mirror of
https://github.com/dbt-labs/dbt-core
synced 2025-12-19 23:01:27 +00:00
Compare commits
1 Commits
add-except
...
db-setup-w
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
03dfb11d2b |
@@ -1,5 +1,5 @@
|
||||
[bumpversion]
|
||||
current_version = 1.0.0b2
|
||||
current_version = 0.21.0b1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
@@ -34,4 +34,17 @@ first_value = 1
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/dbt/adapters/postgres/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/redshift/dbt/adapters/redshift/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/snowflake/dbt/adapters/snowflake/__version__.py]
|
||||
|
||||
[bumpversion:file:plugins/bigquery/dbt/adapters/bigquery/__version__.py]
|
||||
|
||||
|
||||
27
.github/ISSUE_TEMPLATE/beta-minor-version-release.md
vendored
Normal file
27
.github/ISSUE_TEMPLATE/beta-minor-version-release.md
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
---
|
||||
name: Beta minor version release
|
||||
about: Creates a tracking checklist of items for a Beta minor version release
|
||||
title: "[Tracking] v#.##.#B# release "
|
||||
labels: 'release'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Release Core
|
||||
- [ ] [Engineering] Follow [dbt-release workflow](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#03ff37da697d4d8ba63d24fae1bfa817)
|
||||
- [ ] [Engineering] Verify new release branch is created in the repo
|
||||
- [ ] [Product] Finalize migration guide (next.docs.getdbt.com)
|
||||
|
||||
### Release Cloud
|
||||
- [ ] [Engineering] Create a platform issue to update dbt Cloud and verify it is completed. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Engineering] Determine if schemas have changed. If so, generate new schemas and push to schemas.getdbt.com
|
||||
|
||||
### Announce
|
||||
- [ ] [Product] Announce in dbt Slack
|
||||
|
||||
### Post-release
|
||||
- [ ] [Engineering] [Bump plugin versions](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#f01854e8da3641179fbcbe505bdf515c) (dbt-spark + dbt-presto), add compatibility as needed
|
||||
- [ ] [Spark](https://github.com/dbt-labs/dbt-spark)
|
||||
- [ ] [Presto](https://github.com/dbt-labs/dbt-presto)
|
||||
- [ ] [Engineering] Create a platform issue to update dbt-spark versions to dbt Cloud. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Engineering] Create an epic for the RC release
|
||||
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
85
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -1,85 +0,0 @@
|
||||
name: 🐞 Bug
|
||||
description: Report a bug or an issue you've found with dbt
|
||||
title: "[Bug] <title>"
|
||||
labels: ["bug", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing issue for this?
|
||||
description: Please search to see if an issue already exists for the bug you encountered.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Current Behavior
|
||||
description: A concise description of what you're experiencing.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Expected Behavior
|
||||
description: A concise description of what you expected to happen.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Steps To Reproduce
|
||||
description: Steps to reproduce the behavior.
|
||||
placeholder: |
|
||||
1. In this environment...
|
||||
2. With this config...
|
||||
3. Run '...'
|
||||
4. See error...
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Relevant log output
|
||||
description: |
|
||||
If applicable, log output to help explain your problem.
|
||||
render: shell
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.7.2 (`python --version`)
|
||||
- **dbt**: 0.21.0 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
- Python:
|
||||
- dbt:
|
||||
render: markdown
|
||||
validations:
|
||||
required: false
|
||||
- type: dropdown
|
||||
id: database
|
||||
attributes:
|
||||
label: What database are you using dbt with?
|
||||
multiple: true
|
||||
options:
|
||||
- postgres
|
||||
- redshift
|
||||
- snowflake
|
||||
- bigquery
|
||||
- other (mention it in "Additional Context")
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Additional Context
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the issue you are encountering!
|
||||
|
||||
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
||||
validations:
|
||||
required: false
|
||||
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
Normal file
41
.github/ISSUE_TEMPLATE/bug_report.md
vendored
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
name: Bug report
|
||||
about: Report a bug or an issue you've found with dbt
|
||||
title: ''
|
||||
labels: bug, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the bug
|
||||
A clear and concise description of what the bug is. What command did you run? What happened?
|
||||
|
||||
### Steps To Reproduce
|
||||
In as much detail as possible, please provide steps to reproduce the issue. Sample data that triggers the issue, example model code, etc is all very helpful here.
|
||||
|
||||
### Expected behavior
|
||||
A clear and concise description of what you expected to happen.
|
||||
|
||||
### Screenshots and log output
|
||||
If applicable, add screenshots or log output to help explain your problem.
|
||||
|
||||
### System information
|
||||
**Which database are you using dbt with?**
|
||||
- [ ] postgres
|
||||
- [ ] redshift
|
||||
- [ ] bigquery
|
||||
- [ ] snowflake
|
||||
- [ ] other (specify: ____________)
|
||||
|
||||
|
||||
**The output of `dbt --version`:**
|
||||
```
|
||||
<output goes here>
|
||||
```
|
||||
|
||||
**The operating system you're using:**
|
||||
|
||||
**The output of `python --version`:**
|
||||
|
||||
### Additional context
|
||||
Add any other context about the problem here.
|
||||
16
.github/ISSUE_TEMPLATE/config.yml
vendored
16
.github/ISSUE_TEMPLATE/config.yml
vendored
@@ -1,16 +0,0 @@
|
||||
contact_links:
|
||||
- name: Create an issue for dbt-redshift
|
||||
url: https://github.com/dbt-labs/dbt-redshift/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-redshift
|
||||
- name: Create an issue for dbt-bigquery
|
||||
url: https://github.com/dbt-labs/dbt-bigquery/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-bigquery
|
||||
- name: Create an issue for dbt-snowflake
|
||||
url: https://github.com/dbt-labs/dbt-snowflake/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-snowflake
|
||||
- name: Ask a question or get support
|
||||
url: https://docs.getdbt.com/docs/guides/getting-help
|
||||
about: Ask a question or request support
|
||||
- name: Questions on Stack Overflow
|
||||
url: https://stackoverflow.com/questions/tagged/dbt
|
||||
about: Look at questions/answers at Stack Overflow
|
||||
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
49
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
@@ -1,49 +0,0 @@
|
||||
name: ✨ Feature
|
||||
description: Suggest an idea for dbt
|
||||
title: "[Feature] <title>"
|
||||
labels: ["enhancement", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this feature requests!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing feature request for this?
|
||||
description: Please search to see if an issue already exists for the feature you would like.
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe the Feature
|
||||
description: A clear and concise description of what you want to happen.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe alternatives you've considered
|
||||
description: |
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Who will this benefit?
|
||||
description: |
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
validations:
|
||||
required: false
|
||||
- type: input
|
||||
attributes:
|
||||
label: Are you interested in contributing this feature?
|
||||
description: Let us know if you want to write some code, and how we can help.
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Anything else?
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the feature you are suggesting!
|
||||
validations:
|
||||
required: false
|
||||
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
Normal file
23
.github/ISSUE_TEMPLATE/feature_request.md
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
---
|
||||
name: Feature request
|
||||
about: Suggest an idea for dbt
|
||||
title: ''
|
||||
labels: enhancement, triage
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Describe the feature
|
||||
A clear and concise description of what you want to happen.
|
||||
|
||||
### Describe alternatives you've considered
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
|
||||
### Additional context
|
||||
Is this feature database-specific? Which database(s) is/are relevant? Please include any other relevant context here.
|
||||
|
||||
### Who will this benefit?
|
||||
What kind of use case will this feature be useful for? Please be specific and provide examples, this will help us prioritize properly.
|
||||
|
||||
### Are you interested in contributing this feature?
|
||||
Let us know if you want to write some code, and how we can help.
|
||||
28
.github/ISSUE_TEMPLATE/final-minor-version-release.md
vendored
Normal file
28
.github/ISSUE_TEMPLATE/final-minor-version-release.md
vendored
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
name: Final minor version release
|
||||
about: Creates a tracking checklist of items for a final minor version release
|
||||
title: "[Tracking] v#.##.# final release "
|
||||
labels: 'release'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Release Core
|
||||
- [ ] [Engineering] Verify all necessary changes exist on the release branch
|
||||
- [ ] [Engineering] Follow [dbt-release workflow](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#03ff37da697d4d8ba63d24fae1bfa817)
|
||||
- [ ] [Product] Merge `next` into `current` for docs.getdbt.com
|
||||
|
||||
### Release Cloud
|
||||
- [ ] [Engineering] Create a platform issue to update dbt Cloud and verify it is completed. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Engineering] Determine if schemas have changed. If so, generate new schemas and push to schemas.getdbt.com
|
||||
|
||||
### Announce
|
||||
- [ ] [Product] Update discourse
|
||||
- [ ] [Product] Announce in dbt Slack
|
||||
|
||||
### Post-release
|
||||
- [ ] [Engineering] [Bump plugin versions](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#f01854e8da3641179fbcbe505bdf515c) (dbt-spark + dbt-presto), add compatibility as needed
|
||||
- [ ] [Spark](https://github.com/dbt-labs/dbt-spark)
|
||||
- [ ] [Presto](https://github.com/dbt-labs/dbt-presto)
|
||||
- [ ] [Engineering] Create a platform issue to update dbt-spark versions to dbt Cloud. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Product] Release new version of dbt-utils with new dbt version compatibility. If there are breaking changes requiring a minor version, plan upgrades of other packages that depend on dbt-utils.
|
||||
29
.github/ISSUE_TEMPLATE/rc-minor-version-release copy.md
vendored
Normal file
29
.github/ISSUE_TEMPLATE/rc-minor-version-release copy.md
vendored
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
name: RC minor version release
|
||||
about: Creates a tracking checklist of items for a RC minor version release
|
||||
title: "[Tracking] v#.##.#RC# release "
|
||||
labels: 'release'
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
### Release Core
|
||||
- [ ] [Engineering] Verify all necessary changes exist on the release branch
|
||||
- [ ] [Engineering] Follow [dbt-release workflow](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#03ff37da697d4d8ba63d24fae1bfa817)
|
||||
- [ ] [Product] Update migration guide (next.docs.getdbt.com)
|
||||
|
||||
### Release Cloud
|
||||
- [ ] [Engineering] Create a platform issue to update dbt Cloud and verify it is completed. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Engineering] Determine if schemas have changed. If so, generate new schemas and push to schemas.getdbt.com
|
||||
|
||||
### Announce
|
||||
- [ ] [Product] Publish discourse
|
||||
- [ ] [Product] Announce in dbt Slack
|
||||
|
||||
### Post-release
|
||||
- [ ] [Engineering] [Bump plugin versions](https://www.notion.so/dbtlabs/Releasing-b97c5ea9a02949e79e81db3566bbc8ef#f01854e8da3641179fbcbe505bdf515c) (dbt-spark + dbt-presto), add compatibility as needed
|
||||
- [ ] [Spark](https://github.com/dbt-labs/dbt-spark)
|
||||
- [ ] [Presto](https://github.com/dbt-labs/dbt-presto)
|
||||
- [ ] [Engineering] Create a platform issue to update dbt-spark versions to dbt Cloud. [Example issue](https://github.com/dbt-labs/dbt-cloud/issues/3481)
|
||||
- [ ] [Product] Release new version of dbt-utils with new dbt version compatibility. If there are breaking changes requiring a minor version, plan upgrades of other packages that depend on dbt-utils.
|
||||
- [ ] [Engineering] Create an epic for the final release
|
||||
15
.github/dependabot.yml
vendored
15
.github/dependabot.yml
vendored
@@ -11,11 +11,26 @@ updates:
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/bigquery"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/postgres"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/redshift"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/plugins/snowflake"
|
||||
schedule:
|
||||
interval: "daily"
|
||||
rebase-strategy: "disabled"
|
||||
|
||||
# docker dependencies
|
||||
- package-ecosystem: "docker"
|
||||
|
||||
10
.github/pull_request_template.md
vendored
10
.github/pull_request_template.md
vendored
@@ -4,18 +4,18 @@ resolves #
|
||||
Include the number of the issue addressed by this PR above if applicable.
|
||||
PRs for code changes without an associated issue *will not be merged*.
|
||||
See CONTRIBUTING.md for more information.
|
||||
|
||||
Example:
|
||||
resolves #1234
|
||||
-->
|
||||
|
||||
### Description
|
||||
|
||||
<!---
|
||||
Describe the Pull Request here. Add any references and info to help reviewers
|
||||
understand your changes. Include any tradeoffs you considered.
|
||||
-->
|
||||
<!--- Describe the Pull Request here -->
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change to the "dbt next" section.
|
||||
|
||||
2
.github/scripts/integration-test-matrix.js
vendored
2
.github/scripts/integration-test-matrix.js
vendored
@@ -1,7 +1,7 @@
|
||||
module.exports = ({ context }) => {
|
||||
const defaultPythonVersion = "3.8";
|
||||
const supportedPythonVersions = ["3.6", "3.7", "3.8", "3.9"];
|
||||
const supportedAdapters = ["postgres"];
|
||||
const supportedAdapters = ["snowflake", "postgres", "bigquery", "redshift"];
|
||||
|
||||
// if PR, generate matrix based on files changed and PR labels
|
||||
if (context.eventName.includes("pull_request")) {
|
||||
|
||||
46
.github/workflows/integration.yml
vendored
46
.github/workflows/integration.yml
vendored
@@ -91,6 +91,16 @@ jobs:
|
||||
- 'core/**'
|
||||
- 'plugins/postgres/**'
|
||||
- 'dev-requirements.txt'
|
||||
snowflake:
|
||||
- 'core/**'
|
||||
- 'plugins/snowflake/**'
|
||||
bigquery:
|
||||
- 'core/**'
|
||||
- 'plugins/bigquery/**'
|
||||
redshift:
|
||||
- 'core/**'
|
||||
- 'plugins/redshift/**'
|
||||
- 'plugins/postgres/**'
|
||||
|
||||
- name: Generate integration test matrix
|
||||
id: generate-matrix
|
||||
@@ -172,7 +182,7 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
@@ -181,6 +191,40 @@ jobs:
|
||||
if: matrix.adapter == 'postgres'
|
||||
run: tox
|
||||
|
||||
- name: Run tox (redshift)
|
||||
if: matrix.adapter == 'redshift'
|
||||
env:
|
||||
REDSHIFT_TEST_DBNAME: ${{ secrets.REDSHIFT_TEST_DBNAME }}
|
||||
REDSHIFT_TEST_PASS: ${{ secrets.REDSHIFT_TEST_PASS }}
|
||||
REDSHIFT_TEST_USER: ${{ secrets.REDSHIFT_TEST_USER }}
|
||||
REDSHIFT_TEST_PORT: ${{ secrets.REDSHIFT_TEST_PORT }}
|
||||
REDSHIFT_TEST_HOST: ${{ secrets.REDSHIFT_TEST_HOST }}
|
||||
run: tox
|
||||
|
||||
- name: Run tox (snowflake)
|
||||
if: matrix.adapter == 'snowflake'
|
||||
env:
|
||||
SNOWFLAKE_TEST_ACCOUNT: ${{ secrets.SNOWFLAKE_TEST_ACCOUNT }}
|
||||
SNOWFLAKE_TEST_PASSWORD: ${{ secrets.SNOWFLAKE_TEST_PASSWORD }}
|
||||
SNOWFLAKE_TEST_USER: ${{ secrets.SNOWFLAKE_TEST_USER }}
|
||||
SNOWFLAKE_TEST_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN: ${{ secrets.SNOWFLAKE_TEST_OAUTH_REFRESH_TOKEN }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_ID: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_ID }}
|
||||
SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET: ${{ secrets.SNOWFLAKE_TEST_OAUTH_CLIENT_SECRET }}
|
||||
SNOWFLAKE_TEST_ALT_DATABASE: ${{ secrets.SNOWFLAKE_TEST_ALT_DATABASE }}
|
||||
SNOWFLAKE_TEST_ALT_WAREHOUSE: ${{ secrets.SNOWFLAKE_TEST_ALT_WAREHOUSE }}
|
||||
SNOWFLAKE_TEST_DATABASE: ${{ secrets.SNOWFLAKE_TEST_DATABASE }}
|
||||
SNOWFLAKE_TEST_QUOTED_DATABASE: ${{ secrets.SNOWFLAKE_TEST_QUOTED_DATABASE }}
|
||||
SNOWFLAKE_TEST_ROLE: ${{ secrets.SNOWFLAKE_TEST_ROLE }}
|
||||
run: tox
|
||||
|
||||
- name: Run tox (bigquery)
|
||||
if: matrix.adapter == 'bigquery'
|
||||
env:
|
||||
BIGQUERY_TEST_SERVICE_ACCOUNT_JSON: ${{ secrets.BIGQUERY_TEST_SERVICE_ACCOUNT_JSON }}
|
||||
BIGQUERY_TEST_ALT_DATABASE: ${{ secrets.BIGQUERY_TEST_ALT_DATABASE }}
|
||||
run: tox
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
|
||||
8
.github/workflows/main.yml
vendored
8
.github/workflows/main.yml
vendored
@@ -61,7 +61,7 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
@@ -96,7 +96,7 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
@@ -133,7 +133,7 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
@@ -177,7 +177,7 @@ jobs:
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade pip
|
||||
pip install --upgrade wheel
|
||||
pip --version
|
||||
|
||||
|
||||
6
.github/workflows/performance.yml
vendored
6
.github/workflows/performance.yml
vendored
@@ -164,13 +164,11 @@ jobs:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: make results directory
|
||||
run: mkdir ./final-output/
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./ -o ./final-output/
|
||||
run: ./runner calculate -r ./
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final-output/*
|
||||
path: ./final_calculations.json
|
||||
|
||||
87
.github/workflows/schema-check.yml
vendored
87
.github/workflows/schema-check.yml
vendored
@@ -1,87 +0,0 @@
|
||||
# **what?**
|
||||
# Compares the schema of the dbt version of the given ref vs
|
||||
# the latest official schema releases found in schemas.getdbt.com.
|
||||
# If there are differences, the workflow will fail and upload the
|
||||
# diff as an artifact. The metadata team should be alerted to the change.
|
||||
#
|
||||
# **why?**
|
||||
# Reaction work may need to be done if artifact schema changes
|
||||
# occur so we want to proactively alert to it.
|
||||
#
|
||||
# **when?**
|
||||
# On pushes to `develop` and release branches. Manual runs are also enabled.
|
||||
name: Artifact Schema Check
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
pull_request: #TODO: remove before merging
|
||||
push:
|
||||
branches:
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
|
||||
env:
|
||||
LATEST_SCHEMA_PATH: ${{ github.workspace }}/new_schemas
|
||||
SCHEMA_DIFF_ARTIFACT: ${{ github.workspace }}//schema_schanges.txt
|
||||
DBT_REPO_DIRECTORY: ${{ github.workspace }}/dbt
|
||||
SCHEMA_REPO_DIRECTORY: ${{ github.workspace }}/schemas.getdbt.com
|
||||
|
||||
jobs:
|
||||
checking-schemas:
|
||||
name: "Checking schemas"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Checkout dbt repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
path: ${{ env.DBT_REPO_DIRECTORY }}
|
||||
|
||||
- name: Checkout schemas.getdbt.com repo
|
||||
uses: actions/checkout@v2.3.4
|
||||
with:
|
||||
repository: dbt-labs/schemas.getdbt.com
|
||||
ref: 'main'
|
||||
ssh-key: ${{ secrets.SCHEMA_SSH_PRIVATE_KEY }}
|
||||
path: ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
|
||||
- name: Generate current schema
|
||||
run: |
|
||||
cd ${{ env.DBT_REPO_DIRECTORY }}
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
python scripts/collect-artifact-schema.py --path ${{ env.LATEST_SCHEMA_PATH }}
|
||||
|
||||
# Copy generated schema files into the schemas.getdbt.com repo
|
||||
# Do a git diff to find any changes
|
||||
# Ignore any date or version changes though
|
||||
- name: Compare schemas
|
||||
run: |
|
||||
cp -r ${{ env.LATEST_SCHEMA_PATH }}/dbt ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
cd ${{ env.SCHEMA_REPO_DIRECTORY }}
|
||||
diff_results=$(git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' --compact-summary)
|
||||
if [[ $(echo diff_results) ]]; then
|
||||
echo $diff_results
|
||||
echo "Schema changes detected!"
|
||||
git diff -I='*[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])T' \
|
||||
-I='*[0-9]{1}.[0-9]{2}.[0-9]{1}(rc[0-9]|b[0-9]| )' > ${{ env.SCHEMA_DIFF_ARTIFACT }}
|
||||
exit 1
|
||||
else
|
||||
echo "No schema changes detected"
|
||||
fi
|
||||
|
||||
- name: Upload schema diff
|
||||
uses: actions/upload-artifact@v2.2.4
|
||||
if: ${{ failure() }}
|
||||
with:
|
||||
name: 'schema_schanges.txt'
|
||||
path: '${{ env.SCHEMA_DIFF_ARTIFACT }}'
|
||||
18
.github/workflows/stale.yml
vendored
18
.github/workflows/stale.yml
vendored
@@ -1,18 +0,0 @@
|
||||
name: "Close stale issues and PRs"
|
||||
on:
|
||||
schedule:
|
||||
- cron: "30 1 * * *"
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
# pinned at v4 (https://github.com/actions/stale/releases/tag/v4.0.0)
|
||||
- uses: actions/stale@cdf15f641adb27a71842045a94023bef6945e3aa
|
||||
with:
|
||||
stale-issue-message: "This issue has been marked as Stale because it has been open for 180 days with no activity. If you would like the issue to remain open, please remove the stale label or comment on the issue, or it will be closed in 7 days."
|
||||
stale-pr-message: "This PR has been marked as Stale because it has been open for 180 days with no activity. If you would like the PR to remain open, please remove the stale label or comment on the PR, or it will be closed in 7 days."
|
||||
# mark issues/PRs stale when they haven't seen activity in 180 days
|
||||
days-before-stale: 180
|
||||
# ignore checking issues with the following labels
|
||||
exempt-issue-labels: "epic,discussion"
|
||||
109
.github/workflows/version-bump.yml
vendored
109
.github/workflows/version-bump.yml
vendored
@@ -1,109 +0,0 @@
|
||||
# **what?**
|
||||
# This workflow will take a version number and a dry run flag. With that
|
||||
# it will run versionbump to update the version number everywhere in the
|
||||
# code base and then generate an update Docker requirements file. If this
|
||||
# is a dry run, a draft PR will open with the changes. If this isn't a dry
|
||||
# run, the changes will be committed to the branch this is run on.
|
||||
|
||||
# **why?**
|
||||
# This is to aid in releasing dbt and making sure we have updated
|
||||
# the versions and Docker requirements in all places.
|
||||
|
||||
# **when?**
|
||||
# This is triggered either manually OR
|
||||
# from the repository_dispatch event "version-bump" which is sent from
|
||||
# the dbt-release repo Action
|
||||
|
||||
name: Version Bump
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version_number:
|
||||
description: 'The version number to bump to'
|
||||
required: true
|
||||
is_dry_run:
|
||||
description: 'Creates a draft PR to allow testing instead of committing to a branch'
|
||||
required: true
|
||||
default: 'true'
|
||||
repository_dispatch:
|
||||
types: [version-bump]
|
||||
|
||||
jobs:
|
||||
bump:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set version and dry run values
|
||||
id: variables
|
||||
env:
|
||||
VERSION_NUMBER: "${{ github.event.client_payload.version_number == '' && github.event.inputs.version_number || github.event.client_payload.version_number }}"
|
||||
IS_DRY_RUN: "${{ github.event.client_payload.is_dry_run == '' && github.event.inputs.is_dry_run || github.event.client_payload.is_dry_run }}"
|
||||
run: |
|
||||
echo Repository dispatch event version: ${{ github.event.client_payload.version_number }}
|
||||
echo Repository dispatch event dry run: ${{ github.event.client_payload.is_dry_run }}
|
||||
echo Workflow dispatch event version: ${{ github.event.inputs.version_number }}
|
||||
echo Workflow dispatch event dry run: ${{ github.event.inputs.is_dry_run }}
|
||||
echo ::set-output name=VERSION_NUMBER::$VERSION_NUMBER
|
||||
echo ::set-output name=IS_DRY_RUN::$IS_DRY_RUN
|
||||
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
|
||||
- name: Create PR branch
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
run: |
|
||||
git checkout -b bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git push origin bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git branch --set-upstream-to=origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
|
||||
- name: Generate Docker requirements
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r requirements.txt
|
||||
pip freeze -l > docker/requirements/requirements.txt
|
||||
git status
|
||||
|
||||
- name: Bump version
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r dev-requirements.txt
|
||||
env/bin/bumpversion --allow-dirty --new-version ${{steps.variables.outputs.VERSION_NUMBER}} major
|
||||
git status
|
||||
|
||||
- name: Commit version bump directly
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'false' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
|
||||
- name: Commit version bump to branch
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
push: 'origin origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v3
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
||||
draft: true
|
||||
base: ${{github.ref}}
|
||||
title: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
@@ -1,9 +1,8 @@
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
The core function of dbt is SQL compilation and execution. Users create projects of dbt resources (models, tests, seeds, snapshots, ...), defined in SQL and YAML files, and they invoke dbt to create, update, or query associated views and tables. Today, dbt makes heavy use of Jinja2 to enable the templating of SQL, and to construct a DAG (Directed Acyclic Graph) from all of the resources in a project. Users can also extend their projects by installing resources (including Jinja macros) from other projects, called "packages."
|
||||
|
||||
## dbt-core
|
||||
|
||||
Most of the python code in the repository is within the `core/dbt` directory. Currently the main subdirectories are:
|
||||
|
||||
- [`adapters`](core/dbt/adapters): Define base classes for behavior that is likely to differ across databases
|
||||
- [`clients`](core/dbt/clients): Interface with dependencies (agate, jinja) or across operating systems
|
||||
- [`config`](core/dbt/config): Reconcile user-supplied configuration from connection profiles, project files, and Jinja macros
|
||||
@@ -13,20 +12,23 @@ Most of the python code in the repository is within the `core/dbt` directory. Cu
|
||||
- [`graph`](core/dbt/graph): Produce a `networkx` DAG of project resources, and selecting those resources given user-supplied criteria
|
||||
- [`include`](core/dbt/include): The dbt "global project," which defines default implementations of Jinja2 macros
|
||||
- [`parser`](core/dbt/parser): Read project files, validate, construct python objects
|
||||
- [`rpc`](core/dbt/rpc): Provide remote procedure call server for invoking dbt, following JSON-RPC 2.0 spec
|
||||
- [`task`](core/dbt/task): Set forth the actions that dbt can perform when invoked
|
||||
|
||||
### Invoking dbt
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
There are two supported ways of invoking dbt: from the command line and using an RPC server.
|
||||
|
||||
The "tasks" map to top-level dbt commands. So `dbt run` => task.run.RunTask, etc. Some are more like abstract base classes (GraphRunnableTask, for example) but all the concrete types outside of task/rpc should map to tasks. Currently one executes at a time. The tasks kick off their “Runners” and those do execute in parallel. The parallelism is managed via a thread pool, in GraphRunnableTask.
|
||||
|
||||
core/dbt/include/index.html
|
||||
This is the docs website code. It comes from the dbt-docs repository, and is generated when a release is packaged.
|
||||
|
||||
## Adapters
|
||||
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. For testing and development purposes, the dbt-postgres plugin lives alongside the dbt-core codebase, in the [`plugins`](plugins) subdirectory. Like other adapter plugins, it is a self-contained codebase and package that builds on top of dbt-core.
|
||||
dbt uses an adapter-plugin pattern to extend support to different databases, warehouses, query engines, etc. The four core adapters that are in the main repository, contained within the [`plugins`](plugins) subdirectory, are: Postgres Redshift, Snowflake and BigQuery. Other warehouses use adapter plugins defined in separate repositories (e.g. [dbt-spark](https://github.com/dbt-labs/dbt-spark), [dbt-presto](https://github.com/dbt-labs/dbt-presto)).
|
||||
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
Each adapter is a mix of python, Jinja2, and SQL. The adapter code also makes heavy use of Jinja2 to wrap modular chunks of SQL functionality, define default implementations, and allow plugins to override it.
|
||||
|
||||
Each adapter plugin is a standalone python package that includes:
|
||||
|
||||
|
||||
2265
CHANGELOG.md
2265
CHANGELOG.md
File diff suppressed because it is too large
Load Diff
@@ -14,10 +14,6 @@ This document is a guide intended for folks interested in contributing to `dbt`.
|
||||
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
#### Adapters
|
||||
|
||||
If you have an issue or code change suggestion related to a specific database [adapter](https://docs.getdbt.com/docs/available-adapters); please refer to that supported databases seperate repo for those contributions.
|
||||
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to `dbt` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt` codebase. If you are unable to sign the CLA, then the `dbt` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
@@ -28,7 +24,7 @@ Please note that all contributors to `dbt` must sign the [Contributor License Ag
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt-core/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
@@ -40,7 +36,7 @@ After you open an issue, a `dbt` maintainer will follow up by commenting on your
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The `dbt` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt-core/contribute) page.
|
||||
The `dbt` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
@@ -56,15 +52,15 @@ The `dbt` maintainers use labels to categorize open issues. Some labels indicate
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/dbt-labs/dbt-core/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt-core/labels/bug) | This issue represents a defect or regression in `dbt` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt-core/labels/enhancement) | This issue represents net-new functionality in `dbt` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt-core/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt-core/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt-core/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt-core/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt-core/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt-core/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt-core/labels/wontfix) | This issue does not require a code change in the `dbt` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
| [triage](https://github.com/dbt-labs/dbt/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt/labels/bug) | This issue represents a defect or regression in `dbt` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt/labels/enhancement) | This issue represents net-new functionality in `dbt` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt/labels/wontfix) | This issue does not require a code change in the `dbt` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
@@ -72,7 +68,7 @@ The `dbt` maintainers use labels to categorize open issues. Some labels indicate
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `develop` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk branch or a specific release branch.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk brnach or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
@@ -107,7 +103,7 @@ A short list of tools used in `dbt` testing that will be helpful to your underst
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [Github Actions](https://github.com/features/actions)
|
||||
- [CircleCI](https://circleci.com/product/) and [Azure Pipelines](https://azure.microsoft.com/en-us/services/devops/pipelines/)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
@@ -139,7 +135,7 @@ brew install postgresql
|
||||
|
||||
### Installation
|
||||
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Also ensure you have the latest version of pip installed with `pip install --upgrade pip`. Next, install `dbt` (and its dependencies) with:
|
||||
First make sure that you set up your `virtualenv` as described in [Setting up an environment](#setting-up-an-environment). Next, install `dbt` (and its dependencies) with:
|
||||
|
||||
```sh
|
||||
make dev
|
||||
@@ -159,7 +155,7 @@ Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as
|
||||
|
||||
Getting the `dbt` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
Although `dbt` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead you can test all dbt-core code changes with Python and Postgres.
|
||||
Since `dbt` works with a number of different databases, you will need to supply credentials for one or more of these databases in your test environment. Most organizations don't have access to each of a BigQuery, Redshift, Snowflake, and Postgres database, so it's likely that you will be unable to run every integration test locally. Fortunately, dbt Labs provides a CI environment with access to sandboxed Redshift, Snowflake, BigQuery, and Postgres databases. See the section on [_Submitting a Pull Request_](#submitting-a-pull-request) below for more information on this CI setup.
|
||||
|
||||
### Initial setup
|
||||
|
||||
@@ -228,7 +224,7 @@ python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
## Submitting a Pull Request
|
||||
|
||||
dbt Labs provides a CI environment to test changes to specific adapters, and periodic maintenance checks of `dbt-core` through Github Actions. For example, if you submit a pull request to the `dbt-redshift` repo, GitHub will trigger automated code checks and tests against Redshift.
|
||||
dbt Labs provides a sandboxed Redshift, Snowflake, and BigQuery database for use in a CI environment. When pull requests are submitted to the `dbt-labs/dbt` repo, GitHub will trigger automated tests in CircleCI and Azure Pipelines.
|
||||
|
||||
A `dbt` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
|
||||
|
||||
@@ -27,7 +27,7 @@ RUN apt-get update \
|
||||
&& apt-get install -y \
|
||||
python \
|
||||
python-dev \
|
||||
python3-pip \
|
||||
python-pip \
|
||||
python3.6 \
|
||||
python3.6-dev \
|
||||
python3-pip \
|
||||
|
||||
24
Makefile
24
Makefile
@@ -44,6 +44,30 @@ integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: integration-redshift
|
||||
integration-redshift: .env ## Runs redshift integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -nauto
|
||||
|
||||
.PHONY: integration-redshift-fail-fast
|
||||
integration-redshift-fail-fast: .env ## Runs redshift integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-redshift -- -x -nauto
|
||||
|
||||
.PHONY: integration-snowflake
|
||||
integration-snowflake: .env ## Runs snowflake integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -nauto
|
||||
|
||||
.PHONY: integration-snowflake-fail-fast
|
||||
integration-snowflake-fail-fast: .env ## Runs snowflake integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-snowflake -- -x -nauto
|
||||
|
||||
.PHONY: integration-bigquery
|
||||
integration-bigquery: .env ## Runs bigquery integration tests with py38.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -nauto
|
||||
|
||||
.PHONY: integration-bigquery-fail-fast
|
||||
integration-bigquery-fail-fast: .env ## Runs bigquery integration tests with py38 in "fail fast" mode.
|
||||
$(DOCKER_CMD) tox -e py38-bigquery -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
docker-compose up -d database
|
||||
|
||||
18
README.md
18
README.md
@@ -1,18 +1,18 @@
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt-core/fa1ea14ddfb1d5ae319d5141844910dd53ab2834/etc/dbt-core.svg" alt="dbt logo" width="750"/>
|
||||
<img src="https://raw.githubusercontent.com/dbt-labs/dbt/ec7dee39f793aa4f7dd3dae37282cc87664813e4/etc/dbt-logo-full.svg" alt="dbt logo" width="500"/>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
<a href="https://github.com/dbt-labs/dbt/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
<a href="https://github.com/dbt-labs/dbt/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||
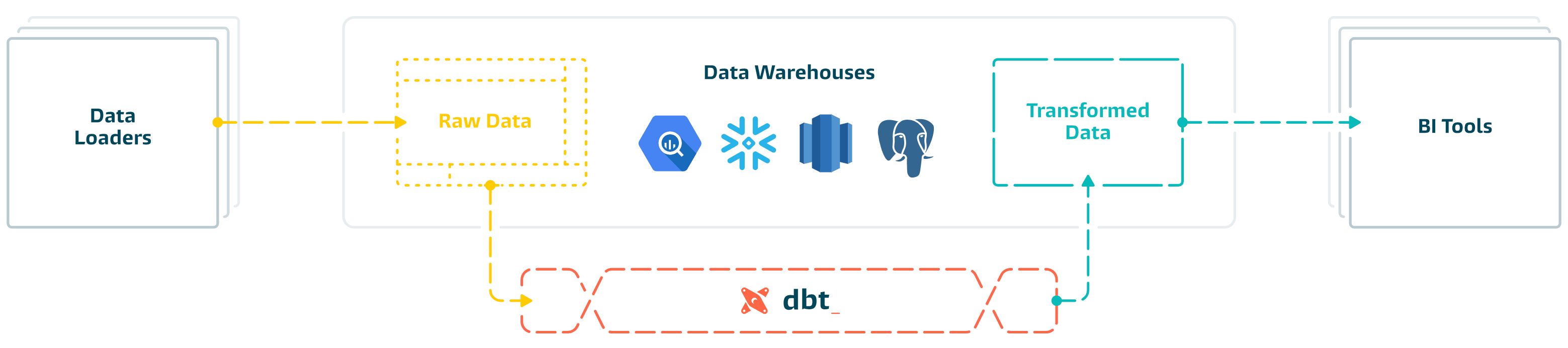
|
||||
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
@@ -20,7 +20,7 @@ Analysts using dbt can transform their data by simply writing select statements,
|
||||
|
||||
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to [manage relationships](https://docs.getdbt.com/docs/ref) between models, and [visualize these relationships](https://docs.getdbt.com/docs/documentation), as well as assure the quality of your transformations through [testing](https://docs.getdbt.com/docs/testing).
|
||||
|
||||
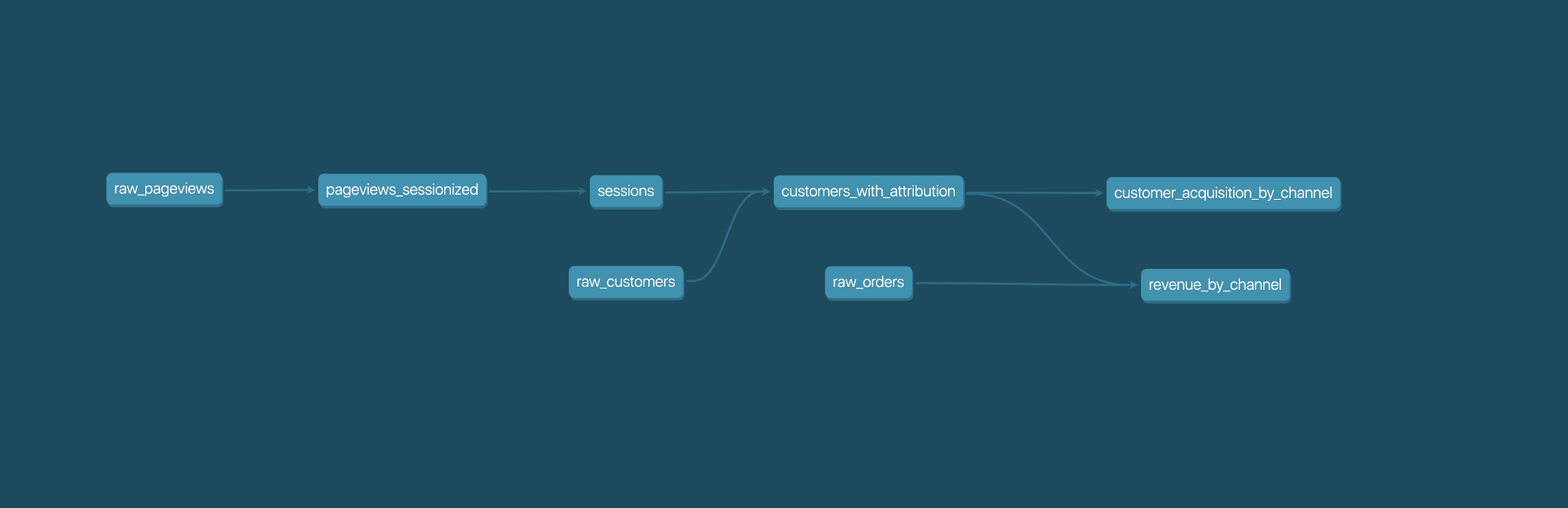
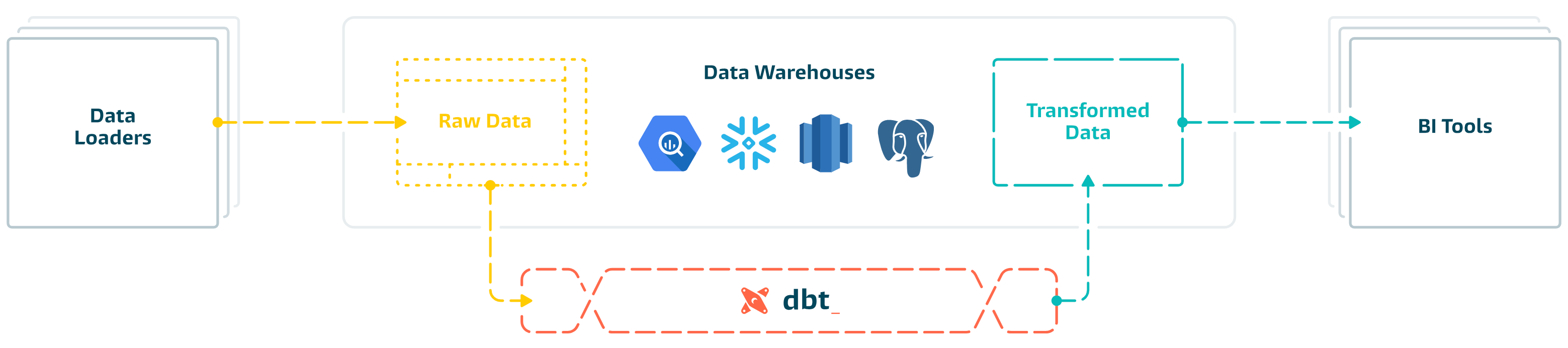
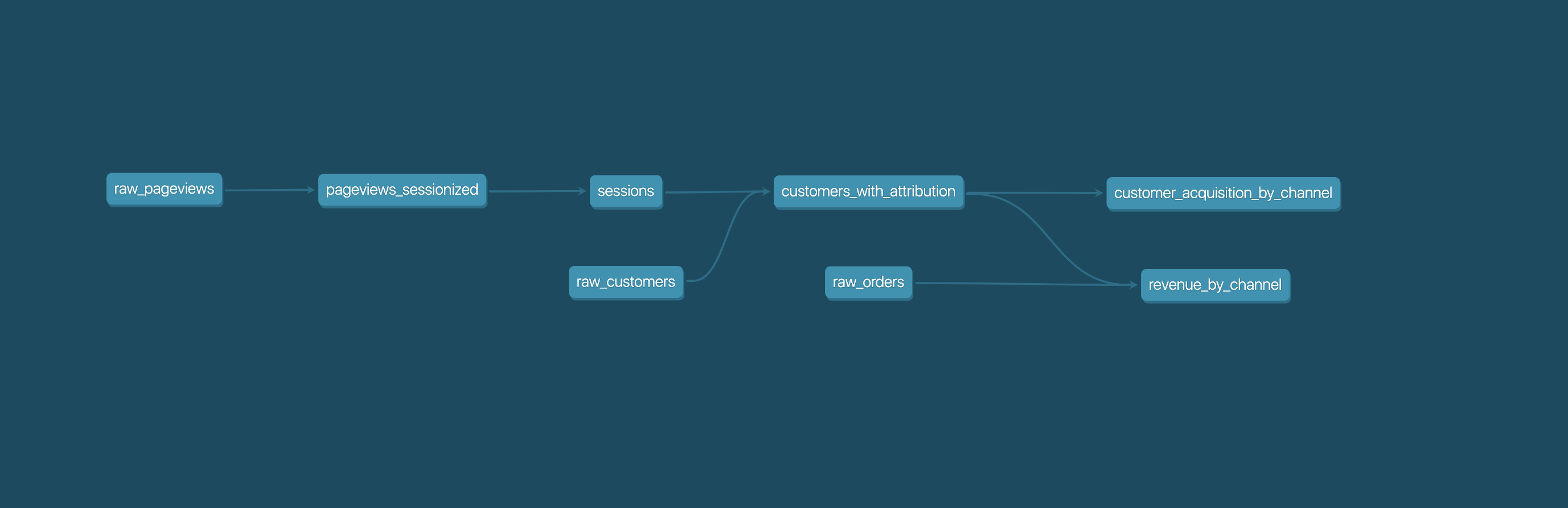
|
||||
|
||||
|
||||
## Getting started
|
||||
|
||||
@@ -34,8 +34,8 @@ These select statements, or "models", form a dbt project. Models frequently buil
|
||||
|
||||
## Reporting bugs and contributing code
|
||||
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt-core/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt-core/blob/HEAD/CONTRIBUTING.md)
|
||||
- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/dbt-labs/dbt/issues/new)
|
||||
- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/dbt-labs/dbt/blob/HEAD/CONTRIBUTING.md)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
@@ -238,6 +238,12 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@classmethod
|
||||
def _rollback(cls, connection: Connection) -> None:
|
||||
"""Roll back the given connection."""
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In _rollback, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'Tried to rollback transaction on connection '
|
||||
@@ -251,6 +257,12 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
|
||||
@classmethod
|
||||
def close(cls, connection: Connection) -> Connection:
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In close, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
# if the connection is in closed or init, there's nothing to do
|
||||
if connection.state in {ConnectionState.CLOSED, ConnectionState.INIT}:
|
||||
return connection
|
||||
|
||||
@@ -16,7 +16,9 @@ from dbt.exceptions import (
|
||||
get_relation_returned_multiple_results,
|
||||
InternalException, NotImplementedException, RuntimeException,
|
||||
)
|
||||
from dbt import flags
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.adapters.protocol import (
|
||||
AdapterConfig,
|
||||
ConnectionManagerProtocol,
|
||||
@@ -287,7 +289,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def _schema_is_cached(self, database: Optional[str], schema: str) -> bool:
|
||||
"""Check if the schema is cached, and by default logs if it is not."""
|
||||
|
||||
if (database, schema) not in self.cache:
|
||||
if flags.USE_CACHE is False:
|
||||
return False
|
||||
elif (database, schema) not in self.cache:
|
||||
logger.debug(
|
||||
'On "{}": cache miss for schema "{}.{}", this is inefficient'
|
||||
.format(self.nice_connection_name(), database, schema)
|
||||
@@ -320,9 +324,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
info_schema_name_map = SchemaSearchMap()
|
||||
nodes: Iterator[CompileResultNode] = chain(
|
||||
[node for node in manifest.nodes.values() if (
|
||||
node.is_relational and not node.is_ephemeral_model
|
||||
)],
|
||||
manifest.nodes.values(),
|
||||
manifest.sources.values(),
|
||||
)
|
||||
for node in nodes:
|
||||
@@ -338,6 +340,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""Populate the relations cache for the given schemas. Returns an
|
||||
iterable of the schemas populated, as strings.
|
||||
"""
|
||||
if not flags.USE_CACHE:
|
||||
return
|
||||
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
with executor(self.config) as tpe:
|
||||
futures: List[Future[List[BaseRelation]]] = []
|
||||
@@ -370,6 +375,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""Run a query that gets a populated cache of the relations in the
|
||||
database and set the cache on this adapter.
|
||||
"""
|
||||
if not flags.USE_CACHE:
|
||||
return
|
||||
|
||||
with self.cache.lock:
|
||||
if clear:
|
||||
self.cache.clear()
|
||||
@@ -383,7 +391,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise_compiler_error(
|
||||
'Attempted to cache a null relation for {}'.format(name)
|
||||
)
|
||||
self.cache.add(relation)
|
||||
if flags.USE_CACHE:
|
||||
self.cache.add(relation)
|
||||
# so jinja doesn't render things
|
||||
return ''
|
||||
|
||||
@@ -397,7 +406,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise_compiler_error(
|
||||
'Attempted to drop a null relation for {}'.format(name)
|
||||
)
|
||||
self.cache.drop(relation)
|
||||
if flags.USE_CACHE:
|
||||
self.cache.drop(relation)
|
||||
return ''
|
||||
|
||||
@available
|
||||
@@ -418,7 +428,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
.format(src_name, dst_name, name)
|
||||
)
|
||||
|
||||
self.cache.rename(from_relation, to_relation)
|
||||
if flags.USE_CACHE:
|
||||
self.cache.rename(from_relation, to_relation)
|
||||
return ''
|
||||
|
||||
###
|
||||
@@ -796,11 +807,12 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
def quote_seed_column(
|
||||
self, column: str, quote_config: Optional[bool]
|
||||
) -> str:
|
||||
quote_columns: bool = True
|
||||
# this is the default for now
|
||||
quote_columns: bool = False
|
||||
if isinstance(quote_config, bool):
|
||||
quote_columns = quote_config
|
||||
elif quote_config is None:
|
||||
pass
|
||||
deprecations.warn('column-quoting-unset')
|
||||
else:
|
||||
raise_compiler_error(
|
||||
f'The seed configuration value of "quote_columns" has an '
|
||||
@@ -932,6 +944,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
project: Optional[str] = None,
|
||||
context_override: Optional[Dict[str, Any]] = None,
|
||||
kwargs: Dict[str, Any] = None,
|
||||
release: bool = False,
|
||||
text_only_columns: Optional[Iterable[str]] = None,
|
||||
) -> agate.Table:
|
||||
"""Look macro_name up in the manifest and execute its results.
|
||||
@@ -945,8 +958,10 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
execution context.
|
||||
:param kwargs: An optional dict of keyword args used to pass to the
|
||||
macro.
|
||||
:param release: Ignored.
|
||||
"""
|
||||
|
||||
if release is not False:
|
||||
deprecations.warn('execute-macro-release')
|
||||
if kwargs is None:
|
||||
kwargs = {}
|
||||
if context_override is None:
|
||||
|
||||
@@ -11,6 +11,7 @@ from dbt.contracts.connection import (
|
||||
Connection, ConnectionState, AdapterResponse
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt import flags
|
||||
|
||||
|
||||
class SQLConnectionManager(BaseConnectionManager):
|
||||
@@ -143,6 +144,13 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def begin(self):
|
||||
connection = self.get_thread_connection()
|
||||
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In begin, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is True:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to begin a new transaction on connection "{}", but '
|
||||
@@ -155,6 +163,12 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def commit(self):
|
||||
connection = self.get_thread_connection()
|
||||
if flags.STRICT_MODE:
|
||||
if not isinstance(connection, Connection):
|
||||
raise dbt.exceptions.CompilerException(
|
||||
f'In commit, got {connection} - not a Connection!'
|
||||
)
|
||||
|
||||
if connection.transaction_open is False:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Tried to commit transaction on connection "{}", but '
|
||||
|
||||
26
core/dbt/clients/gcloud.py
Normal file
26
core/dbt/clients/gcloud.py
Normal file
@@ -0,0 +1,26 @@
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.exceptions
|
||||
from dbt.clients.system import run_cmd
|
||||
|
||||
NOT_INSTALLED_MSG = """
|
||||
dbt requires the gcloud SDK to be installed to authenticate with BigQuery.
|
||||
Please download and install the SDK, or use a Service Account instead.
|
||||
|
||||
https://cloud.google.com/sdk/
|
||||
"""
|
||||
|
||||
|
||||
def gcloud_installed():
|
||||
try:
|
||||
run_cmd('.', ['gcloud', '--version'])
|
||||
return True
|
||||
except OSError as e:
|
||||
logger.debug(e)
|
||||
return False
|
||||
|
||||
|
||||
def setup_default_credentials():
|
||||
if gcloud_installed():
|
||||
run_cmd('.', ["gcloud", "auth", "application-default", "login"])
|
||||
else:
|
||||
raise dbt.exceptions.RuntimeException(NOT_INSTALLED_MSG)
|
||||
@@ -25,8 +25,8 @@ from dbt.utils import (
|
||||
)
|
||||
|
||||
from dbt.clients._jinja_blocks import BlockIterator, BlockData, BlockTag
|
||||
from dbt.contracts.graph.compiled import CompiledGenericTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedGenericTestNode
|
||||
from dbt.contracts.graph.compiled import CompiledSchemaTestNode
|
||||
from dbt.contracts.graph.parsed import ParsedSchemaTestNode
|
||||
from dbt.exceptions import (
|
||||
InternalException, raise_compiler_error, CompilationException,
|
||||
invalid_materialization_argument, MacroReturn, JinjaRenderingException,
|
||||
@@ -627,12 +627,12 @@ def extract_toplevel_blocks(
|
||||
)
|
||||
|
||||
|
||||
GENERIC_TEST_KWARGS_NAME = '_dbt_generic_test_kwargs'
|
||||
SCHEMA_TEST_KWARGS_NAME = '_dbt_schema_test_kwargs'
|
||||
|
||||
|
||||
def add_rendered_test_kwargs(
|
||||
context: Dict[str, Any],
|
||||
node: Union[ParsedGenericTestNode, CompiledGenericTestNode],
|
||||
node: Union[ParsedSchemaTestNode, CompiledSchemaTestNode],
|
||||
capture_macros: bool = False,
|
||||
) -> None:
|
||||
"""Render each of the test kwargs in the given context using the native
|
||||
@@ -662,4 +662,4 @@ def add_rendered_test_kwargs(
|
||||
return value
|
||||
|
||||
kwargs = deep_map(_convert_function, node.test_metadata.kwargs)
|
||||
context[GENERIC_TEST_KWARGS_NAME] = kwargs
|
||||
context[SCHEMA_TEST_KWARGS_NAME] = kwargs
|
||||
|
||||
@@ -96,6 +96,7 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
possible_macro_calls.append(func_name)
|
||||
|
||||
# packages positional argument
|
||||
packages = None
|
||||
macro_namespace = None
|
||||
packages_arg = None
|
||||
packages_arg_type = None
|
||||
@@ -108,7 +109,13 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
# keyword arguments
|
||||
if func_call.kwargs:
|
||||
for kwarg in func_call.kwargs:
|
||||
if kwarg.key == 'macro_name':
|
||||
if kwarg.key == 'packages':
|
||||
# The packages keyword will be deprecated and
|
||||
# eventually removed
|
||||
packages_arg = kwarg.value
|
||||
# This can be a List or a Call
|
||||
packages_arg_type = type(kwarg.value).__name__
|
||||
elif kwarg.key == 'macro_name':
|
||||
# This will remain to enable static resolution
|
||||
if type(kwarg.value).__name__ == 'Const':
|
||||
func_name = kwarg.value.value
|
||||
@@ -135,10 +142,63 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
elif packages_arg_type == 'Const':
|
||||
# This will remain to enable static resolution
|
||||
macro_namespace = packages_arg.value
|
||||
elif packages_arg_type == 'Call':
|
||||
# This is deprecated and should be removed eventually.
|
||||
# It is here to support (hackily) common ways of providing
|
||||
# a packages list to adapter.dispatch
|
||||
if (hasattr(packages_arg, 'node') and
|
||||
hasattr(packages_arg.node, 'node') and
|
||||
hasattr(packages_arg.node.node, 'name') and
|
||||
hasattr(packages_arg.node, 'attr')):
|
||||
package_name = packages_arg.node.node.name
|
||||
macro_name = packages_arg.node.attr
|
||||
if (macro_name.startswith('_get') and 'namespaces' in macro_name):
|
||||
# noqa: https://github.com/dbt-labs/dbt-utils/blob/9e9407b/macros/cross_db_utils/_get_utils_namespaces.sql
|
||||
var_name = f'{package_name}_dispatch_list'
|
||||
# hard code compatibility for fivetran_utils, just a teensy bit different
|
||||
# noqa: https://github.com/fivetran/dbt_fivetran_utils/blob/0978ba2/macros/_get_utils_namespaces.sql
|
||||
if package_name == 'fivetran_utils':
|
||||
default_packages = ['dbt_utils', 'fivetran_utils']
|
||||
else:
|
||||
default_packages = [package_name]
|
||||
|
||||
namespace_names = get_dispatch_list(ctx, var_name, default_packages)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
else:
|
||||
msg = (
|
||||
f"As of v0.19.2, custom macros, such as '{macro_name}', are no longer "
|
||||
"supported in the 'packages' argument of 'adapter.dispatch()'.\n"
|
||||
f"See https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch "
|
||||
"for details."
|
||||
).strip()
|
||||
raise_compiler_error(msg)
|
||||
elif packages_arg_type == 'Add':
|
||||
# This logic is for when there is a variable and an addition of a list,
|
||||
# like: packages = (var('local_utils_dispatch_list', []) + ['local_utils2'])
|
||||
# This is deprecated and should be removed eventually.
|
||||
namespace_var = None
|
||||
default_namespaces = []
|
||||
# This might be a single call or it might be the 'left' piece in an addition
|
||||
for var_call in packages_arg.find_all(jinja2.nodes.Call):
|
||||
if (hasattr(var_call, 'node') and
|
||||
var_call.node.name == 'var' and
|
||||
hasattr(var_call, 'args')):
|
||||
namespace_var = var_call.args[0].value
|
||||
if hasattr(packages_arg, 'right'): # we have a default list of namespaces
|
||||
for item in packages_arg.right.items:
|
||||
default_namespaces.append(item.value)
|
||||
if namespace_var:
|
||||
namespace_names = get_dispatch_list(ctx, namespace_var, default_namespaces)
|
||||
packages = []
|
||||
if namespace_names:
|
||||
packages.extend(namespace_names)
|
||||
|
||||
if db_wrapper:
|
||||
macro = db_wrapper.dispatch(
|
||||
func_name,
|
||||
packages=packages,
|
||||
macro_namespace=macro_namespace
|
||||
).macro
|
||||
func_name = f'{macro.package_name}.{macro.name}'
|
||||
@@ -146,9 +206,20 @@ def statically_parse_adapter_dispatch(func_call, ctx, db_wrapper):
|
||||
else: # this is only for test/unit/test_macro_calls.py
|
||||
if macro_namespace:
|
||||
packages = [macro_namespace]
|
||||
else:
|
||||
if packages is None:
|
||||
packages = []
|
||||
for package_name in packages:
|
||||
possible_macro_calls.append(f'{package_name}.{func_name}')
|
||||
|
||||
return possible_macro_calls
|
||||
|
||||
|
||||
def get_dispatch_list(ctx, var_name, default_packages):
|
||||
namespace_list = None
|
||||
try:
|
||||
# match the logic currently used in package _get_namespaces() macro
|
||||
namespace_list = ctx['var'](var_name) + default_packages
|
||||
except Exception:
|
||||
pass
|
||||
namespace_list = namespace_list if namespace_list else default_packages
|
||||
return namespace_list
|
||||
|
||||
@@ -30,7 +30,7 @@ def find_matching(
|
||||
root_path: str,
|
||||
relative_paths_to_search: List[str],
|
||||
file_pattern: str,
|
||||
) -> List[Dict[str, Any]]:
|
||||
) -> List[Dict[str, str]]:
|
||||
"""
|
||||
Given an absolute `root_path`, a list of relative paths to that
|
||||
absolute root path (`relative_paths_to_search`), and a `file_pattern`
|
||||
@@ -61,19 +61,11 @@ def find_matching(
|
||||
relative_path = os.path.relpath(
|
||||
absolute_path, absolute_path_to_search
|
||||
)
|
||||
modification_time = 0.0
|
||||
try:
|
||||
modification_time = os.path.getmtime(absolute_path)
|
||||
except OSError:
|
||||
logger.exception(
|
||||
f"Error retrieving modification time for file {absolute_path}"
|
||||
)
|
||||
if reobj.match(local_file):
|
||||
matching.append({
|
||||
'searched_path': relative_path_to_search,
|
||||
'absolute_path': absolute_path,
|
||||
'relative_path': relative_path,
|
||||
'modification_time': modification_time,
|
||||
})
|
||||
|
||||
return matching
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
import dbt.exceptions
|
||||
from typing import Any, Dict, Optional
|
||||
import yaml
|
||||
import yaml.scanner
|
||||
|
||||
# the C version is faster, but it doesn't always exist
|
||||
try:
|
||||
|
||||
@@ -10,10 +10,10 @@ from dbt.adapters.factory import get_adapter
|
||||
from dbt.clients import jinja
|
||||
from dbt.clients.system import make_directory
|
||||
from dbt.context.providers import generate_runtime_model
|
||||
from dbt.contracts.graph.manifest import Manifest, UniqueID
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.graph.compiled import (
|
||||
COMPILED_TYPES,
|
||||
CompiledGenericTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
GraphMemberNode,
|
||||
InjectedCTE,
|
||||
ManifestNode,
|
||||
@@ -107,19 +107,6 @@ def _extend_prepended_ctes(prepended_ctes, new_prepended_ctes):
|
||||
_add_prepended_cte(prepended_ctes, new_cte)
|
||||
|
||||
|
||||
def _get_tests_for_node(manifest: Manifest, unique_id: UniqueID) -> List[UniqueID]:
|
||||
""" Get a list of tests that depend on the node with the
|
||||
provided unique id """
|
||||
|
||||
tests = []
|
||||
if unique_id in manifest.child_map:
|
||||
for child_unique_id in manifest.child_map[unique_id]:
|
||||
if child_unique_id.startswith('test.'):
|
||||
tests.append(child_unique_id)
|
||||
|
||||
return tests
|
||||
|
||||
|
||||
class Linker:
|
||||
def __init__(self, data=None):
|
||||
if data is None:
|
||||
@@ -155,7 +142,7 @@ class Linker:
|
||||
include all nodes in their corresponding graph entries.
|
||||
"""
|
||||
out_graph = self.graph.copy()
|
||||
for node_id in self.graph:
|
||||
for node_id in self.graph.nodes():
|
||||
data = manifest.expect(node_id).to_dict(omit_none=True)
|
||||
out_graph.add_node(node_id, **data)
|
||||
nx.write_gpickle(out_graph, outfile)
|
||||
@@ -167,7 +154,7 @@ class Compiler:
|
||||
|
||||
def initialize(self):
|
||||
make_directory(self.config.target_path)
|
||||
make_directory(self.config.packages_install_path)
|
||||
make_directory(self.config.modules_path)
|
||||
|
||||
# creates a ModelContext which is converted to
|
||||
# a dict for jinja rendering of SQL
|
||||
@@ -182,7 +169,7 @@ class Compiler:
|
||||
node, self.config, manifest
|
||||
)
|
||||
context.update(extra_context)
|
||||
if isinstance(node, CompiledGenericTestNode):
|
||||
if isinstance(node, CompiledSchemaTestNode):
|
||||
# for test nodes, add a special keyword args value to the context
|
||||
jinja.add_rendered_test_kwargs(context, node)
|
||||
|
||||
@@ -425,82 +412,13 @@ class Compiler:
|
||||
self.link_node(linker, node, manifest)
|
||||
for exposure in manifest.exposures.values():
|
||||
self.link_node(linker, exposure, manifest)
|
||||
# linker.add_node(exposure.unique_id)
|
||||
|
||||
cycle = linker.find_cycles()
|
||||
|
||||
if cycle:
|
||||
raise RuntimeError("Found a cycle: {}".format(cycle))
|
||||
|
||||
manifest.build_parent_and_child_maps()
|
||||
|
||||
self.resolve_graph(linker, manifest)
|
||||
|
||||
def resolve_graph(self, linker: Linker, manifest: Manifest) -> None:
|
||||
""" This method adds additional edges to the DAG. For a given non-test
|
||||
executable node, add an edge from an upstream test to the given node if
|
||||
the set of nodes the test depends on is a proper/strict subset of the
|
||||
upstream nodes for the given node. """
|
||||
|
||||
# Given a graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | |
|
||||
# | \/
|
||||
# \/ test 2
|
||||
# test1
|
||||
#
|
||||
# Produce the following graph:
|
||||
# model1 --> model2 --> model3
|
||||
# | | /\ /\
|
||||
# | \/ | |
|
||||
# \/ test2 ------- |
|
||||
# test1 -------------------
|
||||
|
||||
for node_id in linker.graph:
|
||||
# If node is executable (in manifest.nodes) and does _not_
|
||||
# represent a test, continue.
|
||||
if (
|
||||
node_id in manifest.nodes and
|
||||
manifest.nodes[node_id].resource_type != NodeType.Test
|
||||
):
|
||||
# Get *everything* upstream of the node
|
||||
all_upstream_nodes = nx.traversal.bfs_tree(
|
||||
linker.graph, node_id, reverse=True
|
||||
)
|
||||
# Get the set of upstream nodes not including the current node.
|
||||
upstream_nodes = set([
|
||||
n for n in all_upstream_nodes if n != node_id
|
||||
])
|
||||
|
||||
# Get all tests that depend on any upstream nodes.
|
||||
upstream_tests = []
|
||||
for upstream_node in upstream_nodes:
|
||||
upstream_tests += _get_tests_for_node(
|
||||
manifest,
|
||||
upstream_node
|
||||
)
|
||||
|
||||
for upstream_test in upstream_tests:
|
||||
# Get the set of all nodes that the test depends on
|
||||
# including the upstream_node itself. This is necessary
|
||||
# because tests can depend on multiple nodes (ex:
|
||||
# relationship tests). Test nodes do not distinguish
|
||||
# between what node the test is "testing" and what
|
||||
# node(s) it depends on.
|
||||
test_depends_on = set(
|
||||
manifest.nodes[upstream_test].depends_on_nodes
|
||||
)
|
||||
|
||||
# If the set of nodes that an upstream test depends on
|
||||
# is a proper (or strict) subset of all upstream nodes of
|
||||
# the current node, add an edge from the upstream test
|
||||
# to the current node. Must be a proper/strict subset to
|
||||
# avoid adding a circular dependency to the graph.
|
||||
if (test_depends_on < upstream_nodes):
|
||||
linker.graph.add_edge(
|
||||
upstream_test,
|
||||
node_id
|
||||
)
|
||||
|
||||
def compile(self, manifest: Manifest, write=True) -> Graph:
|
||||
self.initialize()
|
||||
linker = Linker()
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# all these are just exports, they need "noqa" so flake8 will not complain.
|
||||
from .profile import Profile, read_user_config # noqa
|
||||
from .profile import Profile, PROFILES_DIR, read_user_config # noqa
|
||||
from .project import Project, IsFQNResource # noqa
|
||||
from .runtime import RuntimeConfig, UnsetProfileConfig # noqa
|
||||
|
||||
@@ -4,7 +4,6 @@ import os
|
||||
|
||||
from dbt.dataclass_schema import ValidationError
|
||||
|
||||
from dbt import flags
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.clients.yaml_helper import load_yaml_text
|
||||
from dbt.contracts.connection import Credentials, HasCredentials
|
||||
@@ -21,8 +20,10 @@ from dbt.utils import coerce_dict_str
|
||||
from .renderer import ProfileRenderer
|
||||
|
||||
DEFAULT_THREADS = 1
|
||||
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser('~'), '.dbt')
|
||||
PROFILES_DIR = os.path.expanduser(
|
||||
os.getenv('DBT_PROFILES_DIR', DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
INVALID_PROFILE_MESSAGE = """
|
||||
dbt encountered an error while trying to read your profiles.yml file.
|
||||
@@ -42,7 +43,7 @@ Here, [profile name] should be replaced with a profile name
|
||||
defined in your profiles.yml file. You can find profiles.yml here:
|
||||
|
||||
{profiles_file}/profiles.yml
|
||||
""".format(profiles_file=DEFAULT_PROFILES_DIR)
|
||||
""".format(profiles_file=PROFILES_DIR)
|
||||
|
||||
|
||||
def read_profile(profiles_dir: str) -> Dict[str, Any]:
|
||||
@@ -72,10 +73,10 @@ def read_user_config(directory: str) -> UserConfig:
|
||||
try:
|
||||
profile = read_profile(directory)
|
||||
if profile:
|
||||
user_config = coerce_dict_str(profile.get('config', {}))
|
||||
if user_config is not None:
|
||||
UserConfig.validate(user_config)
|
||||
return UserConfig.from_dict(user_config)
|
||||
user_cfg = coerce_dict_str(profile.get('config', {}))
|
||||
if user_cfg is not None:
|
||||
UserConfig.validate(user_cfg)
|
||||
return UserConfig.from_dict(user_cfg)
|
||||
except (RuntimeException, ValidationError):
|
||||
pass
|
||||
return UserConfig()
|
||||
@@ -88,7 +89,7 @@ def read_user_config(directory: str) -> UserConfig:
|
||||
class Profile(HasCredentials):
|
||||
profile_name: str
|
||||
target_name: str
|
||||
user_config: UserConfig
|
||||
config: UserConfig
|
||||
threads: int
|
||||
credentials: Credentials
|
||||
|
||||
@@ -96,7 +97,7 @@ class Profile(HasCredentials):
|
||||
self,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_config: UserConfig,
|
||||
config: UserConfig,
|
||||
threads: int,
|
||||
credentials: Credentials
|
||||
):
|
||||
@@ -105,7 +106,7 @@ class Profile(HasCredentials):
|
||||
"""
|
||||
self.profile_name = profile_name
|
||||
self.target_name = target_name
|
||||
self.user_config = user_config
|
||||
self.config = config
|
||||
self.threads = threads
|
||||
self.credentials = credentials
|
||||
|
||||
@@ -123,12 +124,12 @@ class Profile(HasCredentials):
|
||||
result = {
|
||||
'profile_name': self.profile_name,
|
||||
'target_name': self.target_name,
|
||||
'user_config': self.user_config,
|
||||
'config': self.config,
|
||||
'threads': self.threads,
|
||||
'credentials': self.credentials,
|
||||
}
|
||||
if serialize_credentials:
|
||||
result['user_config'] = self.user_config.to_dict(omit_none=True)
|
||||
result['config'] = self.config.to_dict(omit_none=True)
|
||||
result['credentials'] = self.credentials.to_dict(omit_none=True)
|
||||
return result
|
||||
|
||||
@@ -142,7 +143,7 @@ class Profile(HasCredentials):
|
||||
'name': self.target_name,
|
||||
'target_name': self.target_name,
|
||||
'profile_name': self.profile_name,
|
||||
'config': self.user_config.to_dict(omit_none=True),
|
||||
'config': self.config.to_dict(omit_none=True),
|
||||
})
|
||||
return target
|
||||
|
||||
@@ -237,7 +238,7 @@ class Profile(HasCredentials):
|
||||
threads: int,
|
||||
profile_name: str,
|
||||
target_name: str,
|
||||
user_config: Optional[Dict[str, Any]] = None
|
||||
user_cfg: Optional[Dict[str, Any]] = None
|
||||
) -> 'Profile':
|
||||
"""Create a profile from an existing set of Credentials and the
|
||||
remaining information.
|
||||
@@ -246,20 +247,20 @@ class Profile(HasCredentials):
|
||||
:param threads: The number of threads to use for connections.
|
||||
:param profile_name: The profile name used for this profile.
|
||||
:param target_name: The target name used for this profile.
|
||||
:param user_config: The user-level config block from the
|
||||
:param user_cfg: The user-level config block from the
|
||||
raw profiles, if specified.
|
||||
:raises DbtProfileError: If the profile is invalid.
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
if user_config is None:
|
||||
user_config = {}
|
||||
UserConfig.validate(user_config)
|
||||
user_config_obj: UserConfig = UserConfig.from_dict(user_config)
|
||||
if user_cfg is None:
|
||||
user_cfg = {}
|
||||
UserConfig.validate(user_cfg)
|
||||
config = UserConfig.from_dict(user_cfg)
|
||||
|
||||
profile = cls(
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
user_config=user_config_obj,
|
||||
config=config,
|
||||
threads=threads,
|
||||
credentials=credentials
|
||||
)
|
||||
@@ -312,7 +313,7 @@ class Profile(HasCredentials):
|
||||
raw_profile: Dict[str, Any],
|
||||
profile_name: str,
|
||||
renderer: ProfileRenderer,
|
||||
user_config: Optional[Dict[str, Any]] = None,
|
||||
user_cfg: Optional[Dict[str, Any]] = None,
|
||||
target_override: Optional[str] = None,
|
||||
threads_override: Optional[int] = None,
|
||||
) -> 'Profile':
|
||||
@@ -324,7 +325,7 @@ class Profile(HasCredentials):
|
||||
disk as yaml and its values rendered with jinja.
|
||||
:param profile_name: The profile name used.
|
||||
:param renderer: The config renderer.
|
||||
:param user_config: The global config for the user, if it
|
||||
:param user_cfg: The global config for the user, if it
|
||||
was present.
|
||||
:param target_override: The target to use, if provided on
|
||||
the command line.
|
||||
@@ -334,9 +335,9 @@ class Profile(HasCredentials):
|
||||
target could not be found
|
||||
:returns: The new Profile object.
|
||||
"""
|
||||
# user_config is not rendered.
|
||||
if user_config is None:
|
||||
user_config = raw_profile.get('config')
|
||||
# user_cfg is not rendered.
|
||||
if user_cfg is None:
|
||||
user_cfg = raw_profile.get('config')
|
||||
# TODO: should it be, and the values coerced to bool?
|
||||
target_name, profile_data = cls.render_profile(
|
||||
raw_profile, profile_name, target_override, renderer
|
||||
@@ -357,7 +358,7 @@ class Profile(HasCredentials):
|
||||
profile_name=profile_name,
|
||||
target_name=target_name,
|
||||
threads=threads,
|
||||
user_config=user_config
|
||||
user_cfg=user_cfg
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -400,13 +401,13 @@ class Profile(HasCredentials):
|
||||
error_string=msg
|
||||
)
|
||||
)
|
||||
user_config = raw_profiles.get('config')
|
||||
user_cfg = raw_profiles.get('config')
|
||||
|
||||
return cls.from_raw_profile_info(
|
||||
raw_profile=raw_profile,
|
||||
profile_name=profile_name,
|
||||
renderer=renderer,
|
||||
user_config=user_config,
|
||||
user_cfg=user_cfg,
|
||||
target_override=target_override,
|
||||
threads_override=threads_override,
|
||||
)
|
||||
@@ -434,7 +435,7 @@ class Profile(HasCredentials):
|
||||
"""
|
||||
threads_override = getattr(args, 'threads', None)
|
||||
target_override = getattr(args, 'target', None)
|
||||
raw_profiles = read_profile(flags.PROFILES_DIR)
|
||||
raw_profiles = read_profile(args.profiles_dir)
|
||||
profile_name = cls.pick_profile_name(getattr(args, 'profile', None),
|
||||
project_profile_name)
|
||||
return cls.from_raw_profiles(
|
||||
|
||||
@@ -9,7 +9,6 @@ from typing_extensions import Protocol, runtime_checkable
|
||||
import hashlib
|
||||
import os
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.clients.system import resolve_path_from_base
|
||||
from dbt.clients.system import path_exists
|
||||
from dbt.clients.system import load_file_contents
|
||||
@@ -124,13 +123,13 @@ def _parse_versions(versions: Union[List[str], str]) -> List[VersionSpecifier]:
|
||||
|
||||
|
||||
def _all_source_paths(
|
||||
model_paths: List[str],
|
||||
seed_paths: List[str],
|
||||
source_paths: List[str],
|
||||
data_paths: List[str],
|
||||
snapshot_paths: List[str],
|
||||
analysis_paths: List[str],
|
||||
macro_paths: List[str],
|
||||
) -> List[str]:
|
||||
return list(chain(model_paths, seed_paths, snapshot_paths, analysis_paths,
|
||||
return list(chain(source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths))
|
||||
|
||||
|
||||
@@ -293,21 +292,6 @@ class PartialProject(RenderComponents):
|
||||
exc.path = os.path.join(self.project_root, 'dbt_project.yml')
|
||||
raise
|
||||
|
||||
def check_config_path(self, project_dict, deprecated_path, exp_path):
|
||||
if deprecated_path in project_dict:
|
||||
if exp_path in project_dict:
|
||||
msg = (
|
||||
'{deprecated_path} and {exp_path} cannot both be defined. The '
|
||||
'`{deprecated_path}` config has been deprecated in favor of `{exp_path}`. '
|
||||
'Please update your `dbt_project.yml` configuration to reflect this '
|
||||
'change.'
|
||||
)
|
||||
raise DbtProjectError(msg.format(deprecated_path=deprecated_path,
|
||||
exp_path=exp_path))
|
||||
deprecations.warn('project_config_path',
|
||||
deprecated_path=deprecated_path,
|
||||
exp_path=exp_path)
|
||||
|
||||
def create_project(self, rendered: RenderComponents) -> 'Project':
|
||||
unrendered = RenderComponents(
|
||||
project_dict=self.project_dict,
|
||||
@@ -319,9 +303,6 @@ class PartialProject(RenderComponents):
|
||||
verify_version=self.verify_version,
|
||||
)
|
||||
|
||||
self.check_config_path(rendered.project_dict, 'source-paths', 'model-paths')
|
||||
self.check_config_path(rendered.project_dict, 'data-paths', 'seed-paths')
|
||||
|
||||
try:
|
||||
ProjectContract.validate(rendered.project_dict)
|
||||
cfg = ProjectContract.from_dict(
|
||||
@@ -343,24 +324,15 @@ class PartialProject(RenderComponents):
|
||||
# to have been a cli argument.
|
||||
profile_name = cfg.profile
|
||||
# these are all the defaults
|
||||
|
||||
# `source_paths` is deprecated but still allowed. Copy it into
|
||||
# `model_paths` to simlify logic throughout the rest of the system.
|
||||
model_paths: List[str] = value_or(cfg.model_paths
|
||||
if 'model-paths' in rendered.project_dict
|
||||
else cfg.source_paths, ['models'])
|
||||
source_paths: List[str] = value_or(cfg.source_paths, ['models'])
|
||||
macro_paths: List[str] = value_or(cfg.macro_paths, ['macros'])
|
||||
# `data_paths` is deprecated but still allowed. Copy it into
|
||||
# `seed_paths` to simlify logic throughout the rest of the system.
|
||||
seed_paths: List[str] = value_or(cfg.seed_paths
|
||||
if 'seed-paths' in rendered.project_dict
|
||||
else cfg.data_paths, ['seeds'])
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ['tests'])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, ['analyses'])
|
||||
data_paths: List[str] = value_or(cfg.data_paths, ['data'])
|
||||
test_paths: List[str] = value_or(cfg.test_paths, ['test'])
|
||||
analysis_paths: List[str] = value_or(cfg.analysis_paths, [])
|
||||
snapshot_paths: List[str] = value_or(cfg.snapshot_paths, ['snapshots'])
|
||||
|
||||
all_source_paths: List[str] = _all_source_paths(
|
||||
model_paths, seed_paths, snapshot_paths, analysis_paths,
|
||||
source_paths, data_paths, snapshot_paths, analysis_paths,
|
||||
macro_paths
|
||||
)
|
||||
|
||||
@@ -369,7 +341,7 @@ class PartialProject(RenderComponents):
|
||||
target_path: str = value_or(cfg.target_path, 'target')
|
||||
clean_targets: List[str] = value_or(cfg.clean_targets, [target_path])
|
||||
log_path: str = value_or(cfg.log_path, 'logs')
|
||||
packages_install_path: str = value_or(cfg.packages_install_path, 'dbt_packages')
|
||||
modules_path: str = value_or(cfg.modules_path, 'dbt_modules')
|
||||
# in the default case we'll populate this once we know the adapter type
|
||||
# It would be nice to just pass along a Quoting here, but that would
|
||||
# break many things
|
||||
@@ -410,14 +382,15 @@ class PartialProject(RenderComponents):
|
||||
# of dicts.
|
||||
manifest_selectors = SelectorDict.parse_from_selectors_list(
|
||||
rendered.selectors_dict['selectors'])
|
||||
|
||||
project = Project(
|
||||
project_name=name,
|
||||
version=version,
|
||||
project_root=project_root,
|
||||
profile_name=profile_name,
|
||||
model_paths=model_paths,
|
||||
source_paths=source_paths,
|
||||
macro_paths=macro_paths,
|
||||
seed_paths=seed_paths,
|
||||
data_paths=data_paths,
|
||||
test_paths=test_paths,
|
||||
analysis_paths=analysis_paths,
|
||||
docs_paths=docs_paths,
|
||||
@@ -426,7 +399,7 @@ class PartialProject(RenderComponents):
|
||||
snapshot_paths=snapshot_paths,
|
||||
clean_targets=clean_targets,
|
||||
log_path=log_path,
|
||||
packages_install_path=packages_install_path,
|
||||
modules_path=modules_path,
|
||||
quoting=quoting,
|
||||
models=models,
|
||||
on_run_start=on_run_start,
|
||||
@@ -527,9 +500,9 @@ class Project:
|
||||
version: Union[SemverString, float]
|
||||
project_root: str
|
||||
profile_name: Optional[str]
|
||||
model_paths: List[str]
|
||||
source_paths: List[str]
|
||||
macro_paths: List[str]
|
||||
seed_paths: List[str]
|
||||
data_paths: List[str]
|
||||
test_paths: List[str]
|
||||
analysis_paths: List[str]
|
||||
docs_paths: List[str]
|
||||
@@ -538,7 +511,7 @@ class Project:
|
||||
snapshot_paths: List[str]
|
||||
clean_targets: List[str]
|
||||
log_path: str
|
||||
packages_install_path: str
|
||||
modules_path: str
|
||||
quoting: Dict[str, Any]
|
||||
models: Dict[str, Any]
|
||||
on_run_start: List[str]
|
||||
@@ -560,7 +533,7 @@ class Project:
|
||||
@property
|
||||
def all_source_paths(self) -> List[str]:
|
||||
return _all_source_paths(
|
||||
self.model_paths, self.seed_paths, self.snapshot_paths,
|
||||
self.source_paths, self.data_paths, self.snapshot_paths,
|
||||
self.analysis_paths, self.macro_paths
|
||||
)
|
||||
|
||||
@@ -588,9 +561,9 @@ class Project:
|
||||
'version': self.version,
|
||||
'project-root': self.project_root,
|
||||
'profile': self.profile_name,
|
||||
'model-paths': self.model_paths,
|
||||
'source-paths': self.source_paths,
|
||||
'macro-paths': self.macro_paths,
|
||||
'seed-paths': self.seed_paths,
|
||||
'data-paths': self.data_paths,
|
||||
'test-paths': self.test_paths,
|
||||
'analysis-paths': self.analysis_paths,
|
||||
'docs-paths': self.docs_paths,
|
||||
@@ -672,24 +645,13 @@ class Project:
|
||||
def hashed_name(self):
|
||||
return hashlib.md5(self.project_name.encode('utf-8')).hexdigest()
|
||||
|
||||
def get_selector(self, name: str) -> Union[SelectionSpec, bool]:
|
||||
def get_selector(self, name: str) -> SelectionSpec:
|
||||
if name not in self.selectors:
|
||||
raise RuntimeException(
|
||||
f'Could not find selector named {name}, expected one of '
|
||||
f'{list(self.selectors)}'
|
||||
)
|
||||
return self.selectors[name]["definition"]
|
||||
|
||||
def get_default_selector_name(self) -> Union[str, None]:
|
||||
"""This function fetch the default selector to use on `dbt run` (if any)
|
||||
:return: either a selector if default is set or None
|
||||
:rtype: Union[SelectionSpec, None]
|
||||
"""
|
||||
for selector_name, selector in self.selectors.items():
|
||||
if selector["default"] is True:
|
||||
return selector_name
|
||||
|
||||
return None
|
||||
return self.selectors[name]
|
||||
|
||||
def get_macro_search_order(self, macro_namespace: str):
|
||||
for dispatch_entry in self.dispatch:
|
||||
|
||||
@@ -12,7 +12,6 @@ from .profile import Profile
|
||||
from .project import Project
|
||||
from .renderer import DbtProjectYamlRenderer, ProfileRenderer
|
||||
from .utils import parse_cli_vars
|
||||
from dbt import flags
|
||||
from dbt import tracking
|
||||
from dbt.adapters.factory import get_relation_class_by_name, get_include_paths
|
||||
from dbt.helper_types import FQNPath, PathSet
|
||||
@@ -87,9 +86,9 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
model_paths=project.model_paths,
|
||||
source_paths=project.source_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
data_paths=project.data_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -98,7 +97,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
modules_path=project.modules_path,
|
||||
quoting=quoting,
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
@@ -118,7 +117,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
unrendered=project.unrendered,
|
||||
profile_name=profile.profile_name,
|
||||
target_name=profile.target_name,
|
||||
user_config=profile.user_config,
|
||||
config=profile.config,
|
||||
threads=profile.threads,
|
||||
credentials=profile.credentials,
|
||||
args=args,
|
||||
@@ -145,7 +144,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
project = Project.from_project_root(
|
||||
project_root,
|
||||
renderer,
|
||||
verify_version=bool(flags.VERSION_CHECK),
|
||||
verify_version=getattr(self.args, 'version_check', False),
|
||||
)
|
||||
|
||||
cfg = self.from_parts(
|
||||
@@ -198,7 +197,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
) -> Tuple[Project, Profile]:
|
||||
# profile_name from the project
|
||||
project_root = args.project_dir if args.project_dir else os.getcwd()
|
||||
version_check = bool(flags.VERSION_CHECK)
|
||||
version_check = getattr(args, 'version_check', False)
|
||||
partial = Project.partial_load(
|
||||
project_root,
|
||||
verify_version=version_check
|
||||
@@ -338,7 +337,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
f'dbt found {count_packages_specified} package(s) '
|
||||
f'specified in packages.yml, but only '
|
||||
f'{count_packages_installed} package(s) installed '
|
||||
f'in {self.packages_install_path}. Run "dbt deps" to '
|
||||
f'in {self.modules_path}. Run "dbt deps" to '
|
||||
f'install package dependencies.'
|
||||
)
|
||||
project_paths = itertools.chain(
|
||||
@@ -376,7 +375,7 @@ class RuntimeConfig(Project, Profile, AdapterRequiredConfig):
|
||||
yield project.project_name, project
|
||||
|
||||
def _get_project_directories(self) -> Iterator[Path]:
|
||||
root = Path(self.project_root) / self.packages_install_path
|
||||
root = Path(self.project_root) / self.modules_path
|
||||
|
||||
if root.exists():
|
||||
for path in root.iterdir():
|
||||
@@ -417,7 +416,7 @@ class UnsetConfig(UserConfig):
|
||||
class UnsetProfile(Profile):
|
||||
def __init__(self):
|
||||
self.credentials = UnsetCredentials()
|
||||
self.user_config = UnsetConfig()
|
||||
self.config = UnsetConfig()
|
||||
self.profile_name = ''
|
||||
self.target_name = ''
|
||||
self.threads = -1
|
||||
@@ -483,9 +482,9 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
project_name=project.project_name,
|
||||
version=project.version,
|
||||
project_root=project.project_root,
|
||||
model_paths=project.model_paths,
|
||||
source_paths=project.source_paths,
|
||||
macro_paths=project.macro_paths,
|
||||
seed_paths=project.seed_paths,
|
||||
data_paths=project.data_paths,
|
||||
test_paths=project.test_paths,
|
||||
analysis_paths=project.analysis_paths,
|
||||
docs_paths=project.docs_paths,
|
||||
@@ -494,7 +493,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
snapshot_paths=project.snapshot_paths,
|
||||
clean_targets=project.clean_targets,
|
||||
log_path=project.log_path,
|
||||
packages_install_path=project.packages_install_path,
|
||||
modules_path=project.modules_path,
|
||||
quoting=project.quoting, # we never use this anyway.
|
||||
models=project.models,
|
||||
on_run_start=project.on_run_start,
|
||||
@@ -514,7 +513,7 @@ class UnsetProfileConfig(RuntimeConfig):
|
||||
unrendered=project.unrendered,
|
||||
profile_name='',
|
||||
target_name='',
|
||||
user_config=UnsetConfig(),
|
||||
config=UnsetConfig(),
|
||||
threads=getattr(args, 'threads', 1),
|
||||
credentials=UnsetCredentials(),
|
||||
args=args,
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
from pathlib import Path
|
||||
from typing import Dict, Any, Union
|
||||
from typing import Dict, Any
|
||||
from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
yaml, Loader, Dumper, load_yaml_text
|
||||
)
|
||||
@@ -29,14 +29,13 @@ Validator Error:
|
||||
"""
|
||||
|
||||
|
||||
class SelectorConfig(Dict[str, Dict[str, Union[SelectionSpec, bool]]]):
|
||||
class SelectorConfig(Dict[str, SelectionSpec]):
|
||||
|
||||
@classmethod
|
||||
def selectors_from_dict(cls, data: Dict[str, Any]) -> 'SelectorConfig':
|
||||
try:
|
||||
SelectorFile.validate(data)
|
||||
selector_file = SelectorFile.from_dict(data)
|
||||
validate_selector_default(selector_file)
|
||||
selectors = parse_from_selectors_definition(selector_file)
|
||||
except ValidationError as exc:
|
||||
yaml_sel_cfg = yaml.dump(exc.instance)
|
||||
@@ -119,24 +118,6 @@ def selector_config_from_data(
|
||||
return selectors
|
||||
|
||||
|
||||
def validate_selector_default(selector_file: SelectorFile) -> None:
|
||||
"""Check if a selector.yml file has more than 1 default key set to true"""
|
||||
default_set: bool = False
|
||||
default_selector_name: Union[str, None] = None
|
||||
|
||||
for selector in selector_file.selectors:
|
||||
if selector.default is True and default_set is False:
|
||||
default_set = True
|
||||
default_selector_name = selector.name
|
||||
continue
|
||||
if selector.default is True and default_set is True:
|
||||
raise DbtSelectorsError(
|
||||
"Error when parsing the selector file. "
|
||||
"Found multiple selectors with `default: true`:"
|
||||
f"{default_selector_name} and {selector.name}"
|
||||
)
|
||||
|
||||
|
||||
# These are utilities to clean up the dictionary created from
|
||||
# selectors.yml by turning the cli-string format entries into
|
||||
# normalized dictionary entries. It parallels the flow in
|
||||
|
||||
@@ -12,8 +12,7 @@ from dbt.clients.yaml_helper import ( # noqa: F401
|
||||
)
|
||||
from dbt.contracts.graph.compiled import CompiledResource
|
||||
from dbt.exceptions import raise_compiler_error, MacroReturn
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import MacroEventInfo, MacroEventDebug
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.version import __version__ as dbt_version
|
||||
|
||||
# These modules are added to the context. Consider alternative
|
||||
@@ -444,9 +443,9 @@ class BaseContext(metaclass=ContextMeta):
|
||||
{% endmacro %}"
|
||||
"""
|
||||
if info:
|
||||
fire_event(MacroEventInfo(msg))
|
||||
logger.info(msg)
|
||||
else:
|
||||
fire_event(MacroEventDebug(msg))
|
||||
logger.debug(msg)
|
||||
return ''
|
||||
|
||||
@contextproperty
|
||||
@@ -525,8 +524,14 @@ class BaseContext(metaclass=ContextMeta):
|
||||
-- no-op
|
||||
{% endif %}
|
||||
|
||||
This supports all flags defined in flags submodule (core/dbt/flags.py)
|
||||
TODO: Replace with object that provides read-only access to flag values
|
||||
The list of valid flags are:
|
||||
|
||||
- `flags.STRICT_MODE`: True if `--strict` (or `-S`) was provided on the
|
||||
command line
|
||||
- `flags.FULL_REFRESH`: True if `--full-refresh` was provided on the
|
||||
command line
|
||||
- `flags.NON_DESTRUCTIVE`: True if `--non-destructive` was provided on
|
||||
the command line
|
||||
"""
|
||||
return flags
|
||||
|
||||
|
||||
@@ -6,6 +6,7 @@ from typing import (
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.adapters.base.column import Column
|
||||
from dbt.adapters.factory import (
|
||||
get_adapter, get_adapter_package_names, get_adapter_type_names
|
||||
@@ -39,7 +40,6 @@ from dbt.exceptions import (
|
||||
InternalException,
|
||||
ValidationException,
|
||||
RuntimeException,
|
||||
macro_invalid_dispatch_arg,
|
||||
missing_config,
|
||||
raise_compiler_error,
|
||||
ref_invalid_args,
|
||||
@@ -49,6 +49,7 @@ from dbt.exceptions import (
|
||||
wrapped_exports,
|
||||
)
|
||||
from dbt.config import IsFQNResource
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
from dbt.node_types import NodeType
|
||||
|
||||
from dbt.utils import (
|
||||
@@ -119,37 +120,39 @@ class BaseDatabaseWrapper:
|
||||
self,
|
||||
macro_name: str,
|
||||
macro_namespace: Optional[str] = None,
|
||||
packages: Optional[List[str]] = None, # eventually remove since it's fully deprecated
|
||||
packages: Optional[List[str]] = None,
|
||||
) -> MacroGenerator:
|
||||
search_packages: List[Optional[str]]
|
||||
|
||||
if '.' in macro_name:
|
||||
suggest_macro_namespace, suggest_macro_name = macro_name.split('.', 1)
|
||||
suggest_package, suggest_macro_name = macro_name.split('.', 1)
|
||||
msg = (
|
||||
f'In adapter.dispatch, got a macro name of "{macro_name}", '
|
||||
f'but "." is not a valid macro name component. Did you mean '
|
||||
f'`adapter.dispatch("{suggest_macro_name}", '
|
||||
f'macro_namespace="{suggest_macro_namespace}")`?'
|
||||
f'packages=["{suggest_package}"])`?'
|
||||
)
|
||||
raise CompilationException(msg)
|
||||
|
||||
if packages is not None:
|
||||
raise macro_invalid_dispatch_arg(macro_name)
|
||||
deprecations.warn('dispatch-packages', macro_name=macro_name)
|
||||
|
||||
namespace = macro_namespace
|
||||
namespace = packages if packages else macro_namespace
|
||||
|
||||
if namespace is None:
|
||||
search_packages = [None]
|
||||
elif isinstance(namespace, str):
|
||||
search_packages = self._adapter.config.get_macro_search_order(namespace)
|
||||
if not search_packages and namespace in self._adapter.config.dependencies:
|
||||
search_packages = [self.config.project_name, namespace]
|
||||
search_packages = [namespace]
|
||||
if not search_packages:
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a string packages argument '
|
||||
f'("{packages}"), but packages should be None or a list.'
|
||||
)
|
||||
else:
|
||||
# Not a string and not None so must be a list
|
||||
raise CompilationException(
|
||||
f'In adapter.dispatch, got a list macro_namespace argument '
|
||||
f'("{macro_namespace}"), but macro_namespace should be None or a string.'
|
||||
)
|
||||
search_packages = namespace
|
||||
|
||||
attempts = []
|
||||
|
||||
@@ -161,10 +164,10 @@ class BaseDatabaseWrapper:
|
||||
macro = self._namespace.get_from_package(
|
||||
package_name, search_name
|
||||
)
|
||||
except CompilationException:
|
||||
# Only raise CompilationException if macro is not found in
|
||||
# any package
|
||||
macro = None
|
||||
except CompilationException as exc:
|
||||
raise CompilationException(
|
||||
f'In dispatch: {exc.msg}',
|
||||
) from exc
|
||||
|
||||
if package_name is None:
|
||||
attempts.append(search_name)
|
||||
@@ -1148,17 +1151,65 @@ class ProviderContext(ManifestContext):
|
||||
|
||||
@contextmember
|
||||
def adapter_macro(self, name: str, *args, **kwargs):
|
||||
"""This was deprecated in v0.18 in favor of adapter.dispatch
|
||||
"""Find the most appropriate macro for the name, considering the
|
||||
adapter type currently in use, and call that with the given arguments.
|
||||
|
||||
If the name has a `.` in it, the first section before the `.` is
|
||||
interpreted as a package name, and the remainder as a macro name.
|
||||
|
||||
If no adapter is found, raise a compiler exception. If an invalid
|
||||
package name is specified, raise a compiler exception.
|
||||
|
||||
|
||||
Some examples:
|
||||
|
||||
{# dbt will call this macro by name, providing any arguments #}
|
||||
{% macro create_table_as(temporary, relation, sql) -%}
|
||||
|
||||
{# dbt will dispatch the macro call to the relevant macro #}
|
||||
{{ adapter_macro('create_table_as', temporary, relation, sql) }}
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{#
|
||||
If no macro matches the specified adapter, "default" will be
|
||||
used
|
||||
#}
|
||||
{% macro default__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
|
||||
{# Example which defines special logic for Redshift #}
|
||||
{% macro redshift__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
|
||||
{# Example which defines special logic for BigQuery #}
|
||||
{% macro bigquery__create_table_as(temporary, relation, sql) -%}
|
||||
...
|
||||
{%- endmacro %}
|
||||
"""
|
||||
msg = (
|
||||
'The "adapter_macro" macro has been deprecated. Instead, use '
|
||||
'the `adapter.dispatch` method to find a macro and call the '
|
||||
'result. For more information, see: '
|
||||
'https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch)'
|
||||
' adapter_macro was called for: {macro_name}'
|
||||
.format(macro_name=name)
|
||||
)
|
||||
raise CompilationException(msg)
|
||||
deprecations.warn('adapter-macro', macro_name=name)
|
||||
original_name = name
|
||||
package_name = None
|
||||
if '.' in name:
|
||||
package_name, name = name.split('.', 1)
|
||||
|
||||
try:
|
||||
macro = self.db_wrapper.dispatch(
|
||||
macro_name=name, macro_namespace=package_name
|
||||
)
|
||||
except CompilationException as exc:
|
||||
raise CompilationException(
|
||||
f'In adapter_macro: {exc.msg}\n'
|
||||
f" Original name: '{original_name}'",
|
||||
node=self.model
|
||||
) from exc
|
||||
return macro(*args, **kwargs)
|
||||
|
||||
|
||||
class MacroContext(ProviderContext):
|
||||
|
||||
@@ -128,14 +128,10 @@ class Credentials(
|
||||
'type not implemented for base credentials class'
|
||||
)
|
||||
|
||||
@property
|
||||
@abc.abstractproperty
|
||||
def unique_field(self) -> str:
|
||||
"""Hashed and included in anonymous telemetry to track adapter adoption.
|
||||
Return the field from Credentials that can uniquely identify
|
||||
one team/organization using this adapter
|
||||
"""
|
||||
raise NotImplementedError(
|
||||
'unique_field not implemented for base credentials class'
|
||||
'type not implemented for base credentials class'
|
||||
)
|
||||
|
||||
def hashed_unique_field(self) -> str:
|
||||
@@ -190,11 +186,14 @@ class UserConfigContract(Protocol):
|
||||
partial_parse: Optional[bool] = None
|
||||
printer_width: Optional[int] = None
|
||||
|
||||
def set_values(self, cookie_dir: str) -> None:
|
||||
...
|
||||
|
||||
|
||||
class HasCredentials(Protocol):
|
||||
credentials: Credentials
|
||||
profile_name: str
|
||||
user_config: UserConfigContract
|
||||
config: UserConfigContract
|
||||
target_name: str
|
||||
threads: int
|
||||
|
||||
|
||||
@@ -18,8 +18,7 @@ class ParseFileType(StrEnum):
|
||||
Model = 'model'
|
||||
Snapshot = 'snapshot'
|
||||
Analysis = 'analysis'
|
||||
SingularTest = 'singular_test'
|
||||
GenericTest = 'generic_test'
|
||||
Test = 'test'
|
||||
Seed = 'seed'
|
||||
Documentation = 'docs'
|
||||
Schema = 'schema'
|
||||
@@ -31,8 +30,7 @@ parse_file_type_to_parser = {
|
||||
ParseFileType.Model: 'ModelParser',
|
||||
ParseFileType.Snapshot: 'SnapshotParser',
|
||||
ParseFileType.Analysis: 'AnalysisParser',
|
||||
ParseFileType.SingularTest: 'SingularTestParser',
|
||||
ParseFileType.GenericTest: 'GenericTestParser',
|
||||
ParseFileType.Test: 'DataTestParser',
|
||||
ParseFileType.Seed: 'SeedParser',
|
||||
ParseFileType.Documentation: 'DocumentationParser',
|
||||
ParseFileType.Schema: 'SchemaParser',
|
||||
@@ -44,7 +42,6 @@ parse_file_type_to_parser = {
|
||||
class FilePath(dbtClassMixin):
|
||||
searched_path: str
|
||||
relative_path: str
|
||||
modification_time: float
|
||||
project_root: str
|
||||
|
||||
@property
|
||||
@@ -135,10 +132,6 @@ class RemoteFile(dbtClassMixin):
|
||||
def original_file_path(self):
|
||||
return 'from remote system'
|
||||
|
||||
@property
|
||||
def modification_time(self):
|
||||
return 'from remote system'
|
||||
|
||||
|
||||
@dataclass
|
||||
class BaseSourceFile(dbtClassMixin, SerializableType):
|
||||
@@ -157,6 +150,8 @@ class BaseSourceFile(dbtClassMixin, SerializableType):
|
||||
def file_id(self):
|
||||
if isinstance(self.path, RemoteFile):
|
||||
return None
|
||||
if self.checksum.name == 'none':
|
||||
return None
|
||||
return f'{self.project_name}://{self.path.original_file_path}'
|
||||
|
||||
def _serialize(self):
|
||||
|
||||
@@ -2,13 +2,13 @@ from dbt.contracts.graph.parsed import (
|
||||
HasTestMetadata,
|
||||
ParsedNode,
|
||||
ParsedAnalysisNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedExposure,
|
||||
ParsedResource,
|
||||
ParsedRPCNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
ParsedSourceDefinition,
|
||||
@@ -107,7 +107,7 @@ class CompiledSnapshotNode(CompiledNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledSingularTestNode(CompiledNode):
|
||||
class CompiledDataTestNode(CompiledNode):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
@@ -115,8 +115,8 @@ class CompiledSingularTestNode(CompiledNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class CompiledGenericTestNode(CompiledNode, HasTestMetadata):
|
||||
# keep this in sync with ParsedGenericTestNode!
|
||||
class CompiledSchemaTestNode(CompiledNode, HasTestMetadata):
|
||||
# keep this in sync with ParsedSchemaTestNode!
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
column_name: Optional[str] = None
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
@@ -134,7 +134,7 @@ class CompiledGenericTestNode(CompiledNode, HasTestMetadata):
|
||||
)
|
||||
|
||||
|
||||
CompiledTestNode = Union[CompiledSingularTestNode, CompiledGenericTestNode]
|
||||
CompiledTestNode = Union[CompiledDataTestNode, CompiledSchemaTestNode]
|
||||
|
||||
|
||||
PARSED_TYPES: Dict[Type[CompiledNode], Type[ParsedResource]] = {
|
||||
@@ -144,8 +144,8 @@ PARSED_TYPES: Dict[Type[CompiledNode], Type[ParsedResource]] = {
|
||||
CompiledRPCNode: ParsedRPCNode,
|
||||
CompiledSeedNode: ParsedSeedNode,
|
||||
CompiledSnapshotNode: ParsedSnapshotNode,
|
||||
CompiledSingularTestNode: ParsedSingularTestNode,
|
||||
CompiledGenericTestNode: ParsedGenericTestNode,
|
||||
CompiledDataTestNode: ParsedDataTestNode,
|
||||
CompiledSchemaTestNode: ParsedSchemaTestNode,
|
||||
}
|
||||
|
||||
|
||||
@@ -156,8 +156,8 @@ COMPILED_TYPES: Dict[Type[ParsedResource], Type[CompiledNode]] = {
|
||||
ParsedRPCNode: CompiledRPCNode,
|
||||
ParsedSeedNode: CompiledSeedNode,
|
||||
ParsedSnapshotNode: CompiledSnapshotNode,
|
||||
ParsedSingularTestNode: CompiledSingularTestNode,
|
||||
ParsedGenericTestNode: CompiledGenericTestNode,
|
||||
ParsedDataTestNode: CompiledDataTestNode,
|
||||
ParsedSchemaTestNode: CompiledSchemaTestNode,
|
||||
}
|
||||
|
||||
|
||||
@@ -185,22 +185,22 @@ def parsed_instance_for(compiled: CompiledNode) -> ParsedResource:
|
||||
|
||||
NonSourceCompiledNode = Union[
|
||||
CompiledAnalysisNode,
|
||||
CompiledSingularTestNode,
|
||||
CompiledDataTestNode,
|
||||
CompiledModelNode,
|
||||
CompiledHookNode,
|
||||
CompiledRPCNode,
|
||||
CompiledGenericTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
CompiledSeedNode,
|
||||
CompiledSnapshotNode,
|
||||
]
|
||||
|
||||
NonSourceParsedNode = Union[
|
||||
ParsedAnalysisNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedRPCNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
]
|
||||
|
||||
@@ -5,7 +5,7 @@ from mashumaro import DataClassMessagePackMixin
|
||||
from multiprocessing.synchronize import Lock
|
||||
from typing import (
|
||||
Dict, List, Optional, Union, Mapping, MutableMapping, Any, Set, Tuple,
|
||||
TypeVar, Callable, Generic, cast, AbstractSet, ClassVar
|
||||
TypeVar, Callable, Iterable, Generic, cast, AbstractSet, ClassVar
|
||||
)
|
||||
from typing_extensions import Protocol
|
||||
from uuid import UUID
|
||||
@@ -95,23 +95,24 @@ class DocLookup(dbtClassMixin):
|
||||
|
||||
class SourceLookup(dbtClassMixin):
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self.storage: Dict[str, Dict[PackageName, UniqueID]] = {}
|
||||
self.storage: Dict[Tuple[str, str], Dict[PackageName, UniqueID]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def get_unique_id(self, search_name, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, search_name, package)
|
||||
def get_unique_id(self, key, package: Optional[PackageName]):
|
||||
return find_unique_id_for_package(self.storage, key, package)
|
||||
|
||||
def find(self, search_name, package: Optional[PackageName], manifest: 'Manifest'):
|
||||
unique_id = self.get_unique_id(search_name, package)
|
||||
def find(self, key, package: Optional[PackageName], manifest: 'Manifest'):
|
||||
unique_id = self.get_unique_id(key, package)
|
||||
if unique_id is not None:
|
||||
return self.perform_lookup(unique_id, manifest)
|
||||
return None
|
||||
|
||||
def add_source(self, source: ParsedSourceDefinition):
|
||||
if source.search_name not in self.storage:
|
||||
self.storage[source.search_name] = {}
|
||||
key = (source.source_name, source.name)
|
||||
if key not in self.storage:
|
||||
self.storage[key] = {}
|
||||
|
||||
self.storage[source.search_name][source.package_name] = source.unique_id
|
||||
self.storage[key][source.package_name] = source.unique_id
|
||||
|
||||
def populate(self, manifest):
|
||||
for source in manifest.sources.values():
|
||||
@@ -168,43 +169,6 @@ class RefableLookup(dbtClassMixin):
|
||||
return manifest.nodes[unique_id]
|
||||
|
||||
|
||||
# This handles both models/seeds/snapshots and sources
|
||||
class DisabledLookup(dbtClassMixin):
|
||||
|
||||
def __init__(self, manifest: 'Manifest'):
|
||||
self.storage: Dict[str, Dict[PackageName, List[Any]]] = {}
|
||||
self.populate(manifest)
|
||||
|
||||
def populate(self, manifest):
|
||||
for node in list(chain.from_iterable(manifest.disabled.values())):
|
||||
self.add_node(node)
|
||||
|
||||
def add_node(self, node):
|
||||
if node.search_name not in self.storage:
|
||||
self.storage[node.search_name] = {}
|
||||
if node.package_name not in self.storage[node.search_name]:
|
||||
self.storage[node.search_name][node.package_name] = []
|
||||
self.storage[node.search_name][node.package_name].append(node)
|
||||
|
||||
# This should return a list of disabled nodes. It's different from
|
||||
# the other Lookup functions in that it returns full nodes, not just unique_ids
|
||||
def find(self, search_name, package: Optional[PackageName]):
|
||||
if search_name not in self.storage:
|
||||
return None
|
||||
|
||||
pkg_dct: Mapping[PackageName, List[Any]] = self.storage[search_name]
|
||||
|
||||
if package is None:
|
||||
if not pkg_dct:
|
||||
return None
|
||||
else:
|
||||
return next(iter(pkg_dct.values()))
|
||||
elif package in pkg_dct:
|
||||
return pkg_dct[package]
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class AnalysisLookup(RefableLookup):
|
||||
_lookup_types: ClassVar[set] = set([NodeType.Analysis])
|
||||
|
||||
@@ -259,7 +223,9 @@ class ManifestMetadata(BaseArtifactMetadata):
|
||||
self.user_id = tracking.active_user.id
|
||||
|
||||
if self.send_anonymous_usage_stats is None:
|
||||
self.send_anonymous_usage_stats = flags.SEND_ANONYMOUS_USAGE_STATS
|
||||
self.send_anonymous_usage_stats = (
|
||||
not tracking.active_user.do_not_track
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def default(cls):
|
||||
@@ -291,7 +257,7 @@ def build_node_edges(nodes: List[ManifestNode]):
|
||||
return _sort_values(forward_edges), _sort_values(backward_edges)
|
||||
|
||||
|
||||
# Build a map of children of macros and generic tests
|
||||
# Build a map of children of macros
|
||||
def build_macro_edges(nodes: List[Any]):
|
||||
forward_edges: Dict[str, List[str]] = {
|
||||
n.unique_id: [] for n in nodes if n.unique_id.startswith('macro') or n.depends_on.macros
|
||||
@@ -414,6 +380,38 @@ class Searchable(Protocol):
|
||||
raise NotImplementedError('search_name not implemented')
|
||||
|
||||
|
||||
N = TypeVar('N', bound=Searchable)
|
||||
|
||||
|
||||
@dataclass
|
||||
class NameSearcher(Generic[N]):
|
||||
name: str
|
||||
package: Optional[str]
|
||||
nodetypes: List[NodeType]
|
||||
|
||||
def _matches(self, model: N) -> bool:
|
||||
"""Return True if the model matches the given name, package, and type.
|
||||
|
||||
If package is None, any package is allowed.
|
||||
nodetypes should be a container of NodeTypes that implements the 'in'
|
||||
operator.
|
||||
"""
|
||||
if model.resource_type not in self.nodetypes:
|
||||
return False
|
||||
|
||||
if self.name != model.search_name:
|
||||
return False
|
||||
|
||||
return self.package is None or self.package == model.package_name
|
||||
|
||||
def search(self, haystack: Iterable[N]) -> Optional[N]:
|
||||
"""Find an entry in the given iterable by name."""
|
||||
for model in haystack:
|
||||
if self._matches(model):
|
||||
return model
|
||||
return None
|
||||
|
||||
|
||||
D = TypeVar('D')
|
||||
|
||||
|
||||
@@ -563,13 +561,15 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
docs: MutableMapping[str, ParsedDocumentation] = field(default_factory=dict)
|
||||
exposures: MutableMapping[str, ParsedExposure] = field(default_factory=dict)
|
||||
selectors: MutableMapping[str, Any] = field(default_factory=dict)
|
||||
disabled: List[CompileResultNode] = field(default_factory=list)
|
||||
files: MutableMapping[str, AnySourceFile] = field(default_factory=dict)
|
||||
metadata: ManifestMetadata = field(default_factory=ManifestMetadata)
|
||||
flat_graph: Dict[str, Any] = field(default_factory=dict)
|
||||
state_check: ManifestStateCheck = field(default_factory=ManifestStateCheck)
|
||||
# Moved from the ParseResult object
|
||||
source_patches: MutableMapping[SourceKey, SourcePatch] = field(default_factory=dict)
|
||||
disabled: MutableMapping[str, List[CompileResultNode]] = field(default_factory=dict)
|
||||
|
||||
# following is from ParseResult
|
||||
_disabled: MutableMapping[str, List[CompileResultNode]] = field(default_factory=dict)
|
||||
_doc_lookup: Optional[DocLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
@@ -579,9 +579,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
_ref_lookup: Optional[RefableLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_disabled_lookup: Optional[DisabledLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
_analysis_lookup: Optional[AnalysisLookup] = field(
|
||||
default=None, metadata={'serialize': lambda x: None, 'deserialize': lambda x: None}
|
||||
)
|
||||
@@ -655,12 +652,26 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
}
|
||||
}
|
||||
|
||||
def build_disabled_by_file_id(self):
|
||||
disabled_by_file_id = {}
|
||||
for node_list in self.disabled.values():
|
||||
for node in node_list:
|
||||
disabled_by_file_id[node.file_id] = node
|
||||
return disabled_by_file_id
|
||||
def find_disabled_by_name(
|
||||
self, name: str, package: Optional[str] = None
|
||||
) -> Optional[ManifestNode]:
|
||||
searcher: NameSearcher = NameSearcher(
|
||||
name, package, NodeType.refable()
|
||||
)
|
||||
result = searcher.search(self.disabled)
|
||||
return result
|
||||
|
||||
def find_disabled_source_by_name(
|
||||
self, source_name: str, table_name: str, package: Optional[str] = None
|
||||
) -> Optional[ParsedSourceDefinition]:
|
||||
search_name = f'{source_name}.{table_name}'
|
||||
searcher: NameSearcher = NameSearcher(
|
||||
search_name, package, [NodeType.Source]
|
||||
)
|
||||
result = searcher.search(self.disabled)
|
||||
if result is not None:
|
||||
assert isinstance(result, ParsedSourceDefinition)
|
||||
return result
|
||||
|
||||
def _materialization_candidates_for(
|
||||
self, project_name: str,
|
||||
@@ -718,6 +729,7 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
chain(self.nodes.values(), self.sources.values())
|
||||
)
|
||||
|
||||
# This is used in dbt.task.rpc.sql_commands 'add_new_refs'
|
||||
def deepcopy(self):
|
||||
return Manifest(
|
||||
nodes={k: _deepcopy(v) for k, v in self.nodes.items()},
|
||||
@@ -727,7 +739,7 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
exposures={k: _deepcopy(v) for k, v in self.exposures.items()},
|
||||
selectors={k: _deepcopy(v) for k, v in self.selectors.items()},
|
||||
metadata=self.metadata,
|
||||
disabled={k: _deepcopy(v) for k, v in self.disabled.items()},
|
||||
disabled=[_deepcopy(n) for n in self.disabled],
|
||||
files={k: _deepcopy(v) for k, v in self.files.items()},
|
||||
state_check=_deepcopy(self.state_check),
|
||||
)
|
||||
@@ -810,15 +822,6 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
def rebuild_ref_lookup(self):
|
||||
self._ref_lookup = RefableLookup(self)
|
||||
|
||||
@property
|
||||
def disabled_lookup(self) -> DisabledLookup:
|
||||
if self._disabled_lookup is None:
|
||||
self._disabled_lookup = DisabledLookup(self)
|
||||
return self._disabled_lookup
|
||||
|
||||
def rebuild_disabled_lookup(self):
|
||||
self._disabled_lookup = DisabledLookup(self)
|
||||
|
||||
@property
|
||||
def analysis_lookup(self) -> AnalysisLookup:
|
||||
if self._analysis_lookup is None:
|
||||
@@ -836,7 +839,7 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
) -> MaybeNonSource:
|
||||
|
||||
node: Optional[ManifestNode] = None
|
||||
disabled: Optional[List[ManifestNode]] = None
|
||||
disabled: Optional[ManifestNode] = None
|
||||
|
||||
candidates = _search_packages(
|
||||
current_project, node_package, target_model_package
|
||||
@@ -849,12 +852,12 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
|
||||
# it's possible that the node is disabled
|
||||
if disabled is None:
|
||||
disabled = self.disabled_lookup.find(
|
||||
disabled = self.find_disabled_by_name(
|
||||
target_model_name, pkg
|
||||
)
|
||||
|
||||
if disabled:
|
||||
return Disabled(disabled[0])
|
||||
if disabled is not None:
|
||||
return Disabled(disabled)
|
||||
return None
|
||||
|
||||
# Called by dbt.parser.manifest._resolve_sources_for_exposure
|
||||
@@ -866,24 +869,24 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
current_project: str,
|
||||
node_package: str
|
||||
) -> MaybeParsedSource:
|
||||
search_name = f'{target_source_name}.{target_table_name}'
|
||||
key = (target_source_name, target_table_name)
|
||||
candidates = _search_packages(current_project, node_package)
|
||||
|
||||
source: Optional[ParsedSourceDefinition] = None
|
||||
disabled: Optional[List[ParsedSourceDefinition]] = None
|
||||
disabled: Optional[ParsedSourceDefinition] = None
|
||||
|
||||
for pkg in candidates:
|
||||
source = self.source_lookup.find(search_name, pkg, self)
|
||||
source = self.source_lookup.find(key, pkg, self)
|
||||
if source is not None and source.config.enabled:
|
||||
return source
|
||||
|
||||
if disabled is None:
|
||||
disabled = self.disabled_lookup.find(
|
||||
f'{target_source_name}.{target_table_name}', pkg
|
||||
disabled = self.find_disabled_source_by_name(
|
||||
target_source_name, target_table_name, pkg
|
||||
)
|
||||
|
||||
if disabled:
|
||||
return Disabled(disabled[0])
|
||||
if disabled is not None:
|
||||
return Disabled(disabled)
|
||||
return None
|
||||
|
||||
# Called by DocsRuntimeContext.doc
|
||||
@@ -1006,11 +1009,10 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
source_file.exposures.append(exposure.unique_id)
|
||||
|
||||
def add_disabled_nofile(self, node: CompileResultNode):
|
||||
# There can be multiple disabled nodes for the same unique_id
|
||||
if node.unique_id in self.disabled:
|
||||
self.disabled[node.unique_id].append(node)
|
||||
if node.unique_id in self._disabled:
|
||||
self._disabled[node.unique_id].append(node)
|
||||
else:
|
||||
self.disabled[node.unique_id] = [node]
|
||||
self._disabled[node.unique_id] = [node]
|
||||
|
||||
def add_disabled(self, source_file: AnySourceFile, node: CompileResultNode, test_from=None):
|
||||
self.add_disabled_nofile(node)
|
||||
@@ -1042,17 +1044,16 @@ class Manifest(MacroMethods, DataClassMessagePackMixin, dbtClassMixin):
|
||||
self.docs,
|
||||
self.exposures,
|
||||
self.selectors,
|
||||
self.disabled,
|
||||
self.files,
|
||||
self.metadata,
|
||||
self.flat_graph,
|
||||
self.state_check,
|
||||
self.source_patches,
|
||||
self.disabled,
|
||||
self._disabled,
|
||||
self._doc_lookup,
|
||||
self._source_lookup,
|
||||
self._ref_lookup,
|
||||
self._disabled_lookup,
|
||||
self._analysis_lookup,
|
||||
)
|
||||
return self.__class__, args
|
||||
|
||||
@@ -1070,7 +1071,7 @@ AnyManifest = Union[Manifest, MacroManifest]
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('manifest', 3)
|
||||
@schema_version('manifest', 2)
|
||||
class WritableManifest(ArtifactMixin):
|
||||
nodes: Mapping[UniqueID, ManifestNode] = field(
|
||||
metadata=dict(description=(
|
||||
@@ -1102,8 +1103,8 @@ class WritableManifest(ArtifactMixin):
|
||||
'The selectors defined in selectors.yml'
|
||||
))
|
||||
)
|
||||
disabled: Optional[Mapping[UniqueID, List[CompileResultNode]]] = field(metadata=dict(
|
||||
description='A mapping of the disabled nodes in the target'
|
||||
disabled: Optional[List[CompileResultNode]] = field(metadata=dict(
|
||||
description='A list of the disabled nodes in the target'
|
||||
))
|
||||
parent_map: Optional[NodeEdgeMap] = field(metadata=dict(
|
||||
description='A mapping from child nodes to their dependencies',
|
||||
|
||||
@@ -156,6 +156,13 @@ class ParsedNodeMixins(dbtClassMixin):
|
||||
self.columns = patch.columns
|
||||
self.meta = patch.meta
|
||||
self.docs = patch.docs
|
||||
if flags.STRICT_MODE:
|
||||
# It seems odd that an instance can be invalid
|
||||
# Maybe there should be validation or restrictions
|
||||
# elsewhere?
|
||||
assert isinstance(self, dbtClassMixin)
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
|
||||
def get_materialization(self):
|
||||
return self.config.materialized
|
||||
@@ -182,7 +189,7 @@ class ParsedNodeMandatory(
|
||||
class ParsedNodeDefaults(ParsedNodeMandatory):
|
||||
tags: List[str] = field(default_factory=list)
|
||||
refs: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[str]] = field(default_factory=list)
|
||||
sources: List[List[Any]] = field(default_factory=list)
|
||||
depends_on: DependsOn = field(default_factory=DependsOn)
|
||||
description: str = field(default='')
|
||||
columns: Dict[str, ColumnInfo] = field(default_factory=dict)
|
||||
@@ -242,9 +249,9 @@ class ParsedNode(ParsedNodeDefaults, ParsedNodeMixins, SerializableType):
|
||||
return ParsedRPCNode.from_dict(dct)
|
||||
elif resource_type == 'test':
|
||||
if 'test_metadata' in dct:
|
||||
return ParsedGenericTestNode.from_dict(dct)
|
||||
return ParsedSchemaTestNode.from_dict(dct)
|
||||
else:
|
||||
return ParsedSingularTestNode.from_dict(dct)
|
||||
return ParsedDataTestNode.from_dict(dct)
|
||||
elif resource_type == 'operation':
|
||||
return ParsedHookNode.from_dict(dct)
|
||||
elif resource_type == 'seed':
|
||||
@@ -412,7 +419,7 @@ class HasTestMetadata(dbtClassMixin):
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedSingularTestNode(ParsedNode):
|
||||
class ParsedDataTestNode(ParsedNode):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
# refactor the various configs.
|
||||
@@ -420,8 +427,8 @@ class ParsedSingularTestNode(ParsedNode):
|
||||
|
||||
|
||||
@dataclass
|
||||
class ParsedGenericTestNode(ParsedNode, HasTestMetadata):
|
||||
# keep this in sync with CompiledGenericTestNode!
|
||||
class ParsedSchemaTestNode(ParsedNode, HasTestMetadata):
|
||||
# keep this in sync with CompiledSchemaTestNode!
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Test]})
|
||||
column_name: Optional[str] = None
|
||||
# Was not able to make mypy happy and keep the code working. We need to
|
||||
@@ -502,6 +509,11 @@ class ParsedMacro(UnparsedBaseNode, HasUniqueID):
|
||||
self.meta = patch.meta
|
||||
self.docs = patch.docs
|
||||
self.arguments = patch.arguments
|
||||
if flags.STRICT_MODE:
|
||||
# What does this actually validate?
|
||||
assert isinstance(self, dbtClassMixin)
|
||||
dct = self.to_dict(omit_none=False)
|
||||
self.validate(dct)
|
||||
|
||||
def same_contents(self, other: Optional['ParsedMacro']) -> bool:
|
||||
if other is None:
|
||||
@@ -773,11 +785,11 @@ class ParsedExposure(UnparsedBaseNode, HasUniqueID, HasFqn):
|
||||
|
||||
ManifestNodes = Union[
|
||||
ParsedAnalysisNode,
|
||||
ParsedSingularTestNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedHookNode,
|
||||
ParsedModelNode,
|
||||
ParsedRPCNode,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedSeedNode,
|
||||
ParsedSnapshotNode,
|
||||
]
|
||||
|
||||
@@ -44,11 +44,6 @@ class UnparsedMacro(UnparsedBaseNode, HasSQL):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Macro]})
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedGenericTest(UnparsedBaseNode, HasSQL):
|
||||
resource_type: NodeType = field(metadata={'restrict': [NodeType.Macro]})
|
||||
|
||||
|
||||
@dataclass
|
||||
class UnparsedNode(UnparsedBaseNode, HasSQL):
|
||||
name: str
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
from dbt.contracts.util import Replaceable, Mergeable, list_str
|
||||
from dbt.contracts.connection import QueryComment, UserConfigContract
|
||||
from dbt.contracts.connection import UserConfigContract, QueryComment
|
||||
from dbt.helper_types import NoValue
|
||||
from dbt.logger import GLOBAL_LOGGER as logger # noqa
|
||||
from dbt import tracking
|
||||
from dbt import ui
|
||||
from dbt.dataclass_schema import (
|
||||
dbtClassMixin, ValidationError,
|
||||
HyphenatedDbtClassMixin,
|
||||
@@ -174,10 +176,8 @@ class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
config_version: int
|
||||
project_root: Optional[str] = None
|
||||
source_paths: Optional[List[str]] = None
|
||||
model_paths: Optional[List[str]] = None
|
||||
macro_paths: Optional[List[str]] = None
|
||||
data_paths: Optional[List[str]] = None
|
||||
seed_paths: Optional[List[str]] = None
|
||||
test_paths: Optional[List[str]] = None
|
||||
analysis_paths: Optional[List[str]] = None
|
||||
docs_paths: Optional[List[str]] = None
|
||||
@@ -187,7 +187,7 @@ class Project(HyphenatedDbtClassMixin, Replaceable):
|
||||
clean_targets: Optional[List[str]] = None
|
||||
profile: Optional[str] = None
|
||||
log_path: Optional[str] = None
|
||||
packages_install_path: Optional[str] = None
|
||||
modules_path: Optional[str] = None
|
||||
quoting: Optional[Quoting] = None
|
||||
on_run_start: Optional[List[str]] = field(default_factory=list_str)
|
||||
on_run_end: Optional[List[str]] = field(default_factory=list_str)
|
||||
@@ -230,21 +230,25 @@ class UserConfig(ExtensibleDbtClassMixin, Replaceable, UserConfigContract):
|
||||
use_colors: Optional[bool] = None
|
||||
partial_parse: Optional[bool] = None
|
||||
printer_width: Optional[int] = None
|
||||
write_json: Optional[bool] = None
|
||||
warn_error: Optional[bool] = None
|
||||
log_format: Optional[bool] = None
|
||||
debug: Optional[bool] = None
|
||||
version_check: Optional[bool] = None
|
||||
fail_fast: Optional[bool] = None
|
||||
use_experimental_parser: Optional[bool] = None
|
||||
static_parser: Optional[bool] = None
|
||||
|
||||
def set_values(self, cookie_dir):
|
||||
if self.send_anonymous_usage_stats:
|
||||
tracking.initialize_tracking(cookie_dir)
|
||||
else:
|
||||
tracking.do_not_track()
|
||||
|
||||
if self.use_colors is not None:
|
||||
ui.use_colors(self.use_colors)
|
||||
|
||||
if self.printer_width:
|
||||
ui.printer_width(self.printer_width)
|
||||
|
||||
|
||||
@dataclass
|
||||
class ProfileConfig(HyphenatedDbtClassMixin, Replaceable):
|
||||
profile_name: str = field(metadata={'preserve_underscore': True})
|
||||
target_name: str = field(metadata={'preserve_underscore': True})
|
||||
user_config: UserConfig = field(metadata={'preserve_underscore': True})
|
||||
config: UserConfig
|
||||
threads: int
|
||||
# TODO: make this a dynamic union of some kind?
|
||||
credentials: Optional[Dict[str, Any]]
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
from collections.abc import Mapping
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, fields
|
||||
from typing import (
|
||||
Optional, Dict,
|
||||
)
|
||||
@@ -7,8 +7,9 @@ from typing_extensions import Protocol
|
||||
|
||||
from dbt.dataclass_schema import dbtClassMixin, StrEnum
|
||||
|
||||
from dbt import deprecations
|
||||
from dbt.contracts.util import Replaceable
|
||||
from dbt.exceptions import raise_dataclass_not_dict, CompilationException
|
||||
from dbt.exceptions import CompilationException
|
||||
from dbt.utils import deep_merge
|
||||
|
||||
|
||||
@@ -42,10 +43,13 @@ class FakeAPIObject(dbtClassMixin, Replaceable, Mapping):
|
||||
raise KeyError(key) from None
|
||||
|
||||
def __iter__(self):
|
||||
raise_dataclass_not_dict(self)
|
||||
deprecations.warn('not-a-dictionary', obj=self)
|
||||
for _, name in self._get_fields():
|
||||
yield name
|
||||
|
||||
def __len__(self):
|
||||
raise_dataclass_not_dict(self)
|
||||
deprecations.warn('not-a-dictionary', obj=self)
|
||||
return len(fields(self.__class__))
|
||||
|
||||
def incorporate(self, **kwargs):
|
||||
value = self.to_dict(omit_none=True)
|
||||
|
||||
@@ -185,7 +185,7 @@ class RunExecutionResult(
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('run-results', 3)
|
||||
@schema_version('run-results', 2)
|
||||
class RunResultsArtifact(ExecutionResult, ArtifactMixin):
|
||||
results: Sequence[RunResultOutput]
|
||||
args: Dict[str, Any] = field(default_factory=dict)
|
||||
@@ -285,9 +285,6 @@ class SourceFreshnessOutput(dbtClassMixin):
|
||||
status: FreshnessStatus
|
||||
criteria: FreshnessThreshold
|
||||
adapter_response: Dict[str, Any]
|
||||
timing: List[TimingInfo]
|
||||
thread_id: str
|
||||
execution_time: float
|
||||
|
||||
|
||||
@dataclass
|
||||
@@ -336,10 +333,7 @@ def process_freshness_result(
|
||||
max_loaded_at_time_ago_in_s=result.age,
|
||||
status=result.status,
|
||||
criteria=criteria,
|
||||
adapter_response=result.adapter_response,
|
||||
timing=result.timing,
|
||||
thread_id=result.thread_id,
|
||||
execution_time=result.execution_time,
|
||||
adapter_response=result.adapter_response
|
||||
)
|
||||
|
||||
|
||||
@@ -369,7 +363,7 @@ class FreshnessResult(ExecutionResult):
|
||||
|
||||
|
||||
@dataclass
|
||||
@schema_version('sources', 2)
|
||||
@schema_version('sources', 1)
|
||||
class FreshnessExecutionResultArtifact(
|
||||
ArtifactMixin,
|
||||
VersionedSchema,
|
||||
|
||||
@@ -121,9 +121,9 @@ class RPCDocsGenerateParameters(RPCParameters):
|
||||
|
||||
@dataclass
|
||||
class RPCBuildParameters(RPCParameters):
|
||||
resource_types: Optional[List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
threads: Optional[int] = None
|
||||
models: Union[None, str, List[str]] = None
|
||||
select: Union[None, str, List[str]] = None
|
||||
exclude: Union[None, str, List[str]] = None
|
||||
selector: Optional[str] = None
|
||||
state: Optional[str] = None
|
||||
|
||||
@@ -9,7 +9,6 @@ class SelectorDefinition(dbtClassMixin):
|
||||
name: str
|
||||
definition: Union[str, Dict[str, Any]]
|
||||
description: str = ''
|
||||
default: bool = False
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
from pathlib import Path
|
||||
from .graph.manifest import WritableManifest
|
||||
from .results import RunResultsArtifact
|
||||
from typing import Optional
|
||||
from dbt.exceptions import IncompatibleSchemaException
|
||||
|
||||
@@ -9,7 +8,6 @@ class PreviousState:
|
||||
def __init__(self, path: Path):
|
||||
self.path: Path = path
|
||||
self.manifest: Optional[WritableManifest] = None
|
||||
self.results: Optional[RunResultsArtifact] = None
|
||||
|
||||
manifest_path = self.path / 'manifest.json'
|
||||
if manifest_path.exists() and manifest_path.is_file():
|
||||
@@ -18,11 +16,3 @@ class PreviousState:
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(manifest_path))
|
||||
raise
|
||||
|
||||
results_path = self.path / 'run_results.json'
|
||||
if results_path.exists() and results_path.is_file():
|
||||
try:
|
||||
self.results = RunResultsArtifact.read(str(results_path))
|
||||
except IncompatibleSchemaException as exc:
|
||||
exc.add_filename(str(results_path))
|
||||
raise
|
||||
|
||||
@@ -170,12 +170,6 @@ class BaseArtifactMetadata(dbtClassMixin):
|
||||
)
|
||||
env: Dict[str, str] = dataclasses.field(default_factory=get_metadata_env)
|
||||
|
||||
def __post_serialize__(self, dct):
|
||||
dct = super().__post_serialize__(dct)
|
||||
if dct['generated_at'] and dct['generated_at'].endswith('+00:00'):
|
||||
dct['generated_at'] = dct['generated_at'].replace('+00:00', '') + "Z"
|
||||
return dct
|
||||
|
||||
|
||||
def schema_version(name: str, version: int):
|
||||
def inner(cls: Type[VersionedSchema]):
|
||||
|
||||
@@ -43,6 +43,94 @@ class DBTDeprecation:
|
||||
active_deprecations.add(self.name)
|
||||
|
||||
|
||||
class DispatchPackagesDeprecation(DBTDeprecation):
|
||||
_name = 'dispatch-packages'
|
||||
_description = '''\
|
||||
The "packages" argument of adapter.dispatch() has been deprecated.
|
||||
Use the "macro_namespace" argument instead.
|
||||
|
||||
Raised during dispatch for: {macro_name}
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch
|
||||
'''
|
||||
|
||||
|
||||
class MaterializationReturnDeprecation(DBTDeprecation):
|
||||
_name = 'materialization-return'
|
||||
|
||||
_description = '''\
|
||||
The materialization ("{materialization}") did not explicitly return a list
|
||||
of relations to add to the cache. By default the target relation will be
|
||||
added, but this behavior will be removed in a future version of dbt.
|
||||
|
||||
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/v0.15/docs/creating-new-materializations#section-6-returning-relations
|
||||
'''
|
||||
|
||||
|
||||
class NotADictionaryDeprecation(DBTDeprecation):
|
||||
_name = 'not-a-dictionary'
|
||||
|
||||
_description = '''\
|
||||
The object ("{obj}") was used as a dictionary. In a future version of dbt
|
||||
this capability will be removed from objects of this type.
|
||||
'''
|
||||
|
||||
|
||||
class ColumnQuotingDeprecation(DBTDeprecation):
|
||||
_name = 'column-quoting-unset'
|
||||
|
||||
_description = '''\
|
||||
The quote_columns parameter was not set for seeds, so the default value of
|
||||
False was chosen. The default will change to True in a future release.
|
||||
|
||||
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/v0.15/docs/seeds#section-specify-column-quoting
|
||||
'''
|
||||
|
||||
|
||||
class ModelsKeyNonModelDeprecation(DBTDeprecation):
|
||||
_name = 'models-key-mismatch'
|
||||
|
||||
_description = '''\
|
||||
"{node.name}" is a {node.resource_type} node, but it is specified in
|
||||
the {patch.yaml_key} section of {patch.original_file_path}.
|
||||
|
||||
|
||||
|
||||
To fix this warning, place the `{node.name}` specification under
|
||||
the {expected_key} key instead.
|
||||
|
||||
This warning will become an error in a future release.
|
||||
'''
|
||||
|
||||
|
||||
class ExecuteMacrosReleaseDeprecation(DBTDeprecation):
|
||||
_name = 'execute-macro-release'
|
||||
_description = '''\
|
||||
The "release" argument to execute_macro is now ignored, and will be removed
|
||||
in a future relase of dbt. At that time, providing a `release` argument
|
||||
will result in an error.
|
||||
'''
|
||||
|
||||
|
||||
class AdapterMacroDeprecation(DBTDeprecation):
|
||||
_name = 'adapter-macro'
|
||||
_description = '''\
|
||||
The "adapter_macro" macro has been deprecated. Instead, use the
|
||||
`adapter.dispatch` method to find a macro and call the result.
|
||||
adapter_macro was called for: {macro_name}
|
||||
'''
|
||||
|
||||
|
||||
class PackageRedirectDeprecation(DBTDeprecation):
|
||||
_name = 'package-redirect'
|
||||
_description = '''\
|
||||
@@ -51,23 +139,6 @@ class PackageRedirectDeprecation(DBTDeprecation):
|
||||
'''
|
||||
|
||||
|
||||
class PackageInstallPathDeprecation(DBTDeprecation):
|
||||
_name = 'install-packages-path'
|
||||
_description = '''\
|
||||
The default package install path has changed from `dbt_modules` to `dbt_packages`.
|
||||
Please update `clean-targets` in `dbt_project.yml` and check `.gitignore` as well.
|
||||
Or, set `packages-install-path: dbt_modules` if you'd like to keep the current value.
|
||||
'''
|
||||
|
||||
|
||||
class ConfigPathDeprecation(DBTDeprecation):
|
||||
_name = 'project_config_path'
|
||||
_description = '''\
|
||||
The `{deprecated_path}` config has been deprecated in favor of `{exp_path}`.
|
||||
Please update your `dbt_project.yml` configuration to reflect this change.
|
||||
'''
|
||||
|
||||
|
||||
_adapter_renamed_description = """\
|
||||
The adapter function `adapter.{old_name}` is deprecated and will be removed in
|
||||
a future release of dbt. Please use `adapter.{new_name}` instead.
|
||||
@@ -106,8 +177,13 @@ def warn(name, *args, **kwargs):
|
||||
active_deprecations: Set[str] = set()
|
||||
|
||||
deprecations_list: List[DBTDeprecation] = [
|
||||
ConfigPathDeprecation(),
|
||||
PackageInstallPathDeprecation(),
|
||||
DispatchPackagesDeprecation(),
|
||||
MaterializationReturnDeprecation(),
|
||||
NotADictionaryDeprecation(),
|
||||
ColumnQuotingDeprecation(),
|
||||
ModelsKeyNonModelDeprecation(),
|
||||
ExecuteMacrosReleaseDeprecation(),
|
||||
AdapterMacroDeprecation(),
|
||||
PackageRedirectDeprecation()
|
||||
]
|
||||
|
||||
|
||||
@@ -91,7 +91,7 @@ class PinnedPackage(BasePackage):
|
||||
|
||||
def get_installation_path(self, project, renderer):
|
||||
dest_dirname = self.get_project_name(project, renderer)
|
||||
return os.path.join(project.packages_install_path, dest_dirname)
|
||||
return os.path.join(project.modules_path, dest_dirname)
|
||||
|
||||
def get_subdirectory(self):
|
||||
return None
|
||||
|
||||
@@ -69,7 +69,7 @@ class RegistryPinnedPackage(RegistryPackageMixin, PinnedPackage):
|
||||
|
||||
download_url = metadata.downloads.tarball
|
||||
system.download_with_retries(download_url, tar_path)
|
||||
deps_path = project.packages_install_path
|
||||
deps_path = project.modules_path
|
||||
package_name = self.get_project_name(project, renderer)
|
||||
system.untar_package(tar_path, deps_path, package_name)
|
||||
|
||||
|
||||
@@ -1,9 +0,0 @@
|
||||
# Events Module
|
||||
|
||||
The Events module is the implmentation for structured logging. These events represent both a programatic interface to dbt processes as well as human-readable messaging in one centralized place. The centralization allows for leveraging mypy to enforce interface invariants across all dbt events, and the distinct type layer allows for decoupling events and libraries such as loggers.
|
||||
|
||||
# Using the Events Module
|
||||
The event module provides types that represent what is happening in dbt in `events.types`. These types are intended to represent an exhaustive list of all things happening within dbt that will need to be logged, streamed, or printed. To fire an event, `events.functions::fire_event` is the entry point to the module from everywhere in dbt.
|
||||
|
||||
# Adding a New Event
|
||||
In `events.types` add a new class that represents the new event. This may be a simple class with no values, or it may be a dataclass with some values to construct downstream messaging. Only include the data necessary to construct this message within this class. You must extend all destinations (e.g. - if your log message belongs on the cli, extend `CliEventABC`) as well as the loglevel this event belongs to.
|
||||
@@ -1,30 +0,0 @@
|
||||
|
||||
import dbt.logger as logger # type: ignore # TODO eventually remove dependency on this logger
|
||||
from dbt.events.history import EVENT_HISTORY
|
||||
from dbt.events.types import CliEventABC, Event
|
||||
|
||||
|
||||
# top-level method for accessing the new eventing system
|
||||
# this is where all the side effects happen branched by event type
|
||||
# (i.e. - mutating the event history, printing to stdout, logging
|
||||
# to files, etc.)
|
||||
def fire_event(e: Event) -> None:
|
||||
EVENT_HISTORY.append(e)
|
||||
if isinstance(e, CliEventABC):
|
||||
if e.level_tag() == 'test':
|
||||
# TODO after implmenting #3977 send to new test level
|
||||
logger.GLOBAL_LOGGER.debug(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'debug':
|
||||
logger.GLOBAL_LOGGER.debug(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'info':
|
||||
logger.GLOBAL_LOGGER.info(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'warn':
|
||||
logger.GLOBAL_LOGGER.warning()(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'error':
|
||||
logger.GLOBAL_LOGGER.error(logger.timestamped_line(e.cli_msg()))
|
||||
elif e.level_tag() == 'exception':
|
||||
logger.GLOBAL_LOGGER.exception(logger.timestamped_line(e.cli_msg()))
|
||||
else:
|
||||
raise AssertionError(
|
||||
f"Event type {type(e).__name__} has unhandled level: {e.level_tag()}"
|
||||
)
|
||||
@@ -1,7 +0,0 @@
|
||||
from dbt.events.types import Event
|
||||
from typing import List
|
||||
|
||||
|
||||
# the global history of events for this session
|
||||
# TODO this is naive and the memory footprint is likely far too large.
|
||||
EVENT_HISTORY: List[Event] = []
|
||||
@@ -1,147 +0,0 @@
|
||||
from abc import ABCMeta, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
# types to represent log levels
|
||||
|
||||
# in preparation for #3977
|
||||
class TestLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "test"
|
||||
|
||||
|
||||
class DebugLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "debug"
|
||||
|
||||
|
||||
class InfoLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "info"
|
||||
|
||||
|
||||
class WarnLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "warn"
|
||||
|
||||
|
||||
class ErrorLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "error"
|
||||
|
||||
|
||||
class ExceptionLevel():
|
||||
def level_tag(self) -> str:
|
||||
return "exception"
|
||||
|
||||
|
||||
# The following classes represent the data necessary to describe a
|
||||
# particular event to both human readable logs, and machine reliable
|
||||
# event streams. classes extend superclasses that indicate what
|
||||
# destinations they are intended for, which mypy uses to enforce
|
||||
# that the necessary methods are defined.
|
||||
|
||||
|
||||
# top-level superclass for all events
|
||||
class Event(metaclass=ABCMeta):
|
||||
# do not define this yourself. inherit it from one of the above level types.
|
||||
@abstractmethod
|
||||
def level_tag(self) -> str:
|
||||
raise Exception("level_tag not implemented for event")
|
||||
|
||||
|
||||
class CliEventABC(Event, metaclass=ABCMeta):
|
||||
# Solely the human readable message. Timestamps and formatting will be added by the logger.
|
||||
@abstractmethod
|
||||
def cli_msg(self) -> str:
|
||||
raise Exception("cli_msg not implemented for cli event")
|
||||
|
||||
|
||||
class ParsingStart(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Start parsing."
|
||||
|
||||
|
||||
class ParsingCompiling(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Compiling."
|
||||
|
||||
|
||||
class ParsingWritingManifest(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Writing manifest."
|
||||
|
||||
|
||||
class ParsingDone(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Done."
|
||||
|
||||
|
||||
class ManifestDependenciesLoaded(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Dependencies loaded"
|
||||
|
||||
|
||||
class ManifestLoaderCreated(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "ManifestLoader created"
|
||||
|
||||
|
||||
class ManifestLoaded(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Manifest loaded"
|
||||
|
||||
|
||||
class ManifestChecked(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Manifest checked"
|
||||
|
||||
|
||||
class ManifestFlatGraphBuilt(InfoLevel, CliEventABC):
|
||||
def cli_msg(self) -> str:
|
||||
return "Flat graph built"
|
||||
|
||||
|
||||
@dataclass
|
||||
class ReportPerformancePath(InfoLevel, CliEventABC):
|
||||
path: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return f"Performance info: {self.path}"
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroEventInfo(InfoLevel, CliEventABC):
|
||||
msg: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return self.msg
|
||||
|
||||
|
||||
@dataclass
|
||||
class MacroEventDebug(DebugLevel, CliEventABC):
|
||||
msg: str
|
||||
|
||||
def cli_msg(self) -> str:
|
||||
return self.msg
|
||||
|
||||
|
||||
# since mypy doesn't run on every file we need to suggest to mypy that every
|
||||
# class gets instantiated. But we don't actually want to run this code.
|
||||
# making the conditional `if False` causes mypy to skip it as dead code so
|
||||
# we need to skirt around that by computing something it doesn't check statically.
|
||||
#
|
||||
# TODO remove these lines once we run mypy everywhere.
|
||||
if 1 == 0:
|
||||
ParsingStart()
|
||||
ParsingCompiling()
|
||||
ParsingWritingManifest()
|
||||
ParsingDone()
|
||||
ManifestDependenciesLoaded()
|
||||
ManifestLoaderCreated()
|
||||
ManifestLoaded()
|
||||
ManifestChecked()
|
||||
ManifestFlatGraphBuilt()
|
||||
ReportPerformancePath(path='')
|
||||
MacroEventInfo(msg='')
|
||||
MacroEventDebug(msg='')
|
||||
@@ -5,7 +5,7 @@ from typing import NoReturn, Optional, Mapping, Any
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt import flags
|
||||
from dbt.ui import line_wrap_message, warning_tag
|
||||
from dbt.ui import line_wrap_message
|
||||
|
||||
import dbt.dataclass_schema
|
||||
|
||||
@@ -466,15 +466,6 @@ def invalid_type_error(method_name, arg_name, got_value, expected_type,
|
||||
got_value=got_value, got_type=got_type))
|
||||
|
||||
|
||||
def invalid_bool_error(got_value, macro_name) -> NoReturn:
|
||||
"""Raise a CompilationException when an macro expects a boolean but gets some
|
||||
other value.
|
||||
"""
|
||||
msg = ("Macro '{macro_name}' returns '{got_value}'. It is not type 'bool' "
|
||||
"and cannot not be converted reliably to a bool.")
|
||||
raise_compiler_error(msg.format(macro_name=macro_name, got_value=got_value))
|
||||
|
||||
|
||||
def ref_invalid_args(model, args) -> NoReturn:
|
||||
raise_compiler_error(
|
||||
"ref() takes at most two arguments ({} given)".format(len(args)),
|
||||
@@ -615,6 +606,14 @@ def source_target_not_found(
|
||||
raise_compiler_error(msg, model)
|
||||
|
||||
|
||||
def ref_disabled_dependency(model, target_model):
|
||||
raise_compiler_error(
|
||||
"Model '{}' depends on model '{}' which is disabled in "
|
||||
"the project config".format(model.unique_id,
|
||||
target_model.unique_id),
|
||||
model)
|
||||
|
||||
|
||||
def dependency_not_found(model, target_model_name):
|
||||
raise_compiler_error(
|
||||
"'{}' depends on '{}' which is not in the graph!"
|
||||
@@ -629,20 +628,6 @@ def macro_not_found(model, target_macro_id):
|
||||
.format(model.unique_id, target_macro_id))
|
||||
|
||||
|
||||
def macro_invalid_dispatch_arg(macro_name) -> NoReturn:
|
||||
msg = '''\
|
||||
The "packages" argument of adapter.dispatch() has been deprecated.
|
||||
Use the "macro_namespace" argument instead.
|
||||
|
||||
Raised during dispatch for: {}
|
||||
|
||||
For more information, see:
|
||||
|
||||
https://docs.getdbt.com/reference/dbt-jinja-functions/dispatch
|
||||
'''
|
||||
raise_compiler_error(msg.format(macro_name))
|
||||
|
||||
|
||||
def materialization_not_available(model, adapter_type):
|
||||
materialization = model.get_materialization()
|
||||
|
||||
@@ -689,14 +674,6 @@ def missing_relation(relation, model=None):
|
||||
model)
|
||||
|
||||
|
||||
def raise_dataclass_not_dict(obj):
|
||||
msg = (
|
||||
'The object ("{obj}") was used as a dictionary. This '
|
||||
'capability has been removed from objects of this type.'
|
||||
)
|
||||
raise_compiler_error(msg)
|
||||
|
||||
|
||||
def relation_wrong_type(relation, expected_type, model=None):
|
||||
raise_compiler_error(
|
||||
('Trying to create {expected_type} {relation}, '
|
||||
@@ -733,7 +710,7 @@ def system_error(operation_name):
|
||||
raise_compiler_error(
|
||||
"dbt encountered an error when attempting to {}. "
|
||||
"If this error persists, please create an issue at: \n\n"
|
||||
"https://github.com/dbt-labs/dbt-core"
|
||||
"https://github.com/dbt-labs/dbt"
|
||||
.format(operation_name))
|
||||
|
||||
|
||||
@@ -939,17 +916,22 @@ def raise_unrecognized_credentials_type(typename, supported_types):
|
||||
)
|
||||
|
||||
|
||||
def warn_invalid_patch(patch, resource_type):
|
||||
def raise_invalid_patch(
|
||||
node, patch_section: str, patch_path: str,
|
||||
) -> NoReturn:
|
||||
msg = line_wrap_message(
|
||||
f'''\
|
||||
'{patch.name}' is a {resource_type} node, but it is
|
||||
specified in the {patch.yaml_key} section of
|
||||
{patch.original_file_path}.
|
||||
To fix this error, place the `{patch.name}`
|
||||
specification under the {resource_type.pluralize()} key instead.
|
||||
'{node.name}' is a {node.resource_type} node, but it is
|
||||
specified in the {patch_section} section of
|
||||
{patch_path}.
|
||||
|
||||
|
||||
|
||||
To fix this error, place the `{node.name}`
|
||||
specification under the {node.resource_type.pluralize()} key instead.
|
||||
'''
|
||||
)
|
||||
warn_or_error(msg, log_fmt=warning_tag('{}'))
|
||||
raise_compiler_error(msg, node)
|
||||
|
||||
|
||||
def raise_not_implemented(msg):
|
||||
@@ -1011,7 +993,6 @@ CONTEXT_EXPORTS = {
|
||||
raise_ambiguous_alias,
|
||||
raise_ambiguous_catalog_match,
|
||||
raise_cache_inconsistent,
|
||||
raise_dataclass_not_dict,
|
||||
raise_compiler_error,
|
||||
raise_database_error,
|
||||
raise_dep_not_found,
|
||||
|
||||
@@ -6,52 +6,18 @@ if os.name != 'nt':
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
# PROFILES_DIR must be set before the other flags
|
||||
# It also gets set in main.py and in set_from_args because the rpc server
|
||||
# doesn't go through exactly the same main arg processing.
|
||||
DEFAULT_PROFILES_DIR = os.path.join(os.path.expanduser('~'), '.dbt')
|
||||
PROFILES_DIR = os.path.expanduser(
|
||||
os.getenv('DBT_PROFILES_DIR', DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
STRICT_MODE = False # Only here for backwards compatibility
|
||||
FULL_REFRESH = False # subcommand
|
||||
STORE_FAILURES = False # subcommand
|
||||
GREEDY = None # subcommand
|
||||
|
||||
# Global CLI commands
|
||||
USE_EXPERIMENTAL_PARSER = None
|
||||
STATIC_PARSER = None
|
||||
# initially all flags are set to None, the on-load call of reset() will set
|
||||
# them for their first time.
|
||||
STRICT_MODE = None
|
||||
FULL_REFRESH = None
|
||||
USE_CACHE = None
|
||||
WARN_ERROR = None
|
||||
TEST_NEW_PARSER = None
|
||||
USE_EXPERIMENTAL_PARSER = None
|
||||
WRITE_JSON = None
|
||||
PARTIAL_PARSE = None
|
||||
USE_COLORS = None
|
||||
DEBUG = None
|
||||
LOG_FORMAT = None
|
||||
VERSION_CHECK = None
|
||||
FAIL_FAST = None
|
||||
SEND_ANONYMOUS_USAGE_STATS = None
|
||||
PRINTER_WIDTH = 80
|
||||
WHICH = None
|
||||
|
||||
# Global CLI defaults. These flags are set from three places:
|
||||
# CLI args, environment variables, and user_config (profiles.yml).
|
||||
# Environment variables use the pattern 'DBT_{flag name}', like DBT_PROFILES_DIR
|
||||
flag_defaults = {
|
||||
"USE_EXPERIMENTAL_PARSER": False,
|
||||
"STATIC_PARSER": True,
|
||||
"WARN_ERROR": False,
|
||||
"WRITE_JSON": True,
|
||||
"PARTIAL_PARSE": True,
|
||||
"USE_COLORS": True,
|
||||
"PROFILES_DIR": DEFAULT_PROFILES_DIR,
|
||||
"DEBUG": False,
|
||||
"LOG_FORMAT": None,
|
||||
"VERSION_CHECK": True,
|
||||
"FAIL_FAST": False,
|
||||
"SEND_ANONYMOUS_USAGE_STATS": True,
|
||||
"PRINTER_WIDTH": 80
|
||||
}
|
||||
STORE_FAILURES = None
|
||||
|
||||
|
||||
def env_set_truthy(key: str) -> Optional[str]:
|
||||
@@ -64,12 +30,6 @@ def env_set_truthy(key: str) -> Optional[str]:
|
||||
return value
|
||||
|
||||
|
||||
def env_set_bool(env_value):
|
||||
if env_value in ('1', 't', 'true', 'y', 'yes'):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def env_set_path(key: str) -> Optional[Path]:
|
||||
value = os.getenv(key)
|
||||
if value is None:
|
||||
@@ -78,6 +38,8 @@ def env_set_path(key: str) -> Optional[Path]:
|
||||
return Path(value)
|
||||
|
||||
|
||||
SINGLE_THREADED_WEBSERVER = env_set_truthy('DBT_SINGLE_THREADED_WEBSERVER')
|
||||
SINGLE_THREADED_HANDLER = env_set_truthy('DBT_SINGLE_THREADED_HANDLER')
|
||||
MACRO_DEBUGGING = env_set_truthy('DBT_MACRO_DEBUGGING')
|
||||
DEFER_MODE = env_set_truthy('DBT_DEFER_TO_STATE')
|
||||
ARTIFACT_STATE_PATH = env_set_path('DBT_ARTIFACT_STATE_PATH')
|
||||
@@ -88,79 +50,56 @@ def _get_context():
|
||||
return multiprocessing.get_context('spawn')
|
||||
|
||||
|
||||
# This is not a flag, it's a place to store the lock
|
||||
MP_CONTEXT = _get_context()
|
||||
|
||||
|
||||
def set_from_args(args, user_config):
|
||||
global STRICT_MODE, FULL_REFRESH, WARN_ERROR, \
|
||||
USE_EXPERIMENTAL_PARSER, STATIC_PARSER, WRITE_JSON, PARTIAL_PARSE, \
|
||||
USE_COLORS, STORE_FAILURES, PROFILES_DIR, DEBUG, LOG_FORMAT, GREEDY, \
|
||||
VERSION_CHECK, FAIL_FAST, SEND_ANONYMOUS_USAGE_STATS, PRINTER_WIDTH, \
|
||||
WHICH
|
||||
def reset():
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
USE_EXPERIMENTAL_PARSER, WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS, \
|
||||
STORE_FAILURES
|
||||
|
||||
STRICT_MODE = False
|
||||
FULL_REFRESH = False
|
||||
USE_CACHE = True
|
||||
WARN_ERROR = False
|
||||
TEST_NEW_PARSER = False
|
||||
USE_EXPERIMENTAL_PARSER = False
|
||||
WRITE_JSON = True
|
||||
PARTIAL_PARSE = False
|
||||
MP_CONTEXT = _get_context()
|
||||
USE_COLORS = True
|
||||
STORE_FAILURES = False
|
||||
|
||||
|
||||
def set_from_args(args):
|
||||
global STRICT_MODE, FULL_REFRESH, USE_CACHE, WARN_ERROR, TEST_NEW_PARSER, \
|
||||
USE_EXPERIMENTAL_PARSER, WRITE_JSON, PARTIAL_PARSE, MP_CONTEXT, USE_COLORS, \
|
||||
STORE_FAILURES
|
||||
|
||||
USE_CACHE = getattr(args, 'use_cache', USE_CACHE)
|
||||
|
||||
STRICT_MODE = False # backwards compatibility
|
||||
# cli args without user_config or env var option
|
||||
FULL_REFRESH = getattr(args, 'full_refresh', FULL_REFRESH)
|
||||
STRICT_MODE = getattr(args, 'strict', STRICT_MODE)
|
||||
WARN_ERROR = (
|
||||
STRICT_MODE or
|
||||
getattr(args, 'warn_error', STRICT_MODE or WARN_ERROR)
|
||||
)
|
||||
|
||||
TEST_NEW_PARSER = getattr(args, 'test_new_parser', TEST_NEW_PARSER)
|
||||
USE_EXPERIMENTAL_PARSER = getattr(args, 'use_experimental_parser', USE_EXPERIMENTAL_PARSER)
|
||||
WRITE_JSON = getattr(args, 'write_json', WRITE_JSON)
|
||||
PARTIAL_PARSE = getattr(args, 'partial_parse', None)
|
||||
MP_CONTEXT = _get_context()
|
||||
|
||||
# The use_colors attribute will always have a value because it is assigned
|
||||
# None by default from the add_mutually_exclusive_group function
|
||||
use_colors_override = getattr(args, 'use_colors')
|
||||
|
||||
if use_colors_override is not None:
|
||||
USE_COLORS = use_colors_override
|
||||
|
||||
STORE_FAILURES = getattr(args, 'store_failures', STORE_FAILURES)
|
||||
GREEDY = getattr(args, 'greedy', GREEDY)
|
||||
WHICH = getattr(args, 'which', WHICH)
|
||||
|
||||
# global cli flags with env var and user_config alternatives
|
||||
USE_EXPERIMENTAL_PARSER = get_flag_value('USE_EXPERIMENTAL_PARSER', args, user_config)
|
||||
STATIC_PARSER = get_flag_value('STATIC_PARSER', args, user_config)
|
||||
WARN_ERROR = get_flag_value('WARN_ERROR', args, user_config)
|
||||
WRITE_JSON = get_flag_value('WRITE_JSON', args, user_config)
|
||||
PARTIAL_PARSE = get_flag_value('PARTIAL_PARSE', args, user_config)
|
||||
USE_COLORS = get_flag_value('USE_COLORS', args, user_config)
|
||||
PROFILES_DIR = get_flag_value('PROFILES_DIR', args, user_config)
|
||||
DEBUG = get_flag_value('DEBUG', args, user_config)
|
||||
LOG_FORMAT = get_flag_value('LOG_FORMAT', args, user_config)
|
||||
VERSION_CHECK = get_flag_value('VERSION_CHECK', args, user_config)
|
||||
FAIL_FAST = get_flag_value('FAIL_FAST', args, user_config)
|
||||
SEND_ANONYMOUS_USAGE_STATS = get_flag_value('SEND_ANONYMOUS_USAGE_STATS', args, user_config)
|
||||
PRINTER_WIDTH = get_flag_value('PRINTER_WIDTH', args, user_config)
|
||||
|
||||
|
||||
def get_flag_value(flag, args, user_config):
|
||||
lc_flag = flag.lower()
|
||||
flag_value = getattr(args, lc_flag, None)
|
||||
if flag_value is None:
|
||||
# Environment variables use pattern 'DBT_{flag name}'
|
||||
env_flag = f"DBT_{flag}"
|
||||
env_value = os.getenv(env_flag)
|
||||
if env_value is not None and env_value != '':
|
||||
env_value = env_value.lower()
|
||||
# non Boolean values
|
||||
if flag in ['LOG_FORMAT', 'PRINTER_WIDTH', 'PROFILES_DIR']:
|
||||
flag_value = env_value
|
||||
else:
|
||||
flag_value = env_set_bool(env_value)
|
||||
elif user_config is not None and getattr(user_config, lc_flag, None) is not None:
|
||||
flag_value = getattr(user_config, lc_flag)
|
||||
else:
|
||||
flag_value = flag_defaults[flag]
|
||||
if flag == 'PRINTER_WIDTH': # printer_width must be an int or it hangs
|
||||
flag_value = int(flag_value)
|
||||
if flag == 'PROFILES_DIR':
|
||||
flag_value = os.path.abspath(flag_value)
|
||||
|
||||
return flag_value
|
||||
|
||||
|
||||
def get_flag_dict():
|
||||
return {
|
||||
"use_experimental_parser": USE_EXPERIMENTAL_PARSER,
|
||||
"static_parser": STATIC_PARSER,
|
||||
"warn_error": WARN_ERROR,
|
||||
"write_json": WRITE_JSON,
|
||||
"partial_parse": PARTIAL_PARSE,
|
||||
"use_colors": USE_COLORS,
|
||||
"profiles_dir": PROFILES_DIR,
|
||||
"debug": DEBUG,
|
||||
"log_format": LOG_FORMAT,
|
||||
"version_check": VERSION_CHECK,
|
||||
"fail_fast": FAIL_FAST,
|
||||
"send_anonymous_usage_stats": SEND_ANONYMOUS_USAGE_STATS,
|
||||
"printer_width": PRINTER_WIDTH,
|
||||
}
|
||||
# initialize everything to the defaults on module load
|
||||
reset()
|
||||
|
||||
@@ -11,6 +11,7 @@ from .selector import ( # noqa: F401
|
||||
)
|
||||
from .cli import ( # noqa: F401
|
||||
parse_difference,
|
||||
parse_test_selectors,
|
||||
parse_from_selectors_definition,
|
||||
)
|
||||
from .queue import GraphQueue # noqa: F401
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
# special support for CLI argument parsing.
|
||||
from dbt import flags
|
||||
import itertools
|
||||
from dbt.clients.yaml_helper import yaml, Loader, Dumper # noqa: F401
|
||||
|
||||
@@ -22,6 +21,8 @@ INTERSECTION_DELIMITER = ','
|
||||
|
||||
DEFAULT_INCLUDES: List[str] = ['fqn:*', 'source:*', 'exposure:*']
|
||||
DEFAULT_EXCLUDES: List[str] = []
|
||||
DATA_TEST_SELECTOR: str = 'test_type:data'
|
||||
SCHEMA_TEST_SELECTOR: str = 'test_type:schema'
|
||||
|
||||
|
||||
def parse_union(
|
||||
@@ -65,11 +66,42 @@ def parse_union_from_default(
|
||||
def parse_difference(
|
||||
include: Optional[List[str]], exclude: Optional[List[str]]
|
||||
) -> SelectionDifference:
|
||||
included = parse_union_from_default(include, DEFAULT_INCLUDES, greedy=bool(flags.GREEDY))
|
||||
included = parse_union_from_default(include, DEFAULT_INCLUDES)
|
||||
excluded = parse_union_from_default(exclude, DEFAULT_EXCLUDES, greedy=True)
|
||||
return SelectionDifference(components=[included, excluded])
|
||||
|
||||
|
||||
def parse_test_selectors(
|
||||
data: bool, schema: bool, base: SelectionSpec
|
||||
) -> SelectionSpec:
|
||||
union_components = []
|
||||
|
||||
if data:
|
||||
union_components.append(
|
||||
SelectionCriteria.from_single_spec(DATA_TEST_SELECTOR)
|
||||
)
|
||||
if schema:
|
||||
union_components.append(
|
||||
SelectionCriteria.from_single_spec(SCHEMA_TEST_SELECTOR)
|
||||
)
|
||||
|
||||
intersect_with: SelectionSpec
|
||||
if not union_components:
|
||||
return base
|
||||
elif len(union_components) == 1:
|
||||
intersect_with = union_components[0]
|
||||
else: # data and schema tests
|
||||
intersect_with = SelectionUnion(
|
||||
components=union_components,
|
||||
expect_exists=True,
|
||||
raw=[DATA_TEST_SELECTOR, SCHEMA_TEST_SELECTOR],
|
||||
)
|
||||
|
||||
return SelectionIntersection(
|
||||
components=[base, intersect_with], expect_exists=True
|
||||
)
|
||||
|
||||
|
||||
RawDefinition = Union[str, Dict[str, Any]]
|
||||
|
||||
|
||||
@@ -148,7 +180,7 @@ def parse_union_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
union_def_parts = _get_list_dicts(definition, 'union')
|
||||
include, exclude = _parse_include_exclude_subdefs(union_def_parts)
|
||||
|
||||
union = SelectionUnion(components=include, greedy_warning=False)
|
||||
union = SelectionUnion(components=include)
|
||||
|
||||
if exclude is None:
|
||||
union.raw = definition
|
||||
@@ -156,8 +188,7 @@ def parse_union_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
else:
|
||||
return SelectionDifference(
|
||||
components=[union, exclude],
|
||||
raw=definition,
|
||||
greedy_warning=False
|
||||
raw=definition
|
||||
)
|
||||
|
||||
|
||||
@@ -166,7 +197,7 @@ def parse_intersection_definition(
|
||||
) -> SelectionSpec:
|
||||
intersection_def_parts = _get_list_dicts(definition, 'intersection')
|
||||
include, exclude = _parse_include_exclude_subdefs(intersection_def_parts)
|
||||
intersection = SelectionIntersection(components=include, greedy_warning=False)
|
||||
intersection = SelectionIntersection(components=include)
|
||||
|
||||
if exclude is None:
|
||||
intersection.raw = definition
|
||||
@@ -174,8 +205,7 @@ def parse_intersection_definition(
|
||||
else:
|
||||
return SelectionDifference(
|
||||
components=[intersection, exclude],
|
||||
raw=definition,
|
||||
greedy_warning=False
|
||||
raw=definition
|
||||
)
|
||||
|
||||
|
||||
@@ -209,7 +239,7 @@ def parse_dict_definition(definition: Dict[str, Any]) -> SelectionSpec:
|
||||
if diff_arg is None:
|
||||
return base
|
||||
else:
|
||||
return SelectionDifference(components=[base, diff_arg], greedy_warning=False)
|
||||
return SelectionDifference(components=[base, diff_arg])
|
||||
|
||||
|
||||
def parse_from_definition(
|
||||
@@ -241,12 +271,10 @@ def parse_from_definition(
|
||||
|
||||
def parse_from_selectors_definition(
|
||||
source: SelectorFile
|
||||
) -> Dict[str, Dict[str, Union[SelectionSpec, bool]]]:
|
||||
result: Dict[str, Dict[str, Union[SelectionSpec, bool]]] = {}
|
||||
) -> Dict[str, SelectionSpec]:
|
||||
result: Dict[str, SelectionSpec] = {}
|
||||
selector: SelectorDefinition
|
||||
for selector in source.selectors:
|
||||
result[selector.name] = {
|
||||
"default": selector.default,
|
||||
"definition": parse_from_definition(selector.definition, rootlevel=True)
|
||||
}
|
||||
result[selector.name] = parse_from_definition(selector.definition,
|
||||
rootlevel=True)
|
||||
return result
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
|
||||
from typing import Set, List, Optional, Tuple
|
||||
|
||||
from .graph import Graph, UniqueId
|
||||
@@ -29,24 +30,6 @@ def alert_non_existence(raw_spec, nodes):
|
||||
)
|
||||
|
||||
|
||||
def alert_unused_nodes(raw_spec, node_names):
|
||||
summary_nodes_str = ("\n - ").join(node_names[:3])
|
||||
debug_nodes_str = ("\n - ").join(node_names)
|
||||
and_more_str = f"\n - and {len(node_names) - 3} more" if len(node_names) > 4 else ""
|
||||
summary_msg = (
|
||||
f"\nSome tests were excluded because at least one parent is not selected. "
|
||||
f"Use the --greedy flag to include them."
|
||||
f"\n - {summary_nodes_str}{and_more_str}"
|
||||
)
|
||||
logger.info(summary_msg)
|
||||
if len(node_names) > 4:
|
||||
debug_msg = (
|
||||
f"Full list of tests that were excluded:"
|
||||
f"\n - {debug_nodes_str}"
|
||||
)
|
||||
logger.debug(debug_msg)
|
||||
|
||||
|
||||
def can_select_indirectly(node):
|
||||
"""If a node is not selected itself, but its parent(s) are, it may qualify
|
||||
for indirect selection.
|
||||
@@ -168,16 +151,16 @@ class NodeSelector(MethodManager):
|
||||
|
||||
return direct_nodes, indirect_nodes
|
||||
|
||||
def select_nodes(self, spec: SelectionSpec) -> Tuple[Set[UniqueId], Set[UniqueId]]:
|
||||
def select_nodes(self, spec: SelectionSpec) -> Set[UniqueId]:
|
||||
"""Select the nodes in the graph according to the spec.
|
||||
|
||||
This is the main point of entry for turning a spec into a set of nodes:
|
||||
- Recurse through spec, select by criteria, combine by set operation
|
||||
- Return final (unfiltered) selection set
|
||||
"""
|
||||
|
||||
direct_nodes, indirect_nodes = self.select_nodes_recursively(spec)
|
||||
indirect_only = indirect_nodes.difference(direct_nodes)
|
||||
return direct_nodes, indirect_only
|
||||
return direct_nodes
|
||||
|
||||
def _is_graph_member(self, unique_id: UniqueId) -> bool:
|
||||
if unique_id in self.manifest.sources:
|
||||
@@ -230,8 +213,6 @@ class NodeSelector(MethodManager):
|
||||
# - If ANY parent is missing, return it separately. We'll keep it around
|
||||
# for later and see if its other parents show up.
|
||||
# We use this for INCLUSION.
|
||||
# Users can also opt in to inclusive GREEDY mode by passing --greedy flag,
|
||||
# or by specifying `greedy: true` in a yaml selector
|
||||
|
||||
direct_nodes = set(selected)
|
||||
indirect_nodes = set()
|
||||
@@ -270,24 +251,15 @@ class NodeSelector(MethodManager):
|
||||
|
||||
- node selection. Based on the include/exclude sets, the set
|
||||
of matched unique IDs is returned
|
||||
- includes direct + indirect selection (for tests)
|
||||
- expand the graph at each leaf node, before combination
|
||||
- selectors might override this. for example, this is where
|
||||
tests are added
|
||||
- filtering:
|
||||
- selectors can filter the nodes after all of them have been
|
||||
selected
|
||||
"""
|
||||
selected_nodes, indirect_only = self.select_nodes(spec)
|
||||
selected_nodes = self.select_nodes(spec)
|
||||
filtered_nodes = self.filter_selection(selected_nodes)
|
||||
|
||||
if indirect_only:
|
||||
filtered_unused_nodes = self.filter_selection(indirect_only)
|
||||
if filtered_unused_nodes and spec.greedy_warning:
|
||||
# log anything that didn't make the cut
|
||||
unused_node_names = []
|
||||
for unique_id in filtered_unused_nodes:
|
||||
name = self.manifest.nodes[unique_id].name
|
||||
unused_node_names.append(name)
|
||||
alert_unused_nodes(spec, unused_node_names)
|
||||
|
||||
return filtered_nodes
|
||||
|
||||
def get_graph_queue(self, spec: SelectionSpec) -> GraphQueue:
|
||||
|
||||
@@ -8,17 +8,17 @@ from dbt.dataclass_schema import StrEnum
|
||||
from .graph import UniqueId
|
||||
|
||||
from dbt.contracts.graph.compiled import (
|
||||
CompiledSingularTestNode,
|
||||
CompiledGenericTestNode,
|
||||
CompiledDataTestNode,
|
||||
CompiledSchemaTestNode,
|
||||
CompileResultNode,
|
||||
ManifestNode,
|
||||
)
|
||||
from dbt.contracts.graph.manifest import Manifest, WritableManifest
|
||||
from dbt.contracts.graph.parsed import (
|
||||
HasTestMetadata,
|
||||
ParsedSingularTestNode,
|
||||
ParsedDataTestNode,
|
||||
ParsedExposure,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedSourceDefinition,
|
||||
)
|
||||
from dbt.contracts.state import PreviousState
|
||||
@@ -45,7 +45,6 @@ class MethodName(StrEnum):
|
||||
ResourceType = 'resource_type'
|
||||
State = 'state'
|
||||
Exposure = 'exposure'
|
||||
Result = 'result'
|
||||
|
||||
|
||||
def is_selected_node(fqn: List[str], node_selector: str):
|
||||
@@ -362,15 +361,14 @@ class TestTypeSelectorMethod(SelectorMethod):
|
||||
self, included_nodes: Set[UniqueId], selector: str
|
||||
) -> Iterator[UniqueId]:
|
||||
search_types: Tuple[Type, ...]
|
||||
# continue supporting 'schema' + 'data' for backwards compatibility
|
||||
if selector in ('generic', 'schema'):
|
||||
search_types = (ParsedGenericTestNode, CompiledGenericTestNode)
|
||||
elif selector in ('singular', 'data'):
|
||||
search_types = (ParsedSingularTestNode, CompiledSingularTestNode)
|
||||
if selector == 'schema':
|
||||
search_types = (ParsedSchemaTestNode, CompiledSchemaTestNode)
|
||||
elif selector == 'data':
|
||||
search_types = (ParsedDataTestNode, CompiledDataTestNode)
|
||||
else:
|
||||
raise RuntimeException(
|
||||
f'Invalid test type selector {selector}: expected "generic" or '
|
||||
'"singular"'
|
||||
f'Invalid test type selector {selector}: expected "data" or '
|
||||
'"schema"'
|
||||
)
|
||||
|
||||
for node, real_node in self.parsed_nodes(included_nodes):
|
||||
@@ -407,38 +405,27 @@ class StateSelectorMethod(SelectorMethod):
|
||||
|
||||
return modified
|
||||
|
||||
def recursively_check_macros_modified(self, node, previous_macros):
|
||||
def recursively_check_macros_modified(self, node):
|
||||
# check if there are any changes in macros the first time
|
||||
if self.modified_macros is None:
|
||||
self.modified_macros = self._macros_modified()
|
||||
|
||||
# loop through all macros that this node depends on
|
||||
for macro_uid in node.depends_on.macros:
|
||||
# avoid infinite recursion if we've already seen this macro
|
||||
if macro_uid in previous_macros:
|
||||
continue
|
||||
previous_macros.append(macro_uid)
|
||||
# is this macro one of the modified macros?
|
||||
if macro_uid in self.modified_macros:
|
||||
return True
|
||||
# if not, and this macro depends on other macros, keep looping
|
||||
macro_node = self.manifest.macros[macro_uid]
|
||||
if len(macro_node.depends_on.macros) > 0:
|
||||
return self.recursively_check_macros_modified(macro_node, previous_macros)
|
||||
macro = self.manifest.macros[macro_uid]
|
||||
if len(macro.depends_on.macros) > 0:
|
||||
return self.recursively_check_macros_modified(macro)
|
||||
else:
|
||||
return False
|
||||
|
||||
def check_macros_modified(self, node):
|
||||
# check if there are any changes in macros the first time
|
||||
if self.modified_macros is None:
|
||||
self.modified_macros = self._macros_modified()
|
||||
# no macros have been modified, skip looping entirely
|
||||
if not self.modified_macros:
|
||||
return False
|
||||
# recursively loop through upstream macros to see if any is modified
|
||||
else:
|
||||
previous_macros = []
|
||||
return self.recursively_check_macros_modified(node, previous_macros)
|
||||
return False
|
||||
|
||||
def check_modified(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
different_contents = not new.same_contents(old) # type: ignore
|
||||
upstream_macro_change = self.check_macros_modified(new)
|
||||
upstream_macro_change = self.recursively_check_macros_modified(new)
|
||||
return different_contents or upstream_macro_change
|
||||
|
||||
def check_modified_body(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
@@ -470,7 +457,7 @@ class StateSelectorMethod(SelectorMethod):
|
||||
return False
|
||||
|
||||
def check_modified_macros(self, _, new: SelectorTarget) -> bool:
|
||||
return self.check_macros_modified(new)
|
||||
return self.recursively_check_macros_modified(new)
|
||||
|
||||
def check_new(self, old: Optional[SelectorTarget], new: SelectorTarget) -> bool:
|
||||
return old is None
|
||||
@@ -517,23 +504,6 @@ class StateSelectorMethod(SelectorMethod):
|
||||
yield node
|
||||
|
||||
|
||||
class ResultSelectorMethod(SelectorMethod):
|
||||
def search(
|
||||
self, included_nodes: Set[UniqueId], selector: str
|
||||
) -> Iterator[UniqueId]:
|
||||
if self.previous_state is None or self.previous_state.results is None:
|
||||
raise InternalException(
|
||||
'No comparison run_results'
|
||||
)
|
||||
matches = set(
|
||||
result.unique_id for result in self.previous_state.results
|
||||
if result.status == selector
|
||||
)
|
||||
for node, real_node in self.all_nodes(included_nodes):
|
||||
if node in matches:
|
||||
yield node
|
||||
|
||||
|
||||
class MethodManager:
|
||||
SELECTOR_METHODS: Dict[MethodName, Type[SelectorMethod]] = {
|
||||
MethodName.FQN: QualifiedNameSelectorMethod,
|
||||
@@ -546,7 +516,6 @@ class MethodManager:
|
||||
MethodName.TestType: TestTypeSelectorMethod,
|
||||
MethodName.State: StateSelectorMethod,
|
||||
MethodName.Exposure: ExposureSelectorMethod,
|
||||
MethodName.Result: ResultSelectorMethod,
|
||||
}
|
||||
|
||||
def __init__(
|
||||
|
||||
@@ -67,7 +67,6 @@ class SelectionCriteria:
|
||||
children: bool
|
||||
children_depth: Optional[int]
|
||||
greedy: bool = False
|
||||
greedy_warning: bool = False # do not raise warning for yaml selectors
|
||||
|
||||
def __post_init__(self):
|
||||
if self.children and self.childrens_parents:
|
||||
@@ -125,11 +124,11 @@ class SelectionCriteria:
|
||||
parents_depth=parents_depth,
|
||||
children=bool(dct.get('children')),
|
||||
children_depth=children_depth,
|
||||
greedy=(greedy or bool(dct.get('greedy'))),
|
||||
greedy=greedy
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def dict_from_single_spec(cls, raw: str):
|
||||
def dict_from_single_spec(cls, raw: str, greedy: bool = False):
|
||||
result = RAW_SELECTOR_PATTERN.match(raw)
|
||||
if result is None:
|
||||
return {'error': 'Invalid selector spec'}
|
||||
@@ -146,8 +145,6 @@ class SelectionCriteria:
|
||||
dct['parents'] = bool(dct.get('parents'))
|
||||
if 'children' in dct:
|
||||
dct['children'] = bool(dct.get('children'))
|
||||
if 'greedy' in dct:
|
||||
dct['greedy'] = bool(dct.get('greedy'))
|
||||
return dct
|
||||
|
||||
@classmethod
|
||||
@@ -165,12 +162,10 @@ class BaseSelectionGroup(Iterable[SelectionSpec], metaclass=ABCMeta):
|
||||
self,
|
||||
components: Iterable[SelectionSpec],
|
||||
expect_exists: bool = False,
|
||||
greedy_warning: bool = True,
|
||||
raw: Any = None,
|
||||
):
|
||||
self.components: List[SelectionSpec] = list(components)
|
||||
self.expect_exists = expect_exists
|
||||
self.greedy_warning = greedy_warning
|
||||
self.raw = raw
|
||||
|
||||
def __iter__(self) -> Iterator[SelectionSpec]:
|
||||
|
||||
@@ -51,7 +51,7 @@
|
||||
{% endmacro %}
|
||||
|
||||
{% macro get_batch_size() -%}
|
||||
{{ return(adapter.dispatch('get_batch_size', 'dbt')()) }}
|
||||
{{ adapter.dispatch('get_batch_size', 'dbt')() }}
|
||||
{%- endmacro %}
|
||||
|
||||
{% macro default__get_batch_size() %}
|
||||
|
||||
@@ -75,7 +75,7 @@
|
||||
table instead of assuming that the user-supplied {{ updated_at }}
|
||||
will be present in the historical data.
|
||||
|
||||
See https://github.com/dbt-labs/dbt-core/issues/2350
|
||||
See https://github.com/dbt-labs/dbt/issues/2350
|
||||
*/ #}
|
||||
{% set row_changed_expr -%}
|
||||
({{ snapshotted_rel }}.dbt_valid_from < {{ current_rel }}.{{ updated_at }})
|
||||
|
||||
@@ -7,7 +7,7 @@ with all_values as (
|
||||
count(*) as n_records
|
||||
|
||||
from {{ model }}
|
||||
group by {{ column_name }}
|
||||
group by 1
|
||||
|
||||
)
|
||||
|
||||
2
core/dbt/include/starter_project/.gitignore
vendored
2
core/dbt/include/starter_project/.gitignore
vendored
@@ -1,4 +1,4 @@
|
||||
|
||||
target/
|
||||
dbt_packages/
|
||||
dbt_modules/
|
||||
logs/
|
||||
|
||||
@@ -2,27 +2,27 @@
|
||||
# Name your project! Project names should contain only lowercase characters
|
||||
# and underscores. A good package name should reflect your organization's
|
||||
# name or the intended use of these models
|
||||
name: '{project_name}'
|
||||
name: 'my_new_project'
|
||||
version: '1.0.0'
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project.
|
||||
profile: '{profile_name}'
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `model-paths` config, for example, states that models in this project can be
|
||||
# The `source-paths` config, for example, states that models in this project can be
|
||||
# found in the "models/" directory. You probably won't need to change these!
|
||||
model-paths: ["models"]
|
||||
analysis-paths: ["analyses"]
|
||||
source-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
test-paths: ["tests"]
|
||||
seed-paths: ["seeds"]
|
||||
data-paths: ["data"]
|
||||
macro-paths: ["macros"]
|
||||
snapshot-paths: ["snapshots"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_packages"
|
||||
- "dbt_modules"
|
||||
|
||||
|
||||
# Configuring models
|
||||
@@ -30,9 +30,9 @@ clean-targets: # directories to be removed by `dbt clean`
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as tables. These settings can be overridden in the individual model files
|
||||
# using the `{{{{ config(...) }}}}` macro.
|
||||
# using the `{{ config(...) }}` macro.
|
||||
models:
|
||||
{project_name}:
|
||||
my_new_project:
|
||||
# Config indicated by + and applies to all files under models/example/
|
||||
example:
|
||||
+materialized: view
|
||||
|
||||
@@ -345,7 +345,7 @@ class TimestampNamed(logbook.Processor):
|
||||
class ScrubSecrets(logbook.Processor):
|
||||
def process(self, record):
|
||||
for secret in get_secret_env():
|
||||
record.message = str(record.message).replace(secret, "*****")
|
||||
record.message = record.message.replace(secret, "*****")
|
||||
|
||||
|
||||
logger = logbook.Logger('dbt')
|
||||
@@ -655,12 +655,8 @@ def get_timestamp():
|
||||
return time.strftime("%H:%M:%S")
|
||||
|
||||
|
||||
def timestamped_line(msg: str) -> str:
|
||||
return "{} | {}".format(get_timestamp(), msg)
|
||||
|
||||
|
||||
def print_timestamped_line(msg: str, use_color: Optional[str] = None):
|
||||
if use_color is not None:
|
||||
msg = dbt.ui.color(msg, use_color)
|
||||
|
||||
GLOBAL_LOGGER.info(timestamped_line(msg))
|
||||
GLOBAL_LOGGER.info("{} | {}".format(get_timestamp(), msg))
|
||||
|
||||
322
core/dbt/main.py
322
core/dbt/main.py
@@ -10,35 +10,31 @@ from pathlib import Path
|
||||
|
||||
import dbt.version
|
||||
import dbt.flags as flags
|
||||
import dbt.task.run as run_task
|
||||
import dbt.task.build as build_task
|
||||
import dbt.task.clean as clean_task
|
||||
import dbt.task.compile as compile_task
|
||||
import dbt.task.debug as debug_task
|
||||
import dbt.task.clean as clean_task
|
||||
import dbt.task.deps as deps_task
|
||||
import dbt.task.freshness as freshness_task
|
||||
import dbt.task.generate as generate_task
|
||||
import dbt.task.init as init_task
|
||||
import dbt.task.list as list_task
|
||||
import dbt.task.parse as parse_task
|
||||
import dbt.task.run as run_task
|
||||
import dbt.task.run_operation as run_operation_task
|
||||
import dbt.task.seed as seed_task
|
||||
import dbt.task.serve as serve_task
|
||||
import dbt.task.snapshot as snapshot_task
|
||||
import dbt.task.test as test_task
|
||||
import dbt.task.snapshot as snapshot_task
|
||||
import dbt.task.generate as generate_task
|
||||
import dbt.task.serve as serve_task
|
||||
import dbt.task.freshness as freshness_task
|
||||
import dbt.task.run_operation as run_operation_task
|
||||
import dbt.task.parse as parse_task
|
||||
from dbt.profiler import profiler
|
||||
from dbt.task.list import ListTask
|
||||
from dbt.task.rpc.server import RPCServerTask
|
||||
from dbt.adapters.factory import reset_adapters, cleanup_connections
|
||||
|
||||
import dbt.tracking
|
||||
|
||||
from dbt.utils import ExitCodes
|
||||
from dbt.config.profile import DEFAULT_PROFILES_DIR, read_user_config
|
||||
from dbt.exceptions import (
|
||||
RuntimeException,
|
||||
InternalException,
|
||||
NotImplementedException,
|
||||
FailedToConnectException
|
||||
)
|
||||
from dbt.config import PROFILES_DIR, read_user_config
|
||||
from dbt.exceptions import RuntimeException, InternalException
|
||||
|
||||
|
||||
class DBTVersion(argparse.Action):
|
||||
@@ -115,6 +111,14 @@ class DBTArgumentParser(argparse.ArgumentParser):
|
||||
return mutex_group
|
||||
|
||||
|
||||
class RPCArgumentParser(DBTArgumentParser):
|
||||
def exit(self, status=0, message=None):
|
||||
if status == 0:
|
||||
return
|
||||
else:
|
||||
raise TypeError(message)
|
||||
|
||||
|
||||
def main(args=None):
|
||||
if args is None:
|
||||
args = sys.argv[1:]
|
||||
@@ -156,6 +160,17 @@ def handle(args):
|
||||
return res
|
||||
|
||||
|
||||
def initialize_config_values(parsed):
|
||||
"""Given the parsed args, initialize the dbt tracking code.
|
||||
|
||||
It would be nice to re-use this profile later on instead of parsing it
|
||||
twice, but dbt's intialization is not structured in a way that makes that
|
||||
easy.
|
||||
"""
|
||||
cfg = read_user_config(parsed.profiles_dir)
|
||||
cfg.set_values(parsed.profiles_dir)
|
||||
|
||||
|
||||
@contextmanager
|
||||
def adapter_management():
|
||||
reset_adapters()
|
||||
@@ -169,15 +184,8 @@ def handle_and_check(args):
|
||||
with log_manager.applicationbound():
|
||||
parsed = parse_args(args)
|
||||
|
||||
# Set flags from args, user config, and env vars
|
||||
user_config = read_user_config(flags.PROFILES_DIR) # This is read again later
|
||||
flags.set_from_args(parsed, user_config)
|
||||
dbt.tracking.initialize_from_flags()
|
||||
# Set log_format from flags
|
||||
parsed.cls.set_log_format()
|
||||
|
||||
# we've parsed the args and set the flags - we can now decide if we're debug or not
|
||||
if flags.DEBUG:
|
||||
# we've parsed the args - we can now decide if we're debug or not
|
||||
if parsed.debug:
|
||||
log_manager.set_debug()
|
||||
|
||||
profiler_enabled = False
|
||||
@@ -190,6 +198,8 @@ def handle_and_check(args):
|
||||
outfile=parsed.record_timing_info
|
||||
):
|
||||
|
||||
initialize_config_values(parsed)
|
||||
|
||||
with adapter_management():
|
||||
|
||||
task, res = run_from_args(parsed)
|
||||
@@ -206,8 +216,8 @@ def track_run(task):
|
||||
dbt.tracking.track_invocation_end(
|
||||
config=task.config, args=task.args, result_type="ok"
|
||||
)
|
||||
except (NotImplementedException,
|
||||
FailedToConnectException) as e:
|
||||
except (dbt.exceptions.NotImplementedException,
|
||||
dbt.exceptions.FailedToConnectException) as e:
|
||||
logger.error('ERROR: {}'.format(e))
|
||||
dbt.tracking.track_invocation_end(
|
||||
config=task.config, args=task.args, result_type="error"
|
||||
@@ -223,17 +233,15 @@ def track_run(task):
|
||||
|
||||
def run_from_args(parsed):
|
||||
log_cache_events(getattr(parsed, 'log_cache_events', False))
|
||||
flags.set_from_args(parsed)
|
||||
|
||||
# we can now use the logger for stdout
|
||||
# set log_format in the logger
|
||||
parsed.cls.pre_init_hook(parsed)
|
||||
# we can now use the logger for stdout
|
||||
|
||||
logger.info("Running with dbt{}".format(dbt.version.installed))
|
||||
|
||||
# this will convert DbtConfigErrors into RuntimeExceptions
|
||||
# task could be any one of the task objects
|
||||
task = parsed.cls.from_args(args=parsed)
|
||||
|
||||
logger.debug("running dbt with arguments {parsed}", parsed=str(parsed))
|
||||
|
||||
log_path = None
|
||||
@@ -248,6 +256,7 @@ def run_from_args(parsed):
|
||||
|
||||
with track_run(task):
|
||||
results = task.run()
|
||||
|
||||
return task, results
|
||||
|
||||
|
||||
@@ -266,12 +275,11 @@ def _build_base_subparser():
|
||||
|
||||
base_subparser.add_argument(
|
||||
'--profiles-dir',
|
||||
default=None,
|
||||
dest='sub_profiles_dir', # Main cli arg precedes subcommand
|
||||
default=PROFILES_DIR,
|
||||
type=str,
|
||||
help='''
|
||||
Which directory to look in for the profiles.yml file. Default = {}
|
||||
'''.format(DEFAULT_PROFILES_DIR)
|
||||
'''.format(PROFILES_DIR)
|
||||
)
|
||||
|
||||
base_subparser.add_argument(
|
||||
@@ -311,6 +319,15 @@ def _build_base_subparser():
|
||||
help=argparse.SUPPRESS,
|
||||
)
|
||||
|
||||
base_subparser.add_argument(
|
||||
'--bypass-cache',
|
||||
action='store_false',
|
||||
dest='use_cache',
|
||||
help='''
|
||||
If set, bypass the adapter-level cache of database state
|
||||
''',
|
||||
)
|
||||
|
||||
base_subparser.set_defaults(defer=None, state=None)
|
||||
return base_subparser
|
||||
|
||||
@@ -343,6 +360,20 @@ def _build_init_subparser(subparsers, base_subparser):
|
||||
Initialize a new DBT project.
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'project_name',
|
||||
type=str,
|
||||
help='''
|
||||
Name of the new project
|
||||
''',
|
||||
)
|
||||
sub.add_argument(
|
||||
'--adapter',
|
||||
type=str,
|
||||
help='''
|
||||
Write sample profiles.yml for which adapter
|
||||
''',
|
||||
)
|
||||
sub.set_defaults(cls=init_task.InitTask, which='init', rpc_method=None)
|
||||
return sub
|
||||
|
||||
@@ -363,46 +394,11 @@ def _build_build_subparser(subparsers, base_subparser):
|
||||
sub.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
dest='sub_fail_fast',
|
||||
action='store_true',
|
||||
help='''
|
||||
Stop execution upon a first failure.
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--store-failures',
|
||||
action='store_true',
|
||||
help='''
|
||||
Store test results (failing rows) in the database
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--greedy',
|
||||
action='store_true',
|
||||
help='''
|
||||
Select all tests that touch the selected resources,
|
||||
even if they also depend on unselected resources
|
||||
'''
|
||||
)
|
||||
resource_values: List[str] = [
|
||||
str(s) for s in build_task.BuildTask.ALL_RESOURCE_VALUES
|
||||
] + ['all']
|
||||
sub.add_argument('--resource-type',
|
||||
choices=resource_values,
|
||||
action='append',
|
||||
default=[],
|
||||
dest='resource_types')
|
||||
# explicity don't support --models
|
||||
sub.add_argument(
|
||||
'-s',
|
||||
'--select',
|
||||
dest='select',
|
||||
nargs='+',
|
||||
help='''
|
||||
Specify the nodes to include.
|
||||
''',
|
||||
)
|
||||
_add_common_selector_arguments(sub)
|
||||
return sub
|
||||
|
||||
|
||||
@@ -412,7 +408,7 @@ def _build_clean_subparser(subparsers, base_subparser):
|
||||
parents=[base_subparser],
|
||||
help='''
|
||||
Delete all folders in the clean-targets list
|
||||
(usually the dbt_packages and target directories.)
|
||||
(usually the dbt_modules and target directories.)
|
||||
'''
|
||||
)
|
||||
sub.set_defaults(cls=clean_task.CleanTask, which='clean', rpc_method=None)
|
||||
@@ -501,7 +497,6 @@ def _build_run_subparser(subparsers, base_subparser):
|
||||
run_sub.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
dest='sub_fail_fast',
|
||||
action='store_true',
|
||||
help='''
|
||||
Stop execution upon a first failure.
|
||||
@@ -616,7 +611,7 @@ def _add_table_mutability_arguments(*subparsers):
|
||||
'--full-refresh',
|
||||
action='store_true',
|
||||
help='''
|
||||
If specified, dbt will drop incremental models and
|
||||
If specified, DBT will drop incremental models and
|
||||
fully-recalculate the incremental table from the model definition.
|
||||
'''
|
||||
)
|
||||
@@ -625,9 +620,8 @@ def _add_table_mutability_arguments(*subparsers):
|
||||
def _add_version_check(sub):
|
||||
sub.add_argument(
|
||||
'--no-version-check',
|
||||
dest='sub_version_check', # main cli arg precedes subcommands
|
||||
dest='version_check',
|
||||
action='store_false',
|
||||
default=None,
|
||||
help='''
|
||||
If set, skip ensuring dbt's version matches the one specified in
|
||||
the dbt_project.yml file ('require-dbt-version')
|
||||
@@ -704,10 +698,23 @@ def _build_test_subparser(subparsers, base_subparser):
|
||||
Runs tests on data in deployed models. Run this after `dbt run`
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--data',
|
||||
action='store_true',
|
||||
help='''
|
||||
Run data tests defined in "tests" directory.
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--schema',
|
||||
action='store_true',
|
||||
help='''
|
||||
Run constraint validations from schema.yml files
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
dest='sub_fail_fast',
|
||||
action='store_true',
|
||||
help='''
|
||||
Stop execution upon a first test failure.
|
||||
@@ -720,14 +727,6 @@ def _build_test_subparser(subparsers, base_subparser):
|
||||
Store test results (failing rows) in the database
|
||||
'''
|
||||
)
|
||||
sub.add_argument(
|
||||
'--greedy',
|
||||
action='store_true',
|
||||
help='''
|
||||
Select all tests that touch the selected resources,
|
||||
even if they also depend on unselected resources
|
||||
'''
|
||||
)
|
||||
|
||||
sub.set_defaults(cls=test_task.TestTask, which='test', rpc_method='test')
|
||||
return sub
|
||||
@@ -777,6 +776,36 @@ def _build_source_freshness_subparser(subparsers, base_subparser):
|
||||
return sub
|
||||
|
||||
|
||||
def _build_rpc_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'rpc',
|
||||
parents=[base_subparser],
|
||||
help='''
|
||||
Start a json-rpc server
|
||||
''',
|
||||
)
|
||||
sub.add_argument(
|
||||
'--host',
|
||||
default='0.0.0.0',
|
||||
help='''
|
||||
Specify the host to listen on for the rpc server.
|
||||
''',
|
||||
)
|
||||
sub.add_argument(
|
||||
'--port',
|
||||
default=8580,
|
||||
type=int,
|
||||
help='''
|
||||
Specify the port number for the rpc server.
|
||||
''',
|
||||
)
|
||||
sub.set_defaults(cls=RPCServerTask, which='rpc', rpc_method=None)
|
||||
# the rpc task does a 'compile', so we need these attributes to exist, but
|
||||
# we don't want users to be allowed to set them.
|
||||
sub.set_defaults(models=None, exclude=None)
|
||||
return sub
|
||||
|
||||
|
||||
def _build_list_subparser(subparsers, base_subparser):
|
||||
sub = subparsers.add_parser(
|
||||
'list',
|
||||
@@ -786,9 +815,9 @@ def _build_list_subparser(subparsers, base_subparser):
|
||||
''',
|
||||
aliases=['ls'],
|
||||
)
|
||||
sub.set_defaults(cls=list_task.ListTask, which='list', rpc_method=None)
|
||||
sub.set_defaults(cls=ListTask, which='list', rpc_method=None)
|
||||
resource_values: List[str] = [
|
||||
str(s) for s in list_task.ListTask.ALL_RESOURCE_VALUES
|
||||
str(s) for s in ListTask.ALL_RESOURCE_VALUES
|
||||
] + ['default', 'all']
|
||||
sub.add_argument('--resource-type',
|
||||
choices=resource_values,
|
||||
@@ -823,14 +852,6 @@ def _build_list_subparser(subparsers, base_subparser):
|
||||
metavar='SELECTOR',
|
||||
required=False,
|
||||
)
|
||||
sub.add_argument(
|
||||
'--greedy',
|
||||
action='store_true',
|
||||
help='''
|
||||
Select all tests that touch the selected resources,
|
||||
even if they also depend on unselected resources
|
||||
'''
|
||||
)
|
||||
_add_common_selector_arguments(sub)
|
||||
|
||||
return sub
|
||||
@@ -901,7 +922,6 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
'-d',
|
||||
'--debug',
|
||||
action='store_true',
|
||||
default=None,
|
||||
help='''
|
||||
Display debug logging during dbt execution. Useful for debugging and
|
||||
making bug reports.
|
||||
@@ -911,14 +931,13 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
p.add_argument(
|
||||
'--log-format',
|
||||
choices=['text', 'json', 'default'],
|
||||
default=None,
|
||||
default='default',
|
||||
help='''Specify the log format, overriding the command's default.'''
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--no-write-json',
|
||||
action='store_false',
|
||||
default=None,
|
||||
dest='write_json',
|
||||
help='''
|
||||
If set, skip writing the manifest and run_results.json files to disk
|
||||
@@ -929,7 +948,6 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
'--use-colors',
|
||||
action='store_const',
|
||||
const=True,
|
||||
default=None,
|
||||
dest='use_colors',
|
||||
help='''
|
||||
Colorize the output DBT prints to the terminal. Output is colorized by
|
||||
@@ -951,17 +969,18 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--printer-width',
|
||||
dest='printer_width',
|
||||
'-S',
|
||||
'--strict',
|
||||
action='store_true',
|
||||
help='''
|
||||
Sets the width of terminal output
|
||||
Run schema validations at runtime. This will surface bugs in dbt, but
|
||||
may incur a performance penalty.
|
||||
'''
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--warn-error',
|
||||
action='store_true',
|
||||
default=None,
|
||||
help='''
|
||||
If dbt would normally warn, instead raise an exception. Examples
|
||||
include --models that selects nothing, deprecations, configurations
|
||||
@@ -970,17 +989,6 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
'''
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--no-version-check',
|
||||
dest='version_check',
|
||||
action='store_false',
|
||||
default=None,
|
||||
help='''
|
||||
If set, skip ensuring dbt's version matches the one specified in
|
||||
the dbt_project.yml file ('require-dbt-version')
|
||||
'''
|
||||
)
|
||||
|
||||
p.add_optional_argument_inverse(
|
||||
'--partial-parse',
|
||||
enable_help='''
|
||||
@@ -1003,57 +1011,23 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
help=argparse.SUPPRESS,
|
||||
)
|
||||
|
||||
# if set, will use the latest features from the static parser instead of
|
||||
# the stable static parser.
|
||||
# if set, extract all models and blocks with the jinja block extractor, and
|
||||
# verify that we don't fail anywhere the actual jinja parser passes. The
|
||||
# reverse (passing files that ends up failing jinja) is fine.
|
||||
# TODO remove?
|
||||
p.add_argument(
|
||||
'--test-new-parser',
|
||||
action='store_true',
|
||||
help=argparse.SUPPRESS
|
||||
)
|
||||
|
||||
# if set, will use the tree-sitter-jinja2 parser and extractor instead of
|
||||
# jinja rendering when possible.
|
||||
p.add_argument(
|
||||
'--use-experimental-parser',
|
||||
action='store_true',
|
||||
default=None,
|
||||
help='''
|
||||
Enables experimental parsing features.
|
||||
'''
|
||||
)
|
||||
|
||||
# if set, will disable the use of the stable static parser and instead
|
||||
# always rely on jinja rendering.
|
||||
p.add_argument(
|
||||
'--no-static-parser',
|
||||
default=None,
|
||||
dest='static_parser',
|
||||
action='store_false',
|
||||
help='''
|
||||
Disables the static parser.
|
||||
'''
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--profiles-dir',
|
||||
default=None,
|
||||
dest='profiles_dir',
|
||||
type=str,
|
||||
help='''
|
||||
Which directory to look in for the profiles.yml file. Default = {}
|
||||
'''.format(DEFAULT_PROFILES_DIR)
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'--no-anonymous-usage-stats',
|
||||
action='store_false',
|
||||
default=None,
|
||||
dest='send_anonymous_usage_stats',
|
||||
help='''
|
||||
Do not send anonymous usage stat to dbt Labs
|
||||
'''
|
||||
)
|
||||
|
||||
p.add_argument(
|
||||
'-x',
|
||||
'--fail-fast',
|
||||
dest='fail_fast',
|
||||
action='store_true',
|
||||
default=None,
|
||||
help='''
|
||||
Stop execution upon a first failure.
|
||||
Uses an experimental parser to extract jinja values.
|
||||
'''
|
||||
)
|
||||
|
||||
@@ -1075,6 +1049,7 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
|
||||
build_sub = _build_build_subparser(subs, base_subparser)
|
||||
snapshot_sub = _build_snapshot_subparser(subs, base_subparser)
|
||||
rpc_sub = _build_rpc_subparser(subs, base_subparser)
|
||||
run_sub = _build_run_subparser(subs, base_subparser)
|
||||
compile_sub = _build_compile_subparser(subs, base_subparser)
|
||||
parse_sub = _build_parse_subparser(subs, base_subparser)
|
||||
@@ -1083,11 +1058,11 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
seed_sub = _build_seed_subparser(subs, base_subparser)
|
||||
# --threads, --no-version-check
|
||||
_add_common_arguments(run_sub, compile_sub, generate_sub, test_sub,
|
||||
seed_sub, parse_sub, build_sub)
|
||||
rpc_sub, seed_sub, parse_sub, build_sub)
|
||||
# --select, --exclude
|
||||
# list_sub sets up its own arguments.
|
||||
_add_selection_arguments(
|
||||
run_sub, compile_sub, generate_sub, test_sub, snapshot_sub, seed_sub)
|
||||
build_sub, run_sub, compile_sub, generate_sub, test_sub, snapshot_sub, seed_sub)
|
||||
# --defer
|
||||
_add_defer_argument(run_sub, test_sub, build_sub)
|
||||
# --full-refresh
|
||||
@@ -1103,31 +1078,8 @@ def parse_args(args, cls=DBTArgumentParser):
|
||||
|
||||
parsed = p.parse_args(args)
|
||||
|
||||
# profiles_dir is set before subcommands and after, so normalize
|
||||
if hasattr(parsed, 'sub_profiles_dir'):
|
||||
if parsed.sub_profiles_dir is not None:
|
||||
parsed.profiles_dir = parsed.sub_profiles_dir
|
||||
delattr(parsed, 'sub_profiles_dir')
|
||||
if hasattr(parsed, 'profiles_dir'):
|
||||
if parsed.profiles_dir is None:
|
||||
parsed.profiles_dir = flags.PROFILES_DIR
|
||||
else:
|
||||
parsed.profiles_dir = os.path.abspath(parsed.profiles_dir)
|
||||
# needs to be set before the other flags, because it's needed to
|
||||
# read the profile that contains them
|
||||
flags.PROFILES_DIR = parsed.profiles_dir
|
||||
|
||||
# version_check is set before subcommands and after, so normalize
|
||||
if hasattr(parsed, 'sub_version_check'):
|
||||
if parsed.sub_version_check is False:
|
||||
parsed.version_check = False
|
||||
delattr(parsed, 'sub_version_check')
|
||||
|
||||
# fail_fast is set before subcommands and after, so normalize
|
||||
if hasattr(parsed, 'sub_fail_fast'):
|
||||
if parsed.sub_fail_fast is True:
|
||||
parsed.fail_fast = True
|
||||
delattr(parsed, 'sub_fail_fast')
|
||||
parsed.profiles_dir = os.path.abspath(parsed.profiles_dir)
|
||||
|
||||
if getattr(parsed, 'project_dir', None) is not None:
|
||||
expanded_user = os.path.expanduser(parsed.project_dir)
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
from .analysis import AnalysisParser # noqa
|
||||
from .base import Parser, ConfiguredParser # noqa
|
||||
from .singular_test import SingularTestParser # noqa
|
||||
from .generic_test import GenericTestParser # noqa
|
||||
from .data_test import DataTestParser # noqa
|
||||
from .docs import DocumentationParser # noqa
|
||||
from .hooks import HookParser # noqa
|
||||
from .macros import MacroParser # noqa
|
||||
@@ -11,6 +10,6 @@ from .seeds import SeedParser # noqa
|
||||
from .snapshots import SnapshotParser # noqa
|
||||
|
||||
from . import ( # noqa
|
||||
analysis, base, generic_test, singular_test, docs, hooks, macros, models, schemas,
|
||||
analysis, base, data_test, docs, hooks, macros, models, schemas,
|
||||
snapshots
|
||||
)
|
||||
|
||||
@@ -13,7 +13,7 @@ from dbt.context.providers import (
|
||||
generate_parser_model,
|
||||
generate_generate_component_name_macro,
|
||||
)
|
||||
from dbt.adapters.factory import get_adapter # noqa: F401
|
||||
from dbt.adapters.factory import get_adapter
|
||||
from dbt.clients.jinja import get_rendered
|
||||
from dbt.config import Project, RuntimeConfig
|
||||
from dbt.context.context_config import (
|
||||
@@ -260,13 +260,17 @@ class ConfiguredParser(
|
||||
# Given the parsed node and a ContextConfig to use during parsing,
|
||||
# render the node's sql wtih macro capture enabled.
|
||||
# Note: this mutates the config object when config calls are rendered.
|
||||
context = self._context_for(parsed_node, config)
|
||||
|
||||
# this goes through the process of rendering, but just throws away
|
||||
# the rendered result. The "macro capture" is the point?
|
||||
get_rendered(
|
||||
parsed_node.raw_sql, context, parsed_node, capture_macros=True
|
||||
)
|
||||
# during parsing, we don't have a connection, but we might need one, so
|
||||
# we have to acquire it.
|
||||
with get_adapter(self.root_project).connection_for(parsed_node):
|
||||
context = self._context_for(parsed_node, config)
|
||||
|
||||
# this goes through the process of rendering, but just throws away
|
||||
# the rendered result. The "macro capture" is the point?
|
||||
get_rendered(
|
||||
parsed_node.raw_sql, context, parsed_node, capture_macros=True
|
||||
)
|
||||
return context
|
||||
|
||||
# This is taking the original config for the node, converting it to a dict,
|
||||
|
||||
26
core/dbt/parser/data_test.py
Normal file
26
core/dbt/parser/data_test.py
Normal file
@@ -0,0 +1,26 @@
|
||||
from dbt.contracts.graph.parsed import ParsedDataTestNode
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.utils import get_pseudo_test_path
|
||||
|
||||
|
||||
class DataTestParser(SimpleSQLParser[ParsedDataTestNode]):
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedDataTestNode:
|
||||
if validate:
|
||||
ParsedDataTestNode.validate(dct)
|
||||
return ParsedDataTestNode.from_dict(dct)
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.Test
|
||||
|
||||
def transform(self, node):
|
||||
if 'data' not in node.tags:
|
||||
node.tags.append('data')
|
||||
return node
|
||||
|
||||
@classmethod
|
||||
def get_compiled_path(cls, block: FileBlock):
|
||||
return get_pseudo_test_path(block.name, block.path.relative_path,
|
||||
'data_test')
|
||||
@@ -1,106 +0,0 @@
|
||||
from typing import Iterable, List
|
||||
|
||||
import jinja2
|
||||
|
||||
from dbt.exceptions import CompilationException
|
||||
from dbt.clients import jinja
|
||||
from dbt.contracts.graph.parsed import ParsedGenericTestNode
|
||||
from dbt.contracts.graph.unparsed import UnparsedMacro
|
||||
from dbt.contracts.graph.parsed import ParsedMacro
|
||||
from dbt.contracts.files import SourceFile
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import BaseParser
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.utils import MACRO_PREFIX
|
||||
|
||||
|
||||
class GenericTestParser(BaseParser[ParsedGenericTestNode]):
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.Macro
|
||||
|
||||
@classmethod
|
||||
def get_compiled_path(cls, block: FileBlock):
|
||||
return block.path.relative_path
|
||||
|
||||
def parse_generic_test(
|
||||
self, block: jinja.BlockTag, base_node: UnparsedMacro, name: str
|
||||
) -> ParsedMacro:
|
||||
unique_id = self.generate_unique_id(name)
|
||||
|
||||
return ParsedMacro(
|
||||
path=base_node.path,
|
||||
macro_sql=block.full_block,
|
||||
original_file_path=base_node.original_file_path,
|
||||
package_name=base_node.package_name,
|
||||
root_path=base_node.root_path,
|
||||
resource_type=base_node.resource_type,
|
||||
name=name,
|
||||
unique_id=unique_id,
|
||||
)
|
||||
|
||||
def parse_unparsed_generic_test(
|
||||
self, base_node: UnparsedMacro
|
||||
) -> Iterable[ParsedMacro]:
|
||||
try:
|
||||
blocks: List[jinja.BlockTag] = [
|
||||
t for t in
|
||||
jinja.extract_toplevel_blocks(
|
||||
base_node.raw_sql,
|
||||
allowed_blocks={'test'},
|
||||
collect_raw_data=False,
|
||||
)
|
||||
if isinstance(t, jinja.BlockTag)
|
||||
]
|
||||
except CompilationException as exc:
|
||||
exc.add_node(base_node)
|
||||
raise
|
||||
|
||||
for block in blocks:
|
||||
try:
|
||||
ast = jinja.parse(block.full_block)
|
||||
except CompilationException as e:
|
||||
e.add_node(base_node)
|
||||
raise
|
||||
|
||||
# generic tests are structured as macros so we want to count the number of macro blocks
|
||||
generic_test_nodes = list(ast.find_all(jinja2.nodes.Macro))
|
||||
|
||||
if len(generic_test_nodes) != 1:
|
||||
# things have gone disastrously wrong, we thought we only
|
||||
# parsed one block!
|
||||
raise CompilationException(
|
||||
f'Found multiple generic tests in {block.full_block}, expected 1',
|
||||
node=base_node
|
||||
)
|
||||
|
||||
generic_test_name = generic_test_nodes[0].name
|
||||
|
||||
if not generic_test_name.startswith(MACRO_PREFIX):
|
||||
continue
|
||||
|
||||
name: str = generic_test_name.replace(MACRO_PREFIX, '')
|
||||
node = self.parse_generic_test(block, base_node, name)
|
||||
yield node
|
||||
|
||||
def parse_file(self, block: FileBlock):
|
||||
assert isinstance(block.file, SourceFile)
|
||||
source_file = block.file
|
||||
assert isinstance(source_file.contents, str)
|
||||
original_file_path = source_file.path.original_file_path
|
||||
logger.debug("Parsing {}".format(original_file_path))
|
||||
|
||||
# this is really only used for error messages
|
||||
base_node = UnparsedMacro(
|
||||
path=original_file_path,
|
||||
original_file_path=original_file_path,
|
||||
package_name=self.project.project_name,
|
||||
raw_sql=source_file.contents,
|
||||
root_path=self.project.project_root,
|
||||
resource_type=NodeType.Macro,
|
||||
)
|
||||
|
||||
for node in self.parse_unparsed_generic_test(base_node):
|
||||
self.manifest.add_macro(block.file, node)
|
||||
@@ -72,13 +72,10 @@ class HookParser(SimpleParser[HookBlock, ParsedHookNode]):
|
||||
|
||||
# Hooks are only in the dbt_project.yml file for the project
|
||||
def get_path(self) -> FilePath:
|
||||
# There ought to be an existing file object for this, but
|
||||
# until that is implemented use a dummy modification time
|
||||
path = FilePath(
|
||||
project_root=self.project.project_root,
|
||||
searched_path='.',
|
||||
relative_path='dbt_project.yml',
|
||||
modification_time=0.0,
|
||||
)
|
||||
return path
|
||||
|
||||
|
||||
@@ -1,12 +1,10 @@
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import field
|
||||
from datetime import datetime
|
||||
import os
|
||||
import traceback
|
||||
from typing import (
|
||||
Dict, Optional, Mapping, Callable, Any, List, Type, Union, Tuple
|
||||
)
|
||||
from itertools import chain
|
||||
import time
|
||||
|
||||
import dbt.exceptions
|
||||
@@ -31,7 +29,7 @@ from dbt.context.configured import generate_macro_context
|
||||
from dbt.context.providers import ParseProvider
|
||||
from dbt.contracts.files import FileHash, ParseFileType, SchemaSourceFile
|
||||
from dbt.parser.read_files import read_files, load_source_file
|
||||
from dbt.parser.partial import PartialParsing, special_override_macros
|
||||
from dbt.parser.partial import PartialParsing
|
||||
from dbt.contracts.graph.compiled import ManifestNode
|
||||
from dbt.contracts.graph.manifest import (
|
||||
Manifest, Disabled, MacroManifest, ManifestStateCheck, ParsingInfo
|
||||
@@ -49,8 +47,7 @@ from dbt.exceptions import (
|
||||
)
|
||||
from dbt.parser.base import Parser
|
||||
from dbt.parser.analysis import AnalysisParser
|
||||
from dbt.parser.generic_test import GenericTestParser
|
||||
from dbt.parser.singular_test import SingularTestParser
|
||||
from dbt.parser.data_test import DataTestParser
|
||||
from dbt.parser.docs import DocumentationParser
|
||||
from dbt.parser.hooks import HookParser
|
||||
from dbt.parser.macros import MacroParser
|
||||
@@ -67,6 +64,7 @@ from dbt.dataclass_schema import StrEnum, dbtClassMixin
|
||||
|
||||
PARTIAL_PARSE_FILE_NAME = 'partial_parse.msgpack'
|
||||
PARSING_STATE = DbtProcessState('parsing')
|
||||
DEFAULT_PARTIAL_PARSE = False
|
||||
|
||||
|
||||
class ReparseReason(StrEnum):
|
||||
@@ -133,9 +131,7 @@ class ManifestLoader:
|
||||
self.root_project: RuntimeConfig = root_project
|
||||
self.all_projects: Mapping[str, Project] = all_projects
|
||||
self.manifest: Manifest = Manifest()
|
||||
self.new_manifest = self.manifest
|
||||
self.manifest.metadata = root_project.get_metadata()
|
||||
self.macro_resolver = None # built after macros are loaded
|
||||
self.started_at = int(time.time())
|
||||
# This is a MacroQueryStringSetter callable, which is called
|
||||
# later after we set the MacroManifest in the adapter. It sets
|
||||
@@ -154,7 +150,6 @@ class ManifestLoader:
|
||||
# We need to know if we're actually partially parsing. It could
|
||||
# have been enabled, but not happening because of some issue.
|
||||
self.partially_parsing = False
|
||||
self.partial_parser = None
|
||||
|
||||
# This is a saved manifest from a previous run that's used for partial parsing
|
||||
self.saved_manifest: Optional[Manifest] = self.read_manifest_for_partial_parse()
|
||||
@@ -208,19 +203,15 @@ class ManifestLoader:
|
||||
# used to get the SourceFiles from the manifest files.
|
||||
start_read_files = time.perf_counter()
|
||||
project_parser_files = {}
|
||||
saved_files = {}
|
||||
if self.saved_manifest:
|
||||
saved_files = self.saved_manifest.files
|
||||
for project in self.all_projects.values():
|
||||
read_files(project, self.manifest.files, project_parser_files, saved_files)
|
||||
orig_project_parser_files = project_parser_files
|
||||
read_files(project, self.manifest.files, project_parser_files)
|
||||
self._perf_info.path_count = len(self.manifest.files)
|
||||
self._perf_info.read_files_elapsed = (time.perf_counter() - start_read_files)
|
||||
|
||||
skip_parsing = False
|
||||
if self.saved_manifest is not None:
|
||||
self.partial_parser = PartialParsing(self.saved_manifest, self.manifest.files)
|
||||
skip_parsing = self.partial_parser.skip_parsing()
|
||||
partial_parsing = PartialParsing(self.saved_manifest, self.manifest.files)
|
||||
skip_parsing = partial_parsing.skip_parsing()
|
||||
if skip_parsing:
|
||||
# nothing changed, so we don't need to generate project_parser_files
|
||||
self.manifest = self.saved_manifest
|
||||
@@ -230,7 +221,7 @@ class ManifestLoader:
|
||||
# files are different, we need to create a new set of
|
||||
# project_parser_files.
|
||||
try:
|
||||
project_parser_files = self.partial_parser.get_parsing_files()
|
||||
project_parser_files = partial_parsing.get_parsing_files()
|
||||
self.partially_parsing = True
|
||||
self.manifest = self.saved_manifest
|
||||
except Exception:
|
||||
@@ -252,18 +243,13 @@ class ManifestLoader:
|
||||
|
||||
# get file info for local logs
|
||||
parse_file_type = None
|
||||
file_id = self.partial_parser.processing_file
|
||||
if file_id:
|
||||
source_file = None
|
||||
if file_id in self.saved_manifest.files:
|
||||
source_file = self.saved_manifest.files[file_id]
|
||||
elif file_id in self.manifest.files:
|
||||
source_file = self.manifest.files[file_id]
|
||||
if source_file:
|
||||
parse_file_type = source_file.parse_file_type
|
||||
logger.debug(f"Partial parsing exception processing file {file_id}")
|
||||
file_dict = source_file.to_dict()
|
||||
logger.debug(f"PP file: {file_dict}")
|
||||
file_id = partial_parsing.processing_file
|
||||
if file_id and file_id in self.manifest.files:
|
||||
old_file = self.manifest.files[file_id]
|
||||
parse_file_type = old_file.parse_file_type
|
||||
logger.debug(f"Partial parsing exception processing file {file_id}")
|
||||
file_dict = old_file.to_dict()
|
||||
logger.debug(f"PP file: {file_dict}")
|
||||
exc_info['parse_file_type'] = parse_file_type
|
||||
logger.debug(f"PP exception info: {exc_info}")
|
||||
|
||||
@@ -276,26 +262,26 @@ class ManifestLoader:
|
||||
self.manifest._parsing_info = ParsingInfo()
|
||||
|
||||
if skip_parsing:
|
||||
logger.debug("Partial parsing enabled, no changes found, skipping parsing")
|
||||
logger.info("Partial parsing enabled, no changes found, skipping parsing")
|
||||
else:
|
||||
# Load Macros and tests
|
||||
# Load Macros
|
||||
# We need to parse the macros first, so they're resolvable when
|
||||
# the other files are loaded. Also need to parse tests, specifically
|
||||
# generic tests
|
||||
# the other files are loaded
|
||||
start_load_macros = time.perf_counter()
|
||||
self.load_and_parse_macros(project_parser_files)
|
||||
|
||||
# If we're partially parsing check that certain macros have not been changed
|
||||
if self.partially_parsing and self.skip_partial_parsing_because_of_macros():
|
||||
logger.info(
|
||||
"Change detected to override macro used during parsing. Starting full parse."
|
||||
)
|
||||
# Get new Manifest with original file records and move over the macros
|
||||
self.manifest = self.new_manifest # contains newly read files
|
||||
project_parser_files = orig_project_parser_files
|
||||
self.partially_parsing = False
|
||||
self.load_and_parse_macros(project_parser_files)
|
||||
|
||||
for project in self.all_projects.values():
|
||||
if project.project_name not in project_parser_files:
|
||||
continue
|
||||
parser_files = project_parser_files[project.project_name]
|
||||
if 'MacroParser' not in parser_files:
|
||||
continue
|
||||
parser = MacroParser(project, self.manifest)
|
||||
for file_id in parser_files['MacroParser']:
|
||||
block = FileBlock(self.manifest.files[file_id])
|
||||
parser.parse_file(block)
|
||||
# increment parsed path count for performance tracking
|
||||
self._perf_info.parsed_path_count = self._perf_info.parsed_path_count + 1
|
||||
# Look at changed macros and update the macro.depends_on.macros
|
||||
self.macro_depends_on()
|
||||
self._perf_info.load_macros_elapsed = (time.perf_counter() - start_load_macros)
|
||||
|
||||
# Now that the macros are parsed, parse the rest of the files.
|
||||
@@ -304,7 +290,7 @@ class ManifestLoader:
|
||||
|
||||
# Load the rest of the files except for schema yaml files
|
||||
parser_types: List[Type[Parser]] = [
|
||||
ModelParser, SnapshotParser, AnalysisParser, SingularTestParser,
|
||||
ModelParser, SnapshotParser, AnalysisParser, DataTestParser,
|
||||
SeedParser, DocumentationParser, HookParser]
|
||||
for project in self.all_projects.values():
|
||||
if project.project_name not in project_parser_files:
|
||||
@@ -321,7 +307,6 @@ class ManifestLoader:
|
||||
# aren't in place yet
|
||||
self.manifest.rebuild_ref_lookup()
|
||||
self.manifest.rebuild_doc_lookup()
|
||||
self.manifest.rebuild_disabled_lookup()
|
||||
|
||||
# Load yaml files
|
||||
parser_types = [SchemaParser]
|
||||
@@ -346,15 +331,22 @@ class ManifestLoader:
|
||||
self._perf_info.patch_sources_elapsed = (
|
||||
time.perf_counter() - start_patch
|
||||
)
|
||||
# We need to rebuild disabled in order to include disabled sources
|
||||
self.manifest.rebuild_disabled_lookup()
|
||||
|
||||
# ParseResults had a 'disabled' attribute which was a dictionary
|
||||
# which is now named '_disabled'. This used to copy from
|
||||
# ParseResults to the Manifest.
|
||||
# TODO: normalize to only one disabled
|
||||
disabled = []
|
||||
for value in self.manifest._disabled.values():
|
||||
disabled.extend(value)
|
||||
self.manifest.disabled = disabled
|
||||
|
||||
# copy the selectors from the root_project to the manifest
|
||||
self.manifest.selectors = self.root_project.manifest_selectors
|
||||
|
||||
# update the refs, sources, and docs
|
||||
# These check the created_at time on the nodes to
|
||||
# determine whether they need processing.
|
||||
# determine whether they need processinga.
|
||||
start_process = time.perf_counter()
|
||||
self.process_sources(self.root_project.project_name)
|
||||
self.process_refs(self.root_project.project_name)
|
||||
@@ -376,32 +368,6 @@ class ManifestLoader:
|
||||
|
||||
return self.manifest
|
||||
|
||||
def load_and_parse_macros(self, project_parser_files):
|
||||
for project in self.all_projects.values():
|
||||
if project.project_name not in project_parser_files:
|
||||
continue
|
||||
parser_files = project_parser_files[project.project_name]
|
||||
if 'MacroParser' in parser_files:
|
||||
parser = MacroParser(project, self.manifest)
|
||||
for file_id in parser_files['MacroParser']:
|
||||
block = FileBlock(self.manifest.files[file_id])
|
||||
parser.parse_file(block)
|
||||
# increment parsed path count for performance tracking
|
||||
self._perf_info.parsed_path_count = self._perf_info.parsed_path_count + 1
|
||||
# generic tests hisotrically lived in the macros directoy but can now be nested
|
||||
# in a /generic directory under /tests so we want to process them here as well
|
||||
if 'GenericTestParser' in parser_files:
|
||||
parser = GenericTestParser(project, self.manifest)
|
||||
for file_id in parser_files['GenericTestParser']:
|
||||
block = FileBlock(self.manifest.files[file_id])
|
||||
parser.parse_file(block)
|
||||
# increment parsed path count for performance tracking
|
||||
self._perf_info.parsed_path_count = self._perf_info.parsed_path_count + 1
|
||||
|
||||
self.build_macro_resolver()
|
||||
# Look at changed macros and update the macro.depends_on.macros
|
||||
self.macro_depends_on()
|
||||
|
||||
# Parse the files in the 'parser_files' dictionary, for parsers listed in
|
||||
# 'parser_types'
|
||||
def parse_project(
|
||||
@@ -457,7 +423,7 @@ class ManifestLoader:
|
||||
if not self.partially_parsing and HookParser in parser_types:
|
||||
hook_parser = HookParser(project, self.manifest, self.root_project)
|
||||
path = hook_parser.get_path()
|
||||
file = load_source_file(path, ParseFileType.Hook, project.project_name, {})
|
||||
file = load_source_file(path, ParseFileType.Hook, project.project_name)
|
||||
if file:
|
||||
file_block = FileBlock(file)
|
||||
hook_parser.parse_file(file_block)
|
||||
@@ -472,23 +438,20 @@ class ManifestLoader:
|
||||
self._perf_info.parsed_path_count + total_parsed_path_count
|
||||
)
|
||||
|
||||
# This should only be called after the macros have been loaded
|
||||
def build_macro_resolver(self):
|
||||
# Loop through macros in the manifest and statically parse
|
||||
# the 'macro_sql' to find depends_on.macros
|
||||
def macro_depends_on(self):
|
||||
internal_package_names = get_adapter_package_names(
|
||||
self.root_project.credentials.type
|
||||
)
|
||||
self.macro_resolver = MacroResolver(
|
||||
macro_resolver = MacroResolver(
|
||||
self.manifest.macros,
|
||||
self.root_project.project_name,
|
||||
internal_package_names
|
||||
)
|
||||
|
||||
# Loop through macros in the manifest and statically parse
|
||||
# the 'macro_sql' to find depends_on.macros
|
||||
def macro_depends_on(self):
|
||||
macro_ctx = generate_macro_context(self.root_project)
|
||||
macro_namespace = TestMacroNamespace(
|
||||
self.macro_resolver, {}, None, MacroStack(), []
|
||||
macro_resolver, {}, None, MacroStack(), []
|
||||
)
|
||||
adapter = get_adapter(self.root_project)
|
||||
db_wrapper = ParseProvider().DatabaseWrapper(
|
||||
@@ -507,7 +470,7 @@ class ManifestLoader:
|
||||
package_name = macro.package_name
|
||||
if '.' in macro_name:
|
||||
package_name, macro_name = macro_name.split('.')
|
||||
dep_macro_id = self.macro_resolver.get_macro_id(package_name, macro_name)
|
||||
dep_macro_id = macro_resolver.get_macro_id(package_name, macro_name)
|
||||
if dep_macro_id:
|
||||
macro.depends_on.add_macro(dep_macro_id) # will check for dupes
|
||||
|
||||
@@ -573,23 +536,18 @@ class ManifestLoader:
|
||||
reparse_reason = ReparseReason.project_config_changed
|
||||
return valid, reparse_reason
|
||||
|
||||
def skip_partial_parsing_because_of_macros(self):
|
||||
if not self.partial_parser:
|
||||
return False
|
||||
if self.partial_parser.deleted_special_override_macro:
|
||||
return True
|
||||
# Check for custom versions of these special macros
|
||||
for macro_name in special_override_macros:
|
||||
macro = self.macro_resolver.get_macro(None, macro_name)
|
||||
if macro and macro.package_name != 'dbt':
|
||||
if (macro.file_id in self.partial_parser.file_diff['changed'] or
|
||||
macro.file_id in self.partial_parser.file_diff['added']):
|
||||
# The file with the macro in it has changed
|
||||
return True
|
||||
return False
|
||||
def _partial_parse_enabled(self):
|
||||
# if the CLI is set, follow that
|
||||
if flags.PARTIAL_PARSE is not None:
|
||||
return flags.PARTIAL_PARSE
|
||||
# if the config is set, follow that
|
||||
elif self.root_project.config.partial_parse is not None:
|
||||
return self.root_project.config.partial_parse
|
||||
else:
|
||||
return DEFAULT_PARTIAL_PARSE
|
||||
|
||||
def read_manifest_for_partial_parse(self) -> Optional[Manifest]:
|
||||
if not flags.PARTIAL_PARSE:
|
||||
if not self._partial_parse_enabled():
|
||||
logger.debug('Partial parsing not enabled')
|
||||
return None
|
||||
path = os.path.join(self.root_project.target_path,
|
||||
@@ -607,13 +565,6 @@ class ManifestLoader:
|
||||
# different version of dbt
|
||||
is_partial_parseable, reparse_reason = self.is_partial_parsable(manifest)
|
||||
if is_partial_parseable:
|
||||
# We don't want to have stale generated_at dates
|
||||
manifest.metadata.generated_at = datetime.utcnow()
|
||||
# or invocation_ids
|
||||
if dbt.tracking.active_user:
|
||||
manifest.metadata.invocation_id = dbt.tracking.active_user.invocation_id
|
||||
else:
|
||||
manifest.metadata.invocation_id = None
|
||||
return manifest
|
||||
except Exception as exc:
|
||||
logger.debug(
|
||||
@@ -623,7 +574,7 @@ class ManifestLoader:
|
||||
)
|
||||
reparse_reason = ReparseReason.load_file_failure
|
||||
else:
|
||||
logger.info("Partial parse save file not found. Starting full parse.")
|
||||
logger.info(f"Unable to do partial parsing because {path} not found")
|
||||
reparse_reason = ReparseReason.file_not_found
|
||||
|
||||
# this event is only fired if a full reparse is needed
|
||||
@@ -633,8 +584,8 @@ class ManifestLoader:
|
||||
|
||||
def build_perf_info(self):
|
||||
mli = ManifestLoaderInfo(
|
||||
is_partial_parse_enabled=flags.PARTIAL_PARSE,
|
||||
is_static_analysis_enabled=flags.STATIC_PARSER
|
||||
is_partial_parse_enabled=self._partial_parse_enabled(),
|
||||
is_static_analysis_enabled=flags.USE_EXPERIMENTAL_PARSER
|
||||
)
|
||||
for project in self.all_projects.values():
|
||||
project_info = ProjectLoaderInfo(
|
||||
@@ -664,7 +615,7 @@ class ManifestLoader:
|
||||
])
|
||||
)
|
||||
|
||||
profile_path = os.path.join(flags.PROFILES_DIR, 'profiles.yml')
|
||||
profile_path = os.path.join(config.args.profiles_dir, 'profiles.yml')
|
||||
with open(profile_path) as fp:
|
||||
profile_hash = FileHash.from_contents(fp.read())
|
||||
|
||||
@@ -697,7 +648,7 @@ class ManifestLoader:
|
||||
macro_parser = MacroParser(project, self.manifest)
|
||||
for path in macro_parser.get_paths():
|
||||
source_file = load_source_file(
|
||||
path, ParseFileType.Macro, project.project_name, {})
|
||||
path, ParseFileType.Macro, project.project_name)
|
||||
block = FileBlock(source_file)
|
||||
# This does not add the file to the manifest.files,
|
||||
# but that shouldn't be necessary here.
|
||||
@@ -912,9 +863,7 @@ def _warn_for_unused_resource_config_paths(
|
||||
manifest: Manifest, config: RuntimeConfig
|
||||
) -> None:
|
||||
resource_fqns: Mapping[str, PathSet] = manifest.get_resource_fqns()
|
||||
disabled_fqns: PathSet = frozenset(
|
||||
tuple(n.fqn) for n in list(chain.from_iterable(manifest.disabled.values()))
|
||||
)
|
||||
disabled_fqns: PathSet = frozenset(tuple(n.fqn) for n in manifest.disabled)
|
||||
config.warn_for_unused_resource_config_paths(resource_fqns, disabled_fqns)
|
||||
|
||||
|
||||
|
||||
@@ -1,18 +1,15 @@
|
||||
from copy import deepcopy
|
||||
from dbt.context.context_config import ContextConfig
|
||||
from dbt.contracts.graph.parsed import ParsedModelNode
|
||||
import dbt.flags as flags
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
import dbt.tracking
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FileBlock
|
||||
import dbt.tracking as tracking
|
||||
from dbt import utils
|
||||
from dbt_extractor import ExtractionError, py_extract_from_source # type: ignore
|
||||
from functools import reduce
|
||||
from itertools import chain
|
||||
import random
|
||||
from typing import Any, Dict, Iterator, List, Optional, Tuple, Union
|
||||
from typing import Any, Dict, List
|
||||
|
||||
|
||||
class ModelParser(SimpleSQLParser[ParsedModelNode]):
|
||||
@@ -34,374 +31,117 @@ class ModelParser(SimpleSQLParser[ParsedModelNode]):
|
||||
) -> None:
|
||||
self.manifest._parsing_info.static_analysis_path_count += 1
|
||||
|
||||
if not flags.STATIC_PARSER:
|
||||
# jinja rendering
|
||||
super().render_update(node, config)
|
||||
logger.debug(f"1605: jinja rendering because of STATIC_PARSER flag. file: {node.path}")
|
||||
return
|
||||
# `True` roughly 1/100 times this function is called
|
||||
sample: bool = random.randint(1, 101) == 100
|
||||
|
||||
# only sample for experimental parser correctness on normal runs,
|
||||
# not when the experimental parser flag is on.
|
||||
exp_sample: bool = False
|
||||
# sampling the stable static parser against jinja is significantly
|
||||
# more expensive and therefor done far less frequently.
|
||||
stable_sample: bool = False
|
||||
# there are two samples above, and it is perfectly fine if both happen
|
||||
# at the same time. If that happens, the experimental parser, stable
|
||||
# parser, and jinja rendering will run on the same model file and
|
||||
# send back codes for experimental v stable, and stable v jinja.
|
||||
# run the experimental parser if the flag is on or if we're sampling
|
||||
if flags.USE_EXPERIMENTAL_PARSER or sample:
|
||||
try:
|
||||
experimentally_parsed: Dict[str, List[Any]] = py_extract_from_source(node.raw_sql)
|
||||
|
||||
# second config format
|
||||
config_call_dict: Dict[str, Any] = {}
|
||||
for c in experimentally_parsed['configs']:
|
||||
ContextConfig._add_config_call(config_call_dict, {c[0]: c[1]})
|
||||
|
||||
# format sources TODO change extractor to match this type
|
||||
source_calls: List[List[str]] = []
|
||||
for s in experimentally_parsed['sources']:
|
||||
source_calls.append([s[0], s[1]])
|
||||
experimentally_parsed['sources'] = source_calls
|
||||
|
||||
except ExtractionError as e:
|
||||
experimentally_parsed = e
|
||||
|
||||
# normal dbt run
|
||||
if not flags.USE_EXPERIMENTAL_PARSER:
|
||||
# `True` roughly 1/5000 times this function is called
|
||||
# sample = random.randint(1, 5001) == 5000
|
||||
stable_sample = random.randint(1, 5001) == 5000
|
||||
# sampling the experimental parser is explicitly disabled here, but use the following
|
||||
# commented code to sample a fraction of the time when new
|
||||
# experimental features are added.
|
||||
# `True` roughly 1/100 times this function is called
|
||||
# exp_sample = random.randint(1, 101) == 100
|
||||
# normal rendering
|
||||
super().render_update(node, config)
|
||||
# if we're sampling, compare for correctness
|
||||
if sample:
|
||||
result: List[str] = []
|
||||
# experimental parser couldn't parse
|
||||
if isinstance(experimentally_parsed, Exception):
|
||||
result += ["01_experimental_parser_cannot_parse"]
|
||||
else:
|
||||
# look for false positive configs
|
||||
for k in config_call_dict.keys():
|
||||
if k not in config._config_call_dict:
|
||||
result += ["02_false_positive_config_value"]
|
||||
break
|
||||
|
||||
# top-level declaration of variables
|
||||
statically_parsed: Optional[Union[str, Dict[str, List[Any]]]] = None
|
||||
experimental_sample: Optional[Union[str, Dict[str, List[Any]]]] = None
|
||||
exp_sample_node: Optional[ParsedModelNode] = None
|
||||
exp_sample_config: Optional[ContextConfig] = None
|
||||
jinja_sample_node: Optional[ParsedModelNode] = None
|
||||
jinja_sample_config: Optional[ContextConfig] = None
|
||||
result: List[str] = []
|
||||
# look for missed configs
|
||||
for k in config._config_call_dict.keys():
|
||||
if k not in config_call_dict:
|
||||
result += ["03_missed_config_value"]
|
||||
break
|
||||
|
||||
# sample the experimental parser only during a normal run
|
||||
if exp_sample and not flags.USE_EXPERIMENTAL_PARSER:
|
||||
logger.debug(f"1610: conducting experimental parser sample on {node.path}")
|
||||
experimental_sample = self.run_experimental_parser(node)
|
||||
# if the experimental parser succeeded, make a full copy of model parser
|
||||
# and populate _everything_ into it so it can be compared apples-to-apples
|
||||
# with a fully jinja-rendered project. This is necessary because the experimental
|
||||
# parser will likely add features that the existing static parser will fail on
|
||||
# so comparing those directly would give us bad results. The comparison will be
|
||||
# conducted after this model has been fully rendered either by the static parser
|
||||
# or by full jinja rendering
|
||||
if isinstance(experimental_sample, dict):
|
||||
model_parser_copy = self.partial_deepcopy()
|
||||
exp_sample_node = deepcopy(node)
|
||||
exp_sample_config = deepcopy(config)
|
||||
model_parser_copy.populate(
|
||||
exp_sample_node,
|
||||
exp_sample_config,
|
||||
experimental_sample
|
||||
)
|
||||
# use the experimental parser exclusively if the flag is on
|
||||
if flags.USE_EXPERIMENTAL_PARSER:
|
||||
statically_parsed = self.run_experimental_parser(node)
|
||||
# run the stable static parser unless it is explicitly turned off
|
||||
else:
|
||||
statically_parsed = self.run_static_parser(node)
|
||||
# look for false positive sources
|
||||
for s in experimentally_parsed['sources']:
|
||||
if s not in node.sources:
|
||||
result += ["04_false_positive_source_value"]
|
||||
break
|
||||
|
||||
# if the static parser succeeded, extract some data in easy-to-compare formats
|
||||
if isinstance(statically_parsed, dict):
|
||||
# only sample jinja for the purpose of comparing with the stable static parser
|
||||
# if we know we don't need to fall back to jinja (i.e. - nothing to compare
|
||||
# with jinja v jinja).
|
||||
# This means we skip sampling for 40% of the 1/5000 samples. We could run the
|
||||
# sampling rng here, but the effect would be the same since we would only roll
|
||||
# it 40% of the time. So I've opted to keep all the rng code colocated above.
|
||||
if stable_sample and not flags.USE_EXPERIMENTAL_PARSER:
|
||||
logger.debug(f"1611: conducting full jinja rendering sample on {node.path}")
|
||||
# if this will _never_ mutate anything `self` we could avoid these deep copies,
|
||||
# but we can't really guarantee that going forward.
|
||||
model_parser_copy = self.partial_deepcopy()
|
||||
jinja_sample_node = deepcopy(node)
|
||||
jinja_sample_config = deepcopy(config)
|
||||
# rendering mutates the node and the config
|
||||
super(ModelParser, model_parser_copy) \
|
||||
.render_update(jinja_sample_node, jinja_sample_config)
|
||||
# look for missed sources
|
||||
for s in node.sources:
|
||||
if s not in experimentally_parsed['sources']:
|
||||
result += ["05_missed_source_value"]
|
||||
break
|
||||
|
||||
# update the unrendered config with values from the static parser.
|
||||
# look for false positive refs
|
||||
for r in experimentally_parsed['refs']:
|
||||
if r not in node.refs:
|
||||
result += ["06_false_positive_ref_value"]
|
||||
break
|
||||
|
||||
# look for missed refs
|
||||
for r in node.refs:
|
||||
if r not in experimentally_parsed['refs']:
|
||||
result += ["07_missed_ref_value"]
|
||||
break
|
||||
|
||||
# if there are no errors, return a success value
|
||||
if not result:
|
||||
result = ["00_exact_match"]
|
||||
|
||||
# fire a tracking event. this fires one event for every sample
|
||||
# so that we have data on a per file basis. Not only can we expect
|
||||
# no false positives or misses, we can expect the number model
|
||||
# files parseable by the experimental parser to match our internal
|
||||
# testing.
|
||||
if dbt.tracking.active_user is not None: # None in some tests
|
||||
tracking.track_experimental_parser_sample({
|
||||
"project_id": self.root_project.hashed_name(),
|
||||
"file_id": utils.get_hash(node),
|
||||
"status": result
|
||||
})
|
||||
|
||||
# if the --use-experimental-parser flag was set, and the experimental parser succeeded
|
||||
elif not isinstance(experimentally_parsed, Exception):
|
||||
# since it doesn't need python jinja, fit the refs, sources, and configs
|
||||
# into the node. Down the line the rest of the node will be updated with
|
||||
# this information. (e.g. depends_on etc.)
|
||||
config._config_call_dict = config_call_dict
|
||||
|
||||
# this uses the updated config to set all the right things in the node.
|
||||
# if there are hooks present, it WILL render jinja. Will need to change
|
||||
# when the experimental parser supports hooks
|
||||
self.update_parsed_node_config(node, config)
|
||||
|
||||
# update the unrendered config with values from the file.
|
||||
# values from yaml files are in there already
|
||||
self.populate(
|
||||
node,
|
||||
config,
|
||||
statically_parsed
|
||||
)
|
||||
node.unrendered_config.update(dict(experimentally_parsed['configs']))
|
||||
|
||||
# if we took a jinja sample, compare now that the base node has been populated
|
||||
if jinja_sample_node is not None and jinja_sample_config is not None:
|
||||
result = _get_stable_sample_result(
|
||||
jinja_sample_node,
|
||||
jinja_sample_config,
|
||||
node,
|
||||
config
|
||||
)
|
||||
# set refs and sources on the node object
|
||||
node.refs += experimentally_parsed['refs']
|
||||
node.sources += experimentally_parsed['sources']
|
||||
|
||||
# if we took an experimental sample, compare now that the base node has been populated
|
||||
if exp_sample_node is not None and exp_sample_config is not None:
|
||||
result = _get_exp_sample_result(
|
||||
exp_sample_node,
|
||||
exp_sample_config,
|
||||
node,
|
||||
config,
|
||||
)
|
||||
# configs don't need to be merged into the node
|
||||
# setting them in config._config_call_dict is sufficient
|
||||
|
||||
self.manifest._parsing_info.static_analysis_parsed_path_count += 1
|
||||
# if the static parser failed, add the correct messages for tracking
|
||||
elif isinstance(statically_parsed, str):
|
||||
if statically_parsed == "cannot_parse":
|
||||
result += ["01_stable_parser_cannot_parse"]
|
||||
elif statically_parsed == "has_banned_macro":
|
||||
result += ["08_has_banned_macro"]
|
||||
|
||||
super().render_update(node, config)
|
||||
logger.debug(
|
||||
f"1602: parser fallback to jinja rendering on {node.path}"
|
||||
)
|
||||
# if the static parser didn't succeed, fall back to jinja
|
||||
# the experimental parser tried and failed on this model.
|
||||
# fall back to python jinja rendering.
|
||||
else:
|
||||
# jinja rendering
|
||||
super().render_update(node, config)
|
||||
logger.debug(
|
||||
f"1602: parser fallback to jinja rendering on {node.path}"
|
||||
)
|
||||
|
||||
# only send the tracking event if there is at least one result code
|
||||
if result:
|
||||
# fire a tracking event. this fires one event for every sample
|
||||
# so that we have data on a per file basis. Not only can we expect
|
||||
# no false positives or misses, we can expect the number model
|
||||
# files parseable by the experimental parser to match our internal
|
||||
# testing.
|
||||
if tracking.active_user is not None: # None in some tests
|
||||
tracking.track_experimental_parser_sample({
|
||||
"project_id": self.root_project.hashed_name(),
|
||||
"file_id": utils.get_hash(node),
|
||||
"status": result
|
||||
})
|
||||
|
||||
def run_static_parser(
|
||||
self, node: ParsedModelNode
|
||||
) -> Optional[Union[str, Dict[str, List[Any]]]]:
|
||||
# if any banned macros have been overridden by the user, we cannot use the static parser.
|
||||
if self._has_banned_macro(node):
|
||||
# this log line is used for integration testing. If you change
|
||||
# the code at the beginning of the line change the tests in
|
||||
# test/integration/072_experimental_parser_tests/test_all_experimental_parser.py
|
||||
logger.debug(
|
||||
f"1601: detected macro override of ref/source/config in the scope of {node.path}"
|
||||
)
|
||||
return "has_banned_macro"
|
||||
|
||||
# run the stable static parser and return the results
|
||||
try:
|
||||
statically_parsed = py_extract_from_source(
|
||||
node.raw_sql
|
||||
)
|
||||
logger.debug(f"1699: static parser successfully parsed {node.path}")
|
||||
return _shift_sources(statically_parsed)
|
||||
# if we want information on what features are barring the static
|
||||
# parser from reading model files, this is where we would add that
|
||||
# since that information is stored in the `ExtractionError`.
|
||||
except ExtractionError:
|
||||
logger.debug(
|
||||
f"1603: static parser failed on {node.path}"
|
||||
)
|
||||
return "cannot_parse"
|
||||
|
||||
def run_experimental_parser(
|
||||
self, node: ParsedModelNode
|
||||
) -> Optional[Union[str, Dict[str, List[Any]]]]:
|
||||
# if any banned macros have been overridden by the user, we cannot use the static parser.
|
||||
if self._has_banned_macro(node):
|
||||
# this log line is used for integration testing. If you change
|
||||
# the code at the beginning of the line change the tests in
|
||||
# test/integration/072_experimental_parser_tests/test_all_experimental_parser.py
|
||||
logger.debug(
|
||||
f"1601: detected macro override of ref/source/config in the scope of {node.path}"
|
||||
)
|
||||
return "has_banned_macro"
|
||||
|
||||
# run the experimental parser and return the results
|
||||
try:
|
||||
# for now, this line calls the stable static parser since there are no
|
||||
# experimental features. Change `py_extract_from_source` to the new
|
||||
# experimental call when we add additional features.
|
||||
experimentally_parsed = py_extract_from_source(
|
||||
node.raw_sql
|
||||
)
|
||||
logger.debug(f"1698: experimental parser successfully parsed {node.path}")
|
||||
return _shift_sources(experimentally_parsed)
|
||||
# if we want information on what features are barring the experimental
|
||||
# parser from reading model files, this is where we would add that
|
||||
# since that information is stored in the `ExtractionError`.
|
||||
except ExtractionError:
|
||||
logger.debug(
|
||||
f"1604: experimental parser failed on {node.path}"
|
||||
)
|
||||
return "cannot_parse"
|
||||
|
||||
# checks for banned macros
|
||||
def _has_banned_macro(
|
||||
self, node: ParsedModelNode
|
||||
) -> bool:
|
||||
# first check if there is a banned macro defined in scope for this model file
|
||||
root_project_name = self.root_project.project_name
|
||||
project_name = node.package_name
|
||||
banned_macros = ['ref', 'source', 'config']
|
||||
|
||||
all_banned_macro_keys: Iterator[str] = chain.from_iterable(
|
||||
map(
|
||||
lambda name: [
|
||||
f"macro.{project_name}.{name}",
|
||||
f"macro.{root_project_name}.{name}"
|
||||
],
|
||||
banned_macros
|
||||
)
|
||||
)
|
||||
|
||||
return reduce(
|
||||
lambda z, key: z or (key in self.manifest.macros),
|
||||
all_banned_macro_keys,
|
||||
False
|
||||
)
|
||||
|
||||
# this method updates the model node rendered and unrendered config as well
|
||||
# as the node object. Used to populate these values when circumventing jinja
|
||||
# rendering like the static parser.
|
||||
def populate(
|
||||
self,
|
||||
node: ParsedModelNode,
|
||||
config: ContextConfig,
|
||||
statically_parsed: Dict[str, Any]
|
||||
):
|
||||
# manually fit configs in
|
||||
config._config_call_dict = _get_config_call_dict(statically_parsed)
|
||||
|
||||
# if there are hooks present this, it WILL render jinja. Will need to change
|
||||
# when the experimental parser supports hooks
|
||||
self.update_parsed_node_config(node, config)
|
||||
|
||||
# update the unrendered config with values from the file.
|
||||
# values from yaml files are in there already
|
||||
node.unrendered_config.update(dict(statically_parsed['configs']))
|
||||
|
||||
# set refs and sources on the node object
|
||||
node.refs += statically_parsed['refs']
|
||||
node.sources += statically_parsed['sources']
|
||||
|
||||
# configs don't need to be merged into the node because they
|
||||
# are read from config._config_call_dict
|
||||
|
||||
# the manifest is often huge so this method avoids deepcopying it
|
||||
def partial_deepcopy(self):
|
||||
return ModelParser(
|
||||
deepcopy(self.project),
|
||||
self.manifest,
|
||||
deepcopy(self.root_project)
|
||||
)
|
||||
|
||||
|
||||
# pure function. safe to use elsewhere, but unlikely to be useful outside this file.
|
||||
def _get_config_call_dict(
|
||||
static_parser_result: Dict[str, Any]
|
||||
) -> Dict[str, Any]:
|
||||
config_call_dict: Dict[str, Any] = {}
|
||||
|
||||
for c in static_parser_result['configs']:
|
||||
ContextConfig._add_config_call(config_call_dict, {c[0]: c[1]})
|
||||
|
||||
return config_call_dict
|
||||
|
||||
|
||||
# TODO if we format sources in the extractor to match this type, we won't need this function.
|
||||
def _shift_sources(
|
||||
static_parser_result: Dict[str, List[Any]]
|
||||
) -> Dict[str, List[Any]]:
|
||||
shifted_result = deepcopy(static_parser_result)
|
||||
source_calls = []
|
||||
|
||||
for s in static_parser_result['sources']:
|
||||
source_calls.append([s[0], s[1]])
|
||||
shifted_result['sources'] = source_calls
|
||||
|
||||
return shifted_result
|
||||
|
||||
|
||||
# returns a list of string codes to be sent as a tracking event
|
||||
def _get_exp_sample_result(
|
||||
sample_node: ParsedModelNode,
|
||||
sample_config: ContextConfig,
|
||||
node: ParsedModelNode,
|
||||
config: ContextConfig
|
||||
) -> List[str]:
|
||||
result: List[Tuple[int, str]] = _get_sample_result(sample_node, sample_config, node, config)
|
||||
|
||||
def process(codemsg):
|
||||
code, msg = codemsg
|
||||
return f"0{code}_experimental_{msg}"
|
||||
|
||||
return list(map(process, result))
|
||||
|
||||
|
||||
# returns a list of string codes to be sent as a tracking event
|
||||
def _get_stable_sample_result(
|
||||
sample_node: ParsedModelNode,
|
||||
sample_config: ContextConfig,
|
||||
node: ParsedModelNode,
|
||||
config: ContextConfig
|
||||
) -> List[str]:
|
||||
result: List[Tuple[int, str]] = _get_sample_result(sample_node, sample_config, node, config)
|
||||
|
||||
def process(codemsg):
|
||||
code, msg = codemsg
|
||||
return f"8{code}_stable_{msg}"
|
||||
|
||||
return list(map(process, result))
|
||||
|
||||
|
||||
# returns a list of string codes that need a single digit prefix to be prepended
|
||||
# before being sent as a tracking event
|
||||
def _get_sample_result(
|
||||
sample_node: ParsedModelNode,
|
||||
sample_config: ContextConfig,
|
||||
node: ParsedModelNode,
|
||||
config: ContextConfig
|
||||
) -> List[Tuple[int, str]]:
|
||||
result: List[Tuple[int, str]] = []
|
||||
# look for false positive configs
|
||||
for k in sample_config._config_call_dict.keys():
|
||||
if k not in config._config_call_dict.keys():
|
||||
result += [(2, "false_positive_config_value")]
|
||||
break
|
||||
|
||||
# look for missed configs
|
||||
for k in config._config_call_dict.keys():
|
||||
if k not in sample_config._config_call_dict.keys():
|
||||
result += [(3, "missed_config_value")]
|
||||
break
|
||||
|
||||
# look for false positive sources
|
||||
for s in sample_node.sources:
|
||||
if s not in node.sources:
|
||||
result += [(4, "false_positive_source_value")]
|
||||
break
|
||||
|
||||
# look for missed sources
|
||||
for s in node.sources:
|
||||
if s not in sample_node.sources:
|
||||
result += [(5, "missed_source_value")]
|
||||
break
|
||||
|
||||
# look for false positive refs
|
||||
for r in sample_node.refs:
|
||||
if r not in node.refs:
|
||||
result += [(6, "false_positive_ref_value")]
|
||||
break
|
||||
|
||||
# look for missed refs
|
||||
for r in node.refs:
|
||||
if r not in sample_node.refs:
|
||||
result += [(7, "missed_ref_value")]
|
||||
break
|
||||
|
||||
# if there are no errors, return a success value
|
||||
if not result:
|
||||
result = [(0, "exact_match")]
|
||||
|
||||
return result
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
from copy import deepcopy
|
||||
from typing import MutableMapping, Dict, List
|
||||
from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.contracts.files import (
|
||||
@@ -13,12 +12,7 @@ mssat_files = (
|
||||
ParseFileType.Seed,
|
||||
ParseFileType.Snapshot,
|
||||
ParseFileType.Analysis,
|
||||
ParseFileType.SingularTest,
|
||||
)
|
||||
|
||||
mg_files = (
|
||||
ParseFileType.Macro,
|
||||
ParseFileType.GenericTest,
|
||||
ParseFileType.Test,
|
||||
)
|
||||
|
||||
|
||||
@@ -38,21 +32,10 @@ parse_file_type_to_key = {
|
||||
}
|
||||
|
||||
|
||||
# These macro names have special treatment in the ManifestLoader and
|
||||
# partial parsing. If they have changed we will skip partial parsing
|
||||
special_override_macros = [
|
||||
'ref', 'source', 'config', 'generate_schema_name',
|
||||
'generate_database_name', 'generate_alias_name'
|
||||
]
|
||||
|
||||
|
||||
# Partial parsing. Create a diff of files from saved manifest and current
|
||||
# files and produce a project_parser_file dictionary to drive parsing of
|
||||
# only the necessary changes.
|
||||
# Will produce a 'skip_parsing' method, and a project_parser_file dictionary
|
||||
# All file objects from the new manifest are deepcopied, because we need
|
||||
# to preserve an unchanged file object in case we need to drop back to a
|
||||
# a full parse (such as for certain macro changes)
|
||||
class PartialParsing:
|
||||
def __init__(self, saved_manifest: Manifest, new_files: MutableMapping[str, AnySourceFile]):
|
||||
self.saved_manifest = saved_manifest
|
||||
@@ -64,8 +47,6 @@ class PartialParsing:
|
||||
self.macro_child_map: Dict[str, List[str]] = {}
|
||||
self.build_file_diff()
|
||||
self.processing_file = None
|
||||
self.deleted_special_override_macro = False
|
||||
self.disabled_by_file_id = self.saved_manifest.build_disabled_by_file_id()
|
||||
|
||||
def skip_parsing(self):
|
||||
return (
|
||||
@@ -93,7 +74,7 @@ class PartialParsing:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Schema:
|
||||
deleted_schema_files.append(file_id)
|
||||
else:
|
||||
if self.saved_files[file_id].parse_file_type in mg_files:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Macro:
|
||||
changed_or_deleted_macro_file = True
|
||||
deleted.append(file_id)
|
||||
|
||||
@@ -111,7 +92,7 @@ class PartialParsing:
|
||||
raise Exception(f"Serialization failure for {file_id}")
|
||||
changed_schema_files.append(file_id)
|
||||
else:
|
||||
if self.saved_files[file_id].parse_file_type in mg_files:
|
||||
if self.saved_files[file_id].parse_file_type == ParseFileType.Macro:
|
||||
changed_or_deleted_macro_file = True
|
||||
changed.append(file_id)
|
||||
file_diff = {
|
||||
@@ -124,10 +105,10 @@ class PartialParsing:
|
||||
}
|
||||
if changed_or_deleted_macro_file:
|
||||
self.macro_child_map = self.saved_manifest.build_macro_child_map()
|
||||
logger.debug(f"Partial parsing enabled: "
|
||||
f"{len(deleted) + len(deleted_schema_files)} files deleted, "
|
||||
f"{len(added)} files added, "
|
||||
f"{len(changed) + len(changed_schema_files)} files changed.")
|
||||
logger.info(f"Partial parsing enabled: "
|
||||
f"{len(deleted) + len(deleted_schema_files)} files deleted, "
|
||||
f"{len(added)} files added, "
|
||||
f"{len(changed) + len(changed_schema_files)} files changed.")
|
||||
self.file_diff = file_diff
|
||||
|
||||
# generate the list of files that need parsing
|
||||
@@ -187,7 +168,7 @@ class PartialParsing:
|
||||
# Add new files, including schema files
|
||||
def add_to_saved(self, file_id):
|
||||
# add file object to saved manifest.files
|
||||
source_file = deepcopy(self.new_files[file_id])
|
||||
source_file = self.new_files[file_id]
|
||||
if source_file.parse_file_type == ParseFileType.Schema:
|
||||
self.handle_added_schema_file(source_file)
|
||||
self.saved_files[file_id] = source_file
|
||||
@@ -218,7 +199,7 @@ class PartialParsing:
|
||||
self.deleted_manifest.files[file_id] = self.saved_manifest.files.pop(file_id)
|
||||
|
||||
# macros
|
||||
if saved_source_file.parse_file_type in mg_files:
|
||||
if saved_source_file.parse_file_type == ParseFileType.Macro:
|
||||
self.delete_macro_file(saved_source_file, follow_references=True)
|
||||
|
||||
# docs
|
||||
@@ -229,12 +210,12 @@ class PartialParsing:
|
||||
|
||||
# Updates for non-schema files
|
||||
def update_in_saved(self, file_id):
|
||||
new_source_file = deepcopy(self.new_files[file_id])
|
||||
new_source_file = self.new_files[file_id]
|
||||
old_source_file = self.saved_files[file_id]
|
||||
|
||||
if new_source_file.parse_file_type in mssat_files:
|
||||
self.update_mssat_in_saved(new_source_file, old_source_file)
|
||||
elif new_source_file.parse_file_type in mg_files:
|
||||
elif new_source_file.parse_file_type == ParseFileType.Macro:
|
||||
self.update_macro_in_saved(new_source_file, old_source_file)
|
||||
elif new_source_file.parse_file_type == ParseFileType.Documentation:
|
||||
self.update_doc_in_saved(new_source_file, old_source_file)
|
||||
@@ -252,43 +233,24 @@ class PartialParsing:
|
||||
return
|
||||
|
||||
# These files only have one node.
|
||||
unique_id = None
|
||||
if old_source_file.nodes:
|
||||
unique_id = old_source_file.nodes[0]
|
||||
else:
|
||||
# It's not clear when this would actually happen.
|
||||
# Logging in case there are other associated errors.
|
||||
logger.debug(f"Partial parsing: node not found for source_file {old_source_file}")
|
||||
unique_id = old_source_file.nodes[0]
|
||||
|
||||
# replace source_file in saved and add to parsing list
|
||||
file_id = new_source_file.file_id
|
||||
self.deleted_manifest.files[file_id] = old_source_file
|
||||
self.saved_files[file_id] = deepcopy(new_source_file)
|
||||
self.saved_files[file_id] = new_source_file
|
||||
self.add_to_pp_files(new_source_file)
|
||||
if unique_id:
|
||||
self.remove_node_in_saved(new_source_file, unique_id)
|
||||
self.remove_node_in_saved(new_source_file, unique_id)
|
||||
|
||||
def remove_node_in_saved(self, source_file, unique_id):
|
||||
if unique_id in self.saved_manifest.nodes:
|
||||
# delete node in saved
|
||||
node = self.saved_manifest.nodes.pop(unique_id)
|
||||
self.deleted_manifest.nodes[unique_id] = node
|
||||
elif (source_file.file_id in self.disabled_by_file_id and
|
||||
unique_id in self.saved_manifest.disabled):
|
||||
# This node is disabled. Find the node and remove it from disabled dictionary.
|
||||
for dis_index, dis_node in enumerate(self.saved_manifest.disabled[unique_id]):
|
||||
if dis_node.file_id == source_file.file_id:
|
||||
node = dis_node
|
||||
break
|
||||
if dis_node:
|
||||
# Remove node from disabled and unique_id from disabled dict if necessary
|
||||
del self.saved_manifest.disabled[unique_id][dis_index]
|
||||
if not self.saved_manifest.disabled[unique_id]:
|
||||
self.saved_manifest.disabled.pop(unique_id)
|
||||
else:
|
||||
# Has already been deleted by another action
|
||||
# Has already been deleted by another action
|
||||
if unique_id not in self.saved_manifest.nodes:
|
||||
return
|
||||
|
||||
# delete node in saved
|
||||
node = self.saved_manifest.nodes.pop(unique_id)
|
||||
self.deleted_manifest.nodes[unique_id] = node
|
||||
|
||||
# look at patch_path in model node to see if we need
|
||||
# to reapply a patch from a schema_file.
|
||||
if node.patch_path:
|
||||
@@ -299,44 +261,36 @@ class PartialParsing:
|
||||
schema_file = self.saved_files[file_id]
|
||||
dict_key = parse_file_type_to_key[source_file.parse_file_type]
|
||||
# look for a matching list dictionary
|
||||
elem_patch = None
|
||||
if dict_key in schema_file.dict_from_yaml:
|
||||
for elem in schema_file.dict_from_yaml[dict_key]:
|
||||
if elem['name'] == node.name:
|
||||
elem_patch = elem
|
||||
break
|
||||
for elem in schema_file.dict_from_yaml[dict_key]:
|
||||
if elem['name'] == node.name:
|
||||
elem_patch = elem
|
||||
break
|
||||
if elem_patch:
|
||||
self.delete_schema_mssa_links(schema_file, dict_key, elem_patch)
|
||||
self.merge_patch(schema_file, dict_key, elem_patch)
|
||||
if unique_id in schema_file.node_patches:
|
||||
schema_file.node_patches.remove(unique_id)
|
||||
if unique_id in self.saved_manifest.disabled:
|
||||
# We have a patch_path in disabled nodes with a patch so
|
||||
# that we can connect the patch to the node
|
||||
for node in self.saved_manifest.disabled[unique_id]:
|
||||
node.patch_path = None
|
||||
|
||||
def update_macro_in_saved(self, new_source_file, old_source_file):
|
||||
if self.already_scheduled_for_parsing(old_source_file):
|
||||
return
|
||||
self.handle_macro_file_links(old_source_file, follow_references=True)
|
||||
file_id = new_source_file.file_id
|
||||
self.saved_files[file_id] = deepcopy(new_source_file)
|
||||
self.saved_files[file_id] = new_source_file
|
||||
self.add_to_pp_files(new_source_file)
|
||||
|
||||
def update_doc_in_saved(self, new_source_file, old_source_file):
|
||||
if self.already_scheduled_for_parsing(old_source_file):
|
||||
return
|
||||
self.delete_doc_node(old_source_file)
|
||||
self.saved_files[new_source_file.file_id] = deepcopy(new_source_file)
|
||||
self.saved_files[new_source_file.file_id] = new_source_file
|
||||
self.add_to_pp_files(new_source_file)
|
||||
|
||||
def remove_mssat_file(self, source_file):
|
||||
# nodes [unique_ids] -- SQL files
|
||||
# There should always be a node for a SQL file
|
||||
if not source_file.nodes:
|
||||
logger.debug(f"No nodes found for source file {source_file.file_id}")
|
||||
return
|
||||
raise Exception(f"No nodes found for source file {source_file.file_id}")
|
||||
# There is generally only 1 node for SQL files, except for macros
|
||||
for unique_id in source_file.nodes:
|
||||
self.remove_node_in_saved(source_file, unique_id)
|
||||
@@ -345,10 +299,7 @@ class PartialParsing:
|
||||
# We need to re-parse nodes that reference another removed node
|
||||
def schedule_referencing_nodes_for_parsing(self, unique_id):
|
||||
# Look at "children", i.e. nodes that reference this node
|
||||
if unique_id in self.saved_manifest.child_map:
|
||||
self.schedule_nodes_for_parsing(self.saved_manifest.child_map[unique_id])
|
||||
else:
|
||||
logger.debug(f"Partial parsing: {unique_id} not found in child_map")
|
||||
self.schedule_nodes_for_parsing(self.saved_manifest.child_map[unique_id])
|
||||
|
||||
def schedule_nodes_for_parsing(self, unique_ids):
|
||||
for unique_id in unique_ids:
|
||||
@@ -362,7 +313,7 @@ class PartialParsing:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.remove_mssat_file(source_file)
|
||||
# content of non-schema files is only in new files
|
||||
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
elif unique_id in self.saved_manifest.sources:
|
||||
source = self.saved_manifest.sources[unique_id]
|
||||
@@ -395,25 +346,14 @@ class PartialParsing:
|
||||
if file_id in self.saved_files and file_id not in self.file_diff['deleted']:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.delete_macro_file(source_file)
|
||||
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
|
||||
def delete_macro_file(self, source_file, follow_references=False):
|
||||
self.check_for_special_deleted_macros(source_file)
|
||||
self.handle_macro_file_links(source_file, follow_references)
|
||||
file_id = source_file.file_id
|
||||
self.deleted_manifest.files[file_id] = self.saved_files.pop(file_id)
|
||||
|
||||
def check_for_special_deleted_macros(self, source_file):
|
||||
for unique_id in source_file.macros:
|
||||
if unique_id in self.saved_manifest.macros:
|
||||
package_name = unique_id.split('.')[1]
|
||||
if package_name == 'dbt':
|
||||
continue
|
||||
macro = self.saved_manifest.macros[unique_id]
|
||||
if macro.name in special_override_macros:
|
||||
self.deleted_special_override_macro = True
|
||||
|
||||
def recursively_gather_macro_references(self, macro_unique_id, referencing_nodes):
|
||||
for unique_id in self.macro_child_map[macro_unique_id]:
|
||||
if unique_id in referencing_nodes:
|
||||
@@ -494,7 +434,7 @@ class PartialParsing:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.remove_mssat_file(source_file)
|
||||
# content of non-schema files is only in new files
|
||||
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
elif unique_id in self.saved_manifest.macros:
|
||||
macro = self.saved_manifest.macros[unique_id]
|
||||
@@ -502,7 +442,7 @@ class PartialParsing:
|
||||
if file_id in self.saved_files and file_id not in self.file_diff['deleted']:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.delete_macro_file(source_file)
|
||||
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
self.add_to_pp_files(self.saved_files[file_id])
|
||||
|
||||
def delete_doc_node(self, source_file):
|
||||
@@ -520,7 +460,7 @@ class PartialParsing:
|
||||
# Changed schema files
|
||||
def change_schema_file(self, file_id):
|
||||
saved_schema_file = self.saved_files[file_id]
|
||||
new_schema_file = deepcopy(self.new_files[file_id])
|
||||
new_schema_file = self.new_files[file_id]
|
||||
saved_yaml_dict = saved_schema_file.dict_from_yaml
|
||||
new_yaml_dict = new_schema_file.dict_from_yaml
|
||||
if 'version' in new_yaml_dict:
|
||||
@@ -699,7 +639,7 @@ class PartialParsing:
|
||||
file_id = node.file_id
|
||||
# need to copy new file to saved files in order to get content
|
||||
if file_id in self.new_files:
|
||||
self.saved_files[file_id] = deepcopy(self.new_files[file_id])
|
||||
self.saved_files[file_id] = self.new_files[file_id]
|
||||
if self.saved_files[file_id]:
|
||||
source_file = self.saved_files[file_id]
|
||||
self.add_to_pp_files(source_file)
|
||||
@@ -747,7 +687,7 @@ class PartialParsing:
|
||||
self.deleted_manifest.macros[macro_unique_id] = macro
|
||||
macro_file_id = macro.file_id
|
||||
if macro_file_id in self.new_files:
|
||||
self.saved_files[macro_file_id] = deepcopy(self.new_files[macro_file_id])
|
||||
self.saved_files[macro_file_id] = self.new_files[macro_file_id]
|
||||
self.add_to_pp_files(self.saved_files[macro_file_id])
|
||||
|
||||
# exposures are created only from schema files, so just delete
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import pathlib
|
||||
from dbt.clients.system import load_file_contents
|
||||
from dbt.contracts.files import (
|
||||
FilePath, ParseFileType, SourceFile, FileHash, AnySourceFile, SchemaSourceFile
|
||||
@@ -13,27 +12,13 @@ from typing import Optional
|
||||
# This loads the files contents and creates the SourceFile object
|
||||
def load_source_file(
|
||||
path: FilePath, parse_file_type: ParseFileType,
|
||||
project_name: str, saved_files,) -> Optional[AnySourceFile]:
|
||||
|
||||
project_name: str) -> Optional[AnySourceFile]:
|
||||
file_contents = load_file_contents(path.absolute_path, strip=False)
|
||||
checksum = FileHash.from_contents(file_contents)
|
||||
sf_cls = SchemaSourceFile if parse_file_type == ParseFileType.Schema else SourceFile
|
||||
source_file = sf_cls(path=path, checksum=FileHash.empty(),
|
||||
source_file = sf_cls(path=path, checksum=checksum,
|
||||
parse_file_type=parse_file_type, project_name=project_name)
|
||||
|
||||
skip_loading_schema_file = False
|
||||
if (parse_file_type == ParseFileType.Schema and
|
||||
saved_files and source_file.file_id in saved_files):
|
||||
old_source_file = saved_files[source_file.file_id]
|
||||
if (source_file.path.modification_time != 0.0 and
|
||||
old_source_file.path.modification_time == source_file.path.modification_time):
|
||||
source_file.checksum = old_source_file.checksum
|
||||
source_file.dfy = old_source_file.dfy
|
||||
skip_loading_schema_file = True
|
||||
|
||||
if not skip_loading_schema_file:
|
||||
file_contents = load_file_contents(path.absolute_path, strip=False)
|
||||
source_file.checksum = FileHash.from_contents(file_contents)
|
||||
source_file.contents = file_contents.strip()
|
||||
|
||||
source_file.contents = file_contents.strip()
|
||||
if parse_file_type == ParseFileType.Schema and source_file.contents:
|
||||
dfy = yaml_from_file(source_file)
|
||||
if dfy:
|
||||
@@ -84,7 +69,7 @@ def load_seed_source_file(match: FilePath, project_name) -> SourceFile:
|
||||
|
||||
# Use the FilesystemSearcher to get a bunch of FilePaths, then turn
|
||||
# them into a bunch of FileSource objects
|
||||
def get_source_files(project, paths, extension, parse_file_type, saved_files):
|
||||
def get_source_files(project, paths, extension, parse_file_type):
|
||||
# file path list
|
||||
fp_list = list(FilesystemSearcher(
|
||||
project, paths, extension
|
||||
@@ -94,24 +79,18 @@ def get_source_files(project, paths, extension, parse_file_type, saved_files):
|
||||
for fp in fp_list:
|
||||
if parse_file_type == ParseFileType.Seed:
|
||||
fb_list.append(load_seed_source_file(fp, project.project_name))
|
||||
# singular tests live in /tests but only generic tests live
|
||||
# in /tests/generic so we want to skip those
|
||||
else:
|
||||
if parse_file_type == ParseFileType.SingularTest:
|
||||
path = pathlib.Path(fp.relative_path)
|
||||
if path.parts[0] == 'generic':
|
||||
continue
|
||||
file = load_source_file(fp, parse_file_type, project.project_name, saved_files)
|
||||
file = load_source_file(fp, parse_file_type, project.project_name)
|
||||
# only append the list if it has contents. added to fix #3568
|
||||
if file:
|
||||
fb_list.append(file)
|
||||
return fb_list
|
||||
|
||||
|
||||
def read_files_for_parser(project, files, dirs, extension, parse_ft, saved_files):
|
||||
def read_files_for_parser(project, files, dirs, extension, parse_ft):
|
||||
parser_files = []
|
||||
source_files = get_source_files(
|
||||
project, dirs, extension, parse_ft, saved_files
|
||||
project, dirs, extension, parse_ft
|
||||
)
|
||||
for sf in source_files:
|
||||
files[sf.file_id] = sf
|
||||
@@ -123,52 +102,46 @@ def read_files_for_parser(project, files, dirs, extension, parse_ft, saved_files
|
||||
# dictionary needs to be passed in. What determines the order of
|
||||
# the various projects? Is the root project always last? Do the
|
||||
# non-root projects need to be done separately in order?
|
||||
def read_files(project, files, parser_files, saved_files):
|
||||
def read_files(project, files, parser_files):
|
||||
|
||||
project_files = {}
|
||||
|
||||
project_files['MacroParser'] = read_files_for_parser(
|
||||
project, files, project.macro_paths, '.sql', ParseFileType.Macro, saved_files
|
||||
project, files, project.macro_paths, '.sql', ParseFileType.Macro,
|
||||
)
|
||||
|
||||
project_files['ModelParser'] = read_files_for_parser(
|
||||
project, files, project.model_paths, '.sql', ParseFileType.Model, saved_files
|
||||
project, files, project.source_paths, '.sql', ParseFileType.Model,
|
||||
)
|
||||
|
||||
project_files['SnapshotParser'] = read_files_for_parser(
|
||||
project, files, project.snapshot_paths, '.sql', ParseFileType.Snapshot, saved_files
|
||||
project, files, project.snapshot_paths, '.sql', ParseFileType.Snapshot,
|
||||
)
|
||||
|
||||
project_files['AnalysisParser'] = read_files_for_parser(
|
||||
project, files, project.analysis_paths, '.sql', ParseFileType.Analysis, saved_files
|
||||
project, files, project.analysis_paths, '.sql', ParseFileType.Analysis,
|
||||
)
|
||||
|
||||
project_files['SingularTestParser'] = read_files_for_parser(
|
||||
project, files, project.test_paths, '.sql', ParseFileType.SingularTest, saved_files
|
||||
)
|
||||
|
||||
# all generic tests within /tests must be nested under a /generic subfolder
|
||||
project_files['GenericTestParser'] = read_files_for_parser(
|
||||
project, files, ["{}{}".format(test_path, '/generic') for test_path in project.test_paths],
|
||||
'.sql', ParseFileType.GenericTest, saved_files
|
||||
project_files['DataTestParser'] = read_files_for_parser(
|
||||
project, files, project.test_paths, '.sql', ParseFileType.Test,
|
||||
)
|
||||
|
||||
project_files['SeedParser'] = read_files_for_parser(
|
||||
project, files, project.seed_paths, '.csv', ParseFileType.Seed, saved_files
|
||||
project, files, project.data_paths, '.csv', ParseFileType.Seed,
|
||||
)
|
||||
|
||||
project_files['DocumentationParser'] = read_files_for_parser(
|
||||
project, files, project.docs_paths, '.md', ParseFileType.Documentation, saved_files
|
||||
project, files, project.docs_paths, '.md', ParseFileType.Documentation,
|
||||
)
|
||||
|
||||
project_files['SchemaParser'] = read_files_for_parser(
|
||||
project, files, project.all_source_paths, '.yml', ParseFileType.Schema, saved_files
|
||||
project, files, project.all_source_paths, '.yml', ParseFileType.Schema,
|
||||
)
|
||||
|
||||
# Also read .yaml files for schema files. Might be better to change
|
||||
# 'read_files_for_parser' accept an array in the future.
|
||||
yaml_files = read_files_for_parser(
|
||||
project, files, project.all_source_paths, '.yaml', ParseFileType.Schema, saved_files
|
||||
project, files, project.all_source_paths, '.yaml', ParseFileType.Schema,
|
||||
)
|
||||
project_files['SchemaParser'].extend(yaml_files)
|
||||
|
||||
|
||||
61
core/dbt/parser/rpc.py
Normal file
61
core/dbt/parser/rpc.py
Normal file
@@ -0,0 +1,61 @@
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
from typing import Iterable
|
||||
|
||||
from dbt.contracts.graph.manifest import SourceFile
|
||||
from dbt.contracts.graph.parsed import ParsedRPCNode, ParsedMacro
|
||||
from dbt.contracts.graph.unparsed import UnparsedMacro
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.macros import MacroParser
|
||||
from dbt.parser.search import FileBlock
|
||||
|
||||
|
||||
@dataclass
|
||||
class RPCBlock(FileBlock):
|
||||
rpc_name: str
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return self.rpc_name
|
||||
|
||||
|
||||
class RPCCallParser(SimpleSQLParser[ParsedRPCNode]):
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedRPCNode:
|
||||
if validate:
|
||||
ParsedRPCNode.validate(dct)
|
||||
return ParsedRPCNode.from_dict(dct)
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.RPCCall
|
||||
|
||||
def get_compiled_path(cls, block: FileBlock):
|
||||
# we do it this way to make mypy happy
|
||||
if not isinstance(block, RPCBlock):
|
||||
raise InternalException(
|
||||
'While parsing RPC calls, got an actual file block instead of '
|
||||
'an RPC block: {}'.format(block)
|
||||
)
|
||||
|
||||
return os.path.join('rpc', block.name)
|
||||
|
||||
def parse_remote(self, sql: str, name: str) -> ParsedRPCNode:
|
||||
source_file = SourceFile.remote(sql, self.project.project_name)
|
||||
contents = RPCBlock(rpc_name=name, file=source_file)
|
||||
return self.parse_node(contents)
|
||||
|
||||
|
||||
class RPCMacroParser(MacroParser):
|
||||
def parse_remote(self, contents) -> Iterable[ParsedMacro]:
|
||||
base = UnparsedMacro(
|
||||
path='from remote system',
|
||||
original_file_path='from remote system',
|
||||
package_name=self.project.project_name,
|
||||
raw_sql=contents,
|
||||
root_path=self.project.project_root,
|
||||
resource_type=NodeType.Macro,
|
||||
)
|
||||
for node in self.parse_unparsed_macros(base):
|
||||
yield node
|
||||
@@ -6,7 +6,7 @@ from typing import (
|
||||
Generic, TypeVar, Dict, Any, Tuple, Optional, List,
|
||||
)
|
||||
|
||||
from dbt.clients.jinja import get_rendered, GENERIC_TEST_KWARGS_NAME
|
||||
from dbt.clients.jinja import get_rendered, SCHEMA_TEST_KWARGS_NAME
|
||||
from dbt.contracts.graph.parsed import UnpatchedSourceDefinition
|
||||
from dbt.contracts.graph.unparsed import (
|
||||
TestDef,
|
||||
@@ -19,7 +19,7 @@ from dbt.exceptions import raise_compiler_error
|
||||
from dbt.parser.search import FileBlock
|
||||
|
||||
|
||||
def get_nice_generic_test_name(
|
||||
def get_nice_schema_test_name(
|
||||
test_type: str, test_name: str, args: Dict[str, Any]
|
||||
) -> Tuple[str, str]:
|
||||
flat_args = []
|
||||
@@ -153,7 +153,7 @@ class TestBlock(TargetColumnsBlock[Testable], Generic[Testable]):
|
||||
|
||||
|
||||
@dataclass
|
||||
class GenericTestBlock(TestBlock[Testable], Generic[Testable]):
|
||||
class SchemaTestBlock(TestBlock[Testable], Generic[Testable]):
|
||||
test: Dict[str, Any]
|
||||
column_name: Optional[str]
|
||||
tags: List[str]
|
||||
@@ -165,7 +165,7 @@ class GenericTestBlock(TestBlock[Testable], Generic[Testable]):
|
||||
test: Dict[str, Any],
|
||||
column_name: Optional[str],
|
||||
tags: List[str],
|
||||
) -> 'GenericTestBlock':
|
||||
) -> 'SchemaTestBlock':
|
||||
return cls(
|
||||
file=src.file,
|
||||
data=src.data,
|
||||
@@ -358,7 +358,7 @@ class TestBuilder(Generic[Testable]):
|
||||
if self.warn_if is not None:
|
||||
config['warn_if'] = self.warn_if
|
||||
if self.error_if is not None:
|
||||
config['error_if'] = self.error_if
|
||||
config['error_id'] = self.error_if
|
||||
if self.fail_calc is not None:
|
||||
config['fail_calc'] = self.fail_calc
|
||||
if self.store_failures is not None:
|
||||
@@ -369,6 +369,8 @@ class TestBuilder(Generic[Testable]):
|
||||
config['database'] = self.database
|
||||
if self.schema is not None:
|
||||
config['schema'] = self.schema
|
||||
if self.alias is not None:
|
||||
config['alias'] = self.alias
|
||||
return config
|
||||
|
||||
def tags(self) -> List[str]:
|
||||
@@ -402,7 +404,7 @@ class TestBuilder(Generic[Testable]):
|
||||
raise self._bad_type()
|
||||
if self.namespace is not None:
|
||||
name = '{}_{}'.format(self.namespace, name)
|
||||
return get_nice_generic_test_name(name, self.target.name, self.args)
|
||||
return get_nice_schema_test_name(name, self.target.name, self.args)
|
||||
|
||||
def construct_config(self) -> str:
|
||||
configs = ",".join([
|
||||
@@ -426,7 +428,7 @@ class TestBuilder(Generic[Testable]):
|
||||
).format(
|
||||
macro=self.macro_name(),
|
||||
config=self.construct_config(),
|
||||
kwargs_name=GENERIC_TEST_KWARGS_NAME,
|
||||
kwargs_name=SCHEMA_TEST_KWARGS_NAME,
|
||||
)
|
||||
|
||||
def build_model_str(self):
|
||||
@@ -1,6 +1,5 @@
|
||||
import itertools
|
||||
import os
|
||||
import pathlib
|
||||
|
||||
from abc import ABCMeta, abstractmethod
|
||||
from hashlib import md5
|
||||
@@ -27,7 +26,7 @@ from dbt.contracts.files import FileHash, SchemaSourceFile
|
||||
from dbt.contracts.graph.parsed import (
|
||||
ParsedNodePatch,
|
||||
ColumnInfo,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
ParsedMacroPatch,
|
||||
UnpatchedSourceDefinition,
|
||||
ParsedExposure,
|
||||
@@ -45,17 +44,18 @@ from dbt.contracts.graph.unparsed import (
|
||||
UnparsedSourceDefinition,
|
||||
)
|
||||
from dbt.exceptions import (
|
||||
warn_invalid_patch, validator_error_message, JSONValidationException,
|
||||
validator_error_message, JSONValidationException,
|
||||
raise_invalid_schema_yml_version, ValidationException,
|
||||
CompilationException, raise_duplicate_patch_name,
|
||||
raise_duplicate_macro_patch_name, InternalException,
|
||||
raise_duplicate_source_patch_name, warn_or_error,
|
||||
raise_duplicate_source_patch_name,
|
||||
warn_or_error,
|
||||
)
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleParser
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.parser.generic_test_builders import (
|
||||
TestBuilder, GenericTestBlock, TargetBlock, YamlBlock,
|
||||
from dbt.parser.schema_test_builders import (
|
||||
TestBuilder, SchemaTestBlock, TargetBlock, YamlBlock,
|
||||
TestBlock, Testable
|
||||
)
|
||||
from dbt.utils import (
|
||||
@@ -163,7 +163,7 @@ def _trimmed(inp: str) -> str:
|
||||
return inp[:44] + '...' + inp[-3:]
|
||||
|
||||
|
||||
class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
class SchemaParser(SimpleParser[SchemaTestBlock, ParsedSchemaTestNode]):
|
||||
def __init__(
|
||||
self, project, manifest, root_project,
|
||||
) -> None:
|
||||
@@ -201,10 +201,10 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.Test
|
||||
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedGenericTestNode:
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedSchemaTestNode:
|
||||
if validate:
|
||||
ParsedGenericTestNode.validate(dct)
|
||||
return ParsedGenericTestNode.from_dict(dct)
|
||||
ParsedSchemaTestNode.validate(dct)
|
||||
return ParsedSchemaTestNode.from_dict(dct)
|
||||
|
||||
def parse_column_tests(
|
||||
self, block: TestBlock, column: UnparsedColumn
|
||||
@@ -226,7 +226,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
raw_sql: str,
|
||||
test_metadata: Dict[str, Any],
|
||||
column_name: Optional[str],
|
||||
) -> ParsedGenericTestNode:
|
||||
) -> ParsedSchemaTestNode:
|
||||
|
||||
HASH_LENGTH = 10
|
||||
|
||||
@@ -267,8 +267,8 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
'checksum': FileHash.empty().to_dict(omit_none=True),
|
||||
}
|
||||
try:
|
||||
ParsedGenericTestNode.validate(dct)
|
||||
return ParsedGenericTestNode.from_dict(dct)
|
||||
ParsedSchemaTestNode.validate(dct)
|
||||
return ParsedSchemaTestNode.from_dict(dct)
|
||||
except ValidationError as exc:
|
||||
msg = validator_error_message(exc)
|
||||
# this is a bit silly, but build an UnparsedNode just for error
|
||||
@@ -288,7 +288,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
test: Dict[str, Any],
|
||||
tags: List[str],
|
||||
column_name: Optional[str],
|
||||
) -> ParsedGenericTestNode:
|
||||
) -> ParsedSchemaTestNode:
|
||||
try:
|
||||
builder = TestBuilder(
|
||||
test=test,
|
||||
@@ -306,14 +306,15 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
)
|
||||
raise CompilationException(msg) from exc
|
||||
original_name = os.path.basename(target.original_file_path)
|
||||
compiled_path = get_pseudo_test_path(builder.compiled_name, original_name)
|
||||
|
||||
# fqn is the relative path of the yaml file where this generic test is defined,
|
||||
# minus the project-level directory and the file name itself
|
||||
# TODO pass a consistent path object from both UnparsedNode and UnpatchedSourceDefinition
|
||||
path = pathlib.Path(target.original_file_path)
|
||||
relative_path = str(path.relative_to(*path.parts[:1]))
|
||||
fqn = self.get_fqn(relative_path, builder.fqn_name)
|
||||
compiled_path = get_pseudo_test_path(
|
||||
builder.compiled_name, original_name, 'schema_test',
|
||||
)
|
||||
fqn_path = get_pseudo_test_path(
|
||||
builder.fqn_name, original_name, 'schema_test',
|
||||
)
|
||||
# the fqn for tests actually happens in the test target's name, which
|
||||
# is not necessarily this package's name
|
||||
fqn = self.get_fqn(fqn_path, builder.fqn_name)
|
||||
|
||||
# this is the ContextConfig that is used in render_update
|
||||
config: ContextConfig = self.initial_config(fqn)
|
||||
@@ -324,6 +325,8 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
'kwargs': builder.args,
|
||||
}
|
||||
tags = sorted(set(itertools.chain(tags, builder.tags())))
|
||||
if 'schema' not in tags:
|
||||
tags.append('schema')
|
||||
|
||||
node = self.create_test_node(
|
||||
target=target,
|
||||
@@ -384,7 +387,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
msg = validator_error_message(exc)
|
||||
raise CompilationException(msg, node=node) from exc
|
||||
|
||||
def parse_node(self, block: GenericTestBlock) -> ParsedGenericTestNode:
|
||||
def parse_node(self, block: SchemaTestBlock) -> ParsedSchemaTestNode:
|
||||
"""In schema parsing, we rewrite most of the part of parse_node that
|
||||
builds the initial node to be parsed, but rendering is basically the
|
||||
same
|
||||
@@ -398,7 +401,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
self.add_test_node(block, node)
|
||||
return node
|
||||
|
||||
def add_test_node(self, block: GenericTestBlock, node: ParsedGenericTestNode):
|
||||
def add_test_node(self, block: SchemaTestBlock, node: ParsedSchemaTestNode):
|
||||
test_from = {"key": block.target.yaml_key, "name": block.target.name}
|
||||
if node.config.enabled:
|
||||
self.manifest.add_node(block.file, node, test_from)
|
||||
@@ -406,7 +409,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
self.manifest.add_disabled(block.file, node, test_from)
|
||||
|
||||
def render_with_context(
|
||||
self, node: ParsedGenericTestNode, config: ContextConfig,
|
||||
self, node: ParsedSchemaTestNode, config: ContextConfig,
|
||||
) -> None:
|
||||
"""Given the parsed node and a ContextConfig to use during
|
||||
parsing, collect all the refs that might be squirreled away in the test
|
||||
@@ -444,7 +447,7 @@ class SchemaParser(SimpleParser[GenericTestBlock, ParsedGenericTestNode]):
|
||||
column_name = get_adapter(self.root_project).quote(column_name)
|
||||
column_tags = column.tags
|
||||
|
||||
block = GenericTestBlock.from_test_block(
|
||||
block = SchemaTestBlock.from_test_block(
|
||||
src=target_block,
|
||||
test=test,
|
||||
column_name=column_name,
|
||||
@@ -813,12 +816,6 @@ class NodePatchParser(
|
||||
source_file: SchemaSourceFile = self.yaml.file
|
||||
if patch.yaml_key in ['models', 'seeds', 'snapshots']:
|
||||
unique_id = self.manifest.ref_lookup.get_unique_id(patch.name, None)
|
||||
if unique_id:
|
||||
resource_type = NodeType(unique_id.split('.')[0])
|
||||
if resource_type.pluralize() != patch.yaml_key:
|
||||
warn_invalid_patch(patch, resource_type)
|
||||
return
|
||||
|
||||
elif patch.yaml_key == 'analyses':
|
||||
unique_id = self.manifest.analysis_lookup.get_unique_id(patch.name, None)
|
||||
else:
|
||||
@@ -827,17 +824,8 @@ class NodePatchParser(
|
||||
f'file {source_file.path.original_file_path}'
|
||||
)
|
||||
if unique_id is None:
|
||||
# Node might be disabled. Following call returns list of matching disabled nodes
|
||||
found_nodes = self.manifest.disabled_lookup.find(patch.name, patch.package_name)
|
||||
if found_nodes:
|
||||
# There might be multiple disabled nodes for this model
|
||||
for node in found_nodes:
|
||||
# We're saving the patch_path because we need to schedule
|
||||
# re-application of the patch in partial parsing.
|
||||
node.patch_path = source_file.file_id
|
||||
else:
|
||||
# Should we issue a warning message here?
|
||||
return
|
||||
# This will usually happen when a node is disabled
|
||||
return
|
||||
|
||||
# patches can't be overwritten
|
||||
node = self.manifest.nodes.get(unique_id)
|
||||
|
||||
@@ -84,7 +84,6 @@ class FilesystemSearcher(Iterable[FilePath]):
|
||||
file_match = FilePath(
|
||||
searched_path=result['searched_path'],
|
||||
relative_path=result['relative_path'],
|
||||
modification_time=result['modification_time'],
|
||||
project_root=root,
|
||||
)
|
||||
yield file_match
|
||||
|
||||
@@ -1,20 +0,0 @@
|
||||
from dbt.contracts.graph.parsed import ParsedSingularTestNode
|
||||
from dbt.node_types import NodeType
|
||||
from dbt.parser.base import SimpleSQLParser
|
||||
from dbt.parser.search import FileBlock
|
||||
from dbt.utils import get_pseudo_test_path
|
||||
|
||||
|
||||
class SingularTestParser(SimpleSQLParser[ParsedSingularTestNode]):
|
||||
def parse_from_dict(self, dct, validate=True) -> ParsedSingularTestNode:
|
||||
if validate:
|
||||
ParsedSingularTestNode.validate(dct)
|
||||
return ParsedSingularTestNode.from_dict(dct)
|
||||
|
||||
@property
|
||||
def resource_type(self) -> NodeType:
|
||||
return NodeType.Test
|
||||
|
||||
@classmethod
|
||||
def get_compiled_path(cls, block: FileBlock):
|
||||
return get_pseudo_test_path(block.name, block.path.relative_path)
|
||||
@@ -15,7 +15,7 @@ from dbt.contracts.graph.model_config import SourceConfig
|
||||
from dbt.contracts.graph.parsed import (
|
||||
UnpatchedSourceDefinition,
|
||||
ParsedSourceDefinition,
|
||||
ParsedGenericTestNode,
|
||||
ParsedSchemaTestNode,
|
||||
)
|
||||
from dbt.contracts.graph.unparsed import (
|
||||
UnparsedSourceDefinition,
|
||||
@@ -211,7 +211,7 @@ class SourcePatcher:
|
||||
|
||||
def get_source_tests(
|
||||
self, target: UnpatchedSourceDefinition
|
||||
) -> Iterable[ParsedGenericTestNode]:
|
||||
) -> Iterable[ParsedSchemaTestNode]:
|
||||
for test, column in target.get_tests():
|
||||
yield self.parse_source_test(
|
||||
target=target,
|
||||
@@ -242,7 +242,7 @@ class SourcePatcher:
|
||||
target: UnpatchedSourceDefinition,
|
||||
test: Dict[str, Any],
|
||||
column: Optional[UnparsedColumn],
|
||||
) -> ParsedGenericTestNode:
|
||||
) -> ParsedSchemaTestNode:
|
||||
column_name: Optional[str]
|
||||
if column is None:
|
||||
column_name = None
|
||||
@@ -269,6 +269,11 @@ class SourcePatcher:
|
||||
tags=tags,
|
||||
column_name=column_name
|
||||
)
|
||||
# we can't go through result.add_node - no file... instead!
|
||||
if node.config.enabled:
|
||||
self.manifest.add_node_nofile(node)
|
||||
else:
|
||||
self.manifest.add_disabled_nofile(node)
|
||||
return node
|
||||
|
||||
def _generate_source_config(self, fqn: List[str], rendered: bool, project_name: str):
|
||||
|
||||
36
core/dbt/rpc/__init__.py
Normal file
36
core/dbt/rpc/__init__.py
Normal file
@@ -0,0 +1,36 @@
|
||||
"""The `rpc` package handles most aspects of the actual execution of dbt's RPC
|
||||
server (except for the server itself and the client tasks, which are defined in
|
||||
the `task.remote` package).
|
||||
|
||||
The general idea from a thread/process management perspective (ignoring the
|
||||
--single-threaded flag!) is as follows:
|
||||
|
||||
- The RPC server runs a web server, in particular `werkzeug`, which manages a
|
||||
thread pool.
|
||||
- When a request comes in, werkzeug spins off a thread to manage the
|
||||
request/response portion. dbt itself has basically no control over this
|
||||
operation - from our viewpoint request/response cycles are fully
|
||||
synchronous.
|
||||
- synchronous requests are defined as methods in the `TaskManager` and handled
|
||||
in the responding thread directly.
|
||||
- Asynchronous requests (defined in `tasks.remote`) are kicked off wrapped in
|
||||
`RequestTaskHandler`s, which manage a new process and a new thread.
|
||||
- The process runs the actual dbt request, logging via a message queue
|
||||
- eventually just before process exit, the process places an "error" or
|
||||
"result" on the queue
|
||||
- The thread monitors the queue, taking logs off the queue and adding them
|
||||
to the `RequestTaskHandler`'s `logs` attribute.
|
||||
- The thread also monitors the `is_alive` state of the process, in case
|
||||
it is killed "unexpectedly" (including via `kill`)
|
||||
- When the thread sees an error or result come over the queue, it join()s
|
||||
the process.
|
||||
- When the thread sees that the process has disappeared without placing
|
||||
anything on the queue, it checks the queue one last time, and then acts
|
||||
as if the queue received an 'Unexpected termination' error
|
||||
- `kill` commands pointed at an asynchronous task kill the process and allow
|
||||
the thread to handle cleanup and management
|
||||
- When the RPC server receives a shutdown instruction, it:
|
||||
- stops responding to requests
|
||||
- `kills` all processes (triggering the end of all processes, right!?)
|
||||
- exits (all remaining threads should die here!)
|
||||
"""
|
||||
258
core/dbt/rpc/builtins.py
Normal file
258
core/dbt/rpc/builtins.py
Normal file
@@ -0,0 +1,258 @@
|
||||
import os
|
||||
import signal
|
||||
from datetime import datetime
|
||||
from typing import Type, Union, Any, List, Dict
|
||||
|
||||
import dbt.exceptions
|
||||
from dbt.contracts.rpc import (
|
||||
TaskTags,
|
||||
StatusParameters,
|
||||
LastParse,
|
||||
GCParameters,
|
||||
GCResult,
|
||||
GetManifestResult,
|
||||
KillParameters,
|
||||
KillResult,
|
||||
KillResultStatus,
|
||||
PSParameters,
|
||||
TaskRow,
|
||||
PSResult,
|
||||
RemoteExecutionResult,
|
||||
RemoteFreshnessResult,
|
||||
RemoteRunResult,
|
||||
RemoteCompileResult,
|
||||
RemoteCatalogResults,
|
||||
RemoteDepsResult,
|
||||
RemoteRunOperationResult,
|
||||
PollParameters,
|
||||
PollResult,
|
||||
PollInProgressResult,
|
||||
PollKilledResult,
|
||||
PollExecuteCompleteResult,
|
||||
PollGetManifestResult,
|
||||
PollRunCompleteResult,
|
||||
PollCompileCompleteResult,
|
||||
PollCatalogCompleteResult,
|
||||
PollFreshnessResult,
|
||||
PollRemoteEmptyCompleteResult,
|
||||
PollRunOperationCompleteResult,
|
||||
TaskHandlerState,
|
||||
TaskTiming,
|
||||
)
|
||||
from dbt.logger import LogMessage
|
||||
from dbt.rpc.error import dbt_error, RPCException
|
||||
from dbt.rpc.method import RemoteBuiltinMethod
|
||||
from dbt.rpc.task_handler import RequestTaskHandler
|
||||
|
||||
|
||||
class GC(RemoteBuiltinMethod[GCParameters, GCResult]):
|
||||
METHOD_NAME = 'gc'
|
||||
|
||||
def set_args(self, params: GCParameters):
|
||||
super().set_args(params)
|
||||
|
||||
def handle_request(self) -> GCResult:
|
||||
if self.params is None:
|
||||
raise dbt.exceptions.InternalException('GC: params not set')
|
||||
return self.task_manager.gc_safe(
|
||||
task_ids=self.params.task_ids,
|
||||
before=self.params.before,
|
||||
settings=self.params.settings,
|
||||
)
|
||||
|
||||
|
||||
class Kill(RemoteBuiltinMethod[KillParameters, KillResult]):
|
||||
METHOD_NAME = 'kill'
|
||||
|
||||
def set_args(self, params: KillParameters):
|
||||
super().set_args(params)
|
||||
|
||||
def handle_request(self) -> KillResult:
|
||||
if self.params is None:
|
||||
raise dbt.exceptions.InternalException('Kill: params not set')
|
||||
result = KillResult()
|
||||
task: RequestTaskHandler
|
||||
try:
|
||||
task = self.task_manager.get_request(self.params.task_id)
|
||||
except dbt.exceptions.UnknownAsyncIDException:
|
||||
# nothing to do!
|
||||
return result
|
||||
|
||||
result.state = KillResultStatus.NotStarted
|
||||
|
||||
if task.process is None:
|
||||
return result
|
||||
pid = task.process.pid
|
||||
if pid is None:
|
||||
return result
|
||||
|
||||
if task.process.is_alive():
|
||||
result.state = KillResultStatus.Killed
|
||||
task.ended = datetime.utcnow()
|
||||
os.kill(pid, signal.SIGINT)
|
||||
task.state = TaskHandlerState.Killed
|
||||
else:
|
||||
result.state = KillResultStatus.Finished
|
||||
# the state must be "Completed"
|
||||
|
||||
return result
|
||||
|
||||
|
||||
class Status(RemoteBuiltinMethod[StatusParameters, LastParse]):
|
||||
METHOD_NAME = 'status'
|
||||
|
||||
def set_args(self, params: StatusParameters):
|
||||
super().set_args(params)
|
||||
|
||||
def handle_request(self) -> LastParse:
|
||||
return self.task_manager.last_parse
|
||||
|
||||
|
||||
class PS(RemoteBuiltinMethod[PSParameters, PSResult]):
|
||||
METHOD_NAME = 'ps'
|
||||
|
||||
def set_args(self, params: PSParameters):
|
||||
super().set_args(params)
|
||||
|
||||
def keep(self, row: TaskRow):
|
||||
if self.params is None:
|
||||
raise dbt.exceptions.InternalException('PS: params not set')
|
||||
if row.state.finished and self.params.completed:
|
||||
return True
|
||||
elif not row.state.finished and self.params.active:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
def handle_request(self) -> PSResult:
|
||||
rows = [
|
||||
row for row in self.task_manager.task_table() if self.keep(row)
|
||||
]
|
||||
rows.sort(key=lambda r: (r.state, r.start, r.method))
|
||||
result = PSResult(rows=rows, logs=[])
|
||||
return result
|
||||
|
||||
|
||||
def poll_complete(
|
||||
timing: TaskTiming, result: Any, tags: TaskTags, logs: List[LogMessage]
|
||||
) -> PollResult:
|
||||
if timing.state not in (TaskHandlerState.Success, TaskHandlerState.Failed):
|
||||
raise dbt.exceptions.InternalException(
|
||||
f'got invalid result state in poll_complete: {timing.state}'
|
||||
)
|
||||
|
||||
cls: Type[Union[
|
||||
PollExecuteCompleteResult,
|
||||
PollRunCompleteResult,
|
||||
PollCompileCompleteResult,
|
||||
PollCatalogCompleteResult,
|
||||
PollRemoteEmptyCompleteResult,
|
||||
PollRunOperationCompleteResult,
|
||||
PollGetManifestResult,
|
||||
PollFreshnessResult,
|
||||
]]
|
||||
|
||||
if isinstance(result, RemoteExecutionResult):
|
||||
cls = PollExecuteCompleteResult
|
||||
# order matters here, as RemoteRunResult subclasses RemoteCompileResult
|
||||
elif isinstance(result, RemoteRunResult):
|
||||
cls = PollRunCompleteResult
|
||||
elif isinstance(result, RemoteCompileResult):
|
||||
cls = PollCompileCompleteResult
|
||||
elif isinstance(result, RemoteCatalogResults):
|
||||
cls = PollCatalogCompleteResult
|
||||
elif isinstance(result, RemoteDepsResult):
|
||||
cls = PollRemoteEmptyCompleteResult
|
||||
elif isinstance(result, RemoteRunOperationResult):
|
||||
cls = PollRunOperationCompleteResult
|
||||
elif isinstance(result, GetManifestResult):
|
||||
cls = PollGetManifestResult
|
||||
elif isinstance(result, RemoteFreshnessResult):
|
||||
cls = PollFreshnessResult
|
||||
else:
|
||||
raise dbt.exceptions.InternalException(
|
||||
'got invalid result in poll_complete: {}'.format(result)
|
||||
)
|
||||
return cls.from_result(result, tags, timing, logs)
|
||||
|
||||
|
||||
def _dict_logs(logs: List[LogMessage]) -> List[Dict[str, Any]]:
|
||||
return [log.to_dict(omit_none=True) for log in logs]
|
||||
|
||||
|
||||
class Poll(RemoteBuiltinMethod[PollParameters, PollResult]):
|
||||
METHOD_NAME = 'poll'
|
||||
|
||||
def set_args(self, params: PollParameters):
|
||||
super().set_args(params)
|
||||
|
||||
def handle_request(self) -> PollResult:
|
||||
if self.params is None:
|
||||
raise dbt.exceptions.InternalException('Poll: params not set')
|
||||
task_id = self.params.request_token
|
||||
task: RequestTaskHandler = self.task_manager.get_request(task_id)
|
||||
|
||||
task_logs: List[LogMessage] = []
|
||||
if self.params.logs:
|
||||
task_logs = task.logs[self.params.logs_start:]
|
||||
|
||||
# Get a state and store it locally so we ignore updates to state,
|
||||
# otherwise things will get confusing. States should always be
|
||||
# "forward-compatible" so if the state has transitioned to error/result
|
||||
# but we aren't there yet, the logs will still be valid.
|
||||
|
||||
timing = task.make_task_timing(datetime.utcnow())
|
||||
state = timing.state
|
||||
if state <= TaskHandlerState.Running:
|
||||
return PollInProgressResult(
|
||||
tags=task.tags,
|
||||
logs=task_logs,
|
||||
state=timing.state,
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
)
|
||||
elif state == TaskHandlerState.Error:
|
||||
err = task.error
|
||||
if err is None:
|
||||
exc = dbt.exceptions.InternalException(
|
||||
f'At end of task {task_id}, error state but error is None'
|
||||
)
|
||||
raise RPCException.from_error(
|
||||
dbt_error(exc, logs=_dict_logs(task_logs))
|
||||
)
|
||||
# the exception has logs already attached from the child, don't
|
||||
# overwrite those
|
||||
raise err
|
||||
elif state in (TaskHandlerState.Success, TaskHandlerState.Failed):
|
||||
|
||||
if task.result is None:
|
||||
exc = dbt.exceptions.InternalException(
|
||||
f'At end of task {task_id}, state={state} but result is '
|
||||
'None'
|
||||
)
|
||||
raise RPCException.from_error(
|
||||
dbt_error(exc, logs=_dict_logs(task_logs))
|
||||
)
|
||||
return poll_complete(
|
||||
timing=timing,
|
||||
result=task.result,
|
||||
tags=task.tags,
|
||||
logs=task_logs
|
||||
)
|
||||
elif state == TaskHandlerState.Killed:
|
||||
return PollKilledResult(
|
||||
tags=task.tags,
|
||||
logs=task_logs,
|
||||
state=timing.state,
|
||||
start=timing.start,
|
||||
end=timing.end,
|
||||
elapsed=timing.elapsed,
|
||||
)
|
||||
else:
|
||||
exc = dbt.exceptions.InternalException(
|
||||
f'Got unknown value state={state} for task {task_id}'
|
||||
)
|
||||
raise RPCException.from_error(
|
||||
dbt_error(exc, logs=_dict_logs(task_logs))
|
||||
)
|
||||
87
core/dbt/rpc/error.py
Normal file
87
core/dbt/rpc/error.py
Normal file
@@ -0,0 +1,87 @@
|
||||
from typing import List, Dict, Any, Optional
|
||||
|
||||
from jsonrpc.exceptions import JSONRPCDispatchException, JSONRPCInvalidParams
|
||||
|
||||
import dbt.exceptions
|
||||
|
||||
|
||||
class RPCException(JSONRPCDispatchException):
|
||||
def __init__(
|
||||
self,
|
||||
code: Optional[int] = None,
|
||||
message: Optional[str] = None,
|
||||
data: Optional[Dict[str, Any]] = None,
|
||||
logs: Optional[List[Dict[str, Any]]] = None,
|
||||
tags: Optional[Dict[str, Any]] = None
|
||||
) -> None:
|
||||
if code is None:
|
||||
code = -32000
|
||||
if message is None:
|
||||
message = 'Server error'
|
||||
if data is None:
|
||||
data = {}
|
||||
|
||||
super().__init__(code=code, message=message, data=data)
|
||||
if logs is not None:
|
||||
self.logs = logs
|
||||
self.error.data['tags'] = tags
|
||||
|
||||
def __str__(self):
|
||||
return (
|
||||
'RPCException({0.code}, {0.message}, {0.data}, {1.logs})'
|
||||
.format(self.error, self)
|
||||
)
|
||||
|
||||
@property
|
||||
def logs(self) -> List[Dict[str, Any]]:
|
||||
return self.error.data.get('logs')
|
||||
|
||||
@logs.setter
|
||||
def logs(self, value):
|
||||
if value is None:
|
||||
return
|
||||
self.error.data['logs'] = value
|
||||
|
||||
@property
|
||||
def tags(self):
|
||||
return self.error.data.get('tags')
|
||||
|
||||
@tags.setter
|
||||
def tags(self, value):
|
||||
if value is None:
|
||||
return
|
||||
self.error.data['tags'] = value
|
||||
|
||||
@classmethod
|
||||
def from_error(cls, err):
|
||||
return cls(
|
||||
code=err.code,
|
||||
message=err.message,
|
||||
data=err.data,
|
||||
logs=err.data.get('logs'),
|
||||
tags=err.data.get('tags'),
|
||||
)
|
||||
|
||||
|
||||
def invalid_params(data):
|
||||
return RPCException(
|
||||
code=JSONRPCInvalidParams.CODE,
|
||||
message=JSONRPCInvalidParams.MESSAGE,
|
||||
data=data
|
||||
)
|
||||
|
||||
|
||||
def server_error(err, logs=None, tags=None):
|
||||
exc = dbt.exceptions.Exception(str(err))
|
||||
return dbt_error(exc, logs, tags)
|
||||
|
||||
|
||||
def timeout_error(timeout_value, logs=None, tags=None):
|
||||
exc = dbt.exceptions.RPCTimeoutException(timeout_value)
|
||||
return dbt_error(exc, logs, tags)
|
||||
|
||||
|
||||
def dbt_error(exc, logs=None, tags=None):
|
||||
exc = RPCException(code=exc.CODE, message=exc.MESSAGE, data=exc.data(),
|
||||
logs=logs, tags=tags)
|
||||
return exc
|
||||
127
core/dbt/rpc/gc.py
Normal file
127
core/dbt/rpc/gc.py
Normal file
@@ -0,0 +1,127 @@
|
||||
import operator
|
||||
from datetime import datetime, timedelta
|
||||
from typing import Optional, List, Iterable, Tuple
|
||||
|
||||
import dbt.exceptions
|
||||
from dbt.contracts.rpc import (
|
||||
GCSettings,
|
||||
GCResultState,
|
||||
GCResult,
|
||||
TaskID,
|
||||
)
|
||||
from dbt.rpc.task_handler_protocol import TaskHandlerMap
|
||||
|
||||
# import this to make sure our timedelta encoder is registered
|
||||
from dbt import helper_types # noqa
|
||||
|
||||
|
||||
class GarbageCollector:
|
||||
def __init__(
|
||||
self,
|
||||
active_tasks: TaskHandlerMap,
|
||||
settings: Optional[GCSettings] = None,
|
||||
) -> None:
|
||||
self.active_tasks: TaskHandlerMap = active_tasks
|
||||
self.settings: GCSettings
|
||||
|
||||
if settings is None:
|
||||
self.settings = GCSettings(
|
||||
maxsize=1000, reapsize=500, auto_reap_age=timedelta(days=30)
|
||||
)
|
||||
else:
|
||||
self.settings = settings
|
||||
|
||||
def _remove_task_if_finished(self, task_id: TaskID) -> GCResultState:
|
||||
"""Remove the task if it was finished. Raises a KeyError if the entry
|
||||
is removed during operation (so hold the lock).
|
||||
"""
|
||||
if task_id not in self.active_tasks:
|
||||
return GCResultState.Missing
|
||||
|
||||
task = self.active_tasks[task_id]
|
||||
if not task.state.finished:
|
||||
return GCResultState.Running
|
||||
|
||||
del self.active_tasks[task_id]
|
||||
return GCResultState.Deleted
|
||||
|
||||
def _get_before_list(self, when: datetime) -> List[TaskID]:
|
||||
removals: List[TaskID] = []
|
||||
for task in self.active_tasks.values():
|
||||
if not task.state.finished:
|
||||
continue
|
||||
elif task.ended is None:
|
||||
continue
|
||||
elif task.ended < when:
|
||||
removals.append(task.task_id)
|
||||
|
||||
return removals
|
||||
|
||||
def _get_oldest_ended_list(self, num: int) -> List[TaskID]:
|
||||
candidates: List[Tuple[datetime, TaskID]] = []
|
||||
for task in self.active_tasks.values():
|
||||
if not task.state.finished:
|
||||
continue
|
||||
elif task.ended is None:
|
||||
continue
|
||||
else:
|
||||
candidates.append((task.ended, task.task_id))
|
||||
candidates.sort(key=operator.itemgetter(0))
|
||||
return [task_id for _, task_id in candidates[:num]]
|
||||
|
||||
def collect_task_id(
|
||||
self, result: GCResult, task_id: TaskID
|
||||
) -> None:
|
||||
"""To collect a task ID, we just delete it from the tasks dict.
|
||||
|
||||
You must hold the lock, as this mutates `tasks`.
|
||||
"""
|
||||
try:
|
||||
state = self._remove_task_if_finished(task_id)
|
||||
except KeyError:
|
||||
# someone was mutating tasks while we had the lock, that's
|
||||
# not right!
|
||||
raise dbt.exceptions.InternalException(
|
||||
'Got a KeyError for task uuid={} during gc'
|
||||
.format(task_id)
|
||||
)
|
||||
|
||||
return result.add_result(task_id=task_id, state=state)
|
||||
|
||||
def collect_multiple_task_ids(
|
||||
self, task_ids: Iterable[TaskID]
|
||||
) -> GCResult:
|
||||
result = GCResult()
|
||||
for task_id in task_ids:
|
||||
self.collect_task_id(result, task_id)
|
||||
return result
|
||||
|
||||
def collect_as_required(self) -> None:
|
||||
to_remove: List[TaskID] = []
|
||||
num_tasks = len(self.active_tasks)
|
||||
if num_tasks > self.settings.maxsize:
|
||||
num = self.settings.maxsize - num_tasks
|
||||
to_remove = self._get_oldest_ended_list(num)
|
||||
elif num_tasks > self.settings.reapsize:
|
||||
before = datetime.utcnow() - self.settings.auto_reap_age
|
||||
to_remove = self._get_before_list(before)
|
||||
|
||||
if to_remove:
|
||||
self.collect_multiple_task_ids(to_remove)
|
||||
|
||||
def collect_selected(
|
||||
self,
|
||||
task_ids: Optional[List[TaskID]] = None,
|
||||
before: Optional[datetime] = None,
|
||||
settings: Optional[GCSettings] = None,
|
||||
) -> GCResult:
|
||||
to_gc = set()
|
||||
|
||||
if task_ids is not None:
|
||||
to_gc.update(task_ids)
|
||||
if settings:
|
||||
self.settings = settings
|
||||
# we need the lock for this!
|
||||
if before is not None:
|
||||
to_gc.update(self._get_before_list(before))
|
||||
return self.collect_multiple_task_ids(to_gc)
|
||||
216
core/dbt/rpc/logger.py
Normal file
216
core/dbt/rpc/logger.py
Normal file
@@ -0,0 +1,216 @@
|
||||
import logbook
|
||||
import logbook.queues
|
||||
from jsonrpc.exceptions import JSONRPCError
|
||||
from dbt.dataclass_schema import StrEnum
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from datetime import datetime, timedelta
|
||||
from queue import Empty
|
||||
from typing import Optional, Any
|
||||
|
||||
from dbt.contracts.rpc import (
|
||||
RemoteResult,
|
||||
)
|
||||
from dbt.exceptions import InternalException
|
||||
from dbt.utils import restrict_to
|
||||
|
||||
|
||||
class QueueMessageType(StrEnum):
|
||||
Error = 'error'
|
||||
Result = 'result'
|
||||
Timeout = 'timeout'
|
||||
Log = 'log'
|
||||
|
||||
terminating = frozenset((Error, Result, Timeout))
|
||||
|
||||
|
||||
# This class was subclassed from JsonSchemaMixin, but it
|
||||
# doesn't appear to be necessary, and Mashumaro does not
|
||||
# handle logbook.LogRecord
|
||||
@dataclass
|
||||
class QueueMessage:
|
||||
message_type: QueueMessageType
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueueLogMessage(QueueMessage):
|
||||
message_type: QueueMessageType = field(
|
||||
metadata=restrict_to(QueueMessageType.Log)
|
||||
)
|
||||
record: logbook.LogRecord
|
||||
|
||||
@classmethod
|
||||
def from_record(cls, record: logbook.LogRecord):
|
||||
return QueueLogMessage(
|
||||
message_type=QueueMessageType.Log,
|
||||
record=record,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueueErrorMessage(QueueMessage):
|
||||
message_type: QueueMessageType = field(
|
||||
metadata=restrict_to(QueueMessageType.Error)
|
||||
)
|
||||
error: JSONRPCError
|
||||
|
||||
@classmethod
|
||||
def from_error(cls, error: JSONRPCError):
|
||||
return QueueErrorMessage(
|
||||
message_type=QueueMessageType.Error,
|
||||
error=error,
|
||||
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueueResultMessage(QueueMessage):
|
||||
message_type: QueueMessageType = field(
|
||||
metadata=restrict_to(QueueMessageType.Result)
|
||||
)
|
||||
result: RemoteResult
|
||||
|
||||
@classmethod
|
||||
def from_result(cls, result: RemoteResult):
|
||||
return cls(
|
||||
message_type=QueueMessageType.Result,
|
||||
result=result,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class QueueTimeoutMessage(QueueMessage):
|
||||
message_type: QueueMessageType = field(
|
||||
metadata=restrict_to(QueueMessageType.Timeout),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def create(cls):
|
||||
return cls(message_type=QueueMessageType.Timeout)
|
||||
|
||||
|
||||
class QueueLogHandler(logbook.queues.MultiProcessingHandler):
|
||||
def emit(self, record: logbook.LogRecord):
|
||||
# trigger the cached proeprties here
|
||||
record.pull_information()
|
||||
self.queue.put_nowait(QueueLogMessage.from_record(record))
|
||||
|
||||
def emit_error(self, error: JSONRPCError):
|
||||
self.queue.put_nowait(QueueErrorMessage.from_error(error))
|
||||
|
||||
def emit_result(self, result: RemoteResult):
|
||||
self.queue.put_nowait(QueueResultMessage.from_result(result))
|
||||
|
||||
|
||||
def _next_timeout(
|
||||
started: datetime,
|
||||
timeout: Optional[float],
|
||||
) -> Optional[float]:
|
||||
if timeout is None:
|
||||
return None
|
||||
|
||||
end = started + timedelta(seconds=timeout)
|
||||
message_timeout = end - datetime.utcnow()
|
||||
return message_timeout.total_seconds()
|
||||
|
||||
|
||||
class QueueSubscriber(logbook.queues.MultiProcessingSubscriber):
|
||||
def _recv_raw(self, timeout: Optional[float]) -> Any:
|
||||
if timeout is None:
|
||||
return self.queue.get()
|
||||
|
||||
if timeout < 0:
|
||||
return QueueTimeoutMessage.create()
|
||||
|
||||
try:
|
||||
return self.queue.get(block=True, timeout=timeout)
|
||||
except Empty:
|
||||
return QueueTimeoutMessage.create()
|
||||
|
||||
def recv(
|
||||
self,
|
||||
timeout: Optional[float] = None
|
||||
) -> QueueMessage:
|
||||
"""Receives one record from the socket, loads it and dispatches it.
|
||||
Returns the message type if something was dispatched or `None` if it
|
||||
timed out.
|
||||
"""
|
||||
rv = self._recv_raw(timeout)
|
||||
if not isinstance(rv, QueueMessage):
|
||||
raise InternalException(
|
||||
'Got invalid queue message: {}'.format(rv)
|
||||
)
|
||||
return rv
|
||||
|
||||
def handle_message(
|
||||
self,
|
||||
timeout: Optional[float]
|
||||
) -> QueueMessage:
|
||||
msg = self.recv(timeout)
|
||||
if isinstance(msg, QueueLogMessage):
|
||||
logbook.dispatch_record(msg.record)
|
||||
return msg
|
||||
elif msg.message_type in QueueMessageType.terminating:
|
||||
return msg
|
||||
else:
|
||||
raise InternalException(
|
||||
'Got invalid queue message type {}'.format(msg.message_type)
|
||||
)
|
||||
|
||||
def dispatch_until_exit(
|
||||
self,
|
||||
started: datetime,
|
||||
timeout: Optional[float] = None
|
||||
) -> QueueMessage:
|
||||
while True:
|
||||
message_timeout = _next_timeout(started, timeout)
|
||||
msg = self.handle_message(message_timeout)
|
||||
if msg.message_type in QueueMessageType.terminating:
|
||||
return msg
|
||||
|
||||
|
||||
# a bunch of processors to push/pop that set various rpc-related extras
|
||||
class ServerContext(logbook.Processor):
|
||||
def process(self, record):
|
||||
# the server context is the last processor in the stack, so it should
|
||||
# not overwrite a context if it's already been set.
|
||||
if not record.extra['context']:
|
||||
record.extra['context'] = 'server'
|
||||
|
||||
|
||||
class HTTPRequest(logbook.Processor):
|
||||
def __init__(self, request):
|
||||
self.request = request
|
||||
|
||||
def process(self, record):
|
||||
record.extra['addr'] = self.request.remote_addr
|
||||
record.extra['http_method'] = self.request.method
|
||||
|
||||
|
||||
class RPCRequest(logbook.Processor):
|
||||
def __init__(self, request):
|
||||
self.request = request
|
||||
super().__init__()
|
||||
|
||||
def process(self, record):
|
||||
record.extra['request_id'] = self.request._id
|
||||
record.extra['method'] = self.request.method
|
||||
|
||||
|
||||
class RPCResponse(logbook.Processor):
|
||||
def __init__(self, response):
|
||||
self.response = response
|
||||
super().__init__()
|
||||
|
||||
def process(self, record):
|
||||
record.extra['response_code'] = 200
|
||||
# the request_id could be None if the request was bad
|
||||
record.extra['request_id'] = getattr(
|
||||
self.response.request, '_id', None
|
||||
)
|
||||
|
||||
|
||||
class RequestContext(RPCRequest):
|
||||
def process(self, record):
|
||||
super().process(record)
|
||||
record.extra['context'] = 'request'
|
||||
153
core/dbt/rpc/method.py
Normal file
153
core/dbt/rpc/method.py
Normal file
@@ -0,0 +1,153 @@
|
||||
import inspect
|
||||
from abc import abstractmethod
|
||||
from typing import List, Optional, Type, TypeVar, Generic, Dict, Any
|
||||
|
||||
from dbt.dataclass_schema import dbtClassMixin, ValidationError
|
||||
|
||||
from dbt.contracts.rpc import RPCParameters, RemoteResult, RemoteMethodFlags
|
||||
from dbt.exceptions import NotImplementedException, InternalException
|
||||
|
||||
Parameters = TypeVar('Parameters', bound=RPCParameters)
|
||||
Result = TypeVar('Result', bound=RemoteResult)
|
||||
|
||||
|
||||
# If you call recursive_subclasses on a subclass of BaseRemoteMethod, it should
|
||||
# only return subtypes of the given subclass.
|
||||
T = TypeVar('T', bound='RemoteMethod')
|
||||
|
||||
|
||||
class RemoteMethod(Generic[Parameters, Result]):
|
||||
METHOD_NAME: Optional[str] = None
|
||||
|
||||
def __init__(self, args, config):
|
||||
self.args = args
|
||||
self.config = config
|
||||
|
||||
@classmethod
|
||||
def get_parameters(cls) -> Type[Parameters]:
|
||||
argspec = inspect.getfullargspec(cls.set_args)
|
||||
annotations = argspec.annotations
|
||||
if 'params' not in annotations:
|
||||
raise InternalException(
|
||||
'set_args must have parameter named params with a valid '
|
||||
'RPCParameters type definition (no params annotation found)'
|
||||
)
|
||||
params_type = annotations['params']
|
||||
if not issubclass(params_type, RPCParameters):
|
||||
raise InternalException(
|
||||
'set_args must have parameter named params with a valid '
|
||||
'RPCParameters type definition (got {}, expected '
|
||||
'RPCParameters subclass)'.format(params_type)
|
||||
)
|
||||
if params_type is RPCParameters:
|
||||
raise InternalException(
|
||||
'set_args must have parameter named params with a valid '
|
||||
'RPCParameters type definition (got RPCParameters itself!)'
|
||||
)
|
||||
return params_type
|
||||
|
||||
def get_flags(self) -> RemoteMethodFlags:
|
||||
return RemoteMethodFlags.Empty
|
||||
|
||||
@classmethod
|
||||
def recursive_subclasses(
|
||||
cls: Type[T],
|
||||
named_only: bool = True,
|
||||
) -> List[Type[T]]:
|
||||
classes = []
|
||||
current = [cls]
|
||||
while current:
|
||||
klass = current.pop()
|
||||
scls = klass.__subclasses__()
|
||||
classes.extend(scls)
|
||||
current.extend(scls)
|
||||
if named_only:
|
||||
classes = [c for c in classes if c.METHOD_NAME is not None]
|
||||
return classes
|
||||
|
||||
@abstractmethod
|
||||
def set_args(self, params: Parameters):
|
||||
"""set_args executes in the parent process for an RPC call"""
|
||||
raise NotImplementedException('set_args not implemented')
|
||||
|
||||
@abstractmethod
|
||||
def handle_request(self) -> Result:
|
||||
"""handle_request executes inside the child process for an RPC call"""
|
||||
raise NotImplementedException('handle_request not implemented')
|
||||
|
||||
def cleanup(self, result: Optional[Result]):
|
||||
"""cleanup is an optional method that executes inside the parent
|
||||
process for an RPC call.
|
||||
|
||||
This will always be executed if set_args was.
|
||||
|
||||
It's optional, and by default it does nothing.
|
||||
"""
|
||||
|
||||
def set_config(self, config):
|
||||
self.config = config
|
||||
|
||||
|
||||
class RemoteManifestMethod(RemoteMethod[Parameters, Result]):
|
||||
def __init__(self, args, config, manifest):
|
||||
super().__init__(args, config)
|
||||
self.manifest = manifest
|
||||
|
||||
|
||||
class RemoteBuiltinMethod(RemoteMethod[Parameters, Result]):
|
||||
def __init__(self, task_manager):
|
||||
self.task_manager = task_manager
|
||||
super().__init__(task_manager.args, task_manager.config)
|
||||
self.params: Optional[Parameters] = None
|
||||
|
||||
def set_args(self, params: Parameters):
|
||||
self.params = params
|
||||
|
||||
def run(self):
|
||||
raise InternalException(
|
||||
'the run() method on builtins should never be called'
|
||||
)
|
||||
|
||||
def __call__(self, **kwargs: Dict[str, Any]) -> dbtClassMixin:
|
||||
try:
|
||||
params = self.get_parameters().from_dict(kwargs)
|
||||
except ValidationError as exc:
|
||||
raise TypeError(exc) from exc
|
||||
self.set_args(params)
|
||||
return self.handle_request()
|
||||
|
||||
|
||||
class TaskTypes(Dict[str, Type[RemoteMethod]]):
|
||||
def __init__(
|
||||
self, tasks: Optional[List[Type[RemoteMethod]]] = None
|
||||
) -> None:
|
||||
task_list: List[Type[RemoteMethod]]
|
||||
if tasks is None:
|
||||
task_list = RemoteMethod.recursive_subclasses(named_only=True)
|
||||
else:
|
||||
task_list = tasks
|
||||
super().__init__(
|
||||
(t.METHOD_NAME, t) for t in task_list
|
||||
if t.METHOD_NAME is not None
|
||||
)
|
||||
|
||||
def manifest(self) -> Dict[str, Type[RemoteManifestMethod]]:
|
||||
return {
|
||||
k: t for k, t in self.items()
|
||||
if issubclass(t, RemoteManifestMethod)
|
||||
}
|
||||
|
||||
def builtin(self) -> Dict[str, Type[RemoteBuiltinMethod]]:
|
||||
return {
|
||||
k: t for k, t in self.items()
|
||||
if issubclass(t, RemoteBuiltinMethod)
|
||||
}
|
||||
|
||||
def non_manifest(self) -> Dict[str, Type[RemoteMethod]]:
|
||||
return {
|
||||
k: t for k, t in self.items()
|
||||
if (
|
||||
not issubclass(t, RemoteManifestMethod) and
|
||||
not issubclass(t, RemoteBuiltinMethod)
|
||||
)
|
||||
}
|
||||
120
core/dbt/rpc/node_runners.py
Normal file
120
core/dbt/rpc/node_runners.py
Normal file
@@ -0,0 +1,120 @@
|
||||
from abc import abstractmethod
|
||||
from datetime import datetime
|
||||
from typing import Generic, TypeVar
|
||||
|
||||
import dbt.exceptions
|
||||
from dbt.contracts.rpc import (
|
||||
RemoteCompileResult,
|
||||
RemoteCompileResultMixin,
|
||||
RemoteRunResult,
|
||||
ResultTable,
|
||||
)
|
||||
from dbt.logger import GLOBAL_LOGGER as logger
|
||||
from dbt.task.compile import CompileRunner
|
||||
from dbt.rpc.error import dbt_error, RPCException, server_error
|
||||
|
||||
|
||||
RPCSQLResult = TypeVar('RPCSQLResult', bound=RemoteCompileResultMixin)
|
||||
|
||||
|
||||
class GenericRPCRunner(CompileRunner, Generic[RPCSQLResult]):
|
||||
def __init__(self, config, adapter, node, node_index, num_nodes):
|
||||
CompileRunner.__init__(
|
||||
self, config, adapter, node, node_index, num_nodes
|
||||
)
|
||||
|
||||
def handle_exception(self, e, ctx):
|
||||
logger.debug('Got an exception: {}'.format(e), exc_info=True)
|
||||
if isinstance(e, dbt.exceptions.Exception):
|
||||
if isinstance(e, dbt.exceptions.RuntimeException):
|
||||
e.add_node(ctx.node)
|
||||
return dbt_error(e)
|
||||
elif isinstance(e, RPCException):
|
||||
return e
|
||||
else:
|
||||
return server_error(e)
|
||||
|
||||
def before_execute(self):
|
||||
pass
|
||||
|
||||
def after_execute(self, result):
|
||||
pass
|
||||
|
||||
def compile(self, manifest):
|
||||
compiler = self.adapter.get_compiler()
|
||||
return compiler.compile_node(self.node, manifest, {}, write=False)
|
||||
|
||||
@abstractmethod
|
||||
def execute(self, compiled_node, manifest) -> RPCSQLResult:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def from_run_result(self, result, start_time, timing_info) -> RPCSQLResult:
|
||||
pass
|
||||
|
||||
def error_result(self, node, error, start_time, timing_info):
|
||||
raise error
|
||||
|
||||
def ephemeral_result(self, node, start_time, timing_info):
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
'cannot execute ephemeral nodes remotely!'
|
||||
)
|
||||
|
||||
|
||||
class RPCCompileRunner(GenericRPCRunner[RemoteCompileResult]):
|
||||
def execute(self, compiled_node, manifest) -> RemoteCompileResult:
|
||||
return RemoteCompileResult(
|
||||
raw_sql=compiled_node.raw_sql,
|
||||
compiled_sql=compiled_node.compiled_sql,
|
||||
node=compiled_node,
|
||||
timing=[], # this will get added later
|
||||
logs=[],
|
||||
generated_at=datetime.utcnow(),
|
||||
)
|
||||
|
||||
def from_run_result(
|
||||
self, result, start_time, timing_info
|
||||
) -> RemoteCompileResult:
|
||||
return RemoteCompileResult(
|
||||
raw_sql=result.raw_sql,
|
||||
compiled_sql=result.compiled_sql,
|
||||
node=result.node,
|
||||
timing=timing_info,
|
||||
logs=[],
|
||||
generated_at=datetime.utcnow(),
|
||||
)
|
||||
|
||||
|
||||
class RPCExecuteRunner(GenericRPCRunner[RemoteRunResult]):
|
||||
def execute(self, compiled_node, manifest) -> RemoteRunResult:
|
||||
_, execute_result = self.adapter.execute(
|
||||
compiled_node.compiled_sql, fetch=True
|
||||
)
|
||||
|
||||
table = ResultTable(
|
||||
column_names=list(execute_result.column_names),
|
||||
rows=[list(row) for row in execute_result],
|
||||
)
|
||||
|
||||
return RemoteRunResult(
|
||||
raw_sql=compiled_node.raw_sql,
|
||||
compiled_sql=compiled_node.compiled_sql,
|
||||
node=compiled_node,
|
||||
table=table,
|
||||
timing=[],
|
||||
logs=[],
|
||||
generated_at=datetime.utcnow(),
|
||||
)
|
||||
|
||||
def from_run_result(
|
||||
self, result, start_time, timing_info
|
||||
) -> RemoteRunResult:
|
||||
return RemoteRunResult(
|
||||
raw_sql=result.raw_sql,
|
||||
compiled_sql=result.compiled_sql,
|
||||
node=result.node,
|
||||
table=result.table,
|
||||
timing=timing_info,
|
||||
logs=[],
|
||||
generated_at=datetime.utcnow(),
|
||||
)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user