
|
||||
|
||||
return model, prepended_ctes
|
||||
|
||||
def _insert_ctes(
|
||||
self,
|
||||
compiled_node: NonSourceCompiledNode,
|
||||
manifest: Manifest,
|
||||
extra_context: Dict[str, Any],
|
||||
) -> NonSourceCompiledNode:
|
||||
"""Insert the CTEs for the model."""
|
||||
|
||||
# for data tests, we need to insert a special CTE at the end of the
|
||||
# list containing the test query, and then have the "real" query be a
|
||||
# select count(*) from that model.
|
||||
# the benefit of doing it this way is that _insert_ctes() can be
|
||||
# rewritten for different adapters to handle databses that don't
|
||||
# support CTEs, or at least don't have full support.
|
||||
if isinstance(compiled_node, CompiledDataTestNode):
|
||||
# the last prepend (so last in order) should be the data test body.
|
||||
# then we can add our select count(*) from _that_ cte as the "real"
|
||||
# compiled_sql, and do the regular prepend logic from CTEs.
|
||||
name = self._get_dbt_test_name()
|
||||
cte = InjectedCTE(
|
||||
id=name,
|
||||
sql=f' {name} as (\n{compiled_node.compiled_sql}\n)'
|
||||
)
|
||||
compiled_node.extra_ctes.append(cte)
|
||||
compiled_node.compiled_sql = f'\nselect count(*) from {name}'
|
||||
|
||||
injected_node, _ = self._recursively_prepend_ctes(
|
||||
compiled_node, manifest, extra_context
|
||||
)
|
||||
return injected_node
|
||||
|
||||
# creates a compiled_node from the ManifestNode passed in,
|
||||
# creates a "context" dictionary for jinja rendering,
|
||||
# and then renders the "compiled_sql" using the node, the
|
||||
# raw_sql and the context.
|
||||
def _compile_node(
|
||||
self,
|
||||
node: ManifestNode,
|
||||
@@ -368,13 +368,12 @@ class Compiler:
|
||||
|
||||
logger.debug("Compiling {}".format(node.unique_id))
|
||||
|
||||
data = node.to_dict()
|
||||
data = node.to_dict(omit_none=True)
|
||||
data.update({
|
||||
'compiled': False,
|
||||
'compiled_sql': None,
|
||||
'extra_ctes_injected': False,
|
||||
'extra_ctes': [],
|
||||
'injected_sql': None,
|
||||
})
|
||||
compiled_node = _compiled_type_for(node).from_dict(data)
|
||||
|
||||
@@ -388,13 +387,11 @@ class Compiler:
|
||||
node,
|
||||
)
|
||||
|
||||
compiled_node.relation_name = self._get_relation_name(node)
|
||||
|
||||
compiled_node.compiled = True
|
||||
|
||||
injected_node = self._insert_ctes(
|
||||
compiled_node, manifest, extra_context
|
||||
)
|
||||
|
||||
return injected_node
|
||||
return compiled_node
|
||||
|
||||
def write_graph_file(self, linker: Linker, manifest: Manifest):
|
||||
filename = graph_file_name
|
||||
@@ -428,13 +425,82 @@ class Compiler:
|
||||
self.link_node(linker, node, manifest)
|
||||
for exposure in manifest.exposures.values():
|
||||
self.link_node(linker, exposure, manifest)
|
||||
# linker.add_node(exposure.unique_id)
|
||||
|
||||
cycle = linker.find_cycles()
|
||||
|
||||
if cycle:
|
||||
raise RuntimeError("Found a cycle: {}".format(cycle))
|
||||
|
||||
manifest.build_parent_and_child_maps()
|
||||
|
||||
self.resolve_graph(linker, manifest)
|
||||
|
||||
def resolve_graph(self, linker: Linker, manifest: Manifest) -> None:
|
||||
""" This method adds additional edges to the DAG. For a given non-test
|
||||
executable node, add an edge from an upstream test to the given node if
|
||||
the set of nodes the test depends on is a proper/strict subset of the
|
||||
upstream nodes for the given node. """
|
||||
|
||||
# Given a graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | |
|
||||
# | \/
|
||||
# \/ test 2
|
||||
# test1
|
||||
#
|
||||
# Produce the following graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | | /\ /\
|
||||
# | \/ | |
|
||||
# \/ test2 ------- |
|
||||
# test1 -------------------
|
||||
|
||||
for node_id in linker.graph:
|
||||
# If node is executable (in manifest.nodes) and does _not_
|
||||
# represent a test, continue.
|
||||
if (
|
||||
node_id in manifest.nodes and
|
||||
manifest.nodes[node_id].resource_type != NodeType.Test
|
||||
):
|
||||
# Get *everything* upstream of the node
|
||||
all_upstream_nodes = nx.traversal.bfs_tree(
|
||||
linker.graph, node_id, reverse=True
|
||||
)
|
||||
# Get the set of upstream nodes not including the current node.
|
||||
upstream_nodes = set([
|
||||
n for n in all_upstream_nodes if n != node_id
|
||||
])
|
||||
|
||||
# Get all tests that depend on any upstream nodes.
|
||||
upstream_tests = []
|
||||
for upstream_node in upstream_nodes:
|
||||
upstream_tests += _get_tests_for_node(
|
||||
manifest,
|
||||
upstream_node
|
||||
)
|
||||
|
||||
for upstream_test in upstream_tests:
|
||||
# Get the set of all nodes that the test depends on
|
||||
# including the upstream_node itself. This is necessary
|
||||
# because tests can depend on multiple nodes (ex:
|
||||
# relationship tests). Test nodes do not distinguish
|
||||
# between what node the test is "testing" and what
|
||||
# node(s) it depends on.
|
||||
test_depends_on = set(
|
||||
manifest.nodes[upstream_test].depends_on_nodes
|
||||
)
|
||||
|
||||
# If the set of nodes that an upstream test depends on
|
||||
# is a proper (or strict) subset of all upstream nodes of
|
||||
# the current node, add an edge from the upstream test
|
||||
# to the current node. Must be a proper/strict subset to
|
||||
# avoid adding a circular dependency to the graph.
|
||||
if (test_depends_on < upstream_nodes):
|
||||
linker.graph.add_edge(
|
||||
upstream_test,
|
||||
node_id
|
||||
)
|
||||
|
||||
def compile(self, manifest: Manifest, write=True) -> Graph:
|
||||
self.initialize()
|
||||
linker = Linker()
|
||||
@@ -449,23 +515,18 @@ class Compiler:
|
||||
|
||||
return Graph(linker.graph)
|
||||
|
||||
# writes the "compiled_sql" into the target/compiled directory
|
||||
def _write_node(self, node: NonSourceCompiledNode) -> ManifestNode:
|
||||
if not _is_writable(node):
|
||||
if (not node.extra_ctes_injected or
|
||||
node.resource_type == NodeType.Snapshot):
|
||||
return node
|
||||
logger.debug(f'Writing injected SQL for node "{node.unique_id}"')
|
||||
|
||||
if node.injected_sql is None:
|
||||
# this should not really happen, but it'd be a shame to crash
|
||||
# over it
|
||||
logger.error(
|
||||
f'Compiled node "{node.unique_id}" had no injected_sql, '
|
||||
'cannot write sql!'
|
||||
)
|
||||
else:
|
||||
node.build_path = node.write_node(
|
||||
if node.compiled_sql:
|
||||
node.compiled_path = node.write_node(
|
||||
self.config.target_path,
|
||||
'compiled',
|
||||
node.injected_sql
|
||||
node.compiled_sql
|
||||
)
|
||||
return node
|
||||
|
||||
@@ -476,18 +537,17 @@ class Compiler:
|
||||
extra_context: Optional[Dict[str, Any]] = None,
|
||||
write: bool = True,
|
||||
) -> NonSourceCompiledNode:
|
||||
"""This is the main entry point into this code. It's called by
|
||||
CompileRunner.compile, GenericRPCRunner.compile, and
|
||||
RunTask.get_hook_sql. It calls '_compile_node' to convert
|
||||
the node into a compiled node, and then calls the
|
||||
recursive method to "prepend" the ctes.
|
||||
"""
|
||||
node = self._compile_node(node, manifest, extra_context)
|
||||
|
||||
if write and _is_writable(node):
|
||||
node, _ = self._recursively_prepend_ctes(
|
||||
node, manifest, extra_context
|
||||
)
|
||||
if write:
|
||||
self._write_node(node)
|
||||
return node
|
||||
|
||||
|
||||
def _is_writable(node):
|
||||
if not node.injected_sql:
|
||||
return False
|
||||
|
||||
if node.resource_type == NodeType.Snapshot:
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# all these are just exports, they need "noqa" so flake8 will not complain.
|
||||
from .profile import Profile, PROFILES_DIR, read_user_config # noqa
|
||||
from .project import Project # noqa
|
||||
from .profile import Profile, read_user_config # noqa
|
||||
from .project import Project, IsFQNResource # noqa
|
||||
from .runtime import RuntimeConfig, UnsetProfileConfig # noqa
|
||||
|
||||
@@ -2,8 +2,9 @@ from dataclasses import dataclass
|
||||
from typing import Any, Dict, Optional, Tuple
|
||||
import os
|
||||
|
||||
from hologram import ValidationError
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from dbt import flags
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.clients.yaml_helper import load_yaml_text
|
||||
from dbt.contracts.connection import Credentials, HasCredentials
|
||||
@@ -20,10 +21,8 @@ from dbt.utils import coerce_dict_str
|
||||
from .renderer import ProfileRenderer
|
||||
|
||||
DEFAULT_THREADS = 1
|
||||
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser('~'), '.dbt')
|
||||
PROFILES_DIR = os.path.expanduser(
|
||||
os.getenv('DBT_PROFILES_DIR', DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
INVALID_PROFILE_MESSAGE = """
|
||||
dbt encountered an error while trying to read your profiles.yml file.
|
||||
@@ -43,7 +42,7 @@ Here, [profile name] should be replaced with a profile name
|
||||
defined in your profiles.yml file. You can find profiles.yml here:
|
||||
|
||||
{profiles_file}/profiles.yml
|
||||
""".format(profiles_file=PROFILES_DIR)
|
||||
""".format(profiles_file=DEFAULT_PROFILES_DIR)
|
||||
|
||||
|
||||
def read_profile(profiles_dir: str) -> Dict[str, Any]:
|
||||
@@ -73,22 +72,43 @@ def read_user_config(directory: str) -> UserConfig:
|
||||
try:
|
||||
profile = read_profile(directory)
|
||||
if profile:
|
||||
user_cfg = coerce_dict_str(profile.get('config', {}))
|
||||
if user_cfg is not None:
|
||||
return UserConfig.from_dict(user_cfg)
|
||||
user_config = coerce_dict_str(profile.get('config', {}))
|
||||
if user_config is not None:
|
||||
UserConfig.validate(user_config)
|
||||
return UserConfig.from_dict(user_config)
|
||||
except (RuntimeException, ValidationError):
|
||||
pass
|
||||
return UserConfig()
|
||||
|
||||
|
||||
@dataclass
|
||||
# The Profile class is included in RuntimeConfig, so any attribute
|
||||
# additions must also be set where the RuntimeConfig class is created
|
||||
# `init=False` is a workaround for https://bugs.python.org/issue45081
|
||||
@dataclass(init=False)
|
||||
class Profile(HasCredentials):
|
||||
profile_name: str
|
||||
target_name: str
|
||||
config: UserConfig
|
||||
user_config: UserConfig
|
||||
threads: int
|
||||
credentials: Credentials
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_config: UserConfig,
|
||||
threads: int,
|
||||
credentials: Credentials
|
||||
):
|
||||
"""Explicitly defining `__init__` to work around bug in Python 3.9.7
|
||||
https://bugs.python.org/issue45081
|
||||
"""
|
||||
self.profile_name = profile_name
|
||||
self.target_name = target_name
|
||||
self.user_config = user_config
|
||||
self.threads = threads
|
||||
self.credentials = credentials
|
||||
|
||||
def to_profile_info(
|
||||
self, serialize_credentials: bool = False
|
||||
) -> Dict[str, Any]:
|
||||
@@ -103,13 +123,13 @@ class Profile(HasCredentials):
|
||||
result = {
|
||||
'profile_name': self.profile_name,
|
||||
'target_name': self.target_name,
|
||||
'config': self.config,
|
||||
'user_config': self.user_config,
|
||||
'threads': self.threads,
|
||||
'credentials': self.credentials,
|
||||
}
|
||||
if serialize_credentials:
|
||||
result['config'] = self.config.to_dict()
|
||||
result['credentials'] = self.credentials.to_dict()
|
||||
result['user_config'] = self.user_config.to_dict(omit_none=True)
|
||||
result['credentials'] = self.credentials.to_dict(omit_none=True)
|
||||
return result
|
||||
|
||||
def to_target_dict(self) -> Dict[str, Any]:
|
||||
@@ -122,7 +142,7 @@ class Profile(HasCredentials):
|
||||
'name': self.target_name,
|
||||
'target_name': self.target_name,
|
||||
'profile_name': self.profile_name,
|
||||
'config': self.config.to_dict(),
|
||||
'config': self.user_config.to_dict(omit_none=True),
|
||||
})
|
||||
return target
|
||||
|
||||
@@ -135,10 +155,10 @@ class Profile(HasCredentials):
|
||||
def validate(self):
|
||||
try:
|
||||
if self.credentials:
|
||||
self.credentials.to_dict(validate=True)
|
||||
ProfileConfig.from_dict(
|
||||
self.to_profile_info(serialize_credentials=True)
|
||||
)
|
||||
dct = self.credentials.to_dict(omit_none=True)
|
||||
self.credentials.validate(dct)
|
||||
dct = self.to_profile_info(serialize_credentials=True)
|
||||
ProfileConfig.validate(dct)
|
||||
except ValidationError as exc:
|
||||
raise DbtProfileError(validator_error_message(exc)) from exc
|
||||
|
||||
@@ -158,7 +178,9 @@ class Profile(HasCredentials):
|
||||
typename = profile.pop('type')
|
||||
try:
|
||||
cls = load_plugin(typename)
|
||||
credentials = cls.from_dict(profile)
|
||||
data = cls.translate_aliases(profile)
|
||||
cls.validate(data)
|
||||
credentials = cls.from_dict(data)
|
||||
except (RuntimeException, ValidationError) as e:
|
||||
msg = str(e) if isinstance(e, RuntimeException) else e.message
|
||||
raise DbtProfileError(
|
||||
@@ -215,7 +237,7 @@ class Profile(HasCredentials):
|
||||
threads: int,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_cfg: Optional[Dict[str, Any]] = None
|
||||
user_config: Optional[Dict[str, Any]] = None
|
||||
) -> 'Profile':
|
||||
"""Create a profile from an existing set of Credentials and the
|
||||
remaining information.
|
||||
@@ -224,19 +246,20 @@ class Profile(HasCredentials):
|
||||
:param threads: The number of threads to use for connections.
|
||||
:param profile_name: The profile name used for this profile.
|
||||
:param target_name: The target name used for this profile.
|
||||
:param user_cfg: The user-level config block from the
|
||||
:param user_config: The user-level config block from the
|
||||
raw profiles, if specified.
|
||||
:raises DbtProfileError: If the profile is invalid.
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
if user_cfg is None:
|
||||
user_cfg = {}
|
||||
config = UserConfig.from_dict(user_cfg)
|
||||
if user_config is None:
|
||||
user_config = {}
|
||||
UserConfig.validate(user_config)
|
||||
user_config_obj: UserConfig = UserConfig.from_dict(user_config)
|
||||
|
||||
profile = cls(
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
config=config,
|
||||
user_config=user_config_obj,
|
||||
threads=threads,
|
||||
credentials=credentials
|
||||
)
|
||||
@@ -289,7 +312,7 @@ class Profile(HasCredentials):
|
||||
raw_profile: Dict[str, Any],
|
||||
profile_name: str,
|
||||
renderer: ProfileRenderer,
|
||||
user_cfg: Optional[Dict[str, Any]] = None,
|
||||
user_config: Optional[Dict[str, Any]] = None,
|
||||
target_override: Optional[str] = None,
|
||||
threads_override: Optional[int] = None,
|
||||
) -> 'Profile':
|
||||
@@ -301,7 +324,7 @@ class Profile(HasCredentials):
|
||||
disk as yaml and its values rendered with jinja.
|
||||
:param profile_name: The profile name used.
|
||||
:param renderer: The config renderer.
|
||||
:param user_cfg: The global config for the user, if it
|
||||
:param user_config: The global config for the user, if it
|
||||
was present.
|
||||
:param target_override: The target to use, if provided on
|
||||
the command line.
|
||||
@@ -311,9 +334,9 @@ class Profile(HasCredentials):
|
||||
target could not be found
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
# user_cfg is not rendered.
|
||||
if user_cfg is None:
|
||||
user_cfg = raw_profile.get('config')
|
||||
# user_config is not rendered.
|
||||
if user_config is None:
|
||||
user_config = raw_profile.get('config')
|
||||
# TODO: should it be, and the values coerced to bool?
|
||||
target_name, profile_data = cls.render_profile(
|
||||
raw_profile, profile_name, target_override, renderer
|
||||
@@ -334,7 +357,7 @@ class Profile(HasCredentials):
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
threads=threads,
|
||||
user_cfg=user_cfg
|
||||
user_config=user_config
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -377,13 +400,13 @@ class Profile(HasCredentials):
|
||||
error_string=msg
|
||||
)
|
||||
)
|
||||
user_cfg = raw_profiles.get('config')
|
||||
user_config = raw_profiles.get('config')
|
||||
|
||||
return cls.from_raw_profile_info(
|
||||
raw_profile=raw_profile,
|
||||
profile_name=profile_name,
|
||||
renderer=renderer,
|
||||
user_cfg=user_cfg,
|
||||
user_config=user_config,
|
||||
target_override=target_override,
|
||||
threads_override=threads_override,
|
||||
)
|
||||
@@ -411,7 +434,7 @@ class Profile(HasCredentials):
|
||||
"""
|
||||
threads_override = getattr(args, 'threads', None)
|
||||
target_override = getattr(args, 'target', None)
|
||||
raw_profiles = read_profile(args.profiles_dir)
|
||||
raw_profiles = read_profile(flags.PROFILES_DIR)
|
||||
profile_name = cls.pick_profile_name(getattr(args, 'profile', None),
|
||||
project_profile_name)
|
||||
return cls.from_raw_profiles(
|
||||
|
||||
@@ -2,21 +2,20 @@ from copy import deepcopy
|
||||
from dataclasses import dataclass, field
|
||||
from itertools import chain
|
||||
from typing import (
|
||||
List, Dict, Any, Optional, TypeVar, Union, Tuple, Callable, Mapping,
|
||||
Iterable, Set
|
||||
List, Dict, Any, Optional, TypeVar, Union, Mapping,
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
from typing_extensions import Protocol, runtime_checkable
|
||||
|
||||
import hashlib
|
||||
import os
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.clients.system import resolve_path_from_base
|
||||
from dbt.clients.system import path_exists
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.clients.yaml_helper import load_yaml_text
|
||||
from dbt.contracts.connection import QueryComment
|
||||
from dbt.exceptions import DbtProjectError
|
||||
from dbt.exceptions import RecursionException
|
||||
from dbt.exceptions import SemverException
|
||||
from dbt.exceptions import validator_error_message
|
||||
from dbt.exceptions import RuntimeException
|
||||
@@ -25,19 +24,15 @@ from dbt.helper_types import NoValue
|
||||
from dbt.semver import VersionSpecifier
|
||||
from dbt.semver import versions_compatible
|
||||
from dbt.version import get_installed_version
|
||||
from dbt.utils import deep_map, MultiDict
|
||||
from dbt.legacy_config_updater import ConfigUpdater, IsFQNResource
|
||||
|
||||
from dbt.utils import MultiDict
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.config.selectors import SelectorDict
|
||||
from dbt.contracts.project import (
|
||||
ProjectV1 as ProjectV1Contract,
|
||||
ProjectV2 as ProjectV2Contract,
|
||||
parse_project_config,
|
||||
Project as ProjectContract,
|
||||
SemverString,
|
||||
)
|
||||
from dbt.contracts.project import PackageConfig
|
||||
|
||||
from hologram import ValidationError
|
||||
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
from .renderer import DbtProjectYamlRenderer
|
||||
from .selectors import (
|
||||
selector_config_from_data,
|
||||
@@ -75,23 +70,11 @@ Validator Error:
|
||||
"""
|
||||
|
||||
|
||||
def _list_if_none(value):
|
||||
if value is None:
|
||||
value = []
|
||||
return value
|
||||
|
||||
|
||||
def _dict_if_none(value):
|
||||
if value is None:
|
||||
value = {}
|
||||
return value
|
||||
|
||||
|
||||
def _list_if_none_or_string(value):
|
||||
value = _list_if_none(value)
|
||||
if isinstance(value, str):
|
||||
return [value]
|
||||
return value
|
||||
@runtime_checkable
|
||||
class IsFQNResource(Protocol):
|
||||
fqn: List[str]
|
||||
resource_type: NodeType
|
||||
package_name: str
|
||||
|
||||
|
||||
def _load_yaml(path):
|
||||
@@ -111,11 +94,12 @@ def package_data_from_root(project_root):
|
||||
return packages_dict
|
||||
|
||||
|
||||
def package_config_from_data(packages_data):
|
||||
if packages_data is None:
|
||||
def package_config_from_data(packages_data: Dict[str, Any]):
|
||||
if not packages_data:
|
||||
packages_data = {'packages': []}
|
||||
|
||||
try:
|
||||
PackageConfig.validate(packages_data)
|
||||
packages = PackageConfig.from_dict(packages_data)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(
|
||||
@@ -140,13 +124,13 @@ def _parse_versions(versions: Union[List[str], str]) -> List[VersionSpecifier]:
|
||||
|
||||
|
||||
def _all_source_paths(
|
||||
source_paths: List[str],
|
||||
data_paths: List[str],
|
||||
model_paths: List[str],
|
||||
seed_paths: List[str],
|
||||
snapshot_paths: List[str],
|
||||
analysis_paths: List[str],
|
||||
macro_paths: List[str],
|
||||
) -> List[str]:
|
||||
return list(chain(source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
return list(chain(model_paths, seed_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths))
|
||||
|
||||
|
||||
@@ -197,11 +181,69 @@ def _query_comment_from_cfg(
|
||||
return cfg_query_comment
|
||||
|
||||
|
||||
def validate_version(dbt_version: List[VersionSpecifier], project_name: str):
|
||||
"""Ensure this package works with the installed version of dbt."""
|
||||
installed = get_installed_version()
|
||||
if not versions_compatible(*dbt_version):
|
||||
msg = IMPOSSIBLE_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
version_spec=[
|
||||
x.to_version_string() for x in dbt_version
|
||||
]
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
if not versions_compatible(installed, *dbt_version):
|
||||
msg = INVALID_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
installed=installed.to_version_string(),
|
||||
version_spec=[
|
||||
x.to_version_string() for x in dbt_version
|
||||
]
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
|
||||
def _get_required_version(
|
||||
project_dict: Dict[str, Any],
|
||||
verify_version: bool,
|
||||
) -> List[VersionSpecifier]:
|
||||
dbt_raw_version: Union[List[str], str] = '>=0.0.0'
|
||||
required = project_dict.get('require-dbt-version')
|
||||
if required is not None:
|
||||
dbt_raw_version = required
|
||||
|
||||
try:
|
||||
dbt_version = _parse_versions(dbt_raw_version)
|
||||
except SemverException as e:
|
||||
raise DbtProjectError(str(e)) from e
|
||||
|
||||
if verify_version:
|
||||
# no name is also an error that we want to raise
|
||||
if 'name' not in project_dict:
|
||||
raise DbtProjectError(
|
||||
'Required "name" field not present in project',
|
||||
)
|
||||
validate_version(dbt_version, project_dict['name'])
|
||||
|
||||
return dbt_version
|
||||
|
||||
|
||||
@dataclass
|
||||
class PartialProject:
|
||||
config_version: int = field(metadata=dict(
|
||||
description='The version of the configuration file format'
|
||||
))
|
||||
class RenderComponents:
|
||||
project_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The project dictionary')
|
||||
)
|
||||
packages_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The packages dictionary')
|
||||
)
|
||||
selectors_dict: Dict[str, Any] = field(
|
||||
metadata=dict(description='The selectors dictionary')
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class PartialProject(RenderComponents):
|
||||
profile_name: Optional[str] = field(metadata=dict(
|
||||
description='The unrendered profile name in the project, if set'
|
||||
))
|
||||
@@ -214,72 +256,251 @@ class PartialProject:
|
||||
project_root: str = field(
|
||||
metadata=dict(description='The root directory of the project'),
|
||||
)
|
||||
project_dict: Dict[str, Any]
|
||||
verify_version: bool = field(
|
||||
metadata=dict(description=(
|
||||
'If True, verify the dbt version matches the required version'
|
||||
))
|
||||
)
|
||||
|
||||
def render(self, renderer):
|
||||
packages_dict = package_data_from_root(self.project_root)
|
||||
selectors_dict = selector_data_from_root(self.project_root)
|
||||
return Project.render_from_dict(
|
||||
self.project_root,
|
||||
self.project_dict,
|
||||
packages_dict,
|
||||
selectors_dict,
|
||||
renderer,
|
||||
verify_version=self.verify_version,
|
||||
)
|
||||
|
||||
def render_profile_name(self, renderer) -> Optional[str]:
|
||||
if self.profile_name is None:
|
||||
return None
|
||||
return renderer.render_value(self.profile_name)
|
||||
|
||||
|
||||
class VarProvider(Protocol):
|
||||
"""Var providers are tied to a particular Project."""
|
||||
def vars_for(
|
||||
self, node: IsFQNResource, adapter_type: str
|
||||
) -> Mapping[str, Any]:
|
||||
raise NotImplementedError(
|
||||
f'vars_for not implemented for {type(self)}!'
|
||||
)
|
||||
|
||||
def to_dict(self):
|
||||
raise NotImplementedError(
|
||||
f'to_dict not implemented for {type(self)}!'
|
||||
)
|
||||
|
||||
|
||||
class V1VarProvider(VarProvider):
|
||||
def __init__(
|
||||
def get_rendered(
|
||||
self,
|
||||
models: Dict[str, Any],
|
||||
seeds: Dict[str, Any],
|
||||
snapshots: Dict[str, Any],
|
||||
) -> None:
|
||||
self.models = models
|
||||
self.seeds = seeds
|
||||
self.snapshots = snapshots
|
||||
self.sources: Dict[str, Any] = {}
|
||||
renderer: DbtProjectYamlRenderer,
|
||||
) -> RenderComponents:
|
||||
|
||||
def vars_for(
|
||||
self, node: IsFQNResource, adapter_type: str
|
||||
) -> Mapping[str, Any]:
|
||||
updater = ConfigUpdater(adapter_type)
|
||||
return updater.get_project_config(node, self).get('vars', {})
|
||||
rendered_project = renderer.render_project(
|
||||
self.project_dict, self.project_root
|
||||
)
|
||||
rendered_packages = renderer.render_packages(self.packages_dict)
|
||||
rendered_selectors = renderer.render_selectors(self.selectors_dict)
|
||||
|
||||
def to_dict(self):
|
||||
raise ValidationError(
|
||||
'to_dict was called on a v1 vars, but it should only be called '
|
||||
'on v2 vars'
|
||||
return RenderComponents(
|
||||
project_dict=rendered_project,
|
||||
packages_dict=rendered_packages,
|
||||
selectors_dict=rendered_selectors,
|
||||
)
|
||||
|
||||
def render(self, renderer: DbtProjectYamlRenderer) -> 'Project':
|
||||
try:
|
||||
rendered = self.get_rendered(renderer)
|
||||
return self.create_project(rendered)
|
||||
except DbtProjectError as exc:
|
||||
if exc.path is None:
|
||||
exc.path = os.path.join(self.project_root, 'dbt_project.yml')
|
||||
raise
|
||||
|
||||
def check_config_path(self, project_dict, deprecated_path, exp_path):
|
||||
if deprecated_path in project_dict:
|
||||
if exp_path in project_dict:
|
||||
msg = (
|
||||
'{deprecated_path} and {exp_path} cannot both be defined. The '
|
||||
'`{deprecated_path}` config has been deprecated in favor of `{exp_path}`. '
|
||||
'Please update your `dbt_project.yml` configuration to reflect this '
|
||||
'change.'
|
||||
)
|
||||
raise DbtProjectError(msg.format(deprecated_path=deprecated_path,
|
||||
exp_path=exp_path))
|
||||
deprecations.warn('project_config_path',
|
||||
deprecated_path=deprecated_path,
|
||||
exp_path=exp_path)
|
||||
|
||||
def create_project(self, rendered: RenderComponents) -> 'Project':
|
||||
unrendered = RenderComponents(
|
||||
project_dict=self.project_dict,
|
||||
packages_dict=self.packages_dict,
|
||||
selectors_dict=self.selectors_dict,
|
||||
)
|
||||
dbt_version = _get_required_version(
|
||||
rendered.project_dict,
|
||||
verify_version=self.verify_version,
|
||||
)
|
||||
|
||||
self.check_config_path(rendered.project_dict, 'source-paths', 'model-paths')
|
||||
self.check_config_path(rendered.project_dict, 'data-paths', 'seed-paths')
|
||||
|
||||
try:
|
||||
ProjectContract.validate(rendered.project_dict)
|
||||
cfg = ProjectContract.from_dict(
|
||||
rendered.project_dict
|
||||
)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
# name/version are required in the Project definition, so we can assume
|
||||
# they are present
|
||||
name = cfg.name
|
||||
version = cfg.version
|
||||
# this is added at project_dict parse time and should always be here
|
||||
# once we see it.
|
||||
if cfg.project_root is None:
|
||||
raise DbtProjectError('cfg must have a project root!')
|
||||
else:
|
||||
project_root = cfg.project_root
|
||||
# this is only optional in the sense that if it's not present, it needs
|
||||
# to have been a cli argument.
|
||||
profile_name = cfg.profile
|
||||
# these are all the defaults
|
||||
|
||||
# `source_paths` is deprecated but still allowed. Copy it into
|
||||
# `model_paths` to simlify logic throughout the rest of the system.
|
||||
model_paths: List[str] = value_or(cfg.model_paths
|
||||
if 'model-paths' in rendered.project_dict
|
||||
else cfg.source_paths, ['models'])
|
||||
macro_paths: List[str] = value_or(cfg.macro_paths, ['macros'])
|
||||
# `data_paths` is deprecated but still allowed. Copy it into
|
||||
# `seed_paths` to simlify logic throughout the rest of the system.
|
||||
seed_paths: List[str] = value_or(cfg.seed_paths
|
||||
if 'seed-paths' in rendered.project_dict
|
||||
else cfg.data_paths, ['seeds'])
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ['tests'])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, ['analyses'])
|
||||
snapshot_paths: List[str] = value_or(cfg.snapshot_paths, ['snapshots'])
|
||||
|
||||
all_source_paths: List[str] = _all_source_paths(
|
||||
model_paths, seed_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths
|
||||
)
|
||||
|
||||
docs_paths: List[str] = value_or(cfg.docs_paths, all_source_paths)
|
||||
asset_paths: List[str] = value_or(cfg.asset_paths, [])
|
||||
target_path: str = value_or(cfg.target_path, 'target')
|
||||
clean_targets: List[str] = value_or(cfg.clean_targets, [target_path])
|
||||
log_path: str = value_or(cfg.log_path, 'logs')
|
||||
packages_install_path: str = value_or(cfg.packages_install_path, 'dbt_packages')
|
||||
# in the default case we'll populate this once we know the adapter type
|
||||
# It would be nice to just pass along a Quoting here, but that would
|
||||
# break many things
|
||||
quoting: Dict[str, Any] = {}
|
||||
if cfg.quoting is not None:
|
||||
quoting = cfg.quoting.to_dict(omit_none=True)
|
||||
|
||||
dispatch: List[Dict[str, Any]]
|
||||
models: Dict[str, Any]
|
||||
seeds: Dict[str, Any]
|
||||
snapshots: Dict[str, Any]
|
||||
sources: Dict[str, Any]
|
||||
tests: Dict[str, Any]
|
||||
vars_value: VarProvider
|
||||
|
||||
dispatch = cfg.dispatch
|
||||
models = cfg.models
|
||||
seeds = cfg.seeds
|
||||
snapshots = cfg.snapshots
|
||||
sources = cfg.sources
|
||||
tests = cfg.tests
|
||||
if cfg.vars is None:
|
||||
vars_dict: Dict[str, Any] = {}
|
||||
else:
|
||||
vars_dict = cfg.vars
|
||||
|
||||
vars_value = VarProvider(vars_dict)
|
||||
on_run_start: List[str] = value_or(cfg.on_run_start, [])
|
||||
on_run_end: List[str] = value_or(cfg.on_run_end, [])
|
||||
|
||||
query_comment = _query_comment_from_cfg(cfg.query_comment)
|
||||
|
||||
packages = package_config_from_data(rendered.packages_dict)
|
||||
selectors = selector_config_from_data(rendered.selectors_dict)
|
||||
manifest_selectors: Dict[str, Any] = {}
|
||||
if rendered.selectors_dict and rendered.selectors_dict['selectors']:
|
||||
# this is a dict with a single key 'selectors' pointing to a list
|
||||
# of dicts.
|
||||
manifest_selectors = SelectorDict.parse_from_selectors_list(
|
||||
rendered.selectors_dict['selectors'])
|
||||
project = Project(
|
||||
project_name=name,
|
||||
version=version,
|
||||
project_root=project_root,
|
||||
profile_name=profile_name,
|
||||
model_paths=model_paths,
|
||||
macro_paths=macro_paths,
|
||||
seed_paths=seed_paths,
|
||||
test_paths=test_paths,
|
||||
analysis_paths=analysis_paths,
|
||||
docs_paths=docs_paths,
|
||||
asset_paths=asset_paths,
|
||||
target_path=target_path,
|
||||
snapshot_paths=snapshot_paths,
|
||||
clean_targets=clean_targets,
|
||||
log_path=log_path,
|
||||
packages_install_path=packages_install_path,
|
||||
quoting=quoting,
|
||||
models=models,
|
||||
on_run_start=on_run_start,
|
||||
on_run_end=on_run_end,
|
||||
dispatch=dispatch,
|
||||
seeds=seeds,
|
||||
snapshots=snapshots,
|
||||
dbt_version=dbt_version,
|
||||
packages=packages,
|
||||
manifest_selectors=manifest_selectors,
|
||||
selectors=selectors,
|
||||
query_comment=query_comment,
|
||||
sources=sources,
|
||||
tests=tests,
|
||||
vars=vars_value,
|
||||
config_version=cfg.config_version,
|
||||
unrendered=unrendered,
|
||||
)
|
||||
# sanity check - this means an internal issue
|
||||
project.validate()
|
||||
return project
|
||||
|
||||
@classmethod
|
||||
def from_dicts(
|
||||
cls,
|
||||
project_root: str,
|
||||
project_dict: Dict[str, Any],
|
||||
packages_dict: Dict[str, Any],
|
||||
selectors_dict: Dict[str, Any],
|
||||
*,
|
||||
verify_version: bool = False,
|
||||
):
|
||||
"""Construct a partial project from its constituent dicts.
|
||||
"""
|
||||
project_name = project_dict.get('name')
|
||||
profile_name = project_dict.get('profile')
|
||||
|
||||
return cls(
|
||||
profile_name=profile_name,
|
||||
project_name=project_name,
|
||||
project_root=project_root,
|
||||
project_dict=project_dict,
|
||||
packages_dict=packages_dict,
|
||||
selectors_dict=selectors_dict,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_project_root(
|
||||
cls, project_root: str, *, verify_version: bool = False
|
||||
) -> 'PartialProject':
|
||||
project_root = os.path.normpath(project_root)
|
||||
project_dict = _raw_project_from(project_root)
|
||||
config_version = project_dict.get('config-version', 1)
|
||||
if config_version != 2:
|
||||
raise DbtProjectError(
|
||||
f'Invalid config version: {config_version}, expected 2',
|
||||
path=os.path.join(project_root, 'dbt_project.yml')
|
||||
)
|
||||
|
||||
packages_dict = package_data_from_root(project_root)
|
||||
selectors_dict = selector_data_from_root(project_root)
|
||||
return cls.from_dicts(
|
||||
project_root=project_root,
|
||||
project_dict=project_dict,
|
||||
selectors_dict=selectors_dict,
|
||||
packages_dict=packages_dict,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
|
||||
|
||||
class V2VarProvider(VarProvider):
|
||||
class VarProvider:
|
||||
"""Var providers are tied to a particular Project."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vars: Dict[str, Dict[str, Any]]
|
||||
@@ -298,41 +519,17 @@ class V2VarProvider(VarProvider):
|
||||
return self.vars
|
||||
|
||||
|
||||
def validate_version(
|
||||
required: List[VersionSpecifier],
|
||||
project_name: str,
|
||||
) -> None:
|
||||
"""Ensure this package works with the installed version of dbt."""
|
||||
installed = get_installed_version()
|
||||
if not versions_compatible(*required):
|
||||
msg = IMPOSSIBLE_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
version_spec=[
|
||||
x.to_version_string() for x in required
|
||||
]
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
if not versions_compatible(installed, *required):
|
||||
msg = INVALID_VERSION_ERROR.format(
|
||||
package=project_name,
|
||||
installed=installed.to_version_string(),
|
||||
version_spec=[
|
||||
x.to_version_string() for x in required
|
||||
]
|
||||
)
|
||||
raise DbtProjectError(msg)
|
||||
|
||||
|
||||
# The Project class is included in RuntimeConfig, so any attribute
|
||||
# additions must also be set where the RuntimeConfig class is created
|
||||
@dataclass
|
||||
class Project:
|
||||
project_name: str
|
||||
version: Union[SemverString, float]
|
||||
project_root: str
|
||||
profile_name: Optional[str]
|
||||
source_paths: List[str]
|
||||
model_paths: List[str]
|
||||
macro_paths: List[str]
|
||||
data_paths: List[str]
|
||||
seed_paths: List[str]
|
||||
test_paths: List[str]
|
||||
analysis_paths: List[str]
|
||||
docs_paths: List[str]
|
||||
@@ -341,210 +538,32 @@ class Project:
|
||||
snapshot_paths: List[str]
|
||||
clean_targets: List[str]
|
||||
log_path: str
|
||||
modules_path: str
|
||||
packages_install_path: str
|
||||
quoting: Dict[str, Any]
|
||||
models: Dict[str, Any]
|
||||
on_run_start: List[str]
|
||||
on_run_end: List[str]
|
||||
dispatch: List[Dict[str, Any]]
|
||||
seeds: Dict[str, Any]
|
||||
snapshots: Dict[str, Any]
|
||||
sources: Dict[str, Any]
|
||||
tests: Dict[str, Any]
|
||||
vars: VarProvider
|
||||
dbt_version: List[VersionSpecifier]
|
||||
packages: Dict[str, Any]
|
||||
manifest_selectors: Dict[str, Any]
|
||||
selectors: SelectorConfig
|
||||
query_comment: QueryComment
|
||||
config_version: int
|
||||
unrendered: RenderComponents
|
||||
|
||||
@property
|
||||
def all_source_paths(self) -> List[str]:
|
||||
return _all_source_paths(
|
||||
self.source_paths, self.data_paths, self.snapshot_paths,
|
||||
self.model_paths, self.seed_paths, self.snapshot_paths,
|
||||
self.analysis_paths, self.macro_paths
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _preprocess(project_dict: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Pre-process certain special keys to convert them from None values
|
||||
into empty containers, and to turn strings into arrays of strings.
|
||||
"""
|
||||
handlers: Dict[Tuple[Union[str, int], ...], Callable[[Any], Any]] = {
|
||||
('on-run-start',): _list_if_none_or_string,
|
||||
('on-run-end',): _list_if_none_or_string,
|
||||
}
|
||||
|
||||
for k in ('models', 'seeds', 'snapshots'):
|
||||
handlers[(k,)] = _dict_if_none
|
||||
handlers[(k, 'vars')] = _dict_if_none
|
||||
handlers[(k, 'pre-hook')] = _list_if_none_or_string
|
||||
handlers[(k, 'post-hook')] = _list_if_none_or_string
|
||||
handlers[('seeds', 'column_types')] = _dict_if_none
|
||||
|
||||
def converter(value: Any, keypath: Tuple[Union[str, int], ...]) -> Any:
|
||||
if keypath in handlers:
|
||||
handler = handlers[keypath]
|
||||
return handler(value)
|
||||
else:
|
||||
return value
|
||||
|
||||
return deep_map(converter, project_dict)
|
||||
|
||||
@classmethod
|
||||
def from_project_config(
|
||||
cls,
|
||||
project_dict: Dict[str, Any],
|
||||
packages_dict: Optional[Dict[str, Any]] = None,
|
||||
selectors_dict: Optional[Dict[str, Any]] = None,
|
||||
required_dbt_version: Optional[List[VersionSpecifier]] = None,
|
||||
) -> 'Project':
|
||||
"""Create a project from its project and package configuration, as read
|
||||
by yaml.safe_load().
|
||||
|
||||
:param project_dict: The dictionary as read from disk
|
||||
:param packages_dict: If it exists, the packages file as
|
||||
read from disk.
|
||||
:raises DbtProjectError: If the project is missing or invalid, or if
|
||||
the packages file exists and is invalid.
|
||||
:returns: The project, with defaults populated.
|
||||
"""
|
||||
if required_dbt_version is None:
|
||||
dbt_version = cls._get_required_version(project_dict)
|
||||
else:
|
||||
dbt_version = required_dbt_version
|
||||
|
||||
try:
|
||||
project_dict = cls._preprocess(project_dict)
|
||||
except RecursionException:
|
||||
raise DbtProjectError(
|
||||
'Cycle detected: Project input has a reference to itself',
|
||||
project=project_dict
|
||||
)
|
||||
try:
|
||||
cfg = parse_project_config(project_dict)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
# name/version are required in the Project definition, so we can assume
|
||||
# they are present
|
||||
name = cfg.name
|
||||
version = cfg.version
|
||||
# this is added at project_dict parse time and should always be here
|
||||
# once we see it.
|
||||
if cfg.project_root is None:
|
||||
raise DbtProjectError('cfg must have a project root!')
|
||||
else:
|
||||
project_root = cfg.project_root
|
||||
# this is only optional in the sense that if it's not present, it needs
|
||||
# to have been a cli argument.
|
||||
profile_name = cfg.profile
|
||||
# these are all the defaults
|
||||
source_paths: List[str] = value_or(cfg.source_paths, ['models'])
|
||||
macro_paths: List[str] = value_or(cfg.macro_paths, ['macros'])
|
||||
data_paths: List[str] = value_or(cfg.data_paths, ['data'])
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ['test'])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, [])
|
||||
snapshot_paths: List[str] = value_or(cfg.snapshot_paths, ['snapshots'])
|
||||
|
||||
all_source_paths: List[str] = _all_source_paths(
|
||||
source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths
|
||||
)
|
||||
|
||||
docs_paths: List[str] = value_or(cfg.docs_paths, all_source_paths)
|
||||
asset_paths: List[str] = value_or(cfg.asset_paths, [])
|
||||
target_path: str = value_or(cfg.target_path, 'target')
|
||||
clean_targets: List[str] = value_or(cfg.clean_targets, [target_path])
|
||||
log_path: str = value_or(cfg.log_path, 'logs')
|
||||
modules_path: str = value_or(cfg.modules_path, 'dbt_modules')
|
||||
# in the default case we'll populate this once we know the adapter type
|
||||
# It would be nice to just pass along a Quoting here, but that would
|
||||
# break many things
|
||||
quoting: Dict[str, Any] = {}
|
||||
if cfg.quoting is not None:
|
||||
quoting = cfg.quoting.to_dict()
|
||||
|
||||
models: Dict[str, Any]
|
||||
seeds: Dict[str, Any]
|
||||
snapshots: Dict[str, Any]
|
||||
sources: Dict[str, Any]
|
||||
vars_value: VarProvider
|
||||
|
||||
if cfg.config_version == 1:
|
||||
assert isinstance(cfg, ProjectV1Contract)
|
||||
# extract everything named 'vars'
|
||||
models = cfg.models
|
||||
seeds = cfg.seeds
|
||||
snapshots = cfg.snapshots
|
||||
sources = {}
|
||||
vars_value = V1VarProvider(
|
||||
models=models, seeds=seeds, snapshots=snapshots
|
||||
)
|
||||
elif cfg.config_version == 2:
|
||||
assert isinstance(cfg, ProjectV2Contract)
|
||||
models = cfg.models
|
||||
seeds = cfg.seeds
|
||||
snapshots = cfg.snapshots
|
||||
sources = cfg.sources
|
||||
if cfg.vars is None:
|
||||
vars_dict: Dict[str, Any] = {}
|
||||
else:
|
||||
vars_dict = cfg.vars
|
||||
vars_value = V2VarProvider(vars_dict)
|
||||
else:
|
||||
raise ValidationError(
|
||||
f'Got unsupported config_version={cfg.config_version}'
|
||||
)
|
||||
|
||||
on_run_start: List[str] = value_or(cfg.on_run_start, [])
|
||||
on_run_end: List[str] = value_or(cfg.on_run_end, [])
|
||||
|
||||
query_comment = _query_comment_from_cfg(cfg.query_comment)
|
||||
|
||||
try:
|
||||
packages = package_config_from_data(packages_dict)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
try:
|
||||
selectors = selector_config_from_data(selectors_dict)
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
project = cls(
|
||||
project_name=name,
|
||||
version=version,
|
||||
project_root=project_root,
|
||||
profile_name=profile_name,
|
||||
source_paths=source_paths,
|
||||
macro_paths=macro_paths,
|
||||
data_paths=data_paths,
|
||||
test_paths=test_paths,
|
||||
analysis_paths=analysis_paths,
|
||||
docs_paths=docs_paths,
|
||||
asset_paths=asset_paths,
|
||||
target_path=target_path,
|
||||
snapshot_paths=snapshot_paths,
|
||||
clean_targets=clean_targets,
|
||||
log_path=log_path,
|
||||
modules_path=modules_path,
|
||||
quoting=quoting,
|
||||
models=models,
|
||||
on_run_start=on_run_start,
|
||||
on_run_end=on_run_end,
|
||||
seeds=seeds,
|
||||
snapshots=snapshots,
|
||||
dbt_version=dbt_version,
|
||||
packages=packages,
|
||||
selectors=selectors,
|
||||
query_comment=query_comment,
|
||||
sources=sources,
|
||||
vars=vars_value,
|
||||
config_version=cfg.config_version,
|
||||
)
|
||||
# sanity check - this means an internal issue
|
||||
project.validate()
|
||||
return project
|
||||
|
||||
def __str__(self):
|
||||
cfg = self.to_project_config(with_packages=True)
|
||||
return str(cfg)
|
||||
@@ -569,9 +588,9 @@ class Project:
|
||||
'version': self.version,
|
||||
'project-root': self.project_root,
|
||||
'profile': self.profile_name,
|
||||
'source-paths': self.source_paths,
|
||||
'model-paths': self.model_paths,
|
||||
'macro-paths': self.macro_paths,
|
||||
'data-paths': self.data_paths,
|
||||
'seed-paths': self.seed_paths,
|
||||
'test-paths': self.test_paths,
|
||||
'analysis-paths': self.analysis_paths,
|
||||
'docs-paths': self.docs_paths,
|
||||
@@ -584,56 +603,40 @@ class Project:
|
||||
'models': self.models,
|
||||
'on-run-start': self.on_run_start,
|
||||
'on-run-end': self.on_run_end,
|
||||
'dispatch': self.dispatch,
|
||||
'seeds': self.seeds,
|
||||
'snapshots': self.snapshots,
|
||||
'sources': self.sources,
|
||||
'tests': self.tests,
|
||||
'vars': self.vars.to_dict(),
|
||||
'require-dbt-version': [
|
||||
v.to_version_string() for v in self.dbt_version
|
||||
],
|
||||
'config-version': self.config_version,
|
||||
})
|
||||
if self.query_comment:
|
||||
result['query-comment'] = self.query_comment.to_dict()
|
||||
result['query-comment'] = \
|
||||
self.query_comment.to_dict(omit_none=True)
|
||||
|
||||
if with_packages:
|
||||
result.update(self.packages.to_dict())
|
||||
|
||||
if self.config_version == 2:
|
||||
result.update({
|
||||
'sources': self.sources,
|
||||
'vars': self.vars.to_dict()
|
||||
})
|
||||
result.update(self.packages.to_dict(omit_none=True))
|
||||
|
||||
return result
|
||||
|
||||
def validate(self):
|
||||
try:
|
||||
ProjectV2Contract.from_dict(self.to_project_config())
|
||||
ProjectContract.validate(self.to_project_config())
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
@classmethod
|
||||
def _get_required_version(
|
||||
cls, rendered_project: Dict[str, Any], verify_version: bool = False
|
||||
) -> List[VersionSpecifier]:
|
||||
dbt_raw_version: Union[List[str], str] = '>=0.0.0'
|
||||
required = rendered_project.get('require-dbt-version')
|
||||
if required is not None:
|
||||
dbt_raw_version = required
|
||||
|
||||
try:
|
||||
dbt_version = _parse_versions(dbt_raw_version)
|
||||
except SemverException as e:
|
||||
raise DbtProjectError(str(e)) from e
|
||||
|
||||
if verify_version:
|
||||
# no name is also an error that we want to raise
|
||||
if 'name' not in rendered_project:
|
||||
raise DbtProjectError(
|
||||
'Required "name" field not present in project',
|
||||
)
|
||||
validate_version(dbt_version, rendered_project['name'])
|
||||
|
||||
return dbt_version
|
||||
def partial_load(
|
||||
cls, project_root: str, *, verify_version: bool = False
|
||||
) -> PartialProject:
|
||||
return PartialProject.from_project_root(
|
||||
project_root,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def render_from_dict(
|
||||
@@ -646,48 +649,14 @@ class Project:
|
||||
*,
|
||||
verify_version: bool = False
|
||||
) -> 'Project':
|
||||
rendered_project = renderer.render_data(project_dict)
|
||||
rendered_project['project-root'] = project_root
|
||||
package_renderer = renderer.get_package_renderer()
|
||||
rendered_packages = package_renderer.render_data(packages_dict)
|
||||
selectors_renderer = renderer.get_selector_renderer()
|
||||
rendered_selectors = selectors_renderer.render_data(selectors_dict)
|
||||
|
||||
try:
|
||||
dbt_version = cls._get_required_version(
|
||||
rendered_project, verify_version=verify_version
|
||||
)
|
||||
|
||||
return cls.from_project_config(
|
||||
rendered_project,
|
||||
rendered_packages,
|
||||
rendered_selectors,
|
||||
dbt_version,
|
||||
)
|
||||
except DbtProjectError as exc:
|
||||
if exc.path is None:
|
||||
exc.path = os.path.join(project_root, 'dbt_project.yml')
|
||||
raise
|
||||
|
||||
@classmethod
|
||||
def partial_load(
|
||||
cls, project_root: str, *, verify_version: bool = False
|
||||
) -> PartialProject:
|
||||
project_root = os.path.normpath(project_root)
|
||||
project_dict = _raw_project_from(project_root)
|
||||
|
||||
project_name = project_dict.get('name')
|
||||
profile_name = project_dict.get('profile')
|
||||
config_version = project_dict.get('config-version', 1)
|
||||
|
||||
return PartialProject(
|
||||
config_version=config_version,
|
||||
profile_name=profile_name,
|
||||
project_name=project_name,
|
||||
partial = PartialProject.from_dicts(
|
||||
project_root=project_root,
|
||||
project_dict=project_dict,
|
||||
packages_dict=packages_dict,
|
||||
selectors_dict=selectors_dict,
|
||||
verify_version=verify_version,
|
||||
)
|
||||
return partial.render(renderer)
|
||||
|
||||
@classmethod
|
||||
def from_project_root(
|
||||
@@ -698,84 +667,32 @@ class Project:
|
||||
verify_version: bool = False,
|
||||
) -> 'Project':
|
||||
partial = cls.partial_load(project_root, verify_version=verify_version)
|
||||
renderer.version = partial.config_version
|
||||
return partial.render(renderer)
|
||||
|
||||
def hashed_name(self):
|
||||
return hashlib.md5(self.project_name.encode('utf-8')).hexdigest()
|
||||
|
||||
def as_v1(self, all_projects: Iterable[str]):
|
||||
if self.config_version == 1:
|
||||
return self
|
||||
|
||||
dct = self.to_project_config()
|
||||
|
||||
mutated = deepcopy(dct)
|
||||
# remove sources, it doesn't exist
|
||||
mutated.pop('sources', None)
|
||||
|
||||
common_config_keys = ['models', 'seeds', 'snapshots']
|
||||
|
||||
if 'vars' in dct and isinstance(dct['vars'], dict):
|
||||
v2_vars_to_v1(mutated, dct['vars'], set(all_projects))
|
||||
# ok, now we want to look through all the existing cfgkeys and mirror
|
||||
# it, except expand the '+' prefix.
|
||||
for cfgkey in common_config_keys:
|
||||
if cfgkey not in dct:
|
||||
continue
|
||||
|
||||
mutated[cfgkey] = _flatten_config(dct[cfgkey])
|
||||
mutated['config-version'] = 1
|
||||
project = Project.from_project_config(mutated)
|
||||
project.packages = self.packages
|
||||
return project
|
||||
|
||||
def get_selector(self, name: str) -> SelectionSpec:
|
||||
def get_selector(self, name: str) -> Union[SelectionSpec, bool]:
|
||||
if name not in self.selectors:
|
||||
raise RuntimeException(
|
||||
f'Could not find selector named {name}, expected one of '
|
||||
f'{list(self.selectors)}'
|
||||
)
|
||||
return self.selectors[name]
|
||||
return self.selectors[name]["definition"]
|
||||
|
||||
def get_default_selector_name(self) -> Union[str, None]:
|
||||
"""This function fetch the default selector to use on `dbt run` (if any)
|
||||
:return: either a selector if default is set or None
|
||||
:rtype: Union[SelectionSpec, None]
|
||||
"""
|
||||
for selector_name, selector in self.selectors.items():
|
||||
if selector["default"] is True:
|
||||
return selector_name
|
||||
|
||||
def v2_vars_to_v1(
|
||||
dst: Dict[str, Any], src_vars: Dict[str, Any], project_names: Set[str]
|
||||
) -> None:
|
||||
# stuff any 'vars' entries into the old-style
|
||||
# models/seeds/snapshots dicts
|
||||
common_config_keys = ['models', 'seeds', 'snapshots']
|
||||
for project_name in project_names:
|
||||
for cfgkey in common_config_keys:
|
||||
if cfgkey not in dst:
|
||||
dst[cfgkey] = {}
|
||||
if project_name not in dst[cfgkey]:
|
||||
dst[cfgkey][project_name] = {}
|
||||
project_type_cfg = dst[cfgkey][project_name]
|
||||
return None
|
||||
|
||||
if 'vars' not in project_type_cfg:
|
||||
project_type_cfg['vars'] = {}
|
||||
project_type_vars = project_type_cfg['vars']
|
||||
|
||||
project_type_vars.update({
|
||||
k: v for k, v in src_vars.items()
|
||||
if not isinstance(v, dict)
|
||||
})
|
||||
|
||||
items = src_vars.get(project_name, None)
|
||||
if isinstance(items, dict):
|
||||
project_type_vars.update(items)
|
||||
# remove this from the v1 form
|
||||
dst.pop('vars')
|
||||
|
||||
|
||||
def _flatten_config(dct: Dict[str, Any]):
|
||||
result = {}
|
||||
for key, value in dct.items():
|
||||
if isinstance(value, dict) and not key.startswith('+'):
|
||||
result[key] = _flatten_config(value)
|
||||
else:
|
||||
if key.startswith('+'):
|
||||
key = key[1:]
|
||||
result[key] = value
|
||||
return result
|
||||
def get_macro_search_order(self, macro_namespace: str):
|
||||
for dispatch_entry in self.dispatch:
|
||||
if dispatch_entry['macro_namespace'] == macro_namespace:
|
||||
return dispatch_entry['search_order']
|
||||
return None
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from typing import Dict, Any, Tuple, Optional, Union
|
||||
from typing import Dict, Any, Tuple, Optional, Union, Callable
|
||||
|
||||
from dbt.clients.jinja import get_rendered, catch_jinja
|
||||
|
||||
@@ -55,12 +55,49 @@ class BaseRenderer:
|
||||
)
|
||||
|
||||
|
||||
def _list_if_none(value):
|
||||
if value is None:
|
||||
value = []
|
||||
return value
|
||||
|
||||
|
||||
def _dict_if_none(value):
|
||||
if value is None:
|
||||
value = {}
|
||||
return value
|
||||
|
||||
|
||||
def _list_if_none_or_string(value):
|
||||
value = _list_if_none(value)
|
||||
if isinstance(value, str):
|
||||
return [value]
|
||||
return value
|
||||
|
||||
|
||||
class ProjectPostprocessor(Dict[Keypath, Callable[[Any], Any]]):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
self[('on-run-start',)] = _list_if_none_or_string
|
||||
self[('on-run-end',)] = _list_if_none_or_string
|
||||
|
||||
for k in ('models', 'seeds', 'snapshots'):
|
||||
self[(k,)] = _dict_if_none
|
||||
self[(k, 'vars')] = _dict_if_none
|
||||
self[(k, 'pre-hook')] = _list_if_none_or_string
|
||||
self[(k, 'post-hook')] = _list_if_none_or_string
|
||||
self[('seeds', 'column_types')] = _dict_if_none
|
||||
|
||||
def postprocess(self, value: Any, key: Keypath) -> Any:
|
||||
if key in self:
|
||||
handler = self[key]
|
||||
return handler(value)
|
||||
|
||||
return value
|
||||
|
||||
|
||||
class DbtProjectYamlRenderer(BaseRenderer):
|
||||
def __init__(
|
||||
self, context: Dict[str, Any], version: Optional[int] = None
|
||||
) -> None:
|
||||
super().__init__(context)
|
||||
self.version: Optional[int] = version
|
||||
_KEYPATH_HANDLERS = ProjectPostprocessor()
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
@@ -72,26 +109,30 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
def get_selector_renderer(self) -> BaseRenderer:
|
||||
return SelectorRenderer(self.context)
|
||||
|
||||
def should_render_keypath_v1(self, keypath: Keypath) -> bool:
|
||||
if not keypath:
|
||||
return True
|
||||
def render_project(
|
||||
self,
|
||||
project: Dict[str, Any],
|
||||
project_root: str,
|
||||
) -> Dict[str, Any]:
|
||||
"""Render the project and insert the project root after rendering."""
|
||||
rendered_project = self.render_data(project)
|
||||
rendered_project['project-root'] = project_root
|
||||
return rendered_project
|
||||
|
||||
first = keypath[0]
|
||||
# run hooks
|
||||
if first in {'on-run-start', 'on-run-end', 'query-comment'}:
|
||||
return False
|
||||
# models have two things to avoid
|
||||
if first in {'seeds', 'models', 'snapshots'}:
|
||||
# model-level hooks
|
||||
if 'pre-hook' in keypath or 'post-hook' in keypath:
|
||||
return False
|
||||
# model-level 'vars' declarations
|
||||
if 'vars' in keypath:
|
||||
return False
|
||||
def render_packages(self, packages: Dict[str, Any]):
|
||||
"""Render the given packages dict"""
|
||||
package_renderer = self.get_package_renderer()
|
||||
return package_renderer.render_data(packages)
|
||||
|
||||
return True
|
||||
def render_selectors(self, selectors: Dict[str, Any]):
|
||||
selector_renderer = self.get_selector_renderer()
|
||||
return selector_renderer.render_data(selectors)
|
||||
|
||||
def should_render_keypath_v2(self, keypath: Keypath) -> bool:
|
||||
def render_entry(self, value: Any, keypath: Keypath) -> Any:
|
||||
result = super().render_entry(value, keypath)
|
||||
return self._KEYPATH_HANDLERS.postprocess(result, keypath)
|
||||
|
||||
def should_render_keypath(self, keypath: Keypath) -> bool:
|
||||
if not keypath:
|
||||
return True
|
||||
|
||||
@@ -104,9 +145,9 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
if first == 'vars':
|
||||
return False
|
||||
|
||||
if first in {'seeds', 'models', 'snapshots', 'seeds'}:
|
||||
if first in {'seeds', 'models', 'snapshots', 'tests'}:
|
||||
keypath_parts = {
|
||||
(k.lstrip('+') if isinstance(k, str) else k)
|
||||
(k.lstrip('+ ') if isinstance(k, str) else k)
|
||||
for k in keypath
|
||||
}
|
||||
# model-level hooks
|
||||
@@ -115,26 +156,6 @@ class DbtProjectYamlRenderer(BaseRenderer):
|
||||
|
||||
return True
|
||||
|
||||
def should_render_keypath(self, keypath: Keypath) -> bool:
|
||||
if self.version == 2:
|
||||
return self.should_render_keypath_v2(keypath)
|
||||
else: # could be None
|
||||
return self.should_render_keypath_v1(keypath)
|
||||
|
||||
def render_data(
|
||||
self, data: Dict[str, Any]
|
||||
) -> Dict[str, Any]:
|
||||
if self.version is None:
|
||||
self.version = data.get('current-version')
|
||||
|
||||
try:
|
||||
return deep_map(self.render_entry, data)
|
||||
except RecursionException:
|
||||
raise DbtProjectError(
|
||||
f'Cycle detected: {self.name} input has a reference to itself',
|
||||
project=data
|
||||
)
|
||||
|
||||
|
||||
class ProfileRenderer(BaseRenderer):
|
||||
@property
|
||||
|
||||
@@ -12,6 +12,7 @@ from .profile import Profile
|
||||
from .project import Project
|
||||
from .renderer import DbtProjectYamlRenderer, ProfileRenderer
|
||||
from .utils import parse_cli_vars
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
from dbt.adapters.factory import get_relation_class_by_name, get_include_paths
|
||||
from dbt.helper_types import FQNPath, PathSet
|
||||
@@ -32,9 +33,8 @@ from dbt.exceptions import (
|
||||
warn_or_error,
|
||||
raise_compiler_error
|
||||
)
|
||||
from dbt.legacy_config_updater import ConfigUpdater
|
||||
|
||||
from hologram import ValidationError
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
|
||||
def _project_quoting_dict(
|
||||
@@ -79,7 +79,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
get_relation_class_by_name(profile.credentials.type)
|
||||
.get_default_quote_policy()
|
||||
.replace_dict(_project_quoting_dict(project, profile))
|
||||
).to_dict()
|
||||
).to_dict(omit_none=True)
|
||||
|
||||
cli_vars: Dict[str, Any] = parse_cli_vars(getattr(args, 'vars', '{}'))
|
||||
|
||||
@@ -87,9 +87,9 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
source_paths=project.source_paths,
|
||||
model_paths=project.model_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
data_paths=project.data_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -98,23 +98,27 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
modules_path=project.modules_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
quoting=quoting,
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
on_run_end=project.on_run_end,
|
||||
dispatch=project.dispatch,
|
||||
seeds=project.seeds,
|
||||
snapshots=project.snapshots,
|
||||
dbt_version=project.dbt_version,
|
||||
packages=project.packages,
|
||||
manifest_selectors=project.manifest_selectors,
|
||||
selectors=project.selectors,
|
||||
query_comment=project.query_comment,
|
||||
sources=project.sources,
|
||||
tests=project.tests,
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
profile_name=profile.profile_name,
|
||||
target_name=profile.target_name,
|
||||
config=profile.config,
|
||||
user_config=profile.user_config,
|
||||
threads=profile.threads,
|
||||
credentials=profile.credentials,
|
||||
args=args,
|
||||
@@ -141,7 +145,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
project = Project.from_project_root(
|
||||
project_root,
|
||||
renderer,
|
||||
verify_version=getattr(self.args, 'version_check', False),
|
||||
verify_version=bool(flags.VERSION_CHECK),
|
||||
)
|
||||
|
||||
cfg = self.from_parts(
|
||||
@@ -173,7 +177,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
:raises DbtProjectError: If the configuration fails validation.
|
||||
"""
|
||||
try:
|
||||
Configuration.from_dict(self.serialize())
|
||||
Configuration.validate(self.serialize())
|
||||
except ValidationError as e:
|
||||
raise DbtProjectError(validator_error_message(e)) from e
|
||||
|
||||
@@ -194,7 +198,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
) -> Tuple[Project, Profile]:
|
||||
# profile_name from the project
|
||||
project_root = args.project_dir if args.project_dir else os.getcwd()
|
||||
version_check = getattr(args, 'version_check', False)
|
||||
version_check = bool(flags.VERSION_CHECK)
|
||||
partial = Project.partial_load(
|
||||
project_root,
|
||||
verify_version=version_check
|
||||
@@ -212,7 +216,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
# get a new renderer using our target information and render the
|
||||
# project
|
||||
ctx = generate_target_context(profile, cli_vars)
|
||||
project_renderer = DbtProjectYamlRenderer(ctx, partial.config_version)
|
||||
project_renderer = DbtProjectYamlRenderer(ctx)
|
||||
project = partial.render(project_renderer)
|
||||
return (project, profile)
|
||||
|
||||
@@ -254,27 +258,6 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
paths.add(path)
|
||||
return frozenset(paths)
|
||||
|
||||
def _get_v1_config_paths(
|
||||
self,
|
||||
config: Dict[str, Any],
|
||||
path: FQNPath,
|
||||
paths: MutableSet[FQNPath],
|
||||
) -> PathSet:
|
||||
keys = ConfigUpdater(self.credentials.type).ConfigKeys
|
||||
|
||||
for key, value in config.items():
|
||||
if isinstance(value, dict):
|
||||
if key in keys:
|
||||
if path not in paths:
|
||||
paths.add(path)
|
||||
else:
|
||||
self._get_v1_config_paths(value, path + (key,), paths)
|
||||
else:
|
||||
if path not in paths:
|
||||
paths.add(path)
|
||||
|
||||
return frozenset(paths)
|
||||
|
||||
def _get_config_paths(
|
||||
self,
|
||||
config: Dict[str, Any],
|
||||
@@ -284,13 +267,15 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
if paths is None:
|
||||
paths = set()
|
||||
|
||||
if self.config_version == 2:
|
||||
return self._get_v2_config_paths(config, path, paths)
|
||||
else:
|
||||
return self._get_v1_config_paths(config, path, paths)
|
||||
for key, value in config.items():
|
||||
if isinstance(value, dict) and not key.startswith('+'):
|
||||
self._get_v2_config_paths(value, path + (key,), paths)
|
||||
else:
|
||||
paths.add(path)
|
||||
return frozenset(paths)
|
||||
|
||||
def get_resource_config_paths(self) -> Dict[str, PathSet]:
|
||||
"""Return a dictionary with 'seeds' and 'models' keys whose values are
|
||||
"""Return a dictionary with resource type keys whose values are
|
||||
lists of lists of strings, where each inner list of strings represents
|
||||
a configured path in the resource.
|
||||
"""
|
||||
@@ -299,6 +284,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
'seeds': self._get_config_paths(self.seeds),
|
||||
'snapshots': self._get_config_paths(self.snapshots),
|
||||
'sources': self._get_config_paths(self.sources),
|
||||
'tests': self._get_config_paths(self.tests),
|
||||
}
|
||||
|
||||
def get_unused_resource_config_paths(
|
||||
@@ -344,6 +330,17 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
if self.dependencies is None:
|
||||
all_projects = {self.project_name: self}
|
||||
internal_packages = get_include_paths(self.credentials.type)
|
||||
# raise exception if fewer installed packages than in packages.yml
|
||||
count_packages_specified = len(self.packages.packages) # type: ignore
|
||||
count_packages_installed = len(tuple(self._get_project_directories()))
|
||||
if count_packages_specified > count_packages_installed:
|
||||
raise_compiler_error(
|
||||
f'dbt found {count_packages_specified} package(s) '
|
||||
f'specified in packages.yml, but only '
|
||||
f'{count_packages_installed} package(s) installed '
|
||||
f'in {self.packages_install_path}. Run "dbt deps" to '
|
||||
f'install package dependencies.'
|
||||
)
|
||||
project_paths = itertools.chain(
|
||||
internal_packages,
|
||||
self._get_project_directories()
|
||||
@@ -379,24 +376,13 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
yield project.project_name, project
|
||||
|
||||
def _get_project_directories(self) -> Iterator[Path]:
|
||||
root = Path(self.project_root) / self.modules_path
|
||||
root = Path(self.project_root) / self.packages_install_path
|
||||
|
||||
if root.exists():
|
||||
for path in root.iterdir():
|
||||
if path.is_dir() and not path.name.startswith('__'):
|
||||
yield path
|
||||
|
||||
def as_v1(self, all_projects: Iterable[str]):
|
||||
if self.config_version == 1:
|
||||
return self
|
||||
|
||||
return self.from_parts(
|
||||
project=Project.as_v1(self, all_projects),
|
||||
profile=self,
|
||||
args=self.args,
|
||||
dependencies=self.dependencies,
|
||||
)
|
||||
|
||||
|
||||
class UnsetCredentials(Credentials):
|
||||
def __init__(self):
|
||||
@@ -406,6 +392,10 @@ class UnsetCredentials(Credentials):
|
||||
def type(self):
|
||||
return None
|
||||
|
||||
@property
|
||||
def unique_field(self):
|
||||
return None
|
||||
|
||||
def connection_info(self, *args, **kwargs):
|
||||
return {}
|
||||
|
||||
@@ -420,14 +410,14 @@ class UnsetConfig(UserConfig):
|
||||
f"'UnsetConfig' object has no attribute {name}"
|
||||
)
|
||||
|
||||
def to_dict(self):
|
||||
def __post_serialize__(self, dct):
|
||||
return {}
|
||||
|
||||
|
||||
class UnsetProfile(Profile):
|
||||
def __init__(self):
|
||||
self.credentials = UnsetCredentials()
|
||||
self.config = UnsetConfig()
|
||||
self.user_config = UnsetConfig()
|
||||
self.profile_name = ''
|
||||
self.target_name = ''
|
||||
self.threads = -1
|
||||
@@ -493,9 +483,9 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
source_paths=project.source_paths,
|
||||
model_paths=project.model_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
data_paths=project.data_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -504,23 +494,27 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
modules_path=project.modules_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
quoting=project.quoting, # we never use this anyway.
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
on_run_end=project.on_run_end,
|
||||
dispatch=project.dispatch,
|
||||
seeds=project.seeds,
|
||||
snapshots=project.snapshots,
|
||||
dbt_version=project.dbt_version,
|
||||
packages=project.packages,
|
||||
manifest_selectors=project.manifest_selectors,
|
||||
selectors=project.selectors,
|
||||
query_comment=project.query_comment,
|
||||
sources=project.sources,
|
||||
tests=project.tests,
|
||||
vars=project.vars,
|
||||
config_version=project.config_version,
|
||||
unrendered=project.unrendered,
|
||||
profile_name='',
|
||||
target_name='',
|
||||
config=UnsetConfig(),
|
||||
user_config=UnsetConfig(),
|
||||
threads=getattr(args, 'threads', 1),
|
||||
credentials=UnsetCredentials(),
|
||||
args=args,
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
from pathlib import Path
|
||||
from typing import Dict, Any, Optional
|
||||
|
||||
from hologram import ValidationError
|
||||
from typing import Dict, Any, Union
|
||||
from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
yaml, Loader, Dumper, load_yaml_text
|
||||
)
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from .renderer import SelectorRenderer
|
||||
|
||||
@@ -10,10 +12,10 @@ from dbt.clients.system import (
|
||||
path_exists,
|
||||
resolve_path_from_base,
|
||||
)
|
||||
from dbt.clients.yaml_helper import load_yaml_text
|
||||
from dbt.contracts.selection import SelectorFile
|
||||
from dbt.exceptions import DbtSelectorsError, RuntimeException
|
||||
from dbt.graph import parse_from_selectors_definition, SelectionSpec
|
||||
from dbt.graph.selector_spec import SelectionCriteria
|
||||
|
||||
MALFORMED_SELECTOR_ERROR = """\
|
||||
The selectors.yml file in this project is malformed. Please double check
|
||||
@@ -27,13 +29,26 @@ Validator Error:
|
||||
"""
|
||||
|
||||
|
||||
class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
class SelectorConfig(Dict[str, Dict[str, Union[SelectionSpec, bool]]]):
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data: Dict[str, Any]) -> 'SelectorConfig':
|
||||
def selectors_from_dict(cls, data: Dict[str, Any]) -> 'SelectorConfig':
|
||||
try:
|
||||
SelectorFile.validate(data)
|
||||
selector_file = SelectorFile.from_dict(data)
|
||||
validate_selector_default(selector_file)
|
||||
selectors = parse_from_selectors_definition(selector_file)
|
||||
except (ValidationError, RuntimeException) as exc:
|
||||
except ValidationError as exc:
|
||||
yaml_sel_cfg = yaml.dump(exc.instance)
|
||||
raise DbtSelectorsError(
|
||||
f"Could not parse selector file data: \n{yaml_sel_cfg}\n"
|
||||
f"Valid root-level selector definitions: "
|
||||
f"union, intersection, string, dictionary. No lists. "
|
||||
f"\nhttps://docs.getdbt.com/reference/node-selection/"
|
||||
f"yaml-selectors",
|
||||
result_type='invalid_selector'
|
||||
) from exc
|
||||
except RuntimeException as exc:
|
||||
raise DbtSelectorsError(
|
||||
f'Could not read selector file data: {exc}',
|
||||
result_type='invalid_selector',
|
||||
@@ -54,7 +69,7 @@ class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
f'Could not render selector data: {exc}',
|
||||
result_type='invalid_selector',
|
||||
) from exc
|
||||
return cls.from_dict(rendered)
|
||||
return cls.selectors_from_dict(rendered)
|
||||
|
||||
@classmethod
|
||||
def from_path(
|
||||
@@ -89,16 +104,98 @@ def selector_data_from_root(project_root: str) -> Dict[str, Any]:
|
||||
|
||||
|
||||
def selector_config_from_data(
|
||||
selectors_data: Optional[Dict[str, Any]]
|
||||
selectors_data: Dict[str, Any]
|
||||
) -> SelectorConfig:
|
||||
if selectors_data is None:
|
||||
if not selectors_data:
|
||||
selectors_data = {'selectors': []}
|
||||
|
||||
try:
|
||||
selectors = SelectorConfig.from_dict(selectors_data)
|
||||
selectors = SelectorConfig.selectors_from_dict(selectors_data)
|
||||
except ValidationError as e:
|
||||
raise DbtSelectorsError(
|
||||
MALFORMED_SELECTOR_ERROR.format(error=str(e.message)),
|
||||
result_type='invalid_selector',
|
||||
) from e
|
||||
return selectors
|
||||
|
||||
|
||||
def validate_selector_default(selector_file: SelectorFile) -> None:
|
||||
"""Check if a selector.yml file has more than 1 default key set to true"""
|
||||
default_set: bool = False
|
||||
default_selector_name: Union[str, None] = None
|
||||
|
||||
for selector in selector_file.selectors:
|
||||
if selector.default is True and default_set is False:
|
||||
default_set = True
|
||||
default_selector_name = selector.name
|
||||
continue
|
||||
if selector.default is True and default_set is True:
|
||||
raise DbtSelectorsError(
|
||||
"Error when parsing the selector file. "
|
||||
"Found multiple selectors with `default: true`:"
|
||||
f"{default_selector_name} and {selector.name}"
|
||||
)
|
||||
|
||||
|
||||
# These are utilities to clean up the dictionary created from
|
||||
# selectors.yml by turning the cli-string format entries into
|
||||
# normalized dictionary entries. It parallels the flow in
|
||||
# dbt/graph/cli.py. If changes are made there, it might
|
||||
# be necessary to make changes here. Ideally it would be
|
||||
# good to combine the two flows into one at some point.
|
||||
class SelectorDict:
|
||||
|
||||
@classmethod
|
||||
def parse_dict_definition(cls, definition):
|
||||
key = list(definition)[0]
|
||||
value = definition[key]
|
||||
if isinstance(value, list):
|
||||
new_values = []
|
||||
for sel_def in value:
|
||||
new_value = cls.parse_from_definition(sel_def)
|
||||
new_values.append(new_value)
|
||||
value = new_values
|
||||
if key == 'exclude':
|
||||
definition = {key: value}
|
||||
elif len(definition) == 1:
|
||||
definition = {'method': key, 'value': value}
|
||||
return definition
|
||||
|
||||
@classmethod
|
||||
def parse_a_definition(cls, def_type, definition):
|
||||
# this definition must be a list
|
||||
new_dict = {def_type: []}
|
||||
for sel_def in definition[def_type]:
|
||||
if isinstance(sel_def, dict):
|
||||
sel_def = cls.parse_from_definition(sel_def)
|
||||
new_dict[def_type].append(sel_def)
|
||||
elif isinstance(sel_def, str):
|
||||
sel_def = SelectionCriteria.dict_from_single_spec(sel_def)
|
||||
new_dict[def_type].append(sel_def)
|
||||
else:
|
||||
new_dict[def_type].append(sel_def)
|
||||
return new_dict
|
||||
|
||||
@classmethod
|
||||
def parse_from_definition(cls, definition):
|
||||
if isinstance(definition, str):
|
||||
definition = SelectionCriteria.dict_from_single_spec(definition)
|
||||
elif 'union' in definition:
|
||||
definition = cls.parse_a_definition('union', definition)
|
||||
elif 'intersection' in definition:
|
||||
definition = cls.parse_a_definition('intersection', definition)
|
||||
elif isinstance(definition, dict):
|
||||
definition = cls.parse_dict_definition(definition)
|
||||
return definition
|
||||
|
||||
# This is the normal entrypoint of this code. Give it the
|
||||
# list of selectors generated from the selectors.yml file.
|
||||
@classmethod
|
||||
def parse_from_selectors_list(cls, selectors):
|
||||
selector_dict = {}
|
||||
for selector in selectors:
|
||||
sel_name = selector['name']
|
||||
selector_dict[sel_name] = selector
|
||||
definition = cls.parse_from_definition(selector['definition'])
|
||||
selector_dict[sel_name]['definition'] = definition
|
||||
return selector_dict
|
||||
|
||||
@@ -7,17 +7,20 @@ from typing import (
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
from dbt.clients.jinja import undefined_error, get_rendered
|
||||
from dbt.clients import yaml_helper
|
||||
from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
yaml, safe_load, SafeLoader, Loader, Dumper
|
||||
)
|
||||
from dbt.contracts.graph.compiled import CompiledResource
|
||||
from dbt.exceptions import raise_compiler_error, MacroReturn
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import MacroEventInfo, MacroEventDebug
|
||||
from dbt.version import __version__ as dbt_version
|
||||
|
||||
import yaml
|
||||
# These modules are added to the context. Consider alternative
|
||||
# approaches which will extend well to potentially many modules
|
||||
import pytz
|
||||
import datetime
|
||||
import re
|
||||
|
||||
|
||||
def get_pytz_module_context() -> Dict[str, Any]:
|
||||
@@ -42,10 +45,19 @@ def get_datetime_module_context() -> Dict[str, Any]:
|
||||
}
|
||||
|
||||
|
||||
def get_re_module_context() -> Dict[str, Any]:
|
||||
context_exports = re.__all__
|
||||
|
||||
return {
|
||||
name: getattr(re, name) for name in context_exports
|
||||
}
|
||||
|
||||
|
||||
def get_context_modules() -> Dict[str, Dict[str, Any]]:
|
||||
return {
|
||||
'pytz': get_pytz_module_context(),
|
||||
'datetime': get_datetime_module_context(),
|
||||
're': get_re_module_context(),
|
||||
}
|
||||
|
||||
|
||||
@@ -162,6 +174,7 @@ class BaseContext(metaclass=ContextMeta):
|
||||
builtins[key] = value
|
||||
return builtins
|
||||
|
||||
# no dbtClassMixin so this is not an actual override
|
||||
def to_dict(self):
|
||||
self._ctx['context'] = self._ctx
|
||||
builtins = self.generate_builtins()
|
||||
@@ -384,7 +397,7 @@ class BaseContext(metaclass=ContextMeta):
|
||||
-- ["good"]
|
||||
"""
|
||||
try:
|
||||
return yaml_helper.safe_load(value)
|
||||
return safe_load(value)
|
||||
except (AttributeError, ValueError, yaml.YAMLError):
|
||||
return default
|
||||
|
||||
@@ -431,9 +444,9 @@ class BaseContext(metaclass=ContextMeta):
|
||||
{% endmacro %}"
|
||||
"""
|
||||
if info:
|
||||
logger.info(msg)
|
||||
fire_event(MacroEventInfo(msg))
|
||||
else:
|
||||
logger.debug(msg)
|
||||
fire_event(MacroEventDebug(msg))
|
||||
return ''
|
||||
|
||||
@contextproperty
|
||||
@@ -512,18 +525,13 @@ class BaseContext(metaclass=ContextMeta):
|
||||
-- no-op
|
||||
{% endif %}
|
||||
|
||||
The list of valid flags are:
|
||||
|
||||
- `flags.STRICT_MODE`: True if `--strict` (or `-S`) was provided on the
|
||||
command line
|
||||
- `flags.FULL_REFRESH`: True if `--full-refresh` was provided on the
|
||||
command line
|
||||
- `flags.NON_DESTRUCTIVE`: True if `--non-destructive` was provided on
|
||||
the command line
|
||||
This supports all flags defined in flags submodule (core/dbt/flags.py)
|
||||
TODO: Replace with object that provides read-only access to flag values
|
||||
"""
|
||||
return flags
|
||||
|
||||
|
||||
def generate_base_context(cli_vars: Dict[str, Any]) -> Dict[str, Any]:
|
||||
ctx = BaseContext(cli_vars)
|
||||
# This is not a Mashumaro to_dict call
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -46,17 +46,16 @@ class ConfiguredVar(Var):
|
||||
if var_name in self._config.cli_vars:
|
||||
return self._config.cli_vars[var_name]
|
||||
|
||||
if self._config.config_version == 2 and my_config.config_version == 2:
|
||||
adapter_type = self._config.credentials.type
|
||||
lookup = FQNLookup(self._project_name)
|
||||
active_vars = self._config.vars.vars_for(lookup, adapter_type)
|
||||
all_vars = MultiDict([active_vars])
|
||||
adapter_type = self._config.credentials.type
|
||||
lookup = FQNLookup(self._project_name)
|
||||
active_vars = self._config.vars.vars_for(lookup, adapter_type)
|
||||
all_vars = MultiDict([active_vars])
|
||||
|
||||
if self._config.project_name != my_config.project_name:
|
||||
all_vars.add(my_config.vars.vars_for(lookup, adapter_type))
|
||||
if self._config.project_name != my_config.project_name:
|
||||
all_vars.add(my_config.vars.vars_for(lookup, adapter_type))
|
||||
|
||||
if var_name in all_vars:
|
||||
return all_vars[var_name]
|
||||
if var_name in all_vars:
|
||||
return all_vars[var_name]
|
||||
|
||||
if default is not Var._VAR_NOTSET:
|
||||
return default
|
||||
@@ -76,8 +75,26 @@ class SchemaYamlContext(ConfiguredContext):
|
||||
)
|
||||
|
||||
|
||||
class MacroResolvingContext(ConfiguredContext):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
@contextproperty
|
||||
def var(self) -> ConfiguredVar:
|
||||
return ConfiguredVar(
|
||||
self._ctx, self.config, self.config.project_name
|
||||
)
|
||||
|
||||
|
||||
def generate_schema_yml(
|
||||
config: AdapterRequiredConfig, project_name: str
|
||||
) -> Dict[str, Any]:
|
||||
ctx = SchemaYamlContext(config, project_name)
|
||||
return ctx.to_dict()
|
||||
|
||||
|
||||
def generate_macro_context(
|
||||
config: AdapterRequiredConfig,
|
||||
) -> Dict[str, Any]:
|
||||
ctx = MacroResolvingContext(config)
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -1,11 +1,11 @@
|
||||
from abc import abstractmethod
|
||||
from copy import deepcopy
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Iterator, Dict, Any, TypeVar, Union
|
||||
from typing import List, Iterator, Dict, Any, TypeVar, Generic
|
||||
|
||||
from dbt.config import RuntimeConfig, Project
|
||||
from dbt.config import RuntimeConfig, Project, IsFQNResource
|
||||
from dbt.contracts.graph.model_config import BaseConfig, get_config_for
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.legacy_config_updater import ConfigUpdater, IsFQNResource
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.utils import fqn_search
|
||||
|
||||
@@ -17,83 +17,66 @@ class ModelParts(IsFQNResource):
|
||||
package_name: str
|
||||
|
||||
|
||||
class LegacyContextConfig:
|
||||
def __init__(
|
||||
self,
|
||||
active_project: RuntimeConfig,
|
||||
own_project: Project,
|
||||
fqn: List[str],
|
||||
node_type: NodeType,
|
||||
):
|
||||
self._config = None
|
||||
self._active_project: RuntimeConfig = active_project
|
||||
self._own_project: Project = own_project
|
||||
T = TypeVar('T') # any old type
|
||||
C = TypeVar('C', bound=BaseConfig)
|
||||
|
||||
self._model = ModelParts(
|
||||
fqn=fqn,
|
||||
resource_type=node_type,
|
||||
package_name=self._own_project.project_name,
|
||||
)
|
||||
|
||||
self._updater = ConfigUpdater(active_project.credentials.type)
|
||||
class ConfigSource:
|
||||
def __init__(self, project):
|
||||
self.project = project
|
||||
|
||||
# the config options defined within the model
|
||||
self.in_model_config: Dict[str, Any] = {}
|
||||
def get_config_dict(self, resource_type: NodeType):
|
||||
...
|
||||
|
||||
def get_default(self) -> Dict[str, Any]:
|
||||
defaults = {"enabled": True, "materialized": "view"}
|
||||
|
||||
if self._model.resource_type == NodeType.Seed:
|
||||
defaults['materialized'] = 'seed'
|
||||
elif self._model.resource_type == NodeType.Snapshot:
|
||||
defaults['materialized'] = 'snapshot'
|
||||
class UnrenderedConfig(ConfigSource):
|
||||
def __init__(self, project: Project):
|
||||
self.project = project
|
||||
|
||||
if self._model.resource_type == NodeType.Test:
|
||||
defaults['severity'] = 'ERROR'
|
||||
|
||||
return defaults
|
||||
|
||||
def build_config_dict(self, base: bool = False) -> Dict[str, Any]:
|
||||
defaults = self.get_default()
|
||||
active_config = self.load_config_from_active_project()
|
||||
|
||||
if self._active_project.project_name == self._own_project.project_name:
|
||||
cfg = self._updater.merge(
|
||||
defaults, active_config, self.in_model_config
|
||||
)
|
||||
def get_config_dict(self, resource_type: NodeType) -> Dict[str, Any]:
|
||||
unrendered = self.project.unrendered.project_dict
|
||||
if resource_type == NodeType.Seed:
|
||||
model_configs = unrendered.get('seeds')
|
||||
elif resource_type == NodeType.Snapshot:
|
||||
model_configs = unrendered.get('snapshots')
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = unrendered.get('sources')
|
||||
elif resource_type == NodeType.Test:
|
||||
model_configs = unrendered.get('tests')
|
||||
else:
|
||||
own_config = self.load_config_from_own_project()
|
||||
model_configs = unrendered.get('models')
|
||||
|
||||
cfg = self._updater.merge(
|
||||
defaults, own_config, self.in_model_config, active_config
|
||||
)
|
||||
|
||||
return cfg
|
||||
|
||||
def _translate_adapter_aliases(self, config: Dict[str, Any]):
|
||||
return self._active_project.credentials.translate_aliases(config)
|
||||
|
||||
def update_in_model_config(self, config: Dict[str, Any]) -> None:
|
||||
config = self._translate_adapter_aliases(config)
|
||||
self._updater.update_into(self.in_model_config, config)
|
||||
|
||||
def load_config_from_own_project(self) -> Dict[str, Any]:
|
||||
return self._updater.get_project_config(self._model, self._own_project)
|
||||
|
||||
def load_config_from_active_project(self) -> Dict[str, Any]:
|
||||
return self._updater.get_project_config(
|
||||
self._model,
|
||||
self._active_project,
|
||||
)
|
||||
if model_configs is None:
|
||||
return {}
|
||||
else:
|
||||
return model_configs
|
||||
|
||||
|
||||
T = TypeVar('T', bound=BaseConfig)
|
||||
class RenderedConfig(ConfigSource):
|
||||
def __init__(self, project: Project):
|
||||
self.project = project
|
||||
|
||||
def get_config_dict(self, resource_type: NodeType) -> Dict[str, Any]:
|
||||
if resource_type == NodeType.Seed:
|
||||
model_configs = self.project.seeds
|
||||
elif resource_type == NodeType.Snapshot:
|
||||
model_configs = self.project.snapshots
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = self.project.sources
|
||||
elif resource_type == NodeType.Test:
|
||||
model_configs = self.project.tests
|
||||
else:
|
||||
model_configs = self.project.models
|
||||
return model_configs
|
||||
|
||||
|
||||
class ContextConfigGenerator:
|
||||
class BaseContextConfigGenerator(Generic[T]):
|
||||
def __init__(self, active_project: RuntimeConfig):
|
||||
self._active_project = active_project
|
||||
|
||||
def get_config_source(self, project: Project) -> ConfigSource:
|
||||
return RenderedConfig(project)
|
||||
|
||||
def get_node_project(self, project_name: str):
|
||||
if project_name == self._active_project.project_name:
|
||||
return self._active_project
|
||||
@@ -108,19 +91,13 @@ class ContextConfigGenerator:
|
||||
def _project_configs(
|
||||
self, project: Project, fqn: List[str], resource_type: NodeType
|
||||
) -> Iterator[Dict[str, Any]]:
|
||||
if resource_type == NodeType.Seed:
|
||||
model_configs = project.seeds
|
||||
elif resource_type == NodeType.Snapshot:
|
||||
model_configs = project.snapshots
|
||||
elif resource_type == NodeType.Source:
|
||||
model_configs = project.sources
|
||||
else:
|
||||
model_configs = project.models
|
||||
src = self.get_config_source(project)
|
||||
model_configs = src.get_config_dict(resource_type)
|
||||
for level_config in fqn_search(model_configs, fqn):
|
||||
result = {}
|
||||
for key, value in level_config.items():
|
||||
if key.startswith('+'):
|
||||
result[key[1:]] = deepcopy(value)
|
||||
result[key[1:].strip()] = deepcopy(value)
|
||||
elif not isinstance(value, dict):
|
||||
result[key] = deepcopy(value)
|
||||
|
||||
@@ -131,9 +108,82 @@ class ContextConfigGenerator:
|
||||
) -> Iterator[Dict[str, Any]]:
|
||||
return self._project_configs(self._active_project, fqn, resource_type)
|
||||
|
||||
@abstractmethod
|
||||
def _update_from_config(
|
||||
self, result: T, partial: Dict[str, Any], validate: bool = False
|
||||
) -> T:
|
||||
...
|
||||
|
||||
@abstractmethod
|
||||
def initial_result(self, resource_type: NodeType, base: bool) -> T:
|
||||
...
|
||||
|
||||
def calculate_node_config(
|
||||
self,
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: Dict[str, Any] = None
|
||||
) -> BaseConfig:
|
||||
own_config = self.get_node_project(project_name)
|
||||
|
||||
result = self.initial_result(resource_type=resource_type, base=base)
|
||||
|
||||
project_configs = self._project_configs(own_config, fqn, resource_type)
|
||||
for fqn_config in project_configs:
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
|
||||
# When schema files patch config, it has lower precedence than
|
||||
# config in the models (config_call_dict), so we add the patch_config_dict
|
||||
# before the config_call_dict
|
||||
if patch_config_dict:
|
||||
result = self._update_from_config(result, patch_config_dict)
|
||||
|
||||
# config_calls are created in the 'experimental' model parser and
|
||||
# the ParseConfigObject (via add_config_call)
|
||||
result = self._update_from_config(result, config_call_dict)
|
||||
|
||||
if own_config.project_name != self._active_project.project_name:
|
||||
for fqn_config in self._active_project_configs(fqn, resource_type):
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
|
||||
# this is mostly impactful in the snapshot config case
|
||||
return result
|
||||
|
||||
@abstractmethod
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: Dict[str, Any],
|
||||
) -> Dict[str, Any]:
|
||||
...
|
||||
|
||||
|
||||
class ContextConfigGenerator(BaseContextConfigGenerator[C]):
|
||||
def __init__(self, active_project: RuntimeConfig):
|
||||
self._active_project = active_project
|
||||
|
||||
def get_config_source(self, project: Project) -> ConfigSource:
|
||||
return RenderedConfig(project)
|
||||
|
||||
def initial_result(self, resource_type: NodeType, base: bool) -> C:
|
||||
# defaults, own_config, config calls, active_config (if != own_config)
|
||||
config_cls = get_config_for(resource_type, base=base)
|
||||
# Calculate the defaults. We don't want to validate the defaults,
|
||||
# because it might be invalid in the case of required config members
|
||||
# (such as on snapshots!)
|
||||
result = config_cls.from_dict({})
|
||||
return result
|
||||
|
||||
def _update_from_config(
|
||||
self, result: C, partial: Dict[str, Any], validate: bool = False
|
||||
) -> C:
|
||||
translated = self._active_project.credentials.translate_aliases(
|
||||
partial
|
||||
)
|
||||
@@ -143,35 +193,67 @@ class ContextConfigGenerator:
|
||||
validate=validate
|
||||
)
|
||||
|
||||
def calculate_node_config(
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_calls: List[Dict[str, Any]],
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
) -> BaseConfig:
|
||||
own_config = self.get_node_project(project_name)
|
||||
# defaults, own_config, config calls, active_config (if != own_config)
|
||||
config_cls = get_config_for(resource_type, base=base)
|
||||
# Calculate the defaults. We don't want to validate the defaults,
|
||||
# because it might be invalid in the case of required config members
|
||||
# (such as on snapshots!)
|
||||
result = config_cls.from_dict({}, validate=False)
|
||||
patch_config_dict: dict = None
|
||||
) -> Dict[str, Any]:
|
||||
config = self.calculate_node_config(
|
||||
config_call_dict=config_call_dict,
|
||||
fqn=fqn,
|
||||
resource_type=resource_type,
|
||||
project_name=project_name,
|
||||
base=base,
|
||||
patch_config_dict=patch_config_dict
|
||||
)
|
||||
finalized = config.finalize_and_validate()
|
||||
return finalized.to_dict(omit_none=True)
|
||||
|
||||
project_configs = self._project_configs(own_config, fqn, resource_type)
|
||||
for fqn_config in project_configs:
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
|
||||
for config_call in config_calls:
|
||||
result = self._update_from_config(result, config_call)
|
||||
class UnrenderedConfigGenerator(BaseContextConfigGenerator[Dict[str, Any]]):
|
||||
def get_config_source(self, project: Project) -> ConfigSource:
|
||||
return UnrenderedConfig(project)
|
||||
|
||||
if own_config.project_name != self._active_project.project_name:
|
||||
for fqn_config in self._active_project_configs(fqn, resource_type):
|
||||
result = self._update_from_config(result, fqn_config)
|
||||
def calculate_node_config_dict(
|
||||
self,
|
||||
config_call_dict: Dict[str, Any],
|
||||
fqn: List[str],
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
base: bool,
|
||||
patch_config_dict: dict = None
|
||||
) -> Dict[str, Any]:
|
||||
return self.calculate_node_config(
|
||||
config_call_dict=config_call_dict,
|
||||
fqn=fqn,
|
||||
resource_type=resource_type,
|
||||
project_name=project_name,
|
||||
base=base,
|
||||
patch_config_dict=patch_config_dict
|
||||
)
|
||||
|
||||
# this is mostly impactful in the snapshot config case
|
||||
return result.finalize_and_validate()
|
||||
def initial_result(
|
||||
self,
|
||||
resource_type: NodeType,
|
||||
base: bool
|
||||
) -> Dict[str, Any]:
|
||||
return {}
|
||||
|
||||
def _update_from_config(
|
||||
self,
|
||||
result: Dict[str, Any],
|
||||
partial: Dict[str, Any],
|
||||
validate: bool = False,
|
||||
) -> Dict[str, Any]:
|
||||
translated = self._active_project.credentials.translate_aliases(
|
||||
partial
|
||||
)
|
||||
result.update(translated)
|
||||
return result
|
||||
|
||||
|
||||
class ContextConfig:
|
||||
@@ -182,23 +264,50 @@ class ContextConfig:
|
||||
resource_type: NodeType,
|
||||
project_name: str,
|
||||
) -> None:
|
||||
self._config_calls: List[Dict[str, Any]] = []
|
||||
self._cfg_source = ContextConfigGenerator(active_project)
|
||||
self._config_call_dict: Dict[str, Any] = {}
|
||||
self._active_project = active_project
|
||||
self._fqn = fqn
|
||||
self._resource_type = resource_type
|
||||
self._project_name = project_name
|
||||
|
||||
def update_in_model_config(self, opts: Dict[str, Any]) -> None:
|
||||
self._config_calls.append(opts)
|
||||
def add_config_call(self, opts: Dict[str, Any]) -> None:
|
||||
dct = self._config_call_dict
|
||||
self._add_config_call(dct, opts)
|
||||
|
||||
def build_config_dict(self, base: bool = False) -> Dict[str, Any]:
|
||||
return self._cfg_source.calculate_node_config(
|
||||
config_calls=self._config_calls,
|
||||
@classmethod
|
||||
def _add_config_call(cls, config_call_dict, opts: Dict[str, Any]) -> None:
|
||||
for k, v in opts.items():
|
||||
# MergeBehavior for post-hook and pre-hook is to collect all
|
||||
# values, instead of overwriting
|
||||
if k in BaseConfig.mergebehavior['append']:
|
||||
if not isinstance(v, list):
|
||||
v = [v]
|
||||
if k in BaseConfig.mergebehavior['update'] and not isinstance(v, dict):
|
||||
raise InternalException(f'expected dict, got {v}')
|
||||
if k in config_call_dict and isinstance(config_call_dict[k], list):
|
||||
config_call_dict[k].extend(v)
|
||||
elif k in config_call_dict and isinstance(config_call_dict[k], dict):
|
||||
config_call_dict[k].update(v)
|
||||
else:
|
||||
config_call_dict[k] = v
|
||||
|
||||
def build_config_dict(
|
||||
self,
|
||||
base: bool = False,
|
||||
*,
|
||||
rendered: bool = True,
|
||||
patch_config_dict: dict = None
|
||||
) -> Dict[str, Any]:
|
||||
if rendered:
|
||||
src = ContextConfigGenerator(self._active_project)
|
||||
else:
|
||||
src = UnrenderedConfigGenerator(self._active_project)
|
||||
|
||||
return src.calculate_node_config_dict(
|
||||
config_call_dict=self._config_call_dict,
|
||||
fqn=self._fqn,
|
||||
resource_type=self._resource_type,
|
||||
project_name=self._project_name,
|
||||
base=base,
|
||||
).to_dict()
|
||||
|
||||
|
||||
ContextConfigType = Union[LegacyContextConfig, ContextConfig]
|
||||
patch_config_dict=patch_config_dict
|
||||
)
|
||||
|
||||
@@ -57,14 +57,19 @@ class DocsRuntimeContext(SchemaYamlContext):
|
||||
else:
|
||||
doc_invalid_args(self.node, args)
|
||||
|
||||
# ParsedDocumentation
|
||||
target_doc = self.manifest.resolve_doc(
|
||||
doc_name,
|
||||
doc_package_name,
|
||||
self._project_name,
|
||||
self.node.package_name,
|
||||
)
|
||||
|
||||
if target_doc is None:
|
||||
if target_doc:
|
||||
file_id = target_doc.file_id
|
||||
if file_id in self.manifest.files:
|
||||
source_file = self.manifest.files[file_id]
|
||||
source_file.add_node(self.node.unique_id)
|
||||
else:
|
||||
doc_target_not_found(self.node, doc_name, doc_package_name)
|
||||
|
||||
return target_doc.block_contents
|
||||
@@ -77,4 +82,5 @@ def generate_runtime_docs(
|
||||
current_project: str,
|
||||
) -> Dict[str, Any]:
|
||||
ctx = DocsRuntimeContext(config, target, manifest, current_project)
|
||||
# This is not a Mashumaro to_dict call
|
||||
return ctx.to_dict()
|
||||
|
||||
199
core/dbt/context/macro_resolver.py
Normal file
199
core/dbt/context/macro_resolver.py
Normal file
@@ -0,0 +1,199 @@
|
||||
from typing import (
|
||||
Dict, MutableMapping, Optional
|
||||
)
|
||||
from dbt.contracts.graph.parsed import ParsedMacro
|
||||
from dbt.exceptions import raise_duplicate_macro_name, raise_compiler_error
|
||||
from dbt.include.global_project import PROJECT_NAME as GLOBAL_PROJECT_NAME
|
||||
from dbt.clients.jinja import MacroGenerator
|
||||
|
||||
MacroNamespace = Dict[str, ParsedMacro]
|
||||
|
||||
|
||||
# This class builds the MacroResolver by adding macros
|
||||
# to various categories for finding macros in the right order,
|
||||
# so that higher precedence macros are found first.
|
||||
# This functionality is also provided by the MacroNamespace,
|
||||
# but the intention is to eventually replace that class.
|
||||
# This enables us to get the macro unique_id without
|
||||
# processing every macro in the project.
|
||||
# Note: the root project macros override everything in the
|
||||
# dbt internal projects. External projects (dependencies) will
|
||||
# use their own macros first, then pull from the root project
|
||||
# followed by dbt internal projects.
|
||||
class MacroResolver:
|
||||
def __init__(
|
||||
self,
|
||||
macros: MutableMapping[str, ParsedMacro],
|
||||
root_project_name: str,
|
||||
internal_package_names,
|
||||
) -> None:
|
||||
self.root_project_name = root_project_name
|
||||
self.macros = macros
|
||||
# internal packages comes from get_adapter_package_names
|
||||
self.internal_package_names = internal_package_names
|
||||
|
||||
# To be filled in from macros.
|
||||
self.internal_packages: Dict[str, MacroNamespace] = {}
|
||||
self.packages: Dict[str, MacroNamespace] = {}
|
||||
self.root_package_macros: MacroNamespace = {}
|
||||
|
||||
# add the macros to internal_packages, packages, and root packages
|
||||
self.add_macros()
|
||||
self._build_internal_packages_namespace()
|
||||
self._build_macros_by_name()
|
||||
|
||||
def _build_internal_packages_namespace(self):
|
||||
# Iterate in reverse-order and overwrite: the packages that are first
|
||||
# in the list are the ones we want to "win".
|
||||
self.internal_packages_namespace: MacroNamespace = {}
|
||||
for pkg in reversed(self.internal_package_names):
|
||||
if pkg in self.internal_packages:
|
||||
# Turn the internal packages into a flat namespace
|
||||
self.internal_packages_namespace.update(
|
||||
self.internal_packages[pkg])
|
||||
|
||||
# search order:
|
||||
# local_namespace (package of particular node), not including
|
||||
# the internal packages or the root package
|
||||
# This means that within an extra package, it uses its own macros
|
||||
# root package namespace
|
||||
# non-internal packages (that aren't local or root)
|
||||
# dbt internal packages
|
||||
def _build_macros_by_name(self):
|
||||
macros_by_name = {}
|
||||
|
||||
# all internal packages (already in the right order)
|
||||
for macro in self.internal_packages_namespace.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
|
||||
# non-internal packages
|
||||
for fnamespace in self.packages.values():
|
||||
for macro in fnamespace.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
|
||||
# root package macros
|
||||
for macro in self.root_package_macros.values():
|
||||
macros_by_name[macro.name] = macro
|
||||
|
||||
self.macros_by_name = macros_by_name
|
||||
|
||||
def _add_macro_to(
|
||||
self,
|
||||
package_namespaces: Dict[str, MacroNamespace],
|
||||
macro: ParsedMacro,
|
||||
):
|
||||
if macro.package_name in package_namespaces:
|
||||
namespace = package_namespaces[macro.package_name]
|
||||
else:
|
||||
namespace = {}
|
||||
package_namespaces[macro.package_name] = namespace
|
||||
|
||||
if macro.name in namespace:
|
||||
raise_duplicate_macro_name(
|
||||
macro, macro, macro.package_name
|
||||
)
|
||||
package_namespaces[macro.package_name][macro.name] = macro
|
||||
|
||||
def add_macro(self, macro: ParsedMacro):
|
||||
macro_name: str = macro.name
|
||||
|
||||
# internal macros (from plugins) will be processed separately from
|
||||
# project macros, so store them in a different place
|
||||
if macro.package_name in self.internal_package_names:
|
||||
self._add_macro_to(self.internal_packages, macro)
|
||||
else:
|
||||
# if it's not an internal package
|
||||
self._add_macro_to(self.packages, macro)
|
||||
# add to root_package_macros if it's in the root package
|
||||
if macro.package_name == self.root_project_name:
|
||||
self.root_package_macros[macro_name] = macro
|
||||
|
||||
def add_macros(self):
|
||||
for macro in self.macros.values():
|
||||
self.add_macro(macro)
|
||||
|
||||
def get_macro(self, local_package, macro_name):
|
||||
local_package_macros = {}
|
||||
if (local_package not in self.internal_package_names and
|
||||
local_package in self.packages):
|
||||
local_package_macros = self.packages[local_package]
|
||||
# First: search the local packages for this macro
|
||||
if macro_name in local_package_macros:
|
||||
return local_package_macros[macro_name]
|
||||
# Now look up in the standard search order
|
||||
if macro_name in self.macros_by_name:
|
||||
return self.macros_by_name[macro_name]
|
||||
return None
|
||||
|
||||
def get_macro_id(self, local_package, macro_name):
|
||||
macro = self.get_macro(local_package, macro_name)
|
||||
if macro is None:
|
||||
return None
|
||||
else:
|
||||
return macro.unique_id
|
||||
|
||||
|
||||
# Currently this is just used by test processing in the schema
|
||||
# parser (in connection with the MacroResolver). Future work
|
||||
# will extend the use of these classes to other parsing areas.
|
||||
# One of the features of this class compared to the MacroNamespace
|
||||
# is that you can limit the number of macros provided to the
|
||||
# context dictionary in the 'to_dict' manifest method.
|
||||
class TestMacroNamespace:
|
||||
def __init__(
|
||||
self, macro_resolver, ctx, node, thread_ctx, depends_on_macros
|
||||
):
|
||||
self.macro_resolver = macro_resolver
|
||||
self.ctx = ctx
|
||||
self.node = node # can be none
|
||||
self.thread_ctx = thread_ctx
|
||||
self.local_namespace = {}
|
||||
self.project_namespace = {}
|
||||
if depends_on_macros:
|
||||
dep_macros = []
|
||||
self.recursively_get_depends_on_macros(depends_on_macros, dep_macros)
|
||||
for macro_unique_id in dep_macros:
|
||||
if macro_unique_id in self.macro_resolver.macros:
|
||||
# Split up the macro unique_id to get the project_name
|
||||
(_, project_name, macro_name) = macro_unique_id.split('.')
|
||||
# Save the plain macro_name in the local_namespace
|
||||
macro = self.macro_resolver.macros[macro_unique_id]
|
||||
macro_gen = MacroGenerator(
|
||||
macro, self.ctx, self.node, self.thread_ctx,
|
||||
)
|
||||
self.local_namespace[macro_name] = macro_gen
|
||||
# We also need the two part macro name
|
||||
if project_name not in self.project_namespace:
|
||||
self.project_namespace[project_name] = {}
|
||||
self.project_namespace[project_name][macro_name] = macro_gen
|
||||
|
||||
def recursively_get_depends_on_macros(self, depends_on_macros, dep_macros):
|
||||
for macro_unique_id in depends_on_macros:
|
||||
if macro_unique_id in dep_macros:
|
||||
continue
|
||||
dep_macros.append(macro_unique_id)
|
||||
if macro_unique_id in self.macro_resolver.macros:
|
||||
macro = self.macro_resolver.macros[macro_unique_id]
|
||||
if macro.depends_on.macros:
|
||||
self.recursively_get_depends_on_macros(macro.depends_on.macros, dep_macros)
|
||||
|
||||
def get_from_package(
|
||||
self, package_name: Optional[str], name: str
|
||||
) -> Optional[MacroGenerator]:
|
||||
macro = None
|
||||
if package_name is None:
|
||||
macro = self.macro_resolver.macros_by_name.get(name)
|
||||
elif package_name == GLOBAL_PROJECT_NAME:
|
||||
macro = self.macro_resolver.internal_packages_namespace.get(name)
|
||||
elif package_name in self.macro_resolver.packages:
|
||||
macro = self.macro_resolver.packages[package_name].get(name)
|
||||
else:
|
||||
raise_compiler_error(
|
||||
f"Could not find package '{package_name}'"
|
||||
)
|
||||
if not macro:
|
||||
return None
|
||||
macro_func = MacroGenerator(
|
||||
macro, self.ctx, self.node, self.thread_ctx
|
||||
)
|
||||
return macro_func
|
||||
@@ -15,13 +15,21 @@ NamespaceMember = Union[FlatNamespace, MacroGenerator]
|
||||
FullNamespace = Dict[str, NamespaceMember]
|
||||
|
||||
|
||||
# The point of this class is to collect the various macros
|
||||
# and provide the ability to flatten them into the ManifestContexts
|
||||
# that are created for jinja, so that macro calls can be resolved.
|
||||
# Creates special iterators and _keys methods to flatten the lists.
|
||||
# When this class is created it has a static 'local_namespace' which
|
||||
# depends on the package of the node, so it only works for one
|
||||
# particular local package at a time for "flattening" into a context.
|
||||
# 'get_by_package' should work for any macro.
|
||||
class MacroNamespace(Mapping):
|
||||
def __init__(
|
||||
self,
|
||||
global_namespace: FlatNamespace,
|
||||
local_namespace: FlatNamespace,
|
||||
global_project_namespace: FlatNamespace,
|
||||
packages: Dict[str, FlatNamespace],
|
||||
global_namespace: FlatNamespace, # root package macros
|
||||
local_namespace: FlatNamespace, # packages for *this* node
|
||||
global_project_namespace: FlatNamespace, # internal packages
|
||||
packages: Dict[str, FlatNamespace], # non-internal packages
|
||||
):
|
||||
self.global_namespace: FlatNamespace = global_namespace
|
||||
self.local_namespace: FlatNamespace = local_namespace
|
||||
@@ -29,20 +37,24 @@ class MacroNamespace(Mapping):
|
||||
self.global_project_namespace: FlatNamespace = global_project_namespace
|
||||
|
||||
def _search_order(self) -> Iterable[Union[FullNamespace, FlatNamespace]]:
|
||||
yield self.local_namespace
|
||||
yield self.global_namespace
|
||||
yield self.packages
|
||||
yield self.local_namespace # local package
|
||||
yield self.global_namespace # root package
|
||||
yield self.packages # non-internal packages
|
||||
yield {
|
||||
GLOBAL_PROJECT_NAME: self.global_project_namespace,
|
||||
GLOBAL_PROJECT_NAME: self.global_project_namespace, # dbt
|
||||
}
|
||||
yield self.global_project_namespace
|
||||
yield self.global_project_namespace # other internal project besides dbt
|
||||
|
||||
# provides special keys method for MacroNamespace iterator
|
||||
# returns keys from local_namespace, global_namespace, packages,
|
||||
# global_project_namespace
|
||||
def _keys(self) -> Set[str]:
|
||||
keys: Set[str] = set()
|
||||
for search in self._search_order():
|
||||
keys.update(search)
|
||||
return keys
|
||||
|
||||
# special iterator using special keys
|
||||
def __iter__(self) -> Iterator[str]:
|
||||
for key in self._keys():
|
||||
yield key
|
||||
@@ -72,6 +84,10 @@ class MacroNamespace(Mapping):
|
||||
)
|
||||
|
||||
|
||||
# This class builds the MacroNamespace by adding macros to
|
||||
# internal_packages or packages, and locals/globals.
|
||||
# Call 'build_namespace' to return a MacroNamespace.
|
||||
# This is used by ManifestContext (and subclasses)
|
||||
class MacroNamespaceBuilder:
|
||||
def __init__(
|
||||
self,
|
||||
@@ -83,10 +99,17 @@ class MacroNamespaceBuilder:
|
||||
) -> None:
|
||||
self.root_package = root_package
|
||||
self.search_package = search_package
|
||||
# internal packages comes from get_adapter_package_names
|
||||
self.internal_package_names = set(internal_packages)
|
||||
self.internal_package_names_order = internal_packages
|
||||
# macro_func is added here if in root package, since
|
||||
# the root package acts as a "global" namespace, overriding
|
||||
# everything else except local external package macro calls
|
||||
self.globals: FlatNamespace = {}
|
||||
# macro_func is added here if it's the package for this node
|
||||
self.locals: FlatNamespace = {}
|
||||
# Create a dictionary of [package name][macro name] =
|
||||
# MacroGenerator object which acts like a function
|
||||
self.internal_packages: Dict[str, FlatNamespace] = {}
|
||||
self.packages: Dict[str, FlatNamespace] = {}
|
||||
self.thread_ctx = thread_ctx
|
||||
@@ -94,25 +117,28 @@ class MacroNamespaceBuilder:
|
||||
|
||||
def _add_macro_to(
|
||||
self,
|
||||
heirarchy: Dict[str, FlatNamespace],
|
||||
hierarchy: Dict[str, FlatNamespace],
|
||||
macro: ParsedMacro,
|
||||
macro_func: MacroGenerator,
|
||||
):
|
||||
if macro.package_name in heirarchy:
|
||||
namespace = heirarchy[macro.package_name]
|
||||
if macro.package_name in hierarchy:
|
||||
namespace = hierarchy[macro.package_name]
|
||||
else:
|
||||
namespace = {}
|
||||
heirarchy[macro.package_name] = namespace
|
||||
hierarchy[macro.package_name] = namespace
|
||||
|
||||
if macro.name in namespace:
|
||||
raise_duplicate_macro_name(
|
||||
macro_func.macro, macro, macro.package_name
|
||||
)
|
||||
heirarchy[macro.package_name][macro.name] = macro_func
|
||||
hierarchy[macro.package_name][macro.name] = macro_func
|
||||
|
||||
def add_macro(self, macro: ParsedMacro, ctx: Dict[str, Any]):
|
||||
macro_name: str = macro.name
|
||||
|
||||
# MacroGenerator is in clients/jinja.py
|
||||
# a MacroGenerator object is a callable object that will
|
||||
# execute the MacroGenerator.__call__ function
|
||||
macro_func: MacroGenerator = MacroGenerator(
|
||||
macro, ctx, self.node, self.thread_ctx
|
||||
)
|
||||
@@ -122,10 +148,12 @@ class MacroNamespaceBuilder:
|
||||
if macro.package_name in self.internal_package_names:
|
||||
self._add_macro_to(self.internal_packages, macro, macro_func)
|
||||
else:
|
||||
# if it's not an internal package
|
||||
self._add_macro_to(self.packages, macro, macro_func)
|
||||
|
||||
# add to locals if it's the package this node is in
|
||||
if macro.package_name == self.search_package:
|
||||
self.locals[macro_name] = macro_func
|
||||
# add to globals if it's in the root package
|
||||
elif macro.package_name == self.root_package:
|
||||
self.globals[macro_name] = macro_func
|
||||
|
||||
@@ -143,11 +171,12 @@ class MacroNamespaceBuilder:
|
||||
global_project_namespace: FlatNamespace = {}
|
||||
for pkg in reversed(self.internal_package_names_order):
|
||||
if pkg in self.internal_packages:
|
||||
# add the macros pointed to by this package name
|
||||
global_project_namespace.update(self.internal_packages[pkg])
|
||||
|
||||
return MacroNamespace(
|
||||
global_namespace=self.globals,
|
||||
local_namespace=self.locals,
|
||||
global_project_namespace=global_project_namespace,
|
||||
packages=self.packages,
|
||||
global_namespace=self.globals, # root package macros
|
||||
local_namespace=self.locals, # packages for *this* node
|
||||
global_project_namespace=global_project_namespace, # internal packages
|
||||
packages=self.packages, # non internal_packages
|
||||
)
|
||||
|
||||
@@ -3,6 +3,7 @@ from typing import List
|
||||
from dbt.clients.jinja import MacroStack
|
||||
from dbt.contracts.connection import AdapterRequiredConfig
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.context.macro_resolver import TestMacroNamespace
|
||||
|
||||
|
||||
from .configured import ConfiguredContext
|
||||
@@ -24,12 +25,20 @@ class ManifestContext(ConfiguredContext):
|
||||
) -> None:
|
||||
super().__init__(config)
|
||||
self.manifest = manifest
|
||||
# this is the package of the node for which this context was built
|
||||
self.search_package = search_package
|
||||
self.macro_stack = MacroStack()
|
||||
# This namespace is used by the BaseDatabaseWrapper in jinja rendering.
|
||||
# The namespace is passed to it when it's constructed. It expects
|
||||
# to be able to do: namespace.get_from_package(..)
|
||||
self.namespace = self._build_namespace()
|
||||
|
||||
def _build_namespace(self):
|
||||
# this takes all the macros in the manifest and adds them
|
||||
# to the MacroNamespaceBuilder stored in self.namespace
|
||||
builder = self._get_namespace_builder()
|
||||
self.namespace = builder.build_namespace(
|
||||
self.manifest.macros.values(),
|
||||
self._ctx,
|
||||
return builder.build_namespace(
|
||||
self.manifest.macros.values(), self._ctx
|
||||
)
|
||||
|
||||
def _get_namespace_builder(self) -> MacroNamespaceBuilder:
|
||||
@@ -46,9 +55,16 @@ class ManifestContext(ConfiguredContext):
|
||||
None,
|
||||
)
|
||||
|
||||
# This does not use the Mashumaro code
|
||||
def to_dict(self):
|
||||
dct = super().to_dict()
|
||||
dct.update(self.namespace)
|
||||
# This moves all of the macros in the 'namespace' into top level
|
||||
# keys in the manifest dictionary
|
||||
if isinstance(self.namespace, TestMacroNamespace):
|
||||
dct.update(self.namespace.local_namespace)
|
||||
dct.update(self.namespace.project_namespace)
|
||||
else:
|
||||
dct.update(self.namespace)
|
||||
return dct
|
||||
|
||||
|
||||
|
||||
@@ -6,18 +6,23 @@ from typing import (
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.adapters.base.column import Column
|
||||
from dbt.adapters.factory import get_adapter, get_adapter_package_names
|
||||
from dbt.adapters.factory import (
|
||||
get_adapter, get_adapter_package_names, get_adapter_type_names
|
||||
)
|
||||
from dbt.clients import agate_helper
|
||||
from dbt.clients.jinja import get_rendered, MacroGenerator
|
||||
from dbt.clients.jinja import get_rendered, MacroGenerator, MacroStack
|
||||
from dbt.config import RuntimeConfig, Project
|
||||
from .base import contextmember, contextproperty, Var
|
||||
from .configured import FQNLookup
|
||||
from .context_config import ContextConfigType
|
||||
from .context_config import ContextConfig
|
||||
from dbt.context.macro_resolver import MacroResolver, TestMacroNamespace
|
||||
from .macros import MacroNamespaceBuilder, MacroNamespace
|
||||
from .manifest import ManifestContext
|
||||
from dbt.contracts.graph.manifest import Manifest, Disabled
|
||||
from dbt.contracts.connection import AdapterResponse
|
||||
from dbt.contracts.graph.manifest import (
|
||||
Manifest, Disabled
|
||||
)
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledResource,
|
||||
CompiledSeedNode,
|
||||
@@ -34,6 +39,7 @@ from dbt.exceptions import (
|
||||
InternalException,
|
||||
ValidationException,
|
||||
RuntimeException,
|
||||
macro_invalid_dispatch_arg,
|
||||
missing_config,
|
||||
raise_compiler_error,
|
||||
ref_invalid_args,
|
||||
@@ -42,8 +48,7 @@ from dbt.exceptions import (
|
||||
source_target_not_found,
|
||||
wrapped_exports,
|
||||
)
|
||||
from dbt.legacy_config_updater import IsFQNResource
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
from dbt.config import IsFQNResource
|
||||
from dbt.node_types import NodeType
|
||||
|
||||
from dbt.utils import (
|
||||
@@ -83,6 +88,7 @@ class BaseDatabaseWrapper:
|
||||
Wrapper for runtime database interaction. Applies the runtime quote policy
|
||||
via a relation proxy.
|
||||
"""
|
||||
|
||||
def __init__(self, adapter, namespace: MacroNamespace):
|
||||
self._adapter = adapter
|
||||
self.Relation = RelationProxy(adapter)
|
||||
@@ -102,36 +108,48 @@ class BaseDatabaseWrapper:
|
||||
return self._adapter.commit_if_has_connection()
|
||||
|
||||
def _get_adapter_macro_prefixes(self) -> List[str]:
|
||||
# a future version of this could have plugins automatically call fall
|
||||
# back to their dependencies' dependencies by using
|
||||
# `get_adapter_type_names` instead of `[self.config.credentials.type]`
|
||||
search_prefixes = [self._adapter.type(), 'default']
|
||||
# order matters for dispatch:
|
||||
# 1. current adapter
|
||||
# 2. any parent adapters (dependencies)
|
||||
# 3. 'default'
|
||||
search_prefixes = get_adapter_type_names(self._adapter.type()) + ['default']
|
||||
return search_prefixes
|
||||
|
||||
def dispatch(
|
||||
self, macro_name: str, packages: Optional[List[str]] = None
|
||||
self,
|
||||
macro_name: str,
|
||||
macro_namespace: Optional[str] = None,
|
||||
packages: Optional[List[str]] = None, # eventually remove since it's fully deprecated
|
||||
) -> MacroGenerator:
|
||||
search_packages: List[Optional[str]]
|
||||
|
||||
if '.' in macro_name:
|
||||
suggest_package, suggest_macro_name = macro_name.split('.', 1)
|
||||
suggest_macro_namespace, suggest_macro_name = macro_name.split('.', 1)
|
||||
msg = (
|
||||
f'In adapter.dispatch, got a macro name of "{macro_name}", '
|
||||
f'but "." is not a valid macro name component. Did you mean '
|
||||
f'`adapter.dispatch("{suggest_macro_name}", '
|
||||
f'packages=["{suggest_package}"])`?'
|
||||
f'macro_namespace="{suggest_macro_namespace}")`?'
|
||||
)
|
||||
raise CompilationException(msg)
|
||||
|
||||
if packages is None:
|
||||
if packages is not None:
|
||||
raise macro_invalid_dispatch_arg(macro_name)
|
||||
|
||||
namespace = macro_namespace
|
||||
|
||||
if namespace is None:
|
||||
search_packages = [None]
|
||||
elif isinstance(packages, str):
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a string packages argument '
|
||||
f'("{packages}"), but packages should be None or a list.'
|
||||
)
|
||||
elif isinstance(namespace, str):
|
||||
search_packages = self._adapter.config.get_macro_search_order(namespace)
|
||||
if not search_packages and namespace in self._adapter.config.dependencies:
|
||||
search_packages = [self.config.project_name, namespace]
|
||||
else:
|
||||
search_packages = packages
|
||||
# Not a string and not None so must be a list
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a list macro_namespace argument '
|
||||
f'("{macro_namespace}"), but macro_namespace should be None or a string.'
|
||||
)
|
||||
|
||||
attempts = []
|
||||
|
||||
@@ -139,13 +157,14 @@ class BaseDatabaseWrapper:
|
||||
for prefix in self._get_adapter_macro_prefixes():
|
||||
search_name = f'{prefix}__{macro_name}'
|
||||
try:
|
||||
# this uses the namespace from the context
|
||||
macro = self._namespace.get_from_package(
|
||||
package_name, search_name
|
||||
)
|
||||
except CompilationException as exc:
|
||||
raise CompilationException(
|
||||
f'In dispatch: {exc.msg}',
|
||||
) from exc
|
||||
except CompilationException:
|
||||
# Only raise CompilationException if macro is not found in
|
||||
# any package
|
||||
macro = None
|
||||
|
||||
if package_name is None:
|
||||
attempts.append(search_name)
|
||||
@@ -253,13 +272,13 @@ class BaseSourceResolver(BaseResolver):
|
||||
|
||||
|
||||
class Config(Protocol):
|
||||
def __init__(self, model, context_config: Optional[ContextConfigType]):
|
||||
def __init__(self, model, context_config: Optional[ContextConfig]):
|
||||
...
|
||||
|
||||
|
||||
# `config` implementations
|
||||
# Implementation of "config(..)" calls in models
|
||||
class ParseConfigObject(Config):
|
||||
def __init__(self, model, context_config: Optional[ContextConfigType]):
|
||||
def __init__(self, model, context_config: Optional[ContextConfig]):
|
||||
self.model = model
|
||||
self.context_config = context_config
|
||||
|
||||
@@ -294,7 +313,7 @@ class ParseConfigObject(Config):
|
||||
raise RuntimeException(
|
||||
'At parse time, did not receive a context config'
|
||||
)
|
||||
self.context_config.update_in_model_config(opts)
|
||||
self.context_config.add_config_call(opts)
|
||||
return ''
|
||||
|
||||
def set(self, name, value):
|
||||
@@ -315,7 +334,7 @@ class ParseConfigObject(Config):
|
||||
|
||||
class RuntimeConfigObject(Config):
|
||||
def __init__(
|
||||
self, model, context_config: Optional[ContextConfigType] = None
|
||||
self, model, context_config: Optional[ContextConfig] = None
|
||||
):
|
||||
self.model = model
|
||||
# we never use or get a config, only the parser cares
|
||||
@@ -379,6 +398,7 @@ class ParseDatabaseWrapper(BaseDatabaseWrapper):
|
||||
"""The parser subclass of the database wrapper applies any explicit
|
||||
parse-time overrides.
|
||||
"""
|
||||
|
||||
def __getattr__(self, name):
|
||||
override = (name in self._adapter._available_ and
|
||||
name in self._adapter._parse_replacements_)
|
||||
@@ -399,6 +419,7 @@ class RuntimeDatabaseWrapper(BaseDatabaseWrapper):
|
||||
"""The runtime database wrapper exposes everything the adapter marks
|
||||
available.
|
||||
"""
|
||||
|
||||
def __getattr__(self, name):
|
||||
if name in self._adapter._available_:
|
||||
return getattr(self._adapter, name)
|
||||
@@ -620,7 +641,7 @@ class ProviderContext(ManifestContext):
|
||||
config: RuntimeConfig,
|
||||
manifest: Manifest,
|
||||
provider: Provider,
|
||||
context_config: Optional[ContextConfigType],
|
||||
context_config: Optional[ContextConfig],
|
||||
) -> None:
|
||||
if provider is None:
|
||||
raise InternalException(
|
||||
@@ -631,13 +652,16 @@ class ProviderContext(ManifestContext):
|
||||
self.model: Union[ParsedMacro, ManifestNode] = model
|
||||
super().__init__(config, manifest, model.package_name)
|
||||
self.sql_results: Dict[str, AttrDict] = {}
|
||||
self.context_config: Optional[ContextConfigType] = context_config
|
||||
self.context_config: Optional[ContextConfig] = context_config
|
||||
self.provider: Provider = provider
|
||||
self.adapter = get_adapter(self.config)
|
||||
# The macro namespace is used in creating the DatabaseWrapper
|
||||
self.db_wrapper = self.provider.DatabaseWrapper(
|
||||
self.adapter, self.namespace
|
||||
)
|
||||
|
||||
# This overrides the method in ManifestContext, and provides
|
||||
# a model, which the ManifestContext builder does not
|
||||
def _get_namespace_builder(self):
|
||||
internal_packages = get_adapter_package_names(
|
||||
self.config.credentials.type
|
||||
@@ -660,18 +684,33 @@ class ProviderContext(ManifestContext):
|
||||
|
||||
@contextmember
|
||||
def store_result(
|
||||
self, name: str, status: Any, agate_table: Optional[agate.Table] = None
|
||||
self, name: str,
|
||||
response: Any,
|
||||
agate_table: Optional[agate.Table] = None
|
||||
) -> str:
|
||||
if agate_table is None:
|
||||
agate_table = agate_helper.empty_table()
|
||||
|
||||
self.sql_results[name] = AttrDict({
|
||||
'status': status,
|
||||
'response': response,
|
||||
'data': agate_helper.as_matrix(agate_table),
|
||||
'table': agate_table
|
||||
})
|
||||
return ''
|
||||
|
||||
@contextmember
|
||||
def store_raw_result(
|
||||
self,
|
||||
name: str,
|
||||
message=Optional[str],
|
||||
code=Optional[str],
|
||||
rows_affected=Optional[str],
|
||||
agate_table: Optional[agate.Table] = None
|
||||
) -> str:
|
||||
response = AdapterResponse(
|
||||
_message=message, code=code, rows_affected=rows_affected)
|
||||
return self.store_result(name, response, agate_table)
|
||||
|
||||
@contextproperty
|
||||
def validation(self):
|
||||
def validate_any(*args) -> Callable[[T], None]:
|
||||
@@ -1089,7 +1128,7 @@ class ProviderContext(ManifestContext):
|
||||
|
||||
@contextproperty('model')
|
||||
def ctx_model(self) -> Dict[str, Any]:
|
||||
return self.model.to_dict()
|
||||
return self.model.to_dict(omit_none=True)
|
||||
|
||||
@contextproperty
|
||||
def pre_hooks(self) -> Optional[List[Dict[str, Any]]]:
|
||||
@@ -1109,66 +1148,17 @@ class ProviderContext(ManifestContext):
|
||||
|
||||
@contextmember
|
||||
def adapter_macro(self, name: str, *args, **kwargs):
|
||||
"""Find the most appropriate macro for the name, considering the
|
||||
adapter type currently in use, and call that with the given arguments.
|
||||
|
||||
If the name has a `.` in it, the first section before the `.` is
|
||||
interpreted as a package name, and the remainder as a macro name.
|
||||
|
||||
If no adapter is found, raise a compiler exception. If an invalid
|
||||
package name is specified, raise a compiler exception.
|
||||
|
||||
|
||||
Some examples:
|
||||
|
||||
{# dbt will call this macro by name, providing any arguments #}
|
||||
{% macro create_table_as(temporary, relation, sql) -%}
|
||||
|
||||
{# dbt will dispatch the macro call to the relevant macro #}
|
||||
{{ adapter_macro('create_table_as', temporary, relation, sql) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{#
|
||||
If no macro matches the specified adapter, "default" will be
|
||||
used
|
||||
#}
|
||||
{% macro default__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
|
||||
{# Example which defines special logic for Redshift #}
|
||||
{% macro redshift__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
|
||||
{# Example which defines special logic for BigQuery #}
|
||||
{% macro bigquery__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
"""This was deprecated in v0.18 in favor of adapter.dispatch
|
||||
"""
|
||||
deprecations.warn('adapter-macro', macro_name=name)
|
||||
original_name = name
|
||||
package_names: Optional[List[str]] = None
|
||||
if '.' in name:
|
||||
package_name, name = name.split('.', 1)
|
||||
package_names = [package_name]
|
||||
|
||||
try:
|
||||
macro = self.db_wrapper.dispatch(
|
||||
macro_name=name, packages=package_names
|
||||
)
|
||||
except CompilationException as exc:
|
||||
raise CompilationException(
|
||||
f'In adapter_macro: {exc.msg}\n'
|
||||
f" Original name: '{original_name}'",
|
||||
node=self.model
|
||||
) from exc
|
||||
return macro(*args, **kwargs)
|
||||
msg = (
|
||||
'The "adapter_macro" macro has been deprecated. Instead, use '
|
||||
'the `adapter.dispatch` method to find a macro and call the '
|
||||
'result. For more information, see: '
|
||||
'https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch)'
|
||||
' adapter_macro was called for: {macro_name}'
|
||||
.format(macro_name=name)
|
||||
)
|
||||
raise CompilationException(msg)
|
||||
|
||||
|
||||
class MacroContext(ProviderContext):
|
||||
@@ -1179,6 +1169,7 @@ class MacroContext(ProviderContext):
|
||||
- 'schema' does not use any 'model' information
|
||||
- they can't be configured with config() directives
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: ParsedMacro,
|
||||
@@ -1201,23 +1192,25 @@ class ModelContext(ProviderContext):
|
||||
|
||||
@contextproperty
|
||||
def pre_hooks(self) -> List[Dict[str, Any]]:
|
||||
if isinstance(self.model, ParsedSourceDefinition):
|
||||
if self.model.resource_type in [NodeType.Source, NodeType.Test]:
|
||||
return []
|
||||
return [
|
||||
h.to_dict() for h in self.model.config.pre_hook
|
||||
h.to_dict(omit_none=True) for h in self.model.config.pre_hook
|
||||
]
|
||||
|
||||
@contextproperty
|
||||
def post_hooks(self) -> List[Dict[str, Any]]:
|
||||
if isinstance(self.model, ParsedSourceDefinition):
|
||||
if self.model.resource_type in [NodeType.Source, NodeType.Test]:
|
||||
return []
|
||||
return [
|
||||
h.to_dict() for h in self.model.config.post_hook
|
||||
h.to_dict(omit_none=True) for h in self.model.config.post_hook
|
||||
]
|
||||
|
||||
@contextproperty
|
||||
def sql(self) -> Optional[str]:
|
||||
return getattr(self.model, 'injected_sql', None)
|
||||
if getattr(self.model, 'extra_ctes_injected', None):
|
||||
return self.model.compiled_sql
|
||||
return None
|
||||
|
||||
@contextproperty
|
||||
def database(self) -> str:
|
||||
@@ -1267,27 +1260,21 @@ class ModelContext(ProviderContext):
|
||||
return self.db_wrapper.Relation.create_from(self.config, self.model)
|
||||
|
||||
|
||||
# This is called by '_context_for', used in 'render_with_context'
|
||||
def generate_parser_model(
|
||||
model: ManifestNode,
|
||||
config: RuntimeConfig,
|
||||
manifest: Manifest,
|
||||
context_config: ContextConfigType,
|
||||
context_config: ContextConfig,
|
||||
) -> Dict[str, Any]:
|
||||
# The __init__ method of ModelContext also initializes
|
||||
# a ManifestContext object which creates a MacroNamespaceBuilder
|
||||
# which adds every macro in the Manifest.
|
||||
ctx = ModelContext(
|
||||
model, config, manifest, ParseProvider(), context_config
|
||||
)
|
||||
return ctx.to_dict()
|
||||
|
||||
|
||||
def generate_parser_macro(
|
||||
macro: ParsedMacro,
|
||||
config: RuntimeConfig,
|
||||
manifest: Manifest,
|
||||
package_name: Optional[str],
|
||||
) -> Dict[str, Any]:
|
||||
ctx = MacroContext(
|
||||
macro, config, manifest, ParseProvider(), package_name
|
||||
)
|
||||
# The 'to_dict' method in ManifestContext moves all of the macro names
|
||||
# in the macro 'namespace' up to top level keys
|
||||
return ctx.to_dict()
|
||||
|
||||
|
||||
@@ -1365,3 +1352,68 @@ def generate_parse_exposure(
|
||||
manifest,
|
||||
)
|
||||
}
|
||||
|
||||
|
||||
# This class is currently used by the schema parser in order
|
||||
# to limit the number of macros in the context by using
|
||||
# the TestMacroNamespace
|
||||
class TestContext(ProviderContext):
|
||||
def __init__(
|
||||
self,
|
||||
model,
|
||||
config: RuntimeConfig,
|
||||
manifest: Manifest,
|
||||
provider: Provider,
|
||||
context_config: Optional[ContextConfig],
|
||||
macro_resolver: MacroResolver,
|
||||
) -> None:
|
||||
# this must be before super init so that macro_resolver exists for
|
||||
# build_namespace
|
||||
self.macro_resolver = macro_resolver
|
||||
self.thread_ctx = MacroStack()
|
||||
super().__init__(model, config, manifest, provider, context_config)
|
||||
self._build_test_namespace()
|
||||
# We need to rebuild this because it's already been built by
|
||||
# the ProviderContext with the wrong namespace.
|
||||
self.db_wrapper = self.provider.DatabaseWrapper(
|
||||
self.adapter, self.namespace
|
||||
)
|
||||
|
||||
def _build_namespace(self):
|
||||
return {}
|
||||
|
||||
# this overrides _build_namespace in ManifestContext which provides a
|
||||
# complete namespace of all macros to only specify macros in the depends_on
|
||||
# This only provides a namespace with macros in the test node
|
||||
# 'depends_on.macros' by using the TestMacroNamespace
|
||||
def _build_test_namespace(self):
|
||||
depends_on_macros = []
|
||||
if self.model.depends_on and self.model.depends_on.macros:
|
||||
depends_on_macros = self.model.depends_on.macros
|
||||
lookup_macros = depends_on_macros.copy()
|
||||
for macro_unique_id in lookup_macros:
|
||||
lookup_macro = self.macro_resolver.macros.get(macro_unique_id)
|
||||
if lookup_macro:
|
||||
depends_on_macros.extend(lookup_macro.depends_on.macros)
|
||||
|
||||
macro_namespace = TestMacroNamespace(
|
||||
self.macro_resolver, self._ctx, self.model, self.thread_ctx,
|
||||
depends_on_macros
|
||||
)
|
||||
self.namespace = macro_namespace
|
||||
|
||||
|
||||
def generate_test_context(
|
||||
model: ManifestNode,
|
||||
config: RuntimeConfig,
|
||||
manifest: Manifest,
|
||||
context_config: ContextConfig,
|
||||
macro_resolver: MacroResolver
|
||||
) -> Dict[str, Any]:
|
||||
ctx = TestContext(
|
||||
model, config, manifest, ParseProvider(), context_config,
|
||||
macro_resolver
|
||||
)
|
||||
# The 'to_dict' method in ManifestContext moves all of the macro names
|
||||
# in the macro 'namespace' up to top level keys
|
||||
return ctx.to_dict()
|
||||
|
||||
@@ -1,27 +1,39 @@
|
||||
import abc
|
||||
import itertools
|
||||
import hashlib
|
||||
from dataclasses import dataclass, field
|
||||
from typing import (
|
||||
Any, ClassVar, Dict, Tuple, Iterable, Optional, NewType, List, Callable,
|
||||
Any, ClassVar, Dict, Tuple, Iterable, Optional, List, Callable,
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from hologram.helpers import (
|
||||
StrEnum, register_pattern, ExtensibleJsonSchemaMixin
|
||||
)
|
||||
|
||||
from dbt.contracts.util import Replaceable
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.utils import translate_aliases
|
||||
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from typing_extensions import Protocol
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, StrEnum, ExtensibleDbtClassMixin, HyphenatedDbtClassMixin,
|
||||
ValidatedStringMixin, register_pattern
|
||||
)
|
||||
from dbt.contracts.util import Replaceable
|
||||
|
||||
|
||||
Identifier = NewType('Identifier', str)
|
||||
class Identifier(ValidatedStringMixin):
|
||||
ValidationRegex = r'^[A-Za-z_][A-Za-z0-9_]+$'
|
||||
|
||||
|
||||
# we need register_pattern for jsonschema validation
|
||||
register_pattern(Identifier, r'^[A-Za-z_][A-Za-z0-9_]+$')
|
||||
|
||||
|
||||
@dataclass
|
||||
class AdapterResponse(dbtClassMixin):
|
||||
_message: str
|
||||
code: Optional[str] = None
|
||||
rows_affected: Optional[int] = None
|
||||
|
||||
def __str__(self):
|
||||
return self._message
|
||||
|
||||
|
||||
class ConnectionState(StrEnum):
|
||||
INIT = 'init'
|
||||
OPEN = 'open'
|
||||
@@ -30,20 +42,19 @@ class ConnectionState(StrEnum):
|
||||
|
||||
|
||||
@dataclass(init=False)
|
||||
class Connection(ExtensibleJsonSchemaMixin, Replaceable):
|
||||
class Connection(ExtensibleDbtClassMixin, Replaceable):
|
||||
type: Identifier
|
||||
name: Optional[str]
|
||||
name: Optional[str] = None
|
||||
state: ConnectionState = ConnectionState.INIT
|
||||
transaction_open: bool = False
|
||||
# prevent serialization
|
||||
_handle: Optional[Any] = None
|
||||
_credentials: JsonSchemaMixin = field(init=False)
|
||||
_credentials: Optional[Any] = None
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
type: Identifier,
|
||||
name: Optional[str],
|
||||
credentials: JsonSchemaMixin,
|
||||
credentials: dbtClassMixin,
|
||||
state: ConnectionState = ConnectionState.INIT,
|
||||
transaction_open: bool = False,
|
||||
handle: Optional[Any] = None,
|
||||
@@ -85,6 +96,7 @@ class LazyHandle:
|
||||
"""Opener must be a callable that takes a Connection object and opens the
|
||||
connection, updating the handle on the Connection.
|
||||
"""
|
||||
|
||||
def __init__(self, opener: Callable[[Connection], Connection]):
|
||||
self.opener = opener
|
||||
|
||||
@@ -102,7 +114,7 @@ class LazyHandle:
|
||||
# will work.
|
||||
@dataclass # type: ignore
|
||||
class Credentials(
|
||||
ExtensibleJsonSchemaMixin,
|
||||
ExtensibleDbtClassMixin,
|
||||
Replaceable,
|
||||
metaclass=abc.ABCMeta
|
||||
):
|
||||
@@ -116,12 +128,25 @@ class Credentials(
|
||||
'type not implemented for base credentials class'
|
||||
)
|
||||
|
||||
@property
|
||||
def unique_field(self) -> str:
|
||||
"""Hashed and included in anonymous telemetry to track adapter adoption.
|
||||
Return the field from Credentials that can uniquely identify
|
||||
one team/organization using this adapter
|
||||
"""
|
||||
raise NotImplementedError(
|
||||
'unique_field not implemented for base credentials class'
|
||||
)
|
||||
|
||||
def hashed_unique_field(self) -> str:
|
||||
return hashlib.md5(self.unique_field.encode('utf-8')).hexdigest()
|
||||
|
||||
def connection_info(
|
||||
self, *, with_aliases: bool = False
|
||||
) -> Iterable[Tuple[str, Any]]:
|
||||
"""Return an ordered iterator of key/value pairs for pretty-printing.
|
||||
"""
|
||||
as_dict = self.to_dict(omit_none=False, with_aliases=with_aliases)
|
||||
as_dict = self.to_dict(omit_none=False)
|
||||
connection_keys = set(self._connection_keys())
|
||||
aliases: List[str] = []
|
||||
if with_aliases:
|
||||
@@ -137,9 +162,10 @@ class Credentials(
|
||||
raise NotImplementedError
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data):
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
data = cls.translate_aliases(data)
|
||||
return super().from_dict(data)
|
||||
return data
|
||||
|
||||
@classmethod
|
||||
def translate_aliases(
|
||||
@@ -147,36 +173,28 @@ class Credentials(
|
||||
) -> Dict[str, Any]:
|
||||
return translate_aliases(kwargs, cls._ALIASES, recurse)
|
||||
|
||||
def to_dict(self, omit_none=True, validate=False, *, with_aliases=False):
|
||||
serialized = super().to_dict(omit_none=omit_none, validate=validate)
|
||||
if with_aliases:
|
||||
serialized.update({
|
||||
new_name: serialized[canonical_name]
|
||||
def __post_serialize__(self, dct):
|
||||
# no super() -- do we need it?
|
||||
if self._ALIASES:
|
||||
dct.update({
|
||||
new_name: dct[canonical_name]
|
||||
for new_name, canonical_name in self._ALIASES.items()
|
||||
if canonical_name in serialized
|
||||
if canonical_name in dct
|
||||
})
|
||||
return serialized
|
||||
return dct
|
||||
|
||||
|
||||
class UserConfigContract(Protocol):
|
||||
send_anonymous_usage_stats: bool
|
||||
use_colors: Optional[bool]
|
||||
partial_parse: Optional[bool]
|
||||
printer_width: Optional[int]
|
||||
|
||||
def set_values(self, cookie_dir: str) -> None:
|
||||
...
|
||||
|
||||
def to_dict(
|
||||
self, omit_none: bool = True, validate: bool = False
|
||||
) -> Dict[str, Any]:
|
||||
...
|
||||
use_colors: Optional[bool] = None
|
||||
partial_parse: Optional[bool] = None
|
||||
printer_width: Optional[int] = None
|
||||
|
||||
|
||||
class HasCredentials(Protocol):
|
||||
credentials: Credentials
|
||||
profile_name: str
|
||||
config: UserConfigContract
|
||||
user_config: UserConfigContract
|
||||
target_name: str
|
||||
threads: int
|
||||
|
||||
@@ -205,9 +223,10 @@ DEFAULT_QUERY_COMMENT = '''
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueryComment(JsonSchemaMixin):
|
||||
class QueryComment(HyphenatedDbtClassMixin):
|
||||
comment: str = DEFAULT_QUERY_COMMENT
|
||||
append: bool = False
|
||||
job_label: bool = False
|
||||
|
||||
|
||||
class AdapterRequiredConfig(HasCredentials, Protocol):
|
||||
|
||||
@@ -1,23 +1,50 @@
|
||||
import hashlib
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
from typing import List, Optional, Union
|
||||
from mashumaro.types import SerializableType
|
||||
from typing import List, Optional, Union, Dict, Any
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
from dbt.exceptions import InternalException
|
||||
|
||||
from .util import MacroKey, SourceKey
|
||||
from .util import SourceKey
|
||||
|
||||
|
||||
MAXIMUM_SEED_SIZE = 1 * 1024 * 1024
|
||||
MAXIMUM_SEED_SIZE_NAME = '1MB'
|
||||
|
||||
|
||||
class ParseFileType(StrEnum):
|
||||
Macro = 'macro'
|
||||
Model = 'model'
|
||||
Snapshot = 'snapshot'
|
||||
Analysis = 'analysis'
|
||||
SingularTest = 'singular_test'
|
||||
GenericTest = 'generic_test'
|
||||
Seed = 'seed'
|
||||
Documentation = 'docs'
|
||||
Schema = 'schema'
|
||||
Hook = 'hook' # not a real filetype, from dbt_project.yml
|
||||
|
||||
|
||||
parse_file_type_to_parser = {
|
||||
ParseFileType.Macro: 'MacroParser',
|
||||
ParseFileType.Model: 'ModelParser',
|
||||
ParseFileType.Snapshot: 'SnapshotParser',
|
||||
ParseFileType.Analysis: 'AnalysisParser',
|
||||
ParseFileType.SingularTest: 'SingularTestParser',
|
||||
ParseFileType.GenericTest: 'GenericTestParser',
|
||||
ParseFileType.Seed: 'SeedParser',
|
||||
ParseFileType.Documentation: 'DocumentationParser',
|
||||
ParseFileType.Schema: 'SchemaParser',
|
||||
ParseFileType.Hook: 'HookParser',
|
||||
}
|
||||
|
||||
|
||||
@dataclass
|
||||
class FilePath(JsonSchemaMixin):
|
||||
class FilePath(dbtClassMixin):
|
||||
searched_path: str
|
||||
relative_path: str
|
||||
modification_time: float
|
||||
project_root: str
|
||||
|
||||
@property
|
||||
@@ -51,7 +78,7 @@ class FilePath(JsonSchemaMixin):
|
||||
|
||||
|
||||
@dataclass
|
||||
class FileHash(JsonSchemaMixin):
|
||||
class FileHash(dbtClassMixin):
|
||||
name: str # the hash type name
|
||||
checksum: str # the hashlib.hash_type().hexdigest() of the file contents
|
||||
|
||||
@@ -91,7 +118,7 @@ class FileHash(JsonSchemaMixin):
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteFile(JsonSchemaMixin):
|
||||
class RemoteFile(dbtClassMixin):
|
||||
@property
|
||||
def searched_path(self) -> str:
|
||||
return 'from remote system'
|
||||
@@ -108,60 +135,169 @@ class RemoteFile(JsonSchemaMixin):
|
||||
def original_file_path(self):
|
||||
return 'from remote system'
|
||||
|
||||
@property
|
||||
def modification_time(self):
|
||||
return 'from remote system'
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFile(JsonSchemaMixin):
|
||||
class BaseSourceFile(dbtClassMixin, SerializableType):
|
||||
"""Define a source file in dbt"""
|
||||
path: Union[FilePath, RemoteFile] # the path information
|
||||
checksum: FileHash
|
||||
# Seems like knowing which project the file came from would be useful
|
||||
project_name: Optional[str] = None
|
||||
# Parse file type: i.e. which parser will process this file
|
||||
parse_file_type: Optional[ParseFileType] = None
|
||||
# we don't want to serialize this
|
||||
_contents: Optional[str] = None
|
||||
contents: Optional[str] = None
|
||||
# the unique IDs contained in this file
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
if isinstance(self.path, RemoteFile):
|
||||
return None
|
||||
return f'{self.project_name}://{self.path.original_file_path}'
|
||||
|
||||
def _serialize(self):
|
||||
dct = self.to_dict()
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, dct: Dict[str, int]):
|
||||
if dct['parse_file_type'] == 'schema':
|
||||
sf = SchemaSourceFile.from_dict(dct)
|
||||
else:
|
||||
sf = SourceFile.from_dict(dct)
|
||||
return sf
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
# remove empty lists to save space
|
||||
dct_keys = list(dct.keys())
|
||||
for key in dct_keys:
|
||||
if isinstance(dct[key], list) and not dct[key]:
|
||||
del dct[key]
|
||||
# remove contents. Schema files will still have 'dict_from_yaml'
|
||||
# from the contents
|
||||
if 'contents' in dct:
|
||||
del dct['contents']
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFile(BaseSourceFile):
|
||||
nodes: List[str] = field(default_factory=list)
|
||||
docs: List[str] = field(default_factory=list)
|
||||
macros: List[str] = field(default_factory=list)
|
||||
sources: List[str] = field(default_factory=list)
|
||||
exposures: List[str] = field(default_factory=list)
|
||||
# any node patches in this file. The entries are names, not unique ids!
|
||||
patches: List[str] = field(default_factory=list)
|
||||
# any macro patches in this file. The entries are package, name pairs.
|
||||
macro_patches: List[MacroKey] = field(default_factory=list)
|
||||
# any source patches in this file. The entries are package, name pairs
|
||||
source_patches: List[SourceKey] = field(default_factory=list)
|
||||
|
||||
@property
|
||||
def search_key(self) -> Optional[str]:
|
||||
if isinstance(self.path, RemoteFile):
|
||||
return None
|
||||
if self.checksum.name == 'none':
|
||||
return None
|
||||
return self.path.search_key
|
||||
|
||||
@property
|
||||
def contents(self) -> str:
|
||||
if self._contents is None:
|
||||
raise InternalException('SourceFile has no contents!')
|
||||
return self._contents
|
||||
|
||||
@contents.setter
|
||||
def contents(self, value):
|
||||
self._contents = value
|
||||
|
||||
@classmethod
|
||||
def empty(cls, path: FilePath) -> 'SourceFile':
|
||||
self = cls(path=path, checksum=FileHash.empty())
|
||||
self.contents = ''
|
||||
return self
|
||||
|
||||
@classmethod
|
||||
def big_seed(cls, path: FilePath) -> 'SourceFile':
|
||||
"""Parse seeds over the size limit with just the path"""
|
||||
self = cls(path=path, checksum=FileHash.path(path.absolute_path))
|
||||
self = cls(path=path, checksum=FileHash.path(path.original_file_path))
|
||||
self.contents = ''
|
||||
return self
|
||||
|
||||
def add_node(self, value):
|
||||
if value not in self.nodes:
|
||||
self.nodes.append(value)
|
||||
|
||||
# TODO: do this a different way. This remote file kludge isn't going
|
||||
# to work long term
|
||||
@classmethod
|
||||
def remote(cls, contents: str) -> 'SourceFile':
|
||||
self = cls(path=RemoteFile(), checksum=FileHash.empty())
|
||||
self.contents = contents
|
||||
def remote(cls, contents: str, project_name: str) -> 'SourceFile':
|
||||
self = cls(
|
||||
path=RemoteFile(),
|
||||
checksum=FileHash.from_contents(contents),
|
||||
project_name=project_name,
|
||||
contents=contents,
|
||||
)
|
||||
return self
|
||||
|
||||
|
||||
@dataclass
|
||||
class SchemaSourceFile(BaseSourceFile):
|
||||
dfy: Dict[str, Any] = field(default_factory=dict)
|
||||
# these are in the manifest.nodes dictionary
|
||||
tests: Dict[str, Any] = field(default_factory=dict)
|
||||
sources: List[str] = field(default_factory=list)
|
||||
exposures: List[str] = field(default_factory=list)
|
||||
# node patches contain models, seeds, snapshots, analyses
|
||||
ndp: List[str] = field(default_factory=list)
|
||||
# any macro patches in this file by macro unique_id.
|
||||
mcp: Dict[str, str] = field(default_factory=dict)
|
||||
# any source patches in this file. The entries are package, name pairs
|
||||
# Patches are only against external sources. Sources can be
|
||||
# created too, but those are in 'sources'
|
||||
sop: List[SourceKey] = field(default_factory=list)
|
||||
pp_dict: Optional[Dict[str, Any]] = None
|
||||
pp_test_index: Optional[Dict[str, Any]] = None
|
||||
|
||||
@property
|
||||
def dict_from_yaml(self):
|
||||
return self.dfy
|
||||
|
||||
@property
|
||||
def node_patches(self):
|
||||
return self.ndp
|
||||
|
||||
@property
|
||||
def macro_patches(self):
|
||||
return self.mcp
|
||||
|
||||
@property
|
||||
def source_patches(self):
|
||||
return self.sop
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
# Remove partial parsing specific data
|
||||
for key in ('pp_files', 'pp_test_index', 'pp_dict'):
|
||||
if key in dct:
|
||||
del dct[key]
|
||||
return dct
|
||||
|
||||
def append_patch(self, yaml_key, unique_id):
|
||||
self.node_patches.append(unique_id)
|
||||
|
||||
def add_test(self, node_unique_id, test_from):
|
||||
name = test_from['name']
|
||||
key = test_from['key']
|
||||
if key not in self.tests:
|
||||
self.tests[key] = {}
|
||||
if name not in self.tests[key]:
|
||||
self.tests[key][name] = []
|
||||
self.tests[key][name].append(node_unique_id)
|
||||
|
||||
def remove_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
del self.tests[yaml_key][name]
|
||||
|
||||
def get_tests(self, yaml_key, name):
|
||||
if yaml_key in self.tests:
|
||||
if name in self.tests[yaml_key]:
|
||||
return self.tests[yaml_key][name]
|
||||
return []
|
||||
|
||||
def get_key_and_name_for_test(self, test_unique_id):
|
||||
yaml_key = None
|
||||
block_name = None
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
for unique_id in self.tests[key][name]:
|
||||
if unique_id == test_unique_id:
|
||||
yaml_key = key
|
||||
block_name = name
|
||||
break
|
||||
return (yaml_key, block_name)
|
||||
|
||||
def get_all_test_ids(self):
|
||||
test_ids = []
|
||||
for key in self.tests.keys():
|
||||
for name in self.tests[key]:
|
||||
test_ids.extend(self.tests[key][name])
|
||||
return test_ids
|
||||
|
||||
|
||||
AnySourceFile = Union[SchemaSourceFile, SourceFile]
|
||||
|
||||
@@ -2,13 +2,13 @@ from dbt.contracts.graph.parsed import (
|
||||
HasTestMetadata,
|
||||
ParsedNode,
|
||||
ParsedAnalysisNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedExposure,
|
||||
ParsedResource,
|
||||
ParsedRPCNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
ParsedSourceDefinition,
|
||||
@@ -19,19 +19,19 @@ from dbt.contracts.graph.parsed import (
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.contracts.util import Replaceable
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional, List, Union, Dict, Type
|
||||
|
||||
|
||||
@dataclass
|
||||
class InjectedCTE(JsonSchemaMixin, Replaceable):
|
||||
class InjectedCTE(dbtClassMixin, Replaceable):
|
||||
id: str
|
||||
sql: str
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledNodeMixin(JsonSchemaMixin):
|
||||
class CompiledNodeMixin(dbtClassMixin):
|
||||
# this is a special mixin class to provide a required argument. If a node
|
||||
# is missing a `compiled` flag entirely, it must not be a CompiledNode.
|
||||
compiled: bool
|
||||
@@ -42,7 +42,8 @@ class CompiledNode(ParsedNode, CompiledNodeMixin):
|
||||
compiled_sql: Optional[str] = None
|
||||
extra_ctes_injected: bool = False
|
||||
extra_ctes: List[InjectedCTE] = field(default_factory=list)
|
||||
injected_sql: Optional[str] = None
|
||||
relation_name: Optional[str] = None
|
||||
_pre_injected_sql: Optional[str] = None
|
||||
|
||||
def set_cte(self, cte_id: str, sql: str):
|
||||
"""This is the equivalent of what self.extra_ctes[cte_id] = sql would
|
||||
@@ -55,6 +56,12 @@ class CompiledNode(ParsedNode, CompiledNodeMixin):
|
||||
else:
|
||||
self.extra_ctes.append(InjectedCTE(id=cte_id, sql=sql))
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if '_pre_injected_sql' in dct:
|
||||
del dct['_pre_injected_sql']
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledAnalysisNode(CompiledNode):
|
||||
@@ -100,23 +107,21 @@ class CompiledSnapshotNode(CompiledNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledDataTestNode(CompiledNode):
|
||||
class CompiledSingularTestNode(CompiledNode):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
config: TestConfig = field(default_factory=TestConfig) # type:ignore
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledSchemaTestNode(CompiledNode, HasTestMetadata):
|
||||
# keep this in sync with ParsedSchemaTestNode!
|
||||
class CompiledGenericTestNode(CompiledNode, HasTestMetadata):
|
||||
# keep this in sync with ParsedGenericTestNode!
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
column_name: Optional[str] = None
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
|
||||
def same_config(self, other) -> bool:
|
||||
return self.config.severity == other.config.severity
|
||||
|
||||
def same_column_name(self, other) -> bool:
|
||||
return self.column_name == other.column_name
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
config: TestConfig = field(default_factory=TestConfig) # type:ignore
|
||||
|
||||
def same_contents(self, other) -> bool:
|
||||
if other is None:
|
||||
@@ -129,7 +134,7 @@ class CompiledSchemaTestNode(CompiledNode, HasTestMetadata):
|
||||
)
|
||||
|
||||
|
||||
CompiledTestNode = Union[CompiledDataTestNode, CompiledSchemaTestNode]
|
||||
CompiledTestNode = Union[CompiledSingularTestNode, CompiledGenericTestNode]
|
||||
|
||||
|
||||
PARSED_TYPES: Dict[Type[CompiledNode], Type[ParsedResource]] = {
|
||||
@@ -139,8 +144,8 @@ PARSED_TYPES: Dict[Type[CompiledNode], Type[ParsedResource]] = {
|
||||
CompiledRPCNode: ParsedRPCNode,
|
||||
CompiledSeedNode: ParsedSeedNode,
|
||||
CompiledSnapshotNode: ParsedSnapshotNode,
|
||||
CompiledDataTestNode: ParsedDataTestNode,
|
||||
CompiledSchemaTestNode: ParsedSchemaTestNode,
|
||||
CompiledSingularTestNode: ParsedSingularTestNode,
|
||||
CompiledGenericTestNode: ParsedGenericTestNode,
|
||||
}
|
||||
|
||||
|
||||
@@ -151,8 +156,8 @@ COMPILED_TYPES: Dict[Type[ParsedResource], Type[CompiledNode]] = {
|
||||
ParsedRPCNode: CompiledRPCNode,
|
||||
ParsedSeedNode: CompiledSeedNode,
|
||||
ParsedSnapshotNode: CompiledSnapshotNode,
|
||||
ParsedDataTestNode: CompiledDataTestNode,
|
||||
ParsedSchemaTestNode: CompiledSchemaTestNode,
|
||||
ParsedSingularTestNode: CompiledSingularTestNode,
|
||||
ParsedGenericTestNode: CompiledGenericTestNode,
|
||||
}
|
||||
|
||||
|
||||
@@ -175,28 +180,27 @@ def parsed_instance_for(compiled: CompiledNode) -> ParsedResource:
|
||||
raise ValueError('invalid resource_type: {}'
|
||||
.format(compiled.resource_type))
|
||||
|
||||
# validate=False to allow extra keys from compiling
|
||||
return cls.from_dict(compiled.to_dict(), validate=False)
|
||||
return cls.from_dict(compiled.to_dict(omit_none=True))
|
||||
|
||||
|
||||
NonSourceCompiledNode = Union[
|
||||
CompiledAnalysisNode,
|
||||
CompiledDataTestNode,
|
||||
CompiledSingularTestNode,
|
||||
CompiledModelNode,
|
||||
CompiledHookNode,
|
||||
CompiledRPCNode,
|
||||
CompiledSchemaTestNode,
|
||||
CompiledGenericTestNode,
|
||||
CompiledSeedNode,
|
||||
CompiledSnapshotNode,
|
||||
]
|
||||
|
||||
NonSourceParsedNode = Union[
|
||||
ParsedAnalysisNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedRPCNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
]
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,21 +1,14 @@
|
||||
from dataclasses import field, Field, dataclass
|
||||
from enum import Enum
|
||||
from itertools import chain
|
||||
from typing import (
|
||||
Any, List, Optional, Dict, MutableMapping, Union, Type, NewType, Tuple,
|
||||
TypeVar, Callable
|
||||
Any, List, Optional, Dict, Union, Type, TypeVar, Callable
|
||||
)
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ValidationError, register_pattern,
|
||||
)
|
||||
|
||||
# TODO: patch+upgrade hologram to avoid this jsonschema import
|
||||
import jsonschema # type: ignore
|
||||
|
||||
# This is protected, but we really do want to reuse this logic, and the cache!
|
||||
# It would be nice to move the custom error picking stuff into hologram!
|
||||
from hologram import _validate_schema
|
||||
from hologram import JsonSchemaMixin, ValidationError
|
||||
from hologram.helpers import StrEnum, register_pattern
|
||||
|
||||
from dbt.contracts.graph.unparsed import AdditionalPropertiesAllowed
|
||||
from dbt.exceptions import CompilationException, InternalException
|
||||
from dbt.exceptions import InternalException, CompilationException
|
||||
from dbt.contracts.util import Replaceable, list_str
|
||||
from dbt import hooks
|
||||
from dbt.node_types import NodeType
|
||||
@@ -169,22 +162,15 @@ def insensitive_patterns(*patterns: str):
|
||||
return '^({})$'.format('|'.join(lowercased))
|
||||
|
||||
|
||||
Severity = NewType('Severity', str)
|
||||
class Severity(str):
|
||||
pass
|
||||
|
||||
|
||||
register_pattern(Severity, insensitive_patterns('warn', 'error'))
|
||||
|
||||
|
||||
class SnapshotStrategy(StrEnum):
|
||||
Timestamp = 'timestamp'
|
||||
Check = 'check'
|
||||
|
||||
|
||||
class All(StrEnum):
|
||||
All = 'all'
|
||||
|
||||
|
||||
@dataclass
|
||||
class Hook(JsonSchemaMixin, Replaceable):
|
||||
class Hook(dbtClassMixin, Replaceable):
|
||||
sql: str
|
||||
transaction: bool = True
|
||||
index: Optional[int] = None
|
||||
@@ -195,19 +181,23 @@ T = TypeVar('T', bound='BaseConfig')
|
||||
|
||||
@dataclass
|
||||
class BaseConfig(
|
||||
AdditionalPropertiesAllowed, Replaceable, MutableMapping[str, Any]
|
||||
AdditionalPropertiesAllowed, Replaceable
|
||||
):
|
||||
# Implement MutableMapping so this config will behave as some macros expect
|
||||
# during parsing (notably, syntax like `{{ node.config['schema'] }}`)
|
||||
|
||||
# enable syntax like: config['key']
|
||||
def __getitem__(self, key):
|
||||
"""Handle parse-time use of `config` as a dictionary, making the extra
|
||||
values available during parsing.
|
||||
"""
|
||||
return self.get(key)
|
||||
|
||||
# like doing 'get' on a dictionary
|
||||
def get(self, key, default=None):
|
||||
if hasattr(self, key):
|
||||
return getattr(self, key)
|
||||
else:
|
||||
elif key in self._extra:
|
||||
return self._extra[key]
|
||||
else:
|
||||
return default
|
||||
|
||||
# enable syntax like: config['key'] = value
|
||||
def __setitem__(self, key, value):
|
||||
if hasattr(self, key):
|
||||
setattr(self, key, value)
|
||||
@@ -242,20 +232,50 @@ class BaseConfig(
|
||||
def __len__(self):
|
||||
return len(self._get_fields()) + len(self._extra)
|
||||
|
||||
def same_contents(self: T, other: T) -> bool:
|
||||
"""This is like __eq__, except it ignores some fields."""
|
||||
for key in self._content_iterator(
|
||||
include_condition=CompareBehavior.should_include
|
||||
):
|
||||
try:
|
||||
if self[key] != other[key]:
|
||||
return False
|
||||
except KeyError:
|
||||
return False
|
||||
return True
|
||||
@staticmethod
|
||||
def compare_key(
|
||||
unrendered: Dict[str, Any],
|
||||
other: Dict[str, Any],
|
||||
key: str,
|
||||
) -> bool:
|
||||
if key not in unrendered and key not in other:
|
||||
return True
|
||||
elif key not in unrendered and key in other:
|
||||
return False
|
||||
elif key in unrendered and key not in other:
|
||||
return False
|
||||
else:
|
||||
return unrendered[key] == other[key]
|
||||
|
||||
@classmethod
|
||||
def _extract_dict(
|
||||
def same_contents(
|
||||
cls, unrendered: Dict[str, Any], other: Dict[str, Any]
|
||||
) -> bool:
|
||||
"""This is like __eq__, except it ignores some fields."""
|
||||
seen = set()
|
||||
for fld, target_name in cls._get_fields():
|
||||
key = target_name
|
||||
seen.add(key)
|
||||
if CompareBehavior.should_include(fld):
|
||||
if not cls.compare_key(unrendered, other, key):
|
||||
return False
|
||||
|
||||
for key in chain(unrendered, other):
|
||||
if key not in seen:
|
||||
seen.add(key)
|
||||
if not cls.compare_key(unrendered, other, key):
|
||||
return False
|
||||
return True
|
||||
|
||||
# This is used in 'add_config_call' to created the combined config_call_dict.
|
||||
# 'meta' moved here from node
|
||||
mergebehavior = {
|
||||
"append": ['pre-hook', 'pre_hook', 'post-hook', 'post_hook', 'tags'],
|
||||
"update": ['quoting', 'column_types', 'meta'],
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def _merge_dicts(
|
||||
cls, src: Dict[str, Any], data: Dict[str, Any]
|
||||
) -> Dict[str, Any]:
|
||||
"""Find all the items in data that match a target_field on this class,
|
||||
@@ -289,29 +309,6 @@ class BaseConfig(
|
||||
)
|
||||
return result
|
||||
|
||||
def to_dict(
|
||||
self,
|
||||
omit_none: bool = True,
|
||||
validate: bool = False,
|
||||
*,
|
||||
omit_hidden: bool = True,
|
||||
) -> Dict[str, Any]:
|
||||
result = super().to_dict(omit_none=omit_none, validate=validate)
|
||||
if omit_hidden and not omit_none:
|
||||
for fld, target_field in self._get_fields():
|
||||
if target_field not in result:
|
||||
continue
|
||||
|
||||
# if the field is not None, preserve it regardless of the
|
||||
# setting. This is in line with existing behavior, but isn't
|
||||
# an endorsement of it!
|
||||
if result[target_field] is not None:
|
||||
continue
|
||||
|
||||
if not ShowBehavior.should_show(fld):
|
||||
del result[target_field]
|
||||
return result
|
||||
|
||||
def update_from(
|
||||
self: T, data: Dict[str, Any], adapter_type: str, validate: bool = True
|
||||
) -> T:
|
||||
@@ -320,35 +317,37 @@ class BaseConfig(
|
||||
"""
|
||||
# sadly, this is a circular import
|
||||
from dbt.adapters.factory import get_config_class_by_name
|
||||
dct = self.to_dict(omit_none=False, validate=False, omit_hidden=False)
|
||||
dct = self.to_dict(omit_none=False)
|
||||
|
||||
adapter_config_cls = get_config_class_by_name(adapter_type)
|
||||
|
||||
self_merged = self._extract_dict(dct, data)
|
||||
self_merged = self._merge_dicts(dct, data)
|
||||
dct.update(self_merged)
|
||||
|
||||
adapter_merged = adapter_config_cls._extract_dict(dct, data)
|
||||
adapter_merged = adapter_config_cls._merge_dicts(dct, data)
|
||||
dct.update(adapter_merged)
|
||||
|
||||
# any remaining fields must be "clobber"
|
||||
dct.update(data)
|
||||
|
||||
# any validation failures must have come from the update
|
||||
return self.from_dict(dct, validate=validate)
|
||||
if validate:
|
||||
self.validate(dct)
|
||||
return self.from_dict(dct)
|
||||
|
||||
def finalize_and_validate(self: T) -> T:
|
||||
# from_dict will validate for us
|
||||
dct = self.to_dict(omit_none=False, validate=False)
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
return self.from_dict(dct)
|
||||
|
||||
def replace(self, **kwargs):
|
||||
dct = self.to_dict(validate=False)
|
||||
dct = self.to_dict(omit_none=True)
|
||||
|
||||
mapping = self.field_mapping()
|
||||
for key, value in kwargs.items():
|
||||
new_key = mapping.get(key, key)
|
||||
dct[new_key] = value
|
||||
return self.from_dict(dct, validate=False)
|
||||
return self.from_dict(dct)
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -357,33 +356,8 @@ class SourceConfig(BaseConfig):
|
||||
|
||||
|
||||
@dataclass
|
||||
class NodeConfig(BaseConfig):
|
||||
class NodeAndTestConfig(BaseConfig):
|
||||
enabled: bool = True
|
||||
materialized: str = 'view'
|
||||
persist_docs: Dict[str, Any] = field(default_factory=dict)
|
||||
post_hook: List[Hook] = field(
|
||||
default_factory=list,
|
||||
metadata=MergeBehavior.Append.meta(),
|
||||
)
|
||||
pre_hook: List[Hook] = field(
|
||||
default_factory=list,
|
||||
metadata=MergeBehavior.Append.meta(),
|
||||
)
|
||||
# this only applies for config v1, so it doesn't participate in comparison
|
||||
vars: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=metas(CompareBehavior.Exclude, MergeBehavior.Update),
|
||||
)
|
||||
quoting: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
# This is actually only used by seeds. Should it be available to others?
|
||||
# That would be a breaking change!
|
||||
column_types: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
# these fields are included in serialized output, but are not part of
|
||||
# config comparison (they are part of database_representation)
|
||||
alias: Optional[str] = field(
|
||||
@@ -404,15 +378,67 @@ class NodeConfig(BaseConfig):
|
||||
MergeBehavior.Append,
|
||||
CompareBehavior.Exclude),
|
||||
)
|
||||
meta: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class NodeConfig(NodeAndTestConfig):
|
||||
# Note: if any new fields are added with MergeBehavior, also update the
|
||||
# 'mergebehavior' dictionary
|
||||
materialized: str = 'view'
|
||||
persist_docs: Dict[str, Any] = field(default_factory=dict)
|
||||
post_hook: List[Hook] = field(
|
||||
default_factory=list,
|
||||
metadata=MergeBehavior.Append.meta(),
|
||||
)
|
||||
pre_hook: List[Hook] = field(
|
||||
default_factory=list,
|
||||
metadata=MergeBehavior.Append.meta(),
|
||||
)
|
||||
quoting: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
# This is actually only used by seeds. Should it be available to others?
|
||||
# That would be a breaking change!
|
||||
column_types: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata=MergeBehavior.Update.meta(),
|
||||
)
|
||||
full_refresh: Optional[bool] = None
|
||||
on_schema_change: Optional[str] = 'ignore'
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data, validate=True):
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
field_map = {'post-hook': 'post_hook', 'pre-hook': 'pre_hook'}
|
||||
# create a new dict because otherwise it gets overwritten in
|
||||
# tests
|
||||
new_dict = {}
|
||||
for key in data:
|
||||
new_dict[key] = data[key]
|
||||
data = new_dict
|
||||
for key in hooks.ModelHookType:
|
||||
if key in data:
|
||||
data[key] = [hooks.get_hook_dict(h) for h in data[key]]
|
||||
return super().from_dict(data, validate=validate)
|
||||
for field_name in field_map:
|
||||
if field_name in data:
|
||||
new_name = field_map[field_name]
|
||||
data[new_name] = data.pop(field_name)
|
||||
return data
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
field_map = {'post_hook': 'post-hook', 'pre_hook': 'pre-hook'}
|
||||
for field_name in field_map:
|
||||
if field_name in dct:
|
||||
dct[field_map[field_name]] = dct.pop(field_name)
|
||||
return dct
|
||||
|
||||
# this is still used by jsonschema validation
|
||||
@classmethod
|
||||
def field_mapping(cls):
|
||||
return {'post_hook': 'post-hook', 'pre_hook': 'pre-hook'}
|
||||
@@ -425,46 +451,44 @@ class SeedConfig(NodeConfig):
|
||||
|
||||
|
||||
@dataclass
|
||||
class TestConfig(NodeConfig):
|
||||
class TestConfig(NodeAndTestConfig):
|
||||
# this is repeated because of a different default
|
||||
schema: Optional[str] = field(
|
||||
default='dbt_test__audit',
|
||||
metadata=CompareBehavior.Exclude.meta(),
|
||||
)
|
||||
materialized: str = 'test'
|
||||
severity: Severity = Severity('ERROR')
|
||||
|
||||
|
||||
SnapshotVariants = Union[
|
||||
'TimestampSnapshotConfig',
|
||||
'CheckSnapshotConfig',
|
||||
'GenericSnapshotConfig',
|
||||
]
|
||||
|
||||
|
||||
def _relevance_without_strategy(error: jsonschema.ValidationError):
|
||||
# calculate the 'relevance' of an error the normal jsonschema way, except
|
||||
# if the validator is in the 'strategy' field and its conflicting with the
|
||||
# 'enum'. This suppresses `"'timestamp' is not one of ['check']` and such
|
||||
if 'strategy' in error.path and error.validator in {'enum', 'not'}:
|
||||
length = 1
|
||||
else:
|
||||
length = -len(error.path)
|
||||
validator = error.validator
|
||||
return length, validator not in {'anyOf', 'oneOf'}
|
||||
|
||||
|
||||
@dataclass
|
||||
class SnapshotWrapper(JsonSchemaMixin):
|
||||
"""This is a little wrapper to let us serialize/deserialize the
|
||||
SnapshotVariants union.
|
||||
"""
|
||||
config: SnapshotVariants # mypy: ignore
|
||||
store_failures: Optional[bool] = None
|
||||
where: Optional[str] = None
|
||||
limit: Optional[int] = None
|
||||
fail_calc: str = 'count(*)'
|
||||
warn_if: str = '!= 0'
|
||||
error_if: str = '!= 0'
|
||||
|
||||
@classmethod
|
||||
def validate(cls, data: Any):
|
||||
schema = _validate_schema(cls)
|
||||
validator = jsonschema.Draft7Validator(schema)
|
||||
error = jsonschema.exceptions.best_match(
|
||||
validator.iter_errors(data),
|
||||
key=_relevance_without_strategy,
|
||||
)
|
||||
if error is not None:
|
||||
raise ValidationError.create_from(error) from error
|
||||
def same_contents(
|
||||
cls, unrendered: Dict[str, Any], other: Dict[str, Any]
|
||||
) -> bool:
|
||||
"""This is like __eq__, except it explicitly checks certain fields."""
|
||||
modifiers = [
|
||||
'severity',
|
||||
'where',
|
||||
'limit',
|
||||
'fail_calc',
|
||||
'warn_if',
|
||||
'error_if',
|
||||
'store_failures'
|
||||
]
|
||||
|
||||
seen = set()
|
||||
for _, target_name in cls._get_fields():
|
||||
key = target_name
|
||||
seen.add(key)
|
||||
if key in modifiers:
|
||||
if not cls.compare_key(unrendered, other, key):
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -472,123 +496,49 @@ class EmptySnapshotConfig(NodeConfig):
|
||||
materialized: str = 'snapshot'
|
||||
|
||||
|
||||
@dataclass(init=False)
|
||||
@dataclass
|
||||
class SnapshotConfig(EmptySnapshotConfig):
|
||||
unique_key: str = field(init=False, metadata=dict(init_required=True))
|
||||
target_schema: str = field(init=False, metadata=dict(init_required=True))
|
||||
strategy: Optional[str] = None
|
||||
unique_key: Optional[str] = None
|
||||
target_schema: Optional[str] = None
|
||||
target_database: Optional[str] = None
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
unique_key: str,
|
||||
target_schema: str,
|
||||
target_database: Optional[str] = None,
|
||||
**kwargs
|
||||
) -> None:
|
||||
self.unique_key = unique_key
|
||||
self.target_schema = target_schema
|
||||
self.target_database = target_database
|
||||
# kwargs['materialized'] = materialized
|
||||
super().__init__(**kwargs)
|
||||
|
||||
# type hacks...
|
||||
@classmethod
|
||||
def _get_fields(cls) -> List[Tuple[Field, str]]: # type: ignore
|
||||
fields: List[Tuple[Field, str]] = []
|
||||
for old_field, name in super()._get_fields():
|
||||
new_field = old_field
|
||||
# tell hologram we're really an initvar
|
||||
if old_field.metadata and old_field.metadata.get('init_required'):
|
||||
new_field = field(init=True, metadata=old_field.metadata)
|
||||
new_field.name = old_field.name
|
||||
new_field.type = old_field.type
|
||||
new_field._field_type = old_field._field_type # type: ignore
|
||||
fields.append((new_field, name))
|
||||
return fields
|
||||
|
||||
def finalize_and_validate(self: 'SnapshotConfig') -> SnapshotVariants:
|
||||
data = self.to_dict()
|
||||
return SnapshotWrapper.from_dict({'config': data}).config
|
||||
|
||||
|
||||
@dataclass(init=False)
|
||||
class GenericSnapshotConfig(SnapshotConfig):
|
||||
strategy: str = field(init=False, metadata=dict(init_required=True))
|
||||
|
||||
def __init__(self, strategy: str, **kwargs) -> None:
|
||||
self.strategy = strategy
|
||||
super().__init__(**kwargs)
|
||||
updated_at: Optional[str] = None
|
||||
check_cols: Optional[Union[str, List[str]]] = None
|
||||
|
||||
@classmethod
|
||||
def _collect_json_schema(
|
||||
cls, definitions: Dict[str, Any]
|
||||
) -> Dict[str, Any]:
|
||||
# this is the method you want to override in hologram if you want
|
||||
# to do clever things about the json schema and have classes that
|
||||
# contain instances of your JsonSchemaMixin respect the change.
|
||||
schema = super()._collect_json_schema(definitions)
|
||||
def validate(cls, data):
|
||||
super().validate(data)
|
||||
if not data.get('strategy') or not data.get('unique_key') or not \
|
||||
data.get('target_schema'):
|
||||
raise ValidationError(
|
||||
"Snapshots must be configured with a 'strategy', 'unique_key', "
|
||||
"and 'target_schema'.")
|
||||
if data.get('strategy') == 'check':
|
||||
if not data.get('check_cols'):
|
||||
raise ValidationError(
|
||||
"A snapshot configured with the check strategy must "
|
||||
"specify a check_cols configuration.")
|
||||
if (isinstance(data['check_cols'], str) and
|
||||
data['check_cols'] != 'all'):
|
||||
raise ValidationError(
|
||||
f"Invalid value for 'check_cols': {data['check_cols']}. "
|
||||
"Expected 'all' or a list of strings.")
|
||||
|
||||
# Instead of just the strategy we'd calculate normally, say
|
||||
# "this strategy except none of our specialization strategies".
|
||||
strategies = [schema['properties']['strategy']]
|
||||
for specialization in (TimestampSnapshotConfig, CheckSnapshotConfig):
|
||||
strategies.append(
|
||||
{'not': specialization.json_schema()['properties']['strategy']}
|
||||
)
|
||||
elif data.get('strategy') == 'timestamp':
|
||||
if not data.get('updated_at'):
|
||||
raise ValidationError(
|
||||
"A snapshot configured with the timestamp strategy "
|
||||
"must specify an updated_at configuration.")
|
||||
if data.get('check_cols'):
|
||||
raise ValidationError(
|
||||
"A 'timestamp' snapshot should not have 'check_cols'")
|
||||
# If the strategy is not 'check' or 'timestamp' it's a custom strategy,
|
||||
# formerly supported with GenericSnapshotConfig
|
||||
|
||||
schema['properties']['strategy'] = {
|
||||
'allOf': strategies
|
||||
}
|
||||
return schema
|
||||
|
||||
|
||||
@dataclass(init=False)
|
||||
class TimestampSnapshotConfig(SnapshotConfig):
|
||||
strategy: str = field(
|
||||
init=False,
|
||||
metadata=dict(
|
||||
restrict=[str(SnapshotStrategy.Timestamp)],
|
||||
init_required=True,
|
||||
),
|
||||
)
|
||||
updated_at: str = field(init=False, metadata=dict(init_required=True))
|
||||
|
||||
def __init__(
|
||||
self, strategy: str, updated_at: str, **kwargs
|
||||
) -> None:
|
||||
self.strategy = strategy
|
||||
self.updated_at = updated_at
|
||||
super().__init__(**kwargs)
|
||||
|
||||
|
||||
@dataclass(init=False)
|
||||
class CheckSnapshotConfig(SnapshotConfig):
|
||||
strategy: str = field(
|
||||
init=False,
|
||||
metadata=dict(
|
||||
restrict=[str(SnapshotStrategy.Check)],
|
||||
init_required=True,
|
||||
),
|
||||
)
|
||||
# TODO: is there a way to get this to accept tuples of strings? Adding
|
||||
# `Tuple[str, ...]` to the list of types results in this:
|
||||
# ['email'] is valid under each of {'type': 'array', 'items':
|
||||
# {'type': 'string'}}, {'type': 'array', 'items': {'type': 'string'}}
|
||||
# but without it, parsing gets upset about values like `('email',)`
|
||||
# maybe hologram itself should support this behavior? It's not like tuples
|
||||
# are meaningful in json
|
||||
check_cols: Union[All, List[str]] = field(
|
||||
init=False,
|
||||
metadata=dict(init_required=True),
|
||||
)
|
||||
|
||||
def __init__(
|
||||
self, strategy: str, check_cols: Union[All, List[str]],
|
||||
**kwargs
|
||||
) -> None:
|
||||
self.strategy = strategy
|
||||
self.check_cols = check_cols
|
||||
super().__init__(**kwargs)
|
||||
def finalize_and_validate(self):
|
||||
data = self.to_dict(omit_none=True)
|
||||
self.validate(data)
|
||||
return self.from_dict(data)
|
||||
|
||||
|
||||
RESOURCE_TYPES: Dict[NodeType, Type[BaseConfig]] = {
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
import os
|
||||
import time
|
||||
from dataclasses import dataclass, field
|
||||
from mashumaro.types import SerializableType
|
||||
from pathlib import Path
|
||||
from typing import (
|
||||
Optional,
|
||||
@@ -13,8 +15,9 @@ from typing import (
|
||||
TypeVar,
|
||||
)
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from hologram.helpers import ExtensibleJsonSchemaMixin
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ExtensibleDbtClassMixin
|
||||
)
|
||||
|
||||
from dbt.clients.system import write_file
|
||||
from dbt.contracts.files import FileHash, MAXIMUM_SEED_SIZE_NAME
|
||||
@@ -38,20 +41,14 @@ from .model_config import (
|
||||
TestConfig,
|
||||
SourceConfig,
|
||||
EmptySnapshotConfig,
|
||||
SnapshotVariants,
|
||||
)
|
||||
# import these 3 so the SnapshotVariants forward ref works.
|
||||
from .model_config import ( # noqa
|
||||
TimestampSnapshotConfig,
|
||||
CheckSnapshotConfig,
|
||||
GenericSnapshotConfig,
|
||||
SnapshotConfig,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ColumnInfo(
|
||||
AdditionalPropertiesMixin,
|
||||
ExtensibleJsonSchemaMixin,
|
||||
ExtensibleDbtClassMixin,
|
||||
Replaceable
|
||||
):
|
||||
name: str
|
||||
@@ -64,7 +61,7 @@ class ColumnInfo(
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasFqn(JsonSchemaMixin, Replaceable):
|
||||
class HasFqn(dbtClassMixin, Replaceable):
|
||||
fqn: List[str]
|
||||
|
||||
def same_fqn(self, other: 'HasFqn') -> bool:
|
||||
@@ -72,12 +69,12 @@ class HasFqn(JsonSchemaMixin, Replaceable):
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasUniqueID(JsonSchemaMixin, Replaceable):
|
||||
class HasUniqueID(dbtClassMixin, Replaceable):
|
||||
unique_id: str
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroDependsOn(JsonSchemaMixin, Replaceable):
|
||||
class MacroDependsOn(dbtClassMixin, Replaceable):
|
||||
macros: List[str] = field(default_factory=list)
|
||||
|
||||
# 'in' on lists is O(n) so this is O(n^2) for # of macros
|
||||
@@ -96,12 +93,22 @@ class DependsOn(MacroDependsOn):
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasRelationMetadata(JsonSchemaMixin, Replaceable):
|
||||
class HasRelationMetadata(dbtClassMixin, Replaceable):
|
||||
database: Optional[str]
|
||||
schema: str
|
||||
|
||||
# Can't set database to None like it ought to be
|
||||
# because it messes up the subclasses and default parameters
|
||||
# so hack it here
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'database' not in data:
|
||||
data['database'] = None
|
||||
return data
|
||||
|
||||
class ParsedNodeMixins(JsonSchemaMixin):
|
||||
|
||||
class ParsedNodeMixins(dbtClassMixin):
|
||||
resource_type: NodeType
|
||||
depends_on: DependsOn
|
||||
config: NodeConfig
|
||||
@@ -110,6 +117,21 @@ class ParsedNodeMixins(JsonSchemaMixin):
|
||||
def is_refable(self):
|
||||
return self.resource_type in NodeType.refable()
|
||||
|
||||
@property
|
||||
def should_store_failures(self):
|
||||
return self.resource_type == NodeType.Test and (
|
||||
self.config.store_failures if self.config.store_failures is not None
|
||||
else flags.STORE_FAILURES
|
||||
)
|
||||
|
||||
# will this node map to an object in the database?
|
||||
@property
|
||||
def is_relational(self):
|
||||
return (
|
||||
self.resource_type in NodeType.refable() or
|
||||
self.should_store_failures
|
||||
)
|
||||
|
||||
@property
|
||||
def is_ephemeral(self):
|
||||
return self.config.materialized == 'ephemeral'
|
||||
@@ -126,21 +148,18 @@ class ParsedNodeMixins(JsonSchemaMixin):
|
||||
"""Given a ParsedNodePatch, add the new information to the node."""
|
||||
# explicitly pick out the parts to update so we don't inadvertently
|
||||
# step on the model name or anything
|
||||
self.patch_path: Optional[str] = patch.original_file_path
|
||||
# Note: config should already be updated
|
||||
self.patch_path: Optional[str] = patch.file_id
|
||||
# update created_at so process_docs will run in partial parsing
|
||||
self.created_at = int(time.time())
|
||||
self.description = patch.description
|
||||
self.columns = patch.columns
|
||||
self.meta = patch.meta
|
||||
self.docs = patch.docs
|
||||
if flags.STRICT_MODE:
|
||||
assert isinstance(self, JsonSchemaMixin)
|
||||
self.to_dict(validate=True, omit_none=False)
|
||||
|
||||
def get_materialization(self):
|
||||
return self.config.materialized
|
||||
|
||||
def local_vars(self):
|
||||
return self.config.vars
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedNodeMandatory(
|
||||
@@ -163,15 +182,19 @@ class ParsedNodeMandatory(
|
||||
class ParsedNodeDefaults(ParsedNodeMandatory):
|
||||
tags: List[str] = field(default_factory=list)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[Any]] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
description: str = field(default='')
|
||||
columns: Dict[str, ColumnInfo] = field(default_factory=dict)
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
docs: Docs = field(default_factory=Docs)
|
||||
patch_path: Optional[str] = None
|
||||
compiled_path: Optional[str] = None
|
||||
build_path: Optional[str] = None
|
||||
deferred: bool = False
|
||||
unrendered_config: Dict[str, Any] = field(default_factory=dict)
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
config_call_dict: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
def write_node(self, target_path: str, subdirectory: str, payload: str):
|
||||
if (os.path.basename(self.path) ==
|
||||
@@ -193,12 +216,55 @@ T = TypeVar('T', bound='ParsedNode')
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins):
|
||||
class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins, SerializableType):
|
||||
|
||||
def _serialize(self):
|
||||
return self.to_dict()
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
if 'config_call_dict' in dct:
|
||||
del dct['config_call_dict']
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, dct: Dict[str, int]):
|
||||
# The serialized ParsedNodes do not differ from each other
|
||||
# in fields that would allow 'from_dict' to distinguis
|
||||
# between them.
|
||||
resource_type = dct['resource_type']
|
||||
if resource_type == 'model':
|
||||
return ParsedModelNode.from_dict(dct)
|
||||
elif resource_type == 'analysis':
|
||||
return ParsedAnalysisNode.from_dict(dct)
|
||||
elif resource_type == 'seed':
|
||||
return ParsedSeedNode.from_dict(dct)
|
||||
elif resource_type == 'rpc':
|
||||
return ParsedRPCNode.from_dict(dct)
|
||||
elif resource_type == 'test':
|
||||
if 'test_metadata' in dct:
|
||||
return ParsedGenericTestNode.from_dict(dct)
|
||||
else:
|
||||
return ParsedSingularTestNode.from_dict(dct)
|
||||
elif resource_type == 'operation':
|
||||
return ParsedHookNode.from_dict(dct)
|
||||
elif resource_type == 'seed':
|
||||
return ParsedSeedNode.from_dict(dct)
|
||||
elif resource_type == 'snapshot':
|
||||
return ParsedSnapshotNode.from_dict(dct)
|
||||
else:
|
||||
return cls.from_dict(dct)
|
||||
|
||||
def _persist_column_docs(self) -> bool:
|
||||
return bool(self.config.persist_docs.get('columns'))
|
||||
if hasattr(self.config, 'persist_docs'):
|
||||
assert isinstance(self.config, NodeConfig)
|
||||
return bool(self.config.persist_docs.get('columns'))
|
||||
return False
|
||||
|
||||
def _persist_relation_docs(self) -> bool:
|
||||
return bool(self.config.persist_docs.get('relation'))
|
||||
if hasattr(self.config, 'persist_docs'):
|
||||
assert isinstance(self.config, NodeConfig)
|
||||
return bool(self.config.persist_docs.get('relation'))
|
||||
return False
|
||||
|
||||
def same_body(self: T, other: T) -> bool:
|
||||
return self.raw_sql == other.raw_sql
|
||||
@@ -229,15 +295,19 @@ class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins):
|
||||
# compares the configured value, rather than the ultimate value (so
|
||||
# generate_*_name and unset values derived from the target are
|
||||
# ignored)
|
||||
return (
|
||||
self.config.database == other.config.database and
|
||||
self.config.schema == other.config.schema and
|
||||
self.config.alias == other.config.alias and
|
||||
True
|
||||
)
|
||||
keys = ('database', 'schema', 'alias')
|
||||
for key in keys:
|
||||
mine = self.unrendered_config.get(key)
|
||||
others = other.unrendered_config.get(key)
|
||||
if mine != others:
|
||||
return False
|
||||
return True
|
||||
|
||||
def same_config(self, old: T) -> bool:
|
||||
return self.config.same_contents(old.config)
|
||||
return self.config.same_contents(
|
||||
self.unrendered_config,
|
||||
old.unrendered_config,
|
||||
)
|
||||
|
||||
def same_contents(self: T, old: Optional[T]) -> bool:
|
||||
if old is None:
|
||||
@@ -330,35 +400,33 @@ class ParsedSeedNode(ParsedNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class TestMetadata(JsonSchemaMixin, Replaceable):
|
||||
namespace: Optional[str]
|
||||
class TestMetadata(dbtClassMixin, Replaceable):
|
||||
name: str
|
||||
kwargs: Dict[str, Any]
|
||||
kwargs: Dict[str, Any] = field(default_factory=dict)
|
||||
namespace: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasTestMetadata(JsonSchemaMixin):
|
||||
class HasTestMetadata(dbtClassMixin):
|
||||
test_metadata: TestMetadata
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedDataTestNode(ParsedNode):
|
||||
class ParsedSingularTestNode(ParsedNode):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
config: TestConfig = field(default_factory=TestConfig) # type: ignore
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedSchemaTestNode(ParsedNode, HasTestMetadata):
|
||||
# keep this in sync with CompiledSchemaTestNode!
|
||||
class ParsedGenericTestNode(ParsedNode, HasTestMetadata):
|
||||
# keep this in sync with CompiledGenericTestNode!
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
column_name: Optional[str] = None
|
||||
config: TestConfig = field(default_factory=TestConfig)
|
||||
|
||||
def same_config(self, other) -> bool:
|
||||
return self.config.severity == other.config.severity
|
||||
|
||||
def same_column_name(self, other) -> bool:
|
||||
return self.column_name == other.column_name
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
config: TestConfig = field(default_factory=TestConfig) # type: ignore
|
||||
|
||||
def same_contents(self, other) -> bool:
|
||||
if other is None:
|
||||
@@ -386,7 +454,7 @@ class IntermediateSnapshotNode(ParsedNode):
|
||||
@dataclass
|
||||
class ParsedSnapshotNode(ParsedNode):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Snapshot]})
|
||||
config: SnapshotVariants
|
||||
config: SnapshotConfig
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -395,6 +463,7 @@ class ParsedPatch(HasYamlMetadata, Replaceable):
|
||||
description: str
|
||||
meta: Dict[str, Any]
|
||||
docs: Docs
|
||||
config: Dict[str, Any]
|
||||
|
||||
|
||||
# The parsed node update is only the 'patch', not the test. The test became a
|
||||
@@ -424,19 +493,15 @@ class ParsedMacro(UnparsedBaseNode, HasUniqueID):
|
||||
docs: Docs = field(default_factory=Docs)
|
||||
patch_path: Optional[str] = None
|
||||
arguments: List[MacroArgument] = field(default_factory=list)
|
||||
|
||||
def local_vars(self):
|
||||
return {}
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
def patch(self, patch: ParsedMacroPatch):
|
||||
self.patch_path: Optional[str] = patch.original_file_path
|
||||
self.patch_path: Optional[str] = patch.file_id
|
||||
self.description = patch.description
|
||||
self.created_at = int(time.time())
|
||||
self.meta = patch.meta
|
||||
self.docs = patch.docs
|
||||
self.arguments = patch.arguments
|
||||
if flags.STRICT_MODE:
|
||||
assert isinstance(self, JsonSchemaMixin)
|
||||
self.to_dict(validate=True, omit_none=False)
|
||||
|
||||
def same_contents(self, other: Optional['ParsedMacro']) -> bool:
|
||||
if other is None:
|
||||
@@ -527,7 +592,8 @@ class ParsedSourceDefinition(
|
||||
UnparsedBaseNode,
|
||||
HasUniqueID,
|
||||
HasRelationMetadata,
|
||||
HasFqn
|
||||
HasFqn,
|
||||
|
||||
):
|
||||
name: str
|
||||
source_name: str
|
||||
@@ -546,6 +612,9 @@ class ParsedSourceDefinition(
|
||||
tags: List[str] = field(default_factory=list)
|
||||
config: SourceConfig = field(default_factory=SourceConfig)
|
||||
patch_path: Optional[Path] = None
|
||||
unrendered_config: Dict[str, Any] = field(default_factory=dict)
|
||||
relation_name: Optional[str] = None
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
def same_database_representation(
|
||||
self, other: 'ParsedSourceDefinition'
|
||||
@@ -571,7 +640,10 @@ class ParsedSourceDefinition(
|
||||
return self.external == other.external
|
||||
|
||||
def same_config(self, old: 'ParsedSourceDefinition') -> bool:
|
||||
return self.config.same_contents(old.config)
|
||||
return self.config.same_contents(
|
||||
self.unrendered_config,
|
||||
old.unrendered_config,
|
||||
)
|
||||
|
||||
def same_contents(self, old: Optional['ParsedSourceDefinition']) -> bool:
|
||||
# existing when it didn't before is a change!
|
||||
@@ -618,6 +690,10 @@ class ParsedSourceDefinition(
|
||||
def depends_on_nodes(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def depends_on(self):
|
||||
return DependsOn(macros=[], nodes=[])
|
||||
|
||||
@property
|
||||
def refs(self):
|
||||
return []
|
||||
@@ -641,12 +717,15 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
type: ExposureType
|
||||
owner: ExposureOwner
|
||||
resource_type: NodeType = NodeType.Exposure
|
||||
description: str = ''
|
||||
maturity: Optional[MaturityType] = None
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
url: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
created_at: int = field(default_factory=lambda: int(time.time()))
|
||||
|
||||
@property
|
||||
def depends_on_nodes(self):
|
||||
@@ -656,11 +735,6 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
def search_name(self):
|
||||
return self.name
|
||||
|
||||
# no tags for now, but we could definitely add them
|
||||
@property
|
||||
def tags(self):
|
||||
return []
|
||||
|
||||
def same_depends_on(self, old: 'ParsedExposure') -> bool:
|
||||
return set(self.depends_on.nodes) == set(old.depends_on.nodes)
|
||||
|
||||
@@ -681,6 +755,7 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
|
||||
def same_contents(self, old: Optional['ParsedExposure']) -> bool:
|
||||
# existing when it didn't before is a change!
|
||||
# metadata/tags changes are not "changes"
|
||||
if old is None:
|
||||
return True
|
||||
|
||||
@@ -696,6 +771,18 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
)
|
||||
|
||||
|
||||
ManifestNodes = Union[
|
||||
ParsedAnalysisNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedRPCNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
]
|
||||
|
||||
|
||||
ParsedResource = Union[
|
||||
ParsedDocumentation,
|
||||
ParsedMacro,
|
||||
|
||||
@@ -8,8 +8,9 @@ from dbt.contracts.util import (
|
||||
import dbt.helper_types # noqa:F401
|
||||
from dbt.exceptions import CompilationException
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from hologram.helpers import StrEnum, ExtensibleJsonSchemaMixin
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, StrEnum, ExtensibleDbtClassMixin
|
||||
)
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import timedelta
|
||||
@@ -18,12 +19,16 @@ from typing import Optional, List, Union, Dict, Any, Sequence
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedBaseNode(JsonSchemaMixin, Replaceable):
|
||||
class UnparsedBaseNode(dbtClassMixin, Replaceable):
|
||||
package_name: str
|
||||
root_path: str
|
||||
path: str
|
||||
original_file_path: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasSQL:
|
||||
@@ -39,6 +44,11 @@ class UnparsedMacro(UnparsedBaseNode, HasSQL):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Macro]})
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedGenericTest(UnparsedBaseNode, HasSQL):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Macro]})
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedNode(UnparsedBaseNode, HasSQL):
|
||||
name: str
|
||||
@@ -66,12 +76,12 @@ class UnparsedRunHook(UnparsedNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class Docs(JsonSchemaMixin, Replaceable):
|
||||
class Docs(dbtClassMixin, Replaceable):
|
||||
show: bool = True
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasDocs(AdditionalPropertiesMixin, ExtensibleJsonSchemaMixin,
|
||||
class HasDocs(AdditionalPropertiesMixin, ExtensibleDbtClassMixin,
|
||||
Replaceable):
|
||||
name: str
|
||||
description: str = ''
|
||||
@@ -100,7 +110,7 @@ class UnparsedColumn(HasTests):
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasColumnDocs(JsonSchemaMixin, Replaceable):
|
||||
class HasColumnDocs(dbtClassMixin, Replaceable):
|
||||
columns: Sequence[HasDocs] = field(default_factory=list)
|
||||
|
||||
|
||||
@@ -110,31 +120,40 @@ class HasColumnTests(HasColumnDocs):
|
||||
|
||||
|
||||
@dataclass
|
||||
class HasYamlMetadata(JsonSchemaMixin):
|
||||
class HasYamlMetadata(dbtClassMixin):
|
||||
original_file_path: str
|
||||
yaml_key: str
|
||||
package_name: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedAnalysisUpdate(HasColumnDocs, HasDocs, HasYamlMetadata):
|
||||
class HasConfig():
|
||||
config: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedAnalysisUpdate(HasConfig, HasColumnDocs, HasDocs, HasYamlMetadata):
|
||||
pass
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedNodeUpdate(HasColumnTests, HasTests, HasYamlMetadata):
|
||||
class UnparsedNodeUpdate(HasConfig, HasColumnTests, HasTests, HasYamlMetadata):
|
||||
quote_columns: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroArgument(JsonSchemaMixin):
|
||||
class MacroArgument(dbtClassMixin):
|
||||
name: str
|
||||
type: Optional[str] = None
|
||||
description: str = ''
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedMacroUpdate(HasDocs, HasYamlMetadata):
|
||||
class UnparsedMacroUpdate(HasConfig, HasDocs, HasYamlMetadata):
|
||||
arguments: List[MacroArgument] = field(default_factory=list)
|
||||
|
||||
|
||||
@@ -148,7 +167,7 @@ class TimePeriod(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
class Time(JsonSchemaMixin, Replaceable):
|
||||
class Time(dbtClassMixin, Replaceable):
|
||||
count: int
|
||||
period: TimePeriod
|
||||
|
||||
@@ -158,19 +177,14 @@ class Time(JsonSchemaMixin, Replaceable):
|
||||
return actual_age > difference
|
||||
|
||||
|
||||
class FreshnessStatus(StrEnum):
|
||||
Pass = 'pass'
|
||||
Warn = 'warn'
|
||||
Error = 'error'
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessThreshold(JsonSchemaMixin, Mergeable):
|
||||
class FreshnessThreshold(dbtClassMixin, Mergeable):
|
||||
warn_after: Optional[Time] = None
|
||||
error_after: Optional[Time] = None
|
||||
filter: Optional[str] = None
|
||||
|
||||
def status(self, age: float) -> FreshnessStatus:
|
||||
def status(self, age: float) -> "dbt.contracts.results.FreshnessStatus":
|
||||
from dbt.contracts.results import FreshnessStatus
|
||||
if self.error_after and self.error_after.exceeded(age):
|
||||
return FreshnessStatus.Error
|
||||
elif self.warn_after and self.warn_after.exceeded(age):
|
||||
@@ -185,7 +199,7 @@ class FreshnessThreshold(JsonSchemaMixin, Mergeable):
|
||||
@dataclass
|
||||
class AdditionalPropertiesAllowed(
|
||||
AdditionalPropertiesMixin,
|
||||
ExtensibleJsonSchemaMixin
|
||||
ExtensibleDbtClassMixin
|
||||
):
|
||||
_extra: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
@@ -217,7 +231,7 @@ class ExternalTable(AdditionalPropertiesAllowed, Mergeable):
|
||||
|
||||
|
||||
@dataclass
|
||||
class Quoting(JsonSchemaMixin, Mergeable):
|
||||
class Quoting(dbtClassMixin, Mergeable):
|
||||
database: Optional[bool] = None
|
||||
schema: Optional[bool] = None
|
||||
identifier: Optional[bool] = None
|
||||
@@ -235,15 +249,15 @@ class UnparsedSourceTableDefinition(HasColumnTests, HasTests):
|
||||
external: Optional[ExternalTable] = None
|
||||
tags: List[str] = field(default_factory=list)
|
||||
|
||||
def to_dict(self, omit_none=True, validate=False):
|
||||
result = super().to_dict(omit_none=omit_none, validate=validate)
|
||||
if omit_none and self.freshness is None:
|
||||
result['freshness'] = None
|
||||
return result
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if 'freshness' not in dct and self.freshness is None:
|
||||
dct['freshness'] = None
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedSourceDefinition(JsonSchemaMixin, Replaceable):
|
||||
class UnparsedSourceDefinition(dbtClassMixin, Replaceable):
|
||||
name: str
|
||||
description: str = ''
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
@@ -257,20 +271,21 @@ class UnparsedSourceDefinition(JsonSchemaMixin, Replaceable):
|
||||
loaded_at_field: Optional[str] = None
|
||||
tables: List[UnparsedSourceTableDefinition] = field(default_factory=list)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
config: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
@property
|
||||
def yaml_key(self) -> 'str':
|
||||
return 'sources'
|
||||
|
||||
def to_dict(self, omit_none=True, validate=False):
|
||||
result = super().to_dict(omit_none=omit_none, validate=validate)
|
||||
if omit_none and self.freshness is None:
|
||||
result['freshness'] = None
|
||||
return result
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if 'freshnewss' not in dct and self.freshness is None:
|
||||
dct['freshness'] = None
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceTablePatch(JsonSchemaMixin):
|
||||
class SourceTablePatch(dbtClassMixin):
|
||||
name: str
|
||||
description: Optional[str] = None
|
||||
meta: Optional[Dict[str, Any]] = None
|
||||
@@ -301,7 +316,7 @@ class SourceTablePatch(JsonSchemaMixin):
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourcePatch(JsonSchemaMixin, Replaceable):
|
||||
class SourcePatch(dbtClassMixin, Replaceable):
|
||||
name: str = field(
|
||||
metadata=dict(description='The name of the source to override'),
|
||||
)
|
||||
@@ -345,12 +360,16 @@ class SourcePatch(JsonSchemaMixin, Replaceable):
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedDocumentation(JsonSchemaMixin, Replaceable):
|
||||
class UnparsedDocumentation(dbtClassMixin, Replaceable):
|
||||
package_name: str
|
||||
root_path: str
|
||||
path: str
|
||||
original_file_path: str
|
||||
|
||||
@property
|
||||
def file_id(self):
|
||||
return f'{self.package_name}://{self.original_file_path}'
|
||||
|
||||
@property
|
||||
def resource_type(self):
|
||||
return NodeType.Documentation
|
||||
@@ -405,17 +424,19 @@ class MaturityType(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
class ExposureOwner(JsonSchemaMixin, Replaceable):
|
||||
class ExposureOwner(dbtClassMixin, Replaceable):
|
||||
email: str
|
||||
name: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedExposure(JsonSchemaMixin, Replaceable):
|
||||
class UnparsedExposure(dbtClassMixin, Replaceable):
|
||||
name: str
|
||||
type: ExposureType
|
||||
owner: ExposureOwner
|
||||
description: str = ''
|
||||
maturity: Optional[MaturityType] = None
|
||||
meta: Dict[str, Any] = field(default_factory=dict)
|
||||
tags: List[str] = field(default_factory=list)
|
||||
url: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
depends_on: List[str] = field(default_factory=list)
|
||||
|
||||
@@ -1,28 +1,40 @@
|
||||
from dbt.contracts.util import Replaceable, Mergeable, list_str
|
||||
from dbt.contracts.connection import UserConfigContract, QueryComment
|
||||
from dbt.contracts.connection import QueryComment, UserConfigContract
|
||||
from dbt.helper_types import NoValue
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
from dbt import tracking
|
||||
from dbt import ui
|
||||
|
||||
from hologram import JsonSchemaMixin, ValidationError
|
||||
from hologram.helpers import HyphenatedJsonSchemaMixin, register_pattern, \
|
||||
ExtensibleJsonSchemaMixin
|
||||
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ValidationError,
|
||||
HyphenatedDbtClassMixin,
|
||||
ExtensibleDbtClassMixin,
|
||||
register_pattern, ValidatedStringMixin
|
||||
)
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional, List, Dict, Union, Any, NewType
|
||||
from typing import Optional, List, Dict, Union, Any
|
||||
from mashumaro.types import SerializableType
|
||||
|
||||
PIN_PACKAGE_URL = 'https://docs.getdbt.com/docs/package-management#section-specifying-package-versions' # noqa
|
||||
PIN_PACKAGE_URL = 'https://docs.getdbt.com/docs/package-management#section-specifying-package-versions' # noqa
|
||||
DEFAULT_SEND_ANONYMOUS_USAGE_STATS = True
|
||||
|
||||
|
||||
Name = NewType('Name', str)
|
||||
class Name(ValidatedStringMixin):
|
||||
ValidationRegex = r'^[^\d\W]\w*$'
|
||||
|
||||
|
||||
register_pattern(Name, r'^[^\d\W]\w*$')
|
||||
|
||||
|
||||
class SemverString(str, SerializableType):
|
||||
def _serialize(self) -> str:
|
||||
return self
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, value: str) -> 'SemverString':
|
||||
return SemverString(value)
|
||||
|
||||
|
||||
# this does not support the full semver (does not allow a trailing -fooXYZ) and
|
||||
# is not restrictive enough for full semver, (allows '1.0'). But it's like
|
||||
# 'semver lite'.
|
||||
SemverString = NewType('SemverString', str)
|
||||
register_pattern(
|
||||
SemverString,
|
||||
r'^(?:0|[1-9]\d*)\.(?:0|[1-9]\d*)(\.(?:0|[1-9]\d*))?$',
|
||||
@@ -30,15 +42,15 @@ register_pattern(
|
||||
|
||||
|
||||
@dataclass
|
||||
class Quoting(JsonSchemaMixin, Mergeable):
|
||||
identifier: Optional[bool]
|
||||
schema: Optional[bool]
|
||||
database: Optional[bool]
|
||||
project: Optional[bool]
|
||||
class Quoting(dbtClassMixin, Mergeable):
|
||||
schema: Optional[bool] = None
|
||||
database: Optional[bool] = None
|
||||
project: Optional[bool] = None
|
||||
identifier: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class Package(Replaceable, HyphenatedJsonSchemaMixin):
|
||||
class Package(Replaceable, HyphenatedDbtClassMixin):
|
||||
pass
|
||||
|
||||
|
||||
@@ -54,8 +66,9 @@ RawVersion = Union[str, float]
|
||||
@dataclass
|
||||
class GitPackage(Package):
|
||||
git: str
|
||||
revision: Optional[RawVersion]
|
||||
revision: Optional[RawVersion] = None
|
||||
warn_unpinned: Optional[bool] = None
|
||||
subdirectory: Optional[str] = None
|
||||
|
||||
def get_revisions(self) -> List[str]:
|
||||
if self.revision is None:
|
||||
@@ -68,6 +81,7 @@ class GitPackage(Package):
|
||||
class RegistryPackage(Package):
|
||||
package: str
|
||||
version: Union[RawVersion, List[RawVersion]]
|
||||
install_prerelease: Optional[bool] = False
|
||||
|
||||
def get_versions(self) -> List[str]:
|
||||
if isinstance(self.version, list):
|
||||
@@ -80,7 +94,7 @@ PackageSpec = Union[LocalPackage, GitPackage, RegistryPackage]
|
||||
|
||||
|
||||
@dataclass
|
||||
class PackageConfig(JsonSchemaMixin, Replaceable):
|
||||
class PackageConfig(dbtClassMixin, Replaceable):
|
||||
packages: List[PackageSpec]
|
||||
|
||||
|
||||
@@ -96,13 +110,13 @@ class ProjectPackageMetadata:
|
||||
|
||||
|
||||
@dataclass
|
||||
class Downloads(ExtensibleJsonSchemaMixin, Replaceable):
|
||||
class Downloads(ExtensibleDbtClassMixin, Replaceable):
|
||||
tarball: str
|
||||
|
||||
|
||||
@dataclass
|
||||
class RegistryPackageMetadata(
|
||||
ExtensibleJsonSchemaMixin,
|
||||
ExtensibleDbtClassMixin,
|
||||
ProjectPackageMetadata,
|
||||
):
|
||||
downloads: Downloads
|
||||
@@ -142,6 +156,7 @@ BANNED_PROJECT_NAMES = {
|
||||
'sql',
|
||||
'sql_now',
|
||||
'store_result',
|
||||
'store_raw_result',
|
||||
'target',
|
||||
'this',
|
||||
'tojson',
|
||||
@@ -153,54 +168,16 @@ BANNED_PROJECT_NAMES = {
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProjectV1(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
name: Name
|
||||
version: Union[SemverString, float]
|
||||
project_root: Optional[str] = None
|
||||
source_paths: Optional[List[str]] = None
|
||||
macro_paths: Optional[List[str]] = None
|
||||
data_paths: Optional[List[str]] = None
|
||||
test_paths: Optional[List[str]] = None
|
||||
analysis_paths: Optional[List[str]] = None
|
||||
docs_paths: Optional[List[str]] = None
|
||||
asset_paths: Optional[List[str]] = None
|
||||
target_path: Optional[str] = None
|
||||
snapshot_paths: Optional[List[str]] = None
|
||||
clean_targets: Optional[List[str]] = None
|
||||
profile: Optional[str] = None
|
||||
log_path: Optional[str] = None
|
||||
modules_path: Optional[str] = None
|
||||
quoting: Optional[Quoting] = None
|
||||
on_run_start: Optional[List[str]] = field(default_factory=list_str)
|
||||
on_run_end: Optional[List[str]] = field(default_factory=list_str)
|
||||
require_dbt_version: Optional[Union[List[str], str]] = None
|
||||
models: Dict[str, Any] = field(default_factory=dict)
|
||||
seeds: Dict[str, Any] = field(default_factory=dict)
|
||||
snapshots: Dict[str, Any] = field(default_factory=dict)
|
||||
packages: List[PackageSpec] = field(default_factory=list)
|
||||
query_comment: Optional[Union[QueryComment, NoValue, str]] = NoValue()
|
||||
config_version: int = 1
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data, validate=True) -> 'ProjectV1':
|
||||
result = super().from_dict(data, validate=validate)
|
||||
if result.name in BANNED_PROJECT_NAMES:
|
||||
raise ValidationError(
|
||||
'Invalid project name: {} is a reserved word'
|
||||
.format(result.name)
|
||||
)
|
||||
return result
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProjectV2(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
name: Name
|
||||
version: Union[SemverString, float]
|
||||
config_version: int
|
||||
project_root: Optional[str] = None
|
||||
source_paths: Optional[List[str]] = None
|
||||
model_paths: Optional[List[str]] = None
|
||||
macro_paths: Optional[List[str]] = None
|
||||
data_paths: Optional[List[str]] = None
|
||||
seed_paths: Optional[List[str]] = None
|
||||
test_paths: Optional[List[str]] = None
|
||||
analysis_paths: Optional[List[str]] = None
|
||||
docs_paths: Optional[List[str]] = None
|
||||
@@ -210,16 +187,18 @@ class ProjectV2(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
clean_targets: Optional[List[str]] = None
|
||||
profile: Optional[str] = None
|
||||
log_path: Optional[str] = None
|
||||
modules_path: Optional[str] = None
|
||||
packages_install_path: Optional[str] = None
|
||||
quoting: Optional[Quoting] = None
|
||||
on_run_start: Optional[List[str]] = field(default_factory=list_str)
|
||||
on_run_end: Optional[List[str]] = field(default_factory=list_str)
|
||||
require_dbt_version: Optional[Union[List[str], str]] = None
|
||||
dispatch: List[Dict[str, Any]] = field(default_factory=list)
|
||||
models: Dict[str, Any] = field(default_factory=dict)
|
||||
seeds: Dict[str, Any] = field(default_factory=dict)
|
||||
snapshots: Dict[str, Any] = field(default_factory=dict)
|
||||
analyses: Dict[str, Any] = field(default_factory=dict)
|
||||
sources: Dict[str, Any] = field(default_factory=dict)
|
||||
tests: Dict[str, Any] = field(default_factory=dict)
|
||||
vars: Optional[Dict[str, Any]] = field(
|
||||
default=None,
|
||||
metadata=dict(
|
||||
@@ -230,56 +209,42 @@ class ProjectV2(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
query_comment: Optional[Union[QueryComment, NoValue, str]] = NoValue()
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data, validate=True) -> 'ProjectV2':
|
||||
result = super().from_dict(data, validate=validate)
|
||||
if result.name in BANNED_PROJECT_NAMES:
|
||||
def validate(cls, data):
|
||||
super().validate(data)
|
||||
if data['name'] in BANNED_PROJECT_NAMES:
|
||||
raise ValidationError(
|
||||
f'Invalid project name: {result.name} is a reserved word'
|
||||
f"Invalid project name: {data['name']} is a reserved word"
|
||||
)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def parse_project_config(
|
||||
data: Dict[str, Any], validate=True
|
||||
) -> Union[ProjectV1, ProjectV2]:
|
||||
config_version = data.get('config-version', 1)
|
||||
if config_version == 1:
|
||||
return ProjectV1.from_dict(data, validate=validate)
|
||||
elif config_version == 2:
|
||||
return ProjectV2.from_dict(data, validate=validate)
|
||||
else:
|
||||
raise ValidationError(
|
||||
f'Got an unexpected config-version={config_version}, expected '
|
||||
f'1 or 2'
|
||||
)
|
||||
# validate dispatch config
|
||||
if 'dispatch' in data and data['dispatch']:
|
||||
entries = data['dispatch']
|
||||
for entry in entries:
|
||||
if ('macro_namespace' not in entry or 'search_order' not in entry or
|
||||
not isinstance(entry['search_order'], list)):
|
||||
raise ValidationError(f"Invalid project dispatch config: {entry}")
|
||||
|
||||
|
||||
@dataclass
|
||||
class UserConfig(ExtensibleJsonSchemaMixin, Replaceable, UserConfigContract):
|
||||
class UserConfig(ExtensibleDbtClassMixin, Replaceable, UserConfigContract):
|
||||
send_anonymous_usage_stats: bool = DEFAULT_SEND_ANONYMOUS_USAGE_STATS
|
||||
use_colors: Optional[bool] = None
|
||||
partial_parse: Optional[bool] = None
|
||||
printer_width: Optional[int] = None
|
||||
|
||||
def set_values(self, cookie_dir):
|
||||
if self.send_anonymous_usage_stats:
|
||||
tracking.initialize_tracking(cookie_dir)
|
||||
else:
|
||||
tracking.do_not_track()
|
||||
|
||||
if self.use_colors is not None:
|
||||
ui.use_colors(self.use_colors)
|
||||
|
||||
if self.printer_width:
|
||||
ui.printer_width(self.printer_width)
|
||||
write_json: Optional[bool] = None
|
||||
warn_error: Optional[bool] = None
|
||||
log_format: Optional[bool] = None
|
||||
debug: Optional[bool] = None
|
||||
version_check: Optional[bool] = None
|
||||
fail_fast: Optional[bool] = None
|
||||
use_experimental_parser: Optional[bool] = None
|
||||
static_parser: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProfileConfig(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
class ProfileConfig(HyphenatedDbtClassMixin, Replaceable):
|
||||
profile_name: str = field(metadata={'preserve_underscore': True})
|
||||
target_name: str = field(metadata={'preserve_underscore': True})
|
||||
config: UserConfig
|
||||
user_config: UserConfig = field(metadata={'preserve_underscore': True})
|
||||
threads: int
|
||||
# TODO: make this a dynamic union of some kind?
|
||||
credentials: Optional[Dict[str, Any]]
|
||||
@@ -287,14 +252,14 @@ class ProfileConfig(HyphenatedJsonSchemaMixin, Replaceable):
|
||||
|
||||
@dataclass
|
||||
class ConfiguredQuoting(Quoting, Replaceable):
|
||||
identifier: bool
|
||||
schema: bool
|
||||
database: Optional[bool]
|
||||
project: Optional[bool]
|
||||
identifier: bool = True
|
||||
schema: bool = True
|
||||
database: Optional[bool] = None
|
||||
project: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class Configuration(ProjectV2, ProfileConfig):
|
||||
class Configuration(Project, ProfileConfig):
|
||||
cli_vars: Dict[str, Any] = field(
|
||||
default_factory=dict,
|
||||
metadata={'preserve_underscore': True},
|
||||
@@ -303,5 +268,5 @@ class Configuration(ProjectV2, ProfileConfig):
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProjectList(JsonSchemaMixin):
|
||||
projects: Dict[str, Union[ProjectV2, ProjectV1]]
|
||||
class ProjectList(dbtClassMixin):
|
||||
projects: Dict[str, Project]
|
||||
|
||||
@@ -1,16 +1,14 @@
|
||||
from collections.abc import Mapping
|
||||
from dataclasses import dataclass, fields
|
||||
from dataclasses import dataclass
|
||||
from typing import (
|
||||
Optional, TypeVar, Generic, Dict,
|
||||
Optional, Dict,
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from hologram.helpers import StrEnum
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.contracts.util import Replaceable
|
||||
from dbt.exceptions import CompilationException
|
||||
from dbt.exceptions import raise_dataclass_not_dict, CompilationException
|
||||
from dbt.utils import deep_merge
|
||||
|
||||
|
||||
@@ -32,7 +30,7 @@ class HasQuoting(Protocol):
|
||||
quoting: Dict[str, bool]
|
||||
|
||||
|
||||
class FakeAPIObject(JsonSchemaMixin, Replaceable, Mapping):
|
||||
class FakeAPIObject(dbtClassMixin, Replaceable, Mapping):
|
||||
# override the mapping truthiness, len is always >1
|
||||
def __bool__(self):
|
||||
return True
|
||||
@@ -44,30 +42,24 @@ class FakeAPIObject(JsonSchemaMixin, Replaceable, Mapping):
|
||||
raise KeyError(key) from None
|
||||
|
||||
def __iter__(self):
|
||||
deprecations.warn('not-a-dictionary', obj=self)
|
||||
for _, name in self._get_fields():
|
||||
yield name
|
||||
raise_dataclass_not_dict(self)
|
||||
|
||||
def __len__(self):
|
||||
deprecations.warn('not-a-dictionary', obj=self)
|
||||
return len(fields(self.__class__))
|
||||
raise_dataclass_not_dict(self)
|
||||
|
||||
def incorporate(self, **kwargs):
|
||||
value = self.to_dict()
|
||||
value = self.to_dict(omit_none=True)
|
||||
value = deep_merge(value, kwargs)
|
||||
return self.from_dict(value)
|
||||
|
||||
|
||||
T = TypeVar('T')
|
||||
|
||||
|
||||
@dataclass
|
||||
class _ComponentObject(FakeAPIObject, Generic[T]):
|
||||
database: T
|
||||
schema: T
|
||||
identifier: T
|
||||
class Policy(FakeAPIObject):
|
||||
database: bool = True
|
||||
schema: bool = True
|
||||
identifier: bool = True
|
||||
|
||||
def get_part(self, key: ComponentName) -> T:
|
||||
def get_part(self, key: ComponentName) -> bool:
|
||||
if key == ComponentName.Database:
|
||||
return self.database
|
||||
elif key == ComponentName.Schema:
|
||||
@@ -80,25 +72,18 @@ class _ComponentObject(FakeAPIObject, Generic[T]):
|
||||
.format(key, list(ComponentName))
|
||||
)
|
||||
|
||||
def replace_dict(self, dct: Dict[ComponentName, T]):
|
||||
kwargs: Dict[str, T] = {}
|
||||
def replace_dict(self, dct: Dict[ComponentName, bool]):
|
||||
kwargs: Dict[str, bool] = {}
|
||||
for k, v in dct.items():
|
||||
kwargs[str(k)] = v
|
||||
return self.replace(**kwargs)
|
||||
|
||||
|
||||
@dataclass
|
||||
class Policy(_ComponentObject[bool]):
|
||||
database: bool = True
|
||||
schema: bool = True
|
||||
identifier: bool = True
|
||||
|
||||
|
||||
@dataclass
|
||||
class Path(_ComponentObject[Optional[str]]):
|
||||
database: Optional[str]
|
||||
schema: Optional[str]
|
||||
identifier: Optional[str]
|
||||
class Path(FakeAPIObject):
|
||||
database: Optional[str] = None
|
||||
schema: Optional[str] = None
|
||||
identifier: Optional[str] = None
|
||||
|
||||
def __post_init__(self):
|
||||
# handle pesky jinja2.Undefined sneaking in here and messing up rende
|
||||
@@ -120,3 +105,22 @@ class Path(_ComponentObject[Optional[str]]):
|
||||
if part is not None:
|
||||
part = part.lower()
|
||||
return part
|
||||
|
||||
def get_part(self, key: ComponentName) -> Optional[str]:
|
||||
if key == ComponentName.Database:
|
||||
return self.database
|
||||
elif key == ComponentName.Schema:
|
||||
return self.schema
|
||||
elif key == ComponentName.Identifier:
|
||||
return self.identifier
|
||||
else:
|
||||
raise ValueError(
|
||||
'Got a key of {}, expected one of {}'
|
||||
.format(key, list(ComponentName))
|
||||
)
|
||||
|
||||
def replace_dict(self, dct: Dict[ComponentName, str]):
|
||||
kwargs: Dict[str, str] = {}
|
||||
for k, v in dct.items():
|
||||
kwargs[str(k)] = v
|
||||
return self.replace(**kwargs)
|
||||
|
||||
@@ -1,9 +1,15 @@
|
||||
from dbt.contracts.graph.manifest import CompileResultNode
|
||||
from dbt.contracts.graph.unparsed import (
|
||||
Time, FreshnessStatus, FreshnessThreshold
|
||||
FreshnessThreshold
|
||||
)
|
||||
from dbt.contracts.graph.parsed import ParsedSourceDefinition
|
||||
from dbt.contracts.util import Writable, Replaceable
|
||||
from dbt.contracts.util import (
|
||||
BaseArtifactMetadata,
|
||||
ArtifactMixin,
|
||||
VersionedSchema,
|
||||
Replaceable,
|
||||
schema_version,
|
||||
)
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.logger import (
|
||||
TimingProcessor,
|
||||
@@ -11,18 +17,21 @@ from dbt.logger import (
|
||||
GLOBAL_LOGGER as logger,
|
||||
)
|
||||
from dbt.utils import lowercase
|
||||
from hologram.helpers import StrEnum
|
||||
from hologram import JsonSchemaMixin
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
import agate
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime
|
||||
from typing import Union, Dict, List, Optional, Any, NamedTuple
|
||||
from typing import (
|
||||
Union, Dict, List, Optional, Any, NamedTuple, Sequence,
|
||||
)
|
||||
|
||||
from dbt.clients.system import write_json
|
||||
|
||||
|
||||
@dataclass
|
||||
class TimingInfo(JsonSchemaMixin):
|
||||
class TimingInfo(dbtClassMixin):
|
||||
name: str
|
||||
started_at: Optional[datetime] = None
|
||||
completed_at: Optional[datetime] = None
|
||||
@@ -48,47 +57,78 @@ class collect_timing_info:
|
||||
logger.debug('finished collecting timing info')
|
||||
|
||||
|
||||
class NodeStatus(StrEnum):
|
||||
Success = "success"
|
||||
Error = "error"
|
||||
Fail = "fail"
|
||||
Warn = "warn"
|
||||
Skipped = "skipped"
|
||||
Pass = "pass"
|
||||
RuntimeErr = "runtime error"
|
||||
|
||||
|
||||
class RunStatus(StrEnum):
|
||||
Success = NodeStatus.Success
|
||||
Error = NodeStatus.Error
|
||||
Skipped = NodeStatus.Skipped
|
||||
|
||||
|
||||
class TestStatus(StrEnum):
|
||||
Pass = NodeStatus.Pass
|
||||
Error = NodeStatus.Error
|
||||
Fail = NodeStatus.Fail
|
||||
Warn = NodeStatus.Warn
|
||||
Skipped = NodeStatus.Skipped
|
||||
|
||||
|
||||
class FreshnessStatus(StrEnum):
|
||||
Pass = NodeStatus.Pass
|
||||
Warn = NodeStatus.Warn
|
||||
Error = NodeStatus.Error
|
||||
RuntimeErr = NodeStatus.RuntimeErr
|
||||
|
||||
|
||||
@dataclass
|
||||
class PartialResult(JsonSchemaMixin, Writable):
|
||||
class BaseResult(dbtClassMixin):
|
||||
status: Union[RunStatus, TestStatus, FreshnessStatus]
|
||||
timing: List[TimingInfo]
|
||||
thread_id: str
|
||||
execution_time: float
|
||||
adapter_response: Dict[str, Any]
|
||||
message: Optional[str]
|
||||
failures: Optional[int]
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'message' not in data:
|
||||
data['message'] = None
|
||||
if 'failures' not in data:
|
||||
data['failures'] = None
|
||||
return data
|
||||
|
||||
|
||||
@dataclass
|
||||
class NodeResult(BaseResult):
|
||||
node: CompileResultNode
|
||||
error: Optional[str] = None
|
||||
status: Union[None, str, int, bool] = None
|
||||
execution_time: Union[str, int] = 0
|
||||
thread_id: Optional[str] = None
|
||||
timing: List[TimingInfo] = field(default_factory=list)
|
||||
fail: Optional[bool] = None
|
||||
warn: Optional[bool] = None
|
||||
|
||||
# if the result got to the point where it could be skipped/failed, we would
|
||||
# be returning a real result, not a partial.
|
||||
@property
|
||||
def skipped(self):
|
||||
return False
|
||||
|
||||
|
||||
@dataclass
|
||||
class WritableRunModelResult(PartialResult):
|
||||
skip: bool = False
|
||||
class RunResult(NodeResult):
|
||||
agate_table: Optional[agate.Table] = field(
|
||||
default=None, metadata={
|
||||
'serialize': lambda x: None, 'deserialize': lambda x: None
|
||||
}
|
||||
)
|
||||
|
||||
@property
|
||||
def skipped(self):
|
||||
return self.skip
|
||||
return self.status == RunStatus.Skipped
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunModelResult(WritableRunModelResult):
|
||||
agate_table: Optional[agate.Table] = None
|
||||
|
||||
def to_dict(self, *args, **kwargs):
|
||||
dct = super().to_dict(*args, **kwargs)
|
||||
dct.pop('agate_table', None)
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
class ExecutionResult(JsonSchemaMixin, Writable):
|
||||
results: List[Union[WritableRunModelResult, PartialResult]]
|
||||
generated_at: datetime
|
||||
class ExecutionResult(dbtClassMixin):
|
||||
results: Sequence[BaseResult]
|
||||
elapsed_time: float
|
||||
|
||||
def __len__(self):
|
||||
@@ -101,141 +141,255 @@ class ExecutionResult(JsonSchemaMixin, Writable):
|
||||
return self.results[idx]
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunResultsMetadata(BaseArtifactMetadata):
|
||||
dbt_schema_version: str = field(
|
||||
default_factory=lambda: str(RunResultsArtifact.dbt_schema_version)
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunResultOutput(BaseResult):
|
||||
unique_id: str
|
||||
|
||||
|
||||
def process_run_result(result: RunResult) -> RunResultOutput:
|
||||
return RunResultOutput(
|
||||
unique_id=result.node.unique_id,
|
||||
status=result.status,
|
||||
timing=result.timing,
|
||||
thread_id=result.thread_id,
|
||||
execution_time=result.execution_time,
|
||||
message=result.message,
|
||||
adapter_response=result.adapter_response,
|
||||
failures=result.failures
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunExecutionResult(
|
||||
ExecutionResult,
|
||||
):
|
||||
results: Sequence[RunResult]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
def write(self, path: str):
|
||||
writable = RunResultsArtifact.from_execution_results(
|
||||
results=self.results,
|
||||
elapsed_time=self.elapsed_time,
|
||||
generated_at=self.generated_at,
|
||||
args=self.args,
|
||||
)
|
||||
writable.write(path)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('run-results', 3)
|
||||
class RunResultsArtifact(ExecutionResult, ArtifactMixin):
|
||||
results: Sequence[RunResultOutput]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
|
||||
@classmethod
|
||||
def from_execution_results(
|
||||
cls,
|
||||
results: Sequence[RunResult],
|
||||
elapsed_time: float,
|
||||
generated_at: datetime,
|
||||
args: Dict,
|
||||
):
|
||||
processed_results = [process_run_result(result) for result in results]
|
||||
meta = RunResultsMetadata(
|
||||
dbt_schema_version=str(cls.dbt_schema_version),
|
||||
generated_at=generated_at,
|
||||
)
|
||||
return cls(
|
||||
metadata=meta,
|
||||
results=processed_results,
|
||||
elapsed_time=elapsed_time,
|
||||
args=args
|
||||
)
|
||||
|
||||
def write(self, path: str):
|
||||
write_json(path, self.to_dict(omit_none=False))
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunOperationResult(ExecutionResult):
|
||||
success: bool
|
||||
|
||||
|
||||
@dataclass
|
||||
class RunOperationResultMetadata(BaseArtifactMetadata):
|
||||
dbt_schema_version: str = field(default_factory=lambda: str(
|
||||
RunOperationResultsArtifact.dbt_schema_version
|
||||
))
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('run-operation-result', 1)
|
||||
class RunOperationResultsArtifact(RunOperationResult, ArtifactMixin):
|
||||
|
||||
@classmethod
|
||||
def from_success(
|
||||
cls,
|
||||
success: bool,
|
||||
elapsed_time: float,
|
||||
generated_at: datetime,
|
||||
):
|
||||
meta = RunOperationResultMetadata(
|
||||
dbt_schema_version=str(cls.dbt_schema_version),
|
||||
generated_at=generated_at,
|
||||
)
|
||||
return cls(
|
||||
metadata=meta,
|
||||
results=[],
|
||||
elapsed_time=elapsed_time,
|
||||
success=success,
|
||||
)
|
||||
|
||||
# due to issues with typing.Union collapsing subclasses, this can't subclass
|
||||
# PartialResult
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFreshnessResult(JsonSchemaMixin, Writable):
|
||||
class SourceFreshnessResult(NodeResult):
|
||||
node: ParsedSourceDefinition
|
||||
status: FreshnessStatus
|
||||
max_loaded_at: datetime
|
||||
snapshotted_at: datetime
|
||||
age: float
|
||||
status: FreshnessStatus
|
||||
error: Optional[str] = None
|
||||
execution_time: Union[str, int] = 0
|
||||
thread_id: Optional[str] = None
|
||||
timing: List[TimingInfo] = field(default_factory=list)
|
||||
fail: Optional[bool] = None
|
||||
|
||||
def __post_init__(self):
|
||||
self.fail = self.status == 'error'
|
||||
|
||||
@property
|
||||
def warned(self):
|
||||
return self.status == 'warn'
|
||||
|
||||
@property
|
||||
def skipped(self):
|
||||
return False
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessMetadata(JsonSchemaMixin):
|
||||
generated_at: datetime
|
||||
elapsed_time: float
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessExecutionResult(FreshnessMetadata):
|
||||
results: List[Union[PartialResult, SourceFreshnessResult]]
|
||||
|
||||
def write(self, path, omit_none=True):
|
||||
"""Create a new object with the desired output schema and write it."""
|
||||
meta = FreshnessMetadata(
|
||||
generated_at=self.generated_at,
|
||||
elapsed_time=self.elapsed_time,
|
||||
)
|
||||
sources = {}
|
||||
for result in self.results:
|
||||
result_value: Union[
|
||||
SourceFreshnessRuntimeError, SourceFreshnessOutput
|
||||
]
|
||||
unique_id = result.node.unique_id
|
||||
if result.error is not None:
|
||||
result_value = SourceFreshnessRuntimeError(
|
||||
error=result.error,
|
||||
state=FreshnessErrorEnum.runtime_error,
|
||||
)
|
||||
else:
|
||||
# we know that this must be a SourceFreshnessResult
|
||||
if not isinstance(result, SourceFreshnessResult):
|
||||
raise InternalException(
|
||||
'Got {} instead of a SourceFreshnessResult for a '
|
||||
'non-error result in freshness execution!'
|
||||
.format(type(result))
|
||||
)
|
||||
# if we're here, we must have a non-None freshness threshold
|
||||
criteria = result.node.freshness
|
||||
if criteria is None:
|
||||
raise InternalException(
|
||||
'Somehow evaluated a freshness result for a source '
|
||||
'that has no freshness criteria!'
|
||||
)
|
||||
result_value = SourceFreshnessOutput(
|
||||
max_loaded_at=result.max_loaded_at,
|
||||
snapshotted_at=result.snapshotted_at,
|
||||
max_loaded_at_time_ago_in_s=result.age,
|
||||
state=result.status,
|
||||
criteria=criteria,
|
||||
)
|
||||
sources[unique_id] = result_value
|
||||
output = FreshnessRunOutput(meta=meta, sources=sources)
|
||||
output.write(path, omit_none=omit_none)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.results)
|
||||
|
||||
def __iter__(self):
|
||||
return iter(self.results)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return self.results[idx]
|
||||
|
||||
|
||||
def _copykeys(src, keys, **updates):
|
||||
return {k: getattr(src, k) for k in keys}
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessCriteria(JsonSchemaMixin):
|
||||
warn_after: Time
|
||||
error_after: Time
|
||||
|
||||
|
||||
class FreshnessErrorEnum(StrEnum):
|
||||
runtime_error = 'runtime error'
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFreshnessRuntimeError(JsonSchemaMixin):
|
||||
error: str
|
||||
state: FreshnessErrorEnum
|
||||
class SourceFreshnessRuntimeError(dbtClassMixin):
|
||||
unique_id: str
|
||||
error: Optional[Union[str, int]]
|
||||
status: FreshnessErrorEnum
|
||||
|
||||
|
||||
@dataclass
|
||||
class SourceFreshnessOutput(JsonSchemaMixin):
|
||||
class SourceFreshnessOutput(dbtClassMixin):
|
||||
unique_id: str
|
||||
max_loaded_at: datetime
|
||||
snapshotted_at: datetime
|
||||
max_loaded_at_time_ago_in_s: float
|
||||
state: FreshnessStatus
|
||||
status: FreshnessStatus
|
||||
criteria: FreshnessThreshold
|
||||
|
||||
|
||||
SourceFreshnessRunResult = Union[SourceFreshnessOutput,
|
||||
SourceFreshnessRuntimeError]
|
||||
adapter_response: Dict[str, Any]
|
||||
timing: List[TimingInfo]
|
||||
thread_id: str
|
||||
execution_time: float
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessRunOutput(JsonSchemaMixin, Writable):
|
||||
meta: FreshnessMetadata
|
||||
sources: Dict[str, SourceFreshnessRunResult]
|
||||
class PartialSourceFreshnessResult(NodeResult):
|
||||
status: FreshnessStatus
|
||||
|
||||
@property
|
||||
def skipped(self):
|
||||
return False
|
||||
|
||||
|
||||
FreshnessNodeResult = Union[PartialSourceFreshnessResult,
|
||||
SourceFreshnessResult]
|
||||
FreshnessNodeOutput = Union[SourceFreshnessRuntimeError, SourceFreshnessOutput]
|
||||
|
||||
|
||||
def process_freshness_result(
|
||||
result: FreshnessNodeResult
|
||||
) -> FreshnessNodeOutput:
|
||||
unique_id = result.node.unique_id
|
||||
if result.status == FreshnessStatus.RuntimeErr:
|
||||
return SourceFreshnessRuntimeError(
|
||||
unique_id=unique_id,
|
||||
error=result.message,
|
||||
status=FreshnessErrorEnum.runtime_error,
|
||||
)
|
||||
|
||||
# we know that this must be a SourceFreshnessResult
|
||||
if not isinstance(result, SourceFreshnessResult):
|
||||
raise InternalException(
|
||||
'Got {} instead of a SourceFreshnessResult for a '
|
||||
'non-error result in freshness execution!'
|
||||
.format(type(result))
|
||||
)
|
||||
# if we're here, we must have a non-None freshness threshold
|
||||
criteria = result.node.freshness
|
||||
if criteria is None:
|
||||
raise InternalException(
|
||||
'Somehow evaluated a freshness result for a source '
|
||||
'that has no freshness criteria!'
|
||||
)
|
||||
return SourceFreshnessOutput(
|
||||
unique_id=unique_id,
|
||||
max_loaded_at=result.max_loaded_at,
|
||||
snapshotted_at=result.snapshotted_at,
|
||||
max_loaded_at_time_ago_in_s=result.age,
|
||||
status=result.status,
|
||||
criteria=criteria,
|
||||
adapter_response=result.adapter_response,
|
||||
timing=result.timing,
|
||||
thread_id=result.thread_id,
|
||||
execution_time=result.execution_time,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessMetadata(BaseArtifactMetadata):
|
||||
dbt_schema_version: str = field(
|
||||
default_factory=lambda: str(
|
||||
FreshnessExecutionResultArtifact.dbt_schema_version
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class FreshnessResult(ExecutionResult):
|
||||
metadata: FreshnessMetadata
|
||||
results: Sequence[FreshnessNodeResult]
|
||||
|
||||
@classmethod
|
||||
def from_node_results(
|
||||
cls,
|
||||
results: List[FreshnessNodeResult],
|
||||
elapsed_time: float,
|
||||
generated_at: datetime,
|
||||
):
|
||||
meta = FreshnessMetadata(generated_at=generated_at)
|
||||
return cls(metadata=meta, results=results, elapsed_time=elapsed_time)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('sources', 2)
|
||||
class FreshnessExecutionResultArtifact(
|
||||
ArtifactMixin,
|
||||
VersionedSchema,
|
||||
):
|
||||
metadata: FreshnessMetadata
|
||||
results: Sequence[FreshnessNodeOutput]
|
||||
elapsed_time: float
|
||||
|
||||
@classmethod
|
||||
def from_result(cls, base: FreshnessResult):
|
||||
processed = [process_freshness_result(r) for r in base.results]
|
||||
return cls(
|
||||
metadata=base.metadata,
|
||||
results=processed,
|
||||
elapsed_time=base.elapsed_time,
|
||||
)
|
||||
|
||||
|
||||
Primitive = Union[bool, str, float, None]
|
||||
PrimitiveDict = Dict[str, Primitive]
|
||||
|
||||
CatalogKey = NamedTuple(
|
||||
'CatalogKey',
|
||||
@@ -244,40 +398,40 @@ CatalogKey = NamedTuple(
|
||||
|
||||
|
||||
@dataclass
|
||||
class StatsItem(JsonSchemaMixin):
|
||||
class StatsItem(dbtClassMixin):
|
||||
id: str
|
||||
label: str
|
||||
value: Primitive
|
||||
description: Optional[str]
|
||||
include: bool
|
||||
description: Optional[str] = None
|
||||
|
||||
|
||||
StatsDict = Dict[str, StatsItem]
|
||||
|
||||
|
||||
@dataclass
|
||||
class ColumnMetadata(JsonSchemaMixin):
|
||||
class ColumnMetadata(dbtClassMixin):
|
||||
type: str
|
||||
comment: Optional[str]
|
||||
index: int
|
||||
name: str
|
||||
comment: Optional[str] = None
|
||||
|
||||
|
||||
ColumnMap = Dict[str, ColumnMetadata]
|
||||
|
||||
|
||||
@dataclass
|
||||
class TableMetadata(JsonSchemaMixin):
|
||||
class TableMetadata(dbtClassMixin):
|
||||
type: str
|
||||
database: Optional[str]
|
||||
schema: str
|
||||
name: str
|
||||
comment: Optional[str]
|
||||
owner: Optional[str]
|
||||
database: Optional[str] = None
|
||||
comment: Optional[str] = None
|
||||
owner: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class CatalogTable(JsonSchemaMixin, Replaceable):
|
||||
class CatalogTable(dbtClassMixin, Replaceable):
|
||||
metadata: TableMetadata
|
||||
columns: ColumnMap
|
||||
stats: StatsDict
|
||||
@@ -293,9 +447,45 @@ class CatalogTable(JsonSchemaMixin, Replaceable):
|
||||
|
||||
|
||||
@dataclass
|
||||
class CatalogResults(JsonSchemaMixin, Writable):
|
||||
class CatalogMetadata(BaseArtifactMetadata):
|
||||
dbt_schema_version: str = field(
|
||||
default_factory=lambda: str(CatalogArtifact.dbt_schema_version)
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class CatalogResults(dbtClassMixin):
|
||||
nodes: Dict[str, CatalogTable]
|
||||
sources: Dict[str, CatalogTable]
|
||||
generated_at: datetime
|
||||
errors: Optional[List[str]]
|
||||
errors: Optional[List[str]] = None
|
||||
_compile_results: Optional[Any] = None
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if '_compile_results' in dct:
|
||||
del dct['_compile_results']
|
||||
return dct
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('catalog', 1)
|
||||
class CatalogArtifact(CatalogResults, ArtifactMixin):
|
||||
metadata: CatalogMetadata
|
||||
|
||||
@classmethod
|
||||
def from_results(
|
||||
cls,
|
||||
generated_at: datetime,
|
||||
nodes: Dict[str, CatalogTable],
|
||||
sources: Dict[str, CatalogTable],
|
||||
compile_results: Optional[Any],
|
||||
errors: Optional[List[str]]
|
||||
) -> 'CatalogArtifact':
|
||||
meta = CatalogMetadata(generated_at=generated_at)
|
||||
return cls(
|
||||
metadata=meta,
|
||||
nodes=nodes,
|
||||
sources=sources,
|
||||
errors=errors,
|
||||
_compile_results=compile_results,
|
||||
)
|
||||
|
||||
@@ -3,18 +3,24 @@ import os
|
||||
import uuid
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime, timedelta
|
||||
from typing import Optional, Union, List, Any, Dict, Type
|
||||
from typing import Optional, Union, List, Any, Dict, Type, Sequence
|
||||
|
||||
from hologram import JsonSchemaMixin
|
||||
from hologram.helpers import StrEnum
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
from dbt.contracts.graph.compiled import CompileResultNode
|
||||
from dbt.contracts.graph.manifest import WritableManifest
|
||||
from dbt.contracts.results import (
|
||||
TimingInfo,
|
||||
RunResult, RunResultsArtifact, TimingInfo,
|
||||
CatalogArtifact,
|
||||
CatalogResults,
|
||||
ExecutionResult,
|
||||
FreshnessExecutionResultArtifact,
|
||||
FreshnessResult,
|
||||
RunOperationResult,
|
||||
RunOperationResultsArtifact,
|
||||
RunExecutionResult,
|
||||
)
|
||||
from dbt.contracts.util import VersionedSchema, schema_version
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.logger import LogMessage
|
||||
from dbt.utils import restrict_to
|
||||
@@ -27,24 +33,57 @@ TaskID = uuid.UUID
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCParameters(JsonSchemaMixin):
|
||||
timeout: Optional[float]
|
||||
class RPCParameters(dbtClassMixin):
|
||||
task_tags: TaskTags
|
||||
timeout: Optional[float]
|
||||
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data, omit_none=True):
|
||||
data = super().__pre_deserialize__(data)
|
||||
if 'timeout' not in data:
|
||||
data['timeout'] = None
|
||||
if 'task_tags' not in data:
|
||||
data['task_tags'] = None
|
||||
return data
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCExecParameters(RPCParameters):
|
||||
name: str
|
||||
sql: str
|
||||
macros: Optional[str]
|
||||
macros: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCCompileParameters(RPCParameters):
|
||||
threads: Optional[int] = None
|
||||
models: Union[None, str, List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
state: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCListParameters(RPCParameters):
|
||||
resource_types: Optional[List[str]] = None
|
||||
models: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
output: Optional[str] = 'json'
|
||||
output_keys: Optional[List[str]] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCRunParameters(RPCParameters):
|
||||
threads: Optional[int] = None
|
||||
models: Union[None, str, List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
state: Optional[str] = None
|
||||
defer: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -53,12 +92,15 @@ class RPCSnapshotParameters(RPCParameters):
|
||||
select: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
state: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCTestParameters(RPCCompileParameters):
|
||||
data: bool = False
|
||||
schema: bool = False
|
||||
state: Optional[str] = None
|
||||
defer: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -68,11 +110,24 @@ class RPCSeedParameters(RPCParameters):
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
show: bool = False
|
||||
state: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCDocsGenerateParameters(RPCParameters):
|
||||
compile: bool = True
|
||||
state: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCBuildParameters(RPCParameters):
|
||||
resource_types: Optional[List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
threads: Optional[int] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
state: Optional[str] = None
|
||||
defer: Optional[bool] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -81,7 +136,7 @@ class RPCCliParameters(RPCParameters):
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCNoParameters(RPCParameters):
|
||||
class RPCDepsParameters(RPCParameters):
|
||||
pass
|
||||
|
||||
|
||||
@@ -109,7 +164,7 @@ class StatusParameters(RPCParameters):
|
||||
|
||||
|
||||
@dataclass
|
||||
class GCSettings(JsonSchemaMixin):
|
||||
class GCSettings(dbtClassMixin):
|
||||
# start evicting the longest-ago-ended tasks here
|
||||
maxsize: int
|
||||
# start evicting all tasks before now - auto_reap_age when we have this
|
||||
@@ -145,6 +200,8 @@ class RPCRunOperationParameters(RPCParameters):
|
||||
class RPCSourceFreshnessParameters(RPCParameters):
|
||||
threads: Optional[int] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -155,65 +212,163 @@ class GetManifestParameters(RPCParameters):
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteResult(JsonSchemaMixin):
|
||||
class RemoteResult(VersionedSchema):
|
||||
logs: List[LogMessage]
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteEmptyResult(RemoteResult):
|
||||
pass
|
||||
@schema_version('remote-list-results', 1)
|
||||
class RemoteListResults(RemoteResult):
|
||||
output: List[Any]
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-deps-result', 1)
|
||||
class RemoteDepsResult(RemoteResult):
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-catalog-result', 1)
|
||||
class RemoteCatalogResults(CatalogResults, RemoteResult):
|
||||
pass
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
def write(self, path: str):
|
||||
artifact = CatalogArtifact.from_results(
|
||||
generated_at=self.generated_at,
|
||||
nodes=self.nodes,
|
||||
sources=self.sources,
|
||||
compile_results=self._compile_results,
|
||||
errors=self.errors,
|
||||
)
|
||||
artifact.write(path)
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteCompileResult(RemoteResult):
|
||||
class RemoteCompileResultMixin(RemoteResult):
|
||||
raw_sql: str
|
||||
compiled_sql: str
|
||||
node: CompileResultNode
|
||||
timing: List[TimingInfo]
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-compile-result', 1)
|
||||
class RemoteCompileResult(RemoteCompileResultMixin):
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
@property
|
||||
def error(self):
|
||||
return None
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-execution-result', 1)
|
||||
class RemoteExecutionResult(ExecutionResult, RemoteResult):
|
||||
pass
|
||||
results: Sequence[RunResult]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
def write(self, path: str):
|
||||
writable = RunResultsArtifact.from_execution_results(
|
||||
generated_at=self.generated_at,
|
||||
results=self.results,
|
||||
elapsed_time=self.elapsed_time,
|
||||
args=self.args,
|
||||
)
|
||||
writable.write(path)
|
||||
|
||||
@classmethod
|
||||
def from_local_result(
|
||||
cls,
|
||||
base: RunExecutionResult,
|
||||
logs: List[LogMessage],
|
||||
) -> 'RemoteExecutionResult':
|
||||
return cls(
|
||||
generated_at=base.generated_at,
|
||||
results=base.results,
|
||||
elapsed_time=base.elapsed_time,
|
||||
args=base.args,
|
||||
logs=logs,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ResultTable(JsonSchemaMixin):
|
||||
class ResultTable(dbtClassMixin):
|
||||
column_names: List[str]
|
||||
rows: List[Any]
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteRunOperationResult(ExecutionResult, RemoteResult):
|
||||
success: bool
|
||||
@schema_version('remote-run-operation-result', 1)
|
||||
class RemoteRunOperationResult(RunOperationResult, RemoteResult):
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
@classmethod
|
||||
def from_local_result(
|
||||
cls,
|
||||
base: RunOperationResultsArtifact,
|
||||
logs: List[LogMessage],
|
||||
) -> 'RemoteRunOperationResult':
|
||||
return cls(
|
||||
generated_at=base.metadata.generated_at,
|
||||
results=base.results,
|
||||
elapsed_time=base.elapsed_time,
|
||||
success=base.success,
|
||||
logs=logs,
|
||||
)
|
||||
|
||||
def write(self, path: str):
|
||||
writable = RunOperationResultsArtifact.from_success(
|
||||
success=self.success,
|
||||
generated_at=self.generated_at,
|
||||
elapsed_time=self.elapsed_time,
|
||||
)
|
||||
writable.write(path)
|
||||
|
||||
|
||||
@dataclass
|
||||
class RemoteRunResult(RemoteCompileResult):
|
||||
@schema_version('remote-freshness-result', 1)
|
||||
class RemoteFreshnessResult(FreshnessResult, RemoteResult):
|
||||
|
||||
@classmethod
|
||||
def from_local_result(
|
||||
cls,
|
||||
base: FreshnessResult,
|
||||
logs: List[LogMessage],
|
||||
) -> 'RemoteFreshnessResult':
|
||||
return cls(
|
||||
metadata=base.metadata,
|
||||
results=base.results,
|
||||
elapsed_time=base.elapsed_time,
|
||||
logs=logs,
|
||||
)
|
||||
|
||||
def write(self, path: str):
|
||||
writable = FreshnessExecutionResultArtifact.from_result(base=self)
|
||||
writable.write(path)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-run-result', 1)
|
||||
class RemoteRunResult(RemoteCompileResultMixin):
|
||||
table: ResultTable
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
|
||||
RPCResult = Union[
|
||||
RemoteCompileResult,
|
||||
RemoteExecutionResult,
|
||||
RemoteFreshnessResult,
|
||||
RemoteCatalogResults,
|
||||
RemoteEmptyResult,
|
||||
RemoteDepsResult,
|
||||
RemoteRunOperationResult,
|
||||
]
|
||||
|
||||
|
||||
# GC types
|
||||
|
||||
|
||||
class GCResultState(StrEnum):
|
||||
Deleted = 'deleted' # successful GC
|
||||
Missing = 'missing' # nothing to GC
|
||||
@@ -221,6 +376,7 @@ class GCResultState(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-gc-result', 1)
|
||||
class GCResult(RemoteResult):
|
||||
logs: List[LogMessage] = field(default_factory=list)
|
||||
deleted: List[TaskID] = field(default_factory=list)
|
||||
@@ -296,24 +452,35 @@ class TaskHandlerState(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
class TaskTiming(JsonSchemaMixin):
|
||||
class TaskTiming(dbtClassMixin):
|
||||
state: TaskHandlerState
|
||||
start: Optional[datetime]
|
||||
end: Optional[datetime]
|
||||
elapsed: Optional[float]
|
||||
|
||||
# These ought to be defaults but superclass order doesn't
|
||||
# allow that to work
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
for field_name in ('start', 'end', 'elapsed'):
|
||||
if field_name not in data:
|
||||
data[field_name] = None
|
||||
return data
|
||||
|
||||
|
||||
@dataclass
|
||||
class TaskRow(TaskTiming):
|
||||
task_id: TaskID
|
||||
request_id: Union[str, int]
|
||||
request_source: str
|
||||
method: str
|
||||
timeout: Optional[float]
|
||||
tags: TaskTags
|
||||
request_id: Union[str, int]
|
||||
tags: TaskTags = None
|
||||
timeout: Optional[float] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-ps-result', 1)
|
||||
class PSResult(RemoteResult):
|
||||
rows: List[TaskRow]
|
||||
|
||||
@@ -326,14 +493,16 @@ class KillResultStatus(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-kill-result', 1)
|
||||
class KillResult(RemoteResult):
|
||||
state: KillResultStatus = KillResultStatus.Missing
|
||||
logs: List[LogMessage] = field(default_factory=list)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-manifest-result', 1)
|
||||
class GetManifestResult(RemoteResult):
|
||||
manifest: Optional[WritableManifest]
|
||||
manifest: Optional[WritableManifest] = None
|
||||
|
||||
|
||||
# this is kind of carefuly structured: BlocksManifestTasks is implied by
|
||||
@@ -357,18 +526,30 @@ class PollResult(RemoteResult, TaskTiming):
|
||||
end: Optional[datetime]
|
||||
elapsed: Optional[float]
|
||||
|
||||
# These ought to be defaults but superclass order doesn't
|
||||
# allow that to work
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
data = super().__pre_deserialize__(data)
|
||||
for field_name in ('start', 'end', 'elapsed'):
|
||||
if field_name not in data:
|
||||
data[field_name] = None
|
||||
return data
|
||||
|
||||
|
||||
@dataclass
|
||||
class PollRemoteEmptyCompleteResult(PollResult, RemoteEmptyResult):
|
||||
@schema_version('poll-remote-deps-result', 1)
|
||||
class PollRemoteEmptyCompleteResult(PollResult, RemoteResult):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
)
|
||||
generated_at: datetime = field(default_factory=datetime.utcnow)
|
||||
|
||||
@classmethod
|
||||
def from_result(
|
||||
cls: Type['PollRemoteEmptyCompleteResult'],
|
||||
base: RemoteEmptyResult,
|
||||
base: RemoteDepsResult,
|
||||
tags: TaskTags,
|
||||
timing: TaskTiming,
|
||||
logs: List[LogMessage],
|
||||
@@ -380,10 +561,12 @@ class PollRemoteEmptyCompleteResult(PollResult, RemoteEmptyResult):
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
generated_at=base.generated_at
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('poll-remote-killed-result', 1)
|
||||
class PollKilledResult(PollResult):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Killed),
|
||||
@@ -391,7 +574,11 @@ class PollKilledResult(PollResult):
|
||||
|
||||
|
||||
@dataclass
|
||||
class PollExecuteCompleteResult(RemoteExecutionResult, PollResult):
|
||||
@schema_version('poll-remote-execution-result', 1)
|
||||
class PollExecuteCompleteResult(
|
||||
RemoteExecutionResult,
|
||||
PollResult,
|
||||
):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
@@ -407,7 +594,6 @@ class PollExecuteCompleteResult(RemoteExecutionResult, PollResult):
|
||||
) -> 'PollExecuteCompleteResult':
|
||||
return cls(
|
||||
results=base.results,
|
||||
generated_at=base.generated_at,
|
||||
elapsed_time=base.elapsed_time,
|
||||
logs=logs,
|
||||
tags=tags,
|
||||
@@ -415,11 +601,16 @@ class PollExecuteCompleteResult(RemoteExecutionResult, PollResult):
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
generated_at=base.generated_at,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class PollCompileCompleteResult(RemoteCompileResult, PollResult):
|
||||
@schema_version('poll-remote-compile-result', 1)
|
||||
class PollCompileCompleteResult(
|
||||
RemoteCompileResult,
|
||||
PollResult,
|
||||
):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
@@ -444,11 +635,16 @@ class PollCompileCompleteResult(RemoteCompileResult, PollResult):
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
generated_at=base.generated_at
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class PollRunCompleteResult(RemoteRunResult, PollResult):
|
||||
@schema_version('poll-remote-run-result', 1)
|
||||
class PollRunCompleteResult(
|
||||
RemoteRunResult,
|
||||
PollResult,
|
||||
):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
@@ -474,11 +670,16 @@ class PollRunCompleteResult(RemoteRunResult, PollResult):
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
generated_at=base.generated_at
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class PollRunOperationCompleteResult(RemoteRunOperationResult, PollResult):
|
||||
@schema_version('poll-remote-run-operation-result', 1)
|
||||
class PollRunOperationCompleteResult(
|
||||
RemoteRunOperationResult,
|
||||
PollResult,
|
||||
):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
@@ -507,6 +708,7 @@ class PollRunOperationCompleteResult(RemoteRunOperationResult, PollResult):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('poll-remote-catalog-result', 1)
|
||||
class PollCatalogCompleteResult(RemoteCatalogResults, PollResult):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
@@ -537,11 +739,13 @@ class PollCatalogCompleteResult(RemoteCatalogResults, PollResult):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('poll-remote-in-progress-result', 1)
|
||||
class PollInProgressResult(PollResult):
|
||||
pass
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('poll-remote-get-manifest-result', 1)
|
||||
class PollGetManifestResult(GetManifestResult, PollResult):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
@@ -566,6 +770,35 @@ class PollGetManifestResult(GetManifestResult, PollResult):
|
||||
elapsed=timing.elapsed,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('poll-remote-freshness-result', 1)
|
||||
class PollFreshnessResult(RemoteFreshnessResult, PollResult):
|
||||
state: TaskHandlerState = field(
|
||||
metadata=restrict_to(TaskHandlerState.Success,
|
||||
TaskHandlerState.Failed),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_result(
|
||||
cls: Type['PollFreshnessResult'],
|
||||
base: RemoteFreshnessResult,
|
||||
tags: TaskTags,
|
||||
timing: TaskTiming,
|
||||
logs: List[LogMessage],
|
||||
) -> 'PollFreshnessResult':
|
||||
return cls(
|
||||
logs=logs,
|
||||
tags=tags,
|
||||
state=timing.state,
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
metadata=base.metadata,
|
||||
results=base.results,
|
||||
elapsed_time=base.elapsed_time,
|
||||
)
|
||||
|
||||
# Manifest parsing types
|
||||
|
||||
|
||||
@@ -577,6 +810,7 @@ class ManifestStatus(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('remote-status-result', 1)
|
||||
class LastParse(RemoteResult):
|
||||
state: ManifestStatus = ManifestStatus.Init
|
||||
logs: List[LogMessage] = field(default_factory=list)
|
||||
|
||||
@@ -1,17 +1,19 @@
|
||||
from dataclasses import dataclass
|
||||
from hologram import JsonSchemaMixin
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
|
||||
from typing import List, Dict, Any, Union
|
||||
|
||||
|
||||
@dataclass
|
||||
class SelectorDefinition(JsonSchemaMixin):
|
||||
class SelectorDefinition(dbtClassMixin):
|
||||
name: str
|
||||
definition: Union[str, Dict[str, Any]]
|
||||
description: str = ''
|
||||
default: bool = False
|
||||
|
||||
|
||||
@dataclass
|
||||
class SelectorFile(JsonSchemaMixin):
|
||||
class SelectorFile(dbtClassMixin):
|
||||
selectors: List[SelectorDefinition]
|
||||
version: int = 2
|
||||
|
||||
|
||||
@@ -1,13 +1,28 @@
|
||||
from pathlib import Path
|
||||
from .graph.manifest import WritableManifest
|
||||
from .results import RunResultsArtifact
|
||||
from typing import Optional
|
||||
from dbt.exceptions import IncompatibleSchemaException
|
||||
|
||||
|
||||
class PreviousState:
|
||||
def __init__(self, path: Path):
|
||||
self.path: Path = path
|
||||
self.manifest: Optional[WritableManifest] = None
|
||||
self.results: Optional[RunResultsArtifact] = None
|
||||
|
||||
manifest_path = self.path / 'manifest.json'
|
||||
if manifest_path.exists() and manifest_path.is_file():
|
||||
self.manifest = WritableManifest.read(str(manifest_path))
|
||||
try:
|
||||
self.manifest = WritableManifest.read(str(manifest_path))
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(manifest_path))
|
||||
raise
|
||||
|
||||
results_path = self.path / 'run_results.json'
|
||||
if results_path.exists() and results_path.is_file():
|
||||
try:
|
||||
self.results = RunResultsArtifact.read(str(results_path))
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(results_path))
|
||||
raise
|
||||
|
||||
@@ -1,11 +1,19 @@
|
||||
import dataclasses
|
||||
from typing import List, Tuple
|
||||
import os
|
||||
from datetime import datetime
|
||||
from typing import (
|
||||
List, Tuple, ClassVar, Type, TypeVar, Dict, Any, Optional
|
||||
)
|
||||
|
||||
from dbt.clients.system import write_json, read_json
|
||||
from dbt.exceptions import RuntimeException
|
||||
from dbt.exceptions import (
|
||||
InternalException,
|
||||
RuntimeException,
|
||||
)
|
||||
from dbt.version import __version__
|
||||
from dbt.tracking import get_invocation_id
|
||||
from dbt.dataclass_schema import dbtClassMixin
|
||||
|
||||
|
||||
MacroKey = Tuple[str, str]
|
||||
SourceKey = Tuple[str, str]
|
||||
|
||||
|
||||
@@ -47,8 +55,10 @@ class Mergeable(Replaceable):
|
||||
|
||||
|
||||
class Writable:
|
||||
def write(self, path: str, omit_none: bool = False):
|
||||
write_json(path, self.to_dict(omit_none=omit_none)) # type: ignore
|
||||
def write(self, path: str):
|
||||
write_json(
|
||||
path, self.to_dict(omit_none=False) # type: ignore
|
||||
)
|
||||
|
||||
|
||||
class AdditionalPropertiesMixin:
|
||||
@@ -59,22 +69,41 @@ class AdditionalPropertiesMixin:
|
||||
"""
|
||||
ADDITIONAL_PROPERTIES = True
|
||||
|
||||
# This takes attributes in the dictionary that are
|
||||
# not in the class definitions and puts them in an
|
||||
# _extra dict in the class
|
||||
@classmethod
|
||||
def from_dict(cls, data, validate=True):
|
||||
self = super().from_dict(data=data, validate=validate)
|
||||
keys = self.to_dict(validate=False, omit_none=False)
|
||||
def __pre_deserialize__(cls, data):
|
||||
# dir() did not work because fields with
|
||||
# metadata settings are not found
|
||||
# The original version of this would create the
|
||||
# object first and then update extra with the
|
||||
# extra keys, but that won't work here, so
|
||||
# we're copying the dict so we don't insert the
|
||||
# _extra in the original data. This also requires
|
||||
# that Mashumaro actually build the '_extra' field
|
||||
cls_keys = cls._get_field_names()
|
||||
new_dict = {}
|
||||
for key, value in data.items():
|
||||
if key not in keys:
|
||||
self.extra[key] = value
|
||||
return self
|
||||
if key not in cls_keys and key != '_extra':
|
||||
if '_extra' not in new_dict:
|
||||
new_dict['_extra'] = {}
|
||||
new_dict['_extra'][key] = value
|
||||
else:
|
||||
new_dict[key] = value
|
||||
data = new_dict
|
||||
data = super().__pre_deserialize__(data)
|
||||
return data
|
||||
|
||||
def to_dict(self, omit_none=True, validate=False):
|
||||
data = super().to_dict(omit_none=omit_none, validate=validate)
|
||||
def __post_serialize__(self, dct):
|
||||
data = super().__post_serialize__(dct)
|
||||
data.update(self.extra)
|
||||
if '_extra' in data:
|
||||
del data['_extra']
|
||||
return data
|
||||
|
||||
def replace(self, **kwargs):
|
||||
dct = self.to_dict(omit_none=False, validate=False)
|
||||
dct = self.to_dict(omit_none=False)
|
||||
dct.update(kwargs)
|
||||
return self.from_dict(dct)
|
||||
|
||||
@@ -94,3 +123,96 @@ class Readable:
|
||||
) from exc
|
||||
|
||||
return cls.from_dict(data) # type: ignore
|
||||
|
||||
|
||||
BASE_SCHEMAS_URL = 'https://schemas.getdbt.com/'
|
||||
SCHEMA_PATH = 'dbt/{name}/v{version}.json'
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class SchemaVersion:
|
||||
name: str
|
||||
version: int
|
||||
|
||||
@property
|
||||
def path(self) -> str:
|
||||
return SCHEMA_PATH.format(
|
||||
name=self.name,
|
||||
version=self.version
|
||||
)
|
||||
|
||||
def __str__(self) -> str:
|
||||
return BASE_SCHEMAS_URL + self.path
|
||||
|
||||
|
||||
SCHEMA_VERSION_KEY = 'dbt_schema_version'
|
||||
|
||||
|
||||
METADATA_ENV_PREFIX = 'DBT_ENV_CUSTOM_ENV_'
|
||||
|
||||
|
||||
def get_metadata_env() -> Dict[str, str]:
|
||||
return {
|
||||
k[len(METADATA_ENV_PREFIX):]: v for k, v in os.environ.items()
|
||||
if k.startswith(METADATA_ENV_PREFIX)
|
||||
}
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class BaseArtifactMetadata(dbtClassMixin):
|
||||
dbt_schema_version: str
|
||||
dbt_version: str = __version__
|
||||
generated_at: datetime = dataclasses.field(
|
||||
default_factory=datetime.utcnow
|
||||
)
|
||||
invocation_id: Optional[str] = dataclasses.field(
|
||||
default_factory=get_invocation_id
|
||||
)
|
||||
env: Dict[str, str] = dataclasses.field(default_factory=get_metadata_env)
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if dct['generated_at'] and dct['generated_at'].endswith('+00:00'):
|
||||
dct['generated_at'] = dct['generated_at'].replace('+00:00', '') + "Z"
|
||||
return dct
|
||||
|
||||
|
||||
def schema_version(name: str, version: int):
|
||||
def inner(cls: Type[VersionedSchema]):
|
||||
cls.dbt_schema_version = SchemaVersion(
|
||||
name=name,
|
||||
version=version,
|
||||
)
|
||||
return cls
|
||||
return inner
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class VersionedSchema(dbtClassMixin):
|
||||
dbt_schema_version: ClassVar[SchemaVersion]
|
||||
|
||||
@classmethod
|
||||
def json_schema(cls, embeddable: bool = False) -> Dict[str, Any]:
|
||||
result = super().json_schema(embeddable=embeddable)
|
||||
if not embeddable:
|
||||
result['$id'] = str(cls.dbt_schema_version)
|
||||
return result
|
||||
|
||||
|
||||
T = TypeVar('T', bound='ArtifactMixin')
|
||||
|
||||
|
||||
# metadata should really be a Generic[T_M] where T_M is a TypeVar bound to
|
||||
# BaseArtifactMetadata. Unfortunately this isn't possible due to a mypy issue:
|
||||
# https://github.com/python/mypy/issues/7520
|
||||
@dataclasses.dataclass(init=False)
|
||||
class ArtifactMixin(VersionedSchema, Writable, Readable):
|
||||
metadata: BaseArtifactMetadata
|
||||
|
||||
@classmethod
|
||||
def validate(cls, data):
|
||||
super().validate(data)
|
||||
if cls.dbt_schema_version is None:
|
||||
raise InternalException(
|
||||
'Cannot call from_dict with no schema version!'
|
||||
)
|
||||
|
||||
169
core/dbt/dataclass_schema.py
Normal file
169
core/dbt/dataclass_schema.py
Normal file
@@ -0,0 +1,169 @@
|
||||
from typing import (
|
||||
Type, ClassVar, cast,
|
||||
)
|
||||
import re
|
||||
from dataclasses import fields
|
||||
from enum import Enum
|
||||
from datetime import datetime
|
||||
from dateutil.parser import parse
|
||||
|
||||
from hologram import JsonSchemaMixin, FieldEncoder, ValidationError
|
||||
|
||||
# type: ignore
|
||||
from mashumaro import DataClassDictMixin
|
||||
from mashumaro.config import (
|
||||
TO_DICT_ADD_OMIT_NONE_FLAG, BaseConfig as MashBaseConfig
|
||||
)
|
||||
from mashumaro.types import SerializableType, SerializationStrategy
|
||||
|
||||
|
||||
class DateTimeSerialization(SerializationStrategy):
|
||||
def serialize(self, value):
|
||||
out = value.isoformat()
|
||||
# Assume UTC if timezone is missing
|
||||
if value.tzinfo is None:
|
||||
out = out + "Z"
|
||||
return out
|
||||
|
||||
def deserialize(self, value):
|
||||
return (
|
||||
value if isinstance(value, datetime) else parse(cast(str, value))
|
||||
)
|
||||
|
||||
|
||||
# This class pulls in both JsonSchemaMixin from Hologram and
|
||||
# DataClassDictMixin from our fork of Mashumaro. The 'to_dict'
|
||||
# and 'from_dict' methods come from Mashumaro. Building
|
||||
# jsonschemas for every class and the 'validate' method
|
||||
# come from Hologram.
|
||||
class dbtClassMixin(DataClassDictMixin, JsonSchemaMixin):
|
||||
"""Mixin which adds methods to generate a JSON schema and
|
||||
convert to and from JSON encodable dicts with validation
|
||||
against the schema
|
||||
"""
|
||||
|
||||
class Config(MashBaseConfig):
|
||||
code_generation_options = [
|
||||
TO_DICT_ADD_OMIT_NONE_FLAG,
|
||||
]
|
||||
serialization_strategy = {
|
||||
datetime: DateTimeSerialization(),
|
||||
}
|
||||
|
||||
_hyphenated: ClassVar[bool] = False
|
||||
ADDITIONAL_PROPERTIES: ClassVar[bool] = False
|
||||
|
||||
# This is called by the mashumaro to_dict in order to handle
|
||||
# nested classes.
|
||||
# Munges the dict that's returned.
|
||||
def __post_serialize__(self, dct):
|
||||
if self._hyphenated:
|
||||
new_dict = {}
|
||||
for key in dct:
|
||||
if '_' in key:
|
||||
new_key = key.replace('_', '-')
|
||||
new_dict[new_key] = dct[key]
|
||||
else:
|
||||
new_dict[key] = dct[key]
|
||||
dct = new_dict
|
||||
|
||||
return dct
|
||||
|
||||
# This is called by the mashumaro _from_dict method, before
|
||||
# performing the conversion to a dict
|
||||
@classmethod
|
||||
def __pre_deserialize__(cls, data):
|
||||
# `data` might not be a dict, e.g. for `query_comment`, which accepts
|
||||
# a dict or a string; only snake-case for dict values.
|
||||
if cls._hyphenated and isinstance(data, dict):
|
||||
new_dict = {}
|
||||
for key in data:
|
||||
if '-' in key:
|
||||
new_key = key.replace('-', '_')
|
||||
new_dict[new_key] = data[key]
|
||||
else:
|
||||
new_dict[key] = data[key]
|
||||
data = new_dict
|
||||
return data
|
||||
|
||||
# This is used in the hologram._encode_field method, which calls
|
||||
# a 'to_dict' method which does not have the same parameters in
|
||||
# hologram and in mashumaro.
|
||||
def _local_to_dict(self, **kwargs):
|
||||
args = {}
|
||||
if 'omit_none' in kwargs:
|
||||
args['omit_none'] = kwargs['omit_none']
|
||||
return self.to_dict(**args)
|
||||
|
||||
|
||||
class ValidatedStringMixin(str, SerializableType):
|
||||
ValidationRegex = ''
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, value: str) -> 'ValidatedStringMixin':
|
||||
cls.validate(value)
|
||||
return ValidatedStringMixin(value)
|
||||
|
||||
def _serialize(self) -> str:
|
||||
return str(self)
|
||||
|
||||
@classmethod
|
||||
def validate(cls, value):
|
||||
res = re.match(cls.ValidationRegex, value)
|
||||
|
||||
if res is None:
|
||||
raise ValidationError(f"Invalid value: {value}") # TODO
|
||||
|
||||
|
||||
# These classes must be in this order or it doesn't work
|
||||
class StrEnum(str, SerializableType, Enum):
|
||||
def __str__(self):
|
||||
return self.value
|
||||
|
||||
# https://docs.python.org/3.6/library/enum.html#using-automatic-values
|
||||
def _generate_next_value_(name, *_):
|
||||
return name
|
||||
|
||||
def _serialize(self) -> str:
|
||||
return self.value
|
||||
|
||||
@classmethod
|
||||
def _deserialize(cls, value: str):
|
||||
return cls(value)
|
||||
|
||||
|
||||
class HyphenatedDbtClassMixin(dbtClassMixin):
|
||||
# used by from_dict/to_dict
|
||||
_hyphenated: ClassVar[bool] = True
|
||||
|
||||
# used by jsonschema validation, _get_fields
|
||||
@classmethod
|
||||
def field_mapping(cls):
|
||||
result = {}
|
||||
for field in fields(cls):
|
||||
skip = field.metadata.get("preserve_underscore")
|
||||
if skip:
|
||||
continue
|
||||
|
||||
if "_" in field.name:
|
||||
result[field.name] = field.name.replace("_", "-")
|
||||
return result
|
||||
|
||||
|
||||
class ExtensibleDbtClassMixin(dbtClassMixin):
|
||||
ADDITIONAL_PROPERTIES = True
|
||||
|
||||
|
||||
# This is used by Hologram in jsonschema validation
|
||||
def register_pattern(base_type: Type, pattern: str) -> None:
|
||||
"""base_type should be a typing.NewType that should always have the given
|
||||
regex pattern. That means that its underlying type ('__supertype__') had
|
||||
better be a str!
|
||||
"""
|
||||
|
||||
class PatternEncoder(FieldEncoder):
|
||||
@property
|
||||
def json_schema(self):
|
||||
return {"type": "string", "pattern": pattern}
|
||||
|
||||
dbtClassMixin.register_field_encoders({base_type: PatternEncoder()})
|
||||
@@ -43,94 +43,28 @@ class DBTDeprecation:
|
||||
active_deprecations.add(self.name)
|
||||
|
||||
|
||||
class MaterializationReturnDeprecation(DBTDeprecation):
|
||||
_name = 'materialization-return'
|
||||
|
||||
class PackageRedirectDeprecation(DBTDeprecation):
|
||||
_name = 'package-redirect'
|
||||
_description = '''\
|
||||
The materialization ("{materialization}") did not explicitly return a list
|
||||
of relations to add to the cache. By default the target relation will be
|
||||
added, but this behavior will be removed in a future version of dbt.
|
||||
|
||||
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/v0.15/docs/creating-new-materializations#section-6-returning-relations
|
||||
The `{old_name}` package is deprecated in favor of `{new_name}`. Please update
|
||||
your `packages.yml` configuration to use `{new_name}` instead.
|
||||
'''
|
||||
|
||||
|
||||
class NotADictionaryDeprecation(DBTDeprecation):
|
||||
_name = 'not-a-dictionary'
|
||||
|
||||
class PackageInstallPathDeprecation(DBTDeprecation):
|
||||
_name = 'install-packages-path'
|
||||
_description = '''\
|
||||
The object ("{obj}") was used as a dictionary. In a future version of dbt
|
||||
this capability will be removed from objects of this type.
|
||||
The default package install path has changed from `dbt_modules` to `dbt_packages`.
|
||||
Please update `clean-targets` in `dbt_project.yml` and check `.gitignore` as well.
|
||||
Or, set `packages-install-path: dbt_modules` if you'd like to keep the current value.
|
||||
'''
|
||||
|
||||
|
||||
class ColumnQuotingDeprecation(DBTDeprecation):
|
||||
_name = 'column-quoting-unset'
|
||||
|
||||
class ConfigPathDeprecation(DBTDeprecation):
|
||||
_name = 'project_config_path'
|
||||
_description = '''\
|
||||
The quote_columns parameter was not set for seeds, so the default value of
|
||||
False was chosen. The default will change to True in a future release.
|
||||
|
||||
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/v0.15/docs/seeds#section-specify-column-quoting
|
||||
'''
|
||||
|
||||
|
||||
class ModelsKeyNonModelDeprecation(DBTDeprecation):
|
||||
_name = 'models-key-mismatch'
|
||||
|
||||
_description = '''\
|
||||
"{node.name}" is a {node.resource_type} node, but it is specified in
|
||||
the {patch.yaml_key} section of {patch.original_file_path}.
|
||||
|
||||
|
||||
|
||||
To fix this warning, place the `{node.name}` specification under
|
||||
the {expected_key} key instead.
|
||||
|
||||
This warning will become an error in a future release.
|
||||
'''
|
||||
|
||||
|
||||
class DbtProjectYamlDeprecation(DBTDeprecation):
|
||||
_name = 'dbt-project-yaml-v1'
|
||||
_description = '''\
|
||||
dbt v0.17.0 introduces a new config format for the dbt_project.yml file.
|
||||
Support for the existing version 1 format will be removed in a future
|
||||
release of dbt. The following packages are currently configured with
|
||||
config version 1:{project_names}
|
||||
|
||||
|
||||
|
||||
For upgrading instructions, consult the documentation:
|
||||
|
||||
https://docs.getdbt.com/docs/guides/migration-guide/upgrading-to-0-17-0
|
||||
|
||||
'''
|
||||
|
||||
|
||||
class ExecuteMacrosReleaseDeprecation(DBTDeprecation):
|
||||
_name = 'execute-macro-release'
|
||||
_description = '''\
|
||||
The "release" argument to execute_macro is now ignored, and will be removed
|
||||
in a future relase of dbt. At that time, providing a `release` argument
|
||||
will result in an error.
|
||||
'''
|
||||
|
||||
|
||||
class AdapterMacroDeprecation(DBTDeprecation):
|
||||
_name = 'adapter-macro'
|
||||
_description = '''\
|
||||
The "adapter_macro" macro has been deprecated. Instead, use the
|
||||
`adapter.dispatch` method to find a macro and call the result.
|
||||
adapter_macro was called for: {macro_name}
|
||||
The `{deprecated_path}` config has been deprecated in favor of `{exp_path}`.
|
||||
Please update your `dbt_project.yml` configuration to reflect this change.
|
||||
'''
|
||||
|
||||
|
||||
@@ -172,13 +106,9 @@ def warn(name, *args, **kwargs):
|
||||
active_deprecations: Set[str] = set()
|
||||
|
||||
deprecations_list: List[DBTDeprecation] = [
|
||||
MaterializationReturnDeprecation(),
|
||||
NotADictionaryDeprecation(),
|
||||
ColumnQuotingDeprecation(),
|
||||
ModelsKeyNonModelDeprecation(),
|
||||
DbtProjectYamlDeprecation(),
|
||||
ExecuteMacrosReleaseDeprecation(),
|
||||
AdapterMacroDeprecation(),
|
||||
ConfigPathDeprecation(),
|
||||
PackageInstallPathDeprecation(),
|
||||
PackageRedirectDeprecation()
|
||||
]
|
||||
|
||||
deprecations: Dict[str, DBTDeprecation] = {
|
||||
|
||||
@@ -91,7 +91,10 @@ class PinnedPackage(BasePackage):
|
||||
|
||||
def get_installation_path(self, project, renderer):
|
||||
dest_dirname = self.get_project_name(project, renderer)
|
||||
return os.path.join(project.modules_path, dest_dirname)
|
||||
return os.path.join(project.packages_install_path, dest_dirname)
|
||||
|
||||
def get_subdirectory(self):
|
||||
return None
|
||||
|
||||
|
||||
SomePinned = TypeVar('SomePinned', bound=PinnedPackage)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
import hashlib
|
||||
from typing import List
|
||||
from typing import List, Optional
|
||||
|
||||
from dbt.clients import git, system
|
||||
from dbt.config import Project
|
||||
@@ -37,18 +37,37 @@ class GitPackageMixin:
|
||||
|
||||
class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
def __init__(
|
||||
self, git: str, revision: str, warn_unpinned: bool = True
|
||||
self,
|
||||
git: str,
|
||||
revision: str,
|
||||
warn_unpinned: bool = True,
|
||||
subdirectory: Optional[str] = None,
|
||||
) -> None:
|
||||
super().__init__(git)
|
||||
self.revision = revision
|
||||
self.warn_unpinned = warn_unpinned
|
||||
self.subdirectory = subdirectory
|
||||
self._checkout_name = md5sum(self.git)
|
||||
|
||||
def get_version(self):
|
||||
return self.revision
|
||||
|
||||
def get_subdirectory(self):
|
||||
return self.subdirectory
|
||||
|
||||
def nice_version_name(self):
|
||||
return 'revision {}'.format(self.revision)
|
||||
if self.revision == 'HEAD':
|
||||
return 'HEAD (default revision)'
|
||||
else:
|
||||
return 'revision {}'.format(self.revision)
|
||||
|
||||
def unpinned_msg(self):
|
||||
if self.revision == 'HEAD':
|
||||
return 'not pinned, using HEAD (default branch)'
|
||||
elif self.revision in ('main', 'master'):
|
||||
return f'pinned to the "{self.revision}" branch'
|
||||
else:
|
||||
return None
|
||||
|
||||
def _checkout(self):
|
||||
"""Performs a shallow clone of the repository into the downloads
|
||||
@@ -57,8 +76,8 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
the path to the checked out directory."""
|
||||
try:
|
||||
dir_ = git.clone_and_checkout(
|
||||
self.git, get_downloads_path(), branch=self.revision,
|
||||
dirname=self._checkout_name
|
||||
self.git, get_downloads_path(), revision=self.revision,
|
||||
dirname=self._checkout_name, subdirectory=self.subdirectory
|
||||
)
|
||||
except ExecutableError as exc:
|
||||
if exc.cmd and exc.cmd[0] == 'git':
|
||||
@@ -72,11 +91,12 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
|
||||
def _fetch_metadata(self, project, renderer) -> ProjectPackageMetadata:
|
||||
path = self._checkout()
|
||||
if self.revision == 'master' and self.warn_unpinned:
|
||||
|
||||
if self.unpinned_msg() and self.warn_unpinned:
|
||||
warn_or_error(
|
||||
'The git package "{}" is not pinned.\n\tThis can introduce '
|
||||
'The git package "{}" \n\tis {}.\n\tThis can introduce '
|
||||
'breaking changes into your project without warning!\n\nSee {}'
|
||||
.format(self.git, PIN_PACKAGE_URL),
|
||||
.format(self.git, self.unpinned_msg(), PIN_PACKAGE_URL),
|
||||
log_fmt=ui.yellow('WARNING: {}')
|
||||
)
|
||||
loaded = Project.from_project_root(path, renderer)
|
||||
@@ -95,11 +115,16 @@ class GitPinnedPackage(GitPackageMixin, PinnedPackage):
|
||||
|
||||
class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
def __init__(
|
||||
self, git: str, revisions: List[str], warn_unpinned: bool = True
|
||||
self,
|
||||
git: str,
|
||||
revisions: List[str],
|
||||
warn_unpinned: bool = True,
|
||||
subdirectory: Optional[str] = None,
|
||||
) -> None:
|
||||
super().__init__(git)
|
||||
self.revisions = revisions
|
||||
self.warn_unpinned = warn_unpinned
|
||||
self.subdirectory = subdirectory
|
||||
|
||||
@classmethod
|
||||
def from_contract(
|
||||
@@ -110,7 +135,7 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
# we want to map None -> True
|
||||
warn_unpinned = contract.warn_unpinned is not False
|
||||
return cls(git=contract.git, revisions=revisions,
|
||||
warn_unpinned=warn_unpinned)
|
||||
warn_unpinned=warn_unpinned, subdirectory=contract.subdirectory)
|
||||
|
||||
def all_names(self) -> List[str]:
|
||||
if self.git.endswith('.git'):
|
||||
@@ -128,12 +153,13 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
git=self.git,
|
||||
revisions=self.revisions + other.revisions,
|
||||
warn_unpinned=warn_unpinned,
|
||||
subdirectory=self.subdirectory,
|
||||
)
|
||||
|
||||
def resolved(self) -> GitPinnedPackage:
|
||||
requested = set(self.revisions)
|
||||
if len(requested) == 0:
|
||||
requested = {'master'}
|
||||
requested = {'HEAD'}
|
||||
elif len(requested) > 1:
|
||||
raise_dependency_error(
|
||||
'git dependencies should contain exactly one version. '
|
||||
@@ -141,5 +167,5 @@ class GitUnpinnedPackage(GitPackageMixin, UnpinnedPackage[GitPinnedPackage]):
|
||||
|
||||
return GitPinnedPackage(
|
||||
git=self.git, revision=requested.pop(),
|
||||
warn_unpinned=self.warn_unpinned
|
||||
warn_unpinned=self.warn_unpinned, subdirectory=self.subdirectory
|
||||
)
|
||||
|
||||
@@ -30,9 +30,13 @@ class RegistryPackageMixin:
|
||||
|
||||
|
||||
class RegistryPinnedPackage(RegistryPackageMixin, PinnedPackage):
|
||||
def __init__(self, package: str, version: str) -> None:
|
||||
def __init__(self,
|
||||
package: str,
|
||||
version: str,
|
||||
version_latest: str) -> None:
|
||||
super().__init__(package)
|
||||
self.version = version
|
||||
self.version_latest = version_latest
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
@@ -44,6 +48,9 @@ class RegistryPinnedPackage(RegistryPackageMixin, PinnedPackage):
|
||||
def get_version(self):
|
||||
return self.version
|
||||
|
||||
def get_version_latest(self):
|
||||
return self.version_latest
|
||||
|
||||
def nice_version_name(self):
|
||||
return 'version {}'.format(self.version)
|
||||
|
||||
@@ -61,8 +68,8 @@ class RegistryPinnedPackage(RegistryPackageMixin, PinnedPackage):
|
||||
system.make_directory(os.path.dirname(tar_path))
|
||||
|
||||
download_url = metadata.downloads.tarball
|
||||
system.download(download_url, tar_path)
|
||||
deps_path = project.modules_path
|
||||
system.download_with_retries(download_url, tar_path)
|
||||
deps_path = project.packages_install_path
|
||||
package_name = self.get_project_name(project, renderer)
|
||||
system.untar_package(tar_path, deps_path, package_name)
|
||||
|
||||
@@ -71,10 +78,14 @@ class RegistryUnpinnedPackage(
|
||||
RegistryPackageMixin, UnpinnedPackage[RegistryPinnedPackage]
|
||||
):
|
||||
def __init__(
|
||||
self, package: str, versions: List[semver.VersionSpecifier]
|
||||
self,
|
||||
package: str,
|
||||
versions: List[semver.VersionSpecifier],
|
||||
install_prerelease: bool
|
||||
) -> None:
|
||||
super().__init__(package)
|
||||
self.versions = versions
|
||||
self.install_prerelease = install_prerelease
|
||||
|
||||
def _check_in_index(self):
|
||||
index = registry.index_cached()
|
||||
@@ -91,13 +102,18 @@ class RegistryUnpinnedPackage(
|
||||
semver.VersionSpecifier.from_version_string(v)
|
||||
for v in raw_version
|
||||
]
|
||||
return cls(package=contract.package, versions=versions)
|
||||
return cls(
|
||||
package=contract.package,
|
||||
versions=versions,
|
||||
install_prerelease=contract.install_prerelease
|
||||
)
|
||||
|
||||
def incorporate(
|
||||
self, other: 'RegistryUnpinnedPackage'
|
||||
) -> 'RegistryUnpinnedPackage':
|
||||
return RegistryUnpinnedPackage(
|
||||
package=self.package,
|
||||
install_prerelease=self.install_prerelease,
|
||||
versions=self.versions + other.versions,
|
||||
)
|
||||
|
||||
@@ -111,12 +127,18 @@ class RegistryUnpinnedPackage(
|
||||
raise DependencyException(new_msg) from e
|
||||
|
||||
available = registry.get_available_versions(self.package)
|
||||
installable = semver.filter_installable(
|
||||
available,
|
||||
self.install_prerelease
|
||||
)
|
||||
available_latest = installable[-1]
|
||||
|
||||
# for now, pick a version and then recurse. later on,
|
||||
# we'll probably want to traverse multiple options
|
||||
# so we can match packages. not going to make a difference
|
||||
# right now.
|
||||
target = semver.resolve_to_specific_version(range_, available)
|
||||
target = semver.resolve_to_specific_version(range_, installable)
|
||||
if not target:
|
||||
package_version_not_found(self.package, range_, available)
|
||||
return RegistryPinnedPackage(package=self.package, version=target)
|
||||
package_version_not_found(self.package, range_, installable)
|
||||
return RegistryPinnedPackage(package=self.package, version=target,
|
||||
version_latest=available_latest)
|
||||
|
||||
@@ -127,7 +127,7 @@ def resolve_packages(
|
||||
final = PackageListing()
|
||||
|
||||
ctx = generate_target_context(config, config.cli_vars)
|
||||
renderer = DbtProjectYamlRenderer(ctx, config.config_version)
|
||||
renderer = DbtProjectYamlRenderer(ctx)
|
||||
|
||||
while pending:
|
||||
next_pending = PackageListing()
|
||||
|
||||
9
core/dbt/events/README.md
Normal file
9
core/dbt/events/README.md
Normal file
@@ -0,0 +1,9 @@
|
||||
# Events Module
|
||||
|
||||
The Events module is the implmentation for structured logging. These events represent both a programatic interface to dbt processes as well as human-readable messaging in one centralized place. The centralization allows for leveraging mypy to enforce interface invariants across all dbt events, and the distinct type layer allows for decoupling events and libraries such as loggers.
|
||||
|
||||
# Using the Events Module
|
||||
The event module provides types that represent what is happening in dbt in `events.types`. These types are intended to represent an exhaustive list of all things happening within dbt that will need to be logged, streamed, or printed. To fire an event, `events.functions::fire_event` is the entry point to the module from everywhere in dbt.
|
||||
|
||||
# Adding a New Event
|
||||
In `events.types` add a new class that represents the new event. This may be a simple class with no values, or it may be a dataclass with some values to construct downstream messaging. Only include the data necessary to construct this message within this class. You must extend all destinations (e.g. - if your log message belongs on the cli, extend `CliEventABC`) as well as the loglevel this event belongs to.
|
||||
30
core/dbt/events/functions.py
Normal file
30
core/dbt/events/functions.py
Normal file
@@ -0,0 +1,30 @@
|
||||
|
||||
import dbt.logger as logger # type: ignore # TODO eventually remove dependency on this logger
|
||||
from dbt.events.history import EVENT_HISTORY
|
||||
from dbt.events.types import CliEventABC, Event
|
||||
|
||||
|
||||
# top-level method for accessing the new eventing system
|
||||
# this is where all the side effects happen branched by event type
|
||||
# (i.e. - mutating the event history, printing to stdout, logging
|
||||
# to files, etc.)
|
||||
def fire_event(e: Event) -> None:
|
||||
EVENT_HISTORY.append(e)
|
||||
if isinstance(e, CliEventABC):
|
||||
if e.level_tag() == 'test':
|
||||
# TODO after implmenting #3977 send to new test level
|
||||
logger.GLOBAL_LOGGER.debug(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'debug':
|
||||
logger.GLOBAL_LOGGER.debug(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'info':
|
||||
logger.GLOBAL_LOGGER.info(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'warn':
|
||||
logger.GLOBAL_LOGGER.warning()(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'error':
|
||||
logger.GLOBAL_LOGGER.error(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'exception':
|
||||
logger.GLOBAL_LOGGER.exception(logger.timestamped_line(e.cli_msg()))
|
||||
else:
|
||||
raise AssertionError(
|
||||
f"Event type {type(e).__name__} has unhandled level: {e.level_tag()}"
|
||||
)
|
||||
7
core/dbt/events/history.py
Normal file
7
core/dbt/events/history.py
Normal file
@@ -0,0 +1,7 @@
|
||||
from dbt.events.types import Event
|
||||
from typing import List
|
||||
|
||||
|
||||
# the global history of events for this session
|
||||
# TODO this is naive and the memory footprint is likely far too large.
|
||||
EVENT_HISTORY: List[Event] = []
|
||||
147
core/dbt/events/types.py
Normal file
147
core/dbt/events/types.py
Normal file
@@ -0,0 +1,147 @@
|
||||
from abc import ABCMeta, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
# types to represent log levels
|
||||
|
||||
# in preparation for #3977
|
||||
class TestLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "test"
|
||||
|
||||
|
||||
class DebugLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "debug"
|
||||
|
||||
|
||||
class InfoLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "info"
|
||||
|
||||
|
||||
class WarnLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "warn"
|
||||
|
||||
|
||||
class ErrorLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "error"
|
||||
|
||||
|
||||
class ExceptionLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "exception"
|
||||
|
||||
|
||||
# The following classes represent the data necessary to describe a
|
||||
# particular event to both human readable logs, and machine reliable
|
||||
# event streams. classes extend superclasses that indicate what
|
||||
# destinations they are intended for, which mypy uses to enforce
|
||||
# that the necessary methods are defined.
|
||||
|
||||
|
||||
# top-level superclass for all events
|
||||
class Event(metaclass=ABCMeta):
|
||||
# do not define this yourself. inherit it from one of the above level types.
|
||||
@abstractmethod
|
||||
def level_tag(self) -> str:
|
||||
raise Exception("level_tag not implemented for event")
|
||||
|
||||
|
||||
class CliEventABC(Event, metaclass=ABCMeta):
|
||||
# Solely the human readable message. Timestamps and formatting will be added by the logger.
|
||||
@abstractmethod
|
||||
def cli_msg(self) -> str:
|
||||
raise Exception("cli_msg not implemented for cli event")
|
||||
|
||||
|
||||
class ParsingStart(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Start parsing."
|
||||
|
||||
|
||||
class ParsingCompiling(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Compiling."
|
||||
|
||||
|
||||
class ParsingWritingManifest(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Writing manifest."
|
||||
|
||||
|
||||
class ParsingDone(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Done."
|
||||
|
||||
|
||||
class ManifestDependenciesLoaded(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Dependencies loaded"
|
||||
|
||||
|
||||
class ManifestLoaderCreated(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "ManifestLoader created"
|
||||
|
||||
|
||||
class ManifestLoaded(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Manifest loaded"
|
||||
|
||||
|
||||
class ManifestChecked(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Manifest checked"
|
||||
|
||||
|
||||
class ManifestFlatGraphBuilt(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Flat graph built"
|
||||
|
||||
|
||||
@dataclass
|
||||
class ReportPerformancePath(InfoLevel, CliEventABC):
|
||||
path: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return f"Performance info: {self.path}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroEventInfo(InfoLevel, CliEventABC):
|
||||
msg: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return self.msg
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroEventDebug(DebugLevel, CliEventABC):
|
||||
msg: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return self.msg
|
||||
|
||||
|
||||
# since mypy doesn't run on every file we need to suggest to mypy that every
|
||||
# class gets instantiated. But we don't actually want to run this code.
|
||||
# making the conditional `if False` causes mypy to skip it as dead code so
|
||||
# we need to skirt around that by computing something it doesn't check statically.
|
||||
#
|
||||
# TODO remove these lines once we run mypy everywhere.
|
||||
if 1 == 0:
|
||||
ParsingStart()
|
||||
ParsingCompiling()
|
||||
ParsingWritingManifest()
|
||||
ParsingDone()
|
||||
ManifestDependenciesLoaded()
|
||||
ManifestLoaderCreated()
|
||||
ManifestLoaded()
|
||||
ManifestChecked()
|
||||
ManifestFlatGraphBuilt()
|
||||
ReportPerformancePath(path='')
|
||||
MacroEventInfo(msg='')
|
||||
MacroEventDebug(msg='')
|
||||
@@ -5,16 +5,16 @@ from typing import NoReturn, Optional, Mapping, Any
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt import flags
|
||||
from dbt.ui import line_wrap_message
|
||||
from dbt.ui import line_wrap_message, warning_tag
|
||||
|
||||
import hologram
|
||||
import dbt.dataclass_schema
|
||||
|
||||
|
||||
def validator_error_message(exc):
|
||||
"""Given a hologram.ValidationError (which is basically a
|
||||
"""Given a dbt.dataclass_schema.ValidationError (which is basically a
|
||||
jsonschema.ValidationError), return the relevant parts as a string
|
||||
"""
|
||||
if not isinstance(exc, hologram.ValidationError):
|
||||
if not isinstance(exc, dbt.dataclass_schema.ValidationError):
|
||||
return str(exc)
|
||||
path = "[%s]" % "][".join(map(repr, exc.relative_path))
|
||||
return 'at path {}: {}'.format(path, exc.message)
|
||||
@@ -132,7 +132,7 @@ class RuntimeException(RuntimeError, Exception):
|
||||
result.update({
|
||||
'raw_sql': self.node.raw_sql,
|
||||
# the node isn't always compiled, but if it is, include that!
|
||||
'compiled_sql': getattr(self.node, 'injected_sql', None),
|
||||
'compiled_sql': getattr(self.node, 'compiled_sql', None),
|
||||
})
|
||||
return result
|
||||
|
||||
@@ -257,10 +257,47 @@ class JSONValidationException(ValidationException):
|
||||
return (JSONValidationException, (self.typename, self.errors))
|
||||
|
||||
|
||||
class IncompatibleSchemaException(RuntimeException):
|
||||
def __init__(self, expected: str, found: Optional[str]):
|
||||
self.expected = expected
|
||||
self.found = found
|
||||
self.filename = 'input file'
|
||||
|
||||
super().__init__(self.get_message())
|
||||
|
||||
def add_filename(self, filename: str):
|
||||
self.filename = filename
|
||||
self.msg = self.get_message()
|
||||
|
||||
def get_message(self) -> str:
|
||||
found_str = 'nothing'
|
||||
if self.found is not None:
|
||||
found_str = f'"{self.found}"'
|
||||
|
||||
msg = (
|
||||
f'Expected a schema version of "{self.expected}" in '
|
||||
f'{self.filename}, but found {found_str}. Are you running with a '
|
||||
f'different version of dbt?'
|
||||
)
|
||||
return msg
|
||||
|
||||
CODE = 10014
|
||||
MESSAGE = "Incompatible Schema"
|
||||
|
||||
|
||||
class JinjaRenderingException(CompilationException):
|
||||
pass
|
||||
|
||||
|
||||
class UndefinedMacroException(CompilationException):
|
||||
|
||||
def __str__(self, prefix='! ') -> str:
|
||||
msg = super().__str__(prefix)
|
||||
return f'{msg}. This can happen when calling a macro that does ' \
|
||||
'not exist. Check for typos and/or install package dependencies ' \
|
||||
'with "dbt deps".'
|
||||
|
||||
|
||||
class UnknownAsyncIDException(Exception):
|
||||
CODE = 10012
|
||||
MESSAGE = 'RPC server got an unknown async ID'
|
||||
@@ -429,6 +466,15 @@ def invalid_type_error(method_name, arg_name, got_value, expected_type,
|
||||
got_value=got_value, got_type=got_type))
|
||||
|
||||
|
||||
def invalid_bool_error(got_value, macro_name) -> NoReturn:
|
||||
"""Raise a CompilationException when an macro expects a boolean but gets some
|
||||
other value.
|
||||
"""
|
||||
msg = ("Macro '{macro_name}' returns '{got_value}'. It is not type 'bool' "
|
||||
"and cannot not be converted reliably to a bool.")
|
||||
raise_compiler_error(msg.format(macro_name=macro_name, got_value=got_value))
|
||||
|
||||
|
||||
def ref_invalid_args(model, args) -> NoReturn:
|
||||
raise_compiler_error(
|
||||
"ref() takes at most two arguments ({} given)".format(len(args)),
|
||||
@@ -569,14 +615,6 @@ def source_target_not_found(
|
||||
raise_compiler_error(msg, model)
|
||||
|
||||
|
||||
def ref_disabled_dependency(model, target_model):
|
||||
raise_compiler_error(
|
||||
"Model '{}' depends on model '{}' which is disabled in "
|
||||
"the project config".format(model.unique_id,
|
||||
target_model.unique_id),
|
||||
model)
|
||||
|
||||
|
||||
def dependency_not_found(model, target_model_name):
|
||||
raise_compiler_error(
|
||||
"'{}' depends on '{}' which is not in the graph!"
|
||||
@@ -591,6 +629,20 @@ def macro_not_found(model, target_macro_id):
|
||||
.format(model.unique_id, target_macro_id))
|
||||
|
||||
|
||||
def macro_invalid_dispatch_arg(macro_name) -> NoReturn:
|
||||
msg = '''\
|
||||
The "packages" argument of adapter.dispatch() has been deprecated.
|
||||
Use the "macro_namespace" argument instead.
|
||||
|
||||
Raised during dispatch for: {}
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch
|
||||
'''
|
||||
raise_compiler_error(msg.format(macro_name))
|
||||
|
||||
|
||||
def materialization_not_available(model, adapter_type):
|
||||
materialization = model.get_materialization()
|
||||
|
||||
@@ -637,6 +689,14 @@ def missing_relation(relation, model=None):
|
||||
model)
|
||||
|
||||
|
||||
def raise_dataclass_not_dict(obj):
|
||||
msg = (
|
||||
'The object ("{obj}") was used as a dictionary. This '
|
||||
'capability has been removed from objects of this type.'
|
||||
)
|
||||
raise_compiler_error(msg)
|
||||
|
||||
|
||||
def relation_wrong_type(relation, expected_type, model=None):
|
||||
raise_compiler_error(
|
||||
('Trying to create {expected_type} {relation}, '
|
||||
@@ -673,11 +733,11 @@ def system_error(operation_name):
|
||||
raise_compiler_error(
|
||||
"dbt encountered an error when attempting to {}. "
|
||||
"If this error persists, please create an issue at: \n\n"
|
||||
"https://github.com/fishtown-analytics/dbt"
|
||||
"https://github.com/dbt-labs/dbt-core"
|
||||
.format(operation_name))
|
||||
|
||||
|
||||
class RegistryException(Exception):
|
||||
class ConnectionException(Exception):
|
||||
pass
|
||||
|
||||
|
||||
@@ -817,11 +877,11 @@ def _fix_dupe_msg(path_1: str, path_2: str, name: str, type_name: str) -> str:
|
||||
)
|
||||
|
||||
|
||||
def raise_duplicate_patch_name(patch_1, patch_2):
|
||||
def raise_duplicate_patch_name(patch_1, existing_patch_path):
|
||||
name = patch_1.name
|
||||
fix = _fix_dupe_msg(
|
||||
patch_1.original_file_path,
|
||||
patch_2.original_file_path,
|
||||
existing_patch_path,
|
||||
name,
|
||||
'resource',
|
||||
)
|
||||
@@ -832,12 +892,12 @@ def raise_duplicate_patch_name(patch_1, patch_2):
|
||||
)
|
||||
|
||||
|
||||
def raise_duplicate_macro_patch_name(patch_1, patch_2):
|
||||
def raise_duplicate_macro_patch_name(patch_1, existing_patch_path):
|
||||
package_name = patch_1.package_name
|
||||
name = patch_1.name
|
||||
fix = _fix_dupe_msg(
|
||||
patch_1.original_file_path,
|
||||
patch_2.original_file_path,
|
||||
existing_patch_path,
|
||||
name,
|
||||
'macros'
|
||||
)
|
||||
@@ -879,22 +939,17 @@ def raise_unrecognized_credentials_type(typename, supported_types):
|
||||
)
|
||||
|
||||
|
||||
def raise_invalid_patch(
|
||||
node, patch_section: str, patch_path: str,
|
||||
) -> NoReturn:
|
||||
def warn_invalid_patch(patch, resource_type):
|
||||
msg = line_wrap_message(
|
||||
f'''\
|
||||
'{node.name}' is a {node.resource_type} node, but it is
|
||||
specified in the {patch_section} section of
|
||||
{patch_path}.
|
||||
|
||||
|
||||
|
||||
To fix this error, place the `{node.name}`
|
||||
specification under the {node.resource_type.pluralize()} key instead.
|
||||
'{patch.name}' is a {resource_type} node, but it is
|
||||
specified in the {patch.yaml_key} section of
|
||||
{patch.original_file_path}.
|
||||
To fix this error, place the `{patch.name}`
|
||||
specification under the {resource_type.pluralize()} key instead.
|
||||
'''
|
||||
)
|
||||
raise_compiler_error(msg, node)
|
||||
warn_or_error(msg, log_fmt=warning_tag('{}'))
|
||||
|
||||
|
||||
def raise_not_implemented(msg):
|
||||
@@ -956,6 +1011,7 @@ CONTEXT_EXPORTS = {
|
||||
raise_ambiguous_alias,
|
||||
raise_ambiguous_catalog_match,
|
||||
raise_cache_inconsistent,
|
||||
raise_dataclass_not_dict,
|
||||
raise_compiler_error,
|
||||
raise_database_error,
|
||||
raise_dep_not_found,
|
||||
|
||||
@@ -1,18 +1,57 @@
|
||||
import os
|
||||
import multiprocessing
|
||||
if os.name != 'nt':
|
||||
# https://bugs.python.org/issue41567
|
||||
import multiprocessing.popen_spawn_posix # type: ignore
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
# initially all flags are set to None, the on-load call of reset() will set
|
||||
# them for their first time.
|
||||
STRICT_MODE = None
|
||||
FULL_REFRESH = None
|
||||
USE_CACHE = None
|
||||
# PROFILES_DIR must be set before the other flags
|
||||
# It also gets set in main.py and in set_from_args because the rpc server
|
||||
# doesn't go through exactly the same main arg processing.
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser('~'), '.dbt')
|
||||
PROFILES_DIR = os.path.expanduser(
|
||||
os.getenv('DBT_PROFILES_DIR', DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
STRICT_MODE = False # Only here for backwards compatibility
|
||||
FULL_REFRESH = False # subcommand
|
||||
STORE_FAILURES = False # subcommand
|
||||
GREEDY = None # subcommand
|
||||
|
||||
# Global CLI commands
|
||||
USE_EXPERIMENTAL_PARSER = None
|
||||
STATIC_PARSER = None
|
||||
WARN_ERROR = None
|
||||
TEST_NEW_PARSER = None
|
||||
WRITE_JSON = None
|
||||
PARTIAL_PARSE = None
|
||||
USE_COLORS = None
|
||||
DEBUG = None
|
||||
LOG_FORMAT = None
|
||||
VERSION_CHECK = None
|
||||
FAIL_FAST = None
|
||||
SEND_ANONYMOUS_USAGE_STATS = None
|
||||
PRINTER_WIDTH = 80
|
||||
WHICH = None
|
||||
|
||||
# Global CLI defaults. These flags are set from three places:
|
||||
# CLI args, environment variables, and user_config (profiles.yml).
|
||||
# Environment variables use the pattern 'DBT_{flag name}', like DBT_PROFILES_DIR
|
||||
flag_defaults = {
|
||||
"USE_EXPERIMENTAL_PARSER": False,
|
||||
"STATIC_PARSER": True,
|
||||
"WARN_ERROR": False,
|
||||
"WRITE_JSON": True,
|
||||
"PARTIAL_PARSE": True,
|
||||
"USE_COLORS": True,
|
||||
"PROFILES_DIR": DEFAULT_PROFILES_DIR,
|
||||
"DEBUG": False,
|
||||
"LOG_FORMAT": None,
|
||||
"VERSION_CHECK": True,
|
||||
"FAIL_FAST": False,
|
||||
"SEND_ANONYMOUS_USAGE_STATS": True,
|
||||
"PRINTER_WIDTH": 80
|
||||
}
|
||||
|
||||
|
||||
def env_set_truthy(key: str) -> Optional[str]:
|
||||
@@ -25,6 +64,12 @@ def env_set_truthy(key: str) -> Optional[str]:
|
||||
return value
|
||||
|
||||
|
||||
def env_set_bool(env_value):
|
||||
if env_value in ('1', 't', 'true', 'y', 'yes'):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def env_set_path(key: str) -> Optional[Path]:
|
||||
value = os.getenv(key)
|
||||
if value is None:
|
||||
@@ -33,8 +78,6 @@ def env_set_path(key: str) -> Optional[Path]:
|
||||
return Path(value)
|
||||
|
||||
|
||||
SINGLE_THREADED_WEBSERVER = env_set_truthy('DBT_SINGLE_THREADED_WEBSERVER')
|
||||
SINGLE_THREADED_HANDLER = env_set_truthy('DBT_SINGLE_THREADED_HANDLER')
|
||||
MACRO_DEBUGGING = env_set_truthy('DBT_MACRO_DEBUGGING')
|
||||
DEFER_MODE = env_set_truthy('DBT_DEFER_TO_STATE')
|
||||
ARTIFACT_STATE_PATH = env_set_path('DBT_ARTIFACT_STATE_PATH')
|
||||
@@ -45,49 +88,79 @@ def _get_context():
|
||||
return multiprocessing.get_context('spawn')
|
||||
|
||||
|
||||
# This is not a flag, it's a place to store the lock
|
||||
MP_CONTEXT = _get_context()
|
||||
|
||||
|
||||
def reset():
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS
|
||||
|
||||
STRICT_MODE = False
|
||||
FULL_REFRESH = False
|
||||
USE_CACHE = True
|
||||
WARN_ERROR = False
|
||||
TEST_NEW_PARSER = False
|
||||
WRITE_JSON = True
|
||||
PARTIAL_PARSE = False
|
||||
MP_CONTEXT = _get_context()
|
||||
USE_COLORS = True
|
||||
|
||||
|
||||
def set_from_args(args):
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS
|
||||
|
||||
USE_CACHE = getattr(args, 'use_cache', USE_CACHE)
|
||||
def set_from_args(args, user_config):
|
||||
global STRICT_MODE, FULL_REFRESH, WARN_ERROR, \
|
||||
USE_EXPERIMENTAL_PARSER, STATIC_PARSER, WRITE_JSON, PARTIAL_PARSE, \
|
||||
USE_COLORS, STORE_FAILURES, PROFILES_DIR, DEBUG, LOG_FORMAT, GREEDY, \
|
||||
VERSION_CHECK, FAIL_FAST, SEND_ANONYMOUS_USAGE_STATS, PRINTER_WIDTH, \
|
||||
WHICH
|
||||
|
||||
STRICT_MODE = False # backwards compatibility
|
||||
# cli args without user_config or env var option
|
||||
FULL_REFRESH = getattr(args, 'full_refresh', FULL_REFRESH)
|
||||
STRICT_MODE = getattr(args, 'strict', STRICT_MODE)
|
||||
WARN_ERROR = (
|
||||
STRICT_MODE or
|
||||
getattr(args, 'warn_error', STRICT_MODE or WARN_ERROR)
|
||||
)
|
||||
STORE_FAILURES = getattr(args, 'store_failures', STORE_FAILURES)
|
||||
GREEDY = getattr(args, 'greedy', GREEDY)
|
||||
WHICH = getattr(args, 'which', WHICH)
|
||||
|
||||
TEST_NEW_PARSER = getattr(args, 'test_new_parser', TEST_NEW_PARSER)
|
||||
WRITE_JSON = getattr(args, 'write_json', WRITE_JSON)
|
||||
PARTIAL_PARSE = getattr(args, 'partial_parse', None)
|
||||
MP_CONTEXT = _get_context()
|
||||
|
||||
# The use_colors attribute will always have a value because it is assigned
|
||||
# None by default from the add_mutually_exclusive_group function
|
||||
use_colors_override = getattr(args, 'use_colors')
|
||||
|
||||
if use_colors_override is not None:
|
||||
USE_COLORS = use_colors_override
|
||||
# global cli flags with env var and user_config alternatives
|
||||
USE_EXPERIMENTAL_PARSER = get_flag_value('USE_EXPERIMENTAL_PARSER', args, user_config)
|
||||
STATIC_PARSER = get_flag_value('STATIC_PARSER', args, user_config)
|
||||
WARN_ERROR = get_flag_value('WARN_ERROR', args, user_config)
|
||||
WRITE_JSON = get_flag_value('WRITE_JSON', args, user_config)
|
||||
PARTIAL_PARSE = get_flag_value('PARTIAL_PARSE', args, user_config)
|
||||
USE_COLORS = get_flag_value('USE_COLORS', args, user_config)
|
||||
PROFILES_DIR = get_flag_value('PROFILES_DIR', args, user_config)
|
||||
DEBUG = get_flag_value('DEBUG', args, user_config)
|
||||
LOG_FORMAT = get_flag_value('LOG_FORMAT', args, user_config)
|
||||
VERSION_CHECK = get_flag_value('VERSION_CHECK', args, user_config)
|
||||
FAIL_FAST = get_flag_value('FAIL_FAST', args, user_config)
|
||||
SEND_ANONYMOUS_USAGE_STATS = get_flag_value('SEND_ANONYMOUS_USAGE_STATS', args, user_config)
|
||||
PRINTER_WIDTH = get_flag_value('PRINTER_WIDTH', args, user_config)
|
||||
|
||||
|
||||
# initialize everything to the defaults on module load
|
||||
reset()
|
||||
def get_flag_value(flag, args, user_config):
|
||||
lc_flag = flag.lower()
|
||||
flag_value = getattr(args, lc_flag, None)
|
||||
if flag_value is None:
|
||||
# Environment variables use pattern 'DBT_{flag name}'
|
||||
env_flag = f"DBT_{flag}"
|
||||
env_value = os.getenv(env_flag)
|
||||
if env_value is not None and env_value != '':
|
||||
env_value = env_value.lower()
|
||||
# non Boolean values
|
||||
if flag in ['LOG_FORMAT', 'PRINTER_WIDTH', 'PROFILES_DIR']:
|
||||
flag_value = env_value
|
||||
else:
|
||||
flag_value = env_set_bool(env_value)
|
||||
elif user_config is not None and getattr(user_config, lc_flag, None) is not None:
|
||||
flag_value = getattr(user_config, lc_flag)
|
||||
else:
|
||||
flag_value = flag_defaults[flag]
|
||||
if flag == 'PRINTER_WIDTH': # printer_width must be an int or it hangs
|
||||
flag_value = int(flag_value)
|
||||
if flag == 'PROFILES_DIR':
|
||||
flag_value = os.path.abspath(flag_value)
|
||||
|
||||
return flag_value
|
||||
|
||||
|
||||
def get_flag_dict():
|
||||
return {
|
||||
"use_experimental_parser": USE_EXPERIMENTAL_PARSER,
|
||||
"static_parser": STATIC_PARSER,
|
||||
"warn_error": WARN_ERROR,
|
||||
"write_json": WRITE_JSON,
|
||||
"partial_parse": PARTIAL_PARSE,
|
||||
"use_colors": USE_COLORS,
|
||||
"profiles_dir": PROFILES_DIR,
|
||||
"debug": DEBUG,
|
||||
"log_format": LOG_FORMAT,
|
||||
"version_check": VERSION_CHECK,
|
||||
"fail_fast": FAIL_FAST,
|
||||
"send_anonymous_usage_stats": SEND_ANONYMOUS_USAGE_STATS,
|
||||
"printer_width": PRINTER_WIDTH,
|
||||
}
|
||||
|
||||
@@ -11,7 +11,6 @@ from .selector import ( # noqa: F401
|
||||
)
|
||||
from .cli import ( # noqa: F401
|
||||
parse_difference,
|
||||
parse_test_selectors,
|
||||
parse_from_selectors_definition,
|
||||
)
|
||||
from .queue import GraphQueue # noqa: F401
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
# special support for CLI argument parsing.
|
||||
from dbt import flags
|
||||
import itertools
|
||||
from dbt.clients.yaml_helper import yaml, Loader, Dumper # noqa: F401
|
||||
|
||||
from typing import (
|
||||
Dict, List, Optional, Tuple, Any, Union
|
||||
@@ -20,12 +22,10 @@ INTERSECTION_DELIMITER = ','
|
||||
|
||||
DEFAULT_INCLUDES: List[str] = ['fqn:*', 'source:*', 'exposure:*']
|
||||
DEFAULT_EXCLUDES: List[str] = []
|
||||
DATA_TEST_SELECTOR: str = 'test_type:data'
|
||||
SCHEMA_TEST_SELECTOR: str = 'test_type:schema'
|
||||
|
||||
|
||||
def parse_union(
|
||||
components: List[str], expect_exists: bool
|
||||
components: List[str], expect_exists: bool, greedy: bool = False
|
||||
) -> SelectionUnion:
|
||||
# turn ['a b', 'c'] -> ['a', 'b', 'c']
|
||||
raw_specs = itertools.chain.from_iterable(
|
||||
@@ -36,7 +36,7 @@ def parse_union(
|
||||
# ['a', 'b', 'c,d'] -> union('a', 'b', intersection('c', 'd'))
|
||||
for raw_spec in raw_specs:
|
||||
intersection_components: List[SelectionSpec] = [
|
||||
SelectionCriteria.from_single_spec(part)
|
||||
SelectionCriteria.from_single_spec(part, greedy=greedy)
|
||||
for part in raw_spec.split(INTERSECTION_DELIMITER)
|
||||
]
|
||||
union_components.append(SelectionIntersection(
|
||||
@@ -44,7 +44,6 @@ def parse_union(
|
||||
expect_exists=expect_exists,
|
||||
raw=raw_spec,
|
||||
))
|
||||
|
||||
return SelectionUnion(
|
||||
components=union_components,
|
||||
expect_exists=False,
|
||||
@@ -53,55 +52,24 @@ def parse_union(
|
||||
|
||||
|
||||
def parse_union_from_default(
|
||||
raw: Optional[List[str]], default: List[str]
|
||||
raw: Optional[List[str]], default: List[str], greedy: bool = False
|
||||
) -> SelectionUnion:
|
||||
components: List[str]
|
||||
expect_exists: bool
|
||||
if raw is None:
|
||||
return parse_union(components=default, expect_exists=False)
|
||||
return parse_union(components=default, expect_exists=False, greedy=greedy)
|
||||
else:
|
||||
return parse_union(components=raw, expect_exists=True)
|
||||
return parse_union(components=raw, expect_exists=True, greedy=greedy)
|
||||
|
||||
|
||||
def parse_difference(
|
||||
include: Optional[List[str]], exclude: Optional[List[str]]
|
||||
) -> SelectionDifference:
|
||||
included = parse_union_from_default(include, DEFAULT_INCLUDES)
|
||||
excluded = parse_union_from_default(exclude, DEFAULT_EXCLUDES)
|
||||
included = parse_union_from_default(include, DEFAULT_INCLUDES, greedy=bool(flags.GREEDY))
|
||||
excluded = parse_union_from_default(exclude, DEFAULT_EXCLUDES, greedy=True)
|
||||
return SelectionDifference(components=[included, excluded])
|
||||
|
||||
|
||||
def parse_test_selectors(
|
||||
data: bool, schema: bool, base: SelectionSpec
|
||||
) -> SelectionSpec:
|
||||
union_components = []
|
||||
|
||||
if data:
|
||||
union_components.append(
|
||||
SelectionCriteria.from_single_spec(DATA_TEST_SELECTOR)
|
||||
)
|
||||
if schema:
|
||||
union_components.append(
|
||||
SelectionCriteria.from_single_spec(SCHEMA_TEST_SELECTOR)
|
||||
)
|
||||
|
||||
intersect_with: SelectionSpec
|
||||
if not union_components:
|
||||
return base
|
||||
elif len(union_components) == 1:
|
||||
intersect_with = union_components[0]
|
||||
else: # data and schema tests
|
||||
intersect_with = SelectionUnion(
|
||||
components=union_components,
|
||||
expect_exists=True,
|
||||
raw=[DATA_TEST_SELECTOR, SCHEMA_TEST_SELECTOR],
|
||||
)
|
||||
|
||||
return SelectionIntersection(
|
||||
components=[base, intersect_with], expect_exists=True
|
||||
)
|
||||
|
||||
|
||||
RawDefinition = Union[str, Dict[str, Any]]
|
||||
|
||||
|
||||
@@ -116,8 +84,7 @@ def _get_list_dicts(
|
||||
values = dct[key]
|
||||
if not isinstance(values, list):
|
||||
raise ValidationException(
|
||||
f'Invalid value type {type(values)} in key "{key}" '
|
||||
f'(value "{values}")'
|
||||
f'Invalid value for key "{key}". Expected a list.'
|
||||
)
|
||||
for value in values:
|
||||
if isinstance(value, dict):
|
||||
@@ -165,9 +132,10 @@ def _parse_include_exclude_subdefs(
|
||||
if isinstance(definition, dict) and 'exclude' in definition:
|
||||
# do not allow multiple exclude: defs at the same level
|
||||
if diff_arg is not None:
|
||||
yaml_sel_cfg = yaml.dump(definition)
|
||||
raise ValidationException(
|
||||
f'Got multiple exclusion definitions in definition list '
|
||||
f'{definitions}'
|
||||
f"You cannot provide multiple exclude arguments to the "
|
||||
f"same selector set operator:\n{yaml_sel_cfg}"
|
||||
)
|
||||
diff_arg = _parse_exclusions(definition)
|
||||
else:
|
||||
@@ -180,7 +148,7 @@ def parse_union_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
union_def_parts = _get_list_dicts(definition, 'union')
|
||||
include, exclude = _parse_include_exclude_subdefs(union_def_parts)
|
||||
|
||||
union = SelectionUnion(components=include)
|
||||
union = SelectionUnion(components=include, greedy_warning=False)
|
||||
|
||||
if exclude is None:
|
||||
union.raw = definition
|
||||
@@ -188,7 +156,8 @@ def parse_union_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
else:
|
||||
return SelectionDifference(
|
||||
components=[union, exclude],
|
||||
raw=definition
|
||||
raw=definition,
|
||||
greedy_warning=False
|
||||
)
|
||||
|
||||
|
||||
@@ -197,20 +166,21 @@ def parse_intersection_definition(
|
||||
) -> SelectionSpec:
|
||||
intersection_def_parts = _get_list_dicts(definition, 'intersection')
|
||||
include, exclude = _parse_include_exclude_subdefs(intersection_def_parts)
|
||||
intersection = SelectionIntersection(components=include)
|
||||
intersection = SelectionIntersection(components=include, greedy_warning=False)
|
||||
|
||||
if exclude is None:
|
||||
intersection.raw = definition
|
||||
return intersection
|
||||
else:
|
||||
return SelectionDifference(
|
||||
components=[intersection, exclude],
|
||||
raw=definition
|
||||
raw=definition,
|
||||
greedy_warning=False
|
||||
)
|
||||
|
||||
|
||||
def parse_dict_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
diff_arg: Optional[SelectionSpec] = None
|
||||
|
||||
if len(definition) == 1:
|
||||
key = list(definition)[0]
|
||||
value = definition[key]
|
||||
@@ -230,19 +200,30 @@ def parse_dict_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
dct = {k: v for k, v in dct.items() if k != 'exclude'}
|
||||
else:
|
||||
raise ValidationException(
|
||||
f'Expected exactly 1 key in the selection definition or "method" '
|
||||
f'Expected either 1 key or else "method" '
|
||||
f'and "value" keys, but got {list(definition)}'
|
||||
)
|
||||
|
||||
# if key isn't a valid method name, this will raise
|
||||
base = SelectionCriteria.from_dict(definition, dct)
|
||||
base = SelectionCriteria.selection_criteria_from_dict(definition, dct)
|
||||
if diff_arg is None:
|
||||
return base
|
||||
else:
|
||||
return SelectionDifference(components=[base, diff_arg])
|
||||
return SelectionDifference(components=[base, diff_arg], greedy_warning=False)
|
||||
|
||||
|
||||
def parse_from_definition(definition: RawDefinition) -> SelectionSpec:
|
||||
def parse_from_definition(
|
||||
definition: RawDefinition, rootlevel=False
|
||||
) -> SelectionSpec:
|
||||
|
||||
if (isinstance(definition, dict) and
|
||||
('union' in definition or 'intersection' in definition) and
|
||||
rootlevel and len(definition) > 1):
|
||||
keys = ",".join(definition.keys())
|
||||
raise ValidationException(
|
||||
f"Only a single 'union' or 'intersection' key is allowed "
|
||||
f"in a root level selector definition; found {keys}."
|
||||
)
|
||||
if isinstance(definition, str):
|
||||
return SelectionCriteria.from_single_spec(definition)
|
||||
elif 'union' in definition:
|
||||
@@ -253,16 +234,19 @@ def parse_from_definition(definition: RawDefinition) -> SelectionSpec:
|
||||
return parse_dict_definition(definition)
|
||||
else:
|
||||
raise ValidationException(
|
||||
f'Expected to find str or dict, instead found '
|
||||
f'{type(definition)}: {definition}'
|
||||
f'Expected to find union, intersection, str or dict, instead '
|
||||
f'found {type(definition)}: {definition}'
|
||||
)
|
||||
|
||||
|
||||
def parse_from_selectors_definition(
|
||||
source: SelectorFile
|
||||
) -> Dict[str, SelectionSpec]:
|
||||
result: Dict[str, SelectionSpec] = {}
|
||||
) -> Dict[str, Dict[str, Union[SelectionSpec, bool]]]:
|
||||
result: Dict[str, Dict[str, Union[SelectionSpec, bool]]] = {}
|
||||
selector: SelectorDefinition
|
||||
for selector in source.selectors:
|
||||
result[selector.name] = parse_from_definition(selector.definition)
|
||||
result[selector.name] = {
|
||||
"default": selector.default,
|
||||
"definition": parse_from_definition(selector.definition, rootlevel=True)
|
||||
}
|
||||
return result
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
import threading
|
||||
from queue import PriorityQueue
|
||||
from typing import (
|
||||
Dict, Set, Optional
|
||||
)
|
||||
|
||||
import networkx as nx # type: ignore
|
||||
import threading
|
||||
|
||||
from queue import PriorityQueue
|
||||
from typing import Dict, Set, List, Generator, Optional
|
||||
|
||||
from .graph import UniqueId
|
||||
from dbt.contracts.graph.parsed import ParsedSourceDefinition, ParsedExposure
|
||||
@@ -21,9 +19,8 @@ class GraphQueue:
|
||||
that separate threads do not call `.empty()` or `__len__()` and `.get()` at
|
||||
the same time, as there is an unlocked race!
|
||||
"""
|
||||
def __init__(
|
||||
self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]
|
||||
):
|
||||
|
||||
def __init__(self, graph: nx.DiGraph, manifest: Manifest, selected: Set[UniqueId]):
|
||||
self.graph = graph
|
||||
self.manifest = manifest
|
||||
self._selected = selected
|
||||
@@ -37,7 +34,7 @@ class GraphQueue:
|
||||
# this lock controls most things
|
||||
self.lock = threading.Lock()
|
||||
# store the 'score' of each node as a number. Lower is higher priority.
|
||||
self._scores = self._calculate_scores()
|
||||
self._scores = self._get_scores(self.graph)
|
||||
# populate the initial queue
|
||||
self._find_new_additions()
|
||||
# awaits after task end
|
||||
@@ -56,30 +53,59 @@ class GraphQueue:
|
||||
return False
|
||||
return True
|
||||
|
||||
def _calculate_scores(self) -> Dict[UniqueId, int]:
|
||||
"""Calculate the 'value' of each node in the graph based on how many
|
||||
blocking descendants it has. We use this score for the internal
|
||||
priority queue's ordering, so the quality of this metric is important.
|
||||
@staticmethod
|
||||
def _grouped_topological_sort(
|
||||
graph: nx.DiGraph,
|
||||
) -> Generator[List[str], None, None]:
|
||||
"""Topological sort of given graph that groups ties.
|
||||
|
||||
The score is stored as a negative number because the internal
|
||||
PriorityQueue picks lowest values first.
|
||||
Adapted from `nx.topological_sort`, this function returns a topo sort of a graph however
|
||||
instead of arbitrarily ordering ties in the sort order, ties are grouped together in
|
||||
lists.
|
||||
|
||||
We could do this in one pass over the graph instead of len(self.graph)
|
||||
passes but this is easy. For large graphs this may hurt performance.
|
||||
Args:
|
||||
graph: The graph to be sorted.
|
||||
|
||||
This operates on the graph, so it would require a lock if called from
|
||||
outside __init__.
|
||||
|
||||
:return Dict[str, int]: The score dict, mapping unique IDs to integer
|
||||
scores. Lower scores are higher priority.
|
||||
Returns:
|
||||
A generator that yields lists of nodes, one list per graph depth level.
|
||||
"""
|
||||
indegree_map = {v: d for v, d in graph.in_degree() if d > 0}
|
||||
zero_indegree = [v for v, d in graph.in_degree() if d == 0]
|
||||
|
||||
while zero_indegree:
|
||||
yield zero_indegree
|
||||
new_zero_indegree = []
|
||||
for v in zero_indegree:
|
||||
for _, child in graph.edges(v):
|
||||
indegree_map[child] -= 1
|
||||
if not indegree_map[child]:
|
||||
new_zero_indegree.append(child)
|
||||
zero_indegree = new_zero_indegree
|
||||
|
||||
def _get_scores(self, graph: nx.DiGraph) -> Dict[str, int]:
|
||||
"""Scoring nodes for processing order.
|
||||
|
||||
Scores are calculated by the graph depth level. Lowest score (0) should be processed first.
|
||||
|
||||
Args:
|
||||
graph: The graph to be scored.
|
||||
|
||||
Returns:
|
||||
A dictionary consisting of `node name`:`score` pairs.
|
||||
"""
|
||||
# split graph by connected subgraphs
|
||||
subgraphs = (
|
||||
graph.subgraph(x) for x in nx.connected_components(nx.Graph(graph))
|
||||
)
|
||||
|
||||
# score all nodes in all subgraphs
|
||||
scores = {}
|
||||
for node in self.graph.nodes():
|
||||
score = -1 * len([
|
||||
d for d in nx.descendants(self.graph, node)
|
||||
if self._include_in_cost(d)
|
||||
])
|
||||
scores[node] = score
|
||||
for subgraph in subgraphs:
|
||||
grouped_nodes = self._grouped_topological_sort(subgraph)
|
||||
for level, group in enumerate(grouped_nodes):
|
||||
for node in group:
|
||||
scores[node] = level
|
||||
|
||||
return scores
|
||||
|
||||
def get(
|
||||
@@ -133,8 +159,6 @@ class GraphQueue:
|
||||
def _find_new_additions(self) -> None:
|
||||
"""Find any nodes in the graph that need to be added to the internal
|
||||
queue and add them.
|
||||
|
||||
Callers must hold the lock.
|
||||
"""
|
||||
for node, in_degree in self.graph.in_degree():
|
||||
if not self._already_known(node) and in_degree == 0:
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
|
||||
from typing import Set, List, Optional
|
||||
from typing import Set, List, Optional, Tuple
|
||||
|
||||
from .graph import Graph, UniqueId
|
||||
from .queue import GraphQueue
|
||||
@@ -25,11 +24,41 @@ def get_package_names(nodes):
|
||||
def alert_non_existence(raw_spec, nodes):
|
||||
if len(nodes) == 0:
|
||||
warn_or_error(
|
||||
f"The selector '{str(raw_spec)}' does not match any nodes and will"
|
||||
f" be ignored"
|
||||
f"The selection criterion '{str(raw_spec)}' does not match"
|
||||
f" any nodes"
|
||||
)
|
||||
|
||||
|
||||
def alert_unused_nodes(raw_spec, node_names):
|
||||
summary_nodes_str = ("\n - ").join(node_names[:3])
|
||||
debug_nodes_str = ("\n - ").join(node_names)
|
||||
and_more_str = f"\n - and {len(node_names) - 3} more" if len(node_names) > 4 else ""
|
||||
summary_msg = (
|
||||
f"\nSome tests were excluded because at least one parent is not selected. "
|
||||
f"Use the --greedy flag to include them."
|
||||
f"\n - {summary_nodes_str}{and_more_str}"
|
||||
)
|
||||
logger.info(summary_msg)
|
||||
if len(node_names) > 4:
|
||||
debug_msg = (
|
||||
f"Full list of tests that were excluded:"
|
||||
f"\n - {debug_nodes_str}"
|
||||
)
|
||||
logger.debug(debug_msg)
|
||||
|
||||
|
||||
def can_select_indirectly(node):
|
||||
"""If a node is not selected itself, but its parent(s) are, it may qualify
|
||||
for indirect selection.
|
||||
Today, only Test nodes can be indirectly selected. In the future,
|
||||
other node types or invocation flags might qualify.
|
||||
"""
|
||||
if node.resource_type == NodeType.Test:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
class NodeSelector(MethodManager):
|
||||
"""The node selector is aware of the graph and manifest,
|
||||
"""
|
||||
@@ -61,8 +90,8 @@ class NodeSelector(MethodManager):
|
||||
|
||||
def get_nodes_from_criteria(
|
||||
self,
|
||||
spec: SelectionCriteria,
|
||||
) -> Set[UniqueId]:
|
||||
spec: SelectionCriteria
|
||||
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
"""Get all nodes specified by the single selection criteria.
|
||||
|
||||
- collect the directly included nodes
|
||||
@@ -79,11 +108,14 @@ class NodeSelector(MethodManager):
|
||||
f"The '{spec.method}' selector specified in {spec.raw} is "
|
||||
f"invalid. Must be one of [{valid_selectors}]"
|
||||
)
|
||||
return set()
|
||||
return set(), set()
|
||||
|
||||
extras = self.collect_specified_neighbors(spec, collected)
|
||||
result = self.expand_selection(collected | extras)
|
||||
return result
|
||||
neighbors = self.collect_specified_neighbors(spec, collected)
|
||||
direct_nodes, indirect_nodes = self.expand_selection(
|
||||
selected=(collected | neighbors),
|
||||
greedy=spec.greedy
|
||||
)
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def collect_specified_neighbors(
|
||||
self, spec: SelectionCriteria, selected: Set[UniqueId]
|
||||
@@ -106,24 +138,46 @@ class NodeSelector(MethodManager):
|
||||
additional.update(self.graph.select_children(selected, depth))
|
||||
return additional
|
||||
|
||||
def select_nodes(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""Select the nodes in the graph according to the spec.
|
||||
|
||||
If the spec is a composite spec (a union, difference, or intersection),
|
||||
def select_nodes_recursively(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
"""If the spec is a composite spec (a union, difference, or intersection),
|
||||
recurse into its selections and combine them. If the spec is a concrete
|
||||
selection criteria, resolve that using the given graph.
|
||||
"""
|
||||
if isinstance(spec, SelectionCriteria):
|
||||
result = self.get_nodes_from_criteria(spec)
|
||||
direct_nodes, indirect_nodes = self.get_nodes_from_criteria(spec)
|
||||
else:
|
||||
node_selections = [
|
||||
self.select_nodes(component)
|
||||
bundles = [
|
||||
self.select_nodes_recursively(component)
|
||||
for component in spec
|
||||
]
|
||||
result = spec.combined(node_selections)
|
||||
|
||||
direct_sets = []
|
||||
indirect_sets = []
|
||||
|
||||
for direct, indirect in bundles:
|
||||
direct_sets.append(direct)
|
||||
indirect_sets.append(direct | indirect)
|
||||
|
||||
initial_direct = spec.combined(direct_sets)
|
||||
indirect_nodes = spec.combined(indirect_sets)
|
||||
|
||||
direct_nodes = self.incorporate_indirect_nodes(initial_direct, indirect_nodes)
|
||||
|
||||
if spec.expect_exists:
|
||||
alert_non_existence(spec.raw, result)
|
||||
return result
|
||||
alert_non_existence(spec.raw, direct_nodes)
|
||||
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def select_nodes(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
"""Select the nodes in the graph according to the spec.
|
||||
|
||||
This is the main point of entry for turning a spec into a set of nodes:
|
||||
- Recurse through spec, select by criteria, combine by set operation
|
||||
- Return final (unfiltered) selection set
|
||||
"""
|
||||
direct_nodes, indirect_nodes = self.select_nodes_recursively(spec)
|
||||
indirect_only = indirect_nodes.difference(direct_nodes)
|
||||
return direct_nodes, indirect_only
|
||||
|
||||
def _is_graph_member(self, unique_id: UniqueId) -> bool:
|
||||
if unique_id in self.manifest.sources:
|
||||
@@ -162,24 +216,78 @@ class NodeSelector(MethodManager):
|
||||
unique_id for unique_id in selected if self._is_match(unique_id)
|
||||
}
|
||||
|
||||
def expand_selection(self, selected: Set[UniqueId]) -> Set[UniqueId]:
|
||||
"""Perform selector-specific expansion."""
|
||||
def expand_selection(
|
||||
self, selected: Set[UniqueId], greedy: bool = False
|
||||
) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
# Test selection can expand to include an implicitly/indirectly selected test.
|
||||
# In this way, `dbt test -m model_a` also includes tests that directly depend on `model_a`.
|
||||
# Expansion has two modes, GREEDY and NOT GREEDY.
|
||||
#
|
||||
# GREEDY mode: If ANY parent is selected, select the test. We use this for EXCLUSION.
|
||||
#
|
||||
# NOT GREEDY mode:
|
||||
# - If ALL parents are selected, select the test.
|
||||
# - If ANY parent is missing, return it separately. We'll keep it around
|
||||
# for later and see if its other parents show up.
|
||||
# We use this for INCLUSION.
|
||||
# Users can also opt in to inclusive GREEDY mode by passing --greedy flag,
|
||||
# or by specifying `greedy: true` in a yaml selector
|
||||
|
||||
direct_nodes = set(selected)
|
||||
indirect_nodes = set()
|
||||
|
||||
for unique_id in self.graph.select_successors(selected):
|
||||
if unique_id in self.manifest.nodes:
|
||||
node = self.manifest.nodes[unique_id]
|
||||
if can_select_indirectly(node):
|
||||
# should we add it in directly?
|
||||
if greedy or set(node.depends_on.nodes) <= set(selected):
|
||||
direct_nodes.add(unique_id)
|
||||
# if not:
|
||||
else:
|
||||
indirect_nodes.add(unique_id)
|
||||
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def incorporate_indirect_nodes(
|
||||
self, direct_nodes: Set[UniqueId], indirect_nodes: Set[UniqueId] = set()
|
||||
) -> Set[UniqueId]:
|
||||
# Check tests previously selected indirectly to see if ALL their
|
||||
# parents are now present.
|
||||
|
||||
selected = set(direct_nodes)
|
||||
|
||||
for unique_id in indirect_nodes:
|
||||
if unique_id in self.manifest.nodes:
|
||||
node = self.manifest.nodes[unique_id]
|
||||
if set(node.depends_on.nodes) <= set(selected):
|
||||
selected.add(unique_id)
|
||||
|
||||
return selected
|
||||
|
||||
def get_selected(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""get_selected runs trhough the node selection process:
|
||||
"""get_selected runs through the node selection process:
|
||||
|
||||
- node selection. Based on the include/exclude sets, the set
|
||||
of matched unique IDs is returned
|
||||
- expand the graph at each leaf node, before combination
|
||||
- selectors might override this. for example, this is where
|
||||
tests are added
|
||||
- includes direct + indirect selection (for tests)
|
||||
- filtering:
|
||||
- selectors can filter the nodes after all of them have been
|
||||
selected
|
||||
"""
|
||||
selected_nodes = self.select_nodes(spec)
|
||||
selected_nodes, indirect_only = self.select_nodes(spec)
|
||||
filtered_nodes = self.filter_selection(selected_nodes)
|
||||
|
||||
if indirect_only:
|
||||
filtered_unused_nodes = self.filter_selection(indirect_only)
|
||||
if filtered_unused_nodes and spec.greedy_warning:
|
||||
# log anything that didn't make the cut
|
||||
unused_node_names = []
|
||||
for unique_id in filtered_unused_nodes:
|
||||
name = self.manifest.nodes[unique_id].name
|
||||
unused_node_names.append(name)
|
||||
alert_unused_nodes(spec, unused_node_names)
|
||||
|
||||
return filtered_nodes
|
||||
|
||||
def get_graph_queue(self, spec: SelectionSpec) -> GraphQueue:
|
||||
|
||||
@@ -3,32 +3,30 @@ from itertools import chain
|
||||
from pathlib import Path
|
||||
from typing import Set, List, Dict, Iterator, Tuple, Any, Union, Type, Optional
|
||||
|
||||
from hologram.helpers import StrEnum
|
||||
from dbt.dataclass_schema import StrEnum
|
||||
|
||||
from .graph import UniqueId
|
||||
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledDataTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
CompiledSingularTestNode,
|
||||
CompiledGenericTestNode,
|
||||
CompileResultNode,
|
||||
ManifestNode,
|
||||
)
|
||||
from dbt.contracts.graph.manifest import Manifest, WritableManifest
|
||||
from dbt.contracts.graph.parsed import (
|
||||
HasTestMetadata,
|
||||
ParsedDataTestNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedExposure,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSourceDefinition,
|
||||
)
|
||||
from dbt.contracts.state import PreviousState
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.exceptions import (
|
||||
InternalException,
|
||||
RuntimeException,
|
||||
)
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.ui import warning_tag
|
||||
|
||||
|
||||
SELECTOR_GLOB = '*'
|
||||
@@ -47,27 +45,26 @@ class MethodName(StrEnum):
|
||||
ResourceType = 'resource_type'
|
||||
State = 'state'
|
||||
Exposure = 'exposure'
|
||||
Result = 'result'
|
||||
|
||||
|
||||
def is_selected_node(real_node, node_selector):
|
||||
for i, selector_part in enumerate(node_selector):
|
||||
def is_selected_node(fqn: List[str], node_selector: str):
|
||||
|
||||
is_last = (i == len(node_selector) - 1)
|
||||
# If qualified_name exactly matches model name (fqn's leaf), return True
|
||||
if fqn[-1] == node_selector:
|
||||
return True
|
||||
# Flatten node parts. Dots in model names act as namespace separators
|
||||
flat_fqn = [item for segment in fqn for item in segment.split('.')]
|
||||
# Selector components cannot be more than fqn's
|
||||
if len(flat_fqn) < len(node_selector.split('.')):
|
||||
return False
|
||||
|
||||
for i, selector_part in enumerate(node_selector.split('.')):
|
||||
# if we hit a GLOB, then this node is selected
|
||||
if selector_part == SELECTOR_GLOB:
|
||||
return True
|
||||
|
||||
# match package.node_name or package.dir.node_name
|
||||
elif is_last and selector_part == real_node[-1]:
|
||||
return True
|
||||
|
||||
elif len(real_node) <= i:
|
||||
return False
|
||||
|
||||
elif real_node[i] == selector_part:
|
||||
elif flat_fqn[i] == selector_part:
|
||||
continue
|
||||
|
||||
else:
|
||||
return False
|
||||
|
||||
@@ -154,31 +151,20 @@ class SelectorMethod(metaclass=abc.ABCMeta):
|
||||
|
||||
|
||||
class QualifiedNameSelectorMethod(SelectorMethod):
|
||||
def node_is_match(
|
||||
self,
|
||||
qualified_name: List[str],
|
||||
package_names: Set[str],
|
||||
fqn: List[str],
|
||||
) -> bool:
|
||||
"""Determine if a qualfied name matches an fqn, given the set of package
|
||||
def node_is_match(self, qualified_name: str, fqn: List[str]) -> bool:
|
||||
"""Determine if a qualified name matches an fqn for all package
|
||||
names in the graph.
|
||||
|
||||
:param List[str] qualified_name: The components of the selector or node
|
||||
name, split on '.'.
|
||||
:param Set[str] package_names: The set of pacakge names in the graph.
|
||||
:param str qualified_name: The qualified name to match the nodes with
|
||||
:param List[str] fqn: The node's fully qualified name in the graph.
|
||||
"""
|
||||
if len(qualified_name) == 1 and fqn[-1] == qualified_name[0]:
|
||||
unscoped_fqn = fqn[1:]
|
||||
|
||||
if is_selected_node(fqn, qualified_name):
|
||||
return True
|
||||
# Match nodes across different packages
|
||||
elif is_selected_node(unscoped_fqn, qualified_name):
|
||||
return True
|
||||
|
||||
if qualified_name[0] in package_names:
|
||||
if is_selected_node(fqn, qualified_name):
|
||||
return True
|
||||
|
||||
for package_name in package_names:
|
||||
local_qualified_node_name = [package_name] + qualified_name
|
||||
if is_selected_node(fqn, local_qualified_node_name):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
@@ -189,15 +175,9 @@ class QualifiedNameSelectorMethod(SelectorMethod):
|
||||
|
||||
:param str selector: The selector or node name
|
||||
"""
|
||||
qualified_name = selector.split(".")
|
||||
parsed_nodes = list(self.parsed_nodes(included_nodes))
|
||||
package_names = {n.package_name for _, n in parsed_nodes}
|
||||
for node, real_node in parsed_nodes:
|
||||
if self.node_is_match(
|
||||
qualified_name,
|
||||
package_names,
|
||||
real_node.fqn,
|
||||
):
|
||||
if self.node_is_match(selector, real_node.fqn):
|
||||
yield node
|
||||
|
||||
|
||||
@@ -382,14 +362,15 @@ class TestTypeSelectorMethod(SelectorMethod):
|
||||
self, included_nodes: Set[UniqueId], selector: str
|
||||
) -> Iterator[UniqueId]:
|
||||
search_types: Tuple[Type, ...]
|
||||
if selector == 'schema':
|
||||
search_types = (ParsedSchemaTestNode, CompiledSchemaTestNode)
|
||||
elif selector == 'data':
|
||||
search_types = (ParsedDataTestNode, CompiledDataTestNode)
|
||||
# continue supporting 'schema' + 'data' for backwards compatibility
|
||||
if selector in ('generic', 'schema'):
|
||||
search_types = (ParsedGenericTestNode, CompiledGenericTestNode)
|
||||
elif selector in ('singular', 'data'):
|
||||
search_types = (ParsedSingularTestNode, CompiledSingularTestNode)
|
||||
else:
|
||||
raise RuntimeException(
|
||||
f'Invalid test type selector {selector}: expected "data" or '
|
||||
'"schema"'
|
||||
f'Invalid test type selector {selector}: expected "generic" or '
|
||||
'"singular"'
|
||||
)
|
||||
|
||||
for node, real_node in self.parsed_nodes(included_nodes):
|
||||
@@ -400,7 +381,7 @@ class TestTypeSelectorMethod(SelectorMethod):
|
||||
class StateSelectorMethod(SelectorMethod):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.macros_were_modified: Optional[List[str]] = None
|
||||
self.modified_macros: Optional[List[str]] = None
|
||||
|
||||
def _macros_modified(self) -> List[str]:
|
||||
# we checked in the caller!
|
||||
@@ -413,44 +394,85 @@ class StateSelectorMethod(SelectorMethod):
|
||||
|
||||
modified = []
|
||||
for uid, macro in new_macros.items():
|
||||
name = f'{macro.package_name}.{macro.name}'
|
||||
if uid in old_macros:
|
||||
old_macro = old_macros[uid]
|
||||
if macro.macro_sql != old_macro.macro_sql:
|
||||
modified.append(f'{name} changed')
|
||||
modified.append(uid)
|
||||
else:
|
||||
modified.append(f'{name} added')
|
||||
modified.append(uid)
|
||||
|
||||
for uid, macro in old_macros.items():
|
||||
if uid not in new_macros:
|
||||
modified.append(f'{macro.package_name}.{macro.name} removed')
|
||||
modified.append(uid)
|
||||
|
||||
return modified[:3]
|
||||
return modified
|
||||
|
||||
def check_modified(
|
||||
self,
|
||||
old: Optional[SelectorTarget],
|
||||
new: SelectorTarget,
|
||||
def recursively_check_macros_modified(self, node, previous_macros):
|
||||
# loop through all macros that this node depends on
|
||||
for macro_uid in node.depends_on.macros:
|
||||
# avoid infinite recursion if we've already seen this macro
|
||||
if macro_uid in previous_macros:
|
||||
continue
|
||||
previous_macros.append(macro_uid)
|
||||
# is this macro one of the modified macros?
|
||||
if macro_uid in self.modified_macros:
|
||||
return True
|
||||
# if not, and this macro depends on other macros, keep looping
|
||||
macro_node = self.manifest.macros[macro_uid]
|
||||
if len(macro_node.depends_on.macros) > 0:
|
||||
return self.recursively_check_macros_modified(macro_node, previous_macros)
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_macros_modified(self, node):
|
||||
# check if there are any changes in macros the first time
|
||||
if self.modified_macros is None:
|
||||
self.modified_macros = self._macros_modified()
|
||||
# no macros have been modified, skip looping entirely
|
||||
if not self.modified_macros:
|
||||
return False
|
||||
# recursively loop through upstream macros to see if any is modified
|
||||
else:
|
||||
previous_macros = []
|
||||
return self.recursively_check_macros_modified(node, previous_macros)
|
||||
|
||||
def check_modified(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
different_contents = not new.same_contents(old) # type: ignore
|
||||
upstream_macro_change = self.check_macros_modified(new)
|
||||
return different_contents or upstream_macro_change
|
||||
|
||||
def check_modified_body(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
if hasattr(new, "same_body"):
|
||||
return not new.same_body(old) # type: ignore
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_modified_configs(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
if hasattr(new, "same_config"):
|
||||
return not new.same_config(old) # type: ignore
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_modified_persisted_descriptions(
|
||||
self, old: Optional[SelectorTarget], new: SelectorTarget
|
||||
) -> bool:
|
||||
# check if there are any changes in macros, if so, log a warning the
|
||||
# first time
|
||||
if self.macros_were_modified is None:
|
||||
self.macros_were_modified = self._macros_modified()
|
||||
if self.macros_were_modified:
|
||||
log_str = ', '.join(self.macros_were_modified)
|
||||
logger.warning(warning_tag(
|
||||
f'During a state comparison, dbt detected a change in '
|
||||
f'macros. This will not be marked as a modification. Some '
|
||||
f'macros: {log_str}'
|
||||
))
|
||||
if hasattr(new, "same_persisted_description"):
|
||||
return not new.same_persisted_description(old) # type: ignore
|
||||
else:
|
||||
return False
|
||||
|
||||
return not new.same_contents(old) # type: ignore
|
||||
|
||||
def check_new(
|
||||
self,
|
||||
old: Optional[SelectorTarget],
|
||||
new: SelectorTarget,
|
||||
def check_modified_relation(
|
||||
self, old: Optional[SelectorTarget], new: SelectorTarget
|
||||
) -> bool:
|
||||
if hasattr(new, "same_database_representation"):
|
||||
return not new.same_database_representation(old) # type: ignore
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_modified_macros(self, _, new: SelectorTarget) -> bool:
|
||||
return self.check_macros_modified(new)
|
||||
|
||||
def check_new(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
return old is None
|
||||
|
||||
def search(
|
||||
@@ -462,8 +484,15 @@ class StateSelectorMethod(SelectorMethod):
|
||||
)
|
||||
|
||||
state_checks = {
|
||||
# it's new if there is no old version
|
||||
'new': lambda old, _: old is None,
|
||||
# use methods defined above to compare properties of old + new
|
||||
'modified': self.check_modified,
|
||||
'new': self.check_new,
|
||||
'modified.body': self.check_modified_body,
|
||||
'modified.configs': self.check_modified_configs,
|
||||
'modified.persisted_descriptions': self.check_modified_persisted_descriptions,
|
||||
'modified.relation': self.check_modified_relation,
|
||||
'modified.macros': self.check_modified_macros,
|
||||
}
|
||||
if selector in state_checks:
|
||||
checker = state_checks[selector]
|
||||
@@ -488,6 +517,23 @@ class StateSelectorMethod(SelectorMethod):
|
||||
yield node
|
||||
|
||||
|
||||
class ResultSelectorMethod(SelectorMethod):
|
||||
def search(
|
||||
self, included_nodes: Set[UniqueId], selector: str
|
||||
) -> Iterator[UniqueId]:
|
||||
if self.previous_state is None or self.previous_state.results is None:
|
||||
raise InternalException(
|
||||
'No comparison run_results'
|
||||
)
|
||||
matches = set(
|
||||
result.unique_id for result in self.previous_state.results
|
||||
if result.status == selector
|
||||
)
|
||||
for node, real_node in self.all_nodes(included_nodes):
|
||||
if node in matches:
|
||||
yield node
|
||||
|
||||
|
||||
class MethodManager:
|
||||
SELECTOR_METHODS: Dict[MethodName, Type[SelectorMethod]] = {
|
||||
MethodName.FQN: QualifiedNameSelectorMethod,
|
||||
@@ -500,6 +546,7 @@ class MethodManager:
|
||||
MethodName.TestType: TestTypeSelectorMethod,
|
||||
MethodName.State: StateSelectorMethod,
|
||||
MethodName.Exposure: ExposureSelectorMethod,
|
||||
MethodName.Result: ResultSelectorMethod,
|
||||
}
|
||||
|
||||
def __init__(
|
||||
|
||||
@@ -66,6 +66,8 @@ class SelectionCriteria:
|
||||
parents_depth: Optional[int]
|
||||
children: bool
|
||||
children_depth: Optional[int]
|
||||
greedy: bool = False
|
||||
greedy_warning: bool = False # do not raise warning for yaml selectors
|
||||
|
||||
def __post_init__(self):
|
||||
if self.children and self.childrens_parents:
|
||||
@@ -93,14 +95,18 @@ class SelectionCriteria:
|
||||
try:
|
||||
method_name = MethodName(method_parts[0])
|
||||
except ValueError as exc:
|
||||
raise InvalidSelectorException(method_parts[0]) from exc
|
||||
raise InvalidSelectorException(
|
||||
f"'{method_parts[0]}' is not a valid method name"
|
||||
) from exc
|
||||
|
||||
method_arguments: List[str] = method_parts[1:]
|
||||
|
||||
return method_name, method_arguments
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, raw: Any, dct: Dict[str, Any]) -> 'SelectionCriteria':
|
||||
def selection_criteria_from_dict(
|
||||
cls, raw: Any, dct: Dict[str, Any], greedy: bool = False
|
||||
) -> 'SelectionCriteria':
|
||||
if 'value' not in dct:
|
||||
raise RuntimeException(
|
||||
f'Invalid node spec "{raw}" - no search value!'
|
||||
@@ -119,16 +125,39 @@ class SelectionCriteria:
|
||||
parents_depth=parents_depth,
|
||||
children=bool(dct.get('children')),
|
||||
children_depth=children_depth,
|
||||
greedy=(greedy or bool(dct.get('greedy'))),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_single_spec(cls, raw: str) -> 'SelectionCriteria':
|
||||
def dict_from_single_spec(cls, raw: str):
|
||||
result = RAW_SELECTOR_PATTERN.match(raw)
|
||||
if result is None:
|
||||
return {'error': 'Invalid selector spec'}
|
||||
dct: Dict[str, Any] = result.groupdict()
|
||||
method_name, method_arguments = cls.parse_method(dct)
|
||||
meth_name = str(method_name)
|
||||
if method_arguments:
|
||||
meth_name = meth_name + '.' + '.'.join(method_arguments)
|
||||
dct['method'] = meth_name
|
||||
dct = {k: v for k, v in dct.items() if (v is not None and v != '')}
|
||||
if 'childrens_parents' in dct:
|
||||
dct['childrens_parents'] = bool(dct.get('childrens_parents'))
|
||||
if 'parents' in dct:
|
||||
dct['parents'] = bool(dct.get('parents'))
|
||||
if 'children' in dct:
|
||||
dct['children'] = bool(dct.get('children'))
|
||||
if 'greedy' in dct:
|
||||
dct['greedy'] = bool(dct.get('greedy'))
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
def from_single_spec(cls, raw: str, greedy: bool = False) -> 'SelectionCriteria':
|
||||
result = RAW_SELECTOR_PATTERN.match(raw)
|
||||
if result is None:
|
||||
# bad spec!
|
||||
raise RuntimeException(f'Invalid selector spec "{raw}"')
|
||||
|
||||
return cls.from_dict(raw, result.groupdict())
|
||||
return cls.selection_criteria_from_dict(raw, result.groupdict(), greedy=greedy)
|
||||
|
||||
|
||||
class BaseSelectionGroup(Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
@@ -136,10 +165,12 @@ class BaseSelectionGroup(Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
self,
|
||||
components: Iterable[SelectionSpec],
|
||||
expect_exists: bool = False,
|
||||
greedy_warning: bool = True,
|
||||
raw: Any = None,
|
||||
):
|
||||
self.components: List[SelectionSpec] = list(components)
|
||||
self.expect_exists = expect_exists
|
||||
self.greedy_warning = greedy_warning
|
||||
self.raw = raw
|
||||
|
||||
def __iter__(self) -> Iterator[SelectionSpec]:
|
||||
|
||||
@@ -2,14 +2,27 @@
|
||||
from dataclasses import dataclass
|
||||
from datetime import timedelta
|
||||
from pathlib import Path
|
||||
from typing import NewType, Tuple, AbstractSet
|
||||
from typing import Tuple, AbstractSet, Union
|
||||
|
||||
from hologram import (
|
||||
FieldEncoder, JsonSchemaMixin, JsonDict, ValidationError
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ValidationError, StrEnum,
|
||||
)
|
||||
from hologram.helpers import StrEnum
|
||||
from hologram import FieldEncoder, JsonDict
|
||||
from mashumaro.types import SerializableType
|
||||
|
||||
Port = NewType('Port', int)
|
||||
|
||||
class Port(int, SerializableType):
|
||||
@classmethod
|
||||
def _deserialize(cls, value: Union[int, str]) -> 'Port':
|
||||
try:
|
||||
value = int(value)
|
||||
except ValueError:
|
||||
raise ValidationError(f'Cannot encode {value} into port number')
|
||||
|
||||
return Port(value)
|
||||
|
||||
def _serialize(self) -> int:
|
||||
return self
|
||||
|
||||
|
||||
class PortEncoder(FieldEncoder):
|
||||
@@ -66,12 +79,12 @@ class NVEnum(StrEnum):
|
||||
|
||||
|
||||
@dataclass
|
||||
class NoValue(JsonSchemaMixin):
|
||||
class NoValue(dbtClassMixin):
|
||||
"""Sometimes, you want a way to say none that isn't None"""
|
||||
novalue: NVEnum = NVEnum.novalue
|
||||
|
||||
|
||||
JsonSchemaMixin.register_field_encoders({
|
||||
dbtClassMixin.register_field_encoders({
|
||||
Port: PortEncoder(),
|
||||
timedelta: TimeDeltaFieldEncoder(),
|
||||
Path: PathEncoder(),
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from hologram.helpers import StrEnum
|
||||
from dbt.dataclass_schema import StrEnum
|
||||
import json
|
||||
|
||||
from typing import Union, Dict, Any
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
{% macro get_columns_in_query(select_sql) -%}
|
||||
{{ return(adapter.dispatch('get_columns_in_query')(select_sql)) }}
|
||||
{{ return(adapter.dispatch('get_columns_in_query', 'dbt')(select_sql)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_columns_in_query(select_sql) %}
|
||||
@@ -15,7 +15,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_schema(relation) -%}
|
||||
{{ adapter.dispatch('create_schema')(relation) }}
|
||||
{{ adapter.dispatch('create_schema', 'dbt')(relation) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__create_schema(relation) -%}
|
||||
@@ -25,7 +25,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro drop_schema(relation) -%}
|
||||
{{ adapter.dispatch('drop_schema')(relation) }}
|
||||
{{ adapter.dispatch('drop_schema', 'dbt')(relation) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__drop_schema(relation) -%}
|
||||
@@ -35,7 +35,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_table_as(temporary, relation, sql) -%}
|
||||
{{ adapter.dispatch('create_table_as')(temporary, relation, sql) }}
|
||||
{{ adapter.dispatch('create_table_as', 'dbt')(temporary, relation, sql) }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__create_table_as(temporary, relation, sql) -%}
|
||||
@@ -51,8 +51,31 @@
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
{% macro get_create_index_sql(relation, index_dict) -%}
|
||||
{{ return(adapter.dispatch('get_create_index_sql', 'dbt')(relation, index_dict)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__get_create_index_sql(relation, index_dict) -%}
|
||||
{% do return(None) %}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_indexes(relation) -%}
|
||||
{{ adapter.dispatch('create_indexes', 'dbt')(relation) }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__create_indexes(relation) -%}
|
||||
{%- set _indexes = config.get('indexes', default=[]) -%}
|
||||
|
||||
{% for _index_dict in _indexes %}
|
||||
{% set create_index_sql = get_create_index_sql(relation, _index_dict) %}
|
||||
{% if create_index_sql %}
|
||||
{% do run_query(create_index_sql) %}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro create_view_as(relation, sql) -%}
|
||||
{{ adapter.dispatch('create_view_as')(relation, sql) }}
|
||||
{{ adapter.dispatch('create_view_as', 'dbt')(relation, sql) }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__create_view_as(relation, sql) -%}
|
||||
@@ -66,7 +89,7 @@
|
||||
|
||||
|
||||
{% macro get_catalog(information_schema, schemas) -%}
|
||||
{{ return(adapter.dispatch('get_catalog')(information_schema, schemas)) }}
|
||||
{{ return(adapter.dispatch('get_catalog', 'dbt')(information_schema, schemas)) }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__get_catalog(information_schema, schemas) -%}
|
||||
@@ -81,7 +104,7 @@
|
||||
|
||||
|
||||
{% macro get_columns_in_relation(relation) -%}
|
||||
{{ return(adapter.dispatch('get_columns_in_relation')(relation)) }}
|
||||
{{ return(adapter.dispatch('get_columns_in_relation', 'dbt')(relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro sql_convert_columns_in_relation(table) -%}
|
||||
@@ -98,13 +121,13 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro alter_column_type(relation, column_name, new_column_type) -%}
|
||||
{{ return(adapter.dispatch('alter_column_type')(relation, column_name, new_column_type)) }}
|
||||
{{ return(adapter.dispatch('alter_column_type', 'dbt')(relation, column_name, new_column_type)) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
|
||||
{% macro alter_column_comment(relation, column_dict) -%}
|
||||
{{ return(adapter.dispatch('alter_column_comment')(relation, column_dict)) }}
|
||||
{{ return(adapter.dispatch('alter_column_comment', 'dbt')(relation, column_dict)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__alter_column_comment(relation, column_dict) -%}
|
||||
@@ -113,7 +136,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro alter_relation_comment(relation, relation_comment) -%}
|
||||
{{ return(adapter.dispatch('alter_relation_comment')(relation, relation_comment)) }}
|
||||
{{ return(adapter.dispatch('alter_relation_comment', 'dbt')(relation, relation_comment)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__alter_relation_comment(relation, relation_comment) -%}
|
||||
@@ -122,7 +145,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro persist_docs(relation, model, for_relation=true, for_columns=true) -%}
|
||||
{{ return(adapter.dispatch('persist_docs')(relation, model, for_relation, for_columns)) }}
|
||||
{{ return(adapter.dispatch('persist_docs', 'dbt')(relation, model, for_relation, for_columns)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__persist_docs(relation, model, for_relation, for_columns) -%}
|
||||
@@ -157,7 +180,7 @@
|
||||
|
||||
|
||||
{% macro drop_relation(relation) -%}
|
||||
{{ return(adapter.dispatch('drop_relation')(relation)) }}
|
||||
{{ return(adapter.dispatch('drop_relation', 'dbt')(relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
@@ -168,7 +191,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro truncate_relation(relation) -%}
|
||||
{{ return(adapter.dispatch('truncate_relation')(relation)) }}
|
||||
{{ return(adapter.dispatch('truncate_relation', 'dbt')(relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
@@ -179,7 +202,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro rename_relation(from_relation, to_relation) -%}
|
||||
{{ return(adapter.dispatch('rename_relation')(from_relation, to_relation)) }}
|
||||
{{ return(adapter.dispatch('rename_relation', 'dbt')(from_relation, to_relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__rename_relation(from_relation, to_relation) -%}
|
||||
@@ -191,7 +214,7 @@
|
||||
|
||||
|
||||
{% macro information_schema_name(database) %}
|
||||
{{ return(adapter.dispatch('information_schema_name')(database)) }}
|
||||
{{ return(adapter.dispatch('information_schema_name', 'dbt')(database)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__information_schema_name(database) -%}
|
||||
@@ -204,7 +227,7 @@
|
||||
|
||||
|
||||
{% macro list_schemas(database) -%}
|
||||
{{ return(adapter.dispatch('list_schemas')(database)) }}
|
||||
{{ return(adapter.dispatch('list_schemas', 'dbt')(database)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__list_schemas(database) -%}
|
||||
@@ -218,7 +241,7 @@
|
||||
|
||||
|
||||
{% macro check_schema_exists(information_schema, schema) -%}
|
||||
{{ return(adapter.dispatch('check_schema_exists')(information_schema, schema)) }}
|
||||
{{ return(adapter.dispatch('check_schema_exists', 'dbt')(information_schema, schema)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__check_schema_exists(information_schema, schema) -%}
|
||||
@@ -233,7 +256,7 @@
|
||||
|
||||
|
||||
{% macro list_relations_without_caching(schema_relation) %}
|
||||
{{ return(adapter.dispatch('list_relations_without_caching')(schema_relation)) }}
|
||||
{{ return(adapter.dispatch('list_relations_without_caching', 'dbt')(schema_relation)) }}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
@@ -244,7 +267,7 @@
|
||||
|
||||
|
||||
{% macro current_timestamp() -%}
|
||||
{{ adapter.dispatch('current_timestamp')() }}
|
||||
{{ adapter.dispatch('current_timestamp', 'dbt')() }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
@@ -255,7 +278,7 @@
|
||||
|
||||
|
||||
{% macro collect_freshness(source, loaded_at_field, filter) %}
|
||||
{{ return(adapter.dispatch('collect_freshness')(source, loaded_at_field, filter))}}
|
||||
{{ return(adapter.dispatch('collect_freshness', 'dbt')(source, loaded_at_field, filter))}}
|
||||
{% endmacro %}
|
||||
|
||||
|
||||
@@ -273,7 +296,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro make_temp_relation(base_relation, suffix='__dbt_tmp') %}
|
||||
{{ return(adapter.dispatch('make_temp_relation')(base_relation, suffix))}}
|
||||
{{ return(adapter.dispatch('make_temp_relation', 'dbt')(base_relation, suffix))}}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__make_temp_relation(base_relation, suffix) %}
|
||||
@@ -288,3 +311,34 @@
|
||||
{{ config.set('sql_header', caller()) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{% macro alter_relation_add_remove_columns(relation, add_columns = none, remove_columns = none) -%}
|
||||
{{ return(adapter.dispatch('alter_relation_add_remove_columns', 'dbt')(relation, add_columns, remove_columns)) }}
|
||||
{% endmacro %}
|
||||
|
||||
{% macro default__alter_relation_add_remove_columns(relation, add_columns, remove_columns) %}
|
||||
|
||||
{% if add_columns is none %}
|
||||
{% set add_columns = [] %}
|
||||
{% endif %}
|
||||
{% if remove_columns is none %}
|
||||
{% set remove_columns = [] %}
|
||||
{% endif %}
|
||||
|
||||
{% set sql -%}
|
||||
|
||||
alter {{ relation.type }} {{ relation }}
|
||||
|
||||
{% for column in add_columns %}
|
||||
add column {{ column.name }} {{ column.data_type }}{{ ',' if not loop.last }}
|
||||
{% endfor %}{{ ',' if remove_columns | length > 0 }}
|
||||
|
||||
{% for column in remove_columns %}
|
||||
drop column {{ column.name }}{{ ',' if not loop.last }}
|
||||
{% endfor %}
|
||||
|
||||
{%- endset -%}
|
||||
|
||||
{% do run_query(sql) %}
|
||||
|
||||
{% endmacro %}
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user