mirror of
https://github.com/dlt-hub/dlt.git
synced 2025-12-17 19:31:30 +00:00
* Initial commit * lesson_1_quick_start adjusted for marimo * lesson_2_dlt_sources_and_resources_create_first_dlt_pipeline marimo * Fundamentals course 3 improved * Marimo badges added * Fundamenta: course 8 * Marimo badge link fix * Fundamentals: course 7 * Fundamentals: course 6 * Fundamentals: course 5 * Fundamentals: cousre 4 * Fundamentals: course 3 * Fundamentals: course 2 * Fundmantals: course 1 * marimo links corrected * Inline deps * Fundamentals: fix lesson 2 * Fundamentals: fix lesson 3 * Fundamentals: fix lesson 4 * Formatting moved to build-molabs * Fundamentals: fix lesson 5 * Removal of scrolls * Fundamentals: fix lesson 6 * Fundamentals: fix lesson 7 * Fundamentals: fix lesson 8 * os.environ replaced with dlt.secrets where relevant * Advanced: fix lesson 5 * Advanced fix lesson 9 * os.environ fixes * Advanced: fix lesson 1 * Comments cleanup * Additional comment removal, fix lesson 6 advanced * Clean main makefile * Get rid of constants.py * Nicer json.loads() * Better functions in preprocess_to_molab * Tests for doc tooling funcs * Validate molab command * Marimo check added * docs pages adjustment * limits sqlglot in dev group until fixed --------- Co-authored-by: Marcin Rudolf <rudolfix@rudolfix.org>
471 lines
11 KiB
Python
471 lines
11 KiB
Python
# /// script
|
|
# dependencies = [
|
|
# "dlt",
|
|
# "loguru",
|
|
# "numpy",
|
|
# "pandas",
|
|
# "sentry-sdk",
|
|
# "sqlalchemy",
|
|
# ]
|
|
# ///
|
|
|
|
import marimo
|
|
|
|
__generated_with = "0.17.4"
|
|
app = marimo.App()
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(
|
|
r"""# **Introduction** [](https://molab.marimo.io/github/dlt-hub/dlt/blob/master/docs/education/dlt-advanced-course/lesson_8_logging_and_tracing.py) [](https://colab.research.google.com/github/dlt-hub/dlt/blob/master/docs/education/dlt-advanced-course/lesson_8_logging_and_tracing.ipynb) [](https://github.com/dlt-hub/dlt/blob/master/docs/education/dlt-advanced-course/lesson_8_logging_and_tracing.ipynb)"""
|
|
)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
In this notebook, we focus more on pipeline metadata, and how to use that to be able to trace and debug our pipelines.
|
|
|
|
First, we create the pipeline we'll inspect throughout this notebook.
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""## Create the pipeline we will inspect""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _():
|
|
import os
|
|
from typing import Iterable, Union
|
|
import dlt
|
|
from dlt.sources.helpers import requests
|
|
from dlt.extract import DltResource
|
|
from dlt.common.typing import TDataItems
|
|
from dlt.sources.helpers.rest_client import RESTClient
|
|
from dlt.sources.helpers.rest_client.auth import BearerTokenAuth
|
|
from dlt.sources.helpers.rest_client.paginators import HeaderLinkPaginator
|
|
|
|
dlt.secrets["SOURCES__SECRET_KEY"] = os.getenv("ACCESS_TOKEN")
|
|
|
|
@dlt.source
|
|
def github_source(secret_key: str = dlt.secrets.value) -> Iterable[DltResource]:
|
|
client = RESTClient(
|
|
base_url="https://api.github.com",
|
|
auth=BearerTokenAuth(token=secret_key),
|
|
paginator=HeaderLinkPaginator(),
|
|
)
|
|
|
|
@dlt.resource
|
|
def github_pulls(
|
|
cursor_date: dlt.sources.incremental[str] = dlt.sources.incremental(
|
|
"updated_at", initial_value="2024-12-01"
|
|
)
|
|
) -> TDataItems:
|
|
params = {"since": cursor_date.last_value, "status": "open"}
|
|
for page in client.paginate("repos/dlt-hub/dlt/pulls", params=params):
|
|
yield page
|
|
|
|
return github_pulls
|
|
|
|
pipeline = dlt.pipeline(
|
|
pipeline_name="github_pipeline",
|
|
destination="duckdb",
|
|
dataset_name="github_data",
|
|
)
|
|
_load_info = pipeline.run(github_source())
|
|
# define new dlt pipeline
|
|
# run the pipeline with the new resource
|
|
print(_load_info)
|
|
return Union, dlt, github_source, os, pipeline
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""## Look at the data""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(pipeline):
|
|
import duckdb
|
|
|
|
conn = duckdb.connect(f"{pipeline.pipeline_name}.duckdb")
|
|
|
|
conn.sql("SHOW ALL TABLES").df()
|
|
return (conn,)
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""More importantly, let's look at the saved load info""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(conn):
|
|
conn.sql("select * from github_data._dlt_loads").df()
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""# **Tracing with Sentry**""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
You can enable tracing through Sentry.
|
|
|
|
## What is `Sentry` 🤔
|
|
|
|
`Sentry` is an open-source error tracking and performance monitoring tool that helps developers **identify**, **monitor**, and **fix issues** in real-time in their applications.
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _():
|
|
import sentry_sdk
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
### Sentry needs to be initialized in normal scripts
|
|
|
|
|
|
|
|
```
|
|
import sentry_sdk
|
|
import os
|
|
|
|
sentry_sdk.init(
|
|
dsn=os.getenv("RUNTIME__SENTRY_DSN"),
|
|
traces_sample_rate=1.0 # Adjust this for performance monitoring if needed
|
|
)
|
|
```
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
### Say, you make an error and it is caught with Sentry:
|
|
|
|
|
|
|
|
```
|
|
try:
|
|
1 / 0
|
|
except ZeroDivisionError as e:
|
|
sentry_sdk.capture_exception(e)
|
|
|
|
```
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""It will then show up on your Sentry dashboard:""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(
|
|
r"""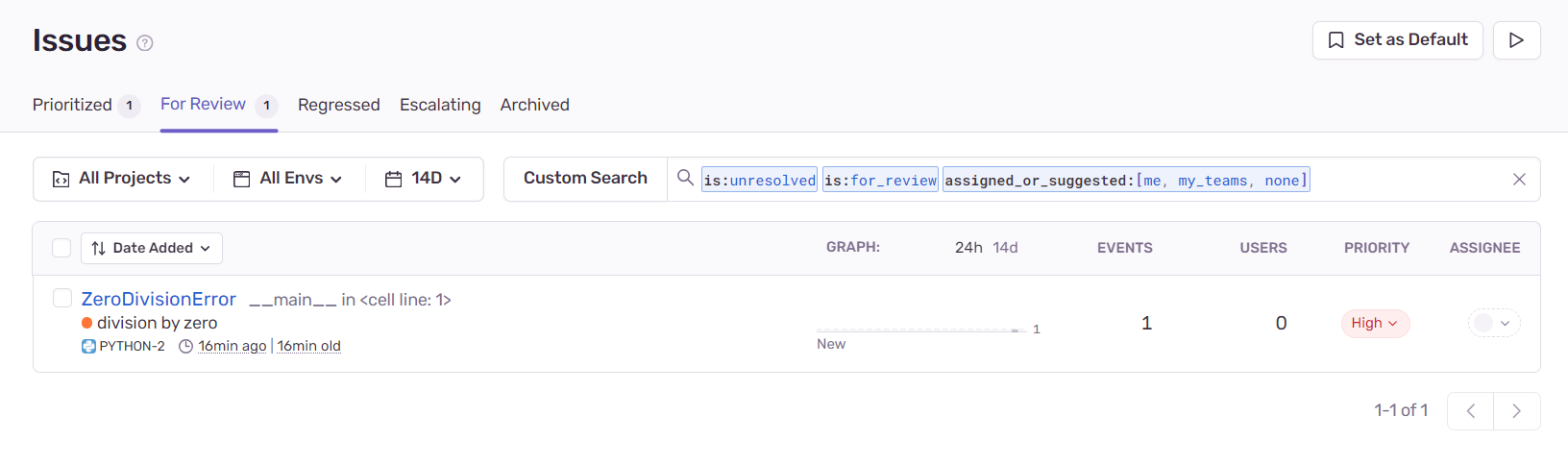"""
|
|
)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(
|
|
r"""Even when a normal error arises after Sentry has been initiated, your program executes normally, but sends that error to your dashboard, so it can be tracked!"""
|
|
)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
### In dlt, you can enable Sentry quite easily
|
|
|
|
You can configure the `DSN` in the `config.toml`:
|
|
|
|
```
|
|
[runtime]
|
|
|
|
sentry_dsn="https:///<...>"
|
|
```
|
|
|
|
|
|
Alternatively, you can use environment variables. **This is what we'll be doing**:
|
|
```
|
|
RUNTIME__SENTRY_DSN="https:///<...>"
|
|
```
|
|
The entry client is configured after the first pipeline is created with `dlt.pipeline()`. Feel free to use `sentry_sdk` init again to cover your specific needs.
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""Let's try introducing the same error again""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(dlt, os):
|
|
dlt.config["RUNTIME__SENTRY_DSN"] = os.getenv("SENTRY_TOKEN")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(pipeline):
|
|
data = {12: 34}
|
|
|
|
info = pipeline.run([data], table_name="issues")
|
|
info
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""And that comes up in Sentry as well""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(
|
|
r"""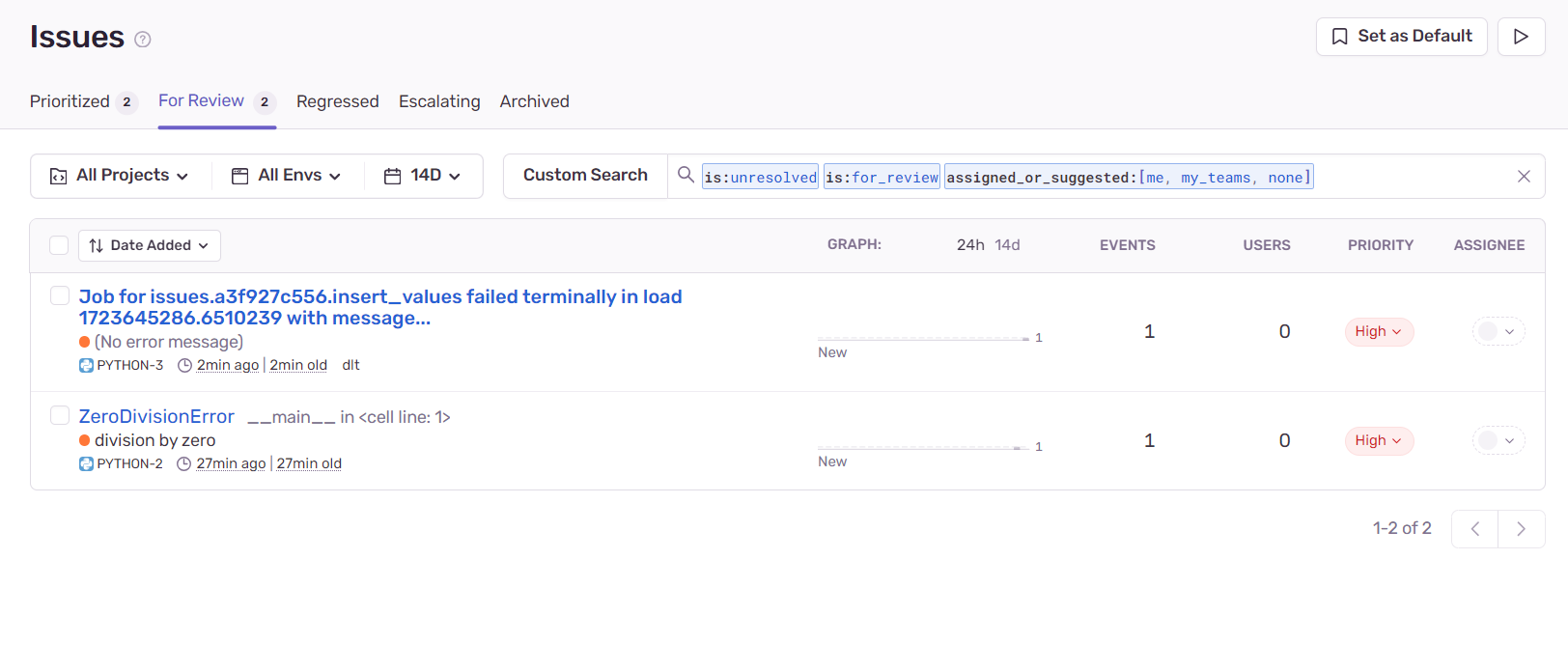"""
|
|
)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
The message sent to Sentry is:
|
|
```
|
|
Job for issues.a3f927c556.insert_values failed terminally in load 1723645286.6510239 with message Constraint Error: NOT NULL constraint failed: issues.id
|
|
```
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""# **Logging**""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
There are various environments where we would be completely lost without logs.
|
|
|
|
Debugging any system would be incredibly hard if we didn't know what was going on, or at what point the program ran into an error.
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""### Setting log levels in `dlt`""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
You can set log levels in your `config.toml` file:
|
|
|
|
|
|
|
|
```
|
|
[runtime]
|
|
log_level="INFO"
|
|
```
|
|
|
|
`log_level` accepts the Python standard logging level names.
|
|
|
|
The default log level is `WARNING`.
|
|
|
|
**`INFO` log level is useful when diagnosing problems in production.**
|
|
|
|
**`CRITICAL` will disable logging.**
|
|
|
|
**`DEBUG` should not be used in production.**
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""We'll be setting the log level in our environment variables:""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(dlt):
|
|
dlt.config["RUNTIME__LOG_LEVEL"] = "INFO"
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""
|
|
dlt logs to a logger named `dlt`.
|
|
|
|
dlt logger uses a regular python logger so you can configure the handlers as per your requirement.
|
|
""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _():
|
|
import logging
|
|
|
|
# Create a logger
|
|
logger = logging.getLogger("dlt")
|
|
|
|
# Set the log level
|
|
logger.setLevel(logging.INFO)
|
|
|
|
# Create a file handler
|
|
handler = logging.FileHandler("dlt.log")
|
|
|
|
# Add the handler to the logger
|
|
logger.addHandler(handler)
|
|
return (logging,)
|
|
|
|
|
|
@app.cell
|
|
def _(dlt, github_source):
|
|
pipeline_1 = dlt.pipeline(
|
|
pipeline_name="github_issues_merge_logger",
|
|
destination="duckdb",
|
|
dataset_name="github_data_merge",
|
|
)
|
|
_load_info = pipeline_1.run(github_source())
|
|
print(_load_info)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""### Logging via `Loguru` in our GitHub example""")
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""let's change the logging level""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(dlt):
|
|
dlt.config["RUNTIME__LOG_LEVEL"] = "INFO"
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(Union, logging):
|
|
import sys
|
|
from loguru import logger as loguru_logger
|
|
|
|
class InterceptHandler(logging.Handler):
|
|
@loguru_logger.catch(default=True, onerror=lambda _: sys.exit(1))
|
|
def emit(self, record: logging.LogRecord) -> None:
|
|
# parent class logging.Handler processes log messages
|
|
try:
|
|
level: Union[str, int] = loguru_logger.level(
|
|
record.levelname
|
|
).name # decorator provided by loguru that catches any exceptions in the decorated function and logs them
|
|
except ValueError:
|
|
level = record.levelno
|
|
(frame, depth) = (
|
|
sys._getframe(6),
|
|
6,
|
|
) # Get corresponding Loguru level if it exists.
|
|
while frame and frame.f_code.co_filename == logging.__file__:
|
|
frame = frame.f_back
|
|
depth = depth + 1
|
|
loguru_logger.opt(depth=depth, exception=record.exc_info).log(
|
|
level, record.getMessage()
|
|
)
|
|
|
|
logger_dlt = logging.getLogger("dlt")
|
|
logger_dlt.addHandler(
|
|
InterceptHandler()
|
|
) # Find caller (call frame) from where originated the logged message.
|
|
# all logs will be written to dlt_loguru.log
|
|
loguru_logger.add(
|
|
"dlt_loguru.log"
|
|
) # logs the message using loguru, with the level, exception information, and depth
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(dlt, github_source):
|
|
pipeline_2 = dlt.pipeline(
|
|
pipeline_name="github_issues_merge_loguru",
|
|
destination="duckdb",
|
|
dataset_name="github_data_merge",
|
|
)
|
|
_load_info = pipeline_2.run(github_source())
|
|
print(_load_info)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(r"""## **Logs for monitoring the progress**""")
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _(dlt, github_source):
|
|
dlt.config["RUNTIME__LOG_LEVEL"] = "WARNING"
|
|
pipeline_3 = dlt.pipeline(
|
|
pipeline_name="github_issues_progress",
|
|
destination="duckdb",
|
|
dataset_name="github_data_merge",
|
|
progress="log",
|
|
)
|
|
_load_info = pipeline_3.run(github_source())
|
|
print(_load_info)
|
|
return
|
|
|
|
|
|
@app.cell(hide_code=True)
|
|
def _(mo):
|
|
mo.md(
|
|
r"""✅ ▶ Proceed to the [next lesson](https://github.com/dlt-hub/dlt/blob/master/docs/education/dlt-advanced-course/lesson_9_performance_optimisation.ipynb)!"""
|
|
)
|
|
return
|
|
|
|
|
|
@app.cell
|
|
def _():
|
|
import marimo as mo
|
|
return (mo,)
|
|
|
|
|
|
if __name__ == "__main__":
|
|
app.run()
|