forked from repo-mirrors/dbt-core
Compare commits
1 Commits
adding-sem
...
fix/docker
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e93a8720a4 |
@@ -1,5 +1,5 @@
|
||||
[bumpversion]
|
||||
current_version = 1.4.0a1
|
||||
current_version = 1.0.1
|
||||
parse = (?P<major>\d+)
|
||||
\.(?P<minor>\d+)
|
||||
\.(?P<patch>\d+)
|
||||
@@ -24,16 +24,16 @@ values =
|
||||
[bumpversion:part:pre]
|
||||
first_value = 1
|
||||
|
||||
[bumpversion:file:setup.py]
|
||||
|
||||
[bumpversion:file:core/setup.py]
|
||||
|
||||
[bumpversion:file:core/dbt/version.py]
|
||||
|
||||
[bumpversion:file:core/scripts/create_adapter_plugins.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/setup.py]
|
||||
|
||||
[bumpversion:file:plugins/postgres/dbt/adapters/postgres/__version__.py]
|
||||
|
||||
[bumpversion:file:docker/Dockerfile]
|
||||
|
||||
[bumpversion:file:tests/adapter/setup.py]
|
||||
|
||||
[bumpversion:file:tests/adapter/dbt/tests/adapter/__version__.py]
|
||||
|
||||
@@ -1,20 +0,0 @@
|
||||
## Previous Releases
|
||||
|
||||
For information on prior major and minor releases, see their changelogs:
|
||||
|
||||
|
||||
* [1.3](https://github.com/dbt-labs/dbt-core/blob/1.3.latest/CHANGELOG.md)
|
||||
* [1.2](https://github.com/dbt-labs/dbt-core/blob/1.2.latest/CHANGELOG.md)
|
||||
* [1.1](https://github.com/dbt-labs/dbt-core/blob/1.1.latest/CHANGELOG.md)
|
||||
* [1.0](https://github.com/dbt-labs/dbt-core/blob/1.0.latest/CHANGELOG.md)
|
||||
* [0.21](https://github.com/dbt-labs/dbt-core/blob/0.21.latest/CHANGELOG.md)
|
||||
* [0.20](https://github.com/dbt-labs/dbt-core/blob/0.20.latest/CHANGELOG.md)
|
||||
* [0.19](https://github.com/dbt-labs/dbt-core/blob/0.19.latest/CHANGELOG.md)
|
||||
* [0.18](https://github.com/dbt-labs/dbt-core/blob/0.18.latest/CHANGELOG.md)
|
||||
* [0.17](https://github.com/dbt-labs/dbt-core/blob/0.17.latest/CHANGELOG.md)
|
||||
* [0.16](https://github.com/dbt-labs/dbt-core/blob/0.16.latest/CHANGELOG.md)
|
||||
* [0.15](https://github.com/dbt-labs/dbt-core/blob/0.15.latest/CHANGELOG.md)
|
||||
* [0.14](https://github.com/dbt-labs/dbt-core/blob/0.14.latest/CHANGELOG.md)
|
||||
* [0.13](https://github.com/dbt-labs/dbt-core/blob/0.13.latest/CHANGELOG.md)
|
||||
* [0.12](https://github.com/dbt-labs/dbt-core/blob/0.12.latest/CHANGELOG.md)
|
||||
* [0.11 and earlier](https://github.com/dbt-labs/dbt-core/blob/0.11.latest/CHANGELOG.md)
|
||||
@@ -1,53 +0,0 @@
|
||||
# CHANGELOG Automation
|
||||
|
||||
We use [changie](https://changie.dev/) to automate `CHANGELOG` generation. For installation and format/command specifics, see the documentation.
|
||||
|
||||
### Quick Tour
|
||||
|
||||
- All new change entries get generated under `/.changes/unreleased` as a yaml file
|
||||
- `header.tpl.md` contains the contents of the entire CHANGELOG file
|
||||
- `0.0.0.md` contains the contents of the footer for the entire CHANGELOG file. changie looks to be in the process of supporting a footer file the same as it supports a header file. Switch to that when available. For now, the 0.0.0 in the file name forces it to the bottom of the changelog no matter what version we are releasing.
|
||||
- `.changie.yaml` contains the fields in a change, the format of a single change, as well as the format of the Contributors section for each version.
|
||||
|
||||
### Workflow
|
||||
|
||||
#### Daily workflow
|
||||
Almost every code change we make associated with an issue will require a `CHANGELOG` entry. After you have created the PR in GitHub, run `changie new` and follow the command prompts to generate a yaml file with your change details. This only needs to be done once per PR.
|
||||
|
||||
The `changie new` command will ensure correct file format and file name. There is a one to one mapping of issues to changes. Multiple issues cannot be lumped into a single entry. If you make a mistake, the yaml file may be directly modified and saved as long as the format is preserved.
|
||||
|
||||
Note: If your PR has been cleared by the Core Team as not needing a changelog entry, the `Skip Changelog` label may be put on the PR to bypass the GitHub action that blacks PRs from being merged when they are missing a `CHANGELOG` entry.
|
||||
|
||||
#### Prerelease Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` to be included in this prerelease and move those files to a directory named for the release version. The `--move-dir` will be created if it does not exist and is created in `/.changes`.
|
||||
|
||||
```
|
||||
changie batch <version> --move-dir '<version>' --prerelease 'rc1'
|
||||
changie merge
|
||||
```
|
||||
|
||||
Example
|
||||
```
|
||||
changie batch 1.0.5 --move-dir '1.0.5' --prerelease 'rc1'
|
||||
changie merge
|
||||
```
|
||||
|
||||
#### Final Release Workflow
|
||||
These commands batch up changes in `/.changes/unreleased` as well as `/.changes/<version>` to be included in this final release and delete all prereleases. This rolls all prereleases up into a single final release. All `yaml` files in `/unreleased` and `<version>` will be deleted at this point.
|
||||
|
||||
```
|
||||
changie batch <version> --include '<version>' --remove-prereleases
|
||||
changie merge
|
||||
```
|
||||
|
||||
Example
|
||||
```
|
||||
changie batch 1.0.5 --include '1.0.5' --remove-prereleases
|
||||
changie merge
|
||||
```
|
||||
|
||||
### A Note on Manual Edits & Gotchas
|
||||
- Changie generates markdown files in the `.changes` directory that are parsed together with the `changie merge` command. Every time `changie merge` is run, it regenerates the entire file. For this reason, any changes made directly to `CHANGELOG.md` will be overwritten on the next run of `changie merge`.
|
||||
- If changes need to be made to the `CHANGELOG.md`, make the changes to the relevant `<version>.md` file located in the `/.changes` directory. You will then run `changie merge` to regenerate the `CHANGELOG.MD`.
|
||||
- Do not run `changie batch` again on released versions. Our final release workflow deletes all of the yaml files associated with individual changes. If for some reason modifications to the `CHANGELOG.md` are required after we've generated the final release `CHANGELOG.md`, the modifications need to be done manually to the `<version>.md` file in the `/.changes` directory.
|
||||
- changie can modify, create and delete files depending on the command you run. This is expected. Be sure to commit everything that has been modified and deleted.
|
||||
@@ -1,6 +0,0 @@
|
||||
# dbt Core Changelog
|
||||
|
||||
- This file provides a full account of all changes to `dbt-core` and `dbt-postgres`
|
||||
- Changes are listed under the (pre)release in which they first appear. Subsequent releases include changes from previous releases.
|
||||
- "Breaking changes" listed under a version may require action from end users or external maintainers when upgrading to that version.
|
||||
- Do not edit this file directly. This file is auto-generated using [changie](https://github.com/miniscruff/changie). For details on how to document a change, see [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#adding-changelog-entry)
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: "Dependency"
|
||||
body: "Update pathspec requirement from ~=0.9.0 to >=0.9,<0.11 in /core"
|
||||
time: 2022-09-23T00:06:46.00000Z
|
||||
custom:
|
||||
Author: dependabot[bot]
|
||||
Issue: 4904
|
||||
PR: 5917
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: "Dependency"
|
||||
body: "Bump black from 22.8.0 to 22.10.0"
|
||||
time: 2022-10-07T00:08:48.00000Z
|
||||
custom:
|
||||
Author: dependabot[bot]
|
||||
Issue: 4904
|
||||
PR: 6019
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: "Dependency"
|
||||
body: "Bump mashumaro[msgpack] from 3.0.4 to 3.1.1 in /core"
|
||||
time: 2022-10-20T00:07:53.00000Z
|
||||
custom:
|
||||
Author: dependabot[bot]
|
||||
Issue: 4904
|
||||
PR: 6108
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: "Dependency"
|
||||
body: "Update colorama requirement from <0.4.6,>=0.3.9 to >=0.3.9,<0.4.7 in /core"
|
||||
time: 2022-10-26T00:09:10.00000Z
|
||||
custom:
|
||||
Author: dependabot[bot]
|
||||
Issue: 4904
|
||||
PR: 6144
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Docs
|
||||
body: minor doc correction
|
||||
time: 2022-09-08T15:41:57.689162-04:00
|
||||
custom:
|
||||
Author: andy-clapson
|
||||
Issue: "5791"
|
||||
PR: "5684"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Docs
|
||||
body: Generate API docs for new CLI interface
|
||||
time: 2022-10-07T09:06:56.446078-05:00
|
||||
custom:
|
||||
Author: stu-k
|
||||
Issue: "5528"
|
||||
PR: "6022"
|
||||
@@ -1,6 +0,0 @@
|
||||
kind: Docs
|
||||
time: 2022-10-17T17:14:11.715348-05:00
|
||||
custom:
|
||||
Author: paulbenschmidt
|
||||
Issue: "5880"
|
||||
PR: "324"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Docs
|
||||
body: Fix rendering of sample code for metrics
|
||||
time: 2022-11-16T15:57:43.204201+01:00
|
||||
custom:
|
||||
Author: jtcohen6
|
||||
Issue: "323"
|
||||
PR: "346"
|
||||
@@ -1,8 +0,0 @@
|
||||
kind: Features
|
||||
body: Added favor-state flag to optionally favor state nodes even if unselected node
|
||||
exists
|
||||
time: 2022-04-08T16:54:59.696564+01:00
|
||||
custom:
|
||||
Author: daniel-murray josephberni
|
||||
Issue: "2968"
|
||||
PR: "5859"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Proto logging messages
|
||||
time: 2022-08-17T15:48:57.225267-04:00
|
||||
custom:
|
||||
Author: gshank
|
||||
Issue: "5610"
|
||||
PR: "5643"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Friendlier error messages when packages.yml is malformed
|
||||
time: 2022-09-12T12:59:35.121188+01:00
|
||||
custom:
|
||||
Author: jared-rimmer
|
||||
Issue: "5486"
|
||||
PR: "5812"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Migrate dbt-utils current_timestamp macros into core + adapters
|
||||
time: 2022-09-14T09:56:25.97818-07:00
|
||||
custom:
|
||||
Author: colin-rogers-dbt
|
||||
Issue: "5521"
|
||||
PR: "5838"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Allow partitions in external tables to be supplied as a list
|
||||
time: 2022-09-25T21:16:51.051239654+02:00
|
||||
custom:
|
||||
Author: pgoslatara
|
||||
Issue: "5929"
|
||||
PR: "5930"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: extend -f flag shorthand for seed command
|
||||
time: 2022-10-03T11:07:05.381632-05:00
|
||||
custom:
|
||||
Author: dave-connors-3
|
||||
Issue: "5990"
|
||||
PR: "5991"
|
||||
@@ -1,8 +0,0 @@
|
||||
kind: Features
|
||||
body: This pulls the profile name from args when constructing a RuntimeConfig in lib.py,
|
||||
enabling the dbt-server to override the value that's in the dbt_project.yml
|
||||
time: 2022-11-02T15:00:03.000805-05:00
|
||||
custom:
|
||||
Author: racheldaniel
|
||||
Issue: "6201"
|
||||
PR: "6202"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Added an md5 function to the base context
|
||||
time: 2022-11-14T18:52:07.788593+02:00
|
||||
custom:
|
||||
Author: haritamar
|
||||
Issue: "6246"
|
||||
PR: "6247"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Features
|
||||
body: Exposures support metrics in lineage
|
||||
time: 2022-11-30T11:29:13.256034-05:00
|
||||
custom:
|
||||
Author: michelleark
|
||||
Issue: "6057"
|
||||
PR: "6342"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Account for disabled flags on models in schema files more completely
|
||||
time: 2022-09-16T10:48:54.162273-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "3992"
|
||||
PR: "5868"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Add validation of enabled config for metrics, exposures and sources
|
||||
time: 2022-10-10T11:32:18.752322-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "6030"
|
||||
PR: "6038"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: check length of args of python model function before accessing it
|
||||
time: 2022-10-11T16:07:15.464093-04:00
|
||||
custom:
|
||||
Author: chamini2
|
||||
Issue: "6041"
|
||||
PR: "6042"
|
||||
@@ -1,8 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Add functors to ensure event types with str-type attributes are initialized
|
||||
to spec, even when provided non-str type params.
|
||||
time: 2022-10-16T17:37:42.846683-07:00
|
||||
custom:
|
||||
Author: versusfacit
|
||||
Issue: "5436"
|
||||
PR: "5874"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Allow hooks to fail without halting execution flow
|
||||
time: 2022-11-07T09:53:14.340257-06:00
|
||||
custom:
|
||||
Author: ChenyuLInx
|
||||
Issue: "5625"
|
||||
PR: "6059"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Fixes
|
||||
body: Clarify Error Message for how many models are allowed in a Python file
|
||||
time: 2022-11-15T08:10:21.527884-05:00
|
||||
custom:
|
||||
Author: justbldwn
|
||||
Issue: "6245"
|
||||
PR: "6251"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Put black config in explicit config
|
||||
time: 2022-09-27T19:42:59.241433-07:00
|
||||
custom:
|
||||
Author: max-sixty
|
||||
Issue: "5946"
|
||||
PR: "5947"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Added flat_graph attribute the Manifest class's deepcopy() coverage
|
||||
time: 2022-09-29T13:44:06.275941-04:00
|
||||
custom:
|
||||
Author: peterallenwebb
|
||||
Issue: "5809"
|
||||
PR: "5975"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Add mypy configs so `mypy` passes from CLI
|
||||
time: 2022-10-05T12:03:10.061263-07:00
|
||||
custom:
|
||||
Author: max-sixty
|
||||
Issue: "5983"
|
||||
PR: "5983"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Exception message cleanup.
|
||||
time: 2022-10-07T09:46:27.682872-05:00
|
||||
custom:
|
||||
Author: emmyoop
|
||||
Issue: "6023"
|
||||
PR: "6024"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Add dmypy cache to gitignore
|
||||
time: 2022-10-07T14:00:44.227644-07:00
|
||||
custom:
|
||||
Author: max-sixty
|
||||
Issue: "6028"
|
||||
PR: "5978"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Provide useful errors when the value of 'materialized' is invalid
|
||||
time: 2022-10-13T18:19:12.167548-04:00
|
||||
custom:
|
||||
Author: peterallenwebb
|
||||
Issue: "5229"
|
||||
PR: "6025"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Fixed extra whitespace in strings introduced by black.
|
||||
time: 2022-10-17T15:15:11.499246-05:00
|
||||
custom:
|
||||
Author: luke-bassett
|
||||
Issue: "1350"
|
||||
PR: "6086"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Clean up string formatting
|
||||
time: 2022-10-17T15:58:44.676549-04:00
|
||||
custom:
|
||||
Author: eve-johns
|
||||
Issue: "6068"
|
||||
PR: "6082"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Remove the 'root_path' field from most nodes
|
||||
time: 2022-10-28T10:48:37.687886-04:00
|
||||
custom:
|
||||
Author: gshank
|
||||
Issue: "6171"
|
||||
PR: "6172"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Combine certain logging events with different levels
|
||||
time: 2022-10-28T11:03:44.887836-04:00
|
||||
custom:
|
||||
Author: gshank
|
||||
Issue: "6173"
|
||||
PR: "6174"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Convert threading tests to pytest
|
||||
time: 2022-11-08T07:45:50.589147-06:00
|
||||
custom:
|
||||
Author: stu-k
|
||||
Issue: "5942"
|
||||
PR: "6226"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Convert postgres index tests to pytest
|
||||
time: 2022-11-08T11:56:33.743042-06:00
|
||||
custom:
|
||||
Author: stu-k
|
||||
Issue: "5770"
|
||||
PR: "6228"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Convert use color tests to pytest
|
||||
time: 2022-11-08T13:31:04.788547-06:00
|
||||
custom:
|
||||
Author: stu-k
|
||||
Issue: "5771"
|
||||
PR: "6230"
|
||||
@@ -1,7 +0,0 @@
|
||||
kind: Under the Hood
|
||||
body: Add github actions workflow to generate high level CLI API docs
|
||||
time: 2022-11-16T13:00:37.916202-06:00
|
||||
custom:
|
||||
Author: stu-k
|
||||
Issue: "5942"
|
||||
PR: "6187"
|
||||
@@ -1,80 +0,0 @@
|
||||
changesDir: .changes
|
||||
unreleasedDir: unreleased
|
||||
headerPath: header.tpl.md
|
||||
versionHeaderPath: ""
|
||||
changelogPath: CHANGELOG.md
|
||||
versionExt: md
|
||||
versionFormat: '## dbt-core {{.Version}} - {{.Time.Format "January 02, 2006"}}'
|
||||
kindFormat: '### {{.Kind}}'
|
||||
changeFormat: '- {{.Body}} ([#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-core/issues/{{.Custom.Issue}}), [#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-core/pull/{{.Custom.PR}}))'
|
||||
|
||||
kinds:
|
||||
- label: Breaking Changes
|
||||
- label: Features
|
||||
- label: Fixes
|
||||
- label: Docs
|
||||
changeFormat: '- {{.Body}} ([dbt-docs/#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-docs/issues/{{.Custom.Issue}}), [dbt-docs/#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-docs/pull/{{.Custom.PR}}))'
|
||||
- label: Under the Hood
|
||||
- label: Dependencies
|
||||
changeFormat: '- {{.Body}} ({{if ne .Custom.Issue ""}}[#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-core/issues/{{.Custom.Issue}}), {{end}}[#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-core/pull/{{.Custom.PR}}))'
|
||||
- label: Security
|
||||
changeFormat: '- {{.Body}} ({{if ne .Custom.Issue ""}}[#{{.Custom.Issue}}](https://github.com/dbt-labs/dbt-core/issues/{{.Custom.Issue}}), {{end}}[#{{.Custom.PR}}](https://github.com/dbt-labs/dbt-core/pull/{{.Custom.PR}}))'
|
||||
|
||||
newlines:
|
||||
afterChangelogHeader: 1
|
||||
afterKind: 1
|
||||
afterChangelogVersion: 1
|
||||
beforeKind: 1
|
||||
endOfVersion: 1
|
||||
|
||||
custom:
|
||||
- key: Author
|
||||
label: GitHub Username(s) (separated by a single space if multiple)
|
||||
type: string
|
||||
minLength: 3
|
||||
- key: Issue
|
||||
label: GitHub Issue Number
|
||||
type: int
|
||||
minInt: 1
|
||||
- key: PR
|
||||
label: GitHub Pull Request Number
|
||||
type: int
|
||||
minInt: 1
|
||||
|
||||
footerFormat: |
|
||||
{{- $contributorDict := dict }}
|
||||
{{- /* any names added to this list should be all lowercase for later matching purposes */}}
|
||||
{{- $core_team := list "michelleark" "peterallenwebb" "emmyoop" "nathaniel-may" "gshank" "leahwicz" "chenyulinx" "stu-k" "iknox-fa" "versusfacit" "mcknight-42" "jtcohen6" "dependabot[bot]" "snyk-bot" "colin-rogers-dbt" }}
|
||||
{{- range $change := .Changes }}
|
||||
{{- $authorList := splitList " " $change.Custom.Author }}
|
||||
{{- /* loop through all authors for a PR */}}
|
||||
{{- range $author := $authorList }}
|
||||
{{- $authorLower := lower $author }}
|
||||
{{- /* we only want to include non-core team contributors */}}
|
||||
{{- if not (has $authorLower $core_team)}}
|
||||
{{- /* Docs kind link back to dbt-docs instead of dbt-core PRs */}}
|
||||
{{- $prLink := $change.Kind }}
|
||||
{{- if eq $change.Kind "Docs" }}
|
||||
{{- $prLink = "[dbt-docs/#pr](https://github.com/dbt-labs/dbt-docs/pull/pr)" | replace "pr" $change.Custom.PR }}
|
||||
{{- else }}
|
||||
{{- $prLink = "[#pr](https://github.com/dbt-labs/dbt-core/pull/pr)" | replace "pr" $change.Custom.PR }}
|
||||
{{- end }}
|
||||
{{- /* check if this contributor has other PRs associated with them already */}}
|
||||
{{- if hasKey $contributorDict $author }}
|
||||
{{- $prList := get $contributorDict $author }}
|
||||
{{- $prList = append $prList $prLink }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- else }}
|
||||
{{- $prList := list $prLink }}
|
||||
{{- $contributorDict := set $contributorDict $author $prList }}
|
||||
{{- end }}
|
||||
{{- end}}
|
||||
{{- end}}
|
||||
{{- end }}
|
||||
{{- /* no indentation here for formatting so the final markdown doesn't have unneeded indentations */}}
|
||||
{{- if $contributorDict}}
|
||||
### Contributors
|
||||
{{- range $k,$v := $contributorDict }}
|
||||
- [@{{$k}}](https://github.com/{{$k}}) ({{ range $index, $element := $v }}{{if $index}}, {{end}}{{$element}}{{end}})
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
2
.flake8
2
.flake8
@@ -8,5 +8,5 @@ ignore =
|
||||
W504
|
||||
E203 # makes Flake8 work like black
|
||||
E741
|
||||
E501 # long line checking is done in black
|
||||
max-line-length = 99
|
||||
exclude = test
|
||||
|
||||
@@ -1,2 +0,0 @@
|
||||
# Reformatting dbt-core via black, flake8, mypy, and assorted pre-commit hooks.
|
||||
43e3fc22c4eae4d3d901faba05e33c40f1f1dc5a
|
||||
60
.github/CODEOWNERS
vendored
60
.github/CODEOWNERS
vendored
@@ -16,57 +16,25 @@
|
||||
# Changes to GitHub configurations including Actions
|
||||
/.github/ @leahwicz
|
||||
|
||||
### LANGUAGE
|
||||
|
||||
# Language core modules
|
||||
/core/dbt/config/ @dbt-labs/core-language
|
||||
/core/dbt/context/ @dbt-labs/core-language
|
||||
/core/dbt/contracts/ @dbt-labs/core-language
|
||||
/core/dbt/deps/ @dbt-labs/core-language
|
||||
/core/dbt/events/ @dbt-labs/core-language # structured logging
|
||||
/core/dbt/parser/ @dbt-labs/core-language
|
||||
|
||||
# Language misc files
|
||||
/core/dbt/dataclass_schema.py @dbt-labs/core-language
|
||||
/core/dbt/hooks.py @dbt-labs/core-language
|
||||
/core/dbt/node_types.py @dbt-labs/core-language
|
||||
/core/dbt/semver.py @dbt-labs/core-language
|
||||
|
||||
|
||||
### EXECUTION
|
||||
/core/dbt/config/ @dbt-labs/core-language
|
||||
/core/dbt/context/ @dbt-labs/core-language
|
||||
/core/dbt/contracts/ @dbt-labs/core-language
|
||||
/core/dbt/deps/ @dbt-labs/core-language
|
||||
/core/dbt/parser/ @dbt-labs/core-language
|
||||
|
||||
# Execution core modules
|
||||
/core/dbt/graph/ @dbt-labs/core-execution
|
||||
/core/dbt/task/ @dbt-labs/core-execution
|
||||
/core/dbt/events/ @dbt-labs/core-execution @dbt-labs/core-language # eventually remove language but they have knowledge here now
|
||||
/core/dbt/graph/ @dbt-labs/core-execution
|
||||
/core/dbt/task/ @dbt-labs/core-execution
|
||||
|
||||
# Execution misc files
|
||||
/core/dbt/compilation.py @dbt-labs/core-execution
|
||||
/core/dbt/flags.py @dbt-labs/core-execution
|
||||
/core/dbt/lib.py @dbt-labs/core-execution
|
||||
/core/dbt/main.py @dbt-labs/core-execution
|
||||
/core/dbt/profiler.py @dbt-labs/core-execution
|
||||
/core/dbt/selected_resources.py @dbt-labs/core-execution
|
||||
/core/dbt/tracking.py @dbt-labs/core-execution
|
||||
/core/dbt/version.py @dbt-labs/core-execution
|
||||
# Adapter interface, scaffold, Postgres plugin
|
||||
/core/dbt/adapters @dbt-labs/core-adapters
|
||||
/core/scripts/create_adapter_plugin.py @dbt-labs/core-adapters
|
||||
/plugins/ @dbt-labs/core-adapters
|
||||
|
||||
|
||||
### ADAPTERS
|
||||
|
||||
# Adapter interface ("base" + "sql" adapter defaults, cache)
|
||||
/core/dbt/adapters @dbt-labs/core-adapters
|
||||
|
||||
# Global project (default macros + materializations), starter project
|
||||
/core/dbt/include @dbt-labs/core-adapters
|
||||
|
||||
# Postgres plugin
|
||||
/plugins/ @dbt-labs/core-adapters
|
||||
|
||||
# Functional tests for adapter plugins
|
||||
/tests/adapter @dbt-labs/core-adapters
|
||||
|
||||
### TESTS
|
||||
|
||||
# Overlapping ownership for vast majority of unit + functional tests
|
||||
# Global project: default macros, including generic tests + materializations
|
||||
/core/dbt/include/global_project @dbt-labs/core-execution @dbt-labs/core-adapters
|
||||
|
||||
# Perf regression testing framework
|
||||
# This excludes the test project files itself since those aren't specific
|
||||
|
||||
30
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
30
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -9,33 +9,23 @@ body:
|
||||
Thanks for taking the time to fill out this bug report!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is this a new bug in dbt-core?
|
||||
description: >
|
||||
In other words, is this an error, flaw, failure or fault in our software?
|
||||
|
||||
If this is a bug that broke existing functionality that used to work, please open a regression issue.
|
||||
If this is a bug in an adapter plugin, please open an issue in the adapter's repository.
|
||||
If this is a bug experienced while using dbt Cloud, please report to [support](mailto:support@getdbt.com).
|
||||
If this is a request for help or troubleshooting code in your own dbt project, please join our [dbt Community Slack](https://www.getdbt.com/community/join-the-community/) or open a [Discussion question](https://github.com/dbt-labs/docs.getdbt.com/discussions).
|
||||
|
||||
Please search to see if an issue already exists for the bug you encountered.
|
||||
label: Is there an existing issue for this?
|
||||
description: Please search to see if an issue already exists for the bug you encountered.
|
||||
options:
|
||||
- label: I believe this is a new bug in dbt-core
|
||||
required: true
|
||||
- label: I have searched the existing issues, and I could not find an existing issue for this bug
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Current Behavior
|
||||
description: A concise description of what you're experiencing.
|
||||
validations:
|
||||
required: true
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Expected Behavior
|
||||
description: A concise description of what you expected to happen.
|
||||
validations:
|
||||
required: true
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Steps To Reproduce
|
||||
@@ -46,7 +36,7 @@ body:
|
||||
3. Run '...'
|
||||
4. See error...
|
||||
validations:
|
||||
required: true
|
||||
required: false
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
@@ -62,8 +52,8 @@ body:
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.9.12 (`python3 --version`)
|
||||
- **dbt-core**: 1.1.1 (`dbt --version`)
|
||||
- **Python**: 3.7.2 (`python --version`)
|
||||
- **dbt**: 0.21.0 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
- Python:
|
||||
@@ -74,15 +64,13 @@ body:
|
||||
- type: dropdown
|
||||
id: database
|
||||
attributes:
|
||||
label: Which database adapter are you using with dbt?
|
||||
description: If the bug is specific to the database or adapter, please open the issue in that adapter's repository instead
|
||||
label: What database are you using dbt with?
|
||||
multiple: true
|
||||
options:
|
||||
- postgres
|
||||
- redshift
|
||||
- snowflake
|
||||
- bigquery
|
||||
- spark
|
||||
- other (mention it in "Additional Context")
|
||||
validations:
|
||||
required: false
|
||||
|
||||
19
.github/ISSUE_TEMPLATE/config.yml
vendored
19
.github/ISSUE_TEMPLATE/config.yml
vendored
@@ -1,14 +1,4 @@
|
||||
blank_issues_enabled: false
|
||||
contact_links:
|
||||
- name: Ask the community for help
|
||||
url: https://github.com/dbt-labs/docs.getdbt.com/discussions
|
||||
about: Need help troubleshooting? Check out our guide on how to ask
|
||||
- name: Contact dbt Cloud support
|
||||
url: mailto:support@getdbt.com
|
||||
about: Are you using dbt Cloud? Contact our support team for help!
|
||||
- name: Participate in Discussions
|
||||
url: https://github.com/dbt-labs/dbt-core/discussions
|
||||
about: Do you have a Big Idea for dbt? Read open discussions, or start a new one
|
||||
- name: Create an issue for dbt-redshift
|
||||
url: https://github.com/dbt-labs/dbt-redshift/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-redshift
|
||||
@@ -18,6 +8,9 @@ contact_links:
|
||||
- name: Create an issue for dbt-snowflake
|
||||
url: https://github.com/dbt-labs/dbt-snowflake/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-snowflake
|
||||
- name: Create an issue for dbt-spark
|
||||
url: https://github.com/dbt-labs/dbt-spark/issues/new/choose
|
||||
about: Report a bug or request a feature for dbt-spark
|
||||
- name: Ask a question or get support
|
||||
url: https://docs.getdbt.com/docs/guides/getting-help
|
||||
about: Ask a question or request support
|
||||
- name: Questions on Stack Overflow
|
||||
url: https://stackoverflow.com/questions/tagged/dbt
|
||||
about: Look at questions/answers at Stack Overflow
|
||||
|
||||
22
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
22
.github/ISSUE_TEMPLATE/feature-request.yml
vendored
@@ -1,32 +1,22 @@
|
||||
name: ✨ Feature
|
||||
description: Propose a straightforward extension of dbt functionality
|
||||
description: Suggest an idea for dbt
|
||||
title: "[Feature] <title>"
|
||||
labels: ["enhancement", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this feature request!
|
||||
Thanks for taking the time to fill out this feature requests!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is this your first time submitting a feature request?
|
||||
description: >
|
||||
We want to make sure that features are distinct and discoverable,
|
||||
so that other members of the community can find them and offer their thoughts.
|
||||
|
||||
Issues are the right place to request straightforward extensions of existing dbt functionality.
|
||||
For "big ideas" about future capabilities of dbt, we ask that you open a
|
||||
[discussion](https://github.com/dbt-labs/dbt-core/discussions) in the "Ideas" category instead.
|
||||
label: Is there an existing feature request for this?
|
||||
description: Please search to see if an issue already exists for the feature you would like.
|
||||
options:
|
||||
- label: I have read the [expectations for open source contributors](https://docs.getdbt.com/docs/contributing/oss-expectations)
|
||||
required: true
|
||||
- label: I have searched the existing issues, and I could not find an existing issue for this feature
|
||||
required: true
|
||||
- label: I am requesting a straightforward extension of existing dbt functionality, rather than a Big Idea better suited to a discussion
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Describe the feature
|
||||
label: Describe the Feature
|
||||
description: A clear and concise description of what you want to happen.
|
||||
validations:
|
||||
required: true
|
||||
|
||||
93
.github/ISSUE_TEMPLATE/regression-report.yml
vendored
93
.github/ISSUE_TEMPLATE/regression-report.yml
vendored
@@ -1,93 +0,0 @@
|
||||
name: ☣️ Regression
|
||||
description: Report a regression you've observed in a newer version of dbt
|
||||
title: "[Regression] <title>"
|
||||
labels: ["bug", "regression", "triage"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this regression report!
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is this a regression in a recent version of dbt-core?
|
||||
description: >
|
||||
A regression is when documented functionality works as expected in an older version of dbt-core,
|
||||
and no longer works after upgrading to a newer version of dbt-core
|
||||
options:
|
||||
- label: I believe this is a regression in dbt-core functionality
|
||||
required: true
|
||||
- label: I have searched the existing issues, and I could not find an existing issue for this regression
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Current Behavior
|
||||
description: A concise description of what you're experiencing.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Expected/Previous Behavior
|
||||
description: A concise description of what you expected to happen.
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Steps To Reproduce
|
||||
description: Steps to reproduce the behavior.
|
||||
placeholder: |
|
||||
1. In this environment...
|
||||
2. With this config...
|
||||
3. Run '...'
|
||||
4. See error...
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Relevant log output
|
||||
description: |
|
||||
If applicable, log output to help explain your problem.
|
||||
render: shell
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Environment
|
||||
description: |
|
||||
examples:
|
||||
- **OS**: Ubuntu 20.04
|
||||
- **Python**: 3.9.12 (`python3 --version`)
|
||||
- **dbt-core (working version)**: 1.1.1 (`dbt --version`)
|
||||
- **dbt-core (regression version)**: 1.2.0 (`dbt --version`)
|
||||
value: |
|
||||
- OS:
|
||||
- Python:
|
||||
- dbt (working version):
|
||||
- dbt (regression version):
|
||||
render: markdown
|
||||
validations:
|
||||
required: true
|
||||
- type: dropdown
|
||||
id: database
|
||||
attributes:
|
||||
label: Which database adapter are you using with dbt?
|
||||
description: If the regression is specific to the database or adapter, please open the issue in that adapter's repository instead
|
||||
multiple: true
|
||||
options:
|
||||
- postgres
|
||||
- redshift
|
||||
- snowflake
|
||||
- bigquery
|
||||
- spark
|
||||
- other (mention it in "Additional Context")
|
||||
validations:
|
||||
required: false
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Additional Context
|
||||
description: |
|
||||
Links? References? Anything that will give us more context about the issue you are encountering!
|
||||
|
||||
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
||||
validations:
|
||||
required: false
|
||||
216
.github/_README.md
vendored
216
.github/_README.md
vendored
@@ -1,216 +0,0 @@
|
||||
<!-- GitHub will publish this readme on the main repo page if the name is `README.md` so we've added the leading underscore to prevent this -->
|
||||
<!-- Do not rename this file `README.md` -->
|
||||
<!-- See https://docs.github.com/en/repositories/managing-your-repositorys-settings-and-features/customizing-your-repository/about-readmes -->
|
||||
|
||||
## What are GitHub Actions?
|
||||
|
||||
GitHub Actions are used for many different purposes. We use them to run tests in CI, validate PRs are in an expected state, and automate processes.
|
||||
|
||||
- [Overview of GitHub Actions](https://docs.github.com/en/actions/learn-github-actions/understanding-github-actions)
|
||||
- [What's a workflow?](https://docs.github.com/en/actions/using-workflows/about-workflows)
|
||||
- [GitHub Actions guides](https://docs.github.com/en/actions/guides)
|
||||
|
||||
___
|
||||
|
||||
## Where do actions and workflows live
|
||||
|
||||
We try to maintain actions that are shared across repositories in a single place so that necesary changes can be made in a single place.
|
||||
|
||||
[dbt-labs/actions](https://github.com/dbt-labs/actions/) is the central repository of actions and workflows we use across repositories.
|
||||
|
||||
GitHub Actions also live locally within a repository. The workflows can be found at `.github/workflows` from the root of the repository. These should be specific to that code base.
|
||||
|
||||
Note: We are actively moving actions into the central Action repository so there is currently some duplication across repositories.
|
||||
|
||||
___
|
||||
|
||||
## Basics of Using Actions
|
||||
|
||||
### Viewing Output
|
||||
|
||||
- View the detailed action output for your PR in the **Checks** tab of the PR. This only shows the most recent run. You can also view high level **Checks** output at the bottom on the PR.
|
||||
|
||||
- View _all_ action output for a repository from the [**Actions**](https://github.com/dbt-labs/dbt-core/actions) tab. Workflow results last 1 year. Artifacts last 90 days, unless specified otherwise in individual workflows.
|
||||
|
||||
This view often shows what seem like duplicates of the same workflow. This occurs when files are renamed but the workflow name has not changed. These are in fact _not_ duplicates.
|
||||
|
||||
You can see the branch the workflow runs from in this view. It is listed in the table between the workflow name and the time/duration of the run. When blank, the workflow is running in the context of the `main` branch.
|
||||
|
||||
### How to view what workflow file is being referenced from a run
|
||||
|
||||
- When viewing the output of a specific workflow run, click the 3 dots at the top right of the display. There will be an option to `View workflow file`.
|
||||
|
||||
### How to manually run a workflow
|
||||
|
||||
- If a workflow has the `on: workflow_dispatch` trigger, it can be manually triggered
|
||||
- From the [**Actions**](https://github.com/dbt-labs/dbt-core/actions) tab, find the workflow you want to run, select it and fill in any inputs requied. That's it!
|
||||
|
||||
### How to re-run jobs
|
||||
|
||||
- Some actions cannot be rerun in the GitHub UI. Namely the snyk checks and the cla check. Snyk checks are rerun by closing and reopening the PR. You can retrigger the cla check by commenting on the PR with `@cla-bot check`
|
||||
|
||||
___
|
||||
|
||||
## General Standards
|
||||
|
||||
### Permissions
|
||||
- By default, workflows have read permissions in the repository for the contents scope only when no permissions are explicitly set.
|
||||
- It is best practice to always define the permissions explicitly. This will allow actions to continue to work when the default permissions on the repository are changed. It also allows explicit grants of the least permissions possible.
|
||||
- There are a lot of permissions available. [Read up on them](https://docs.github.com/en/actions/using-jobs/assigning-permissions-to-jobs) if you're unsure what to use.
|
||||
|
||||
```yaml
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: write
|
||||
```
|
||||
|
||||
### Secrets
|
||||
- When to use a [Personal Access Token (PAT)](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token) vs the [GITHUB_TOKEN](https://docs.github.com/en/actions/security-guides/automatic-token-authentication) generated for the action?
|
||||
|
||||
The `GITHUB_TOKEN` is used by default. In most cases it is sufficient for what you need.
|
||||
|
||||
If you expect the workflow to result in a commit to that should retrigger workflows, you will need to use a Personal Access Token for the bot to commit the file. When using the GITHUB_TOKEN, the resulting commit will not trigger another GitHub Actions Workflow run. This is due to limitations set by GitHub. See [the docs](https://docs.github.com/en/actions/security-guides/automatic-token-authentication#using-the-github_token-in-a-workflow) for a more detailed explanation.
|
||||
|
||||
For example, we must use a PAT in our workflow to commit a new changelog yaml file for bot PRs. Once the file has been committed to the branch, it should retrigger the check to validate that a changelog exists on the PR. Otherwise, it would stay in a failed state since the check would never retrigger.
|
||||
|
||||
### Triggers
|
||||
You can configure your workflows to run when specific activity on GitHub happens, at a scheduled time, or when an event outside of GitHub occurs. Read more details in the [GitHub docs](https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows).
|
||||
|
||||
These triggers are under the `on` key of the workflow and more than one can be listed.
|
||||
|
||||
```yaml
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
# catch when the PR is opened with the label or when the label is added
|
||||
types: [opened, labeled]
|
||||
workflow_dispatch:
|
||||
```
|
||||
|
||||
Some triggers of note that we use:
|
||||
|
||||
- `push` - Runs your workflow when you push a commit or tag.
|
||||
- `pull_request` - Runs your workflow when activity on a pull request in the workflow's repository occurs. Takes in a list of activity types (opened, labeled, etc) if appropriate.
|
||||
- `pull_request_target` - Same as `pull_request` but runs in the context of the PR target branch.
|
||||
- `workflow_call` - used with reusable workflows. Triggered by another workflow calling it.
|
||||
- `workflow_dispatch` - Gives the ability to manually trigger a workflow from the GitHub API, GitHub CLI, or GitHub browser interface.
|
||||
|
||||
|
||||
### Basic Formatting
|
||||
- Add a description of what your workflow does at the top in this format
|
||||
|
||||
```
|
||||
# **what?**
|
||||
# Describe what the action does.
|
||||
|
||||
# **why?**
|
||||
# Why does this action exist?
|
||||
|
||||
# **when?**
|
||||
# How/when will it be triggered?
|
||||
```
|
||||
|
||||
- Leave blank lines between steps and jobs
|
||||
|
||||
```yaml
|
||||
jobs:
|
||||
dependency_changelog:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Get File Name Timestamp
|
||||
id: filename_time
|
||||
uses: nanzm/get-time-action@v1.1
|
||||
with:
|
||||
format: 'YYYYMMDD-HHmmss'
|
||||
|
||||
- name: Get File Content Timestamp
|
||||
id: file_content_time
|
||||
uses: nanzm/get-time-action@v1.1
|
||||
with:
|
||||
format: 'YYYY-MM-DDTHH:mm:ss.000000-05:00'
|
||||
|
||||
- name: Generate Filepath
|
||||
id: fp
|
||||
run: |
|
||||
FILEPATH=.changes/unreleased/Dependencies-${{ steps.filename_time.outputs.time }}.yaml
|
||||
echo "::set-output name=FILEPATH::$FILEPATH"
|
||||
```
|
||||
|
||||
- Print out all variables you will reference as the first step of a job. This allows for easier debugging. The first job should log all inputs. Subsequent jobs should reference outputs of other jobs, if present.
|
||||
|
||||
When possible, generate variables at the top of your workflow in a single place to reference later. This is not always strictly possible since you may generate a value to be used later mid-workflow.
|
||||
|
||||
Be sure to use quotes around these logs so special characters are not interpreted.
|
||||
|
||||
```yaml
|
||||
job1:
|
||||
- name: "[DEBUG] Print Variables"
|
||||
run: |
|
||||
echo "all variables defined as inputs"
|
||||
echo "The last commit sha in the release: ${{ inputs.sha }}"
|
||||
echo "The release version number: ${{ inputs.version_number }}"
|
||||
echo "The changelog_path: ${{ inputs.changelog_path }}"
|
||||
echo "The build_script_path: ${{ inputs.build_script_path }}"
|
||||
echo "The s3_bucket_name: ${{ inputs.s3_bucket_name }}"
|
||||
echo "The package_test_command: ${{ inputs.package_test_command }}"
|
||||
|
||||
# collect all the variables that need to be used in subsequent jobs
|
||||
- name: Set Variables
|
||||
id: variables
|
||||
run: |
|
||||
echo "::set-output name=important_path::'performance/runner/Cargo.toml'"
|
||||
echo "::set-output name=release_id::${{github.event.inputs.release_id}}"
|
||||
echo "::set-output name=open_prs::${{github.event.inputs.open_prs}}"
|
||||
|
||||
job2:
|
||||
needs: [job1]
|
||||
- name: "[DEBUG] Print Variables"
|
||||
run: |
|
||||
echo "all variables defined in job1 > Set Variables > outputs"
|
||||
echo "important_path: ${{ needs.job1.outputs.important_path }}"
|
||||
echo "release_id: ${{ needs.job1.outputs.release_id }}"
|
||||
echo "open_prs: ${{ needs.job1.outputs.open_prs }}"
|
||||
```
|
||||
|
||||
- When it's not obvious what something does, add a comment!
|
||||
|
||||
___
|
||||
|
||||
## Tips
|
||||
|
||||
### Context
|
||||
- The [GitHub CLI](https://cli.github.com/) is available in the default runners
|
||||
- Actions run in your context. ie, using an action from the marketplace that uses the GITHUB_TOKEN uses the GITHUB_TOKEN generated by your workflow run.
|
||||
|
||||
### Actions from the Marketplace
|
||||
- Don’t use external actions for things that can easily be accomplished manually.
|
||||
- Always read through what an external action does before using it! Often an action in the GitHub Actions Marketplace can be replaced with a few lines in bash. This is much more maintainable (and won’t change under us) and clear as to what’s actually happening. It also prevents any
|
||||
- Pin actions _we don't control_ to tags.
|
||||
|
||||
### Connecting to AWS
|
||||
- Authenticate with the aws managed workflow
|
||||
|
||||
```yaml
|
||||
- name: Configure AWS credentials from Test account
|
||||
uses: aws-actions/configure-aws-credentials@v1
|
||||
with:
|
||||
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
|
||||
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
|
||||
aws-region: us-east-1
|
||||
```
|
||||
|
||||
- Then access with the aws command that comes installed on the action runner machines
|
||||
|
||||
```yaml
|
||||
- name: Copy Artifacts from S3 via CLI
|
||||
run: aws s3 cp ${{ env.s3_bucket }} . --recursive
|
||||
```
|
||||
|
||||
### Testing
|
||||
|
||||
- Depending on what your action does, you may be able to use [`act`](https://github.com/nektos/act) to test the action locally. Some features of GitHub Actions do not work with `act`, among those are reusable workflows. If you can't use `act`, you'll have to push your changes up before being able to test. This can be slow.
|
||||
4
.github/pull_request_template.md
vendored
4
.github/pull_request_template.md
vendored
@@ -15,9 +15,7 @@ resolves #
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] I have read [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md) and understand what's expected of me
|
||||
- [ ] I have signed the [CLA](https://docs.getdbt.com/docs/contributor-license-agreements)
|
||||
- [ ] I have run this code in development and it appears to resolve the stated issue
|
||||
- [ ] This PR includes tests, or tests are not required/relevant for this PR
|
||||
- [ ] I have [opened an issue to add/update docs](https://github.com/dbt-labs/docs.getdbt.com/issues/new/choose), or docs changes are not required/relevant for this PR
|
||||
- [ ] I have run `changie new` to [create a changelog entry](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#adding-a-changelog-entry)
|
||||
- [ ] I have updated the `CHANGELOG.md` and added information about my change
|
||||
|
||||
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
95
.github/scripts/integration-test-matrix.js
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
module.exports = ({ context }) => {
|
||||
const defaultPythonVersion = "3.8";
|
||||
const supportedPythonVersions = ["3.7", "3.8", "3.9"];
|
||||
const supportedAdapters = ["postgres"];
|
||||
|
||||
// if PR, generate matrix based on files changed and PR labels
|
||||
if (context.eventName.includes("pull_request")) {
|
||||
// `changes` is a list of adapter names that have related
|
||||
// file changes in the PR
|
||||
// ex: ['postgres', 'snowflake']
|
||||
const changes = JSON.parse(process.env.CHANGES);
|
||||
const labels = context.payload.pull_request.labels.map(({ name }) => name);
|
||||
console.log("labels", labels);
|
||||
console.log("changes", changes);
|
||||
const testAllLabel = labels.includes("test all");
|
||||
const include = [];
|
||||
|
||||
for (const adapter of supportedAdapters) {
|
||||
if (
|
||||
changes.includes(adapter) ||
|
||||
testAllLabel ||
|
||||
labels.includes(`test ${adapter}`)
|
||||
) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
if (
|
||||
pythonVersion === defaultPythonVersion ||
|
||||
labels.includes(`test python${pythonVersion}`) ||
|
||||
testAllLabel
|
||||
) {
|
||||
// always run tests on ubuntu by default
|
||||
include.push({
|
||||
os: "ubuntu-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
|
||||
if (labels.includes("test windows") || testAllLabel) {
|
||||
include.push({
|
||||
os: "windows-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
|
||||
if (labels.includes("test macos") || testAllLabel) {
|
||||
include.push({
|
||||
os: "macos-latest",
|
||||
adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
}
|
||||
// if not PR, generate matrix of python version, adapter, and operating
|
||||
// system to run integration tests on
|
||||
|
||||
const include = [];
|
||||
// run for all adapters and python versions on ubuntu
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const pythonVersion of supportedPythonVersions) {
|
||||
include.push({
|
||||
os: 'ubuntu-latest',
|
||||
adapter: adapter,
|
||||
"python-version": pythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
// additionally include runs for all adapters, on macos and windows,
|
||||
// but only for the default python version
|
||||
for (const adapter of supportedAdapters) {
|
||||
for (const operatingSystem of ["windows-latest", "macos-latest"]) {
|
||||
include.push({
|
||||
os: operatingSystem,
|
||||
adapter: adapter,
|
||||
"python-version": defaultPythonVersion,
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
console.log("matrix", { include });
|
||||
|
||||
return {
|
||||
include,
|
||||
};
|
||||
};
|
||||
18
.github/workflows/backport.yml
vendored
18
.github/workflows/backport.yml
vendored
@@ -13,28 +13,22 @@
|
||||
# This automates the backporting process
|
||||
|
||||
# **when?**
|
||||
# Once a PR is "Squash and merge"'d, by adding a backport label, this is triggered
|
||||
# Once a PR is "Squash and merge"'d and it has been correctly labeled
|
||||
# according to the naming convention.
|
||||
|
||||
name: Backport
|
||||
on:
|
||||
pull_request:
|
||||
types:
|
||||
- closed
|
||||
- labeled
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
backport:
|
||||
runs-on: ubuntu-18.04
|
||||
name: Backport
|
||||
runs-on: ubuntu-latest
|
||||
# Only react to merged PRs for security reasons.
|
||||
# See https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#pull_request_target.
|
||||
if: >
|
||||
github.event.pull_request.merged
|
||||
&& contains(github.event.label.name, 'backport')
|
||||
steps:
|
||||
- uses: tibdex/backport@v2.0.2
|
||||
- name: Backport
|
||||
uses: tibdex/backport@v1.1.1
|
||||
with:
|
||||
github_token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
61
.github/workflows/bot-changelog.yml
vendored
61
.github/workflows/bot-changelog.yml
vendored
@@ -1,61 +0,0 @@
|
||||
# **what?**
|
||||
# When bots create a PR, this action will add a corresponding changie yaml file to that
|
||||
# PR when a specific label is added.
|
||||
#
|
||||
# The file is created off a template:
|
||||
#
|
||||
# kind: <per action matrix>
|
||||
# body: <PR title>
|
||||
# time: <current timestamp>
|
||||
# custom:
|
||||
# Author: <PR User Login (generally the bot)>
|
||||
# Issue: 4904
|
||||
# PR: <PR number>
|
||||
#
|
||||
# **why?**
|
||||
# Automate changelog generation for more visability with automated bot PRs.
|
||||
#
|
||||
# **when?**
|
||||
# Once a PR is created, label should be added to PR before or after creation. You can also
|
||||
# manually trigger this by adding the appropriate label at any time.
|
||||
#
|
||||
# **how to add another bot?**
|
||||
# Add the label and changie kind to the include matrix. That's it!
|
||||
#
|
||||
|
||||
name: Bot Changelog
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
# catch when the PR is opened with the label or when the label is added
|
||||
types: [labeled]
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: read
|
||||
|
||||
jobs:
|
||||
generate_changelog:
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- label: "dependencies"
|
||||
changie_kind: "Dependency"
|
||||
- label: "snyk"
|
||||
changie_kind: "Security"
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
|
||||
- name: Create and commit changelog on bot PR
|
||||
if: ${{ contains(github.event.pull_request.labels.*.name, matrix.label) }}
|
||||
id: bot_changelog
|
||||
uses: emmyoop/changie_bot@v1.0.1
|
||||
with:
|
||||
GITHUB_TOKEN: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
commit_author_name: "Github Build Bot"
|
||||
commit_author_email: "<buildbot@fishtownanalytics.com>"
|
||||
commit_message: "Add automated changelog yaml from template for bot PR"
|
||||
changie_kind: ${{ matrix.changie_kind }}
|
||||
label: ${{ matrix.label }}
|
||||
custom_changelog_string: "custom:\n Author: ${{ github.event.pull_request.user.login }}\n Issue: 4904\n PR: ${{ github.event.pull_request.number }}"
|
||||
40
.github/workflows/changelog-existence.yml
vendored
40
.github/workflows/changelog-existence.yml
vendored
@@ -1,40 +0,0 @@
|
||||
# **what?**
|
||||
# Checks that a file has been committed under the /.changes directory
|
||||
# as a new CHANGELOG entry. Cannot check for a specific filename as
|
||||
# it is dynamically generated by change type and timestamp.
|
||||
# This workflow should not require any secrets since it runs for PRs
|
||||
# from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code change gets reflected in the CHANGELOG.
|
||||
|
||||
# **when?**
|
||||
# This will run for all PRs going into main and *.latest. It will
|
||||
# run when they are opened, reopened, when any label is added or removed
|
||||
# and when new code is pushed to the branch. The action will then get
|
||||
# skipped if the 'Skip Changelog' label is present is any of the labels.
|
||||
|
||||
name: Check Changelog Entry
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [opened, reopened, labeled, unlabeled, synchronize]
|
||||
workflow_dispatch:
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
changelog:
|
||||
uses: dbt-labs/actions/.github/workflows/changelog-existence.yml@main
|
||||
with:
|
||||
changelog_comment: 'Thank you for your pull request! We could not find a changelog entry for this change. For details on how to document a change, see [the contributing guide](https://github.com/dbt-labs/dbt-core/blob/main/CONTRIBUTING.md#adding-changelog-entry).'
|
||||
skip_label: 'Skip Changelog'
|
||||
secrets: inherit
|
||||
166
.github/workflows/generate-cli-api-docs.yml
vendored
166
.github/workflows/generate-cli-api-docs.yml
vendored
@@ -1,166 +0,0 @@
|
||||
# **what?**
|
||||
# On push, if anything in core/dbt/docs or core/dbt/cli has been
|
||||
# created or modified, regenerate the CLI API docs using sphinx.
|
||||
|
||||
# **why?**
|
||||
# We watch for changes in core/dbt/cli because the CLI API docs rely on click
|
||||
# and all supporting flags/params to be generated. We watch for changes in
|
||||
# core/dbt/docs since any changes to sphinx configuration or any of the
|
||||
# .rst files there could result in a differently build final index.html file.
|
||||
|
||||
# **when?**
|
||||
# Whenever a change has been pushed to a branch, and only if there is a diff
|
||||
# between the PR branch and main's core/dbt/cli and or core/dbt/docs dirs.
|
||||
|
||||
# TODO: add bot comment to PR informing contributor that the docs have been committed
|
||||
# TODO: figure out why github action triggered pushes cause github to fail to report
|
||||
# the status of jobs
|
||||
|
||||
name: Generate CLI API docs
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
env:
|
||||
CLI_DIR: ${{ github.workspace }}/core/dbt/cli
|
||||
DOCS_DIR: ${{ github.workspace }}/core/dbt/docs
|
||||
DOCS_BUILD_DIR: ${{ github.workspace }}/core/dbt/docs/build
|
||||
|
||||
jobs:
|
||||
check_gen:
|
||||
name: check if generation needed
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
cli_dir_changed: ${{ steps.check_cli.outputs.cli_dir_changed }}
|
||||
docs_dir_changed: ${{ steps.check_docs.outputs.docs_dir_changed }}
|
||||
|
||||
steps:
|
||||
- name: "[DEBUG] print variables"
|
||||
run: |
|
||||
echo "env.CLI_DIR: ${{ env.CLI_DIR }}"
|
||||
echo "env.DOCS_BUILD_DIR: ${{ env.DOCS_BUILD_DIR }}"
|
||||
echo "env.DOCS_DIR: ${{ env.DOCS_DIR }}"
|
||||
echo ">>>>> git log"
|
||||
git log --pretty=oneline | head -5
|
||||
|
||||
- name: git checkout
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.head_ref }}
|
||||
|
||||
- name: set shas
|
||||
id: set_shas
|
||||
run: |
|
||||
THIS_SHA=$(git rev-parse @)
|
||||
LAST_SHA=$(git rev-parse @~1)
|
||||
|
||||
echo "this sha: $THIS_SHA"
|
||||
echo "last sha: $LAST_SHA"
|
||||
|
||||
echo "this_sha=$THIS_SHA" >> $GITHUB_OUTPUT
|
||||
echo "last_sha=$LAST_SHA" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: check for changes in core/dbt/cli
|
||||
id: check_cli
|
||||
run: |
|
||||
CLI_DIR_CHANGES=$(git diff \
|
||||
${{ steps.set_shas.outputs.last_sha }} \
|
||||
${{ steps.set_shas.outputs.this_sha }} \
|
||||
-- ${{ env.CLI_DIR }})
|
||||
|
||||
if [ -n "$CLI_DIR_CHANGES" ]; then
|
||||
echo "changes found"
|
||||
echo $CLI_DIR_CHANGES
|
||||
echo "cli_dir_changed=true" >> $GITHUB_OUTPUT
|
||||
exit 0
|
||||
fi
|
||||
echo "cli_dir_changed=false" >> $GITHUB_OUTPUT
|
||||
echo "no changes found"
|
||||
|
||||
- name: check for changes in core/dbt/docs
|
||||
id: check_docs
|
||||
if: steps.check_cli.outputs.cli_dir_changed == 'false'
|
||||
run: |
|
||||
DOCS_DIR_CHANGES=$(git diff --name-only \
|
||||
${{ steps.set_shas.outputs.last_sha }} \
|
||||
${{ steps.set_shas.outputs.this_sha }} \
|
||||
-- ${{ env.DOCS_DIR }} ':!${{ env.DOCS_BUILD_DIR }}')
|
||||
|
||||
DOCS_BUILD_DIR_CHANGES=$(git diff --name-only \
|
||||
${{ steps.set_shas.outputs.last_sha }} \
|
||||
${{ steps.set_shas.outputs.this_sha }} \
|
||||
-- ${{ env.DOCS_BUILD_DIR }})
|
||||
|
||||
if [ -n "$DOCS_DIR_CHANGES" ] && [ -z "$DOCS_BUILD_DIR_CHANGES" ]; then
|
||||
echo "changes found"
|
||||
echo $DOCS_DIR_CHANGES
|
||||
echo "docs_dir_changed=true" >> $GITHUB_OUTPUT
|
||||
exit 0
|
||||
fi
|
||||
echo "docs_dir_changed=false" >> $GITHUB_OUTPUT
|
||||
echo "no changes found"
|
||||
|
||||
gen_docs:
|
||||
name: generate docs
|
||||
runs-on: ubuntu-latest
|
||||
needs: [check_gen]
|
||||
if: |
|
||||
needs.check_gen.outputs.cli_dir_changed == 'true'
|
||||
|| needs.check_gen.outputs.docs_dir_changed == 'true'
|
||||
|
||||
steps:
|
||||
- name: "[DEBUG] print variables"
|
||||
run: |
|
||||
echo "env.DOCS_DIR: ${{ env.DOCS_DIR }}"
|
||||
echo "github head_ref: ${{ github.head_ref }}"
|
||||
|
||||
- name: git checkout
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
ref: ${{ github.head_ref }}
|
||||
|
||||
- name: install python
|
||||
uses: actions/setup-python@v4.3.0
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: install dev requirements
|
||||
run: |
|
||||
python3 -m venv env
|
||||
source env/bin/activate
|
||||
python -m pip install --upgrade pip
|
||||
pip install -r requirements.txt -r dev-requirements.txt
|
||||
|
||||
- name: generate docs
|
||||
run: |
|
||||
source env/bin/activate
|
||||
cd ${{ env.DOCS_DIR }}
|
||||
|
||||
echo "cleaning existing docs"
|
||||
make clean
|
||||
|
||||
echo "creating docs"
|
||||
make html
|
||||
|
||||
- name: debug
|
||||
run: |
|
||||
echo ">>>>> status"
|
||||
git status
|
||||
echo ">>>>> remotes"
|
||||
git remote -v
|
||||
echo ">>>>> branch"
|
||||
git branch -v
|
||||
echo ">>>>> log"
|
||||
git log --pretty=oneline | head -5
|
||||
|
||||
- name: commit docs
|
||||
run: |
|
||||
git config user.name 'Github Build Bot'
|
||||
git config user.email 'buildbot@fishtownanalytics.com'
|
||||
git commit -am "Add generated CLI API docs"
|
||||
git push -u origin ${{ github.head_ref }}
|
||||
222
.github/workflows/integration.yml
vendored
Normal file
222
.github/workflows/integration.yml
vendored
Normal file
@@ -0,0 +1,222 @@
|
||||
# **what?**
|
||||
# This workflow runs all integration tests for supported OS
|
||||
# and python versions and core adapters. If triggered by PR,
|
||||
# the workflow will only run tests for adapters related
|
||||
# to code changes. Use the `test all` and `test ${adapter}`
|
||||
# label to run all or additional tests. Use `ok to test`
|
||||
# label to mark PRs from forked repositories that are safe
|
||||
# to run integration tests for. Requires secrets to run
|
||||
# against different warehouses.
|
||||
|
||||
# **why?**
|
||||
# This checks the functionality of dbt from a user's perspective
|
||||
# and attempts to catch functional regressions.
|
||||
|
||||
# **when?**
|
||||
# This workflow will run on every push to a protected branch
|
||||
# and when manually triggered. It will also run for all PRs, including
|
||||
# PRs from forks. The workflow will be skipped until there is a label
|
||||
# to mark the PR as safe to run.
|
||||
|
||||
name: Adapter Integration Tests
|
||||
|
||||
on:
|
||||
# pushes to release branches
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
# all PRs, important to note that `pull_request_target` workflows
|
||||
# will run in the context of the target branch of a PR
|
||||
pull_request_target:
|
||||
# manual tigger
|
||||
workflow_dispatch:
|
||||
|
||||
# explicitly turn off permissions for `GITHUB_TOKEN`
|
||||
permissions: read-all
|
||||
|
||||
# will cancel previous workflows triggered by the same event and for the same ref for PRs or same SHA otherwise
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event_name }}-${{ contains(github.event_name, 'pull_request') && github.event.pull_request.head.ref || github.sha }}
|
||||
cancel-in-progress: true
|
||||
|
||||
# sets default shell to bash, for all operating systems
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
jobs:
|
||||
# generate test metadata about what files changed and the testing matrix to use
|
||||
test-metadata:
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
if: >-
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
outputs:
|
||||
matrix: ${{ steps.generate-matrix.outputs.result }}
|
||||
|
||||
steps:
|
||||
- name: Check out the repository (non-PR)
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Check if relevant files changed
|
||||
# https://github.com/marketplace/actions/paths-changes-filter
|
||||
# For each filter, it sets output variable named by the filter to the text:
|
||||
# 'true' - if any of changed files matches any of filter rules
|
||||
# 'false' - if none of changed files matches any of filter rules
|
||||
# also, returns:
|
||||
# `changes` - JSON array with names of all filters matching any of the changed files
|
||||
uses: dorny/paths-filter@v2
|
||||
id: get-changes
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
filters: |
|
||||
postgres:
|
||||
- 'core/**'
|
||||
- 'plugins/postgres/**'
|
||||
- 'dev-requirements.txt'
|
||||
|
||||
- name: Generate integration test matrix
|
||||
id: generate-matrix
|
||||
uses: actions/github-script@v4
|
||||
env:
|
||||
CHANGES: ${{ steps.get-changes.outputs.changes }}
|
||||
with:
|
||||
script: |
|
||||
const script = require('./.github/scripts/integration-test-matrix.js')
|
||||
const matrix = script({ context })
|
||||
console.log(matrix)
|
||||
return matrix
|
||||
|
||||
test:
|
||||
name: ${{ matrix.adapter }} / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
# run if not a PR from a forked repository or has a label to mark as safe to test
|
||||
# also checks that the matrix generated is not empty
|
||||
if: >-
|
||||
needs.test-metadata.outputs.matrix &&
|
||||
fromJSON( needs.test-metadata.outputs.matrix ).include[0] &&
|
||||
(
|
||||
github.event_name != 'pull_request_target' ||
|
||||
github.event.pull_request.head.repo.full_name == github.repository ||
|
||||
contains(github.event.pull_request.labels.*.name, 'ok to test')
|
||||
)
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
needs: test-metadata
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix: ${{ fromJSON(needs.test-metadata.outputs.matrix) }}
|
||||
|
||||
env:
|
||||
TOXENV: integration-${{ matrix.adapter }}
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
if: github.event_name != 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
# explicity checkout the branch for the PR,
|
||||
# this is necessary for the `pull_request_target` event
|
||||
- name: Check out the repository (PR)
|
||||
if: github.event_name == 'pull_request_target'
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
ref: ${{ github.event.pull_request.head.sha }}
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: |
|
||||
matrix.adapter == 'postgres' &&
|
||||
runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox (postgres)
|
||||
if: matrix.adapter == 'postgres'
|
||||
run: tox
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs
|
||||
path: ./logs
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y-%m-%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ matrix.adapter }}-${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
require-label-comment:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
needs: test
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
|
||||
steps:
|
||||
- name: Needs permission PR comment
|
||||
if: >-
|
||||
needs.test.result == 'skipped' &&
|
||||
github.event_name == 'pull_request_target' &&
|
||||
github.event.pull_request.head.repo.full_name != github.repository
|
||||
uses: unsplash/comment-on-pr@master
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
with:
|
||||
msg: |
|
||||
"You do not have permissions to run integration tests, @dbt-labs/core "\
|
||||
"needs to label this PR with `ok to test` in order to run integration tests!"
|
||||
check_for_duplicate_msg: true
|
||||
3
.github/workflows/jira-transition.yml
vendored
3
.github/workflows/jira-transition.yml
vendored
@@ -15,9 +15,6 @@ on:
|
||||
issues:
|
||||
types: [closed, deleted, reopened]
|
||||
|
||||
# no special access is needed
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
call-label-action:
|
||||
uses: dbt-labs/jira-actions/.github/workflows/jira-transition.yml@main
|
||||
|
||||
168
.github/workflows/main.yml
vendored
168
.github/workflows/main.yml
vendored
@@ -1,8 +1,9 @@
|
||||
# **what?**
|
||||
# Runs code quality checks, unit tests, integration tests and
|
||||
# verifies python build on all code commited to the repository. This workflow
|
||||
# should not require any secrets since it runs for PRs from forked repos. By
|
||||
# default, secrets are not passed to workflows running from a forked repos.
|
||||
# Runs code quality checks, unit tests, and verifies python build on
|
||||
# all code commited to the repository. This workflow should not
|
||||
# require any secrets since it runs for PRs from forked repos.
|
||||
# By default, secrets are not passed to workflows running from
|
||||
# a forked repo.
|
||||
|
||||
# **why?**
|
||||
# Ensure code for dbt meets a certain quality standard.
|
||||
@@ -17,6 +18,7 @@ on:
|
||||
push:
|
||||
branches:
|
||||
- "main"
|
||||
- "develop"
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
pull_request:
|
||||
@@ -38,27 +40,25 @@ jobs:
|
||||
name: code-quality
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 10
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4.3.0
|
||||
with:
|
||||
python-version: '3.8'
|
||||
uses: actions/setup-python@v2
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install pre-commit
|
||||
pip install --user --upgrade pip
|
||||
pip install pre-commit
|
||||
pip install mypy==0.782
|
||||
pip install -r editable-requirements.txt
|
||||
pip --version
|
||||
pre-commit --version
|
||||
python -m pip install mypy==0.942
|
||||
mypy --version
|
||||
python -m pip install -r requirements.txt
|
||||
python -m pip install -r dev-requirements.txt
|
||||
dbt --version
|
||||
|
||||
- name: Run pre-commit hooks
|
||||
@@ -68,12 +68,11 @@ jobs:
|
||||
name: unit test / python ${{ matrix.python-version }}
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
timeout-minutes: 10
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.7", "3.8", "3.9", "3.10"]
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
|
||||
env:
|
||||
TOXENV: "unit"
|
||||
@@ -82,17 +81,19 @@ jobs:
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v4.3.0
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
pip install --user --upgrade pip
|
||||
pip install tox
|
||||
pip --version
|
||||
tox --version
|
||||
|
||||
- name: Run tox
|
||||
@@ -109,79 +110,6 @@ jobs:
|
||||
name: unit_results_${{ matrix.python-version }}-${{ steps.date.outputs.date }}.csv
|
||||
path: unit_results.csv
|
||||
|
||||
integration:
|
||||
name: integration test / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
timeout-minutes: 45
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
python-version: ["3.7", "3.8", "3.9", "3.10"]
|
||||
os: [ubuntu-20.04]
|
||||
include:
|
||||
- python-version: 3.8
|
||||
os: windows-latest
|
||||
- python-version: 3.8
|
||||
os: macos-latest
|
||||
|
||||
env:
|
||||
TOXENV: integration
|
||||
PYTEST_ADDOPTS: "-v --color=yes -n4 --csv integration_results.csv"
|
||||
DBT_INVOCATION_ENV: github-actions
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v4.3.0
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Set up postgres (linux)
|
||||
if: runner.os == 'Linux'
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
|
||||
- name: Set up postgres (macos)
|
||||
if: runner.os == 'macOS'
|
||||
uses: ./.github/actions/setup-postgres-macos
|
||||
|
||||
- name: Set up postgres (windows)
|
||||
if: runner.os == 'Windows'
|
||||
uses: ./.github/actions/setup-postgres-windows
|
||||
|
||||
- name: Install python tools
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip --version
|
||||
python -m pip install tox
|
||||
tox --version
|
||||
|
||||
- name: Run tests
|
||||
run: tox
|
||||
|
||||
- name: Get current date
|
||||
if: always()
|
||||
id: date
|
||||
run: echo "::set-output name=date::$(date +'%Y_%m_%dT%H_%M_%S')" #no colons allowed for artifacts
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: logs_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}
|
||||
path: ./logs
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: always()
|
||||
with:
|
||||
name: integration_results_${{ matrix.python-version }}_${{ matrix.os }}_${{ steps.date.outputs.date }}.csv
|
||||
path: integration_results.csv
|
||||
|
||||
build:
|
||||
name: build packages
|
||||
|
||||
@@ -190,17 +118,19 @@ jobs:
|
||||
steps:
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4.3.0
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: '3.8'
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
python -m pip install --user --upgrade pip
|
||||
python -m pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
python -m pip --version
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade setuptools wheel twine check-wheel-contents
|
||||
pip --version
|
||||
|
||||
- name: Build distributions
|
||||
run: ./scripts/build-dist.sh
|
||||
@@ -216,9 +146,47 @@ jobs:
|
||||
run: |
|
||||
check-wheel-contents dist/*.whl --ignore W007,W008
|
||||
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
test-build:
|
||||
name: verify packages / python ${{ matrix.python-version }} / ${{ matrix.os }}
|
||||
|
||||
needs: build
|
||||
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
os: [ubuntu-latest, macos-latest, windows-latest]
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
|
||||
steps:
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip install --upgrade wheel
|
||||
pip --version
|
||||
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dist
|
||||
path: dist/
|
||||
|
||||
- name: Show distributions
|
||||
run: ls -lh dist/
|
||||
|
||||
- name: Install wheel distributions
|
||||
run: |
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
find ./dist/*.whl -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check wheel distributions
|
||||
run: |
|
||||
@@ -227,7 +195,7 @@ jobs:
|
||||
- name: Install source distributions
|
||||
# ignore dbt-1.0.0, which intentionally raises an error when installed from source
|
||||
run: |
|
||||
find ./dist/dbt-[a-z]*.gz -maxdepth 1 -type f | xargs python -m pip install --force-reinstall --find-links=dist/
|
||||
find ./dist/dbt-[a-z]*.gz -maxdepth 1 -type f | xargs pip install --force-reinstall --find-links=dist/
|
||||
|
||||
- name: Check source distributions
|
||||
run: |
|
||||
|
||||
176
.github/workflows/performance.yml
vendored
Normal file
176
.github/workflows/performance.yml
vendored
Normal file
@@ -0,0 +1,176 @@
|
||||
name: Performance Regression Tests
|
||||
# Schedule triggers
|
||||
on:
|
||||
# runs twice a day at 10:05am and 10:05pm
|
||||
schedule:
|
||||
- cron: "5 10,22 * * *"
|
||||
# Allows you to run this workflow manually from the Actions tab
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
# checks fmt of runner code
|
||||
# purposefully not a dependency of any other job
|
||||
# will block merging, but not prevent developing
|
||||
fmt:
|
||||
name: Cargo fmt
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- run: rustup component add rustfmt
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: fmt
|
||||
args: --manifest-path performance/runner/Cargo.toml --all -- --check
|
||||
|
||||
# runs any tests associated with the runner
|
||||
# these tests make sure the runner logic is correct
|
||||
test-runner:
|
||||
name: Test Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns errors into warnings
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --manifest-path performance/runner/Cargo.toml
|
||||
|
||||
# build an optimized binary to be used as the runner in later steps
|
||||
build-runner:
|
||||
needs: [test-runner]
|
||||
name: Build Runner
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
RUSTFLAGS: "-D warnings"
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --release --manifest-path performance/runner/Cargo.toml
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
path: performance/runner/target/release/runner
|
||||
|
||||
# run the performance measurements on the current or default branch
|
||||
measure-dev:
|
||||
needs: [build-runner]
|
||||
name: Measure Dev Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run
|
||||
run: ./runner measure -b dev -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
path: performance/results/
|
||||
|
||||
# run the performance measurements on the release branch which we use
|
||||
# as a performance baseline. This part takes by far the longest, so
|
||||
# we do everything we can first so the job fails fast.
|
||||
# -----
|
||||
# we need to checkout dbt twice in this job: once for the baseline dbt
|
||||
# version, and once to get the latest regression testing projects,
|
||||
# metrics, and runner code from the develop or current branch so that
|
||||
# the calculations match for both versions of dbt we are comparing.
|
||||
measure-baseline:
|
||||
needs: [build-runner]
|
||||
name: Measure Baseline Branch
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: checkout latest
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
ref: "0.20.latest"
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v2.2.2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: move repo up a level
|
||||
run: mkdir ${{ github.workspace }}/../baseline/ && cp -r ${{ github.workspace }} ${{ github.workspace }}/../baseline
|
||||
- name: "[debug] ls new dbt location"
|
||||
run: ls ${{ github.workspace }}/../baseline/dbt/
|
||||
# installation creates egg-links so we have to preserve source
|
||||
- name: install dbt from new location
|
||||
run: cd ${{ github.workspace }}/../baseline/dbt/ && pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
# checkout the current branch to get all the target projects
|
||||
# this deletes the old checked out code which is why we had to copy before
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
- name: install hyperfine
|
||||
run: wget https://github.com/sharkdp/hyperfine/releases/download/v1.11.0/hyperfine_1.11.0_amd64.deb && sudo dpkg -i hyperfine_1.11.0_amd64.deb
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: run runner
|
||||
run: ./runner measure -b baseline -p ${{ github.workspace }}/performance/projects/
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
path: performance/results/
|
||||
|
||||
# detect regressions on the output generated from measuring
|
||||
# the two branches. Exits with non-zero code if a regression is detected.
|
||||
calculate-regressions:
|
||||
needs: [measure-dev, measure-baseline]
|
||||
name: Compare Results
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: dev-results
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: baseline-results
|
||||
- name: "[debug] ls result files"
|
||||
run: ls
|
||||
- uses: actions/download-artifact@v2
|
||||
with:
|
||||
name: runner
|
||||
- name: change permissions
|
||||
run: chmod +x ./runner
|
||||
- name: make results directory
|
||||
run: mkdir ./final-output/
|
||||
- name: run calculation
|
||||
run: ./runner calculate -r ./ -o ./final-output/
|
||||
# always attempt to upload the results even if there were regressions found
|
||||
- uses: actions/upload-artifact@v2
|
||||
if: ${{ always() }}
|
||||
with:
|
||||
name: final-calculations
|
||||
path: ./final-output/*
|
||||
62
.github/workflows/release-branch-tests.yml
vendored
62
.github/workflows/release-branch-tests.yml
vendored
@@ -1,62 +0,0 @@
|
||||
# **what?**
|
||||
# The purpose of this workflow is to trigger CI to run for each
|
||||
# release branch and main branch on a regular cadence. If the CI workflow
|
||||
# fails for a branch, it will post to dev-core-alerts to raise awareness.
|
||||
# The 'aurelien-baudet/workflow-dispatch' Action triggers the existing
|
||||
# CI worklow file on the given branch to run so that even if we change the
|
||||
# CI workflow file in the future, the one that is tailored for the given
|
||||
# release branch will be used.
|
||||
|
||||
# **why?**
|
||||
# Ensures release branches and main are always shippable and not broken.
|
||||
# Also, can catch any dependencies shifting beneath us that might
|
||||
# introduce breaking changes (could also impact Cloud).
|
||||
|
||||
# **when?**
|
||||
# Mainly on a schedule of 9:00, 13:00, 18:00 UTC everyday.
|
||||
# Manual trigger can also test on demand
|
||||
|
||||
name: Release branch scheduled testing
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '0 9,13,18 * * *' # 9:00, 13:00, 18:00 UTC
|
||||
|
||||
workflow_dispatch: # for manual triggering
|
||||
|
||||
# no special access is needed
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
kick-off-ci:
|
||||
name: Kick-off CI
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
# must run CI 1 branch at a time b/c the workflow-dispatch Action polls for
|
||||
# latest run for results and it gets confused when we kick off multiple runs
|
||||
# at once. There is a race condition so we will just run in sequential order.
|
||||
max-parallel: 1
|
||||
fail-fast: false
|
||||
matrix:
|
||||
branch: [1.0.latest, 1.1.latest, 1.2.latest, 1.3.latest, main]
|
||||
|
||||
steps:
|
||||
- name: Call CI workflow for ${{ matrix.branch }} branch
|
||||
id: trigger-step
|
||||
uses: aurelien-baudet/workflow-dispatch@v2.1.1
|
||||
with:
|
||||
workflow: main.yml
|
||||
ref: ${{ matrix.branch }}
|
||||
token: ${{ secrets.FISHTOWN_BOT_PAT }}
|
||||
|
||||
- name: Post failure to Slack
|
||||
uses: ravsamhq/notify-slack-action@v1
|
||||
if: ${{ always() && !contains(steps.trigger-step.outputs.workflow-conclusion,'success') }}
|
||||
with:
|
||||
status: ${{ job.status }}
|
||||
notification_title: 'dbt-core scheduled run of "${{ matrix.branch }}" branch not successful'
|
||||
message_format: ':x: CI on branch "${{ matrix.branch }}" ${{ steps.trigger-step.outputs.workflow-conclusion }}'
|
||||
footer: 'Linked failed CI run ${{ steps.trigger-step.outputs.workflow-url }}'
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_DEV_CORE_ALERTS }}
|
||||
3
.github/workflows/release.yml
vendored
3
.github/workflows/release.yml
vendored
@@ -20,9 +20,6 @@ on:
|
||||
description: 'The release version number (i.e. 1.0.0b1)'
|
||||
required: true
|
||||
|
||||
permissions:
|
||||
contents: write # this is the permission that allows creating a new release
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
@@ -12,9 +12,6 @@
|
||||
|
||||
name: Docker release
|
||||
|
||||
permissions:
|
||||
packages: write
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
@@ -77,7 +74,7 @@ jobs:
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
registry: ghcr.io
|
||||
username: ${{ github.actor }}
|
||||
username: USERNAME
|
||||
password: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Build and push MAJOR.MINOR.PATCH tag
|
||||
3
.github/workflows/schema-check.yml
vendored
3
.github/workflows/schema-check.yml
vendored
@@ -21,9 +21,6 @@ on:
|
||||
- "*.latest"
|
||||
- "releases/*"
|
||||
|
||||
# no special access is needed
|
||||
permissions: read-all
|
||||
|
||||
env:
|
||||
LATEST_SCHEMA_PATH: ${{ github.workspace }}/new_schemas
|
||||
SCHEMA_DIFF_ARTIFACT: ${{ github.workspace }}//schema_schanges.txt
|
||||
|
||||
16
.github/workflows/stale.yml
vendored
16
.github/workflows/stale.yml
vendored
@@ -3,10 +3,16 @@ on:
|
||||
schedule:
|
||||
- cron: "30 1 * * *"
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
uses: dbt-labs/actions/.github/workflows/stale-bot-matrix.yml@main
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
# pinned at v4 (https://github.com/actions/stale/releases/tag/v4.0.0)
|
||||
- uses: actions/stale@cdf15f641adb27a71842045a94023bef6945e3aa
|
||||
with:
|
||||
stale-issue-message: "This issue has been marked as Stale because it has been open for 180 days with no activity. If you would like the issue to remain open, please remove the stale label or comment on the issue, or it will be closed in 7 days."
|
||||
stale-pr-message: "This PR has been marked as Stale because it has been open for 180 days with no activity. If you would like the PR to remain open, please remove the stale label or comment on the PR, or it will be closed in 7 days."
|
||||
# mark issues/PRs stale when they haven't seen activity in 180 days
|
||||
days-before-stale: 180
|
||||
# ignore checking issues with the following labels
|
||||
exempt-issue-labels: "epic,discussion"
|
||||
|
||||
@@ -6,6 +6,7 @@
|
||||
# version of our structured logging and add new documentation to
|
||||
# communicate these changes.
|
||||
|
||||
|
||||
name: Structured Logging Schema Check
|
||||
on:
|
||||
push:
|
||||
@@ -22,20 +23,16 @@ jobs:
|
||||
# run the performance measurements on the current or default branch
|
||||
test-schema:
|
||||
name: Test Log Schema
|
||||
runs-on: ubuntu-20.04
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
# turns warnings into errors
|
||||
RUSTFLAGS: "-D warnings"
|
||||
# points tests to the log file
|
||||
LOG_DIR: "/home/runner/work/dbt-core/dbt-core/logs"
|
||||
# tells integration tests to output into json format
|
||||
DBT_LOG_FORMAT: "json"
|
||||
# Additional test users
|
||||
DBT_TEST_USER_1: dbt_test_user_1
|
||||
DBT_TEST_USER_2: dbt_test_user_2
|
||||
DBT_TEST_USER_3: dbt_test_user_3
|
||||
|
||||
DBT_LOG_FORMAT: 'json'
|
||||
steps:
|
||||
|
||||
- name: checkout dev
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
@@ -46,12 +43,14 @@ jobs:
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install python dependencies
|
||||
run: |
|
||||
pip install --user --upgrade pip
|
||||
pip --version
|
||||
pip install tox
|
||||
tox --version
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
profile: minimal
|
||||
toolchain: stable
|
||||
override: true
|
||||
|
||||
- name: install dbt
|
||||
run: pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
|
||||
- name: Set up postgres
|
||||
uses: ./.github/actions/setup-postgres-linux
|
||||
@@ -62,4 +61,11 @@ jobs:
|
||||
# integration tests generate a ton of logs in different files. the next step will find them all.
|
||||
# we actually care if these pass, because the normal test run doesn't usually include many json log outputs
|
||||
- name: Run integration tests
|
||||
run: tox -e integration -- -nauto
|
||||
run: tox -e py38-postgres -- -nauto
|
||||
|
||||
# apply our schema tests to every log event from the previous step
|
||||
# skips any output that isn't valid json
|
||||
- uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: run
|
||||
args: --manifest-path test/interop/log_parsing/Cargo.toml
|
||||
|
||||
33
.github/workflows/triage-labels.yml
vendored
33
.github/workflows/triage-labels.yml
vendored
@@ -1,33 +0,0 @@
|
||||
# **what?**
|
||||
# When the core team triages, we sometimes need more information from the issue creator. In
|
||||
# those cases we remove the `triage` label and add the `awaiting_response` label. Once we
|
||||
# recieve a response in the form of a comment, we want the `awaiting_response` label removed
|
||||
# in favor of the `triage` label so we are aware that the issue needs action.
|
||||
|
||||
# **why?**
|
||||
# To help with out team triage issue tracking
|
||||
|
||||
# **when?**
|
||||
# This will run when a comment is added to an issue and that issue has to `awaiting_response` label.
|
||||
|
||||
name: Update Triage Label
|
||||
|
||||
on: issue_comment
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
|
||||
jobs:
|
||||
triage_label:
|
||||
if: contains(github.event.issue.labels.*.name, 'awaiting_response')
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: initial labeling
|
||||
uses: andymckay/labeler@master
|
||||
with:
|
||||
add-labels: "triage"
|
||||
remove-labels: "awaiting_response"
|
||||
130
.github/workflows/version-bump.yml
vendored
130
.github/workflows/version-bump.yml
vendored
@@ -1,15 +1,18 @@
|
||||
# **what?**
|
||||
# This workflow will take the new version number to bump to. With that
|
||||
# This workflow will take a version number and a dry run flag. With that
|
||||
# it will run versionbump to update the version number everywhere in the
|
||||
# code base and then run changie to create the corresponding changelog.
|
||||
# A PR will be created with the changes that can be reviewed before committing.
|
||||
# code base and then generate an update Docker requirements file. If this
|
||||
# is a dry run, a draft PR will open with the changes. If this isn't a dry
|
||||
# run, the changes will be committed to the branch this is run on.
|
||||
|
||||
# **why?**
|
||||
# This is to aid in releasing dbt and making sure we have updated
|
||||
# the version in all places and generated the changelog.
|
||||
# the versions and Docker requirements in all places.
|
||||
|
||||
# **when?**
|
||||
# This is triggered manually
|
||||
# This is triggered either manually OR
|
||||
# from the repository_dispatch event "version-bump" which is sent from
|
||||
# the dbt-release repo Action
|
||||
|
||||
name: Version Bump
|
||||
|
||||
@@ -17,25 +20,35 @@ on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version_number:
|
||||
description: 'The version number to bump to (ex. 1.2.0, 1.3.0b1)'
|
||||
description: 'The version number to bump to'
|
||||
required: true
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
is_dry_run:
|
||||
description: 'Creates a draft PR to allow testing instead of committing to a branch'
|
||||
required: true
|
||||
default: 'true'
|
||||
repository_dispatch:
|
||||
types: [version-bump]
|
||||
|
||||
jobs:
|
||||
bump:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: "[DEBUG] Print Variables"
|
||||
run: |
|
||||
echo "all variables defined as inputs"
|
||||
echo The version_number: ${{ github.event.inputs.version_number }}
|
||||
|
||||
- name: Check out the repository
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set version and dry run values
|
||||
id: variables
|
||||
env:
|
||||
VERSION_NUMBER: "${{ github.event.client_payload.version_number == '' && github.event.inputs.version_number || github.event.client_payload.version_number }}"
|
||||
IS_DRY_RUN: "${{ github.event.client_payload.is_dry_run == '' && github.event.inputs.is_dry_run || github.event.client_payload.is_dry_run }}"
|
||||
run: |
|
||||
echo Repository dispatch event version: ${{ github.event.client_payload.version_number }}
|
||||
echo Repository dispatch event dry run: ${{ github.event.client_payload.is_dry_run }}
|
||||
echo Workflow dispatch event version: ${{ github.event.inputs.version_number }}
|
||||
echo Workflow dispatch event dry run: ${{ github.event.inputs.is_dry_run }}
|
||||
echo ::set-output name=VERSION_NUMBER::$VERSION_NUMBER
|
||||
echo ::set-output name=IS_DRY_RUN::$IS_DRY_RUN
|
||||
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
@@ -46,80 +59,51 @@ jobs:
|
||||
source env/bin/activate
|
||||
pip install --upgrade pip
|
||||
|
||||
- name: Add Homebrew to PATH
|
||||
run: |
|
||||
echo "/home/linuxbrew/.linuxbrew/bin:/home/linuxbrew/.linuxbrew/sbin" >> $GITHUB_PATH
|
||||
|
||||
- name: Install Homebrew packages
|
||||
run: |
|
||||
brew install pre-commit
|
||||
brew tap miniscruff/changie https://github.com/miniscruff/changie
|
||||
brew install changie
|
||||
|
||||
- name: Audit Version and Parse Into Parts
|
||||
id: semver
|
||||
uses: dbt-labs/actions/parse-semver@v1
|
||||
with:
|
||||
version: ${{ github.event.inputs.version_number }}
|
||||
|
||||
- name: Set branch value
|
||||
id: variables
|
||||
run: |
|
||||
echo "::set-output name=BRANCH_NAME::prep-release/${{ github.event.inputs.version_number }}_$GITHUB_RUN_ID"
|
||||
|
||||
- name: Create PR branch
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
run: |
|
||||
git checkout -b ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
git push origin ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
git branch --set-upstream-to=origin/${{ steps.variables.outputs.BRANCH_NAME }} ${{ steps.variables.outputs.BRANCH_NAME }}
|
||||
git checkout -b bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git push origin bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
git branch --set-upstream-to=origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_$GITHUB_RUN_ID
|
||||
|
||||
# - name: Generate Docker requirements
|
||||
# run: |
|
||||
# source env/bin/activate
|
||||
# pip install -r requirements.txt
|
||||
# pip freeze -l > docker/requirements/requirements.txt
|
||||
# git status
|
||||
|
||||
- name: Bump version
|
||||
run: |
|
||||
source env/bin/activate
|
||||
pip install -r dev-requirements.txt
|
||||
env/bin/bumpversion --allow-dirty --new-version ${{ github.event.inputs.version_number }} major
|
||||
env/bin/bumpversion --allow-dirty --new-version ${{steps.variables.outputs.VERSION_NUMBER}} major
|
||||
git status
|
||||
|
||||
- name: Run changie
|
||||
run: |
|
||||
if [[ ${{ steps.semver.outputs.is-pre-release }} -eq 1 ]]
|
||||
then
|
||||
changie batch ${{ steps.semver.outputs.base-version }} --move-dir '${{ steps.semver.outputs.base-version }}' --prerelease '${{ steps.semver.outputs.pre-release }}'
|
||||
else
|
||||
changie batch ${{ steps.semver.outputs.base-version }} --include '${{ steps.semver.outputs.base-version }}' --remove-prereleases
|
||||
fi
|
||||
changie merge
|
||||
git status
|
||||
|
||||
# this step will fail on whitespace errors but also correct them
|
||||
- name: Remove trailing whitespace
|
||||
continue-on-error: true
|
||||
run: |
|
||||
pre-commit run trailing-whitespace --files .bumpversion.cfg CHANGELOG.md .changes/*
|
||||
git status
|
||||
|
||||
# this step will fail on newline errors but also correct them
|
||||
- name: Removing extra newlines
|
||||
continue-on-error: true
|
||||
run: |
|
||||
pre-commit run end-of-file-fixer --files .bumpversion.cfg CHANGELOG.md .changes/*
|
||||
git status
|
||||
|
||||
- name: Commit version bump to branch
|
||||
- name: Commit version bump directly
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'false' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{ github.event.inputs.version_number }} and generate CHANGELOG'
|
||||
branch: '${{ steps.variables.outputs.BRANCH_NAME }}'
|
||||
push: 'origin origin/${{ steps.variables.outputs.BRANCH_NAME }}'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
|
||||
- name: Commit version bump to branch
|
||||
uses: EndBug/add-and-commit@v7
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author_name: 'Github Build Bot'
|
||||
author_email: 'buildbot@fishtownanalytics.com'
|
||||
message: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
push: 'origin origin/bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
|
||||
- name: Create Pull Request
|
||||
uses: peter-evans/create-pull-request@v3
|
||||
if: ${{ steps.variables.outputs.IS_DRY_RUN == 'true' }}
|
||||
with:
|
||||
author: 'Github Build Bot <buildbot@fishtownanalytics.com>'
|
||||
draft: true
|
||||
base: ${{github.ref}}
|
||||
title: 'Bumping version to ${{ github.event.inputs.version_number }} and generate changelog'
|
||||
branch: '${{ steps.variables.outputs.BRANCH_NAME }}'
|
||||
labels: |
|
||||
Skip Changelog
|
||||
title: 'Bumping version to ${{steps.variables.outputs.VERSION_NUMBER}}'
|
||||
branch: 'bumping-version/${{steps.variables.outputs.VERSION_NUMBER}}_${{GITHUB.RUN_ID}}'
|
||||
|
||||
8
.gitignore
vendored
8
.gitignore
vendored
@@ -11,7 +11,6 @@ __pycache__/
|
||||
env*/
|
||||
dbt_env/
|
||||
build/
|
||||
!core/dbt/docs/build
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
@@ -25,8 +24,7 @@ var/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
*.mypy_cache/
|
||||
logs/
|
||||
|
||||
# PyInstaller
|
||||
@@ -97,7 +95,3 @@ venv/
|
||||
|
||||
# vscode
|
||||
.vscode/
|
||||
*.code-workspace
|
||||
|
||||
# poetry
|
||||
poetry.lock
|
||||
|
||||
@@ -2,11 +2,11 @@
|
||||
# Eventually the hooks described here will be run as tests before merging each PR.
|
||||
|
||||
# TODO: remove global exclusion of tests when testing overhaul is complete
|
||||
exclude: ^(test/|core/dbt/docs/build/)
|
||||
exclude: ^test/
|
||||
|
||||
# Force all unspecified python hooks to run python 3.8
|
||||
default_language_version:
|
||||
python: python3
|
||||
python: python3.8
|
||||
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
@@ -21,16 +21,21 @@ repos:
|
||||
- "markdown"
|
||||
- id: check-case-conflict
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 22.3.0
|
||||
rev: 21.12b0
|
||||
hooks:
|
||||
- id: black
|
||||
args:
|
||||
- "--line-length=99"
|
||||
- "--target-version=py38"
|
||||
- id: black
|
||||
alias: black-check
|
||||
stages: [manual]
|
||||
args:
|
||||
- "--line-length=99"
|
||||
- "--target-version=py38"
|
||||
- "--check"
|
||||
- "--diff"
|
||||
- repo: https://github.com/pycqa/flake8
|
||||
- repo: https://gitlab.com/pycqa/flake8
|
||||
rev: 4.0.1
|
||||
hooks:
|
||||
- id: flake8
|
||||
@@ -38,7 +43,7 @@ repos:
|
||||
alias: flake8-check
|
||||
stages: [manual]
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
rev: v0.942
|
||||
rev: v0.782
|
||||
hooks:
|
||||
- id: mypy
|
||||
# N.B.: Mypy is... a bit fragile.
|
||||
|
||||
3554
CHANGELOG.md
Executable file → Normal file
3554
CHANGELOG.md
Executable file → Normal file
File diff suppressed because it is too large
Load Diff
202
CONTRIBUTING.md
202
CONTRIBUTING.md
@@ -1,30 +1,79 @@
|
||||
# Contributing to `dbt-core`
|
||||
|
||||
`dbt-core` is open source software. It is what it is today because community members have opened issues, provided feedback, and [contributed to the knowledge loop](https://www.getdbt.com/dbt-labs/values/). Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
# Contributing to `dbt`
|
||||
|
||||
1. [About this document](#about-this-document)
|
||||
2. [Getting the code](#getting-the-code)
|
||||
3. [Setting up an environment](#setting-up-an-environment)
|
||||
4. [Running `dbt` in development](#running-dbt-core-in-development)
|
||||
5. [Testing dbt-core](#testing)
|
||||
6. [Debugging](#debugging)
|
||||
7. [Adding a changelog entry](#adding-a-changelog-entry)
|
||||
8. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
2. [Proposing a change](#proposing-a-change)
|
||||
3. [Getting the code](#getting-the-code)
|
||||
4. [Setting up an environment](#setting-up-an-environment)
|
||||
5. [Running `dbt` in development](#running-dbt-in-development)
|
||||
6. [Testing](#testing)
|
||||
7. [Submitting a Pull Request](#submitting-a-pull-request)
|
||||
|
||||
## About this document
|
||||
|
||||
There are many ways to contribute to the ongoing development of `dbt-core`, such as by participating in discussions and issues. We encourage you to first read our higher-level document: ["Expectations for Open Source Contributors"](https://docs.getdbt.com/docs/contributing/oss-expectations).
|
||||
This document is a guide intended for folks interested in contributing to `dbt-core`. Below, we document the process by which members of the community should create issues and submit pull requests (PRs) in this repository. It is not intended as a guide for using `dbt-core`, and it assumes a certain level of familiarity with Python concepts such as virtualenvs, `pip`, python modules, filesystems, and so on. This guide assumes you are using macOS or Linux and are comfortable with the command line.
|
||||
|
||||
The rest of this document serves as a more granular guide for contributing code changes to `dbt-core` (this repository). It is not intended as a guide for using `dbt-core`, and some pieces assume a level of familiarity with Python development (virtualenvs, `pip`, etc). Specific code snippets in this guide assume you are using macOS or Linux and are comfortable with the command line.
|
||||
If you're new to python development or contributing to open-source software, we encourage you to read this document from start to finish. If you get stuck, drop us a line in the `#dbt-core-development` channel on [slack](https://community.getdbt.com).
|
||||
|
||||
If you get stuck, we're happy to help! Drop us a line in the `#dbt-core-development` channel in the [dbt Community Slack](https://community.getdbt.com).
|
||||
#### Adapters
|
||||
|
||||
### Notes
|
||||
If you have an issue or code change suggestion related to a specific database [adapter](https://docs.getdbt.com/docs/available-adapters); please refer to that supported databases seperate repo for those contributions.
|
||||
|
||||
- **Adapters:** Is your issue or proposed code change related to a specific [database adapter](https://docs.getdbt.com/docs/available-adapters)? If so, please open issues, PRs, and discussions in that adapter's repository instead. The sole exception is Postgres; the `dbt-postgres` plugin lives in this repository (`dbt-core`).
|
||||
- **CLA:** Please note that anyone contributing code to `dbt-core` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements). If you are unable to sign the CLA, the `dbt-core` maintainers will unfortunately be unable to merge any of your Pull Requests. We welcome you to participate in discussions, open issues, and comment on existing ones.
|
||||
- **Branches:** All pull requests from community contributors should target the `main` branch (default). If the change is needed as a patch for a minor version of dbt that has already been released (or is already a release candidate), a maintainer will backport the changes in your PR to the relevant "latest" release branch (`1.0.latest`, `1.1.latest`, ...). If an issue fix applies to a release branch, that fix should be first committed to the development branch and then to the release branch (rarely release-branch fixes may not apply to `main`).
|
||||
- **Releases**: Before releasing a new minor version of Core, we prepare a series of alphas and release candidates to allow users (especially employees of dbt Labs!) to test the new version in live environments. This is an important quality assurance step, as it exposes the new code to a wide variety of complicated deployments and can surface bugs before official release. Releases are accessible via pip, homebrew, and dbt Cloud.
|
||||
### Signing the CLA
|
||||
|
||||
Please note that all contributors to `dbt-core` must sign the [Contributor License Agreement](https://docs.getdbt.com/docs/contributor-license-agreements) to have their Pull Request merged into the `dbt-core` codebase. If you are unable to sign the CLA, then the `dbt-core` maintainers will unfortunately be unable to merge your Pull Request. You are, however, welcome to open issues and comment on existing ones.
|
||||
|
||||
## Proposing a change
|
||||
|
||||
`dbt-core` is Apache 2.0-licensed open source software. `dbt-core` is what it is today because community members like you have opened issues, provided feedback, and contributed to the knowledge loop for the entire communtiy. Whether you are a seasoned open source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
|
||||
|
||||
### Defining the problem
|
||||
|
||||
If you have an idea for a new feature or if you've discovered a bug in `dbt-core`, the first step is to open an issue. Please check the list of [open issues](https://github.com/dbt-labs/dbt-core/issues) before creating a new one. If you find a relevant issue, please add a comment to the open issue instead of creating a new one. There are hundreds of open issues in this repository and it can be hard to know where to look for a relevant open issue. **The `dbt-core` maintainers are always happy to point contributors in the right direction**, so please err on the side of documenting your idea in a new issue if you are unsure where a problem statement belongs.
|
||||
|
||||
> **Note:** All community-contributed Pull Requests _must_ be associated with an open issue. If you submit a Pull Request that does not pertain to an open issue, you will be asked to create an issue describing the problem before the Pull Request can be reviewed.
|
||||
|
||||
### Discussing the idea
|
||||
|
||||
After you open an issue, a `dbt-core` maintainer will follow up by commenting on your issue (usually within 1-3 days) to explore your idea further and advise on how to implement the suggested changes. In many cases, community members will chime in with their own thoughts on the problem statement. If you as the issue creator are interested in submitting a Pull Request to address the issue, you should indicate this in the body of the issue. The `dbt-core` maintainers are _always_ happy to help contributors with the implementation of fixes and features, so please also indicate if there's anything you're unsure about or could use guidance around in the issue.
|
||||
|
||||
### Submitting a change
|
||||
|
||||
If an issue is appropriately well scoped and describes a beneficial change to the `dbt-core` codebase, then anyone may submit a Pull Request to implement the functionality described in the issue. See the sections below on how to do this.
|
||||
|
||||
The `dbt-core` maintainers will add a `good first issue` label if an issue is suitable for a first-time contributor. This label often means that the required code change is small, limited to one database adapter, or a net-new addition that does not impact existing functionality. You can see the list of currently open issues on the [Contribute](https://github.com/dbt-labs/dbt-core/contribute) page.
|
||||
|
||||
Here's a good workflow:
|
||||
- Comment on the open issue, expressing your interest in contributing the required code change
|
||||
- Outline your planned implementation. If you want help getting started, ask!
|
||||
- Follow the steps outlined below to develop locally. Once you have opened a PR, one of the `dbt-core` maintainers will work with you to review your code.
|
||||
- Add a test! Tests are crucial for both fixes and new features alike. We want to make sure that code works as intended, and that it avoids any bugs previously encountered. Currently, the best resource for understanding `dbt-core`'s [unit](test/unit) and [integration](test/integration) tests is the tests themselves. One of the maintainers can help by pointing out relevant examples.
|
||||
- Check your formatting and linting with [Flake8](https://flake8.pycqa.org/en/latest/#), [Black](https://github.com/psf/black), and the rest of the hooks we have in our [pre-commit](https://pre-commit.com/) [config](https://github.com/dbt-labs/dbt-core/blob/75201be9db1cb2c6c01fa7e71a314f5e5beb060a/.pre-commit-config.yaml).
|
||||
|
||||
In some cases, the right resolution to an open issue might be tangential to the `dbt-core` codebase. The right path forward might be a documentation update or a change that can be made in user-space. In other cases, the issue might describe functionality that the `dbt-core` maintainers are unwilling or unable to incorporate into the `dbt-core` codebase. When it is determined that an open issue describes functionality that will not translate to a code change in the `dbt-core` repository, the issue will be tagged with the `wontfix` label (see below) and closed.
|
||||
|
||||
### Using issue labels
|
||||
|
||||
The `dbt-core` maintainers use labels to categorize open issues. Most labels describe the domain in the `dbt-core` codebase germane to the discussion.
|
||||
|
||||
| tag | description |
|
||||
| --- | ----------- |
|
||||
| [triage](https://github.com/dbt-labs/dbt-core/labels/triage) | This is a new issue which has not yet been reviewed by a `dbt-core` maintainer. This label is removed when a maintainer reviews and responds to the issue. |
|
||||
| [bug](https://github.com/dbt-labs/dbt-core/labels/bug) | This issue represents a defect or regression in `dbt-core` |
|
||||
| [enhancement](https://github.com/dbt-labs/dbt-core/labels/enhancement) | This issue represents net-new functionality in `dbt-core` |
|
||||
| [good first issue](https://github.com/dbt-labs/dbt-core/labels/good%20first%20issue) | This issue does not require deep knowledge of the `dbt-core` codebase to implement. This issue is appropriate for a first-time contributor. |
|
||||
| [help wanted](https://github.com/dbt-labs/dbt-core/labels/help%20wanted) / [discussion](https://github.com/dbt-labs/dbt-core/labels/discussion) | Conversation around this issue in ongoing, and there isn't yet a clear path forward. Input from community members is most welcome. |
|
||||
| [duplicate](https://github.com/dbt-labs/dbt-core/issues/duplicate) | This issue is functionally identical to another open issue. The `dbt-core` maintainers will close this issue and encourage community members to focus conversation on the other one. |
|
||||
| [snoozed](https://github.com/dbt-labs/dbt-core/labels/snoozed) | This issue describes a good idea, but one which will probably not be addressed in a six-month time horizon. The `dbt-core` maintainers will revist these issues periodically and re-prioritize them accordingly. |
|
||||
| [stale](https://github.com/dbt-labs/dbt-core/labels/stale) | This is an old issue which has not recently been updated. Stale issues will periodically be closed by `dbt-core` maintainers, but they can be re-opened if the discussion is restarted. |
|
||||
| [wontfix](https://github.com/dbt-labs/dbt-core/labels/wontfix) | This issue does not require a code change in the `dbt-core` repository, or the maintainers are unwilling/unable to merge a Pull Request which implements the behavior described in the issue. |
|
||||
|
||||
#### Branching Strategy
|
||||
|
||||
`dbt-core` has three types of branches:
|
||||
|
||||
- **Trunks** are where active development of the next release takes place. There is one trunk named `main` at the time of writing this, and will be the default branch of the repository.
|
||||
- **Release Branches** track a specific, not yet complete release of `dbt-core`. Each minor version release has a corresponding release branch. For example, the `0.11.x` series of releases has a branch called `0.11.latest`. This allows us to release new patch versions under `0.11` without necessarily needing to pull them into the latest version of `dbt-core`.
|
||||
- **Feature Branches** track individual features and fixes. On completion they should be merged into the trunk branch or a specific release branch.
|
||||
|
||||
## Getting the code
|
||||
|
||||
@@ -36,17 +85,15 @@ You will need `git` in order to download and modify the `dbt-core` source code.
|
||||
|
||||
If you are not a member of the `dbt-labs` GitHub organization, you can contribute to `dbt-core` by forking the `dbt-core` repository. For a detailed overview on forking, check out the [GitHub docs on forking](https://help.github.com/en/articles/fork-a-repo). In short, you will need to:
|
||||
|
||||
1. Fork the `dbt-core` repository
|
||||
2. Clone your fork locally
|
||||
3. Check out a new branch for your proposed changes
|
||||
4. Push changes to your fork
|
||||
5. Open a pull request against `dbt-labs/dbt-core` from your forked repository
|
||||
1. fork the `dbt-core` repository
|
||||
2. clone your fork locally
|
||||
3. check out a new branch for your proposed changes
|
||||
4. push changes to your fork
|
||||
5. open a pull request against `dbt-labs/dbt` from your forked repository
|
||||
|
||||
### dbt Labs contributors
|
||||
|
||||
If you are a member of the `dbt-labs` GitHub organization, you will have push access to the `dbt-core` repo. Rather than forking `dbt-core` to make your changes, just clone the repository, check out a new branch, and push directly to that branch. Branch names should be fixed by `CT-XXX/` where:
|
||||
* CT stands for 'core team'
|
||||
* XXX stands for a JIRA ticket number
|
||||
If you are a member of the `dbt-labs` GitHub organization, you will have push access to the `dbt-core` repo. Rather than forking `dbt-core` to make your changes, just clone the repository, check out a new branch, and push directly to that branch.
|
||||
|
||||
## Setting up an environment
|
||||
|
||||
@@ -54,21 +101,19 @@ There are some tools that will be helpful to you in developing locally. While th
|
||||
|
||||
### Tools
|
||||
|
||||
These are the tools used in `dbt-core` development and testing:
|
||||
A short list of tools used in `dbt-core` testing that will be helpful to your understanding:
|
||||
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.7, 3.8, 3.9, and 3.10
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to define, discover, and run tests
|
||||
- [`tox`](https://tox.readthedocs.io/en/latest/) to manage virtualenvs across python versions. We currently target the latest patch releases for Python 3.7, Python 3.8, and Python 3.9
|
||||
- [`pytest`](https://docs.pytest.org/en/latest/) to discover/run tests
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) - but don't worry too much, nobody _really_ understands how make works and our Makefile is super simple
|
||||
- [`flake8`](https://flake8.pycqa.org/en/latest/) for code linting
|
||||
- [`black`](https://github.com/psf/black) for code formatting
|
||||
- [`mypy`](https://mypy.readthedocs.io/en/stable/) for static type checking
|
||||
- [`pre-commit`](https://pre-commit.com) to easily run those checks
|
||||
- [`changie`](https://changie.dev/) to create changelog entries, without merge conflicts
|
||||
- [`make`](https://users.cs.duke.edu/~ola/courses/programming/Makefiles/Makefiles.html) to run multiple setup or test steps in combination. Don't worry too much, nobody _really_ understands how `make` works, and our Makefile aims to be super simple.
|
||||
- [GitHub Actions](https://github.com/features/actions) for automating tests and checks, once a PR is pushed to the `dbt-core` repository
|
||||
- [Github Actions](https://github.com/features/actions)
|
||||
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about each one.
|
||||
A deep understanding of these tools in not required to effectively contribute to `dbt-core`, but we recommend checking out the attached documentation if you're interested in learning more about them.
|
||||
|
||||
#### Virtual environments
|
||||
#### virtual environments
|
||||
|
||||
We strongly recommend using virtual environments when developing code in `dbt-core`. We recommend creating this virtualenv
|
||||
in the root of the `dbt-core` repository. To create a new virtualenv, run:
|
||||
@@ -79,12 +124,12 @@ source env/bin/activate
|
||||
|
||||
This will create and activate a new Python virtual environment.
|
||||
|
||||
#### Docker and `docker-compose`
|
||||
#### docker and docker-compose
|
||||
|
||||
Docker and `docker-compose` are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
Docker and docker-compose are both used in testing. Specific instructions for you OS can be found [here](https://docs.docker.com/get-docker/).
|
||||
|
||||
|
||||
#### Postgres (optional)
|
||||
#### postgres (optional)
|
||||
|
||||
For testing, and later in the examples in this document, you may want to have `psql` available so you can poke around in the database and see what happened. We recommend that you use [homebrew](https://brew.sh/) for that on macOS, and your package manager on Linux. You can install any version of the postgres client that you'd like. On macOS, with homebrew setup, you can run:
|
||||
|
||||
@@ -104,26 +149,24 @@ make dev
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
```
|
||||
|
||||
When installed in this way, any changes you make to your local copy of the source code will be reflected immediately in your next `dbt` run.
|
||||
When `dbt-core` is installed this way, any changes you make to the `dbt-core` source code will be reflected immediately in your next `dbt-core` run.
|
||||
|
||||
|
||||
### Running `dbt-core`
|
||||
|
||||
With your virtualenv activated, the `dbt` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
With your virtualenv activated, the `dbt-core` script should point back to the source code you've cloned on your machine. You can verify this by running `which dbt`. This command should show you a path to an executable in your virtualenv.
|
||||
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local Postgres instance, or a specific test sandbox within your data warehouse if appropriate.
|
||||
Configure your [profile](https://docs.getdbt.com/docs/configure-your-profile) as necessary to connect to your target databases. It may be a good idea to add a new profile pointing to a local postgres instance, or a specific test sandbox within your data warehouse if appropriate.
|
||||
|
||||
## Testing
|
||||
|
||||
Once you're able to manually test that your code change is working as expected, it's important to run existing automated tests, as well as adding some new ones. These tests will ensure that:
|
||||
- Your code changes do not unexpectedly break other established functionality
|
||||
- Your code changes can handle all known edge cases
|
||||
- The functionality you're adding will _keep_ working in the future
|
||||
Getting the `dbt-core` integration tests set up in your local environment will be very helpful as you start to make changes to your local version of `dbt-core`. The section that follows outlines some helpful tips for setting up the test environment.
|
||||
|
||||
Although `dbt-core` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead, you can test most `dbt-core` code changes with Python and Postgres.
|
||||
Although `dbt-core` works with a number of different databases, you won't need to supply credentials for every one of these databases in your test environment. Instead you can test all dbt-core code changes with Python and Postgres.
|
||||
|
||||
### Initial setup
|
||||
|
||||
Postgres offers the easiest way to test most `dbt-core` functionality today. They are the fastest to run, and the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
We recommend starting with `dbt-core`'s Postgres tests. These tests cover most of the functionality in `dbt-core`, are the fastest to run, and are the easiest to set up. To run the Postgres integration tests, you'll have to do one extra step of setting up the test database:
|
||||
|
||||
```sh
|
||||
make setup-db
|
||||
@@ -149,74 +192,39 @@ make test
|
||||
# Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
make integration
|
||||
```
|
||||
> These make targets assume you have a local installation of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> These make targets assume you have a local install of a recent version of [`tox`](https://tox.readthedocs.io/en/latest/) for unit/integration testing and pre-commit for code quality checks,
|
||||
> unless you use choose a Docker container to run tests. Run `make help` for more info.
|
||||
|
||||
Check out the other targets in the Makefile to see other commonly used test
|
||||
suites.
|
||||
|
||||
#### `pre-commit`
|
||||
[`pre-commit`](https://pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment (we recommend running this command with a python virtual environment active). This command installs several pip executables including black, mypy, and flake8. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
[`pre-commit`](https.pre-commit.com) takes care of running all code-checks for formatting and linting. Run `make dev` to install `pre-commit` in your local environment. Once this is done you can use any of the linter-based make targets as well as a git pre-commit hook that will ensure proper formatting and linting.
|
||||
|
||||
#### `tox`
|
||||
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.7, Python 3.8, Python 3.9, and Python 3.10 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py37`. The configuration for these tests in located in `tox.ini`.
|
||||
[`tox`](https://tox.readthedocs.io/en/latest/) takes care of managing virtualenvs and install dependencies in order to run tests. You can also run tests in parallel, for example, you can run unit tests for Python 3.7, Python 3.8, and Python 3.9 checks in parallel with `tox -p`. Also, you can run unit tests for specific python versions with `tox -e py37`. The configuration for these tests in located in `tox.ini`.
|
||||
|
||||
#### `pytest`
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv active and dev dependencies installed you can do things like:
|
||||
|
||||
Finally, you can also run a specific test or group of tests using [`pytest`](https://docs.pytest.org/en/latest/) directly. With a virtualenv
|
||||
active and dev dependencies installed you can do things like:
|
||||
```sh
|
||||
# run specific postgres integration tests
|
||||
python -m pytest -m profile_postgres test/integration/001_simple_copy_test
|
||||
# run all unit tests in a file
|
||||
python3 -m pytest test/unit/test_graph.py
|
||||
python -m pytest test/unit/test_graph.py
|
||||
# run a specific unit test
|
||||
python3 -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
# run specific Postgres integration tests (old way)
|
||||
python3 -m pytest -m profile_postgres test/integration/074_postgres_unlogged_table_tests
|
||||
# run specific Postgres integration tests (new way)
|
||||
python3 -m pytest tests/functional/sources
|
||||
python -m pytest test/unit/test_graph.py::GraphTest::test__dependency_list
|
||||
```
|
||||
|
||||
> See [pytest usage docs](https://docs.pytest.org/en/6.2.x/usage.html) for an overview of useful command-line options.
|
||||
|
||||
### Unit, Integration, Functional?
|
||||
|
||||
Here are some general rules for adding tests:
|
||||
* unit tests (`test/unit` & `tests/unit`) don’t need to access a database; "pure Python" tests should be written as unit tests
|
||||
* functional tests (`test/integration` & `tests/functional`) cover anything that interacts with a database, namely adapter
|
||||
* *everything in* `test/*` *is being steadily migrated to* `tests/*`
|
||||
|
||||
## Debugging
|
||||
|
||||
1. The logs for a `dbt run` have stack traces and other information for debugging errors (in `logs/dbt.log` in your project directory).
|
||||
2. Try using a debugger, like `ipdb`. For pytest: `--pdb --pdbcls=IPython.terminal.debugger:pdb`
|
||||
3. Sometimes, it’s easier to debug on a single thread: `dbt --single-threaded run`
|
||||
4. To make print statements from Jinja macros: `{{ log(msg, info=true) }}`
|
||||
5. You can also add `{{ debug() }}` statements, which will drop you into some auto-generated code that the macro wrote.
|
||||
6. The dbt “artifacts” are written out to the ‘target’ directory of your dbt project. They are in unformatted json, which can be hard to read. Format them with:
|
||||
> python -m json.tool target/run_results.json > run_results.json
|
||||
|
||||
### Assorted development tips
|
||||
* Append `# type: ignore` to the end of a line if you need to disable `mypy` on that line.
|
||||
* Sometimes flake8 complains about lines that are actually fine, in which case you can put a comment on the line such as: # noqa or # noqa: ANNN, where ANNN is the error code that flake8 issues.
|
||||
* To collect output for `CProfile`, run dbt with the `-r` option and the name of an output file, i.e. `dbt -r dbt.cprof run`. If you just want to profile parsing, you can do: `dbt -r dbt.cprof parse`. `pip` install `snakeviz` to view the output. Run `snakeviz dbt.cprof` and output will be rendered in a browser window.
|
||||
|
||||
## Adding a CHANGELOG Entry
|
||||
|
||||
We use [changie](https://changie.dev) to generate `CHANGELOG` entries. **Note:** Do not edit the `CHANGELOG.md` directly. Your modifications will be lost.
|
||||
|
||||
Follow the steps to [install `changie`](https://changie.dev/guide/installation/) for your system.
|
||||
|
||||
Once changie is installed and your PR is created, simply run `changie new` and changie will walk you through the process of creating a changelog entry. Commit the file that's created and your changelog entry is complete!
|
||||
|
||||
You don't need to worry about which `dbt-core` version your change will go into. Just create the changelog entry with `changie`, and open your PR against the `main` branch. All merged changes will be included in the next minor version of `dbt-core`. The Core maintainers _may_ choose to "backport" specific changes in order to patch older minor versions. In that case, a maintainer will take care of that backport after merging your PR, before releasing the new version of `dbt-core`.
|
||||
|
||||
> [Here](https://docs.pytest.org/en/reorganize-docs/new-docs/user/commandlineuseful.html)
|
||||
> is a list of useful command-line options for `pytest` to use while developing.
|
||||
## Submitting a Pull Request
|
||||
|
||||
Code can be merged into the current development branch `main` by opening a pull request. A `dbt-core` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
dbt Labs provides a CI environment to test changes to specific adapters, and periodic maintenance checks of `dbt-core` through Github Actions. For example, if you submit a pull request to the `dbt-redshift` repo, GitHub will trigger automated code checks and tests against Redshift.
|
||||
|
||||
A `dbt-core` maintainer will review your PR. They may suggest code revision for style or clarity, or request that you add unit or integration test(s). These are good things! We believe that, with a little bit of help, anyone can contribute high-quality code.
|
||||
- First time contributors should note code checks + unit tests require a maintainer to approve.
|
||||
|
||||
Automated tests run via GitHub Actions. If you're a first-time contributor, all tests (including code checks and unit tests) will require a maintainer to approve. Changes in the `dbt-core` repository trigger integration tests against Postgres. dbt Labs also provides CI environments in which to test changes to other adapters, triggered by PRs in those adapters' repositories, as well as periodic maintenance checks of each adapter in concert with the latest `dbt-core` code changes.
|
||||
|
||||
Once all tests are passing and your PR has been approved, a `dbt-core` maintainer will merge your changes into the active development branch. And that's it! Happy developing :tada:
|
||||
|
||||
Sometimes, the content license agreement auto-check bot doesn't find a user's entry in its roster. If you need to force a rerun, add `@cla-bot check` in a comment on the pull request.
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
# See `/docker` for a generic and production-ready docker file
|
||||
##
|
||||
|
||||
FROM ubuntu:22.04
|
||||
FROM ubuntu:20.04
|
||||
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
|
||||
@@ -46,9 +46,6 @@ RUN apt-get update \
|
||||
python3.9 \
|
||||
python3.9-dev \
|
||||
python3.9-venv \
|
||||
python3.10 \
|
||||
python3.10-dev \
|
||||
python3.10-venv \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
|
||||
|
||||
|
||||
46
Makefile
46
Makefile
@@ -6,23 +6,11 @@ ifeq ($(USE_DOCKER),true)
|
||||
DOCKER_CMD := docker-compose run --rm test
|
||||
endif
|
||||
|
||||
LOGS_DIR := ./logs
|
||||
|
||||
# Optional flag to invoke tests using our CI env.
|
||||
# But we always want these active for structured
|
||||
# log testing.
|
||||
CI_FLAGS =\
|
||||
DBT_TEST_USER_1=dbt_test_user_1\
|
||||
DBT_TEST_USER_2=dbt_test_user_2\
|
||||
DBT_TEST_USER_3=dbt_test_user_3\
|
||||
RUSTFLAGS="-D warnings"\
|
||||
LOG_DIR=./logs\
|
||||
DBT_LOG_FORMAT=json
|
||||
|
||||
.PHONY: dev
|
||||
dev: ## Installs dbt-* packages in develop mode along with development dependencies.
|
||||
@\
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt
|
||||
pip install -r dev-requirements.txt -r editable-requirements.txt && \
|
||||
pre-commit install
|
||||
|
||||
.PHONY: mypy
|
||||
mypy: .env ## Runs mypy against staged changes for static type checking.
|
||||
@@ -46,34 +34,33 @@ lint: .env ## Runs flake8 and mypy code checks against staged changes.
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: unit
|
||||
unit: .env ## Runs unit tests with py
|
||||
unit: .env ## Runs unit tests with py38.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py
|
||||
$(DOCKER_CMD) tox -e py38
|
||||
|
||||
.PHONY: test
|
||||
test: .env ## Runs unit tests with py and code checks against staged changes.
|
||||
test: .env ## Runs unit tests with py38 and code checks against staged changes.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py; \
|
||||
$(DOCKER_CMD) tox -p -e py38; \
|
||||
$(DOCKER_CMD) pre-commit run black-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run flake8-check --hook-stage manual | grep -v "INFO"; \
|
||||
$(DOCKER_CMD) pre-commit run mypy-check --hook-stage manual | grep -v "INFO"
|
||||
|
||||
.PHONY: integration
|
||||
integration: .env ## Runs postgres integration tests with py-integration
|
||||
@\
|
||||
$(if $(USE_CI_FLAGS), $(CI_FLAGS)) $(DOCKER_CMD) tox -e py-integration -- -nauto
|
||||
integration: .env integration-postgres ## Alias for integration-postgres.
|
||||
|
||||
.PHONY: integration-fail-fast
|
||||
integration-fail-fast: .env ## Runs postgres integration tests with py-integration in "fail fast" mode.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py-integration -- -x -nauto
|
||||
integration-fail-fast: .env integration-postgres-fail-fast ## Alias for integration-postgres-fail-fast.
|
||||
|
||||
.PHONY: interop
|
||||
interop: clean
|
||||
.PHONY: integration-postgres
|
||||
integration-postgres: .env ## Runs postgres integration tests with py38.
|
||||
@\
|
||||
mkdir $(LOGS_DIR) && \
|
||||
$(CI_FLAGS) $(DOCKER_CMD) tox -e py-integration -- -nauto && \
|
||||
LOG_DIR=$(LOGS_DIR) cargo run --manifest-path test/interop/log_parsing/Cargo.toml
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -nauto
|
||||
|
||||
.PHONY: integration-postgres-fail-fast
|
||||
integration-postgres-fail-fast: .env ## Runs postgres integration tests with py38 in "fail fast" mode.
|
||||
@\
|
||||
$(DOCKER_CMD) tox -e py38-postgres -- -x -nauto
|
||||
|
||||
.PHONY: setup-db
|
||||
setup-db: ## Setup Postgres database with docker-compose for system testing.
|
||||
@@ -96,7 +83,6 @@ endif
|
||||
clean: ## Resets development environment.
|
||||
@echo 'cleaning repo...'
|
||||
@rm -f .coverage
|
||||
@rm -f .coverage.*
|
||||
@rm -rf .eggs/
|
||||
@rm -f .env
|
||||
@rm -rf .tox/
|
||||
|
||||
@@ -3,13 +3,16 @@
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
**[dbt](https://www.getdbt.com/)** enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
|
||||
|
||||

|
||||
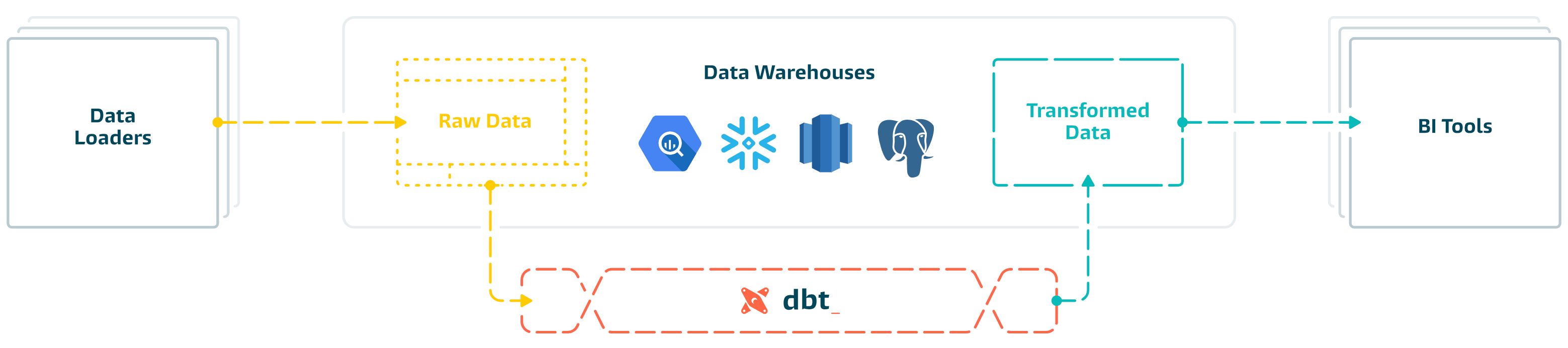
|
||||
|
||||
## Understanding dbt
|
||||
|
||||
|
||||
@@ -1,2 +1 @@
|
||||
recursive-include dbt/include *.py *.sql *.yml *.html *.md .gitkeep .gitignore
|
||||
include dbt/py.typed
|
||||
|
||||
@@ -3,7 +3,10 @@
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="CI Badge"/>
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/main.yml/badge.svg?event=push" alt="Unit Tests Badge"/>
|
||||
</a>
|
||||
<a href="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml">
|
||||
<img src="https://github.com/dbt-labs/dbt-core/actions/workflows/integration.yml/badge.svg?event=push" alt="Integration Tests Badge"/>
|
||||
</a>
|
||||
</p>
|
||||
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
# N.B.
|
||||
# This will add to the package’s __path__ all subdirectories of directories on sys.path named after the package which effectively combines both modules into a single namespace (dbt.adapters)
|
||||
# The matching statement is in plugins/postgres/dbt/__init__.py
|
||||
|
||||
from pkgutil import extend_path
|
||||
|
||||
__path__ = extend_path(__path__, __name__)
|
||||
@@ -1,30 +1 @@
|
||||
# Adapters README
|
||||
|
||||
The Adapters module is responsible for defining database connection methods, caching information from databases, how relations are defined, and the two major connection types we have - base and sql.
|
||||
|
||||
# Directories
|
||||
|
||||
## `base`
|
||||
|
||||
Defines the base implementation Adapters can use to build out full functionality.
|
||||
|
||||
## `sql`
|
||||
|
||||
Defines a sql implementation for adapters that initially inherits the above base implementation and comes with some premade methods and macros that can be overwritten as needed per adapter. (most common type of adapter.)
|
||||
|
||||
# Files
|
||||
|
||||
## `cache.py`
|
||||
|
||||
Cached information from the database.
|
||||
|
||||
## `factory.py`
|
||||
Defines how we generate adapter objects
|
||||
|
||||
## `protocol.py`
|
||||
|
||||
Defines various interfaces for various adapter objects. Helps mypy correctly resolve methods.
|
||||
|
||||
## `reference_keys.py`
|
||||
|
||||
Configures naming scheme for cache elements to be universal.
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
# N.B.
|
||||
# This will add to the package’s __path__ all subdirectories of directories on sys.path named after the package which effectively combines both modules into a single namespace (dbt.adapters)
|
||||
# The matching statement is in plugins/postgres/dbt/adapters/__init__.py
|
||||
|
||||
from pkgutil import extend_path
|
||||
|
||||
__path__ = extend_path(__path__, __name__)
|
||||
@@ -1,10 +0,0 @@
|
||||
|
||||
## Base adapters
|
||||
|
||||
### impl.py
|
||||
|
||||
The class `SQLAdapter` in [base/imply.py](https://github.com/dbt-labs/dbt-core/blob/main/core/dbt/adapters/base/impl.py) is a (mostly) abstract object that adapter objects inherit from. The base class scaffolds out methods that every adapter project usually should implement for smooth communication between dbt and database.
|
||||
|
||||
Some target databases require more or fewer methods--it all depends on what the warehouse's featureset is.
|
||||
|
||||
Look into the class for function-level comments.
|
||||
@@ -10,5 +10,5 @@ from dbt.adapters.base.relation import ( # noqa
|
||||
SchemaSearchMap,
|
||||
)
|
||||
from dbt.adapters.base.column import Column # noqa
|
||||
from dbt.adapters.base.impl import AdapterConfig, BaseAdapter, PythonJobHelper # noqa
|
||||
from dbt.adapters.base.impl import AdapterConfig, BaseAdapter # noqa
|
||||
from dbt.adapters.base.plugin import AdapterPlugin # noqa
|
||||
|
||||
@@ -12,7 +12,6 @@ class Column:
|
||||
"TIMESTAMP": "TIMESTAMP",
|
||||
"FLOAT": "FLOAT",
|
||||
"INTEGER": "INT",
|
||||
"BOOLEAN": "BOOLEAN",
|
||||
}
|
||||
column: str
|
||||
dtype: str
|
||||
|
||||
@@ -1,25 +1,10 @@
|
||||
import abc
|
||||
import os
|
||||
from time import sleep
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
# multiprocessing.RLock is a function returning this type
|
||||
from multiprocessing.synchronize import RLock
|
||||
from threading import get_ident
|
||||
from typing import (
|
||||
Any,
|
||||
Dict,
|
||||
Tuple,
|
||||
Hashable,
|
||||
Optional,
|
||||
ContextManager,
|
||||
List,
|
||||
Type,
|
||||
Union,
|
||||
Iterable,
|
||||
Callable,
|
||||
)
|
||||
from typing import Dict, Tuple, Hashable, Optional, ContextManager, List, Union
|
||||
|
||||
import agate
|
||||
|
||||
@@ -36,23 +21,18 @@ from dbt.contracts.graph.manifest import Manifest
|
||||
from dbt.adapters.base.query_headers import (
|
||||
MacroQueryStringSetter,
|
||||
)
|
||||
from dbt.events import AdapterLogger
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
NewConnection,
|
||||
ConnectionReused,
|
||||
ConnectionLeftOpenInCleanup,
|
||||
ConnectionLeftOpen,
|
||||
ConnectionClosedInCleanup,
|
||||
ConnectionLeftOpen2,
|
||||
ConnectionClosed,
|
||||
ConnectionClosed2,
|
||||
Rollback,
|
||||
RollbackFailed,
|
||||
)
|
||||
from dbt import flags
|
||||
from dbt.utils import cast_to_str
|
||||
|
||||
SleepTime = Union[int, float] # As taken by time.sleep.
|
||||
AdapterHandle = Any # Adapter connection handle objects can be any class.
|
||||
|
||||
|
||||
class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@@ -179,94 +159,6 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
conn.name = conn_name
|
||||
return conn
|
||||
|
||||
@classmethod
|
||||
def retry_connection(
|
||||
cls,
|
||||
connection: Connection,
|
||||
connect: Callable[[], AdapterHandle],
|
||||
logger: AdapterLogger,
|
||||
retryable_exceptions: Iterable[Type[Exception]],
|
||||
retry_limit: int = 1,
|
||||
retry_timeout: Union[Callable[[int], SleepTime], SleepTime] = 1,
|
||||
_attempts: int = 0,
|
||||
) -> Connection:
|
||||
"""Given a Connection, set its handle by calling connect.
|
||||
|
||||
The calls to connect will be retried up to retry_limit times to deal with transient
|
||||
connection errors. By default, one retry will be attempted if retryable_exceptions is set.
|
||||
|
||||
:param Connection connection: An instance of a Connection that needs a handle to be set,
|
||||
usually when attempting to open it.
|
||||
:param connect: A callable that returns the appropiate connection handle for a
|
||||
given adapter. This callable will be retried retry_limit times if a subclass of any
|
||||
Exception in retryable_exceptions is raised by connect.
|
||||
:type connect: Callable[[], AdapterHandle]
|
||||
:param AdapterLogger logger: A logger to emit messages on retry attempts or errors. When
|
||||
handling expected errors, we call debug, and call warning on unexpected errors or when
|
||||
all retry attempts have been exhausted.
|
||||
:param retryable_exceptions: An iterable of exception classes that if raised by
|
||||
connect should trigger a retry.
|
||||
:type retryable_exceptions: Iterable[Type[Exception]]
|
||||
:param int retry_limit: How many times to retry the call to connect. If this limit
|
||||
is exceeded before a successful call, a FailedToConnectException will be raised.
|
||||
Must be non-negative.
|
||||
:param retry_timeout: Time to wait between attempts to connect. Can also take a
|
||||
Callable that takes the number of attempts so far, beginning at 0, and returns an int
|
||||
or float to be passed to time.sleep.
|
||||
:type retry_timeout: Union[Callable[[int], SleepTime], SleepTime] = 1
|
||||
:param int _attempts: Parameter used to keep track of the number of attempts in calling the
|
||||
connect function across recursive calls. Passed as an argument to retry_timeout if it
|
||||
is a Callable. This parameter should not be set by the initial caller.
|
||||
:raises dbt.exceptions.FailedToConnectException: Upon exhausting all retry attempts without
|
||||
successfully acquiring a handle.
|
||||
:return: The given connection with its appropriate state and handle attributes set
|
||||
depending on whether we successfully acquired a handle or not.
|
||||
"""
|
||||
timeout = retry_timeout(_attempts) if callable(retry_timeout) else retry_timeout
|
||||
if timeout < 0:
|
||||
raise dbt.exceptions.FailedToConnectException(
|
||||
"retry_timeout cannot be negative or return a negative time."
|
||||
)
|
||||
|
||||
if retry_limit < 0 or retry_limit > sys.getrecursionlimit():
|
||||
# This guard is not perfect others may add to the recursion limit (e.g. built-ins).
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException("retry_limit cannot be negative")
|
||||
|
||||
try:
|
||||
connection.handle = connect()
|
||||
connection.state = ConnectionState.OPEN
|
||||
return connection
|
||||
|
||||
except tuple(retryable_exceptions) as e:
|
||||
if retry_limit <= 0:
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException(str(e))
|
||||
|
||||
logger.debug(
|
||||
f"Got a retryable error when attempting to open a {cls.TYPE} connection.\n"
|
||||
f"{retry_limit} attempts remaining. Retrying in {timeout} seconds.\n"
|
||||
f"Error:\n{e}"
|
||||
)
|
||||
|
||||
sleep(timeout)
|
||||
return cls.retry_connection(
|
||||
connection=connection,
|
||||
connect=connect,
|
||||
logger=logger,
|
||||
retry_limit=retry_limit - 1,
|
||||
retry_timeout=retry_timeout,
|
||||
retryable_exceptions=retryable_exceptions,
|
||||
_attempts=_attempts + 1,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
connection.handle = None
|
||||
connection.state = ConnectionState.FAIL
|
||||
raise dbt.exceptions.FailedToConnectException(str(e))
|
||||
|
||||
@abc.abstractmethod
|
||||
def cancel_open(self) -> Optional[List[str]]:
|
||||
"""Cancel all open connections on the adapter. (passable)"""
|
||||
@@ -274,8 +166,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
"`cancel_open` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def open(cls, connection: Connection) -> Connection:
|
||||
"""Open the given connection on the adapter and return it.
|
||||
|
||||
@@ -306,9 +197,9 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
with self.lock:
|
||||
for connection in self.thread_connections.values():
|
||||
if connection.state not in {"closed", "init"}:
|
||||
fire_event(ConnectionLeftOpenInCleanup(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(ConnectionLeftOpen(conn_name=connection.name))
|
||||
else:
|
||||
fire_event(ConnectionClosedInCleanup(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(ConnectionClosed(conn_name=connection.name))
|
||||
self.close(connection)
|
||||
|
||||
# garbage collect these connections
|
||||
@@ -334,21 +225,17 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
try:
|
||||
connection.handle.rollback()
|
||||
except Exception:
|
||||
fire_event(
|
||||
RollbackFailed(
|
||||
conn_name=cast_to_str(connection.name), exc_info=traceback.format_exc()
|
||||
)
|
||||
)
|
||||
fire_event(RollbackFailed(conn_name=connection.name))
|
||||
|
||||
@classmethod
|
||||
def _close_handle(cls, connection: Connection) -> None:
|
||||
"""Perform the actual close operation."""
|
||||
# On windows, sometimes connection handles don't have a close() attr.
|
||||
if hasattr(connection.handle, "close"):
|
||||
fire_event(ConnectionClosed(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(ConnectionClosed2(conn_name=connection.name))
|
||||
connection.handle.close()
|
||||
else:
|
||||
fire_event(ConnectionLeftOpen(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(ConnectionLeftOpen2(conn_name=connection.name))
|
||||
|
||||
@classmethod
|
||||
def _rollback(cls, connection: Connection) -> None:
|
||||
@@ -359,7 +246,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
f'"{connection.name}", but it does not have one open!'
|
||||
)
|
||||
|
||||
fire_event(Rollback(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(Rollback(conn_name=connection.name))
|
||||
cls._rollback_handle(connection)
|
||||
|
||||
connection.transaction_open = False
|
||||
@@ -371,7 +258,7 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
return connection
|
||||
|
||||
if connection.transaction_open and connection.handle:
|
||||
fire_event(Rollback(conn_name=cast_to_str(connection.name)))
|
||||
fire_event(Rollback(conn_name=connection.name))
|
||||
cls._rollback_handle(connection)
|
||||
connection.transaction_open = False
|
||||
|
||||
@@ -394,15 +281,15 @@ class BaseConnectionManager(metaclass=abc.ABCMeta):
|
||||
@abc.abstractmethod
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL.
|
||||
|
||||
:param str sql: The sql to execute.
|
||||
:param bool auto_begin: If set, and dbt is not currently inside a
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the query status and results (empty if fetch=False).
|
||||
:rtype: Tuple[AdapterResponse, agate.Table]
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
"`execute` is not implemented for this adapter!"
|
||||
|
||||
@@ -2,7 +2,6 @@ import abc
|
||||
from concurrent.futures import as_completed, Future
|
||||
from contextlib import contextmanager
|
||||
from datetime import datetime
|
||||
import time
|
||||
from itertools import chain
|
||||
from typing import (
|
||||
Optional,
|
||||
@@ -41,15 +40,10 @@ from dbt.clients.jinja import MacroGenerator
|
||||
from dbt.contracts.graph.compiled import CompileResultNode, CompiledSeedNode
|
||||
from dbt.contracts.graph.manifest import Manifest, MacroManifest
|
||||
from dbt.contracts.graph.parsed import ParsedSeedNode
|
||||
from dbt.events.functions import fire_event, warn_or_error
|
||||
from dbt.events.types import (
|
||||
CacheMiss,
|
||||
ListRelations,
|
||||
CodeExecution,
|
||||
CodeExecutionStatus,
|
||||
CatalogGenerationError,
|
||||
)
|
||||
from dbt.utils import filter_null_values, executor, cast_to_str
|
||||
from dbt.exceptions import warn_or_error
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import CacheMiss, ListRelations
|
||||
from dbt.utils import filter_null_values, executor
|
||||
|
||||
from dbt.adapters.base.connections import Connection, AdapterResponse
|
||||
from dbt.adapters.base.meta import AdapterMeta, available
|
||||
@@ -60,8 +54,7 @@ from dbt.adapters.base.relation import (
|
||||
SchemaSearchMap,
|
||||
)
|
||||
from dbt.adapters.base import Column as BaseColumn
|
||||
from dbt.adapters.base import Credentials
|
||||
from dbt.adapters.cache import RelationsCache, _make_ref_key_msg
|
||||
from dbt.adapters.cache import RelationsCache, _make_key
|
||||
|
||||
|
||||
SeedModel = Union[ParsedSeedNode, CompiledSeedNode]
|
||||
@@ -128,35 +121,6 @@ def _relation_name(rel: Optional[BaseRelation]) -> str:
|
||||
return str(rel)
|
||||
|
||||
|
||||
def log_code_execution(code_execution_function):
|
||||
# decorator to log code and execution time
|
||||
if code_execution_function.__name__ != "submit_python_job":
|
||||
raise ValueError("this should be only used to log submit_python_job now")
|
||||
|
||||
def execution_with_log(*args):
|
||||
self = args[0]
|
||||
connection_name = self.connections.get_thread_connection().name
|
||||
fire_event(CodeExecution(conn_name=connection_name, code_content=args[2]))
|
||||
start_time = time.time()
|
||||
response = code_execution_function(*args)
|
||||
fire_event(
|
||||
CodeExecutionStatus(
|
||||
status=response._message, elapsed=round((time.time() - start_time), 2)
|
||||
)
|
||||
)
|
||||
return response
|
||||
|
||||
return execution_with_log
|
||||
|
||||
|
||||
class PythonJobHelper:
|
||||
def __init__(self, parsed_model: Dict, credential: Credentials) -> None:
|
||||
raise NotImplementedError("PythonJobHelper is not implemented yet")
|
||||
|
||||
def submit(self, compiled_code: str) -> Any:
|
||||
raise NotImplementedError("PythonJobHelper submit function is not implemented yet")
|
||||
|
||||
|
||||
class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""The BaseAdapter provides an abstract base class for adapters.
|
||||
|
||||
@@ -166,15 +130,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
methods are marked with a (passable) in their docstrings. Check docstrings
|
||||
for type information, etc.
|
||||
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}" in the
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}". in the
|
||||
adapter's internal project.
|
||||
|
||||
To invoke a method in an adapter macro, call it on the 'adapter' Jinja
|
||||
object using dot syntax.
|
||||
|
||||
To invoke a method in model code, add the @available decorator atop a method
|
||||
declaration. Methods are invoked as macros.
|
||||
|
||||
Methods:
|
||||
- exception_handler
|
||||
- date_function
|
||||
@@ -195,7 +153,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
- convert_datetime_type
|
||||
- convert_date_type
|
||||
- convert_time_type
|
||||
- standardize_grants_dict
|
||||
|
||||
Macros:
|
||||
- get_catalog
|
||||
@@ -264,7 +221,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
@available.parse(lambda *a, **k: ("", empty_table()))
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
"""Execute the given SQL. This is a thin wrapper around
|
||||
ConnectionManager.execute.
|
||||
|
||||
@@ -272,8 +229,8 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
:param bool auto_begin: If set, and dbt is not currently inside a
|
||||
transaction, automatically begin one.
|
||||
:param bool fetch: If set, fetch results.
|
||||
:return: A tuple of the query status and results (empty if fetch=False).
|
||||
:rtype: Tuple[AdapterResponse, agate.Table]
|
||||
:return: A tuple of the status and the results (empty if fetch=False).
|
||||
:rtype: Tuple[Union[str, AdapterResponse], agate.Table]
|
||||
"""
|
||||
return self.connections.execute(sql=sql, auto_begin=auto_begin, fetch=fetch)
|
||||
|
||||
@@ -313,17 +270,12 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
return self._macro_manifest_lazy
|
||||
|
||||
def load_macro_manifest(self, base_macros_only=False) -> MacroManifest:
|
||||
# base_macros_only is for the test framework
|
||||
def load_macro_manifest(self) -> MacroManifest:
|
||||
if self._macro_manifest_lazy is None:
|
||||
# avoid a circular import
|
||||
from dbt.parser.manifest import ManifestLoader
|
||||
|
||||
manifest = ManifestLoader.load_macros(
|
||||
self.config,
|
||||
self.connections.set_query_header,
|
||||
base_macros_only=base_macros_only,
|
||||
)
|
||||
manifest = ManifestLoader.load_macros(self.config, self.connections.set_query_header)
|
||||
# TODO CT-211
|
||||
self._macro_manifest_lazy = manifest # type: ignore[assignment]
|
||||
# TODO CT-211
|
||||
@@ -341,11 +293,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
|
||||
if (database, schema) not in self.cache:
|
||||
fire_event(
|
||||
CacheMiss(
|
||||
conn_name=self.nice_connection_name(),
|
||||
database=cast_to_str(database),
|
||||
schema=schema,
|
||||
)
|
||||
CacheMiss(conn_name=self.nice_connection_name(), database=database, schema=schema)
|
||||
)
|
||||
return False
|
||||
else:
|
||||
@@ -389,14 +337,11 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
# databases
|
||||
return info_schema_name_map
|
||||
|
||||
def _relations_cache_for_schemas(
|
||||
self, manifest: Manifest, cache_schemas: Set[BaseRelation] = None
|
||||
) -> None:
|
||||
def _relations_cache_for_schemas(self, manifest: Manifest) -> None:
|
||||
"""Populate the relations cache for the given schemas. Returns an
|
||||
iterable of the schemas populated, as strings.
|
||||
"""
|
||||
if not cache_schemas:
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
cache_schemas = self._get_cache_schemas(manifest)
|
||||
with executor(self.config) as tpe:
|
||||
futures: List[Future[List[BaseRelation]]] = []
|
||||
for cache_schema in cache_schemas:
|
||||
@@ -422,19 +367,14 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
cache_update.add((relation.database, relation.schema))
|
||||
self.cache.update_schemas(cache_update)
|
||||
|
||||
def set_relations_cache(
|
||||
self,
|
||||
manifest: Manifest,
|
||||
clear: bool = False,
|
||||
required_schemas: Set[BaseRelation] = None,
|
||||
) -> None:
|
||||
def set_relations_cache(self, manifest: Manifest, clear: bool = False) -> None:
|
||||
"""Run a query that gets a populated cache of the relations in the
|
||||
database and set the cache on this adapter.
|
||||
"""
|
||||
with self.cache.lock:
|
||||
if clear:
|
||||
self.cache.clear()
|
||||
self._relations_cache_for_schemas(manifest, required_schemas)
|
||||
self._relations_cache_for_schemas(manifest)
|
||||
|
||||
@available
|
||||
def cache_added(self, relation: Optional[BaseRelation]) -> str:
|
||||
@@ -480,14 +420,12 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
###
|
||||
# Abstract methods for database-specific values, attributes, and types
|
||||
###
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def date_function(cls) -> str:
|
||||
"""Get the date function used by this adapter's database."""
|
||||
raise NotImplementedException("`date_function` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def is_cancelable(cls) -> bool:
|
||||
raise NotImplementedException("`is_cancelable` is not implemented for this adapter!")
|
||||
|
||||
@@ -581,36 +519,9 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
:rtype: List[self.Relation]
|
||||
"""
|
||||
raise NotImplementedException(
|
||||
"`list_relations_without_caching` is not implemented for this adapter!"
|
||||
"`list_relations_without_caching` is not implemented for this " "adapter!"
|
||||
)
|
||||
|
||||
###
|
||||
# Methods about grants
|
||||
###
|
||||
@available
|
||||
def standardize_grants_dict(self, grants_table: agate.Table) -> dict:
|
||||
"""Translate the result of `show grants` (or equivalent) to match the
|
||||
grants which a user would configure in their project.
|
||||
|
||||
Ideally, the SQL to show grants should also be filtering:
|
||||
filter OUT any grants TO the current user/role (e.g. OWNERSHIP).
|
||||
If that's not possible in SQL, it can be done in this method instead.
|
||||
|
||||
:param grants_table: An agate table containing the query result of
|
||||
the SQL returned by get_show_grant_sql
|
||||
:return: A standardized dictionary matching the `grants` config
|
||||
:rtype: dict
|
||||
"""
|
||||
grants_dict: Dict[str, List[str]] = {}
|
||||
for row in grants_table:
|
||||
grantee = row["grantee"]
|
||||
privilege = row["privilege_type"]
|
||||
if privilege in grants_dict.keys():
|
||||
grants_dict[privilege].append(grantee)
|
||||
else:
|
||||
grants_dict.update({privilege: [grantee]})
|
||||
return grants_dict
|
||||
|
||||
###
|
||||
# Provided methods about relations
|
||||
###
|
||||
@@ -715,10 +626,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
return self.cache.get_relations(database, schema)
|
||||
|
||||
schema_relation = self.Relation.create(
|
||||
database=database,
|
||||
schema=schema,
|
||||
identifier="",
|
||||
quote_policy=self.config.quoting,
|
||||
database=database, schema=schema, identifier="", quote_policy=self.config.quoting
|
||||
).without_identifier()
|
||||
|
||||
# we can't build the relations cache because we don't have a
|
||||
@@ -726,9 +634,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
relations = self.list_relations_without_caching(schema_relation)
|
||||
fire_event(
|
||||
ListRelations(
|
||||
database=cast_to_str(database),
|
||||
schema=schema,
|
||||
relations=[_make_ref_key_msg(x) for x in relations],
|
||||
database=database, schema=schema, relations=[_make_key(x) for x in relations]
|
||||
)
|
||||
)
|
||||
|
||||
@@ -814,8 +720,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
raise NotImplementedException("`drop_schema` is not implemented for this adapter!")
|
||||
|
||||
@available
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def quote(cls, identifier: str) -> str:
|
||||
"""Quote the given identifier, as appropriate for the database."""
|
||||
raise NotImplementedException("`quote` is not implemented for this adapter!")
|
||||
@@ -861,8 +766,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
# Conversions: These must be implemented by concrete implementations, for
|
||||
# converting agate types into their sql equivalents.
|
||||
###
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_text_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Text
|
||||
type for the given agate table and column index.
|
||||
@@ -873,8 +777,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_text_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_number_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Number
|
||||
type for the given agate table and column index.
|
||||
@@ -885,8 +788,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_number_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_boolean_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Boolean
|
||||
type for the given agate table and column index.
|
||||
@@ -899,8 +801,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"`convert_boolean_type` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_datetime_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.DateTime
|
||||
type for the given agate table and column index.
|
||||
@@ -913,8 +814,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"`convert_datetime_type` is not implemented for this adapter!"
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_date_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the agate.Date
|
||||
type for the given agate table and column index.
|
||||
@@ -925,8 +825,7 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
"""
|
||||
raise NotImplementedException("`convert_date_type` is not implemented for this adapter!")
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
@abc.abstractclassmethod
|
||||
def convert_time_type(cls, agate_table: agate.Table, col_idx: int) -> str:
|
||||
"""Return the type in the database that best maps to the
|
||||
agate.TimeDelta type for the given agate table and column index.
|
||||
@@ -1212,74 +1111,6 @@ class BaseAdapter(metaclass=AdapterMeta):
|
||||
|
||||
return sql
|
||||
|
||||
@property
|
||||
def python_submission_helpers(self) -> Dict[str, Type[PythonJobHelper]]:
|
||||
raise NotImplementedError("python_submission_helpers is not specified")
|
||||
|
||||
@property
|
||||
def default_python_submission_method(self) -> str:
|
||||
raise NotImplementedError("default_python_submission_method is not specified")
|
||||
|
||||
@log_code_execution
|
||||
def submit_python_job(self, parsed_model: dict, compiled_code: str) -> AdapterResponse:
|
||||
submission_method = parsed_model["config"].get(
|
||||
"submission_method", self.default_python_submission_method
|
||||
)
|
||||
if submission_method not in self.python_submission_helpers:
|
||||
raise NotImplementedError(
|
||||
"Submission method {} is not supported for current adapter".format(
|
||||
submission_method
|
||||
)
|
||||
)
|
||||
job_helper = self.python_submission_helpers[submission_method](
|
||||
parsed_model, self.connections.profile.credentials
|
||||
)
|
||||
submission_result = job_helper.submit(compiled_code)
|
||||
# process submission result to generate adapter response
|
||||
return self.generate_python_submission_response(submission_result)
|
||||
|
||||
def generate_python_submission_response(self, submission_result: Any) -> AdapterResponse:
|
||||
raise NotImplementedException(
|
||||
"Your adapter need to implement generate_python_submission_response"
|
||||
)
|
||||
|
||||
def valid_incremental_strategies(self):
|
||||
"""The set of standard builtin strategies which this adapter supports out-of-the-box.
|
||||
Not used to validate custom strategies defined by end users.
|
||||
"""
|
||||
return ["append"]
|
||||
|
||||
def builtin_incremental_strategies(self):
|
||||
return ["append", "delete+insert", "merge", "insert_overwrite"]
|
||||
|
||||
@available.parse_none
|
||||
def get_incremental_strategy_macro(self, model_context, strategy: str):
|
||||
# Construct macro_name from strategy name
|
||||
if strategy is None:
|
||||
strategy = "default"
|
||||
|
||||
# validate strategies for this adapter
|
||||
valid_strategies = self.valid_incremental_strategies()
|
||||
valid_strategies.append("default")
|
||||
builtin_strategies = self.builtin_incremental_strategies()
|
||||
if strategy in builtin_strategies and strategy not in valid_strategies:
|
||||
raise RuntimeException(
|
||||
f"The incremental strategy '{strategy}' is not valid for this adapter"
|
||||
)
|
||||
|
||||
strategy = strategy.replace("+", "_")
|
||||
macro_name = f"get_incremental_{strategy}_sql"
|
||||
# The model_context should have MacroGenerator callable objects for all macros
|
||||
if macro_name not in model_context:
|
||||
raise RuntimeException(
|
||||
'dbt could not find an incremental strategy macro with the name "{}" in {}'.format(
|
||||
macro_name, self.config.project_name
|
||||
)
|
||||
)
|
||||
|
||||
# This returns a callable macro
|
||||
return model_context[macro_name]
|
||||
|
||||
|
||||
COLUMNS_EQUAL_SQL = """
|
||||
with diff_count as (
|
||||
@@ -1327,7 +1158,7 @@ def catch_as_completed(
|
||||
elif isinstance(exc, KeyboardInterrupt) or not isinstance(exc, Exception):
|
||||
raise exc
|
||||
else:
|
||||
warn_or_error(CatalogGenerationError(exc=str(exc)))
|
||||
warn_or_error(f"Encountered an error while generating catalog: {str(exc)}")
|
||||
# exc is not None, derives from Exception, and isn't ctrl+c
|
||||
exceptions.append(exc)
|
||||
return merge_tables(tables), exceptions
|
||||
|
||||
@@ -1,16 +1,10 @@
|
||||
import re
|
||||
import threading
|
||||
from copy import deepcopy
|
||||
from typing import Any, Dict, Iterable, List, Optional, Set, Tuple
|
||||
|
||||
from dbt.adapters.reference_keys import (
|
||||
_make_ref_key,
|
||||
_make_ref_key_msg,
|
||||
_make_msg_from_ref_key,
|
||||
_ReferenceKey,
|
||||
)
|
||||
from dbt.adapters.reference_keys import _make_key, _ReferenceKey
|
||||
import dbt.exceptions
|
||||
from dbt.events.functions import fire_event, fire_event_if
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import (
|
||||
AddLink,
|
||||
AddRelation,
|
||||
@@ -26,8 +20,8 @@ from dbt.events.types import (
|
||||
UncachedRelation,
|
||||
UpdateReference,
|
||||
)
|
||||
import dbt.flags as flags
|
||||
from dbt.utils import lowercase
|
||||
from dbt.helper_types import Lazy
|
||||
|
||||
|
||||
def dot_separated(key: _ReferenceKey) -> str:
|
||||
@@ -87,7 +81,7 @@ class _CachedRelation:
|
||||
|
||||
:return _ReferenceKey: A key for this relation.
|
||||
"""
|
||||
return _make_ref_key(self)
|
||||
return _make_key(self)
|
||||
|
||||
def add_reference(self, referrer: "_CachedRelation"):
|
||||
"""Add a reference from referrer to self, indicating that if this node
|
||||
@@ -299,18 +293,13 @@ class RelationsCache:
|
||||
:param BaseRelation dependent: The dependent model.
|
||||
:raises InternalError: If either entry does not exist.
|
||||
"""
|
||||
ref_key = _make_ref_key(referenced)
|
||||
dep_key = _make_ref_key(dependent)
|
||||
ref_key = _make_key(referenced)
|
||||
dep_key = _make_key(dependent)
|
||||
if (ref_key.database, ref_key.schema) not in self:
|
||||
# if we have not cached the referenced schema at all, we must be
|
||||
# referring to a table outside our control. There's no need to make
|
||||
# a link - we will never drop the referenced relation during a run.
|
||||
fire_event(
|
||||
UncachedRelation(
|
||||
dep_key=_make_msg_from_ref_key(dep_key),
|
||||
ref_key=_make_msg_from_ref_key(ref_key),
|
||||
)
|
||||
)
|
||||
fire_event(UncachedRelation(dep_key=dep_key, ref_key=ref_key))
|
||||
return
|
||||
if ref_key not in self.relations:
|
||||
# Insert a dummy "external" relation.
|
||||
@@ -320,11 +309,7 @@ class RelationsCache:
|
||||
# Insert a dummy "external" relation.
|
||||
dependent = dependent.replace(type=referenced.External)
|
||||
self.add(dependent)
|
||||
fire_event(
|
||||
AddLink(
|
||||
dep_key=_make_msg_from_ref_key(dep_key), ref_key=_make_msg_from_ref_key(ref_key)
|
||||
)
|
||||
)
|
||||
fire_event(AddLink(dep_key=dep_key, ref_key=ref_key))
|
||||
with self.lock:
|
||||
self._add_link(ref_key, dep_key)
|
||||
|
||||
@@ -335,12 +320,12 @@ class RelationsCache:
|
||||
:param BaseRelation relation: The underlying relation.
|
||||
"""
|
||||
cached = _CachedRelation(relation)
|
||||
fire_event(AddRelation(relation=_make_ref_key_msg(cached)))
|
||||
fire_event_if(flags.LOG_CACHE_EVENTS, lambda: DumpBeforeAddGraph(dump=self.dump_graph()))
|
||||
fire_event(AddRelation(relation=_make_key(cached)))
|
||||
fire_event(DumpBeforeAddGraph(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
with self.lock:
|
||||
self._setdefault(cached)
|
||||
fire_event_if(flags.LOG_CACHE_EVENTS, lambda: DumpAfterAddGraph(dump=self.dump_graph()))
|
||||
fire_event(DumpAfterAddGraph(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
def _remove_refs(self, keys):
|
||||
"""Removes all references to all entries in keys. This does not
|
||||
@@ -355,6 +340,19 @@ class RelationsCache:
|
||||
for cached in self.relations.values():
|
||||
cached.release_references(keys)
|
||||
|
||||
def _drop_cascade_relation(self, dropped_key):
|
||||
"""Drop the given relation and cascade it appropriately to all
|
||||
dependent relations.
|
||||
|
||||
:param _CachedRelation dropped: An existing _CachedRelation to drop.
|
||||
"""
|
||||
if dropped_key not in self.relations:
|
||||
fire_event(DropMissingRelation(relation=dropped_key))
|
||||
return
|
||||
consequences = self.relations[dropped_key].collect_consequences()
|
||||
fire_event(DropCascade(dropped=dropped_key, consequences=consequences))
|
||||
self._remove_refs(consequences)
|
||||
|
||||
def drop(self, relation):
|
||||
"""Drop the named relation and cascade it appropriately to all
|
||||
dependent relations.
|
||||
@@ -366,19 +364,10 @@ class RelationsCache:
|
||||
:param str schema: The schema of the relation to drop.
|
||||
:param str identifier: The identifier of the relation to drop.
|
||||
"""
|
||||
dropped_key = _make_ref_key(relation)
|
||||
dropped_key_msg = _make_ref_key_msg(relation)
|
||||
fire_event(DropRelation(dropped=dropped_key_msg))
|
||||
dropped_key = _make_key(relation)
|
||||
fire_event(DropRelation(dropped=dropped_key))
|
||||
with self.lock:
|
||||
if dropped_key not in self.relations:
|
||||
fire_event(DropMissingRelation(relation=dropped_key_msg))
|
||||
return
|
||||
consequences = self.relations[dropped_key].collect_consequences()
|
||||
# convert from a list of _ReferenceKeys to a list of ReferenceKeyMsgs
|
||||
consequence_msgs = [_make_msg_from_ref_key(key) for key in consequences]
|
||||
|
||||
fire_event(DropCascade(dropped=dropped_key_msg, consequences=consequence_msgs))
|
||||
self._remove_refs(consequences)
|
||||
self._drop_cascade_relation(dropped_key)
|
||||
|
||||
def _rename_relation(self, old_key, new_relation):
|
||||
"""Rename a relation named old_key to new_key, updating references.
|
||||
@@ -394,17 +383,13 @@ class RelationsCache:
|
||||
relation = self.relations.pop(old_key)
|
||||
new_key = new_relation.key()
|
||||
|
||||
# relation has to rename its innards, so it needs the _CachedRelation.
|
||||
# relaton has to rename its innards, so it needs the _CachedRelation.
|
||||
relation.rename(new_relation)
|
||||
# update all the relations that refer to it
|
||||
for cached in self.relations.values():
|
||||
if cached.is_referenced_by(old_key):
|
||||
fire_event(
|
||||
UpdateReference(
|
||||
old_key=_make_ref_key_msg(old_key),
|
||||
new_key=_make_ref_key_msg(new_key),
|
||||
cached_key=_make_ref_key_msg(cached.key()),
|
||||
)
|
||||
UpdateReference(old_key=old_key, new_key=new_key, cached_key=cached.key())
|
||||
)
|
||||
cached.rename_key(old_key, new_key)
|
||||
|
||||
@@ -428,29 +413,14 @@ class RelationsCache:
|
||||
:raises InternalError: If the new key is already present.
|
||||
"""
|
||||
if new_key in self.relations:
|
||||
# Tell user when collision caused by model names truncated during
|
||||
# materialization.
|
||||
match = re.search("__dbt_backup|__dbt_tmp$", new_key.identifier)
|
||||
if match:
|
||||
truncated_model_name_prefix = new_key.identifier[: match.start()]
|
||||
message_addendum = (
|
||||
"\n\nName collisions can occur when the length of two "
|
||||
"models' names approach your database's builtin limit. "
|
||||
"Try restructuring your project such that no two models "
|
||||
"share the prefix '{}'.".format(truncated_model_name_prefix)
|
||||
+ " Then, clean your warehouse of any removed models."
|
||||
)
|
||||
else:
|
||||
message_addendum = ""
|
||||
|
||||
dbt.exceptions.raise_cache_inconsistent(
|
||||
"in rename, new key {} already in cache: {}{}".format(
|
||||
new_key, list(self.relations.keys()), message_addendum
|
||||
"in rename, new key {} already in cache: {}".format(
|
||||
new_key, list(self.relations.keys())
|
||||
)
|
||||
)
|
||||
|
||||
if old_key not in self.relations:
|
||||
fire_event(TemporaryRelation(key=_make_msg_from_ref_key(old_key)))
|
||||
fire_event(TemporaryRelation(key=old_key))
|
||||
return False
|
||||
return True
|
||||
|
||||
@@ -466,17 +436,11 @@ class RelationsCache:
|
||||
:param BaseRelation new: The new relation name information.
|
||||
:raises InternalError: If the new key is already present.
|
||||
"""
|
||||
old_key = _make_ref_key(old)
|
||||
new_key = _make_ref_key(new)
|
||||
fire_event(
|
||||
RenameSchema(
|
||||
old_key=_make_msg_from_ref_key(old_key), new_key=_make_msg_from_ref_key(new)
|
||||
)
|
||||
)
|
||||
old_key = _make_key(old)
|
||||
new_key = _make_key(new)
|
||||
fire_event(RenameSchema(old_key=old_key, new_key=new_key))
|
||||
|
||||
fire_event_if(
|
||||
flags.LOG_CACHE_EVENTS, lambda: DumpBeforeRenameSchema(dump=self.dump_graph())
|
||||
)
|
||||
fire_event(DumpBeforeRenameSchema(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
with self.lock:
|
||||
if self._check_rename_constraints(old_key, new_key):
|
||||
@@ -484,9 +448,7 @@ class RelationsCache:
|
||||
else:
|
||||
self._setdefault(_CachedRelation(new))
|
||||
|
||||
fire_event_if(
|
||||
flags.LOG_CACHE_EVENTS, lambda: DumpAfterRenameSchema(dump=self.dump_graph())
|
||||
)
|
||||
fire_event(DumpAfterRenameSchema(dump=Lazy.defer(lambda: self.dump_graph())))
|
||||
|
||||
def get_relations(self, database: Optional[str], schema: Optional[str]) -> List[Any]:
|
||||
"""Case-insensitively yield all relations matching the given schema.
|
||||
@@ -534,6 +496,6 @@ class RelationsCache:
|
||||
"""
|
||||
for relation in to_remove:
|
||||
# it may have been cascaded out already
|
||||
drop_key = _make_ref_key(relation)
|
||||
drop_key = _make_key(relation)
|
||||
if drop_key in self.relations:
|
||||
self.drop(drop_key)
|
||||
|
||||
@@ -1,18 +1,23 @@
|
||||
import threading
|
||||
import traceback
|
||||
from contextlib import contextmanager
|
||||
from importlib import import_module
|
||||
from pathlib import Path
|
||||
from typing import Any, Dict, List, Optional, Set, Type
|
||||
from importlib import import_module
|
||||
from typing import Type, Dict, Any, List, Optional, Set
|
||||
|
||||
from dbt.adapters.base.plugin import AdapterPlugin
|
||||
from dbt.adapters.protocol import AdapterConfig, AdapterProtocol, RelationProtocol
|
||||
from dbt.contracts.connection import AdapterRequiredConfig, Credentials
|
||||
from dbt.exceptions import RuntimeException, InternalException
|
||||
from dbt.include.global_project import (
|
||||
PACKAGE_PATH as GLOBAL_PROJECT_PATH,
|
||||
PROJECT_NAME as GLOBAL_PROJECT_NAME,
|
||||
)
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import AdapterImportError, PluginLoadError
|
||||
from dbt.exceptions import InternalException, RuntimeException
|
||||
from dbt.include.global_project import PACKAGE_PATH as GLOBAL_PROJECT_PATH
|
||||
from dbt.include.global_project import PROJECT_NAME as GLOBAL_PROJECT_NAME
|
||||
from dbt.contracts.connection import Credentials, AdapterRequiredConfig
|
||||
from dbt.adapters.protocol import (
|
||||
AdapterProtocol,
|
||||
AdapterConfig,
|
||||
RelationProtocol,
|
||||
)
|
||||
from dbt.adapters.base.plugin import AdapterPlugin
|
||||
|
||||
|
||||
Adapter = AdapterProtocol
|
||||
|
||||
@@ -59,12 +64,12 @@ class AdapterContainer:
|
||||
# if we failed to import the target module in particular, inform
|
||||
# the user about it via a runtime error
|
||||
if exc.name == "dbt.adapters." + name:
|
||||
fire_event(AdapterImportError(exc=str(exc)))
|
||||
fire_event(AdapterImportError(exc=exc))
|
||||
raise RuntimeException(f"Could not find adapter type {name}!")
|
||||
# otherwise, the error had to have come from some underlying
|
||||
# library. Log the stack trace.
|
||||
|
||||
fire_event(PluginLoadError(exc_info=traceback.format_exc()))
|
||||
fire_event(PluginLoadError())
|
||||
raise
|
||||
plugin: AdapterPlugin = mod.Plugin
|
||||
plugin_type = plugin.adapter.type()
|
||||
@@ -135,6 +140,8 @@ class AdapterContainer:
|
||||
raise InternalException(f"No plugin found for {plugin_name}") from None
|
||||
plugins.append(plugin)
|
||||
seen.add(plugin_name)
|
||||
if plugin.dependencies is None:
|
||||
continue
|
||||
for dep in plugin.dependencies:
|
||||
if dep not in seen:
|
||||
plugin_names.append(dep)
|
||||
@@ -170,10 +177,6 @@ def get_adapter(config: AdapterRequiredConfig):
|
||||
return FACTORY.lookup_adapter(config.credentials.type)
|
||||
|
||||
|
||||
def get_adapter_by_type(adapter_type):
|
||||
return FACTORY.lookup_adapter(adapter_type)
|
||||
|
||||
|
||||
def reset_adapters():
|
||||
"""Clear the adapters. This is useful for tests, which change configs."""
|
||||
FACTORY.reset_adapters()
|
||||
@@ -212,12 +215,3 @@ def get_adapter_package_names(name: Optional[str]) -> List[str]:
|
||||
|
||||
def get_adapter_type_names(name: Optional[str]) -> List[str]:
|
||||
return FACTORY.get_adapter_type_names(name)
|
||||
|
||||
|
||||
@contextmanager
|
||||
def adapter_management():
|
||||
reset_adapters()
|
||||
try:
|
||||
yield
|
||||
finally:
|
||||
cleanup_connections()
|
||||
|
||||
@@ -7,6 +7,7 @@ from typing import (
|
||||
List,
|
||||
Generic,
|
||||
TypeVar,
|
||||
ClassVar,
|
||||
Tuple,
|
||||
Union,
|
||||
Dict,
|
||||
@@ -87,13 +88,10 @@ class AdapterProtocol( # type: ignore[misc]
|
||||
Compiler_T,
|
||||
],
|
||||
):
|
||||
# N.B. Technically these are ClassVars, but mypy doesn't support putting type vars in a
|
||||
# ClassVar due to the restrictiveness of PEP-526
|
||||
# See: https://github.com/python/mypy/issues/5144
|
||||
AdapterSpecificConfigs: Type[AdapterConfig_T]
|
||||
Column: Type[Column_T]
|
||||
Relation: Type[Relation_T]
|
||||
ConnectionManager: Type[ConnectionManager_T]
|
||||
AdapterSpecificConfigs: ClassVar[Type[AdapterConfig_T]]
|
||||
Column: ClassVar[Type[Column_T]]
|
||||
Relation: ClassVar[Type[Relation_T]]
|
||||
ConnectionManager: ClassVar[Type[ConnectionManager_T]]
|
||||
connections: ConnectionManager_T
|
||||
|
||||
def __init__(self, config: AdapterRequiredConfig):
|
||||
@@ -157,7 +155,7 @@ class AdapterProtocol( # type: ignore[misc]
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[str, AdapterResponse], agate.Table]:
|
||||
...
|
||||
|
||||
def get_compiler(self) -> Compiler_T:
|
||||
|
||||
@@ -1,8 +1,7 @@
|
||||
# this module exists to resolve circular imports with the events module
|
||||
|
||||
from collections import namedtuple
|
||||
from typing import Any, Optional
|
||||
from dbt.events.proto_types import ReferenceKeyMsg
|
||||
from typing import Optional
|
||||
|
||||
|
||||
_ReferenceKey = namedtuple("_ReferenceKey", "database schema identifier")
|
||||
@@ -15,12 +14,7 @@ def lowercase(value: Optional[str]) -> Optional[str]:
|
||||
return value.lower()
|
||||
|
||||
|
||||
# For backwards compatibility. New code should use _make_ref_key
|
||||
def _make_key(relation: Any) -> _ReferenceKey:
|
||||
return _make_ref_key(relation)
|
||||
|
||||
|
||||
def _make_ref_key(relation: Any) -> _ReferenceKey:
|
||||
def _make_key(relation) -> _ReferenceKey:
|
||||
"""Make _ReferenceKeys with lowercase values for the cache so we don't have
|
||||
to keep track of quoting
|
||||
"""
|
||||
@@ -28,13 +22,3 @@ def _make_ref_key(relation: Any) -> _ReferenceKey:
|
||||
return _ReferenceKey(
|
||||
lowercase(relation.database), lowercase(relation.schema), lowercase(relation.identifier)
|
||||
)
|
||||
|
||||
|
||||
def _make_ref_key_msg(relation: Any):
|
||||
return _make_msg_from_ref_key(_make_ref_key(relation))
|
||||
|
||||
|
||||
def _make_msg_from_ref_key(ref_key: _ReferenceKey) -> ReferenceKeyMsg:
|
||||
return ReferenceKeyMsg(
|
||||
database=ref_key.database, schema=ref_key.schema, identifier=ref_key.identifier
|
||||
)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import abc
|
||||
import time
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict
|
||||
from typing import List, Optional, Tuple, Any, Iterable, Dict, Union
|
||||
|
||||
import agate
|
||||
|
||||
@@ -10,7 +10,6 @@ from dbt.adapters.base import BaseConnectionManager
|
||||
from dbt.contracts.connection import Connection, ConnectionState, AdapterResponse
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import ConnectionUsed, SQLQuery, SQLCommit, SQLQueryStatus
|
||||
from dbt.utils import cast_to_str
|
||||
|
||||
|
||||
class SQLConnectionManager(BaseConnectionManager):
|
||||
@@ -56,7 +55,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
connection = self.get_thread_connection()
|
||||
if auto_begin and connection.transaction_open is False:
|
||||
self.begin()
|
||||
fire_event(ConnectionUsed(conn_type=self.TYPE, conn_name=cast_to_str(connection.name)))
|
||||
fire_event(ConnectionUsed(conn_type=self.TYPE, conn_name=connection.name))
|
||||
|
||||
with self.exception_handler(sql):
|
||||
if abridge_sql_log:
|
||||
@@ -64,7 +63,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
else:
|
||||
log_sql = sql
|
||||
|
||||
fire_event(SQLQuery(conn_name=cast_to_str(connection.name), sql=log_sql))
|
||||
fire_event(SQLQuery(conn_name=connection.name, sql=log_sql))
|
||||
pre = time.time()
|
||||
|
||||
cursor = connection.handle.cursor()
|
||||
@@ -78,9 +77,8 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
return connection, cursor
|
||||
|
||||
@classmethod
|
||||
@abc.abstractmethod
|
||||
def get_response(cls, cursor: Any) -> AdapterResponse:
|
||||
@abc.abstractclassmethod
|
||||
def get_response(cls, cursor: Any) -> Union[AdapterResponse, str]:
|
||||
"""Get the status of the cursor."""
|
||||
raise dbt.exceptions.NotImplementedException(
|
||||
"`get_response` is not implemented for this adapter!"
|
||||
@@ -119,7 +117,7 @@ class SQLConnectionManager(BaseConnectionManager):
|
||||
|
||||
def execute(
|
||||
self, sql: str, auto_begin: bool = False, fetch: bool = False
|
||||
) -> Tuple[AdapterResponse, agate.Table]:
|
||||
) -> Tuple[Union[AdapterResponse, str], agate.Table]:
|
||||
sql = self._add_query_comment(sql)
|
||||
_, cursor = self.add_query(sql, auto_begin)
|
||||
response = self.get_response(cursor)
|
||||
|
||||
@@ -5,7 +5,7 @@ import dbt.clients.agate_helper
|
||||
from dbt.contracts.connection import Connection
|
||||
import dbt.exceptions
|
||||
from dbt.adapters.base import BaseAdapter, available
|
||||
from dbt.adapters.cache import _make_ref_key_msg
|
||||
from dbt.adapters.cache import _make_key
|
||||
from dbt.adapters.sql import SQLConnectionManager
|
||||
from dbt.events.functions import fire_event
|
||||
from dbt.events.types import ColTypeChange, SchemaCreation, SchemaDrop
|
||||
@@ -27,7 +27,7 @@ ALTER_COLUMN_TYPE_MACRO_NAME = "alter_column_type"
|
||||
|
||||
class SQLAdapter(BaseAdapter):
|
||||
"""The default adapter with the common agate conversions and some SQL
|
||||
methods was implemented. This adapter has a different much shorter list of
|
||||
methods implemented. This adapter has a different much shorter list of
|
||||
methods to implement, but some more macros that must be implemented.
|
||||
|
||||
To implement a macro, implement "${adapter_type}__${macro_name}". in the
|
||||
@@ -110,7 +110,7 @@ class SQLAdapter(BaseAdapter):
|
||||
ColTypeChange(
|
||||
orig_type=target_column.data_type,
|
||||
new_type=new_type,
|
||||
table=_make_ref_key_msg(current),
|
||||
table=_make_key(current),
|
||||
)
|
||||
)
|
||||
|
||||
@@ -155,7 +155,7 @@ class SQLAdapter(BaseAdapter):
|
||||
|
||||
def create_schema(self, relation: BaseRelation) -> None:
|
||||
relation = relation.without_identifier()
|
||||
fire_event(SchemaCreation(relation=_make_ref_key_msg(relation)))
|
||||
fire_event(SchemaCreation(relation=_make_key(relation)))
|
||||
kwargs = {
|
||||
"relation": relation,
|
||||
}
|
||||
@@ -166,12 +166,11 @@ class SQLAdapter(BaseAdapter):
|
||||
|
||||
def drop_schema(self, relation: BaseRelation) -> None:
|
||||
relation = relation.without_identifier()
|
||||
fire_event(SchemaDrop(relation=_make_ref_key_msg(relation)))
|
||||
fire_event(SchemaDrop(relation=_make_key(relation)))
|
||||
kwargs = {
|
||||
"relation": relation,
|
||||
}
|
||||
self.execute_macro(DROP_SCHEMA_MACRO_NAME, kwargs=kwargs)
|
||||
self.commit_if_has_connection()
|
||||
# we can update the cache here
|
||||
self.cache.drop_schema(relation.database, relation.schema)
|
||||
|
||||
@@ -219,25 +218,3 @@ class SQLAdapter(BaseAdapter):
|
||||
kwargs = {"information_schema": information_schema, "schema": schema}
|
||||
results = self.execute_macro(CHECK_SCHEMA_EXISTS_MACRO_NAME, kwargs=kwargs)
|
||||
return results[0][0] > 0
|
||||
|
||||
# This is for use in the test suite
|
||||
def run_sql_for_tests(self, sql, fetch, conn):
|
||||
cursor = conn.handle.cursor()
|
||||
try:
|
||||
cursor.execute(sql)
|
||||
if hasattr(conn.handle, "commit"):
|
||||
conn.handle.commit()
|
||||
if fetch == "one":
|
||||
return cursor.fetchone()
|
||||
elif fetch == "all":
|
||||
return cursor.fetchall()
|
||||
else:
|
||||
return
|
||||
except BaseException as e:
|
||||
if conn.handle and not getattr(conn.handle, "closed", True):
|
||||
conn.handle.rollback()
|
||||
print(sql)
|
||||
print(e)
|
||||
raise
|
||||
finally:
|
||||
conn.transaction_open = False
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
TODO
|
||||
@@ -1,44 +0,0 @@
|
||||
# TODO Move this to /core/dbt/flags.py when we're ready to break things
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
from multiprocessing import get_context
|
||||
from pprint import pformat as pf
|
||||
|
||||
from click import get_current_context
|
||||
|
||||
if os.name != "nt":
|
||||
# https://bugs.python.org/issue41567
|
||||
import multiprocessing.popen_spawn_posix # type: ignore # noqa: F401
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class Flags:
|
||||
def __init__(self, ctx=None) -> None:
|
||||
|
||||
if ctx is None:
|
||||
ctx = get_current_context()
|
||||
|
||||
def assign_params(ctx):
|
||||
"""Recursively adds all click params to flag object"""
|
||||
for param_name, param_value in ctx.params.items():
|
||||
# N.B. You have to use the base MRO method (object.__setattr__) to set attributes
|
||||
# when using frozen dataclasses.
|
||||
# https://docs.python.org/3/library/dataclasses.html#frozen-instances
|
||||
if hasattr(self, param_name):
|
||||
raise Exception(f"Duplicate flag names found in click command: {param_name}")
|
||||
object.__setattr__(self, param_name.upper(), param_value)
|
||||
if ctx.parent:
|
||||
assign_params(ctx.parent)
|
||||
|
||||
assign_params(ctx)
|
||||
|
||||
# Hard coded flags
|
||||
object.__setattr__(self, "WHICH", ctx.info_name)
|
||||
object.__setattr__(self, "MP_CONTEXT", get_context("spawn"))
|
||||
|
||||
# Support console DO NOT TRACK initiave
|
||||
if os.getenv("DO_NOT_TRACK", "").lower() in (1, "t", "true", "y", "yes"):
|
||||
object.__setattr__(self, "ANONYMOUS_USAGE_STATS", False)
|
||||
|
||||
def __str__(self) -> str:
|
||||
return str(pf(self.__dict__))
|
||||
@@ -1,412 +0,0 @@
|
||||
import inspect # This is temporary for RAT-ing
|
||||
from copy import copy
|
||||
from pprint import pformat as pf # This is temporary for RAT-ing
|
||||
|
||||
import click
|
||||
from dbt.adapters.factory import adapter_management
|
||||
from dbt.cli import params as p
|
||||
from dbt.cli.flags import Flags
|
||||
from dbt.profiler import profiler
|
||||
|
||||
|
||||
def cli_runner():
|
||||
# Alias "list" to "ls"
|
||||
ls = copy(cli.commands["list"])
|
||||
ls.hidden = True
|
||||
cli.add_command(ls, "ls")
|
||||
|
||||
# Run the cli
|
||||
cli()
|
||||
|
||||
|
||||
# dbt
|
||||
@click.group(
|
||||
context_settings={"help_option_names": ["-h", "--help"]},
|
||||
invoke_without_command=True,
|
||||
no_args_is_help=True,
|
||||
epilog="Specify one of these sub-commands and you can find more help from there.",
|
||||
)
|
||||
@click.pass_context
|
||||
@p.anonymous_usage_stats
|
||||
@p.cache_selected_only
|
||||
@p.debug
|
||||
@p.enable_legacy_logger
|
||||
@p.event_buffer_size
|
||||
@p.fail_fast
|
||||
@p.log_cache_events
|
||||
@p.log_format
|
||||
@p.macro_debugging
|
||||
@p.partial_parse
|
||||
@p.print
|
||||
@p.printer_width
|
||||
@p.quiet
|
||||
@p.record_timing_info
|
||||
@p.static_parser
|
||||
@p.use_colors
|
||||
@p.use_experimental_parser
|
||||
@p.version
|
||||
@p.version_check
|
||||
@p.warn_error
|
||||
@p.write_json
|
||||
def cli(ctx, **kwargs):
|
||||
"""An ELT tool for managing your SQL transformations and data models.
|
||||
For more documentation on these commands, visit: docs.getdbt.com
|
||||
"""
|
||||
incomplete_flags = Flags()
|
||||
|
||||
# Profiling
|
||||
if incomplete_flags.RECORD_TIMING_INFO:
|
||||
ctx.with_resource(profiler(enable=True, outfile=incomplete_flags.RECORD_TIMING_INFO))
|
||||
|
||||
# Adapter management
|
||||
ctx.with_resource(adapter_management())
|
||||
|
||||
# Version info
|
||||
if incomplete_flags.VERSION:
|
||||
click.echo(f"`version` called\n ctx.params: {pf(ctx.params)}")
|
||||
return
|
||||
else:
|
||||
del ctx.params["version"]
|
||||
|
||||
|
||||
# dbt build
|
||||
@cli.command("build")
|
||||
@click.pass_context
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.fail_fast
|
||||
@p.full_refresh
|
||||
@p.indirect_selection
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.show
|
||||
@p.state
|
||||
@p.store_failures
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def build(ctx, **kwargs):
|
||||
"""Run all Seeds, Models, Snapshots, and tests in DAG order"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt clean
|
||||
@cli.command("clean")
|
||||
@click.pass_context
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.vars
|
||||
def clean(ctx, **kwargs):
|
||||
"""Delete all folders in the clean-targets list (usually the dbt_packages and target directories.)"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt docs
|
||||
@cli.group()
|
||||
@click.pass_context
|
||||
def docs(ctx, **kwargs):
|
||||
"""Generate or serve the documentation website for your project"""
|
||||
|
||||
|
||||
# dbt docs generate
|
||||
@docs.command("generate")
|
||||
@click.pass_context
|
||||
@p.compile_docs
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def docs_generate(ctx, **kwargs):
|
||||
"""Generate the documentation website for your project"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt docs serve
|
||||
@docs.command("serve")
|
||||
@click.pass_context
|
||||
@p.browser
|
||||
@p.port
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.vars
|
||||
def docs_serve(ctx, **kwargs):
|
||||
"""Serve the documentation website for your project"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt compile
|
||||
@cli.command("compile")
|
||||
@click.pass_context
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.full_refresh
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.parse_only
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def compile(ctx, **kwargs):
|
||||
"""Generates executable SQL from source, model, test, and analysis files. Compiled SQL files are written to the target/ directory."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt debug
|
||||
@cli.command("debug")
|
||||
@click.pass_context
|
||||
@p.config_dir
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def debug(ctx, **kwargs):
|
||||
"""Show some helpful information about dbt for debugging. Not to be confused with the --debug option which increases verbosity."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt deps
|
||||
@cli.command("deps")
|
||||
@click.pass_context
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.vars
|
||||
def deps(ctx, **kwargs):
|
||||
"""Pull the most recent version of the dependencies listed in packages.yml"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt init
|
||||
@cli.command("init")
|
||||
@click.pass_context
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.skip_profile_setup
|
||||
@p.target
|
||||
@p.vars
|
||||
def init(ctx, **kwargs):
|
||||
"""Initialize a new DBT project."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt list
|
||||
@cli.command("list")
|
||||
@click.pass_context
|
||||
@p.exclude
|
||||
@p.indirect_selection
|
||||
@p.models
|
||||
@p.output
|
||||
@p.output_keys
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.resource_type
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.vars
|
||||
def list(ctx, **kwargs):
|
||||
"""List the resources in your project"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt parse
|
||||
@cli.command("parse")
|
||||
@click.pass_context
|
||||
@p.compile_parse
|
||||
@p.log_path
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
@p.write_manifest
|
||||
def parse(ctx, **kwargs):
|
||||
"""Parses the project and provides information on performance"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt run
|
||||
@cli.command("run")
|
||||
@click.pass_context
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.fail_fast
|
||||
@p.full_refresh
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def run(ctx, **kwargs):
|
||||
"""Compile SQL and execute against the current target database."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt run operation
|
||||
@cli.command("run-operation")
|
||||
@click.pass_context
|
||||
@p.args
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.target
|
||||
@p.vars
|
||||
def run_operation(ctx, **kwargs):
|
||||
"""Run the named macro with any supplied arguments."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt seed
|
||||
@cli.command("seed")
|
||||
@click.pass_context
|
||||
@p.exclude
|
||||
@p.full_refresh
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.show
|
||||
@p.state
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def seed(ctx, **kwargs):
|
||||
"""Load data from csv files into your data warehouse."""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt snapshot
|
||||
@cli.command("snapshot")
|
||||
@click.pass_context
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.threads
|
||||
@p.vars
|
||||
def snapshot(ctx, **kwargs):
|
||||
"""Execute snapshots defined in your project"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt source
|
||||
@cli.group()
|
||||
@click.pass_context
|
||||
def source(ctx, **kwargs):
|
||||
"""Manage your project's sources"""
|
||||
|
||||
|
||||
# dbt source freshness
|
||||
@source.command("freshness")
|
||||
@click.pass_context
|
||||
@p.exclude
|
||||
@p.models
|
||||
@p.output_path # TODO: Is this ok to re-use? We have three different output params, how much can we consolidate?
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.target
|
||||
@p.threads
|
||||
@p.vars
|
||||
def freshness(ctx, **kwargs):
|
||||
"""Snapshots the current freshness of the project's sources"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# dbt test
|
||||
@cli.command("test")
|
||||
@click.pass_context
|
||||
@p.defer
|
||||
@p.exclude
|
||||
@p.fail_fast
|
||||
@p.indirect_selection
|
||||
@p.log_path
|
||||
@p.models
|
||||
@p.profile
|
||||
@p.profiles_dir
|
||||
@p.project_dir
|
||||
@p.selector
|
||||
@p.state
|
||||
@p.store_failures
|
||||
@p.target
|
||||
@p.target_path
|
||||
@p.threads
|
||||
@p.vars
|
||||
@p.version_check
|
||||
def test(ctx, **kwargs):
|
||||
"""Runs tests on data in deployed models. Run this after `dbt run`"""
|
||||
flags = Flags()
|
||||
click.echo(f"`{inspect.stack()[0][3]}` called\n flags: {flags}")
|
||||
|
||||
|
||||
# Support running as a module
|
||||
if __name__ == "__main__":
|
||||
cli_runner()
|
||||
@@ -1,33 +0,0 @@
|
||||
from click import ParamType
|
||||
import yaml
|
||||
|
||||
|
||||
class YAML(ParamType):
|
||||
"""The Click YAML type. Converts YAML strings into objects."""
|
||||
|
||||
name = "YAML"
|
||||
|
||||
def convert(self, value, param, ctx):
|
||||
# assume non-string values are a problem
|
||||
if not isinstance(value, str):
|
||||
self.fail(f"Cannot load YAML from type {type(value)}", param, ctx)
|
||||
try:
|
||||
return yaml.load(value, Loader=yaml.Loader)
|
||||
except yaml.parser.ParserError:
|
||||
self.fail(f"String '{value}' is not valid YAML", param, ctx)
|
||||
|
||||
|
||||
class Truthy(ParamType):
|
||||
"""The Click Truthy type. Converts strings into a "truthy" type"""
|
||||
|
||||
name = "TRUTHY"
|
||||
|
||||
def convert(self, value, param, ctx):
|
||||
# assume non-string / non-None values are a problem
|
||||
if not isinstance(value, (str, None)):
|
||||
self.fail(f"Cannot load TRUTHY from type {type(value)}", param, ctx)
|
||||
|
||||
if value is None or value.lower() in ("0", "false", "f"):
|
||||
return None
|
||||
else:
|
||||
return value
|
||||
@@ -1,386 +0,0 @@
|
||||
from pathlib import Path, PurePath
|
||||
|
||||
import click
|
||||
from dbt.cli.option_types import YAML
|
||||
from dbt.cli.resolvers import default_project_dir, default_profiles_dir
|
||||
|
||||
|
||||
# TODO: The name (reflected in flags) is a correction!
|
||||
# The original name was `SEND_ANONYMOUS_USAGE_STATS` and used an env var called "DBT_SEND_ANONYMOUS_USAGE_STATS"
|
||||
# Both of which break existing naming conventions (doesn't match param flag).
|
||||
# This will need to be fixed before use in the main codebase and communicated as a change to the community!
|
||||
anonymous_usage_stats = click.option(
|
||||
"--anonymous-usage-stats/--no-anonymous-usage-stats",
|
||||
envvar="DBT_ANONYMOUS_USAGE_STATS",
|
||||
help="Send anonymous usage stats to dbt Labs.",
|
||||
default=True,
|
||||
)
|
||||
|
||||
args = click.option(
|
||||
"--args",
|
||||
envvar=None,
|
||||
help="Supply arguments to the macro. This dictionary will be mapped to the keyword arguments defined in the selected macro. This argument should be a YAML string, eg. '{my_variable: my_value}'",
|
||||
type=YAML(),
|
||||
)
|
||||
|
||||
browser = click.option(
|
||||
"--browser/--no-browser",
|
||||
envvar=None,
|
||||
help="Wether or not to open a local web browser after starting the server",
|
||||
default=True,
|
||||
)
|
||||
|
||||
cache_selected_only = click.option(
|
||||
"--cache-selected-only/--no-cache-selected-only",
|
||||
envvar="DBT_CACHE_SELECTED_ONLY",
|
||||
help="Pre cache database objects relevant to selected resource only.",
|
||||
)
|
||||
|
||||
compile_docs = click.option(
|
||||
"--compile/--no-compile",
|
||||
envvar=None,
|
||||
help="Wether or not to run 'dbt compile' as part of docs generation",
|
||||
default=True,
|
||||
)
|
||||
|
||||
compile_parse = click.option(
|
||||
"--compile/--no-compile",
|
||||
envvar=None,
|
||||
help="TODO: No help text currently available",
|
||||
default=True,
|
||||
)
|
||||
|
||||
config_dir = click.option(
|
||||
"--config-dir",
|
||||
envvar=None,
|
||||
help="If specified, DBT will show path information for this project",
|
||||
type=click.STRING,
|
||||
)
|
||||
|
||||
debug = click.option(
|
||||
"--debug/--no-debug",
|
||||
"-d/ ",
|
||||
envvar="DBT_DEBUG",
|
||||
help="Display debug logging during dbt execution. Useful for debugging and making bug reports.",
|
||||
)
|
||||
|
||||
# TODO: The env var and name (reflected in flags) are corrections!
|
||||
# The original name was `DEFER_MODE` and used an env var called "DBT_DEFER_TO_STATE"
|
||||
# Both of which break existing naming conventions.
|
||||
# This will need to be fixed before use in the main codebase and communicated as a change to the community!
|
||||
defer = click.option(
|
||||
"--defer/--no-defer",
|
||||
envvar="DBT_DEFER",
|
||||
help="If set, defer to the state variable for resolving unselected nodes.",
|
||||
)
|
||||
|
||||
enable_legacy_logger = click.option(
|
||||
"--enable-legacy-logger/--no-enable-legacy-logger",
|
||||
envvar="DBT_ENABLE_LEGACY_LOGGER",
|
||||
hidden=True,
|
||||
)
|
||||
|
||||
event_buffer_size = click.option(
|
||||
"--event-buffer-size",
|
||||
envvar="DBT_EVENT_BUFFER_SIZE",
|
||||
help="Sets the max number of events to buffer in EVENT_HISTORY.",
|
||||
default=100000,
|
||||
type=click.INT,
|
||||
)
|
||||
|
||||
exclude = click.option("--exclude", envvar=None, help="Specify the nodes to exclude.")
|
||||
|
||||
fail_fast = click.option(
|
||||
"--fail-fast/--no-fail-fast",
|
||||
"-x/ ",
|
||||
envvar="DBT_FAIL_FAST",
|
||||
help="Stop execution on first failure.",
|
||||
)
|
||||
|
||||
full_refresh = click.option(
|
||||
"--full-refresh",
|
||||
"-f",
|
||||
envvar="DBT_FULL_REFRESH",
|
||||
help="If specified, dbt will drop incremental models and fully-recalculate the incremental table from the model definition.",
|
||||
is_flag=True,
|
||||
)
|
||||
|
||||
indirect_selection = click.option(
|
||||
"--indirect-selection",
|
||||
envvar="DBT_INDIRECT_SELECTION",
|
||||
help="Select all tests that are adjacent to selected resources, even if they those resources have been explicitly selected.",
|
||||
type=click.Choice(["eager", "cautious"], case_sensitive=False),
|
||||
default="eager",
|
||||
)
|
||||
|
||||
log_cache_events = click.option(
|
||||
"--log-cache-events/--no-log-cache-events",
|
||||
help="Enable verbose adapter cache logging.",
|
||||
envvar="DBT_LOG_CACHE_EVENTS",
|
||||
)
|
||||
|
||||
log_format = click.option(
|
||||
"--log-format",
|
||||
envvar="DBT_LOG_FORMAT",
|
||||
help="Specify the log format, overriding the command's default.",
|
||||
type=click.Choice(["text", "json", "default"], case_sensitive=False),
|
||||
default="default",
|
||||
)
|
||||
|
||||
log_path = click.option(
|
||||
"--log-path",
|
||||
envvar="DBT_LOG_PATH",
|
||||
help="Configure the 'log-path'. Only applies this setting for the current run. Overrides the 'DBT_LOG_PATH' if it is set.",
|
||||
type=click.Path(),
|
||||
)
|
||||
|
||||
macro_debugging = click.option(
|
||||
"--macro-debugging/--no-macro-debugging",
|
||||
envvar="DBT_MACRO_DEBUGGING",
|
||||
hidden=True,
|
||||
)
|
||||
|
||||
models = click.option(
|
||||
"-m",
|
||||
"-s",
|
||||
"models",
|
||||
envvar=None,
|
||||
help="Specify the nodes to include.",
|
||||
multiple=True,
|
||||
)
|
||||
|
||||
output = click.option(
|
||||
"--output",
|
||||
envvar=None,
|
||||
help="TODO: No current help text",
|
||||
type=click.Choice(["json", "name", "path", "selector"], case_sensitive=False),
|
||||
default="name",
|
||||
)
|
||||
|
||||
output_keys = click.option(
|
||||
"--output-keys", envvar=None, help="TODO: No current help text", type=click.STRING
|
||||
)
|
||||
|
||||
output_path = click.option(
|
||||
"--output",
|
||||
"-o",
|
||||
envvar=None,
|
||||
help="Specify the output path for the json report. By default, outputs to 'target/sources.json'",
|
||||
type=click.Path(file_okay=True, dir_okay=False, writable=True),
|
||||
default=PurePath.joinpath(Path.cwd(), "target/sources.json"),
|
||||
)
|
||||
|
||||
parse_only = click.option(
|
||||
"--parse-only",
|
||||
envvar=None,
|
||||
help="TODO: No help text currently available",
|
||||
is_flag=True,
|
||||
)
|
||||
|
||||
partial_parse = click.option(
|
||||
"--partial-parse/--no-partial-parse",
|
||||
envvar="DBT_PARTIAL_PARSE",
|
||||
help="Allow for partial parsing by looking for and writing to a pickle file in the target directory. This overrides the user configuration file.",
|
||||
default=True,
|
||||
)
|
||||
|
||||
port = click.option(
|
||||
"--port",
|
||||
envvar=None,
|
||||
help="Specify the port number for the docs server",
|
||||
default=8080,
|
||||
type=click.INT,
|
||||
)
|
||||
|
||||
# TODO: The env var and name (reflected in flags) are corrections!
|
||||
# The original name was `NO_PRINT` and used the env var `DBT_NO_PRINT`.
|
||||
# Both of which break existing naming conventions.
|
||||
# This will need to be fixed before use in the main codebase and communicated as a change to the community!
|
||||
print = click.option(
|
||||
"--print/--no-print",
|
||||
envvar="DBT_PRINT",
|
||||
help="Output all {{ print() }} macro calls.",
|
||||
default=True,
|
||||
)
|
||||
|
||||
printer_width = click.option(
|
||||
"--printer-width",
|
||||
envvar="DBT_PRINTER_WIDTH",
|
||||
help="Sets the width of terminal output",
|
||||
type=click.INT,
|
||||
default=80,
|
||||
)
|
||||
|
||||
profile = click.option(
|
||||
"--profile",
|
||||
envvar=None,
|
||||
help="Which profile to load. Overrides setting in dbt_project.yml.",
|
||||
)
|
||||
|
||||
profiles_dir = click.option(
|
||||
"--profiles-dir",
|
||||
envvar="DBT_PROFILES_DIR",
|
||||
help="Which directory to look in for the profiles.yml file. If not set, dbt will look in the current working directory first, then HOME/.dbt/",
|
||||
default=default_profiles_dir(),
|
||||
type=click.Path(exists=True),
|
||||
)
|
||||
|
||||
project_dir = click.option(
|
||||
"--project-dir",
|
||||
envvar=None,
|
||||
help="Which directory to look in for the dbt_project.yml file. Default is the current working directory and its parents.",
|
||||
default=default_project_dir(),
|
||||
type=click.Path(exists=True),
|
||||
)
|
||||
|
||||
quiet = click.option(
|
||||
"--quiet/--no-quiet",
|
||||
envvar="DBT_QUIET",
|
||||
help="Suppress all non-error logging to stdout. Does not affect {{ print() }} macro calls.",
|
||||
)
|
||||
|
||||
record_timing_info = click.option(
|
||||
"--record-timing-info",
|
||||
"-r",
|
||||
envvar=None,
|
||||
help="When this option is passed, dbt will output low-level timing stats to the specified file. Example: `--record-timing-info output.profile`",
|
||||
type=click.Path(exists=False),
|
||||
)
|
||||
|
||||
resource_type = click.option(
|
||||
"--resource-type",
|
||||
envvar=None,
|
||||
help="TODO: No current help text",
|
||||
type=click.Choice(
|
||||
[
|
||||
"metric",
|
||||
"source",
|
||||
"analysis",
|
||||
"model",
|
||||
"test",
|
||||
"exposure",
|
||||
"snapshot",
|
||||
"seed",
|
||||
"default",
|
||||
"all",
|
||||
],
|
||||
case_sensitive=False,
|
||||
),
|
||||
default="default",
|
||||
)
|
||||
|
||||
selector = click.option(
|
||||
"--selector", envvar=None, help="The selector name to use, as defined in selectors.yml"
|
||||
)
|
||||
|
||||
show = click.option(
|
||||
"--show", envvar=None, help="Show a sample of the loaded data in the terminal", is_flag=True
|
||||
)
|
||||
|
||||
skip_profile_setup = click.option(
|
||||
"--skip-profile-setup", "-s", envvar=None, help="Skip interative profile setup.", is_flag=True
|
||||
)
|
||||
|
||||
# TODO: The env var and name (reflected in flags) are corrections!
|
||||
# The original name was `ARTIFACT_STATE_PATH` and used the env var `DBT_ARTIFACT_STATE_PATH`.
|
||||
# Both of which break existing naming conventions.
|
||||
# This will need to be fixed before use in the main codebase and communicated as a change to the community!
|
||||
state = click.option(
|
||||
"--state",
|
||||
envvar="DBT_STATE",
|
||||
help="If set, use the given directory as the source for json files to compare with this project.",
|
||||
type=click.Path(
|
||||
dir_okay=True,
|
||||
exists=True,
|
||||
file_okay=False,
|
||||
readable=True,
|
||||
resolve_path=True,
|
||||
),
|
||||
)
|
||||
|
||||
static_parser = click.option(
|
||||
"--static-parser/--no-static-parser",
|
||||
envvar="DBT_STATIC_PARSER",
|
||||
help="Use the static parser.",
|
||||
default=True,
|
||||
)
|
||||
|
||||
store_failures = click.option(
|
||||
"--store-failures",
|
||||
envvar="DBT_STORE_FAILURES",
|
||||
help="Store test results (failing rows) in the database",
|
||||
is_flag=True,
|
||||
)
|
||||
|
||||
target = click.option(
|
||||
"--target", "-t", envvar=None, help="Which target to load for the given profile"
|
||||
)
|
||||
|
||||
target_path = click.option(
|
||||
"--target-path",
|
||||
envvar="DBT_TARGET_PATH",
|
||||
help="Configure the 'target-path'. Only applies this setting for the current run. Overrides the 'DBT_TARGET_PATH' if it is set.",
|
||||
type=click.Path(),
|
||||
)
|
||||
|
||||
threads = click.option(
|
||||
"--threads",
|
||||
envvar=None,
|
||||
help="Specify number of threads to use while executing models. Overrides settings in profiles.yml.",
|
||||
default=1,
|
||||
type=click.INT,
|
||||
)
|
||||
|
||||
use_colors = click.option(
|
||||
"--use-colors/--no-use-colors",
|
||||
envvar="DBT_USE_COLORS",
|
||||
help="Output is colorized by default and may also be set in a profile or at the command line.",
|
||||
default=True,
|
||||
)
|
||||
|
||||
use_experimental_parser = click.option(
|
||||
"--use-experimental-parser/--no-use-experimental-parser",
|
||||
envvar="DBT_USE_EXPERIMENTAL_PARSER",
|
||||
help="Enable experimental parsing features.",
|
||||
)
|
||||
|
||||
vars = click.option(
|
||||
"--vars",
|
||||
envvar=None,
|
||||
help="Supply variables to the project. This argument overrides variables defined in your dbt_project.yml file. This argument should be a YAML string, eg. '{my_variable: my_value}'",
|
||||
type=YAML(),
|
||||
)
|
||||
|
||||
version = click.option(
|
||||
"--version",
|
||||
envvar=None,
|
||||
help="Show version information",
|
||||
is_flag=True,
|
||||
)
|
||||
|
||||
version_check = click.option(
|
||||
"--version-check/--no-version-check",
|
||||
envvar="DBT_VERSION_CHECK",
|
||||
help="Ensure dbt's version matches the one specified in the dbt_project.yml file ('require-dbt-version')",
|
||||
default=True,
|
||||
)
|
||||
|
||||
warn_error = click.option(
|
||||
"--warn-error/--no-warn-error",
|
||||
envvar="DBT_WARN_ERROR",
|
||||
help="If dbt would normally warn, instead raise an exception. Examples include --models that selects nothing, deprecations, configurations with no associated models, invalid test configurations, and missing sources/refs in tests.",
|
||||
)
|
||||
|
||||
write_json = click.option(
|
||||
"--write-json/--no-write-json",
|
||||
envvar="DBT_WRITE_JSON",
|
||||
help="Writing the manifest and run_results.json files to disk",
|
||||
default=True,
|
||||
)
|
||||
|
||||
write_manifest = click.option(
|
||||
"--write-manifest/--no-write-manifest",
|
||||
envvar=None,
|
||||
help="TODO: No help text currently available",
|
||||
default=True,
|
||||
)
|
||||
@@ -1,11 +0,0 @@
|
||||
from pathlib import Path
|
||||
|
||||
|
||||
def default_project_dir():
|
||||
paths = list(Path.cwd().parents)
|
||||
paths.insert(0, Path.cwd())
|
||||
return next((x for x in paths if (x / "dbt_project.yml").exists()), Path.cwd())
|
||||
|
||||
|
||||
def default_profiles_dir():
|
||||
return Path.cwd() if (Path.cwd() / "profiles.yml").exists() else Path.home() / ".dbt"
|
||||
@@ -1,19 +1 @@
|
||||
# Clients README
|
||||
|
||||
### Jinja
|
||||
|
||||
#### How are materializations defined
|
||||
|
||||
Model materializations are kept in `core/dbt/include/global_project/macros/materializations/models/`. Materializations are defined using syntax that isn't part of the Jinja standard library. These tags are referenced internally, and materializations can be overridden in user projects when users have specific needs.
|
||||
|
||||
```
|
||||
-- Pseudocode for arguments
|
||||
{% materialization <name>, <target name := one_of{default, adapter}> %}'
|
||||
…
|
||||
{% endmaterialization %}
|
||||
```
|
||||
|
||||
These blocks are referred to Jinja extensions. Extensions are defined as part of the accepted Jinja code encapsulated within a dbt project. This includes system code used internally by dbt and user space (i.e. user-defined) macros. Extensions exist to help Jinja users create reusable code blocks or abstract objects--for us, materializations are a great use-case since we pass these around as arguments within dbt system code.
|
||||
|
||||
The code that defines this extension is a class `MaterializationExtension` and a `parse` routine. That code lives in [clients/jinja.py](https://github.com/dbt-labs/dbt-core/blob/main/core/dbt/clients/jinja.py). The routine
|
||||
enables Jinja to parse (i.e. recognize) the unique comma separated arg structure our `materialization` tags exhibit (the `table, default` as seen above).
|
||||
|
||||
@@ -367,9 +367,9 @@ class BlockIterator:
|
||||
if self.current:
|
||||
linecount = self.data[: self.current.end].count("\n") + 1
|
||||
dbt.exceptions.raise_compiler_error(
|
||||
("Reached EOF without finding a close tag for {} (searched from line {})").format(
|
||||
self.current.block_type_name, linecount
|
||||
)
|
||||
(
|
||||
"Reached EOF without finding a close tag for " "{} (searched from line {})"
|
||||
).format(self.current.block_type_name, linecount)
|
||||
)
|
||||
|
||||
if collect_raw_data:
|
||||
|
||||
@@ -80,7 +80,7 @@ def table_from_rows(
|
||||
|
||||
|
||||
def table_from_data(data, column_names: Iterable[str]) -> agate.Table:
|
||||
"Convert a list of dictionaries into an Agate table"
|
||||
"Convert list of dictionaries into an Agate table"
|
||||
|
||||
# The agate table is generated from a list of dicts, so the column order
|
||||
# from `data` is not preserved. We can use `select` to reorder the columns
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user